INTRODUCTION
Nonparametric tests of utility maximization, and especially the general axiom of revealed preference (GARP) defined by Varian (1982), have been widely used on both aggregated and disaggregated data. For instance, Famulari (1995) and Diaye and Gardes (1997) used nonparametric tests on microeconomic data, whereas Swofford and Whitney (1987), Belongia and Chrystal (1991), or Fisher and Fleissig (1997) used the so-called NONPAR procedure on aggregated data.
Nevertheless, it is well known that GARP is not totally satisfactory, being nonstochastic. Indeed, a single violation of the axiom leads to rejection of the maximization hypothesis, even if this violation has purely stochastic causes, as measurement error. To improve this binary decision rule, that is, to deal with the significance of violations, two strategies have been proposed. The first one, introduced by Afriat (1967) and Varian (1990), is clearly nonstochastic. It consists of relaxing the perfect optimization hypothesis. The agents are then allowed to waste a portion (1−e) of their income, e∈[0, 1] being defined as the Afriat efficiency index. Using this index, Varian (1990) redefined a weaker version of GARP, written GARP (e): xiR(e)xj[xrArr ]e(pj·xj)[les ]pj·xi, where R(e) is the transitive closure of R0(e), and therefore e(pi·xi)[ges ]pi·xj. Typically, data will be consistent with the maximization principle if, for an inefficiency index of 5%, no violation appears [Famulari (1995)]. Nevertheless, such a strategy leads to focus on bundles that are far in constant terms. It then lowers the number of budget hyperplane intersections, and thus the power of the test, as emphasized by Sippel (1999). Moreover, the decision rule about the choice of a threshold for e is far from clear.
The second strategy, advocated by Varian (1985), leads to statistically testing the magnitude of the adjustment. Under the null, it is assumed that data behave as if they were generated by an optimization behavior, but are unobservable.1
See also Yatchew and Epstein (1985).
They are related to the observed one by multiplicative or additive i.i.d. error terms, assumed to be normally distributed. Because the magnitude of error terms are generally unknown, Varian (
1985) has suggested searching for the minimal adjustment in the data in order to satisfy the so-called Afriat inequalities. Testing the adjustment for its significance is then achieved by computing a lower bound
S on the true statistic
T, and by comparing it to a chi-squared statistic. Nevertheless, the procedure is computationaly burdensome and requires the knowledge of the second moment of true errors, which is generally unknown. Moreover, the true measurement error and the computed adjustment are unlikely to match and are generally not comparable. Thus, a test based on the computed adjustment that uses assumptions about the moments of the true measurement error may be misleading, especially under the alternative. Finally, the power of the procedure is totally unknown.
The purpose of this paper is to introduce a new procedure that allows us to test the departures from utility maximization for their significance, departures defined as violations of GARP. This procedure is based on both a new efficient algorithm that computes the minimal2
To avoid any confusion, the word “minimal” is used according to the iterative procedure introduced in this paper. The adjustments returned by this procedure are not strictly comparable to the adjustments returned by the Varian (1985) program.
adjustment in order to satisfy GARP, and a statistical test based on distributional assumptions about the computed adjustment. Following Varian (
1985), under the null, we assume that data behave as if they were generated by an optimization behavior, but are actually measured with errors. In particular, true quantities are unobservable and are related to the observed ones by multiplicative error terms. If violations appear, we then search for the minimal adjustment in the data in order to satisfy GARP. This is achieved by iteratively minimizing a quadratic function and by taking advantage of the information in the transitive closure matrix
R. Under the null, the adjustment is assumed to inherit the i.i.d. property of true errors. Hence, testing for the significance of the violations is simply achieved by implementing i.i.d. tests, based on two auxiliary regressions. This procedure has several advantages:
- Being based on the transitive closure matrix R, it leads to focus only on a few bundles violating GARP. This dramatically reduces the number of constraints of the program. Thus, with regard to the Varian's one, the procedure is not time-consuming.
- The test can be easily implemented and programmed.
- It requires neither knowledge of the law of the adjustment nor knowledge of the moments of the distribution.
- The test appears to be quite powerful.
This paper is structured as follows. Section 2 introduces the general axiom of revealed preference. Section 3 discusses the problem associated with GARP and introduces a procedure to test the violations of GARP for their significance. Section 4 details how the procedure is solved and programmed. Section 5 presents two applications. Section 6 focuses on the power of the procedure and presents some results about the distribution of the adjustment.
