


1. Introduction
Variation is intrinsic to human language and it is manifested in different ways. There are four generally accepted dimensions of language variation, namely diaphasic, diastratic, diachronic, and diatopic. Diaphasic variation is related to the setting or the medium of communication, for example, different levels of style and register, oral versus written language. Diastratic variation is related to language variation in different social groups (e.g., age, gender), whereas diachronic is language variation across time. Finally, diatopic variation is language variation in space such as different dialects or national varieties of the same languages (e.g., British and American English). All these dimensions of language variation pose challenges for Natural Language Processing (NLP) applications developed to process text and speech. As a result, there has been a growing interest in language variation in the NLP community, as evidenced by a large number of publications and events, for example, conferences, shared tasks, tutorials, and workshops on the topic, some of which we cover in this survey.
One of these initiatives is the series of workshops on NLP for Similar Languages, Language Varieties, and Dialects (VarDial), a workshop series with a special focus on diatopic language variation. VarDial started in 2014, and since then it has become an important venue for work on the study of language variation from a computational perspective, co-located with international NLP conferences such as COLING, EACL, and NAACL. Past editions of the workshop included papers on machine translation (MT) (Shapiro and Duh Reference Shapiro and Duh2019; Myint Oo, Kyaw Thu, and Mar Soe Reference Myint Oo, Kyaw Thu and Mar Soe2019; Popović et al. Reference Popović, Poncelas, Brkic and Way2020), part-of-speech tagging (Huck, Dutka, and Fraser Reference Huck, Dutka and Fraser2019; AlGhamdi and Diab Reference AlGhamdi and Diab2019), text normalization (Lusetti et al. Reference Lusetti, Ruzsics, Göhring, Samardžić and Stark2018), and many other relevant topics applied to the computational processing of similar languages, varieties, and dialects. The workshop also featured evaluation campaigns with multiple shared tasks on a number of topics such as cross-lingual morphological analysis, cross-lingual parsing, language and dialect identification, and morphosyntactic tagging (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Ali, Shon, Glass, Scherrer, Samardžić, Ljubešić, Tiedemann, van der Lee, Grondelaers, Oostdijk, Speelman, van den Bosch, Kumar, Lahiri and Jain2018, Reference Zampieri, Malmasi, Scherrer, Samardžić, Tyers, Silfverberg, Klyueva, Pan, Huang, Ionescu, Butnaru and Jauhiainen2019; Găman et al. Reference Găman, Hovy, Ionescu, Jauhiainen, Jauhiainen, Lindén, Ljubešić, Partanen, Purschke, Scherrer and Zampieri2020). These shared tasks have provided important datasets for the community, and we will present some of them in Section 2.
Below, we will use the terms varieties and language varieties interchangeably as synonyms for (standard) national language varieties of pluricentric languages, that is, languages with multiple interacting standard forms in different countries. Examples of pluricentric languages include English, French, Portuguese, and Spanish; see Clyne (Reference Clyne1992) for a discussion on the status of national language varieties and pluricentric languages. Furthermore, in this survey, we do not draw a clear separating line between languages, language varieties, and dialects. This is on purpose, as in many cases this is a political rather than a linguistic distinction. From a computational perspective, problems faced by systems processing, for example, Croatian and Serbian are very similar to those that occur when dealing with Dutch and Flemish, with Brazilian and European Portuguese, or with the various dialects of Arabic.
Our focus below is on the computational processing of diatopic language variation. Section 2 describes the process of data collection and presents some available corpora. Section 3 discusses some part-of-speech tagging and parsing methods that have been successful for processing similar languages, varieties, and dialects. Section 4 focuses on relevant applications such as language and dialect identification, and MT. Finally, Section 5 concludes this survey, and Section 6 presents some avenues for future work.
2. Available corpora and data collection
It is well-known that the performance of NLP systems degrades when faced with language variation and ideally, applications should be trained on data that enables it to model the different dimensions of variation discussed in the introduction of this article: spoken vs. written language, different registers and genres, and regional variation, etc. Thus, it is somewhat simplistic to assume that corpora could fully represent a language without considering variation. In corpus linguistics, researchers have tried to address variation and represent it in corpora. One such example is the Brown corpus for English (Francis and Kucera Reference Francis and Kucera1979).
A well-known early attempt to represent diatopic language variation in corpora is the International Corpus of English (Greenbaum Reference Greenbaum1991), which follows sampling methods similar to those used for the Brown corpus, and includes multiple varieties of English with texts from thirteen countries including Canada, Great Britain, Ireland, Jamaica, and the USA.
One of the main challenges when dealing with diatopic variation for low-resource languages is finding suitable resources and tools. Acquiring text corpora for dialects is particularly challenging as dialects are typically vastly underrepresented in written text. Thus, the typical solution is to produce text corpora by transcribing speech, as it is much easier to obtain spoken dialectal data. The transcription can be done automatically, for example, using Automatic Speech Recognition, which was used to produce Arabic dialectal text corpora (Ali et al. Reference Ali, Dehak, Cardinal, Khurana, Yella, Glass, Bell and Renals2016), or manually, which was used to build the ArchiMob corpus for (Swiss) German dialects (Scherrer, Samardžić, and Glaser Reference Scherrer, Samardžić and Glaser2019) used in past editions of the German Dialect Identification shared tasks at VarDial. Alternative approaches to dialectal data collection include social media, for example, Twitter, (Cotterell and Callison-Burch Reference Cotterell and Callison-Burch2014) and translations (Bouamor et al. Reference Bouamor, Habash, Salameh, Zaghouani, Rambow, Abdulrahim, Obeid, Khalifa, Eryani, Erdmann and Oflazer2018) as in the case of the MADAR corpus used in the MADAR shared task (Bouamor, Hassan, and Habash Reference Bouamor, Hassan and Habash2019) on fine-grained identification of Arabic dialects.
