


1. INTRODUCTION
Multiple Global Navigation Satellite System (GNSS) constellations, including the Global Positioning System (GPS), GLONASS, Galileo and BeiDou are currently being deployed or modernised, and are foreseen to be fully operational in the 2020–2030 time frame. The completed, combined multi-constellation GNSS will broadcast new signals from a large number of additional ranging sources, and is therefore expected to provide improved positioning performance. In particular, the abundantly redundant range measurements available using multi-constellation GNSS can significantly increase the performance of receiver autonomous integrity monitoring (RAIM) (Parkinson and Axelrad, Reference Parkinson and Axelrad1988; Brown, Reference Brown1996). This potential performance improvement has raised a renewed interest in using RAIM as the main method for aircraft integrity monitoring. Recent research on RAIM performance for aviation applications, for example in the framework of the Advanced RAIM (ARAIM) research effort described in Walter et al. (Reference Walter, Enge, Blanch and Pervan2008) and Blanch et al. (Reference Blanch, Walter, Enge, Wallner, Amarillo Fernandez, Dellago, Ioannides, Hernandes, Belabbas, Spletter and Rippl2013) has shown the potential for very good global system availability for specific aviation applications using multi-constellation GNSS (Blanch et al., Reference Blanch, Ene, Walter and Enge2007; Lee and McLauglin, Reference Lee and McLaughlin2007; FAA, 2011).
However, most RAIM algorithms require knowledge of the prior probability of fault occurrence. Further, RAIM performance is often sensitive to variations in the assumed values of this prior probability. Due to the scarcity of observed faults over the relatively short operational history of GNSS and the difficulty in developing analytical failure models for such sophisticated systems, it is not clear how to rigorously establish the probability of fault occurrence for use in RAIM algorithms. Moreover, the probability of satellite failure might evolve with satellite age. In the end it will be extremely difficult, if not impossible, to confidently specify a precise prior probability of fault occurrence. Overly optimistic values will result in misleading integrity performance predictions, and could even endanger aircraft safety when implemented for real-time detection. On the other hand, using overly conservative values will ensure conservative integrity performance predictions, but at the expense of decreased navigation availability.
Bayesian analysis is well known for its robustness to uncertainty in prior probabilities (Berger, Reference Berger1985). In Bayesian analysis, the posterior probability of fault occurrence can be evaluated based on current measurements, an approximated prior probability of fault occurrence (Ober, Reference Ober2003), and the probability density function of the fault magnitude. However, information on fault magnitude distributions is usually not available, and in this work, upper bounds on the posterior fault probabilities are instead sought by considering the worst-case fault magnitude. In Section 2 of this paper, a new method is developed to compute an upper bound on the posterior probability of a given fault hypothesis using Bayes’ theorem. The penalty for the lack of information on the fault magnitude distribution will affect the tightness of the posterior probability bound.
In Section 3, an upper bound on integrity risk is analytically derived using the measurement-updated posterior probability bounds developed in Section 2. The method is illustrated using a quantitative example, which is used to demonstrate that the resulting risk assessment is robust to uncertainty in the assumed prior probabilities.
In addition, it is noted that currently most GNSS position estimators optimise accuracy (e.g., using weighted least squares estimators or Kalman filters) rather than integrity. This is true even for aviation applications that must comply with extremely stringent requirements on system integrity in order to address safety-of-life concerns. In Section 4, we introduce a Bayesian fault-tolerant position estimation (FTE) technique to optimise integrity risk instead of accuracy. The concept of using FTEs together with RAIM is not new (Pervan et al., Reference Pervan, Pullen and Christie1998; Hwang and Brown, Reference Hwang and Brown2006; Lee, 2006; Blanch et al., Reference Blanch, Walter and Enge2012; Joerger et al., Reference Joerger, Chan, Langel and Pervan2012). However, non-Bayesian RAIM methods for this purpose often result in complicated derivations and solutions that are difficult to obtain (ibid). Furthermore, they are subject to the same sensitivity to uncertainty prior fault probability noted earlier. The Bayesian FTE method, in contrast, can be derived analytically in a straightforward manner and is much less sensitive to prior fault probabilities. In the remainder of Section 4 the Bayesian FTE is then seamlessly incorporated with a fault detection algorithm developed in Pervan et al. (Reference Pervan, Pullen and Christie1998), which serves as the RAIM detection method. The test statistic adopted for fault detection is the computed system integrity risk bound, which is directly compared with the integrity risk requirement.
Continuity risk is a competing requirement (to integrity) in practical applications, including aviation applications. It is conventionally represented as a frequentist probability of monitor alarm under fault-free conditions. In order to demonstrate compliance with such a requirement, the fault-free performance of the Bayesian algorithm developed in Section 4 must be evaluated relative to the frequentist continuity risk requirement. While this is straightforward to do in principle, in practice it is extremely time consuming to precisely compute the false alarm probability. This issue is addressed in Section 5, where an efficient method suitable for real-time implementation is developed to establish an upper bound on continuity risk.
Finally, the performance of the Bayesian FTE algorithm is analysed for an example GNSS navigation system. A benchmark application, the LPV 200 aircraft precision approach (FAA, 2007), is selected for this purpose. The performance of a conventional ARAIM method is also evaluated for comparison. The simulation results demonstrate that the Bayesian FTE algorithm is robust to uncertainty in fault prior probability, while the conventional ARAIM results in much larger unaccounted for variations in integrity risk.
2. POSTERIOR PROBABILITY OF FAULT OCCURRENCE USING MEASUREMENTS AND BAYESIAN PROBABILITY
In Bayesian statistics a posterior probability is determined based on a given prior probability and on available measurements. This posterior probability is conditioned upon actual measurements. The algorithm derived in Pervan et al. (Reference Pervan, Pullen and Christie1998) to compute the integrity of a position estimate using a multiple hypothesis approach for differential GPS positioning systems is extended in this work to stand-alone positioning using a Bayesian approach. The concept of using mutually exclusive multiple hypotheses has been widely adopted in recent GNSS navigation integrity research (Walter et al., Reference Walter, Enge, Blanch and Pervan2008; Blanch et al., Reference Blanch, Ene, Walter and Enge2007; Lee and McLauglin, Reference Lee and McLaughlin2007).
A set of mutually exclusive and exhaustive hypotheses (H i, i=1 … n f) is considered, where each hypothesis is associated with a specific failure mode (a particular set of faulted measurements) except the hypothesis H 0, which represents the fault-free hypothesis.
 $$1 = \sum\limits_{i = 0}^{n_f} {P(H_i )} $$
$$1 = \sum\limits_{i = 0}^{n_f} {P(H_i )} $$where P(H 0) is the prior probability for fault-free hypothesis H 0, P(H i) is the prior probability for the hypothesis H i of the ith failure mode, and n f is the total number of hypotheses under consideration.
