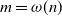1. Introduction
Communities are local structures that are more densely connected than the network average. They are present in numerous real-life networks [Reference Girvan and Newman25], such as the internet, collaboration networks, and social networks, and they offer a possible explanation for the frequently observed high clustering (transitivity) [Reference Newman40, Chapters 7.9, 11].
There are several possible reasons why communities arise, e.g. an underlying geometry or properties shared by the vertices. We focus on networks with an underlying structure of individuals and communities that they are part of. While our terminology and examples are mainly taken from social networks, the model is applicable to any network that builds on some kind of community structure. Such structures exist in many real-life networks [Reference Guillaume and Latapy27, Reference Guillaume and Latapy28], the most evident example being collaboration networks, like the Internet Movie Database (IMDb) or the ArXiv. In these examples, the ‘individuals’ are the actors and actresses or the authors, and the ‘communities’ are the movies or articles they collaborate on. We can also consider a social network based on communities, where ‘communities’ can represent families, common interests, workplaces, or cities.

Figure 1. Two models for overlapping communities: RIG and RIGC.
Because of the complexity of real-world networks, they are often modeled using random graphs [Reference Bollobás14, Reference Durrett20, Reference Janson, Łuczak and Ruciński35]. Properties and processes of interest, e.g. distances, clustering, network evolution, and information or epidemic spreading processes, are studied on the random graph models to predict their behavior on real-life networks. An underlying community structure such as the ones mentioned above is modeled using bipartite graphs, where the two partitions correspond to the individuals (people) and the communities (or attributes), and an edge represents a community membership; see Fig. 1a. The historical random graph model for networks with community structure is the random intersection graph (RIG) first introduced in [Reference Singer44]. Over the years, several ways have been introduced to generate the (random) bipartite graph of community memberships [Reference Bloznelis12], ranging from independent percolation on the complete bipartite graph (binomial RIG [Reference Fill, Scheinerman and Singer-Cohen21, Reference Karonski, Scheinerman and Singer-Cohen37, Reference Singer44] or inhomogeneous RIG [Reference Bloznelis and Damarackas11, Reference Deijfen and Kets18]), through pre-assigning the number of community memberships to each individual and connecting them to uniformly chosen communities (uniform RIG [Reference Blackburn and Gerke7, Reference Rybarczyk43] or generalized RIG [Reference Bloznelis8, Reference Bloznelis9, Reference Bloznelis10, Reference Bloznelis, Jaworski and Kurauskas13, Reference Godehardt and Jaworski26]), to pre-assigning the number of community memberships to each individual as well as the number of community members to each community, then matching these ‘tokens’ uniformly (i.e., the community memberships are generated via the bipartite configuration model) [Reference Coupechoux and Lelarge17, Reference Newman39]. What all of these models have in common is that once the community memberships are generated, every two individuals that share a community are connected. As a result, communities do overlap, while each community is a complete graph (see Fig. 1b), which may not be a realistic assumption for large communities.
One easy and natural way to go about this is thinning communities [Reference Karjalainen, van Leeuwaarden and Leskelä36, Reference Newman39]; however, this may not give the full generality we desire. The recently introduced hierarchical configuration model [Reference Van der Hofstad, van Leeuwaarden and Stegehuis33, Reference Van der Hofstad, van Leeuwaarden and Stegehuis34], which extends the household model [Reference Ball, Sirl and Trapman2, Reference Ball, Sirl and Trapman3], offers an alternative approach, using arbitrary communities as building blocks with random connections between the communities, resulting in non-overlapping communities. In this paper, we aim to bridge the gap: we introduce a new random graph model, the random intersection graph with community structure (RIGC), which accommodates arbitrary, yet at the same time overlapping, communities, as long as these communities are connected; see Fig. 1c.
The RIGC model is flexible in terms of the choice of parameters, ranging from independent and identically distributed (i.i.d.) random variables to data taken from real-life networks; see Section 2.4 for a brief discussion. The model also turns out to be analytically tractable. In this paper, we keep our assumptions as general as possible, and present results on the overlapping structure and local properties of the model (including local weak convergence, degree structure, and non-trivial clustering). Its global properties, including the existence and quantification of the so-called giant component (a unique linear-sized connected component), and percolation on the RIGC model are studied in the companion paper [Reference Van der Hofstad, Komjáthy and Vadon32]. In [Reference Vadon, Komjáthy and van der Hofstad45], we introduce the model to a more applied audience and state all results informally and without proof. The proofs in this paper rely on the connection to the bipartite configuration model that generates the community memberships. The matching results that we present on the bipartite configuration model are hence both instrumental to the RIGC and of independent interest.
Outline of the paper. The rest of this paper is organized as follows. In s:RIGC Section 2, we introduce the random intersection graph with community structure (RIGC), state our results, and provide a brief discussion. We provide the proofs of our results in Section 3.
Notational conventions. We will consider a sequence of graphs, and consequently a sequence of input parameters, both indexed by
 $n\in\mathbb{N}$
. We note that n only serves as the index; it does not necessarily mean the size or any other parameter of the graph, which allows for the study of more general (growing) graph sequences. We often omit the dependence on n to keep the notation light, as long as it does not cause confusion. Throughout this paper, we distinguish the set of positive integers as
$n\in\mathbb{N}$
. We note that n only serves as the index; it does not necessarily mean the size or any other parameter of the graph, which allows for the study of more general (growing) graph sequences. We often omit the dependence on n to keep the notation light, as long as it does not cause confusion. Throughout this paper, we distinguish the set of positive integers as
 $\mathbb{Z}^+\,{:}\,{\raise-1.5pt{=}}\,\{1,2,3, \dots\}$
and the set of non-negative integers as
$\mathbb{Z}^+\,{:}\,{\raise-1.5pt{=}}\,\{1,2,3, \dots\}$
and the set of non-negative integers as
 $\mathbb{N}=\{0,1,2, \dots\}$
. The notions
$\mathbb{N}=\{0,1,2, \dots\}$
. The notions
 $\buildrel {\mathbb{P}}\over{\longrightarrow}$
and
$\buildrel {\mathbb{P}}\over{\longrightarrow}$
and
 $\buildrel d\over{\longrightarrow}$
stand for convergence in probability and convergence in distribution (weak convergence), respectively. We write
$\buildrel d\over{\longrightarrow}$
stand for convergence in probability and convergence in distribution (weak convergence), respectively. We write
 $X\buildrel d\over{=} Y$
to mean that the random variables X and Y have the same distribution. For an
$X\buildrel d\over{=} Y$
to mean that the random variables X and Y have the same distribution. For an
 $\mathbb{N}$
-valued random variable X such that
$\mathbb{N}$
-valued random variable X such that
 $\mathbb{E}[X]<\infty$
, we define its size-biased distribution
$\mathbb{E}[X]<\infty$
, we define its size-biased distribution
 $X^\star$
and the transform
$X^\star$
and the transform
 $\widetilde X$
with the following probability mass functions (PMFs): for all
$\widetilde X$
with the following probability mass functions (PMFs): for all
 $k\in\mathbb{N}$
,
$k\in\mathbb{N}$
,
 \begin{equation} \mathbb{P}(X^\star = k) = k \,\mathbb{P}(X=k) / \mathbb{E}[X],\qquad \mathbb{P}(\widetilde X = k) = \mathbb{P}(X^\star - 1 = k). \end{equation}
\begin{equation} \mathbb{P}(X^\star = k) = k \,\mathbb{P}(X=k) / \mathbb{E}[X],\qquad \mathbb{P}(\widetilde X = k) = \mathbb{P}(X^\star - 1 = k). \end{equation}
We say that a sequence of events
 $(A_n)_{n\in\mathbb{N}}$
occurs with high probability (w.h.p.) if
$(A_n)_{n\in\mathbb{N}}$
occurs with high probability (w.h.p.) if
 $\lim_{n\to\infty}\mathbb{P}(A_n)=1$
. For two (possibly) random sequences
$\lim_{n\to\infty}\mathbb{P}(A_n)=1$
. For two (possibly) random sequences
 $(X_n)_{n\in\mathbb{N}}$
and
$(X_n)_{n\in\mathbb{N}}$
and
 $(Y_n)_{n\in\mathbb{N}}$
, we say that
$(Y_n)_{n\in\mathbb{N}}$
, we say that
 $X_n = o_{\mathbb{P}}(Y_n)$
if
$X_n = o_{\mathbb{P}}(Y_n)$
if
 $X_n/Y_n \buildrel {\mathbb{P}}\over{\longrightarrow} 0$
as
$X_n/Y_n \buildrel {\mathbb{P}}\over{\longrightarrow} 0$
as
 $n\to\infty$
. We write
$n\to\infty$
. We write
 $[n]\,{:}\,{\raise-1.5pt{=}}\,\{1,2,\ldots,n\}$
and denote the indicator of an event A by
$[n]\,{:}\,{\raise-1.5pt{=}}\,\{1,2,\ldots,n\}$
and denote the indicator of an event A by
 $\mathbb{1}_A$
. For a graph G, we denote its vertex set by
$\mathbb{1}_A$
. For a graph G, we denote its vertex set by
 $\mathscr{V}(G)$
, its size by
$\mathscr{V}(G)$
, its size by
 $\lvert{G}\rvert = \lvert{\mathscr{V}(G)}\rvert$
, and its edge set by
$\lvert{G}\rvert = \lvert{\mathscr{V}(G)}\rvert$
, and its edge set by
 $\mathscr{E}(G)$
.
