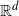1. Introduction
Multivariate extreme value theory is complicated by the lack of natural ordering in
 $ \mathbb{R}^d$
, and the infinite possibilities for the underlying set of dependence structures between random variables. Some of the earliest characterizations of multivariate extremes were inspired by consideration of the vector of normalized componentwise maxima. Let
$ \mathbb{R}^d$
, and the infinite possibilities for the underlying set of dependence structures between random variables. Some of the earliest characterizations of multivariate extremes were inspired by consideration of the vector of normalized componentwise maxima. Let
 $ {\boldsymbol{X}} =(X_1,\ldots,X_d) \in \mathbb{R}^d$
with
$ {\boldsymbol{X}} =(X_1,\ldots,X_d) \in \mathbb{R}^d$
with
 $ X_{j} \sim F_j$
, and consider a sample
$ X_{j} \sim F_j$
, and consider a sample
 $ {\boldsymbol{X}}_i =(X_{1i},\ldots,X_{di})$
,
$ {\boldsymbol{X}}_i =(X_{1i},\ldots,X_{di})$
,
 $ i=1,\ldots,n$
, of independent copies of
$ i=1,\ldots,n$
, of independent copies of
 $ {\boldsymbol{X}}$
. For a fixed j, defining
$ {\boldsymbol{X}}$
. For a fixed j, defining
 $ M_{j,n} = \max_{1 \leq i \leq n}\big(X_{ji}\big)$
, we know from the extremal types theorem that if we can find sequences such that
$ M_{j,n} = \max_{1 \leq i \leq n}\big(X_{ji}\big)$
, we know from the extremal types theorem that if we can find sequences such that
 $ \big(M_{j,n} -b_{j,n}\big)/a_{j,n}$
converges to a nondegenerate distribution, then this is the generalized extreme value distribution. Moreover, the sequence
$ \big(M_{j,n} -b_{j,n}\big)/a_{j,n}$
converges to a nondegenerate distribution, then this is the generalized extreme value distribution. Moreover, the sequence
 $ b_{j,n} \sim F_j^{-1}(1-c/n)$
,
$ b_{j,n} \sim F_j^{-1}(1-c/n)$
,
 $ n \to \infty$
, i.e., is of the same order as the
$ n \to \infty$
, i.e., is of the same order as the
 $ 1-1/n$
quantile. A natural multivariate extension is then to examine the distribution of the vector of componentwise maxima,
$ 1-1/n$
quantile. A natural multivariate extension is then to examine the distribution of the vector of componentwise maxima,
 $ \big({\boldsymbol{M}}_n -{\boldsymbol{b}}_n\big)/{\boldsymbol{a}}_n$
. This is intrinsically tied up with the theory of multivariate regular variation, because it leads to examination of the joint behaviour of the random vector when all components are growing at the rate determined by their
$ \big({\boldsymbol{M}}_n -{\boldsymbol{b}}_n\big)/{\boldsymbol{a}}_n$
. This is intrinsically tied up with the theory of multivariate regular variation, because it leads to examination of the joint behaviour of the random vector when all components are growing at the rate determined by their
 $ 1-1/n$
quantile. If all components were marginally standardized to focus only on the dependence, then all normalizations would be the same.
$ 1-1/n$
quantile. If all components were marginally standardized to focus only on the dependence, then all normalizations would be the same.
In normalizing all components by the same amount, we only consider the dependence structure in a single ‘direction’ in
 $ \mathbb{R}^d$
. In some cases this turns out to provide a rich description of the extremal dependence: if the limiting distribution of componentwise maxima does not have independent components, then an infinite variety of dependence structures are possible, indexed by a moment-constrained measure on a
$ \mathbb{R}^d$
. In some cases this turns out to provide a rich description of the extremal dependence: if the limiting distribution of componentwise maxima does not have independent components, then an infinite variety of dependence structures are possible, indexed by a moment-constrained measure on a
 $ (d-1)$
-dimensional unit sphere. However, when the limiting dependence structure is independence, or even when some pairs are independent, this representation fails to discriminate between qualitatively different underlying dependence structures. While consideration of componentwise maxima is not necessarily a commonly applied methodology these days, the legacy of this approach persists: statistical methods that assume multivariate regular variation, such as multivariate generalized Pareto distributions, are still very popular in practice (e.g. [Reference Engelke and Hitz16]). A recent theoretical treatment of multivariate regular variation is given in [Reference Kulik and Soulier31].
$ (d-1)$
-dimensional unit sphere. However, when the limiting dependence structure is independence, or even when some pairs are independent, this representation fails to discriminate between qualitatively different underlying dependence structures. While consideration of componentwise maxima is not necessarily a commonly applied methodology these days, the legacy of this approach persists: statistical methods that assume multivariate regular variation, such as multivariate generalized Pareto distributions, are still very popular in practice (e.g. [Reference Engelke and Hitz16]). A recent theoretical treatment of multivariate regular variation is given in [Reference Kulik and Soulier31].
Various other representations for multivariate extremes have emerged that analyze the structure of the dependence when some variables are growing at different rates from others. These include the so-called conditional extreme value model [Reference Heffernan and Tawn25, Reference Heffernan and Resnick24], where the components of
 $ {\boldsymbol{X}}$
are normalized according to how they grow with a single component,
$ {\boldsymbol{X}}$
are normalized according to how they grow with a single component,
 $ X_j$
say. Related work examines behaviour in relation to an arbitrary linear functional of
$ X_j$
say. Related work examines behaviour in relation to an arbitrary linear functional of
 $ {\boldsymbol{X}}$
[Reference Balkema and Embrechts3]. The conditional representation allows consideration of those regions where some or all variables grow at a lesser rate than
$ {\boldsymbol{X}}$
[Reference Balkema and Embrechts3]. The conditional representation allows consideration of those regions where some or all variables grow at a lesser rate than
 $ X_j$
if this is the region where the observations tend to lie. In other words, the limit theory is suited to giving a more detailed description of a broader range of underlying dependence structures. Another representation that explicitly considers different growth rates is that of [Reference Wadsworth and Tawn44]. They focus particularly on characterizing joint survival probabilities under certain classes of inhomogeneous normalization; this was found to reveal additional structure that is not evident when applying a common scaling. More recently, [Reference Simpson, Wadsworth and Tawn42] have examined certain types of unequal scaling with a view to classifying the strength of dependence in any subgroup of variables of
$ X_j$
if this is the region where the observations tend to lie. In other words, the limit theory is suited to giving a more detailed description of a broader range of underlying dependence structures. Another representation that explicitly considers different growth rates is that of [Reference Wadsworth and Tawn44]. They focus particularly on characterizing joint survival probabilities under certain classes of inhomogeneous normalization; this was found to reveal additional structure that is not evident when applying a common scaling. More recently, [Reference Simpson, Wadsworth and Tawn42] have examined certain types of unequal scaling with a view to classifying the strength of dependence in any subgroup of variables of
 $ {\boldsymbol{X}}$
.
$ {\boldsymbol{X}}$
.
An alternative approach to adding detail to the extremal dependence structure focuses not on different scaling orders, but rather on second-order effects when applying a common scaling. This idea was introduced by [Reference Ledford and Tawn33] and falls under the broader umbrella of hidden regular variation [Reference Resnick39]. Various manuscripts have focused on analogizing concepts from standard multivariate regular variation to the case of hidden regular variation (e.g. [Reference Ramos and Ledford37]), but this approach still only focuses on a restricted region of the multivariate space where all variables are large simultaneously. For this reason, although higher-dimensional analogues exist, they are often not practically useful for dimension
 $ d>2$
.
$ d>2$
.
Another manner of examining the extremal behaviour of
 $ {\boldsymbol{X}}$
is to consider normalizing the variables so that they converge onto a limit set (e.g. [Reference Davis, Mulrow and Resnick12, Reference Balkema and Nolde4]), described by a so-called gauge function. This requires light-tailed margins, which may occur naturally or through a transformation. If the margins are standardized to a common light-tailed form, then the shape of the limit set is revealing about the extremal dependence structure of the random variables, exposing in which directions we expect to see more observations.
$ {\boldsymbol{X}}$
is to consider normalizing the variables so that they converge onto a limit set (e.g. [Reference Davis, Mulrow and Resnick12, Reference Balkema and Nolde4]), described by a so-called gauge function. This requires light-tailed margins, which may occur naturally or through a transformation. If the margins are standardized to a common light-tailed form, then the shape of the limit set is revealing about the extremal dependence structure of the random variables, exposing in which directions we expect to see more observations.
Although various connections have been made in the literature, many of these representations remain somewhat disjointed. For example, there is no obvious connection between the conditional extremes methodology and the representation of [Reference Ledford and Tawn33, Reference Ledford and Tawn34], and whilst [Reference Wadsworth and Tawn44] provided a modest connection to conditional extremes, many open questions remain. In this paper we reveal several hitherto unknown connections that can be made through the shape of the limit set and its corresponding gauge function, when it exists, and provide a step towards unifying the treatment of multivariate extremes.
We next provide further elaboration and definition of the different representations of extremal dependence. For some definitions, it is convenient to have a standardized marginal form; we focus mainly on standard Pareto or standard exponential margins with notation
 $ {\boldsymbol{X}}_P$
and
$ {\boldsymbol{X}}_P$
and
 $ {\boldsymbol{X}}_E$
, respectively. As mentioned above, working with common margins highlights dependence features. In Section 2 we recall the formulations of various representations for multivariate extremes, and provide a thorough background to the concepts of limit sets and their gauge functions, proving a useful new result on marginalization. Section 3 details connections linking conditional extremes, the representation of [Reference Wadsworth and Tawn44], [Reference Ledford and Tawn33], and that of [Reference Simpson, Wadsworth and Tawn42]. We provide illustrative examples in Section 4 and conclude in Section 5.
$ {\boldsymbol{X}}_E$
, respectively. As mentioned above, working with common margins highlights dependence features. In Section 2 we recall the formulations of various representations for multivariate extremes, and provide a thorough background to the concepts of limit sets and their gauge functions, proving a useful new result on marginalization. Section 3 details connections linking conditional extremes, the representation of [Reference Wadsworth and Tawn44], [Reference Ledford and Tawn33], and that of [Reference Simpson, Wadsworth and Tawn42]. We provide illustrative examples in Section 4 and conclude in Section 5.
2. Background and definitions
2.1. Multivariate regular variation
A measurable function
 $ f\,:\, \mathbb{R}_+ \to \mathbb{R}_+$
is regularly varying at infinity (respectively, zero) with index
$ f\,:\, \mathbb{R}_+ \to \mathbb{R}_+$
is regularly varying at infinity (respectively, zero) with index
 $ \rho \in\mathbb{R}$
if, for any
$ \rho \in\mathbb{R}$
if, for any
 $ x>0$
,
$ x>0$
,
 $ f(tx)/f(t) \to x^\rho$
as
$ f(tx)/f(t) \to x^\rho$
as
 $ t \to \infty$
(respectively,
$ t \to \infty$
(respectively,
 $ t \to 0$
). We write
$ t \to 0$
). We write
 $ f \in \mathrm{RV}_\rho^\infty$
or
$ f \in \mathrm{RV}_\rho^\infty$
or
 $ f \in \mathrm{RV}_\rho^0$
, omitting the superscript in generic cases. If
$ f \in \mathrm{RV}_\rho^0$
, omitting the superscript in generic cases. If
 $ f \in \mathrm{RV}_0$
, then it is called slowly varying.
$ f \in \mathrm{RV}_0$
, then it is called slowly varying.
The random vector
 $ {\boldsymbol{X}}$
is multivariate regularly varying on the cone
$ {\boldsymbol{X}}$
is multivariate regularly varying on the cone
 $ \mathbb{E} = [0,\infty]^d \setminus \{\boldsymbol{0}\}$
, with index
$ \mathbb{E} = [0,\infty]^d \setminus \{\boldsymbol{0}\}$
, with index
 $ \alpha>0$
, if for any relatively compact
$ \alpha>0$
, if for any relatively compact
 $ B \subset \mathbb{E}$
,
$ B \subset \mathbb{E}$
,
 \begin{align}t{\mathbb P}({\boldsymbol{X}}/b(t) \in B) \to \nu(B), \qquad t \to \infty, \end{align}
\begin{align}t{\mathbb P}({\boldsymbol{X}}/b(t) \in B) \to \nu(B), \qquad t \to \infty, \end{align}
with
 $ \nu(\partial B) = 0$
,
$ \nu(\partial B) = 0$
,
 $ b(t) \in \mathrm{RV}^\infty_{1/\alpha}$
, and the limit measure
$ b(t) \in \mathrm{RV}^\infty_{1/\alpha}$
, and the limit measure
 $ \nu$
homogeneous of order
$ \nu$
homogeneous of order
 $ -\alpha$
; see e.g. [Reference Resnick40, Section 6.1.4]. The parts of
$ -\alpha$
; see e.g. [Reference Resnick40, Section 6.1.4]. The parts of
 $ \mathbb{E}$
where
$ \mathbb{E}$
where
 $ \nu$
places mass reveal the broad-scale extremal dependence structure of
$ \nu$
places mass reveal the broad-scale extremal dependence structure of
 $ {\boldsymbol{X}}$
. Specifically, note that we have the disjoint union
$ {\boldsymbol{X}}$
. Specifically, note that we have the disjoint union
 $ \mathbb{E} = \bigcup_{C} \mathbb{E}_C$
, where
$ \mathbb{E} = \bigcup_{C} \mathbb{E}_C$
, where
 \begin{align}\mathbb{E}_C = \big\{\boldsymbol{x} \in \mathbb{E}\,:\, x_j > 0, j\in C;\, x_i = 0, i\not\in C\big\}\,=\!:\,(0,\infty]^C\times\{0\}^{D \setminus C}, \end{align}
\begin{align}\mathbb{E}_C = \big\{\boldsymbol{x} \in \mathbb{E}\,:\, x_j > 0, j\in C;\, x_i = 0, i\not\in C\big\}\,=\!:\,(0,\infty]^C\times\{0\}^{D \setminus C}, \end{align}
and the union is over all possible subsets
 $ C \subseteq D=\{1,\ldots, d\}$
, excluding the empty set. If
$ C \subseteq D=\{1,\ldots, d\}$
, excluding the empty set. If
 $ \nu\big(\mathbb{E}_C\big)>0$
then the variables indexed by C can take their most extreme values simultaneously, whilst those indexed by
$ \nu\big(\mathbb{E}_C\big)>0$
then the variables indexed by C can take their most extreme values simultaneously, whilst those indexed by
 $ D \setminus C$
are non-extreme.
$ D \setminus C$
are non-extreme.
The definition of multivariate regular variation in (2.1) requires tail equivalence of the margins. In practice, it is rare to find variables that have regularly varying tails with common indices, and multivariate regular variation is a dependence assumption placed on standardized variables. Without loss of generality, therefore, we henceforth consider
 $ {\boldsymbol{X}}={\boldsymbol{X}}_P$
with standard Pareto(1) margins, in which case
$ {\boldsymbol{X}}={\boldsymbol{X}}_P$
with standard Pareto(1) margins, in which case
 $ \alpha=1$
and
$ \alpha=1$
and
 $ b(t) = t$
.
$ b(t) = t$
.
Frequently, the set B in (2.1) is taken as
 $ [\boldsymbol{0},\boldsymbol{x}]^c = \mathbb{E}\setminus [\boldsymbol{0},\boldsymbol{x}]$
, leading to the exponent function,
$ [\boldsymbol{0},\boldsymbol{x}]^c = \mathbb{E}\setminus [\boldsymbol{0},\boldsymbol{x}]$
, leading to the exponent function,
 \begin{align}V(\boldsymbol{x}) = \nu([\boldsymbol{0},\boldsymbol{x}]^c). \end{align}
\begin{align}V(\boldsymbol{x}) = \nu([\boldsymbol{0},\boldsymbol{x}]^c). \end{align}
Suppose that derivatives of V exist almost everywhere; this is the case for popular parametric models, such as the multivariate logistic [Reference Gumbel23], Hüsler–Reiss [Reference Hüsler and Reiss27], and asymmetric logistic distributions [Reference Tawn43]. Let
 $ \partial^{|C|}/\partial \boldsymbol{x}_C = \prod_{i \in C} \partial/ \partial x_i$
. If the quantity
$ \partial^{|C|}/\partial \boldsymbol{x}_C = \prod_{i \in C} \partial/ \partial x_i$
. If the quantity
 $ \lim_{x_j \to 0, j \not\in C}\partial^{|C|}V(\boldsymbol{x})/\partial \boldsymbol{x}_C$
is nonzero, then the group of variables indexed by C places mass on
$ \lim_{x_j \to 0, j \not\in C}\partial^{|C|}V(\boldsymbol{x})/\partial \boldsymbol{x}_C$
is nonzero, then the group of variables indexed by C places mass on
 $ \mathbb{E}_C$
(see [Reference Coles and Tawn10]).
$ \mathbb{E}_C$
(see [Reference Coles and Tawn10]).
Multivariate regular variation is often phrased in terms of a radial–angular decomposition. If (2.1) holds, then for
 $ r\geq1$
,
$ r\geq1$
,
 \begin{align*}{\mathbb P}({\boldsymbol{X}}_P /\|{\boldsymbol{X}}_P\| \in A, \|{\boldsymbol{X}}_P\|>tr) /{\mathbb P}(\|{\boldsymbol{X}}_P\|>t) \to H(A)r^{-1},\qquad t\to\infty,\end{align*}
\begin{align*}{\mathbb P}({\boldsymbol{X}}_P /\|{\boldsymbol{X}}_P\| \in A, \|{\boldsymbol{X}}_P\|>tr) /{\mathbb P}(\|{\boldsymbol{X}}_P\|>t) \to H(A)r^{-1},\qquad t\to\infty,\end{align*}
where
 $ A \subset \mathcal{S}=\Big\{\boldsymbol{w}\in\mathbb{R}^d_+\,:\, \|\boldsymbol{w}\| = 1\Big\}$
and
$ A \subset \mathcal{S}=\Big\{\boldsymbol{w}\in\mathbb{R}^d_+\,:\, \|\boldsymbol{w}\| = 1\Big\}$
and
 $ \|{\cdot}\|$
is any norm. That is, the radial variable
$ \|{\cdot}\|$
is any norm. That is, the radial variable
 $ R= \|{\boldsymbol{X}}_P\|$
and the angular variable
$ R= \|{\boldsymbol{X}}_P\|$
and the angular variable
 $ {\boldsymbol{W}}={\boldsymbol{X}}_P /\|{\boldsymbol{X}}_P\|$
are independent in the limit, with
$ {\boldsymbol{W}}={\boldsymbol{X}}_P /\|{\boldsymbol{X}}_P\|$
are independent in the limit, with
 $ R \sim$
Pareto(1) and
$ R \sim$
Pareto(1) and
 $ {\boldsymbol{W}} \in \mathcal{S}$
following the distribution H. The support of the so-called spectral measure H can also be partitioned in a similar manner to
$ {\boldsymbol{W}} \in \mathcal{S}$
following the distribution H. The support of the so-called spectral measure H can also be partitioned in a similar manner to
 $ \mathbb{E}$
. Letting
$ \mathbb{E}$
. Letting
 \begin{equation*}\mathbb{A}_C = \big\{\boldsymbol{w} \in \mathcal{S}\,:\, w_j > 0, j\in C;\, w_i = 0, i\not\in C\big\},\end{equation*}
\begin{equation*}\mathbb{A}_C = \big\{\boldsymbol{w} \in \mathcal{S}\,:\, w_j > 0, j\in C;\, w_i = 0, i\not\in C\big\},\end{equation*}
we have
 $ \mathcal{S} = \bigcup_C \mathbb{A}_C$
. The measure
$ \mathcal{S} = \bigcup_C \mathbb{A}_C$
. The measure
 $ \nu$
places mass on
$ \nu$
places mass on
 $ \mathbb{E}_C$
if and only if H places mass on
$ \mathbb{E}_C$
if and only if H places mass on
 $ \mathbb{A}_C$
.
$ \mathbb{A}_C$
.
2.2. Hidden regular variation
Hidden regular variation arises when (i) there is multivariate regular variation on a cone (say
 $ \mathbb{E}$
), but the mass concentrates on a subcone
$ \mathbb{E}$
), but the mass concentrates on a subcone
 $ \tilde{\mathbb{E}} \subset \mathbb{E}$
, and (ii) there is multivariate regular variation on the subcone
$ \tilde{\mathbb{E}} \subset \mathbb{E}$
, and (ii) there is multivariate regular variation on the subcone
 $ \mathbb{E}^{\prime} \subseteq \mathbb{E} \setminus \tilde{\mathbb{E}}$
with a scaling function of smaller order than on the full cone. Suppose that (2.1) holds, and
$ \mathbb{E}^{\prime} \subseteq \mathbb{E} \setminus \tilde{\mathbb{E}}$
with a scaling function of smaller order than on the full cone. Suppose that (2.1) holds, and
 $ \nu$
concentrates on
$ \nu$
concentrates on
 $ \tilde{\mathbb{E}}$
, in the sense that
$ \tilde{\mathbb{E}}$
, in the sense that
 $ \nu\big(\mathbb{E} \setminus \tilde{\mathbb{E}}\big) = 0$
. For measurable
$ \nu\big(\mathbb{E} \setminus \tilde{\mathbb{E}}\big) = 0$
. For measurable
 $ B \subset \mathbb{E}^{\prime}$
, we have hidden regular variation on
$ B \subset \mathbb{E}^{\prime}$
, we have hidden regular variation on
 $ \mathbb{E}^{\prime}$
if
$ \mathbb{E}^{\prime}$
if
 \begin{align}t{\mathbb P}\big({\boldsymbol{X}}_P/c(t) \in B\big) \to \nu^{\prime}(B), \qquad t \to \infty, \qquad c(t) = o(t),\quad c(t) \in \mathrm{RV}_{\zeta}^\infty, \quad\zeta \in (0,1], \end{align}
\begin{align}t{\mathbb P}\big({\boldsymbol{X}}_P/c(t) \in B\big) \to \nu^{\prime}(B), \qquad t \to \infty, \qquad c(t) = o(t),\quad c(t) \in \mathrm{RV}_{\zeta}^\infty, \quad\zeta \in (0,1], \end{align}
with
 $ \nu^{\prime}(\partial B) = 0$
and the limit measure
$ \nu^{\prime}(\partial B) = 0$
and the limit measure
 $ \nu^{\prime}$
homogeneous of order
$ \nu^{\prime}$
homogeneous of order
 $ -1/\zeta$
(see [Reference Resnick40, Section 9.4.1]).
$ -1/\zeta$
(see [Reference Resnick40, Section 9.4.1]).
The most common cone to consider is
 $ \mathbb{E}^{\prime} = (0,\infty]^d$
. This leads to the residual tail dependence coefficient,
$ \mathbb{E}^{\prime} = (0,\infty]^d$
. This leads to the residual tail dependence coefficient,
 $ \eta_D \in (0,1]$
(see [Reference Ledford and Tawn33]). That is, suppose that (2.4) holds on
$ \eta_D \in (0,1]$
(see [Reference Ledford and Tawn33]). That is, suppose that (2.4) holds on
 $ (0,\infty]^d$
; then the regular variation index
$ (0,\infty]^d$
; then the regular variation index
 $ \zeta=\eta_D$
. The residual tail dependence coefficient for the subset
$ \zeta=\eta_D$
. The residual tail dependence coefficient for the subset
 $ C \subset D$
is found through considering cones of the form
$ C \subset D$
is found through considering cones of the form
 \begin{equation*}\mathbb{E}^{\prime}_C = \big\{\boldsymbol{x} \in \mathbb{E}\,:\, x_j > 0, j\in C;\, x_i \in[0,\infty], i\not\in C\big\} \,=\!:\,(0,\infty]^C\times[0,\infty]^{D \setminus C},\end{equation*}
\begin{equation*}\mathbb{E}^{\prime}_C = \big\{\boldsymbol{x} \in \mathbb{E}\,:\, x_j > 0, j\in C;\, x_i \in[0,\infty], i\not\in C\big\} \,=\!:\,(0,\infty]^C\times[0,\infty]^{D \setminus C},\end{equation*}
for which
 $ \zeta= \eta_C$
.
$ \zeta= \eta_C$
.
2.3. Different scaling orders
2.3.1. Coefficients
 $ \tau_C(\delta)$
$ \tau_C(\delta)$

Simpson et al. [Reference Simpson, Wadsworth and Tawn42] sought to examine the extremal dependence structure of a random vector through determination of the cones
 $ \mathbb{E}_C$
for which
$ \mathbb{E}_C$
for which
 $ \nu\big(\mathbb{E}_C\big)>0$
. Direct consideration of (hidden) regular variation conditions on these cones is impeded by the fact that
$ \nu\big(\mathbb{E}_C\big)>0$
. Direct consideration of (hidden) regular variation conditions on these cones is impeded by the fact that
 $ {\mathbb P}({\boldsymbol{X}}_P/b(t) \in B) = 0$
for all
$ {\mathbb P}({\boldsymbol{X}}_P/b(t) \in B) = 0$
for all
 $ B \subset \mathbb{E}_C$
,
$ B \subset \mathbb{E}_C$
,
 $ C \neq D$
, since no components of
$ C \neq D$
, since no components of
 $ {\boldsymbol{X}}_P/b(t)$
are equal to zero for
$ {\boldsymbol{X}}_P/b(t)$
are equal to zero for
 $ t< \infty$
. Simpson et al. [Reference Simpson, Wadsworth and Tawn42] circumvent this issue by assuming that if
$ t< \infty$
. Simpson et al. [Reference Simpson, Wadsworth and Tawn42] circumvent this issue by assuming that if
 $ \nu\big(\mathbb{E}_C\big)>0$
, then there exists
$ \nu\big(\mathbb{E}_C\big)>0$
, then there exists
 $ \delta<1$
such that
$ \delta<1$
such that
 \begin{align}\lim_{t \to \infty} &t{\mathbb P}\Big(\!\min_{i \in C}X_{P,i}> xt, \max_{j \in D \setminus C}X_{P,j} \leq y t^\delta\Big) \nonumber\\&= \lim_{t \to \infty} t{\mathbb P}\Big(\!\min_{i \in C}X_{P,i}/t> x, \max_{j \in D \setminus C}X_{P,j}/t \leq y t^{\delta-1}\Big)>0, \qquad x,y>0. \end{align}
\begin{align}\lim_{t \to \infty} &t{\mathbb P}\Big(\!\min_{i \in C}X_{P,i}> xt, \max_{j \in D \setminus C}X_{P,j} \leq y t^\delta\Big) \nonumber\\&= \lim_{t \to \infty} t{\mathbb P}\Big(\!\min_{i \in C}X_{P,i}/t> x, \max_{j \in D \setminus C}X_{P,j}/t \leq y t^{\delta-1}\Big)>0, \qquad x,y>0. \end{align}
Consequently, under normalization by t, components of the random vector indexed by C remain positive, whereas those indexed by
 $ D\setminus C$
concentrate at zero. Note that if the assumption (2.5) holds for some
$ D\setminus C$
concentrate at zero. Note that if the assumption (2.5) holds for some
 $ \delta<1$
, then it also holds for all
$ \delta<1$
, then it also holds for all
 $ \delta^{\prime} \in [\delta,1]$
. Simpson et al. [Reference Simpson, Wadsworth and Tawn42] expanded the assumption (2.5) to
$ \delta^{\prime} \in [\delta,1]$
. Simpson et al. [Reference Simpson, Wadsworth and Tawn42] expanded the assumption (2.5) to
 \begin{align}{\mathbb P}\Big(\!\min_{i \in C}X_{P,i}> xt, \max_{j \in D \setminus C}X_{P,j} \leq y t^\delta\Big) \in \mathrm{RV}_{-1/\tau_C(\delta)}^{\infty}, \qquad \delta \in [0,1] ,\end{align}
\begin{align}{\mathbb P}\Big(\!\min_{i \in C}X_{P,i}> xt, \max_{j \in D \setminus C}X_{P,j} \leq y t^\delta\Big) \in \mathrm{RV}_{-1/\tau_C(\delta)}^{\infty}, \qquad \delta \in [0,1] ,\end{align}
where (2.6) is viewed as a function of t, and the regular variation coefficients
 $ \tau_C(\delta) \in (0,1]$
. For a fixed
$ \tau_C(\delta) \in (0,1]$
. For a fixed
 $ \delta$
,
$ \delta$
,
 $ \tau_C(\delta)<1$
implies either that
$ \tau_C(\delta)<1$
implies either that
 $ \nu\big(\mathbb{E}_C\big)=0$
, or that
$ \nu\big(\mathbb{E}_C\big)=0$
, or that
 $ \nu\big(\mathbb{E}_C\big)>0$
, but that
$ \nu\big(\mathbb{E}_C\big)>0$
, but that
 $ \delta$
is too small for (2.5) to hold; see [Reference Simpson, Wadsworth and Tawn42] for further details. Considering the coefficients
$ \delta$
is too small for (2.5) to hold; see [Reference Simpson, Wadsworth and Tawn42] for further details. Considering the coefficients
 $ \tau_C(\delta)$
over all C and
$ \tau_C(\delta)$
over all C and
 $ \delta \in [0,1]$
provides information about the cones on which
$ \delta \in [0,1]$
provides information about the cones on which
 $ \nu$
concentrates.
$ \nu$
concentrates.
2.3.2. Angular dependence function
$ \lambda(\boldsymbol{\omega})$

