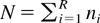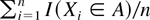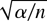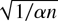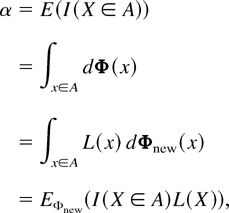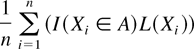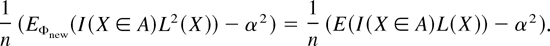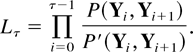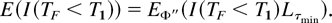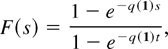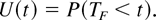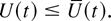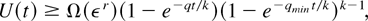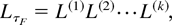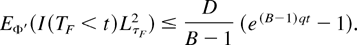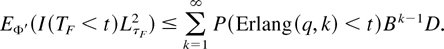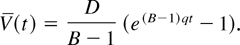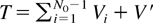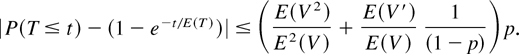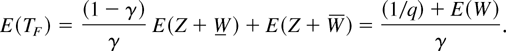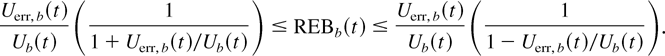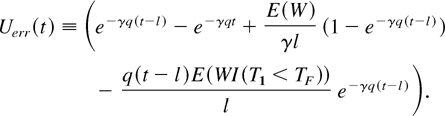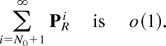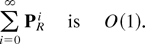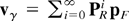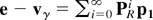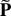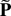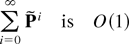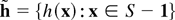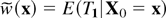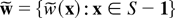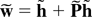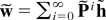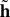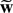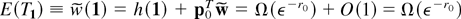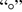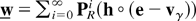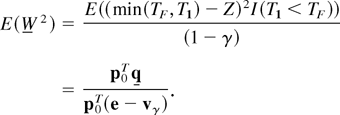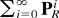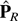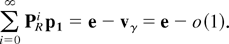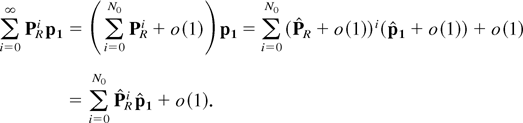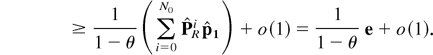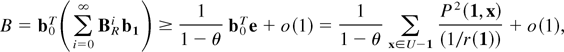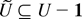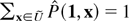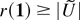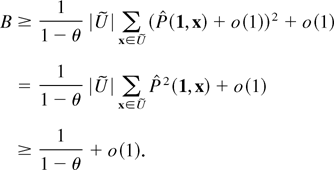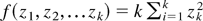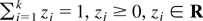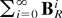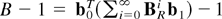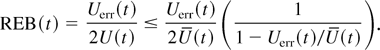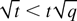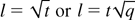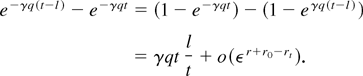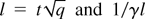1. INTRODUCTION
This article deals with the estimation of the unreliability (i.e.,
probability of system failure within a given time horizon) in large
regenerative models of highly reliable systems. For example, we might
be interested in the probability that the computer system aboard a
space shuttle fails before the mission end time. Similarly, we might be
interested in the probability that the web server used for real-time
monitoring and displaying scores in the Olympic Games crashes during
the period of the games.
The class of systems we study in this article includes a large class
of systems that can be modeled by the System Availability Estimator
(SAVE) modeling tool (Blum, Goyal, Heidelberger, Lavenberg, Nakayama,
and Shahabuddin [2,3]; also see Goyal, Carter, de Souza e Silva,
Lavenberg, and Trivedi [13] and
Goyal and Lavenberg [14] for
earlier versions). This tool is mainly used for the
availability/reliability modeling of computer and communication
systems. It models systems consisting of components, each of which
fails and gets repaired. The system is considered to be up or down
depending on the states of the individual components. All components
are highly reliable (i.e., their expected failure times are much larger
than their expected repair times). There are a limited number of
repairmen in the system. In addition, there are component dependencies
and interactions like failure propagation (the failure of a component
could cause some other components to fail instantaneously), operational
dependencies (the operation of an up component requires some other
components to be up), and repair dependencies (the repair of a failed
component requires some other components to be up). SAVE considers
models for which component failure- and repair-time distributions are
exponentially distributed; we will call these highly reliable Markovian
systems. The techniques in this article can easily be extended to
systems for which the repair times of components have general
distributions.
Highly reliable Markovian systems can be modeled as continuous-time
Markov chains (CTMCs). However, due to the size of the state space (the
state space grows exponentially with the number of components in the
system), analytical and numerical (nonsimulation) methods are very
difficult. These methods include Gaussian elimination (see, e.g., Young
[42]) for computing steady-state
measures and uniformization (see, e.g., Gross and Miller [16] and Jensen [19]) for computing transient measures. Hence,
approximations have to be used. Although some useful approximations
based on lumping and state aggregation have been developed for the
steady-state case (see, e.g., Muntz, de Souza e Silva, and Goyal
[26]), very few exist for the
transient setting. Further complications arise because the embedded
Markov chain is stiff due to the wide difference between the
failure rates and the repair rates of components. In any case, when no
exact solutions are easily computable, simulation presents a viable
alternative.
In the case of simulation, because system failures are rare, it takes
long CPU times for naive simulation to produce good estimates.
Importance sampling (see, e.g., Glynn and Iglehart [12] for the basic technique) has been used
successfully to increase the speed of simulation in highly reliable
Markovian systems (see Alexopoulos and Shultes [1], Carrasco [5,6], Conway and
Goyal [7], Geist and Smotherman
[9], Goyal, Shahabuddin,
Heidelberger, Nicola, and Glynn [15], Juneja and Shahabuddin [20,21,22], Lewis and Böhm [25], Obal and Sanders [33], Shahabuddin [36], Shultes [39], and references therein). Surveys can be
found in Heidelberger [17],
Nakayama [28], Nicola, Shahabuddin,
and Nakayama [32], and Shahabuddin
[37]. The most widely researched
importance-sampling technique for Markovian models is failure biasing.
In failure biasing (Lewis and Böhm [25]), we artificially accelerate the
occurrence of component-failure events with respect to component-repair
events so that the system fails more often. The resulting estimates are
then adjusted to make them unbiased. Mathematical analyses of
failure-biasing techniques for estimating steady-state measures in
highly reliable Markovian systems has been done in Nakayama [27,29], Shahabuddin
[36], and Strickland [41]. In [36], it was shown that a failure-biasing
heuristic called balanced failure biasing (Goyal et al. [15] and Shahabuddin [36]), produces a bounded relative error (BRE)
in the estimation of steady-state measures like the unavailability (the
relative error of the estimate remains bounded as the failure rates
tend to zero). This is in contrast to naive simulation, for which the
relative error tends to infinity. Balanced failure biasing was then
implemented in SAVE (Blum et al. [2,3]).
In the case of transient measures, an additional technique that is
used is forcing (Lewis and Böhm [25]). In this case, the first
component-failure transition is accelerated to make it happen within
the time horizon. As has been shown experimentally (Goyal et al.
[15] and Shahabuddin [35]), for most transient measures, forcing and
failure biasing work well for the case where the time horizon is
“small.”