TESTING FOR UTILITY MAXIMIZATION: GARP
This section focuses on GARP as defined by Varian (1982) within the Samuelson's (1947) revealed preference theory. Let xi=(xi1, xi2, …, xik)′, i∈{1, …, T} be a (k×1) vector of observed real quantities, and let pi=(pi1, pi2, …, pik)′, i∈{1, …, T} be the associated prices. Let the set D={(xi, pi)∈(R+)2k, i=1, …, T} thus grouping a finite number of observations of the couples (xi, pi). Varian (1982), extending Afriat's (1967, 1973) work, has suggested an operational procedure to test if a dataset D behaves as if it were generated by utility maximization.
First, define the binary strict direct revealed preference relation P0 by xiP0xj if pi·xi>pi·xj i∈{1, …, T}, j∈{1, …, T}, and the (T×T) P0 matrix, whose element p0ij (ith row, jth column) is defined as follows:
Similarly, define the binary direct revealed preference relation R0 by xiR0xj if pi·xi[ges ]pi·xji∈{1, …, T}, j∈{1, …, T}, and the (T×T) R0 matrix, whose element r0ij is defined as follows:
At last, define the binary revealed preference relation R by xiRxj if there exists a sequence between xi and xj such that pi·xi[ges ]pi·xm, pm·xm[ges ]pm·xn, …, pp·xp[ges ]pp·xj, or xiR0xm, xmR0xn, …, xpR0xj, where R is the transitive closure of R0. Define the (T×T) R matrix, whose element rij is defined according to the Warshall's algorithm (see Appendix A).
Using the above definitions, GARP is defined as follows:
DEFINITION 1 [Varian (1982)]. The data satisfy the general axiom of revealed preference if ∀i∈{1, …, T}∀j∈{1, …, T} xiRxj implies not xjP0xi (rij=1 does not imply p0ji=1) or xiRxj[xrArr ]pj·xj[les ]pj·xi.
If xi is revealed preferred to xj, then xj cannot be strictly directly revealed preferred to xi. Using GARP, Varian (1982) proved the following theorem.
THEOREM 1 [Varian (1982)]. For a set D, the three following conditions are equivalent:
- There exists a locally nonsatiated utility function U(·) that rationalizes the data.
- There exist strictly positive utility indices Ui and marginal income indices λi that satisfy ∀i∈{1, …, T}∀j∈{1, …, T} the Afriat inequalities (1),
- The data satisfy GARP.
Hence, since GARP is both necessary and sufficient for utility maximization, the decision rule is
H0: There is no violation of the axiom; that is, ∀i∈{1, …, T}∀j∈{1, …, T} xiRxj {does not imply} xjP0xi and the data set D is rationalized by a utility function.
HA: There are at least a couple of indices (i, j), i∈{1, …, T}j∈{1, …, T} such that xiRxj and xjP0xi, and the data set D is not rationalized by a utility function.
Varian's decision rule is rather stringent since a single violation of the axiom leads to rejection of the maximization hypothesis. Nevertheless, violations of the axiom may be caused by purely stochastic elements as measurement error, data being actually consistent with the maximization principle. Hence, when implementing GARP, it is crucial that one should distinguish significant from nonsignificant violations, that is, between violations caused by stochastic elements and violations caused by some ruptures in the utility function or by a nonmaximization behavior. We next introduce such a procedure.
TESTING THE VIOLATIONS OF GARP FOR THEIR SIGNIFICANCE
In Varian's (1982) work, two strong assumptions are made: (i) data are measured without error and (ii) agents are perfectly rational, adjusting quantities at once following a movement in prices. In this paper, we deal only with the first point.3
Dealing with incomplete adjustment can be done by smoothing prices, by using lagged prices, or by using incomplete adjustment models [see, e.g., Swofford and Whitney (1994)].
Relaxing this assumption leads to consider that some violations of GARP may be caused by purely stochastic elements. Hence the need for testing the violations for their significance.
Assumption 1. Under the null hypothesis, data D={(x*i, pi)∈(R+)2k, i=1, …, T} behave as if they were generated by an optimization behavior.
Assumption 2. Under the null hypothesis, prices are perfectly known and measured, but quantities x*i are unobservable. In particular, we consider the stochastic generating mechanism4
Additive error terms can also be used, but a multiplicative error assumption is more realistic.
(2) relating the “true” unobservable quantity
x*
ij to the observed one
xij.
where εij is distributed as f(θ); f(θ) possesses finite absolute moments up to fourth order, in particular, with E(εij)=0 and V(εij)=σ2.
In (2), εij can be seen either as a measurement error or as an optimization error. In this case, x*i appears to be a theoretical demand, whereas xi is the realized one. In the following, we use the term measurement error to speak about those two concepts.
