


1 Introduction
Mortality forecasting is a problem of fundamental importance for the insurance and pensions industry. Due to the increasing focus on risk management and measurement for insurers and pension funds, stochastic mortality models have attracted considerable interest in recent years. A range of stochastic models for mortality have been proposed, for example the seminal models of Lee & Carter (Reference Lee and Carter1992), Renshaw & Haberman (Reference Renshaw and Haberman2006) and Cairns et al. (Reference Cairns, Blake and Dowd2006b). Some models build on an assumption of smoothness in mortality rates between ages in any given year (e.g. Cairns et al., Reference Cairns, Blake and Dowd2006b), while others allow for roughness, (e.g. Lee & Carter Reference Lee and Carter1992; Renshaw & Haberman, Reference Renshaw and Haberman2006).
In this paper we propose a new Bayesian method for two-dimensional mortality modelling. Our method is based on natural cubic smoothing splines, which are popular in statistical applications, since the smoothing problem can be solved using simple linear algebra. In this approach the distinct data values are taken as knots of the spline, and its smoothness is achieved by employing roughness penalty in a penalized likelihood function. In the Bayesian approach, the prior distribution takes the role of the roughness penalty term. A useful introduction to smoothing splines may be found, for example, in Green & Silverman (Reference Green and Silverman1994).
A more general penalized splines approach would employ a set of basis functions, such as B-splines. In the case that cubic B-splines are used, one may obtain the same solution as in the smoothing spline approach by using the same roughness penalty and by choosing the knots to be the distinct values of the data points. Compared to the general penalized splines approach our approach has the advantage that one does not need to optimize with respect to the number of knots and their locations. However, the drawback in our approach is that the matrices involved in computations become too large, unless one restricts the size of the estimation data set.
We use age-cohort data instead of age-period data, since we wish to preserve the sequential dependence of observations within each cohort. Therefore, we have to deal with imbalanced data, since more recent cohorts have fewer observations. We suggest an initial model for the observed death rates, and an improved model which deals with the numbers of deaths directly. We assume the number of deaths to follow a Poisson distribution, a common model for the number of deaths in a year in a particular cohort. Unobserved death rates are estimated by smoothing the data with one of our spline models. The proposed method is illustrated using Finnish mortality data for females, provided by the Human Mortality Database. We implement the Bayesian approach using the Markov chain Monte Carlo method (MCMC), or more specifically, the single-component Metropolis-Hastings algorithm.
The use of Bayesian methods is not new in this general context. Dellaportas et al. (Reference Dellaportas, Smith and Stavropoulos2001) proposed a Bayesian mortality model in a parametric curve modelling context. Czado et al. (Reference Czado, Delwarde and Denuit2005) and Pedroza (Reference Pedroza2006) provided Bayesian analyses for the Lee-Carter model using MCMC, with further work by Kogure & Kurachi (Reference Kogure and Kurachi2010). More recently, Reichmuth & Sarferaz (Reference Reichmuth and Sarferaz2008) have applied MCMC to a version of the Renshaw & Haberman (Reference Renshaw and Haberman2006) model. Schmid & Held (Reference Schmid and Held2007) present software which allows analysis of incidence count data with a Bayesian age-period-cohort model. Cairns et al. (Reference Cairns, Blake, Dowd, Coughlan and Khalaf-Allah2011) use the same model to compare results based on a two-population approach with single-population results. Currie et al. (Reference Currie, Durban and Eilers2004) and Richards et al. (Reference Richards, Kirkby and Currie2006) assume smoothness in both age and cohort dimensions through the use of P-splines in a non-Bayesian set-up. Lang & Brezger (Reference Lang and Brezger2004) introduce two-dimensional P-splines in a Bayesian set-up but in a different context.
Cairns et al. (Reference Cairns, Blake and Dowd2008) evaluated several types of stochastic mortality models using a checklist of criteria. These criteria are based on general characteristics and the ability of the model to explain historical patterns of mortality. None of the existing models met all of the criteria. However, Plat (Reference Plat2009) later proposed a model which apart from partly meeting the parsimony criteria meets all of the criteria. We also follow the same list in assessing the fit and plausibility of our model.
The plan of the paper is as follows. In the next section we describe the data and its use in estimation. In Section 3 we explain the smoothing problem and present the Bayesian formulation of the preliminary model, and in Section 4 we describe our final model. In Section 5 we introduce the estimation method and provide some convergence results. The model checks are described in Section 6, after which we conclude with a brief discussion.
2 Data
We use mortality data provided by the Human Mortality Database. This was created to provide detailed mortality and population data to those interested in the history of human longevity. In our work we use Finnish cohort mortality data for females. We use age-cohort data instead of age-period data, since we wish to take into account the dependence of consecutive observations within each cohort. In the complete data matrix the years of birth included are between 1807 and 1977; hence there are 171 different cohorts. The most recent data are from 2006. When the age group of persons 110 years and older is excluded, the dimensions of the data matrix become 110 × 171. These data are illustrated in Figure 1, in which the observed area is denoted by vertical lines and the unobserved by two white triangles in the upper left and lower right corners.

Figure 1 Age-cohort representation of the data set. The complete data set is indicated by the streaked area, and the imbalanced estimation set by the white rectangle.
