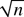1. INTRODUCTION
Modeling of heteroskedasticity in financial returns is one of the
most important and interesting themes of financial econometrics.
Well-known conditional heteroskedastic (CH) models are the
autoregressive conditional heteroskedastic ARCH (Engle, 1982) and (generalized ARCH) GARCH (Bollerslev, 1986) together with numerous
extensions. Most GARCH variants are however stationary models and are
hence time homoskedastic with constant unconditional variance. In
practice it is realized that financial returns are often not only
conditional but also time heteroskedastic with time varying
unconditional variance. This is shown by, e.g., Beran and Ocker (2001) by fitting a trend function to some
volatility series defined by Ding, Granger, and Engle (1993). Nonstationarity in financial returns is
investigated in detail by, e.g., Mikosch and Stărică
(2004). They show that the phenomenon
by
a fitted GARCH(1, 1) model often implies nonstationarity.
In recent years different approaches for simultaneously modeling
conditional and time heteroskedasticity have been introduced in the
literature by defining the volatility as a function not only of the
past values but also of the time, e.g., GARCH model with change points
(the piecewise GARCH model of Mikosch and
Stărică, 2004) and local time homogeneous model with
change points (Mercurio and Spokoiny, 2002). A
general continuous time model to perform this may be found in Fan, Jiang,
Zhang, and Zhou (2002). One can also obtain a
similar model for discrete time series by introducing past information into
the mean and volatility functions in the indexed stochastic model proposed
by Yao and Morgan (1999). Another proposal in
this context is the time heteroskedastic stochastic volatility model
(Härdle, Spokoiny, and Teyssière,
2000).
In this paper another approach, called a semiparametric GARCH
(SEMIGARCH) model is proposed by introducing a scale function
σ(t) into the parametric GARCH model. This proposal is
motivated by the observation that one important reason for the time
heteroskedasticity is a slowly changing scale function in volatility.
The advantages of this approach are as follows. 1. The volatility is
decomposed into two multiplicative components corresponding to the
location and the past information, respectively. 2. The GARCH
parameters are estimated globally, and hence asymptotically normal,
-consistent estimators are
available. 3. The SEMIGARCH model can also be used for predicting the
future volatility. A semiparametric estimation procedure combining
kernel estimation of the scale function and maximum likelihood
estimation of the GARCH parameters is proposed. Asymptotic properties
of the estimators are investigated in detail. A data-driven algorithm
is developed for practical implementation. Finite sample performance of
the proposal is examined through a simulation study. The proposal is
applied to model CH and scale change in the daily S&P 500 and DAX
100 returns. It is shown that both series have simultaneously
significant scale change and CH.
This approach provides an interesting alternative for modeling
financial volatility. Whether or not it is better than another approach
depends on the case considered. The idea proposed in this paper can be
used to obtain semiparametric generalizations of other GARCH variants.
Change points can also be introduced into the SEMIGARCH model.
The paper is organized as follows. Section 2 introduces the model.
Section 3 describes the semiparametric estimation procedure. Asymptotic
properties of the proposals are investigated in Section 4. Section 5
proposes a data-driven algorithm for practical implementation. Results
of the simulation study are reported in Section 6. The proposal is
applied to the log-returns of the daily S&P 500 and DAX 100 indices
in Section 7. Section 8 contains some final discussion. Proofs of
results are in the Appendix.
2. THE MODEL
Consider the equidistant time series model
where μ is an unknown constant, ti =
i/n, σ(t) > 0 is a smooth,
bounded scale (or volatility) function, and
{εi} is assumed to be a
GARCH(r,s) process defined by
(Bollerslev, 1986), where
ηi are independent and identically distributed
(i.i.d.) N(0,1) random variables, α0 > 0 and
α1,…,αr,β1,…,βs
≥ 0. Let v(t) = σ2(t)
denote the local variance of Yi. The
rescaled time index ti =
i/n is introduced to guarantee that the
information increases as n increases and the availability of a
consistent estimator of v. Now, model (1) defines indeed a
sequence of processes.
Let θ =
(α0,α1,…,αr,β1,…,βs)′
be the unknown parameter vector. It is assumed that
,
which ensures the existence of a
unique strictly stationary solution of (2). The practical
implementation of a nonparametric estimator
requires the moment condition
E(εi8) < ∞.
However, as pointed out by an anonymous referee, the condition of
E(εi4) < ∞ is
sufficient for the derivation of the asymptotic results. Necessary and
sufficient conditions that guarantee the existence of high-order
moments of a GARCH process may be found in Ling and Li (1997), Ling (1999), and
Ling and McAleer (2002). It is further
assumed var(εi) =
E(εi2) = 1, implying
,
to avoid identifiability problems.
The process defined by (1) and (2) is locally stationary in the sense
of Dahlhaus (1997), which is a special case
of Example 1 given there. Such a model provides a semiparametric
extension of the standard GARCH model (Bollerslev,
1986) by introducing the scale function σ(t) into
it, where hi1/2 stand for
the conditional standard deviations of the standardized process
εi. The total standard deviation at
ti is hence given by
σ(ti)hi1/2.
For σ(t) ≡ σ0, model (1) and (2)
reduces to the standard GARCH model. Our purpose is to estimate
v(t) and hi separately.
