


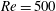
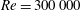
1. Introduction
In this study we present an optimal nonlinear eddy-viscosity closure for flow models based on the proper orthogonal decomposition (POD). We will focus on flows in unbounded domains which will be referred to here as ‘open flows’. A reduced-order model (ROM) may serve as a testbed for physical understanding of actual flow phenomena, as a computationally inexpensive surrogate model for optimization and as a low-order plant for control design. The oldest quantitative ROMs are vortex models which are over 100 years old (see, e.g., Lamb Reference Lamb1945). Most low-order vortex models of open flows are hybrid systems with a heuristic account of the creation, merging and annihilation of vorticity, and are thus not amenable to most approaches of system reduction, stability analysis and control design. Many current ROMs of fluid flows are based on the traditional Galerkin method (see, e.g., Fletcher Reference Fletcher1984). In the kinematical step of this method, the flow variables are expanded in terms of
 $N$
orthogonal basis functions
$N$
orthogonal basis functions
 $\boldsymbol{u}_{i}$
,
$\boldsymbol{u}_{i}$
,
 $i=1,\dots ,N$
, as
$i=1,\dots ,N$
, as
 $\boldsymbol{u}(\boldsymbol{x},t)=\sum _{i=1}^{N}a_{i}(t)\boldsymbol{u}_{i}(\boldsymbol{x})$
. Thus, the mode coefficients
$\boldsymbol{u}(\boldsymbol{x},t)=\sum _{i=1}^{N}a_{i}(t)\boldsymbol{u}_{i}(\boldsymbol{x})$
. Thus, the mode coefficients
 $\boldsymbol{a}(t)=[a_{1}(t),\dots ,a_{N}(t)]^{\text{T}}\in \mathbb{R}^{N}$
parameterize the fluid flow. The dynamical step consists in representing the dependent variables in the Navier–Stokes system in terms of such expansions and then projecting on the individual modes which leads to the Galerkin system in the general form
$\boldsymbol{a}(t)=[a_{1}(t),\dots ,a_{N}(t)]^{\text{T}}\in \mathbb{R}^{N}$
parameterize the fluid flow. The dynamical step consists in representing the dependent variables in the Navier–Stokes system in terms of such expansions and then projecting on the individual modes which leads to the Galerkin system in the general form
 $$\begin{eqnarray}\frac{\text{d}\boldsymbol{a}}{\text{d}t}=\boldsymbol{f}(\boldsymbol{a}),\quad t>0\end{eqnarray}$$
$$\begin{eqnarray}\frac{\text{d}\boldsymbol{a}}{\text{d}t}=\boldsymbol{f}(\boldsymbol{a}),\quad t>0\end{eqnarray}$$
with propagator
 $\boldsymbol{f}:\mathbb{R}^{N}\rightarrow \mathbb{R}^{N}$
. Many ROMs originate via post-processing of flow data obtained from simulations or experiments and rely on the POD (see, e.g., Noack, Morzyński & Tadmor Reference Noack, Morzyński and Tadmor2011; Holmes et al.
Reference Holmes, Lumley, Berkooz and Rowley2012). In the following, we focus on such POD models.
$\boldsymbol{f}:\mathbb{R}^{N}\rightarrow \mathbb{R}^{N}$
. Many ROMs originate via post-processing of flow data obtained from simulations or experiments and rely on the POD (see, e.g., Noack, Morzyński & Tadmor Reference Noack, Morzyński and Tadmor2011; Holmes et al.
Reference Holmes, Lumley, Berkooz and Rowley2012). In the following, we focus on such POD models.
The error of the Galerkin model is expected to vanish for increasing dimension
 $N$
. Since only a finite, and typically small, number of modes is retained, this procedure results in a loss of information. Hence, the ROM (1.1) must be amended to restore some physical features. Which features can be eliminated and which can be retained tends to depend on the nature of the particular problem. In general, however, the large-scale coherent structures with the associated production of turbulent kinetic energy (TKE) are approximately resolved, while the small-scale fluctuations responsible for most of the dissipation are ignored. The resulting excess production of the fluctuation energy requires an additional stabilization in order to ensure the long-term boundedness of solutions of system (1.1). The need to introduce a suitable subscale turbulence representation gives rise to a ‘closure problem’ analogous to the problem encountered when modelling turbulent flows based on the Reynolds-averaged Navier–Stokes (RANS) equations and large-eddy simulations (LES), despite the fact that the latter two approaches rely on flow descriptions in terms of partial differential equations (PDEs), while system (1.1) is finite-dimensional. In particular, additional terms involving an ‘eddy viscosity’ have been used in ROMs starting with the pioneering work of Aubry et al. (Reference Aubry, Holmes, Lumley and Stone1988). These closure terms have been refined in numerous studies leading to, e.g. the modal eddy viscosities proposed by Rempfer & Fasel (Reference Rempfer and Fasel1994b
), calibration of an auxiliary linear term investigated by Galletti et al. (Reference Galletti, Bruneau, Zannetti and Iollo2004), a nonlinear term introduced by Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013), combinations thereof studied by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014) and projections of the filtered Navier–Stokes equation (Wang et al.
Reference Wang, Akhtar, Borggaard and Iliescu2011), just to name only a few approaches. In addition, projections onto more dissipative subspaces were considered by Balajewicz, Dowell & Noack (Reference Balajewicz, Dowell and Noack2013). We refer the reader to Wang et al. (Reference Wang, Akhtar, Borggaard and Iliescu2012) for some new proposals and a critical assessment of several earlier approaches.
$N$
. Since only a finite, and typically small, number of modes is retained, this procedure results in a loss of information. Hence, the ROM (1.1) must be amended to restore some physical features. Which features can be eliminated and which can be retained tends to depend on the nature of the particular problem. In general, however, the large-scale coherent structures with the associated production of turbulent kinetic energy (TKE) are approximately resolved, while the small-scale fluctuations responsible for most of the dissipation are ignored. The resulting excess production of the fluctuation energy requires an additional stabilization in order to ensure the long-term boundedness of solutions of system (1.1). The need to introduce a suitable subscale turbulence representation gives rise to a ‘closure problem’ analogous to the problem encountered when modelling turbulent flows based on the Reynolds-averaged Navier–Stokes (RANS) equations and large-eddy simulations (LES), despite the fact that the latter two approaches rely on flow descriptions in terms of partial differential equations (PDEs), while system (1.1) is finite-dimensional. In particular, additional terms involving an ‘eddy viscosity’ have been used in ROMs starting with the pioneering work of Aubry et al. (Reference Aubry, Holmes, Lumley and Stone1988). These closure terms have been refined in numerous studies leading to, e.g. the modal eddy viscosities proposed by Rempfer & Fasel (Reference Rempfer and Fasel1994b
), calibration of an auxiliary linear term investigated by Galletti et al. (Reference Galletti, Bruneau, Zannetti and Iollo2004), a nonlinear term introduced by Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013), combinations thereof studied by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014) and projections of the filtered Navier–Stokes equation (Wang et al.
Reference Wang, Akhtar, Borggaard and Iliescu2011), just to name only a few approaches. In addition, projections onto more dissipative subspaces were considered by Balajewicz, Dowell & Noack (Reference Balajewicz, Dowell and Noack2013). We refer the reader to Wang et al. (Reference Wang, Akhtar, Borggaard and Iliescu2012) for some new proposals and a critical assessment of several earlier approaches.
The discussed ROMs are all based on the Navier–Stokes equation. In principle, also the subscale closures can be approximately modelled based on first-principle considerations by means of structure and parameter identification. However, the availability of highly resolved numerical and experimental data sets makes data-driven modelling an appealing approach (see, e.g., Cacuci, Navon & Ionescu-Bujor Reference Cacuci, Navon and Ionescu-Bujor2013; Kutz Reference Kutz2013). For example, in the context of POD-based models, parameters of Galerkin systems and the required closure relations can be accurately identified using variational techniques of data assimilation (Cordier et al.
Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013), collectively known in the geosciences as ‘4D-VAR’ (Kalnay Reference Kalnay2003). A relatively recent development is the construction of subscale turbulence models based on optimization problems in which the closure model is adapted using available measurements. In the context of LES, this approach has been pioneered by Moser et al. leading to the concept of an ‘optimal LES’ (Langford & Moser Reference Langford and Moser1999). Optimization-based formulations of the closure problem for Galerkin ROMs were recently pursued by D’Adamo et al. (Reference D’Adamo, Papadakis, Mémin and Artana2007), Artana et al. (Reference Artana, Cammilleri, Carlier and Mémin2012) and Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013). In these studies the authors obtained time-dependent eddy viscosities
 ${\it\nu}_{T}={\it\nu}_{T}(t)$
as minimizers of cost functionals representing the misfit between the measured and reconstructed data. However, the eddy viscosity obtained in this way is a function of time and the ROM (1.1) is no longer autonomous. Since flow models with such time-dependent closures cannot be used to make predictions outside the time window on which the closure
${\it\nu}_{T}={\it\nu}_{T}(t)$
as minimizers of cost functionals representing the misfit between the measured and reconstructed data. However, the eddy viscosity obtained in this way is a function of time and the ROM (1.1) is no longer autonomous. Since flow models with such time-dependent closures cannot be used to make predictions outside the time window on which the closure
 ${\it\nu}_{T}(t)$
was defined, this limits the practical applicability of such approaches. In this context, we also mention the recent study by Hemati, Eldredge & Speyer (Reference Hemati, Eldredge and Speyer2014) in which an analogous time-dependent closure was obtained for a vortex-based flow model.
${\it\nu}_{T}(t)$
was defined, this limits the practical applicability of such approaches. In this context, we also mention the recent study by Hemati, Eldredge & Speyer (Reference Hemati, Eldredge and Speyer2014) in which an analogous time-dependent closure was obtained for a vortex-based flow model.
In the present investigation we follow an optimization approach which is fundamentally different: the optimal eddy viscosity is sought as a function of the state
 $\boldsymbol{a}$
, more precisely, its (turbulent) fluctuation energy
$\boldsymbol{a}$
, more precisely, its (turbulent) fluctuation energy
 $E(t):=\Vert \boldsymbol{a}(t)\Vert _{2}^{2}=(\sum _{i=1}^{N}a_{i}(t)^{2})/2$
, so that the resulting ROM (1.1) will then be autonomous. Consequently, flow models with such closures can be used to make predictions also outside the time window on which the data assimilation was performed. The proposed reconstruction approach is ‘non-parametric’, in the sense that no assumptions are made concerning the form of the dependence
$E(t):=\Vert \boldsymbol{a}(t)\Vert _{2}^{2}=(\sum _{i=1}^{N}a_{i}(t)^{2})/2$
, so that the resulting ROM (1.1) will then be autonomous. Consequently, flow models with such closures can be used to make predictions also outside the time window on which the data assimilation was performed. The proposed reconstruction approach is ‘non-parametric’, in the sense that no assumptions are made concerning the form of the dependence
 ${\it\nu}_{T}={\it\nu}_{T}(E)$
other than smoothness and the limiting behaviour for small and large values of
${\it\nu}_{T}={\it\nu}_{T}(E)$
other than smoothness and the limiting behaviour for small and large values of
 $E$
. Relying on the concepts of data assimilation, the proposed approach allows one to use measurement data in order to systematically refine nonlinear eddy viscosity models obtained theoretically. Therefore, it may be applicable to study the performance limitations of a given ansatz for the eddy viscosity. The method builds on the approach to the optimal reconstruction of constitutive relations in complex multiphysics PDE problems developed by Bukshtynov, Volkov & Protas (Reference Bukshtynov, Volkov and Protas2011) and Bukshtynov & Protas (Reference Bukshtynov and Protas2013). An application of this method to finite-dimensional Galerkin models was carefully validated using a three-state ROM of laminar vortex shedding in the cylinder wake by Protas, Noack & Morzynski (Reference Protas, Noack and Morzynski2014). In the present study, we employ this approach to identify optimal turbulence closures in two medium and high-
$E$
. Relying on the concepts of data assimilation, the proposed approach allows one to use measurement data in order to systematically refine nonlinear eddy viscosity models obtained theoretically. Therefore, it may be applicable to study the performance limitations of a given ansatz for the eddy viscosity. The method builds on the approach to the optimal reconstruction of constitutive relations in complex multiphysics PDE problems developed by Bukshtynov, Volkov & Protas (Reference Bukshtynov, Volkov and Protas2011) and Bukshtynov & Protas (Reference Bukshtynov and Protas2013). An application of this method to finite-dimensional Galerkin models was carefully validated using a three-state ROM of laminar vortex shedding in the cylinder wake by Protas, Noack & Morzynski (Reference Protas, Noack and Morzynski2014). In the present study, we employ this approach to identify optimal turbulence closures in two medium and high-
 $\mathit{Re}$
flows, namely, a 2D incompressible mixing layer and a 3D wake flow behind a blunt-back Ahmed body. The dimensions of the corresponding Galerkin models are
$\mathit{Re}$
flows, namely, a 2D incompressible mixing layer and a 3D wake flow behind a blunt-back Ahmed body. The dimensions of the corresponding Galerkin models are
 $N=20$
for the mixing layer and
$N=20$
for the mixing layer and
 $N=100$
for the Ahmed body wake. As will be evident from the discussion below, these two flows exhibit distinct properties from the point of view of subgrid modelling and bear characteristics of, respectively, laminar and turbulent flows. In addition to offering predictability improvements over existing approaches (Östh et al.
Reference Östh, Noack, Krajnović, Barros and Borée2014), the optimal turbulence closures also reveal a number of unexpected yet physically plausible features, such as negative values of the eddy viscosity in some ranges of the TKE
$N=100$
for the Ahmed body wake. As will be evident from the discussion below, these two flows exhibit distinct properties from the point of view of subgrid modelling and bear characteristics of, respectively, laminar and turbulent flows. In addition to offering predictability improvements over existing approaches (Östh et al.
Reference Östh, Noack, Krajnović, Barros and Borée2014), the optimal turbulence closures also reveal a number of unexpected yet physically plausible features, such as negative values of the eddy viscosity in some ranges of the TKE
 $E$
. We note that in fact the concept of a negative eddy viscosity has already been invoked in the studies of turbulent flows (see, e.g., Liberzon et al.
Reference Liberzon, Lüthi, Guala, Kinzelbach, Tsinober, Oberlack, Khujadze, Günther, Weller, Frewer, Peinke and Barth2007).
$E$
. We note that in fact the concept of a negative eddy viscosity has already been invoked in the studies of turbulent flows (see, e.g., Liberzon et al.
Reference Liberzon, Lüthi, Guala, Kinzelbach, Tsinober, Oberlack, Khujadze, Günther, Weller, Frewer, Peinke and Barth2007).
The structure of the paper is as follows. In § 2 we briefly recapitulate POD Galerkin models and highlight some properties of the eddy viscosity in such models. Our computational approach is outlined in § 3. Optimal eddy viscosities and the properties of the resulting ROMs of the mixing layer and the Ahmed body flow are presented and analysed in § 4. Summary and future directions are provided in § 5, whereas some technical material concerning the optimization approach is collected in appendix A.
2. POD modelling
In this section, POD models for turbulent flows are briefly reviewed. First (§ 2.1), the assumed flow configurations are specified. The POD expansion and the corresponding Galerkin projection of the Navier–Stokes equation are described in §§ 2.2 and 2.3, respectively. In § 2.4, a nonlinear eddy viscosity ansatz is introduced against which the optimal relations of the next section will be benchmarked. Finally (§ 2.5), conditions for the appearance of negative values of eddy viscosity are identified thus setting the stage for the optimization formulation of § 3 and the initially somewhat surprising results reported in § 4.
2.1. Flow configurations
We assume an incompressible flow of a Newtonian fluid in a stationary domain
 ${\it\Omega}$
. The fluid is described by the density
${\it\Omega}$
. The fluid is described by the density
 ${\it\rho}$
and kinematic viscosity
${\it\rho}$
and kinematic viscosity
 $\tilde{{\it\nu}}$
. The position and time are denoted by
$\tilde{{\it\nu}}$
. The position and time are denoted by
 $\boldsymbol{x}$
and
$\boldsymbol{x}$
and
 $t$
, respectively. The flow field is described by the velocity
$t$
, respectively. The flow field is described by the velocity
 $\boldsymbol{u}$
and pressure
$\boldsymbol{u}$
and pressure
 $p$
. The fluid motion is characterized by a velocity scale
$p$
. The fluid motion is characterized by a velocity scale
 $U$
and a length scale
$U$
and a length scale
 $L$
, which will take different numerical values in the problems studied here, and define the Reynolds number as
$L$
, which will take different numerical values in the problems studied here, and define the Reynolds number as
 $\mathit{Re}:=UL/\tilde{{\it\nu}}$
. In the following, all quantities are assumed to be non-dimensionalized by
$\mathit{Re}:=UL/\tilde{{\it\nu}}$
. In the following, all quantities are assumed to be non-dimensionalized by
 $U$
,
$U$
,
 $L$
and
$L$
and
 ${\it\rho}$
, and
${\it\rho}$
, and
 ${\it\nu}:=1/\mathit{Re}$
represents the reciprocal Reynolds number (‘
${\it\nu}:=1/\mathit{Re}$
represents the reciprocal Reynolds number (‘
 $:=$
’ means that the left-hand side of the equation is defined by the right-hand side). The fluid motion is governed by the continuity equation and the momentum balance
$:=$
’ means that the left-hand side of the equation is defined by the right-hand side). The fluid motion is governed by the continuity equation and the momentum balance
 $$\begin{eqnarray}\displaystyle \boldsymbol{{\rm\nabla}}\boldsymbol{\cdot }\boldsymbol{u} & = & \displaystyle 0,\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \boldsymbol{{\rm\nabla}}\boldsymbol{\cdot }\boldsymbol{u} & = & \displaystyle 0,\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle \frac{\partial \boldsymbol{u}}{\partial t}+\boldsymbol{u}\boldsymbol{\cdot }\boldsymbol{{\rm\nabla}}\boldsymbol{u} & = & \displaystyle -\boldsymbol{{\rm\nabla}}p+{\it\nu}{\rm\Delta}\boldsymbol{u}\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \frac{\partial \boldsymbol{u}}{\partial t}+\boldsymbol{u}\boldsymbol{\cdot }\boldsymbol{{\rm\nabla}}\boldsymbol{u} & = & \displaystyle -\boldsymbol{{\rm\nabla}}p+{\it\nu}{\rm\Delta}\boldsymbol{u}\end{eqnarray}$$
While the proposed methodology is fairly general, to fix attention, in this study we investigate two shear flows, a 2D spatially evolving mixing layer with a narrow frequency bandwidth and a 3D wake behind an Ahmed body with a broad frequency bandwidth including a slow drift of the base flow. In both flows, the origin of the Cartesian coordinate system is at the centre of the inlet of the observation domain, i.e. is located at the maximum shear position in the case of the mixing layer and at the centre of the rear face of the Ahmed body (figure 1). The
 $x$
-axis points in the direction of the flow, the
$x$
-axis points in the direction of the flow, the
 $y$
-axis is aligned with the shear and the
$y$
-axis is aligned with the shear and the
 $z$
-axis is orthogonal to the
$z$
-axis is orthogonal to the
 $x$
- and
$x$
- and
 $y$
-coordinates.
$y$
-coordinates.