Wadsworth and Tawn [Reference Wadsworth and Tawn44] detail a representation for the tail of
 $ {\boldsymbol{X}}_P$
where the scaling functions are of different order in each component. They focus principally on a sequence of univariate regular variation conditions, characterizing
$ {\boldsymbol{X}}_P$
where the scaling functions are of different order in each component. They focus principally on a sequence of univariate regular variation conditions, characterizing
 \begin{align}{\mathbb P}\big({\boldsymbol{X}}_P>t^{\boldsymbol{\omega}}\big) = \ell(t;\, \boldsymbol{\omega})t^{-\lambda(\boldsymbol{\omega})}, \qquad \boldsymbol{\omega} \in \mathcal{S}_{\Sigma}=\left\{\boldsymbol{\omega} \in [0,1]^d \,:\, \sum_{j=1}^d \omega_j = 1\right\}, \end{align}
\begin{align}{\mathbb P}\big({\boldsymbol{X}}_P>t^{\boldsymbol{\omega}}\big) = \ell(t;\, \boldsymbol{\omega})t^{-\lambda(\boldsymbol{\omega})}, \qquad \boldsymbol{\omega} \in \mathcal{S}_{\Sigma}=\left\{\boldsymbol{\omega} \in [0,1]^d \,:\, \sum_{j=1}^d \omega_j = 1\right\}, \end{align}
where
 $ \ell(t;\, \boldsymbol{\omega}) \in \mathrm{RV}_0^\infty$
for each
$ \ell(t;\, \boldsymbol{\omega}) \in \mathrm{RV}_0^\infty$
for each
 $ \boldsymbol{\omega}$
and
$ \boldsymbol{\omega}$
and
 $ \lambda\,:\,\mathcal{S}_{\Sigma} \to [0,1]$
. Equivalently,
$ \lambda\,:\,\mathcal{S}_{\Sigma} \to [0,1]$
. Equivalently,
 $ {\mathbb P}\big({\boldsymbol{X}}_E > {\boldsymbol{\omega}}v\big) = \ell\big(e^v;\, \boldsymbol{\omega}\big)e^{-\lambda(\boldsymbol{\omega})v}$
. When all components of
$ {\mathbb P}\big({\boldsymbol{X}}_E > {\boldsymbol{\omega}}v\big) = \ell\big(e^v;\, \boldsymbol{\omega}\big)e^{-\lambda(\boldsymbol{\omega})v}$
. When all components of
 $ \boldsymbol{\omega}$
are equal to
$ \boldsymbol{\omega}$
are equal to
 $ 1/d$
, connection with hidden regular variation on the cone
$ 1/d$
, connection with hidden regular variation on the cone
 $ \mathbb{E}_D$
is restored, and we have
$ \mathbb{E}_D$
is restored, and we have
 $ \eta_D = d\lambda(1/d,\ldots,1/d)$
. When the subcone
$ \eta_D = d\lambda(1/d,\ldots,1/d)$
. When the subcone
 $ \mathbb{E}_D$
of
$ \mathbb{E}_D$
of
 $ \mathbb{E}$
is charged with mass in the limit (2.1), we have
$ \mathbb{E}$
is charged with mass in the limit (2.1), we have
 $ \lambda(\boldsymbol{\omega}) = \max_{1\leq j \leq d}\omega_j$
. One can equally focus on subvectors indexed by C to define
$ \lambda(\boldsymbol{\omega}) = \max_{1\leq j \leq d}\omega_j$
. One can equally focus on subvectors indexed by C to define
 $ \lambda_{C}(\boldsymbol{\omega})$
for
$ \lambda_{C}(\boldsymbol{\omega})$
for
 $ \boldsymbol{\omega}$
in a
$ \boldsymbol{\omega}$
in a
 $ (|C|-1)$
-dimensional simplex; we continue to have
$ (|C|-1)$
-dimensional simplex; we continue to have
 $ \eta_C = |C|\lambda_C(1/|C|,\ldots,1/|C|)$
and
$ \eta_C = |C|\lambda_C(1/|C|,\ldots,1/|C|)$
and
 $ \nu\big(\mathbb{E}_C\big)>0$
implies
$ \nu\big(\mathbb{E}_C\big)>0$
implies
 $ \lambda_{C}(\boldsymbol{\omega}) = \max_{1 \leq j \leq |C|} \omega_j$
.
$ \lambda_{C}(\boldsymbol{\omega}) = \max_{1 \leq j \leq |C|} \omega_j$
.
2.4. Conditional extremes
For conditional extreme value theory [Reference Heffernan and Resnick24, Reference Heffernan and Tawn25], we focus on
 $ {\boldsymbol{X}}_E$
. Let
$ {\boldsymbol{X}}_E$
. Let
 $ {\boldsymbol{X}}_{E,-j}$
represent the vector
$ {\boldsymbol{X}}_{E,-j}$
represent the vector
 $ {\boldsymbol{X}}_E$
without the jth component. The basic assumption is that there exist functions
$ {\boldsymbol{X}}_E$
without the jth component. The basic assumption is that there exist functions
 $ {\boldsymbol{a}}^j\,:\,\mathbb{R} \to \mathbb{R}^{d-1}$
,
$ {\boldsymbol{a}}^j\,:\,\mathbb{R} \to \mathbb{R}^{d-1}$
,
 $ {\boldsymbol{b}}^j\,:\,\mathbb{R} \to \mathbb{R}_+^{d-1}$
and a nondegenerate distribution
$ {\boldsymbol{b}}^j\,:\,\mathbb{R} \to \mathbb{R}_+^{d-1}$
and a nondegenerate distribution
 $ K^j$
on
$ K^j$
on
 $ \mathbb{R}^{d-1}$
with no mass at infinity, such that
$ \mathbb{R}^{d-1}$
with no mass at infinity, such that
 \begin{align}{\mathbb P}\left(\frac{{\boldsymbol{X}}_{E,-j} - {\boldsymbol{a}}^j\big(X_{E,j}\big)}{{\boldsymbol{b}}^j\big(X_{E,j}\big)} \leq {\boldsymbol{z}}, X_{E,j}-t>x \Big| X_{E,j}>t\right) \to K^j({\boldsymbol{z}}) e^{-x}, \qquad t \to \infty. \end{align}
\begin{align}{\mathbb P}\left(\frac{{\boldsymbol{X}}_{E,-j} - {\boldsymbol{a}}^j\big(X_{E,j}\big)}{{\boldsymbol{b}}^j\big(X_{E,j}\big)} \leq {\boldsymbol{z}}, X_{E,j}-t>x \Big| X_{E,j}>t\right) \to K^j({\boldsymbol{z}}) e^{-x}, \qquad t \to \infty. \end{align}
Typically, such assumptions are made for each
 $ j \in D$
. The normalization functions satisfy some regularity conditions detailed in [Reference Heffernan and Resnick24], but as [Reference Heffernan and Resnick24] only standardize the marginal distribution of the conditioning variable (i.e.
$ j \in D$
. The normalization functions satisfy some regularity conditions detailed in [Reference Heffernan and Resnick24], but as [Reference Heffernan and Resnick24] only standardize the marginal distribution of the conditioning variable (i.e.
 $ X_j$
), allowing different margins in other variables, these conditions do not strongly characterize the functions
$ X_j$
), allowing different margins in other variables, these conditions do not strongly characterize the functions
 $ {\boldsymbol{a}}^j$
and
$ {\boldsymbol{a}}^j$
and
 $ {\boldsymbol{b}}^j$
as used in (2.8).
$ {\boldsymbol{b}}^j$
as used in (2.8).
When joint densities exist, application of L’Hôpital’s rule gives that the convergence (2.8) is equivalent to
 \begin{align*}{\mathbb P}\left(\frac{{\boldsymbol{X}}_{E,-j} - {\boldsymbol{a}}^j(t)}{{\boldsymbol{b}}^j(t)} \leq {\boldsymbol{z}} \Big| X_{E,j}=t\right) \to K^j({\boldsymbol{z}}), \qquad t \to \infty.\end{align*}
\begin{align*}{\mathbb P}\left(\frac{{\boldsymbol{X}}_{E,-j} - {\boldsymbol{a}}^j(t)}{{\boldsymbol{b}}^j(t)} \leq {\boldsymbol{z}} \Big| X_{E,j}=t\right) \to K^j({\boldsymbol{z}}), \qquad t \to \infty.\end{align*}
We will further assume convergence of the full joint density
 \begin{align}\frac{\partial^{d-1}}{\partial {\boldsymbol{z}}}{\mathbb P}\left(\frac{{\boldsymbol{X}}_{E,-j} - {\boldsymbol{a}}^j(t)}{{\boldsymbol{b}}^j(t)} \leq {\boldsymbol{z}} \Big| X_{E,j}=t\right) \to \frac{\partial^{d-1}}{\partial {\boldsymbol{z}}} K^j({\boldsymbol{z}}) \,=\!:\, k^j({\boldsymbol{z}}), \qquad t \to \infty, \end{align}
\begin{align}\frac{\partial^{d-1}}{\partial {\boldsymbol{z}}}{\mathbb P}\left(\frac{{\boldsymbol{X}}_{E,-j} - {\boldsymbol{a}}^j(t)}{{\boldsymbol{b}}^j(t)} \leq {\boldsymbol{z}} \Big| X_{E,j}=t\right) \to \frac{\partial^{d-1}}{\partial {\boldsymbol{z}}} K^j({\boldsymbol{z}}) \,=\!:\, k^j({\boldsymbol{z}}), \qquad t \to \infty, \end{align}
which is the practical assumption needed for undertaking likelihood-based statistical inference using this model.
Connected to this approach is the work of [Reference Balkema and Embrechts3], who study asymptotic behaviour of a suitably normalized random vector
 $ {\boldsymbol{X}}$
conditional on lying in tH, where H is a half-space not containing the origin and
$ {\boldsymbol{X}}$
conditional on lying in tH, where H is a half-space not containing the origin and
 $ t\to\infty$
. The distribution of
$ t\to\infty$
. The distribution of
 $ {\boldsymbol{X}}$
is assumed to have a light-tailed density whose level sets are homothetic and convex and have a smooth boundary. In this setting, with H taken to be the vertical half-space
$ {\boldsymbol{X}}$
is assumed to have a light-tailed density whose level sets are homothetic and convex and have a smooth boundary. In this setting, with H taken to be the vertical half-space
 $ \big\{\boldsymbol{x}\in{\mathbb R}^d\,:\,\ x_d>1\big\}$
, the limit is the so-called Gauss–exponential distribution with density
$ \big\{\boldsymbol{x}\in{\mathbb R}^d\,:\,\ x_d>1\big\}$
, the limit is the so-called Gauss–exponential distribution with density
 $ \exp\big\{-{\boldsymbol{u}}^T{\boldsymbol{u}}/2-v\big\}/(2\pi)^{(d-1)/2}$
,
$ \exp\big\{-{\boldsymbol{u}}^T{\boldsymbol{u}}/2-v\big\}/(2\pi)^{(d-1)/2}$
,
 $ {\boldsymbol{u}}\in{\mathbb R}^{d-1}$
,
$ {\boldsymbol{u}}\in{\mathbb R}^{d-1}$
,
 $ v>0$
.
$ v>0$
.
2.5. Limit sets
2.5.1. Background
Let
 $ {\boldsymbol{X}}_1,\ldots,{\boldsymbol{X}}_n$
be independent and identically distributed random vectors in
$ {\boldsymbol{X}}_1,\ldots,{\boldsymbol{X}}_n$
be independent and identically distributed random vectors in
 $ {\mathbb R}^d$
. A random set
$ {\mathbb R}^d$
. A random set
 $ N_n=\big\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\big\}$
represents a scaled n-point sample cloud. We consider situations in which there exists a scaling sequence
$ N_n=\big\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\big\}$
represents a scaled n-point sample cloud. We consider situations in which there exists a scaling sequence
 $ r_n>0$
,
$ r_n>0$
,
 $ r_n\to\infty$
, such that scaled sample clouds
$ r_n\to\infty$
, such that scaled sample clouds
 $ N_n$
converge onto a deterministic set containing at least two points. Figure 1 illustrates examples of sample clouds for which a limit set exists. Let
$ N_n$
converge onto a deterministic set containing at least two points. Figure 1 illustrates examples of sample clouds for which a limit set exists. Let
 $ {{\mathcal{K}}}_d$
denote the family of non-empty compact subsets of
$ {{\mathcal{K}}}_d$
denote the family of non-empty compact subsets of
 $ {\mathbb R}^d$
, and let
$ {\mathbb R}^d$
, and let
 $ d_H({\cdot},{\cdot})$
denote the Hausdorff distance between two sets [Reference Matheron35]. A sequence of random sets
$ d_H({\cdot},{\cdot})$
denote the Hausdorff distance between two sets [Reference Matheron35]. A sequence of random sets
 $ N_n$
in
$ N_n$
in
 $ {{\mathcal{K}}}_d$
converges in probability onto a limit set
$ {{\mathcal{K}}}_d$
converges in probability onto a limit set
 $ G\in{{\mathcal{K}}}_d$
if
$ G\in{{\mathcal{K}}}_d$
if
 $ d_H(N_n,G)\buildrel{\mathbb P}\over\rightarrow 0$
for
$ d_H(N_n,G)\buildrel{\mathbb P}\over\rightarrow 0$
for
 $ n\to\infty$
. The following result gives convenient criteria for showing convergence in probability onto a limit set; see [Reference Balkema, Embrechts and Nolde2].
$ n\to\infty$
. The following result gives convenient criteria for showing convergence in probability onto a limit set; see [Reference Balkema, Embrechts and Nolde2].

Figure 1. Sample clouds of
 $ n=10^5$
points simulated from meta-Gaussian distributions with standard exponential margins and copula correlation parameter
$ n=10^5$
points simulated from meta-Gaussian distributions with standard exponential margins and copula correlation parameter
 $ \rho=0.5$
(left panel),
$ \rho=0.5$
(left panel),
 $ \rho=0$
(middle panel), and
$ \rho=0$
(middle panel), and
 $ \rho=-0.5$
(right panel). The samples are scaled by the factor
$ \rho=-0.5$
(right panel). The samples are scaled by the factor
 $ r_n=\log n$
. See Examples 4.1.1 and 4.1.2 for details.
$ r_n=\log n$
. See Examples 4.1.1 and 4.1.2 for details.
Proposition 2.1. Random samples on
 $ {\mathbb R}^d$
scaled by
$ {\mathbb R}^d$
scaled by
 $ r_n$
converge in probability onto a deterministic set G in
$ r_n$
converge in probability onto a deterministic set G in
 $ {{\mathcal{K}}}_d$
if and only if
$ {{\mathcal{K}}}_d$
if and only if
-
(i)
$ n{\mathbb P}({\boldsymbol{X}}/r_n \in U^c)\to0$
for any open set U containing G; -
(ii)
$ n{\mathbb P}({\boldsymbol{X}}/r_n \in \{\boldsymbol{x}+\epsilon B\})\to\infty$
for all
$ \boldsymbol{x}\in G$
and any
$ \epsilon>0$
, where B is the Euclidean unit ball.