If the scale function σ(t) in (1) changes over time, then
the assumption of a GARCH model is a misspecification. In this case the
estimation of the GARCH model will be inconsistent. It can be shown
through simulation that, if a nonconstant scale function is not
eliminated, one will obtain
by a fitted GARCH(1,1) model as
n → ∞, even when εi are
i.i.d. Furthermore, in the presence of scale change the estimation of
v(t) is also necessary for the prediction. On the
other hand, if Yi follows a GARCH model
but model (1) and (2) is used, then the estimation is still
-consistent but with some loss
in efficiency due to the estimation of σ(t).
The assumptions of model (1) and (2) can be weakened in different
ways. For instance, if the constant mean μ in (1) is replaced by a
smooth mean function g, then we obtain the following
nonparametric regression with heteroskedastic and dependent errors:
where {εi} is a zero mean stationary process.
Estimation of the mean function g in model (3) with i.i.d.
εi is discussed in, e.g., Ruppert and Wand
(1994), Fan and Gijbels (1995), and Efromovich (1999). Discussion on the estimation of the scale
function in heteroskedastic nonparametric regression may be found in,
e.g., Efromovich (1999). This paper focuses
on investigating the estimation of σ(t) and θ under
model (1) and (2).
3. A SEMIPARAMETRIC ESTIMATION PROCEDURE
Model (1) and (2) can be estimated by a semiparametric procedure
combining nonparametric estimation of v(t) and
parametric estimation of θ. A linear smoother of the squared
residuals will estimate v(t). Let
Zi = (Yi
− μ). Then model (1) can be rewritten as follows:
where Xi =
Zi2 and
ξi = εi2
− 1 ≥ −1 are zero mean stationary time series errors.
Model (4) transfers the estimation of the scale function to a general
nonparametric regression problem (for a related idea, see Efromovich,
1999, Sect. 4.3). On the one hand, model (4)
is a special case of (3) with g(t) and
σ(t) both being replaced by v(t). On the
other hand, model (4) also applies to (3) by defining
Zi = Yi
− g(ti). Hence, the
extension of our results to model (3) is expected.
The kernel estimator of conditional variance proposed by Feng and
Heiler (1998) will be adapted to estimate
v(t). Let
y1,…,yn, denote
the observations. Let
.
Let
K(u) denote a second-order kernel with compact
support [−1,1]. The Nadaraya–Watson estimator of
v at t based on
is defined by
where
and b is
the bandwidth. And we define
.
It is assumed
that b → 0, nb → ∞ as n
→ ∞, which together with other regular conditions ensures
the consistency of
.
The estimator defined
in (5) does not depend on the dependence structure of the errors
because
is a linear smoother. It is clear that
if all observations for which
|ti − t| ≤
b are not identical. The bias of
at a
boundary point is of a larger order than in the interior because of the
asymmetry in the observations. This is the so-called boundary effect of
the kernel estimator, which can be overcome by using a local linear
estimator (see, e.g., Härdle, Tsybakov, and
Yang, 1998). However, as mentioned in Feng and Heiler (1998), a local linear estimator of v may
sometimes be nonpositive. Hence, the kernel estimator is more
preferable in the current context.
Following Bollerslev (1986), the
conditional Gaussian log-likelihood in a parametric GARCH model takes
the form (ignoring constants)
The maximizer of L(θ), denoted by
,
is not available, because εi are unobservable
in the current context. Hence we define the approximate log-likelihood
by
where
are the standardized
residuals given by
The symbols
are used to
indicate that, for a given value of θ,
hi(ε;θ) in L(θ)
depends on
.
Similar to the parameter
estimation in the SEMIFAR (semiparametric fractional autoregressive)
model (Beran, 1999), θ will be estimated
by
,
the maximizer of
.
Any standard GARCH packet can be used for estimating
.
In this paper the
S+ GARCH will be used.
obtained in this way is an approximate
maximum likelihood estimator (MLE), which may perform differently from
(provided
were available).
4. MAIN RESULTS
For the derivation of the asymptotic results the following
assumptions are required.
A1. Model (1) and (2) holds with i.i.d. N(0,1)
ηi and strictly stationary εi
such that E(εi4) < ∞.
Furthermore, it is assumed that
.
A2. The function v(t) is strictly positive, bounded, and
at least twice continuously differentiable on [0,1].
A3. The kernel K(u) is a symmetric density with compact
support [−1,1].
A4. The bandwidth b satisfies b → 0 and nb
→ ∞ as n → ∞.
Assumptions A2–A4 are regular conditions in nonparametric
regression. A1 summarizes conditions required on the GARCH model. For a
GARCH(1,1) model, these conditions are stronger than those used by,
e.g., Lee and Hansen (1994) and Lumsdaine
(1996). Now, the condition
E(εi4) < ∞ implies
in particular α1 + β1 < 1, and hence
E
[ln(α1ηi2 +
β1)] < 0, one of the conditions used by Lee and
Hansen (1994) and Lumsdaine (1996). In this paper the innovations
ηi are assumed to be i.i.d. N(0,1)
random variables as in, e.g., Bollerslev (1986) and Ling and Li (1997) for simplicity, which implies Assumption 2 in
Lumsdaine (1996). If non-Gaussian innovations
are considered, suitable moment conditions have to be used, which might
depend on the orders of the GARCH model. For instance, for a GARCH(1,1)
model, Lumsdaine (1996) introduces the moment
condition E(ηi32) <
∞ together with further regular conditions on the distribution of
ηi (Assumption 2 therein). Furthermore, it can
be shown that, under A1, other assumptions in Lee and Hansen (1994) hold. The additional assumption
in A1 is introduced to avoid the
naive case with αi ≡ 0 for all i
= 1,…,r.