Figure 1. Schematic of the coordinate system used in the example problems studied here. The velocity profile in the mixing-layer problem is indicated with (blue online) solid lines, whereas the Ahmed body configuration together with the corresponding mean velocity profiles are marked with (dark red online) dashed lines.
2.2. Proper orthogonal decomposition
We perform a POD expansion (Lumley Reference Lumley1970) of
 $M$
velocity snapshots
$M$
velocity snapshots
 $\boldsymbol{u}^{m}:=\boldsymbol{u}(\boldsymbol{x},t^{m})$
sampled at equispaced time instances
$\boldsymbol{u}^{m}:=\boldsymbol{u}(\boldsymbol{x},t^{m})$
sampled at equispaced time instances
 $t^{m}=m{\rm\Delta}t,~m=1,\dots ,M$
, with the time step
$t^{m}=m{\rm\Delta}t,~m=1,\dots ,M$
, with the time step
 ${\rm\Delta}t$
. The averaging operation of any velocity-dependent function
${\rm\Delta}t$
. The averaging operation of any velocity-dependent function
 $\boldsymbol{F}(\boldsymbol{u})$
over this ensemble is denoted by an overbar, i.e.
$\boldsymbol{F}(\boldsymbol{u})$
over this ensemble is denoted by an overbar, i.e.
 $$\begin{eqnarray}\overline{\boldsymbol{F}(\boldsymbol{u})}:=\frac{1}{M}\mathop{\sum }_{m=1}^{M}\boldsymbol{F}(\boldsymbol{u}^{m}).\end{eqnarray}$$
$$\begin{eqnarray}\overline{\boldsymbol{F}(\boldsymbol{u})}:=\frac{1}{M}\mathop{\sum }_{m=1}^{M}\boldsymbol{F}(\boldsymbol{u}^{m}).\end{eqnarray}$$
The inner product for two velocity fields
 $\mathbf{z}_{1},\mathbf{z}_{2}\in L_{2}({\it\Omega})$
is defined as
$\mathbf{z}_{1},\mathbf{z}_{2}\in L_{2}({\it\Omega})$
is defined as
 $$\begin{eqnarray}\langle \mathbf{z}_{1},\mathbf{z}_{2}\rangle _{L_{2}({\it\Omega})}:=\int _{{\it\Omega}}\,\mathbf{z}_{1}\boldsymbol{\cdot }\mathbf{z}_{2}\,\text{d}\boldsymbol{x}.\end{eqnarray}$$
$$\begin{eqnarray}\langle \mathbf{z}_{1},\mathbf{z}_{2}\rangle _{L_{2}({\it\Omega})}:=\int _{{\it\Omega}}\,\mathbf{z}_{1}\boldsymbol{\cdot }\mathbf{z}_{2}\,\text{d}\boldsymbol{x}.\end{eqnarray}$$
This inner product defines the energy norm
 $\Vert \boldsymbol{u}\Vert _{L_{2}({\it\Omega})}=\sqrt{\langle \boldsymbol{u },\boldsymbol{ u }\rangle _{L_{2}({\it\Omega})}}$
.
$\Vert \boldsymbol{u}\Vert _{L_{2}({\it\Omega})}=\sqrt{\langle \boldsymbol{u },\boldsymbol{ u }\rangle _{L_{2}({\it\Omega})}}$
.
The averaging operation and the inner product uniquely define the corresponding snapshot POD (Sirovich Reference Sirovich1987; Holmes et al.
Reference Holmes, Lumley, Berkooz and Rowley2012). First, following the Reynolds decomposition, the velocity field is decomposed into a mean field
 $\boldsymbol{u}_{0}$
and a fluctuating contribution
$\boldsymbol{u}_{0}$
and a fluctuating contribution
 $\boldsymbol{u}^{\prime }$
defined as
$\boldsymbol{u}^{\prime }$
defined as
 $$\begin{eqnarray}\boldsymbol{u}_{0}:=\overline{\boldsymbol{u}},\quad \boldsymbol{u}^{\prime }:=\boldsymbol{u}-\overline{\boldsymbol{u}}.\end{eqnarray}$$
$$\begin{eqnarray}\boldsymbol{u}_{0}:=\overline{\boldsymbol{u}},\quad \boldsymbol{u}^{\prime }:=\boldsymbol{u}-\overline{\boldsymbol{u}}.\end{eqnarray}$$
Then, the fluctuating part is approximated by a Galerkin expansion with space-dependent modes
 $\boldsymbol{u}_{i}(\boldsymbol{x})$
,
$\boldsymbol{u}_{i}(\boldsymbol{x})$
,
 $i=1,2,\dots ,N$
, used as the basis functions and the corresponding mode coefficients
$i=1,2,\dots ,N$
, used as the basis functions and the corresponding mode coefficients
 $a_{i}(t)$
$a_{i}(t)$
 $$\begin{eqnarray}\boldsymbol{u}(\boldsymbol{x},t)=\boldsymbol{u}_{0}(\boldsymbol{x})+\mathop{\sum }_{i=1}^{N}a_{i}(t)\boldsymbol{u}_{i}(\boldsymbol{x})+\boldsymbol{u}_{res}(\boldsymbol{x},t),\end{eqnarray}$$
$$\begin{eqnarray}\boldsymbol{u}(\boldsymbol{x},t)=\boldsymbol{u}_{0}(\boldsymbol{x})+\mathop{\sum }_{i=1}^{N}a_{i}(t)\boldsymbol{u}_{i}(\boldsymbol{x})+\boldsymbol{u}_{res}(\boldsymbol{x},t),\end{eqnarray}$$
where
 $\boldsymbol{u}_{res}$
represents the residual. POD yields a Galerkin expansion with the minimal average squared residual
$\boldsymbol{u}_{res}$
represents the residual. POD yields a Galerkin expansion with the minimal average squared residual
 $\overline{\Vert \boldsymbol{u}_{res}\Vert _{L_{2}({\it\Omega})}^{2}}$
as compared with any other Galerkin expansion with
$\overline{\Vert \boldsymbol{u}_{res}\Vert _{L_{2}({\it\Omega})}^{2}}$
as compared with any other Galerkin expansion with
 $N$
modes (Lumley Reference Lumley1970). We note that the snapshot POD method limits the number of POD modes to
$N$
modes (Lumley Reference Lumley1970). We note that the snapshot POD method limits the number of POD modes to
 $N\leqslant M-1$
.
$N\leqslant M-1$
.
To facilitate subsequent developments, we rewrite the POD expansion more compactly following the convention of Rempfer & Fasel (Reference Rempfer and Fasel1994a ,Reference Rempfer and Fasel b ):
 $$\begin{eqnarray}\boldsymbol{u}(\boldsymbol{x},t)=\mathop{\sum }_{i=0}^{N}a_{i}(t)\boldsymbol{u}_{i}(\boldsymbol{x}),\end{eqnarray}$$
$$\begin{eqnarray}\boldsymbol{u}(\boldsymbol{x},t)=\mathop{\sum }_{i=0}^{N}a_{i}(t)\boldsymbol{u}_{i}(\boldsymbol{x}),\end{eqnarray}$$
where
 $a_{0}(t)\equiv 1$
(because of this property we will refer to the phase space as
$a_{0}(t)\equiv 1$
(because of this property we will refer to the phase space as
 $N$
-dimensional, even though the state vector
$N$
-dimensional, even though the state vector
 $\boldsymbol{a}(t)$
has formally the dimension
$\boldsymbol{a}(t)$
has formally the dimension
 $N+1$
). For later reference, we recapitulate the first and second moments of the POD mode coefficients:
$N+1$
). For later reference, we recapitulate the first and second moments of the POD mode coefficients:
 $$\begin{eqnarray}\overline{a_{i}}=0,\quad \overline{a_{i}a_{j}}={\it\lambda}_{i}{\it\delta}_{ij},\quad i,j=1,\dots ,N,\end{eqnarray}$$
$$\begin{eqnarray}\overline{a_{i}}=0,\quad \overline{a_{i}a_{j}}={\it\lambda}_{i}{\it\delta}_{ij},\quad i,j=1,\dots ,N,\end{eqnarray}$$
where
 ${\it\lambda}_{i}$
are the POD eigenvalues. The energy content in each mode is given by
${\it\lambda}_{i}$
are the POD eigenvalues. The energy content in each mode is given by
 $E_{i}(t):=a_{i}^{2}(t)/2$
and the TKE resolved by the Galerkin expansion
$E_{i}(t):=a_{i}^{2}(t)/2$
and the TKE resolved by the Galerkin expansion
 $E(t)$
is
$E(t)$
is
 $$\begin{eqnarray}E(t)=\mathop{\sum }_{i=1}^{N}E_{i}(t).\end{eqnarray}$$
$$\begin{eqnarray}E(t)=\mathop{\sum }_{i=1}^{N}E_{i}(t).\end{eqnarray}$$
At any fixed time
 $t$
, the limit
$t$
, the limit
 $\lim _{N\rightarrow \infty }E(t)$
for POD yields the total TKE
$\lim _{N\rightarrow \infty }E(t)$
for POD yields the total TKE
 $K(t)$
of the original velocity field. We note that, by (2.7), the average modal energy and POD eigenvalues are synonymous:
$K(t)$
of the original velocity field. We note that, by (2.7), the average modal energy and POD eigenvalues are synonymous:
 $\overline{E_{i}}={\it\lambda}_{i}/2$
.
$\overline{E_{i}}={\it\lambda}_{i}/2$
.
2.3. Galerkin projection
The Galerkin expansion (2.6) satisfies the incompressibility condition and the boundary conditions by construction. The evolution equation for the mode coefficients
 $a_{i}$
is derived by a Galerkin projection of the Navier–Stokes equation (2.1), written in the operator form as
$a_{i}$
is derived by a Galerkin projection of the Navier–Stokes equation (2.1), written in the operator form as
 $\boldsymbol{R}(\boldsymbol{u})=\mathbf{0}$
, onto individual POD modes, i.e. via
$\boldsymbol{R}(\boldsymbol{u})=\mathbf{0}$
, onto individual POD modes, i.e. via
 $\langle \boldsymbol{u}_{i},\boldsymbol{R}(\boldsymbol{u})\rangle _{L^{2}({\it\Omega})}=0$
,
$\langle \boldsymbol{u}_{i},\boldsymbol{R}(\boldsymbol{u})\rangle _{L^{2}({\it\Omega})}=0$
,
 $i=1,\dots ,N$
. Details are provided in the monographs by Noack et al. (Reference Noack, Morzyński and Tadmor2011) and Holmes et al. (Reference Holmes, Lumley, Berkooz and Rowley2012). For internal flows, the Galerkin representation of the pressure term vanishes. For open flows with large domains and three-dimensional fluctuations, the pressure term can generally be neglected as discussed by Deane et al. (Reference Deane, Kevrekidis, Karniadakis and Orszag1991), Ma & Karniadakis (Reference Ma and Karniadakis2002) and Noack, Papas & Monkewitz (Reference Noack, Papas and Monkewitz2005). Here, the Galerkin projection of the pressure term was found to be negligible and it is therefore omitted from the model. Thus, the Galerkin system describing the temporal evolution of the modal coefficients,
$i=1,\dots ,N$
. Details are provided in the monographs by Noack et al. (Reference Noack, Morzyński and Tadmor2011) and Holmes et al. (Reference Holmes, Lumley, Berkooz and Rowley2012). For internal flows, the Galerkin representation of the pressure term vanishes. For open flows with large domains and three-dimensional fluctuations, the pressure term can generally be neglected as discussed by Deane et al. (Reference Deane, Kevrekidis, Karniadakis and Orszag1991), Ma & Karniadakis (Reference Ma and Karniadakis2002) and Noack, Papas & Monkewitz (Reference Noack, Papas and Monkewitz2005). Here, the Galerkin projection of the pressure term was found to be negligible and it is therefore omitted from the model. Thus, the Galerkin system describing the temporal evolution of the modal coefficients,
 $a_{i}(t)$
, reads
$a_{i}(t)$
, reads
 $$\begin{eqnarray}\frac{\text{d}a_{i}}{\text{d}t}=f_{i}(\boldsymbol{a})={\it\nu}\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}+\mathop{\sum }_{j,k=0}^{N}q_{ijk}^{c}a_{j}a_{k},\quad i=1,\dots ,N.\end{eqnarray}$$
$$\begin{eqnarray}\frac{\text{d}a_{i}}{\text{d}t}=f_{i}(\boldsymbol{a})={\it\nu}\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}+\mathop{\sum }_{j,k=0}^{N}q_{ijk}^{c}a_{j}a_{k},\quad i=1,\dots ,N.\end{eqnarray}$$
The coefficients
 $l_{ij}^{{\it\nu}}$
and
$l_{ij}^{{\it\nu}}$
and
 $q_{ijk}^{c}$
,
$q_{ijk}^{c}$
,
 $i,j,k=0,\dots ,N$
, are the Galerkin coefficients describing, respectively, the viscous and convective effects in the Navier–Stokes system (2.1). For internal flows with the Dirichlet or periodic boundary conditions, the quadratic term can be shown to be exactly energy-preserving
$i,j,k=0,\dots ,N$
, are the Galerkin coefficients describing, respectively, the viscous and convective effects in the Navier–Stokes system (2.1). For internal flows with the Dirichlet or periodic boundary conditions, the quadratic term can be shown to be exactly energy-preserving
 $$\begin{eqnarray}q_{ijk}^{c}+q_{ikj}^{c}+q_{kij}^{c}+q_{kji}^{c}+q_{ikj}^{c}+q_{jik}^{c}=0,\quad i,j,k=1,\dots ,N.\end{eqnarray}$$
$$\begin{eqnarray}q_{ijk}^{c}+q_{ikj}^{c}+q_{kij}^{c}+q_{kji}^{c}+q_{ikj}^{c}+q_{jik}^{c}=0,\quad i,j,k=1,\dots ,N.\end{eqnarray}$$
Energy preservation (2.10) can be also be proven for flows past obstacles in unbounded domains under the condition that the velocity fluctuations decay at infinity. For finite domains, relation (2.10) is still a good approximation assuming that the fluctuations have significantly decreased at the downstream boundary, as is the case for the cylinder wake example discussed below. Even when more significant fluctuation levels are present at the downstream boundary as in the mixing layer flow, the enforced antisymmetry of
 $q_{ijk}$
is numerically found not to noticeably change the behaviour of the POD model in the examples considered.
$q_{ijk}$
is numerically found not to noticeably change the behaviour of the POD model in the examples considered.
2.4. Post-transient fluctuation levels
For turbulent flows, POD models face one well-known challenge addressed already in the pioneering work of Aubry et al. (Reference Aubry, Holmes, Lumley and Stone1988): the finite POD expansion often contains a fraction of the total fluctuation energy. While a significant portion of the TKE production may be resolved by the large-scale structures contained in the POD expansion, most of the dissipation in the small-scale eddies is ignored in the Galerkin system. The resulting over-production of TKE in the POD model leads to over-prediction of the fluctuation level, including possible divergence to infinity in finite time. A common cure is the inclusion of an ‘eddy viscosity’ term absorbing the excess energy,
 $$\begin{eqnarray}\frac{\text{d}a_{i}}{\text{d}t}=f_{i}(\boldsymbol{a})+{\it\nu}_{T}\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\quad i=1,\dots ,N.\end{eqnarray}$$
$$\begin{eqnarray}\frac{\text{d}a_{i}}{\text{d}t}=f_{i}(\boldsymbol{a})+{\it\nu}_{T}\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\quad i=1,\dots ,N.\end{eqnarray}$$
In general, off-diagonal elements
 $l_{ij}^{{\it\nu}},~i\neq j$
, are small and therefore negligible.
$l_{ij}^{{\it\nu}},~i\neq j$
, are small and therefore negligible.
In early studies eddy viscosity
 ${\it\nu}_{T}$
was assumed to be a constant parameter. Yet, the non-physical implication is that the POD-resolved part of the turbulent flow effectively behaves like a laminar flow with reciprocal Reynolds number
${\it\nu}_{T}$
was assumed to be a constant parameter. Yet, the non-physical implication is that the POD-resolved part of the turbulent flow effectively behaves like a laminar flow with reciprocal Reynolds number
 ${\it\nu}_{eff}={\it\nu}+{\it\nu}_{T}$
. Another non-physical implication is that a linear Galerkin term is to represent the nonlinear energy cascade. Numerous refinements of this eddy viscosity term have been suggested as discussed by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014). To simplify the notation, hereafter we will use the convention that the superscript symbol ‘
${\it\nu}_{eff}={\it\nu}+{\it\nu}_{T}$
. Another non-physical implication is that a linear Galerkin term is to represent the nonlinear energy cascade. Numerous refinements of this eddy viscosity term have been suggested as discussed by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014). To simplify the notation, hereafter we will use the convention that the superscript symbol ‘
 $\text{}^{\circ }$
’ will denote quantities related to closure models obtained based on theoretical arguments, whereas the superscript symbol ‘
$\text{}^{\circ }$
’ will denote quantities related to closure models obtained based on theoretical arguments, whereas the superscript symbol ‘
 $\text{}^{\bullet }$
’ will denote the corresponding quantities related to closure models derived from actual data. In this study, our point of departure is a nonlinear modal eddy viscosity
$\text{}^{\bullet }$
’ will denote the corresponding quantities related to closure models derived from actual data. In this study, our point of departure is a nonlinear modal eddy viscosity
 $$\begin{eqnarray}{\it\nu}_{T}^{\circ }:={\it\nu}_{T}^{a}\,\sqrt{\frac{E(t)}{\overline{E}}}\,{\it\kappa}_{i}\end{eqnarray}$$
$$\begin{eqnarray}{\it\nu}_{T}^{\circ }:={\it\nu}_{T}^{a}\,\sqrt{\frac{E(t)}{\overline{E}}}\,{\it\kappa}_{i}\end{eqnarray}$$
with the mode-dependent factor
 ${\it\kappa}_{i}$
,
${\it\kappa}_{i}$
,
 $i=1,\dots ,N$
. This factor is equal to unity,
$i=1,\dots ,N$
. This factor is equal to unity,
 ${\it\kappa}_{i}\equiv 1$
, for the global eddy-viscosity ansatz and is derived from the modal power balance of the flow (Noack et al.
Reference Noack, Papas and Monkewitz2005) for the modal eddy viscosity. The quantity
${\it\kappa}_{i}\equiv 1$
, for the global eddy-viscosity ansatz and is derived from the modal power balance of the flow (Noack et al.
Reference Noack, Papas and Monkewitz2005) for the modal eddy viscosity. The quantity
 ${\it\nu}_{T}^{a}$
represents a constant reference value of the eddy viscosity obtained from a long-time average of energy dissipation in the flow on the attractor, where the latter is defined as usual in dynamical systems as a subset of the phase space to which all trajectories converge regardless of the initial positions. Thus, the eddy viscosity
${\it\nu}_{T}^{a}$
represents a constant reference value of the eddy viscosity obtained from a long-time average of energy dissipation in the flow on the attractor, where the latter is defined as usual in dynamical systems as a subset of the phase space to which all trajectories converge regardless of the initial positions. Thus, the eddy viscosity
 ${\it\nu}_{T}^{\circ }$
defined in (2.12) becomes larger than the reference value
${\it\nu}_{T}^{\circ }$
defined in (2.12) becomes larger than the reference value
 ${\it\nu}_{T}^{a}$
when the instantaneous resolved fluctuation energy
${\it\nu}_{T}^{a}$
when the instantaneous resolved fluctuation energy
 $E(t)$
exceeds
$E(t)$
exceeds
 $\overline{E}$
and vice versa. The square-root dependency of
$\overline{E}$
and vice versa. The square-root dependency of
 ${\it\nu}_{T}^{\circ }$
on
${\it\nu}_{T}^{\circ }$
on
 $E(t)$
is motivated by a scaling argument (Noack et al.
Reference Noack, Morzyński and Tadmor2011) and we add that this nonlinear eddy viscosity term guarantees the boundedness of any Galerkin solution (Cordier et al.
Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013). Hereafter we will refer to relation (2.12) as the ‘reference eddy viscosity’.
$E(t)$
is motivated by a scaling argument (Noack et al.
Reference Noack, Morzyński and Tadmor2011) and we add that this nonlinear eddy viscosity term guarantees the boundedness of any Galerkin solution (Cordier et al.
Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013). Hereafter we will refer to relation (2.12) as the ‘reference eddy viscosity’.
2.5. Transient dynamics
The nonlinear eddy viscosity term effectively has the ability to prevent non-physically large fluctuation levels. Another frequently observed shortcoming of POD systems are significantly over-predicted transient times, even for laminar flows. To shed light on this issue and show how it can be remedied through a suitable choice of a nonlinear eddy viscosity, in the following we consider one of the simplest POD Galerkin models exhibiting non-physical transient times and non-physical fluctuation levels. The starting point is the 2D laminar cylinder wake at
 $\mathit{Re}=100$
in an unbounded domain truncated for computational purposes to a finite box (Noack et al.
Reference Noack, Afanasiev, Morzyński, Tadmor and Thiele2003). The first two POD modes resolve already 95 % of the fluctuation energy and we chose
$\mathit{Re}=100$
in an unbounded domain truncated for computational purposes to a finite box (Noack et al.
Reference Noack, Afanasiev, Morzyński, Tadmor and Thiele2003). The first two POD modes resolve already 95 % of the fluctuation energy and we chose
 $N=2$
as the model order. The POD system is effectively phase-invariant and is well approximated by a linear oscillator:
$N=2$
as the model order. The POD system is effectively phase-invariant and is well approximated by a linear oscillator:
 $$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{1}}{\text{d}t}=\,f_{1}(a_{1},a_{2})={\it\sigma}^{\circ }a_{1}-{\it\omega}^{\circ }a_{2}, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{1}}{\text{d}t}=\,f_{1}(a_{1},a_{2})={\it\sigma}^{\circ }a_{1}-{\it\omega}^{\circ }a_{2}, & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{2}}{\text{d}t}=\,f_{2}(a_{1},a_{2})={\it\sigma}^{\circ }a_{2}+{\it\omega}^{\circ }a_{1}, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{2}}{\text{d}t}=\,f_{2}(a_{1},a_{2})={\it\sigma}^{\circ }a_{2}+{\it\omega}^{\circ }a_{1}, & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle {\it\sigma}^{\circ }=0.0073, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle {\it\sigma}^{\circ }=0.0073, & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle {\it\omega}^{\circ }=1.0763, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle {\it\omega}^{\circ }=1.0763, & \displaystyle\end{eqnarray}$$
The mode coefficients
 $a_{i}^{\bullet },~i=1,2$
, obtained from a direct numerical simulation (DNS) starting from the steady solution quickly converge to a limit cycle. This transient is far better approximated by the following mean-field model exhibiting a stable limit cycle at
$a_{i}^{\bullet },~i=1,2$
, obtained from a direct numerical simulation (DNS) starting from the steady solution quickly converge to a limit cycle. This transient is far better approximated by the following mean-field model exhibiting a stable limit cycle at
 $r_{\infty }\approx 2.3$
(Protas et al.
Reference Protas, Noack and Morzynski2014):
$r_{\infty }\approx 2.3$
(Protas et al.
Reference Protas, Noack and Morzynski2014):
 $$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{1}}{\text{d}t}={\it\sigma}^{\bullet }a_{1}-{\it\omega}^{\bullet }a_{2}, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{1}}{\text{d}t}={\it\sigma}^{\bullet }a_{1}-{\it\omega}^{\bullet }a_{2}, & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{2}}{\text{d}t}={\it\sigma}^{\bullet }a_{2}+{\it\omega}^{\bullet }a_{1}, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{2}}{\text{d}t}={\it\sigma}^{\bullet }a_{2}+{\it\omega}^{\bullet }a_{1}, & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle {\it\sigma}^{\bullet }={\it\sigma}_{1}[1-r^{2}/r_{\infty }^{2}], & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle {\it\sigma}^{\bullet }={\it\sigma}_{1}[1-r^{2}/r_{\infty }^{2}], & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle {\it\omega}^{\bullet }={\it\omega}_{1}+0.150\,r^{2}/r_{\infty }^{2}, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle {\it\omega}^{\bullet }={\it\omega}_{1}+0.150\,r^{2}/r_{\infty }^{2}, & \displaystyle\end{eqnarray}$$
 $r:=\sqrt{a_{1}^{2}+a_{2}^{2}}$
, and
$r:=\sqrt{a_{1}^{2}+a_{2}^{2}}$
, and
 ${\it\sigma}_{1}=0.151$
and
${\it\sigma}_{1}=0.151$
and
 ${\it\omega}_{1}=0.886$
representing the initial (i.e. evaluated at the unstable fixed point) growth rate and frequency of the transient solution (these values are obtained via calibration against the DNS data).
${\it\omega}_{1}=0.886$
representing the initial (i.e. evaluated at the unstable fixed point) growth rate and frequency of the transient solution (these values are obtained via calibration against the DNS data).
The growth rate (2.13c ) of the POD model is thus initially under-predicted by more than a factor of 20 while it is increasingly over-predicted near and beyond the limit cycle. We aim to correct this growth rate using the eddy viscosity ansatz of the form (2.11) which results in
 $$\begin{eqnarray}\displaystyle \frac{\text{d}a_{1}}{\text{d}t} & = & \displaystyle f_{1}(a_{1},a_{2})+{\it\nu}_{T}l_{11}^{{\it\nu}}a_{1},\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \frac{\text{d}a_{1}}{\text{d}t} & = & \displaystyle f_{1}(a_{1},a_{2})+{\it\nu}_{T}l_{11}^{{\it\nu}}a_{1},\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle \frac{\text{d}a_{2}}{\text{d}t} & = & \displaystyle f_{2}(a_{1},a_{2})+{\it\nu}_{T}l_{22}^{{\it\nu}}a_{2}.\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \frac{\text{d}a_{2}}{\text{d}t} & = & \displaystyle f_{2}(a_{1},a_{2})+{\it\nu}_{T}l_{22}^{{\it\nu}}a_{2}.\end{eqnarray}$$
 $l_{11}^{{\it\nu}}=l_{22}^{{\it\nu}}<0$
by the assumed phase invariance and the dissipativity property of the viscous term. Matching the growth rate of (2.15) with the DNS-inferred mean-field model (2.14) yields
$l_{11}^{{\it\nu}}=l_{22}^{{\it\nu}}<0$
by the assumed phase invariance and the dissipativity property of the viscous term. Matching the growth rate of (2.15) with the DNS-inferred mean-field model (2.14) yields  $$\begin{eqnarray}{\it\sigma}^{\circ }+{\it\nu}_{T}\,l_{11}^{{\it\nu}}={\it\sigma}^{\bullet }~\Longrightarrow ~{\it\nu}_{T}\,l_{11}^{{\it\nu}}={\it\sigma}^{\bullet }-{\it\sigma}^{\circ }={\it\sigma}_{1}\left[1-r^{2}/r_{\infty }^{2}\right]-{\it\sigma}^{\circ }.\end{eqnarray}$$
$$\begin{eqnarray}{\it\sigma}^{\circ }+{\it\nu}_{T}\,l_{11}^{{\it\nu}}={\it\sigma}^{\bullet }~\Longrightarrow ~{\it\nu}_{T}\,l_{11}^{{\it\nu}}={\it\sigma}^{\bullet }-{\it\sigma}^{\circ }={\it\sigma}_{1}\left[1-r^{2}/r_{\infty }^{2}\right]-{\it\sigma}^{\circ }.\end{eqnarray}$$
Evidently, the eddy viscosity is an affine function of the fluctuation energy
 $E(t)=r(t)^{2}/2$
, i.e.
$E(t)=r(t)^{2}/2$
, i.e.
 $$\begin{eqnarray}{\it\nu}_{T}(E)=a+bE\end{eqnarray}$$
$$\begin{eqnarray}{\it\nu}_{T}(E)=a+bE\end{eqnarray}$$
with a negative intercept
 $a=({\it\sigma}_{1}-{\it\sigma}^{\circ })/l_{11}^{{\it\nu}}$
and a positive slope
$a=({\it\sigma}_{1}-{\it\sigma}^{\circ })/l_{11}^{{\it\nu}}$
and a positive slope
 $b=-{\it\sigma}_{1}/(E_{\infty }\,l_{11}^{{\it\nu}})$
, in which
$b=-{\it\sigma}_{1}/(E_{\infty }\,l_{11}^{{\it\nu}})$
, in which
 $E_{\infty }=\overline{(a_{1}^{2}+a_{2}^{2})}/2=r_{\infty }^{2}/2$
, so that
$E_{\infty }=\overline{(a_{1}^{2}+a_{2}^{2})}/2=r_{\infty }^{2}/2$
, so that
 ${\it\nu}_{T}=-{\it\sigma}_{1}/l_{11}^{{\it\nu}}>0$
at
${\it\nu}_{T}=-{\it\sigma}_{1}/l_{11}^{{\it\nu}}>0$
at
 $E=E^{a}$
, where
$E=E^{a}$
, where
 $E^{a}$
is the fluctuating energy level corresponding to the attractor. Different aspects of these observations are illustrated in figure 2. In addition to the growth rate predicted by the standard POD model (2.13c
) and the growth rate
$E^{a}$
is the fluctuating energy level corresponding to the attractor. Different aspects of these observations are illustrated in figure 2. In addition to the growth rate predicted by the standard POD model (2.13c
) and the growth rate
 $r^{-1}\,(\text{d}r/\text{d}t)|_{r(t)}$
characterizing the DNS of the actual Navier–Stokes flow, in figure 2(a) we also show the optimal growth rate
$r^{-1}\,(\text{d}r/\text{d}t)|_{r(t)}$
characterizing the DNS of the actual Navier–Stokes flow, in figure 2(a) we also show the optimal growth rate
 ${\it\sigma}^{\bullet }(E)$
reconstructed by Protas et al. (Reference Protas, Noack and Morzynski2014) using a similar methodology as employed in the present study. It is clear from this figure that the optimal growth rate depending on the fluctuating energy provides a much better representation of the actual data than does the constant growth rate produced by the Galerkin procedure. The eddy viscosity
${\it\sigma}^{\bullet }(E)$
reconstructed by Protas et al. (Reference Protas, Noack and Morzynski2014) using a similar methodology as employed in the present study. It is clear from this figure that the optimal growth rate depending on the fluctuating energy provides a much better representation of the actual data than does the constant growth rate produced by the Galerkin procedure. The eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
corresponding to the optimal growth rate
${\it\nu}_{T}^{\bullet }$
corresponding to the optimal growth rate
 ${\it\sigma}^{\bullet }$
is shown as a function of
${\it\sigma}^{\bullet }$
is shown as a function of
 $E$
in figure 2(b) (this data is not shown for system (2.14), because it does not explicitly involve a term with eddy viscosity, hence
$E$
in figure 2(b) (this data is not shown for system (2.14), because it does not explicitly involve a term with eddy viscosity, hence
 ${\it\nu}_{T}^{\bullet }$
is not defined in that case). The key message from this figure is that the form of the optimally reconstructed eddy viscosity is quite similar to (2.17) and features both positive and negative values. We also remark here that the form of (2.17) as an affine function of
${\it\nu}_{T}^{\bullet }$
is not defined in that case). The key message from this figure is that the form of the optimally reconstructed eddy viscosity is quite similar to (2.17) and features both positive and negative values. We also remark here that the form of (2.17) as an affine function of
 $E$
is different from (2.12) which involves a square-root expression. There is, however, no contradiction, since (2.12) is obtained for the flow energy cascade with triadic mode interactions, while the mean-field model (2.14) describes the change of the growth rate due to base-flow variations with the associated Reynolds stresses proportional to
$E$
is different from (2.12) which involves a square-root expression. There is, however, no contradiction, since (2.12) is obtained for the flow energy cascade with triadic mode interactions, while the mean-field model (2.14) describes the change of the growth rate due to base-flow variations with the associated Reynolds stresses proportional to
 $E$
.
$E$
.