The measurement vector z, made of n stacked GNSS ranging signals, is expressed using the n by m (n>m) observation matrix G, the m by one state vector x, and the n by one nominal measurement error vector v (assumed normally distributed with zero mean) as:
 $$z = Gx + v, \quad v\sim N(0,\sigma ^2 )$$
$$z = Gx + v, \quad v\sim N(0,\sigma ^2 )$$The least squares position estimate is:
 $$\hat x_0 = (G_0 ^T R_0^{ - 1} G_0 )^{ - 1} G_0 ^T R_0^{ - 1} z_0, \quad R_0 {\rm} = [E(v_0 v_0 ^T )]$$
$$\hat x_0 = (G_0 ^T R_0^{ - 1} G_0 )^{ - 1} G_0 ^T R_0^{ - 1} z_0, \quad R_0 {\rm} = [E(v_0 v_0 ^T )]$$where the subscript 0 indicates the full-set solution (i.e., using measurements from all visible satellites), R 0 is the measurement error covariance matrix, and the m estimated states  $\hat x_0 $ are three position components and one receiver clock bias (or multiple receiver clock biases for multiple constellations).
$\hat x_0 $ are three position components and one receiver clock bias (or multiple receiver clock biases for multiple constellations).
Given the fault-free hypothesis H 0 and the full-set measurement vector z 0, the conditional probability density function (PDF) of the true position can be expressed as:
 $$f\,(x|H_0, z_0 ) = N(\hat x_0, P_0 ), \quad P_0 = (G_0 ^T R_0^{ - 1} G_0 )^{ - 1} $$
$$f\,(x|H_0, z_0 ) = N(\hat x_0, P_0 ), \quad P_0 = (G_0 ^T R_0^{ - 1} G_0 )^{ - 1} $$where P 0 is the covariance matrix of position estimate error.
For the hypothesis H i corresponding to the ith failure mode with a prior probability P(H i), a fault-free sub-set solution is obtained using the least squares estimate which excludes the ith set of assumed faulty measurements:
 $$\hat x_i = (G_i ^T R_i^{ - 1} G_i )^{ - 1} G_i ^T R_i^{ - 1} z_i, \quad R_i {\rm} = [E(v_i v_i ^T )]$$
$$\hat x_i = (G_i ^T R_i^{ - 1} G_i )^{ - 1} G_i ^T R_i^{ - 1} z_i, \quad R_i {\rm} = [E(v_i v_i ^T )]$$The conditional PDF of true position under the hypothesis H i given the sub-set measurement vector z i can be written as:
 $$f\,(x|H_i, z_0 ) = N(\hat x_i, P_i ), \quad P_i = (G_i ^T R_i^{ - 1} G_i )^{ - 1} $$
$$f\,(x|H_i, z_0 ) = N(\hat x_i, P_i ), \quad P_i = (G_i ^T R_i^{ - 1} G_i )^{ - 1} $$Because the hypotheses are mutually exclusive and exhaustive, a composite PDF for true position given all available measurements z 0 can be derived as the weighted sum of the PDFs associated with each hypothesis:
 $$f\,(x|z_0 ) = \sum\limits_{i = 0}^{n_f} {\,f\,(x|H_i, z_0 ){\rm}} P(H_i |z_0 ) = \sum\limits_{i = 0}^{n_f} {\,f\,(x|H_i, z_i )} {\rm} P(H_i |z_0 )$$
$$f\,(x|z_0 ) = \sum\limits_{i = 0}^{n_f} {\,f\,(x|H_i, z_0 ){\rm}} P(H_i |z_0 ) = \sum\limits_{i = 0}^{n_f} {\,f\,(x|H_i, z_i )} {\rm} P(H_i |z_0 )$$where f(x|H i, z 0)=f(x|H i, zi) because the ith set of assumed faulty measurements are not informative under H i.
A simplified graph showing a composite PDF from the PDFs of three sub-set solutions  $\hat x_i $ (i=1 to 3) and the full solution
$\hat x_i $ (i=1 to 3) and the full solution  $\hat x_0 $ is shown in Figure 1.
$\hat x_0 $ is shown in Figure 1.

Figure 1. Illustration of the composite PDF of the true position using the multiple-hypothesis approach.
The  $\hat x$ represents a single component of the estimated position vector in the figure. In the illustrative examples in this work, which are aviation examples, we will mainly focus on the vertical position coordinate, because vertical requirements are typically more stringent in aviation applications. However, the same methodology applies to the horizontal components of the position estimate as well.
$\hat x$ represents a single component of the estimated position vector in the figure. In the illustrative examples in this work, which are aviation examples, we will mainly focus on the vertical position coordinate, because vertical requirements are typically more stringent in aviation applications. However, the same methodology applies to the horizontal components of the position estimate as well.
In Equation (7), the composite PDF can be defined only if the posterior probability P(H i|z 0) for each hypothesis can be obtained precisely. However, for GNSS this is not possible because distributions of failure magnitudes are generally not available. An alternative approach, which we pursue in this work, is to derive an upper bound on the posterior probability, which will then be used to form an upper bound on integrity risk.
Using Bayes’ theorem, the posterior probability given all available measurements z 0 can be expressed as:
 $$P(H_i |z_0 ) = \displaystyle{{\,f\,(z_0 |H_i ){\rm} P(H_i )} \over {\sum\limits_{\,j = 0}^{n_f} {\,f\,(z_0 |H_j ){\rm} P(H_j )}}} $$
$$P(H_i |z_0 ) = \displaystyle{{\,f\,(z_0 |H_i ){\rm} P(H_i )} \over {\sum\limits_{\,j = 0}^{n_f} {\,f\,(z_0 |H_j ){\rm} P(H_j )}}} $$Given the full-set of n measurements z 0, the information about the faults is carried only by the associated n-m by 1 parity vector p, which is defined using Equation (8.1) (Pervan et al., Reference Pervan, Lawrence, Cohen and Parkinson1996; Sturza, Reference Sturza1989):
 $$p = Lz_0 $$
$$p = Lz_0 $$where L is an n-m by n projection matrix. The details of how to compute matrix L and parity vector p will be discussed later.
For the moment, it is only relevant that the only part of measurement vector z 0 that is informative about the faults is more compactly expressed by the parity vector p. Therefore, this vector will be used to in place of z 0 to derive the posterior probability of fault occurrence:
 $$P(H_i |z_0 ) = P(H_i |p)\quad \Rightarrow \quad P(H_i |p) = \displaystyle{{\,f\,(\,p|H_i ){\rm} P(H_i )} \over {\sum\limits_{\,j = 0}^{n_f} {\,f\,(\,p|H_j ){\rm} P(H_j )}}} $$
$$P(H_i |z_0 ) = P(H_i |p)\quad \Rightarrow \quad P(H_i |p) = \displaystyle{{\,f\,(\,p|H_i ){\rm} P(H_i )} \over {\sum\limits_{\,j = 0}^{n_f} {\,f\,(\,p|H_j ){\rm} P(H_j )}}} $$The conditional PDF f(p|H j) can be further expanded as:
 $$f\,(\,p|H_j ) = \int_{ - \infty} ^\infty {\,f\,(\,p|b_j, H_j )f_b (b_j |H_j )} {\rm} db_j $$
$$f\,(\,p|H_j ) = \int_{ - \infty} ^\infty {\,f\,(\,p|b_j, H_j )f_b (b_j |H_j )} {\rm} db_j $$where f b(b j|Hj) is the unknown conditional failure-magnitude distribution function for the jth failure mode.