Empirically, the magnitude of the measurement error as well as f(θ) are generally unknown. Thus, following Varian (1985), and given the multiplicative relationship (2), we compute the minimal perturbation in the data in order to satisfy GARP. This is achieved by solving over zij the quadratic program (3):
subject to ∀i∈{1, …, T}∀j∈{1, …, T}ziRzj implies not zjP0zi.
Let
be the solution of the above program, and define the realization
as
.
Assumption 3. Given Assumptions 1 and 2, under the null,
is distributed as g(β), where g(·) is not necessarily equal to f(·) and g(β) possesses finite absolute moments up to fourth order, in particular with
and
.
Note that Assumption 3 emphasizes a clear distinction between the true and unobservable measurement error
and
, which is the minimal adjustment, in order to satisfy GARP. Since some measurement errors will cause violations, and other will not, especially for bundles that are far in constant terms, there is no reason why
and εij will match and then have the same distribution. Thus, in this work, the main assumption is that, under the null, the computed adjustment inherit the i.i.d. property of the true errors.5
We don't give a formal proof of this intuitive assumption, but rather implement Monte Carlo simulations. See Sections 5 and 6. For a more formal proof in a closely related framework, see Yatchew and Epstein (1985).
With the above comments in mind, at least three strategies can be used to test the necessary adjustment for its significance. The first one consists of assuming a particular form for g(β), and then testing if
follows g(β). Second, by using the central limit theorem as in Yatchew and Epstein (1985), one can derive a statistic asymptotically distributed as N(0, 1). Nevertheless, this strategy requires the knowledge of the first and second moments of the true errors, which is generally unknown in empirical work. At last, since Assumption 3 implies that the adjustment is i.i.d., testing the adjustment for its significance can be achieved simply by implementing i.i.d. tests. This is the strategy used in this paper.
To implement i.i.d. tests, two sets of residuals can be used: s1 and s2 (s2 being a subset of s1). They are defined as follows. Let
be a (T×k) matrix whose element at the ith row and jth column is given by
and let s1 be a (Tk×1) vector defined as
The first T elements of s1 form a sample realization of the errors associated with good 1, the T + 1 to 2T elements are the T realizations of the errors associated with good 2, and so on. As our procedure leads to focus on only a few bundles, an alternative set of residuals can also be used. Let
be a (r×k) matrix whose element at the ith row and jth column is given by
if and only if
, r being the number of bundles altered to ensure the compatibility with GARP. Let
. The first r elements of s2 are the r realizations of the errors associated with good 1, the r + 1 to 2r elements are the r realizations of the errors associated with good 2, and so on.
Given s1 or s2, following Spanos (1999), testing if residuals are i.i.d. is achieved by estimating two auxiliary regressions and by testing restrictions. For first-order dependence and trend heterogeneity, we estimate (4) and test the joint significance of the coefficients α and γj, j=1, …, τ1 by using an F-test, or a Wald test. For second-order dependence and trend heterogeneity, we estimate (4) and test the joint significance of the coefficients δ and βjk, j, k=1, …, τ2 by using an F-test, or a Wald test.6
In this paper, we also test for independence by using moment-based tests, and especially the Ljung and Box (1978) Q statistic (first-order independence) and the McLeod and Li (1983) ML statistic (second-order independence). Note that auxiliary regressions are preferred because they are more powerful, especially for second-order dependence and for small samples.
where
Let P1 and P2 be the probabilities associated with the Fisher or the Wald test, respectively, for (4) and (4). The decision rule at a threshold α is then
H′0: min(P1, P2)[ges ]α: Violations are caused by stochastic elements as measurement error; the maximization hypothesis is not rejected.
H′A: min(P1, P2)<α: Violations are not caused by stochastic elements; the maximization hypothesis is rejected. Data are not generated by a maximization behavior, or there exists one or several ruptures in the utility function.
We next explain how the quadratic program is solved.
SOLVING THE PROCEDURE
In this section we explain how the quadratic program (3) is solved. Basically, if GARP is satisfied for a dataset D, then, by definition, there exist ∀i∈{1, …, T}∀j∈{1, …, T} indices satisfying the Afriat inequalities (Theorem 1). It is thus possible to order all the bundles (or observations) into a coherent sequence according to either utility indices Ui satisfying (1) (cardinal) or by simply using the transitive closure matrix R (ordinal). Indeed, this latter contains all the transitive relations. We call this unique transitive sequence, in which all bundles are linked by the binary relation [sccue ] (standing for “preferred or indifferent to”), a preference chain. We say that a bundle xi is located at the nth place in the preference chain if it is revealed as preferred to T−n bundle(s) (excluding xi). For example, if n=1, then xi is at the top of the preference chain, being revealed as preferred to all the other bundles, implying U(xi)[ges ]U(xj), ∀j∈{1, …, T}; if n=T, then xi is at the bottom of the preference chain, all the other bundles being revealed as preferred to it, implying U(xi)[les ]U(xj), ∀j∈{1, …, T}. If GARP is violated, it is not possible to order all the bundles. Hence, solving (3) amounts to rebuilding a preference chain, such that for this sequence the objective function is minimal.
