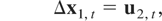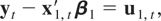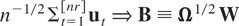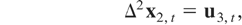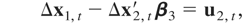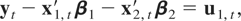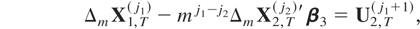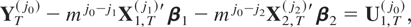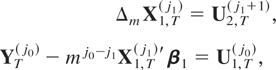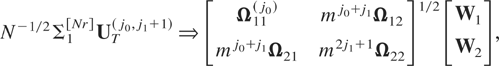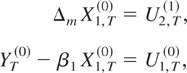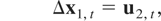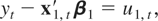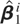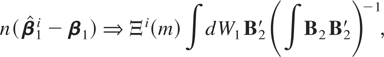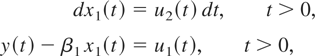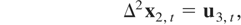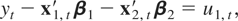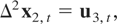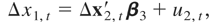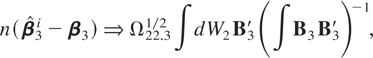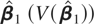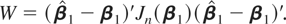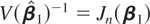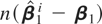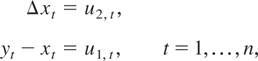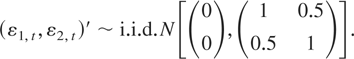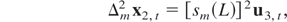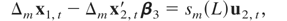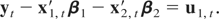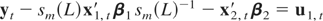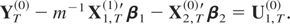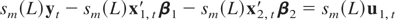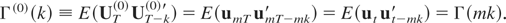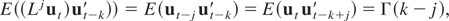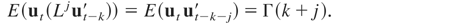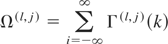We will now discuss the asymptotic effects of different types of
aggregation on the estimation of β1,
β2, and β3 and on the
observed information. Even though we focus on optimal CI(1,1) regressions
we also provide theoretical results for two examples of CI(2,2) and
CI(2,1) processes.
3.1. Temporally Aggregated Mixed Normal
Distribution
Suppose that a k-dimensional time series
zt =
{(yt,x1,t′)′}t=1n,
where yt is a scalar time series4
and x1,t is a
k1-dimensional time series, is generated by
where ut =
(u1,t,u2,t′)′
is a stationary process that satisfies (3). Let
denote an optimal regression-type estimator of β1
using the time series
ZT(j0,j1)
where i = I for ZT(0),
i = II for
ZT(01), i =
III for ZT(10), and
i = IV for ZT(1). The
following theorem presents its limiting distribution.
THEOREM 3.1. The asymptotic distribution of the optimal
regression-type estimator of β1 in model
(10) and (11) with temporally aggregated time series is
where the relative dispersion across the sampling interval
Ξi(m) is
ΞI(m) = (Ω11.2 +
Λ(m))1/2, ΞII(m) =
m−1(Ω11.2 +
Λ(m))1/2, ΞIII(m) =
mΩ11.21/2, and
ΞIV(m) =
Ω11.21/2.
Proof. See the Appendix.
From Theorem 3.1, comparing these asymptotic distributions with the
one for an optimal estimator of the disaggregated model,
Ω11.21/2
∫dW1B2′(∫B2B2′)−1,
there is no loss of efficiency when the regressand and the regressor are
average sampled (aggregation IV), whereas there is a loss of efficiency
when the regressors are systematically sampled, i.e., aggregation schemes
I and III. These results are in keeping with those of Chambers (2003), who considers a similar scenario where the
disaggregated model is a continuous time cointegrated model.
However, in contrast with Chambers (2003),
in case II three situations are possible depending on the relative size of
the aliasing component Λ(m) in relation to the conditional
long-run variance Ω11.2. To be more specific,
when Λ(m) = (m2 −
1)Ω11.2, which implies that
2Σj=1m−1F11(2πj/m)
= (m2 − 1)F11.2(0), there is
no loss of efficiency, whereas for
2Σj=1m−1F11(2πj/m)
> (m2 − 1)F11.2(0), there
is a loss of asymptotic efficiency, and when
2Σj=1m−1F11(2πj/m)
< (m2 − 1)F11.2(0) there
is a gain in asymptotic efficiency. In any case
ΞII(m) < ΞI(m), and
when Λ(m) < (m4 −
1)Ω11.2, then ΞII(m) <
ΞIII(m).
To summarize, type II aggregation is always more efficient than type I
aggregation, and type IV aggregation is always more efficient than types I
and III aggregation. When Λ(m) < (m2
− 1)Ω11.2 type II is more efficient than IV
aggregation and therefore is the most efficient option.
Continuing with the example of Section 2.2 and for m = 3, a
situation of no loss of asymptotic efficiency with aggregation II occurs
when ρ = −0.27, for −1 < ρ < −0.27 there
is a loss of efficiency, whereas for −0.27 < ρ < −1
there is a gain of efficiency.