After substituting Equation (9) into Equation (8.2), the Bayesian posterior probability of hypothesis i is:
 $$P(H_i |p) = \displaystyle{{\int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )} \over {\sum\limits_{\,j = 0}^{n_f} {\int_{ - \infty} ^\infty {\,f\,(\,p|b_j, H_j )f_b (b_j |H_j )} {\rm} db_j {\rm} P(H_j )}}} $$
$$P(H_i |p) = \displaystyle{{\int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )} \over {\sum\limits_{\,j = 0}^{n_f} {\int_{ - \infty} ^\infty {\,f\,(\,p|b_j, H_j )f_b (b_j |H_j )} {\rm} db_j {\rm} P(H_j )}}} $$Since every term in Equation (10) has a positive value, an upper bound of the Bayesian posterior probability can be obtained by lower bounding all denominator terms by zero, except for terms corresponding to j=0 and j=i. The upper bound on the posterior probability for fault-free hypothesis, i=0, is simply one since in this special case all terms other than j=0 in the denominator are lower bounded by zeros. For values i>1, Equation (10) can be upper bounded more tightly as:
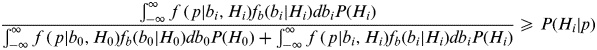 $$\displaystyle{{\int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )} \over {\int_{ - \infty} ^\infty {\,f\,(\,p|b_0, H_0 )f_b (b_0 |H_0 )} {\rm} db_0 {\rm} P(H_0 ) + \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )}} \geqslant P(H_i |p)$$
$$\displaystyle{{\int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )} \over {\int_{ - \infty} ^\infty {\,f\,(\,p|b_0, H_0 )f_b (b_0 |H_0 )} {\rm} db_0 {\rm} P(H_0 ) + \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )}} \geqslant P(H_i |p)$$For the fault-free hypothesis (H 0), the failure magnitude b 0 is known to be zero. Therefore, the first integral in the denominator of the inequality above can be evaluated directly. The left-hand side of the inequality then takes the form of w/(c+w), where c is a constant and w is an integral that depends on the failure magnitude distribution. This form is a monotonically ascending function in the variable w. Therefore, maximizing w will also maximize the function w/(c+w). As a result, a bounding value on the posterior probability P(H i|p) is obtained by finding the maximum value of the integral term w:
 $$\hat {P}\, (H_i |p) = \displaystyle{{\mathop {\max} \limits_{\,f_b, b_i} \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i ){\rm}} db_i {\rm} P(H_i )} \over {\,f\,(\,p|b_0 = 0,H_0 ){\rm} P(H_0 ) + \mathop {\max} \limits_{\,f_b, b_i} \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )}} \geqslant P(H_i |p)$$
$$\hat {P}\, (H_i |p) = \displaystyle{{\mathop {\max} \limits_{\,f_b, b_i} \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i ){\rm}} db_i {\rm} P(H_i )} \over {\,f\,(\,p|b_0 = 0,H_0 ){\rm} P(H_0 ) + \mathop {\max} \limits_{\,f_b, b_i} \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i {\rm} P(H_i )}} \geqslant P(H_i |p)$$Finding the maximum value of the integral term in Equation (11) involves dealing with the unknown failure magnitude distribution. Considering only single measurement faults, the parameter b i in Equation (11) is a scalar, and the failure magnitude b i* which corresponds to the maximum value of the conditional PDF of the parity vector p is defined as:
 $$b_i^* = \mathop {\arg \max} \limits_{b_i} f\,(\,p|b_i, H_i )$$
$$b_i^* = \mathop {\arg \max} \limits_{b_i} f\,(\,p|b_i, H_i )$$The worst-case scenario for the unknown failure magnitude PDF is therefore a Dirac delta function centred at b i*. The resulting maximum value of the integral becomes:
 $$\mathop {\max} \limits_{\,f_b, b_i} \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i = \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )\delta _b (b_i - b_i^* |H_i )} {\rm} db_i = f\,(\,p|b_i^*, H_i )$$
$$\mathop {\max} \limits_{\,f_b, b_i} \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )f_b (b_i |H_i )} {\rm} db_i = \int_{ - \infty} ^\infty {\,f\,(\,p|b_i, H_i )\delta _b (b_i - b_i^* |H_i )} {\rm} db_i = f\,(\,p|b_i^*, H_i )$$Substituting the above result into Equation (11), the bounding posterior probability can be expressed as:
 $$\hat{P}\, (H_i |p) = \displaystyle{{\,f\,(\,p|b_i^*, H_i ){\rm} P(H_i )} \over {\,f\,(\,p|b_0 = 0, H_0 ){\rm} P(H_0 ) + f\,(\,p|b_i^*, H_i ){\rm} P(H_i )}}$$
$$\hat{P}\, (H_i |p) = \displaystyle{{\,f\,(\,p|b_i^*, H_i ){\rm} P(H_i )} \over {\,f\,(\,p|b_0 = 0, H_0 ){\rm} P(H_0 ) + f\,(\,p|b_i^*, H_i ){\rm} P(H_i )}}$$Equation (14) assumes the worst-case failure magnitude b i* defined in Equation (12) is known.
2.1. Derivation of the worst case failure magnitude bi*
Consider the general linear measurement Equation (2) under a fault condition. A failure vector b is added to Equation (2), and the equation is then normalised by pre-multiplying with the inverse square root of the measurement noise covariance matrix R. The subscript 0 in this derivation is omitted since all equations use the full set of measurements:
 $$R^{ - 1/2} z = R^{ - 1/2} Gx + R^{ - 1/2} b + R^{ - 1/2} v\; \Rightarrow \;z^{*} = G^{*} x + R^{ - 1/2} b + v^{*} $$
$$R^{ - 1/2} z = R^{ - 1/2} Gx + R^{ - 1/2} b + R^{ - 1/2} v\; \Rightarrow \;z^{*} = G^{*} x + R^{ - 1/2} b + v^{*} $$The n by m (n>m) observation matrix G* can be decomposed by singular value decomposition (SVD):
 $$G_{n \times m}^* = U_{n \times n} \left[ {\matrix{ {S_{m \times m}} \cr {0_{(n - m) \times m}} \cr}} \right]V_{m \times m}^T $$
$$G_{n \times m}^* = U_{n \times n} \left[ {\matrix{ {S_{m \times m}} \cr {0_{(n - m) \times m}} \cr}} \right]V_{m \times m}^T $$where the n by n matrix U can be partitioned into an n by m matrix U 1 and an n by n-m matrix U 2. U 2 maps the measurements into the parity space (Pervan et al., Reference Pervan, Lawrence, Cohen and Parkinson1996):
 $$U_{n \times n} = \left[ {\matrix{ {U_{1,n \times m}} & {U_{2,n \times (n - m)}} \cr}} \right]^{} $$
$$U_{n \times n} = \left[ {\matrix{ {U_{1,n \times m}} & {U_{2,n \times (n - m)}} \cr}} \right]^{} $$The parity vector p is the projection of the normalized measurements in parity space. Under fault-free conditions, the elements of p are independent and identically distributed (i.i.d.) Gaussian random variables with zero mean and unit variance. Under faulty conditions, the fault vector b causes the parity vector to have a non-zero mean, which can be expressed as:
 $$p = U_2^T z^* = U_2^T R^{ - 1/2} b + U_2^T v^*, \quad\Rightarrow p = Lb + U_2^T v^* $$
$$p = U_2^T z^* = U_2^T R^{ - 1/2} b + U_2^T v^*, \quad\Rightarrow p = Lb + U_2^T v^* $$where L=U 2TR− 1/2, f(p|b, H i)=N(Lb, I n-m), and I n-m is the identity matrix of size n-m by n-m.