Limit sets under various assumptions on the underlying distribution have been derived in [Reference Geffroy20, Reference Geffroy21, Reference Fisher18, Reference Davis, Mulrow and Resnick12, Reference Balkema, Embrechts and Nolde2]. Kinoshita and Resnick [Reference Kinoshita and Resnick30] give a complete characterization of the possible limit sets, as well as describing the class of distribution functions for which sample clouds can be scaled to converge (almost surely) onto a limit set. Furthermore, convergence in probability onto a limit set is implied by the tail large deviation principle studied in [Reference De Valk15, Reference De Valk14].
Kinoshita and Resnick [Reference Kinoshita and Resnick30] showed that if sample clouds can be scaled to converge onto a limit set almost surely, then the limit set is compact and star-shaped. A set G in
 $ {\mathbb R}^d$
is star-shaped if
$ {\mathbb R}^d$
is star-shaped if
 $ \boldsymbol{x}\in G$
implies
$ \boldsymbol{x}\in G$
implies
 $ t\boldsymbol{x} \in G$
for all
$ t\boldsymbol{x} \in G$
for all
 $ t \in [0,1]$
. For a set
$ t \in [0,1]$
. For a set
 $ G\in{{\mathcal{K}}}_d$
, if the line segment
$ G\in{{\mathcal{K}}}_d$
, if the line segment
 $ {\textbf{0}}+t \boldsymbol{x}$
,
$ {\textbf{0}}+t \boldsymbol{x}$
,
 $ t\in [0,1)$
, is contained in the interior of G for every
$ t\in [0,1)$
, is contained in the interior of G for every
 $ \boldsymbol{x}\in G$
, then G can be characterized by a continuous gauge function:
$ \boldsymbol{x}\in G$
, then G can be characterized by a continuous gauge function:
 \begin{equation*}g(\boldsymbol{x})=\inf\{t\ge0\,:\,\ \boldsymbol{x}\in tG\},\qquad \boldsymbol{x}\in{\mathbb R}^d.\end{equation*}
\begin{equation*}g(\boldsymbol{x})=\inf\{t\ge0\,:\,\ \boldsymbol{x}\in tG\},\qquad \boldsymbol{x}\in{\mathbb R}^d.\end{equation*}
A gauge function satisfies homogeneity—
 $ g(t\boldsymbol{x})=tg(\boldsymbol{x})$
for all
$ g(t\boldsymbol{x})=tg(\boldsymbol{x})$
for all
 $ t>0$
—and the set G can be recovered from its gauge function via
$ t>0$
—and the set G can be recovered from its gauge function via
 $ G=\big\{\boldsymbol{x}\in{\mathbb R}^d\,:\,\ g(\boldsymbol{x})\le1\big\}.$
Examples of a gauge function include a norm
$ G=\big\{\boldsymbol{x}\in{\mathbb R}^d\,:\,\ g(\boldsymbol{x})\le1\big\}.$
Examples of a gauge function include a norm
 $ \|{\cdot}\|$
on
$ \|{\cdot}\|$
on
 $ {\mathbb R}^d$
, in which case
$ {\mathbb R}^d$
, in which case
 $ G=\{\boldsymbol{x}\in{\mathbb R}^d\,:\,\ \|\boldsymbol{x}\|\le1\}$
is the unit ball in that norm.
$ G=\{\boldsymbol{x}\in{\mathbb R}^d\,:\,\ \|\boldsymbol{x}\|\le1\}$
is the unit ball in that norm.
The shape of the limit set conveys information about extremal dependence properties of the underlying distribution. In particular, [Reference Balkema and Nolde4] make a connection between the shape of the limit set and asymptotic independence, whilst [Reference Nolde36] links its shape to the coefficient of residual tail dependence. We emphasize that the shape of the limit set depends on the choice of marginal distributions, as well as the dependence structure. For example, if the components of
 $ (X_1,X_2)$
are independent with common marginal distribution, then
$ (X_1,X_2)$
are independent with common marginal distribution, then
 $ G = \big\{(x,y) \in \mathbb{R}_+^2\,:\, x+y \leq 1\big\}$
if the margins are exponential;
$ G = \big\{(x,y) \in \mathbb{R}_+^2\,:\, x+y \leq 1\big\}$
if the margins are exponential;
 $ G = \big\{(x,y) \in \mathbb{R}^2\,:\, |x|+|y| \leq 1\big\}$
if the margins are Laplace; and
$ G = \big\{(x,y) \in \mathbb{R}^2\,:\, |x|+|y| \leq 1\big\}$
if the margins are Laplace; and
 $ G = \big\{(x,y) \in \mathbb{R}_+^2\,:\, \big(x^\beta +y^\beta\big)^{1/\beta} \leq 1\big\}$
if the margins are Weibull with shape
$ G = \big\{(x,y) \in \mathbb{R}_+^2\,:\, \big(x^\beta +y^\beta\big)^{1/\beta} \leq 1\big\}$
if the margins are Weibull with shape
 $ \beta>0$
. In contrast, if the margins are exponential but G takes the latter form, this implies some dependence between the components.
$ \beta>0$
. In contrast, if the margins are exponential but G takes the latter form, this implies some dependence between the components.
2.5.2. Conditions for convergence onto a limit set
Proposition 2.1 provides necessary and sufficient conditions for convergence onto the limit set G, but these conditions are not particularly helpful for determining the form of G in practice.
In the following proposition, we state a criterion in terms of the joint probability density for convergence of suitably scaled random samples onto a limit set. This result is an adaptation of Proposition 3.7 in [Reference Balkema and Nolde4]. The marginal tails of the underlying distribution are assumed to be asymptotically equal to a von Mises function. A function of the form
 $ e^{-\psi}$
is said to be a von Mises function if
$ e^{-\psi}$
is said to be a von Mises function if
 $ \psi$
is a
$ \psi$
is a
 $ C^2$
function with a positive derivative such that
$ C^2$
function with a positive derivative such that
 $ (1/\psi^{\prime}(x))^{\prime}\to 0$
for
$ (1/\psi^{\prime}(x))^{\prime}\to 0$
for
 $ x\to\infty$
. This condition on the margins says that they are light-tailed and lie in the maximum domain of attraction of the Gumbel distribution; i.e., for a random sample from such a univariate distribution, coordinatewise maxima can be normalized to converge weakly to the Gumbel distribution (see [Reference Resnick38, Proposition 1.1]).
$ x\to\infty$
. This condition on the margins says that they are light-tailed and lie in the maximum domain of attraction of the Gumbel distribution; i.e., for a random sample from such a univariate distribution, coordinatewise maxima can be normalized to converge weakly to the Gumbel distribution (see [Reference Resnick38, Proposition 1.1]).
Proposition 2.2. Let the random vector
 $ {\boldsymbol{X}}$
on
$ {\boldsymbol{X}}$
on
 $ [0,\infty)^d$
have marginal distribution functions asymptotically equal to a von Mises function, i.e.
$ [0,\infty)^d$
have marginal distribution functions asymptotically equal to a von Mises function, i.e.
 $ 1-F_j(x) \sim e^{-\psi_j(x)}$
for
$ 1-F_j(x) \sim e^{-\psi_j(x)}$
for
 $ \psi_j(x)\sim \psi(x)$
,
$ \psi_j(x)\sim \psi(x)$
,
 $ x\to\infty$
(
$ x\to\infty$
(
 $ j=1,\ldots,d$
), and a joint probability density f satisfying
$ j=1,\ldots,d$
), and a joint probability density f satisfying
 \begin{equation}\dfrac{{-}\log f(t\boldsymbol{x}_t)}{\psi(t)}\to g_*(\boldsymbol{x}),\qquad t\to\infty,\qquad \boldsymbol{x}_t\to\boldsymbol{x},\qquad \boldsymbol{x}\in[0,\infty)^d\end{equation}
\begin{equation}\dfrac{{-}\log f(t\boldsymbol{x}_t)}{\psi(t)}\to g_*(\boldsymbol{x}),\qquad t\to\infty,\qquad \boldsymbol{x}_t\to\boldsymbol{x},\qquad \boldsymbol{x}\in[0,\infty)^d\end{equation}
for a continuous function
 $ g_*$
on
$ g_*$
on
 $ [0,\infty)^d$
, which is positive outside a bounded set. Then a sequence of scaled random samples
$ [0,\infty)^d$
, which is positive outside a bounded set. Then a sequence of scaled random samples
 $ N_n=\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\}$
from f converges in probability onto a limit set G with
$ N_n=\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\}$
from f converges in probability onto a limit set G with
 $ G=\{\boldsymbol{x}\in[0,\infty)^d \,:\, g_*(\boldsymbol{x})\le 1\}$
. The scaling sequence
$ G=\{\boldsymbol{x}\in[0,\infty)^d \,:\, g_*(\boldsymbol{x})\le 1\}$
. The scaling sequence
 $ r_n$
can be chosen as
$ r_n$
can be chosen as
 $ \psi(r_n)\sim \log n$
. Moreover,
$ \psi(r_n)\sim \log n$
. Moreover,
 $ \max G=(1,\ldots,1)$
.
$ \max G=(1,\ldots,1)$
.
Proof. The mean measure of
 $ N_n$
is given by
$ N_n$
is given by
 $ n{\mathbb P}({\boldsymbol{X}}/r_n\in{\cdot})$
with intensity
$ n{\mathbb P}({\boldsymbol{X}}/r_n\in{\cdot})$
with intensity
 $ h_n(\boldsymbol{x}) = nr_n^df(r_n\boldsymbol{x})$
. We show the convergence of that mean measure onto G, implying convergence of scaled samples
$ h_n(\boldsymbol{x}) = nr_n^df(r_n\boldsymbol{x})$
. We show the convergence of that mean measure onto G, implying convergence of scaled samples
 $ N_n$
; see [Reference Balkema, Embrechts and Nolde2, Proposition 2.3]. By (2.10) and the choice of
$ N_n$
; see [Reference Balkema, Embrechts and Nolde2, Proposition 2.3]. By (2.10) and the choice of
 $ r_n$
, we have
$ r_n$
, we have
 \begin{equation}{-}\log f(r_n\boldsymbol{x}_n)/\log n\sim {-}\log f(r_n\boldsymbol{x}_n)/\psi(r_n)\to g_*(\boldsymbol{x}), \quad n\to\infty,\quad \boldsymbol{x}_n\to\boldsymbol{x}.\end{equation}
\begin{equation}{-}\log f(r_n\boldsymbol{x}_n)/\log n\sim {-}\log f(r_n\boldsymbol{x}_n)/\psi(r_n)\to g_*(\boldsymbol{x}), \quad n\to\infty,\quad \boldsymbol{x}_n\to\boldsymbol{x}.\end{equation}
Continuous convergence in (2.11) with
 $ g_*$
continuous implies uniform convergence on compact sets. Hence,
$ g_*$
continuous implies uniform convergence on compact sets. Hence,
 $ g_*$
is bounded on compact sets. For
$ g_*$
is bounded on compact sets. For
 $ G=\{g_*(\boldsymbol{x})\le1\}$
, we have
$ G=\{g_*(\boldsymbol{x})\le1\}$
, we have
 $ g_*(\boldsymbol{x})<1$
on the interior of G and
$ g_*(\boldsymbol{x})<1$
on the interior of G and
 $ g_*(\boldsymbol{x})>1$
on the complement of G. Furthermore, applying L’Hôpital’s rule and Lemma 1.2(a) in [Reference Resnick38], we have
$ g_*(\boldsymbol{x})>1$
on the complement of G. Furthermore, applying L’Hôpital’s rule and Lemma 1.2(a) in [Reference Resnick38], we have
 \begin{equation*}\log r_n/\psi(r_n)\sim (1/\psi^{\prime}(r_n))/r_n\to 0,\qquad r_n\to\infty.\end{equation*}
\begin{equation*}\log r_n/\psi(r_n)\sim (1/\psi^{\prime}(r_n))/r_n\to 0,\qquad r_n\to\infty.\end{equation*}
Combining these results, we see that
 $ {-}\log h_n(\boldsymbol{x}_n)\sim (g_*(\boldsymbol{x}_n)-1)\log n$
, which diverges to
$ {-}\log h_n(\boldsymbol{x}_n)\sim (g_*(\boldsymbol{x}_n)-1)\log n$
, which diverges to
 $ -\infty$
on the interior of G and to
$ -\infty$
on the interior of G and to
 $ +\infty$
outside of G. This implies that
$ +\infty$
outside of G. This implies that
 \begin{equation*}h_n(\boldsymbol{x}_n)\to\begin{cases} \infty, & \boldsymbol{x}\in G^o,\\ 0, & \boldsymbol{x}\in G^c,\end{cases} \end{equation*}
\begin{equation*}h_n(\boldsymbol{x}_n)\to\begin{cases} \infty, & \boldsymbol{x}\in G^o,\\ 0, & \boldsymbol{x}\in G^c,\end{cases} \end{equation*}
giving convergence (in probability) of
 $ N_n$
onto the limit set G.
$ N_n$
onto the limit set G.
The form of the margins
 $ 1-F_j(x) \sim e^{-\psi_j(x)}$
with
$ 1-F_j(x) \sim e^{-\psi_j(x)}$
with
 $ \psi_j(x) \sim \psi(x)\to\infty$
gives
$ \psi_j(x) \sim \psi(x)\to\infty$
gives
 $ {-}\log(1-F_j(x))\sim\psi(x)$
; i.e.,
$ {-}\log(1-F_j(x))\sim\psi(x)$
; i.e.,
 \begin{equation*}{-}\log\big(1-F_j(r_n)\big)\sim \psi(r_n)\sim\log n,\qquad n\to\infty.\end{equation*}
\begin{equation*}{-}\log\big(1-F_j(r_n)\big)\sim \psi(r_n)\sim\log n,\qquad n\to\infty.\end{equation*}
This choice of
 $ r_n$
implies that the coordinatewise maxima scaled by
$ r_n$
implies that the coordinatewise maxima scaled by
 $ r_n$
converge in probability to 1 [Reference De Haan13, Reference Gnedenko22], so that
$ r_n$
converge in probability to 1 [Reference De Haan13, Reference Gnedenko22], so that
 $ \max G = (1,\ldots,1).$
$ \max G = (1,\ldots,1).$
Remark 2.1. The condition (2.10) implies that
 $ {-}\log f$
is multivariate regularly varying on
$ {-}\log f$
is multivariate regularly varying on
 $ [0,\infty)^d$
. Such densities are referred to as Weibull-like. The limit function
$ [0,\infty)^d$
. Such densities are referred to as Weibull-like. The limit function
 $ g_*$
is homogeneous of some positive order k:
$ g_*$
is homogeneous of some positive order k:
 $ g_*(t\boldsymbol{x})=t^k g_*(\boldsymbol{x})$
for all
$ g_*(t\boldsymbol{x})=t^k g_*(\boldsymbol{x})$
for all
 $ t>0$
. The gauge function g of the limit set G can thus be obtained from
$ t>0$
. The gauge function g of the limit set G can thus be obtained from
 $ g_*$
by setting
$ g_*$
by setting
 $ g(\boldsymbol{x})=g_*^{1/k}(\boldsymbol{x})$
.
$ g(\boldsymbol{x})=g_*^{1/k}(\boldsymbol{x})$
.
When the margins are standard exponential,
 $ \psi(t)=t$
. Hence, for the random vector
$ \psi(t)=t$
. Hence, for the random vector
 $ {\boldsymbol{X}}_E$
with a Lebesgue density
$ {\boldsymbol{X}}_E$
with a Lebesgue density
 $ f_E$
on
$ f_E$
on
 $ \mathbb{R}^d_+$
, the condition (2.10) is equivalent to
$ \mathbb{R}^d_+$
, the condition (2.10) is equivalent to
 \begin{align}{-}\log f_E(t\boldsymbol{x}_t)/t\to g_*(\boldsymbol{x}), \qquad t \to \infty,\qquad \boldsymbol{x}_t\to\boldsymbol{x},\qquad \boldsymbol{x} \in [0,\infty)^d,\end{align}
\begin{align}{-}\log f_E(t\boldsymbol{x}_t)/t\to g_*(\boldsymbol{x}), \qquad t \to \infty,\qquad \boldsymbol{x}_t\to\boldsymbol{x},\qquad \boldsymbol{x} \in [0,\infty)^d,\end{align}
with the limit function
 $ g_*$
equal to the gauge function g.
$ g_*$
equal to the gauge function g.
Whilst the assumption of a Lebesgue density might appear strict, it is a common feature in statistical practice of extreme value analysis. The assumption permits simple elucidation of the connection between different representations for multivariate extremes. Furthermore, many statistical models, including elliptical distributions and vine copulas [Reference Bedford and Cooke7, Reference Bedford and Cooke8, Reference Joe28], are specified most readily in terms of their densities.
Convergence at the density level such as in (2.10) may not always hold. The condition requires the limit function and hence the gauge function of the limit set to be continuous, excluding limit sets for which rays from the origin cross the boundary in more than one point. We provide an example of such a situation in Section 4; see Example 4.1.2. A less restrictive set of sufficient conditions for convergence of sample clouds onto a limit set can be obtained using the survival function. The following proposition is Theorem 2.1 in [Reference Davis, Mulrow and Resnick12], with a minor reformulation in terms of scaling.
Proposition 2.3. Suppose that the random vector
 $ {\boldsymbol{X}}$
has support on
$ {\boldsymbol{X}}$
has support on
 $ [0,\infty)^d$
; the margins are asymptotically equal to a von Mises function,
$ [0,\infty)^d$
; the margins are asymptotically equal to a von Mises function,
 $ 1-F_j(x) \sim e^{-\psi(x)}$
for
$ 1-F_j(x) \sim e^{-\psi(x)}$
for
 $ x\to\infty$
(
$ x\to\infty$
(
 $ j=1,\ldots,d$
); and the joint survival function satisfies
$ j=1,\ldots,d$
); and the joint survival function satisfies
 \begin{equation}\dfrac{{-}\log {\mathbb P}({\boldsymbol{X}} \geq t\boldsymbol{x})}{\psi(t)}\to g_*(\boldsymbol{x}),\qquad t\to\infty,\qquad \boldsymbol{x}\in [0,\infty)^d \setminus\{0\}.\end{equation}
\begin{equation}\dfrac{{-}\log {\mathbb P}({\boldsymbol{X}} \geq t\boldsymbol{x})}{\psi(t)}\to g_*(\boldsymbol{x}),\qquad t\to\infty,\qquad \boldsymbol{x}\in [0,\infty)^d \setminus\{0\}.\end{equation}
Further assume that
 $ g_*$
is strictly increasing, so that
$ g_*$
is strictly increasing, so that
 $ g_*(\boldsymbol{x})<g_*({\boldsymbol{y}})$
if
$ g_*(\boldsymbol{x})<g_*({\boldsymbol{y}})$
if
 $ \boldsymbol{x} \leq {\boldsymbol{y}}$
and
$ \boldsymbol{x} \leq {\boldsymbol{y}}$
and
 $ \boldsymbol{x} \neq {\boldsymbol{y}}$
. Then for
$ \boldsymbol{x} \neq {\boldsymbol{y}}$
. Then for
 $ r_n$
satisfying
$ r_n$
satisfying
 $ \psi(r_n) \sim \log n$
, the sample cloud
$ \psi(r_n) \sim \log n$
, the sample cloud
 $ N_n=\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\}$
converges onto
$ N_n=\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\}$
converges onto
 $ G=\big\{\boldsymbol{x}\in[0,\infty)^d \,:\, g_*(\boldsymbol{x})\le 1\big\}$
.
$ G=\big\{\boldsymbol{x}\in[0,\infty)^d \,:\, g_*(\boldsymbol{x})\le 1\big\}$
.
2.5.3. Marginalization
When
 $ d>2$
, a key question is the marginalization from dimension d to dimension
$ d>2$
, a key question is the marginalization from dimension d to dimension
 $ m<d$
. We prove below that, as long as the minimum over each coordinate of g is well-defined, the gauge function determining the limit set in m dimensions is found through minimizing over the coordinates to be marginalized.
$ m<d$
. We prove below that, as long as the minimum over each coordinate of g is well-defined, the gauge function determining the limit set in m dimensions is found through minimizing over the coordinates to be marginalized.
A continuous map h from the vector space V into the vector space
 $ \widetilde V$
is positive-homogeneous if
$ \widetilde V$
is positive-homogeneous if
 $ h(r\boldsymbol{x})=rh(\boldsymbol{x})$
for all
$ h(r\boldsymbol{x})=rh(\boldsymbol{x})$
for all
 $ \boldsymbol{x}\in V$
and all
$ \boldsymbol{x}\in V$
and all
 $ r>0$
. If
$ r>0$
. If
 $ \widetilde V={\mathbb R}^{m}$
, the map h is determined by the m coordinate maps
$ \widetilde V={\mathbb R}^{m}$
, the map h is determined by the m coordinate maps
 $ h_j\,:\,V\to{\mathbb R}$
,
$ h_j\,:\,V\to{\mathbb R}$
,
 $ j=1,\ldots,m$
, and in this case it suffices that these maps are continuous and positive-homogeneous.
$ j=1,\ldots,m$
, and in this case it suffices that these maps are continuous and positive-homogeneous.
Convergence onto a limit set is preserved under linear transformations (e.g. Lemma 4.1 in [Reference Nolde36]) and more generally under continuous positive-homogeneous maps with the same scaling sequences (Theorem 1.9 in [Reference Balkema and Nolde6]). A consequence of the latter result, referred to as the Mapping Theorem, is that projections of sample clouds onto lower-dimensional subspaces also converge onto a limit set.
Proposition 2.4. Let
 $ N_n$
be an n-point sample cloud from a distribution of the random vector
$ N_n$
be an n-point sample cloud from a distribution of the random vector
 $ {\boldsymbol{X}}$
on
$ {\boldsymbol{X}}$
on
 $ {\mathbb R}^d$
. Assume
$ {\mathbb R}^d$
. Assume
 $ N_n$
converges in probability, as
$ N_n$
converges in probability, as
 $ n\to\infty$
, onto a limit set
$ n\to\infty$
, onto a limit set
 $ G=\{\boldsymbol{x}\in{\mathbb R}^d \,:\, g(\boldsymbol{x})\le1\}$
for a gauge function g. Let
$ G=\{\boldsymbol{x}\in{\mathbb R}^d \,:\, g(\boldsymbol{x})\le1\}$
for a gauge function g. Let
 $ \widetilde{\boldsymbol{X}} = (X_i)_{i\in I_m}$
denote an m-dimensional marginal of
$ \widetilde{\boldsymbol{X}} = (X_i)_{i\in I_m}$
denote an m-dimensional marginal of
 $ {\boldsymbol{X}}$
, where
$ {\boldsymbol{X}}$
, where
 $ I_m\subset I=\{1,\ldots,d\}$
is an index set with
$ I_m\subset I=\{1,\ldots,d\}$
is an index set with
 $ |I_m|=m$
. Sample clouds from
$ |I_m|=m$
. Sample clouds from
 $ \widetilde{\boldsymbol{X}}$
also converge, with the same scaling, and the limit set
$ \widetilde{\boldsymbol{X}}$
also converge, with the same scaling, and the limit set
 $ \tilde G = P_m(G) = \big\{{\boldsymbol{y}}\in{\mathbb R}^m \,:\, \tilde g({\boldsymbol{y}})\le1\big\}$
, where
$ \tilde G = P_m(G) = \big\{{\boldsymbol{y}}\in{\mathbb R}^m \,:\, \tilde g({\boldsymbol{y}})\le1\big\}$
, where
 $ P_m$
is a projection map onto the coordinates of
$ P_m$
is a projection map onto the coordinates of
 $ \widetilde{\boldsymbol{X}}$
and
$ \widetilde{\boldsymbol{X}}$
and
 \begin{equation*}\tilde g({\boldsymbol{y}}) = \min_{\{x_i \,:\, i\in I\setminus I_m\}} g(\boldsymbol{x}),\qquad \boldsymbol{x}=(x_1,\ldots,x_d),\qquad {\boldsymbol{y}}=(x_i)_{i\in I_m}.\end{equation*}
\begin{equation*}\tilde g({\boldsymbol{y}}) = \min_{\{x_i \,:\, i\in I\setminus I_m\}} g(\boldsymbol{x}),\qquad \boldsymbol{x}=(x_1,\ldots,x_d),\qquad {\boldsymbol{y}}=(x_i)_{i\in I_m}.\end{equation*}
Proof. Consider the bivariate case first with
 $ \widetilde{\boldsymbol{X}}=X_2$
. Sample clouds from
$ \widetilde{\boldsymbol{X}}=X_2$
. Sample clouds from
 $ X_2$
converge onto the limit set
$ X_2$
converge onto the limit set
 $ \tilde G\subset{\mathbb R}$
, which is the projection of G onto the
$ \tilde G\subset{\mathbb R}$
, which is the projection of G onto the
 $ x_1$
-coordinate axis, by the Mapping Theorem. The projection is determined by the tangent to the level curve
$ x_1$
-coordinate axis, by the Mapping Theorem. The projection is determined by the tangent to the level curve
 $ \big\{\boldsymbol{x}\in{\mathbb R}^2 \,:\, g(\boldsymbol{x})=1\big\}$
orthogonal to the
$ \big\{\boldsymbol{x}\in{\mathbb R}^2 \,:\, g(\boldsymbol{x})=1\big\}$
orthogonal to the
 $ x_1$
-coordinate axis. Similarly, level curves of the gauge function
$ x_1$
-coordinate axis. Similarly, level curves of the gauge function
 $ \tilde g$
of the set
$ \tilde g$
of the set
 $ \widetilde G$
are determined by tangents to the level curves
$ \widetilde G$
are determined by tangents to the level curves
 $ \big\{\boldsymbol{x}\in{\mathbb R}^2 \,:\, g(\boldsymbol{x})=c\big\}$
for
$ \big\{\boldsymbol{x}\in{\mathbb R}^2 \,:\, g(\boldsymbol{x})=c\big\}$
for
 $ c\in[0,1]$
orthogonal to the
$ c\in[0,1]$
orthogonal to the
 $ x_1$
-coordinate axis. These projections correspond to
$ x_1$
-coordinate axis. These projections correspond to
 $ x_1$
values which minimize
$ x_1$
values which minimize
 $ g(x_1,x_2)$
. Sequentially minimizing over each of the coordinates to be marginalized gives the result.
$ g(x_1,x_2)$
. Sequentially minimizing over each of the coordinates to be marginalized gives the result.
An illustration of this result is given in Section 4.2.
3. Linking representations for extremes to the limit set
For simplicity of presentation, in what follows we standardize to consider exponential margins for the light-tailed case. This choice is convenient when there is positive association in the extremes, but hides structure related to negative dependence. We comment further on this case in Section 5. Owing to the standardized marginals, it makes sense to refer to the limit set, rather than a limit set.
Connections between multivariate and hidden regular variation are well established, with the latter requiring the former for proper definition. Some connection between regular variation and conditional extremes was made in [Reference Das and Resnick11, Reference Heffernan and Resnick24], although they did not specify to exponential-tailed margins. The shape of the limit set has been linked to the asymptotic (in)dependence structure of a random vector [Reference Balkema and Nolde4, Reference Balkema and Nolde5]. Asymptotic independence is related to the position of mass from the convergence (2.1) on
 $ \mathbb{E}$
, but regular variation and the existence of a limit set in suitable margins are different conditions and one need not imply the other. The paper [Reference Nolde36] links the limit set G to the coefficient of residual tail dependence,
$ \mathbb{E}$
, but regular variation and the existence of a limit set in suitable margins are different conditions and one need not imply the other. The paper [Reference Nolde36] links the limit set G to the coefficient of residual tail dependence,
 $ \eta_D$
.
$ \eta_D$
.
In this section we present some new connections between the shape of the limit set, when it exists, and normalizing functions in conditional extreme value theory, the residual tail dependence coefficient, the function
 $ \lambda(\boldsymbol{\omega})$
, and the coefficients
$ \lambda(\boldsymbol{\omega})$
, and the coefficients
 $ \tau_{C}(\delta)$
.
$ \tau_{C}(\delta)$
.
3.1. Conditional extremes
For the conditional extreme value model, the form of the normalizing functions
 $ {\boldsymbol{a}}^j,{\boldsymbol{b}}^j$
is determined by the pairwise dependencies between
$ {\boldsymbol{a}}^j,{\boldsymbol{b}}^j$
is determined by the pairwise dependencies between
 $ \big(X_{E,i},X_{E,j}\big)$
,
$ \big(X_{E,i},X_{E,j}\big)$
,
 $ i \in D \setminus j$
. The two-dimensional marginalization of any d-dimensional gauge function is given by Proposition 2.4, and we simply denote this by g here.
$ i \in D \setminus j$
. The two-dimensional marginalization of any d-dimensional gauge function is given by Proposition 2.4, and we simply denote this by g here.
Proposition 3.1. Suppose that for
 $ {\boldsymbol{X}}_E = \big(X_{E,1},X_{E,2}\big)$
, the convergence (2.9) and the assumption (2.12) hold, where the domain of
$ {\boldsymbol{X}}_E = \big(X_{E,1},X_{E,2}\big)$
, the convergence (2.9) and the assumption (2.12) hold, where the domain of
 $ K^j$
includes
$ K^j$
includes
 $ (0,\infty)$
. Define
$ (0,\infty)$
. Define
 $ \alpha_j = \lim_{x \to \infty} a^j(x)/x$
,
$ \alpha_j = \lim_{x \to \infty} a^j(x)/x$
,
 $ j= 1,2$
. Then the following hold:
$ j= 1,2$
. Then the following hold:
-
(i) We have
$ g(1,\alpha_1) = 1$
,
$ g(\alpha_2, 1) = 1$
. -
(ii) Suppose that
$ {-}\log f_E(t\boldsymbol{x}_t)/t = g(\boldsymbol{x}_t) + v(t)$
, with
$ v(t) \in \mathrm{RV}_{-1}^{\infty}$
or
$ v(t)=o(1/t)$
, and
$ a^j(t) = \alpha_j t + B^j(t)$
, with either
$ B^j(t)/b^j(t) \in \mathrm{RV}^\infty_0$
or
$ B^j(t) = o(b^j(t))$
. For
$ \beta_1,\beta_2 \leq 1$
, if
$ g(1, \alpha_1 + {\cdot}) -1 \in \mathrm{RV}_{1/(1-\beta_1)}^0$
, then
$ b^1(x) \in \mathrm{RV}_{\beta_1}^\infty$
; similarly if
$ g(\alpha_2 + {\cdot},1) -1 \in \mathrm{RV}_{1/(1-\beta_2)}^0$
, then
$ b^2(x) \in \mathrm{RV}_{\beta_2}^\infty$
. -
(iii) If there are multiple values
$ \alpha$
satisfying
$ g(1,\alpha) = 1$
, then
$ \alpha_1$
is the maximum such
$ \alpha$
, and likewise for
$ \alpha_2$
.


















Before the proof of Proposition 3.1, we give some geometric intuition. Figure 2 presents several examples of the unit level set of possible gauge functions, illustrating the shape of the limit set, for two-dimensional random vectors with exponential margins. On each figure, the slope of the red line indicates the value of
 $ \alpha_1$
; i.e., the equation of the red line is
$ \alpha_1$
; i.e., the equation of the red line is
 $ y=\alpha_1 x$
. Intuitively, conditional extreme value theory poses the following question: given that the variable X is growing, how does the variable Y grow as a function of X? We can now see that this is neatly described by the shape of the limit set: to first order, the values of Y occurring with large X are determined by the direction for which X is growing at its maximum rate. The necessity of a scale normalization in the conditional extreme value limit depends on the local curvature and particularly on the rate at which
$ y=\alpha_1 x$
. Intuitively, conditional extreme value theory poses the following question: given that the variable X is growing, how does the variable Y grow as a function of X? We can now see that this is neatly described by the shape of the limit set: to first order, the values of Y occurring with large X are determined by the direction for which X is growing at its maximum rate. The necessity of a scale normalization in the conditional extreme value limit depends on the local curvature and particularly on the rate at which
 $ g(\alpha_1+u,1)$
approaches 1 as
$ g(\alpha_1+u,1)$
approaches 1 as
 $ u \to 0$
. For Cases (i), (iv), (v), and (vi) of Figure 2, the function approaches zero linearly in u: as a consequence
$ u \to 0$
. For Cases (i), (iv), (v), and (vi) of Figure 2, the function approaches zero linearly in u: as a consequence
 $ b^j(t) \in \mathrm{RV}_0^\infty$
. For Case (ii) the order of decay is
$ b^j(t) \in \mathrm{RV}_0^\infty$
. For Case (ii) the order of decay is
 $ u^2$
and so
$ u^2$
and so
 $ b^j(t) \in \mathrm{RV}_{1/2}^\infty$
, whilst for Case (iii) the order is
$ b^j(t) \in \mathrm{RV}_{1/2}^\infty$
, whilst for Case (iii) the order is
 $ u^{1/\theta}$
so
$ u^{1/\theta}$
so
 $ b^j(t) \in \mathrm{RV}_{1-\theta}^\infty$
.
$ b^j(t) \in \mathrm{RV}_{1-\theta}^\infty$
.