We now explain how the violations of GARP affect the transitive closure matrix and thus the preference chain. We first introduce some definitions.
DEFINITION 2. Two observations xi and xj satisfy the binary relation xiVRxj if xiRxj and xjP0xi (i.e., if rij=1 and p0ji=1), or if there exists a sequence between xi and xj such that xiRxk and xkP0xi, xkRxl and xlP0xk, …, xmRxj and xjP0xm. We call such a sequence a violation chain.
DEFINITION 3. Two observations xi and xj satisfy the binary relation xiSRxj if S(i)=S(j), where S(i)=([sum ]Tj=1rij)−1 is a function returning the sum m of the elements of the ith row of the transitive closure matrix, minus 1. With 0[les ]m[les ]T−1 indicating to how many bundles xi is revealed preferred to (excluding itself).
PROPOSITION 1. For two observations xi and xj, satisfying xiVRxj implies xiSRxj.
Proposition 1 follows directly from the Warshall's algorithm. If xi is directly revealed preferred to xk, xk is directly revealed preferred to xl, …, and this latter is directly revealed as preferred to xj, then we will have, by using the Warshall's algorithm xiRxk, xiRxl, …, xiRxj and S(i)=m. If xiVRxj, we have rij=1 and p0ji=1; that is, pj·xj > pj·xi, implying xjRxi. Hence, by the Warshall's algorithm, xj is going to be revealed preferred to xi, and to all the bundles xi was revealed preferred to implying S(j)=m and thus xiSRxj.7
It is not because xiVRxj implies xiSRxj that xiSRxj implies xiVRxj, because GARP allows for flat indifference curves.
Proposition 1 implies that all the bundles
xi and
xj satisfying
xiVRxj and hence
xiSRxj are candidates to be at the same place in the preference chain, that is, at the same (
T−
m) position, thus giving several possible preference chains.
Let V∈D, be a set grouping all the unique observations (xi, pi), violating one or several times GARP. For example, if we have the violations x1Rx3 and x3P0x1, x2Rx1 and x1P0x2, x2Rx3 and x3P0x2, and x3Rx2 and x2P0x3, then V={(x1, p1), (x2, p2), (x3, p3)}.
PROPOSITION 2. There exist(s) Bl set(s), l=1, …, n such that B1∪B2∪…∪Bn=V, B1∩B2∩…∩Bn=[empty ] and such that every couple (xi, pi)∈Bl, (xj, pj)∈Bl ∀l∈{1, …, n} satisfy xiSRxj.
Proposition 2 follows directly from Proposition 1. It states that the bundles violating GARP can be ordered in n, set(s) Bl, l=1, …, n, and that each set contains bundles that are potential candidates to be at the same position in the preference chain. In each set, all the bundles enter at least one violation chain. Let Nl, be the number of bundles (or observations) in a set Bl. From Proposition 2, it follows that we thus have a priori at least n ruptures in the preference chain, and thus [prod ]nl=1Nl! possible preference chains.
To illustrate this, let the set D1={(xi, pi)∈(R+)2k, i=1, …, 5}, thus grouping five observations of the couple (xi, pi), and let the matrices P01, R01 and R1, represent the preferences.
Four violations appear, giving the set V={(x2, p2), (x3, p3), (x4, p4), (x5, p5)}. As x2VRx3 (and x3VRx2), x4VRx5 (and x5VRx4), S(2)=3, S(3)=3, S(4)=1, S(5)=1, the set V can be broken up into two subsets B1 and B2 such that B1∪B2=V and B1∩B2=[empty ], where B1={(x2, p2), (x3, p3)} and B2={(x4, p4), (x5, p5)}. The set B1 contains bundles that are all candidates to be located at the second place in the preference chain, and the set B2 contains bundles that are potentially at the fourth place in the chain, giving a priori [prod ]2l=1Nl!=2!*2!=4 possible preference chains. These latter are given by (6):
It is thus apparent that solving the quadratic program (3) amounts to finding, in each set Bl, the bundle that will be revealed preferred to the other bundle(s) of the set, that is, to rebuild a coherent preference chain. We next explain how, in each set, the unobserved bundles
are computed, and then we introduce an iterative procedure.
