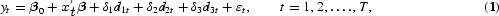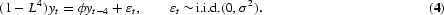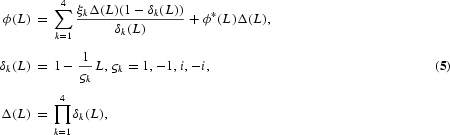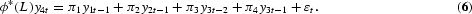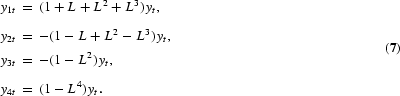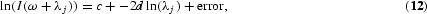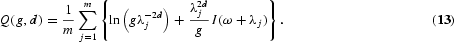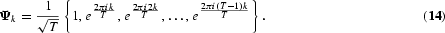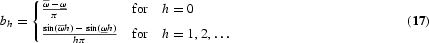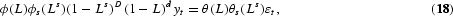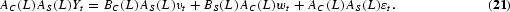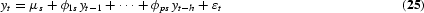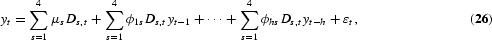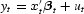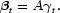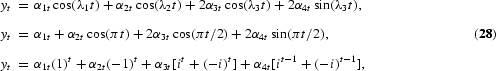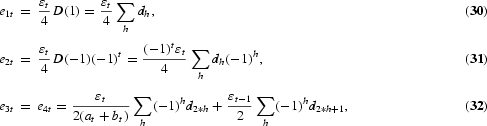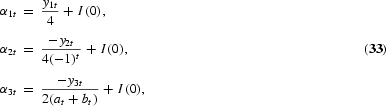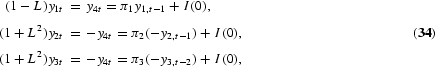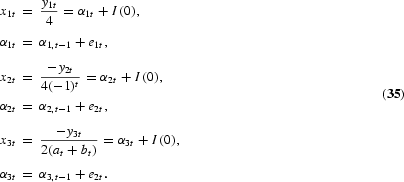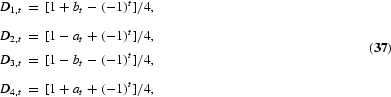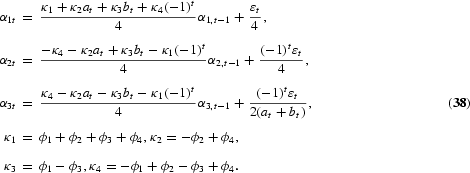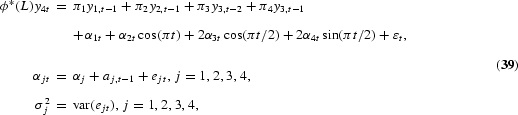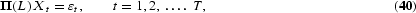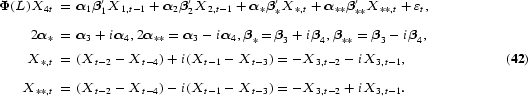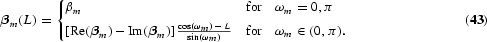Seasonal integration and seasonal fractional integration
A simple filter often applied in empirical econometric work is the seasonal difference filter (1−Ls), where s is the number of observations per year; typically s=2, 4, 12 or 52 [see Box and Jenkins (1970)]. The seasonal differencing of Box and Jenkins assumes that there are unit roots at all the seasonal frequencies in the autoregressive representation, and they recommend that the seasonal difference filter be applied until the transformed series is stationary. The seasonal difference filter can be written as (1−Ls)=(1−L)(1+L+L2+[sdot ][sdot ][sdot ][sdot ][sdot ][sdot ]+Ls−1), where the long-run- or zero-frequency unit root is in the first factor and the seasonal unit roots are in the seasonal summation filter S(L)=(1+L+L2+[sdot ][sdot ][sdot ][sdot ][sdot ][sdot ]+Ls−1). The seasonal summation filter has the real root −1 if s=2 (and indeed for any even s), the real −1, and the two complex conjugate roots ±i if s=4, and one real and five pairs of complex conjugate roots if s=12, etc.