$\mathscr{E}(G)$
.
2. Model and results
In this section, we give a formal definition of the RIGC model and present our results on its local properties, as well as providing a discussion on its applicability.
2.1. Definition of the random intersection graph with communities
First, we give a short, intuitive description of the random intersection graph with communities (RIGC), followed by a detailed, formal construction. After the parameters are introduced, the construction happens in two steps. First, we construct the community structure: an underlying bipartite graph that represents the community memberships, from which all the randomness arises. Then we explain how to derive the RIGC based on the given community structure.
Intuitive model description. The aim of the model is to create a network that uses given (arbitrary but connected) community graphs as its building blocks, but at the same time allows them to overlap. We achieve this by thinking of vertices in the community graphs as community roles that may be taken by the individuals. We represent the community roles as the right-hand side of an underlying bipartite graph: the set of vertices on the right-hand side of the underlying bipartite graph is the disjoint union of the vertices of a set of communities, labeled by their community number and role within the community. The individuals then are represented as a distinct set of vertices, forming the left-hand side of the bipartite graph, and we allow them to take on (possibly several) community roles by assigning them membership tokens. Each membership token corresponds to one community role taken, and we match membership tokens with community roles one-to-one, uniformly at random (u.a.r.). That is, each role in each community is assumed by a unique individual. The total number of membership tokens given out to individuals has to equal the total number of community roles for this matching to be possible. Finally, to obtain the RIGCs, we identify each individual with all the community roles it takes, ‘gluing’ together the community graphs, which introduces overlaps and creates the (much more interconnected) network.
Parameters. Intuitively, we think of the individuals being placed on the left-hand side and the communities on the right-hand side, and consequently we sometimes refer to them as
 $\mathscr{l}$
-vertices and
$\mathscr{l}$
-vertices and
 $\mathscr{r}$
-vertices, respectively. We denote the set of individuals by
$\mathscr{r}$
-vertices, respectively. We denote the set of individuals by
 $\mathscr{V}^{\mathscr{l}} = [N_n]$
, where the number of individuals
$\mathscr{V}^{\mathscr{l}} = [N_n]$
, where the number of individuals
 $N_n$
satisfies
$N_n$
satisfies
 $N_n\to\infty$
as
$N_n\to\infty$
as
 $n\to\infty$
. Similarly, we denote the set of communities by
$n\to\infty$
. Similarly, we denote the set of communities by
 $\mathscr{V}^{\mathscr{r}} = [M_n]$
, where
$\mathscr{V}^{\mathscr{r}} = [M_n]$
, where
 $M_n\to\infty$
is to be defined later.
$M_n\to\infty$
is to be defined later.
In this paper, we will encounter three relevant types of degrees, as we work with three types of graphs: the RIGC model itself, the bipartite graph used to generate its community memberships, and the community graphs we use as building blocks. The term ‘degree’ is reserved for the most natural concept, namely, the number of connections of the individual in the resulting RIGC; we sometimes refer to this notion of degree as ‘projected degree’ (
 $\mathscr{p}$
-degree) for clarity. On the level of the underlying bipartite graph, the role of ‘degrees’ is taken by the number of community memberships (for individuals) and the number of community members (for communities). Hence we introduce the concept of
$\mathscr{p}$
-degree) for clarity. On the level of the underlying bipartite graph, the role of ‘degrees’ is taken by the number of community memberships (for individuals) and the number of community members (for communities). Hence we introduce the concept of
 $\mathscr{l}$
-degrees and
$\mathscr{l}$
-degrees and
 $\mathscr{r}$
-degrees (of
$\mathscr{r}$
-degrees (of
 $\mathscr{l}$
- and
$\mathscr{l}$
- and
 $\mathscr{r}$
-vertices, respectively), to which we may collectively refer as bipartite degrees (
$\mathscr{r}$
-vertices, respectively), to which we may collectively refer as bipartite degrees (
 $\mathscr{b}$
-degrees). Within the community graphs, we will refer to the degree of a community vertex as its community degree (
$\mathscr{b}$
-degrees). Within the community graphs, we will refer to the degree of a community vertex as its community degree (
 $\mathscr{c}$
-degree). We will soon introduce notation for all three types of degree.
$\mathscr{c}$
-degree). We will soon introduce notation for all three types of degree.
As mentioned above, the number of community memberships of an individual
 $v\in\mathscr{V}^{\mathscr{l}}$
is called its
$v\in\mathscr{V}^{\mathscr{l}}$
is called its
 $\mathscr{l}$
-degree, and we denote it by
$\mathscr{l}$
-degree, and we denote it by
 $d_v^{\mathscr{l}}$
. For a community
$d_v^{\mathscr{l}}$
. For a community
 $a\in\mathscr{V}^{\mathscr{r}}$
, we denote its community graph by
$a\in\mathscr{V}^{\mathscr{r}}$
, we denote its community graph by
 $\textrm{Com}_a$
; this graph can be arbitrary as long as it is connected. For convenience, we introduce the set of possible community graphs
$\textrm{Com}_a$
; this graph can be arbitrary as long as it is connected. For convenience, we introduce the set of possible community graphs
 $\mathscr{H}$
, as the set of (non-empty) simple, finite, connected graphs. Further, we separately equip each graph with its own fixed labeling, i.e., we arbitrarily number the vertices of each graph
$\mathscr{H}$
, as the set of (non-empty) simple, finite, connected graphs. Further, we separately equip each graph with its own fixed labeling, i.e., we arbitrarily number the vertices of each graph
 $H\in\mathscr{H}$
by the set
$H\in\mathscr{H}$
by the set
 $[\lvert{H}\rvert]$
. We note that we allow several communities to have the same community graph. We call the size
$[\lvert{H}\rvert]$
. We note that we allow several communities to have the same community graph. We call the size
 $\lvert{\textrm{Com}_a}\rvert$
of the community graph the
$\lvert{\textrm{Com}_a}\rvert$
of the community graph the
 $\mathscr{r}$
-degree of a, denoted by
$\mathscr{r}$
-degree of a, denoted by
 $d_a^{\mathscr{r}}$
. We collect the
$d_a^{\mathscr{r}}$
. We collect the
 $\mathscr{l}$
- and
$\mathscr{l}$
- and
 $\mathscr{r}$
-degrees and the community graphs in the vectors
$\mathscr{r}$
-degrees and the community graphs in the vectors
 $\textbf{d}^{\mathscr{l}} \,{:}\,{\raise-1.5pt{=}}\, (d_v^{\mathscr{l}})_{v\in\mathscr{V}^{\mathscr{l}}}$
,
$\textbf{d}^{\mathscr{l}} \,{:}\,{\raise-1.5pt{=}}\, (d_v^{\mathscr{l}})_{v\in\mathscr{V}^{\mathscr{l}}}$
,
 $\textbf{d}^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\, (d_a^{\mathscr{r}})_{a\in\mathscr{V}^{\mathscr{r}}}$
, and
$\textbf{d}^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\, (d_a^{\mathscr{r}})_{a\in\mathscr{V}^{\mathscr{r}}}$
, and
 $\textbf{Com} \,{:}\,{\raise-1.5pt{=}}\, (\textrm{Com}_a)_{a\in\mathscr{V}^{\mathscr{r}}}$
, respectively. Without loss of generality we assume that
$\textbf{Com} \,{:}\,{\raise-1.5pt{=}}\, (\textrm{Com}_a)_{a\in\mathscr{V}^{\mathscr{r}}}$
, respectively. Without loss of generality we assume that
 $\textbf{d}^{\mathscr{l}} \geq 1$
and
$\textbf{d}^{\mathscr{l}} \geq 1$
and
 $\textbf{d}^{\mathscr{r}} \geq 1$
(element-wise) for each n, as isolated vertices can simply be excluded by adjusting
$\textbf{d}^{\mathscr{r}} \geq 1$
(element-wise) for each n, as isolated vertices can simply be excluded by adjusting
 $N_n$
and
$N_n$
and
 $M_n$
. Also note that
$M_n$
. Also note that
 $\textbf{d}^{\mathscr{r}}$
is derived from
$\textbf{d}^{\mathscr{r}}$
is derived from
 $\textbf{Com}$
; thus the RIGC is parametrized by the pair
$\textbf{Com}$
; thus the RIGC is parametrized by the pair
 $(\textbf{d}^{\mathscr{l}},\textbf{Com})$
. For a visual representation of the parameters, see Fig. 2.