Computing the Bundles
Suppose that for a dataset D, GARP is violated, and let B1 be one of the n set(s). For reasons that will become apparent later, define B1 such that for (xi, pi)∈B1 and (xj, pj) ∉ B1, S(i)>S(j). Let for a couple {(xi, pi), (xj, pj)} (xi, pi)∈B1, (xj, pj)∈B1 such that xiRxj and xjP0xi, the quadratic program (7), minimized over zij:
Empirically, the constraint of (7) is replaced by only two kinds of constraints, which are defined as follows:
First kind: pi·xi=pi·zi and pj·xj[les ]pj·zi, and if N1>2, pm·xm[les ]pm·zi for all xm related to xi by xiVRxm, xm ≠ xj.8
If, in addition, we have xiP0xj and xjP0xi or xiP0xm and xmP0xi, then strict inequalities are used. Note also that the first kind of constraints implies that a bundle violating GARP with more than one bundle is adjusted once.
That is, for all other observations (
xm,
pm) of the set
B1, we add
pm·
xm[les ]
pm·
zi. For example if we have
x1VRx2 and
x1VRx3, then we will have
p1·
x1=
p1·
z1,
p2·
x2[les ]
p2·
z1 and
p3·
x3[les ]
p3·
z1.
Second kind: pk·xk[les ]pk·zi for all (xk, pk) ∉ B1 such that rik=1.
The two kinds of constraints above ensure that (i) ∀xj, ziVRxj will not hold any more, (ii) zi will not cause new violations with bundles it was revealed preferred to (directly or indirectly), (iii) zi will be located at a given place in the preference chain.9
Note that a main difference between this procedure and an Afriat-inequalities-based procedure is that we force total expenditure in period i to remain unchanged (pi·xi=pi·zi). Thus, zi will not become strictly directly revealed as preferred to bundles located higher in the preference chain, possibly causing new violations. This ensures the convergence of the iterative procedure introduced next and reduces the number of constraints, thus simplifying the program.
Given (7), to rebuild a preference chain, that is, to choose the bundle zi which will be revealed preferred to the other bundles of the set B1, we solve (7) for each (xi, pi)∈B1 violating GARP, and choose the one having the minimal objective function obji. This bundle,
, will be revealed preferred to the others of the set.
An Iterative Procedure
The above procedure, consisting of solving (7) for each bundle of a set B1, and then choosing the one having the minimal objective function, can be implemented to rebuild a preference chain, independently for all sets if and only if Nl=2 ∀l∈{1, …, n}. The reason is that if ∃l∈{1, …, n} such that Nl > 2, then nothing ensures that finding the bundle
and replacing (xi, pi) by
in D, the other bundles of the set Bl will not violate GARP, being now candidates to be at a lower place in the preference chain. To deal with this problem, we propose the following four-step iterative procedure:
Step 1. Test D for consistency with GARP, let nvio be the number of violations [0[les ]nvio[les ]T(T−1)]
Step 2. Build a set V and n set(s) Bl, l=1, …, n. Go to step 3.
Step 3. Among the sets Bl, search for the one written B1, containing the bundles being potentially at the same highest place in the preference chain, such that if n>2 for (xi, pi)∈B1 and (xj, pj) ∉ B1: S(i)>S(j). Go to step 4.
Step 4. In the set B1, search, by using (7), for the bundle that will be revealed as preferred to the others, such that, for this bundle, among all objective functions, its objective function is minimal. Let
be the bundle solution of this procedure. Replace, in D, (xi, pi) with
and go to step 1.
We now illustrate this procedure.
