















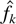


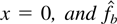

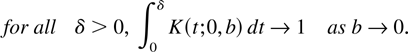

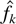






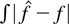




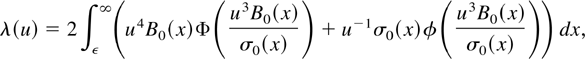
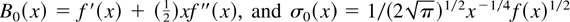
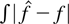
























Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Couderc, Fabien
2005.
Understanding Default Risk and Ttc Ratings Through Hazard Rates.
SSRN Electronic Journal,
Fernandes, Marcelo
and
Grammig, Joachim
2005.
Nonparametric specification tests for conditional duration models.
Journal of Econometrics,
Vol. 127,
Issue. 1,
p.
35.
Gustafsson, Jim
Hagmann-von Arx, Matthias
Scaillet, O.
and
Nielsen, Jens Perch
2006.
Local Transformation Kernel Density Estimation of Loss Distributions.
SSRN Electronic Journal,
Bouezmarni, Taoufik
and
Rombouts, J. V. K.
2006.
Nonparametric Density Estimation for Positive Time Series.
SSRN Electronic Journal,
Bouezmarni, Taoufik
and
Rombouts, J. V. K.
2006.
Density and Hazard Rate Estimation for Censored and A-Mixing Data Using Gamma Kernels.
SSRN Electronic Journal,
Hagmann, M.
and
Scaillet, O.
2007.
Local multiplicative bias correction for asymmetric kernel density estimators.
Journal of Econometrics,
Vol. 141,
Issue. 1,
p.
213.
Sancetta, Alessio
2007.
Nonparametric estimation of distributions with given marginals via Bernstein–Kantorovich polynomials: L1 and pointwise convergence theory.
Journal of Multivariate Analysis,
Vol. 98,
Issue. 7,
p.
1376.
Bouezmarni, Taoufik
and
Rombouts, J. V. K.
2007.
Semiparametric Multivariate Density Estimation for Positive Data Using Copulas.
SSRN Electronic Journal,
Wu, Yuefeng
and
Ghosal, Subhashis
2008.
Kullback Leibler property of kernel mixture priors in Bayesian density estimation.
Electronic Journal of Statistics,
Vol. 2,
Issue. none,
Grillenzoni, Carlo
2008.
Robust nonparametric estimation of the intensity function of point data.
AStA Advances in Statistical Analysis,
Vol. 92,
Issue. 2,
p.
117.
McCrary, Justin
2008.
Manipulation of the running variable in the regression discontinuity design: A density test.
Journal of Econometrics,
Vol. 142,
Issue. 2,
p.
698.
Bareche, Aïcha
and
Aïssani, Djamil
2008.
Kernel density in the study of the strong stability of the queueing system.
Operations Research Letters,
Vol. 36,
Issue. 5,
p.
535.
Bouezmarni, Taoufik
and
Rombouts, Jeroen V.K.
2008.
Density and hazard rate estimation for censored and α-mixing data using gamma kernels.
Journal of Nonparametric Statistics,
Vol. 20,
Issue. 7,
p.
627.
Bouezmarni, T.
and
Rombouts, J.V.K.
2009.
Semiparametric multivariate density estimation for positive data using copulas.
Computational Statistics & Data Analysis,
Vol. 53,
Issue. 6,
p.
2040.
Sardet, Laure
and
Patilea, Valentin
2009.
Advances in Data Analysis, Data Handling and Business Intelligence.
p.
271.
Gustafsson, J.
Hagmann, M.
Nielsen, J. P.
and
Scaillet, O.
2009.
Local Transformation Kernel Density Estimation of Loss Distributions.
Journal of Business & Economic Statistics,
Vol. 27,
Issue. 2,
p.
161.
Bouezmarni, Taoufik
and
Rombouts, Jeroen V.K.
2010.
Nonparametric density estimation for positive time series.
Computational Statistics & Data Analysis,
Vol. 54,
Issue. 2,
p.
245.
Charpentier, Arthur
and
Oulidi, Abder
2010.
Beta kernel quantile estimators of heavy-tailed loss distributions.
Statistics and Computing,
Vol. 20,
Issue. 1,
p.
35.
Kristensen, Dennis
2010.
NONPARAMETRIC FILTERING OF THE REALIZED SPOT VOLATILITY: A KERNEL-BASED APPROACH.
Econometric Theory,
Vol. 26,
Issue. 1,
p.
60.
Bouezmarni, T.
El Ghouch, A.
Mesfioui, M.
and
Lavine, Michael
2011.
Gamma Kernel Estimators for Density and Hazard Rate of Right‐Censored Data.
Journal of Probability and Statistics,
Vol. 2011,
Issue. 1,