$(\textbf{d}^{\mathscr{l}},\textbf{Com})$
. For a visual representation of the parameters, see Fig. 2.

Figure 2. An example of the parameters. Individuals form the left-hand side partition
 $\mathscr{V}^{\mathscr{l}}$
, and their
$\mathscr{V}^{\mathscr{l}}$
, and their
 $\mathscr{l}$
-degree, i.e., the number of community memberships, is represented by outgoing half-edges. Communities form the right-hand side partition
$\mathscr{l}$
-degree, i.e., the number of community memberships, is represented by outgoing half-edges. Communities form the right-hand side partition
 $\mathscr{V}^{\mathscr{r}}$
, and each is assigned an arbitrary connected community graph. As before, we represent the
$\mathscr{V}^{\mathscr{r}}$
, and each is assigned an arbitrary connected community graph. As before, we represent the
 $\mathscr{r}$
-degree, i.e., the number of community members, by outgoing half-edges. In fact, each half-edge represents a specific vertex (role) in the community graph; thus they are labeled the same way. In the next step, we assign community memberships (community roles) through a (bipartite) matching of the half-edges.
$\mathscr{r}$
-degree, i.e., the number of community members, by outgoing half-edges. In fact, each half-edge represents a specific vertex (role) in the community graph; thus they are labeled the same way. In the next step, we assign community memberships (community roles) through a (bipartite) matching of the half-edges.

Figure 3. The community projection.
Community memberships. Recall that the
 $\mathscr{l}$
-degree of
$\mathscr{l}$
-degree of
 $v\in\mathscr{V}^{\mathscr{l}}$
denotes the number of community memberships of v; we intuitively think of this as giving
$v\in\mathscr{V}^{\mathscr{l}}$
denotes the number of community memberships of v; we intuitively think of this as giving
 $d_v^{\mathscr{l}}$
membership tokens to v. We represent these as
$d_v^{\mathscr{l}}$
membership tokens to v. We represent these as
 $d_v^{\mathscr{l}}$
$d_v^{\mathscr{l}}$
 $\mathscr{l}$
-half-edges incident to v and label them by
$\mathscr{l}$
-half-edges incident to v and label them by
 \begin{equation*}(v,i)_{i \leq d_v^{\mathscr{l}}}.\end{equation*}
\begin{equation*}(v,i)_{i \leq d_v^{\mathscr{l}}}.\end{equation*}
Let us denote the union of all vertices in community graphs by
 $\mathscr{V}(\textbf{Com})$
; we call this the set of community roles or community vertices. For a community vertex
$\mathscr{V}(\textbf{Com})$
; we call this the set of community roles or community vertices. For a community vertex
 $j\in\mathscr{V}(\textrm{Com}_{a})$
, we can uniquely identify j by the tuple (a,l), where l is the vertex label of j in
$j\in\mathscr{V}(\textrm{Com}_{a})$
, we can uniquely identify j by the tuple (a,l), where l is the vertex label of j in
 $\textrm{Com}_{a}$
. Now, similarly as with individuals, we give each community
$\textrm{Com}_{a}$
. Now, similarly as with individuals, we give each community
 $a\in\mathscr{V}^{\mathscr{r}}$
$a\in\mathscr{V}^{\mathscr{r}}$
 $d_a^{\mathscr{r}}$
community role tokens, represented by
$d_a^{\mathscr{r}}$
community role tokens, represented by
 $d_a^{\mathscr{r}}$
$d_a^{\mathscr{r}}$
 $\mathscr{r}$
-half-edges incident to a and labeled by
$\mathscr{r}$
-half-edges incident to a and labeled by
 $(a,l)_{l \leq d_a^{\mathscr{r}}}$
, so that we can represent
$(a,l)_{l \leq d_a^{\mathscr{r}}}$
, so that we can represent
 $j\in\mathscr{V}(\textbf{Com})$
by the
$j\in\mathscr{V}(\textbf{Com})$
by the
 $\mathscr{r}$
-half-edge (a,l).
$\mathscr{r}$
-half-edge (a,l).
Next, we introduce the random matching of membership tokens and community role tokens. To ensure that the half-edges can indeed be matched, we assume and define
 \begin{equation} \mathscr{h}_n \,{:}\,{\raise-1.5pt{=}}\, \sum_{v\in\mathscr{V}^{\mathscr{l}}} d_v^{\mathscr{l}} = \sum_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}}. \end{equation}
\begin{equation} \mathscr{h}_n \,{:}\,{\raise-1.5pt{=}}\, \sum_{v\in\mathscr{V}^{\mathscr{l}}} d_v^{\mathscr{l}} = \sum_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}}. \end{equation}
Let
 $\Omega_n$
denote the set of all possible bijections between the
$\Omega_n$
denote the set of all possible bijections between the
 $\mathscr{l}$
-half-edges
$\mathscr{l}$
-half-edges
 \begin{equation*}(v,i)_{i
< d_v^{\mathscr{l}}, v\in\mathscr{V}^{\mathscr{l}}}\end{equation*}
\begin{equation*}(v,i)_{i
< d_v^{\mathscr{l}}, v\in\mathscr{V}^{\mathscr{l}}}\end{equation*}
and the
 $\mathscr{r}$
-half-edges
$\mathscr{r}$
-half-edges
 \begin{equation*}(a,l)_{l \leq d_a^{\mathscr{r}},a\in\mathscr{V}^{\mathscr{r}}}.\end{equation*}
\begin{equation*}(a,l)_{l \leq d_a^{\mathscr{r}},a\in\mathscr{V}^{\mathscr{r}}}.\end{equation*}
Equivalently, we can think of
 $\Omega_n$
as bijections between the
$\Omega_n$
as bijections between the
 $\mathscr{l}$
-half-edges and
$\mathscr{l}$
-half-edges and
 $\mathscr{V}(\textbf{Com})$
, since each
$\mathscr{V}(\textbf{Com})$
, since each
 $\mathscr{r}$
-half-edge (a,l),
$\mathscr{r}$
-half-edge (a,l),
 $l \leq d_a^{\mathscr{r}}, a\in\mathscr{V}^{\mathscr{r}}$
corresponds to a unique community vertex
$l \leq d_a^{\mathscr{r}}, a\in\mathscr{V}^{\mathscr{r}}$
corresponds to a unique community vertex
 $j\in\mathscr{V}(\textbf{Com})$
. Let the community memberships be determined by a uniform random bipartite matching (bipartite configuration)
$j\in\mathscr{V}(\textbf{Com})$
. Let the community memberships be determined by a uniform random bipartite matching (bipartite configuration)
 $\omega_n \sim \textrm{Unif}[\Omega_n]$
. In fact, we can produce the uniform bipartite matching
$\omega_n \sim \textrm{Unif}[\Omega_n]$
. In fact, we can produce the uniform bipartite matching
 $\omega_n$
sequentially, as follows. In each step, we pick an arbitrary unpaired half-edge, and match it to a uniform unpaired half-edge of the opposite type (so that we always match one
$\omega_n$
sequentially, as follows. In each step, we pick an arbitrary unpaired half-edge, and match it to a uniform unpaired half-edge of the opposite type (so that we always match one
 $\mathscr{l}$
-half-edge and one
$\mathscr{l}$
-half-edge and one
 $\mathscr{r}$
-half-edge). The arbitrary choices may even depend on the past of the pairing process, as long as we pair them u.a.r. with one of the remaining half-edges.
$\mathscr{r}$
-half-edge). The arbitrary choices may even depend on the past of the pairing process, as long as we pair them u.a.r. with one of the remaining half-edges.
Definition 2.1
(The ‘underlying BCM’) Considering the half-edges as tokens to form edges, the bipartite matching
 $\omega_n$
also determines a bipartite (multi)graph, defined as follows. For each matched pair of an
$\omega_n$
also determines a bipartite (multi)graph, defined as follows. For each matched pair of an
 $\mathscr{l}$
-half-edge (v,i) and
$\mathscr{l}$
-half-edge (v,i) and
 $\mathscr{r}$
-half-edge (a,l), add an edge with label (i,l) between v and a. We call this edge-labeled graph the underlying bipartite configuration model (BCM). As the edge labels allow us to reconstruct the paired half-edges, the underlying BCM is an equivalent representation of the bipartite matching
$\mathscr{r}$
-half-edge (a,l), add an edge with label (i,l) between v and a. We call this edge-labeled graph the underlying bipartite configuration model (BCM). As the edge labels allow us to reconstruct the paired half-edges, the underlying BCM is an equivalent representation of the bipartite matching
 $\omega_n$
, and thus encodes the community memberships.
$\omega_n$
, and thus encodes the community memberships.
Deleting the edge-labels, we obtain a bipartite version of the configuration model, i.e., the bipartite configuration model with degree sequences
 $(\textbf{d}^{\mathscr{l}},\textbf{d}^{\mathscr{r}})$
.
