


The most basic question one can ask of a model is ‘According to the model, what is the effect on variable y 2 of an intervention on variable y 1?, ’ where y 1 and y 2 are two variables determined by the model. Two answers are possible. The first involves observing that many possible interventions on the model’s external variables could have led to the assumed change in y 1, and in general the effects of these interventions on y 2 are different. Therefore the question ‘What is the effect of y 1 on y 2?’ does not have an unambiguous answer: the information given about the intervention – its effect on y 1 – is insufficient to characterize its effect on y 2.
The second answer is that even though the intervention is not completely characterized for the reason just noted, all interventions consistent with the assumed change in y 1 may map onto the same change in y 2. In that case the question ‘What is the effect of y 1 on y 2?’ has a well-defined answer. In linear systems, to which our attention will be restricted in this paper, the effect is captured by a single constant, here labelled a 21. This coefficient gives the effect on y 2 of a unit change of y 1, regardless of what intervention on the external variables caused the change in y 1.
If, as in the second case above, the effect of a change in y 1 on y 2 is independent of how the change in y 1 is implemented – in other words, independent of the specific interventions on the external variables that determine the assumed change in y 1 – we will say that the causation of y 2 by y 1 is implementation neutral, and will write y 1⇒y 2. Hereafter implementation-neutral causation is abbreviated IN-causation, so that y 1 IN-causes y 2 in the specified circumstance. If the implementation neutrality condition fails we will say that y 1 causes y 2, but does not IN-cause y 2. In that case different interventions on the determinants of y 1 have different effects on y 2, implying that we cannot characterize the effect of y 1 on y 2 without knowing more about the intervention. ‘Knowing more about the intervention’ amounts to redirecting the discussion from the causal relation between y 1 and y 2 to the causal relation between the determinants of y 1 and y 2.
If we know only that y 1 causes y 2 – that is, if we do not have implementation neutrality – we know that interventions that affect y 1 also affect y 2, but we cannot identify a unique coefficient that gives the effect of y 1 on y 2. For many – arguably, most – scientific purposes it is useful to have implementation neutrality, so as to know that the effect of y 1 on y 2 does not depend on what caused the change in y 1.
It is not necessarily essential that the causation represented in a model be implementation neutral. However, in interpreting the model it is necessary to know whether a particular causal link is implementation neutral. If so one can make quantitative statements about causality: ‘The training programme results in an 11 per cent increase in employment probability’. Here the subtext is that this is so regardless of the fact that different trainee candidates do or do not enter the programme for different reasons. In the absence of implementation neutrality the associated statement is ‘The extent to which the training programme affects a worker’s employment probability depends on his individual circumstances, so that the effect of training on the employment probability depends on why he enrolled’, for example. Obviously the first answer is preferable when it is available, so it is important to know when a model supports that answer.
Use of diagrammatical methods in causal analysis has become widespread in recent years, due to work by Spirtes et al. (Reference Spirtes, Glymour and Schienes1993), Hausman (Reference Hausman1998), Pearl (Reference Pearl2001), Woodward (Reference Woodward2003), Cartwright (Reference Cartwright2007) and others. These authors do not include implementation neutrality in their definition of causation (at least not explicitly; see discussion below). As we will see, implementation-neutral causation is antisymmetric, so it can be used to define directed acyclic diagrams of the type in common use. Therefore one has the option of imposing implementation neutrality in the derivation of directed acyclic diagrams and comparing the causal diagrams so derived with diagrams obtained under characterizations of causation that do not impose implementation neutrality.
1. CHARACTERIZATION OF IN-CAUSATION
A distinction that is central in any model that deals with issues of causation is that between internal and external variables. Internal variables are those determined by the model, while external variables are those taken as given; that is, determined outside the model.Footnote 1 We will use y to denote internal variables and x to denote external variables.
All changes in solution values of internal variables are assumed to be attributable to interventions on external variables, as opposed to alterations of equations. Implementing this attribution requires the analyst to be explicit about which hypothetical alterations in the model are permitted and which are ruled out, a specification that is essential in inquiries dealing with causation. Of course, the analyst can always model a shift in any of the equations of the model simply by specifying that the relevant equation includes an external shift variable. In that case the shift variable is a cause of any internal variable that depends on it. Doing so is not the same as converting one of the internal variables to an external variable, which constitutes an alteration of the model, and which, as discussed below, we will avoid.
External variables are assumed to be variation free: that is, the analyst is free to alter them independently. Independent variation corresponds to the assumption that by definition external variables are not linked by functional relations; otherwise they would be classified as internal.
The solution form of a model expresses each internal variable as a function of the set of external variables that determine it.Footnote 2 We will refer to the set of external variables that determine any internal variable as its external set, and will denote the external set for yi as  $\mathcal {E}(y_{i}).$ In examples we will adopt the convention that the external set for any internal variable consists of at least two external variables.Footnote 3
$\mathcal {E}(y_{i}).$ In examples we will adopt the convention that the external set for any internal variable consists of at least two external variables.Footnote 3
There is no difficulty in defining causation when the cause variable is external: x 1 causes y 1 whenever x 1 is in the external set for y 1. In that case, by virtue of linearity, a unique constant b 11 gives the effect of a unit change in x 1 on y 1 for any values of the external variables. If x 1 is not in the external set for y 1 the former does not cause the latter.
The ambiguity comes up when the cause variable is internal, because then an assumed change in the cause variable could come from interventions on any or all of the variables in its external set, and in general the effect on y 2 of the interventions of the external variables of y 1 is different for each possible set of interventions. This is so even if all the contemplated interventions on external variables are restricted to have the same effect on y 1. Given this ambiguity, we cannot associate causation with a single number giving the effect of y 1 on y 2: the intervention is not described with sufficient detail to generate a clear characterization of the effect.
However, consider a special case in which two conditions are satisfied. These conditions involve two internal variables, y 1 and y 2, their external sets  $\mathcal {E}(y_{1})$ and
$\mathcal {E}(y_{1})$ and  $\mathcal {E}(y_{2})$, and the functions relating the former to the latter. The first is the subset condition, which requires that the external set for y 1 be a proper subset of that of y 2. The subset condition guarantees that any external variable that affects y 1 also affects y 2, but not vice versa. Hoover (Reference Hoover2001) in particular emphasized this condition, which assures the antisymmetry of causation.Footnote 4 If the subset condition is satisfied we will say that y 1 causes y 2, and will write y 1 → y 2.
$\mathcal {E}(y_{2})$, and the functions relating the former to the latter. The first is the subset condition, which requires that the external set for y 1 be a proper subset of that of y 2. The subset condition guarantees that any external variable that affects y 1 also affects y 2, but not vice versa. Hoover (Reference Hoover2001) in particular emphasized this condition, which assures the antisymmetry of causation.Footnote 4 If the subset condition is satisfied we will say that y 1 causes y 2, and will write y 1 → y 2.