Our estimation method would produce huge matrices if all these data were used simultaneously. Therefore, we define estimation areas which are parts of the complete data set. A rectangular estimation area shown in Figure 1 indicates the cohorts and ages for which a smooth spline surface is fitted. The mortality rates are known for part of this area, and they are predicted for the unknown part. More specifically, an estimation area is defined by minimum age x 1, maximum age xK, minimum cohort t 1 and maximum cohort tT. The maximum age for which data are available in cohort tT is denoted as x *. Thus, the number of ages included is K = xK − x 1 + 1 and the number of cohorts T = tT − t 1 + 1.
Since the reader might be more familiar with age-period data, we have also plotted the data set in the dimensions of age and year in Figure 2. One should, however, remember that the figures in these two types of mortality tables are not computed in the same way. One figure in an age-period table is based on persons who have a certain (discrete) age during one calendar year and are born during two consecutive years, while each figure in an age-cohort table is based on data from two consecutive calendar years about persons born in a certain year (for details, see Wilmoth et al., Reference Wilmoth, Andreev, Jdanov and Glei2007).

Figure 2 Age-period representation of the data set. The complete data set is indicated by the streaked area, and the imbalanced estimation set by the white parallelogram.
3 Preliminary model
We start building our model in a simplified set-up. Let us denote the logarithms of observed death rates as yxt = log(mxt) for ages x = x 1, x 2,…, xK and cohorts (years of birth) t = t 1, t 2,…, tT. The observed death rates are defined as
where dxt is the number of deaths and ext the person years of exposure. In our preliminary set-up we model the observed death rates directly, while in our final set-up we model the theoretical, unobserved death rates μxt.
3.1 The smoothing problem
Our goal is to smooth and predict logarithms of observed death rates. We fit a smooth two-dimensional curve θ(x,t), and denote its values at discrete points as θx ,t. In matrix form we may write
where Y is a K × T matrix of observations, Θ is a matrix of smoothed values, and E is a matrix of errors. We denote the columns of Y, Θ and E by yj, θj and εj, respectively. Concatenating the columns we obtain y = vec(Y), θ = vec(Θ) and ε = vec(E).
We further assume that the death rates within a cohort follow a multivariate normal distribution having an AR(1) correlation structure with autocorrelation coefficient φ. Thus,
where P is a correlation matrix with elements ![]() . The observations in different cohorts are assumed to be independent.
. The observations in different cohorts are assumed to be independent.
In general, all observations are not available for all cohorts. For each j, we may partition yj into observed yj 1 and unobserved yj 2, and θj correspondingly into θj 1 and θj 2, and P into Pj,r,s, r, s = 1,2. The unobserved part of the data can be predicted using the result about the conditional distribution of the multivariate normal distribution:
where ![]() and
and ![]() .
.
When estimating θ we wish to minimize the generalized sum of squares
The vector of all observed mortality rates is yobs = Sy, where S is a selection matrix selecting the known values from the complete data vector y. The matrix S can be constructed from the identity matrix of size KT by including the ith row (i = 1, 2,…, KT) if the ith element of y is known. Now we can write (1) as
where P* = IT⊗P.
In addition to maximizing fit, we wish to smooth Θ in the dimensions of cohort and age. Specifically, we minimize the roughness functional
for each j = 1,2,…,T and
for each k = 1,2,…,K.
If θ(x,tj) is considered a smooth function of x obtaining fixed values at points x 1,x 2,…, x K, then using variational calculus it can be shown that the integral in (3) is minimized by choosing θ(x,tj) to be a cubic splines curve with knots at x 1,x 2,…, x K. Furthermore, this integral can be expressed as a squared form ![]() , where GK is a so-called roughness matrix with dimensions K × K (for proof, see Green & Silverman, Reference Green and Silverman1994). Similarly, if θ(xk,t) is a cubic splines curve with knots at t 1,…, tT, the integral in (4) equals
, where GK is a so-called roughness matrix with dimensions K × K (for proof, see Green & Silverman, Reference Green and Silverman1994). Similarly, if θ(xk,t) is a cubic splines curve with knots at t 1,…, tT, the integral in (4) equals ![]() , where θ(k) denotes the kth row of Θ and GT is a T × T roughness matrix. Thus, we wish to minimize
, where θ(k) denotes the kth row of Θ and GT is a T × T roughness matrix. Thus, we wish to minimize
and
An N × N roughness matrix is defined as ![]() where the non-zero elements of banded N×(N−2) and (N−2)×(N−2) matrices
where the non-zero elements of banded N×(N−2) and (N−2)×(N−2) matrices ![]() and
and ![]() , respectively, are defined as follows:
, respectively, are defined as follows:
and
with data points xi, i = 1,…, n. In our case the data are given at equal intervals, implying that
and
Combining the previous results, we obtain the bivariate smoothing splines solution for θ by minimizing the expression SS 1 + λ 1SS 2 + λ 2SS 3, where SS 1, SS 2 and SS 3 are given in the equations (2), (5) and (6), respectively, and the parameters λ 1 and λ 2 control smoothing in the dimensions of age and cohort, respectively. Using matrix differentiation and the properties of Kronecker's product, it is easy to show that for fixed values of λ 1 and λ 2 the minimal solution is given by
where
In the special case that the data set is balanced (S is an identity matrix), the solution is simplified to ![]() .
.