$(\textbf{d}^{\mathscr{l}},\textbf{d}^{\mathscr{r}})$
.
The ‘community projection’. We now introduce the community projection, i.e., the method of projecting the community graphs to the individuals and generating the RIGC model, given the realization of the uniform(ly random) bipartite matching
 $\omega_n$
. This procedure is deterministic, and the only randomness of the model comes from the choice of
$\omega_n$
. This procedure is deterministic, and the only randomness of the model comes from the choice of
 $\omega_n$
; thus we can think of the community projection as an operator
$\omega_n$
; thus we can think of the community projection as an operator
 $\mathscr{P}$
from
$\mathscr{P}$
from
 $\Omega_n$
to the space of multigraphs. Alternatively, since the underlying BCM (see Definition 2.1) provides an equivalent representation of the bipartite matching
$\Omega_n$
to the space of multigraphs. Alternatively, since the underlying BCM (see Definition 2.1) provides an equivalent representation of the bipartite matching
 $\omega_n$
, we can think of the projection as an operator that maps the underlying BCM into the RIGC. This operator can be further generalized as an operator mapping any bipartite graph, which we may interpret as the graph of community memberships, into a network. We will describe the multigraph RIGC by its edge multiplicities.
$\omega_n$
, we can think of the projection as an operator that maps the underlying BCM into the RIGC. This operator can be further generalized as an operator mapping any bipartite graph, which we may interpret as the graph of community memberships, into a network. We will describe the multigraph RIGC by its edge multiplicities.
Recall that the
 $\mathscr{r}$
-half-edge labeled (a,l) represents the community role (community vertex)
$\mathscr{r}$
-half-edge labeled (a,l) represents the community role (community vertex)
 $j\in\mathscr{V}(\textrm{Com}_a)$
with vertex label l, and the
$j\in\mathscr{V}(\textrm{Com}_a)$
with vertex label l, and the
 $\mathscr{l}$
-half-edge (v,i) is one of the membership tokens of
$\mathscr{l}$
-half-edge (v,i) is one of the membership tokens of
 $v\in\mathscr{V}^{\mathscr{l}}$
. Then, if (v,i) and (a,l) are matched by
$v\in\mathscr{V}^{\mathscr{l}}$
. Then, if (v,i) and (a,l) are matched by
 $\omega_n$
, this intuitively means one of the community roles taken by v is j. We denote this by
$\omega_n$
, this intuitively means one of the community roles taken by v is j. We denote this by
![]() .
.
Note that each community role j is assigned to a unique individual v; however, each individual v has
 $d_v^{\mathscr{l}}$
community roles j assigned to it. We want to ‘identify’ each individual with all community roles taken, and we carry this out by copying each edge between community roles
$d_v^{\mathscr{l}}$
community roles j assigned to it. We want to ‘identify’ each individual with all community roles taken, and we carry this out by copying each edge between community roles
 $j_1, j_2 \in \mathscr{V}(\textrm{Com}_a)$
(for each community a) to the individuals
$j_1, j_2 \in \mathscr{V}(\textrm{Com}_a)$
(for each community a) to the individuals
![]()
and
![]() .
.
We emphasize that each community edge is copied individually, even when
 $v=w$
or when there is already an edge (or more) between v and w; that is, we allow self-loops and multi-edges (see Section 2.4 for a discussion on multigraphs).
$v=w$
or when there is already an edge (or more) between v and w; that is, we allow self-loops and multi-edges (see Section 2.4 for a discussion on multigraphs).
Let us denote the disjoint union of the edges in all community graphs by
 $\mathscr{E}(\textbf{Com})$
; we refer to this as the set of community edges. Now, we shift perspective to obtain the multiplicity
$\mathscr{E}(\textbf{Com})$
; we refer to this as the set of community edges. Now, we shift perspective to obtain the multiplicity
 $X(v,w;\omega_n)$
of an edge (v,w) (for
$X(v,w;\omega_n)$
of an edge (v,w) (for
 $v,w\in\mathscr{V}^{\mathscr{l}}$
) for a given bipartite matching
$v,w\in\mathscr{V}^{\mathscr{l}}$
) for a given bipartite matching
 $\omega_n$
. We can do so by counting the number of community edges
$\omega_n$
. We can do so by counting the number of community edges
 $(j_1,j_2)$
such that the community roles
$(j_1,j_2)$
such that the community roles
 $j_1$
and
$j_1$
and
 $j_2$
are taken by v and w (in some order); formally,
$j_2$
are taken by v and w (in some order); formally,
The random intersection graph with communities
 $\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
is the random multigraph given by the edge multiplicities
$\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
is the random multigraph given by the edge multiplicities
 $(X(v,w))_{v,w\in\mathscr{V}^{\mathscr{l}}}$
determined by the uniform(ly random) bipartite matching
$(X(v,w))_{v,w\in\mathscr{V}^{\mathscr{l}}}$
determined by the uniform(ly random) bipartite matching
 $\omega_n$
.
$\omega_n$
.
2.2. Notation and assumptions
In this section, we introduce the quantities and assumptions that are crucial throughout the paper.
Bipartite degrees. Throughout this paper, we make use of the following description of the
 $\mathscr{b}$
-degree sequences. Let
$\mathscr{b}$
-degree sequences. Let
 $V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
and
$V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
and
 $V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
denote uniformly chosen
$V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
denote uniformly chosen
 $\mathscr{l}$
- and
$\mathscr{l}$
- and
 $\mathscr{r}$
-vertices respectively, and denote their random degrees by
$\mathscr{r}$
-vertices respectively, and denote their random degrees by
 \begin{equation} D_n^{\mathscr{l}} \,{:}\,{\raise-1.5pt{=}}\, d_{V_n^{\mathscr{l}}}^{\mathscr{l}},\qquad D_n^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\, d_{V_n^{\mathscr{r}}}^{\mathscr{r}}. \end{equation}
\begin{equation} D_n^{\mathscr{l}} \,{:}\,{\raise-1.5pt{=}}\, d_{V_n^{\mathscr{l}}}^{\mathscr{l}},\qquad D_n^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\, d_{V_n^{\mathscr{r}}}^{\mathscr{r}}. \end{equation}
Then the PMF
 \begin{equation} {p^{(n)}_k} \,{:}\,{\raise-1.5pt{=}}\, \lvert{\{v\in\mathscr{V}^{\mathscr{l}}\,:\, d^{\mathscr{l}}_v = k\}}\rvert/N_n, \end{equation}
\begin{equation} {p^{(n)}_k} \,{:}\,{\raise-1.5pt{=}}\, \lvert{\{v\in\mathscr{V}^{\mathscr{l}}\,:\, d^{\mathscr{l}}_v = k\}}\rvert/N_n, \end{equation}
for
 $k\in\mathbb{Z}^+$
, describes the distribution of
$k\in\mathbb{Z}^+$
, describes the distribution of
 $D_n^{\mathscr{l}}$
as well as the empirical distribution of
$D_n^{\mathscr{l}}$
as well as the empirical distribution of
 $\textbf{d}^{\mathscr{l}}$
. Similarly, we can describe
$\textbf{d}^{\mathscr{l}}$
. Similarly, we can describe
 $D_n^{\mathscr{r}}$
and
$D_n^{\mathscr{r}}$
and
 $\textbf{d}^{\mathscr{r}}$
by the PMF
$\textbf{d}^{\mathscr{r}}$
by the PMF
 \begin{equation} {q^{(n)}_k} \,{:}\,{\raise-1.5pt{=}}\, \lvert{\{a\in\mathscr{V}^{\mathscr{r}}\,:\, d_a^{\mathscr{r}} = k\}}\rvert/M_n. \end{equation}
\begin{equation} {q^{(n)}_k} \,{:}\,{\raise-1.5pt{=}}\, \lvert{\{a\in\mathscr{V}^{\mathscr{r}}\,:\, d_a^{\mathscr{r}} = k\}}\rvert/M_n. \end{equation}
We collect the PMFs in the (infinite-dimensional) probability vectors
 ${\textbf{p}}^{(n)} = ({p^{(n)}_k})_{k\in\mathbb{Z}^+}$
,
${\textbf{p}}^{(n)} = ({p^{(n)}_k})_{k\in\mathbb{Z}^+}$
,
 ${\textbf{q}}^{(n)} = ({q^{(n)}_k})_{k\in\mathbb{Z}^+}$
.
${\textbf{q}}^{(n)} = ({q^{(n)}_k})_{k\in\mathbb{Z}^+}$
.