Figure 2. Results obtained for the two-dimensional cylinder wake flow at
 $\mathit{Re}=100$
: (a) the growth rates
$\mathit{Re}=100$
: (a) the growth rates
 ${\it\sigma}$
in ROMs (2.13) and (2.14) and (b) the corresponding optimal eddy viscosity
${\it\sigma}$
in ROMs (2.13) and (2.14) and (b) the corresponding optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
in system (2.15) as functions of the fluctuation energy
${\it\nu}_{T}^{\bullet }$
in system (2.15) as functions of the fluctuation energy
 $E$
; optimal reconstructions
$E$
; optimal reconstructions
 ${\it\sigma}^{\bullet }$
and
${\it\sigma}^{\bullet }$
and
 ${\it\nu}_{T}^{\bullet }$
computed by Protas et al. (Reference Protas, Noack and Morzynski2014) (dashed lines, red online), prediction from Galerkin model (2.13) (dotted line, blue online) and the quantity
${\it\nu}_{T}^{\bullet }$
computed by Protas et al. (Reference Protas, Noack and Morzynski2014) (dashed lines, red online), prediction from Galerkin model (2.13) (dotted line, blue online) and the quantity
 $r^{-1}\,(\text{d}r/\text{d}t)|_{r(t)}$
computed based on the solution of the Navier–Stokes problem (black solid line).
$r^{-1}\,(\text{d}r/\text{d}t)|_{r(t)}$
computed based on the solution of the Navier–Stokes problem (black solid line).
Summarizing, a negative eddy viscosity at low fluctuation values and positive at large fluctuation values can cure non-physically long transient times to the attractor. In the following we thus allow the eddy viscosity to be an essentially arbitrary function of
 $E$
$E$
 $$\begin{eqnarray}{\it\nu}_{T}^{\bullet }:={\it\nu}_{T}^{\bullet }(E).\end{eqnarray}$$
$$\begin{eqnarray}{\it\nu}_{T}^{\bullet }:={\it\nu}_{T}^{\bullet }(E).\end{eqnarray}$$
In light of the cylinder wake example, one may therefore expect small or negative values of the eddy viscosity to arise for
 $E<\overline{E}$
and positive values for
$E<\overline{E}$
and positive values for
 $E>E^{a}$
.
$E>E^{a}$
.
The marginal growth rates of POD models may be also related to unresolved base flow variations (Aubry et al. Reference Aubry, Holmes, Lumley and Stone1988; Noack et al. Reference Noack, Afanasiev, Morzyński, Tadmor and Thiele2003; Podvin Reference Podvin2009) and mode deformation during transients (Noack et al. Reference Noack, Afanasiev, Morzyński, Tadmor and Thiele2003; Sapsis & Majda Reference Sapsis and Majda2013). While it is possible to address these issues in our framework, it would significantly complicate the exposition, hence they will not be considered in the present study.
3. Optimal eddy viscosity
In this section we describe a variational approach for determination of an optimal dependence of the nonlinear eddy viscosity
 ${\it\nu}_{T}$
in the Galerkin system (2.11) on the TKE
${\it\nu}_{T}$
in the Galerkin system (2.11) on the TKE
 $E$
. Here, ‘optimality’ means that the eddy viscosity minimizes a performance criterion quantifying how well the evolution described by ROM (2.11) matches the actual evolution governed by Navier–Stokes system (2.1). We consider a time window
$E$
. Here, ‘optimality’ means that the eddy viscosity minimizes a performance criterion quantifying how well the evolution described by ROM (2.11) matches the actual evolution governed by Navier–Stokes system (2.1). We consider a time window
 $[0,T]$
whose length
$[0,T]$
whose length
 $T$
is a parameter and assume that over this time window the flow is characterized by the resolved TKE
$T$
is a parameter and assume that over this time window the flow is characterized by the resolved TKE
 $\widetilde{E}(t)$
representing the energy content of its first
$\widetilde{E}(t)$
representing the energy content of its first
 $N$
POD modes, i.e.
$N$
POD modes, i.e.
 $$\begin{eqnarray}\widetilde{E}(t):=\frac{1}{2}\,\mathop{\sum }_{i=1}^{N}\langle \boldsymbol{u}^{\prime }(\cdot ,t),\boldsymbol{u}_{i}\rangle _{L_{2}({\it\Omega})}^{2},\end{eqnarray}$$
$$\begin{eqnarray}\widetilde{E}(t):=\frac{1}{2}\,\mathop{\sum }_{i=1}^{N}\langle \boldsymbol{u}^{\prime }(\cdot ,t),\boldsymbol{u}_{i}\rangle _{L_{2}({\it\Omega})}^{2},\end{eqnarray}$$
where
 $\boldsymbol{u}^{\prime }$
,
$\boldsymbol{u}^{\prime }$
,
 $\boldsymbol{u}_{i}$
and the inner product
$\boldsymbol{u}_{i}$
and the inner product
 $\langle \cdot ,\cdot \rangle _{L_{2}({\it\Omega})}$
were defined in § 2.2. This fluctuation energy is determined from the solution (here, DNS or LES) of the Navier–Stokes problem. Then, we can define the following cost functional
$\langle \cdot ,\cdot \rangle _{L_{2}({\it\Omega})}$
were defined in § 2.2. This fluctuation energy is determined from the solution (here, DNS or LES) of the Navier–Stokes problem. Then, we can define the following cost functional
 $$\begin{eqnarray}\mathscr{J}({\it\nu}_{T})=\frac{1}{2T}\int _{0}^{\text{T}}[E(t;{\it\nu}_{T})-\widetilde{E}(t)]^{2}\,\text{d}t,\end{eqnarray}$$
$$\begin{eqnarray}\mathscr{J}({\it\nu}_{T})=\frac{1}{2T}\int _{0}^{\text{T}}[E(t;{\it\nu}_{T})-\widetilde{E}(t)]^{2}\,\text{d}t,\end{eqnarray}$$
where
 $E(t;{\it\nu}_{T})$
is the TKE characterizing system (2.11) which depends on eddy viscosity
$E(t;{\it\nu}_{T})$
is the TKE characterizing system (2.11) which depends on eddy viscosity
 ${\it\nu}_{T}$
. Since the length
${\it\nu}_{T}$
. Since the length
 $T$
of the time window on which measurements
$T$
of the time window on which measurements
 $\widetilde{E}(t)$
are available can be quite long compared to the times over which the ROM (2.11) is capable of reproducing accurately the actual trajectory, in evaluating
$\widetilde{E}(t)$
are available can be quite long compared to the times over which the ROM (2.11) is capable of reproducing accurately the actual trajectory, in evaluating
 $E(t;{\it\nu}_{T})$
we will periodically restart system (2.11) using projections of the actual flow evolution on the POD modes as the initial data
$E(t;{\it\nu}_{T})$
we will periodically restart system (2.11) using projections of the actual flow evolution on the POD modes as the initial data
 $\boldsymbol{a}^{0}$
. More precisely, we will subdivide the interval
$\boldsymbol{a}^{0}$
. More precisely, we will subdivide the interval
 $[0,T]$
into
$[0,T]$
into
 $M$
subintervals of length
$M$
subintervals of length
 ${\rm\Delta}T=T/M$
, so that
${\rm\Delta}T=T/M$
, so that
 $[0,T]=[0,{\rm\Delta}T]\cup [{\rm\Delta}T,2{\rm\Delta}T]\cup \cdots \cup [(M-1){\rm\Delta}T,M{\rm\Delta}T]$
, see figure 3. On each of the subintervals
$[0,T]=[0,{\rm\Delta}T]\cup [{\rm\Delta}T,2{\rm\Delta}T]\cup \cdots \cup [(M-1){\rm\Delta}T,M{\rm\Delta}T]$
, see figure 3. On each of the subintervals
 $[(m-1){\rm\Delta}T,m{\rm\Delta}T]$
,
$[(m-1){\rm\Delta}T,m{\rm\Delta}T]$
,
 $m=1,\dots ,M$
, the Galerkin system will therefore take the form
$m=1,\dots ,M$
, the Galerkin system will therefore take the form
 $$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{i}}{\text{d}t}=\mathop{\sum }_{j,k=0}^{N}q_{ijk}^{c}a_{j}a_{k}+\left[{\it\nu}+{\it\nu}_{T}(E(t))\right]\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\quad t\in ((m-1){\rm\Delta}T,m{\rm\Delta}T], & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle \frac{\text{d}a_{i}}{\text{d}t}=\mathop{\sum }_{j,k=0}^{N}q_{ijk}^{c}a_{j}a_{k}+\left[{\it\nu}+{\it\nu}_{T}(E(t))\right]\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\quad t\in ((m-1){\rm\Delta}T,m{\rm\Delta}T], & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle a_{i}((m-1){\rm\Delta}T)=a_{i}^{0,m},\quad i=1,\dots ,N, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle a_{i}((m-1){\rm\Delta}T)=a_{i}^{0,m},\quad i=1,\dots ,N, & \displaystyle\end{eqnarray}$$
 $a_{i}^{0,m}=\langle \boldsymbol{u}^{\prime }(\cdot ,(m-1){\rm\Delta}T),\boldsymbol{u}_{i}\rangle _{L_{2}({\it\Omega})}$
and
$a_{i}^{0,m}=\langle \boldsymbol{u}^{\prime }(\cdot ,(m-1){\rm\Delta}T),\boldsymbol{u}_{i}\rangle _{L_{2}({\it\Omega})}$
and
 $m=1,\dots ,M$
. Periodic restarts of Galerkin system (3.3) ensure that its trajectory never departs too far from the projected trajectory of the actual flow, which is important given the form of the cost functional adopted in (3.2).
$m=1,\dots ,M$
. Periodic restarts of Galerkin system (3.3) ensure that its trajectory never departs too far from the projected trajectory of the actual flow, which is important given the form of the cost functional adopted in (3.2).