Figure 2. Unit level sets of six possible gauge functions for bivariate random vectors with exponential margins (bold lines). The limit set G is the set bounded by these level sets and the axes. In each case the red dotted line is
 $ y=\alpha_1 x$
, the blue solid lines represent
$ y=\alpha_1 x$
, the blue solid lines represent
 $ \lambda(\omega,1-\omega)$
, and the dot
$ \lambda(\omega,1-\omega)$
, and the dot
 $ \eta_{1,2}$
(see Section 3.2). Black dashed lines represent the boundary
$ \eta_{1,2}$
(see Section 3.2). Black dashed lines represent the boundary
 $ \max\!(x,y)=1$
. Clockwise from top left, the gauge functions represented are as follows: (i)
$ \max\!(x,y)=1$
. Clockwise from top left, the gauge functions represented are as follows: (i)
 $ \max\!(x,y)/\theta+(1-1/\theta)\min\!(x,y)$
; (ii)
$ \max\!(x,y)/\theta+(1-1/\theta)\min\!(x,y)$
; (ii)
 $ (x+y-2\theta\sqrt{xy})/(1-\theta^2)$
; (iii)
$ (x+y-2\theta\sqrt{xy})/(1-\theta^2)$
; (iii)
 $ \big(x^{1/\theta}+y^{1/\theta}\big)^\theta$
; (iv)
$ \big(x^{1/\theta}+y^{1/\theta}\big)^\theta$
; (iv)
 $ \max\{(x-y)/\theta,(y-x)/\theta,\min\!(x-\mu y,y-\mu x)/(1-\theta-\mu)\}$
; (v)
$ \max\{(x-y)/\theta,(y-x)/\theta,\min\!(x-\mu y,y-\mu x)/(1-\theta-\mu)\}$
; (v)
 $ \max\!((x-y)/\theta,(y-x)/\theta,(x+y)/(2-\theta))$
; (vi)
$ \max\!((x-y)/\theta,(y-x)/\theta,(x+y)/(2-\theta))$
; (vi)
 $ \min\big\{\max\!(x,y)/\theta_1+\big(1-1/\theta_1\big)\min\!(x,y), \big(x^{1/\theta_2}+y^{1/\theta_2}\big)^{\theta_2}\big\}$
. In each case,
$ \min\big\{\max\!(x,y)/\theta_1+\big(1-1/\theta_1\big)\min\!(x,y), \big(x^{1/\theta_2}+y^{1/\theta_2}\big)^{\theta_2}\big\}$
. In each case,
 $ \theta \in (0,1)$
; in some cases the endpoints are permitted as well. For Case (iv),
$ \theta \in (0,1)$
; in some cases the endpoints are permitted as well. For Case (iv),
 $ \theta+\mu<1$
.
$ \theta+\mu<1$
.
The class of distributions represented by the gauge function (vi) (bottom left) can be thought of as those arising from a mixture of distributions with gauge functions (i) and (iii), up to differences in parameter values. In such an example, there are two normalizations that would lead to a nondegenerate limit in (2.8), but ruling out mass at infinity produces the unique choice
 $ \alpha_1=\alpha_2=1$
,
$ \alpha_1=\alpha_2=1$
,
 $ \beta_1=\beta_2=0$
. If instead we chose to rule out mass at
$ \beta_1=\beta_2=0$
. If instead we chose to rule out mass at
 $ -\infty$
, then we would have
$ -\infty$
, then we would have
 $ \alpha_1=\alpha_2 = 0$
and
$ \alpha_1=\alpha_2 = 0$
and
 $ \beta_1=\beta_2 = 1-\theta$
.
$ \beta_1=\beta_2 = 1-\theta$
.
Proof of Proposition 3.1. In every case we prove just one statement, as the other follows analogously.
(i) By the assumption (2.12),
 $ \big(X_{E,1},X_{E,2}\big)$
have a joint density
$ \big(X_{E,1},X_{E,2}\big)$
have a joint density
 $ f_E$
, and so the conditional extremes convergence (2.9) can be expressed as
$ f_E$
, and so the conditional extremes convergence (2.9) can be expressed as
 \begin{equation*}b^1(t)f_E\big(t,b^1(t)z+a^1(t)\big)e^t \to k^1(z) \,=\!:\,e^{-h^1(z)}, \qquad t \to \infty,z \in \Big[\lim_{t \to \infty}-a^1(t)/b^1(t), \infty\Big),\end{equation*}
\begin{equation*}b^1(t)f_E\big(t,b^1(t)z+a^1(t)\big)e^t \to k^1(z) \,=\!:\,e^{-h^1(z)}, \qquad t \to \infty,z \in \Big[\lim_{t \to \infty}-a^1(t)/b^1(t), \infty\Big),\end{equation*}
with
 $ k^1 = e^{-h^1}$
a density. Taking logs, we have
$ k^1 = e^{-h^1}$
a density. Taking logs, we have
 \begin{align}{-}\log f_E\big(t,b^1(t)z+a^1(t)\big) - t {-}\log b^1(t) \to h^1(z),\qquad t\to\infty. \end{align}
\begin{align}{-}\log f_E\big(t,b^1(t)z+a^1(t)\big) - t {-}\log b^1(t) \to h^1(z),\qquad t\to\infty. \end{align}
Now use the assumption (2.12) with
 $ \boldsymbol{x}_t =(1,x_t)= \big(1,a^1(t)/t + zb^1(t)/t\big)$
. That is,
$ \boldsymbol{x}_t =(1,x_t)= \big(1,a^1(t)/t + zb^1(t)/t\big)$
. That is,
 \begin{align}{-}\log f_E\big(t,b^1(t)z+a^1(t)\big) =t g(1,x)[1+o(1)] = t g(1,x_t)[1+o(1)] , \end{align}
\begin{align}{-}\log f_E\big(t,b^1(t)z+a^1(t)\big) =t g(1,x)[1+o(1)] = t g(1,x_t)[1+o(1)] , \end{align}
with
 $ x = \lim_{t\to\infty} a^1(t)/t + zb^1(t)/t$
. As the support of
$ x = \lim_{t\to\infty} a^1(t)/t + zb^1(t)/t$
. As the support of
 $ K^1$
includes
$ K^1$
includes
 $ (0,\infty)$
,
$ (0,\infty)$
,
 $ h^1(z)<\infty$
for all
$ h^1(z)<\infty$
for all
 $ z \in (0,\infty)$
, and combining (3.1) and (3.2) we have
$ z \in (0,\infty)$
, and combining (3.1) and (3.2) we have
 \begin{align}g(1,x_t)[1+o(1)] = 1 + h^1(z)/t +\log b^1(t)/t + o(1/t).\end{align}
\begin{align}g(1,x_t)[1+o(1)] = 1 + h^1(z)/t +\log b^1(t)/t + o(1/t).\end{align}
Suppose that
 $ b^1(t)/t \to \gamma>0$
. Then
$ b^1(t)/t \to \gamma>0$
. Then
 $ x_t \to \alpha_1 + \gamma z$
, and taking
$ x_t \to \alpha_1 + \gamma z$
, and taking
 $ t\to \infty$
in (3.3) leads to
$ t\to \infty$
in (3.3) leads to
 $ g(1,\alpha_1 + \gamma z) =1$
for any z. But since the coordinatewise supremum of G is (1, 1),
$ g(1,\alpha_1 + \gamma z) =1$
for any z. But since the coordinatewise supremum of G is (1, 1),
 $ g(x,y) \geq \max\!(x,y)$
, which would entail
$ g(x,y) \geq \max\!(x,y)$
, which would entail
 $ z \leq (1-\alpha_1)/\gamma$
. No such upper bound applies, so we conclude
$ z \leq (1-\alpha_1)/\gamma$
. No such upper bound applies, so we conclude
 $ \gamma=0$
, i.e.,
$ \gamma=0$
, i.e.,
 $ b^1(t) = o(t)$
. Now taking limits in (3.3) leads to
$ b^1(t) = o(t)$
. Now taking limits in (3.3) leads to
 $ g(1,\alpha_1)=1.$
$ g(1,\alpha_1)=1.$
(ii) Let
 $ g(1,\alpha_1+u)-1 \,=\!:\,r(u) \in \mathrm{RV}_\rho^0$
,
$ g(1,\alpha_1+u)-1 \,=\!:\,r(u) \in \mathrm{RV}_\rho^0$
,
 $ \rho>0$
. From (3.3) we also have
$ \rho>0$
. From (3.3) we also have
 \begin{equation*}g\big(1,\alpha_1 + b^1(t)/t+B^1(t)/t\big)-1 = h^1(1)/t + \log b^1(t)/t - v(t) + o(1/t),\end{equation*}
\begin{equation*}g\big(1,\alpha_1 + b^1(t)/t+B^1(t)/t\big)-1 = h^1(1)/t + \log b^1(t)/t - v(t) + o(1/t),\end{equation*}
so that the function
 $ b^1(t)$
is a solution to the equation
$ b^1(t)$
is a solution to the equation
 \begin{align}r\big(b^1(t)/t+B^1(t)/t\big) = h^1(1)/t + \log b^1(t)/t - v(t)+ o(1/t). \end{align}
\begin{align}r\big(b^1(t)/t+B^1(t)/t\big) = h^1(1)/t + \log b^1(t)/t - v(t)+ o(1/t). \end{align}
Equation (3.4) admits a solution if
 $ b^1$
is regularly varying at infinity. A rearrangement provides that
$ b^1$
is regularly varying at infinity. A rearrangement provides that
 \begin{align*}b^1(t) = t r^{-1}\big(h^1(1)/t + \log b^1(t)/t - v(t)+ o(1/t)\big)\big[1+ B^1(t)/b^1(t)\big]^{-1};\end{align*}
\begin{align*}b^1(t) = t r^{-1}\big(h^1(1)/t + \log b^1(t)/t - v(t)+ o(1/t)\big)\big[1+ B^1(t)/b^1(t)\big]^{-1};\end{align*}
if
 $ b^1$
is regularly varying then
$ b^1$
is regularly varying then
 $ \log b^1(t)/t \in \mathrm{RV}_{-1}^{\infty}$
, so that using the fact that
$ \log b^1(t)/t \in \mathrm{RV}_{-1}^{\infty}$
, so that using the fact that
 $ v(t) \in \mathrm{RV}_{-1}^\infty$
or
$ v(t) \in \mathrm{RV}_{-1}^\infty$
or
 $ v(t)=o(1/t)$
, combined with
$ v(t)=o(1/t)$
, combined with
 $ r^{-1} \in \mathrm{RV}_{1/\rho}^0$
, yields
$ r^{-1} \in \mathrm{RV}_{1/\rho}^0$
, yields
 $ b^1(t) \in \mathrm{RV}_{1-1/\rho}^{\infty}$
. We now argue that such a solution is unique in this context. We know that the normalization functions
$ b^1(t) \in \mathrm{RV}_{1-1/\rho}^{\infty}$
. We now argue that such a solution is unique in this context. We know that the normalization functions
 $ a^1,b^1$
lead to a nondegenerate distribution
$ a^1,b^1$
lead to a nondegenerate distribution
 $ K^1$
that places no mass at infinity. By the convergence to types theorem ([Reference Leadbetter, Lindgren and Rootzén32, p. 7]; see also Part (iii) of this proof), any other function
$ K^1$
that places no mass at infinity. By the convergence to types theorem ([Reference Leadbetter, Lindgren and Rootzén32, p. 7]; see also Part (iii) of this proof), any other function
 $ \tilde{b}^1$
leading to a nondegenerate limit with no mass at infinity must satisfy
$ \tilde{b}^1$
leading to a nondegenerate limit with no mass at infinity must satisfy
 $ \tilde{b}^1(t) \sim d b^1(t)$
,
$ \tilde{b}^1(t) \sim d b^1(t)$
,
 $ t \to \infty$
, for some
$ t \to \infty$
, for some
 $ d>0$
, so that
$ d>0$
, so that
 $ \tilde{b}^1 \in \mathrm{RV}_{1-1/\rho}^\infty$
also. Finally, setting
$ \tilde{b}^1 \in \mathrm{RV}_{1-1/\rho}^\infty$
also. Finally, setting
 $ \beta_1=1-1/\rho$
gives
$ \beta_1=1-1/\rho$
gives
 $ b^1 \in \mathrm{RV}_{\beta_1}^{\infty}$
.
$ b^1 \in \mathrm{RV}_{\beta_1}^{\infty}$
.
(iii) Suppose that
 \begin{equation*}{\mathbb P}\left(\frac{X_{E,2}-a^1(t)}{b^1(t)} \leq z \big| X_{E,1}>t\right) \to K^1(z), {\mathbb P}\left(\frac{X_{E,2}-\tilde{a}^1(t)}{\tilde{b}^1(t)} \leq z \big| X_{E,1}>t\right) \to \tilde{K}^1(z),\end{equation*}
\begin{equation*}{\mathbb P}\left(\frac{X_{E,2}-a^1(t)}{b^1(t)} \leq z \big| X_{E,1}>t\right) \to K^1(z), {\mathbb P}\left(\frac{X_{E,2}-\tilde{a}^1(t)}{\tilde{b}^1(t)} \leq z \big| X_{E,1}>t\right) \to \tilde{K}^1(z),\end{equation*}
where neither
 $ K^1$
nor
$ K^1$
nor
 $ \tilde{K}^1$
has mass at
$ \tilde{K}^1$
has mass at
 $ + \infty$
. Then by the convergence to types theorem,
$ + \infty$
. Then by the convergence to types theorem,
 $ \tilde{a}^1(t) = a^1(t) + cb^1(t) +o(b^1(t))$
and
$ \tilde{a}^1(t) = a^1(t) + cb^1(t) +o(b^1(t))$
and
 $ \tilde{b}^1(t) = db^1(t) +o(b^1(t))$
, for some
$ \tilde{b}^1(t) = db^1(t) +o(b^1(t))$
, for some
 $ d>0$
, and
$ d>0$
, and
 $ \tilde{K}^1(z) = $
$ \tilde{K}^1(z) = $
 $ K^1(z/d+c)$
. Therefore,
$ K^1(z/d+c)$
. Therefore,
 $ \tilde{a}^1(t)/t \sim a^1(t)/t \sim \alpha_1$
. We conclude that if there were a nondegenerate
$ \tilde{a}^1(t)/t \sim a^1(t)/t \sim \alpha_1$
. We conclude that if there were a nondegenerate
 $ \tilde{K}^1$
limit for which
$ \tilde{K}^1$
limit for which
 $ \tilde{a}^1(t)/t \sim \tilde{\alpha}_1>\alpha_1$
, then
$ \tilde{a}^1(t)/t \sim \tilde{\alpha}_1>\alpha_1$
, then
 $ K^1$
must place mass at
$ K^1$
must place mass at
 $ +\infty$
; since by assumption it does not, we conclude that
$ +\infty$
; since by assumption it does not, we conclude that
 $ \alpha_1$
is the maximum value satisfying
$ \alpha_1$
is the maximum value satisfying
 $ g(1,\alpha_1) = 1$
.
$ g(1,\alpha_1) = 1$
.
For distributions whose sample clouds converge onto a limit set described by a gauge function with piecewise continuous partial derivatives possessing finite left and right limits, further detail can be given about
 $ \beta_j$
.
$ \beta_j$
.
Proposition 3.2. Let G be a limit set whose gauge function g has piecewise continuous partial derivatives
 $ g_1(x,y)=\partial g(x,y)/\partial x$
,
$ g_1(x,y)=\partial g(x,y)/\partial x$
,
 $ g_2(x,y)=\partial g(x,y)/\partial y$
possessing finite left and right limits, and for which the conditions of Proposition 3.1 hold. Then (i)
$ g_2(x,y)=\partial g(x,y)/\partial y$
possessing finite left and right limits, and for which the conditions of Proposition 3.1 hold. Then (i)
 $ \beta_1\geq0$
if
$ \beta_1\geq0$
if
 $ g_2(1,(\alpha_1)_+)=0$
; (ii)
$ g_2(1,(\alpha_1)_+)=0$
; (ii)
 $ \beta_1=0$
if
$ \beta_1=0$
if
 $ 0<g_2(1,(\alpha_1)_+)<\infty$
. Furthermore, if
$ 0<g_2(1,(\alpha_1)_+)<\infty$
. Furthermore, if
 $ \alpha_1>0$
then
$ \alpha_1>0$
then
 $ 0 \leq g_2(1,(\alpha_1)_+)< \infty$
, so that
$ 0 \leq g_2(1,(\alpha_1)_+)< \infty$
, so that
 $ \beta_1 \geq 0$
. Analogous statements hold for
$ \beta_1 \geq 0$
. Analogous statements hold for
 $ \alpha_2,\beta_2$
.
$ \alpha_2,\beta_2$
.
Proof. Consider the partial derivative
 \begin{equation*}g_2(1,(\alpha_1)_+) = \lim_{u\to 0^+} \frac{g(1,\alpha_1+u)-g(1,\alpha_1)}{u} \geq 0,\end{equation*}
\begin{equation*}g_2(1,(\alpha_1)_+) = \lim_{u\to 0^+} \frac{g(1,\alpha_1+u)-g(1,\alpha_1)}{u} \geq 0,\end{equation*}
as
 $ g(1,\alpha_1+u) \geq g(1,\alpha_1)$
. We note
$ g(1,\alpha_1+u) \geq g(1,\alpha_1)$
. We note
 $ g(1,\alpha_1)=1$
, so that
$ g(1,\alpha_1)=1$
, so that
 $ g(1,\alpha_1+u)-1 \sim u g_2(1,(\alpha_1)_+)$
,
$ g(1,\alpha_1+u)-1 \sim u g_2(1,(\alpha_1)_+)$
,
 $ u \to 0^+$
. Since this is regularly varying with index
$ u \to 0^+$
. Since this is regularly varying with index
 $ 1/(1-\beta_1)$
by assumption,
$ 1/(1-\beta_1)$
by assumption,
 $ g_2(1,(\alpha_1)_+)=0$
implies
$ g_2(1,(\alpha_1)_+)=0$
implies
 $ g(1,\alpha_1+u)-1=o(u)$
, so
$ g(1,\alpha_1+u)-1=o(u)$
, so
 $ 1/(1-\beta_1)\geq1$
, and
$ 1/(1-\beta_1)\geq1$
, and
 $ 0<g_2(1,(\alpha_1)_+)<\infty$
implies
$ 0<g_2(1,(\alpha_1)_+)<\infty$
implies
 $ 1/(1-\beta_1)=1$
, so (i) and (ii) follow. If g is differentiable at the point
$ 1/(1-\beta_1)=1$
, so (i) and (ii) follow. If g is differentiable at the point
 $ (1,\alpha_1)$
, then since
$ (1,\alpha_1)$
, then since
 $ g(1,y)\geq 1$
,
$ g(1,y)\geq 1$
,
 $ g_2(1,(\alpha_1)_+) = g_2(1,(\alpha_1)_-)=0$
and (i) holds. Otherwise, in a neighbourhood of
$ g_2(1,(\alpha_1)_+) = g_2(1,(\alpha_1)_-)=0$
and (i) holds. Otherwise, in a neighbourhood of
 $ (1,\alpha_1)$
, we can write
$ (1,\alpha_1)$
, we can write
 \begin{align*}g(x,y) = \begin{cases}\hat{g}(x,y),& y \leq \alpha_1 x,\\\tilde{g}(x,y),& y \geq \alpha_1 x,\end{cases}\end{align*}
\begin{align*}g(x,y) = \begin{cases}\hat{g}(x,y),& y \leq \alpha_1 x,\\\tilde{g}(x,y),& y \geq \alpha_1 x,\end{cases}\end{align*}
where the homogeneous functions
 $ \tilde{g}$
and
$ \tilde{g}$
and
 $ \hat{g}$
have continuous partial derivatives at
$ \hat{g}$
have continuous partial derivatives at
 $ (1,\alpha_1)$
. Euler’s homogeneous function theorem gives
$ (1,\alpha_1)$
. Euler’s homogeneous function theorem gives
 $ 1 = \tilde{g}_1(1,\alpha_1)+\tilde{g}_2(1,\alpha_1)\alpha_1 = g_1(1_-,\alpha_1)+\alpha_1 g_2(1,(\alpha_1)_+)$
, so that for
$ 1 = \tilde{g}_1(1,\alpha_1)+\tilde{g}_2(1,\alpha_1)\alpha_1 = g_1(1_-,\alpha_1)+\alpha_1 g_2(1,(\alpha_1)_+)$
, so that for
 $ \alpha_1>0$
,
$ \alpha_1>0$
,
 $ g_2(1,(\alpha_1)_+)<\infty$
, and hence (i) or (ii) holds.
$ g_2(1,(\alpha_1)_+)<\infty$
, and hence (i) or (ii) holds.
We remark on links with existing work on conditional extreme value limits for variables with a polar-type representation, whereby
 $ (X_1,X_2)=R(W_1,W_2)$
for
$ (X_1,X_2)=R(W_1,W_2)$
for
 $ R>0$
and
$ R>0$
and
 $ (W_1,W_2)$
constrained by some functional dependence. The papers [Reference Abdous, Fougères and Ghoudi1, Reference Fougères and Soulier19, Reference Seifert41] consider a type of conditional extremes limit for certain such polar constructions, where in the light-tailed case, the shape of the constraint on
$ (W_1,W_2)$
constrained by some functional dependence. The papers [Reference Abdous, Fougères and Ghoudi1, Reference Fougères and Soulier19, Reference Seifert41] consider a type of conditional extremes limit for certain such polar constructions, where in the light-tailed case, the shape of the constraint on
 $ (W_1,W_2)$
feeds into the normalization and limit distribution. However, limit sets are sensitive to marginal choice, and because the above papers do not consider conditional extreme value limits in standardized exponential-tailed margins, further connections are limited.
$ (W_1,W_2)$
feeds into the normalization and limit distribution. However, limit sets are sensitive to marginal choice, and because the above papers do not consider conditional extreme value limits in standardized exponential-tailed margins, further connections are limited.
3.2. Different scaling orders:
$ \lambda(\boldsymbol{\omega})$

We now focus on the connection with
 $ \lambda(\boldsymbol{\omega})$
, as defined in Section 2.3. When
$ \lambda(\boldsymbol{\omega})$
, as defined in Section 2.3. When
 $ \boldsymbol{\omega} = (1/d,\ldots,1/d)$
, this yields the link with the residual tail dependence coefficient
$ \boldsymbol{\omega} = (1/d,\ldots,1/d)$
, this yields the link with the residual tail dependence coefficient
 $ \eta_{D}$
, which has already been considered in [Reference Nolde36]. Define the region
$ \eta_{D}$
, which has already been considered in [Reference Nolde36]. Define the region
 \begin{equation*}R_{\boldsymbol{\omega}}=\left(\frac{\omega_1}{\max\!(\omega_1,\ldots,\omega_d)} , \infty\right] \times {\cdots} \times \left(\frac{\omega_d}{\max\!(\omega_1,\ldots,\omega_d)}, \infty\right].\end{equation*}
\begin{equation*}R_{\boldsymbol{\omega}}=\left(\frac{\omega_1}{\max\!(\omega_1,\ldots,\omega_d)} , \infty\right] \times {\cdots} \times \left(\frac{\omega_d}{\max\!(\omega_1,\ldots,\omega_d)}, \infty\right].\end{equation*}
Proposition 3.3. Suppose that the sample cloud
 $ N_n = \big\{{\boldsymbol{X}}_E^1/\log n,\ldots,{\boldsymbol{X}}_E^n/\log n\big\}$
converges onto a limit set G, and that for each
$ N_n = \big\{{\boldsymbol{X}}_E^1/\log n,\ldots,{\boldsymbol{X}}_E^n/\log n\big\}$
converges onto a limit set G, and that for each
 $ \boldsymbol{\omega}\in\mathcal{S}_{\Sigma}$
, Equation (2.7) holds. Then
$ \boldsymbol{\omega}\in\mathcal{S}_{\Sigma}$
, Equation (2.7) holds. Then
 \begin{equation*}\lambda(\boldsymbol{\omega}) = \max\!(\boldsymbol{\omega}) \times r_{\boldsymbol{\omega}}^{-1} ,\end{equation*}
\begin{equation*}\lambda(\boldsymbol{\omega}) = \max\!(\boldsymbol{\omega}) \times r_{\boldsymbol{\omega}}^{-1} ,\end{equation*}
where
 \begin{equation*}r_{\boldsymbol{\omega}}=\min\big\{r \in [0,1] \,:\, r R_{\boldsymbol{\omega}} \cap G = \emptyset \big\}.\end{equation*}
\begin{equation*}r_{\boldsymbol{\omega}}=\min\big\{r \in [0,1] \,:\, r R_{\boldsymbol{\omega}} \cap G = \emptyset \big\}.\end{equation*}
Corollary 3.1. ([Reference Nolde36]) We have
 \begin{equation*}1/\eta_{D} = d \lambda(1/d,\ldots,1/d) =r_{(1/d,\ldots,1/d)}^{-1} = \big[\!\min\big\{r \in [0,1] \,:\, \left(r , \infty\right]^d \cap G = \emptyset \big\}\big]^{-1}.\end{equation*}
\begin{equation*}1/\eta_{D} = d \lambda(1/d,\ldots,1/d) =r_{(1/d,\ldots,1/d)}^{-1} = \big[\!\min\big\{r \in [0,1] \,:\, \left(r , \infty\right]^d \cap G = \emptyset \big\}\big]^{-1}.\end{equation*}
Proof of Proposition 3.3. The lines of the proof are very similar to those of the proof of [Reference Nolde36, Proposition 2.1]. First note that
 $ \lambda(\boldsymbol{\omega}) = \kappa(\boldsymbol{\omega})$
, where
$ \lambda(\boldsymbol{\omega}) = \kappa(\boldsymbol{\omega})$
, where
 $ \kappa\,:\, [0,\infty)^d \setminus \{\boldsymbol{0}\} \to (0,\infty)$
is a 1-homogeneous function defined by
$ \kappa\,:\, [0,\infty)^d \setminus \{\boldsymbol{0}\} \to (0,\infty)$
is a 1-homogeneous function defined by
 \begin{equation*}{\mathbb P}\big({\boldsymbol{X}}_{E}> \boldsymbol{\beta} t\big) = \ell\big(e^{t};\, \boldsymbol{\beta}\big)e^{-t \kappa(\boldsymbol{\beta})},\qquad \ell({\cdot};\,\boldsymbol{\beta}) \in \mathrm{RV}_{0}^\infty\text{for every} \boldsymbol{\beta} \in [0,\infty)^d \setminus \{\boldsymbol{0}\} .\end{equation*}
\begin{equation*}{\mathbb P}\big({\boldsymbol{X}}_{E}> \boldsymbol{\beta} t\big) = \ell\big(e^{t};\, \boldsymbol{\beta}\big)e^{-t \kappa(\boldsymbol{\beta})},\qquad \ell({\cdot};\,\boldsymbol{\beta}) \in \mathrm{RV}_{0}^\infty\text{for every} \boldsymbol{\beta} \in [0,\infty)^d \setminus \{\boldsymbol{0}\} .\end{equation*}
As a consequence,
 \begin{align}\frac{\lambda(\boldsymbol{\omega})}{\max\!(\boldsymbol{\omega})} = \lim_{t\to\infty}{-}\log{\mathbb P}\{{\boldsymbol{X}}_{E} > t\boldsymbol{\omega}/\max\!(\boldsymbol{\omega}) \}/t. \end{align}
\begin{align}\frac{\lambda(\boldsymbol{\omega})}{\max\!(\boldsymbol{\omega})} = \lim_{t\to\infty}{-}\log{\mathbb P}\{{\boldsymbol{X}}_{E} > t\boldsymbol{\omega}/\max\!(\boldsymbol{\omega}) \}/t. \end{align}
Without loss of generality, suppose that
 $ \max\!(\boldsymbol{\omega}) = \omega_d$
, so that
$ \max\!(\boldsymbol{\omega}) = \omega_d$
, so that
 $ R_{\boldsymbol{\omega}}=(\omega_1/\omega_d,\infty] \times {\cdots} \times (\omega_{d-1}/\omega_d,\infty] \times (1,\infty]$
. Because of the convergence of the sample cloud onto G, we have by Proposition 2.1 that for any
$ R_{\boldsymbol{\omega}}=(\omega_1/\omega_d,\infty] \times {\cdots} \times (\omega_{d-1}/\omega_d,\infty] \times (1,\infty]$
. Because of the convergence of the sample cloud onto G, we have by Proposition 2.1 that for any
 $ \epsilon >0$
and large enough t,
$ \epsilon >0$
and large enough t,
 \begin{equation*}{\mathbb P}\big({\boldsymbol{X}}_E \in t e^\epsilon r_{\boldsymbol{\omega}} R_{\boldsymbol{\omega}}\big) \leq {\mathbb P}\big({\boldsymbol{X}}_E \in t R_{(0,\ldots,0,1)}\big) = e^{-t} \leq {\mathbb P}\big({\boldsymbol{X}}_E \in t e^{-\epsilon} r_{\boldsymbol{\omega}} R_{\boldsymbol{\omega}}\big),\end{equation*}
\begin{equation*}{\mathbb P}\big({\boldsymbol{X}}_E \in t e^\epsilon r_{\boldsymbol{\omega}} R_{\boldsymbol{\omega}}\big) \leq {\mathbb P}\big({\boldsymbol{X}}_E \in t R_{(0,\ldots,0,1)}\big) = e^{-t} \leq {\mathbb P}\big({\boldsymbol{X}}_E \in t e^{-\epsilon} r_{\boldsymbol{\omega}} R_{\boldsymbol{\omega}}\big),\end{equation*}
implying
 $ {-}\log{\mathbb P}\big({\boldsymbol{X}}_E \in t r_{\boldsymbol{\omega}} R_{\boldsymbol{\omega}}\big) \sim t$
. Therefore
$ {-}\log{\mathbb P}\big({\boldsymbol{X}}_E \in t r_{\boldsymbol{\omega}} R_{\boldsymbol{\omega}}\big) \sim t$
. Therefore
 $ {-}\log{\mathbb P}\big({\boldsymbol{X}}_E \in t R_{\boldsymbol{\omega}}\big) \sim t r_{\boldsymbol{\omega}}^{-1}$
, and combining with Equation (3.5) gives the result.
$ {-}\log{\mathbb P}\big({\boldsymbol{X}}_E \in t R_{\boldsymbol{\omega}}\big) \sim t r_{\boldsymbol{\omega}}^{-1}$
, and combining with Equation (3.5) gives the result.
Figure 3 illustrates some of the concepts used in the proof of Proposition 3.3 when
 $ d=2$
and
$ d=2$
and
 $ \boldsymbol{\omega} = (\omega,1-\omega)$
.
$ \boldsymbol{\omega} = (\omega,1-\omega)$
.