For hypothesis H i of a fault on measurement i, we define the failure magnitude b i of the fault vector b. The product of the matrix L and the fault vector b becomes: Lb=L ibi, where L i is the ith column of L. Using Equation (18), the PDF of the parity vector given hypothesis H i can then be written as:
 $$f\,(\,p|b,H_i ) = f\,(\,p|b_i, H_i ) = N(L_i b_i, I_{n - m} ) = \displaystyle{1 \over {(2\pi )^{(n - m)/2}}} \exp \left( { - \displaystyle{{(\,p - L_i b_i )^T (\,p - L_i b_i )} \over 2}} \right)$$
$$f\,(\,p|b,H_i ) = f\,(\,p|b_i, H_i ) = N(L_i b_i, I_{n - m} ) = \displaystyle{1 \over {(2\pi )^{(n - m)/2}}} \exp \left( { - \displaystyle{{(\,p - L_i b_i )^T (\,p - L_i b_i )} \over 2}} \right)$$For fault-free hypothesis H 0, Equation (19) becomes:
 $$f\,(\,p|b_0 = 0,H_0 ) = \displaystyle{1 \over {(2\pi )^{(n - m)/2}}} \exp \left( { - \displaystyle{{\,p^T p} \over 2}} \right)$$
$$f\,(\,p|b_0 = 0,H_0 ) = \displaystyle{1 \over {(2\pi )^{(n - m)/2}}} \exp \left( { - \displaystyle{{\,p^T p} \over 2}} \right)$$To maximize the conditional PDF shown in Equation (19), the exponent (p − L ibi)T(p − L ibi) must be minimised. To do this we take the partial derivative with respect to b i and equate it to zero:
 $$\displaystyle{\partial \over {\partial b_i}} [(\,p - L_i b_i )^T (\,p - L_i b_i )] = 0\; \Rightarrow \;{\rm} L_i^T (\,p - L_i b_i ) = 0$$
$$\displaystyle{\partial \over {\partial b_i}} [(\,p - L_i b_i )^T (\,p - L_i b_i )] = 0\; \Rightarrow \;{\rm} L_i^T (\,p - L_i b_i ) = 0$$It can be shown that the second partial derivative is always negative. Therefore, the failure magnitude b i satisfying Equation (21) minimises the inner product and is the worst-case fault magnitude defined in Equation (12):
 $$b_i^* = \mathop {\arg \max} \limits_{b_i} f\,(\,p|b_i, H_i ) = (L_i^T L_i )^{ - 1} L_i^T p$$
$$b_i^* = \mathop {\arg \max} \limits_{b_i} f\,(\,p|b_i, H_i ) = (L_i^T L_i )^{ - 1} L_i^T p$$Substituting Equation (22) into Equation (19) and rearranging terms, the maximum value of the conditional PDF of the parity vector is:
 $$f\,(\,p|b_i^*, H_i ) = \displaystyle{1 \over {(2\pi )^{(n - m)/2}}} \exp \left( { - \displaystyle{{\,p^T (I_{n - m} - L_i (L_i^T L_i )^{ - 1} L_i^T )p} \over 2}} \right)$$
$$f\,(\,p|b_i^*, H_i ) = \displaystyle{1 \over {(2\pi )^{(n - m)/2}}} \exp \left( { - \displaystyle{{\,p^T (I_{n - m} - L_i (L_i^T L_i )^{ - 1} L_i^T )p} \over 2}} \right)$$Using the results from Equations (20) and (23), the bound on the posterior probability shown in Equation (14) is:
 $$\hat{P}\, (H_i |p) = \displaystyle{{\exp \left( { - \displaystyle{{\,p^T (I_{n - m} - L_i (L_i^T L_i )^{ - 1} L_i^T )p} \over 2}} \right)P(H_i )} \over {\exp \left( { - \displaystyle{{\,p^T p} \over 2}} \right)P(H_0 ) + \exp \left( { - \displaystyle{{\,p^T (I_{n - m} - L_i (L_i^T L_i )^{ - 1} L_i^T )p} \over 2}} \right)P(H_i )}}$$
$$\hat{P}\, (H_i |p) = \displaystyle{{\exp \left( { - \displaystyle{{\,p^T (I_{n - m} - L_i (L_i^T L_i )^{ - 1} L_i^T )p} \over 2}} \right)P(H_i )} \over {\exp \left( { - \displaystyle{{\,p^T p} \over 2}} \right)P(H_0 ) + \exp \left( { - \displaystyle{{\,p^T (I_{n - m} - L_i (L_i^T L_i )^{ - 1} L_i^T )p} \over 2}} \right)P(H_i )}}$$3. ROBUSTNESS OF INTEGRITY EVALUATION USING BAYESIAN APPROACH
From the Bayesian point-of-view, integrity risk is defined as the conditional probability, given the measurements, that the state estimation error, δx, exceeds a prescribed limit ±l (often called an alert limit):
 $$I_{risk} |_z \equiv P(|\delta x| \gt l|z)$$
$$I_{risk} |_z \equiv P(|\delta x| \gt l|z)$$ The Bayesian integrity risk is a function of the composite PDF of the true position x in Equation (7), the alert limit, and the choice of position estimate  $\hat x$ used for navigation. We start by using the full-set solution
$\hat x$ used for navigation. We start by using the full-set solution  $\hat x_0 $ as the navigation estimate. As illustrated in Figure 2, the integrity risk is the cumulative probability of the true position being outside the interval of length 2l centred at the navigation solution
$\hat x_0 $ as the navigation estimate. As illustrated in Figure 2, the integrity risk is the cumulative probability of the true position being outside the interval of length 2l centred at the navigation solution  $\hat x_0 $. It can be expressed as the sum of the tail-probability of each hypothesis weighted by the posterior probability of occurrence of each hypothesis given the measurements:
$\hat x_0 $. It can be expressed as the sum of the tail-probability of each hypothesis weighted by the posterior probability of occurrence of each hypothesis given the measurements:
 $$I_{risk} (\hat x_0, l)|_{z_0} = P(|x - \hat x_0 | \gt l|z_0 ) = \sum\limits_{i = 0}^{n_f} {P(|x - \hat x_0 | \gt l|H_i, z_0 )} {\rm} P(H_i |z_0 )$$
$$I_{risk} (\hat x_0, l)|_{z_0} = P(|x - \hat x_0 | \gt l|z_0 ) = \sum\limits_{i = 0}^{n_f} {P(|x - \hat x_0 | \gt l|H_i, z_0 )} {\rm} P(H_i |z_0 )$$
Figure 2. Illustration of the integrity risk using Bayesian approach.