4.1. Asymptotic Properties of
Equation (4) is a nonparametric regression model with dependent and
heteroskedastic errors. Pointwise results in nonparametric regression
with dependent errors as given in, e.g., Altman (1990) and Hart (1991) can
be adapted to
defined in (5) without any
difficulty. Let γξ(k) denote the
autocovariance function of ξi. It is well known
that
depends on cf = f (0), where
is the spectral
density of ξi. Let r′ =
max(r,s). Following equations (6) and (7) in
Bollerslev (1986) and observing that
,
we have the
ARMA(r′,s) representation of
ξi:
where αj′ = αj
+ βj for j ≤
min(r,s), αj′ =
αj for j > s, if
r > s, and αj′ =
βj for j > r, if
s > r, and
is a sequence of zero mean, uncorrelated random variables with
independent ηi ∼ N(0,1).
Equations (9) and (10) allow us to calculate cf .
Define R(K) = ∫
K2(u) du and
I(K) = ∫
u2K(u) du. At an
interior point 0 < t < 1 the following results hold.
THEOREM 1. Under Assumptions A1–A4 we have the following
results.
(i) The bias of
is given by
(ii) The variance of
is given by
(iii) Assume that nb5 → d2
as n → ∞, for some d > 0; then
where D =
I(K)v′′(t)/2 and
V(t) = 2πcf
R(K)v2(t).
The proof of Theorem 1 is given in the Appendix. The asymptotic bias
of
is the same as in nonparametric regression
with i.i.d. errors. The asymptotic variance of
it is similar to that in nonparametric regression with short-range
dependence, which depends, however, on the unknown underlying function
v itself.
Let
.
Under A1 we
have
If εi follows a GARCH(1,1) model, we have
The last equation in (15) is due to the standardization of
εi. The proof of (14) and (15) is given in the
Appendix.
The mean integrated squared error (MISE) defined on [Δ,1
− Δ] will be used as a goodness-of-fit criterion, where
Δ > 0 is used to avoid the boundary effect of
.
Define
.
The following theorem
holds.
THEOREM 2. Under the assumptions of Theorem 1 we have the
following results.
(i) The MISE of
is
(ii) Assume that I((v′′)2) ≠
0. The asymptotically optimal bandwidth for estimating v,
which minimizes the dominant part of the MISE, is given by
with
The proof of Theorem 2 is straightforward and is omitted. If a
bandwidth b = O(bA) =
O(n−1/5) is used, we have
.
4.2. Asymptotic Properties of
Asymptotic properties of
defined in Section 3 are
investigated by Ling and Li (1997) under the
general fractionally autoregressive integrated moving
average–GARCH (FARIMA-GARCH) framework. More detailed asymptotic
results in the special case of a GARCH(1,1) model may be found in Lee
and Hansen (1994) and Lumsdaine (1996). Asymptotic properties of
will be studied by comparing its performance with that of
based on the results in Ling and Li (1997). At first we will introduce a general lemma.
Let θ0 =
(θ10,…,θm0)′
be the true value of a m-dimensional parameter vector θ
and be in the interior of the compact set Θ. Assume that there
exists a consistent MLE
satisfying the equation
∂L(θ)/∂θ = 0, where L(θ)
is a standard likelihood or log likelihood function. Furthermore,
assume that L(θ) is three times differentiable,
L′′(θ) converges in probability to a positive
definite matrix, and all third-order partial derivatives of
L(θ) have bounded expectations in Θ. Let
be a consistent estimate of
L(θ). Then we have the following result.
LEMMA 1. Assume
for θ in a neighborhood
of θ0.
Under the preceding regular conditions on L(θ) there
exists a consistent MLE
satisfying
and
The proof of Lemma 1 is straightforward and is omitted. Lemma 1
ensures the existence of an approximate MLE and provides a tool to
quantify the distance between it and an infeasible MLE. Note that
is in general
-consistent and asymptotically
normal. Hence,
will have the same properties if
.
Now, denote by θ0 =
(α00,α10,…,αr0,β10,…,βs0)′
the true value of the unknown parameter vector θ. Assumption A1
ensures that θ0 is in the interior of a compact
parameter set Θ. Let
be
as defined in Section 3. Let
and Ω0, the value of Ωθ at
θ = θ0, denote the information matrix. Then,
following Lemma 1 and Theorems 3.1 and 3.2 in Ling and Li (1997), we have the following result.
THEOREM 3. Assume that A1–A4 hold.
We see that
is
-consistent and asymptotically
normal up to a bias term Bθ. The proof of
Theorem 3 is given in the Appendix and shows that the
O(b2) term in Bθ
is due to
and the
O[(nb)−1] term is due to
.
If O(n−1/2) < b
< O(n−1/4),
Bθ is negligible, and we have
.
Similar
observations have been made in other semiparametric contexts, e.g.,
within the context of partially linear models. There, for a certain
choice of bandwidth the nonparametric part has no effect on the rate of
convergence of the parametric estimator (see Härdle, Liang, and Gao, 2000). If
is estimated using b =
O(bA), then Bθ =
O(n−2/5). If
Yi follow a GARCH model and b
> O(n−1/2), then
is
-consistent and asymptotically
normal because now
is unbiased.