Figure 3. Illustration of the concepts used in the proof of Proposition 3.2: the green line from the origin represents the ray
 $ x=\{\omega/(1-\omega)\}y$
,
$ x=\{\omega/(1-\omega)\}y$
,
 $ \omega<1/2$
. The region above the purple line
$ \omega<1/2$
. The region above the purple line
 $ y=1$
represents
$ y=1$
represents
 $ R_{(0,1)}$
, the region to the northeast of the thick blue dotted lines represents
$ R_{(0,1)}$
, the region to the northeast of the thick blue dotted lines represents
 $ r_{\omega}R_{\omega}$
, and the two sets of thin blue dotted lines illustrate the regions
$ r_{\omega}R_{\omega}$
, and the two sets of thin blue dotted lines illustrate the regions
 $ e^{-\epsilon }r_{\omega}R_{\omega}$
and
$ e^{-\epsilon }r_{\omega}R_{\omega}$
and
 $ e^{\epsilon}r_{\omega}R_{\omega}$
. The ratio of the distance from the origin to where the green line intersects the boundary of the limit set G, and the distance from the origin to where the green line intersects the boundary
$ e^{\epsilon}r_{\omega}R_{\omega}$
. The ratio of the distance from the origin to where the green line intersects the boundary of the limit set G, and the distance from the origin to where the green line intersects the boundary
 $ \max\!(x,y)=1$
, is equal to
$ \max\!(x,y)=1$
, is equal to
 $ r_{\omega}$
.
$ r_{\omega}$
.
The blue lines in Figure 2 represent
 $ \lambda(\boldsymbol{\omega})$
, depicting the unit level set of
$ \lambda(\boldsymbol{\omega})$
, depicting the unit level set of
 $ \lambda(\omega,1-\omega)/ \max\!(\omega,1-\omega)$
, and the dots illustrate the value of
$ \lambda(\omega,1-\omega)/ \max\!(\omega,1-\omega)$
, and the dots illustrate the value of
 $ r_{1/2} = \eta_{1,2}$
. We can now see clearly how, in two dimensions, different dependence features are picked out by the conditional extremes representation and hidden regular variation based on
$ r_{1/2} = \eta_{1,2}$
. We can now see clearly how, in two dimensions, different dependence features are picked out by the conditional extremes representation and hidden regular variation based on
 $ \eta_{1,2}$
. Often, values of
$ \eta_{1,2}$
. Often, values of
 $ \eta_{1,2}>1/2$
or
$ \eta_{1,2}>1/2$
or
 $ \alpha>0$
are associated with positive extremal dependence. From Case (iv) of Figure 2 (bottom right), we observe
$ \alpha>0$
are associated with positive extremal dependence. From Case (iv) of Figure 2 (bottom right), we observe
 $ \eta_{1,2}<1/2$
but
$ \eta_{1,2}<1/2$
but
 $ \alpha>0$
. We have that Y does grow with X (and vice versa) but only at a specific rate. On the other hand, joint extremes, where (X,Y) take similar values, are rare, occurring less frequently than under independence.
$ \alpha>0$
. We have that Y does grow with X (and vice versa) but only at a specific rate. On the other hand, joint extremes, where (X,Y) take similar values, are rare, occurring less frequently than under independence.
From Case (iv) we can also see that one of the conclusions following Proposition 2.1 in [Reference Nolde36] is not true: the point
 $ (r_{1/2},r_{1/2})$
need not lie on the boundary of G, meaning that we do not necessarily have
$ (r_{1/2},r_{1/2})$
need not lie on the boundary of G, meaning that we do not necessarily have
 $ \eta_{D} = 1/g(\boldsymbol{1})$
, although we can deduce the bound
$ \eta_{D} = 1/g(\boldsymbol{1})$
, although we can deduce the bound
 $ \eta_{D} \geq 1/g(\boldsymbol{1})$
. Similarly, there are occasions when
$ \eta_{D} \geq 1/g(\boldsymbol{1})$
. Similarly, there are occasions when
 $ g(r_{\boldsymbol{\omega}}\boldsymbol{\omega}/\max\!(\boldsymbol{\omega})) = 1$
, implying
$ g(r_{\boldsymbol{\omega}}\boldsymbol{\omega}/\max\!(\boldsymbol{\omega})) = 1$
, implying
 $ \lambda(\boldsymbol{\omega})=g(\boldsymbol{\omega})$
, but clearly this is not always true. In Proposition 3.4, we resolve when this is the case by representing
$ \lambda(\boldsymbol{\omega})=g(\boldsymbol{\omega})$
, but clearly this is not always true. In Proposition 3.4, we resolve when this is the case by representing
 $ r_{\boldsymbol{\omega}}$
in terms of g.
$ r_{\boldsymbol{\omega}}$
in terms of g.
Define
 $ B_{\boldsymbol{\omega}}$
to be the boundary of the region
$ B_{\boldsymbol{\omega}}$
to be the boundary of the region
 $ R_{\boldsymbol{\omega}}$
, i.e.,
$ R_{\boldsymbol{\omega}}$
, i.e.,
 \begin{equation*}B_{\boldsymbol{\omega}} = \bigcup_{i=1}^d \Big\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, x_i = \omega_i/\max\!(\boldsymbol{\omega}), x_j \geq \omega_j/\max\!(\boldsymbol{\omega}), j \neq i\Big\}.\end{equation*}
\begin{equation*}B_{\boldsymbol{\omega}} = \bigcup_{i=1}^d \Big\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, x_i = \omega_i/\max\!(\boldsymbol{\omega}), x_j \geq \omega_j/\max\!(\boldsymbol{\omega}), j \neq i\Big\}.\end{equation*}
Proposition 3.4. Assume the conditions of Proposition 3.3. Then
 \begin{equation*}r_{\boldsymbol{\omega}} = \left[\!\min_{\boldsymbol{y} \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y})\right]^{-1},\text{and hence}\quad \lambda(\boldsymbol{\omega}) = \max\!(\boldsymbol{\omega}) \times \min_{\boldsymbol{y} \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y}).\end{equation*}
\begin{equation*}r_{\boldsymbol{\omega}} = \left[\!\min_{\boldsymbol{y} \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y})\right]^{-1},\text{and hence}\quad \lambda(\boldsymbol{\omega}) = \max\!(\boldsymbol{\omega}) \times \min_{\boldsymbol{y} \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y}).\end{equation*}
From Proposition 3.4, we observe that
 $ \lambda(\boldsymbol{\omega}) = g(\boldsymbol{\omega})$
if
$ \lambda(\boldsymbol{\omega}) = g(\boldsymbol{\omega})$
if
 $ \arg\min_{y \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y}) = \boldsymbol{\omega}/\max\!(\boldsymbol{\omega})$
, i.e., the vertex of the set
$ \arg\min_{y \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y}) = \boldsymbol{\omega}/\max\!(\boldsymbol{\omega})$
, i.e., the vertex of the set
 $ B_{\boldsymbol{\omega}}$
. The proof of Proposition 3.4 is deferred until after Proposition 3.7, for which the proof is very similar.
$ B_{\boldsymbol{\omega}}$
. The proof of Proposition 3.4 is deferred until after Proposition 3.7, for which the proof is very similar.
Remark 3.1. We note that
 $ \min_{\boldsymbol{y} \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y}) = \min_{\boldsymbol{y} \in R_{\boldsymbol{\omega}}} g(\boldsymbol{y})$
.
$ \min_{\boldsymbol{y} \in B_{\boldsymbol{\omega}}} g(\boldsymbol{y}) = \min_{\boldsymbol{y} \in R_{\boldsymbol{\omega}}} g(\boldsymbol{y})$
.
3.3. Coefficients
$ \tau_C(\delta)$

3.3.1. Connections to limit set G
In two dimensions, the coefficients
 $ \tau_{1}(\delta)$
and
$ \tau_{1}(\delta)$
and
 $ \tau_{2}(\delta)$
provide a somewhat complementary concept to the function
$ \tau_{2}(\delta)$
provide a somewhat complementary concept to the function
 $ \lambda(\boldsymbol{\omega})$
. Rather than considering the impact of the limit set G on the shape of the function defined by both variables exceeding thresholds growing at different rates, we are considering what is occurring when one variable exceeds a growing threshold and the other is bounded above by a certain lesser growth rate. The left and centre panels in Figure 4 provide an illustration of
$ \lambda(\boldsymbol{\omega})$
. Rather than considering the impact of the limit set G on the shape of the function defined by both variables exceeding thresholds growing at different rates, we are considering what is occurring when one variable exceeds a growing threshold and the other is bounded above by a certain lesser growth rate. The left and centre panels in Figure 4 provide an illustration of
 $ \lambda(\boldsymbol{\omega})$
and
$ \lambda(\boldsymbol{\omega})$
and
 $ \tau_j(\delta)$
in two dimensions.
$ \tau_j(\delta)$
in two dimensions.

Figure 4. Illustration of
 $ \lambda(\boldsymbol{\omega})$
and
$ \lambda(\boldsymbol{\omega})$
and
 $ \tau_{j}(\delta)$
for the gauge function
$ \tau_{j}(\delta)$
for the gauge function
 $ g(x,y) = \max\{(x-y)/\theta,(y-x)/\theta,(x+y)/(2-\theta)\}$
. In the left and centre panels the unit level set of g is illustrated with black dashed lines. The left panel illustrates
$ g(x,y) = \max\{(x-y)/\theta,(y-x)/\theta,(x+y)/(2-\theta)\}$
. In the left and centre panels the unit level set of g is illustrated with black dashed lines. The left panel illustrates
 $ \lambda(\omega,1-\omega)$
with blue solid lines. The centre panel illustrates
$ \lambda(\omega,1-\omega)$
with blue solid lines. The centre panel illustrates
 $ \tau_j(\delta)$
with purple solid lines:
$ \tau_j(\delta)$
with purple solid lines:
 $ \tau_1(\delta), \delta \in [0,1]$
is represented by the values below the main diagonal, whilst
$ \tau_1(\delta), \delta \in [0,1]$
is represented by the values below the main diagonal, whilst
 $ \tau_2(\delta)$
is represented by the values above. The set G is added on both panels with dashed lines. The right panel illustrates
$ \tau_2(\delta)$
is represented by the values above. The set G is added on both panels with dashed lines. The right panel illustrates
 $ \tau_1(\delta)$
and
$ \tau_1(\delta)$
and
 $ \tau_2(\delta)$
in terms of the gauge function.
$ \tau_2(\delta)$
in terms of the gauge function.
Define the region
 \begin{equation*}R_{C,\delta} = (1,\infty]^C \times [0,\delta]^{D \setminus C} = \{\boldsymbol{x}\,:\, x_i \in (1,\infty], i \in C, x_j \in [0,\delta], j \in D\setminus C\},\end{equation*}
\begin{equation*}R_{C,\delta} = (1,\infty]^C \times [0,\delta]^{D \setminus C} = \{\boldsymbol{x}\,:\, x_i \in (1,\infty], i \in C, x_j \in [0,\delta], j \in D\setminus C\},\end{equation*}
so that, for example, when
 $ d=3$
,
$ d=3$
,
 $ R_{\{1,3\},\delta} = (1,\infty] \times [0,\delta] \times (1,\infty]$
.
$ R_{\{1,3\},\delta} = (1,\infty] \times [0,\delta] \times (1,\infty]$
.
Proposition 3.5. Suppose that the sample cloud
 $ N_n = \big\{{\boldsymbol{X}}_E^1/\log n,\ldots,{\boldsymbol{X}}_E^n/\log n\big\}$
converges onto a limit set G, and that the assumption in (2.6) holds. For
$ N_n = \big\{{\boldsymbol{X}}_E^1/\log n,\ldots,{\boldsymbol{X}}_E^n/\log n\big\}$
converges onto a limit set G, and that the assumption in (2.6) holds. For
 $ \delta \in [0,1]$
and
$ \delta \in [0,1]$
and
 $ C \subset D$
,
$ C \subset D$
,
 \begin{align*}\tau_C(\delta) &= r_{C,\delta} = \min\left\{r \in [0,1] \,:\, r R_{C,\delta} \cap G =\emptyset \right\}.\end{align*}
\begin{align*}\tau_C(\delta) &= r_{C,\delta} = \min\left\{r \in [0,1] \,:\, r R_{C,\delta} \cap G =\emptyset \right\}.\end{align*}
The coefficient
 $ \tau_{D} = \eta_{D}$
, and does not depend on
$ \tau_{D} = \eta_{D}$
, and does not depend on
 $ \delta$
.
$ \delta$
.
Proof. The coefficient
 $ \tau_{D}$
describes the order of hidden regular variation on the cone
$ \tau_{D}$
describes the order of hidden regular variation on the cone
 $ (0,\infty]^d$
, which is precisely the same as
$ (0,\infty]^d$
, which is precisely the same as
 $ \eta_{D}$
. For
$ \eta_{D}$
. For
 $ \tau_C(\delta)$
,
$ \tau_C(\delta)$
,
 $ |C|<d$
, we consider the function of t given by
$ |C|<d$
, we consider the function of t given by
 \begin{align*}{\mathbb P}\Big(\!\min_{i \in C} X_{P,i}\gt tx, \max_{j \in D \setminus C} X_{P,j} \leq y t^\delta\Big) \in \mathrm{RV}_{-1/\tau_C(\delta)}^\infty, \qquad 0\lt x,y\lt \infty.\end{align*}
\begin{align*}{\mathbb P}\Big(\!\min_{i \in C} X_{P,i}\gt tx, \max_{j \in D \setminus C} X_{P,j} \leq y t^\delta\Big) \in \mathrm{RV}_{-1/\tau_C(\delta)}^\infty, \qquad 0\lt x,y\lt \infty.\end{align*}
Take
 $ x=y=1$
. Then
$ x=y=1$
. Then
 \begin{align}\tau_C(\delta) &= \lim_{t \to \infty} \frac{{-}\log{\mathbb P}(X_{P,1}>t)}{{-}\log {\mathbb P}\big(\!\min_{i \in C} X_{P,i}>t, \max_{j \in D \setminus C} X_{P,j} \leq t^\delta\big)} \notag \\[5pt]&= \lim_{t \to \infty} \frac{{-}\log{\mathbb P}(X_{E,1}>t)}{{-}\log{\mathbb P}\big(\!\min_{i \in C} X_{E,i}>t, \max_{j \in D \setminus C} X_{E,j} \leq \delta t\big)} ,\end{align}
\begin{align}\tau_C(\delta) &= \lim_{t \to \infty} \frac{{-}\log{\mathbb P}(X_{P,1}>t)}{{-}\log {\mathbb P}\big(\!\min_{i \in C} X_{P,i}>t, \max_{j \in D \setminus C} X_{P,j} \leq t^\delta\big)} \notag \\[5pt]&= \lim_{t \to \infty} \frac{{-}\log{\mathbb P}(X_{E,1}>t)}{{-}\log{\mathbb P}\big(\!\min_{i \in C} X_{E,i}>t, \max_{j \in D \setminus C} X_{E,j} \leq \delta t\big)} ,\end{align}
where the denominator in (3.6) can be expressed as
 $ {-}\log{\mathbb P}({\boldsymbol{X}}_E \in t R_{\delta})$
. As in the proof of Proposition 3.3, the convergence onto the limit set and exponential margins enable us to conclude that
$ {-}\log{\mathbb P}({\boldsymbol{X}}_E \in t R_{\delta})$
. As in the proof of Proposition 3.3, the convergence onto the limit set and exponential margins enable us to conclude that
 $ {-}\log {\mathbb P}({\boldsymbol{X}}_E \in t r_{C,\delta} R_{\delta}) \sim t$
, and hence
$ {-}\log {\mathbb P}({\boldsymbol{X}}_E \in t r_{C,\delta} R_{\delta}) \sim t$
, and hence
 $ {-}\log {\mathbb P}({\boldsymbol{X}}_E \in t R_{\delta}) \sim tr_{C,\delta}^{-1}$
. Combining with (3.6) gives
$ {-}\log {\mathbb P}({\boldsymbol{X}}_E \in t R_{\delta}) \sim tr_{C,\delta}^{-1}$
. Combining with (3.6) gives
 $ \tau_C(\delta) = r_{C,\delta}$
.
$ \tau_C(\delta) = r_{C,\delta}$
.
In the two-dimensional case, it is possible to express
 $ \tau_j(\delta)$
simply in terms of the gauge function. For higher dimensions, we refer to Proposition 3.7.
$ \tau_j(\delta)$
simply in terms of the gauge function. For higher dimensions, we refer to Proposition 3.7.
Proposition 3.6. Assume the conditions of Proposition 3.5. When
 $ d=2$
,
$ d=2$
,
 $ \tau_1(\delta) = [\!\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1}$
and
$ \tau_1(\delta) = [\!\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1}$
and
 $ \tau_2(\delta) = [\!\min_{\gamma \in [0,\delta]} g(\gamma,1)]^{-1}$
.
$ \tau_2(\delta) = [\!\min_{\gamma \in [0,\delta]} g(\gamma,1)]^{-1}$
.
Proof. For
 $ \gamma \in [0,1]$
, the points
$ \gamma \in [0,1]$
, the points
 $ \left(1/g(1,\gamma), \gamma/g(1,\gamma)\right)$
lie on the curve
$ \left(1/g(1,\gamma), \gamma/g(1,\gamma)\right)$
lie on the curve
 $ \{(x,y) \in [0,1]^2\,:\,g(x,y)=1, x\geq y\}$
. The value
$ \{(x,y) \in [0,1]^2\,:\,g(x,y)=1, x\geq y\}$
. The value
 $ r_{1,\delta}$
is the maximum value of
$ r_{1,\delta}$
is the maximum value of
 $ 1/g(1,\gamma)$
for
$ 1/g(1,\gamma)$
for
 $ \gamma \in [0,\delta]$
; hence
$ \gamma \in [0,\delta]$
; hence
 $ \tau_1(\delta) = [\!\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1}$
. A symmetric argument applies to
$ \tau_1(\delta) = [\!\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1}$
. A symmetric argument applies to
 $ \tau_2(\delta)$
.
$ \tau_2(\delta)$
.
The right panel of Figure 4 provides an illustration: in blue (bottom right), the value of
 $ \delta$
is such that
$ \delta$
is such that
 $ \tau_1(\delta)<1$
; in red (top left), the value of
$ \tau_1(\delta)<1$
; in red (top left), the value of
 $ \delta$
is such that
$ \delta$
is such that
 $ \tau_2(\delta)=1$
. Further detail on this example is given in Section 4.1.5.
$ \tau_2(\delta)=1$
. Further detail on this example is given in Section 4.1.5.
The question arises: does Proposition 3.6 still hold for
 $ d>2$
,
$ d>2$
,
 $ |C| = 1$
? Let
$ |C| = 1$
? Let
 $ g_C$
denote the gauge function for the limit set of
$ g_C$
denote the gauge function for the limit set of
 $ (X_{E,j}\,:\, j \in C)$
. By Proposition 2.4, we know that
$ (X_{E,j}\,:\, j \in C)$
. By Proposition 2.4, we know that
 \begin{equation*}g_{i,j}(x_i,x_j) = \min_{\boldsymbol{x}_{-i,-j} \in [0,\infty)^{d-2}}g_D(\boldsymbol{x}).\end{equation*}
\begin{equation*}g_{i,j}(x_i,x_j) = \min_{\boldsymbol{x}_{-i,-j} \in [0,\infty)^{d-2}}g_D(\boldsymbol{x}).\end{equation*}
Therefore, equality will hold if
 \begin{equation*}\arg\min_{\boldsymbol{x}_{-i,-j} \in [0,\infty)^{d-2}}g_D(\boldsymbol{x}) \in [0,\delta]^{d-2}.\end{equation*}
\begin{equation*}\arg\min_{\boldsymbol{x}_{-i,-j} \in [0,\infty)^{d-2}}g_D(\boldsymbol{x}) \in [0,\delta]^{d-2}.\end{equation*}
Note that the dimension does indeed play a key role here: when looking at
 $ \tau_j(\delta)$
for a d-dimensional problem, we are looking at the situation where
$ \tau_j(\delta)$
for a d-dimensional problem, we are looking at the situation where
 $ d-1$
coordinates are bounded above by a growth rate determined by
$ d-1$
coordinates are bounded above by a growth rate determined by
 $ \delta$
. In contrast, if we marginalize and look at
$ \delta$
. In contrast, if we marginalize and look at
 $ \tau_j(\delta)$
for a two-dimensional problem, the
$ \tau_j(\delta)$
for a two-dimensional problem, the
 $ d-2$
coordinates that we have marginalized over are unrestricted and so can represent small or large values. Thus, the answer to our question is negative in general.
$ d-2$
coordinates that we have marginalized over are unrestricted and so can represent small or large values. Thus, the answer to our question is negative in general.
Proposition 3.7 details the precise value of
 $ \tau_C(\delta)$
in terms of g for any dimension d. In a similar spirit to that of Section 3.2, define the boundary of the region
$ \tau_C(\delta)$
in terms of g for any dimension d. In a similar spirit to that of Section 3.2, define the boundary of the region
 $ R_{C,\delta}$
as
$ R_{C,\delta}$
as
 \begin{equation*}B_{C,\delta} = B_{C,\delta}^1 \cup B_{C,\delta}^\delta,\end{equation*}
\begin{equation*}B_{C,\delta} = B_{C,\delta}^1 \cup B_{C,\delta}^\delta,\end{equation*}
where
 \begin{align*}B_{C,\delta}^1 &= \bigcup_{i \in C} \big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = 1, x_j \geq 1 \forall j \in C \setminus i, x_k \leq \delta \forall k \in D \setminus C \big\},\\B_{C,\delta}^\delta &= \bigcup_{i \in D \setminus C} \big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = \delta, x_j \leq \delta \forall j \in (D\setminus C) \setminus i, x_k \geq 1 \forall k \in C \big\},\end{align*}
\begin{align*}B_{C,\delta}^1 &= \bigcup_{i \in C} \big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = 1, x_j \geq 1 \forall j \in C \setminus i, x_k \leq \delta \forall k \in D \setminus C \big\},\\B_{C,\delta}^\delta &= \bigcup_{i \in D \setminus C} \big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = \delta, x_j \leq \delta \forall j \in (D\setminus C) \setminus i, x_k \geq 1 \forall k \in C \big\},\end{align*}
so, for example, when
 $ d=3$
,
$ d=3$
,
 \begin{align*}B_{\{1,3\},\delta} = \, &\big\{\boldsymbol{x}\in \mathbb{R}^3_+\,:\, x_1 = 1, x_2 \leq \delta, x_3 \geq 1\big\}\\&\cup \big\{\boldsymbol{x}\in \mathbb{R}^3_+\,:\, x_1 \geq 1, x_2 = \delta, x_3 \geq 1\big\} \cup \big\{\boldsymbol{x}\in \mathbb{R}^3_+\,:\, x_1 \geq 1, x_2 \leq \delta, x_3 = 1\big\}.\end{align*}
\begin{align*}B_{\{1,3\},\delta} = \, &\big\{\boldsymbol{x}\in \mathbb{R}^3_+\,:\, x_1 = 1, x_2 \leq \delta, x_3 \geq 1\big\}\\&\cup \big\{\boldsymbol{x}\in \mathbb{R}^3_+\,:\, x_1 \geq 1, x_2 = \delta, x_3 \geq 1\big\} \cup \big\{\boldsymbol{x}\in \mathbb{R}^3_+\,:\, x_1 \geq 1, x_2 \leq \delta, x_3 = 1\big\}.\end{align*}
For
 $ C=D$
,
$ C=D$
,
 $ R_D = (1,\infty]^d$
, and
$ R_D = (1,\infty]^d$
, and
 $ B_D =\{\boldsymbol{x}\,:\, \min\!(\boldsymbol{x}) = 1\}$
.
$ B_D =\{\boldsymbol{x}\,:\, \min\!(\boldsymbol{x}) = 1\}$
.
Proposition 3.7. Assume the conditions of Proposition 3.5. For any
 $ C \subseteq D$
,
$ C \subseteq D$
,
 \begin{equation*}\tau_C(\delta) = \left[\!\min_{\boldsymbol{y} \in B_{C,\delta}}g(\boldsymbol{y})\right]^{-1} =\left[\!\min_{\boldsymbol{y} \in B_{C,\delta}^1}g(\boldsymbol{y})\right]^{-1}. \end{equation*}
\begin{equation*}\tau_C(\delta) = \left[\!\min_{\boldsymbol{y} \in B_{C,\delta}}g(\boldsymbol{y})\right]^{-1} =\left[\!\min_{\boldsymbol{y} \in B_{C,\delta}^1}g(\boldsymbol{y})\right]^{-1}. \end{equation*}
Proof. The vertex of the region
 $ R_{C,\delta}$
, or its boundary
$ R_{C,\delta}$
, or its boundary
 $ B_{C,\delta}$
, which has components 1 on the coordinates indexed by C, and
$ B_{C,\delta}$
, which has components 1 on the coordinates indexed by C, and
 $ \delta$
in the other coordinates, lies on
$ \delta$
in the other coordinates, lies on
 $ \mathcal{S}_{\vee} \,:\,=\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, \max\!(\boldsymbol{x}) = 1\}$
. The region
$ \mathcal{S}_{\vee} \,:\,=\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, \max\!(\boldsymbol{x}) = 1\}$
. The region
 $ G \subseteq \mathcal{S}_{\vee}$
, and because the coordinatewise supremum of G is
$ G \subseteq \mathcal{S}_{\vee}$
, and because the coordinatewise supremum of G is
 $ \boldsymbol{1}$
, the boundary of G intersects
$ \boldsymbol{1}$
, the boundary of G intersects
 $ \mathcal{S}_{\vee}$
. Now consider scaling the region
$ \mathcal{S}_{\vee}$
. Now consider scaling the region
 $ R_{C,\delta}$
by
$ R_{C,\delta}$
by
 $ r_{C,\delta} \in (0,1]$
until it intersects G. The point of intersection must lie on the boundary of the scaled region
$ r_{C,\delta} \in (0,1]$
until it intersects G. The point of intersection must lie on the boundary of the scaled region
 $ r_{C,\delta}R_{C,\delta}$
, i.e., on
$ r_{C,\delta}R_{C,\delta}$
, i.e., on
 $ r_{C,\delta}B_{C,\delta}$
, and on the boundary of G,
$ r_{C,\delta}B_{C,\delta}$
, and on the boundary of G,
 $ \big\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, g(\boldsymbol{x}) = 1\big\}$
. Therefore, there exists
$ \big\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, g(\boldsymbol{x}) = 1\big\}$
. Therefore, there exists
 $ \boldsymbol{x}^\star \in B_{C,\delta}$
such that
$ \boldsymbol{x}^\star \in B_{C,\delta}$
such that
 $ g(r_{C,\delta}\boldsymbol{x}^\star) = 1$
, which is rearranged to give
$ g(r_{C,\delta}\boldsymbol{x}^\star) = 1$
, which is rearranged to give
 $ \tau_C(\delta) = r_{C,\delta} = 1/ g(\boldsymbol{x}^\star)$
. Furthermore, we must have that such a point
$ \tau_C(\delta) = r_{C,\delta} = 1/ g(\boldsymbol{x}^\star)$
. Furthermore, we must have that such a point
 $ \boldsymbol{x}^\star = \arg\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y})$
; otherwise there exists some
$ \boldsymbol{x}^\star = \arg\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y})$
; otherwise there exists some
 $ \boldsymbol{x}^{\prime} \in B_{C,\delta}$
such that
$ \boldsymbol{x}^{\prime} \in B_{C,\delta}$
such that
 $ g(\boldsymbol{x}^{\prime})<g(\boldsymbol{x}^\star)$
and so
$ g(\boldsymbol{x}^{\prime})<g(\boldsymbol{x}^\star)$
and so
 $ g(r_{C,\delta}\boldsymbol{x}^{\prime}) < 1$
, meaning that
$ g(r_{C,\delta}\boldsymbol{x}^{\prime}) < 1$
, meaning that
 $ r_{C,\delta} \neq \min\{r \in (0,1]\,:\, r R_{C,\delta} \cap G = \emptyset\}$
. We conclude that
$ r_{C,\delta} \neq \min\{r \in (0,1]\,:\, r R_{C,\delta} \cap G = \emptyset\}$
. We conclude that
 $ \boldsymbol{x}^\star = \arg\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y})$
, so
$ \boldsymbol{x}^\star = \arg\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y})$
, so
 $ \tau_{C}(\delta) = 1/\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y})$
. To show that
$ \tau_{C}(\delta) = 1/\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y})$
. To show that
 $ \arg\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y}) \in B_{C,\delta}^1$
, let
$ \arg\min_{\boldsymbol{y} \in B_{C,\delta}} g(\boldsymbol{y}) \in B_{C,\delta}^1$
, let
 $ \bar{\boldsymbol{x}} = \arg\min_{\boldsymbol{y} \in B_{C,\delta}^1} g(\boldsymbol{y})$
,
$ \bar{\boldsymbol{x}} = \arg\min_{\boldsymbol{y} \in B_{C,\delta}^1} g(\boldsymbol{y})$
,
 $ \tilde{\boldsymbol{x}} = \arg\min_{\boldsymbol{y} \in B_{C,\delta}^\delta} g(\boldsymbol{y})$
, and
$ \tilde{\boldsymbol{x}} = \arg\min_{\boldsymbol{y} \in B_{C,\delta}^\delta} g(\boldsymbol{y})$
, and
 $ \tilde{x}_{l} = \min_{k \in C}\tilde{x}_k \geq 1$
. Then
$ \tilde{x}_{l} = \min_{k \in C}\tilde{x}_k \geq 1$
. Then
 $ g(\tilde{\boldsymbol{x}}) = \tilde{x}_l g(\tilde{\boldsymbol{x}}/\tilde{x}_l)$
, but
$ g(\tilde{\boldsymbol{x}}) = \tilde{x}_l g(\tilde{\boldsymbol{x}}/\tilde{x}_l)$
, but
 $ \tilde{\boldsymbol{x}}/\tilde{x}_l \in B_{C,\delta}^1$
, so
$ \tilde{\boldsymbol{x}}/\tilde{x}_l \in B_{C,\delta}^1$
, so
 $ g(\tilde{\boldsymbol{x}}/\tilde{x}_l) \geq g(\bar{\boldsymbol{x}})$
, and hence
$ g(\tilde{\boldsymbol{x}}/\tilde{x}_l) \geq g(\bar{\boldsymbol{x}})$
, and hence
 $ \tilde{x}_{l}g(\tilde{\boldsymbol{x}}/\tilde{x}_l) \geq g(\bar{\boldsymbol{x}})$
as
$ \tilde{x}_{l}g(\tilde{\boldsymbol{x}}/\tilde{x}_l) \geq g(\bar{\boldsymbol{x}})$
as
 $ \tilde{x}_l \geq 1$
.
$ \tilde{x}_l \geq 1$
.
When
 $ d=2$
and
$ d=2$
and
 $ |C|=1$
, we note that
$ |C|=1$
, we note that
 $ B_{\{j\},\delta}^1 = \{\boldsymbol{x}\,:\,x_j = 1, x_i \leq \delta\}$
, which gives the equality in Proposition 3.6.
$ B_{\{j\},\delta}^1 = \{\boldsymbol{x}\,:\,x_j = 1, x_i \leq \delta\}$
, which gives the equality in Proposition 3.6.
Proof of Proposition 3.4. The proof follows exactly as for the first equality in Proposition 3.7, replacing
 $ R_{C,\delta}, B_{C,\delta}$
, and
$ R_{C,\delta}, B_{C,\delta}$
, and
 $ r_{C,\delta}$
with
$ r_{C,\delta}$
with
 $ R_{\boldsymbol{\omega}}, B_{\boldsymbol{\omega}}$
, and
$ R_{\boldsymbol{\omega}}, B_{\boldsymbol{\omega}}$
, and
 $ r_{ \boldsymbol{\omega}}$
.
$ r_{ \boldsymbol{\omega}}$
.
3.3.2. Estimation of coefficients
$ \tau_C(\delta)$