When the time horizon is “large,” simulation using
importance sampling is not efficient. Some work in the
large-time-horizon case has been done in Carrasco [5] by numerically inverting a discretized
Laplace transform. Another approach suggested in Shahabuddin and
Nakayama [38] and Shahabuddin
[35] is to bound the transient
measure in terms of regenerative-cycle-based measures and then directly
estimate (using simulation) the regenerative-cycle-based measures. In
highly reliable systems, regenerative cycle-based measures can be
estimated with bounded relative error using importance sampling
(Shahabuddin [36]). In Shahabuddin
[35], such bounds were developed
for the expected interval unavailability (the expected fraction of time
in (0,t] that the system is down). It was also shown that
these bounds converge to the expected interval unavailability as
component failure rates tend to zero.
This article has two main contributions. First, we prove that for the
case of small time horizons, failure biasing and forcing give bounded
relative error in the estimation of the unreliability. A crucial
proposition (Proposition 1) proved in this article also allows the
bounded-relative-error result to be extended to the small-time-horizon
estimation of the expected interval unavailability using the
infrastructure already developed by Shahabuddin [35]. Second, we investigate the
“bounding approach” mentioned in the previous paragraph,
for large-time-horizon estimation of the unreliability. Since a highly
reliable Markovian system is regenerative, the time to failure is
roughly the “geometric sum” of independent and identically
distributed (i.i.d.) random variables, where a “success” in
the geometric distribution is defined as failure occurring in a
regenerative cycle. It is well known that if the probability of success
is small, then this geometric sum is approximately exponentially
distributed (see, e.g., Keilson [24] and Solovyev [40]). There is some literature regarding
bounds for the cumulative distribution function (which, in our case, is
the unreliability) of such random variables (e.g., Brown [4], Kalashnikov [23], and Solovyev [40]). We consider bounds proposed in
[4] and [23]. Mathematical analysis reveals that these
bounds converge to the unreliability (as the component failure rates
tend to zero) only for a certain range of time horizons. We develop new
improved bounds that take into consideration the special structure of
the type of highly reliable systems we consider; the bounds in
[4], [23] and [40] do not make use of this special structure.
We show that these new bounds converge to the unreliability for a much
wider range of time horizons. We implement these bounds and do some
experimental comparisons between our bounds and the bounds in
[4]. Preliminary versions of some
of the results mentioned earlier appeared (without proofs) in
Shahabuddin and Nakayama [38].
In Section 2, we briefly review the Markovian framework considered in
Shahabuddin [36] and results for
regenerative-cycle-based measures. Section 3 contains asymptotic
expressions for the unreliability and the variance of unreliability
estimates without and with importance sampling. The
bounded-relative-error property of the estimate of the unreliability
for the small-time-horizon case is proven here. In Section 3.2, we
explain why the efficiency deteriorates for large-time-horizon cases.
Then, we consider bounds developed in Brown [4] and determine the range of the time
horizons for which these bounds converge. Finally, we develop bounds on
the unreliability and investigate their convergence. Section 4 contains
experimental results. Difficult proofs of intermediate results are
relegated to the Appendix.
2. REVIEW OF HIGHLY RELIABLE SYSTEMS AND
FAST SIMULATION
2.1. CTMC Models of Highly Reliable Systems
We further elaborate on the description of the highly reliable
Markovian systems presented in Section 1. Let there be R types
of components in the system with ni
components of type i. Some of the
ni components can act as spares for that
type. Let N be the total number of components of all types in
the system (i.e.,
). There are many repairman classes in
the system, with a finite number of repairmen in each repairman class.
Each component type is assigned a repairman class. The component types
assigned to a repairman class are divided into priority classes and
repaired in a preemptive or nonpreemptive manner. Any service
discipline can be used for members of the same priority class.
Let {X(t) : t ≥ 0} be a CTMC model
(assume left-continuous with right limits) of a highly reliable
Markovian system. For the simplest such system, X(t)
=
(X1(t),X2(t),…,XR(t)),
where Xi(t) is the number of
components of type i that are failed. For the general, highly
reliable Markovian systems we consider, we have to add some more
process descriptors in the state of the system. For example, we might
have to add an ordered list of components waiting to be repaired in
each repairman class. The following analysis is independent of which
definition of X(t) we use.
Transitions in the CTMC correspond either to a component failing
(which may cause the instantaneous failure of other components through
failure propagation) or a component completing repair. We will refer to
the first as a “failure transition” and to the second as a
“repair transition.” We label the state with all components
up as 1. We will also use 1 to denote the set of
states that contains only the single state 1. Assume that
X(0) = 1 unless stated otherwise. Let S
be the set of states that are accessible from 1. For the
purpose of simulation analysis, we will restrict
{X(t) : t ≥ 0} to the set S. We
partition S into two subsets: S = U ∪
F, where U is the set of up states and F
≠ [empty ] is the set of down states. Of course, 1 ∈
U and the state where all components are failed is in
F. We will need the following assumptions:
(A.1) The CTMC is irreducible over the set
S.
(A.2) From all states in S except 1, there is
at least one repair transition (with positive probability).
(A.3) From all states in U, there is at least one
failure transition (with positive probability).
(A.4) From 1, there is at least one failure transition
to a state in U − 1 (with positive
probability).
Let Q = {q(x,y),
x,y ∈ S} be the rate matrix (also
called the infinitesimal generator matrix) of the CTMC. In this matrix,
we arrange the states in the order of increasing number of components
failed. Thus, the first state is one in which no components are failed
(i.e., 1). This is followed by states in which exactly one
component is failed and so on. Let q(x) =
−q(x,x) denote the total rate out of
state x and h(x) =
1/q(x) be the mean holding time in that state.
From (A.2) and (A.3), q(x) > 0 for all x
∈ S. Let Φ denote the probability measure on the
sample paths of this CTMC. For any E ⊂ S, let
TE = inf{t > 0 :
X(t−) ∉ E,X(t)
∈ E}. Of particular interest are
T1 and TF.
Let {Yn : n ≥ 0} denote the
embedded discrete-time Markov chain (DTMC) of {X(t) :
t ≥ 0}; that is, {Yn :
n ≥ 0} has transition matrix P =
{P(x,y) : x,y ∈
S}, where P(x,x) = 0 and
P(x,y) =
q(x,y)/q(x) for
x ≠ y. One can simulate a CTMC by progressively
generating the next state of the embedded DTMC and generating the
random holding time in that state. For any E ∈
S, let τE = inf{n ≥ 1 :
Yn ∈ E}. Of particular
interest are τ1 and
τF.
As is well known, positive-recurrent CTMCs are regenerative (see,
e.g., Crane and Iglehart [8] for
the definition) in nature. In the following study, we will be
considering system regenerations that occur when the system enters
state 1. In any regenerative cycle, let Z be the
random variable denoting the holding time in state 1 and let
W be the remaining time until either state 1 is
reached (again) or the system fails. In mathematical terms, W
= min(T1,TF)
− Z, where T1 and
TF are measured from the start of the
cycle. We will let W (resp., W) be the random
variable having the distribution of W given that a system failure
(resp., no system failure) occurs in a regenerative cycle. Another quantity
that will be used in the following analysis will be γ ≡
P{TF <
T1} =
P(τF < τ1)
(i.e., the probability of system failure occurring in a cycle).