The case of national language varieties is generally less challenging. Each such variety (e.g., British vs. American English) has its own written standard, which often differs from other varieties of the same language in several aspects. This includes spelling, for example, favour in the UK versus favor in the USA and lexical preferences for example, rubbish in the UK versus garbage in the USA. Most books, magazines, and newspapers reflect these differences, which makes them suitable training resources for most language varieties. One example of a corpus collected for language varieties is the Discriminating between Similar Language (DSL) Corpus Collection (DSLCC)Footnote a (Tan et al. Reference Tan, Zampieri, Ljubešić and Tiedemann2014), which contains short excerpts of texts (from 20 to 100 tokens each), collected from multiple newspapers per country.
The DSLCC was created to serve as a dataset for discriminating between similar languages and language varieties for the DSL shared tasks, organized annually within the scope of the VarDial workshop (Zampieri et al. Reference Zampieri, Tan, Ljubešić and Tiedemann2014, Reference Zampieri, Tan, Ljubešić, Tiedemann and Nakov2015, Reference Zampieri, Malmasi, Ljubešić, Nakov, Ali, Tiedemann, Scherrer and Aepli2017; Malmasi et al. Reference Malmasi, Zampieri, Ljubešić, Nakov, Ali and Tiedemann2016). The texts in DSLCC were compiled from existing corpora such as HC Corpora (Christensen Reference Christensen2014), the SETimes Corpus (Tyers and Alperen Reference Tyers and Alperen2010), and the Leipzig Corpora Collection (Biemann et al. Reference Biemann, Heyer, Quasthoff and Richter2007). Five versions including 20,000–22,000 texts per language or language variety have been released with data from several pairs or groups of similar languages such as Bulgarian and Macedonian, Czech and Slovak, Bosnian, Croatian, and Serbian, Malay and Indonesian, and pairs or groups of language varieties such as Brazilian and European Portuguese, British and American English, and several varieties of Spanish for example, Argentinian and Peninsular Spanish. The languages and the language varieties included in all versions of the corpus collection are presented in Table 1.
The DSLCC features journalistic texts collected from multiple newspapers in each target country in order to alleviate potential topical and stylistic biases, which are intrinsic to any newspaper, that is, in order to prevent systems from learning a specific newspaper’s writing style as opposed to learning the language variety it represents. Newspaper texts were chosen with the assumption that they are the most accurate representation of the contemporary written standard of a language in a given country and therefore could be used to represent national language varieties.
Table 1. Languages and language varieties used in the five versions of the DSLCC, grouped by language similarity. The checkboxes show which language variety was present in a particular version of the corpus
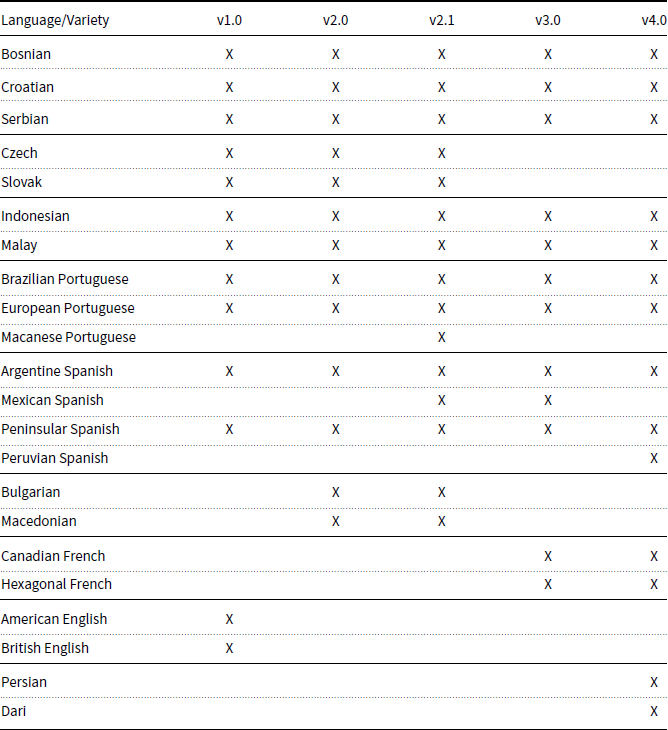
We should note that other popular data sources, which have been used in a variety of NLP tasks, for example, Wikipedia, are not suited to serve as training data for modeling diatopic variation in language as they disregard language varieties. Wikipedia is a collaborative resource, which allows speakers of multiple language varieties and non-native speakers to contribute to the same article(s) available in a single English, Portuguese, or Spanish Wikipedia. Notable exceptions are the Simple English Wikipedia, which, as the name suggests, contains simplified English, and a few (small) dialect Wikipedias.
Finally, movie and TV subtitles have also been used as data sources for Dutch and Flemish (van der Lee and van den Bosch Reference van der Lee and van den Bosch2017), as well as in related NLP applications such as MT between Brazilian and European Portuguese (Costa-jussà, Zampieri, and Pal 2018).
3. POS tagging and parsing
Part-of-speech tagging and parsing are two core morphosyntactic annotation tasks. Their output often serves as a pre-annotation for downstream applications such as information retrieval or natural language understanding, but morphosyntactic annotation is also useful for corpus linguistics research as it enables search queries that are independent of the lexical forms. This is especially practical for nonstandardized language varieties such as dialects.