The second is the sufficiency condition (the definition of which presumes satisfaction of the subset condition). The sufficiency condition states that the map from  $\mathcal {E}(y_{2})$ to y 2 can be expressed as two functions. The first is the composition of a function from
$\mathcal {E}(y_{2})$ to y 2 can be expressed as two functions. The first is the composition of a function from  $\mathcal {E} (y_{1})$ to y 1 and a function from y 1 to y 2, while the second is a function from
$\mathcal {E} (y_{1})$ to y 1 and a function from y 1 to y 2, while the second is a function from  $\mathcal {E}(y_{2})-\ \mathcal {E}(y_{1})$ to y 2. If such functions exist then y 1 is a sufficient statistic for
$\mathcal {E}(y_{2})-\ \mathcal {E}(y_{1})$ to y 2. If such functions exist then y 1 is a sufficient statistic for  $\mathcal {E} (y_{1})$ for the purpose of determining y 2, meaning that for the purpose of determining y 2 an intervention on any or all of the variables in
$\mathcal {E} (y_{1})$ for the purpose of determining y 2, meaning that for the purpose of determining y 2 an intervention on any or all of the variables in  $\mathcal {E}(y_{1})$ is adequately characterized by the resulting induced change in y 1. If y 1 → y 2 and in addition the sufficiency condition is satisfied, we will say that y 1 IN-causes y 2, and will write y 1⇒y 2.
$\mathcal {E}(y_{1})$ is adequately characterized by the resulting induced change in y 1. If y 1 → y 2 and in addition the sufficiency condition is satisfied, we will say that y 1 IN-causes y 2, and will write y 1⇒y 2.
The theme of this paper is that for evaluation of the magnitude of causal effects one is interested primarily in IN-causation (requiring satisfaction of both the subset and the sufficiency conditions), not just causation (requiring satisfaction of only the subset condition).
In the IN-causal form of a model the equations are written so as to reflect the model’s IN-causal structure. Starting from the solution form of the model and having in hand a set of restrictions on the parameters of that model, one can readily derive its IN-causal form. First one derives the IN-causal ordering, which consists of determining for each i and j whether or not we have that yi is a parent of yj.Footnote 5 In the IN-causal form of the model, as in the solution form, each equation has one of the internal variables on the left-hand side. The equation for each internal variable yj that has no internal variables as causal parents coincides with the corresponding equation in the solution form of the model (that is, consists of a map from  $\mathcal {E}(y_{j})$ to yj). The causal form for internal variables yj that have one or more internal variables as causal parents consists of a map from the parent, or from each of the parents, to yj, plus a map to yj from the elements of
$\mathcal {E}(y_{j})$ to yj). The causal form for internal variables yj that have one or more internal variables as causal parents consists of a map from the parent, or from each of the parents, to yj, plus a map to yj from the elements of  $\mathcal {E}(y_{j})$ that are not in the external sets of any of the parents of yj.
$\mathcal {E}(y_{j})$ that are not in the external sets of any of the parents of yj.
In the linear setting assumed here the equations of the causal form can be written in the form
 \begin{equation}
y_{j}\Leftarrow a_{ji}y_{i}+b_{jk}x_{k}.
\end{equation}
\begin{equation}
y_{j}\Leftarrow a_{ji}y_{i}+b_{jk}x_{k}.
\end{equation}
Here yi is the (single, in this case) internal variable that is a parent of yj, and xk is an external variable (again, single) that is the only element of  $\mathcal {E}(y_{j})-\mathcal {E}(y_{i})$. The cases in which yj has more than one parent, or in which
$\mathcal {E}(y_{j})-\mathcal {E}(y_{i})$. The cases in which yj has more than one parent, or in which  $\mathcal {E} (y_{j})-\mathcal {E}(y_{i})$ contains more than one external variable, are handled by expanding (1) appropriately. Note our substitution of ⇐ for = ; since IN-causation is irreflexive and antisymmetric it is inappropriate to use the equality relation in writing the causal form of a model, as many analysts have observed. Also, it is convenient to have notation that distinguishes the causal form of a model (⇐) from its structural form (=).
$\mathcal {E} (y_{j})-\mathcal {E}(y_{i})$ contains more than one external variable, are handled by expanding (1) appropriately. Note our substitution of ⇐ for = ; since IN-causation is irreflexive and antisymmetric it is inappropriate to use the equality relation in writing the causal form of a model, as many analysts have observed. Also, it is convenient to have notation that distinguishes the causal form of a model (⇐) from its structural form (=).
In models that are structural (in the sense that every internal variable is written as a function of the other internal variables and a subset of the external variables) it may or may not be true that the IN-causal form coincides with the structural form. To determine whether a given structural model can be interpreted as an IN-causal model the analyst (1) computes the solution form of the model, (2) determines its IN-causal ordering by checking whether for all i, j the conditions for yi to be a parent of yj are satisfied, and (3) constructs the indicated causal form. If one ends with the same model that one began with, causation in the assumed structural model is implementation-neutral. In that case for each equation each right-hand side variable IN-causes the left-hand side variable. If not, one cannot necessarily interpret parameters of structural models as measuring IN-causation. For example, a structural model with simultaneous blocks can obviously not be interpreted as a model in causal form due to the antisymmetry of causation.
One can represent the causal form of a model by a causal diagram. For variables yi without internal variables as IN-parents this consists of arrows drawn to yi from each element of  $\mathcal {E}(y_{i}),$ as in a diagram of the solution form. For variables with internal IN-parents the arrows run to yj from the IN-parent(s) of yj, and also to yj from each variable that is an element of the external set of yj but is not in the external sets of any of its IN-parents. Thus the IN-causal diagram corresponds exactly to the model written in IN-causal form.
$\mathcal {E}(y_{i}),$ as in a diagram of the solution form. For variables with internal IN-parents the arrows run to yj from the IN-parent(s) of yj, and also to yj from each variable that is an element of the external set of yj but is not in the external sets of any of its IN-parents. Thus the IN-causal diagram corresponds exactly to the model written in IN-causal form.