Assumption (A.3) ensures that γ is not trivially equal to zero.
Assumptions (A.2) and (A.4) ensure that 1 − γ is not equal to
zero. For any regenerative-cycle-based random variable, say W,
we will use Wi to denote its value in the
ith regenerative cycle.
2.2. Modeling Highly Reliable Components
In mathematical models of highly reliable Markovian systems, the
failure rate of any component, say component i, is assumed to
be of the form
λiεri,
where ε is a small positive parameter called the rarity parameter;
ri and λi are
positive constants (Shahabuddin [36]; see also Gertsbakh [10]). Let r0 =
min{r1,…,rN}
> 0. Because the repair rates are large compared to failure rates,
the repair rate of component i is represented by a constant
μi > 0. The failure-propagation
probabilities are either assumed to be constants or of the same form as
the failure rates (i.e., constants multiplied by ε raised to
positive powers). Once we introduce this ε-parameterization, then
the performance measures become functions of ε. However, for
simplicity, we do not specify this dependence in the notation. For
example, we continue to use γ for what should ideally be denoted by
γ(ε). In highly reliable Markovian systems, the aim is to study
the performance measures and the variance of their estimators for small
ε.
This particular ε-parameterization guarantees that if
Q(x,y) > 0 (resp.,
P(x,y) > 0) for some ε =
ε0 > 0, then Q(x,y) > 0
(resp., P(x,y) > 0) for all 0 < ε
< ε0. Given the arrangement of states in Q
that we mentioned earlier, it can easily be seen that all the elements
above the diagonal are O(ε) and all elements below the
diagonal are O(1). (A function f (ε) is defined
to be O(εd) (resp.,
O(εd)), d ≥ 0,
if there exists a constant K such that | f
(ε)| ≤ Kεd (resp., ≥
Kεd) for all sufficiently small ε.
A function is said to be Ω(εd), d
≥ 0, if it is both O(εd) and
O(εd); that is, a function
is Ω(εd) if it is exactly of order
εd. A function f (ε) is defined to
be o(εd), d ≥ 0, if
| f (ε)|/εd
→ 0 as ε → 0.) This structure played an important role in
the steady-state-simulation analysis of highly reliable Markovian
systems in Shahabuddin [36].
One key property of highly reliable Markovian systems that will be
used later is the special structure of the regenerative cycle. Because
state 1 has no repair transitions, q(1) is
Ω(εr0) since it is the sum of
only component failure rates. An important consequence of this is that
E(Z) is
Ω(ε−r0). By Assumption
(A.2) and the fact that μi's are positive
constants, we have that q(x) = Ω(1) for all
x ∈ S − 1. Finally, as mentioned
earlier, repair rates are very large compared to failure rates. Using
these three facts, we see that most of the regenerative cycles consist
of a long time interval in which the system is in state 1,
after which there is a single failure transition (which might
correspond to more than one component failing because of failure
propagation), followed by a short time interval in which the failed
components are repaired (and thus the cycle completes). This is the
intuition behind the fact shown in Shahabuddin [36] that
E(min(TF,T1))
= E(Z + W) is of the same order as
E(Z) (i.e.,
Ω(ε−r0)). Using similar
methods, we can show that the expected regenerative-cycle time,
E(T1), is also
Ω(ε−r0) and that
E(W), E(W),
and E(W2) are O(1).
For completeness, the formal proofs are given in the Appendix. It was
also shown in [36] that γ =
Ω(εr), where r is some
nonnegative number depending on the structure of the system. Using the
fact that the mean time to system failure (MTTF) for regenerative
systems can be expressed as
E(min(TF,T1))/γ
(see, e.g., Goyal et al. [15]), we
see that the MTTF is
Ω(ε−(r0+r)).
2.3. Importance Sampling for Highly Reliable Systems
Consider the problem of estimating the probability, α, of a rare
event {X ∈ A}, where X is a random
sample path with probability measure Φ and A is
a rare set. The “naive” way of estimation is to generate
samples of X, say
X1,X2,…,Xn,
from Φ and then form the sample mean
where I(·) is the indicator
function of the event inside the bracket. The variance of this
estimator is (α − α2)/n ≈
α/n, as α is small. The expected half-width of the
100(1 − δ)% confidence interval, HW, is proportional
to
.
Thus, the
relative error (RE), which is defined by RE = HW/α, is
proportional to
.
For fixed n, as α → 0, RE → ∞. This is the
problem with naive estimation of the probability of rare events.
In importance sampling, we use a change of measure
Φnew, such that for each sample path
x ∈ A, Φnew(x)
> 0 if Φ(x) > 0. Then, we can express
α as
where L(x) =
dΦ(x)/dΦnew(x)
when dΦnew(x) > 0 and 0
otherwise. The function L is the Radon–Nikodym
derivative; it is also called the likelihood ratio. The subscript in
the second expectation operator denotes the new probability measure
under which the expectation is taken. Equation (1) forms the basis of
the technique of importance sampling. The last expectation term
suggests that we use the probability measure
Φnew(·) and generate the samples
(Xi,L(Xi)).
Then, a new unbiased estimator is given by
and its variance is
The main problem in importance sampling is to find an easily
implementable Φnew so that
E(I(X ∈
A)L(X)) << α, and so the variance
of the new estimator is significantly less than that of the naive
one.
The most common importance-sampling technique used for highly
reliable systems is failure biasing, proposed by Lewis and Böhm
[25]. The basic idea behind failure
biasing is to make component-failure transitions in the embedded DTMC
happen with a probability that is much higher than in the original
system. In state 1, there are no repair transitions.
Therefore, we do not need to failure bias in this state. However, in
states that have both failure and repair transitions, the total
probability of repair transitions ≈ 1 and the total probability of
failure transitions ≈ 0. In such states, the total probability of
failure transitions is increased to θ, where θ is some
constant (i.e., it is independent of ε) between 0 and 1 that is
significantly larger than the failure transition probabilities (in
practice, θ is typically taken to be 0.5). Therefore, the total
probability of repair transitions is decreased to 1 − θ. In
a version of failure biasing called balanced failure biasing (Goyal et
al. [15] and Shahabuddin
[36]), the probability of each
failure transition (that had positive probabilities in the original
system), conditioned on the event that the transition that occurs is a
failure transition, is made the same (this is also done in state
1). The probability of each repair transition, conditioned on
the event that the transition that occurs is a repair transition, is
left unchanged. Let P′ be the new transition-probability
matrix corresponding to balanced failure biasing. Note that
P′(x,y) > 0 if and only if
P(x,y) > 0.
We will now review the order of magnitude results for the variance
associated with importance sampling in the estimation of γ. To
obtain a sample of I(TF <
T1), we need only simulate one
regenerative cycle of the CTMC. Thus, γ is called a
“regenerative-cycle-based measure.” Other examples of
regenerative-cycle-based measures are E(W),
E(WI(TF <
T1)),
E(WI(TF >
T1)),
E(T1), and
E(min{TF,T1}).
Let Φ′′ be a change of measure on the sample
paths of the CTMC where we use P′ until time
min(TF,T1)
and then P after that. For any stopping time τ of the
embedded DTMC, define
Let τmin =
min(τF,τ1). Then, in
the same spirit as Eq. (1), we can write
The variance of the importance sampling estimator,
σγ2(Φ′′)
≡
VarΦ′′(I(TF
<
T1)Lτmin),
is given by
σγ2(Φ′′) =
EΦ′′(I(TF <
T1)Lτmin2)
− γ2. Let
σγ2(Φ) be the variance of
the naive estimator.