Recent research on tagging and parsing similar languages, varieties, and dialects typically assumes that the availability of linguistic resources is asymmetric, in the sense that some varieties have more resources than other ones, and that low-resource language varieties can benefit from resources for high-resource ones. In such a scenario, a tagger or a parser for a new language variety can be produced using cross-lingual transfer learning (Tiedemann and Agić Reference Tiedemann and Agić2016). The general goal of cross-lingual transfer learning is to create tools for a low-resource language (LRL) when training data are only available for a (not necessarily related) high-resource language (HRL). In this context, the high-resource language is also referred to as a donor language or a source language and the low-resource language as the recipient language or the target language. While transfer learning as such is not restricted to similar language varieties, the common assumption is that the closer the HRL and the LRL are, the simpler the transfer would be.
A straightforward cross-lingual transfer learning technique is plain model transfer, or using a more recent name, zero-shot learning. It assumes that the HRL and the LRL are the same, and that a model trained on HRL data can be applied directly and without any modification to LRL data. While this assumption is too naïve in most cases, plain model transfer results are often presented as simple baselines to which more sophisticated approaches are compared. For instance, Scherrer (Reference Scherrer2014) reported baseline tagging results for various related languages, and Huck et al. (Reference Huck, Dutka and Fraser2019) used zero-shot learning as a baseline for more sophisticated experiments of Russian  $\to$ Ukrainian tagging transfer. Zampieri et al. (Reference Zampieri, Malmasi, Ljubešić, Nakov, Ali, Tiedemann, Scherrer and Aepli2017) trained dependency cross-lingual dependency parsing baselines for pairs like Slovenian $\to$ Croatian, Danish/Swedish $\to$ Norwegian, and Czech $\to$ Slovak.
$\to$ Ukrainian tagging transfer. Zampieri et al. (Reference Zampieri, Malmasi, Ljubešić, Nakov, Ali, Tiedemann, Scherrer and Aepli2017) trained dependency cross-lingual dependency parsing baselines for pairs like Slovenian $\to$ Croatian, Danish/Swedish $\to$ Norwegian, and Czech $\to$ Slovak.
Zero-shot learning can be extended to multi-source scenarios, where there is a clearly defined low-resource variety, but several related high-resource varieties, all of which are expected to contribute to various extent to the analysis of the low-resource variety. Scherrer and Rabus (Reference Scherrer and Rabus2017, Reference Scherrer and Rabus2019) trained a tagger on the concatenation of Slovak, Ukrainian, Polish, and Russian data and applied it directly to Rusyn (a Slavic variety spoken predominantly in Transcarpathian Ukraine, Eastern Slovakia, and Southeastern Poland). The only preprocessing consists in transliterating all data into a common script, in the present case Cyrillic. Likewise, Zampieri et al. (Reference Zampieri, Malmasi, Ljubešić, Nakov, Ali, Tiedemann, Scherrer and Aepli2017) showed that dependency parsing for Norwegian works best with a model trained on both Danish and Swedish data, rather than on just one of the source languages.
Another popular cross-lingual transfer learning technique is annotation projection (Yarowsky and Ngai Reference Yarowsky and Ngai2001), which crucially requires a parallel corpus relating the HRL and the LRL. The HRL side of the parallel corpus is annotated using an existing model, and the labels are projected to the LRL side along the word alignment links. The annotated LRL side can then serve as a training corpus. A multilingual variant of annotation projection was introduced in Agić, Hovy, and Søgaard (Reference Bahdanau, Cho and Bengio2015). They projected annotations from all available source languages and used simple majority voting to resolve the ambiguities. A similar approach was proposed in Aepli, von Waldenfels, and Samardžić (Reference Aepli, von Waldenfels and Samardžić2014). They created a tagger for Macedonian using majority voting from related languages such as Bulgarian, Czech, Slovene, and Serbian, as well as from English. Their full setup is somewhat more complicated and allows different morphological features to be inferred from different sets of source languages. In the cross-lingual dependency parsing task at VarDial 2017 (Zampieri et al. Reference Zampieri, Malmasi, Ljubešić, Nakov, Ali, Tiedemann, Scherrer and Aepli2017), all participants opted for some variant of annotation projection. In particular, two teams relied on word-by-word translation models inferred from the provided parallel data (Rosa et al. Reference Rosa, Zeman, Mareček and Žabokrtský2017; Çöltekin and Rama Reference Çöltekin and Rama2017).
Despite these examples, annotation projection is often not a particularly popular choice for configurations involving closely related varieties because large parallel corpora can be hard to find. For example, parallel corpora involving a dialect and its corresponding standard variety are not naturally available, as dialects do not have an official status and speakers are generally fluent in both varieties, which obviates the need for translations.
Delexicalization is an alternative transfer learning technique that attempts to create models that do not rely on language-specific information, but rather on language-independent features and representations. It was first proposed for dependency parsing (Zeman and Resnik Reference Zeman and Resnik2008; McDonald, Petrov, and Hall Reference McDonald, Petrov and Hall2011), where the (language-dependent) word forms were replaced as input features by (language-independent) part-of-speech tags. For tagging, Täckström, McDonald, and Uszkoreit (Reference Täckström, McDonald and Uszkoreit2012) proposed to replace the (language-dependent) word forms by (language-independent) cluster ids obtained by clustering together all words with the same distributional properties. More recently, clusters were superseded by cross-lingual word embeddings as language-independent input features. However, a bottleneck of this approach is that the embeddings have to be trained on large amounts of raw data, typically in the order of millions of words. For low-resource varieties such as dialects or similar varieties, this requirement is unrealistic. For example, Magistry, Ligozat, and Rosset (Reference Magistry, Ligozat and Rosset2019) trained cross-lingual word embeddings for three French regional languages – Alsatian, Occitan, and Picard – in view of using them for part-of-speech tagging. They showed that embeddings trained on corpora containing one to two million words were not sufficient to train taggers that would be competitive to much simpler adaptation strategies.