Many empirical studies have applied the so-called HEGY test developed by Hylleberg et al. (1990) and Engle et al. (1993) for quarterly data and extended to monthly data by Franses (1991) and Beaulieu and Miron (1993). These tests are extensions of the well-known Dickey and Fuller (1979) test for a unit root at the long-run frequency (see also Dickey et al., 1984). Another test where the null is that of no unit root at the zero frequency is suggested by Kwiatkowski et al. (1992) (KPSS test) and extended to the seasonal frequencies by Canova and Hansen (1995).
The existence of seasonal unit roots in the data-generating process (DGP) implies a varying seasonal pattern where “summer may become winter.” In most cases, such a situation is not feasible and the finding of seasonal unit roots should be interpreted with care and taken as an indication of a varying seasonal pattern, where the unit root model is a parsimonious approximation and not the true DGP. Furthermore, a proper choice of the initial condition may render “summer may become winter” arbitrarily unlikely in finite samples, thus alleviating this main criticism on the existence of seasonal unit roots.
Recently, Arteche (2000) and Arteche and Robinson (2000), among others, have extended the analysis to seasonal long-memory or fractionally integrated models, for which a seasonal fractional difference filter would be appropriate in the Box-Jenkins spirit. Their estimation methods rely heavily on previous results from the analysis of standard (nonseasonal) long-memory or fractionally integrated models [see Granger and Joveux (1980), Hosking (1981), Geweke and Peter-Hudak (1983), Robinson (1995a,b)].
One source of such fractionally integrated models is the aggregation of stationary dynamic models. Granger (1981) showed that aggregating many AR(1) models with random coefficients leads to a time series with long memory. Long-memory models may also be the result of aggregation over time. Recently, these ideas have been extended to the seasonal case by Lildholdt (2001), who considers aggregation of stationary seasonal AR models and also has an extensive simulation study. Common examples of such aggregated models are production, price indices, and many other macroeconomic and financial time series.
Seasonal unit roots. In the standard unit root literature, a time series is said to be integrated of order d if its dth difference has a stationary and invertible ARMA representation. Hylleberg et al. (1990) generalized this to seasonal integration and defined a real-valued stochastic process {yt, t=0, ±1, …} to be integrated of order d at frequency ω if its spectral density satisfies
where g is a positive constant, the symbol “∼” means that the ratio of the left- and right-hand sides tends to 1, ω is a seasonal frequency, and d is a nonnegative integer. In case of quarterly data, ω={0, π, π/2, 3π/2}, where the frequency is measured in radians. When convenient, the seasonal frequency may also be represented as a fraction of a total circle, that is, as a fraction of
; hence ω=2πθ. A series whose spectral density satisfies (2) with ω=2πθ is denoted yt∼Iθ(d). An example is the process (1−L4) yt=εt, εt∼i.i.d.(0, σ2), which is integrated of order 1 at frequencies
.
In general, consider the autoregressive representation
where ϕ(L) is a finite lag polynomial. Suppose ϕ(L) has all its roots outside the unit circle except for possible unit roots at the long-run frequency ω=0 corresponding to L=1, semiannual frequency ω=π corresponding to L=−1, and annual frequencies ω={π/2, 3π/2} corresponding to L=±i. The standard unit root literature considers the estimation and testing of hypotheses regarding the long-run unit root L=1, and much of this work has now been generalized to include the seasonal cases L=−1 and/or L=±i.
Dickey et al. (1984) suggested a simple test [Dickey–Hasza–Fuller (DHF) test] for seasonal unit roots in the spirit of the Dickey and Fuller (1979) test for long-run unit roots. In the quarterly case, they suggest estimating the auxiliary regression
The DHF test statistic is the t-value corresponding to ϕ, which is nonstandard distributed and thus tabulated in Dickey et al. (1984). This test, however, is a joint test for unit roots at the long-run and all the seasonal frequencies; for instance, the polynomial (1−L4) can be written as (1−L)(1+L)(1−iL)(1+iL) and have the roots L={±1, ±i}.
To overcome the lack of flexibility in the DHF test, Hylleberg et al. (1990) refined this idea. By use of the result that any lag polynomial of order p, ϕ(L), with possible unit roots at each of the frequencies ω=0, π, [π/2, 3π/2], can be written as
where ξk is a constant and ϕ*(z)=0 has all its roots outside the unit circle, it can be shown that, in the case of a quarterly time series, (3) can be written in the equivalent form
This is a generalized version of (4), where
Notice that, in this representation, ϕ*(L) is a stationary and finite polynomial if ϕ(L) from (3) only has roots outside the unit circle except for possible unit roots at the long-run, semiannual, and annual frequencies.