The following theorem was proved in Shahabuddin [36] under the following strengthened version
of Assumption (A.4):
(A.4′) For all
x ∈ F, P(1,x) is
o(1) (this implies that there exists x ∈
U − 1 such that
P(1,x) is Ω(1)).
Theorem 1: Both γ and
σγ2(Φ) are
Ω(εr), where r is a positive constant
depending on the structure of the system, the
ri's, and the failure propagation
probabilities. Also,
EΦ′′(I(TF
<
T1)Lτmin2)
is Ω(ε2r) and, so,
σγ2(Φ′′) is
O(ε2r).
This theorem implies that we get a bounded RE in the estimation of
γ. One can prove similar bounded RE results for other
“rare” regenerative-cycle-based measures like
E(WI(TF <
T1)). Moreover, observe that Assumption
(A.4′) is not at all restrictive. If it does not hold, then γ
is Ω(1) and we do not have to use importance sampling to estimate
it. Unless otherwise stated, in the following sections we will assume
that Assumptions (A.1), (A.2), (A.3), and (A.4′) hold.
For transient measures like the unreliability and expected interval
unavailability, in addition to failure biasing, we have to use another
technique called forcing (Lewis and Böhm [25]). If the time horizon is orders of
magnitude less than E(Z), then the system will fail
very rarely in [0,t], even though we failure bias.
To avoid this, the time of the first event is sampled from the
distribution of Z conditioned on the fact that it is less than
t. Because Z is exponentially distributed with rate
q(1), the time of the first event that we use in the
simulation is sampled from the distribution function given by
where 0 ≤ s ≤ t.
3. ESTIMATION OF THE UNRELIABILITY
Given a finite time horizon t, the unreliability,
U(t), is defined to be the probability that the
system fails before time t given that it starts in state
1; that is,
We wish to estimate the unreliability of the system for different
orders of magnitude of the time horizon. A modeling technique that is
used in Shahabuddin [35] and
Shahabuddin and Nakayama [38] is to
represent t as being
Ω(ε−rt), where
rt ≥ 0, and then model different orders
of magnitude of the time horizon by varying
rt. Hence, for
rt = 0, t is of the same order as
the expected repair times, and for rt =
r0, t is of the same order as the expected
first component-failure time in the system (which is of the same order
as the expected regenerative cycle time). For
rt = r0 + r,
t is of the same order as the MTTF.
In the following subsection, we will prove that a combination of
forcing and importance sampling gives bounded RE in the estimation of
the unreliability for the case where rt =
0; that is, the time horizon is “small.” Before that, we
will need to significantly extend the importance-sampling theory
developed for “rare” regenerative-cycle-based measures
(which was partially reviewed in Section 2.3) to a
“nonrare” measure. In particular, the following proposition
is crucial to the main result of the next subsection. The proof is
technical, so it is deferred to the Appendix.
Proposition 1:
EΦ′′(I(TF
>
T1)Lτmin2)
− 1 = Ω(1).
3.1. The Small-Time-Horizon Case
We can express the unreliability as U(t) =
E(I(A)), where A is the event
{TF < t}. Let
Φ′ be the new measure on the sample paths of
{X(t) : t ≥ 0}, in which in each
replication we use P′ until the system fails and
P from then on. For the unreliability, for each sample, we
only need to simulate the CTMC until either the system fails or the
time horizon is exceeded. Let ΦForcing′
be the measure corresponding to both balanced failure biasing and
forcing. The variances, without and with balanced failure biasing, are
denoted by
σU(t)2(Φ) and
σU(t)2(Φ′),
respectively. The variance with balanced failure biasing and forcing is
denoted by
σU(t)2(ΦForcing′).
The following theorem provides the orders of magnitude of the
unreliability and the variances of its estimators when the time horizon
is small.
Theorem 2: Consider the case where t =
Ω(εrt) with
rt = 0. Then, both U(t)
and σU(t)2(Φ)
are Ω(εr+r0). Also,
σU(t)2(Φ′)
= O(ε2r+r0)
and
σU(t)2(ΦForcing′)
= O(ε2(r+r0))
(r is the same as in the order of magnitude expression for
γ in Theorem 1).
From Theorem 2, we get the following corollary:
Corollary 1: The RE using
ΦForcing′ (corresponding to a
fixed 100(1 − δ)% level of confidence), for a fixed number
n of replications, remains bounded as ε → 0.
Lemmas 1 and 2 give bounds on U(t) that are used to
prove the order of magnitude result for U(t) in
Theorem 2. The result for
σU(t)2(Φ) is
a consequence of the fact that
σU(t)2(Φ) =
U(t) − U2(t). To
simplify notation, let q ≡ q(1). Let
K be the random variable denoting the number of times the
Markov chain is in state 1 (including the first time) before
hitting a state in F. Clearly, K has a geometric
distribution with parameter (i.e., success probability) γ.
Lemma 1: Let U(t) = 1 −
e−qtγ. Then, for all ε
and t,
Proof: Let Wtot be the total amount of
time the CTMC spends in states other than 1 before hitting
F. Let
fWtot|k(·)
be the density of Wtot given that K =
k and let Erlang(q,k) denote an Erlang
random variable with rate q and shape parameter k.
For a real-valued a, let (a)+ =
max(a,0). Then,
Lemma 2: Let qmin =
min(q(x) : x ∈ U −
1). Then, for all ε and t,
where k is some constant.
Proof: From Shahabuddin [36], it can be shown that there exists a
sequence of transitions that start from state 1 and reach a
state in F without reentering state 1 such that the
product of their probabilities is Ω(εr).
All other paths have probability of order
O(εr). In highly reliable systems
terminology (see, e.g., Gertsbakh [10]), this is one of the “most likely
paths” to system failure. Let
(x0,x1,x2,…xk)
be the sequence of states visited in one such path, where
x0 = 1 and xk
∈ F and xi ∈ U
− 1 for 1 ≤ i < k. Then,
where the inequality in the fifth line above follows from the fact
that the region of integration in the fifth line is contained in that
of the previous line. █
In the same spirit as Eq. (1), we can write U(t) =
E(I(TF < t))
=
EΦ′(I(TF
< t)LτF)
because we terminate a replication once the failed state is reached.
Hence, now we can use Φ′ and obtain samples of
(I(TF <
t),LτF).
Consequently, if we use balanced failure biasing, the new variance is
given by
σU(t)2(Φ′)
≡
VarΦ′(I(TF
< t)LτF) =
EΦ′(I(TF
<
t)LτF2)
− U2(t).
Lemma 3, which follows, gives an upper bound on
EΦ′(I(TF
<
t)LτF2)
which will enable us to evaluate the order of magnitude of
σU(t)2(Φ′).
Let D ≡
EΦ′′(I(TF
<
T1)Lτmin2)
= E(I(TF <
T1)Lτmin)
and B ≡
EΦ′′(I(TF
>
T1)Lτmin2)
= E(I(TF >
T1)Lτmin),
where Φ′′ has been defined in Section 2.3. The order
of magnitude of D (resp., B − 1) is given in
Theorem 1 (resp., Proposition 1).