Relexicalization is a variant of delexicalization in which the HRL input features are replaced by LRL features within the model. For example, the HRL word forms of the original models can be replaced by LRL word forms extracted from a bilingual dictionary (Feldman, Hana, and Brew Reference Feldman, Hana and Brew2006). This approach was adapted to closely related language varieties by Scherrer (Reference Scherrer2014), who built the bilingual dictionary in an unsupervised way, taking advantage of the prevalence of cognates, similar word forms and phrases. Following the success of cross-lingual word embeddings, relexicalization became less popular in recent years.
The cross-lingual transfer techniques presented above assume that no annotated training data are available for the target variety, but that other types of data can be obtained, for example, raw text for training word embeddings, parallel corpora, bilingual dictionaries, etc. However, in many cases, at least small amounts of annotated data of the target variety can be made available. In this situation, the domain adaptation problem – where the annotated training data have different properties than the data the trained model is supposed to be applied to – can be reformulated as a language adaptation problem. The resulting approaches are typically subsumed as multilingual or multi-lectal models.
For example, Jørgensen, Hovy, and Søgaard (Reference Jørgensen, Hovy and Søgaard2016) created a tagger for African American Vernacular English (AAVE) tweets by first training a model on a large, non-AAVE-specific Twitter corpus and then added variety-specific information into the model. Similarly, in a range of experiments on tagging Ukrainian, Huck et al. (Reference Huck, Dutka and Fraser2019) obtained the best results with a multilingual model trained on a large corpus of Russian and a small corpus of Ukrainian. In earlier work, Cotterell and Heigold (Reference Cotterell and Heigold2017) used several related resource-rich source languages to improve the performance of their taggers.
Multilingual models can be trained in a completely language-agnostic way, that is, by making the model believe that all training instances stem from the same language, but they generally work better if they are given information about the language variety of each training instance. One way of doing so is to use multi-task learning (Ruder Reference Ruder2017), where the task of detecting the language variety is introduced as an auxiliary task on top of the main task, for example, tagging or parsing (Cotterell and Heigold Reference Cotterell and Heigold2017; Scherrer and Rabus Reference Scherrer and Rabus2019).
All approaches discussed above rely on two crucial assumptions: (1) that there is significant overlap of the input features (which, in most cases, are word forms) across the languages or that the model is able to share information across similar but non-identical input features and (2) that the output labels (part-of-speech tags, dependency labels, constituent names, etc.) are unified across the languages or the varieties.
Let us first discuss assumption 2, that is, that the output labels (part-of-speech tags, dependency labels, constituent names, etc.) are unified across the languages or the varieties. For decades, the exact task definitions and annotation conventions have been determined more or less independently for each language, which made the generalization across languages difficult, both when creating models and when evaluating them (Scherrer Reference Scherrer2014). It is only in recent years that this situation has improved through the development of a language-independent universal part-of-speech tag set (Petrov, Das, and McDonald Reference Petrov, Das and McDonald2012), a language-independent universal dependency annotation scheme (McDonald et al. Reference McDonald, Nivre, Quirmbach-Brundage, Goldberg, Das, Ganchev, Hall, Petrov, Zhang, Täckström, Bedini, Castelló and Lee2013), a unified feature-value inventory for morphological features (Zeman Reference Zeman2008), and the subsequent merging of the three schemes within the Universal Dependencies project (Nivre et al. Reference Nivre, de Marneffe, Ginter, Goldberg, Hajič, Manning, McDonald, Petrov, Pyysalo, Silveira, Silveira and Zeman2016). However, despite these huge harmonization efforts, different annotation traditions still shine in the currently available corpora (Zupan, Ljubešić, and Erjavec Reference Zupan, Ljubešić and Erjavec2019), and as a result even recent research sometimes resorts to some kind of ad hoc label normalization (Rosa et al. Reference Rosa, Zeman, Mareček and Žabokrtský2017).
Regarding assumption 1, that is, that there is significant overlap of the input features (which, in most cases, are word forms) across the languages or that the model is able to share information across similar but non-identical input features, there have been essentially two extreme strategies: either one aggressively normalizes and standardizes the data, so that related words or word forms from different varieties are made to look the same, or one avoids all types of normalization and makes sure to choose a model architecture that is still capable of generalizing from variation within the data.
In NLP for historical language varieties, this question has largely been answered in favor of the first approach: namely, the massive amounts of variation occurring in the original data are normalized to some canonical spelling, which usually coincides with the modern-day standardized spelling (Tjong Kim Sang et al. Reference Tjong Kim Sang, Bollmann, Boschker, Casacuberta, Dietz, Dipper, Domingo, van der Goot, van Koppen, Ljubešić, Östling, Petran, Pettersson, Scherrer, Schraagen, Sevens, Tiedemann, Vanallemeersch and Zervanou2017). While the normalization approach has been applied to dialectal varieties (Samardžić, Scherrer, and Glaser Reference Samardžić, Scherrer and Glaser2016), recent work (Scherrer, Rabus, and Mocken Reference Scherrer, Rabus and Mocken2018) suggested that neural networks can actually extract sufficient information from raw (non-normalized) data, provided that the words are represented as character sequences rather than as atomic units. In this case, information can be shared across similarly spelled words both within the same language variety (e.g., if there is no orthographic standard) as well as across language varieties (e.g, in a multilingual model). For example, Scherrer and Rabus (Reference Scherrer and Rabus2019) represented the input words using a bidirectional character-level long short-term memory (LSTM) recurrent neural network and obtained up to 13% absolute boost in terms of F1-score compared to using atomic word-level representations. Zupan et al. (Reference Zupan, Ljubešić and Erjavec2019) also stressed the importance of character-level input representations. In high-resource settings, character-level input representations, which are computationally costly, have lately been replaced by fixed-size vocabularies obtained by unsupervised subword segmentation methods such as byte-pair encodings and word-pieces (Sennrich, Haddow, and Birch Reference Sennrich, Haddow and Birch2016; Kudo and Richardson Reference Kudo and Richardson2018); however, for the moment this change appears to be less relevant in low-resource tagging and parsing settings.
