


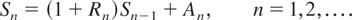
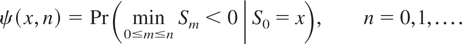
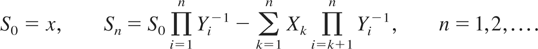
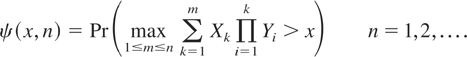


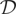
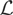
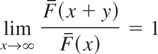
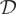















Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Zhu, Chun-hua
and
Gao, Qi-bing
2008.
The uniform approximation of the tail probability of the randomly weighted sums of subexponential random variables.
Statistics & Probability Letters,
Vol. 78,
Issue. 15,
p.
2552.
Chen, Yiqing
Ng, Kai W.
and
Yuen, Kam C.
2011.
The Maximum of Randomly Weighted Sums with Long Tails in Insurance and Finance.
Stochastic Analysis and Applications,
Vol. 29,
Issue. 6,
p.
1033.
Chen, Yiqing
2011.
The Finite-Time Ruin Probability with Dependent Insurance and Financial Risks.
Journal of Applied Probability,
Vol. 48,
Issue. 4,
p.
1035.
Chen, Yiqing
2011.
The Finite-Time Ruin Probability with Dependent Insurance and Financial Risks.
Journal of Applied Probability,
Vol. 48,
Issue. 04,
p.
1035.
Zhou, Min
Wang, Kai-yong
and
Wang, Yue-bao
2012.
Estimates for the finite-time ruin probability with insurance and financial risks.
Acta Mathematicae Applicatae Sinica, English Series,
Vol. 28,
Issue. 4,
p.
795.
Cheng, Dongya
Ni, Fenglian
Pakes, Anthony G.
and
Wang, Yuebao
2012.
Some properties of the exponential distribution class with applications to risk theory.
Journal of the Korean Statistical Society,
Vol. 41,
Issue. 4,
p.
515.
Yuen, Kam Chuen
and
Yin, Chuancun
2012.
Asymptotic results for tail probabilities of sums of dependent and heavy-tailed random variables.
Chinese Annals of Mathematics, Series B,
Vol. 33,
Issue. 4,
p.
557.
Hashorva, Enkelejd
and
Li, Jinzhu
2014.
ASYMPTOTICS FOR A DISCRETE-TIME RISK MODEL WITH THE EMPHASIS ON FINANCIAL RISK.
Probability in the Engineering and Informational Sciences,
Vol. 28,
Issue. 4,
p.
573.
Chen, Yiqing
Liu, Jiajun
and
Liu, Fei
2015.
Ruin with insurance and financial risks following the least risky FGM dependence structure.
Insurance: Mathematics and Economics,
Vol. 62,
Issue. ,
p.
98.
Yang, Haizhong
Gao, Wei
and
Li, Jinzhu
2016.
Asymptotic ruin probabilities for a discrete-time risk model with dependent insurance and financial risks.
Scandinavian Actuarial Journal,
Vol. 2016,
Issue. 1,
p.
1.
Wang, Kaiyong
Gao, Miaomiao
Yang, Yang
and
Chen, Yang
2018.
Asymptotics for the finite-time ruin probability in a discrete-time risk model with dependent insurance and financial risks*.
Lithuanian Mathematical Journal,
Vol. 58,
Issue. 1,
p.
113.
Cui, Zhaolei
Omey, Edward
Wang, Wenyuan
and
Wang, Yuebao
2018.
Asymptotics of convolution with the semi-regular-variation tail and its application to risk.
Extremes,
Vol. 21,
Issue. 4,
p.
509.
Chen, Yiqing
Liu, Jiajun
and
Yang, Yang
2023.
Ruin under Light-Tailed or Moderately Heavy-Tailed Insurance Risks Interplayed with Financial Risks.
Methodology and Computing in Applied Probability,
Vol. 25,
Issue. 1,