Figure 3. Schematic showing the partition of the time window
 $[0,T]$
into subintervals
$[0,T]$
into subintervals
 $[(m-1){\rm\Delta}T,m{\rm\Delta}T]$
,
$[(m-1){\rm\Delta}T,m{\rm\Delta}T]$
,
 $m=1,\dots ,M$
.
$m=1,\dots ,M$
.
The nonlinear eddy viscosity
 ${\it\nu}_{T}^{\circ }$
introduced in § 2.4, cf. (2.12), will serve as a reference and point of departure for the present optimization approach. As regards the functional form of the optimal eddy viscosity
${\it\nu}_{T}^{\circ }$
introduced in § 2.4, cf. (2.12), will serve as a reference and point of departure for the present optimization approach. As regards the functional form of the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
, we will make the following rather non-restrictive assumptions (hereafter we will use the symbol
${\it\nu}_{T}^{\bullet }$
, we will make the following rather non-restrictive assumptions (hereafter we will use the symbol
 $e$
as the variable corresponding to the TKE
$e$
as the variable corresponding to the TKE
 $E$
).
$E$
).
Assumption 1. We assume that:
-
(a)
 ${\it\nu}_{T}^{\bullet }(e)$
is defined for
$e\in I:=[0,E_{max}]$
, where
$E_{max}$
is chosen such that
$E_{max}>\max _{t\in [0,T]}E(t)$
;
${\it\nu}_{T}^{\bullet }(e)$
is defined for
$e\in I:=[0,E_{max}]$
, where
$E_{max}$
is chosen such that
$E_{max}>\max _{t\in [0,T]}E(t)$
; -
(b)
${\it\nu}_{T}^{\bullet }(e)$
is a continuous function of
$e$
with square-integrable derivatives on
$I$
; this implies that
${\it\nu}_{T}^{\bullet }\in H^{1}(I)$
, where
$H^{1}(I)$
is the Sobolev function space equipped with the inner product (Adams & Fournier Reference Adams and Fournier2005) (3.4)where
$$\begin{eqnarray}\forall _{z_{1},z_{2}\in H^{1}(I)}\quad \langle z_{1},z_{2}\rangle _{H^{1}(I)}=\int _{0}^{E_{max}}z_{1}z_{2}+\ell ^{2}\frac{\partial z_{1}}{\partial e}\frac{\partial z_{2}}{\partial e}\,\text{d}e,\end{eqnarray}$$
$\ell >0$
;
-
(c)
(3.5)
$$\begin{eqnarray}{\it\nu}_{T}^{\bullet }(0)={\it\nu}_{T}^{\circ }(0)=0;\end{eqnarray}$$
-
(d)
(3.6)
$$\begin{eqnarray}\frac{\text{d}{\it\nu}_{T}^{\bullet }}{\text{d}e}|_{e=E_{max}}=\frac{\text{d}{\it\nu}_{T}^{\circ }}{\text{d}e}|_{e=E_{max}}=:G.\end{eqnarray}$$













Some comments are in place as regards the physical interpretation of the above assumptions. Assumption 1(a) guarantees that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(e)$
is defined over a range of
${\it\nu}_{T}^{\bullet }(e)$
is defined over a range of
 $e$
relevant for the given flow. Our experience shows that the specific value of
$e$
relevant for the given flow. Our experience shows that the specific value of
 $E_{max}$
does not noticeably influence the results, provided it is slightly larger than
$E_{max}$
does not noticeably influence the results, provided it is slightly larger than
 $\max _{t\in [0,T]}E(t)$
, typically by a factor in the range 1.1–3.0. Assumption 1(b) concerns the minimal smoothness of the optimal eddy viscosity as a function of
$\max _{t\in [0,T]}E(t)$
, typically by a factor in the range 1.1–3.0. Assumption 1(b) concerns the minimal smoothness of the optimal eddy viscosity as a function of
 $e$
. We emphasize that, as shown by Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011), omitting the differentiability requirement and assuming that
$e$
. We emphasize that, as shown by Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011), omitting the differentiability requirement and assuming that
 ${\it\nu}_{T}^{\bullet }$
is only square-integrable (
${\it\nu}_{T}^{\bullet }$
is only square-integrable (
 ${\it\nu}_{T}^{\bullet }\in L_{2}(I)$
) could in fact produce discontinuous eddy viscosities which are unphysical. Assumptions 1(c,d) imply that for limiting values of
${\it\nu}_{T}^{\bullet }\in L_{2}(I)$
) could in fact produce discontinuous eddy viscosities which are unphysical. Assumptions 1(c,d) imply that for limiting values of
 $e$
the behaviour of the optimal eddy viscosity
$e$
the behaviour of the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
is the same as in the reference relation (2.12). More specifically, at
${\it\nu}_{T}^{\bullet }$
is the same as in the reference relation (2.12). More specifically, at
 $e=0$
the optimal eddy viscosity
$e=0$
the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
will vanish, whereas at
${\it\nu}_{T}^{\bullet }$
will vanish, whereas at
 $e=E_{max}$
it will have the same slope (with respect to
$e=E_{max}$
it will have the same slope (with respect to
 $e$
) as the reference relation
$e$
) as the reference relation
 ${\it\nu}_{T}^{\circ }$
. The latter assumption is justified by the fact, shown by Noack et al. (Reference Noack, Morzyński and Tadmor2011), that the reference relation (2.12) is accurate in the limit of large
${\it\nu}_{T}^{\circ }$
. The latter assumption is justified by the fact, shown by Noack et al. (Reference Noack, Morzyński and Tadmor2011), that the reference relation (2.12) is accurate in the limit of large
 $e$
. Thus, Assumption 1 ensures that for small and large values of the fluctuation energy, for which no sensitivity information can be extracted from the model, the optimal reconstruction smoothly falls back to the reference eddy viscosity (2.12), or any other relation chosen in its place. We add that from the practical point of view this is not a problem, because in any given flow the fluctuation energy will not exceed
$e$
. Thus, Assumption 1 ensures that for small and large values of the fluctuation energy, for which no sensitivity information can be extracted from the model, the optimal reconstruction smoothly falls back to the reference eddy viscosity (2.12), or any other relation chosen in its place. We add that from the practical point of view this is not a problem, because in any given flow the fluctuation energy will not exceed
 $\max _{t\in [0,T]}E(t)$
by a significant fraction and, hence, the values of
$\max _{t\in [0,T]}E(t)$
by a significant fraction and, hence, the values of
 ${\it\nu}_{T}^{\bullet }(e)$
for
${\it\nu}_{T}^{\bullet }(e)$
for
 $e>\max _{t\in [0,T]}E(t)$
are not very important for the accuracy of the ROM (the optimal eddy viscosity is defined for such
$e>\max _{t\in [0,T]}E(t)$
are not very important for the accuracy of the ROM (the optimal eddy viscosity is defined for such
 $e$
for technical reasons only). It should be also emphasized that the optimal eddy viscosity
$e$
for technical reasons only). It should be also emphasized that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(e)$
is allowed to become negative for some values of the TKE
${\it\nu}_{T}^{\bullet }(e)$
is allowed to become negative for some values of the TKE
 $e$
.
$e$
.
The optimization problem for finding
 ${\it\nu}_{T}^{\bullet }$
can therefore be stated as follows
${\it\nu}_{T}^{\bullet }$
can therefore be stated as follows
 $$\begin{eqnarray}{\it\nu}_{T}^{\bullet }=\mathop{\text{argmin}}_{\stackrel{{\it\nu}_{T}\in H^{1}(I),}{{\it\nu}_{T}(0)=0,~\left.\frac{\text{d}{\it\nu}_{T}}{\text{d}e}\!\right|_{e=E_{max}}=G}}\mathscr{J}({\it\nu}_{T})\end{eqnarray}$$
$$\begin{eqnarray}{\it\nu}_{T}^{\bullet }=\mathop{\text{argmin}}_{\stackrel{{\it\nu}_{T}\in H^{1}(I),}{{\it\nu}_{T}(0)=0,~\left.\frac{\text{d}{\it\nu}_{T}}{\text{d}e}\!\right|_{e=E_{max}}=G}}\mathscr{J}({\it\nu}_{T})\end{eqnarray}$$
with cost functional
 $\mathscr{J}({\it\nu}_{T})$
given in (3.2) together with (3.3). While problem (3.7) is of the ‘parameter identification’ type, it is in fact quite different from the related problems already studied in the literature on reduced-order modelling (D’Adamo et al.
Reference D’Adamo, Papadakis, Mémin and Artana2007; Artana et al.
Reference Artana, Cammilleri, Carlier and Mémin2012; Cordier et al.
Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013), in which the optimal eddy viscosity
$\mathscr{J}({\it\nu}_{T})$
given in (3.2) together with (3.3). While problem (3.7) is of the ‘parameter identification’ type, it is in fact quite different from the related problems already studied in the literature on reduced-order modelling (D’Adamo et al.
Reference D’Adamo, Papadakis, Mémin and Artana2007; Artana et al.
Reference Artana, Cammilleri, Carlier and Mémin2012; Cordier et al.
Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013), in which the optimal eddy viscosity
 ${\it\nu}_{T}$
was sought as a function of time (i.e. an independent variable in the problem). The ROM resulting from such formulation is non-autonomous and therefore restricted to the time window and the initial condition used in the determination of the optimal eddy viscosity. Consequently, such time-dependent optimal eddy viscosity cannot be considered a proper ‘closure model’. On the other hand, our formulation (3.7) is fundamentally different and leads to an optimal eddy viscosity as a constitutive relation of the form
${\it\nu}_{T}$
was sought as a function of time (i.e. an independent variable in the problem). The ROM resulting from such formulation is non-autonomous and therefore restricted to the time window and the initial condition used in the determination of the optimal eddy viscosity. Consequently, such time-dependent optimal eddy viscosity cannot be considered a proper ‘closure model’. On the other hand, our formulation (3.7) is fundamentally different and leads to an optimal eddy viscosity as a constitutive relation of the form
 ${\it\nu}_{T}^{\bullet }={\it\nu}_{T}^{\bullet }(\Vert \boldsymbol{a}\Vert _{2}^{2}/2)$
, so that the corresponding ROM is autonomous.
${\it\nu}_{T}^{\bullet }={\it\nu}_{T}^{\bullet }(\Vert \boldsymbol{a}\Vert _{2}^{2}/2)$
, so that the corresponding ROM is autonomous.
In order to ensure that optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
satisfies Assumption 1, we will adopt the ‘optimize-then-discretize’ paradigm (Gunzburger Reference Gunzburger2003) in solving problem (3.7). While the solution of this problem relies on a standard gradient-based approach, it requires a specialized technique for the evaluation of gradients. Its mathematical and computational foundations were established by Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011) and Bukshtynov & Protas (Reference Bukshtynov and Protas2013), and here we use an adaptation of this approach to the identification of ROMs recently developed by Protas et al. (Reference Protas, Noack and Morzynski2014). Below we present the main elements of the algorithm deferring technical details to appendix A.
${\it\nu}_{T}^{\bullet }$
satisfies Assumption 1, we will adopt the ‘optimize-then-discretize’ paradigm (Gunzburger Reference Gunzburger2003) in solving problem (3.7). While the solution of this problem relies on a standard gradient-based approach, it requires a specialized technique for the evaluation of gradients. Its mathematical and computational foundations were established by Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011) and Bukshtynov & Protas (Reference Bukshtynov and Protas2013), and here we use an adaptation of this approach to the identification of ROMs recently developed by Protas et al. (Reference Protas, Noack and Morzynski2014). Below we present the main elements of the algorithm deferring technical details to appendix A.
The (local) minimizer
 ${\it\nu}_{T}^{\bullet }$
of (3.2) is characterized by the first-order optimality condition (Luenberger Reference Luenberger1969) requiring the vanishing of the Gâteaux differential
${\it\nu}_{T}^{\bullet }$
of (3.2) is characterized by the first-order optimality condition (Luenberger Reference Luenberger1969) requiring the vanishing of the Gâteaux differential
 $\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime }):=\lim _{{\it\epsilon}\rightarrow 0}{\it\epsilon}^{-1}[\mathscr{J}({\it\nu}_{T}+{\it\epsilon}{\it\nu}_{T}^{\prime })-\mathscr{J}({\it\nu}_{T})]$
, i.e.
$\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime }):=\lim _{{\it\epsilon}\rightarrow 0}{\it\epsilon}^{-1}[\mathscr{J}({\it\nu}_{T}+{\it\epsilon}{\it\nu}_{T}^{\prime })-\mathscr{J}({\it\nu}_{T})]$
, i.e.
 $$\begin{eqnarray}\forall _{{\it\nu}_{T}^{\prime }\in H^{1}(I),{\it\nu}_{T}^{\prime }(0)=0,\left.\frac{\text{d}{\it\nu}_{T}^{\prime }}{\text{d}e}\!\right|_{e=E_{max}}=0}\quad \mathscr{J}^{\prime }({\it\nu}_{T}^{\bullet };{\it\nu}_{T}^{\prime })=0,\end{eqnarray}$$
$$\begin{eqnarray}\forall _{{\it\nu}_{T}^{\prime }\in H^{1}(I),{\it\nu}_{T}^{\prime }(0)=0,\left.\frac{\text{d}{\it\nu}_{T}^{\prime }}{\text{d}e}\!\right|_{e=E_{max}}=0}\quad \mathscr{J}^{\prime }({\it\nu}_{T}^{\bullet };{\it\nu}_{T}^{\prime })=0,\end{eqnarray}$$
where
 ${\it\nu}_{T}^{\prime }$
is an arbitrary perturbation direction. This minimizer can be computed as
${\it\nu}_{T}^{\prime }$
is an arbitrary perturbation direction. This minimizer can be computed as
 ${\it\nu}_{T}^{\bullet }=\lim _{n\rightarrow \infty }{\it\nu}_{T}^{(n)}$
using the following iterative procedure
${\it\nu}_{T}^{\bullet }=\lim _{n\rightarrow \infty }{\it\nu}_{T}^{(n)}$
using the following iterative procedure
 $$\begin{eqnarray}\begin{array}{@{}c@{}}{\it\nu}_{T}^{(n+1)}={\it\nu}_{T}^{(n)}-{\it\tau}^{(n)}\boldsymbol{{\rm\nabla}}\mathscr{J}({\it\nu}_{T}^{(n)}),\quad n=1,\dots ,\\ {\it\nu}_{T}^{(1)}={\it\nu}_{T}^{\circ }\end{array}\end{eqnarray}$$
$$\begin{eqnarray}\begin{array}{@{}c@{}}{\it\nu}_{T}^{(n+1)}={\it\nu}_{T}^{(n)}-{\it\tau}^{(n)}\boldsymbol{{\rm\nabla}}\mathscr{J}({\it\nu}_{T}^{(n)}),\quad n=1,\dots ,\\ {\it\nu}_{T}^{(1)}={\it\nu}_{T}^{\circ }\end{array}\end{eqnarray}$$
where the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }$
from § 2.4 is taken as the initial guess,
${\it\nu}_{T}^{\circ }$
from § 2.4 is taken as the initial guess,
 $n$
denotes the iteration count and
$n$
denotes the iteration count and
 $\boldsymbol{{\rm\nabla}}\!\mathscr{J}:I\rightarrow \mathbb{R}$
is the gradient of cost functional
$\boldsymbol{{\rm\nabla}}\!\mathscr{J}:I\rightarrow \mathbb{R}$
is the gradient of cost functional
 $\mathscr{J}$
. The length
$\mathscr{J}$
. The length
 ${\it\tau}^{(n)}$
of the step along the descent direction is determined by solving line minimization problem
${\it\tau}^{(n)}$
of the step along the descent direction is determined by solving line minimization problem
 $$\begin{eqnarray}{\it\tau}^{(n)}=\mathop{\text{argmin}}_{{\it\tau}>0}\;\mathscr{J}\left({\it\nu}_{T}^{(n)}-{\it\tau}\boldsymbol{{\rm\nabla}}\mathscr{J}_{1}({\it\nu}_{T}^{(n)})\right)\end{eqnarray}$$
$$\begin{eqnarray}{\it\tau}^{(n)}=\mathop{\text{argmin}}_{{\it\tau}>0}\;\mathscr{J}\left({\it\nu}_{T}^{(n)}-{\it\tau}\boldsymbol{{\rm\nabla}}\mathscr{J}_{1}({\it\nu}_{T}^{(n)})\right)\end{eqnarray}$$
which can be done efficiently using standard techniques such as Brent’s method (Press et al.
Reference Press, Flanner, Teukolsky and Vetterling1986). For the sake of clarity, formulation (3.9) represents the steepest-descent method, however, in practice one typically uses more advanced minimization techniques, such as the conjugate gradient method, or one of the quasi-Newton techniques (Nocedal & Wright Reference Nocedal and Wright2002). Evidently, the key element of minimization algorithm (3.9) is the computation of the cost functional gradient
 $\boldsymbol{{\rm\nabla}}\mathscr{J}$
. It ought to be emphasized that, while the governing system (3.3) is finite-dimensional, the gradient
$\boldsymbol{{\rm\nabla}}\mathscr{J}$
. It ought to be emphasized that, while the governing system (3.3) is finite-dimensional, the gradient
 $\boldsymbol{{\rm\nabla}}\mathscr{J}$
is a function of the TKE
$\boldsymbol{{\rm\nabla}}\mathscr{J}$
is a function of the TKE
 $e$
and as such represents a continuous (infinite-dimensional) sensitivity of cost functional
$e$
and as such represents a continuous (infinite-dimensional) sensitivity of cost functional
 $\mathscr{J}({\it\nu}_{T})$
to the perturbations
$\mathscr{J}({\it\nu}_{T})$
to the perturbations
 ${\it\nu}_{T}^{\prime }={\it\nu}_{T}^{\prime }(e)$
. As shown in appendix A, the
${\it\nu}_{T}^{\prime }={\it\nu}_{T}^{\prime }(e)$
. As shown in appendix A, the
 $L_{2}$
gradient of cost functional (3.2) can for
$L_{2}$
gradient of cost functional (3.2) can for
 $e\in [0,E_{max}]$
be evaluated as
$e\in [0,E_{max}]$
be evaluated as
 $$\begin{eqnarray}{\rm\nabla}^{L_{2}}\mathscr{J}(e)=\mathop{\sum }_{\stackrel{t}{E(\boldsymbol{a}(t))=e}}\frac{\displaystyle \mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}(t)a_{i}^{\ast }(t)}{\displaystyle \mathop{\sum }_{i=1}^{N}a_{i}(t)\left[f_{i}(\boldsymbol{a}(t))+{\it\nu}_{T}(\Vert \boldsymbol{a}(t)\Vert _{2}^{2}/2)\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}(t)\right]}\end{eqnarray}$$
$$\begin{eqnarray}{\rm\nabla}^{L_{2}}\mathscr{J}(e)=\mathop{\sum }_{\stackrel{t}{E(\boldsymbol{a}(t))=e}}\frac{\displaystyle \mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}(t)a_{i}^{\ast }(t)}{\displaystyle \mathop{\sum }_{i=1}^{N}a_{i}(t)\left[f_{i}(\boldsymbol{a}(t))+{\it\nu}_{T}(\Vert \boldsymbol{a}(t)\Vert _{2}^{2}/2)\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}(t)\right]}\end{eqnarray}$$
in which
 $f_{i}(\boldsymbol{a}(t))$
is defined in (2.9), whereas
$f_{i}(\boldsymbol{a}(t))$
is defined in (2.9), whereas
 $\boldsymbol{a}^{\ast }(t)=[0,a_{1}^{\ast }(t),\dots ,a_{N}^{\ast }(t)]^{\text{T}}\in \mathbb{R}^{N+1}$
is the solution of adjoint system
$\boldsymbol{a}^{\ast }(t)=[0,a_{1}^{\ast }(t),\dots ,a_{N}^{\ast }(t)]^{\text{T}}\in \mathbb{R}^{N+1}$
is the solution of adjoint system
 $$\begin{eqnarray}\displaystyle & \displaystyle -\frac{\text{d}a_{i}^{\ast }}{\text{d}t}=\mathop{\sum }_{j=0}^{N}A_{ji}a_{j}^{\ast }+\frac{a_{i}}{T}\left[E(t)-\widetilde{E}(t)\right],\quad t\in ((m-1){\rm\Delta}T,m{\rm\Delta}T], & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle -\frac{\text{d}a_{i}^{\ast }}{\text{d}t}=\mathop{\sum }_{j=0}^{N}A_{ji}a_{j}^{\ast }+\frac{a_{i}}{T}\left[E(t)-\widetilde{E}(t)\right],\quad t\in ((m-1){\rm\Delta}T,m{\rm\Delta}T], & \displaystyle\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & \displaystyle a_{i}^{\ast }(m{\rm\Delta}T)=0,\quad i=1,\dots ,N,~m=1,\dots ,M, & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & \displaystyle a_{i}^{\ast }(m{\rm\Delta}T)=0,\quad i=1,\dots ,N,~m=1,\dots ,M, & \displaystyle\end{eqnarray}$$
 $\boldsymbol{A}$
is the linearized operator defined in appendix A. So that it has the same dimension
$\boldsymbol{A}$
is the linearized operator defined in appendix A. So that it has the same dimension
 $(N+1)$
as the state vector
$(N+1)$
as the state vector
 $\boldsymbol{a}(t)$
, cf. § 2.2, the adjoint state
$\boldsymbol{a}(t)$
, cf. § 2.2, the adjoint state
 $\boldsymbol{a}^{\ast }(t)$
is defined to have an extra (zero) element in the first position. In order to ensure that the optimal eddy viscosity
$\boldsymbol{a}^{\ast }(t)$
is defined to have an extra (zero) element in the first position. In order to ensure that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
possesses the smoothness and boundary behaviour required by Assumption 1, in iterations (3.9) we need to use the
${\it\nu}_{T}^{\bullet }$
possesses the smoothness and boundary behaviour required by Assumption 1, in iterations (3.9) we need to use the
 $H^{1}$
Sobolev gradient
$H^{1}$
Sobolev gradient
 $\boldsymbol{{\rm\nabla}}\mathscr{J}={\rm\nabla}^{H^{1}}\mathscr{J}$
defined with respect to inner product (3.4), rather than the
$\boldsymbol{{\rm\nabla}}\mathscr{J}={\rm\nabla}^{H^{1}}\mathscr{J}$
defined with respect to inner product (3.4), rather than the
 $L_{2}$
gradient given in (3.11). The two gradients are related through the following elliptic boundary-value problem (Protas, Bewley & Hagen Reference Protas, Bewley and Hagen2004)
$L_{2}$
gradient given in (3.11). The two gradients are related through the following elliptic boundary-value problem (Protas, Bewley & Hagen Reference Protas, Bewley and Hagen2004)  $$\begin{eqnarray}\displaystyle \left(1-\ell ^{2}\frac{\text{d}^{2}}{\text{d}e^{2}}\right){\rm\nabla}^{H^{1}}\mathscr{J} & = & \displaystyle {\rm\nabla}^{L_{2}}\mathscr{J}\quad \text{in}~(0,E_{max}),\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \left(1-\ell ^{2}\frac{\text{d}^{2}}{\text{d}e^{2}}\right){\rm\nabla}^{H^{1}}\mathscr{J} & = & \displaystyle {\rm\nabla}^{L_{2}}\mathscr{J}\quad \text{in}~(0,E_{max}),\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle {\rm\nabla}^{H^{1}}\mathscr{J} & = & \displaystyle 0\quad \text{at}~e=0,\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle {\rm\nabla}^{H^{1}}\mathscr{J} & = & \displaystyle 0\quad \text{at}~e=0,\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle \frac{\text{d}}{\text{d}e}{\rm\nabla}^{H^{1}}\mathscr{J} & = & \displaystyle 0\quad \text{at}~e=E_{max},\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \frac{\text{d}}{\text{d}e}{\rm\nabla}^{H^{1}}\mathscr{J} & = & \displaystyle 0\quad \text{at}~e=E_{max},\end{eqnarray}$$
 $\ell \in \mathbb{R}$
is a parameter with the meaning of a ‘length scale’. Protas et al. (Reference Protas, Bewley and Hagen2004) showed that extraction of cost functional gradients in the space
$\ell \in \mathbb{R}$
is a parameter with the meaning of a ‘length scale’. Protas et al. (Reference Protas, Bewley and Hagen2004) showed that extraction of cost functional gradients in the space
 $H^{1}$
with the inner product defined as in (3.4) can be regarded as low-pass filtering the
$H^{1}$
with the inner product defined as in (3.4) can be regarded as low-pass filtering the
 $L_{2}$
gradients with the cut-off wavenumber given by
$L_{2}$
gradients with the cut-off wavenumber given by
 $\ell ^{-1}$
. As regards the behaviour of the gradients
$\ell ^{-1}$
. As regards the behaviour of the gradients
 ${\rm\nabla}^{H^{1}}\mathscr{J}$
at the endpoints of the interval
${\rm\nabla}^{H^{1}}\mathscr{J}$
at the endpoints of the interval
 $I$
, boundary conditions (3.13b
,
c
) ensure that all iterates
$I$
, boundary conditions (3.13b
,
c
) ensure that all iterates
 ${\it\nu}_{T}^{(n)}$
have the same behaviour as the initial guess
${\it\nu}_{T}^{(n)}$
have the same behaviour as the initial guess
 ${\it\nu}_{T}^{\circ }$
, cf. Assumption 1(c,d). At every iteration (3.9) of the computational algorithm one first evaluates the
${\it\nu}_{T}^{\circ }$
, cf. Assumption 1(c,d). At every iteration (3.9) of the computational algorithm one first evaluates the
 $L_{2}$
gradient (3.11), which requires integration along the system trajectory in the phase space
$L_{2}$
gradient (3.11), which requires integration along the system trajectory in the phase space
 $\mathbb{R}^{N}$
(Protas et al.
Reference Protas, Noack and Morzynski2014), and then solves problem (3.13) as a ‘post-processing’ step to obtain the Sobolev gradient
$\mathbb{R}^{N}$
(Protas et al.
Reference Protas, Noack and Morzynski2014), and then solves problem (3.13) as a ‘post-processing’ step to obtain the Sobolev gradient
 ${\rm\nabla}^{H^{1}}\mathscr{J}$
. Application of this approach to identification of the optimal eddy viscosity in ROMs of two complex flow problems is discussed in the next section.
${\rm\nabla}^{H^{1}}\mathscr{J}$
. Application of this approach to identification of the optimal eddy viscosity in ROMs of two complex flow problems is discussed in the next section.