When
 $ C=D$
, Equation (2.6) yields
$ C=D$
, Equation (2.6) yields
 \begin{equation*}{\mathbb P}\Big(\!\min_{i \in D} X_{P,i}> t\Big) \in \mathrm{RV}^{\infty}_{-1/\tau_{D}},\end{equation*}
\begin{equation*}{\mathbb P}\Big(\!\min_{i \in D} X_{P,i}> t\Big) \in \mathrm{RV}^{\infty}_{-1/\tau_{D}},\end{equation*}
implying that
 $ \tau_D$
can be estimated as the reciprocal of the tail index of the so-called structure variable
$ \tau_D$
can be estimated as the reciprocal of the tail index of the so-called structure variable
 $ \min_{i \in D} X_{P,i}$
. This is identical to estimating the residual tail dependence coefficient
$ \min_{i \in D} X_{P,i}$
. This is identical to estimating the residual tail dependence coefficient
 $ \eta_D$
, for which the Hill estimator is commonly employed. However, for C with
$ \eta_D$
, for which the Hill estimator is commonly employed. However, for C with
 $ |C|<d$
, we assume
$ |C|<d$
, we assume
 \begin{equation*}{\mathbb P}\left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< t^{\delta} \right) \in \mathrm{RV}^{\infty}_{-1/\tau_{C}(\delta)},\end{equation*}
\begin{equation*}{\mathbb P}\left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< t^{\delta} \right) \in \mathrm{RV}^{\infty}_{-1/\tau_{C}(\delta)},\end{equation*}
but this representation does not lend itself immediately to an estimation strategy, as there is no longer a simple structure variable for which
 $ 1/\tau_{C}(\delta)$
is the tail index.
$ 1/\tau_{C}(\delta)$
is the tail index.
In order to allow estimation, [Reference Simpson, Wadsworth and Tawn42] considered
 \begin{equation*}{\mathbb P} \left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< \left(\!\min_{i \in C} X_{P,i} \right)^{\delta}\right),\end{equation*}
\begin{equation*}{\mathbb P} \left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< \left(\!\min_{i \in C} X_{P,i} \right)^{\delta}\right),\end{equation*}
but they offered only empirical evidence that the assumed index of regular variation for this probability was the same as in (2.6). We now prove this to be the case.
Define
 \begin{equation*}R_{C,\delta}^x = \Big\{\boldsymbol{x}\in \mathbb{R}^d_+\,:\, x_i>1, i \in C,x_j \leq \delta \min_{l \in C} x_l, j \in D\setminus C\Big\},\end{equation*}
\begin{equation*}R_{C,\delta}^x = \Big\{\boldsymbol{x}\in \mathbb{R}^d_+\,:\, x_i>1, i \in C,x_j \leq \delta \min_{l \in C} x_l, j \in D\setminus C\Big\},\end{equation*}
and let
 $ B_{C,\delta}^x = B_{C,\delta}^{x,1} \cup B_{C,\delta}^{x,\delta}$
denote its boundary, where
$ B_{C,\delta}^x = B_{C,\delta}^{x,1} \cup B_{C,\delta}^{x,\delta}$
denote its boundary, where
 \begin{align*}B_{C,\delta}^{x,1}= B_{C,\delta}^1 &= \bigcup_{i \in C} \Big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = 1, x_j \geq 1 \forall j \in C \setminus i, x_k \leq \delta \min_{l \in C} x_l = \delta \forall k \in D \setminus C \Big\}, \\B_{C,\delta}^{x,\delta} &= \bigcup_{i \in D \setminus C} \Big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = \delta\min_{l \in C} x_l, x_j \leq \delta\min_{l \in C} x_l \forall j \in (D\setminus C) \setminus i, x_k \geq 1 \forall k \in C \Big\},\end{align*}
\begin{align*}B_{C,\delta}^{x,1}= B_{C,\delta}^1 &= \bigcup_{i \in C} \Big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = 1, x_j \geq 1 \forall j \in C \setminus i, x_k \leq \delta \min_{l \in C} x_l = \delta \forall k \in D \setminus C \Big\}, \\B_{C,\delta}^{x,\delta} &= \bigcup_{i \in D \setminus C} \Big\{\boldsymbol{x}\in\mathbb{R}^d_+\,:\, x_i = \delta\min_{l \in C} x_l, x_j \leq \delta\min_{l \in C} x_l \forall j \in (D\setminus C) \setminus i, x_k \geq 1 \forall k \in C \Big\},\end{align*}
and we specifically note the equality
 $ B_{C,\delta}^{x,1} = B_{C,\delta}^{1}$
.
$ B_{C,\delta}^{x,1} = B_{C,\delta}^{1}$
.
Proposition 3.8. Assume the conditions of Proposition 3.5. If
 \begin{equation*}{\mathbb P} \left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< t^{\delta} \right) \in \mathrm{RV}^{\infty}_{-1/\tau_{C}(\delta)}\end{equation*}
\begin{equation*}{\mathbb P} \left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< t^{\delta} \right) \in \mathrm{RV}^{\infty}_{-1/\tau_{C}(\delta)}\end{equation*}
and
 \begin{equation*}{\mathbb P} \left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< \left(\!\min_{i \in C} X_{P,i} \right)^{\delta} \right) \in \mathrm{RV}_{-1/\tilde{\tau}_C(\delta)}^\infty,\end{equation*}
\begin{equation*}{\mathbb P} \left(\!\min_{i \in C} X_{P,i}> t , \max_{j \in D \setminus C} X_{P,j}< \left(\!\min_{i \in C} X_{P,i} \right)^{\delta} \right) \in \mathrm{RV}_{-1/\tilde{\tau}_C(\delta)}^\infty,\end{equation*}
then
 $ \tilde{\tau}_C(\delta) = \tau_C(\delta)$
.
$ \tilde{\tau}_C(\delta) = \tau_C(\delta)$
.
Proof. Define
 \begin{equation*}r_{C,\delta}^x = \min\left\{r \in [0,1] \,:\, r R_{C,\delta}^x \cap G =\emptyset \right\},\end{equation*}
\begin{equation*}r_{C,\delta}^x = \min\left\{r \in [0,1] \,:\, r R_{C,\delta}^x \cap G =\emptyset \right\},\end{equation*}
where for
 $ r>0$
,
$ r>0$
,
 $ rR_{C,\delta}^x = \big\{\boldsymbol{x}\in \mathbb{R}^d_+\,:\, x_i>r, i \in C,x_j \leq \delta \min_{l \in C} x_l, j \in D\setminus C\big\}$
. Similarly to Propositions 3.3 and 3.5, we have
$ rR_{C,\delta}^x = \big\{\boldsymbol{x}\in \mathbb{R}^d_+\,:\, x_i>r, i \in C,x_j \leq \delta \min_{l \in C} x_l, j \in D\setminus C\big\}$
. Similarly to Propositions 3.3 and 3.5, we have
 \begin{align*}{-}\log {\mathbb P}\Big({\boldsymbol{X}}_E \in tr_{C,\delta}^x R_{C,\delta}^x\Big) = {-}\log {\mathbb P}\bigg(\!\min_{i \in C} X_{E,i}>tr_{C,\delta}^x, \max_{j \in D \setminus C} X_{E,j}< \delta \min_{i \in C} X_{E,i}\bigg) \sim t,\end{align*}
\begin{align*}{-}\log {\mathbb P}\Big({\boldsymbol{X}}_E \in tr_{C,\delta}^x R_{C,\delta}^x\Big) = {-}\log {\mathbb P}\bigg(\!\min_{i \in C} X_{E,i}>tr_{C,\delta}^x, \max_{j \in D \setminus C} X_{E,j}< \delta \min_{i \in C} X_{E,i}\bigg) \sim t,\end{align*}
and we conclude
 $ \tilde{\tau}_C(\delta) = r_{C,\delta}^{x}$
. As in Proposition 3.7, we have
$ \tilde{\tau}_C(\delta) = r_{C,\delta}^{x}$
. As in Proposition 3.7, we have
 $ r_{C,\delta}^{x}=\min_{\boldsymbol{y} \in B_{C,\delta}^x} g(\boldsymbol{y})$
. Noting again that
$ r_{C,\delta}^{x}=\min_{\boldsymbol{y} \in B_{C,\delta}^x} g(\boldsymbol{y})$
. Noting again that
 $ \arg\min_{\boldsymbol{y} \in B_{C,\delta}^x} g(\boldsymbol{y}) \in B_{C,\delta}^{x,1}=B_{C,\delta}^1$
shows that
$ \arg\min_{\boldsymbol{y} \in B_{C,\delta}^x} g(\boldsymbol{y}) \in B_{C,\delta}^{x,1}=B_{C,\delta}^1$
shows that
 $ r_{C,\delta}^{x} = r_{C,\delta} = \tau_{C}(\delta)$
.
$ r_{C,\delta}^{x} = r_{C,\delta} = \tau_{C}(\delta)$
.
4. Examples
We illustrate several of the findings of Section 3 with some concrete examples. In Section 4.1 we focus on the intuitive and geometrically simple case
 $ d=2$
; in Section 4.2, we examine some three-dimensional examples for which visualization is still possible but more intricate. Additional examples are given in the arXiv version of this article.
$ d=2$
; in Section 4.2, we examine some three-dimensional examples for which visualization is still possible but more intricate. Additional examples are given in the arXiv version of this article.
Proposition 2.2 implies that on
 $ \mathbb{R}^d_+$
, the same limit set G as in exponential margins will arise for any marginal choice with
$ \mathbb{R}^d_+$
, the same limit set G as in exponential margins will arise for any marginal choice with
 $ \psi_j(x) \sim x$
,
$ \psi_j(x) \sim x$
,
 $ x \to \infty$
, provided
$ x \to \infty$
, provided
 $ e^{-\psi_j(x)}$
is a von Mises function. In some of the examples below, it is convenient to establish a limit set and its gauge function using this observation rather than transforming to exactly exponential margins.
$ e^{-\psi_j(x)}$
is a von Mises function. In some of the examples below, it is convenient to establish a limit set and its gauge function using this observation rather than transforming to exactly exponential margins.
Models with convenient dependence properties are often constructed through judicious combinations of random vectors with known dependence structures; see, for example, [Reference Engelke, Opitz and Wadsworth17] for a detailed study of so-called random-scale or random-location constructions. In Section 4.3, we use our results to elucidate the shape of the limit set when independent exponential-tailed variables are mixed additively. The spatial dependence model of [Reference Huser and Wadsworth26] provides a case study.
4.1. Examples and illustrations for
$ d=2$

All of the examples considered in this section are symmetric, so, for the conditional extremes representation and coefficients
 $ \tau_j(\delta)$
, we consider only one case, omitting the subscript on the quantities
$ \tau_j(\delta)$
, we consider only one case, omitting the subscript on the quantities
 $ \alpha_j$
and
$ \alpha_j$
and
 $ \beta_j$
. Table 1 summarizes the dependence information from various bivariate distributions described in Sections 4.1.1–4.1.4, as well as the arXiv version.
$ \beta_j$
. Table 1 summarizes the dependence information from various bivariate distributions described in Sections 4.1.1–4.1.4, as well as the arXiv version.
Table 1. Summary of dependence measures across a range of bivariate examples

4.1.1. Meta-Gaussian distribution: nonnegative correlation
Starting with a Gaussian bivariate random vector and transforming its margins to standard exponential, we obtain a meta-Gaussian distribution with exponential margins. Such a distribution inherits the copula of the Gaussian distribution. For simplicity, we consider the case where the underlying Gaussian random vector has standard normal components with correlation
 $ \rho$
.
$ \rho$
.
Then, for
 $ \rho\ge0$
, the joint probability density
$ \rho\ge0$
, the joint probability density
 $ f_E$
satisfies
$ f_E$
satisfies
 \begin{align*}{-}\log f_E(tx,ty)/t = \big(x + y -2\rho(xy)^{1/2}\big)/\big(1-\rho^2\big) + O(\!\log t/t),\quad t\to\infty,\quad x,y\ge 0,\end{align*}
\begin{align*}{-}\log f_E(tx,ty)/t = \big(x + y -2\rho(xy)^{1/2}\big)/\big(1-\rho^2\big) + O(\!\log t/t),\quad t\to\infty,\quad x,y\ge 0,\end{align*}
so that
 $ g(x,y) = \big(x + y -2\rho(xy)^{1/2}\big)/\big(1-\rho^2\big)$
. The convergence in (2.10) holds on
$ g(x,y) = \big(x + y -2\rho(xy)^{1/2}\big)/\big(1-\rho^2\big)$
. The convergence in (2.10) holds on
 $ [0,\infty)^d$
, and hence the limit set exists and is given by
$ [0,\infty)^d$
, and hence the limit set exists and is given by
 $ \{\boldsymbol{x}\in[0,\infty)^d\,:\, g(\boldsymbol{x})\le1\}$
. This is Case (ii) in Figure 2.
$ \{\boldsymbol{x}\in[0,\infty)^d\,:\, g(\boldsymbol{x})\le1\}$
. This is Case (ii) in Figure 2.
Conditional extremes: Setting
 $ g(\alpha,1) = 1$
leads to
$ g(\alpha,1) = 1$
leads to
 $ \big(\alpha^{1/2} - \rho\big)^2 = 0$
, i.e.,
$ \big(\alpha^{1/2} - \rho\big)^2 = 0$
, i.e.,
 $ \alpha = \rho^2$
. For
$ \alpha = \rho^2$
. For
 $ \beta$
we have
$ \beta$
we have
 $ g\big(\rho^2+u, 1\big) - 1 = u^2/\big\{2\rho\big(1-\rho^2\big)\big\} + O\big(u^3\big) \in \mathrm{RV}_2^0$
; hence
$ g\big(\rho^2+u, 1\big) - 1 = u^2/\big\{2\rho\big(1-\rho^2\big)\big\} + O\big(u^3\big) \in \mathrm{RV}_2^0$
; hence
 $ \beta = 1/2$
.
$ \beta = 1/2$
.
Function
 $ \lambda(\boldsymbol{\omega})$
: By Proposition 3.4, we need to find
$ \lambda(\boldsymbol{\omega})$
: By Proposition 3.4, we need to find
 $ 1/r_{\omega} = \min_{\boldsymbol{y} \in B_{\omega}} g(x,y)$
. If
$ 1/r_{\omega} = \min_{\boldsymbol{y} \in B_{\omega}} g(x,y)$
. If
 $ \min\!(\omega,$
$ \min\!(\omega,$
 $ 1-\omega)/\max\!(\omega,1-\omega) \leq \rho^2$
, then
$ 1-\omega)/\max\!(\omega,1-\omega) \leq \rho^2$
, then
 $ \min_{\boldsymbol{y} \in B_{\omega}} g(x,y) = 1$
, with the minima occuring at the points
$ \min_{\boldsymbol{y} \in B_{\omega}} g(x,y) = 1$
, with the minima occuring at the points
 $ (1,\rho^2)$
,
$ (1,\rho^2)$
,
 $ (\rho^2,1)$
. Otherwise, if
$ (\rho^2,1)$
. Otherwise, if
 $ \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \geq \rho^2$
, then
$ \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \geq \rho^2$
, then
 $ \min_{\boldsymbol{y} \in B_{\omega}} g(x,y) = g(1, \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega))$
. Putting this together with Proposition 3.3, we find
$ \min_{\boldsymbol{y} \in B_{\omega}} g(x,y) = g(1, \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega))$
. Putting this together with Proposition 3.3, we find
 \begin{equation*}\lambda(\omega,1-\omega) = \begin{cases}\max\!(\omega,1-\omega), & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \leq \rho^2,\\g(\omega,1-\omega) = \frac{1 -2\rho(\omega(1-\omega))^{1/2}}{1-\rho^2}, & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \geq \rho^2.\end{cases}\end{equation*}
\begin{equation*}\lambda(\omega,1-\omega) = \begin{cases}\max\!(\omega,1-\omega), & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \leq \rho^2,\\g(\omega,1-\omega) = \frac{1 -2\rho(\omega(1-\omega))^{1/2}}{1-\rho^2}, & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \geq \rho^2.\end{cases}\end{equation*}
This is the same form as given in [Reference Wadsworth and Tawn44]. We therefore have
 $ \eta_{1,2} = [2g(1/2,1/2)]^{-1} = g(1, 1)^{-1} = (1+\rho)/2$
.
$ \eta_{1,2} = [2g(1/2,1/2)]^{-1} = g(1, 1)^{-1} = (1+\rho)/2$
.
Coefficients
 $ \tau_j(\delta)$
: From Proposition 3.6, we have
$ \tau_j(\delta)$
: From Proposition 3.6, we have
 $ \tau_1(\delta) = \big[\!\min_{\gamma \in [0,\delta]} g(1,\gamma)\big]^{-1} = \big[g\big(1,\min\big(\delta,\rho^2\big)\big)\big]^{-1}$
. Therefore,
$ \tau_1(\delta) = \big[\!\min_{\gamma \in [0,\delta]} g(1,\gamma)\big]^{-1} = \big[g\big(1,\min\big(\delta,\rho^2\big)\big)\big]^{-1}$
. Therefore,
 $ \tau_{1}(\delta) = 1$
if
$ \tau_{1}(\delta) = 1$
if
 $ \delta \geq \rho^2$
, and otherwise
$ \delta \geq \rho^2$
, and otherwise
 $ \tau_{1}(\delta) = (1-\rho^2)/\big(1+\delta-2\rho\delta^{1/2}\big) < 1$
. Note that these values are very laborious to calculate via Gaussian survival functions, and they were not given in [Reference Simpson, Wadsworth and Tawn42].
$ \tau_{1}(\delta) = (1-\rho^2)/\big(1+\delta-2\rho\delta^{1/2}\big) < 1$
. Note that these values are very laborious to calculate via Gaussian survival functions, and they were not given in [Reference Simpson, Wadsworth and Tawn42].
4.1.2. Meta-Gaussian distribution: negative correlation
When
 $ \rho<0$
, Proposition 2.2 cannot be applied as the continuous convergence condition (2.10) does not hold along the axes. Hence we gain only a partial specification, when
$ \rho<0$
, Proposition 2.2 cannot be applied as the continuous convergence condition (2.10) does not hold along the axes. Hence we gain only a partial specification, when
 $ x>0$
,
$ x>0$
,
 $ y>0$
, through this route. Instead, here we can apply Proposition 2.3, since the limit function g in (2.13) satisfies the monotonicity condition given immediately thereafter. This limit function is given by
$ y>0$
, through this route. Instead, here we can apply Proposition 2.3, since the limit function g in (2.13) satisfies the monotonicity condition given immediately thereafter. This limit function is given by
 \begin{align*}g(x,y) = \begin{cases}\big(x + y -2\rho(xy)^{1/2}\big)/\big(1-\rho^2\big), & x>0, y>0,\\x, & y=0,\\y, & x=0.\end{cases}\end{align*}
\begin{align*}g(x,y) = \begin{cases}\big(x + y -2\rho(xy)^{1/2}\big)/\big(1-\rho^2\big), & x>0, y>0,\\x, & y=0,\\y, & x=0.\end{cases}\end{align*}
Figure 5 illustrates the limit sets G for the three cases
 $ \rho>0$
,
$ \rho>0$
,
 $ \rho=0$
, and
$ \rho=0$
, and
 $ \rho<0$
. In the latter case, large values of one variable tend to occur with small values of the other, which causes the limit set to include lines along the axes, and the function g is not continuous. Such difficulties can be alleviated by consideration of Laplace margins for distributions displaying negative dependence, which is discussed further in Section 5.
$ \rho<0$
. In the latter case, large values of one variable tend to occur with small values of the other, which causes the limit set to include lines along the axes, and the function g is not continuous. Such difficulties can be alleviated by consideration of Laplace margins for distributions displaying negative dependence, which is discussed further in Section 5.