The HEGY tests of the null hypothesis of a unit root are now conducted by simple t-value tests on π1 for the long-run unit root, π2 for the semiannual unit root, and F-value tests on π3, π4 for the annual unit roots. As in the Dickey-Fuller and DHF models, the statistics are not t- or F-distributed but have nonstandard distributions. Critical values for the t-tests are tabulated by Fuller (1976), while critical values for the F-test are tabulated by Hylleberg et al. (1990). The test for the complex unit roots may also be conducted by two tests based on the t-value on π3 and the t-value on π4. The t-value on π3 has a distribution as the DHF test with lag 2, provided π4=0. Hence, the test for complex unit roots using the t-values on π3 and π4 starts by testing π4=0 by the t-value on π4, which, under the null and ϕ*(L)=1, has a distribution tabulated by Hylleberg et al. (1990), and continues by testing π3=0 as in the DHF case. The F-value can be shown to be the sum of the squared t-values on π3 and π4. The t-tests are almost never used, possibly due to the fact that the t-tests cannot be saved by augmenting with lagged values of y4t in case of autocorrelation, as shown by Burridge and Taylor (2001). Tests for combinations of unit roots at the seasonal frequencies are suggested by Ghysels et al. (1994). See also Ghysels and Osborn (2001), who correctly argue that if the null hypothesis is four unit roots, that is, the proper transformation is (1−L4), the test applied should be an F-test of πi, i=1, 2, 3, 4, all equal to zero.
As in the Dickey-Fuller case the correct lag-augmentation in the auxiliary regression (6) is crucial. The errors need to be rendered white noise in order for the size to be close to the stipulated significance level, but the use of too many lag coefficients reduces the power of the tests.
Obviously, if the DGP contains a moving-average component, the augmentation of the autoregressive part may require long lags [see Hylleberg (1995)]. As is the case for the Dickey-Fuller test, the HEGY test may be seriously affected by moving-average terms with roots close to the unit circle [see, e.g., the Monte Carlo analyses of Rodrigues and Osborn (1999) and Ghysels et al. (1994)], but also one-time jumps in the series, often denoted structural breaks in the seasonal pattern, and noisy data with outliers may cause problems, as shown by a number of authors such as Ghysels et al. (1994, 1996), Harvey and Scott (1994), Canova and Hansen (1995), Breitung and Franses (1998), Franses and Vogelsang (1998), Haldrup et al. (2000), Taylor and Smith (2001), Kunst and Rutter (2002), Hassler and Rodrigues (2003), and others.
The sensitivity of the HEGY test to structural breaks has led to extensions, such as the one suggested by Hassler and Rodrigues (2003). They first examine the behavior of several seasonal unit root tests in the context of structural breaks, and show that the HEGY test and an LM\ variant of the HEGY test [see Breitung and Franses (1998) or Rodrigues (2002)] are asymptotically unaffected by a finite seasonal mean shift. However, in finite samples, both tests suffer from severe size and power distortions. To correct for this, Hassler and Rodrigues (2003) propose a new break-corrected LM-type test, which has asymptotic distributions already tabulated in the literature, but is robust to seasonal mean shifts. Furthermore, it is shown by a Monte Carlo experiment that although the test assumes that the break point is known a priori, it is robust to misspecification of the break time even in finite samples.
An alternative procedure was suggested by Canova and Hansen (1995) (CH procedure), who extended the KPSS test to the seasonal case. The KPSS test for a unit root at the zero frequency is based on a state-space representation of the process, often called the structural or unobserved components model, such as
where et is white noise with variance σ2e, and the errors et and εs are independent for all t and s. The null hypothesis of no unit root is parameterized as H0:σ2e=0. Canova and Hansen (1995) extend the test to the seasonal case by constructing similar models as (8) for the zero-frequency unit roots to each of the seasonal unit roots [see Section 2.2.3].
The CH test is an LM-type test based on the residuals from the auxiliary regression
where the regressand, yω, ω=0, π, or π/2, is a transformation of the observed variable, leaving only the corresponding potential unit root in the series. The regressors are deterministic seasonal terms (G) and other nonstochastic terms (X) present under the null hypothesis. Canova and Hansen (1995) use the first difference of the series as the regressand in order to remove a unit root at the zero frequency. However, for the T×1 error term to be of the form e=u+τCωξ, where u and ξ are independent white-noise errors, and where the known T×T matrix Cω projects ξ into a process with a unit root at frequency ω, the regressand must be free of unit roots at all frequencies except ω [see Hylleberg (1995) and Hylleberg and Pagan (1997)].