Figure 4. An instantaneous vorticity field (with red and blue representing, respectively, positive and negative values) in the 2D mixing layer flow studied in § 4.1.
4. Results
In this section we present the results obtained applying the procedure from § 3 to determine the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
for two realistic flow problems with distinct properties from the point of view of reduced-order modelling. The first, discussed in § 4.1, concerns a 2D mixing layer at a medium Reynolds number. It features a small number of dominating frequencies and most of the flow energy is resolved by a 20-dimensional Galerkin model. The second problem, discussed in § 4.2, concerns a high-Reynolds-number wake flow past an Ahmed body. This flow problem is characterized by a broadband frequency spectrum such that a 100-dimensional Galerkin model resolves less than half of the total energy only.
${\it\nu}_{T}^{\bullet }$
for two realistic flow problems with distinct properties from the point of view of reduced-order modelling. The first, discussed in § 4.1, concerns a 2D mixing layer at a medium Reynolds number. It features a small number of dominating frequencies and most of the flow energy is resolved by a 20-dimensional Galerkin model. The second problem, discussed in § 4.2, concerns a high-Reynolds-number wake flow past an Ahmed body. This flow problem is characterized by a broadband frequency spectrum such that a 100-dimensional Galerkin model resolves less than half of the total energy only.
4.1. Mixing layer model
The 2D mixing layer has a Reynolds number of 500 based on the initial vorticity thickness
 $L={\it\delta}_{v}$
and the maximum velocity of the upper stream
$L={\it\delta}_{v}$
and the maximum velocity of the upper stream
 $U=U_{1}$
. The inflow is described by a
$U=U_{1}$
. The inflow is described by a
 $\tanh$
profile with stochastic perturbations and the velocity ratio between the upper and lower stream is equal to
$\tanh$
profile with stochastic perturbations and the velocity ratio between the upper and lower stream is equal to
 $U_{1}/U_{2}=3$
. The observation region for the POD analysis coincides with the computational domain and is given by
$U_{1}/U_{2}=3$
. The observation region for the POD analysis coincides with the computational domain and is given by
 $$\begin{eqnarray}{\it\Omega}:=\{(x,y):0\leqslant x\leqslant 140,-28\leqslant y\leqslant 28\}.\end{eqnarray}$$
$$\begin{eqnarray}{\it\Omega}:=\{(x,y):0\leqslant x\leqslant 140,-28\leqslant y\leqslant 28\}.\end{eqnarray}$$
The DNS is based on the sixth-order accurate compact finite-difference approximations for the derivatives in space and a third-order accurate approximation for the derivatives with respect to time. The post-transient flow is computed over 2000 convective time units and sampled with the uniform time step
 ${\rm\Delta}t=1$
. Further details concerning the numerical approach are described by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014) and Kasten et al. (Reference Kasten, Reininghaus, Hotz, Hege, Noack, Daviller, Comte and Morzyński2014), and figure 4 shows a snapshot of the vorticity field in the flow. The numerical data is used to construct the Galerkin system (2.11) with dimension
${\rm\Delta}t=1$
. Further details concerning the numerical approach are described by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014) and Kasten et al. (Reference Kasten, Reininghaus, Hotz, Hege, Noack, Daviller, Comte and Morzyński2014), and figure 4 shows a snapshot of the vorticity field in the flow. The numerical data is used to construct the Galerkin system (2.11) with dimension
 $N=20$
using the procedure discussed in § 2 and setting
$N=20$
using the procedure discussed in § 2 and setting
 ${\it\kappa}_{i}=1$
,
${\it\kappa}_{i}=1$
,
 $i=1,\dots ,N$
, in (2.12). The dimension
$i=1,\dots ,N$
, in (2.12). The dimension
 $N=20$
ensures that the Galerkin system captures 80 % of the flow energy. Optimization problem (3.7) is solved for a broad range of time intervals
$N=20$
ensures that the Galerkin system captures 80 % of the flow energy. Optimization problem (3.7) is solved for a broad range of time intervals
 $4\leqslant {\rm\Delta}T\leqslant 2000~(500\geqslant M\geqslant 1)$
at which the governing system (3.3) is restarted with new initial conditions. In general, optimal eddy viscosities with two distinct sets of properties are recovered and in order to illustrate these reconstructions below we will present the results for two representative cases with
$4\leqslant {\rm\Delta}T\leqslant 2000~(500\geqslant M\geqslant 1)$
at which the governing system (3.3) is restarted with new initial conditions. In general, optimal eddy viscosities with two distinct sets of properties are recovered and in order to illustrate these reconstructions below we will present the results for two representative cases with
 ${\rm\Delta}T=10$
and
${\rm\Delta}T=10$
and
 ${\rm\Delta}T=200$
which will be referred to as optimization over, respectively, short and long windows.
${\rm\Delta}T=200$
which will be referred to as optimization over, respectively, short and long windows.
We begin by presenting in figure 5 the decrease of cost functional (3.2) with iterations (3.9). We see that in the case of the short window (
 ${\rm\Delta}T=10$
) not only are the values of functional (3.2) smaller, but also the relative decrease achieved during iterations is less significant (approximately 8 % in figure 5
a). This implies that over such short time windows the reference ansatz (2.12) for eddy viscosity performs satisfactorily and the improvement obtained with optimization is marginal only. On the other hand, in the case with longer time windows (
${\rm\Delta}T=10$
) not only are the values of functional (3.2) smaller, but also the relative decrease achieved during iterations is less significant (approximately 8 % in figure 5
a). This implies that over such short time windows the reference ansatz (2.12) for eddy viscosity performs satisfactorily and the improvement obtained with optimization is marginal only. On the other hand, in the case with longer time windows (
 ${\rm\Delta}T=200$
, see figure 5
b), the values of the cost functional are much larger as is its relative reduction (approximately 74 %) achieved with optimization. The corresponding optimal eddy viscosities
${\rm\Delta}T=200$
, see figure 5
b), the values of the cost functional are much larger as is its relative reduction (approximately 74 %) achieved with optimization. The corresponding optimal eddy viscosities
 ${\it\nu}_{T}^{\bullet }$
are presented in figure 6 together with the reference relation (2.12). We see that the optimal relation
${\it\nu}_{T}^{\bullet }$
are presented in figure 6 together with the reference relation (2.12). We see that the optimal relation
 ${\it\nu}_{T}^{\bullet }$
deviates from the reference eddy viscosity
${\it\nu}_{T}^{\bullet }$
deviates from the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }$
for
${\it\nu}_{T}^{\circ }$
for
 $E\in [0,100]$
, which is the range of values spanned by the DNS solution, see figure 7(a). On the other hand, for values of
$E\in [0,100]$
, which is the range of values spanned by the DNS solution, see figure 7(a). On the other hand, for values of
 $E$
outside that range the sensitivity information is not available and therefore by construction, cf. Assumption 1(d), the optimal eddy viscosity
$E$
outside that range the sensitivity information is not available and therefore by construction, cf. Assumption 1(d), the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
exhibits the same behaviour as the reference relation
${\it\nu}_{T}^{\bullet }$
exhibits the same behaviour as the reference relation
 ${\it\nu}_{T}^{\circ }$
. Two distinct behaviours are observed, with the optimal eddy viscosity
${\it\nu}_{T}^{\circ }$
. Two distinct behaviours are observed, with the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
becoming negative for
${\it\nu}_{T}^{\bullet }$
becoming negative for
 $E\in [0,40]$
in the case with optimization over long windows (
$E\in [0,40]$
in the case with optimization over long windows (
 ${\rm\Delta}T=200$
). We remark that this feature of the eddy viscosity was already discussed in § 2.5 where it was found to arise in a two-dimensional Galerkin model of laminar vortex shedding in the cylinder wake. The bimodal form of the optimal eddy viscosity shown in figure 6 for the short optimization window helps stabilize multiple energy levels in the flow. On the other hand, the negative eddy viscosity obtained with long optimization windows creates an excitation mechanism for the coherent structures. The physical aspects of the optimal eddy viscosities are further discussed and compared among different flow problems in § 5.
${\rm\Delta}T=200$
). We remark that this feature of the eddy viscosity was already discussed in § 2.5 where it was found to arise in a two-dimensional Galerkin model of laminar vortex shedding in the cylinder wake. The bimodal form of the optimal eddy viscosity shown in figure 6 for the short optimization window helps stabilize multiple energy levels in the flow. On the other hand, the negative eddy viscosity obtained with long optimization windows creates an excitation mechanism for the coherent structures. The physical aspects of the optimal eddy viscosities are further discussed and compared among different flow problems in § 5.

Figure 5. Mixing layer: decrease of the cost functional (3.2) with iterations
 $n$
for optimization over (a) over short windows (
$n$
for optimization over (a) over short windows (
 ${\rm\Delta}T=10$
) and (b) over long windows (
${\rm\Delta}T=10$
) and (b) over long windows (
 ${\rm\Delta}T=200$
). The two sets of data are plotted on separate graphs because of the widely different values of
${\rm\Delta}T=200$
). The two sets of data are plotted on separate graphs because of the widely different values of
 $\mathscr{J}({\it\nu}_{T}^{(n)})$
.
$\mathscr{J}({\it\nu}_{T}^{(n)})$
.

Figure 6. Mixing layer: optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=10$
; dashed line, purple online); reference eddy viscosity
${\rm\Delta}T=10$
; dashed line, purple online); reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
is marked with a thick (blue online) dotted line.
${\it\nu}_{T}^{\circ }(E)$
is marked with a thick (blue online) dotted line.

Figure 7. Mixing layer: (a) TKE
 $E(t)$
as a function of time
$E(t)$
as a function of time
 $t$
and (b) time-averaged modal energy
$t$
and (b) time-averaged modal energy
 $\overline{E}_{i}$
as a function of mode index
$\overline{E}_{i}$
as a function of mode index
 $i$
for DNS projected on
$i$
for DNS projected on
 $N=20$
POD modes (thick black solid line), ROM with the reference eddy viscosity
$N=20$
POD modes (thick black solid line), ROM with the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=10$
; dashed line, purple online).
${\rm\Delta}T=10$
; dashed line, purple online).
Table 1. Mixing layer: mean resolved TKE
 $\overline{E}$
and its standard deviation
$\overline{E}$
and its standard deviation
 $\text{std}(E)$
in the different cases considered in § 4.1.
$\text{std}(E)$
in the different cases considered in § 4.1.