Figure 5. Top row: limit sets
 $ \{(x,y)\,:\, g(x,y)\le1\}$
for a bivariate meta-Gaussian distribution with exponential margins. Bottom row: corresponding plots of function g(x,y) for a fixed value of y.
$ \{(x,y)\,:\, g(x,y)\le1\}$
for a bivariate meta-Gaussian distribution with exponential margins. Bottom row: corresponding plots of function g(x,y) for a fixed value of y.
4.1.3. Logistic generalized Pareto copula
The logistic generalized Pareto distribution with conditionally exponential margins
 $ \big({\mathbb P}\big(X_{\tilde{E}}>x\big) = {\mathbb P}\big(X_{\tilde{E}}>0\big)e^{-x}, x>0\big)$
and dependence parameter
$ \big({\mathbb P}\big(X_{\tilde{E}}>x\big) = {\mathbb P}\big(X_{\tilde{E}}>0\big)e^{-x}, x>0\big)$
and dependence parameter
 $ \theta \in(0,1)$
satisfies
$ \theta \in(0,1)$
satisfies
 \begin{align*}f_{\tilde{E}}(x,y) &= \theta^{-1}2^{-\theta} e^{-(x+y)/\theta}\big(e^{-x/\theta}+e^{-y/\theta}\big)^{\theta-2},\\{-}\log f_{\tilde{E}}(tx,ty)/t &= \theta^{-1}\max\!(x,y) + \big(1-\theta^{-1}\big)\min\!(x,y) + O(1/t),\end{align*}
\begin{align*}f_{\tilde{E}}(x,y) &= \theta^{-1}2^{-\theta} e^{-(x+y)/\theta}\big(e^{-x/\theta}+e^{-y/\theta}\big)^{\theta-2},\\{-}\log f_{\tilde{E}}(tx,ty)/t &= \theta^{-1}\max\!(x,y) + \big(1-\theta^{-1}\big)\min\!(x,y) + O(1/t),\end{align*}
so the gauge function is
 $ g(x,y) = \theta^{-1}\max\!(x,y) + \big(1-\theta^{-1}\big)\min\!(x,y)$
. This form of gauge function is found throughout several symmetric asymptotically dependent examples, such as those distributions whose spectral measure H places no mass on 0 and 1 and whose densities are regularly varying at the endpoints 0, 1, so that
$ g(x,y) = \theta^{-1}\max\!(x,y) + \big(1-\theta^{-1}\big)\min\!(x,y)$
. This form of gauge function is found throughout several symmetric asymptotically dependent examples, such as those distributions whose spectral measure H places no mass on 0 and 1 and whose densities are regularly varying at the endpoints 0, 1, so that
 $ \mathrm{d}H(w)/\mathrm{d}w \in \mathrm{RV}_{1/\theta-2}^{0}$
,
$ \mathrm{d}H(w)/\mathrm{d}w \in \mathrm{RV}_{1/\theta-2}^{0}$
,
 $ -\mathrm{d}H(1-w)/\mathrm{d}w \in \mathrm{RV}_{1/\theta-2}^{0}$
. This is Case (i) in Figure 2.
$ -\mathrm{d}H(1-w)/\mathrm{d}w \in \mathrm{RV}_{1/\theta-2}^{0}$
. This is Case (i) in Figure 2.
Conditional extremes: Solving for
 $ g(\alpha,1)=1$
, we obtain
$ g(\alpha,1)=1$
, we obtain
 $ \alpha=1$
, whilst
$ \alpha=1$
, whilst
 $ g(1+u,1) -1 = u/\theta \in \mathrm{RV}_1^0$
, and hence
$ g(1+u,1) -1 = u/\theta \in \mathrm{RV}_1^0$
, and hence
 $ \beta=0$
.
$ \beta=0$
.
Function
 $ \lambda(\boldsymbol{\omega})$
: We have that
$ \lambda(\boldsymbol{\omega})$
: We have that
 $ \arg\min_{\boldsymbol{y} \in B_\omega}g(\boldsymbol{y}) = (1, 1)$
, so
$ \arg\min_{\boldsymbol{y} \in B_\omega}g(\boldsymbol{y}) = (1, 1)$
, so
 $ r_{ \omega} = 1$
and
$ r_{ \omega} = 1$
and
 $ \lambda(\omega,1-\omega) = \max\!(\omega,1-\omega)$
. Therefore
$ \lambda(\omega,1-\omega) = \max\!(\omega,1-\omega)$
. Therefore
 $ \eta_{1,2} =1$
.
$ \eta_{1,2} =1$
.
Coefficients
 $ \tau_j(\delta)$
: We have
$ \tau_j(\delta)$
: We have
 $ \tau_1(\delta) = [\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1} = [g(1,\delta)]^{-1} = [\theta^{-1}+(1-\theta^{-1}\delta)]^{-1}$
. This matches the value calculated in the Supplementary Material of [Reference Simpson, Wadsworth and Tawn42].
$ \tau_1(\delta) = [\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1} = [g(1,\delta)]^{-1} = [\theta^{-1}+(1-\theta^{-1}\delta)]^{-1}$
. This matches the value calculated in the Supplementary Material of [Reference Simpson, Wadsworth and Tawn42].
4.1.4. Inverted extreme value distribution
The inverted extreme value copula is the joint lower tail of an extreme value copula, translated to be the joint upper tail. That is, if
 $ (U_1,U_2)$
have an extreme value copula with uniform margins, then
$ (U_1,U_2)$
have an extreme value copula with uniform margins, then
 $ (1-U_1,1-U_2)$
have an inverted extreme value copula. In two dimensions, its density in exponential margins may be expressed as
$ (1-U_1,1-U_2)$
have an inverted extreme value copula. In two dimensions, its density in exponential margins may be expressed as
 \begin{equation*}f_E(x,y) = \{l_{1}(x,y)l_2(x,y)-l_{12}(x,y)\}\exp\{-l(x,y)\},\end{equation*}
\begin{equation*}f_E(x,y) = \{l_{1}(x,y)l_2(x,y)-l_{12}(x,y)\}\exp\{-l(x,y)\},\end{equation*}
where
 $ l(\boldsymbol{x}) = V(1/\boldsymbol{x})$
, for V the exponent function in (2.3), is the 1-homogeneous stable tail dependence function (e.g. [9, Chapter 8]) of the corresponding extreme value distribution, and
$ l(\boldsymbol{x}) = V(1/\boldsymbol{x})$
, for V the exponent function in (2.3), is the 1-homogeneous stable tail dependence function (e.g. [9, Chapter 8]) of the corresponding extreme value distribution, and
 $ l_1(x,y) = \partial l(x,y) /\partial x$
, etc. We thus have
$ l_1(x,y) = \partial l(x,y) /\partial x$
, etc. We thus have
 \begin{equation*}{-}\log f_E(tx,ty)/t = l(x,y) + O(1/t),\qquad t \to\infty,\end{equation*}
\begin{equation*}{-}\log f_E(tx,ty)/t = l(x,y) + O(1/t),\qquad t \to\infty,\end{equation*}
so
 $ g(x,y) = l(x,y)$
.
$ g(x,y) = l(x,y)$
.
Conditional extremes: Stable tail dependence functions always satisfy
 $ l(x,0) = x$
,
$ l(x,0) = x$
,
 $ l(0,y) = y$
, and so
$ l(0,y) = y$
, and so
 $ g(1,0) = g(0,1) = 1$
. Hence, if
$ g(1,0) = g(0,1) = 1$
. Hence, if
 $ \alpha=0$
is the only solution to
$ \alpha=0$
is the only solution to
 $ g(\alpha,1) =1$
, then
$ g(\alpha,1) =1$
, then
 $ a(x)/x \sim 0$
. An example of this is given by the inverted extreme value logistic copula, whereby
$ a(x)/x \sim 0$
. An example of this is given by the inverted extreme value logistic copula, whereby
 $ l(x,y) = \big(x^{1/\theta}+y^{1/\theta}\big)^\theta, \theta \in (0,1]$
. This is Case (iii) of Figure 2, for which we have
$ l(x,y) = \big(x^{1/\theta}+y^{1/\theta}\big)^\theta, \theta \in (0,1]$
. This is Case (iii) of Figure 2, for which we have
 $ \alpha=0$
and
$ \alpha=0$
and
 $ \beta=1-\theta$
.
$ \beta=1-\theta$
.
Further examples in this class are given in the arXiv version of this paper.
Function
 $ \lambda(\boldsymbol{\omega})$
: Since
$ \lambda(\boldsymbol{\omega})$
: Since
 $ g(x,y) = l(x,y)$
, and l is a convex function satisfying
$ g(x,y) = l(x,y)$
, and l is a convex function satisfying
 $ l(x,0)=x$
,
$ l(x,0)=x$
,
 $ l(0,y) = y$
, we have
$ l(0,y) = y$
, we have
 $ \arg\min_{\boldsymbol{y} \in B_{\omega}} g(\boldsymbol{y}) = (\omega,1-\omega)/\max\!(\omega,1-\omega)$
. Hence,
$ \arg\min_{\boldsymbol{y} \in B_{\omega}} g(\boldsymbol{y}) = (\omega,1-\omega)/\max\!(\omega,1-\omega)$
. Hence,
 $ \lambda(\omega,1-\omega) = g(\omega,1-\omega)$
in this case.
$ \lambda(\omega,1-\omega) = g(\omega,1-\omega)$
in this case.
Coefficients
 $ \tau_j(\delta)$
: Since
$ \tau_j(\delta)$
: Since
 $ g(1,0)=1$
, we have
$ g(1,0)=1$
, we have
 $ \tau_1(\delta) = 1$
for all
$ \tau_1(\delta) = 1$
for all
 $ \delta \in [0,1]$
.
$ \delta \in [0,1]$
.
4.1.5. Density defined by g
If
 $ g\,:\,\mathbb{R}^d_+ \to \mathbb{R}_+$
is a gauge function describing a limit set G, then
$ g\,:\,\mathbb{R}^d_+ \to \mathbb{R}_+$
is a gauge function describing a limit set G, then
 $ f(\boldsymbol{x}) = e^{-g(\boldsymbol{x})}/(d! |G|)$
is a density (see [Reference Balkema and Nolde4]). In general, except for the case of
$ f(\boldsymbol{x}) = e^{-g(\boldsymbol{x})}/(d! |G|)$
is a density (see [Reference Balkema and Nolde4]). In general, except for the case of
 $ g(\boldsymbol{x}) = \sum_{i=1}^d x_i$
, the margins are not exactly exponential, and may be heavier than exponential, for example in the case
$ g(\boldsymbol{x}) = \sum_{i=1}^d x_i$
, the margins are not exactly exponential, and may be heavier than exponential, for example in the case
 $ g(\boldsymbol{x}) = \max_{1\leq i \leq d}(x_i)$
.
$ g(\boldsymbol{x}) = \max_{1\leq i \leq d}(x_i)$
.
We consider the density defined by
 $ g(x,y) = \max\{(x-y)/\theta,(y-x)/\theta,(x+y)/(2-\theta)\}$
,
$ g(x,y) = \max\{(x-y)/\theta,(y-x)/\theta,(x+y)/(2-\theta)\}$
,
 $ \theta \in (0,1]$
: this is Case (vi) in Figure 2, and illustrated in Figure 4. The marginal density is given by
$ \theta \in (0,1]$
: this is Case (vi) in Figure 2, and illustrated in Figure 4. The marginal density is given by
 \begin{equation*}\Big[2 e^{-x} - \theta e^{-x/\theta} -2(1-\theta)e^{-x/(1-\theta)}\Big]/\big[4\theta - 3\theta^2\big].\end{equation*}
\begin{equation*}\Big[2 e^{-x} - \theta e^{-x/\theta} -2(1-\theta)e^{-x/(1-\theta)}\Big]/\big[4\theta - 3\theta^2\big].\end{equation*}
Conditional extremes: Solving for
 $ g(\alpha,1)=1$
, we obtain
$ g(\alpha,1)=1$
, we obtain
 $ \alpha=1-\theta$
, whilst
$ \alpha=1-\theta$
, whilst
 $ g(1-\theta+u,1) -1 = u/(2-\theta) \in \mathrm{RV}_1^0$
, and hence
$ g(1-\theta+u,1) -1 = u/(2-\theta) \in \mathrm{RV}_1^0$
, and hence
 $ \beta=0$
.
$ \beta=0$
.
Function
 $ \lambda(\boldsymbol{\omega})$
: If
$ \lambda(\boldsymbol{\omega})$
: If
 $ \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \leq 1-\theta$
, then
$ \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \leq 1-\theta$
, then
 $ \arg\min_{\boldsymbol{y} \in B_\omega} = (1,1-\theta)$
, or
$ \arg\min_{\boldsymbol{y} \in B_\omega} = (1,1-\theta)$
, or
 $ (1-\theta,1)$
and
$ (1-\theta,1)$
and
 $ r_{\omega}=1$
; otherwise,
$ r_{\omega}=1$
; otherwise,
 $ \arg\min_{\boldsymbol{y} \in B_\omega} = (1,\omega/(1-\omega))$
or
$ \arg\min_{\boldsymbol{y} \in B_\omega} = (1,\omega/(1-\omega))$
or
 $ ((1-\omega)/\omega, 1)$
, and
$ ((1-\omega)/\omega, 1)$
, and
 $ r_{\omega} =\{1+ \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega)/(2-\theta)\}$
. Therefore,
$ r_{\omega} =\{1+ \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega)/(2-\theta)\}$
. Therefore,
 \begin{equation*}\lambda(\omega,1-\omega) = \begin{cases}\max\!(\omega,1-\omega), & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \leq 1-\theta,\\g(\omega,1-\omega) = \frac{1}{2-\theta}, & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \geq 1-\theta,\end{cases}\end{equation*}
\begin{equation*}\lambda(\omega,1-\omega) = \begin{cases}\max\!(\omega,1-\omega), & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \leq 1-\theta,\\g(\omega,1-\omega) = \frac{1}{2-\theta}, & \min\!(\omega,1-\omega)/\max\!(\omega,1-\omega) \geq 1-\theta,\end{cases}\end{equation*}
and the residual tail dependence coefficient
 $ \eta_{1,2} = 1-\theta/2$
.
$ \eta_{1,2} = 1-\theta/2$
.
Coefficients
 $ \tau_j(\delta)$
: We have
$ \tau_j(\delta)$
: We have
 $ \tau_1(\delta) = [\!\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1} = [g(1,\min\!(\delta,1-\theta))]^{-1}$
. Therefore,
$ \tau_1(\delta) = [\!\min_{\gamma \in [0,\delta]} g(1,\gamma)]^{-1} = [g(1,\min\!(\delta,1-\theta))]^{-1}$
. Therefore,
 $ \tau_{1}(\delta) = 1$
if
$ \tau_{1}(\delta) = 1$
if
 $ \delta \geq 1-\theta$
; otherwise,
$ \delta \geq 1-\theta$
; otherwise,
 $ \tau_{1}(\delta) = \theta/(1-\delta)< 1$
.
$ \tau_{1}(\delta) = \theta/(1-\delta)< 1$
.
Further examples presented in the arXiv version include the Hüsler–Reiss generalized Pareto copula and two boundary cases with
 $ g(x,y)=\max\!(x,y)$
, one displaying asymptotic dependence and one asymptotic independence. In the latter of these, we find that there is no conditional extreme value limit with positive support, but there is one with negative support. We comment that the results of Proposition 3.1 do indeed focus predominantly on the positive end of the support for limit distributions, but most known examples of conditional limits have support including
$ g(x,y)=\max\!(x,y)$
, one displaying asymptotic dependence and one asymptotic independence. In the latter of these, we find that there is no conditional extreme value limit with positive support, but there is one with negative support. We comment that the results of Proposition 3.1 do indeed focus predominantly on the positive end of the support for limit distributions, but most known examples of conditional limits have support including
 $ (0,\infty)$
. A natural next step is to consider the implications relating to negative support. We particularly note the possibility that the orders of regular variation of the two functions
$ (0,\infty)$
. A natural next step is to consider the implications relating to negative support. We particularly note the possibility that the orders of regular variation of the two functions
 $ g(1,\alpha_1+u)-1 \in \mathrm{RV}^0_{1/\big(1-\beta_1^+\big)}$
and
$ g(1,\alpha_1+u)-1 \in \mathrm{RV}^0_{1/\big(1-\beta_1^+\big)}$
and
 $ g\big(1,\alpha_1-u\big)-1\in \mathrm{RV}^0_{1/\big(1-\beta_1^-\big)}$
need not be equal, though for each of our examples where both functions are regularly varying,
$ g\big(1,\alpha_1-u\big)-1\in \mathrm{RV}^0_{1/\big(1-\beta_1^-\big)}$
need not be equal, though for each of our examples where both functions are regularly varying,
 $ \beta^+=\beta^-$
. If
$ \beta^+=\beta^-$
. If
 $ \beta^+>\beta^-$
, it seems likely that a limit distribution with positive support only would arise, and vice versa when
$ \beta^+>\beta^-$
, it seems likely that a limit distribution with positive support only would arise, and vice versa when
 $ \beta^+<\beta^-$
.
$ \beta^+<\beta^-$
.
4.2. Examples and illustrations for
$ d=3$

In this section we give two examples, focusing on issues that arise for
 $ d>2$
.
$ d>2$
.
4.2.1. Gaussian copula
The general form of the gauge function for a meta-Gaussian distribution with standard exponential margins and correlation matrix
 $ \Sigma$
with nonnegative entries is
$ \Sigma$
with nonnegative entries is
 \begin{equation*}g(\boldsymbol{x}) = \big(\boldsymbol{x}^{1/2}\big)^\top \Sigma^{-1} \boldsymbol{x}^{1/2}.\end{equation*}
\begin{equation*}g(\boldsymbol{x}) = \big(\boldsymbol{x}^{1/2}\big)^\top \Sigma^{-1} \boldsymbol{x}^{1/2}.\end{equation*}
Figure 6 displays the level set
 $ g(\boldsymbol{x}) = 1$
when the Gaussian correlations in
$ g(\boldsymbol{x}) = 1$
when the Gaussian correlations in
 $ \Sigma$
are
$ \Sigma$
are
 $ \rho_{12}=0.75$
,
$ \rho_{12}=0.75$
,
 $ \rho_{13}=0.25$
,
$ \rho_{13}=0.25$
,
 $ \rho_{23} =0.4$
. The red dots on the level set are the points
$ \rho_{23} =0.4$
. The red dots on the level set are the points
 $ (1,1,\gamma)/g(1,1,\gamma)$
,
$ (1,1,\gamma)/g(1,1,\gamma)$
,
 $ (1,\gamma,1)/g(1,\gamma,1)$
, and
$ (1,\gamma,1)/g(1,\gamma,1)$
, and
 $ (\gamma,1,1)/g(\gamma,1,1)$
for
$ (\gamma,1,1)/g(\gamma,1,1)$
for
 $ \gamma \in [0,1]$
. The figure also provides an illustration of
$ \gamma \in [0,1]$
. The figure also provides an illustration of
 $ \tau_{2,3}(\delta)$
for
$ \tau_{2,3}(\delta)$
for
 $ \delta =0.2$
and
$ \delta =0.2$
and
 $ \delta=0.8$
: in each case the light blue line from the origin is
$ \delta=0.8$
: in each case the light blue line from the origin is
 $ \gamma \times (\delta,1,1)$
,
$ \gamma \times (\delta,1,1)$
,
 $ \gamma \in [0,1]$
, whilst the pink lines trace out the boundary
$ \gamma \in [0,1]$
, whilst the pink lines trace out the boundary
 $ B_{\{2,3\},\delta}$
and
$ B_{\{2,3\},\delta}$
and
 $ \tau_{2,3}(\delta)B_{\{2,3\},\delta}$
. We see that when
$ \tau_{2,3}(\delta)B_{\{2,3\},\delta}$
. We see that when
 $ \delta = 0.2$
(left panel),
$ \delta = 0.2$
(left panel),
 $ \tau_{2,3}(0.2) = 1/g(0.2,1,1)$
, i.e.,
$ \tau_{2,3}(0.2) = 1/g(0.2,1,1)$
, i.e.,
 $ \min_{\boldsymbol{y} \in B_{\{2,3\},0.2}}g(\boldsymbol{y}) = g(0.2,1,1)$
. However, when
$ \min_{\boldsymbol{y} \in B_{\{2,3\},0.2}}g(\boldsymbol{y}) = g(0.2,1,1)$
. However, when
 $ \delta = 0.8$
,
$ \delta = 0.8$
,
 $ \min_{\boldsymbol{y} \in B_{\{2,3\},0.8}}g(\boldsymbol{y}) = g(\gamma^\star,1,1)$
, for
$ \min_{\boldsymbol{y} \in B_{\{2,3\},0.8}}g(\boldsymbol{y}) = g(\gamma^\star,1,1)$
, for
 $ \gamma^\star \in [0,0.8]$
, so
$ \gamma^\star \in [0,0.8]$
, so
 $ \tau_{2,3}(0.8) = 1/g(\gamma^\star,1,1)$
. We note that the same value of
$ \tau_{2,3}(0.8) = 1/g(\gamma^\star,1,1)$
. We note that the same value of
 $ \tau_{2,3}(\delta)$
applies for any
$ \tau_{2,3}(\delta)$
applies for any
 $ \delta \geq \gamma^\star$
: for this example, when
$ \delta \geq \gamma^\star$
: for this example, when
 $ \delta \geq \gamma^\star \approx 0.51$
,
$ \delta \geq \gamma^\star \approx 0.51$
,
 $ \tau_{2,3}(\delta) = 0.7 = \eta_{2,3}$
.
$ \tau_{2,3}(\delta) = 0.7 = \eta_{2,3}$
.

Figure 6. Level set
 $ g(\boldsymbol{x})=1$
for a trivariate meta-Gaussian distribution with exponential margins. The left panel illustrates
$ g(\boldsymbol{x})=1$
for a trivariate meta-Gaussian distribution with exponential margins. The left panel illustrates
 $ \tau_{2,3}(0.2)$
: the boundary set indicated by the pink solid lines is scaled along the blue trajectory emanating from the origin until it touches G, which happens in this case at the corner point
$ \tau_{2,3}(0.2)$
: the boundary set indicated by the pink solid lines is scaled along the blue trajectory emanating from the origin until it touches G, which happens in this case at the corner point
 $ (0.2,1,1)/g(0.2,1,1)$
. The centre panel illustrates
$ (0.2,1,1)/g(0.2,1,1)$
. The centre panel illustrates
 $ \tau_{2,3}(0.8)$
: the boundary set is again pulled back along the indicated trajectory until it touches G; in this case this does not occur at a corner point. The right panel illustrates
$ \tau_{2,3}(0.8)$
: the boundary set is again pulled back along the indicated trajectory until it touches G; in this case this does not occur at a corner point. The right panel illustrates
 $ \tau_1(\delta)$
in a similar manner, for
$ \tau_1(\delta)$
in a similar manner, for
 $ \delta =0.2,0.6$
.
$ \delta =0.2,0.6$
.
The reason that
 $ \tau_{2,3}(\delta) = \eta_{2,3}$
for sufficiently large
$ \tau_{2,3}(\delta) = \eta_{2,3}$
for sufficiently large
 $ \delta$
is that, in this case,
$ \delta$
is that, in this case,
 $ \arg\min_{x_1} g(x_1,1,1) = \gamma^\star,$
meaning that the two-dimensional marginalization
$ \arg\min_{x_1} g(x_1,1,1) = \gamma^\star,$
meaning that the two-dimensional marginalization
 $ g_{\{2,3\}}(1, 1) = g(\gamma^\star,1,1)$
, and we further have that
$ g_{\{2,3\}}(1, 1) = g(\gamma^\star,1,1)$
, and we further have that
 $ g_{\{2,3\}}(1, 1) = \min_{\boldsymbol{y} \in B_{2,3}} g_{\{2,3\}}(\boldsymbol{y})$
, so
$ g_{\{2,3\}}(1, 1) = \min_{\boldsymbol{y} \in B_{2,3}} g_{\{2,3\}}(\boldsymbol{y})$
, so
 $ \eta_{2,3} = 1/g_{2,3}(1, 1)$
. In Section 4.2.2 we will illustrate a gauge function for which
$ \eta_{2,3} = 1/g_{2,3}(1, 1)$
. In Section 4.2.2 we will illustrate a gauge function for which
 $ \arg\min_{x_3} g(1,1,x_3)>1$
, and consequently
$ \arg\min_{x_3} g(1,1,x_3)>1$
, and consequently
 $ \tau_{1,2}(\delta) < \eta_{1,2}$
for all
$ \tau_{1,2}(\delta) < \eta_{1,2}$
for all
 $ \delta\leq 1$
.
$ \delta\leq 1$
.
The right panel of Figure 6 illustrates
 $ \tau_{1}(\delta)$
for
$ \tau_{1}(\delta)$
for
 $ \delta = 0.2$
and
$ \delta = 0.2$
and
 $ \delta =0.6$
. When
$ \delta =0.6$
. When
 $ \delta =0.6$
, the boundary
$ \delta =0.6$
, the boundary
 $ B_{1,\delta}$
already touches G, and so
$ B_{1,\delta}$
already touches G, and so
 $ \tau_{1}(0.6)=1$
. In this example,
$ \tau_{1}(0.6)=1$
. In this example,
 $ \tau_1(\delta) =1$
for any
$ \tau_1(\delta) =1$
for any
 $ \delta \geq 0.5625 = \rho_{12}^2$
. Thus,
$ \delta \geq 0.5625 = \rho_{12}^2$
. Thus,
 $ \tau_{1}(0.2)<1$
as illustrated in the figure. We comment that if we had marginalized over
$ \tau_{1}(0.2)<1$
as illustrated in the figure. We comment that if we had marginalized over
 $ X_2$
, and were looking at
$ X_2$
, and were looking at
 $ \tau_1(\delta)$
for the variables
$ \tau_1(\delta)$
for the variables
 $ (X_1,X_3)$
, then we would have
$ (X_1,X_3)$
, then we would have
 $ \tau_1(\delta) = 1$
for any
$ \tau_1(\delta) = 1$
for any
 $ \delta \geq 0.0625 = \rho_{13}^2$
. This provides an illustration of the dimensionality of the problem interacting with
$ \delta \geq 0.0625 = \rho_{13}^2$
. This provides an illustration of the dimensionality of the problem interacting with
 $ \tau_{C}(\delta)$
, and is again related to the point at which the minimum point defining the lower-dimensional gauge function occurs.
$ \tau_{C}(\delta)$
, and is again related to the point at which the minimum point defining the lower-dimensional gauge function occurs.
4.2.2. Vine copula
Three-dimensional vine copulas are specified by three bivariate copulas: two in the ‘base layer’, giving the dependence between, e.g.,
 $ X_1,X_2$
and
$ X_1,X_2$
and
 $ X_2,X_3$
, and a further copula specifying the dependence between
$ X_2,X_3$
, and a further copula specifying the dependence between
 $ X_1|X_2$
and
$ X_1|X_2$
and
 $ X_3|X_2$
. Here we take the base copulas to be independence for
$ X_3|X_2$
. Here we take the base copulas to be independence for
 $ (X_1,X_2)$
, and the inverted Clayton copula with parameter
$ (X_1,X_2)$
, and the inverted Clayton copula with parameter
 $ \beta>0$
for
$ \beta>0$
for
 $ (X_2,X_3)$
. The final copula is taken as inverted Clayton with parameter
$ (X_2,X_3)$
. The final copula is taken as inverted Clayton with parameter
 $ \gamma>0$
. The gauge function that arises in exponential margins is
$ \gamma>0$
. The gauge function that arises in exponential margins is
 \begin{align}g(\boldsymbol{x}) = (1+\beta)\max\!(x_2,x_3) &-\beta \min\!(x_2,x_3) -\gamma x_1-(\gamma+1)(\beta+1)(\max\!(x_2,x_3)-x_2) \notag \\&+ (2\gamma+1)\max\!(x_1,(\beta+1)(\max\!(x_2,x_3)-x_2)).\end{align}
\begin{align}g(\boldsymbol{x}) = (1+\beta)\max\!(x_2,x_3) &-\beta \min\!(x_2,x_3) -\gamma x_1-(\gamma+1)(\beta+1)(\max\!(x_2,x_3)-x_2) \notag \\&+ (2\gamma+1)\max\!(x_1,(\beta+1)(\max\!(x_2,x_3)-x_2)).\end{align}
Figure 7 displays the level set
 $ g(\boldsymbol{x})=1$
. In this figure we also give an illustration of a case where
$ g(\boldsymbol{x})=1$
. In this figure we also give an illustration of a case where
 $ \tau_C(1)<\eta_C$
: in particular, for this example
$ \tau_C(1)<\eta_C$
: in particular, for this example
 $ \tau_{1,2}(1)<\eta_{1,2,3}=\eta_{1,2}=1/2$
. The purple lines (near right of image) represent the boundary of the region
$ \tau_{1,2}(1)<\eta_{1,2,3}=\eta_{1,2}=1/2$
. The purple lines (near right of image) represent the boundary of the region
 $ \tau_{1,2}(1)R_{\{1,2\},1} = \tau_{1,2}(1,\infty]^2 \times [0,1]$
, while the green lines (back right of image) represent the boundary of the region
$ \tau_{1,2}(1)R_{\{1,2\},1} = \tau_{1,2}(1,\infty]^2 \times [0,1]$
, while the green lines (back right of image) represent the boundary of the region
 $ \eta_{1,2,3}(1,\infty]^3$
. Theorem 1 of [Reference Simpson, Wadsworth and Tawn42] tells us that
$ \eta_{1,2,3}(1,\infty]^3$
. Theorem 1 of [Reference Simpson, Wadsworth and Tawn42] tells us that
 $ \eta_{1,2} = \max\!(\tau_{1,2}(1),\tau_{1,2,3})$
, where
$ \eta_{1,2} = \max\!(\tau_{1,2}(1),\tau_{1,2,3})$
, where
 $ \tau_{1,2,3}=\eta_{1,2,3}$
. Therefore
$ \tau_{1,2,3}=\eta_{1,2,3}$
. Therefore
 $ \tau_{1,2}(1)<\eta_{1,2}$
guarantees that
$ \tau_{1,2}(1)<\eta_{1,2}$
guarantees that
 $ \eta_{1,2}=\eta_{1,2,3}$
.
$ \eta_{1,2}=\eta_{1,2,3}$
.