IMPLEMENTATIONS
In this section, we illustrate the iterative procedure by two examples. Let the dataset D1={(xi, pi)∈(R+)2k, i=1, …, 5}, for which the preferences are given by the above P01, R01 and R1 matrices. As we have seen, four violations give the sets V={(x2, p2), (x3, p3), (x4, p4), (x5, p5)}, B1={(x2, p2), (x3, p3)}, and B2={(x4, p4), (x5, p5)}. As S(2)=3, S(3)=3, S(4)=1, S(5)=1, the procedure consists in first finding which of the two bundles in B1 will be at the second place in the preference chain. This is achieved by solving (7) over z2 subject to p2·z2=p2·x2, p3·x3[les ]p3·z2, and p4·x4[les ]p4·z2, p5·x5[les ]p5·z2(since r24=1 and r25=1), and then (7) over z3 subject to p3·z3=p3·x3, p2·x2[les ]p2·z3, and p4·x4[les ]p4·z3, p5·x5[les ]p5·z3. Then, choose the bundle zi, i∈{2, 3} for which the objective function obji is minimal. Assuming, for example, that obj2<obj3, replace x2 with the computed value
in D1. Rerunning GARP gives now the following preferences:
Only two violations appear giving the set V=B1={(x4, p4), (x5, p5)}, and a priori 2! two possible preference chains:
Similarly, solve (7) over z4 and z5, subject to, respectively, p4·z4=p4·x4, p5·x5[les ]p5·z4 for the first program and p5·z5=p5·x5, p4·x4[les ]p4·z5 for the second program. Then, choose zi, i∈{4, 5} such that the corresponding obji is minimal. Suppose that obj4>obj5; then, the final preferences are given by the following P01, R01, and R matrices, and the coherent preference chain by (9):
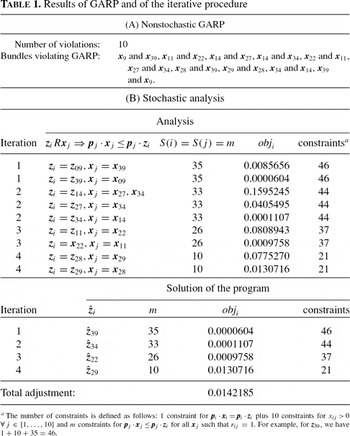
Consider now a numerical application. Let D2={(xi, pi)∈(R+)20, i=1, …, 40} be a set of simulated data, where quantities x*ij, i=1, …, 40, j=1, …, 10, are solution of a Cobb-Douglas maximization program (see next section), and xij is related to x*ij by the relationship (2), where εij is distributed as N(0, 0.22) (see Tables (B.1) and (C.1) in Appendixes B and C). Table 1 presents both the results of GARP and of the iterative procedure.
Running GARP, 10 violations appear, giving the set V={(x9, p9), (x11, p11), (x14, p14), (x22, p22), (x27, p27), (x28, p28), (x29, p29), (x34, p34), (x39, p39)} and 4 sets: B1={(x9, p9), (x39, p39)}, B2={(x14, p14), (x27, p27), (x34, p34)}, B3={(x11, p11), (x22, p22)}, and B4={(x28, p28), (x29, p29)}. As there are more than two bundles in the set B2, we run the iterative procedure. The set B1 contains two bundles that are revealed preferred to all the others in the other sets. Thus, we first search (iteration 1 of the procedure) if z9Rx39[xrArr ]p39·x39[les ]p39·z9 or if z39Rx9[xrArr ]p9·x9[les ]p9·z39. The two objective functions associated with these two hypotheses are, respectively, 0.0085656 and 0.0000604. Since 0.0000604<0.0085656, we conclude that z39Rx9[xrArr ]p9·x9[les ]p9·z39, that is, z39 will be at the fifth place in the preference chain. Replacing in D2 x39 with
and rerunning GARP (iteration 2) now gives eight violations and the sets V={(x11, p11), (x14, p14), (x22, p22), (x27, p27), (x28, p28), (x29, p29), (x34, p34)}, B1={(x14, p14), (x27, p27), (x34, p34)}, B2={(x11, p11), (x22, p22)}, and B3={(x28, p28), (x29, p29)}.
Focusing on the set B1, as previously, as for (xi, pi)∈B1 and (xj, pj) ∉ B1S(i) > S(j), three hypotheses are tested: z14Rx27[xrArr ]p27·x27[les ]p27·z14, z14Rx34[xrArr ]p34·x34[les ]p34·z14, z27Rx34[xrArr ]p34·x34[les ]p34·z27, and z34Rx14[xrArr ]p14·x14[les ]p14·z34. Since we have min (0.1565245, 0.0405495, 0.0001107)=0.0001107, we conclude that z34Rx14[xrArr ]p14·x14[les ]p14·z34 and of course that z34Rx27[xrArr ]p27·x27[les ]p27·z34, z34 being located at the seventh place in the preference chain. Replacing x34 by
in D2 and rerunning GARP (iteration 3), now gives four violations10
Concerning iteration 2, replacing only one bundle rules out four violations.
and the sets
V={(
x11,
p11), (
x22,
p22), (
x28,
p28), (
x29,
p29)},
B1={(
x11,
p11), (
x22,
p22)}, and
B2={(
x28,
p28), (
x29,
p29)}. Given
B1, we select the bundle having the minimal objective function, here
z22 (
obj22=0.0009758). Last, we replace in
D2x22 with
and rerun GARP (iteration 4). Only two violations appear giving the set V=B1={(x28, p28), (x29, p29)}. Since the adjustments associated with z28Rx29[xrArr ]p29·x29[les ]p29·z28 and z29Rx28[xrArr ]p28·x28[les ]p28·z29 are, respectively, 0.077527 and 0.0130716, we choose z29 as the solution of the iteration 4. Replacing x29 with
in D2, and rerunning GARP gives no more violation.11
Note that, by way of comparison with Varian (1985), it took around 5 seconds with a PIV PC to solve the quadratic program.