The histories of the resolved total kinetic energy
 $E(t)$
, which is the quantity used as the performance criterion in our optimization problem, cf. (3.2), are presented in figure 7(a), whereas in figure 7(b) we show the corresponding average modal energies
$E(t)$
, which is the quantity used as the performance criterion in our optimization problem, cf. (3.2), are presented in figure 7(a), whereas in figure 7(b) we show the corresponding average modal energies
 $\overline{E}_{i}$
,
$\overline{E}_{i}$
,
 $i=1,\dots ,20$
. The mean values of the total kinetic energy
$i=1,\dots ,20$
. The mean values of the total kinetic energy
 $\overline{E}$
and their standard deviations are summarized in table 1. An interesting observation one can make about this data is that the standard deviation of the TKE is quite high and equal to about a third of its mean value
$\overline{E}$
and their standard deviations are summarized in table 1. An interesting observation one can make about this data is that the standard deviation of the TKE is quite high and equal to about a third of its mean value
 $\overline{E}$
. The reason is that the mixing-layer flow is dominated by a relatively small number of large coherent structures (cf. figure 4). Although this may not be evident from the data in table 1, figure 7(a) shows that the optimal eddy viscosity
$\overline{E}$
. The reason is that the mixing-layer flow is dominated by a relatively small number of large coherent structures (cf. figure 4). Although this may not be evident from the data in table 1, figure 7(a) shows that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
) allows the Galerkin system (2.11) to track the total kinetic energy
${\rm\Delta}T=200$
) allows the Galerkin system (2.11) to track the total kinetic energy
 $\widetilde{E}(t)$
of the original DNS simulation better than when the reference ansatz
$\widetilde{E}(t)$
of the original DNS simulation better than when the reference ansatz
 ${\it\nu}_{T}^{\circ }$
is used. This improvement is quantified by a 74 % decrease of the cost functional, representing the least-squares reconstruction error, cf. (3.2), starting from the initial guess given by the reference relation
${\it\nu}_{T}^{\circ }$
is used. This improvement is quantified by a 74 % decrease of the cost functional, representing the least-squares reconstruction error, cf. (3.2), starting from the initial guess given by the reference relation
 ${\it\nu}_{T}^{\circ }$
and the final iteration producing the optimal reconstruction
${\it\nu}_{T}^{\circ }$
and the final iteration producing the optimal reconstruction
 ${\it\nu}_{T}^{\bullet }$
(figure 5
b). Figure 7(b) indicates that this improvement is achieved with the optimal eddy viscosity
${\it\nu}_{T}^{\bullet }$
(figure 5
b). Figure 7(b) indicates that this improvement is achieved with the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
by a more accurate reconstruction of the average modal energy of the first two modes which comes at the price of a somewhat poorer reconstruction of
${\it\nu}_{T}^{\bullet }$
by a more accurate reconstruction of the average modal energy of the first two modes which comes at the price of a somewhat poorer reconstruction of
 $E_{i}$
when
$E_{i}$
when
 $i\geqslant 2$
. On the other hand, when the optimal eddy viscosity is obtained with optimization over short windows (
$i\geqslant 2$
. On the other hand, when the optimal eddy viscosity is obtained with optimization over short windows (
 ${\rm\Delta}T=10$
), only a modest improvement is observed. The reason for that is that, as will be discussed in more detail in § 5, the optimization horizon
${\rm\Delta}T=10$
), only a modest improvement is observed. The reason for that is that, as will be discussed in more detail in § 5, the optimization horizon
 ${\rm\Delta}T=10$
is shorter than the time scale of the characteristic events in the flow. These observations are also corroborated by the results presented in figure 8, where we show the time-histories of selected Galerkin coefficients
${\rm\Delta}T=10$
is shorter than the time scale of the characteristic events in the flow. These observations are also corroborated by the results presented in figure 8, where we show the time-histories of selected Galerkin coefficients
 $a_{i}(t)$
,
$a_{i}(t)$
,
 $i=1,5,10,20$
. In that figure we see that the optimal eddy viscosity
$i=1,5,10,20$
. In that figure we see that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
obtained with long optimization windows allows one to capture the amplitude
${\it\nu}_{T}^{\bullet }$
obtained with long optimization windows allows one to capture the amplitude
 $a_{1}$
of the first POD mode with a higher accuracy than when the reference relation
$a_{1}$
of the first POD mode with a higher accuracy than when the reference relation
 ${\it\nu}_{T}^{\circ }$
is used. On the other hand, this optimal eddy viscosity tends to underestimate the amplitudes of the higher modes with
${\it\nu}_{T}^{\circ }$
is used. On the other hand, this optimal eddy viscosity tends to underestimate the amplitudes of the higher modes with
 $i=5,10,20$
. Such trade-offs, which are typical of solutions obtained with optimization approaches, are a consequence of our choice of the cost functional (3.2) based on energy, a quantity which in the present flow is captured by the first few POD modes (figure 7
b). In other words, POD modes with
$i=5,10,20$
. Such trade-offs, which are typical of solutions obtained with optimization approaches, are a consequence of our choice of the cost functional (3.2) based on energy, a quantity which in the present flow is captured by the first few POD modes (figure 7
b). In other words, POD modes with
 $i\geqslant 3$
contribute much less to the cost functional than the first two modes, and therefore their behaviour is to a lesser extent improved by optimization. In figure 9 we present the ‘unbiased’ correlation function (Orfanidis Reference Orfanidis1996)
$i\geqslant 3$
contribute much less to the cost functional than the first two modes, and therefore their behaviour is to a lesser extent improved by optimization. In figure 9 we present the ‘unbiased’ correlation function (Orfanidis Reference Orfanidis1996)
 $$\begin{eqnarray}C({\it\tau}):=\frac{1}{T-{\it\tau}}\int _{{\it\tau}}^{\text{T}}\langle \boldsymbol{u}^{\prime }(\cdot ,t-{\it\tau})\boldsymbol{\cdot }\boldsymbol{u}^{\prime }(\cdot ,t)\rangle _{L_{2}({\it\Omega})}\,\text{d}t,\quad {\it\tau}\in [0,T)\end{eqnarray}$$
$$\begin{eqnarray}C({\it\tau}):=\frac{1}{T-{\it\tau}}\int _{{\it\tau}}^{\text{T}}\langle \boldsymbol{u}^{\prime }(\cdot ,t-{\it\tau})\boldsymbol{\cdot }\boldsymbol{u}^{\prime }(\cdot ,t)\rangle _{L_{2}({\it\Omega})}\,\text{d}t,\quad {\it\tau}\in [0,T)\end{eqnarray}$$
after normalization with respect to
 $C(0)$
. We note that using ansatz (2.5) and the orthogonality property of the POD modes, it can be conveniently evaluated in terms of the autocorrelations of the individual Galerkin coefficients, i.e.
$C(0)$
. We note that using ansatz (2.5) and the orthogonality property of the POD modes, it can be conveniently evaluated in terms of the autocorrelations of the individual Galerkin coefficients, i.e.
 $$\begin{eqnarray}C({\it\tau})=\frac{1}{T-{\it\tau}}\mathop{\sum }_{i=1}^{N}\int _{{\it\tau}}^{\text{T}}a_{i}(t-{\it\tau})a_{i}(t)\,\text{d}t.\end{eqnarray}$$
$$\begin{eqnarray}C({\it\tau})=\frac{1}{T-{\it\tau}}\mathop{\sum }_{i=1}^{N}\int _{{\it\tau}}^{\text{T}}a_{i}(t-{\it\tau})a_{i}(t)\,\text{d}t.\end{eqnarray}$$
In figure 9 illustrating this correlation function the oscillatory behaviour at levels around 0.3 reveals a dominant periodicity in the mixing layer. This rather low level comes from the fact that any vortex configuration is a new realization and is never exactly reproduced at any other time. The increasing correlation level as
 ${\it\tau}\rightarrow 2000$
indicates that the final state is close to the initial one. The large numerical values result from the narrowing of the integration window in (4.3) and the corresponding normalization. Due to this effect, there is hardly any averaging possible for large values of the correlation time
${\it\tau}\rightarrow 2000$
indicates that the final state is close to the initial one. The large numerical values result from the narrowing of the integration window in (4.3) and the corresponding normalization. Due to this effect, there is hardly any averaging possible for large values of the correlation time
 ${\it\tau}$
.
${\it\tau}$
.

Figure 8. Mixing layer: Galerkin expansion coefficients
 $a_{k}(t)$
,
$a_{k}(t)$
,
 $k=1,5,10,20$
, as a function of time
$k=1,5,10,20$
, as a function of time
 $t$
for DNS projected on
$t$
for DNS projected on
 $N=20$
POD modes (thick black solid line), ROM with the reference eddy viscosity
$N=20$
POD modes (thick black solid line), ROM with the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=10$
; dashed line, purple online).
${\rm\Delta}T=10$
; dashed line, purple online).

Figure 9. Mixing layer: normalized unbiased two-time correlation function
 $C({\it\tau})/C(0)$
for DNS projected on
$C({\it\tau})/C(0)$
for DNS projected on
 $N=20$
POD modes (thick black solid line), ROM with the reference eddy viscosity
$N=20$
POD modes (thick black solid line), ROM with the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=10$
; dashed line, purple online).
${\rm\Delta}T=10$
; dashed line, purple online).
Finally, in figure 10 we compare our results concerning the history of the total kinetic energy
 $E(t)$
with the results obtained by Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013) who used an optimization approach to determine eddy viscosities as functions of time
$E(t)$
with the results obtained by Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013) who used an optimization approach to determine eddy viscosities as functions of time
 ${\it\nu}_{T}={\it\nu}_{T}(t)$
with different cost functionals. We see that the optimization formulation proposed here, in which the optimal eddy viscosity is sought as a function of the instantaneous TKE
${\it\nu}_{T}={\it\nu}_{T}(t)$
with different cost functionals. We see that the optimization formulation proposed here, in which the optimal eddy viscosity is sought as a function of the instantaneous TKE
 ${\it\nu}_{T}^{\bullet }={\it\nu}_{T}^{\bullet }(E)$
, leads to a more accurate tracking of the energy
${\it\nu}_{T}^{\bullet }={\it\nu}_{T}^{\bullet }(E)$
, leads to a more accurate tracking of the energy
 $\widetilde{E}(t)$
characterizing the DNS than any of the time-dependent eddy viscosities
$\widetilde{E}(t)$
characterizing the DNS than any of the time-dependent eddy viscosities
 ${\it\nu}_{T}(t)$
, especially at later times (
${\it\nu}_{T}(t)$
, especially at later times (
 $t>800$
).
$t>800$
).

Figure 10. Mixing layer: comparison of TKE
 $E(t)$
as a function of time
$E(t)$
as a function of time
 $t$
for DNS (thick black solid line), optimal reconstruction on long windows (
$t$
for DNS (thick black solid line), optimal reconstruction on long windows (
 ${\rm\Delta}T=200$
; thin solid line, red online) and the results from Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013) corresponding to three different objective functionals (dotted lines, green online).
${\rm\Delta}T=200$
; thin solid line, red online) and the results from Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013) corresponding to three different objective functionals (dotted lines, green online).
4.2. Ahmed body wake model
The 3D flow over the blunt Ahmed body has the Reynolds number
 $\mathit{Re}=300\,000$
based on the height
$\mathit{Re}=300\,000$
based on the height
 $L=H$
of the body and the oncoming velocity
$L=H$
of the body and the oncoming velocity
 $U=U_{\infty }$
. The computational domain has dimensions
$U=U_{\infty }$
. The computational domain has dimensions
 $28H\times 8.05H\times 5.35H$
(length
$28H\times 8.05H\times 5.35H$
(length
 $\times$
width
$\times$
width
 $\times$
height), whereas the observation domain is a small wake-centred subset of the computational domain:
$\times$
height), whereas the observation domain is a small wake-centred subset of the computational domain:
 $$\begin{eqnarray}{\it\Omega}_{0}:=\{(x,y,z)\in {\it\Omega}:0\leqslant x\leqslant 5H,-0.67H\leqslant y\leqslant 1.12H,|z|\leqslant 1.21H\}.\end{eqnarray}$$
$$\begin{eqnarray}{\it\Omega}_{0}:=\{(x,y,z)\in {\it\Omega}:0\leqslant x\leqslant 5H,-0.67H\leqslant y\leqslant 1.12H,|z|\leqslant 1.21H\}.\end{eqnarray}$$
This domain is large enough to resolve the recirculation region and the absolutely unstable wake dynamics, but at the same time small enough to keep the model dimension affordable. The LES equations are discretized in space using a hybrid of central differencing and upwind schemes applied to the convective fluxes and second-order central differences applied to the viscous and subgrid terms. The time-discretization is performed with a second-order accurate implicit method. A computational grid consisting of approximately 34 million mesh points ensures that the LES is well resolved. The post-transient flow is computed over 250 convective time units, which is half of the time window analysed by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014), and sampled with the uniform time step
 ${\rm\Delta}t=1$
. The reason for taking a shorter time window is that the optimization problem (3.7) becomes hard to solve for very large
${\rm\Delta}t=1$
. The reason for taking a shorter time window is that the optimization problem (3.7) becomes hard to solve for very large
 $T$
. Further details of the LES are described by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014) and a typical flow pattern is illustrated in figure 11. As expected from a flow at this Reynolds number, this flow pattern exhibits highly complex multiscale vortex structures, which makes it quite different from the mixing-layer flow illustrated in figure 4. The numerical data is used to construct Galerkin system (2.11) with dimension
$T$
. Further details of the LES are described by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014) and a typical flow pattern is illustrated in figure 11. As expected from a flow at this Reynolds number, this flow pattern exhibits highly complex multiscale vortex structures, which makes it quite different from the mixing-layer flow illustrated in figure 4. The numerical data is used to construct Galerkin system (2.11) with dimension
 $N=100$
using the procedure discussed in § 2. In contrast to the example studied in § 4.1, in the present problem with the chosen dimension
$N=100$
using the procedure discussed in § 2. In contrast to the example studied in § 4.1, in the present problem with the chosen dimension
 $N=100$
the Galerkin model captures only approximately 35 % of the TKE of the entire flow. We emphasize that the ‘target’ TKE
$N=100$
the Galerkin model captures only approximately 35 % of the TKE of the entire flow. We emphasize that the ‘target’ TKE
 $\widetilde{E}(t)$
is computed based on the projection of the actual flow evolution on the first
$\widetilde{E}(t)$
is computed based on the projection of the actual flow evolution on the first
 $N=100$
modes, rather than based on the entire flow field. As in the case of the mixing layer, we performed optimization calculations for a range of different
$N=100$
modes, rather than based on the entire flow field. As in the case of the mixing layer, we performed optimization calculations for a range of different
 ${\rm\Delta}T$
and below we will show the results corresponding to two representative time intervals, namely,
${\rm\Delta}T$
and below we will show the results corresponding to two representative time intervals, namely,
 ${\rm\Delta}T=20$
and
${\rm\Delta}T=20$
and
 ${\rm\Delta}T=200$
, which will be referred to as the short and long window, respectively.
${\rm\Delta}T=200$
, which will be referred to as the short and long window, respectively.

Figure 11. Illustration of a typical flow pattern in the turbulent wake behind an Ahmed body (Östh et al.
Reference Östh, Noack, Krajnović, Barros and Borée2014). The flow is visualized using the quantity
 $Q(\boldsymbol{x},t):={\bf\omega}\boldsymbol{\cdot }{\bf\omega}-\unicode[STIX]{x1D64E}:\unicode[STIX]{x1D64E}$
where
$Q(\boldsymbol{x},t):={\bf\omega}\boldsymbol{\cdot }{\bf\omega}-\unicode[STIX]{x1D64E}:\unicode[STIX]{x1D64E}$
where
 ${\bf\omega}:=\boldsymbol{{\rm\nabla}}\times \boldsymbol{u}$
is the vorticity and
${\bf\omega}:=\boldsymbol{{\rm\nabla}}\times \boldsymbol{u}$
is the vorticity and
 $\unicode[STIX]{x1D64E}:=\left[\boldsymbol{{\rm\nabla}}\boldsymbol{u}+(\boldsymbol{{\rm\nabla}}\boldsymbol{u})^{\text{T}}\right]\!/2$
is the symmetric part of the velocity gradient tensor.
$\unicode[STIX]{x1D64E}:=\left[\boldsymbol{{\rm\nabla}}\boldsymbol{u}+(\boldsymbol{{\rm\nabla}}\boldsymbol{u})^{\text{T}}\right]\!/2$
is the symmetric part of the velocity gradient tensor.

Figure 12. Ahmed body: decrease of the cost functional (3.2) with iterations
 $n$
for optimization over short windows (
$n$
for optimization over short windows (
 ${\rm\Delta}T=20$
; small symbols, purple online) and over long windows (
${\rm\Delta}T=20$
; small symbols, purple online) and over long windows (
 ${\rm\Delta}T=200$
; big symbols, red online).
${\rm\Delta}T=200$
; big symbols, red online).

Figure 13. Ahmed body: optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=20$
; dashed line, purple online); reference eddy viscosity
${\rm\Delta}T=20$
; dashed line, purple online); reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
is marked with a thick dotted line (blue online).
${\it\nu}_{T}^{\circ }(E)$
is marked with a thick dotted line (blue online).