Observe that under our characterization the IN-causal form does not include as arguments internal variables that are ancestors of some internal variable when these are not also parents. The corresponding convention applies to causal diagrams: no arrow directly connects variables with their ancestors when these are not direct parents. If, contrary to this specification, y 1 were entered as a separate cause for y 3 in a causal model that has y 1⇒y 2 and also y 2⇒y 3 the effect would be to link each element of  $\mathcal {E}(y_{1})$ to y 3 via both the direct effect a 31 and the indirect effect a 32a 21. But we have a 31 = a 32a 21, so the outcome would be a doubling of the coefficients linking elements of
$\mathcal {E}(y_{1})$ to y 3 via both the direct effect a 31 and the indirect effect a 32a 21. But we have a 31 = a 32a 21, so the outcome would be a doubling of the coefficients linking elements of  $\mathcal {E}(y_{1})$ with y 3. This is an obvious error.
$\mathcal {E}(y_{1})$ with y 3. This is an obvious error.
The argument just stated implies that an internal variable never has both an indirect IN-causal effect on another variable via an IN-causal chain involving one or more third variables, and also a distinct direct IN-causal effect; rather, the direct effect is always the composition of the indirect effects. In section 3 we will point out that a different formalization of causation, that of Simon, does not share this property.
Examples will make these results clear.
1.1. Examples
Consider the following model written in solution form:
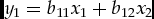 \begin{equation}
y_{1} = b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} = b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} = b_{21}x_{1}+b_{22}x_{2}+b_{23}x_{3}.
\end{equation}
\begin{equation}
y_{2} = b_{21}x_{1}+b_{22}x_{2}+b_{23}x_{3}.
\end{equation}
The external sets for y 1 and y 2 are  $\mathcal {E} (y_{1})=\lbrace x_{1},x_{2}\rbrace$ and
$\mathcal {E} (y_{1})=\lbrace x_{1},x_{2}\rbrace$ and  $\ \mathcal {E}(y_{2})=$ {x 1, x 2, x 3}. The former is a proper subset of the latter, so the subset condition is satisfied, and we have y 1 → y 2.
$\ \mathcal {E}(y_{2})=$ {x 1, x 2, x 3}. The former is a proper subset of the latter, so the subset condition is satisfied, and we have y 1 → y 2.
Without parameter restrictions the sufficiency condition for y 1⇒y 2 is not satisfied. However, if the condition
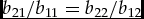 \begin{equation}
b_{21}/b_{11}=b_{22}/b_{12}
\end{equation}
\begin{equation}
b_{21}/b_{11}=b_{22}/b_{12}
\end{equation}
obtains the sufficiency condition is satisfied. In that case we can define a 21 by
 \begin{equation}
a_{21}\equiv b_{21}/b_{11}=b_{22}/b_{12},
\end{equation}
\begin{equation}
a_{21}\equiv b_{21}/b_{11}=b_{22}/b_{12},
\end{equation}
allowing replacement of (3) with
 \begin{equation}
y_{2}=a_{21}y_{1}+b_{23}x_{3}.
\end{equation}
\begin{equation}
y_{2}=a_{21}y_{1}+b_{23}x_{3}.
\end{equation}
We have y 1⇒y 2.
The IN-causal form of the model is
 \begin{equation}
y_{1} \Leftarrow b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} \Leftarrow b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} \Leftarrow a_{21}y_{1}+b_{23}x_{3}.
\end{equation}
\begin{equation}
y_{2} \Leftarrow a_{21}y_{1}+b_{23}x_{3}.
\end{equation}
The argument just presented implies that in the structural model
 \begin{equation}
y_{1} =b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} =b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} =a_{21}y_{1}+b_{23}x_{3}
\end{equation}
\begin{equation}
y_{2} =a_{21}y_{1}+b_{23}x_{3}
\end{equation}
the coefficient a 21 represents IN-causation. This is so because its structural form (9)–(10) coincides with its IN-causal form (7)–(8).
The upper panel of Figure 1 shows the causal diagram of the model under discussion if the restriction (4) is satisfied; the lower panel shows the causal diagram if the restriction is not satisfied.
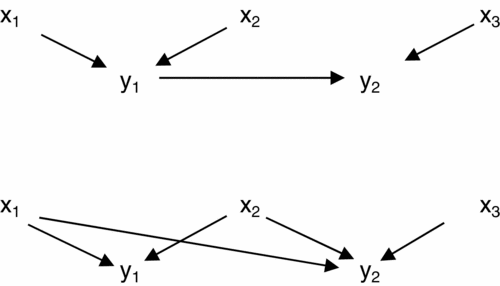
Figure 1. Upper panel: y 1 causes y 2. Lower panel: y 1 does not cause y 2 due to failure of the sufficiency condition
As observed above, one can equally well begin by specifying a model in IN-causal form, as in (7)–(8). Using (2) to eliminate y 1 in (6) results in
 \begin{equation}
y_{2}=a_{21}b_{11}x_{1}+a_{21}b_{12}x_{2}+b_{23}x_{3}.
\end{equation}
\begin{equation}
y_{2}=a_{21}b_{11}x_{1}+a_{21}b_{12}x_{2}+b_{23}x_{3}.
\end{equation}
Comparing this equation with the solution equation (3) for y 2 results in a 21b 11 = b 21 and a 21b 12 = b 22, agreeing with (5). Thus writing a model in IN-causal form is equivalent to assuming the parameter restrictions on the solution form associated with the assumed causal ordering.
One cannot write down an arbitrary structural model and then interpret that model as if it were in IN-causal form. Some models that are acceptable as structural models are inadmissible as IN-causal models. For example, consider the model
 \begin{equation}
y_{1} =a_{12}y_{2}+b_{11}x_{1}
\end{equation}
\begin{equation}
y_{1} =a_{12}y_{2}+b_{11}x_{1}
\end{equation}
 \begin{equation}
y_{2} =a_{21}y_{1}+b_{22}x_{2}
\end{equation}
\begin{equation}
y_{2} =a_{21}y_{1}+b_{22}x_{2}
\end{equation}
 \begin{equation}
y_{3} =a_{31}y_{1}+a_{32}y_{2}+b_{33}x_{3}.
\end{equation}
\begin{equation}
y_{3} =a_{31}y_{1}+a_{32}y_{2}+b_{33}x_{3}.
\end{equation}
This is an acceptable block-recursive structural model, but not an acceptable IN-causal model because it contains both y 1⇒y 2 and y 2⇒y 1, violating the antisymmetry of IN-causation. The conclusion is that the model (12)–(14) is not in fact an IN-causal model.
Generically (that is, barring coefficient restrictions), the IN-causal form of the model (12)–(14) is
 \begin{equation}
y_{1} \Leftarrow b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} \Leftarrow b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} \Leftarrow b_{21}x_{1}+b_{22}x_{2}
\end{equation}
\begin{equation}
y_{2} \Leftarrow b_{21}x_{1}+b_{22}x_{2}
\end{equation}
 \begin{equation}
y_{3} \Leftarrow b_{31}x_{1}+b_{32}x_{2}+b_{34}x_{4}+b_{33}x_{3},
\end{equation}
\begin{equation}
y_{3} \Leftarrow b_{31}x_{1}+b_{32}x_{2}+b_{34}x_{4}+b_{33}x_{3},
\end{equation}
coinciding with the solution form. The causal ordering is empty (in the sense that none of the internal variables IN-cause any other internal variables). Therefore if one begins with a model like (12)–(14) that is not interpretable as an IN-causal model one cannot view all the coefficients aij of that model as measuring IN-causal effects, although some may do so.