Then Canova and Hansen (1995) test the hypothesis H0:τ=0, i.e., the null is no unit root at the frequency ω against the alternative of a unit root, and the test statistic suggested by Canova and Hansen (1995) is
for frequencies ω=0, π, or (π/2, 3π/2). Here,
are the OLS residuals from the regression (9) and
is a consistent estimate of the long-run variance of et. The distribution of the Lω-test is nonstandard but depends only on the number of unit roots being tested, and is tabulated by Canova and Hansen (1995).
Besides the problems caused by the test being conditional on assumptions about the integratedness at other frequencies, the introduction of lagged dependent variables into the auxiliary regression may cause problems for testing for seasonal unit roots, unless sufficient care is exercised when choosing specific lags in the augmentation that do not conflict with the seasonal unit roots [see Canova and Hansen (1995) and Hylleberg (1995)]. Specifically, the use of lag 1 when testing for a semiannual unit root may ruin the test.
Recently, some authors have begun developing an optimality theory for seasonal unit root testing. Though no uniformly most-powerful test has been proposed (and most likely none exists), several attempts have been made applying other optimality criteria. The CH test is extended by Cancer (1998) who uses a parametric correction for autocorrelation instead of the nonparametric correction employed by CH. Thus, he is able to prove that his test is locally best invariant unbiased (LBIU). In a Monte Carlo study, Caner's test shows considerable power gains over the CH test. A related approach is considered by Tam and Reinsel (1997) who develop an LBIU test and a point optimal invariant (POI) test for a seasonal unit root in the MA representation, corresponding to seasonal overdifferencing. Thus, their null hypothesis is that of seasonal trend stationarity. By simulations it is shown that the LBIU test is approximately uniformly most powerful since its power curve is very close to the power envelope.
A recent promising addition to the battery of tests is the variance ratio test suggested by Taylor (2002). The test is an extension of a test for a unit root at the zero frequency suggested by Breitung (2002). For quarterly data, the null hypotheses considered are a unit root at the zero frequency, a unit root at the frequency π, and the complex unit root at the frequency π/2 (and the corresponding complex conjugate root at 3π/2), against their stationary alternatives. The test statistic of Breitung is
where
, and
is the residual from a regression of the observed variable xt on deterministic terms such as an intercept, a trend, and seasonal dummies. The null of a unit root is rejected for small values of VR. The necessary assumptions for the test are somewhat weaker than the assumptions for the HEGY test. Especially, one avoids the problems of finding the right lag augmentation, but prefiltering the observed series for possible unit roots at other frequencies is required and may cause problems in small samples.
Hylleberg (1995) argues that the CH test and the HEGY test complement each other. Kunst and Reutter (2002) consider the problem of choosing between the Caner test, the CH test, and the HEGY test, using a Bayesian decision setup, and Monte Carlo experiments show that the gains of such combinations over just applying the HEGY test are small in most cases.
Although unit root testing in the case of semiannual and quarterly data is relatively easy to perform in practice, and feasible in case of monthly observations, it is not possible in practice to handle cases where the auxiliary regressions contain more than 20 regressors as would be the case for weekly or daily data (even with several years of weekly or daily data).4
Note that sometimes the techniques are used to detect weekly effects in daily data, but here at most seven “seasons” are considered, not 52 or 365.
The results of a number of studies testing for seasonal unit roots in economic data series suggest the presence of one or more seasonal unit roots, but often not all required for the application of the seasonal difference filter, (1−Ls), advocated by Box and Jenkins (1970), or the application of the seasonal summation filter, S(L). Thus, these filters should be modified by applying a filter that removes the unit roots at the frequencies where they were found, and not at the frequencies where no unit roots can be detected. Another and maybe more satisfactory possibility would be to continue the analysis applying the theory of seasonal cointegration, which is the subject of Section 2.2.5.