4. Applications
In this section, we describe studies addressing diatopic language variation on two relevant NLP applications: language and dialect identification and MT. Language and dialect identification is an important part of many NLP pipelines. For example, it can be used to help collecting suitable language-specific training data (Bergsma et al. Reference Bergsma, McNamee, Bagdouri, Fink and Wilson2012), or to aid geolocation prediction systems (Han, Cook, and Baldwin Reference Han, Cook and Baldwin2012). MT can address diatopic variation when translating between pairs of closely related languages (Nakov and Tiedemann Reference Nakov and Tiedemann2012; Lakew, Cettolo, and Federico Reference Lakew, Cettolo and Federico2018), language varieties (Costa-jussà et al. 2018), and dialects (Zbib et al. Reference Zbib, Malchiodi, Devlin, Stallard, Matsoukas, Schwartz, Makhoul, Zaidan and Callison-Burch2012), or when using similar language data to augment the training data for low-resource languages, that is, by merging datasets from closely related languages to form larger parallel corpora (Nakov and Ng Reference Nakov and Ng2009, Reference Nakov and Ng2012).
4.1. Language and dialect identification
Language identification is a well-known research topic in NLP, and it represents an important part of many NLP applications. Language identification has been applied to speech (Zissman and Berkling Reference Zissman and Berkling2001), to sign language (Gebre, Wittenburg, and Heskes Reference Gebre, Wittenburg and Heskes2013), and to written texts (Jauhiainen et al. Reference Jauhiainen, Lui, Zampieri, Baldwin and Lindén2019b), as we will see below. When applied to texts, language identification systems are trained to identify the language a document or a part of a document is written in.
Language identification is most commonly modeled as a supervised multi-class single-label document classification task, where each document is assigned one class from a small inventory of classes (languages, dialects, varieties). Given a set of n documents, a language identification system will typically implement the following four major steps (Lui Reference Lui2014):
1. Represent the texts using characters, words, linguistically motivated features such as POS tags, or a combination of multiple features;
-
2. Train a model or build a language profile from documents known to be written in each of the target languages;
-
3. Define a classification function that best represents the similarity between a document and each language model or language profile;
-
4. Compute the probability of each class using the models to determine the most likely language for a given test document.
While most work has addressed language identification in sentences, paragraphs, or full texts, for example, newspaper articles, including the work we discuss in this section, some papers have focused at the word level (Nguyen and Dogruoz Reference Nguyen and Dogruoz2014).
As discussed in a recent survey (Jauhiainen et al. Reference Jauhiainen, Lui, Zampieri, Baldwin and Lindén2019b), in the early 2000s, language identification was widely considered to be a solved task as n-gram methods performed very well at discriminating between unrelated languages in standard contemporary texts (McNamee Reference McNamee2005). There are, however, several challenging scenarios that have been explored in recent years, where the performance of language identification systems is far from perfect.
This is the case of multilingual documents (Lui, Lau, and Baldwin Reference Lui, Lau and Baldwin2014), of short and noisy texts (Vogel and Tresner-Kirsch Reference Vogel and Tresner-Kirsch2012) (such as user-generated content, e.g., microblogs and social media posts), of data containing code-switching, or code-mixing (Solorio et al. Reference Solorio, Blair, Maharjan, Bethard, Diab, Ghoneim, Hawwari, AlGhamdi, Hirschberg, Chang and Fung2014), and finally, of similar languages, language varieties, and dialects, which we address in this section.
There have been a number of studies discussing methods to discriminate between similar languages. The study by Suzuki et al. (Reference Suzuki, Mikami, Ohsato and Chubachi2002), for example, addressed the identification of language, script, and text encoding and showed that closely related language pairs that also share a common script and text encoding (e.g., Hindi and Marathi) are most difficult to discriminate between. Other studies have investigated the limitations of the use of general-purpose n-gram language identification methods, which are commonly trained using character trigrams. Some of these studies have proposed solutions tailored to particular pairs or groups of languages. Ranaivo-Malançon (Reference Ranaivo-Malançon2006) added a list of words exclusive to one of the languages to help a language identification system discriminate between Malay and Indonesian. In the same vein, Tiedemann and Ljubešić (Reference Tiedemann and Ljubešić2012) improved the performance of a baseline language identification system and reported 98% accuracy for discriminating between Bosnian, Croatian, and Serbian by applying a blacklist, that is, a list of words that do not appear in one of the three languages.
Previous research on the topic, including the aforementioned VarDial shared tasks, has shown that high-performing approaches to the task of discriminating between related languages, language varieties, and dialects tend to use word-based representations or character n-gram models of higher order (4-, 5-, or 6-grams), which can also cover entire words (Goutte et al. Reference Goutte, Léger, Malmasi and Zampieri2016). There have been studies that went beyond lexical features in an attempt to capture some of the abstract systemic differences between similar languages using linguistically motivated features. This includes the use of semi-delexicalized text representations in which named entities or content words are replaced by placeholders, or fully de-lexicalized representations using POS tags and other morphosyntactic information (Zampieri, Gebre, and Diwersy Reference Zampieri, Gebre and Diwersy2013; Diwersy, Evert, and Neumann Reference Diwersy, Evert and Neumann2014; Lui et al. Reference Lui2014; Bestgen Reference Bestgen2017).