The causal form of any model is recursive by construction. It might be thought that the converse is also true, so that all structural models that are recursive (which the model (12)–(14) is not) would qualify as causal models. This is not so. Triangular models provide a counterexample when they have more than two internal variables. For example, consider the structural model
 \begin{equation}
y_{1} =b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} =b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} =a_{21}y_{1}+b_{23}x_{3}
\end{equation}
\begin{equation}
y_{2} =a_{21}y_{1}+b_{23}x_{3}
\end{equation}
 \begin{equation}
y_{3} =a_{31}y_{1}+a_{32}y_{2}+b_{34}x_{4}.
\end{equation}
\begin{equation}
y_{3} =a_{31}y_{1}+a_{32}y_{2}+b_{34}x_{4}.
\end{equation}
This model does not have the IN-causal representation
 \begin{equation}
y_{1} \Leftarrow b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} \Leftarrow b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} \Leftarrow a_{21}y_{1}+b_{23}x_{3}
\end{equation}
\begin{equation}
y_{2} \Leftarrow a_{21}y_{1}+b_{23}x_{3}
\end{equation}
 \begin{equation}
y_{3} \Leftarrow a_{31}y_{1}+a_{32}y_{2}+b_{34}x_{4}.
\end{equation}
\begin{equation}
y_{3} \Leftarrow a_{31}y_{1}+a_{32}y_{2}+b_{34}x_{4}.
\end{equation}
This is so because the purported cause variable y 1 is not a parent of the effect variable y 3 (although it is an ancestor), contrary to the requirement assumed for construction of IN-causal models. The model (18)–(20) can be interpreted as a causal model only under restrictions on the structural coefficients (for example, a 31 = 0 or a 32 = 0). In the absence of such restrictions a model like (18)–(20) has a causal ordering consisting only of y 1⇒y 2, plus the equations relating internal variables to their external sets.
As another way to establish the same point, suppose that we have y 1⇒y 2 and y 2⇒y 3. Then implementation neutrality implies that the total effect of an intervention Δy 1 of y 1 on y 3 equals a 32a 21Δy 1, and this is so regardless of which element of  $\mathcal {E}(y_{1})$ caused the change in y 1. This is the total effect of y 1 on y 2 implied by the causal ordering, and it coincides with the indirect effect. There is no distinct direct effect.
$\mathcal {E}(y_{1})$ caused the change in y 1. This is the total effect of y 1 on y 2 implied by the causal ordering, and it coincides with the indirect effect. There is no distinct direct effect.
2. CRITIQUES OF IMPLEMENTATION NEUTRALITY
Philosophers sometimes reject this focus on settings in which causation is implementation neutral. For example, Cartwright (Reference Cartwright2007: 246) states that ‘[w]e must be careful . . . not to be misled by [LeRoy’s] own use of the language of ‘causal order’ to suppose it tells us whether and how much one quantity causally contributes to another’. Why are we misled by this supposition? How much one variable causally contributes to another is exactly what IN-causation tells us, and is exactly what we want to know. And what meaning can we attach to a purported measure of the effects of an intervention on an internal variable if the model is such that the causation is not implementation neutral, so that that measure is not well defined? In that case there is no alternative to redirecting the analysis to implementation-specific interventions on the external variables, avoiding reference to the intermediate variable – the purported cause – which in fact plays no role in the causation.
It is not difficult to find passages in the philosophy literature where the idea of implementation neutrality is implicitly introduced. Further, it is not unusual to find use of the term ‘causation’ reserved to settings in which implementation neutrality is satisfied. For example, Woodward (Reference Woodward, Price and Corry2007) listed ‘invariance’ among the requirements for causation: the effect of the cause variable on the effect variable should be invariant to interventions on other variables. He observed that ‘[o]ne condition for a successful intervention is that the intervention I on X [the cause variable] with respect to Y should not cause Y via a route that does not go through X, and that I should be independent of any variable Z that causes Y but not through a route that goes through I and X’. If one reads I as consisting of a variable in the external set of X, then Woodward’s criterion for a ‘successful intervention’ corresponds to that for our implementation-neutral causation.
Woodward gave an example. Suppose that patients are treated or not treated for a medical condition based on a randomized assignment mechanism such as a coin toss. So stated, the assignment mechanism is an IN-cause (assuming that the treatment is effective) of remission of the condition. But suppose that another doctor influences the outcome of the coin toss using a magnet, and does so to ensure that patients with a strong immune system get the treatment. This alteration invalidates implementation neutrality. In our terminology the state of the patient’s immune system is an external variable for the use of the magnet, and the external set for the use of the magnet is a proper subset of the external set of the variable representing the assignment mechanism. The sufficiency condition for causation of the remission variable by the assignment variable is not satisfied. This is so because the variable representing the strength of the immune condition also affects the remission variable via a direct path.
Critics of the analysis of causation presented here express the view that the conception of IN-causation here unnecessarily departs from the ordinary-language usage of ‘causation’. The opposite is the case. Under the ordinary-language usage of ‘causation’, in settings where the conditions for IN-causation fail the answer to the question ‘What is the effect of y 1 on y 2?’ would be ‘It depends on what causes the variation in y 1’. This coincides exactly with the usage prescribed in this paper.
3. COMPARISON WITH SIMON
It is instructive to compare the representation of causation just presented to that of Simon’s classic (Reference Simon, Hood and Koopmans1953) paper.
Simon characterized a structural model as a partially ordered set of self-contained sub-models, with some (or all) of the internal variables determined in each sub-model. Each sub-model contains the internal variables determined in that sub-model and, except for the lowest-ordered sub-models, also some or all of the internal variables determined in lower-ordered sub-models. Triangular models, in which each sub-model consists of a single equation, are the most extreme special case. In triangular models a complete ordering is defined on the internal variables, with the explanatory internal variables for each internal variable consisting of internal variables that are lower in the ordering.
Under Simon’s definition of causation y 1 causes y 2 if y 1 enters the sub-model that determines y 2, and is determined in a lower-order sub-model. Thus for Simon causation is determined from a model’s structural form. The fact that a model’s IN-causal form may differ from its structural form (as in the model (18)–(20)) implies that causation under Simon’s definition differs from IN-causation, which is determined from the solution form. The easiest way to verify this difference is to note that Simon’s definition of causation allows indirect and direct causation to coexist (again, as in the model (18)–(20)), whereas under IN-causation this cannot occur, as noted above.