Thus, 10 violations for 40 observations and 10 goods in each bundle are ruled out only by altering 4 bundles, with a total adjustment of 0.0142185. Now, let's turn to some statistical inference. Figure 1 plots the vector s2, where
,
are the first four observations,
,
,
,
, are the observations 4 to 8
,
,
,
are the observations 36 to 40. Tables 2 and 3 present the results of the i.i.d. tests (first and second order) for s1 and s2. In addition, to test for independence, two statistics are also computed: the Ljung-Box Q-stat and the McLeod-Li ML-stat. Both tables are structured as follows: The first part is related to independence tests, whereas the second part is dedicated to i.i.d. tests. Concerning the latter, we first select the order τ1 and τ2 for the auxiliary regressions (4) and (4) by using F-tests (Wald tests are also presented). Second, given the selected models, we present the i.i.d. tests. Here, for the set s1, we choose τ1=1 and τ2=1. For those models, the probabilities associated with the i.i.d. tests, respectively, for the first and second order are 0.2088 (Wald 0.2075) and 0.3876 (Wald 0.3867) leading us to accept the i.i.d. hypothesis. Similar conclusions are drown from Table 3, the probabilities being, respectively, 0.1321 (Wald 0.1174) and 0.3434 (Wald 0.3324) for τ1=1 and τ2=1. Thus, in both cases, we accept
. Violations are caused by measurement error, which is coherent with our data generating process.
MONTE CARLO SIMULATIONS
In this section, we run Monte Carlo simulations to (i) estimate the power of GARP under measurement error; (ii) estimate the type I and II errors of the procedure; (iii) present, under the null, some key results about the distribution of the law of residuals, since g(·) and f(·) are unlikely to match. We first introduce our data generating process.
To estimate the type I error, that is, the probability of rejecting maximization, whereas there is maximization, we proceed as follows:
Step 1. We generate 10 series of prices, each series having 40 observations. Each series is defined as a random walk. For instance, for a period i∈{1, …, 40} and for a good j∈{1, …, 10}, pij is defined as
where νij is a normally distributed term with zero mean and unit variance.
Step 2. In a similar way, we generate a series of income {\bf I}. For a period i∈{1, …, 40}, the income Ii is defined as
where εi is a normally distributed term with zero mean and unit variance.
Step 3. Given the above prices and income, we solve a maximization program for a Cobb-Douglas function. For a period i∈{1, …, 40}, the vector x*i=(x*i1, x*i2, …, x*i10)′ is the solution of (10), where
.
where
Step 4. We compute xi=(xi1, xi2, …, xi10)′ related to x*i by the relationship
where εij is a normally distributed term with zero mean and standard error σ.
Step 5. We build the set D={(xi, pi)∈(R+)20, i=1, …, 40} and run the procedure; that is, we find the minimal adjustment, compute τ1 and τ2 by using F-tests or Wald tests, and test for i.i.d.-ness.
We repeat steps 1 to 5, 10,000 times for three different measurement errors: σ=5%, σ=10%, and σ=15%. We compute the type I error of GARP and of the procedure (at a threshold α) defined respectively as (12) and (13).
To estimate the type II error, we first need a definition of a “random behavior.” We will say that a dataset D is rationalized by a unique utility function if its parameters are constant over the entire period. We will say that there is a random behavior if the parameters aij change every periods. Thus, in our definition of the random behavior, a utility function rationalizes the data each period, but the weights change from one period to another.12
For other definitions of the random behavior, see Bronars (1987).
To estimate the type II error, that is, the probability of accepting the null whereas data are generated at random, we use the same sequence as before, except for steps 3 to 4 which are replaced by:
Step 3. Given prices and income, we solve a maximization program, where preferences are given by a Cobb-Douglas function. For a period i∈{1, …, 40}, the vector x*i=xi=(xi1, xi2, …, xi10)′ is the solution of gram (14), where for j=1, …, 10, ∀(i, t)∈{1, …, 40} and i ≠ t:aij ≠ atj; aij=bij/[sum ]10j=1bij, and bij∈[0, 1] is a uniformly distributed term.
where
and i ≠ t:aij ≠ atj,
where
is a uniformly distributed term.
Step 4. We build the set D={(xi, pi)∈(R+)20, i=1, …, 40}, and run the procedure; that is, we find the minimal adjustment, we compute τ1 and τ2 by using F-tests or Wald tests, and test for i.i.d.-ness.