5. THE PROPOSED DATA-DRIVEN ALGORITHM
A plug-in bandwidth selector may be developed by replacing the
unknowns cf,
I(v2), and
I((v′′)2) in (18) with some
suitable estimators. At first, it is proposed to estimate
cf by
where
is a
nonparametric estimator of
E(εi4). Although explicit
formulas of E(εi4) are
known (for common results, see He and
Teräsvirta, 1999a; Karanasos,
1999; for results in some special cases, see Bollerslev, 1986; He and
Teräsvirta, 1999b), we prefer to use
defined in (21) because
the formulas of E(εi4) are
in general too complex. For a GARCH(1,1) model, another simple
estimator,
,
say, may be
defined based on (15) by replacing α0,
α1, and β1 with their estimates. Now
perform quite similarly.
Assume that a bandwidth bε is used for
estimating E(εi4), which
satisfies A4 but is not necessarily the same as b.
Furthermore, make the following assumption.
A1′. The same as A1 but with
E(εi8) < ∞.
Then the following proposition holds.
PROPOSITION 1. Under Assumptions A1′ and A2–A4 we
have
and
where cfε denotes the
value of the spectral density of the process
εi4 at the origin.
The proof of Proposition 1 is given in the Appendix.
Remark 1. Equations (22) and (23) show that
is
-consistent, if
O(n−1/2) ≤
bε ≤
O(n−1/4). The optimal bandwidth
in a second-order sense, which balances the two terms on the right-hand
side of (22), is of order
O(n−1/3). In this paper, we
propose to use a bandwidth bε =
O(n−1/4) for estimating
E(εi4) so that the
estimator is more stable. Note that
is no
longer
-consistent if a
bandwidth bε =
O(bA) =
O(n−1/5) is used. The finally
selected bandwidth is not so sensitive to the bandwidth for estimating
E(εi4).
The integral I(v2) can be estimated by
where n1 and n2 denote the
integer parts of nΔ and n(1 − Δ),
respectively, and
is the same as defined in (5)
but obtained with another bandwidth bv,
say, that satisfies A4. The following results hold for
.
PROPOSITION 2. Under the assumptions of Proposition 1 we have
and
The proof of Proposition 2 is given in the Appendix.
Remark 2. Note that the dominated orders of the biases and variances of
are the same. Hence
similar statements as given in Remark 1 apply for results given in (25)
and (26). This is not surprising because both
v2(ti) and
εi4 are related to the fourth moment
of the errors.
A well-known estimator of
I((v′′)2) is given by
(see, e.g., Ruppert, Sheather, and Wand, 1995),
where
is a kernel estimator of
v′′ using a fourth-order kernel
K2 for estimating the second derivative (see, e.g.,
Müller, 1988) and again another
bandwidth bd. Corresponding results as
given in Proposition 2 hold for
,
for
which the following adapted assumptions are required.
A2′. The function v(t) is strictly positive on
[0,1] and is at least four times continuously differentiable.
A3′. v′′ is estimated with a symmetric
fourth-order kernel for estimating the second derivative with compact
support [−1,1].
A4′. The bandwidth bd satisfies
bd → 0 and
nbd5 → ∞ as
n → ∞.
PROPOSITION 3. Under Assumptions A1′–A4′ we
have
and
The proof of Proposition 3 is omitted because it is well known in
nonparametric regression (for results with i.i.d. errors, see, e.g.,
Ruppert et al., 1995; for results with
dependent errors, see, e.g., Beran and Feng, 2002a, 2000b).
Remark 3. The MSE (mean squared error) of
is
dominated by the squared bias. The optimal bandwidth for estimating
I((v′′)2), which balances the
two terms on the right-hand side of (28), is of order
O(n−1/7). With a bandwidth
bd =
O(n−1/7) we have
.
We see that for selecting the bandwidth b we have to choose
at first three pilot bandwidths bε,
bv, and bd.
This problem will be solved using the iterative plug-in idea (Gasser, Kneip, and Köhler, 1991) with a
so-called exponential inflation method (see Beran and Feng, 2002a, 2002b). Let
bj−1 denote the bandwidth for
estimating v in the (j − 1)th iteration. Then
in the jth iteration, the bandwidths
bε,j =
bv,j =
bj−15/4 and
bd,j =
bj−15/7 will be used
for estimating E(ε4),
I(v2), and
I((v′′)2), respectively. These
inflation methods are chosen so that
bε,j and
bv,j are both of order
Op(n−1/4)
and bd,j is of the optimal order
Op(n−1/7),
when bj−1 is of the optimal order
Op(n−1/5).
By an iterative plug-in algorithm the unknown constants in the pilot
bandwidths can be simply omitted. Furthermore, we also need to choose a
starting bandwidth b0. In the current context,
b0 should satisfy A4 because we have to estimate
θ in the first iteration. Theoretically, a bandwidth
b0 =
O(n−1/5) is more preferable. Our
experience shows that b0 =
0.5n−1/5 is a good choice. Detailed
discussions on this topic may be found in the next two sections,
especially in Section 6.3.
The proposed data-driven algorithm processes as follows:
1. Start with the bandwidth
b0 = c0
n−1/5 with, e.g., c0
= 0.5.
2. In the jth iteration
3. Increase j by one and repeatedly carry out step 2 until
convergence is reached or until a given maximal number of iterations has
been completed. Put
.
The condition |bj −
bj−1| < 1/n
is used as a convergence criterion of
,
because
such a difference is negligible. The maximal number of iterations is
put to be 20. In this algorithm,
is estimated using
bj−1 as for
because we do not have a proper bandwidth selector for estimating
θ. The asymptotic performance of
is
quantified by the following theorem
THEOREM 4. Assume that A3 and A1′–A3′ hold and
that I((v′′)2) ≠ 0. Then we
have
The proof of Theorem 4 is given in the Appendix. Note that A4 and
A4′ are automatically satisfied. The second
O(n−2/5) term on the right-hand
side of (31) is due to the error in
caused by the bias in
,
which is indeed negligible compared with the first
term.