Figure 7. Level set
 $ g(\boldsymbol{x})=1$
with g as in (4.1). The figure illustrates
$ g(\boldsymbol{x})=1$
with g as in (4.1). The figure illustrates
 $ \tau_{1,2}(1)$
and
$ \tau_{1,2}(1)$
and
 $ \eta_{1,2,3} = \eta_{1,2} = 1/2$
.
$ \eta_{1,2,3} = \eta_{1,2} = 1/2$
.
We also illustrate Proposition 2.4, minimizing (4.1) over
 $ x_3$
. If
$ x_3$
. If
 $ x_2>x_3$
then the minimum over
$ x_2>x_3$
then the minimum over
 $ x_3$
occurs if we set
$ x_3$
occurs if we set
 $ x_3=x_2$
and is equal to
$ x_3=x_2$
and is equal to
 $ x_2+(1+\gamma)x_1$
. If
$ x_2+(1+\gamma)x_1$
. If
 $ x_2< x_3$
then owing to the final term we need to consider the cases
$ x_2< x_3$
then owing to the final term we need to consider the cases
 $ x_3 \lessgtr x_1/(1+\beta)+x_2$
. In both cases, the minimum is attained at
$ x_3 \lessgtr x_1/(1+\beta)+x_2$
. In both cases, the minimum is attained at
 $ x_3 = x_1/(1+\beta)+x_2$
, and is equal to
$ x_3 = x_1/(1+\beta)+x_2$
, and is equal to
 $ x_1+x_2 < (1+\gamma)x_1+x_2$
. Therefore,
$ x_1+x_2 < (1+\gamma)x_1+x_2$
. Therefore,
 $ \min_{x_3} g(x_1,x_2,x_3) = x_1+x_2$
. This result is as expected since the bivariate margins of vine copulas that are directly specified in the base layer are equal to the specified copula: in this case, independence.
$ \min_{x_3} g(x_1,x_2,x_3) = x_1+x_2$
. This result is as expected since the bivariate margins of vine copulas that are directly specified in the base layer are equal to the specified copula: in this case, independence.
4.3. Mixing independent vectors
Here we exploit the results from previous sections to consider what happens when independent exponential random vectors are additively mixed so that the resulting vector still has exponential-type tails. We consider as a case study the spatial model of [Reference Huser and Wadsworth26], which following a reparameterization can be expressed as
 \begin{align}\big\{X_{\tilde{E}}(s) = \gamma S_E + V_E(s)\,:\, s \in \mathcal{S}\subset \mathbb{R}^2\big\}, \qquad \gamma \in (0,\infty), \end{align}
\begin{align}\big\{X_{\tilde{E}}(s) = \gamma S_E + V_E(s)\,:\, s \in \mathcal{S}\subset \mathbb{R}^2\big\}, \qquad \gamma \in (0,\infty), \end{align}
where
 $ S_E \sim \mbox{Exp}(1)$
is independent of the spatial process
$ S_E \sim \mbox{Exp}(1)$
is independent of the spatial process
 $ V_{E}$
, which also possesses unit exponential margins and is asymptotically independent at all spatial lags
$ V_{E}$
, which also possesses unit exponential margins and is asymptotically independent at all spatial lags
 $ s_1-s_2 \neq 0$
. The process
$ s_1-s_2 \neq 0$
. The process
 $ V_E$
is assumed to possess hidden regular variation, with residual tail dependence coefficient satisfying
$ V_E$
is assumed to possess hidden regular variation, with residual tail dependence coefficient satisfying
 $ \eta^{V}(s_1,s_2)<1$
for all
$ \eta^{V}(s_1,s_2)<1$
for all
 $ s_1 \neq s_2$
. The resulting process
$ s_1 \neq s_2$
. The resulting process
 $ X_{\tilde{E}}$
is asymptotically independent for
$ X_{\tilde{E}}$
is asymptotically independent for
 $ \gamma \in (0,1]$
and asymptotically dependent for
$ \gamma \in (0,1]$
and asymptotically dependent for
 $ \gamma>1$
; see also [Reference Engelke, Opitz and Wadsworth17] for related results.
$ \gamma>1$
; see also [Reference Engelke, Opitz and Wadsworth17] for related results.
When
 $ \gamma <1$
,
$ \gamma <1$
,
 $ {\mathbb P}\big(X_{\tilde{E}}(s) > x\big) \sim e^{-x}/(1-\gamma)$
. In this case, [Reference Huser and Wadsworth26] show that the residual tail dependence coefficient for the process
$ {\mathbb P}\big(X_{\tilde{E}}(s) > x\big) \sim e^{-x}/(1-\gamma)$
. In this case, [Reference Huser and Wadsworth26] show that the residual tail dependence coefficient for the process
 $ X_{\tilde{E}}$
is given by
$ X_{\tilde{E}}$
is given by
 \begin{align}\eta^{X} = \begin{cases}\eta^{V}, & \gamma < \eta^V,\\\gamma, & \eta^V \leq \gamma \leq 1.\end{cases} \end{align}
\begin{align}\eta^{X} = \begin{cases}\eta^{V}, & \gamma < \eta^V,\\\gamma, & \eta^V \leq \gamma \leq 1.\end{cases} \end{align}
That is, the strength of the extremal dependence as measured by the residual tail dependence coefficient
 $ \eta^X$
is increasing in
$ \eta^X$
is increasing in
 $ \gamma$
for
$ \gamma$
for
 $ \gamma \geq \eta^V$
. In contrast, [Reference Wadsworth and Tawn45] show that under mild conditions, the process (4.2) has the same conditional extremes normalization as the process
$ \gamma \geq \eta^V$
. In contrast, [Reference Wadsworth and Tawn45] show that under mild conditions, the process (4.2) has the same conditional extremes normalization as the process
 $ V_E(s)$
, with identical limit distribution when the scale normalizations
$ V_E(s)$
, with identical limit distribution when the scale normalizations
 $ b_{s-s_0}(t) \to \infty$
as
$ b_{s-s_0}(t) \to \infty$
as
 $ t \to \infty$
. Here, the subscript
$ t \to \infty$
. Here, the subscript
 $ s-s_0$
alludes to the fact that the conditioning event in (2.8) is
$ s-s_0$
alludes to the fact that the conditioning event in (2.8) is
 $ \{V_{E}(s_0)>t\}$
and we study the normalization at some other arbitrary location
$ \{V_{E}(s_0)>t\}$
and we study the normalization at some other arbitrary location
 $ s \in \mathcal{S}$
. In combination, we see that the results of [Reference Huser and Wadsworth26, Reference Wadsworth and Tawn45] suggest that the addition of the variable
$ s \in \mathcal{S}$
. In combination, we see that the results of [Reference Huser and Wadsworth26, Reference Wadsworth and Tawn45] suggest that the addition of the variable
 $ \gamma S_E$
to
$ \gamma S_E$
to
 $ V_E$
affects the extremal dependence of
$ V_E$
affects the extremal dependence of
 $ X_{\tilde{E}}$
differently for different extreme value representations. We elucidate these results further in the context of the limit sets and their gauge functions. A summary is provided here, with full derivations in the arXiv version of the paper.
$ X_{\tilde{E}}$
differently for different extreme value representations. We elucidate these results further in the context of the limit sets and their gauge functions. A summary is provided here, with full derivations in the arXiv version of the paper.
Let us suppose that
 $ {\boldsymbol{S}}_E \in \mathbb{R}^{d}_+$
has unit exponential margins, density
$ {\boldsymbol{S}}_E \in \mathbb{R}^{d}_+$
has unit exponential margins, density
 $ f_{S_E}$
, and gauge function
$ f_{S_E}$
, and gauge function
 $ g_S$
, and is independent of
$ g_S$
, and is independent of
 $ {\boldsymbol{V}}_E \in \mathbb{R}^{d}_+$
, which has unit exponential margins, density
$ {\boldsymbol{V}}_E \in \mathbb{R}^{d}_+$
, which has unit exponential margins, density
 $ f_{V_E}$
, and gauge function
$ f_{V_E}$
, and gauge function
 $ g_V$
. Let
$ g_V$
. Let
 $ {\boldsymbol{Z}}_E = ({\boldsymbol{S}}_E,{\boldsymbol{V}}_E) \in \mathbb{R}^{2d}_+$
be the concatenation of these vectors; this has exponential margins and gauge function
$ {\boldsymbol{Z}}_E = ({\boldsymbol{S}}_E,{\boldsymbol{V}}_E) \in \mathbb{R}^{2d}_+$
be the concatenation of these vectors; this has exponential margins and gauge function
 $ g_Z({\boldsymbol{z}}) = g_{S}(z_1,\ldots,z_{d}) + g_{V}(z_{d+1},\ldots,z_{2d})$
.
$ g_Z({\boldsymbol{z}}) = g_{S}(z_1,\ldots,z_{d}) + g_{V}(z_{d+1},\ldots,z_{2d})$
.
Now consider the linear transformation of
 $ {\boldsymbol{Z}}_E$
to
$ {\boldsymbol{Z}}_E$
to
 \begin{align*}A{\boldsymbol{Z}}_E &= \big(\gamma Z_{E,1}+ Z_{E,d+1},\ldots, \gamma Z_{E,d}+ Z_{E,2d}, Z_{E,1},\ldots, Z_{E,d}\big)\\&= \big(\gamma {\boldsymbol{S}}_E+{\boldsymbol{V}}_{E}, {\boldsymbol{S}}_E\big) = \big({\boldsymbol{X}}_{\tilde{E}},{\boldsymbol{S}}_E\big),\end{align*}
\begin{align*}A{\boldsymbol{Z}}_E &= \big(\gamma Z_{E,1}+ Z_{E,d+1},\ldots, \gamma Z_{E,d}+ Z_{E,2d}, Z_{E,1},\ldots, Z_{E,d}\big)\\&= \big(\gamma {\boldsymbol{S}}_E+{\boldsymbol{V}}_{E}, {\boldsymbol{S}}_E\big) = \big({\boldsymbol{X}}_{\tilde{E}},{\boldsymbol{S}}_E\big),\end{align*}
where
 $ A \in \mathbb{R}^{2d \times 2d}$
is the matrix describing this transformation. By Lemma 4.1 of [Reference Nolde36], the normalized sample cloud
$ A \in \mathbb{R}^{2d \times 2d}$
is the matrix describing this transformation. By Lemma 4.1 of [Reference Nolde36], the normalized sample cloud
 $ \{A{\boldsymbol{Z}}_{E,i}/\log n \,:\, i=1,\ldots, n\}$
converges onto the set AG, where
$ \{A{\boldsymbol{Z}}_{E,i}/\log n \,:\, i=1,\ldots, n\}$
converges onto the set AG, where
 $ G=\big\{{\boldsymbol{z}}\in\mathbb{R}^{2d}_+\,:\,g_Z({\boldsymbol{z}}) \leq 1\big\}$
, so
$ G=\big\{{\boldsymbol{z}}\in\mathbb{R}^{2d}_+\,:\,g_Z({\boldsymbol{z}}) \leq 1\big\}$
, so
 \begin{equation*}AG = \{{\boldsymbol{z}}\in\mathbb{R}^{2d}_+\,:\,A^{-1}{\boldsymbol{z}} \in G\} = \big\{{\boldsymbol{z}}\in\mathbb{R}^{2d}_+\,:\, g_Z(A^{-1}{\boldsymbol{z}}) \leq 1\big\}.\end{equation*}
\begin{equation*}AG = \{{\boldsymbol{z}}\in\mathbb{R}^{2d}_+\,:\,A^{-1}{\boldsymbol{z}} \in G\} = \big\{{\boldsymbol{z}}\in\mathbb{R}^{2d}_+\,:\, g_Z(A^{-1}{\boldsymbol{z}}) \leq 1\big\}.\end{equation*}
Consequently, the gauge function of
 $ A{\boldsymbol{Z}}_E$
is
$ A{\boldsymbol{Z}}_E$
is
 $ g_Z(A^{-1}{\boldsymbol{z}})$
; i.e.,
$ g_Z(A^{-1}{\boldsymbol{z}})$
; i.e.,
 $ g_{Z}(\boldsymbol{x},{\boldsymbol{s}})=g_{S}({\boldsymbol{s}}) + g_{V}(\boldsymbol{x}-\gamma{\boldsymbol{s}})$
, for
$ g_{Z}(\boldsymbol{x},{\boldsymbol{s}})=g_{S}({\boldsymbol{s}}) + g_{V}(\boldsymbol{x}-\gamma{\boldsymbol{s}})$
, for
 $ \boldsymbol{x}>\gamma{\boldsymbol{s}}$
.
$ \boldsymbol{x}>\gamma{\boldsymbol{s}}$
.
Next we apply Proposition 2.4 to the vector
 $ A{\boldsymbol{Z}}$
, marginalizing over the last d coordinates, which are equal to
$ A{\boldsymbol{Z}}$
, marginalizing over the last d coordinates, which are equal to
 $ {\boldsymbol{S}}_{E}$
. This leaves us with the gauge function of
$ {\boldsymbol{S}}_{E}$
. This leaves us with the gauge function of
 $ X_{\tilde{E}}$
, denoted by
$ X_{\tilde{E}}$
, denoted by
 $ g_X$
, and given by
$ g_X$
, and given by
 \begin{align*}g_X(\boldsymbol{x}) = \min_{{\boldsymbol{s}} \in [\boldsymbol{0},\boldsymbol{x}/\gamma]} g_S(s_1,\ldots,s_d) + g_{V}(x_1-\gamma s_1,\ldots, x_d - \gamma s_d).\end{align*}
\begin{align*}g_X(\boldsymbol{x}) = \min_{{\boldsymbol{s}} \in [\boldsymbol{0},\boldsymbol{x}/\gamma]} g_S(s_1,\ldots,s_d) + g_{V}(x_1-\gamma s_1,\ldots, x_d - \gamma s_d).\end{align*}
To illustrate the results of [Reference Huser and Wadsworth26, Reference Wadsworth and Tawn45] concerning the model (4.2), we need to take
 $ {\boldsymbol{S}}_{E} = S_{E}\boldsymbol{1}$
, i.e., perfect dependence. Although such a vector does not have a d-dimensional Lebesgue density, convergence of the sample cloud based on the univariate random variable
$ {\boldsymbol{S}}_{E} = S_{E}\boldsymbol{1}$
, i.e., perfect dependence. Although such a vector does not have a d-dimensional Lebesgue density, convergence of the sample cloud based on the univariate random variable
 $ S_E$
onto the unit interval [0,Reference Abdous, Fougères and Ghoudi1] implies that the limit set is
$ S_E$
onto the unit interval [0,Reference Abdous, Fougères and Ghoudi1] implies that the limit set is
 $ G_S = \big\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, x_1=x_2={\cdots}=x_d=x, x \leq 1\big\}$
. Such a set can be described by the gauge function
$ G_S = \big\{\boldsymbol{x} \in \mathbb{R}^d_+\,:\, x_1=x_2={\cdots}=x_d=x, x \leq 1\big\}$
. Such a set can be described by the gauge function
 \begin{equation*}g_S({\boldsymbol{s}}) = \begin{cases}\infty, & \quad s_i \neq s_j\ \mbox{for any } i,j,\\s, & \quad s_1={\cdots}=s_d = s.\end{cases}\end{equation*}
\begin{equation*}g_S({\boldsymbol{s}}) = \begin{cases}\infty, & \quad s_i \neq s_j\ \mbox{for any } i,j,\\s, & \quad s_1={\cdots}=s_d = s.\end{cases}\end{equation*}
Therefore, in this case,
 $ g_X(\boldsymbol{x}) = \min_{s \in[0,\min\!(\boldsymbol{x})/\gamma]} \{s + g_{V}(\boldsymbol{x}-\gamma s)\}.$
$ g_X(\boldsymbol{x}) = \min_{s \in[0,\min\!(\boldsymbol{x})/\gamma]} \{s + g_{V}(\boldsymbol{x}-\gamma s)\}.$
Residual tail dependence: To find the residual tail dependence coefficient
 $ \eta^X$
, we require
$ \eta^X$
, we require
 \begin{align*}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{X}(\boldsymbol{x}) &= \min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1}\min_{s \in[0,\min\!(\boldsymbol{x})/\gamma]} \{s + g_{V}(\boldsymbol{x}-\gamma s)\}\\&=\min_{s \in[0,1/\gamma]}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} \{s + g_{V}(\boldsymbol{x}-\gamma s)\}.\end{align*}
\begin{align*}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{X}(\boldsymbol{x}) &= \min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1}\min_{s \in[0,\min\!(\boldsymbol{x})/\gamma]} \{s + g_{V}(\boldsymbol{x}-\gamma s)\}\\&=\min_{s \in[0,1/\gamma]}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} \{s + g_{V}(\boldsymbol{x}-\gamma s)\}.\end{align*}
For fixed s, consider
 \begin{equation*}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{V}(\boldsymbol{x}-\gamma s) = \min_{{\boldsymbol{z}}\,:\min\!({\boldsymbol{z}})=1-\gamma s} g_{V}({\boldsymbol{z}}) = g_{V}(\boldsymbol{y}^\star\times(1-\gamma s)),\end{equation*}
\begin{equation*}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{V}(\boldsymbol{x}-\gamma s) = \min_{{\boldsymbol{z}}\,:\min\!({\boldsymbol{z}})=1-\gamma s} g_{V}({\boldsymbol{z}}) = g_{V}(\boldsymbol{y}^\star\times(1-\gamma s)),\end{equation*}
where
 $ \boldsymbol{y}^\star = \arg\min_{\boldsymbol{y}\,:\min\!(\boldsymbol{y})=1} g_V(\boldsymbol{y})$
. Thus
$ \boldsymbol{y}^\star = \arg\min_{\boldsymbol{y}\,:\min\!(\boldsymbol{y})=1} g_V(\boldsymbol{y})$
. Thus
 \begin{align*}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{X}(\boldsymbol{x}) &= \min_{s \in[0,1/\gamma]}\{s + g_V(\boldsymbol{y}^\star)(1-\gamma s)\} = \begin{cases} g_V(\boldsymbol{y}^\star),& \gamma < 1/g_V(\boldsymbol{y}^\star),\\ 1/\gamma, & \gamma \geq 1/g_V(\boldsymbol{y}^\star). \end{cases}\end{align*}
\begin{align*}\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{X}(\boldsymbol{x}) &= \min_{s \in[0,1/\gamma]}\{s + g_V(\boldsymbol{y}^\star)(1-\gamma s)\} = \begin{cases} g_V(\boldsymbol{y}^\star),& \gamma < 1/g_V(\boldsymbol{y}^\star),\\ 1/\gamma, & \gamma \geq 1/g_V(\boldsymbol{y}^\star). \end{cases}\end{align*}
Recalling that
 $ \eta^X = [\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{X}(\boldsymbol{x})]^{-1}$
and
$ \eta^X = [\min_{\boldsymbol{x}\,:\min\!(\boldsymbol{x})=1} g_{X}(\boldsymbol{x})]^{-1}$
and
 $ \eta^V=1/g_{V}(\boldsymbol{y}^\star)$
, this yields (4.3).
$ \eta^V=1/g_{V}(\boldsymbol{y}^\star)$
, this yields (4.3).
Conditional extremes: For the conditional extremes normalization, we now let
 $ g_V$
and
$ g_V$
and
 $ g_X$
denote two-dimensional gauge functions. Suppose that
$ g_X$
denote two-dimensional gauge functions. Suppose that
 $ \alpha_V, \beta_V$
are such that
$ \alpha_V, \beta_V$
are such that
 $ g_V(\alpha_V,1) = 1$
and
$ g_V(\alpha_V,1) = 1$
and
 $ g_V(\alpha_V + u,1) - 1 \in \mathrm{RV}_{1/(1-\beta_V)}^0$
. We have
$ g_V(\alpha_V + u,1) - 1 \in \mathrm{RV}_{1/(1-\beta_V)}^0$
. We have
 \begin{align}1= g_X(\alpha_X,1) = \min_{s} \{s + g_{V}(\alpha_X-\gamma s,1-\gamma s)\}. \end{align}
\begin{align}1= g_X(\alpha_X,1) = \min_{s} \{s + g_{V}(\alpha_X-\gamma s,1-\gamma s)\}. \end{align}
Suppose that the right-hand side of (4.4) is minimized at
 $ s^\star \geq 0$
; i.e.,
$ s^\star \geq 0$
; i.e.,
 $ g_X(\alpha_X,1) = s^\star + g_{V}(\alpha_X-\gamma s^\star,1-\gamma s^\star)$
. Because
$ g_X(\alpha_X,1) = s^\star + g_{V}(\alpha_X-\gamma s^\star,1-\gamma s^\star)$
. Because
 $ \alpha_X \leq 1$
and
$ \alpha_X \leq 1$
and
 $ g_V(v_1,v_2)\geq \max\!(v_1,v_2)$
, this yields
$ g_V(v_1,v_2)\geq \max\!(v_1,v_2)$
, this yields
 $ 1=g_X(\alpha_X,1) \geq 1+ (1-\gamma) s^\star$
; therefore we must have
$ 1=g_X(\alpha_X,1) \geq 1+ (1-\gamma) s^\star$
; therefore we must have
 $ s^\star=0$
for
$ s^\star=0$
for
 $ \gamma \in (0,1)$
. Consequently,
$ \gamma \in (0,1)$
. Consequently,
 $ \alpha_X = \alpha_V = \alpha$
.
$ \alpha_X = \alpha_V = \alpha$
.
Calculations for the scale normalization are more involved and can be found in the arXiv version of the paper. We find that for
 $ g_V$
differentiable at
$ g_V$
differentiable at
 $ (\alpha,1)$
,
$ (\alpha,1)$
,
 $ g_{X}(\alpha+u,1)-1 \sim g_{V}(\alpha+u,1)-1$
,
$ g_{X}(\alpha+u,1)-1 \sim g_{V}(\alpha+u,1)-1$
,
 $ u \to 0$
, whereas in the non-differentiable case we do not necessarily have this link but can deduce that the regular variation indices are
$ u \to 0$
, whereas in the non-differentiable case we do not necessarily have this link but can deduce that the regular variation indices are
 $ \beta_X=\beta_V = 0$
.
$ \beta_X=\beta_V = 0$
.
Figure 8 displays examples of gauge functions
 $ g_V$
and
$ g_V$
and
 $ g_X$
. We observe from this figure how, when
$ g_X$
. We observe from this figure how, when
 $ \gamma$
is sufficiently large, the shape of
$ \gamma$
is sufficiently large, the shape of
 $ g_V$
is modified to produce
$ g_V$
is modified to produce
 $ g_X$
. The modification is focused around the diagonal, and explains visually why the residual tail dependence coefficient changes while the conditional extremes normalization does not. The left and right panels illustrate differentiable cases, and the centre panel a non-differentiable case.
$ g_X$
. The modification is focused around the diagonal, and explains visually why the residual tail dependence coefficient changes while the conditional extremes normalization does not. The left and right panels illustrate differentiable cases, and the centre panel a non-differentiable case.

Figure 8. Red solid lines depict the level sets
 $ g_V(\boldsymbol{x})=1$
, where
$ g_V(\boldsymbol{x})=1$
, where
 $ g_V$
is of the form (ii), (iii), and (iv) (left to right) from Figure 2. Black dashed lines depict the level sets
$ g_V$
is of the form (ii), (iii), and (iv) (left to right) from Figure 2. Black dashed lines depict the level sets
 $ g_X(\boldsymbol{x}) =1$
. In each picture the blue solid line segment is from (0,0) to
$ g_X(\boldsymbol{x}) =1$
. In each picture the blue solid line segment is from (0,0) to
 $ (\gamma,\gamma)$
and denotes the limit set of the fully dependent random vector
$ (\gamma,\gamma)$
and denotes the limit set of the fully dependent random vector
 $ \gamma S_E$
. From left to right,
$ \gamma S_E$
. From left to right,
 $ \gamma=0.9,0.5,0.8$
.
$ \gamma=0.9,0.5,0.8$
.
5. Discussion
In this work we have demonstrated how several concepts of extremal dependence can be unified through the shape of the limit set G of the scaled sample cloud
 $ N_n =\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\}$
arising for distributions with light-tailed margins. For concreteness our focus has been on exponential margins, but other choices can be useful. In the case of negative dependence between extremes—such that large values of one variable are most likely to occur with small values of another—the double exponential-tailed Laplace margins can be more enlightening. As an example, for the bivariate Gaussian copula with
$ N_n =\{{\boldsymbol{X}}_1/r_n,\ldots,{\boldsymbol{X}}_n/r_n\}$
arising for distributions with light-tailed margins. For concreteness our focus has been on exponential margins, but other choices can be useful. In the case of negative dependence between extremes—such that large values of one variable are most likely to occur with small values of another—the double exponential-tailed Laplace margins can be more enlightening. As an example, for the bivariate Gaussian copula with
 $ \rho<0$
we observed that the limit set G is described by a discontinuous gauge function g that cannot be established through the simple mechanism of Proposition 2.2. In [Reference Nolde36], the gauge function for this distribution in Laplace margins is calculated as
$ \rho<0$
we observed that the limit set G is described by a discontinuous gauge function g that cannot be established through the simple mechanism of Proposition 2.2. In [Reference Nolde36], the gauge function for this distribution in Laplace margins is calculated as
 \begin{align*}g(x,y) = \begin{cases}\big(|x|+|y|-2\rho|xy|^{1/2}\big)/\big(1-\rho^2\big), & x,y \geq 0\ \mbox{or}\ x,y \leq 0, \\[3pt]\big(|x|+|y|+2\rho|xy|^{1/2}\big)/\big(1-\rho^2\big), & x\geq 0, y \leq 0\ \mbox{or}\ x\leq 0,y \geq 0.\end{cases}\end{align*}
\begin{align*}g(x,y) = \begin{cases}\big(|x|+|y|-2\rho|xy|^{1/2}\big)/\big(1-\rho^2\big), & x,y \geq 0\ \mbox{or}\ x,y \leq 0, \\[3pt]\big(|x|+|y|+2\rho|xy|^{1/2}\big)/\big(1-\rho^2\big), & x\geq 0, y \leq 0\ \mbox{or}\ x\leq 0,y \geq 0.\end{cases}\end{align*}
When
 $ \rho<0$
, this yields
$ \rho<0$
, this yields
 $ g\big(1,-\rho^2\big) = 1$
, and
$ g\big(1,-\rho^2\big) = 1$
, and
 $ g\big(1,-\rho^2 + u\big) \in \mathrm{RV}_{2}^0$
, so that, extending Proposition 3.1, we would find that the conditional extremes normalizations are
$ g\big(1,-\rho^2 + u\big) \in \mathrm{RV}_{2}^0$
, so that, extending Proposition 3.1, we would find that the conditional extremes normalizations are
 $ a^j(t) \sim -\rho^2 t$
and
$ a^j(t) \sim -\rho^2 t$
and
 $ b^j(t) \in \mathrm{RV}^0_{1/2}$
, as given in [Reference Keef, Papastathopoulos and Tawn29].
$ b^j(t) \in \mathrm{RV}^0_{1/2}$
, as given in [Reference Keef, Papastathopoulos and Tawn29].
The study of extremal dependence features through the limit set G is enlightening both for asymptotically dependent and asymptotically independent random vectors, particularly as it can be revealing for mixture structures where mass is placed on a variety of cones
 $ \mathbb{E}_C$
as defined in (2.2). However, many traditional measures of dependence within the asymptotically dependent framework, which are typically functions of the exponent function V given in (2.3), or the spectral measure H, are not revealed by the limit set G. For example, it was noted in the example of Section 4.1.3 that the limit set described by the gauge function
$ \mathbb{E}_C$
as defined in (2.2). However, many traditional measures of dependence within the asymptotically dependent framework, which are typically functions of the exponent function V given in (2.3), or the spectral measure H, are not revealed by the limit set G. For example, it was noted in the example of Section 4.1.3 that the limit set described by the gauge function
 $ g(x,y) = \theta^{-1}\max\!(x,y) + (1-\theta^{-1})\min\!(x,y)$
can arise for several different spectral measures, although clearly the parameter
$ g(x,y) = \theta^{-1}\max\!(x,y) + (1-\theta^{-1})\min\!(x,y)$
can arise for several different spectral measures, although clearly the parameter
 $ \theta$
demonstrates some link between strength of dependence and shape of G.
$ \theta$
demonstrates some link between strength of dependence and shape of G.
Nonetheless, multivariate regular variation and associated limiting measures have been well studied in extreme value theory, but representations that allow greater discrimination between asymptotically independent or mixture structures much less so. The limit set elucidates many of these alternative dependence concepts and provides meaningful connections between them. We have not directly considered connections between the various dependence measures without reference to G, and we note that the limit set might not always exist. We leave such study to future work.
Acknowledgements
The authors are grateful to the editor and two reviewers for constructive feedback and valuable comments that helped improve the paper.
Funding information
N. N. acknowledges financial support of the Natural Sciences and Research Council of Canada. J. L. W. gratefully acknowledges funding from EPSRC grant EP/P002838/1.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process for this article.