Seasonal fractional integration. Recently, Arteche (2000) and Arteche and Robinson (2000) extended the analysis to include noninteger values of d in the definition (2) of an Iω(d) process. In particular, let {yt, t=0, ±1, …} be a real-valued stochastic process with spectral density satisfying (2) for any real number
. This defines a seasonal fractionally integrated process, which is said to have strong dependence or long memory at frequency ω since the autocorrelations die out at a hyperbolic rate in contrast to the much faster exponential rate in the weak dependence case. The parameter d determines the memory of the process, and its parameter space
is chosen to ensure that the process is stationary and invertible, that is, has a one-sided linear representation. If d=0, the spectral density is bounded at ω and the process has only weak dependence. For proofs of these properties and many more, see, for example, Granger and Joyeux (1980) or Hosking (1981).
When ω=0, the process has standard long memory and when ω is a seasonal frequency the process is said to have seasonal long memory. Many estimators of the memory parameter d and the scale parameter g have been developed in the standard long memory context. Beran (1994), Robinson (1994b), and Baillie (1996) provide overviews of both theoretical and empirical results in the area of (standard) long-memory processes in econometrics and time-series analyses up to about 1995. Basically, there are two dominant estimation methods. The semiparametric method [developed by Geweke and Porter-Hudak (1983), Künsch (1987), and Robinson (1995a,b)] assumes only the model (2) for the spectral density and uses a degenerating part of the periodogram around ω to estimate the model. It therefore has the advantage of being invariant to any dynamics at other frequencies; for example, when estimating standard long-memory models the estimator is invariant to short-run dynamics. Some estimators based on fully specified parametric models have also been developed [e.g., Fox and Taqqu (1986), Dahlhaus (1989), Robinson (1994a), and Nielsen (2004)], which are much more efficient using the entire sample, but will be inconsistent if the parametric model is specified incorrectly.
One of the two commonly used semiparametric estimators is the log-periodogram estimator originally introduced by Geweke and Porter-Hudak (1983), extended to seasonal long memory by Porter-Hudak (1990), and analyzed in detail by Robinson (1995b) and Arteche and Robinson (2000). Taking logs in (2) and inserting sample quantities, we get the approximate regression relationship
where λj=2πj/n are the Fourier frequencies and
is the periodogram of the observed process {yt, t=1, …, n}. The estimator
is defined as the OLS estimator in the regression (12) using j=±1, …, ±m, where m=m(n) is a bandwidth number that tends to infinity as n→∞. Under suitable regularity conditions, including {yt} being Gaussian and a restriction on the bandwidth, Arteche and Robinson (2000) showed consistency and asymptotic normality of the estimator.
The Gaussian semiparametric estimator (or local Whittle estimator) is attractive because of its nice asymptotic properties and very mild assumptions. The estimator is defined as the pair
that minimizes the (local Whittle likelihood) function
One drawback compared to log-periodogram estimation is that numerical optimization is needed. However, this estimator does not require the Gaussianity condition, and Arteche (2000) and Arteche and Robinson (2000) showed that
. An extremely simple asymptotic distribution facilitating easy asymptotic inference.
The problem with the semiparametric approach is that only
-consistency is achieved in comparison to
-consistency in the parametric case. Thus, the semiparametric approach is much less efficient than the parametric one since it requires at least m/n→0.
A more practical difficulty with the application of seasonal long-memory models or seasonal fractional models is caused by estimating several d parameters. Even in the standard long-memory model with only one d parameter, difficulties may arise, but in case of quarterly data where there are three possible d parameters, the testing procedure becomes very elaborate, with a sequence of clustered tests as in Gil-Alana and Robinson (1997); see also Robinson (1994a) and Nielsen (2004).
Band spectrum regression and band pass filters
A natural way to analyze time series with a strong periodic component seems to be in the frequency domain, where the time series is represented as a weighted sum of cosine and sine waves. Hence, the time series are Fourier transformed and time-domain tools as autocovariance functions and cross-covariance functions are replaced by frequency-domain counterparts such as spectra and cross-spectra. The spectrum is the Fourier transformation of the autocovariance functions, and the autocovariance is the inverse Fourier transformation for the spectrum.5
In practice, estimation of the spectra often takes place as a histogram approximation or smoothing of the periodogram across adjacent frequencies. The periodogram is obtained as the norm of the Fourier-transformed time series.