In terms of computational methods, the bulk of research on this topic and the systems submitted to the DSL shared tasks at VarDial have shown that traditional machine learning classifiers such as support vector machines (Cortes and Vapnik Reference Cortes and Vapnik1995) tend to outperform dense neural network approaches for similar languages and language varieties (Bestgen Reference Bestgen2017; Medvedeva, Kroon, and Plank Reference Medvedeva, Kroon and Plank2017). The best system (Bernier-Colborne, Goutte, and Léger Reference Bernier-Colborne, Goutte and Léger2019) submitted to the VarDial 2019 Cuneiform Language Identification (CLI) shared task (Zampieri et al. Reference Zampieri, Malmasi, Scherrer, Samardžić, Tyers, Silfverberg, Klyueva, Pan, Huang, Ionescu, Butnaru and Jauhiainen2019), however, has outperformed traditional machine learning methods using a BERT-based (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) system to discriminating between Sumerian and Akkadian historical dialects in Cuneiform script (Jauhiainen et al. Reference Jauhiainen, Jauhiainen, Alstola and Lindén2019a). BERT and other Transformer-based contextual representations have been recently applied to various NLP tasks achieving state-of-the-art results. The results by Bernier-Colborne et al. (Reference Bernier-Colborne, Goutte and Léger2019) in the CLI shared task seem to indicate that recent developments in contextual embedding representations may also yield performance improvement in language identification applied to similar languages, varieties, and dialects.
Language identification was studied for closely related languages such as Malay–Indonesian (Ranaivo-Malançon Reference Ranaivo-Malançon2006), South Slavic languages (Ljubešić, Mikelić, and Boras Reference Ljubešić, Mikelić and Boras2007; Tiedemann and Ljubešić Reference Tiedemann and Ljubešić2012), and languages of the Iberian Peninsula (Zubiaga et al. Reference Zubiaga, Vicente, Gamallo, Pichel, Alegria, Aranberri, Ezeiza and Fresno2014). It was also applied to national varieties of English (Lui and Cook Reference Lui and Cook2013; Simaki et al. Reference Simaki, Simakis, Paradis and Kerren2017), French (Mokhov Reference Mokhov2010; Diwersy et al. Reference Diwersy, Evert and Neumann2014), Chinese (Huang and Lee Reference Huang and Lee2008), and Portuguese (Zampieri and Gebre Reference Zampieri and Gebre2012; Zampieri et al. Reference Zampieri, Malmasi, Sulea and Dinu2016), as well as to dialects of Romanian (Ciobanu and Dinu Reference Ciobanu and Dinu2016), Arabic (Elfardy and Diab Reference Elfardy and Diab2013; Zaidan and Callison-Burch Reference Zaidan and Callison-Burch2014; Tillmann, Al-Onaizan, and Mansour Reference Tillmann, Al-Onaizan and Mansour2014; Sadat, Kazemi, and Farzindar Reference Sadat, Kazemi and Farzindar2014; Wray Reference Wray2018), and German (Hollenstein and Aepli Reference Hollenstein and Aepli2015). The VarDial shared tasks included the languages in the DSLCC, as well as Chinese varieties, Dutch and Flemish, dialects of Arabic, Romanian, and German, and many others.
Arabic is particularly interesting as its standard form coexists with several regional dialects in a large dialect continuum. This has motivated the bulk of recent work on processing Arabic dialects including a number of studies on the identification of Arabic dialects (Elfardy and Diab Reference Elfardy and Diab2013; Zaidan and Callison-Burch Reference Zaidan and Callison-Burch2014). Tillmann et al. (Reference Tillmann, Al-Onaizan and Mansour2014) used a linear-kernel SVM to distinguish between MSA and Egyptian Arabic in the Arabic online commentary dataset (Zaidan and Callison-Burch Reference Zaidan and Callison-Burch2011). Salloum et al. (Reference Salloum, Elfardy, Alamir-Salloum, Habash and Diab2014) carried out an extrinsic evaluation of an Arabic dialect identification used as part of the preprocessing steps of a MT system. Salloum et al. (Reference Salloum, Elfardy, Alamir-Salloum, Habash and Diab2014) reported improvements in terms of BLEU score compared to a baseline that did not differentiate between dialects. Moreover, shared tasks on Arabic dialect identification were organized in recent years providing participants with annotated dialectal data from various genres and domains. This includes the Arabic Dialect Identification (ADI) task at the VarDial workshop (Malmasi et al. Reference Malmasi, Zampieri, Ljubešić, Nakov, Ali and Tiedemann2016) and the Multi-Genre Broadcast (MGB) challenge (Ali, Vogel, and Renals Reference Ali, Vogel and Renals2017), which included broadcast speech, and the MADAR shared task (Bouamor et al. Reference Bouamor, Hassan and Habash2019), which included translations of tourism-related texts. There have been also a number of other multi-dialectal corpora compiled for Arabic including a parallel corpus of 2000 sentences in English, MSA, and multiple Arabic dialects (Bouamor, Habash, and Oflazer Reference Bouamor, Habash and Oflazer2014); a corpus from web forums with data from eighteen Arabic-speaking countries (Sadat et al. Reference Sadat, Kazemi and Farzindar2014); as well as some multi-dialect corpora consisting of Twitter posts (Elgabou and Kazakov Reference Elgabou and Kazakov2017; Alshutayri and Atwell Reference Alshutayri and Atwell2017).