The key to this result lies in the fact that we can decompose the
likelihood ratio LτF into a
product of likelihood ratios over individual cycles. For any sample
path with K = k, we can write
where L(i) represents the likelihood
ratio over the ith regenerative cycle in the sample path.
Given K = k, the L(i)
are mutually (conditionally) independent, with
L(1),…,L(k−1)
having the distribution of Lτmin
given that {τ1 < τF}
and L(k) has the distribution of
Lτmin given that
{τ1 > τF}.
Lemma 3: For all ε and t,
Proof: In the same spirit as Eq. (1),
Given K = k, (Z1 +
Z2 + ··· +
Zk) is (conditionally) independent of
LτF. Therefore, we can
write
Substituting this in Eq. (4), we obtain
Carrying out the necessary algebra, we get the result of the lemma.
█
We will now describe the contribution of forcing to the reduction in
variance. Recall that ΦForcing′ denotes
the new measure on the sample paths of {X(t) :
t ≥ 0} when with balanced failure biasing (i.e.,
Φ′) we also use forcing. Then, we have the
following lemma.
Lemma 4:
σU(t)2(ΦForcing′)
= (1 −
e−qt)EΦ′(I(TF
≤
t)LτF2)
− U2(t).
Proof: Let LForcing be the likelihood
ratio incurred due to forcing. Note that LForcing =
1 − e−qt. Then,
Proof of Theorem 2: From Lemma 1, we get that
U(t) is
O(εr+r0). Because
q is Ω(εr0), we have
that (1 − e−qt/k)
is Ω(εr0). Moreover, since
qmin is Ω(1), we have that (1 −
e−qmin
t/k) is also Ω(1). It then follows
that U(t) is
O(εr+r0)
and we get the first part of the theorem.
From Theorem 1, we see that D =
Ω(ε2r). Using Proposition 1 and the fact
that ex = 1 + x +
o(x), we get that
e(B−1)qt − 1 is
Ω(εr0). Therefore, by Lemma 3,
we get that
EΦ′(I(TF
<
t)LτF2)
is O(ε2r+r0).
Hence,
σU(t)2(Φ′)
=
EΦ′(I(TF
< t)L2) −
U2(t) is
O(ε2r+r0). Then,
using Lemma 4, we get that
3.2. The Large-Time-Horizon Case
Consider the following generalization of Theorem 2, which gives the
orders of magnitude of the variances of our estimators for large time
horizons.
Theorem 3: Consider the case of large time horizons
where t =
Ω(ε−rt)
with 0 ≤ rt ≤
r0. Then, both U(t) and
σU(t)2(Φ)
are
Ω(εr+r0−rt)
and
σU(t)2(ΦForcing′)
=
O(ε2(r+r0−rt)).
The proof of this theorem follows from Lemmas 1–4 and
Proposition 1 by substituting t =
Ω(εrt) in all of the
expressions involving t and using the same method as in the
proof of Theorem 2.
We saw in the previous section that for small t, for the
bounded RE property to hold, the variance reduction using importance
sampling had to be of the same order as the unreliability. From Theorem
3, we see that for the case of large time horizons, we also get a
variance reduction that is of the same order as the unreliability as
long as rt ≤ r0.
Let
We can easily show that for 0 < rt
≤ r0,
EΦ′(I(TF
<
t)LτF2)/V(t)
→ 1 as ε → 0. We conjecture that this holds even for
r0 < rt <
r0 + rt. If this
conjecture is true, then we have an approximate expression for the
variance for the case when ε is small. Then, it is easy to see why
simulation using importance sampling becomes very inefficient for the
case where rt > r0.
This is also explained by the results in Glynn [11]; the variance of the likelihood ratio
increases (roughly) exponentially fast in the number of transitions of
the Markov chain. In experiments in Nicola, Nakayama, Heidelberger, and
Goyal [30], it is shown that even
for the case where rt =
r0, one has to tune the value of the
failure-biasing parameter θ by trial and error, which can be
computationally expensive. Hence, for the case where
rt ≥ r0, it is best
to use the “bounding approach,” as mentioned in Section
1.
Motivated by this, we now investigate bounds on the unreliability. As
mentioned in Section 1, because the system is regenerative, the time to
failure is roughly a geometric sum of i.i.d. random variables. There is
some literature on bounds on the distribution function of such random
variables, which, in our case, corresponds to the unreliability. We
investigate the bounds given in [4]. For completeness, we first present the
bound in its original form. We then adapt it to the reliability model
described in this article. Let Vi
(generically denoted by V) be i.i.d. nonnegative random
variables and let V′ be another nonnegative random
variable independent of the Vi's. Let
,
where
N0 is a geometric random variable, independent of
the Vi's and V′, with
probability of “success” p (i.e.,
P(N0 = i) = (1 −
p)i−1p for i ≥
1). It is well known in the literature (e.g., Keilson [24] and Solovyev [40]) that as p → 0, T
converges in distribution to an exponentially distributed random
variable with mean E(T). Here, E(T)
= (1 − p)E(V)/p +
E(V′). Theorem 2.2 of Brown [4] gives the following bound:
In our setting, a “success” in the geometric random
variable definition corresponds to system failure happening in a
regenerative cycle. More specifically, if we define
N0 ≡ K,
Vi ≡ Zi
+ Wi for 0 ≤ i
≤ K − 1, V′ ≡
ZK + WK (recall
that Wi is the random variable
Wi conditioned on no failure event occurring in
that cycle and that Wi is the random variable
Wi conditioned on a failure event
occurring in that cycle), and p ≡ γ, then T
≡ TF. An important point to note is
that in our setting, even though Wi is not
independent of K, the
Wi, 0 ≤ i ≤
K − 1, and WK
are independent of K. Also,
Define Ub(t) = 1 −
e−t/E(TF).
Let I ≡ I(TF
< T1) (resp., I
≡ I(TF >
T1)) and define
Then, using Eq. (5), we see that upper and lower bounds on
U(t) = P(TF
≤ t) are given by
Ub(t) =
Ub(t) +
Uerr,b(t) and
Ub(t) =
Ub(t) −
Uerr,b(t), respectively. The
bounds are in terms of regenerative-cycle-based measures.
The quality of any upper bound and lower bound combination depends on
how close they are to each other. Define the relative error of the
bounds (this should not be confused with the relative error, RE,
in the simulation context, that was defined earlier), REB, to be the
difference between the upper bound and the lower bound divided by twice
the measure of interest. (The “twice” is motivated by the
fact that if we use the arithmetic mean of the upper and lower bound as
an approximation for our measure of interest, then the relative error
between the approximation and the actual value is always less than
REB.) In this case, the REB is given by
REBb(t) ≡
(Ub(t) −
Ub(t))/2U(t)
=
Uerr,b(t)/U(t).
Theorem 4: If rt >
r0, then
Uerr,b(t)/Ub(t)
→ 0 as ε → 0; if rt =
r0, then
Uerr,b(t)/Ub(t)
is Ω(1); if rt <
r0, then
Uerr,b(t)/Ub(t)
→ ∞ as ε → 0. Hence,
REBb(t) → 0, as ε
→ 0 if and only if rt >
r0.
Proof: We use the representation given in Eq. (6).