The proposed algorithm is coded in an S-Plus function called
SEMIGARCH. A practical restriction 1/n ≤
b ≤ 0.5 − 1/n is used in the program for
simplicity. Four commonly used kernels, namely, the uniform, the
Epanechnikov, the bisquare, and the triweight kernels (see, e.g., Müller, 1988), are built into the program. As
a standard version we propose the use of the Epanechnikov kernel with
Δ = 0.05 and c0 = 0.5, which will be used in
the next two sections.
Remark 4. Note that bA is not well defined if
I((v′′)2) = 0 implying
v′′(t) ≡ 0. However, the SEMIGARCH
model also applies to this case. In particular, the proposed algorithm
does work if Yi follow a GARCH model. Now
it can be shown that, theoretically, bj
→ Op(1) as j → ∞.
Following the context after Theorem 3,
has the same
asymptotic properties as by a GARCH model because
.
And
is
-consistent with some loss in
the efficiency compared with a parametric estimator, provided that no
maximal number of iterations is given, because
(nbj)−1 →
Op(n−1) now.
6. THE SIMULATION STUDY
6.1. Design of the Simulation
To show the practical performance of our proposal, a simulation study
was carried out. In the simulation study, εi
were generated using the simulate.garch function in S+GARCH
following one of the two GARCH(1,1) models.
Model 1 (M1). εi = ηi
hi1/2,
hi = 0.6 +
0.2εi−12 +
0.2hi−1 and
Model 2 (M2). εi = ηi
hi1/2,
hi = 0.15 +
0.1εi−12 +
0.75hi−1.
The yi are generated following model (1)
with μ ≡ 0 and one of the three scale functions:
The terms v1(t) and
v2(t) are quite similar, and they are
designed following the estimated scale function in the daily DAX 100
returns. The scale change with v2 is stronger than
that with v1. It is strongest with
v3. To this end see the bandwidths required for
estimating them given in Table 2. The scale
function σ2(t) may be found in Figure 2b, which follows. To confirm the statements
in Remark 4, a constant scale function
v0(t) =
σ02(t) ≡ 16 is also used. The
simulation was carried out for three sample sizes n = 1,000,
2,000, 4,000. For each case 400 replications were done. For each
replication, three GARCH (1,1) models were fitted to
εi, the data-driven
.
The estimators of α1
and β1 are denoted by
,
respectively. For
v0 we have
.
Here,
are used as a benchmark.
Note in particular that the estimated parameters may sometimes be
negative using the S+GARCH.
6.2. Results of the Simulation Study
To give a summary of the performance of
,
and to
compare them with
,
the empirical
efficiency (EFF) of an estimator w.r.t. the corresponding one estimated
from εi is calculated. For instance,
These results are listed in Table 1. The
difference between two related EFFs, e.g.,
,
in a given
case may be thought of as the gain by using the SEMIGARCH model. Table 1 shows that the EFFs of
seem to tend
to 100%, whereas those of
seem to tend to
zero, as n → ∞. Hence, the gains seem to tend to
100% as n → ∞. The EFFs of
under M2 are
relatively low. In particular, for n = 1,000, the EFFs of
in the two
cases of M2 with v1 and v3 are
even smaller than those of
;
i.e., the gain in
these cases is slightly negative. This shows that n = 1,000 is
sometimes not large enough for estimating the scale function when
β1 is large.
Empirical efficiencies (%) of the estimated parameters
Box plots of the 400 replications of
for n =
1,000 are shown in Figures 1a–1f, where the
symbols E1, E2, and E3 denote estimators obtained from
,
respectively. Those for n =
2,000 and n = 4,000 are omitted to save space. The simulation
results show that
perform in
general quite well. One clear problem arises with
under M2 with
n = 1,000. Now, both the variance and the bias of
are strongly
affected by some extremely small estimates (see Figures
1m–1p). This is due to the nonrobustness of the bandwidth
selection. Hence, it is worthwhile to develop a robust procedure to
improve the poor performance of
for small
n. The quality of
is clearly improved as
n increases. In particular, the estimation becomes more and
more stable. Detailed statistics (in the first version of this paper)
show that the standard deviations of
seem to
converge at the same rate as those of
,
but their biases
converge a little more slowly. This confirms the results of Theorem 3.
The simulation results show clearly that, in the case with scale
change,
are inconsistent as
a result of their biases. The situation become worse as n
increases. In particular, we can see that
will tend to one as
n → ∞, no matter how large
β10 is. However, if there is no scale change
the estimators
should of course be
used. It is hence helpful to test whether or not the estimated scale
function is significant. For the data examples given in the next
section it is proposed to carry out such a test based on simulation.
Box plots of
(E3), respectively, with n = 1,000, where the
horizontal lines show the true values.
Now let us consider the quality of
.
The sample
means, standard deviations, and square roots of the MSEs of
together with the true asymptotic optimal
bandwidths bA are given in Table
2. Note that bA and the MSE in cases with
v0 are not defined. Kernel density estimates of
(omitted to
save space) show that the performance of
is
satisfactory. In all cases the variance of
decreases as n increases. It is also true for the bias in most
of the cases. Both the variance and the bias of
depend on the scale function and the model of the errors. For two
related cases, the variance of
under M1 is
smaller than that under M2. Generally, the stronger the scale change,
the larger the variance of
.
