


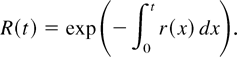
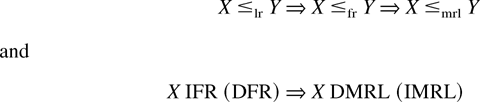


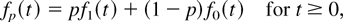
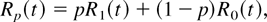

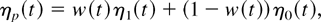

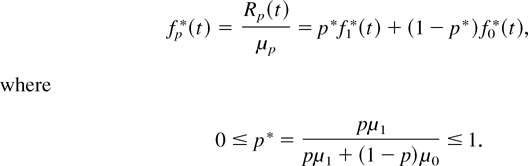
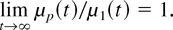
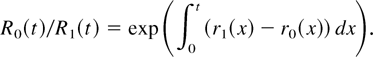

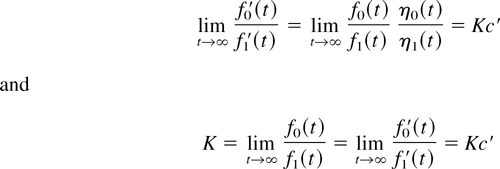
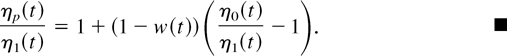
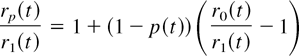
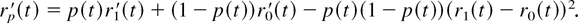









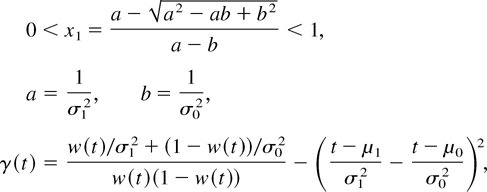
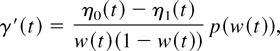
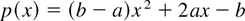
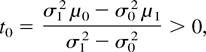















Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Wondmagegnehu, E.T.
Navarro, J.
and
Hernandez, P.J.
2005.
Bathtub Shaped Failure Rates From Mixtures: A Practical Point of View.
IEEE Transactions on Reliability,
Vol. 54,
Issue. 2,
p.
270.
Navarro, Jorge
and
Shaked, Moshe
2006.
Hazard rate ordering of order statistics and systems.
Journal of Applied Probability,
Vol. 43,
Issue. 02,
p.
391.
Block, Henry W.
2006.
Advances in Distribution Theory, Order Statistics, and Inference.
p.
267.
Navarro, Jorge
and
Shaked, Moshe
2006.
Hazard rate ordering of order statistics and systems.
Journal of Applied Probability,
Vol. 43,
Issue. 2,
p.
391.
Belzunce, Félix
Ortega, Eva-María
and
Ruiz, José M.
2007.
On non-monotonic ageing properties from the Laplace transform, with actuarial applications.
Insurance: Mathematics and Economics,
Vol. 40,
Issue. 1,
p.
1.
Navarro, Jorge
Rychlik, Tomasz
and
Shaked, Moshe
2007.
Are the Order Statistics Ordered? A Survey of Recent Results.
Communications in Statistics - Theory and Methods,
Vol. 36,
Issue. 7,
p.
1273.
Ali, M. Masoom
Woo, Jungsoo
and
Nadarajah, Saralees
2008.
Stochastic Orderings of Integer Valued Random Variables.
American Journal of Mathematical and Management Sciences,
Vol. 28,
Issue. 1-2,
p.
101.
Navarro, Jorge
and
Hernandez, Pedro J.
2008.
Mean residual life functions of finite mixtures, order statistics and coherent systems.
Metrika,
Vol. 67,
Issue. 3,
p.
277.
Navarro, Jorge
and
Hernández, Pedro J.
2008.
Advances in Mathematical and Statistical Modeling.
p.
89.
Navarro, Jorge
2008.
Likelihood ratio ordering of order statistics, mixtures and systems.
Journal of Statistical Planning and Inference,
Vol. 138,
Issue. 5,
p.
1242.
Nair, N. Unnikrishnan
and
Preeth, M.
2008.
Multivariate equilibrium distributions of order.
Statistics & Probability Letters,
Vol. 78,
Issue. 18,
p.
3312.
Nair, N. Unnikrishnan
and
Preeth, M.
2009.
On some properties of equilibrium distributions of order n.
Statistical Methods and Applications,
Vol. 18,
Issue. 4,
p.
453.
Navarro, Jorge
Guillamón, Antonio
and
Ruiz, María del Carmen
2009.
Generalized mixtures in reliability modelling: Applications to the construction of bathtub shaped hazard models and the study of systems.
Applied Stochastic Models in Business and Industry,
Vol. 25,
Issue. 3,
p.
323.
Navarro, Jorge
2009.
‘Understanding the shape of the mixture failure rate’ by Maxim Finkelstein: Discussion 2.
Applied Stochastic Models in Business and Industry,
Vol. 25,
Issue. 6,
p.
669.
Nadarajah, Saralees
2009.
Bathtub-shaped failure rate functions.
Quality & Quantity,
Vol. 43,
Issue. 5,
p.
855.
Finkelstein, Maxim
2009.
Understanding the shape of the mixture failure rate (with engineering and demographic applications).
Applied Stochastic Models in Business and Industry,
Vol. 25,
Issue. 6,
p.
643.
Bebbington, Mark
Lai, Chin-Diew
and
Zitikis, Ričardas
2010.
Life expectancy of a bathtub shaped failure distribution.
Statistical Papers,
Vol. 51,
Issue. 3,
p.
599.
Navarro, Jorge
and
Sarabia, José María
2010.
Alternative definitions of bivariate equilibrium distributions.
Journal of Statistical Planning and Inference,
Vol. 140,
Issue. 7,
p.
2046.
Mi, Jie
2011.
Limit of hazard rate function of coherent system with discrete life.
Applied Stochastic Models in Business and Industry,
Vol. 27,
Issue. 5,
p.
551.
Bagkavos, Dimitrios
2011.
Local linear hazard rate estimation and bandwidth selection.
Annals of the Institute of Statistical Mathematics,
Vol. 63,
Issue. 5,
p.
1019.