In the so-called real-business-cycle literature, it has become common practice to filter out components such as the trend and also components with short periods such as the seasonal component, and concentrate on the so-called business-cycle component. This is done by applying band-pass filters, which ideally should leave only the business-cycle component in the series. For a recent discussion of band-pass filters, see Baxter and King (1999). However, application of such filters dates back a long time [see Hannan (1960)]. The application of band spectrum regression was further developed and analyzed by Engle (1974, 1980) and extended to the seasonal case by Hylleberg (1977, 1986) and Bunzel and Hylleberg (1982).
Band spectrum regression. Band spectrum regression is based on a frequency-domain representation of the time series. Let us assume that we have data series with T observations in a T×1 vector y and a T×k matrix X related by y=Xβ+ε, where ε is the disturbance term and β is a k×1 coefficient vector. The finite Fourier transformations of the data\ series are obtained by premultiplying the data matrices by a T×T matrix Ψ, with the k+1 row equal to
The Ψ matrix is complex and a Hermitian unitary matrix; that is, Ψ=Ψ[dagger] and Ψ[dagger]Ψ=I, where Ψ[dagger] is the transposed complex conjugate matrix of Ψ. Hence, the OLS estimate in the regression of the transformed series
is the same as the original OLS estimate. Let us premultiply the transformed model by a diagonal T×T matrix A with zeros and ones on the diagonal to obtain
The effect of having zeros along the diagonal of A is to take out the corresponding frequency components in the Fourier-transformed data series.
6 Note that A must be symmetric around the southwest-northeast diagonal in order for the coefficient estimates to be real.
Hence, by an appropriate choice of zeros in the main diagonal of
A, the exact seasonal frequencies,
7 In case only the exact seasonal frequencies, i.e, π and π/2 in the quarterly case, are removed, OLS on (16) will produce coefficient estimates that are identical to those obtained by adding quarterly seasonal dummies to the regression equation.
that is, in the quarterly case the (
k+1)th diagonal element of
A, where (2π
k)/
T=π/2, π, and 3π/2 for
k=0, 1, ….,
T−1, may be filtered from the series. In case of a varying seasonal pattern, frequencies in a band around the exact seasonal frequencies may be filtered from the series as well [see Hylleberg (
1977,
1986) and Bunzel and Hylleberg (
1982)].
8 The fact that some regression programs are unable to handle complex variables as in (16) implies that the filtered data should be transformed back to the time domain before applying the least-squares algorithm. The inverse Fourier transformation of the transformed filtered variables in the model is obtained by premultiplying (16) with Ψ.
One of the advantages of the band spectrum regression is that it is possible to test directly for the appropriate filtering, as argued by Engle (1974).
Band-pass filters. Most of the literature on the use of band-pass filters is connected to the real-business-cycle literature, following Hodrick and Prescott (1980), Prescott (1986), and Kydland and Prescott (1990). The focus of that literature is the business-cycle component, and the ideal band-pass filter is a filter that leaves out all the components not connected to the business cycle.
Obviously, similar procedures could be applied to leave out only the seasonal components. The ideal seasonal band-pass filter is a filter that leaves out the nonseasonal components of the economic time series.
Following Baxter and King (1999), for instance, it can be shown that an ideal seasonal band-pass filter that passes through only the frequencies
has frequency response function β(ω)=1 for
and β(ω)=0 elsewhere, has the form
, where
However, the filter
is an infinite moving average, and in practice, we are forced to apply an approximate finite moving-average filter, such as
.
If the optimization criteria are based on minimizing
, it can be shown that the optimal approximate band-pass filter is
for a given truncation K. Hence, the optimal approximating band-pass filter aK(L) is constructed from the ideal band-pass filter b(L) by letting the weights be equal within the truncation lag, that is, ak=bk for k=0, ±1, [sdot ][sdot ]±K.
The effect of the truncation with lag length K is to lose K observations at each end of the sample. However, a large K implies a better approximation. In fact, a small K may result in admitting substantial components just above
and below
, an effect called leakage, whereas the frequency response may be both below the unit frequency response (compression) and above it (exacerbation). Hence, there exists a trade-off between large and small K's for a given sample size T.
Whether one applies filtering in the frequency domain as in band spectrum regression or in the time domain as in band-pass filtering, the actual success of the filtering depends on the choice of bandwidth K, and the spectral characteristics of the series at hand. Even a small leakage in the filter may give rise to severe disturbances if the spectrum of the filtered series has mass at particular frequencies.