Figure 14. Ahmed body: (a) TKE
 $E(t)$
as a function of time
$E(t)$
as a function of time
 $t$
and (b) time-averaged modal energy
$t$
and (b) time-averaged modal energy
 $\overline{E}_{i}$
as a function of mode index
$\overline{E}_{i}$
as a function of mode index
 $i$
for LES projected on
$i$
for LES projected on
 $N=100$
POD modes (thick black solid line), ROM with the reference eddy viscosity
$N=100$
POD modes (thick black solid line), ROM with the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=20$
; dashed line, purple online).
${\rm\Delta}T=20$
; dashed line, purple online).
Decrease of cost functional (3.2) with iterations is shown in figure 12 in which a significant reduction can be observed in both cases. This implies that the reference eddy viscosity (2.12) can be improved by performing optimization on either short or long time intervals. The values of the cost functional corresponding to long optimization intervals are again larger which is due to the fact that, with fewer restarts, the trajectory of (3.3) diverges further away from the projected trajectory of the actual flow. The resulting optimal eddy viscosities
 ${\it\nu}_{T}^{\bullet }$
are presented in figure 13, together with the reference relation (2.12). We see that the obtained profile of the optimal eddy viscosity has a similar general form for both values of
${\it\nu}_{T}^{\bullet }$
are presented in figure 13, together with the reference relation (2.12). We see that the obtained profile of the optimal eddy viscosity has a similar general form for both values of
 ${\rm\Delta}T$
, except that it is smoother for the case of the longer window. This suggests that allowing for a longer assimilation interval before the constraint system (3.3) is restarted with a new initial condition may have a regularizing effect (i.e. may produce smoother optimal eddy viscosity relations). We also note that, in contrast to the findings of § 4.1, in the present case the optimal eddy viscosity
${\rm\Delta}T$
, except that it is smoother for the case of the longer window. This suggests that allowing for a longer assimilation interval before the constraint system (3.3) is restarted with a new initial condition may have a regularizing effect (i.e. may produce smoother optimal eddy viscosity relations). We also note that, in contrast to the findings of § 4.1, in the present case the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
is uniformly increased with respect to the reference relation
${\it\nu}_{T}^{\bullet }$
is uniformly increased with respect to the reference relation
 ${\it\nu}_{T}^{\circ }$
. While the function
${\it\nu}_{T}^{\circ }$
. While the function
 ${\it\nu}_{T}^{\bullet }(E)$
is defined for
${\it\nu}_{T}^{\bullet }(E)$
is defined for
 $E\in [0,2]$
, cf. Assumption 1(a), deviations from the reference relation
$E\in [0,2]$
, cf. Assumption 1(a), deviations from the reference relation
 ${\it\nu}_{T}^{\circ }(E)$
are confined to the range
${\it\nu}_{T}^{\circ }(E)$
are confined to the range
 $[0,0.7]$
which is approximately the range of energy values visited by the system trajectory (more precisely,
$[0,0.7]$
which is approximately the range of energy values visited by the system trajectory (more precisely,
 $\max _{t\in [0,T]}E(t)\approx 0.6$
as can be seen from figure 14
a). Outside that range the sensitivity information is not available and the optimal eddy viscosity
$\max _{t\in [0,T]}E(t)\approx 0.6$
as can be seen from figure 14
a). Outside that range the sensitivity information is not available and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
essentially coincides with the reference relation
${\it\nu}_{T}^{\bullet }$
essentially coincides with the reference relation
 ${\it\nu}_{T}^{\circ }$
, cf. Assumption 1(d). Discussion of the physical aspects of the optimal eddy viscosities obtained for the Ahmed body wake is deferred to § 5. Figure 14(a) shows the improvement in the tracking of the instantaneous TKE
${\it\nu}_{T}^{\circ }$
, cf. Assumption 1(d). Discussion of the physical aspects of the optimal eddy viscosities obtained for the Ahmed body wake is deferred to § 5. Figure 14(a) shows the improvement in the tracking of the instantaneous TKE
 $\widetilde{E}(t)$
achieved by Galerkin system (2.11) with the optimal eddy viscosity
$\widetilde{E}(t)$
achieved by Galerkin system (2.11) with the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
with respect to the use of the reference relation
${\it\nu}_{T}^{\bullet }$
with respect to the use of the reference relation
 ${\it\nu}_{T}^{\circ }$
. We see that the optimal eddy viscosities
${\it\nu}_{T}^{\circ }$
. We see that the optimal eddy viscosities
 ${\it\nu}_{T}^{\bullet }$
obtained both with short and long optimization windows allow the Galerkin model to track the target energy
${\it\nu}_{T}^{\bullet }$
obtained both with short and long optimization windows allow the Galerkin model to track the target energy
 $\widetilde{E}(t)$
more accurately than with the reference relation, although in fairness to the latter it has to be recognized that the choice of
$\widetilde{E}(t)$
more accurately than with the reference relation, although in fairness to the latter it has to be recognized that the choice of
 ${\it\nu}_{T}^{a}$
in (2.12) was not optimal resulting in overestimated TKE. In fact, the present approach may be considered a systematic way of using data to refine closures proposed based on theoretical or empirical arguments. The above observations are confirmed by the values of the mean TKE and its standard deviation collected for the different cases in table 2. We note, in particular, that with optimization performed over long time windows the proposed approach captures the mean energy of the flow with the accuracy of two significant digits. The average modal energies
${\it\nu}_{T}^{a}$
in (2.12) was not optimal resulting in overestimated TKE. In fact, the present approach may be considered a systematic way of using data to refine closures proposed based on theoretical or empirical arguments. The above observations are confirmed by the values of the mean TKE and its standard deviation collected for the different cases in table 2. We note, in particular, that with optimization performed over long time windows the proposed approach captures the mean energy of the flow with the accuracy of two significant digits. The average modal energies
 $\overline{E}_{i}$
,
$\overline{E}_{i}$
,
 $i=1,\dots ,100$
, are presented in figure 14(b) and we see that the optimal eddy viscosity
$i=1,\dots ,100$
, are presented in figure 14(b) and we see that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
yields an improved reconstruction essentially across the entire mode spectrum. This should be contrasted with figure 7(b), where an improvement was observed only for the first energy-containing modes. This difference is attributed to the spectral properties of the two flows and our choice of the cost functional (3.2): while in the mixing-layer flow most of the flow energy is contained in the first few modes, in the Ahmed body wake this energy is spread over a very large number of modes. These findings are corroborated by the plots of the time histories of selected Galerkin coefficients
${\it\nu}_{T}^{\bullet }$
yields an improved reconstruction essentially across the entire mode spectrum. This should be contrasted with figure 7(b), where an improvement was observed only for the first energy-containing modes. This difference is attributed to the spectral properties of the two flows and our choice of the cost functional (3.2): while in the mixing-layer flow most of the flow energy is contained in the first few modes, in the Ahmed body wake this energy is spread over a very large number of modes. These findings are corroborated by the plots of the time histories of selected Galerkin coefficients
 $a_{i}(t)$
,
$a_{i}(t)$
,
 $i=1,5,25,100$
, shown in figure 15. In those plots we note that, unlike the case of the mixing layer, some improvement is also obtained for higher modes. Finally, the correlation functions (4.2) and (4.3) for the POD projections of the original flow data and the solutions of the ROM (2.11) with the reference and optimal eddy viscosities are shown in figure 16. All curves reveal a small oscillatory component corresponding to the von Kármán vortex shedding at the Strouhal number
$i=1,5,25,100$
, shown in figure 15. In those plots we note that, unlike the case of the mixing layer, some improvement is also obtained for higher modes. Finally, the correlation functions (4.2) and (4.3) for the POD projections of the original flow data and the solutions of the ROM (2.11) with the reference and optimal eddy viscosities are shown in figure 16. All curves reveal a small oscillatory component corresponding to the von Kármán vortex shedding at the Strouhal number
 $\mathit{St}_{H}\approx 0.2$
. These oscillations are not very pronounced in the velocity fields, but show up more clearly in the pressure field and the aerodynamic forces as reported by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014). The curve corresponding to the LES data shows an anticorrelation after roughly 100 convection times. This behaviour can be traced back to the asymmetric base flow drift from a state with positive to a state with negative transverse forces. This base flow drift is resolved by the shift mode (
$\mathit{St}_{H}\approx 0.2$
. These oscillations are not very pronounced in the velocity fields, but show up more clearly in the pressure field and the aerodynamic forces as reported by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014). The curve corresponding to the LES data shows an anticorrelation after roughly 100 convection times. This behaviour can be traced back to the asymmetric base flow drift from a state with positive to a state with negative transverse forces. This base flow drift is resolved by the shift mode (
 $a_{1}$
in figure 15). From the same plot of the POD mode coefficients, the ROMs are seen to display a smaller base flow variation than exhibited by the actual LES data. This explains the decreased variation of the correlation function of the POD models. We emphasize that it is very difficult for POD models to resolve multiscale phenomena, such as vortex shedding combined with base flow drifts, the time scales of which are two orders of magnitude apart. For further details concerning the reduced-order modelling of the Ahmed body wake, we refer the reader to the original publication by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014).
$a_{1}$
in figure 15). From the same plot of the POD mode coefficients, the ROMs are seen to display a smaller base flow variation than exhibited by the actual LES data. This explains the decreased variation of the correlation function of the POD models. We emphasize that it is very difficult for POD models to resolve multiscale phenomena, such as vortex shedding combined with base flow drifts, the time scales of which are two orders of magnitude apart. For further details concerning the reduced-order modelling of the Ahmed body wake, we refer the reader to the original publication by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014).

Figure 15. Ahmed body: Galerkin expansion coefficients
 $a_{k}(t)$
,
$a_{k}(t)$
,
 $k=1,5,25,100$
, as a function of time
$k=1,5,25,100$
, as a function of time
 $t$
for LES projected on
$t$
for LES projected on
 $N=100$
POD modes (thick black solid line), ROM with the reference eddy viscosity
$N=100$
POD modes (thick black solid line), ROM with the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=20$
; dashed line, purple online).
${\rm\Delta}T=20$
; dashed line, purple online).

Figure 16. Ahmed body: normalized unbiased two-time correlation function
 $C({\it\tau})/C(0)$
for LES projected on
$C({\it\tau})/C(0)$
for LES projected on
 $N=100$
POD modes (thick black solid line), ROM with the reference eddy viscosity
$N=100$
POD modes (thick black solid line), ROM with the reference eddy viscosity
 ${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
${\it\nu}_{T}^{\circ }(E)$
(thick dotted line, blue online) and the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
${\it\nu}_{T}^{\bullet }(E)$
obtained with optimization over long windows (
 ${\rm\Delta}T=200$
; solid line, red online) and over short windows (
${\rm\Delta}T=200$
; solid line, red online) and over short windows (
 ${\rm\Delta}T=20$
; dashed line, purple online).
${\rm\Delta}T=20$
; dashed line, purple online).
Table 2. Ahmed body: mean resolved TKE
 $\overline{E}$
and its standard deviation
$\overline{E}$
and its standard deviation
 $\text{std}(E)$
in the different cases considered in § 4.2.
$\text{std}(E)$
in the different cases considered in § 4.2.