3.2 Bayesian formulation
Bayesian statistical inference is based on the posterior distribution, which is the conditional distribution of unknown parameters given the data. In order to compute the posterior distribution one needs to define the prior distribution, which is the unconditional distribution of parameters, and the likelihood function, which is the probability density of observations given the parameters. Bayes’ theorem implies that the posterior distribution is proportional to the product of the prior distribution and the likelihood:
where y is the data vector and η the vector of all unknown parameters.
In our case, the likelihood is given by
where K * is the length of yobs.
In order to facilitate estimation we reparametrize the smoothing parameters as follows: λ = λ 1 and ω = λ 2/λ 1, where λ 1 and λ 2 control the smoothing in the dimensions of age and cohort, respectively. Furthermore, we use the following hierarchical prior for η:
where
![\[--><$$>\displaylines{ & p({{\sigma }^2} ) \propto \frac{1}{{{{\sigma }^2} }} \cr p(\lambda ) \propto {{\lambda }^{{{\alpha }_1}{\rm{ - }}1}} {{e}^{{\rm{ - }}{{\beta }_1}\lambda }} \cr p(\omega ) \propto {{\omega }^{{{\alpha }_2}{\rm{ - }}1}} {{e}^{{\rm{ - }}{{\beta }_2}\omega }} \cr p(\phi ) \propto 1,\; \; {\rm{ - }}1\, \lt \,\phi \, \lt \,1. \cr}\eqno<$$><!--\]](https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20160319083720764-0452:S174849951200005X_eqnU29.gif?pub-status=live)
As hyperparameters we set α 1 = β 1 = 0.001 and α 2 = β 2 = 10. Thus, the prior of σ 2 is the standard uninformative improper prior used for positive parameters, and the priors of λ and φ are also fairly uninformative. The prior of ω is instead more informative, having mean 1 and variance 0.1, since we found that the data do not contain enough information about ω, and with a looser prior we would face convergence problems in estimation. We made sensitivity analysis with respect to the prior of λ and found that increasing or decreasing the order of magnitude of α 1 and β 1 did not essentially affect the results.
The smoothing effect can now be obtained by choosing a conditional prior for θ which is consistent with the smoothing splines solution. Such a prior contains information only on the curvature, or roughness, of the spline surface, not on its position or gradient. Thus, we assume that ![]() is multivarite normal with density
is multivarite normal with density
where GK ,γ is a positive definite matrix approximating GK. More specifically, we define GK ,γ = GK + γ XX′, where γ > 0 can be chosen to be arbitrarily small, and X = (1x) with 1 = (1,…,1)′ and x = (x 1 ,…, xK)′. Initially, we use GK ,γ instead of GK, since otherwise p(θ | σ 2, λ, ω, φ) would be improper, which would lead to difficulties when deriving the conditional posteriors for λ and ω.
Multiplying the densities in (11) and (9) and picking the factors which include θ we obtain the full conditional posterior for θ up to a constant of proportionality:
Manipulating this expression and replacing GK,γ with Gk we obtain
where ![]() is given in (7) and
is given in (7) and ![]() . From this we see that the conditional posterior distribution of θ is multivariate normal with mean
. From this we see that the conditional posterior distribution of θ is multivariate normal with mean ![]() and covariance matrix σ 2B−1 in the limiting case when
and covariance matrix σ 2B−1 in the limiting case when ![]() . This implies that the conditional posterior mode for θ is equal to the smoothing splines solution provided in the previous section. Thus, using the multivariate prior described above, we can implement the roughness penalty of smoothing splines in the Bayesian framework.
. This implies that the conditional posterior mode for θ is equal to the smoothing splines solution provided in the previous section. Thus, using the multivariate prior described above, we can implement the roughness penalty of smoothing splines in the Bayesian framework.
In order to implement estimation using the Gibbs sampler, the full conditional posterior distributions of the parameters are needed. In the following, we will provide these for σ 2, λ, ω and φ in the limiting case when ![]() .
.
The conditional posterior of σ 2 is
which is the density of the scaled inverted χ 2 -distribution ![]() Footnote 1, where γ = K * + KT and
Footnote 1, where γ = K * + KT and ![]() with SS 1, SS 2 and SS 3 given in (2), (5) and (6).
with SS 1, SS 2 and SS 3 given in (2), (5) and (6).
The conditional posterior of λ is
which is the density of Gamma ![]() .
.
The conditional posterior of ω is
where μj, j = 1,…, T−2 and vK, k = 1,…, K−2, are the nonzero eigenvalues of GT and GK, respectively. This is not a standard distribution, but since it is log-concave, it is possible to generate values from it using adaptive rejection sampling, introduced by Gilks & Wild (Reference Gilks and Wild1992).
Finally, the conditional posterior of φ, given by
is not of standard form, and it is therefore difficult to generate random variates from it directly. Instead, we may employ a Metropolis step within the Gibbs sampler.
Now, the estimation algorithm is implemented so that the parameters λ, ω, σ 2 and θ are updated one by one using Gibbs steps, and φ is updated using a Metropolis step. Further details will be given in Section 5.
4 The final model
In our final set-up we are able to control for unsystematic mortality risk in addition to systematic risk. Unsystematic risk means that even if the true mortality rate were known, the numbers of deaths would remain unpredictable. When the population becomes larger, the unsystematic mortality risk becomes smaller due to diversification.