The empirical community distribution. Recall that
 $\mathscr{H}$
denotes the set of possible community graphs: simple, connected, finite graphs, each
$\mathscr{H}$
denotes the set of possible community graphs: simple, connected, finite graphs, each
 $H\in\mathscr{H}$
equipped with an arbitrary, fixed labeling using
$H\in\mathscr{H}$
equipped with an arbitrary, fixed labeling using
 $[\lvert{H}\rvert]$
as labels, so that any two community graphs that are isomorphic are labeled in exactly the same way. For a fixed
$[\lvert{H}\rvert]$
as labels, so that any two community graphs that are isomorphic are labeled in exactly the same way. For a fixed
 $H\in\mathscr{H}$
, define
$H\in\mathscr{H}$
, define
 \begin{equation} \mathscr{V}_H^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\,\{a\in\mathscr{V}^{\mathscr{r}}\,:\, \textrm{Com}_a=H\}. \end{equation}
\begin{equation} \mathscr{V}_H^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\,\{a\in\mathscr{V}^{\mathscr{r}}\,:\, \textrm{Com}_a=H\}. \end{equation}
We introduce the PMF
 \begin{equation} {\mu^{(n)}_H} \,{:}\,{\raise-1.5pt{=}}\, M_n^{-1} \lvert{\mathscr{V}_H^{\mathscr{r}}}\rvert, \qquad {\boldsymbol{\mu}}^{(n)} = ({\mu^{(n)}_H})_{H\in\mathscr{H}}, \end{equation}
\begin{equation} {\mu^{(n)}_H} \,{:}\,{\raise-1.5pt{=}}\, M_n^{-1} \lvert{\mathscr{V}_H^{\mathscr{r}}}\rvert, \qquad {\boldsymbol{\mu}}^{(n)} = ({\mu^{(n)}_H})_{H\in\mathscr{H}}, \end{equation}
so that
 ${\boldsymbol{\mu}}^{(n)}$
describes the empirical PMF of
${\boldsymbol{\mu}}^{(n)}$
describes the empirical PMF of
 $\textbf{Com}$
as well as the PMF of
$\textbf{Com}$
as well as the PMF of
 $\textrm{Com}_{V_n^{\mathscr{r}}}$
, with
$\textrm{Com}_{V_n^{\mathscr{r}}}$
, with
 $V_n^{\mathscr{r}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
. For
$V_n^{\mathscr{r}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
. For
 $k\in\mathbb{Z}^+$
, define the (finite) set
$k\in\mathbb{Z}^+$
, define the (finite) set
 \begin{equation} \mathscr{H}_k \,{:}\,{\raise-1.5pt{=}}\, \bigl\{ H\in\mathscr{H}\,:\, \lvert{H}\rvert=k \bigr\}. \end{equation}
\begin{equation} \mathscr{H}_k \,{:}\,{\raise-1.5pt{=}}\, \bigl\{ H\in\mathscr{H}\,:\, \lvert{H}\rvert=k \bigr\}. \end{equation}
Note that since
 $d_a^{\mathscr{r}} = \lvert{\textrm{Com}_a}\rvert$
,
$d_a^{\mathscr{r}} = \lvert{\textrm{Com}_a}\rvert$
,
 ${\textbf{q}}^{(n)}$
from (2.4b) can be obtained by
${\textbf{q}}^{(n)}$
from (2.4b) can be obtained by
 \begin{equation*}{q^{(n)}_k} = \sum_{H\in\mathscr{H}_k} {\mu^{(n)}_H.}\end{equation*}
\begin{equation*}{q^{(n)}_k} = \sum_{H\in\mathscr{H}_k} {\mu^{(n)}_H.}\end{equation*}
Community degrees and triangles. Let us denote the disjoint union of the vertices in all community graphs by
 $\mathscr{V}(\textbf{Com})$
; we refer to this as the set of community roles. To a community role
$\mathscr{V}(\textbf{Com})$
; we refer to this as the set of community roles. To a community role
 $j\in\mathscr{V}(\textbf{Com})$
we assign the vector
$j\in\mathscr{V}(\textbf{Com})$
we assign the vector
 $(d_j^{\mathscr{c}},\Delta_{{j}}^{\mathscr{c}})$
, where
$(d_j^{\mathscr{c}},\Delta_{{j}}^{\mathscr{c}})$
, where
 $d_j^{\mathscr{c}}$
denotes the degree of j in its community graph and
$d_j^{\mathscr{c}}$
denotes the degree of j in its community graph and
 $\Delta_{{j}}^{\mathscr{c}}$
denotes the number of triangles that j is part of within its community graph. Let
$\Delta_{{j}}^{\mathscr{c}}$
denotes the number of triangles that j is part of within its community graph. Let
 $J_n \sim \textrm{Unif}[\mathscr{V}(\textbf{Com})]$
denote a community role chosen u.a.r. Note that the community that
$J_n \sim \textrm{Unif}[\mathscr{V}(\textbf{Com})]$
denote a community role chosen u.a.r. Note that the community that
 $J_n$
is part of is chosen in a size-biased fashion, and then a vertex in that community is chosen uniformly at random. Define the random vector
$J_n$
is part of is chosen in a size-biased fashion, and then a vertex in that community is chosen uniformly at random. Define the random vector
 $(D_n^{\mathscr{c}},\Lambda_{{n}}^{\mathscr{c}}) \,{:}\,{\raise-1.5pt{=}}\, (d_{J_n}^{\mathscr{c}},\Delta_{J_n}^{\mathscr{c}})$
, keeping in mind that its coordinates are dependent. Define the PMF
$(D_n^{\mathscr{c}},\Lambda_{{n}}^{\mathscr{c}}) \,{:}\,{\raise-1.5pt{=}}\, (d_{J_n}^{\mathscr{c}},\Delta_{J_n}^{\mathscr{c}})$
, keeping in mind that its coordinates are dependent. Define the PMF
 \begin{equation} {\varrho^{(n)}_{(k,t)}} \,{:}\,{\raise-1.5pt{=}}\, \frac1{\mathscr{h}_n} \sum_{j\in\mathscr{V}(\textbf{Com})} \mathbb{1}_{ \{ (d_{j}^{\mathscr{c}},\Delta_{{j}}^{\mathscr{c}}) = (k,t) \} },\qquad {{\boldsymbol{\varrho}}}^{(n)} \,{:}\,{\raise-1.5pt{=}}\, \bigl( {\varrho^{(n)}_{(k,t)}} \bigr)_{k\in\mathbb{Z}^+,0\leq t\leq \binom{k}{2}}, \end{equation}
\begin{equation} {\varrho^{(n)}_{(k,t)}} \,{:}\,{\raise-1.5pt{=}}\, \frac1{\mathscr{h}_n} \sum_{j\in\mathscr{V}(\textbf{Com})} \mathbb{1}_{ \{ (d_{j}^{\mathscr{c}},\Delta_{{j}}^{\mathscr{c}}) = (k,t) \} },\qquad {{\boldsymbol{\varrho}}}^{(n)} \,{:}\,{\raise-1.5pt{=}}\, \bigl( {\varrho^{(n)}_{(k,t)}} \bigr)_{k\in\mathbb{Z}^+,0\leq t\leq \binom{k}{2}}, \end{equation}
so that
 ${{\boldsymbol{\varrho}}}^{(n)}$
describes the joint distribution of
${{\boldsymbol{\varrho}}}^{(n)}$
describes the joint distribution of
 $(D_n^{\mathscr{c}},\Lambda_{{n}}^{\mathscr{c}})$
as well as the empirical distribution of
$(D_n^{\mathscr{c}},\Lambda_{{n}}^{\mathscr{c}})$
as well as the empirical distribution of
 $(d_{j}^{\mathscr{c}}, \Delta_{{j}}^{\mathscr{c}})_{j\in\mathscr{V}(\textbf{Com})}$
.
$(d_{j}^{\mathscr{c}}, \Delta_{{j}}^{\mathscr{c}})_{j\in\mathscr{V}(\textbf{Com})}$
.