An internal variable y 1 causes y 2 in Simon’s sense if and only if our subset condition is satisfied. However, Simon did not go on to consider implementation neutrality. Instead he implicitly defined the intervention associated with causation to be conditional on the values of the explanatory variables other than the cause variable in the structural equation determining the effect variable. The intervention so defined can readily be translated into the implied intervention on the variables in the external set for the cause variable. This intervention will involve linear restrictions on the intervention in the external variables, so that some external variables are treated as causing other supposedly external variables. This dependence implies a violation of the variation-free condition, and therefore raises the question of what meaning can be attached to causation so defined.
Simon’s definition of causation differs from that analysed here in settings where the modeller is willing to specify a structural model that is distinct from the associated solution form, and only in such settings. Defining causation in reference to the structural model is justified, if at all, only insofar as the analyst believes that the structural form is somehow superior to the solution form, in that it contains information that is lost in passing to the solution form. The Cowles economists clearly believed that this was the case, but they never succeeded in articulating clearly what this information is. It is difficult to see why performing arithmetic operations in order to pass from the structural form to the solution form should affect a model’s interpretation to the point where causation has a different interpretation in the two cases.
Recognizing this, contemporary economic theorists typically do not specify a structural form distinct from the solution form. Thus the characterization of IN-causation as defined here, being based on the solution form, is consistent with current practice in a way that Simon’s treatment of causation is not.
4. EMPIRICAL ASPECTS OF CAUSATION
Up to this point we have considered models in which variables are specified as to their status as internal or external. We have not specified which variables are observable or what we are assuming about the probability distributions of unobserved external variables. That we could postpone discussion of observability to this point reflects the fact that, for any pair of internal variables, the existence or non-existence of IN-causation depends only on whether the conditions for implementation neutrality are satisfied. It does not depend on which variables are observable or what is assumed about those that are not. However, without specifying which variables are observable and characterizing the probability distribution of unobserved external variables there is no way to estimate IN-causal coefficients empirically: the correlations among internal variables implied by the model’s causal structure cannot be disentangled from those induced by correlations among unobserved external variables.
The most direct way to launch an investigation of the empirical aspects of causation is to specify, first, that external variables are unobservable and internal variables are observable. This specification covers most of the cases of interest. Second, it is assumed that the external variables are statistically independent random variables. This assumption implies that whatever correlations exist among the model’s internal variables are generated by the equations of the model, not by uninterpreted correlations among external variables. An analyst who is uncomfortable with the assumption that the external variables x 1 and x 2 in two equations are independent can replace x 2 with x 2 + λx 1, which allows for correlation even if x 1 and x 2 are independent. Of course, adopting such flexible specifications results in sparse causal orderings. As always, the analyst must deal with a tradeoff between how general a model’s specification is and how rich its empirical implications are.
The assumptions just listed imply that if we have y 1⇒y 2 the IN-causal coefficient measuring the effect of y 1 on y 2 is identified (apart from special cases in which observability is limited, as discussed below), and can be estimated consistently using a least-squares regression of y 2 on y 1. This is so because the external variable(s) in  $\mathcal {E}(y_{2})-\mathcal {E}(y_{1})$ – the constituent(s) of the error term in the regression – is (are) independent of
$\mathcal {E}(y_{2})-\mathcal {E}(y_{1})$ – the constituent(s) of the error term in the regression – is (are) independent of  $\mathcal {E} (y_{1})$, and therefore of y 1 itself. Therefore the conditions for the Gauss–Markov theorem of linear regression are satisfied and least-squares regression coefficients provide optimal estimators.
$\mathcal {E} (y_{1})$, and therefore of y 1 itself. Therefore the conditions for the Gauss–Markov theorem of linear regression are satisfied and least-squares regression coefficients provide optimal estimators.
The contrapositive of this statement is that the existence of econometric problems in the estimation of a parameter implies that the parameter is not one associated with IN-causation. For example, consider the system
 \begin{equation}
y_{1} =b_{11}x_{1}+b_{12}x_{2}
\end{equation}
\begin{equation}
y_{1} =b_{11}x_{1}+b_{12}x_{2}
\end{equation}
 \begin{equation}
y_{2} =a_{21}y_{1}+b_{21}x_{1}
\end{equation}
\begin{equation}
y_{2} =a_{21}y_{1}+b_{21}x_{1}
\end{equation}
 \begin{equation}
y_{3} =b_{32}x_{2}+b_{33}x_{3}.
\end{equation}
\begin{equation}
y_{3} =b_{32}x_{2}+b_{33}x_{3}.
\end{equation}
Here the external variables x 1, x 2 and x 3 are assumed to be independently distributed. Analysis of the solution form of this model reveals that the population parameter a 21 does not equal cov(y 2, y 1)/var(y 1), the population regression coefficient of y 2 on y 1. This is so because y 1 and x 1 are correlated due to the presence of x 1 in the external set for y 1. Therefore a 21 is not estimated consistently by least squares on (25). Further, if y 3 and (26) are dropped from the model, then a 21 is not even identified. This can be seen by inspection of the solution form of the model (24)–(25).
However, in the presence of y 3 and (26) we have a 21 = cov(y 2, y 3)/cov(y 1, y 3), implying that a 21 is identified and can be estimated consistently by taking y 3 as an instrument. Here we make use of the fact that y 3 is correlated with y 1, due to the common presence of x 2 in their external sets, but not with x 1.
The result that the least-squares estimate of a 21 is not estimated consistently by least squares reflects the fact that y 1 does not IN-cause y 2, a fact that is also easily verified directly from the definition of IN-causation. Thus the inconsistency of the least-squares estimate of a 21 via a regression of y 2 on y 1 does not contradict our assertion that coefficients associated with IN-causal orderings are identified and estimable by least squares.
The finding that IN-causal coefficients are always identified differs from the conclusion of the Cowles economists. The reason for the difference is that, as noted, the Cowles economists used a different conception of causation – one that does not include implementation neutrality – than that we focus on here. Parameters that are causal in the Cowles sense may or may not be identified and may or may not correspond to coefficients associated with IN-causation. Here our attention is restricted to the smaller set of coefficients that are IN-causal.
The result that causal coefficients are always identified should not be taken to imply that identification is not a major problem in the analysis of causation. Obviously, there exist coefficients associated with IN-causation only when the associated variables are in fact IN-causally ordered, and whether two variables are IN-causally ordered depends on the coefficients that link observed internal variables to unobserved external variables. These coefficients, in contrast to those linking observed internal variables that are known (or assumed) to be causally ordered, are generally not identified. Therefore there may be no way to directly test models that make particular specifications of causation.
