
















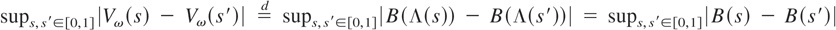

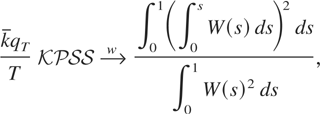


















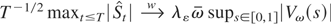
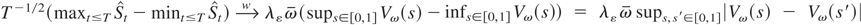
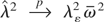

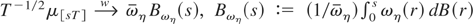























Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Cavaliere, Giuseppe
and
Robert Taylor, A. M.
2006.
Testing the Null of Co‐integration in the Presence of Variance Breaks.
Journal of Time Series Analysis,
Vol. 27,
Issue. 4,
p.
613.
Cavaliere, Giuseppe
and
Robert Taylor, A. M.
2006.
Testing for a Change in Persistence in the Presence of a Volatility Shift*.
Oxford Bulletin of Economics and Statistics,
Vol. 68,
Issue. s1,
p.
761.
Bos, Charles S.
Koopman, Siem Jan
and
Ooms, Marius
2007.
Long Memory Modelling of Inflation with Stochastic Variance and Structural Breaks.
SSRN Electronic Journal,
Cavaliere, Giuseppe
Rahbek, Anders
and
Robert Taylor, A. M.
2008.
Testing for Co-Integration in Vector Autoregressions with Non-Stationary Volatility.
SSRN Electronic Journal,
Xu, Ke-Li
2008.
Bootstrapping Autoregression under Non-stationary Volatility.
The Econometrics Journal,
Vol. 11,
Issue. 1,
p.
1.
Cavaliere, Giuseppe
Harvey, David I.
Leybourne, Stephen J.
and
Taylor, A. M. Robert
2008.
Testing for Unit Roots in the Presence of a Possible Break in Trend and Non-Stationary Volatility.
SSRN Electronic Journal,
Cavaliere, Giuseppe
and
Taylor, A.M. Robert
2008.
Testing for a change in persistence in the presence of non-stationary volatility.
Journal of Econometrics,
Vol. 147,
Issue. 1,
p.
84.
Cavaliere, Giuseppe
Rahbek, Anders
and
Taylor, A.M. Robert
2010.
Testing for co-integration in vector autoregressions with non-stationary volatility.
Journal of Econometrics,
Vol. 158,
Issue. 1,
p.
7.
Busetti, Fabio
and
Harvey, Andrew
2010.
Tests of strict stationarity based on quantile indicators.
Journal of Time Series Analysis,
Vol. 31,
Issue. 6,
p.
435.
Kourogenis, Nikolaos
2011.
A Note on Bootstrapping Autoregression Under Nonstationary Volatility.
SSRN Electronic Journal,
Cheng, Xu
and
Phillips, Peter C.B.
2012.
Cointegrating rank selection in models with time-varying variance.
Journal of Econometrics,
Vol. 169,
Issue. 2,
p.
155.
Wagner, Martin
and
Wied, Dominik
2015.
Monitoring Stationarity and Cointegration.
SSRN Electronic Journal,
Giacomini, Raffaella
and
Rossi, Barbara
2016.
MODEL COMPARISONS IN UNSTABLE ENVIRONMENTS.
International Economic Review,
Vol. 57,
Issue. 2,
p.
369.
Demetrescu, Matei
and
Sibbertsen, Philipp
2016.
Inference on the long-memory properties of time series with non-stationary volatility.
Economics Letters,
Vol. 144,
Issue. ,
p.
80.
Cavaliere, Giuseppe
Nielsen, Morten Ørregaard
and
Taylor, A.M. Robert
2017.
Quasi-maximum likelihood estimation and bootstrap inference in fractional time series models with heteroskedasticity of unknown form.
Journal of Econometrics,
Vol. 198,
Issue. 1,
p.
165.
Tu, Yundong
and
Yi, Yanping
2017.
Forecasting cointegrated nonstationary time series with time-varying variance.
Journal of Econometrics,
Vol. 196,
Issue. 1,
p.
83.
Harris, David
and
Kew, Hsein
2017.
ADAPTIVE LONG MEMORY TESTING UNDER HETEROSKEDASTICITY.
Econometric Theory,
Vol. 33,
Issue. 3,
p.
755.
Sen, Amit
2018.
Lagrange multiplier unit root test in the presence of a break in the innovation variance.
Communications in Statistics - Theory and Methods,
Vol. 47,
Issue. 7,
p.
1580.
Georgiev, Iliyan
Harvey, David I.
Leybourne, Stephen J.
and
Taylor, A.M. Robert
2018.
Testing for parameter instability in predictive regression models.
Journal of Econometrics,
Vol. 204,
Issue. 1,
p.
101.
Georgiev, Iliyan
Harvey, David I.
Leybourne, Stephen J.
and
Taylor, A. M. Robert
2019.
A Bootstrap Stationarity Test for Predictive Regression Invalidity.
Journal of Business & Economic Statistics,
Vol. 37,
Issue. 3,
p.
528.