The difference between the ith sub-set solution and the full-set solution is defined as the ith solution separation value Δi: Δi≡ $\hat x_i - \hat x_0$. Assuming zero-mean, normally distributed measurement noise, the tail-probability of each hypothesis can be evaluated as a sum of complementary error functions:
$\hat x_i - \hat x_0$. Assuming zero-mean, normally distributed measurement noise, the tail-probability of each hypothesis can be evaluated as a sum of complementary error functions:
 $$\eqalign{ P(|x - \hat x_0 | \gt l|H_i, z_0 ) = & \int_{ - \infty} ^{\hat x_0 - l} {\,f\,(x|H_i, z_0 )dx} + \int_{\hat x_0 + l}^\infty {\,f\,(x|H_i, z_0 )} dx \cr = &\displaystyle{1 \over 2}\left( {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right)} $$
$$\eqalign{ P(|x - \hat x_0 | \gt l|H_i, z_0 ) = & \int_{ - \infty} ^{\hat x_0 - l} {\,f\,(x|H_i, z_0 )dx} + \int_{\hat x_0 + l}^\infty {\,f\,(x|H_i, z_0 )} dx \cr = &\displaystyle{1 \over 2}\left( {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right)} $$The Bayesian integrity risk using the full-solution can then be written as:
 $$\eqalign{ I_{risk} (\hat x_0, l)|_{z_0} = &\displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} P(H_i |z_0 )} \cr = & \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} P(H_i |p)}} $$
$$\eqalign{ I_{risk} (\hat x_0, l)|_{z_0} = &\displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} P(H_i |z_0 )} \cr = & \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} P(H_i |p)}} $$It is important to note that, as shown in Chan and Pervan (Reference Chan and Pervan2010), the solution separation values Δi can be directly obtained from the parity vector p as a scaled vector projection of p on the ith row of U 2, which is the same direction as the fault mode L i:
 $$[\matrix{ {\Delta _{i,x}} & {\Delta _{i,y}} & {\Delta _{i,z}} & {\Delta _{i,clk}} \cr} ]^T = - (I - P_0 g_i g_i^T )^{ - 1} P_0 g_i r_i, \quad r_i = U_2 (i,:)p$$
$$[\matrix{ {\Delta _{i,x}} & {\Delta _{i,y}} & {\Delta _{i,z}} & {\Delta _{i,clk}} \cr} ]^T = - (I - P_0 g_i g_i^T )^{ - 1} P_0 g_i r_i, \quad r_i = U_2 (i,:)p$$where Δi,x, Δi,y, Δi,z, Δi,clk are the x, y, z and receiver clock bias components in the ith solution separation vector, g i is the ith column in the observation matrix G, r i is the ith residual element obtained by projecting the parity vector onto the ith fault mode which is represented by the ith row of U 2 matrix (U 2 (i,:)).
Equation (28) is the Bayesian system integrity risk. As noted earlier, the posterior probability of each hypothesis’ given measurements cannot be precisely evaluated when the failure-magnitude distribution function is unknown. Instead, the posterior bounds in Equations (8) to (24) are used to obtain an upper bound on the Bayesian integrity risk:
 $$\hat{I} _{risk} (\hat x_0, l)|_{z_0} = \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P}\, (H_i |p)}\hskip5pt \geqslant \hskip5pt{\rm} I_{risk} (\hat x_0, l)|_{z_0} $$
$$\hat{I} _{risk} (\hat x_0, l)|_{z_0} = \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - \Delta _i} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + \Delta _i} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P}\, (H_i |p)}\hskip5pt \geqslant \hskip5pt{\rm} I_{risk} (\hat x_0, l)|_{z_0} $$One particularly interesting property of the integrity risk bound Equation (29), which is inherited from Bayesian approach, is its relative insensitivity to prior probabilities (also known as posterior robustness (Berger, Reference Berger1985)). A frequentist approach for system integrity evaluation uses a fixed prior probability for each assumed hypothesis. Proving that these fixed values upper bound the actual prior probabilities is typically not possible. The Bayesian approach mitigates the issue by generating a posterior probability update based on current time measurements.
We illustrate the Bayesian approach through an example of positioning using a nominal GPS constellation. The constellation used is adopted from earlier ARAIM research described by the GNSS Evolutionary Architecture Study (GEAS) in FAA (2011). We consider a single satellite geometry epoch at one location, in which six satellites (SVs) are in view. In this case, the parity space is two-dimensional and is easy to represent graphically. Measurement error was modelled as a function of elevation based on the GEAS/ARAIM error models in Lee and McLaughlin (Reference Lee and McLaughlin2007).
Figure 3 shows the parity space for this example and the failure mode lines for each fault mode hypothesis (only single satellite failures are considered). The failure mode direction for satellite i can be obtained by replacing the fault vector b in Equation (18) with L ibi. The direction of the blue dashed arrow is arbitrarily picked as an example (actual) parity vector direction; the parity vector magnitude is made to vary linearly to illustrate the variation of the posterior probability bound. The resulting posterior probability bounds for each hypothesis are shown in Figure 4 as functions of the parity vector magnitude. A prior probability P(H i)=1×10−5, for all i, was used to generate the results. The figure shows that the larger the magnitude of a parity vector, the more likely it is to be the result of a fault. Figure 5 illustrates one specific parity vector p and two associated worst-case fault magnitudes for single SV 5 and 6 fault modes derived using Equation (22).
Figure 3. Parity space and fault modes.
Figure 4. Bayesian posterior probability bounds.
Figure 5. Illustration of a specific parity vector p.
Figure 6 shows the Bayesian integrity risk bounds from Equation (29) (the z axis is logarithmic in scale) corresponding to all parity vectors (the p 1 and p 2 axes) for the example geometry using a 35 metre vertical alert limit (l=±35 m). The figure illustrates that the integrity risk bound is convex in a valley shape. The horizontal blue curve in the middle of the valley represents an example constant integrity risk contour, which is also shown in Figure 7. The integrity risk value is 8·7×10−8 in this example. (The reason for the choice of this particular value will become evident later in Section 5.) In addition, Figure 7 shows two other constant integrity risk contours (red and magenta) associated with the same integrity risk (8·7×10−8), but respectively evaluated with ten and 100 times larger prior probabilities (1×10−4 and 1×10−3). In the figure, the Bayesian integrity risk bound contours change only slightly with large variations in prior probability. This visually illustrates that the Bayesian integrity risk bound is not sensitive to prior probability variation. The significance of the robustness of the Bayesian integrity risk to prior probability will become compelling in Section 5 when system performance using traditional RAIM will be compared to the Bayesian approach.
Figure 6. Bayesian integrity risk bounds in parity space.
Figure 7. Bayesian integrity risk bound contours in parity space.