The bias of
by v1 is always negative,
and it is always positive by v3. The bandwidth for
v2 is easiest to choose. The choice of the
bandwidth by v3 is in general easier than that by
v1, except for the case of M2 with n =
1,000. In this case, the detailed structure of v3
may sometimes be smoothed away because of the large variation caused by
the GARCH model. This shows again that n = 1,000 is sometimes
not large enough for distinguishing the CH and the scale change.
Statistics on the selected bandwidth
Remark 5. As suggested by a referee, the performance of the proposed
procedure for the cases with highly persistent GARCH effect is investigated
through an additional simulation under a third model, model 3 (M3), with
α1 = 0.07 and β1 = 0.87 and without trend. As
expected, the proposed procedure does not work well for n = 1,000
because the variance of
and in
particular that of
are too large
as a result of some extreme estimates. This shows again that a robust
estimation procedure should be developed. For n ≥ 2,000,
the procedure works well. The empirical efficiencies are a little lower
than those for M2. Detailed results of this additional simulation are
omitted to save space.
Remark 6. In this paper, the bandwidth is selected by minimizing the
dominant part of the MISE of
.
In a semiparametric
context, the performance of the bandwidth selection and the resulting
parameter estimation may be improved if a plug-in algorithm that takes the
MSE of
into account is developed. For this purpose a more
detailed formula of the MSE of
is required, and one
has to develop a suitable procedure to estimate the MSE. This is still
an important open question and will be discussed elsewhere.
6.3. Detailed Analysis of Two Simulated Examples
In the following discussion, two simulated data sets are selected to
show some details. The first example (called Sim 1) is a typical
example of the replications under M2 with the scale function
σ2(t) and n = 2,000. The observations
yi, i = 1,…,2,000, are
shown in Figure 2a. For Sim 1 we have
by starting with any bandwidth
3/n ≤ b0 ≤ 0.5 −
1/n; i.e.,
does not depend on
b0 if b0 is not too small. The
σ2(t) (solid line) and
(dashed line) are shown in
Figure 2b. Figure
2c shows the standardized residuals
,
which look stationary. The
estimated GARCH(1,1) models are
Estimation results for the first simulated data set.
for yi and
for
.
For model (32) we have
,
so
that the fourth moment of this model does not exist. On the opposite
model (33) has finite moments until at least twelfth order as for the
underlying GARCH model. The estimated SEMIGARCH conditional and total
standard deviations, i.e.,
,
are shown in Figures 2d and 2e. The true
conditional and total standard deviations of
yi, i.e.,
(hi)1/2 and
σ2(ti)(hi)1/2,
are shown in Figures 2f and 2g. Figure 2h shows the estimated GARCH conditional (in
this case also the total) standard deviations
(hiy)1/2.
The analysis of Sim 1 shows the following results.
(1) If a standard GARCH model is used, the
scale change will be wrongly estimated as a part of the CH.
Furthermore, the total variance tends to be overestimated when it is
large and underestimated when it is small (compare Figures 2g and 2h). This phenomenon is mainly due
to the overestimation of
and will be
called the (volatility) inflation effect of the GARCH model in the
presence of scale change.
(2) Following the SEMIGARCH model, both the conditional
heteroskedasticity and the scale change are well estimated. The
estimated SEMIGARCH total variances are quite close to the true values
and are more stable and accurate than those following the standard
GARCH model (compare Figures 2e and 2h). The
errors in
are caused by the errors in these two estimates, and both of them can
be clearly reduced if more dense observations are available, e.g., by
analyzing high-frequency financial data. The MSE of the estimated total
variances are 0.687 for the SEMIGARCH and 4.979 for the standard GARCH
models; the latter is about seven times as large as the former.
Furthermore,
(hiy)1/2
shown in Figure 2h (see also Figure 3f) exhibit a clear signal of covariance
nonstationarity, a property not shared by the true and the estimated
SEMIGARCH conditional standard deviations.
The estimation results for the S&P 500 returns.
The second simulated data set (called Sim 2) is one of the
replications under M1 with v3 and n =
1,000, which is chosen to show that sometimes the selected bandwidth
will be wrong if b0 is too small or too large. That
is, a moderate b0 should be used as proposed in
Section 5. For this data set we have either
if b0 <
0.020. On the other hand, we have
,
the
largest allowed bandwidth in the program, if b0
> 0.262. For any starting bandwidth b0 ∈
[0.021, 0.262] a bandwidth
will be selected. Now,
does
not depend on
b0. Note that the proposed default starting
bandwidth b0 =
0.5n−1/5 = 0.126 lies in the middle part
of the interval [0.021, 0.262]. In case when it is doubtful,
if the selected bandwidth with b0 =
0.5n−1/5 is the optimal one, we recommend
that the user try with some different b0's and
choose the most reasonable
from all possible
selected bandwidths by means of further analysis (see Feng, 2002).
7. APPLICATIONS
In this section the proposal will be applied to the log-returns of
the daily S&P 500 and DAX 100 financial indexes from January 3,
1994, to August 23, 2000. For the S&P 500 returns shown in Figure 3a we have
(for any b0 ≥ 0.075). The fitted GARCH models
are
for yi and
for
.
As before, for model (34)
we have
so
that the fourth moment of this model does not exist. Model (35) has
finite moments until twelfth order. To test whether the estimated trend
is significantly nonconstant, 400 replications were generated following
model (35) with the corresponding sample variance and without trend.