Projected degrees. For
 $v\in\mathscr{V}^{\mathscr{l}}$
, its (random) projected degree, i.e. its degree in the RIGC, is by definition given in terms of the edge multiplicities (see (2.2)) as
$v\in\mathscr{V}^{\mathscr{l}}$
, its (random) projected degree, i.e. its degree in the RIGC, is by definition given in terms of the edge multiplicities (see (2.2)) as
 \begin{equation} d_v^{\mathscr{p}} = \mathscr{p}\text{-}\textrm{deg}(v) \,{:}\,{\raise-1.5pt{=}}\, X(v,v) + \sum_{w\in\mathscr{V}^{\mathscr{l}}} X(v,w) = 2 X(v,v) + \sum_{w\in\mathscr{V}^{\mathscr{l}},w\neq v} X(v,w). \end{equation}
\begin{equation} d_v^{\mathscr{p}} = \mathscr{p}\text{-}\textrm{deg}(v) \,{:}\,{\raise-1.5pt{=}}\, X(v,v) + \sum_{w\in\mathscr{V}^{\mathscr{l}}} X(v,w) = 2 X(v,v) + \sum_{w\in\mathscr{V}^{\mathscr{l}},w\neq v} X(v,w). \end{equation}
However, it is more intuitive to look at
 $\mathscr{p}\text{-}\textrm{deg}(v)$
in terms of the community roles taken by v. Recall that each community edge incident to some j such that
$\mathscr{p}\text{-}\textrm{deg}(v)$
in terms of the community roles taken by v. Recall that each community edge incident to some j such that
![]()
is added between v and some other vertex; thus j contributes
 $\mathscr{c}\text{-}\textrm{deg}(j)$
to the degree of v. Then
$\mathscr{c}\text{-}\textrm{deg}(j)$
to the degree of v. Then
Analogously to
 $D_n^{\mathscr{l}}$
, with
$D_n^{\mathscr{l}}$
, with
 $V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
as before, we define
$V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
as before, we define
 \begin{equation} D_n^{\mathscr{p}} \,{:}\,{\raise-1.5pt{=}}\, \mathscr{p}\text{-}\textrm{deg}(V_n^{\mathscr{l}}). \end{equation}
\begin{equation} D_n^{\mathscr{p}} \,{:}\,{\raise-1.5pt{=}}\, \mathscr{p}\text{-}\textrm{deg}(V_n^{\mathscr{l}}). \end{equation}
Recall that
 $\mathscr{p}\text{-}\textrm{deg}(v)$
is random for each
$\mathscr{p}\text{-}\textrm{deg}(v)$
is random for each
 $v\in\mathscr{V}^{\mathscr{l}}$
, since
$v\in\mathscr{V}^{\mathscr{l}}$
, since
 $\omega_n$
is random. Thus,
$\omega_n$
is random. Thus,
 $D_n^{\mathscr{p}}$
has two sources of randomness:
$D_n^{\mathscr{p}}$
has two sources of randomness:
 $V_n^{\mathscr{l}}$
and
$V_n^{\mathscr{l}}$
and
 $\omega_n$
. We denote the random empirical cumulative distribution function (CDF) of
$\omega_n$
. We denote the random empirical cumulative distribution function (CDF) of
 $D_n^{\mathscr{p}}$
by
$D_n^{\mathscr{p}}$
by
 \begin{equation} F_n^{\mathscr{p}}(x) = F_n^{\mathscr{p}}(x;\omega_n) \,{:}\,{\raise-1.5pt{=}}\, \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \mathbb{1}_{ \{ \mathscr{p}\text{-}\textrm{deg}(v) \leq x \} }\,=\!:\, \mathbb{P}\bigl( D_n^{\mathscr{p}} \leq x \;\big\vert\; \omega_n \bigr), \end{equation}
\begin{equation} F_n^{\mathscr{p}}(x) = F_n^{\mathscr{p}}(x;\omega_n) \,{:}\,{\raise-1.5pt{=}}\, \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \mathbb{1}_{ \{ \mathscr{p}\text{-}\textrm{deg}(v) \leq x \} }\,=\!:\, \mathbb{P}\bigl( D_n^{\mathscr{p}} \leq x \;\big\vert\; \omega_n \bigr), \end{equation}
where
 $\mathbb{P}(\;\cdot \mid \omega_n)$
denotes the conditional probability with respect to
$\mathbb{P}(\;\cdot \mid \omega_n)$
denotes the conditional probability with respect to
 $\omega_n$
.
$\omega_n$
.
Assumptions. Recall (2.3), (2.4), and (2.6). We can now summarize our assumptions on the model parameters, in particular, the conditions under which our results hold.
Assumption 2.2 The conditions for the empirical distributions are summarized as follows:
-
(A) There exists a random variable
 $D^{\mathscr{l}}$
with PMF
$\textbf{p}$
such that
${\textbf{p} \to \textbf{p}}^{(n)}$
pointwise as
$n\to\infty$
, i.e.,
(2.13)
\begin{equation} D_n^{\mathscr{l}} \buildrel d\over{\longrightarrow} D^{\mathscr{l}}. \end{equation}
$D^{\mathscr{l}}$
with PMF
$\textbf{p}$
such that
${\textbf{p} \to \textbf{p}}^{(n)}$
pointwise as
$n\to\infty$
, i.e.,
(2.13)
\begin{equation} D_n^{\mathscr{l}} \buildrel d\over{\longrightarrow} D^{\mathscr{l}}. \end{equation}
-
(B)
$\mathbb{E}[D^{\mathscr{l}}]$
is finite, and as
$n\to\infty$
,
(2.14)
\begin{equation} \mathbb{E}[D_n^{\mathscr{l}}] \to \mathbb{E}[D^{\mathscr{l}}]. \end{equation}
-
(C) There exists a PMF
$\boldsymbol{\mu}$
on
$\mathscr{H}$
such that
${{\boldsymbol{\mu}}}^{(n)}\to\boldsymbol{\mu}$
pointwise as
$n\to\infty$
. (1) Consequently, since
${q^{(n)}_k} =\sum_{H\in\mathscr{H}_k} {\mu^{(n)}_H}$
, with the finite set
$\mathscr{H}_k$
from (2.7), there exists a random variable
$D^{\mathscr{r}}$
with PMF
$\textbf{q}$
such that
${\textbf{q}}^{(n)}\to\textbf{q}$
pointwise as
$n\to\infty$
, or equivalently,
(2.15)
\begin{equation} D_n^{\mathscr{r}}\buildrel d\over{\longrightarrow} D^{\mathscr{r}}. \end{equation}
-
(D)
$\mathbb{E}[D^{\mathscr{r}}]$
is finite, and as
$n\to\infty$
,
(2.16)
\begin{equation} \mathbb{E}[D_n^{\mathscr{r}}] \to \mathbb{E}[D^{\mathscr{r}}]. \end{equation}






















Remark 2.3 (Consequences of Assumption 2.2) We note the following:
-
(i) By its definition in (2.1),
$\mathscr{h}_n = N_n \mathbb{E}[D_n^{\mathscr{l}}] = M_n \mathbb{E}[D_n^{\mathscr{r}}]$
. By Assumption 2.2(B,D),
(2.17)
\begin{equation} M_n / N_n = \mathbb{E}[D_n^{\mathscr{l}}] / \mathbb{E}[D_n^{\mathscr{r}}] \to \mathbb{E}[D^{\mathscr{l}}] / \mathbb{E}[D^{\mathscr{r}}] \,=\!:\, \gamma \in \mathbb{R}^+. \end{equation}
-
(ii) Since
${{\boldsymbol{\varrho}}}^{(n)}$
(see (2.8)) can be obtained from
${{\boldsymbol{\mu}}}^{(n)}$
, Assumption 2.2(C) also implies that there exists a random variable
$(D^{\mathscr{c}}, \Lambda^{\mathscr{c}})$
with PMF
$\boldsymbol{\varrho}$
such that
${{\boldsymbol{\varrho}}}^{(n)}\to\boldsymbol{\varrho}$
pointwise as
$n\to\infty$
, or equivalently,
$(D_n^{\mathscr{c}},\Lambda_n^{\mathscr{c}}) \buildrel d\over{\longrightarrow} (D^{\mathscr{c}},\Lambda^{\mathscr{c}})$
. -
(iii) Assumption 2.2(A,B) imply that
$d_{\textrm{max}}^{\mathscr{l}} \,{:}\,{\raise-1.5pt{=}}\, \max_{v\in\mathscr{V}^{\mathscr{l}}} d_v^{\mathscr{l}} = o(\mathscr{h}_n)$
. This implication is proved for a similar setting in [Reference Van der Hofstad29, Exercise 6.3]. Similarly, the conditions (C1,D) imply that
$d_{\textrm{max}}^{\mathscr{r}} \,{:}\,{\raise-1.5pt{=}}\, \max_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}} = o(\mathscr{h}_n)$
.