4. FAULT-TOLERANT POSITION ESTIMATION AND BAYESIAN RAIM DETECTION
The Bayesian integrity risk bound derived in the previous section uses a least-squares solution  $\hat x_0 $ as navigation solution, but this is not necessarily the only choice. In fact, Equation (26) defines the Bayesian integrity risk for any arbitrary position estimate
$\hat x_0 $ as navigation solution, but this is not necessarily the only choice. In fact, Equation (26) defines the Bayesian integrity risk for any arbitrary position estimate  $\hat x$:
$\hat x$:
 $$I_{risk} (\hat x,l)|_{z_0} = P(|x - \hat x| \gt l|z_0 ) = \sum\limits_{i = 0}^{n_f} {P(|x - \hat x| \gt l|H_i, z_0 )} {\rm} P(H_i |z_0 )$$
$$I_{risk} (\hat x,l)|_{z_0} = P(|x - \hat x| \gt l|z_0 ) = \sum\limits_{i = 0}^{n_f} {P(|x - \hat x| \gt l|H_i, z_0 )} {\rm} P(H_i |z_0 )$$ Following the derivation in Pervan et al. (Reference Pervan, Pullen and Christie1998), an arbitrary position estimate can be expressed as an offset from the full-set least-squares solution: Δ ≡  $\hat x$−
$\hat x$− $\hat x_0 $. The Bayesian integrity risk bound for an arbitrary position estimate can be derived similarly to Equations (27)–(29) to be:
$\hat x_0 $. The Bayesian integrity risk bound for an arbitrary position estimate can be derived similarly to Equations (27)–(29) to be:
 $$\hat {I} _{risk} (\hat x,l)|_{z_0} = \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc} \left[ {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P} (H_i |p)} {\rm} \geqslant {\rm} I_{risk} (\hat x,l)|_{z_0} $$
$$\hat {I} _{risk} (\hat x,l)|_{z_0} = \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc} \left[ {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P} (H_i |p)} {\rm} \geqslant {\rm} I_{risk} (\hat x,l)|_{z_0} $$ Given the alert limit l and current measurements, the Bayesian integrity risk bound in Equation (31) is only a function of the offset Δ. Therefore, we may choose Δ to minimize the Bayesian integrity risk bound. This results in a ‘fault-tolerant’ position estimate (FTE):  $\hat x_{FTE} = \Delta + \hat x_0 $.
$\hat x_{FTE} = \Delta + \hat x_0 $.
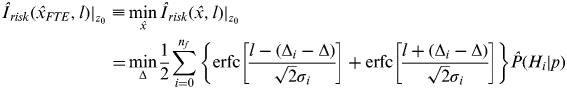 $$\eqalign{\hat {I} _{risk} (\hat x_{FTE}, l)|_{z_0} \equiv & \mathop {\min} \limits_{\hat x} \hat {I} _{risk} (\hat x,l)|_{z_0} \cr = & \mathop {\min} \limits_\Delta \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P} (H_i |p)}} $$
$$\eqalign{\hat {I} _{risk} (\hat x_{FTE}, l)|_{z_0} \equiv & \mathop {\min} \limits_{\hat x} \hat {I} _{risk} (\hat x,l)|_{z_0} \cr = & \mathop {\min} \limits_\Delta \displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P} (H_i |p)}} $$The derivation of the FTE has been shown in Pervan et al. (Reference Pervan, Pullen and Christie1998), and the result is expressed below:
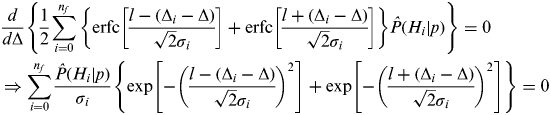 $$\eqalign{ & \displaystyle{d \over {d\Delta}} \left\{ {\displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P} (H_i |p)}} \right\} = 0 \cr & \Rightarrow \sum\limits_{i = 0}^{n_f} {\displaystyle{{\hat {P} (H_i |p)} \over {\sigma _i}} \left\{ {\exp \left[ { - \left( {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right)^2} \right] + \exp \left[ { - \left( {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right)^2} \right]} \right\}} = 0} $$
$$\eqalign{ & \displaystyle{d \over {d\Delta}} \left\{ {\displaystyle{1 \over 2}\sum\limits_{i = 0}^{n_f} {\left\{ {{\rm erfc}\left[ {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right] + {\rm erfc}\left[ {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right]} \right\}{\rm} \hat {P} (H_i |p)}} \right\} = 0 \cr & \Rightarrow \sum\limits_{i = 0}^{n_f} {\displaystyle{{\hat {P} (H_i |p)} \over {\sigma _i}} \left\{ {\exp \left[ { - \left( {\displaystyle{{l - (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right)^2} \right] + \exp \left[ { - \left( {\displaystyle{{l + (\Delta _i - \Delta )} \over {\sqrt 2 \sigma _i}}} \right)^2} \right]} \right\}} = 0} $$The FTE solution Δ cannot be expressed in closed form, but it can be obtained numerically with great efficiency. Therefore, a real-time implementation is feasible. Figure 8 shows numerical results of the Bayesian integrity risk bound for the vertical positioning component using the example from the previous section. In this figure, the Bayesian integrity risk bound resulting from the FTE is about +3·2 m off the least squares estimate, but its integrity risk is two orders of magnitude lower.
Figure 8. The Bayesian integrity risk bounds for different position estimate.
The fault detection algorithm for this Bayesian approach is a direct comparison between two values: the computed Bayesian integrity risk bounds, noted as I comp, and a detection threshold using the allocated integrity risk requirement, noted as I req.
 $$I_{comp} \equiv \hat {I} _{risk} (\hat x,l)|_{z_0} {\rm,} \quad {\rm detection:} \ I_{comp} \geqslant I_{req}, \quad {\rm no {\hbox -} detection:} \ I_{comp} \lt I_{req} $$
$$I_{comp} \equiv \hat {I} _{risk} (\hat x,l)|_{z_0} {\rm,} \quad {\rm detection:} \ I_{comp} \geqslant I_{req}, \quad {\rm no {\hbox -} detection:} \ I_{comp} \lt I_{req} $$This detection mechanism is different from conventional RAIM methods, which normally set detection thresholds based on a continuity requirement. Using this Bayesian detection algorithm, system continuity is yet to be evaluated. This will be addressed in Section 5.
5. CONTINUITY AND EXAMPLE SYSTEM PERFORMANCE EVALUATION
For civil aviation applications, continuity risk is defined as the probability of interrupting an aircraft operation that has already been initiated. It is directly related to the false alarm rate of the fault detection algorithm. To illustrate the connection between fault detection performance and continuity requirement using the Bayesian approach, an example application, LPV-200 precision approach (FAA, 2007), is considered.
LPV-200 precision approach has been wildly studied for the next generation GNSS. As in the example in Section 3, measurement error models are adopted from GEAS/ARAIM (FAA, 2011), with exception of the bias errors treated in that prior work, which are excluded here for simplicity. Further, only the vertical position error, which has the most stringent requirements in LPV-200 performance, is considered.
The simulation parameters used in Section 3 are implemented again for one example geometry with six satellites in view at the same example location. For the purpose of the example, a continuity risk requirement of 4×10−6 and an integrity risk requirement of 8·7×10−8, with an associated 35 m alert limit, are allocated to the vertical positioning component from the total LPV-200 requirements. To better understand the methods for continuity risk evaluation, the least-squares position estimate is first used and only single-satellite-failure modes are considered. Then, the same methods are extended to the Bayesian FTE solution for system performance evaluation.