5. Conclusions and future directions
We have proposed an optimal nonlinear eddy viscosity relation for a large class of ROMs which improves on the results from a number of earlier studies. In the pioneering investigation concerning POD-based ROMs by Aubry et al. (Reference Aubry, Holmes, Lumley and Stone1988), a single constant eddy viscosity parameter was assumed. Rempfer & Fasel (Reference Rempfer and Fasel1994b ) proposed a mode-dependent refinement of the constant eddy viscosity ansatz which significantly improves the accuracy of ROMs. Later, Noack et al. (Reference Noack, Morzyński and Tadmor2011) derived a nonlinear eddy viscosity as a function of the square root of the resolved fluctuation energy in which constant ratios between the modal energies were assumed. This nonlinearity guarantees the boundedness of the Galerkin solution (Cordier et al. Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013). As shown by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014), combinations of modal and nonlinear eddy viscosities may improve the accuracy and robustness of POD-based ROMs. The key new aspect of the approach proposed here is that the eddy viscosity relations are defined to be optimal in a mathematically precise sense. As such, these relations can be viewed as systematic, data-based refinements of closures obtained from theoretical or empirical considerations.
The current study addresses the limitations of earlier approaches by considering the eddy viscosity as an arbitrary function of the resolved TKE which is optimized by matching the fluctuation level of the ROM to the corresponding quantity of the reference data. This optimization is performed with a generalization of the 4D-VAR data assimilation method adopted for the reconstruction of constitutive equations by Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011), Bukshtynov & Protas (Reference Bukshtynov and Protas2013).
POD models with the optimal eddy viscosity are constructed for three shear flows with progressively richer dynamics spanning the laminar and turbulent regimes. First, the 2D POD model for the transient behaviour in the 2D cylinder wake is recalled from an earlier study (Protas et al. Reference Protas, Noack and Morzynski2014). Here, a negative eddy viscosity is derived at low fluctuation levels to compensate for the significantly under-predicted growth rate of the POD model (figure 2 b). On the other hand, on the limit cycle and beyond, a positive eddy viscosity models the energy transfer to the higher-order modes. In this example, the eddy viscosity not only assures correct amplitudes on the limit cycle, but also yields more accurate transient times (figure 2 a).
Second, a 20-dimensional POD model of the 2D mixing layer at
 $\mathit{Re}=500$
with velocity ratio three is investigated. The starting point was a ROM with a single nonlinear eddy viscosity calibrated against a DNS of the Navier–Stokes system by Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013). Good agreement between the POD model and the DNS was observed with respect to the frequency content and the modal fluctuation levels for the energy-containing modes (figures 7
b and 8). Surprisingly, the optimal eddy viscosity significantly deviates from the square-root ansatz (2.12) and attains negative values for a range of low fluctuation levels, thus accelerating the slow transients of the ROM (Noack et al.
Reference Noack, Papas and Monkewitz2005). However, the optimal eddy viscosity
$\mathit{Re}=500$
with velocity ratio three is investigated. The starting point was a ROM with a single nonlinear eddy viscosity calibrated against a DNS of the Navier–Stokes system by Cordier et al. (Reference Cordier, Noack, Daviller, Delvile, Lehnasch, Tissot, Balajewicz and Niven2013). Good agreement between the POD model and the DNS was observed with respect to the frequency content and the modal fluctuation levels for the energy-containing modes (figures 7
b and 8). Surprisingly, the optimal eddy viscosity significantly deviates from the square-root ansatz (2.12) and attains negative values for a range of low fluctuation levels, thus accelerating the slow transients of the ROM (Noack et al.
Reference Noack, Papas and Monkewitz2005). However, the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
is larger than the square-root ansatz
${\it\nu}_{T}^{\bullet }$
is larger than the square-root ansatz
 ${\it\nu}_{T}^{\circ }$
at larger fluctuation levels thus limiting more energetic events (figure 6).
${\it\nu}_{T}^{\circ }$
at larger fluctuation levels thus limiting more energetic events (figure 6).
Third, a 100-dimensional POD model of the 3D Ahmed body wake at Reynolds number 300 000 is constructed. The starting point is a LES and the best one from the Galerkin POD models developed and analysed by Östh et al. (Reference Östh, Noack, Krajnović, Barros and Borée2014, model ‘GS-D’) is used as a benchmark. The subscale turbulence representation in this model includes the modal eddy viscosities proportional to the square-root of the resolved TKE (cf. § 2.4). The optimal eddy viscosity respects the ratio between the modal viscosities while allowing for an arbitrary scaling with the resolved TKE. As regards the comparison between the optimal and reference eddy viscosity (figure 13), for all values of the fluctuation energy the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
exhibits larger values than the reference relation
${\it\nu}_{T}^{\bullet }$
exhibits larger values than the reference relation
 ${\it\nu}_{T}^{\circ }$
, consistently with the over-prediction of the energy fluctuation level in the latter case (figure 14
a).
${\it\nu}_{T}^{\circ }$
, consistently with the over-prediction of the energy fluctuation level in the latter case (figure 14
a).
A key advantage of variational optimization formulations such as that proposed here is that they reveal certain performance trade-offs inherent in the solution of complex flow problems which can hardly be identified based on the physical intuition alone. This is evident when one compares the results obtained in the mixing-layer flow, which can be considered ‘laminar’, and the Ahmed body wake, which is ‘turbulent’ in all respects. Since in the first case most of the TKE was associated with the first two POD modes, these were also the components of the ROM mostly affected by the optimization process (figure 7
b). On the other hand, in the second case, in which the energy was distributed more evenly among different modes, optimization affected the entire spectrum (cf. figure 14
b). This comparison demonstrates that the optimal eddy viscosities do indeed adapt to situations characterized by essentially different flow physics. At the same time, these results also reveal certain fundamental performance limitations inherent in the ansatz
 ${\it\nu}_{T}={\it\nu}_{T}(E)$
commonly used for the eddy viscosity. Needless to say, this process can be modified by using a different cost functional and/or a different ansatz for
${\it\nu}_{T}={\it\nu}_{T}(E)$
commonly used for the eddy viscosity. Needless to say, this process can be modified by using a different cost functional and/or a different ansatz for
 ${\it\nu}_{T}$
. For example, adopting a cost functional penalizing deviations of, say, enstrophy rather than energy, would have certainly yielded different results. We emphasize that such decisions are a part of the problem formulation and can be handled by the proposed solution approach in a straightforward manner.
${\it\nu}_{T}$
. For example, adopting a cost functional penalizing deviations of, say, enstrophy rather than energy, would have certainly yielded different results. We emphasize that such decisions are a part of the problem formulation and can be handled by the proposed solution approach in a straightforward manner.
The observed features of the optimal eddy viscosity identified as a function of the fluctuation energy deserve additional discussion. From the results we conjecture that the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
does not strongly depend on the chosen time window
${\it\nu}_{T}^{\bullet }$
does not strongly depend on the chosen time window
 $[0,T]$
, provided that it is equal to or longer than the characteristic time scale of the dominant coherent structures. This was the case for both of the time windows used for the Ahmed body wake (figure 14
a), but not for the short time window used for the mixing layer (figure 7
a). Second, the eddy viscosity obtained for the mixing layer shows two minima helping stabilize two different energy levels (figure 6). This bimodal behaviour is consistent with the cluster-based analysis of the same data performed by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). It is shown there that the mixing layer flow has two quasi-attractors: one which is dominated by the Kelvin–Helmholtz instability at a lower energy level and another one dominated by period-doubling at a higher energy level. Third, the mixing layer model exhibits a negative eddy viscosity while the model of the Ahmed body flow does not. We conjecture that this difference has two reasons: the first is that the fluctuation levels of the mixing layer have relatively larger variations (figure 7
a), hence we can estimate transient times for this 2D flow better than for the 3D wake; the second is that a negative eddy viscosity excites coherent structures with similar scales in the POD model of the mixing layer flow. On the other hand, for the Ahmed body wake, a negative eddy viscosity would imply that the strongly damped high-order modes would suddenly become excited which would in turn lead to an unphysical inverse energy cascade. Summarizing, the different features of the optimal eddy viscosity found for the 2D and 3D shear flows are consistent with our expectations based on the behaviour of POD models.
$[0,T]$
, provided that it is equal to or longer than the characteristic time scale of the dominant coherent structures. This was the case for both of the time windows used for the Ahmed body wake (figure 14
a), but not for the short time window used for the mixing layer (figure 7
a). Second, the eddy viscosity obtained for the mixing layer shows two minima helping stabilize two different energy levels (figure 6). This bimodal behaviour is consistent with the cluster-based analysis of the same data performed by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). It is shown there that the mixing layer flow has two quasi-attractors: one which is dominated by the Kelvin–Helmholtz instability at a lower energy level and another one dominated by period-doubling at a higher energy level. Third, the mixing layer model exhibits a negative eddy viscosity while the model of the Ahmed body flow does not. We conjecture that this difference has two reasons: the first is that the fluctuation levels of the mixing layer have relatively larger variations (figure 7
a), hence we can estimate transient times for this 2D flow better than for the 3D wake; the second is that a negative eddy viscosity excites coherent structures with similar scales in the POD model of the mixing layer flow. On the other hand, for the Ahmed body wake, a negative eddy viscosity would imply that the strongly damped high-order modes would suddenly become excited which would in turn lead to an unphysical inverse energy cascade. Summarizing, the different features of the optimal eddy viscosity found for the 2D and 3D shear flows are consistent with our expectations based on the behaviour of POD models.
Concerning the choice of the parameters in the optimization formulation, we note that the cost functional tracking the error of the fluctuation energy gives quite comparable results over different time windows (cf. figure 3), provided that the windows cover at minimum several characteristic flow periods. This was the case for the Ahmed body flow in which the shedding period was 5–10 time units, whereas optimization was performed over intervals with
 ${\rm\Delta}T=20$
and
${\rm\Delta}T=20$
and
 ${\rm\Delta}T=200$
(figure 14
a). On the other hand, for the mixing layer the shorter window with
${\rm\Delta}T=200$
(figure 14
a). On the other hand, for the mixing layer the shorter window with
 ${\rm\Delta}T=10$
covered only about half of the Kelvin–Helmholtz shedding period (figure 7
a) and the resulting optimal eddy viscosity was significantly different from the relations found by solving optimization problem (3.7) with subintervals 10 times longer (figure 6). As regards Assumption 1 and its validity, we remark that statements (a) and (b) are mathematical in nature and ensure that model (2.11) is well-posed. Statements (c) and (d) stipulate that for values of
${\rm\Delta}T=10$
covered only about half of the Kelvin–Helmholtz shedding period (figure 7
a) and the resulting optimal eddy viscosity was significantly different from the relations found by solving optimization problem (3.7) with subintervals 10 times longer (figure 6). As regards Assumption 1 and its validity, we remark that statements (a) and (b) are mathematical in nature and ensure that model (2.11) is well-posed. Statements (c) and (d) stipulate that for values of
 $E$
for which the sensitivity information is not available the optimal eddy viscosity
$E$
for which the sensitivity information is not available the optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }(E)$
should revert to some chosen reference relation, in our case relation (2.12).
${\it\nu}_{T}^{\bullet }(E)$
should revert to some chosen reference relation, in our case relation (2.12).
In providing a closure relation for unresolved fluctuations based on solution data, the proposed approach to identifying the optimal eddy viscosity bears some resemblance to the ‘optimal LES’ methodology which originated with Langford & Moser (Reference Langford and Moser1999). However, it differs from the optimal LES in that our optimal eddy viscosity
 ${\it\nu}_{T}^{\bullet }$
is reconstructed in a non-parametric manner. The proposed closure strategy can be employed in a straightforward manner to identify closure relations depending on one variable for a large class of ROMs both for laminar and turbulent flows. A highly relevant problem complementary to the problem solved in this study is optimization of the dependence of the eddy viscosity on the mode index
${\it\nu}_{T}^{\bullet }$
is reconstructed in a non-parametric manner. The proposed closure strategy can be employed in a straightforward manner to identify closure relations depending on one variable for a large class of ROMs both for laminar and turbulent flows. A highly relevant problem complementary to the problem solved in this study is optimization of the dependence of the eddy viscosity on the mode index
 $i$
while keeping the dependence on the TKE fixed. The approach developed here can be adapted to solve such problems by treating the discrete mode index
$i$
while keeping the dependence on the TKE fixed. The approach developed here can be adapted to solve such problems by treating the discrete mode index
 $i$
as a continuous variable, i.e. an effective wavenumber of the mode. It will be interesting to see whether such a formulation can lead to improved performance with respect to the ansatz
$i$
as a continuous variable, i.e. an effective wavenumber of the mode. It will be interesting to see whether such a formulation can lead to improved performance with respect to the ansatz
 ${\it\nu}_{T}={\it\nu}_{T}(E)$
used in the present investigation. This problem will be studied in the near future. Another related problem concerns determination of optimal turbulence closure strategies for simplified flow models defined in the PDE setting such as the RANS and LES approaches (in fact, these are the type of problems the reconstruction method we used was initially developed for, see Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011) and Bukshtynov & Protas (Reference Bukshtynov and Protas2013)). As regards LES models, an interesting open problem is determination of optimal wall damping functions (Van Driest Reference Van Driest1956). Problems of such type also arise in fundamental turbulence research, for example, in the context of the Kármán–Howarth equation. Other, possibly less obvious, extensions of this methodology include optimal identification of inertial manifolds and feedback control laws, and the authors are already pursuing these applications in the context of closed-loop turbulence control.
${\it\nu}_{T}={\it\nu}_{T}(E)$
used in the present investigation. This problem will be studied in the near future. Another related problem concerns determination of optimal turbulence closure strategies for simplified flow models defined in the PDE setting such as the RANS and LES approaches (in fact, these are the type of problems the reconstruction method we used was initially developed for, see Bukshtynov et al. (Reference Bukshtynov, Volkov and Protas2011) and Bukshtynov & Protas (Reference Bukshtynov and Protas2013)). As regards LES models, an interesting open problem is determination of optimal wall damping functions (Van Driest Reference Van Driest1956). Problems of such type also arise in fundamental turbulence research, for example, in the context of the Kármán–Howarth equation. Other, possibly less obvious, extensions of this methodology include optimal identification of inertial manifolds and feedback control laws, and the authors are already pursuing these applications in the context of closed-loop turbulence control.
Acknowledgements
The authors thank S. Bagheri, L. Cordier and S. Krajnović for stimulating discussions and for providing the data used in figure 10 (L. Cordier). Funding for this research was provided by the French Agence Nationale de la Recherche (ANR) via the Chair of Excellence TUCOROM and is gratefully acknowledged. B.P. was also partially supported by a Discovery Grant from the Natural Sciences and Engineering Research Council of Canada (NSERC). A part of this work was based on the PhD thesis of J.Ö. which was financially supported by Trafikverket (Swedish Transport Administration). The authors also thank the referees for their detailed, thoughtful and helpful suggestions.
Appendix A. Derivation of gradient expression
In this appendix we derive expression (3.11) for the
 $L_{2}$
gradient of cost functional (3.2). The key observation is that, since the Gâteaux differential of
$L_{2}$
gradient of cost functional (3.2). The key observation is that, since the Gâteaux differential of
 $\mathscr{J}({\it\nu}_{T})$
appearing in (3.8) is a bounded linear functional with respect to its second argument
$\mathscr{J}({\it\nu}_{T})$
appearing in (3.8) is a bounded linear functional with respect to its second argument
 ${\it\nu}_{T}^{\prime }\in \mathscr{X}(I)$
,
${\it\nu}_{T}^{\prime }\in \mathscr{X}(I)$
,
 $\mathscr{X}(I)$
being an appropriate Hilbert function space, by the Riesz representation theorem (Berger Reference Berger1977) we have
$\mathscr{X}(I)$
being an appropriate Hilbert function space, by the Riesz representation theorem (Berger Reference Berger1977) we have
 $$\begin{eqnarray}\forall _{{\it\nu}_{T}^{\prime }\in \mathscr{X}(I)}\quad \mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\langle {\rm\nabla}^{\mathscr{X}}\mathscr{J},{\it\nu}_{T}^{\prime }\rangle _{\mathscr{ X}(I)},\end{eqnarray}$$
$$\begin{eqnarray}\forall _{{\it\nu}_{T}^{\prime }\in \mathscr{X}(I)}\quad \mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\langle {\rm\nabla}^{\mathscr{X}}\mathscr{J},{\it\nu}_{T}^{\prime }\rangle _{\mathscr{ X}(I)},\end{eqnarray}$$
where
 $\langle \cdot ,\cdot \rangle _{\mathscr{X}(I)}$
denotes the inner product in the space
$\langle \cdot ,\cdot \rangle _{\mathscr{X}(I)}$
denotes the inner product in the space
 $\mathscr{X}(I)$
. We identify the Riesz representer
$\mathscr{X}(I)$
. We identify the Riesz representer
 ${\rm\nabla}^{\mathscr{X}}\mathscr{J}$
as the gradient of
${\rm\nabla}^{\mathscr{X}}\mathscr{J}$
as the gradient of
 $\mathscr{J}$
with respect to the topology of the space
$\mathscr{J}$
with respect to the topology of the space
 $\mathscr{X}(I)$
(in the present problem, we have either
$\mathscr{X}(I)$
(in the present problem, we have either
 $\mathscr{X}(I)=L_{2}(I)$
or
$\mathscr{X}(I)=L_{2}(I)$
or
 $\mathscr{X}(I)=H^{1}(I)$
). We begin by computing the Gâteaux differential of (3.2) which yields
$\mathscr{X}(I)=H^{1}(I)$
). We begin by computing the Gâteaux differential of (3.2) which yields
 $$\begin{eqnarray}\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\frac{1}{T}\int _{0}^{\text{T}}[E(t)-\widetilde{E}(t)]E^{\prime }(t)\,\text{d}t=\frac{1}{T}\int _{0}^{\text{T}}[E(t)-\widetilde{E}(t)]\mathop{\sum }_{i=1}^{N}a_{i}(t)a_{i}^{\prime }(t)\,\text{d}t,\end{eqnarray}$$
$$\begin{eqnarray}\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\frac{1}{T}\int _{0}^{\text{T}}[E(t)-\widetilde{E}(t)]E^{\prime }(t)\,\text{d}t=\frac{1}{T}\int _{0}^{\text{T}}[E(t)-\widetilde{E}(t)]\mathop{\sum }_{i=1}^{N}a_{i}(t)a_{i}^{\prime }(t)\,\text{d}t,\end{eqnarray}$$
where
 $E^{\prime }:=\sum _{i=1}^{N}a_{i}a_{i}^{\prime }$
and
$E^{\prime }:=\sum _{i=1}^{N}a_{i}a_{i}^{\prime }$
and
 $a_{i}^{\prime }(t)$
,
$a_{i}^{\prime }(t)$
,
 $i=1,\dots ,N$
, solve the linearization of system (3.3). Following the approach described by Protas et al. (Reference Protas, Noack and Morzynski2014), this linearization can be shown to have the form
$i=1,\dots ,N$
, solve the linearization of system (3.3). Following the approach described by Protas et al. (Reference Protas, Noack and Morzynski2014), this linearization can be shown to have the form
 $$\begin{eqnarray}\displaystyle \frac{\text{d}a_{i}^{\prime }}{\text{d}t} & = & \displaystyle \mathop{\sum }_{j=0}^{N}\left[\mathop{\sum }_{k=0}^{N}(q_{ijk}+q_{ikj})a_{k}+l_{ij}^{{\it\nu}}\left({\it\nu}+{\it\nu}_{T}(E(t))+\frac{\text{d}{\it\nu}_{T}}{\text{d}e}a_{i}a_{j}\right)\right]a_{j}^{\prime }\nonumber\\ \displaystyle & & \displaystyle +\,{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\nonumber\\ \displaystyle & =: & \displaystyle \mathop{\sum }_{j=0}^{N}A_{ij}a_{j}^{\prime }+{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\quad t\in ((m-1){\rm\Delta}T,m{\rm\Delta}T],\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \frac{\text{d}a_{i}^{\prime }}{\text{d}t} & = & \displaystyle \mathop{\sum }_{j=0}^{N}\left[\mathop{\sum }_{k=0}^{N}(q_{ijk}+q_{ikj})a_{k}+l_{ij}^{{\it\nu}}\left({\it\nu}+{\it\nu}_{T}(E(t))+\frac{\text{d}{\it\nu}_{T}}{\text{d}e}a_{i}a_{j}\right)\right]a_{j}^{\prime }\nonumber\\ \displaystyle & & \displaystyle +\,{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\nonumber\\ \displaystyle & =: & \displaystyle \mathop{\sum }_{j=0}^{N}A_{ij}a_{j}^{\prime }+{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j},\quad t\in ((m-1){\rm\Delta}T,m{\rm\Delta}T],\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle a_{0}^{\prime }(t) & = & \displaystyle 0,\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle a_{0}^{\prime }(t) & = & \displaystyle 0,\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle a_{i}^{\prime }((m-1){\rm\Delta}T) & = & \displaystyle 0,\quad i=1,\dots ,N,~m=1,\dots ,M,\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle a_{i}^{\prime }((m-1){\rm\Delta}T) & = & \displaystyle 0,\quad i=1,\dots ,N,~m=1,\dots ,M,\end{eqnarray}$$
 $\boldsymbol{A}$
. We note that differential (A 2) is not yet in a form consistent with Riesz representation (A 1), because the perturbation variable
$\boldsymbol{A}$
. We note that differential (A 2) is not yet in a form consistent with Riesz representation (A 1), because the perturbation variable
 ${\it\nu}_{T}^{\prime }$
does not enter as a linear factor in (A 2), but is instead hidden in a source term in (A 3a
). In order to transform (A 2) into Riesz form (A 1), we introduce the adjoint state
${\it\nu}_{T}^{\prime }$
does not enter as a linear factor in (A 2), but is instead hidden in a source term in (A 3a
). In order to transform (A 2) into Riesz form (A 1), we introduce the adjoint state
 $\boldsymbol{a}^{\ast }(t)=[0,a_{1}^{\ast }(t),\dots ,a_{N}^{\ast }(t)]^{\text{T}}\in \mathbb{R}^{N+1}$
, so that integrating it against the perturbation equation (A 3a
) and applying integration by parts we obtain
$\boldsymbol{a}^{\ast }(t)=[0,a_{1}^{\ast }(t),\dots ,a_{N}^{\ast }(t)]^{\text{T}}\in \mathbb{R}^{N+1}$
, so that integrating it against the perturbation equation (A 3a
) and applying integration by parts we obtain  $$\begin{eqnarray}\displaystyle & & \displaystyle \mathop{\sum }_{i=1}^{N}\,\int _{0}^{\text{T}}\left(\frac{\text{d}a_{i}^{\prime }}{\text{d}t}-\mathop{\sum }_{j=0}^{N}A_{ij}a_{j}^{\prime }-{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right)a_{i}^{\ast }\,\text{d}t\nonumber\\ \displaystyle & & \displaystyle \quad =\mathop{\sum }_{i=1}^{N}a_{i}^{\prime }a_{i}^{\ast }\big|_{t=0}^{t=T}+\mathop{\sum }_{i=1}^{N}\,\int _{0}^{\text{T}}a_{i}^{\prime }\left(-\frac{\text{d}a_{i}^{\ast }}{\text{d}t}-\mathop{\sum }_{j=0}^{N}A_{ji}a_{j}^{\ast }\right)\,\text{d}t\nonumber\\ \displaystyle & & \displaystyle \qquad -\,\int _{0}^{\text{T}}{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{i=1,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }\,\text{d}t=0.\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle \mathop{\sum }_{i=1}^{N}\,\int _{0}^{\text{T}}\left(\frac{\text{d}a_{i}^{\prime }}{\text{d}t}-\mathop{\sum }_{j=0}^{N}A_{ij}a_{j}^{\prime }-{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right)a_{i}^{\ast }\,\text{d}t\nonumber\\ \displaystyle & & \displaystyle \quad =\mathop{\sum }_{i=1}^{N}a_{i}^{\prime }a_{i}^{\ast }\big|_{t=0}^{t=T}+\mathop{\sum }_{i=1}^{N}\,\int _{0}^{\text{T}}a_{i}^{\prime }\left(-\frac{\text{d}a_{i}^{\ast }}{\text{d}t}-\mathop{\sum }_{j=0}^{N}A_{ji}a_{j}^{\ast }\right)\,\text{d}t\nonumber\\ \displaystyle & & \displaystyle \qquad -\,\int _{0}^{\text{T}}{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{i=1,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }\,\text{d}t=0.\end{eqnarray}$$
Since
 $a_{0}^{\ast }(t)\equiv 0$
, summation over index
$a_{0}^{\ast }(t)\equiv 0$
, summation over index
 $i$
in (A 4) starts at 1. Defining the adjoint system as in (3.12), and using it together with (A 2) and (A 3), we obtain from (A 4)
$i$
in (A 4) starts at 1. Defining the adjoint system as in (3.12), and using it together with (A 2) and (A 3), we obtain from (A 4)
 $$\begin{eqnarray}\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\int _{0}^{\text{T}}{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }\,\text{d}t.\end{eqnarray}$$
$$\begin{eqnarray}\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\int _{0}^{\text{T}}{\it\nu}_{T}^{\prime }(E(t))\,\mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }\,\text{d}t.\end{eqnarray}$$
In order to transform this expression to the Riesz form induced by
 $\mathscr{X}(I)=L_{2}(I)$
, i.e.
$\mathscr{X}(I)=L_{2}(I)$
, i.e.
 $$\begin{eqnarray}\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\int _{0}^{E_{max}}{\rm\nabla}^{L_{2}}\mathscr{J}\,{\it\nu}_{T}^{\prime }\,\text{d}e,\end{eqnarray}$$
$$\begin{eqnarray}\mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime })=\int _{0}^{E_{max}}{\rm\nabla}^{L_{2}}\mathscr{J}\,{\it\nu}_{T}^{\prime }\,\text{d}e,\end{eqnarray}$$
we need to change the integration variable in (A 5) from time
 $t$
to TKE
$t$
to TKE
 $e$
$e$
 $$\begin{eqnarray}\displaystyle & & \displaystyle \frac{\text{d}e}{\text{d}t}=\mathop{\sum }_{i=1}^{N}a_{i}\frac{\text{d}a_{i}}{\text{d}t}=\mathop{\sum }_{i=1}^{N}a_{i}\left(f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right)\nonumber\\ \displaystyle & & \displaystyle \quad \Longrightarrow ~\text{d}t=\frac{\text{d}e}{\displaystyle \mathop{\sum }_{i=1}^{N}a_{i}\left[f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right]},\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle \frac{\text{d}e}{\text{d}t}=\mathop{\sum }_{i=1}^{N}a_{i}\frac{\text{d}a_{i}}{\text{d}t}=\mathop{\sum }_{i=1}^{N}a_{i}\left(f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right)\nonumber\\ \displaystyle & & \displaystyle \quad \Longrightarrow ~\text{d}t=\frac{\text{d}e}{\displaystyle \mathop{\sum }_{i=1}^{N}a_{i}\left[f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right]},\end{eqnarray}$$
so that Gâteaux differential (A 5) becomes
 $$\begin{eqnarray}\displaystyle \mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime }) & = & \displaystyle \int _{\mathscr{C}}\frac{\displaystyle \mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }}{\displaystyle \mathop{\sum }_{i=1}^{N}a_{i}\left[f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right]}\,{\it\nu}_{T}^{\prime }(e)\,\text{d}e\nonumber\\ \displaystyle & = & \displaystyle \int _{0}^{E_{max}}\mathop{\sum }_{\stackrel{t}{E(\boldsymbol{a}(t))=e}}\frac{\displaystyle \mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }}{\displaystyle \mathop{\sum }_{i=1}^{N}|a_{i}f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{i}a_{j}|}\,{\it\nu}_{T}^{\prime }(e)\,\text{d}e,\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \mathscr{J}^{\prime }({\it\nu}_{T};{\it\nu}_{T}^{\prime }) & = & \displaystyle \int _{\mathscr{C}}\frac{\displaystyle \mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }}{\displaystyle \mathop{\sum }_{i=1}^{N}a_{i}\left[f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{j}\right]}\,{\it\nu}_{T}^{\prime }(e)\,\text{d}e\nonumber\\ \displaystyle & = & \displaystyle \int _{0}^{E_{max}}\mathop{\sum }_{\stackrel{t}{E(\boldsymbol{a}(t))=e}}\frac{\displaystyle \mathop{\sum }_{i,j=0}^{N}l_{ij}^{{\it\nu}}a_{j}a_{i}^{\ast }}{\displaystyle \mathop{\sum }_{i=1}^{N}|a_{i}f_{i}(\boldsymbol{a})+{\it\nu}_{T}(E(t))\,\mathop{\sum }_{j=0}^{N}l_{ij}^{{\it\nu}}a_{i}a_{j}|}\,{\it\nu}_{T}^{\prime }(e)\,\text{d}e,\end{eqnarray}$$
where the first expression on the right-hand side in (A 8) is an integral over the system trajectory
 $\mathscr{C}$
in the phase space
$\mathscr{C}$
in the phase space
 $\mathbb{R}^{n}$
(i.e. a line integral in which
$\mathbb{R}^{n}$
(i.e. a line integral in which
 $\text{d}e$
can be either positive or negative), whereas the second expression is a definite integral consistent with Riesz form (A 6). Thus, identifying (A 8) with (A 6), we finally obtain gradient expression (3.11).
$\text{d}e$
can be either positive or negative), whereas the second expression is a definite integral consistent with Riesz form (A 6). Thus, identifying (A 8) with (A 6), we finally obtain gradient expression (3.11).


