Under causation as characterized here, as with other definitions of causation, the restrictions justifying an assumed causal ordering can in principle be tested indirectly by identifying pairs of variables that are or are not statistically independent according to the model, and then determining whether these independence implications are satisfied empirically. We now consider whether powerful empirical tests of causal models along these lines are likely to be available. It appears that they are not: only in special cases is it possible to characterize independence or the lack thereof among internal variables as testable implications of IN-causal models.
Among the few results that are available is the obvious fact that any two internal variables for which the external sets are disjoint are statistically independent. As an implication, if an internal variable has two ancestors, then either the two are statistically independent or one ancestor causes the other. To see this, suppose that y 1⇒y 3 and y 2⇒y 3, so that y 3 has ancestors y 1 and y 2. If  $\mathcal {E}(y_{1})$ and
$\mathcal {E}(y_{1})$ and  $\mathcal {E}(y_{2})$ are disjoint, then y 1 and y 2 are statistically independent. Suppose instead that
$\mathcal {E}(y_{2})$ are disjoint, then y 1 and y 2 are statistically independent. Suppose instead that  $ \mathcal {E}(y_{1})$ and
$ \mathcal {E}(y_{1})$ and  $\mathcal {E}(y_{2})$ have a non-empty intersection that contains external variable x. Then because (1)
$\mathcal {E}(y_{2})$ have a non-empty intersection that contains external variable x. Then because (1)  $x\in \mathcal {E} (y_{1}),$ and (2)
$x\in \mathcal {E} (y_{1}),$ and (2)  $\mathcal {E}(y_{1})$ is a proper subset of
$\mathcal {E}(y_{1})$ is a proper subset of  $\mathcal {E} (y_{3}),$ there exists a path from x to y 3 that includes y 1. Similarly, there exists a path from x to y 3 that includes y 2. These must be the same path, since if the path included y 1 but not y 2 then y 2 could not be a sufficient statistic for
$\mathcal {E} (y_{3}),$ there exists a path from x to y 3 that includes y 1. Similarly, there exists a path from x to y 3 that includes y 2. These must be the same path, since if the path included y 1 but not y 2 then y 2 could not be a sufficient statistic for  $\mathcal {E} (y_{2}),$ contradicting y 2⇒y 3. Thus there is a single path connecting x and y 3, and that path includes both y 1 and y 2. This can occur only if y 1⇒y 2 or y 2⇒y 1.
$\mathcal {E} (y_{2}),$ contradicting y 2⇒y 3. Thus there is a single path connecting x and y 3, and that path includes both y 1 and y 2. This can occur only if y 1⇒y 2 or y 2⇒y 1.
Past this there are not many results available about correlation of variables in causal models. Assume that y 1 and y 2 have y 3 as a common ancestor. If also y 1⇒y 2, then we have y 3⇒y 1⇒y 2. In that case we have that all pairs of these three variables are correlated since their external sets have a non-empty intersection (consisting of the external set for y 3). If, on the other hand, y 1⇏y 2 the causal coefficient associated with y 1⇒y 2 is not defined. In the absence of IN-causation, no inference about the correlation among variables is possible.
Despite the foregoing discussion, it happens that some of the techniques of diagrammatical analysis developed in the causation literature do carry over in the present setting. For example, it is shown in the received literature that if two internal variables are connected only by paths that are ‘blocked’ because each contains a ‘collider’ (a variable with incoming arrows from both directions), those variables are independent. That result appears to carry over here. An example will demonstrate this.
4.1. Example
Consider the following model:
 \begin{equation}
y_{1} =x_{1}+x_{2}
\end{equation}
\begin{equation}
y_{1} =x_{1}+x_{2}
\end{equation}
 \begin{equation}
y_{2}=x_{3}+x_{4}
\end{equation}
\begin{equation}
y_{2}=x_{3}+x_{4}
\end{equation}
 \begin{equation}
y_{3}=x_{1}+x_{2}+x_{3}+x_{4}
\end{equation}
\begin{equation}
y_{3}=x_{1}+x_{2}+x_{3}+x_{4}
\end{equation}
 \begin{equation}
y_{4}=x_{1}+x_{2}-x_{3}-x_{4}
\end{equation}
\begin{equation}
y_{4}=x_{1}+x_{2}-x_{3}-x_{4}
\end{equation}
(note that here we have supplied specific coefficient values as well as external sets). The causal form of this model is
 \begin{equation}
y_{1} \Leftarrow x_{1}+x_{2}
\end{equation}
\begin{equation}
y_{1} \Leftarrow x_{1}+x_{2}
\end{equation}
 \begin{equation}
y_{2} \Leftarrow x_{3}+x_{4}
\end{equation}
\begin{equation}
y_{2} \Leftarrow x_{3}+x_{4}
\end{equation}
 \begin{equation}
y_{3} \Leftarrow y_{1}+y_{2}
\end{equation}
\begin{equation}
y_{3} \Leftarrow y_{1}+y_{2}
\end{equation}
 \begin{equation}
y_{4} \Leftarrow y_{1}-y_{2},
\end{equation}
\begin{equation}
y_{4} \Leftarrow y_{1}-y_{2},
\end{equation}
with Figure 2 as its causal diagram. Here y 1 and y 2 are statistically independent due to the fact that their external sets are disjoint. We have that y 1 and y 2 are parents of y 3 (and also of y 4), so the result illustrates the general fact noted above that if any internal variable has more than one ancestor, either these are independent or one ancestor causes the other.
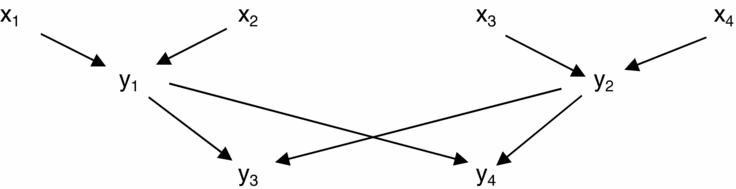
Figure 2. Paths connecting y 1 and y 2 are blocked by colliders y 3 and y 4
This independence result can be generated using the diagrammatical techniques developed by Pearl and others for analysis of causation in settings where implementation neutrality is not imposed. In the example there exist two paths from y 1 to y 2, but both are blocked by the colliders y 3 and y 4. Therefore these paths do not transmit association. Independence of y 1 and y 2 results. Note that here the diagrammatical analysis applies by virtue of the assumption that the external variables are independently distributed. The result suggests that even though the conditions for causation analysed here are different from those in the received literature, at least some of the diagrammatical techniques for analysis of causation carry over. This is a topic that deserves further study.