4.1 Formulation and estimation
In the final model the inference is rendered more accurate by modelling the observed numbers of deaths directly. Specifically, we assume that
where dxt is the number of deaths at age x and cohort t, μxt is the theoretical death rate (also called intensity of mortality or force of mortality) and ext is the person years of exposure. This is an approximation, since neither the death rate nor the exposure is constant during any given year. Our purpose is to model θxt = log(μxt) with a smooth spline surface. Compared to the preliminary model we have replaced mxt with μxt and removed the error term and its autocorrelation structure.
Similarly to the preliminary model, we obtain the smoothing effect by using a suitable conditional prior distribution for θ. Specifically, we obtain p(θ|λ,ω) by replacing σ 2 with 1 in equation (11). For λ and ω we use the same prior distributions as earlier, given by (10), and their conditional posteriors are obtained from (13) and (14) when σ 2 is set at 1. However, here we use hyperparameters α 1 = β 1 = 10−6, since removing σ 2 changes the scale of λ several orders of magnitude.
Now the full conditional posterior distribution of θ may be written as
where dobs is a vector of observed death numbers, and Kt the number of ages for which data are available in cohort t. The double sum in this expression comes from the likelihood function and the squared form from the prior distribution.
This model can be estimated similarly to the preliminary model, using Gibbs sampling. However, since the conditional distribution in (15) is non-standard, it is difficult to sample from it directly. Here we may use a Metropolis-Hastings step within the Gibbs sampler. As a proposal distribution we may use a multivariate normal approximation to (15), given by
where yobs is a vector of observed log death rates, ![]() is a diagonal matrix with approximate variances of log death rates, denoted as
is a diagonal matrix with approximate variances of log death rates, denoted as ![]() as its diagonal elements, and S is a selection matrix defined in Section 3.1. We obtain vxt by applying the delta method to the relevant transformation of the underlying Poisson variable. More specifically, we use
as its diagonal elements, and S is a selection matrix defined in Section 3.1. We obtain vxt by applying the delta method to the relevant transformation of the underlying Poisson variable. More specifically, we use ![]() , where
, where ![]() is an initial approximation to the log death rate.
is an initial approximation to the log death rate.
Thus, the proposal θ* is distributed as
where C = A + S′(SΣS′)−1S, and is accepted with probability
The whole algorithm is once more a special case of the single-component Metropolis-Hastings. Further details on this algorithm will be provided in the next section.
5 Estimation
5.1 Estimation procedure
Our estimation procedure is a single-component (or cyclic) Metropolis-Hastings algorithm. This is one of the Markov Chain Monte Carlo (MCMC) methods, which are useful in drawing samples from posterior distributions. Generally, MCMC methods are based on drawing values from approximate distributions and then correcting these draws to better approximate the target distribution, and hence they are used when direct sampling from a target distribution is difficult. A useful reference for different versions of MCMC is Gilks et al. (Reference Gilks, Richardson and Spiegelhalter1996).
The Metropolis-Hastings algorithm was introduced by Hastings (Reference Hastings1970) as a generalization of the Metropolis algorithm (Metropolis et al., Reference Metropolis, Rosenbluth, Rosenbluth, Teller and Teller1953). Also the Gibbs sampler proposed by Geman & Geman (Reference Geman and Geman1984) is its special case. The Gibbs sampler assumes the full conditional distributions of the target distribution to be such that one is able to generate random numbers or vectors from them. The Metropolis and Metropolis-Hastings algorithms are more flexible than the Gibbs sampler; with them one only needs to know the joint density function of the target distribution with density p(θ) up to a constant of proportionality.
With the Metropolis algorithm the target distribution is generated as follows: first a starting distribution p 0(θ) is assigned, and from it a starting-point θ 0 is drawn such that p(θ 0) > 0. For iterations t = 1,2,…, a proposal θ* is generated from a jumping distribution ![]() , which is symmetric in the sense that
, which is symmetric in the sense that ![]() for all θa and θb. Finally, iteration t is completed by calculating the ratio
for all θa and θb. Finally, iteration t is completed by calculating the ratio
and by setting the new value at
It can be shown that, under mild conditions, the algorithm produces an ergodic Markov Chain whose stationary distribution is the target distribution.
Metropolis-Hastings algorithm generalizes the Metropolis algorithm by removing the assumption of symmetric jumping distribution. The ratio r in (16) is replaced by
to correct for the asymmetry in the jumping rule.
In the single-component Metropolis-Hastings algorithm the simulated random vector is divided into components or subvectors which are updated one by one. If the jumping distribution for a component is its full conditional posterior distribution, the proposals are accepted with probability one. In the case that all the components are simulated in this way, the algorithm is called a Gibbs sampler. As stated above, in the case of our preliminary model we can simulate all parameters except φ directly, and may therefore use a Gibbs sampler with one Metropolis step. As the jumping distribution of φ we use the normal distribution N(φ t−1,0.052). For the final model we use a Gibbs sampler with one Metropolis-Hastings step for θ. The proposal distribution and its acceptance probability were already given in Section 4.