Figure 9 shows the a priori joint PDF of the parity vector under fault-free conditions. The integrity risk contour (red line contour) corresponding to posterior Bayesian integrity risk bound of 8·7×10−8 is also shown. The contour was evaluated using the above-mentioned example with 1×10−5 prior probabilities for all fault hypotheses. It represents the detection boundary in parity space (a parity plane in this example) for the Bayesian detection algorithm. If a parity vector falls outside the contour (I comp⩾I req), detection is declared and the aircraft approach is interrupted. Therefore, the false alarm contribution to continuity risk is the cumulative probability that the parity vector, under fault-free conditions, falls outside the detection contour. Precisely computing this accumulated probability is challenging, because the contour of constant integrity risk is a smooth and continuous enclosed curve (as seen in Figure 9), which cannot be represented analytically in closed form. This becomes even more challenging when the dimension of the parity space becomes higher (i.e. when more visible satellites are available). A potential method to solve the issue was presented in Pervan et al. (Reference Pervan, Pullen and Christie1998) and Chan and Pervan (Reference Chan and Pervan2010), and one of them is briefly reviewed below. Then, a new more effective method is developed.
Figure 9. Probability density in parity space under fault-free hypothesis.
The cumulative probability outside a circular contour in parity space can be easily computed using the chi-squared cumulative density function (CDF). Continuity requirements are guaranteed to be met if the largest circular contour that can be inscribed within the actual detection contour has a computed continuity risk equal to or smaller than the required continuity risk (Chan and Pervan, Reference Chan and Pervan2010). However, as Figure 10 illustrates, this method of evaluating continuity risk can be very conservative (because the black-dashed areas in Figure 10 are not accounted for using this method). Another less conservative approach for evaluating the continuity contour uses a convex polytope contour instead of a circle. Figure 11 shows a circular contour and a convex polytope contour side by side. The radius r of the circular contour can be computed using the chi-squared CDF to meet the continuity requirement. Also shown in the figure are f 1, f2 and f 3, which represent the unit vectors of each fault mode. (For clarity, only three fault hypotheses are assumed in this illustration.) The convex polytope is defined by a set of straight-line segments perpendicular to the fault mode lines. The specific line segments are chosen to intersect with the fault mode lines at distances ±k 1, ±k 2 and ±k 3 from the origin. The intersection points on the polytope boundary contour, ±k 1f1, ±k 2f2 and ±k 3f3, are called boundary points, and they will be used to bound continuity risk. Although the continuity risk of a convex polytope contour is not trivial to compute either, a bound can easily be found. If C is defined as an event where the parity vector lies inside a convex polytope contour, it is shown in the Appendix that the continuity risk is bounded by:
 $$\hat {P} (\,p \in \bar C|H_0 ) = \sum\limits_{i = 1}^{n_f} {P(|a_i | \gt k_i |H_0 )} \geqslant P(\,p \in \bar C|H_0 )$$
$$\hat {P} (\,p \in \bar C|H_0 ) = \sum\limits_{i = 1}^{n_f} {P(|a_i | \gt k_i |H_0 )} \geqslant P(\,p \in \bar C|H_0 )$$where a i is the magnitude of the projection on the fault mode direction from a parity vector. Therefore it is a normally distributed random variable with a unity standard deviation and zero mean under H 0.
Figure 10. Computed continuity risk (2×10−4) using circular continuity contour.
Figure 11. Different continuity contours in parity space.
For our current purpose, the boundary points are specifically selected to have equal distances to the origin (k 1=k 2= …=k i) by allocating the required continuity risk evenly on each fault mode.
Computing continuity risk using the convex polytope contour is less conservative than using a circular continuity contour. The reason is that the corners of a convex polytope extend the circumscribed area beyond that of a circular contour, which ultimately provides a tighter bound on the continuity risk. This reduction in the continuity risk bound improves significantly when the dimension of the parity space increases, i.e., with a larger number of redundant satellites. Figure 12 shows the numerical results in this respect using evenly-allocated continuity for a total 4×10−6 continuity risk. The y-axis in the figure is the minimum magnitude of the parity vector along each fault mode that meets the continuity risk requirement using each of the two methods. The x-axis is the number of redundant satellites. To meet the continuity requirement, the posterior Bayesian integrity risks associated with all parity vectors with these lengths must not exceed the integrity risk requirement; otherwise the likelihood of fault-free detection will be too high. However, the bigger the magnitudes of these parity vectors become, the higher the resulting posterior integrity risk they have. Therefore, to achieve the same integrity risk using either method (i.e. both continuity contours inscribed within the detection contour), the computed fault free alarm probability using the convex polytope will be relatively much lower as the number of redundant satellites increases.
Figure 12. Distance to the origin of parity space for two continuity contours.
In addition, the convex polytope contour also offers flexibility in varying boundary points along each fault mode to more closely resemble the actual detection surface contour. In other words, the continuity risk can be allocated by individually selecting k i for each fault mode in Equation (35). However, it should be noted that in most example ARAIM cases that we evaluated, the resulting continuity improvement is typically small.
In practice, the convex polytope contour is first defined to achieve the required continuity risk. Then, it must be determined whether the Bayesian integrity risk bound meets the given integrity risk requirement at all points within the contour. This can be efficiently done by evaluating the risk bound on the polytope contour itself. Because the Bayesian integrity risk bound is a convex function (as shown in Figure 6), the maximum value of Bayesian integrity risk bound must fall on the contour. Moreover, again because of the convexity of the function, one of the two end points of each segment of the contour (i.e., the vertices of the polytope) will have risk bound larger than or equal to the risk bounds at points within the segment (Luenberger, Reference Luenberger2003). Therefore, only the vertices of the given convex polytope are needed to evaluate the Bayesian integrity risk bounds for the whole continuity counter. The total number of risk bound evaluation points can be further reduced to half because the integrity contour is symmetric with respect to the origin of parity space. A numerical demonstration of evaluating integrity risk bounds along the continuity contour is illustrated in the Appendix.
A Protection Level (PL) is the minimum interval l (see Figure 2) which meets the required integrity and continuity risks. The smaller the Vertical Protection Level (VPL), the better the system performance is. In Figure 13, the VPL differences are generated over 24 hours at the previous example location by subtracting the VPLs of the convex polytope method from the VPLs of the circular contour method. It is clear in the figure that the convex polytope method performs better (smaller VPLs resulting in positive VPL difference).
Figure 13. VPL system performance difference for two different continuity evaluation methods.
The ARAIM algorithm uses a fixed set of prior probabilities for each hypothesis, but the validity of any chosen value for prior probability is often debatable. In the following example four possible values are considered: 1×10−2, 1×10−3, 1×10−4 and 1×10−5. VPLs for the Bayesian FTE method are compared to those obtained using the baseline ARAIM algorithm described in FAA (2011). Simulations are performance at one location for 24 hours using a 24-minus-1 SV GPS constellation (the GPS Standard Positioning Service Performance Standard (US DOD, 2001) depleted by one satellite). Figure 14 illustrates the VPL variations for both methods using the actual prior probabilities of 1×10−2, 1×10−3, 1×10−4 relative to an assumed value of 1×10−5. The deviations are shown in terms of the ratio of VPLs relative to the 1×10−5 case. Because the Bayesian FTE algorithm is less sensitive to prior probability variations, for clarity only relative VPLs corresponding to the 1×10−2 prior probability case are shown (this is the largest deviation from the assumed value, 1×10−5).
Figure 14. VPL variations with different prior probabilities for single constellation.
