


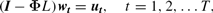
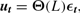
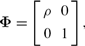
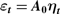












Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Francis, Neville
Owyang, Michael
and
Theodorou, Athena T.
2004.
What Explains the Varying Monetary Response to Technology Shocks in G-7 Countries?.
SSRN Electronic Journal,
Gil-Alana, Luis A.
and
Moreno, Antonio
2005.
Technology Shocks and Hours Worked: A Fractional Integration Perspective.
SSRN Electronic Journal,
Pesavento, Elena
and
Rossi, Barbara
2006.
Small‐sample confidence intervals for multivariate impulse response functions at long horizons.
Journal of Applied Econometrics,
Vol. 21,
Issue. 8,
p.
1135.
Roush, Jennifer E.
Francis, Neville
and
Owyang, Michael
2007.
A Flexible Finite-Horizon Identification of Technology Shocks.
SSRN Electronic Journal,
Ravn, Morten O.
and
Simonelli, Saverio
2007.
Labor Market Dynamics and the Business Cycle: Structural Evidence for the United States*.
The Scandinavian Journal of Economics,
Vol. 109,
Issue. 4,
p.
743.
Gil-Alana, Luis Alberiko
and
Moreno, Antonio
2009.
TECHNOLOGY SHOCKS AND HOURS WORKED: A FRACTIONAL INTEGRATION PERSPECTIVE.
Macroeconomic Dynamics,
Vol. 13,
Issue. 5,
p.
580.
Ghent, Andra C.
2009.
Comparing DSGE-VAR forecasting models: How big are the differences?.
Journal of Economic Dynamics and Control,
Vol. 33,
Issue. 4,
p.
864.
Fève, Patrick
and
Guay, Alain
2010.
Identification of Technology Shocks in Structural Vars.
The Economic Journal,
Vol. 120,
Issue. 549,
p.
1284.
Gospodinov, Nikolay
2010.
Inference in Nearly Nonstationary SVAR Models With Long-Run Identifying Restrictions.
Journal of Business & Economic Statistics,
Vol. 28,
Issue. 1,
p.
1.
DiCecio, Riccardo
and
Owyang, Michael
2010.
Identifying Technology Shocks in the Frequency Domain.
SSRN Electronic Journal,
Gospodinov, Nikolay
Maynard, Alex
and
Pesavento, Elena
2011.
Sensitivity of Impulse Responses to Small Low-Frequency Comovements: Reconciling the Evidence on the Effects of Technology Shocks.
Journal of Business & Economic Statistics,
Vol. 29,
Issue. 4,
p.
455.
Caporale, Guglielmo Maria
and
Gil-Alana, Luis A.
2014.
Persistence and cycles in US hours worked.
Economic Modelling,
Vol. 38,
Issue. ,
p.
504.
Fout, Hamilton B.
and
Francis, Neville R.
2014.
IMPERFECT TRANSMISSION OF TECHNOLOGY SHOCKS AND THE BUSINESS CYCLE CONSEQUENCES.
Macroeconomic Dynamics,
Vol. 18,
Issue. 2,
p.
418.
Kim, Soyoung
and
Lee, Jaewoo
2015.
INTERNATIONAL MACROECONOMIC FLUCTUATIONS.
Macroeconomic Dynamics,
Vol. 19,
Issue. 7,
p.
1509.
Charles, Amélie
Darné, Olivier
and
Tripier, Fabien
2015.
ARE UNIT ROOT TESTS USEFUL IN THE DEBATE OVER THE (NON)STATIONARITY OF HOURS WORKED?.
Macroeconomic Dynamics,
Vol. 19,
Issue. 1,
p.
167.
Lovcha, Yuliya
and
Perez-Laborda, Alejandro
2015.
THE HOURS WORKED–PRODUCTIVITY PUZZLE: IDENTIFICATION IN A FRACTIONAL INTEGRATION SETTING.
Macroeconomic Dynamics,
Vol. 19,
Issue. 7,
p.
1593.
Chevillon, Guillaume
and
Zhan, Zhaoguo
2016.
Robust Inference in Structural Vars with Long-Run Restrictions.
SSRN Electronic Journal ,
Giuli, Francesco
and
Tancioni, Massimiliano
2017.
CONTRACTIONARY TECHNOLOGY SHOCKS.
Macroeconomic Dynamics,
Vol. 21,
Issue. 7,
p.
1752.
Chevillon, Guillaume
Mavroeidis, Sophocles
and
Zhan, Zhaoguo
2020.
ROBUST INFERENCE IN STRUCTURAL VECTOR AUTOREGRESSIONS WITH LONG-RUN RESTRICTIONS.
Econometric Theory,
Vol. 36,
Issue. 1,
p.
86.
Yan, Han
Yan, Meng
and
Ziba, Karjoo
2020.
Technology Shock and Labor Market Dynamics: International Evidence.
SSRN Electronic Journal ,