5.2 Empirical results
All the computations in this article were performed and figures produced using the R computing environment (R Development Core Team, 2010). The functions and data needed to replicate the results can be found at http://mtl.uta.fi/codes/mortality. A minor drawback is that we cannot use all available data in estimation but must restrict ourselves to a relevant subset. This is due to the huge matrices involved in computations if many ages and cohorts are included in the data set. For example, if we used our complete data set, whose dimensions are T = 110 and K = 171, we would have to deal with Kronecker product matrices of dimension 18810 × 18810. This would require 5 GB of memory for storing one matrix and much more for computations. Although we can alleviate the storage problem and also speed up the computations using sparse matrix methods, we still cannot use the complete data set. In our implementation we use the R package SparseM.
To assess the convergence of the simulated Markov chain to its stationary distribution we used 5 representative values of θ, denoted as θ 1,…,θ 5, from each corner and the middle of the data matrix, in addition to the upper level parameters. The value θ 5 is in the lower right corner of the matrix and corresponds to an unobserved data item.
For each data set and both models we assessed the convergence of iterative simulation using three simulated sequences with 5000 iterations. In the case of the final model we discarded 1500 first iterations of each chain as a burn-in period, while in the case of the preliminary model the convergence was more rapid and we discarded only 200 iterations.
Figure 3 shows one simulated chain corresponding to the final model and the data set with ages 50–90 and cohorts 1901–1941. The series of λ and ω do not mix well, that is, they are fairly autocorrelated. To obtain accurate results for the estimates, more iterations would be needed. However, the chains converge to their stationary distribution fairly quickly, as indicated by the values of the potential scale reduction factor, which is a convergence diagnostic introduced by Gelman & Rubin (Reference Gelman and Rubin1992). The diagnostic values for the final model are less than 1.1 indicating approximate convergence. Summaries of the estimation results for both preliminary and final model as well as the diagnostics are provided in Appendix 1.

Figure 3 Posterior simulations of the final model.
6 Model checking
Cairns et al. (Reference Cairns, Blake and Dowd2008) provide a checklist of criteria against which a stochastic mortality model can be assessed. We will follow this list as we assess the fit and plausibility of our two models. The list is as follows:
1. Mortality rates should be positive.
2. The model should be consistent with historical data.
3. Long-term dynamics under the model should be biologically reasonable.
4. Parameter estimates should be robust relative to the period of data and range of ages employed.
5. Model forecasts should be robust relative to the period of data and range of ages employed.
6. Forecast levels of uncertainty and central trajectories should be plausible and consistent with historical trends and variability in mortality data.
7. The model should be straightforward to implement using analytical methods or fast numerical algorithms.
8. The model should be relatively parsimonious.
9. It should be possible to use the model to generate sample paths and calculate prediction intervals.
10. The structure of the model should make it possible to incorporate parameter uncertainty in simulations.
11. At least for some countries, the model should incorporate a stochastic cohort effect.
12. The model should have a non-trivial correlation structure.
Both of our models fulfil the first item in the list, since we model log death rates. To assess the consistency of the models with historical data we will introduce three Bayesian test quantities in Section 6.1.
A model is defined by Cairns et al. (Reference Cairns, Blake and Dowd2006a) to be biologically reasonable if the mortality rates are increasing with age and if there is no long-run mean reversion around a deterministic trend. Our spline approach implies that the log death rate increases linearly beyond the estimable region. The preliminary model allows for short-term mean reversion (or autocorrelation) for the observed death rate, while there is no mean reversion at all in the final model.
The fourth and fifth points in the list, that is, the robustness of parameter estimates and model forecasts, will be studied in Sections 6.2 and 6.3. The figures of posterior predictions in Section 6.3 help assess the plausibility and uncertainty of forecasts and their consistency with historical trends and variability.
Implementing the models is fairly straightforward but involves several algorithms. Basically, we use the Gibbs sampler, and supplement it with rejection sampling and Metropolis and Metropolis-Hastings steps, which are needed to update certain parameters or parameter blocks. A further complication is that we have to use sparse matrix methods to increase the maximum size of the data set.
In the Bayesian approach one typically uses posterior predictive simulation, in which parameter uncertainty is taken into account, to generate sample paths and calculate prediction intervals. This will be explained in detail in Section 6.3.
The hierarchical structure of the spline models makes them parsimonious: on the upper level the preliminary model has 4 parameters, the final model only 2. Both models also incorporate a stochastic cohort effect. The preliminary model incorporates an AR(1) structure for observed mortality, while the final model has no correlation structure for deviations from the spline surface.
One should note, however, that the spline model in itself implies a covariance structure. In the one-dimensional case the Bayesian smoothing spline model can be interpreted as a sum of a linear trend and integrated Brownian motion (Wahba, Reference Wahba1978). The prior distribution does not contain information on the intercept or slope of the trend but implies the covariance structure of the integrated Brownian motion. Similarily, in our two-dimensional case, the spline surface can be interpreted as a sum of a plane and deviations from this plane. The conditional prior of θ, given the smoothing parameters, does not include information on the plane but implies a specific spatial covariance structure for the deviations.
6.1 Tests for the consistency of the model
In the Bayesian framework, posterior predictive simulations of replicated data sets may be used to check the model fit (see Gelman et al., Reference Gelman, Carlin, Stern and Rubin2004). Once several replicated data sets y rep have been produced, they may be compared with the original data set y. If they look similar to y, the model fits.