Assumptions (A.2) and (A.4′) imply that 1 − γ is
Ω(1). Using the orders of γ, 1 − γ,
E(W), E(W),
E(W2), and
E(Z) (see Sect. 2.2), we get that
E(Z + W) =
Ω(ε−r0),
E(Z + W) =
Ω(ε−r0), and
E((Z + W)2) =
Ω(ε−2r0). Consequently,
Uerr,b(t) =
Ω(εr). Moreover, since
E(TF) =
Ω(ε−r−r0),
Ub(t) =
Ω(εr+r0−rt)
for rt < r +
r0 and Ub(t)
= Ω(1) for rt ≥ r +
r0. The result for all three cases follows from
these facts. The last part of the theorem follows from the fact that
Therefore, REBb(t) → 0 if and only
if
Uerr,b(t)/Ub(t)
→ 0. █
We also tried using the bounds in Kalashnikov [23], but there seems to be some error in the
bounds. Moreover, as mentioned earlier, the bounds do not make use of
the special structure of the regenerative cycles; that is, they do not
make use of the fact that
min{T1,TF} =
Z + W, where Z is exponentially distributed
and E(Z) >> E(W). The
following theorem provides bounds that make use of this special
structure.
Theorem 5:
(i) Let
U(t) = 1 −
e−qγt. Define
and let
U(t) ≡ U(t)
− Uerr(t),
where
Then, U(t) ≤
U(t) ≤ U(t) for all ε
and
t.
(b) Let REB(t) denote the REB in this case.
For rt > 0, REB(t)
≡ (U(t) −
U(t))/2U(t) =
Uerr(t)/2U(t)
→ 0 as ε → 0.
Remark 1: These bounds are in terms of
regenerative-cycle-based measures.
Remark 2: These bounds converge for a much wider range of
the time horizon as compared to the range in Theorem 4.
4. EXPERIMENTAL RESULTS WITH A LARGE
MARKOVIAN MODEL
We took an example of a large computing system originally considered
in Goyal et al. [15] and
subsequently in many other articles. The system is depicted in Figure 1. It consists of two sets of processors
with two processors per set, two sets of disk controllers with two
controllers per set, and six clusters of disks with four disks per
cluster. In a disk cluster, data are replicated so that we can have one
disk fail without affecting the system. The failure rates of
processors, controllers, and disks are assumed to be
per hour, respectively. If a processor of a
given set fails, it has a 0.01 probability of causing the operating
processor of the other set to fail. Each unit in the system can fail in
one of two failure modes which occur with equal probability. The repair
rates for all mode 1 and all mode 2 failures are 1 per hour and
½ per hour, respectively. The system is defined to be
operational if all data are accessible to both processor types, which
means that at least one processor in each set, one controller in each
set, and three out of four disks in each of the six disk clusters are
operational. We also assume that operational components continue to
fail at the given rates when the system failed.
Block diagram of the computing system modeled.
To keep the state space within manageable limits (in order to
facilitate comparison with approximate numerical results from SAVE),
Goyal et al. [15] assumed that
after each transition (whether failure or repair), the repairman picks
a component at random from the set of failed components. In this way,
the state variable does not have to include the order of components
waiting at the repair queue. For the purpose of comparison, we first
use the same repair discipline. Later, we also consider the same
example with first-come first-served (FCFS), where the numerical
methods implemented in SAVE cannot be used.
In order to see the effect of our simulation schemes, we estimate the
unreliability for different values of the time horizon using different
techniques. The results are presented in Table
1. The time horizon is given in the first column. This model has
1,265,625 states and is thus very difficult to solve by exact
techniques. Goyal et al. [15] used
SAVE to numerically compute approximations for values of the time
horizon up to 1024, but give no bounds on the approximation error. We
used SAVE to complete these computations for the other time horizons.
All these are reproduced in column 2. The third column gives the
estimate and the RE corresponding to 99% confidence intervals (CIs) if
we use naive simulation. The fourth column gives the estimate and the
RE using failure biasing and forcing. Each of the naive and
importance-sampling-simulation cases were simulated for 400,000 events.
In the fifth and sixth columns, we estimate the bounds of Brown
[4] mentioned earlier (henceforth
referred to as M.B. bounds). We do this by running 1 simulation of
400,000 events and estimating γ, E(W),
E(WI(T1 <
TF)), and
E(W2I(T1
< TF)). We then used them to compute
the bounds for all t. These regenerative-cycle-based measures
can be estimated using the dynamic importance sampling (DIS) approach
with balanced failure biasing as described in Goyal et al. [15]. For building confidence intervals, we use
the delta method (e.g., see Serfling [34, p.124]) to establish a central limit
theorem.
Estimates of the Unreliability, Brown's [4] Bounds, and the New Bounds
Next, we estimate the bounds which we developed. In this case, one
has to first estimate the regenerative-cycle-based measures γ,
E(W), and
E(WI(T1 <
TF)). The last two columns of Table 1 give the experimental results using these
new bounds. We again use 1 simulation run of 400,000 events to estimate
the bound for all t. Compared to the M.B. bounds, it is
simpler to build confidence intervals in this case, as there are fewer
measures to be estimated and the expressions are less complicated.
In this example, E(T1) ≈ 125
and E(TF) ≈ 152,240. For time
horizons that are significantly larger than 125, one should not expect
balanced failure biasing and forcing to work well. One can observe in
Table 1 that for time horizon 1024 and
beyond, the estimates of the unreliability and/or their REs, using
balanced failure biasing and forcing, become highly unstable. In fact,
we suspect infinite variance, either in the estimation of the quantity
or its RE, in this range of the time horizon; that is, no matter how
long we run the simulation, we will never get stability. The estimates
of the M.B. bounds are “satisfactory” (we define this to be
less than 10% REB) only for time horizon 4096 and beyond. However, for
all time horizons where failure biasing and forcing do not work well
(i.e., time horizon 1024 and beyond), the estimates of the new bounds
are satisfactory. For very large values of t, estimates using
M.B. bounds do better than those using the new ones. Hence, these could
be used for better accuracy for the higher time ranges.
To verify the robustness of our methods for simulating rare events,
we consider a more “rare” case where all the failure rates
and the failure propagation probabilities are reduced by a factor of
100. We also use the FCFS service discipline. In this case,
E(T1) ≈ 12,500 and
E(TF) ≈ 16.44 ×
108. As earlier, a total of 400,000 events were simulated
for each case. The results are presented in Table
2. In this case, importance sampling starts to become unstable
from time horizons 105 and beyond, and we note the same
relative trends in the bounds as we did earlier. In addition, the RE
using naive simulation goes up about 10 times from the previous less
rare case; however, the relative errors in the simulation of the bounds
are almost unchanged. All of the (estimated) REs in the estimates of
the bounds, except for t = 10, ranged from 3.7% to 3.8%.
Estimates of the Unreliability and the Bounds for Another
Model
In these experiments, we used balanced failure biasing to estimate
the regenerative-cycle-based measures. As mentioned earlier, this is
guaranteed to produce a bounded RE in the estimation of these measures.
However, other failure-biasing schemes that are efficient in practice
(e.g., the failure distance scheme of Carrasco [5]) can also be used in the estimation of
these regenerative-cycle-based measures.