The scale function was then estimated with the bandwidth b =
0.183 from each replication. Symmetric Monte Carlo confidence bounds
that covered 95% or 99% of all estimated trends were calculated and are
shown in Figure 3b together with the sample
standard deviation (0.0099) and the estimated scale function
.
We see that there is significant scale
change in this data set. Furthermore, both
in
model (35) are strongly significant. That is, this series has
simultaneously significant scale change and CH. Figures
3c–3f show
,
the SEMIGARCH
conditional standard deviations
,
the SEMIGARCH total standard deviations
,
and the GARCH conditional standard deviations
(hiy)1/2.
Comparing Figures 3e and 3f we see again that
the estimated total variances following the SEMIGARCH model are more
stable and those following the GARCH model are inflated.
For the DAX 100 returns we have
(for
any b0 ≥ 0.075). The fitted GARCH models are
for yi and
for
.
The condition for the
existence of the fourth moment of model (36) is slightly satisfied, but
the eighth moment of this model does not exist. Again, model (37) has
finite moments until twelfth order. The S&P 500 and DAX 100 returns
series perform quite similarly, and the conclusions on the former given
previously apply to the latter.
Now, we will compare the performance of the GARCH and SEMIGARCH by
predicting future volatility. The GARCH unconditional variance,
,
say, is calculated following (34) or
(36). For the SEMIGARCH,
is used as the unconditional variance
in the near future. The predicted (expected) conditional standard
deviations
following the GARCH and
following the SEMIGARCH, k = 1,2,…,100, for the S&P
500 and DAX 100 returns are shown in Figure 4
together with
.
Note that,
the conditional standard deviations by both series at the right end are
lower than
.
Consequently,
increase for both series. The
look quite reasonable and converge to
quickly.
However,
in both cases seem to be underestimated, because of the inflation
effect mentioned previously. Furthermore,
converge very slowly to some wrongly estimated limits. The sample
standard deviation for the S&P 500 returns is 0.0099. Following
(34) we have
,
which is clearly overestimated
as a result of the instability of this model. For the DAX 100 returns,
is about equal to its sample value, which is,
however, clearly lower than the locally unconditional standard
deviation at t = 1. There are two problems if the fitted
parametric GARCH models from these data sets are used for predicting
future volatility: (1) the unconditional variance at the current end
was wrongly estimated; and (2) the predicted conditional variance
converges very slowly, because these models only have finite moments of
low orders. Both of these problems were overcome by applying the
SEMIGARCH model.
Predicted standard deviations
(middle dashes) and
(solid line) together with their limits
following the GARCH (short dashes) and
following the SEMIGARCH (long dashes) for (a) the S&P 500 and (b)
the DAX 100 returns.
8. DISCUSSION
The SEMIGARCH introduced in this paper provides a useful tool for
estimating financial volatility in cases when the stationary assumption
of a GARCH model is likely to break down, which decomposes the
volatility into a smooth scale function of the location and a CH
component depending on the past information. A data-driven algorithm is
developed for practical implementation. Simulation and data examples
show that the proposal works well in practice. There are some other
recent proposals to deal with similar problems, e.g., the parametric
GARCH model with change points (Mikosch and
Stărică, 2004) for modeling structural breaks in the
unconditional variance, which cannot be used for modeling slowly changing
unconditional variance. On the other hand, structural breaks in the
unconditional variance cannot be modeled by the SEMIGARCH. It is worthwhile
to combine these two approaches. Another related work is Mercurio and
Spokoiny (2002), where the volatility is
assumed to be constant in some unknown time intervals. By this approach
scale change and CH are modeled together but not separately.
APPENDIX: PROOFS OF RESULTS
Under model (1) and (2) v(t) is integrable. This
implies that y is
-consistent. Hence, in the
following discussion,
can be replaced by
zi and xi
respectively.
Proof of Theorem 1.
(i) The bias. Note that
is a linear smoother
where wi are the weights defined by (5).
The bias of
,
which is just the same as in nonparametric
regression with i.i.d. errors. That is, the bias depends neither on the
dependence structure nor on the heteroskedasticity of the errors. This
leads to the result given in (11).
(ii) The variance. Let ζi =
v(ti)ξi
denote the errors in (4). Note that wi =
0. For |ti −
t| > b we have
For |ti −
t| ≤ b and
|tj − t| ≤
b we have ζi =
[v(t) +
O(b)]ξi and
ζj = [v(t) +
O(b)]ξj. This leads
to
Insert this into (A.2), then we have
Results in (12) follow from known results on
[sum ][sum ]wi
wjγξ(i −
j) in nonparametric regression with dependent errors (see,
e.g., Beran, 1999; Beran
and Feng, 2002a).
(iii) Asymptotic normality. Consider the estimation problem under the
model without scale change:
Define
where
are observations
obtained following model (A.5). Following the results in (i) and (ii)
we see
.