The discrepancy between data and model can be measured using arbitrarily defined test quantities. A test quantity T(y,θ) is a scalar summary of parameters and data which is used to compare data with predictive simulations. If the test quantity depends only on data and not on parameters, then it is said to be a test statistic. If we already have N posterior simulations θi, i = 1,…, N, we can generate one replication ![]() using each θi, and compute the test quantities T(y,θi) and
using each θi, and compute the test quantities T(y,θi) and ![]() . The Bayesian p-value is defined to be the posterior probability that the test quantity computed from a replication, T(y rep,θ), will exceed that computed from the original data, T(y,θ). This test may be illustrated by a scatter plot of
. The Bayesian p-value is defined to be the posterior probability that the test quantity computed from a replication, T(y rep,θ), will exceed that computed from the original data, T(y,θ). This test may be illustrated by a scatter plot of ![]() where the same scale is used for both coordinates. Further details on this approach can be found in Chapter 6 of Gelman et al. (Reference Gelman, Carlin, Stern and Rubin2004) or Chapter 11 of Gilks et al. (Reference Gilks, Richardson and Spiegelhalter1996).
where the same scale is used for both coordinates. Further details on this approach can be found in Chapter 6 of Gelman et al. (Reference Gelman, Carlin, Stern and Rubin2004) or Chapter 11 of Gilks et al. (Reference Gilks, Richardson and Spiegelhalter1996).
In the case of our preliminary model, a replication of data is generated as follows: First, θ, σ 2 and φ are generated from their joint posterior distribution. Then, using these parameter values, a replicated data vector yrep is generated from the multivariate normal distribution ![]() . Finally, the elements of yrep which correspond to the observed values in yobs are selected. In the case of the final model, θ is first generated and then the numbers of deaths dxt and exposures ext are generated recursively by starting from the smallest age included in the estimation data set. The numbers for the smallest age are not generated but they are taken to be the same as in the estimation set. Finally, the replicated death rates are computed as yxt = log(dxt/ext), and the values corresponding to the observed values in yobs are selected. Further details about this procedure are provided in Appendix 2.
. Finally, the elements of yrep which correspond to the observed values in yobs are selected. In the case of the final model, θ is first generated and then the numbers of deaths dxt and exposures ext are generated recursively by starting from the smallest age included in the estimation data set. The numbers for the smallest age are not generated but they are taken to be the same as in the estimation set. Finally, the replicated death rates are computed as yxt = log(dxt/ext), and the values corresponding to the observed values in yobs are selected. Further details about this procedure are provided in Appendix 2.
We introduce three test quantities to check the model fit. The first measures the autocorrelation of the observed log death rate and the second and third its mean square error:
![\[--><$$>AC(y,\bitheta )\, = \,\frac{{\mathop{\sum}\limits_{t\, = \,{{t}_1}}^{{{t}_T}} \, \mathop{\sum}\limits_{x\, = \,{{x}_1}}^{{{x}_K}{\rm{ - }}1} ({{y}_{x\, + \,1,t}}{\rm{ - }}{{\theta }_{x\, + \,1,t}})({{y}_{xt}}{\rm{ - }}{{\theta }_{xt}})}}{{\mathop{\sum}\limits_{t\, = \,{{t}_1}}^{{{t}_T}} {{K}_t}}},\eqno<$$><!--\]](https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20160319083720764-0452:S174849951200005X_eqnU64.gif?pub-status=live)
where Kt is the number of observations in cohort t, and
![\[--><$$>MS\,{{E}_1}(y,\bitheta )\, = \,\frac{{\mathop{\sum}\limits_{t\, = \,{{t}_1}}^{{{t}_T}} \,\mathop{\sum}\limits_{x\, = \,{{x}_1}}^{{{x}_{{{K}_t}}}} {{{\left( {{{y}_{xt}}{\rm{ - }}{{\theta }_{xt}}} \right)}}^2} }}{{\mathop{\sum}\limits_{t\, = \,{{t}_1}}^{{{t}_T}} {{K}_t}}},\quad MS\,{{E}_2}(y,\bitheta )\, = \,\frac{{\mathop{\sum}\limits_{t\, = \,{{t}_1}}^{{{t}_T}} {{{\left( {{{y}_{{{x}_{{{K}_t}}}t}}{\rm{ - }}{{\theta }_{{{x}_{{{K}_t}}}t}}} \right)}}^2} }}{T}.\eqno<$$><!--\]](https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20160319083720764-0452:S174849951200005X_eqnU65.gif?pub-status=live)
Figure 4 and 5 show the results when using the data set with ages 50–90 and cohorts 1901–1941. Each figure is based on 500 simulations. If the original data and replicated data were consistent, about half the points in the scatter plot would fall above the 45° line and half below. Figure 4(a) indicates that the preliminary model adequately explains the autocorrelation observed in the original data set, while Figure 5(a) suggests that there might be slight negative autocorrelation in the residuals not explained by the model. However, since the Bayesian p-value, which is the proportion of points above the line, is approximately 0.95, there is no sufficient evidence to reject the assumption of independent Poisson observations.

Figure 4 Goodness-of-fit testing for the preliminary model. (a) Autocorrelation test. (b) MSE test.

Figure 5 Goodness-of-fit testing for the final model. (a) Autocorrelation test. (b) MSE test.
