
















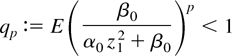


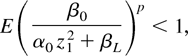
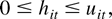

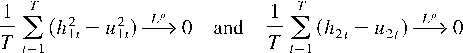


























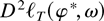

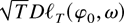


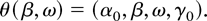
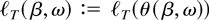
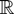
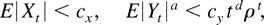
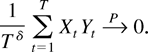
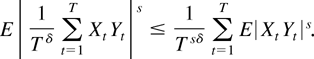




















Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Kristensen, Dennis
and
Rahbek, Anders
2005.
ASYMPTOTICS OF THE QMLE FOR A CLASS OF ARCH(q) MODELS.
Econometric Theory,
Vol. 21,
Issue. 05,
Iglesias, Emma M.
and
Linton, Oliver B.
2007.
HIGHER ORDER ASYMPTOTIC THEORY WHEN A PARAMETER IS ON A BOUNDARY WITH AN APPLICATION TO GARCH MODELS.
Econometric Theory,
Vol. 23,
Issue. 06,
Jensen, Søren Tolver
and
Rahbek, Anders
2007.
ON THE LAW OF LARGE NUMBERS FOR (GEOMETRICALLY) ERGODIC MARKOV CHAINS.
Econometric Theory,
Vol. 23,
Issue. 04,
Han, Heejoon
and
Park, Joon
2007.
Arch with Persistent Covariate.
SSRN Electronic Journal,
Dahl, Christian
and
Iglesias, Emma M.
2008.
The Limiting Properties of the QMLE in a General Class of Asymmetric Volatility Models.
SSRN Electronic Journal,
Escanciano, Juan Carlos
2008.
Quasi-Maximum Likelihood Estimation of Semi-Strong GARCH Models.
SSRN Electronic Journal,
Rapach, David E.
Strauss, Jack K.
and
Wohar, Mark E.
2008.
Forecasting in the Presence of Structural Breaks and Model Uncertainty.
Vol. 3,
Issue. ,
p.
381.
Fokianos, Konstantinos
Rahbek, Anders
and
Tjostheim, Dag
2008.
Poisson Autoregression.
SSRN Electronic Journal,
Ma, Jun
2008.
A Closed-Form Asymptotic Variance-Covariance Matrix for the Quasi-Maximum Likelihood Estimator of the Garch(1,1) Model.
SSRN Electronic Journal,
Christensen, Bent Jesper
Dahl, Christian M.
and
Iglesias, Emma M.
2008.
Semiparametric Inference in a GARCH-in-Mean Model.
SSRN Electronic Journal,
Rapach, David E.
and
Strauss, Jack K.
2008.
Structural breaks and GARCH models of exchange rate volatility.
Journal of Applied Econometrics,
Vol. 23,
Issue. 1,
p.
65.
Meitz, Mika
and
Saikkonen, Pentti
2008.
Parameter Estimation in Nonlinear AR-GARCH Models.
SSRN Electronic Journal,
Meitz, Mika
and
Saikkonen, Pentti
2008.
Parameter Estimation in Nonlinear AR-GARCH Models.
SSRN Electronic Journal,
Amado, Christina
and
Terasvirta, Timo
2008.
Modelling Conditional and Unconditional Heteroskedasticity with Smoothly Time-Varying Structure.
SSRN Electronic Journal,
Wang, Fangfang
and
Ghysels, Eric
2008.
Statistical Inference for Volatility Component Models.
SSRN Electronic Journal,
Aknouche, Abdelhakim
and
Bibi, Abdelouahab
2009.
Quasi‐maximum likelihood estimation of periodic GARCH and periodic ARMA‐GARCH processes.
Journal of Time Series Analysis,
Vol. 30,
Issue. 1,
p.
19.
Chan, Ngai Hang
and
Ng, Chi Tim
2009.
Statistical inference for non-stationary GARCH(p,q) models.
Electronic Journal of Statistics,
Vol. 3,
Issue. none,
Berkes, István
Horváth, Lajos
and
Ling, Shiqing
2009.
Estimation in nonstationary random coefficient autoregressive models.
Journal of Time Series Analysis,
Vol. 30,
Issue. 4,
p.
395.
Escanciano, Juan Carlos
2009.
QUASI-MAXIMUM LIKELIHOOD ESTIMATION OF SEMI-STRONG GARCH MODELS.
Econometric Theory,
Vol. 25,
Issue. 2,
p.
561.
LEE, TAEWOOK
and
LEE, SANGYEOL
2009.
Normal Mixture Quasi‐maximum Likelihood Estimator for GARCH Models.
Scandinavian Journal of Statistics,
Vol. 36,
Issue. 1,
p.
157.