Remark 2.4 (Random parameters) The results in Section 2.3 below remain valid when the sequence of parameters
 $(\textbf{d}^{\mathscr{l}},\textbf{Com})$
(resp.,
$(\textbf{d}^{\mathscr{l}},\textbf{Com})$
(resp.,
 $(\textbf{d}^{\mathscr{l}},\textbf{d}^{\mathscr{r}})$
) is itself random. In this case, we require that
$(\textbf{d}^{\mathscr{l}},\textbf{d}^{\mathscr{r}})$
) is itself random. In this case, we require that
 $N_n\to\infty$
and
$N_n\to\infty$
and
 $M_n\to\infty$
almost surely, and we replace Assumption 2.2(A–D) (resp., Assumption 2.2(A,B,C1,D)) by the conditions
$M_n\to\infty$
almost surely, and we replace Assumption 2.2(A–D) (resp., Assumption 2.2(A,B,C1,D)) by the conditions
 ${\textbf{p}}^{(n)}\buildrel {\mathbb{P}}\over{\longrightarrow}\textbf{p}$
pointwise,
${\textbf{p}}^{(n)}\buildrel {\mathbb{P}}\over{\longrightarrow}\textbf{p}$
pointwise,
 $\mathbb{E}[D_n^{\mathscr{l}} \mid \textbf{d}^{\mathscr{l}}] \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}[D^{\mathscr{l}}]$
,
$\mathbb{E}[D_n^{\mathscr{l}} \mid \textbf{d}^{\mathscr{l}}] \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}[D^{\mathscr{l}}]$
,
 ${{\boldsymbol{\mu}}}^{(n)}\buildrel {\mathbb{P}}\over{\longrightarrow}\boldsymbol{\mu}$
pointwise (resp.,
${{\boldsymbol{\mu}}}^{(n)}\buildrel {\mathbb{P}}\over{\longrightarrow}\boldsymbol{\mu}$
pointwise (resp.,
 ${\textbf{q}}^{(n)}\buildrel {\mathbb{P}}\over{\longrightarrow}\textbf{q}$
), and
${\textbf{q}}^{(n)}\buildrel {\mathbb{P}}\over{\longrightarrow}\textbf{q}$
), and
 $\mathbb{E}[D_n^{\mathscr{r}} \mid \textbf{d}^{\mathscr{r}}] \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}[D^{\mathscr{r}}]$
, where we assume the limiting PMFs
$\mathbb{E}[D_n^{\mathscr{r}} \mid \textbf{d}^{\mathscr{r}}] \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}[D^{\mathscr{r}}]$
, where we assume the limiting PMFs
 $\textbf{p}$
and
$\textbf{p}$
and
 $\boldsymbol{\mu}$
(resp.,
$\boldsymbol{\mu}$
(resp.,
 $\textbf{q}$
) to be deterministic. For a similar setting in the configuration model, see [Reference Van der Hofstad29, Remark 7.9 on ‘regularity of random degrees’], where this is spelled out in more detail.
$\textbf{q}$
) to be deterministic. For a similar setting in the configuration model, see [Reference Van der Hofstad29, Remark 7.9 on ‘regularity of random degrees’], where this is spelled out in more detail.
Note that analogously to Remark 2.3(i), under the conditions of Remark 2.4,
 $M_n/N_n \buildrel {\mathbb{P}}\over{\longrightarrow} \gamma$
.
$M_n/N_n \buildrel {\mathbb{P}}\over{\longrightarrow} \gamma$
.
2.3. Results
In this section, we state our results on local properties of the RIGC. The main result is the local weak convergence (LWC) of the RIGC (defined shortly), which is equivalent to the convergence of subgraph counts (neighborhood counts). LWC also implies the convergence of degrees and local clustering, and provides some insight into the overlapping structure of communities. We use the following notions throughout this section. Recall that
 $V_n^{\mathscr{l}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
denotes an
$V_n^{\mathscr{l}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
denotes an
 $\mathscr{l}$
-vertex chosen u.a.r., and
$\mathscr{l}$
-vertex chosen u.a.r., and
 $\mathbb{P}(\;\cdot \mid \omega_n)$
denotes conditional probability with respect to
$\mathbb{P}(\;\cdot \mid \omega_n)$
denotes conditional probability with respect to
 $\omega_n$
. Let
$\omega_n$
. Let
 $\mathbb{E}_{V_n^{\mathscr{l}}}[\;\cdot \mid \omega_n]$
denote the corresponding conditional expectation, that is, empirical averages for a given
$\mathbb{E}_{V_n^{\mathscr{l}}}[\;\cdot \mid \omega_n]$
denote the corresponding conditional expectation, that is, empirical averages for a given
 $\omega_n$
.
$\omega_n$
.
Local weak convergence. First, we give a brief definition of LWC to state our results. We give a much more detailed introduction to the concept in Section 3.1.
Definition 2.5 (Rooted (multi)graph, rooted isomorphism, and neighborhood)
-
(i) We call a pair (G,o) a rooted (multi)graph if G is a locally finite, connected (multi)graph and o is a distinguished vertex of G.
-
(ii) We say that two multigraphs
$G_1$
and
$G_2$
are isomorphic if there exists a bijection
$\varphi\,:\, \mathscr{V}(G_1) \to \mathscr{V}(G_2)$
such that for any
$v,w\in\mathscr{V}(G_1)$
, the number of edges between v,w in
$G_1$
equals the number of edges between
$\varphi(v),\varphi(w)$
in
$G_2$
. -
(iii) We say that the rooted (multi)graphs
$(G_1,o_1) \simeq (G_2,o_2)$
, are rooted isomorphic if there exists a graph-isomorphism between
$G_1$
and
$G_2$
that maps
$o_1$
to
$o_2$
. -
(iv) For some
$r\in\mathbb{N}$
, we define
$B_r(G,o)$
, the (closed) r-ball around o in G or r-neighborhood of o in G, as the subgraph of G spanned by all vertices of graph distance at most r from o. We think of
$B_r(G,o)$
as a rooted (multi)graph with root o.















Definition 2.6. (Local weak convergence in probability) Let
 $(G_n)_{n\in\mathbb{N}}$
with size
$(G_n)_{n\in\mathbb{N}}$
with size
 $\lvert{G_n}\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} \infty$
be a sequence of random (multi)graphs, and let
$\lvert{G_n}\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} \infty$
be a sequence of random (multi)graphs, and let
 $U_n \mid G_n \sim\textrm{Unif}[\mathscr{V}(G_n)]$
. By
$U_n \mid G_n \sim\textrm{Unif}[\mathscr{V}(G_n)]$
. By
 $\lvert{G_n}\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} \infty$
, we mean that for all
$\lvert{G_n}\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} \infty$
, we mean that for all
 $K\in\mathbb{R}^+$
,
$K\in\mathbb{R}^+$
,
 $\mathbb{P}(\lvert{G_n}\rvert \geq K) \to 1$
as
$\mathbb{P}(\lvert{G_n}\rvert \geq K) \to 1$
as
 $n\to\infty$
. Let
$n\to\infty$
. Let
 $(\mathcal{R},o)$
denote a random element of the set of rooted (multi)graphs, which we call a random rooted (multi)graph. We say that
$(\mathcal{R},o)$
denote a random element of the set of rooted (multi)graphs, which we call a random rooted (multi)graph. We say that
 $(G_n,U_n)$
converges to
$(G_n,U_n)$
converges to
 $(\mathcal{R},o)$
in probability in the LWC sense, and write
$(\mathcal{R},o)$
in probability in the LWC sense, and write
 $(G_n,U_n) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\mathcal{R},o)$
, if for any fixed rooted (multi)graph (G,o) and
$(G_n,U_n) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\mathcal{R},o)$
, if for any fixed rooted (multi)graph (G,o) and
 $r\in\mathbb{N}$
,
$r\in\mathbb{N}$
,
 \begin{equation} \begin{aligned} \mathbb{P}\bigl( B_r(G_n,U_n) \simeq B_r(G,o) \;\big\vert\; G_n \bigr) &\,{:}\,{\raise-1.5pt{=}}\,\frac{1}{\lvert{G_n}\rvert} \sum_{u\in\mathscr{V}(G_n)} \mathbb{1}_{\{ B_r(G_n,u) \simeq B_r(G,o) \}} \\&\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl( B_r(\mathcal{R},o) \simeq B_r(G,o) \bigr).\end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb{P}\bigl( B_r(G_n,U_n) \simeq B_r(G,o) \;\big\vert\; G_n \bigr) &\,{:}\,{\raise-1.5pt{=}}\,\frac{1}{\lvert{G_n}\rvert} \sum_{u\in\mathscr{V}(G_n)} \mathbb{1}_{\{ B_r(G_n,u) \simeq B_r(G,o) \}} \\&\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl( B_r(\mathcal{R},o) \simeq B_r(G,o) \bigr).\end{aligned} \end{equation}
We also say that
 $(\mathcal{R},o)$
is the local weak limit in probability of
$(\mathcal{R},o)$
is the local weak limit in probability of
 $(G_n,U_n)$
.
$(G_n,U_n)$
.
We can now state our first main result on the LWC of the RIGC model.
Theorem 2.7.
(Local weak convergence of the RIGC) Consider
 $\textrm{RIGC}_n = \textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under Assumption 2.2. Then, with
$\textrm{RIGC}_n = \textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under Assumption 2.2. Then, with
 $V_n^{\mathscr{l}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
, as
$V_n^{\mathscr{l}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} \bigl(\textrm{RIGC}_n,V_n^{\mathscr{l}}\bigr) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{CP},o), \end{equation}
\begin{equation} \bigl(\textrm{RIGC}_n,V_n^{\mathscr{l}}\bigr) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{CP},o), \end{equation}
where
 $(\textrm{CP},o)$
is a random rooted graph with distribution as specified in Section 3.3.
$(\textrm{CP},o)$
is a random rooted graph with distribution as specified in Section 3.3.
The proof of Theorem 2.7 is completed in Section 3.3. The local weak limit generalizes random clique trees, which are shown to be the local weak limit of RIGs (see e.g. [Reference Kurauskas38]). Our construction replaces the cliques by arbitrary connected graphs and is slightly more involved, hence Section 3.3. In the following, we present some corollaries of Theorem 2.7.