5. DISCUSSION AND OPEN PROBLEMS
In this article, we discussed the estimation of the unreliability in
large Markovian models of highly reliable systems. We show that for
small time horizons, simulation using the importance-sampling
techniques of failure biasing and forcing are provably effective. For
large time horizons, simulation using the above techniques becomes
difficult. In this case, the approach used is to first bound the
unreliability in terms of regenerative-cycle-based measures and then
estimate the regenerative-cycle-based measures using importance
sampling. We explore bounds existing in the literature and develop some
bounds of our own.
For the small-time-horizon case (rt =
0), this work complements the work in Heidelberger, Shahabuddin, and
Nicola [18] and Nicola et al.
[30], which deals with the
estimation of transient measures and proving corresponding BRE results
for non-Markovian reliability models. However, the frameworks used for
simulation and thus importance sampling in the non-Markovian setting
are very different from those used for Markovian models. In particular,
a discrete-event-simulation approach and/or uniformization is used
in [18] and [30], whereas the CTMC approach is recommended
and used for large Markovian models (e.g., SAVE). As was the case in
this article, the direct importance-sampling approaches
described in [18] and [30] do not work when the time horizon is
large.
For the large-time-horizon non-Markovian case, we can easily extend
the bounding approach in this article, for the case when failure times
are exponentially distributed but repair times are generally
distributed. This is because the regenerative property is still
preserved and one can use the techniques in Nicola et al. [30] and Nicola, Shahabuddin, Heidelberger, and
Glynn [31] to estimate the
regenerative-cycle-based measures efficiently. However, results on the
convergence of the bounds to the actual measure, although intuitively
apparent, are difficult to prove rigorously. The development of
efficient large-time-horizon simulation techniques in models for which
both the failure times and repair times are nonexponentially
distributed is still an open problem, because, then, the regenerative
structure is lost.
It should be mentioned that even though we use balanced failure
biasing for estimating the transient measures (for small time horizons)
and the regenerative-cycle-based measures, one could also have used
balanced failure transition distance biasing (Carrasco [5,6]) or the
balanced likelihood ratio method (Alexopoulos and Shultes [1] and Shultes [39]). Balanced failure transition distance
biasing uses structural information about the system to failure bias
and, thus, tends to produce more accurate estimates. However, there is
an implementation overhead that comes with using more information that
is not present in the case of balanced failure biasing. Bounded
relative error results for regenerative-cycle-based measures in the
case of balanced failure transition distance biasing follow as
straightforward extensions of the work in Shahabuddin [36] (see, e.g., Nakayama [27,29] and Nicola et
al. [32]); we expect the same to be
true for transient measures in the case of small time horizons. The
balanced likelihood ratio method has empirically been shown to work
better than balanced failure biasing on systems with larger redundancy
(minimum number of component failures required for the system to fail)
than those originally considered in SAVE (Blum et al. [2,3]). Bounded
relative error results for estimating regenerative-cycle-based measures
using the balanced likelihood ratio method, and an extension of the
technique that uses structural information about the system are also
described in Alexopoulos and Shultes [1] and Shultes [39].
Acknowledgments
The work of the first author was supported by National Science
Foundation (NSF) CAREER Award DMI-96-24469 and NSF grant DMI-99-00117.
The work of the second author was supported in part by NSF grant
DMS-95-08709, NSF CAREER Award DMI-96-25291, and a 1998 IBM University
Partnership Program Award. The authors would like to thank Chia-wei Hu
for computational assistance.
APPENDIX
We first briefly review the notation and framework considered in
Shahabuddin [36]. Let
PR be the matrix constructed from
P where the rows and columns corresponding to state 1
and states in F are removed. Since all states represented in
PR have at least one ongoing repair
transition, PR is a matrix in which the
positive elements above the diagonal (i.e., probabilities of failure
transitions) are of the form cεd +
o(εd), c > 0, d
> 0, where c and d are generic representations of
constants. The positive elements below the diagonal (i.e.,
probabilities of repair transitions) are of the form c +
o(1), c > 0. For x ∈ U, let
pF(x) =
[sum ]y∈F
P(x,y),
p1(x) =
P(x,1), and
p0(x) = P(1,x).
Let the vectors pF,
p1, and p0 be given by
pF =
{pF(x) : x ∈
U − 1}, p1 =
{p1(x) : x ∈
U − 1}, and p0 =
{p0(x) : x ∈ U
− 1}, respectively. All vectors are assumed to be column
vectors. The positive elements of p1 are of the
form c + o(1), c > 0, the positive
elements of pF are o(1), and the
positive elements of p0 are O(1). From
Assumption (A.4), we have that at least one element of
p0 is positive. Let
vγ(x) =
P(TF <
T1|Y0 =
x) and vγ =
{vγ(x) : x ∈ U
− 1}. By Assumption (A.3), all elements of
vγ are positive. By Assumption (A.1), starting
from any state x ∈ U − 1, the
Markov chain hits 1 ∪ F with probability 1.
Consequently, for x ∈ U,
P(T1 <
TF|Y0 =
x) = 1 − vγ(x). By
Assumption (A.2), we have that all elements of e −
vγ are positive, where e is a vector
of 1's.
By a matrix or a vector being o(εd)
(resp., O(εd),
O(εd),
Ω(εd)), d ≥ 0, we mean that
all elements of that matrix or vector are
o(εd) (resp.,
O(εd),
O(εd),
Ω(εd)). It has been shown in Shahabuddin
[36] (see the proof of Lemma 3 in
that article) that there exists a nonnegative integer constant
N0 such that
Therefore,
It was shown in Shahabuddin [36]
that
.
Similarly, one can show that
.
From Eq. (A.2) and the fact mentioned earlier that
pF is o(1), we get that
vγ is o(1).
Let
be a matrix constructed out of P
by removing the row and column corresponding to state 1.
has the same structure as
PR in the sense that the positive elements
above the diagonal are of the form cεd
+ o(εd), c > 0, d
> 0, and the positive elements below the diagonal are of the form
c + o(1), c > 0. Thus,
for exactly the same reason as Eq. (A.2).
Lemma A.1: E(T1) =
Ω(ε−r0).
Proof: Let
(recall that
h(x) ≡ 1/q(x)),
,
and
.
Then, we have that
,
from which we get
.
From
Assumption (A.2) and the fact that the repair rates are Ω(1), we
get that
is Ω(1), and so from Eq. (A.3),
is O(1). In addition,
p0 is O(1), so
.
█
Lemma A.2: E(W) and
E(W) are O(1).
Proof: For x ∈ U, let
w(x) =
E(min(T1,TF)I(TF
< T1)|Y0 =
x), and w(x) =
E(min(T1,TF)I(T1
< TF)|Y0 =
x). Let = {(x) : x ∈
U − 1} and =
{w(x) : x ∈ U
− 1}. Let h = {h(x) :
x ∈ U − 1}. Note that
(the
denotes the scalar product) from which we
get
.
Then, using
the fact from Section 2.1 that 1 − γ > 0, we get that
In a similar fashion, we get that
and using the fact from Section 2.1
that γ > 0, we get that
By Assumption (A.4) and the fact that all elements of
vγ are positive,
p0Tvγ
> 0. We will now show that (resp., ) and
e − vγ (resp.,
vγ) are of the same order. From Assumption (A.2)
and the fact that the repair rates are Ω(1), we get that h
is Ω(1). Consequently, if an element of e −
vγ (resp., vγ) is
Ω(εd) for some d ≥ 0, then the
corresponding element of
(resp.,
is also Ω(εd)
for the same d. Because
,
the corresponding element of (resp., ) is similarly
O(εd) for the same d. Using
this fact in Eq. (A.4) (resp., Eq. (A.5)), we see that
E(W) (resp., E(W)) is O(1).