Let us compare the relative dispersions
Ξi(m) with those derived with the
continuous time aggregation approach (see Chambers,
2003), which we denote as
ΞCi. To do so, let us consider
a bivariate triangular continuous time cointegrated model:
where
(u1(t),u2(t))′
is a stationary continuous time process with spectral density function
FC(ω) with −∞ < ω
< ∞. From Chambers (2003, p. 59) and
given that for j ≠ 0 h(2πij) =
(2πij)−1, h(2πij) +
h(−2πij) = 0 and
|h(2πij)|2 =
(4π2j2)−1, we obtain
the expressions
There are important differences between
ΞCi and
Ξi(m). First of all, in the continuous
time setting, type II aggregation is the most inefficient option for any
FC(ω), a result that contrasts with the findings
obtained in the discrete time approach where type II aggregation may be
the most efficient way to aggregate the time series and in any case is
less efficient than schemes I. Second, the cointegration coefficient
β1 appears at the limiting distributions of the discrete
time optimal estimator derived from the continuous time cointegrated
system, a result that is in contradiction with the optimal theory of
estimation of cointegrating vectors (see Saikkonen,
1991; Phillips, 1991b). Finally, in the
continuous time approach, the aliasing affects the distributions through
the error process of the cointegrated relations
(2πΣj≠0
FC,11(2πj)), and through the
error process of the common stochastic trends
(2πβ12Σj≠0(4π2j2)−1FC,22(2πj)),
a surprising result because for both types of aggregation the process
u2(t) is at least cumulated once
∫u2(t − s)
ds, a transformation that eliminates the
components FC,22(2πj) in scheme
IV of continuous time aggregation for the errors of the cointegrating
relations. Thus, the continuous time aggregation fails to explain the
discrete time aggregation results.
Theorem 3.1 has practical implications. If we consider the common
situation where the practitioner may decide how to aggregate a stock time
series, then we have two different situations depending on whether it is
the regressand or the regressor that is temporally aggregated. When a
practitioner has to aggregate a stock regressand and the regressor is a
stock, the best aggregation option depends on the sign of
Λ(m) − (m2 −
1)Ω11.2. If this magnitude is negative, the best
option, in terms of estimation efficiency, is to use systematic sampling
(aggregation I), whereas if it is positive, the optimal choice is average
sampling (aggregation III). When the regressor is a flow, the best option
depends on Λ(m) − (m2 −
1)Ω11.2, in the sense that when this parameter is
positive the stock regressand should be aggregated by average sampling
(aggregation IV), whereas when it is negative the regressand should be
aggregated by systematic sampling (aggregation II). When a practitioner
has to aggregate a stock regressor, the best option, in terms of the
asymptotic dispersion of the estimator, is always to apply average
sampling to the regressor because aggregations II and IV are superior in
efficiency to aggregations I and III, respectively. Therefore, the picture
that emerges from the discrete time aggregation analysis is more complex
than the one obtained from the continuous time approach where the best
option seems to be in any situation to apply average sampling. We provide
finite-sample evidence favoring our theoretical findings in Section 4.
In practice, when deciding whether to aggregate the stock regressand
by systematic or average sampling, we need to compare Λ(m)
with (m2 − 1)Ω11.2.
However, because the flow variables are observable at a longer sampling
interval than the stock variables, it is necessary to get
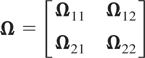
Ω12Ω22−1Ω21
from the observable
Ω12(j0,2)Ω22(3)−1Ω21(2,j1).
Then, from the relation
we can estimate
Ω12Ω22−1Ω21
and Ω11.2 and compare the estimations of
Λ(m) and (m2 −
1)Ω11.2.
To summarize, when a stock regressand must be temporally aggregated
because some of the regressors are not available at the finest sampling
interval, then depending on the magnitudes Λ(m) and
(m2 − 1)Ω11.2
systematic or average sampling are the best aggregation options in terms
of the dispersion of the mixed normal distribution. When a practitioner
has to choose an aggregation option for the stock regressor, the best
choice is always to apply average sampling.
The main results found for case CI(1,1) can be extended to models with
I(2) variables. We do not aim to cover all possible situations of
cointegration in models with I(2) variables but to show the robustness of
the aggregation theory for some relevant examples. First, let us assume
the following disaggregated model:
where ut =
(u1,t,u2,t′,u3,t′)′
satisfies the assumptions described in Section 2 and the long-run
covariances are zero Ω12 =
Ω13 = Ω23 = 0. For this
model the optimal estimator is the OLS estimator. Theorem 3.2 shows the
asymptotic distribution of the optimal estimator of
β1 and β2 for the
aggregation schemes ZT(0)
(aggregation I),
ZT(011)
(aggregation II),
ZT(100)
(aggregation III), and ZT(1)
(aggregation IV).