4.2. Machine translation
Early work on machine translation between closely related languages and dialects used word-for-word translation and manual language-specific rules to handle morphological and syntactic transformations. This was tried for a number of language pairs such as Czech–Slovak (Hajič, Hric, and Kuboň Reference Hajič, Hric and Kuboň2000), Czech–Russian (Bemova, Oliva, and Panevova Reference Bemova, Oliva and Panevova1988), Turkish–Crimean Tatar (Altintas and Cicekli Reference Altintas and Cicekli2002), Irish–Scottish Gaelic (Scannell Reference Scannell2006), Punjabi–Hindi (Josan and Lehal Reference Josan and Lehal2008), Levantine/Egyptian/Iraqi/Gulf–Standard Arabic (Salloum and Habash Reference Salloum and Habash2012), and Cantonese–Mandarin (Zhang Reference Zhang1998).
The Apertium MT platform (Corbí-Bellot et al. Reference Corbí-Bellot, Forcada, Ortiz-Rojas, Pérez-Ortiz, Ramírez-Sánchez, Sánchez-Martínez, Alegria, Mayor and Sarasola2005) used bilingual dictionaries and manual rules to translate between a number of related Romance languages such as Spanish–Catalan, Spanish–Galician, Occitan–Catalan, and Portuguese–Spanish (Armentano-Oller et al. Reference Armentano-Oller, Carrasco, Corbí-Bellot, Forcada, Ginestí-Rosell, Ortiz-Rojas, Pérez-Ortiz, Ramírez-Sánchez, Sánchez-Martínez and Scalco2006), and it also supports some very small languages such as the Aranese variety of Occitan (Forcada Reference Forcada2006). There has also been work on rule-based MT using related language pairs, for example, improving Norwegian–English using Danish–English (Bick and Nygaard Reference Bick and Nygaard2007). Finally, there have been rule-based MT systems for translating from English to American sign language (Zhao et al. Reference Zhao, Kipper, Schuler, Vogler, Badler and Palmer2000).
A special case is the translation between different dialects of the same language, for example, between Cantonese and Mandarin Chinese (Zhang Reference Zhang1998), or between a dialect of a language and a standard version of that language, for example, between Arabic dialects (Bakr, Shaalan, and Ziedan Reference Bakr, Shaalan and Ziedan2008; Sawaf Reference Sawaf2010; Salloum and Habash Reference Salloum and Habash2011; Sajjad, Darwish, and Belinkov Reference Sajjad, Darwish and Belinkov2013). Here again, manual rules and/or language-specific tools and resources are typically used. In the case of Arabic dialects, a further complication arises due to their informal status, which means that they are primarily used in spoken interactions, or in informal text, for example, in social media, chats, forums, and SMS messages; this also causes mismatches in domain and genre. Thus, translating from Arabic dialects to Modern Standard Arabic requires, among other things, normalizing informal text to a formal form. For example, Sajjad et al. (Reference Sajjad, Darwish and Belinkov2013) first normalized a dialectal Egyptian Arabic to look like MSA, and then translated the transformed text to English. In fact, this kind of adaptation is a more general problem, which arises with informal sources such as SMS messages and tweets for just any language (Aw et al. Reference Aw, Zhang, Xiao and Su2006; Han and Baldwin Reference Han and Baldwin2011; Wang and Ng Reference Wang and Ng2013; Bojja, Nedunchezhian, and Wang Reference Bojja, Nedunchezhian and Wang2015). Here the main focus is on coping with spelling errors, abbreviations, and slang, which are typically addressed using string edit distance, while also taking pronunciation into account.
Another line of research is on language adaptation and normalization, when done specifically for improving MT into another language. For example, Marujo et al. (Reference Marujo, Grazina, Luís, Ling, Coheur and Trancoso2011) built a rule-based system for adapting Brazilian Portuguese (BP) to European Portuguese (EP), which they used to adapt BP–English bitexts to EP–English. They reported small improvements in BLEU for EP–English translation when training on the adapted “EP”–English bitext compared to using the unadapted BP–English, or when an EP–English bitext is used in addition to the adapted/unadapted one.
For closely related languages and dialects, especially when they use the same writing script, many differences might occur at the spelling/morphological level. Thus, there have been many successful attempts at performing translation using character-level representations, especially with phrase-based statistical machine translation (PBSMT) (Vilar, Peter, and Ney Reference Vilar, Peter and Ney2007; Tiedemann Reference Tiedemann2012; Nakov and Tiedemann Reference Nakov and Tiedemann2012). As switching to characters as the basic unit of representation yields a severely reduced vocabulary, this causes a problem for word alignment, which is an essential step for PBSMT; one solution is to align character n-grams instead of single characters (Nakov and Tiedemann Reference Nakov and Tiedemann2012; Tiedemann Reference Tiedemann2012; Tiedemann and Nakov Reference Tiedemann and Nakov2013).
A third line of research is on reusing bitexts between related languages without or with very little adaptation. For example, Nakov and Ng (Reference Nakov and Ng2009, Reference Nakov and Ng2012) experimented with various techniques to combine a small bitext for a resource-poor language, for example, Indonesian–English, with a much larger bitext for a related resource-rich language, for example, Malay–English. It has been further shown that it makes sense to combine the two ideas, that is, to adapt the resource-rich training bitext to look more similar to the resource-poor one, while also applying certain smart text combination techniques (Wang, Nakov, and Ng Reference Wang, Nakov and Ng2012, Reference Wang, Nakov and Ng2016).
A further idea is to use cascaded translation using a resource-rich language as a pivot, for example, translating from Macedonian to English by pivoting over Bulgarian (Tiedemann and Nakov Reference Tiedemann and Nakov2013). The closer the pivot and the source, the better the results, that is, for Macedonian to English translation it is better to pivot over Bulgarian than over Slovenian or Czech, which are less related Slavic languages.