█
Lemma A.3: E(W2) is
O(1).
Proof: We use notation from the proof of Lemma A.2.
Furthermore, let H(x) denote the holding-time random
variable in state x. Clearly, H(x) is
exponentially distributed with rate q(x). Define
l(x) = E(H2(x))
= 2/q2(x), l =
{l(x) : x ∈ U −
1}, q(x) =
E((min(T1,TF))2
× I(T1 <
TF)|Y0 =
x), and =
{q(x) : x ∈ U
− 1}. Then, one can easily derive the recursive equation
that
from which one gets that
.
In that
case,
Using the fact that vγ is o(1), we
get that the elements of e − vγ
are Ω(1). In addition, from what was stated in the proof of Lemma
A.2, is O(1). The l and
h are Ω(1),
is O(1),
and, therefore, is O(1). Then, the
proof follows from Eq. (A.6). █
Proof of Proposition 1: For any matrix (vector), say
PR, with elements of the form c +
o(1), c ≥ 0, let
be the matrix containing
the “c part” of the elements. Using the fact
mentioned earlier that vγ is o(1), we
get that
Using Eq. (A.1) and the fact that the positive elements of
p1 are of the form c + o(1),
c > 0, we have that
Comparing Eq. (A.8) with Eq. (A.7), we see that
As in Shahabuddin [36], we
construct the matrix B = {B(x,y) :
x,y ∈ S} by setting
B(x,y) =
P2(x,y)/P′(x,y)
for all x, y such that
P′(x,y) ≠ 0;
B(x,y) = 0 otherwise. The
BR, bF,
b1, and b0 are
constructed from B the same way as
PR, pF,
p1, and p0 were
constructed from P. Note that BR
is a matrix in which the positive elements above the diagonal are of
the form cεd +
o(εd), c > 0, d
≥ 2, and the positive elements below the diagonal are of the form
c + o(1), c > 0. It has been shown in
Shahabuddin [36] that for the same
N0 as earlier,
.
Thus,
is O(1). It has
also been shown in Shahabuddin [36]
that
.
Using a similar method, we can show
that
.
The positive elements of b1 are of the
form c + o(1), where c > 0. Hence,
Equation (A.10) follows from the form of the elements of
P′ and the fact that in the Markov chain corresponding
to P, the sum of all the repair transition probabilities from
any state other than 1 is 1 − o(1). The last
equality follows from Eq. (A.9). From Eq. (A.11), we get that
where r(1) is the number of positive probability
failure transitions from 1. The last equality follows from the
fact that P′(1,x) =
1/r(1).
The elements of P(1,x) can be represented
in the form c + o(1), c ≥ 0. Let
be the set
of x for which P(1,x) is of the
form c + o(1), c > 0. From Assumption
(A.4′), we see that
.
Since
,
we
have that
The last inequality follows because the minimum of the function
subject to the constraints
,
∀i, is 1. Therefore,
so B − 1 = O(1). Using the fact
that
,
b0, and b1 are
O(1), we get that
is O(1). Hence, B − 1 = Ω(1).
█
Proof of Theorem 5:
(a) The U(t) ≤
U(t) bound can be proved by exactly the same method
as Lemma 1. We will now prove the lower bound.
Let f(q,k)(x) be
the density of an Erlang random variable with rate q and shape
parameter k (i.e., the density of Z1 +
Z2 + ··· +
ZK given that K = k).
Then,
We now have to prove that the second term above is upper bounded
by Uerr(t). Given K = k,
the Wi's are (conditionally)
independent of the Zi's. Also given
K = k, the
W1,W2,…,Wk−1
are i.i.d. and have the distribution of W.
Moreover, given K = k,
Wk is independent of the
W1,W2,…Wk−1
and has the distribution of W. Thus, we can
rewrite the second term and bound it as follows:
(b) We will first show that
Uerr(t)/U(t)
→ 0 as ε → 0. The result then follows from the fact
that
We use the representation of Uerr(t)
given by Eq. (A.12).
First, let us study the properties of l. If
rt < r0 (resp.,
rt > r0), then for all
sufficiently small ε, t < 1/q (resp., t
> 1/q), which implies that
(resp.,
). Thus, l
is Ω(ε−rt
/2) (resp., l is
Ω(ε−rt+r0
/2)). If rt =
r0, then
,
but in either case,
l = Ω(ε−rt
/2). Since rt > 0 and for
rt > r0,
rt − r0 /2
> 0, we have that 1/l is o(1). Since
r0 > 0 and rt >
0, we have that l/t = o(1). It then
follows that t − l is
Ω(ε−rt).
Consider the case where rt <
r + r0, so that
εr+r0−rt
→ 0 as ε → 0. Using the well-known fact that 1 −
e−x = x + o(x),
we get that U(t) is
Ω(εr+r0−rt).
Hence, all we have to show is that Uerr(t) =
o(εr+r0−rt).
Since t − l is
Ω(ε−rt), (1 −
e−γq(t−l)) =
γq(t − l) +
o(εr+r0−rt)
is
Ω(εr+r0−rt).
Lemma A.2 shows that both E(W) and
E(W) are O(1). Since 1/l
is o(1), the first term in Eq. (A.12) is
o(εr+r0−rt).
Using the well-known fact that 1 −
e−x −
xe−x is x2/2 +
o(x2) and the fact that t −
l is Ω(ε−rt),
one can easily show that (1 −
e−γq(t−l)
− γq(t −
l)e−γq(t−l))
is γq(t − l) ×
Ω(εr+r0−rt).
Considering separately the two cases of 0 < rt
≤ r0 and r0 <
rt < r + r0, one
can show that q(t − l)/l is
o(1) and, therefore, the second term in Eq. (A.12) is
o(εr+r0−rt).
Finally,
Using the fact mentioned earlier that l/t
is o(1), we can show that the last part of Eq. (A.12) is
o(εr+r0−rt).
Now, consider the case where rt
≥ r + r0. In this case,
U(t) is Ω(1). Thus, all we have to show is that
Uerr,t(t) is o(1). For
rt = r + r0,
1 −
e−γq(t−l)
and 1 −
e−γq(t−l)
− γq(t −
l)e−γq(t−l)
are Ω(1). For rt > r +
r0, one can show the same by using the fact that 1
− e−1/x and 1 −
e−1/x −
(1/x)e−1/x approach
1 as x → 0. Using the fact that 1/l is
o(1), one can show that the first term of Eq. (A.12) is
o(1). Note that rt ≥
r + r0 implies that
rt > r0.
Consequently,
is
Ω(εrt−r−r0
/2) = o(1). Using this fact, one can show that the
second term of Eq. (A.12) is o(1). Express the last term of
Eq. (A.12) as
.
For rt > r +
r0, it is easy to see that as ε → 0, this
term tends to 0 and, hence, it is o(1). For
rt = r + r0,
e−γqt is Ω(1) and
is o(1), and so the last term is also
o(1). █