The test statistic MS E 1 measures the overall fit of the models, and both models pass it (figures not shown). The test statistic MS E 2 measures the fit at the largest ages of the cohorts. From Figure 5(b) we see that the final model passes this test. However, Figure 4(b) suggests that under the preliminary model the MS E 2 simulations based on the original data are smaller than those based on replicated data sets (pB = 0.98). The reason here is that the homoscedasticity assumption of logarithmic mortality data is not valid. The validity of the homoscedasticity and independence assumptions could be further assessed by plotting the standardized residuals (not shown here).
6.2 Robustness of the parameter estimates
The robustness of the parameters may be studied by comparing the posterior distributions when two different but equally sized data sets are used. Here we used two data sets with ages 40–70 and 60–90, and cohorts 1917–1947 and 1886–1916, respectively. We refer to these as the younger and older age groups, respectively. Figure 6 (c) indicates that the variance parameter σ 2 of the preliminary model is clearly higher for the younger age group. This results from the fact that the variance of observed log mortality becomes smaller when the age grows. This also causes a robustness problem for λ, since its posterior distribution is dependent on that of σ 2. Also φ seems to be somewhat unrobust.

Figure 6 Distributions of (a) λ, (b) ω, (c) σ 2 and (d) φ for the preliminary model. The solid line corresponds to the younger (ages 40–70) and the dashed line the older (ages 60–90) age group.
Figure 7 (a) indicates that under the final model the posterior of λ is more concentrated on small values for the older age group. This is compensated by smaller values of ω for the younger group, which indicates that the smoothing effect in the cohort dimension is similar in both groups. However, the difference between the age groups is not as clear as in the case of the preliminary model. Besides, the range of the distribution is fairly large in both cases.
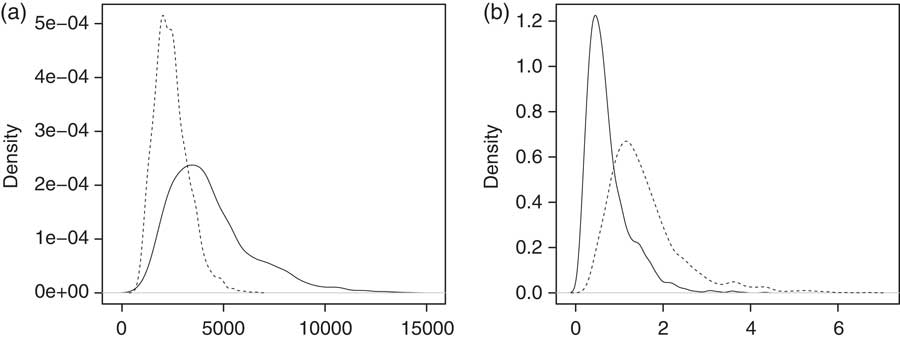
Figure 7 Distributions of (a) λ and (b) ω for the final model. The solid line corresponds to the younger (ages 40–70) and the dashed line the older (ages 60–90) age group.
6.3 Forecasting
Our procedure for forecasting mortality is as follows. We first select a rectangular estimation area which includes in its lower right corner the ages and cohorts for which the death rates are to be predicted. Thus we have in our estimation set earlier observations from the same age as the predicted age and from the same cohort as the predicted cohort. An example of an estimation area is shown in Figure 1.
In the Bayesian approach, forecasting is based on the posterior predictive distribution. In the case of our preliminary model, a simulation from this distribution is drawn as follows: First, θ, σ 2 and φ are generated from their joint posterior distribution. Then the unobserved data vectors yj 2, j = 1,2,…,T, (which are to be predicted) are generated from their conditional multivariate normal distributions, given the observed data vectors yj 1 and the parameters θ, σ 2 and φ. These distributions were provided in Section 3. In the case of our final model, θ is first generated. Then the numbers of deaths dxt and the exposures ext are generated recursively starting from the most recent observed values within each cohort. In this way we obtain simulation paths for each cohort and a predictive distribution for each missing value in the mortality table. Further details are provided in Appendix 2.
In studying the accuracy and robustness of forecasts, we use estimation areas similar to those used earlier. However, we choose them so that we can compare the predictive distribution of the death rate with its realized value. The estimation is done as if the triangular area in the right lower corner of the estimation area, indicated in Figure 1, were not known. The posterior predictive distributions shown in Figure 8 are based on the preliminary model, while those in Figure 9 are based on the final model. The four cases in both figures correspond to forecasts 1, 9, 17 and 25 years ahead, for cohorts 1892, 1900, 1908 and 1916, respectively, when the death rate at ages 70 and 90 are forecast. The distributions indicated by solid lines are based on larger estimation sets than those indicated by dashed lines.

Figure 8 Posterior predictive distributions of the death rates at ages 70 and 90, based on the preliminary model. The solid curves correspond to the larger data set (cohorts 1876–1916, and ages 30–70 when the death rate at age 70 is predicted, and ages 50–90 when the death rate at age 90 is predicted) and the dashed curves the smaller (cohorts 1886–1916, and ages 40–70 when the death rate at age 70 is predicted, and ages 60–90 when the death rate at age 90 is predicted). The vertical lines indicate the realized death rates.