Most of the above work relates to rule-based or statistical MT, which has now become somewhat obsolete, as a result of the ongoing neural networks revolution in the field. The rise of word embeddings in 2013 had an immediate impact on MT, as word embeddings proved helpful for translating between related languages (Mikolov, Le, and Sutskever Reference Mikolov, Le and Sutskever2013). The subsequent Neural MT revolution of 2014 (Cho et al. Reference Cho, van Merriënboer, Gulcehre, Bahdanau, Bougares, Schwenk and Bengio2014; Sutskever, Vinyals, and Le Reference Sutskever, Vinyals and Le2014; Bahdanau, Cho, and Bengio Reference Bahdanau, Cho and Bengio2015) yielded LSTM-based recurrent neural language models with attention, known as seq2seq, which enabled easy translation between multiple languages, including many-to-many and zero-shot translation (Johnson et al. Reference Johnson, Schuster, Le, Krikun, Wu, Chen, Thorat, Viégas, Wattenberg, Corrado, Hughes and Dean2017; Aharoni, Johnson, and Firat Reference Aharoni, Johnson and Firat2019), and proved to be especially effective for related languages. It has been further shown that neural MT outperforms phrase-based statistical MT for closely related language varieties such as European–Brazilian Portuguese (Costa-jussà, Zampieri, and Pal 2018).
Neural MT also allows for an easy transfer from a resource-rich “parent”–target language pair such as Uzbek–English to a related resource-poor “child”–target language pair such as Uyghur–English (Nguyen and Chiang Reference Nguyen and Chiang2017) by simply pre-training on the “parent”–target language pair and then training on the “child”–target pair, using a form of transfer learning, originally proposed in Zoph et al. (Reference Zoph, Yuret, May and Knight2016). In 2017, along came the Transformer variant (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) of neural MT, which yielded improvements over RNN-based seq2seq, for example, for Romanian–Italian and Dutch–German in bilingual, multilingual and zero-shot setups (Lakew et al. Reference Lakew, Cettolo and Federico2018).
Neural MT also makes it very easy to train multilingual models with multiple languages on the source side, on the target side, or on both sides (Johnson et al. Reference Johnson, Schuster, Le, Krikun, Wu, Chen, Thorat, Viégas, Wattenberg, Corrado, Hughes and Dean2017; Lakew et al. Reference Lakew, Cettolo and Federico2018; Aharoni et al. Reference Aharoni, Johnson and Firat2019). This is especially useful for closely related languages and language variants, as the model can learn from many languages simultaneously, but it has been shown that even distant languages can help in this setup. Part of the benefit comes from sharing subword-level vocabularies with tied embeddings, which allows models to learn some spelling and morphological variations between related languages.
Last but not least, there has been a lot of recent research interest in building cross-language word embeddings (Lample et al. Reference Lample, Conneau, Ranzato, Denoyer and Jégou2018) or sentence representations without the need for parallel training bitexts or using both parallel and non-parallel data (Joty et al. Reference Joty, Nakov, Màrquez and Jaradat2017; Artetxe and Schwenk Reference Artetxe and Schwenk2019; Conneau and Lample Reference Conneau and Lample2019; Søgaard et al. Reference Søgaard, Vulic, Ruder and Faruqui2019; Guzmán et al. Reference Guzmán, Chen, Ott, Pino, Lample, Koehn, Chaudhary and Ranzato2019; Cao, Kitaev, and Klein Reference Cao, Kitaev and Klein2020), which can be quite helpful in a low-resource setting.
5. Conclusion
We have presented a survey of the growing field of research that focuses on computational methods for processing similar languages, language varieties, and dialects, with focus on diatopic language variation and integration in NLP applications. We have described some of the available datasets and the most common strategies used to create datasets for similar languages, language varieties, and dialects. We further noted that popular data sources used in NLP such as Wikipedia are not suited for language varieties and dialects, which motivated researchers to look for alternative data sources such as social media posts and speech transcripts. We further presented a number of studies describing methods for preprocessing, normalization, part-of-speech tagging, and parsing applied to similar languages, language varieties, and dialects. Finally, we discussed how closely related languages, language varieties, and dialects are handled in two prominent NLP applications: language and dialect identification, and MT.
6. Future perspectives
Given our discussion above, it is clear that more and more NLP applications developed in industry and in academia are addressing issues related to closely related languages, language variants, and dialects, with specific emphasis on diatopic variation. In recent years, we have seen a substantial increase in the number of resources such as corpora and tools created for similar languages, language varieties, and dialects, and we have described some of them in this survey. We have also seen an increase in the number of publications on these topics in scientific journals as well as in the main international conferences in Computational Linguistics such as ACL, EMNLP, NAACL, EACL, COLING, and LREC. The success of recent initiatives such as the aforementioned annual VarDial workshop series and the associated VarDial evaluation campaigns, which keep attracting a large number of participants, are another indication of the importance of these topics.
Finally, another recent evidence of the interest of the community in the computational processing of diatopic variation is the special issue of the Journal of Natural Language Engineering (NLE) on NLP for Similar Languages, Varieties and, Dialects, where this survey appears.Footnote b
The special issue received a record number of submissions for an NLE special issue and it was eventually split into two parts. The articles published in Part 1 (NLE 25:5) have demonstrated the vibrancy of research on the topic, covering a number of applications areas such as morphosyntactic tagging (Scherrer and Rabus Reference Scherrer and Rabus2019), text normalization (Martinc and Pollak Reference Martinc and Pollak2019), and language identification (Jauhiainen, Lindén, and Jauhiainen Reference Jauhiainen, Lindén and Jauhiainen2019).