The independence result does not extend to the children y 3 and y 4 except in special situations. For example, if the xi are normally distributed and all have the same variance, y 3 and y 4 are independent. However, if x 1 and x 2 have higher (lower) variance than x 3 and x 4, then y 3 and y 4 will be positively (negatively) correlated.
5. CONDITIONING ON INTERNAL VARIABLES
The result in the preceding section that the coefficient associated with any causal relation is identified and can be estimated consistently using least squares depends critically on the underlying assumption that external variables are independently distributed and internal variables are fully observable. If some internal variable yi is observed only when it lies in a certain region, the distribution for the external variables that is relevant for determining the identifiability of causal coefficients is that conditional on this restriction, not the unconditional distribution.
The joint distribution of the external variables conditional on yi will generally display statistical dependence even if the unconditional distribution of the external variables incorporates independence. This situation will not affect the causal ordering of the variables, but it does invalidate the result that the coefficients associated with the causal ordering can be estimated consistently by least squares. This is so because failure of independence in the external variables implies that the error term covaries with the explanatory variable in the relevant regression, inducing bias and inconsistency.
As an extreme case, suppose that the analyst only has data in which yi takes on a single value, for some i. Obviously the coefficient associated with yi⇒yj or yj⇒yi for some yj is not identified, there being no variation in the observed values of the cause variable in one case or the effect variable in the other. A more common situation occurs when the data for yi are truncated, as by yi ⩾ 0. In that case the sample regression coefficient associated with yj⇒yk is not a consistent estimate of the associated causal coefficient if either yj or yk has an external set that overlaps with that of yi. This is so because if yi is subject to a restriction like yi ⩾ 0 the relevant joint distribution of the external variables in  $\mathcal {E}(y_{i})$ is that conditional on yi ⩾ 0, and this does not generally have any independence property.
$\mathcal {E}(y_{i})$ is that conditional on yi ⩾ 0, and this does not generally have any independence property.
Berkson’s Paradox illustrates this. Suppose, following Elwert (Reference Elwert and Morgan2013), that movie actors become famous if they are good looking or can act well, or both. Assume, probably realistically, that being good looking and being a good actor are independently distributed. If the analyst has a data set consisting only of actors who are famous, then any actor in that set who is not good looking must be a good actor, since otherwise he would not be famous. Thus in the data set of famous actors there will be a negative correlation between being good looking and being a good actor, even though by assumption there is no such correlation in the general population. Any statistical exercise that makes no allowance for this effect will be biased.
We will not discuss statistical procedures to deal with this problem since the problem does not directly involve causal issues. The point here is only to demonstrate that the attractive statistical properties of least squares in estimating causal coefficients do not apply universally when data on internal variables are not fully observed.
6. COMPARISON WITH ‘FIXING’
The analysis of IN-causation outlined in this paper differs in major respects from what is found in the causation literature. Most important, interventions here consist exclusively of hypothetical alterations in the assumed values of external variables. In contrast, the usual treatment in the literature (based on Haavelmo Reference Haavelmo1943; Strotz and Wold Reference Strotz and Wold1960) involves modelling policy interventions on, say, y 1 by deleting from the model the equation determining y 1 and replacing it with the specification that y 1 is external.
This practice of ‘fixing’ internal variables and deleting equations when analysing interventions seems misdirected. It violates the autonomy assumption (which consists of the assertion that the model equations are invariant to assumed interventions). It does not make sense to claim to analyse interventions using a model if doing so involves changing the model to accommodate the intervention. Fixing corresponds to measuring a person’s height using a yardstick that expands or shrinks according to the height being measured.
Fixing internal variables involves a troubling inconsistency between how model solutions are generated in the routine operation of the model – via realizations of external variables – and how they are modelled under a policy intervention – via relabelling internal variables as external and suppressing equations. What is it about policy interventions that motivates this difference in treatment? We are not told. As suggested above, it seems simpler and more satisfactory to be consistent about carrying over the attribution of assumed interventions on internal variables to underlying changes in the external variables that determine them, and thereby to avoid altering the equations of the model.
Besides this, there are several major problems with modelling interventions by fixing internal variables. Most obviously, doing so applies only in recursive systems, since in the presence of simultaneity y 1 is determined jointly with other variables in a group of several or many equations. In that case there does not exist any obvious way to identify which equations are to be deleted. In contrast, our analysis of IN-causation applies in non-recursive models, although of course IN-causal relations among internal variables are likely to be sparse in models with large simultaneous blocks.
The Haavelmo–Strotz–Wold procedure assumes that causal models are modular, meaning that causal relations can be modified individually without invalidating the other equations of the model (modularity has been discussed widely in the philosophical literature on causation; see, for example, Cartwright (Reference Cartwright2007) and the works cited there). Under our treatment, in contrast, the question of modularity does not come up because we are not modifying the model.
Modelling interventions by respecifying internal variables as external implies that causation is treated as if it were implementation neutral whether or not this treatment is justified. If implementation neutrality fails coefficients will be interpreted as IN-causal when they do not support that interpretation. It is far from clear why one would want to take this route. In general the answer to the question ‘What is the effect of y 1 on y 2?’ is properly viewed as possibly, but not necessarily, depending on what brings about the change in y 1. The model encodes exactly this information in the equations determining y 1. Therefore the analyst can determine whether the question of causation has an unambiguous answer.
7. APPLICATION: GRANGER CAUSATIONFootnote 6
Granger (Reference Granger1969) proposed a definition of causation that can be implemented empirically without relying on theoretical restrictions: a stochastic process (that is, sequence of random variables) y 1 = {y 1t} Granger-causes another process y 2 if the optimal prediction of future values of y 2 based on past values of y 2 alone can be improved by including current and lagged values of y 1 as explanatory variables. It is asserted that if y 1 does not Granger-cause y 2, then y 2t can be treated as strictly exogenous with respect to y 1t, so that correlations between the two can be interpreted as reflecting the causal effect of y 2 on y 1. The problem here is to determine the relation between Granger-causation and IN-causation as defined in this paper.
Analysts recognized immediately that Granger-causation is not the same as causation as that term is used in ordinary discussion. For example, Granger pointed out that under the definition just stated cattle stamping their hooves before an earthquake implies that the cattle Granger-cause the earthquake. Granger termed such cases ‘spurious causation’, implying that the question of how to define causation that is not spurious remained open.