Figure 9 Posterior predictive distributions of the death rates at ages 70 and 90, based on the final model. The solid curves correspond to the larger data set (cohorts 1876–1916; ages 30–70 when the death rate at age 70 is predicted, and ages 50–90 when the death rate at age 90 is predicted) and the dashed curves the smaller (cohorts 1886–1916; ages 40–70 when the death rate at age 70 is predicted, and ages 60–90 when the death rate at age 90 is predicted). The vertical lines indicate the realized death rates.
It may be seen that increasing uncertainty is reflected by the growing width of the distributions. Furthermore, the size of the estimation set does not considerably affect the distributions when the death rate at age 90 is predicted, while when it is predicted at age 70, the smaller data sets produce more accurate distributions. The obvious reason is that in the latter case the larger estimation set contains observations from the age interval 30–40 in which the growth of mortality is less regular than at larger ages, inducing more variability in the estimated model. In all cases, the realized values lie within the 90% prediction intervals.
Figure 10 and 11 show posterior predictive simulations for the log death rate when the preliminary and the final model is used, respectively. In each case, the estimation region includes cohorts 1901–1941 and ages 35–100. Three paths of posterior simulations are shown for cohort 1941, for which the data are available until age 65. As may be seen, the variability of the predictions resembles that of the observed path. Furthermore, the 95% posterior limits for the log death rate (θxt) and the 95% posterior predictive limits for the observed log death rate (yxt) are shown. These two types of limits differ substantially only in the beginning of the forecast horizon. The prediction belt is narrower for the final model, which reflects better model fit.

Figure 10 Posterior predictions with the preliminary model for ages 66−100 and cohort 1941. The solid lines represents the 95% posterior limits for θ, the dotted lines the 95% posterior predictive limits for the observed log death rate, and the dashed lines the observed log death rate for ages 35−65 and three predictive paths for ages 66−100.

Figure 11 Posterior predictions with the final model for ages 66−100 and cohort 1941. The solid lines represent the 95% posterior limits for θ, the dotted lines the 95% posterior predictive limits for the observed log death rate, and the dashed lines the observed log death rate for ages 35−65 and three predictive paths for ages 66−100.
7 Conclusions
In this article we have introduced a new method to model mortality data in both age and cohort dimensions with Bayesian smoothing splines. The smoothing effect is obtained by means of a suitable prior distribution. The advantage in this approach compared to other splines approaches is that we do not need to optimize with respect to the number of knots and their locations. In order to take into account the serial dependence of observations within cohorts, we use cohort data sets, which are imbalanced in the sense that they contain fewer observations for more recent cohorts. We consider two versions of modelling: first, we model the observed death rates, and second, the numbers of deaths directly.
To assess the fit and plausibility of our models we follow the checklist provided by Cairns et al. (Reference Cairns, Blake and Dowd2008). The Bayesian framework allows us to easily assess parameter and prediction uncertainty using the posterior and posterior predictive distributions, respectively. In order to assess the consistency of the models with historical data we introduce test quantities. We find that our models are biologically reasonable, have non-trivial correlation structures, fit the historical data well, capture the stochastic cohort effect, and are parsimonious and relatively simple. Our final model has the further advantages that it has less robustness problems with respect to parameters, and avoids the heteroscedasticity of standardized residuals. A further remedy for the unrobustness of the smoothing parameters might be generalizing the model to allow for dependence between these parameters and age.
A minor drawback is that we cannot use all available data in estimation but must restrict ourselves to a relevant subset. This is due to the huge matrices involved in computations if many ages and cohorts are included in the data set. However, this problem can be alleviated using sparse matrix computations. Besides, for practical applications using “local” data sets should be sufficient.
In conclusion, we may say that our final model meets well the mortality model selection criteria proposed by Cairns et al. (Reference Cairns, Blake and Dowd2008) except that it has a somewhat local character. This locality is partly due to limitations on the size of the estimation set and partly due to slight robustness problems related to the smoothing parameters and forecasting uncertainty.
Acknowledgments
The authors are grateful to referees for their insightful comments and suggestions, which substantially helped in improving the manuscript. The second author of the article would like to thank the Finnish Academy of Science and Letters, Väisälä Fund, for the scholarship during which she could complete this project.
Appendix 1
The posterior simulations were performed using the R computing environment. The following outputs were obtained using the summary function of the add-on package MCMCpack:
Table 1. Estimation results of the preliminary mortality model.

Table 2. Estimation results of the final mortality model.

Appendix 2
In the case of the final model, the numbers of deaths dxt and the exposures ext should be forecast for the ages and cohorts for which they are unknown. Furthermore, these values should be generated when replications of the original estimation data set are produced.
In the case of forecasting, we use an iterative procedure to generate dxt and ext, starting from the most recent observation of death rate within each cohort. In the case of data replication, we start from the smallest age available in the data set. In each case, the initial cohort size is estimated on the basis of the relationship
where qxt is the probability that a person in cohort t dies at age x. The same equality applies for the maximum likelihood estimates of qxt and μxt, given by ![]() and mxt = dxt/ext, where nxt is the number of persons reaching age x in cohort t. Thus, we obtain the formula
and mxt = dxt/ext, where nxt is the number of persons reaching age x in cohort t. Thus, we obtain the formula
from which we may solve nxt when dxt and ext are known.
Further, the number of persons alive is updated recursively as nx + 1,t = nxt−dxt, and the number of deaths is generated from the binomial distribution:
Then ex + 1,t is solved using (17).