Figure 15 shows the same simulation using two constellations: a 24-minus-1 SV GPS constellation and a 27-minus-1 SV Galileo constellation (Zandbergen et al., Reference Zandbergen, Dinwiddy, Hahn, Breeuwer and Blonski2004). It is evident from both figures that the actual VPL values using the Bayesian FTE method are higher than the presumed values by only 10% or less most of the time, even if the actual prior probability value is 1000 times larger than what was assumed (1×10−5). In contrast, the ARAIM VPLs increase approximately in proportion to the order of prior probability. This example illustrates that the Bayesian FTE is more robust to lack of knowledge of prior probability.
Figure 15. VPL variations with different prior probabilities for dual constellation.
Robustness of the Bayesian method to the prior probability uncertainty has two meanings in terms of the system performance. Firstly, protection level robustness can further help ensure the validity of system availability evaluations (from a performance prediction point of view). To illustrate this, one example geometry is selected from the dual constellation case above for a user location near Chicago's O'Hare airport. For an LPV-200 aircraft approach, the vertical alert limit (VAL) is 35 m. Figure 16 shows variations in VPL compared to VAL for different prior probabilities. Both Bayesian approaches (one using the all-in-view position estimate as the navigation solution and the other using FTE) show that VPL variations are much less pronounced than the ARAIM case. Further, the Bayesian FTE algorithm provides extra performance improvement (smaller VPLs). The general inference is that the relative insensitivity of VPL variation will therefore lead to lower system availability degradation if prior probabilities are increased.
Figure 16. Demonstration of VPL variation due to prior probability.
Secondly, satellite fault probabilities may vary over time, due to aging or other reasons, so the underlying probability of satellite fault may eventually become larger than the assumed value in the ARAIM algorithm. In this scenario the aircraft-computed VPLs will be smaller than the actual VPLs, which is a potential integrity hazard.
6. CONCLUSION
RAIM-type detection methods will be an important contributor to navigation system integrity in the near future with the advent of modernized and multi-constellation GNSS. However, most current RAIM methods rely on a fixed set of assumed prior fault probabilities. These prior probabilities are difficult to determine (and even more difficult to certify for aviation applications). They may even change over time for individual satellites, depending on satellite age and health history. In this work, Bayesian analysis was used to generate posterior fault probability bounds by updating the prior probabilities using current measurements. It was shown how this leads to an integrity monitoring method that is more robust to lack of knowledge in prior probabilities relative to existing, state-of-the-art Advanced RAIM (ARAIM) algorithms. The specific contributions of the paper are briefly outlined below.
A bound on the posterior probability was derived and used to define a bound on Bayesian system integrity risk. Using these results, a Bayesian detection algorithm was developed and a fault-tolerant position estimator (FTE) was derived.
It was noted that the main challenge in using a Bayesian approach for integrity monitoring is that the fault-free alarm probability (continuity risk) is difficult to precisely compute. In response a new, computationally efficient method was developed to obtain a tight upper bound on continuity risk.
System performance using the new Bayesian FTE algorithm was analysed by evaluating protection level variations for an example aircraft approach application. It was shown that the performance of the Bayesian FTE algorithm is more robust to the prior probability variations than state-of-the-art Advanced RAIM algorithms.
ACKNOWLEDGMENT
The authors would like to express their appreciation to the Federal Aviation Administration for supporting this work. They are also grateful to their colleagues in the Navigation Laboratory at the Illinois Institute of Technology for their valuable advice.
APPENDIX PROOF OF CONVEX POLYTOPE BOUND FOR CONTINUITY RISK EVALUATION
For clarity of explanation, the same convex polytope with three fault modes in Figure 11 is used and displayed in Figure A-1. Three unit direction vectors associated with three fault modes are defined as f 1, f2 and f 3. Three random variables can be defined as the magnitudes of the projection on three fault-mode directions from a parity vector:
Figure A-1. Convex polytope continuity contour in parity space.
 $$a_1 \equiv f_1^T p{\rm,} \quad a_2 \equiv f_2^T p{\rm,} \quad a_3 \equiv f_3^T p$$
$$a_1 \equiv f_1^T p{\rm,} \quad a_2 \equiv f_2^T p{\rm,} \quad a_3 \equiv f_3^T p$$Under fault-free conditions, the probability that a parity vector falls inside the convex polytope contour (we call this ‘event C’) can be expressed as:
 $$P(\,p \in C|H_0 ) = 1 - P(\,p \in \bar C|H_0 )$$
$$P(\,p \in C|H_0 ) = 1 - P(\,p \in \bar C|H_0 )$$where
 $$P(\,p \in \bar C|H_0 ) = P(|a_1 | \geqslant k_1 \;{\rm or}\;|a_2 | \geqslant k_2 \;{\rm or}\;|a_3 | \geqslant k_3 |H_0 )$$
$$P(\,p \in \bar C|H_0 ) = P(|a_1 | \geqslant k_1 \;{\rm or}\;|a_2 | \geqslant k_2 \;{\rm or}\;|a_3 | \geqslant k_3 |H_0 )$$which is the continuity risk. Using the Venn diagram (Frank and Weston, Reference Frank and Weston1997), it is easily observed that the continuity risk can be bounded as follows:
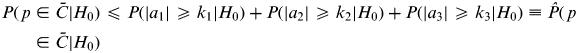 $$P(\,p \in \bar C|H_0 ) \leqslant P(|a_1 | \geqslant k_1 |H_0 ) + P(|a_2 | \geqslant k_2 |H_0 ) + P(|a_3 | \geqslant k_3 |H_0 ) \equiv \hat P(\,p \in \bar C|H_0 )$$
$$P(\,p \in \bar C|H_0 ) \leqslant P(|a_1 | \geqslant k_1 |H_0 ) + P(|a_2 | \geqslant k_2 |H_0 ) + P(|a_3 | \geqslant k_3 |H_0 ) \equiv \hat P(\,p \in \bar C|H_0 )$$Using the same example as in Section 3, it is easy to numerically demonstrate that the vertices of the polytope will correspond to the maximum Bayesian integrity risk bound along the polytope contour. A convex ploytope contour is first generated using evenly allocated continuity risks; it is shown in Figure A-2. Sample points are taken on the six contour line segments densely with small incremental steps, which include all the vertices and the boundary points, starting at p s and progressing in a counter-clockwise direction until p e. Due to the symmetry of the polytope and the system integrity risk bound, only half of the continuity contour needs to be considered. The corresponding solution separations for each sampled parity vector can be generated using the mapping function in Equation (28.a), and the results substituted into Equation (28) to obtain the Bayesian integrity risk bounds. Figure A-3 shows these integrity risk bounds for the sampled parity vectors along the contour. In the figure, the x axis shows the distance travelled along the contour from the starting vector p s and the y axis shows the associated probabilities (Bayesian integrity risk bounds). The marked points represent the vertices and boundary points on the contour. It can be easily seen that the maximum Bayesian system integrity risk bound is on segment three (red line segment). It is also evident that all points on segment three have essentially the same probability values because the third fault mode is the dominant fault; in particular, this example demonstrates that the vertices of the segment three have risk bounds equal to the risk bounds at points within the segment. This numerical example demonstrates the method of evaluating the Bayesian integrity risk bound for the given continuity contour described in Section 5.
Figure A-2. Numerical simulation of a convex polytope contour.
Figure A-3. Bayesian integrity risk bounds on the convex polytope contour.