To determine the relation between Granger causation and IN-causation, we formulate a two-variable vector autoregression generating the values of the money stock m = {mt} and gross domestic product y = {yt} (note that henceforth in this section we use y to denote GDP, not to represent a general internal variable as above):
 \begin{equation}
m_{t} =a_{my}y_{t}+b_{mm}m_{t-1}+b_{my}y_{t-1}+x_{1t}
\end{equation}
\begin{equation}
m_{t} =a_{my}y_{t}+b_{mm}m_{t-1}+b_{my}y_{t-1}+x_{1t}
\end{equation}
 \begin{equation}
y_{t} =a_{ym}m_{t}+b_{ym}m_{t-1}+b_{yy}y_{t-1}+x_{2t}.
\end{equation}
\begin{equation}
y_{t} =a_{ym}m_{t}+b_{ym}m_{t-1}+b_{yy}y_{t-1}+x_{2t}.
\end{equation}
Here the external variables x 1t and x 2t are independent of each other, and are independent over time. The reduced form corresponding to this system is
 \begin{equation}
m_{t}=c_{mm}m_{t-1}+c_{my}y_{t-1}+u_{1t}
\end{equation}
\begin{equation}
m_{t}=c_{mm}m_{t-1}+c_{my}y_{t-1}+u_{1t}
\end{equation}
 \begin{equation}
y_{t}=c_{ym}m_{t-1}+c_{yy}y_{t-1}+u_{2t}.
\end{equation}
\begin{equation}
y_{t}=c_{ym}m_{t-1}+c_{yy}y_{t-1}+u_{2t}.
\end{equation}
GDP fails to Granger-cause the money stock if
 \begin{equation}
c_{my}=\frac{a_{my}b_{yy}+b_{my}}{1-a_{my}a_{ym}}=0.
\end{equation}
\begin{equation}
c_{my}=\frac{a_{my}b_{yy}+b_{my}}{1-a_{my}a_{ym}}=0.
\end{equation}
The money stock is strictly exogenous with respect to GDP if amy = bmy = 0. Strict exogeneity implies that GDP shocks do not feed back into the equation determining money, either currently or with a lag. From (39) Granger non-causation is a necessary condition for strict exogeneity, but not a sufficient condition.
We wish to know what parameter restrictions are necessary for mt⇒yt. To determine this we first write the solution form of the model under the assumption that mt is strictly exogenous:
 \begin{equation}
m_{t}=x_{1t}+b_{mm}x_{1,t-1}+. . .
\end{equation}
\begin{equation}
m_{t}=x_{1t}+b_{mm}x_{1,t-1}+. . .
\end{equation}
 \begin{equation}
y_{t}=a_{ym}x_{1t}+(a_{ym}b_{mm}+b_{ym})x_{1,t-1}+x_{2t}+b_{yy}x_{2,t-1}+. . .
\end{equation}
\begin{equation}
y_{t}=a_{ym}x_{1t}+(a_{ym}b_{mm}+b_{ym})x_{1,t-1}+x_{2t}+b_{yy}x_{2,t-1}+. . .
\end{equation}
IN-causation requires that the ratio of the coefficients of x 1t in determining mt and yt equal the corresponding ratio for x 1, t − 1:
 \begin{equation}
\frac{1}{a_{ym}}=\frac{b_{mm}}{a_{ym}b_{mm}+b_{ym}}.
\end{equation}
\begin{equation}
\frac{1}{a_{ym}}=\frac{b_{mm}}{a_{ym}b_{mm}+b_{ym}}.
\end{equation}
Here the reasoning is exactly the same as in section 1.1. This equality is satisfied if and only if bym = 0.
Thus even strict exogeneity of m is not a sufficient condition for interpreting the coefficient of mt in equation (36) for yt as the causal coefficient associated with mt⇒yt. This is so because if bym ≠ 0 the lagged values of x 1 – the external variables that determine yt through their effect on mt – also affect yt via m t − 1. Thus we have a failure of implementation neutrality: if bym ≠ 0 characterizing an intervention as a hypothesized change in mt does not give enough information about the intervention to determine the resulting change in yt. Avoiding this outcome requires imposing the implementation-neutrality condition bym = 0 in addition to the strict exogeneity of m, so as to shut down m t − 1 as a determinant of yt.
We see that to make the transition from Granger-noncausation to IN-causation, one has to make two further restrictions on the model (35)–(36), beyond cmy = 0. The first is that cmy = 0 must be strengthened to amy = bmy = 0. Analysts aware of the distinction between strict exogeneity and Granger non-causality frequently state that cmy = 0 is consistent with amy = bmy = 0, but then incorrectly go on to treat ‘is consistent with’ as having the same meaning as ‘implies’. Second, as we have just seen implementation neutrality requires that one rule out m t − 1 as an argument in the equation for yt.
The conclusion is that Granger causation is a specialized – and, to be sure, a very useful – form of forecastability, but it cannot be directly interpreted as having anything to do with IN-causation.
It may be that we are being too narrow in trying to relate Granger-causation to causation between current values of m and y as defined here. The definition of causation here relates a single cause variable and a single effect variable at the same date, whereas Granger causation involves the stochastic processes m and y. The suggestion is that a more general notion of causation is required. If so, the task at hand for proponents of Granger causation would seem to be to propose a more general characterization of (true) causation and then relate Granger causation to that.
8. CONCLUSION
In this paper we distinguish between two conceptions of causation, one a restricted version of the other. As is conventional, we use the term ‘causation’ if any intervention that produces a change in the cause variable also produces a change in the effect variable. We direct attention to a stronger meaning for causation: IN-causation. One variable IN-causes another if, in addition to causing the other in the above sense, it is the case that all interventions that produce a given change in the cause variable induce the same change in the effect variable. If both conditions are satisfied the answer to the question ‘What is the effect of a change in y 1 on y 2?’ does not depend on what caused the assumed change in y 1. This, as argued above, captures what scientists want to know when they investigate questions dealing with causation. If the conditions for IN-causation are not satisfied one cannot identify a single number that measures the effect of y 1 on y 2. In that case one can only discuss the effects of changes in the determinants of y 1 on y 2, which is unambiguous.
The question of how to implement the definition of causation proposed here is a difficult one. At a minimum, the analysis here can play the role of raising questions about discussions of causation that use purported measures of causal magnitudes which make no attempt to justify the implicit assumption of implementation neutrality. On a more ambitious level, the results here may provide guidance on how to justify identifying particular model parameters with causation in applied models. The underlying idea is to encourage clear communication about what exactly is involved in causal assertions. A great deal remains to be done.
ACKNOWLEDGEMENTS
Abbreviated versions of this material were presented in LeRoy (Reference LeRoy and Hoover1995, Reference LeRoy2006) (these papers are discussed at some length in Cartwright Reference Cartwright2007). Here more detail is supplied, and the packaging is different. I have received helpful comments from Judea Pearl and Hrishikesh Singhania, and from two referees.