THEOREM 3.2. The asymptotic distribution of the optimal
regression-type estimator of β =
(β1′,
β2′)′ in model (12)–(14)
with temporally aggregated time series is
Proof. See the Appendix.
From Theorem 3.2, temporal aggregation has the same effect on the
separate distribution of the estimator of β1 as on
the separate distribution of the estimator of β2,
and this effect is exactly like that found for case CI(1,1).
Now consider the estimation of CI(2,1) relations, which we assume are
generated by the following model:
where ut =
(u2,t,u3,t′)′
satisfies the general assumptions for the cointegrated model with I(2)
variables described in Section 2. In this situation, the optimal
regression-type estimators of β3 are those
estimators for the CI(1,1) model with differenced variables. The limiting
distribution for the different aggregation schemes is given in the next
corollary.
COROLLARY 3.3. The asymptotic distribution of the optimal
regression-type estimator of β3 in model
(15) and (16) with temporally aggregated time series is
where ΞI(m) =
Ω22.31/2, ΞII(m) =
m−1Ω22.31/2,
ΞIII(m) =
mΩ22.31/2, and
ΞIV(m) =
Ω22.31/2.
In this case, as a result of the absence of the aliasing effect
because the errors are average and double-average sampled, we find
slightly different results. Now, for pure aggregation schemes I and IV the
limiting distribution remains invariant despite the sampling interval,
whereas in the case of mixed sampling the dispersion is reduced with
m for aggregation II, and it increases with m for
aggregation III.
Now, when a practitioner has to aggregate a stock regressand, the best
option is always to apply systematic sampling. This is slightly different
from case CI(1,1) where in some situations the best way to aggregate the
regressand was average sampling when the regressor was a flow. When it is
the stock regressor that needs to be aggregated, the practitioner has to
apply average sampling in all cases, in keeping with case CI(1,1).
The limiting properties of the optimal estimator of
β1 are derived under the assumption that the
long-run variance Ω must be consistently estimated, and
there may be a loss of valuable information when this matrix is estimated
with temporally aggregated time series. Consequently, the aggregation
effects on the estimation of Ω may alter the preceding
conclusions reached on the best aggregation option for the estimation of
long-run relations in finite samples. However, the Monte Carlo evidence
provided in Section 4 shows that the estimation of Ω does
not make any significant difference to the order in which the types of
aggregation are ranked.
3.2. Temporally Aggregated Observed Information
When the purpose of the analysis is to test a hypothesis on the
cointegrating vectors, such as the PPP theory or permanent income
hypothesis, the aggregation effect on the marginal distribution of the
estimator provides us with half the story, because for nonstationary
cointegrating regressions, the observed information
Jn(β1) ≡
−∂2 log
L(β1)/∂β1∂β1
where log L(β1) is the log likelihood
function, and not the variance of
,
is used as the normalizing matrix of the χ2-distributed
Wald test (see Johansen, 1995):
This situation is different from a stationary regression where
,
and the marginal distribution of the estimator is sufficient to discuss
the aggregation effect. However, the observed information in a
cointegrated model is different from the inverse of the variance of the
estimator, and the aggregation effect must be considered on both the
estimator and the information. This task is straightforward when we only
consider the asymptotic properties, because the χ2
distribution of the Wald test implies that the aggregation effect on the
observed information should neutralize the aggregation effect on the
estimator. Thus, an increase in the dispersion of the asymptotic
distribution of the estimator due to aggregation should be counterbalanced
by a reduction in the dispersion of the distribution of the information.
For example, for Λ(m) = (m2 −
1)Ω11.2, the asymptotic dispersion of the
observed information increases for cases I and III, whereas it is
invariant for cases II and IV. Therefore, in asymptotic terms it is not
relevant which type of aggregation we select to test restrictions on
β1.
However, this asymptotic result may be different when we consider the
more realistic finite-sample framework. In such a setting, as shown by
Johansen (2002), the distribution of the test is
slightly different from the χ2 distribution, depending not
only on the number of observations but also on the parameters of the
model. As shown in Section 2, different combinations of aggregation
schemes have different effects on the short-run dynamics, and therefore in
finite samples one aggregation scheme may be clearly superior to another
for hypothesis testing. Moreover, the faster convergence of the observed
information
n−2Jni(β1)
than the estimator
may contribute to the fact that the aggregation effect on
Jn(β1) has a bigger influence
on the finite-sample properties of the test than the aggregation effect
on
.
However, the Monte Carlo experiment in Section 4 shows that, for the
selected model, all the aggregation options have similar effects on the
size of the test.