Hence
is asymptotically normal if and only
if
is. Furthermore, following
Theorem 4 in Beran and Feng (2001) it can be
shown that the kernel estimator
is
asymptotically normal if and only if the sample mean of the squared
GARCH process εi2 or equivalently
the sample variance of εi is asymptotically
normal. Basrak, Davis, and Mikosch (2002)
show that the squared GARCH process
εi2 is strongly mixing with
geometric rate. The condition
E(εi4) < ∞ implies
that there is a δ > 0 such that
E|εi2|2+δ
< ∞. The conditions of Theorem 18.5.3 in Ibragimov and Linnik
(1971) hold. This shows that
n−1[sum ]εi2
of a GARCH process with finite
fourth moment is asymptotically normal. Theorem 1 is proved. █
Proof of (14) and (15). Note that ξi has
the autoregressive moving average (ARMA) representation
where φ(z) and ψ(z) are as defined
before. Under A5 φ(z) and ψ(z) have no
common roots. Under A1 all roots of φ(z) and
ψ(z) lie outside the unit circle. Then the spectral
density of ξ is given by
Note that E(εi4) =
3E(hi2) (Bollerslev, 1986) and
var(ui) =
E(ui2) =
2E(hi2). The last
equation follows from (10). That is,
var(ui) =
2/3E(εi4). The result
in (14) is proved by inserting this formula, ψ(1), and φ(1)
into (A.8). The result in (15) is obtained by further inserting the
explicit formula of E(εi4)
for a GARCH(1,1) model (Bollerslev, 1986)
into (14). █
The following analysis involves infinite past history of
.
The presample values of
will be assumed to be zero. The
presample values of εi2 and
hi(ε;θ) (resp.
are chosen
to be
(resp.
.
For
simplicity, it is also assumed that
(and hence
are of the same order of
magnitude, if i and j are not far from each other.
This is true if ti and
tj are both in the interior or both in the
boundary area. The preceding simplifications do not affect the
asymptotic properties of
.
Consistency and asymptotic normality of
defined in
Section 3 are a part of the results of Theorem 3.2 in Ling and Li
(1997). Theorems 3.1 and 3.2 therein together
show that conditions of Lemma 1 are fulfilled for the log-likelihood
function L(θ). In the following discussion, we will
investigate the difference between
caused by replacing the unobservable
εi with
.
Two lemmas are introduced at first.
LEMMA A.1. Under the assumptions of Theorem 3 we have
Proof of Lemma A.1. For any trial value θ =
(α0,α1,…,αr,β1,…,βs)′
∈ Θ, one can rewrite
hi(ε;θ) as
and
as
This leads to
where aj are obtained by matching the
powers in B, which decay exponentially. █
LEMMA A.2. Under the assumptions of Theorem 3 we have,
∀θ ∈ Θ, the first element of
is zero and the other elements of it are all of the order
.
Proof of Lemma A.2. Following (21) in Bollerslev (1986) we have
where ζi =
(1,εi−12,…,εi−r2,hi−1(ε;θ),…,hi−s(ε;θ))′.
Analogously, we have
where
.
Denote by
,
we have
This leads to
Again, cj decay exponentially. Observe
that the first element of
is zero. Results of Lemma A.2 follow
from (A.13) and Lemma A.1. █
Proof of Theorem 3.
(i) Under the conditions of Theorem 3, we have
.
Following Lemmas A.1 and A.2,
.
Following Lemma 1 there exists a
consistent approximate MLE
satisfying the equation
such that
(ii) Note that
(see Ling and Li, 1997). Results given in this part hold
if we can show
.
Because
,
we have to
show that
,
or
equivalently
,
is a
matrix of the order o(n−1).
Note that
By means of Taylor expansion and using the results of Lemmas A.1 and
A.2 we have
where Op denote the order of magnitude
of a random vector and
Furthermore, note that
Inserting these results into (A.15), we obtain
where the random vector
Observe that
.
We have that each element of T is of the order
Hence, the variance of each element of T is of the order
and so far
is consistent. This shows that all
entries of
are of the order o(n−1).
(iii) Now, we will calculate the order of magnitude of
.
Observe that
at any point
and
in the interior. We have, at an
interior point ti,
Furthermore, note that
at the boundary and that the length of the
boundary area is equal to 2b. This shows that the expected
value of each element of T is of the order
O[b2 +
(nb)−1] and hence
Theorem 3 is proved. █
A sketched proof of Proposition 1. Taylor expansion on
leads to
We have
Furthermore, we have E(T1) =
O(bε2) and
T2 [esdot ] MISE[0,1] =
O(nbε)−1 +
o(T1), where
MISE[0,1] denotes the MISE on [0,1]. The
results given in (22) are proved.
Observe that
.
We have
Note that εi4 follow a squared
ARMA process, which is again a second-order stationary process with
absolute summable autocovariances under the assumption
E(εi8) < ∞. Hence
the spectral density of εi4 exists
and
where cfε is the value of
the spectral density of εi4 at the
origin (see, e.g., Brockwell and Davis, 1991,
pp. 218ff). Proposition 1 is proved. █
A sketched proof of Proposition 2. Estimation of functionals
∫{v(ν)(t)}2
dt, where v(ν) is the νth
derivative of v, was investigated by Ruppert et al. (1995) and Beran and Feng (2002b) in nonparametric regression with independent
and dependent errors, respectively. Note that
I(v2) =
∫{v2(t)}2 dt is a
special case of such functionals with ν = 0. Furthermore, the
results in Ruppert et al. (1995) and Beran
and Feng (2002b) together show that the
orders of magnitude in these results stay unchanged if short-range
dependence and/or a bounded, smooth scale function are introduced
into the error process. We obtain the results of Proposition 2 by
setting k = 0, l = 2, and δ = 0 in the results in
Beran and Feng (2002b), where k and
l correspond to ν = 0 and the kernel order used here and
δ is the long-memory parameter, which is zero in the current
context. █
A sketched proof of Theorem 4. Note that
,
where
CA is as defined in (18). Hence we have
Taylor expansion shows that
Observe that
The term
is
of a much smaller order than that given in (A.25) and hence is omitted.
As a result of the bias in
one has
The results as given in Theorem 4 hold. █