We repeat steps 1 to 410,000 times and compute the type II error of GARP and of the procedure (at a threshold α), respectively, defined by (15) and (16):
Tables 4 and 5 give the results of the simulations for three different standard errors and at four different thresholds. Table 4 focuses on the power of GARP and presents some summary statistics about the iterative procedure. Concerning GARP, it appears that, on the one hand, the test is extremely powerful against the random behavior hypothesis, since the type II error is null. On the other hand, when data are rationalized by a utility function, but are measured with errors, GARP seems accurate only for a very small measurement error13
Similar results can be found in Fisher and Whitney (2003).
(σ=5%). A large measurement error, σ=10% or σ=15%, produces a high type I error, respectively, 67.73% and 82.01%. Thus, GARP should not be used if data are suspected to incorporate some stochastic elements. One should also note that measurement error generates very few violations, and that the adjustment required to satisfy GARP appears to be very small, with average objective functions of 0.0010574, 0.0047034, and 0.0145508, respectively, for σ=0.05, σ=0.10, and σ=0.15.
Table 5 presents the type I and II errors associated with the i.i.d. tests for s1 and s2. At the usual threshold of 5%, the procedure appears to be quite powerful. Indeed, the type I error does not exceed 8.91% for a large measurement error for s2 (10.39% for s1) and is less than 5% for a small measurement error for s1 and s2. Concerning the type II error, it is about 5% for s2 (8.54% for s1), indicating that the probability of accepting maximization whereas there is not maximization is small. By way of comparison with Figure 1, we plot the necessary adjustment when data are generated at random (non-i.i.d. set), Figure 2. One will also note that s1 and s2 return approximately the same information. Nevertheless, using s2 in empirical work seems more accurate giving the type II error and the type I error for a large measurement error.
At last, since Assumption 3 appears to be empirically justified, the question arises about the distribution of the residuals. Basically, the minimization program (3) may appear as some kind of regression under linear constraints. Then, the question arises about whether the residuals are normally distributed. To investigate the distribution of the adjustment, we have collected, at each of the 10,000 iterations concerning the estimation of the type I error, the sets s2. We thus have three sets corresponding to the three measurement errors: σ=0.05, 0.10, and 0.15. Table 6 presents some summary statistics about the three distributions as well as two normality tests. In the Cobb-Douglas framework, for the three measurement errors, the adjustment needed to satisfy maximization is clearly centered at zero. Concerning the standard errors, for σ=0.05, 0.10, and 0.15, the estimated standard error
is, respectively, 0.0074, 0.0168, and 0.0263, which confirms that the computed adjustment is much smaller than the true measurement error. Last, the law of residuals is clearly nonnormal. Hence, even if the true measurement is normally distributed, the iterative procedure will return i.i.d. but not normally distributed errors. Figure 3 plots the three empirical cumulative distribution functions. Figures D.1 to D.3 plot the three kernel densities. It appears that the distributions are likely to be approximately distributed as a power exponential law or Laplace law.
Empirical cumulative distribution functions: σ=0.05, σ=0.10, and σ=0.15, for s2.
CONCLUSION AND DISCUSSION
The purpose of this article was to introduce a procedure that allows us to test the violations of GARP for their significance. We have first proposed an algorithm to compute the minimal perturbation in the data that takes advantage of the information contained in the transitive closure matrix R. Second, we have suggested that testing the significance of the adjustment could be achieved by implementing i.i.d. tests, and we have shown the empirical validity of such a procedure. There are at least two directions for future research. First, concerning the procedure itself, the i.i.d. tests are not the only way to test the significance of the adjustment, and new statistical tests may be introduced. A second important direction would be to develop a weak separability test based on the procedure introduced here, answering then to Barnett and Choi (1989).
APPENDIX A: WARSHALL'S ALGORITHM
Warshall's algorithm, converted into SaS IML language, is
/*warshall's algorithm*/
R=R0;
do k=1 to nrow(R);
do i=1 to nrow(R);
do j=1 to nrow(R);
if R[i, k]=0|R[k, j]=0 then R[i, j]=R[i, j];
else R[i, j]=1;
end;
end;
end;
where: ‘|’ stands for ‘or’, and R[i, k]=rik
testing GARP is then achieved by doing,
/*GARP*/
nvio=0;
do i=1 to nrow(R);
do j=1 to nrow(R);
if R[i, j]=1 & P0[j, i]=1 then nvio=nvio+1;
end;
end;
where nvio returns the number of violations.
APPENDIX B: GENERATED QUANTITIES WITH MEASUREMENT ERROR
APPENDIX C: GENERATED PRICES
APPENDIX D: KERNEL DENSITIES
Kernel density (s2), σ=0.05.
Kernel density (s2), σ=0.10.
Kernel density (s2), σ=0.15.