Degrees. Recall (2.11) and (2.12). We define the random variable
 $D^{\mathscr{p}}$
and its distribution function
$D^{\mathscr{p}}$
and its distribution function
 \begin{equation} D^{\mathscr{p}} \buildrel d\over{=} \sum_{i=1}^{D^{\mathscr{l}}} D_{(i)}^{\mathscr{c}}, \qquad F^{\mathscr{p}}(x) \,{:}\,{\raise-1.5pt{=}}\, \mathbb{P}\bigl(D^{\mathscr{p}} \leq x\bigr), \end{equation}
\begin{equation} D^{\mathscr{p}} \buildrel d\over{=} \sum_{i=1}^{D^{\mathscr{l}}} D_{(i)}^{\mathscr{c}}, \qquad F^{\mathscr{p}}(x) \,{:}\,{\raise-1.5pt{=}}\, \mathbb{P}\bigl(D^{\mathscr{p}} \leq x\bigr), \end{equation}
with
 $D^{\mathscr{l}}$
from Assumption 2.2(A), and
$D^{\mathscr{l}}$
from Assumption 2.2(A), and
 $D_{(i)}^{\mathscr{c}}$
are i.i.d. copies of
$D_{(i)}^{\mathscr{c}}$
are i.i.d. copies of
 $D^{\mathscr{c}}$
from Remark 2.3(ii).
$D^{\mathscr{c}}$
from Remark 2.3(ii).
Corollary 2.8. (Degrees in the RIGC) Consider
 $\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under the conditions of Theorem 2.7. Then, as
$\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under the conditions of Theorem 2.7. Then, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} \bigl\lVert F_n^{\mathscr{p}} - F^{\mathscr{p}} \bigr\rVert_\infty= \sup_{x\in\mathbb{R}} \, \bigl\lvert F_n^{\mathscr{p}}(x) - F^{\mathscr{p}}(x) \bigr\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} 0, \end{equation}
\begin{equation} \bigl\lVert F_n^{\mathscr{p}} - F^{\mathscr{p}} \bigr\rVert_\infty= \sup_{x\in\mathbb{R}} \, \bigl\lvert F_n^{\mathscr{p}}(x) - F^{\mathscr{p}}(x) \bigr\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} 0, \end{equation}
and consequently,
 \begin{equation} D_n^{\mathscr{p}} \buildrel d\over{\longrightarrow} D^{\mathscr{p}}. \end{equation}
\begin{equation} D_n^{\mathscr{p}} \buildrel d\over{\longrightarrow} D^{\mathscr{p}}. \end{equation}
Corollary 2.8 is almost a direct consequence of Theorem 2.7. Pointwise convergence in probability of the empirical CDF follows directly; however, the convergence of the sup-norm requires a proof that we provide in Section 3.4.1. We remark that Corollary 2.8 can alternatively be proved independently through a first and second moment method under weaker conditions. In particular, Assumption 2.2(C) can be replaced by
 $D_n^{\mathscr{c}}\buildrel d\over{\longrightarrow} D^{\mathscr{c}}$
. Let us also note that while (2.22) is more intuitive, (2.21) is a stronger statement. Indeed, (2.21) implies that the random empirical degree distribution, i.e., the observed degree sequence, is close to its theoretical limit w.h.p.
$D_n^{\mathscr{c}}\buildrel d\over{\longrightarrow} D^{\mathscr{c}}$
. Let us also note that while (2.22) is more intuitive, (2.21) is a stronger statement. Indeed, (2.21) implies that the random empirical degree distribution, i.e., the observed degree sequence, is close to its theoretical limit w.h.p.
Clustering. We proceed by studying the clustering in the RIGC, in particular focusing on local clustering. For an arbitrary individual
 $v\in\mathscr{V}^{\mathscr{l}}$
, let
$v\in\mathscr{V}^{\mathscr{l}}$
, let
 $\Delta^{\mathscr{p}}(v)$
denote the (random) number of triangles that v is part of in the RIGC. Here we also include degenerate triangles, where one or more vertices are the same, and count triangles with multiplicity, i.e., all possible ways we can choose the three edges. We define the local clustering at v as
$\Delta^{\mathscr{p}}(v)$
denote the (random) number of triangles that v is part of in the RIGC. Here we also include degenerate triangles, where one or more vertices are the same, and count triangles with multiplicity, i.e., all possible ways we can choose the three edges. We define the local clustering at v as
 \begin{equation} \textrm{Cl}(v) \,{:}\,{\raise-1.5pt{=}}\, \frac{\Delta^{\mathscr{p}}(v)}{\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}, \end{equation}
\begin{equation} \textrm{Cl}(v) \,{:}\,{\raise-1.5pt{=}}\, \frac{\Delta^{\mathscr{p}}(v)}{\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}, \end{equation}
with the convention that
 $\textrm{Cl}(v) \,{:}\,{\raise-1.5pt{=}}\, 0$
whenever
$\textrm{Cl}(v) \,{:}\,{\raise-1.5pt{=}}\, 0$
whenever
 $\mathscr{p}\text{-}\textrm{deg}(v) < 2$
. Define the empirical local clustering coefficient
$\mathscr{p}\text{-}\textrm{deg}(v) < 2$
. Define the empirical local clustering coefficient
 $\zeta_n \,{:}\,{\raise-1.5pt{=}}\, \textrm{Cl}(V_n^{\mathscr{l}})$
and denote its random empirical CDF by
$\zeta_n \,{:}\,{\raise-1.5pt{=}}\, \textrm{Cl}(V_n^{\mathscr{l}})$
and denote its random empirical CDF by
 \begin{equation} F_n^\zeta(x) = F_n^\zeta(x;\omega_n)\,{:}\,{\raise-1.5pt{=}}\, \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \mathbb{1}_{ \{\textrm{Cl}(v) \leq x \} }= \mathbb{P}\bigl( \zeta_n \leq x \;\big\vert\; \omega_n \bigr). \end{equation}
\begin{equation} F_n^\zeta(x) = F_n^\zeta(x;\omega_n)\,{:}\,{\raise-1.5pt{=}}\, \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \mathbb{1}_{ \{\textrm{Cl}(v) \leq x \} }= \mathbb{P}\bigl( \zeta_n \leq x \;\big\vert\; \omega_n \bigr). \end{equation}
We introduce
 \begin{equation} \zeta \buildrel d\over{=} \biggl( \sum_{i=1}^{D^{\mathscr{l}}} \Lambda_{{(i)}}^{\mathscr{c}} \biggr)\Big/ \binom{\sum_{i=1}^{D^{\mathscr{l}}} D_{(i)}^{\mathscr{c}}}{2},\qquad F^\zeta(x) \,{:}\,{\raise-1.5pt{=}}\, \mathbb{P}(\zeta\leq x), \end{equation}
\begin{equation} \zeta \buildrel d\over{=} \biggl( \sum_{i=1}^{D^{\mathscr{l}}} \Lambda_{{(i)}}^{\mathscr{c}} \biggr)\Big/ \binom{\sum_{i=1}^{D^{\mathscr{l}}} D_{(i)}^{\mathscr{c}}}{2},\qquad F^\zeta(x) \,{:}\,{\raise-1.5pt{=}}\, \mathbb{P}(\zeta\leq x), \end{equation}
where
 $(D_{(i)}^{\mathscr{c}},\Lambda_{{(i)}}^{\mathscr{c}})$
are i.i.d. copies of the random vector
$(D_{(i)}^{\mathscr{c}},\Lambda_{{(i)}}^{\mathscr{c}})$
are i.i.d. copies of the random vector
 $(D^{\mathscr{c}},\Lambda_{}^{\mathscr{c}})$
from Remark 2.3(ii) and are independent of
$(D^{\mathscr{c}},\Lambda_{}^{\mathscr{c}})$
from Remark 2.3(ii) and are independent of
 $D^{\mathscr{l}}$
(see Assumption 2.2(A)).
$D^{\mathscr{l}}$
(see Assumption 2.2(A)).
Corollary 2.9. (Local clustering in the RIGC) Consider
 $\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under the conditions of Theorem 2.7. Then, as
$\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under the conditions of Theorem 2.7. Then, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} \lVert{F_n^\zeta - F^\zeta}\rVert_\infty= \sup_{x\in\mathbb{R}} \;\bigl\lvert F_n^\zeta(x) - F^\zeta(x) \bigr\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} 0. \end{equation}
\begin{equation} \lVert{F_n^\zeta - F^\zeta}\rVert_\infty= \sup_{x\in\mathbb{R}} \;\bigl\lvert F_n^\zeta(x) - F^\zeta(x) \bigr\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} 0. \end{equation}
In particular,
 $\zeta_n \buildrel d\over{\longrightarrow} \zeta$
and thus the average local clustering converges:
$\zeta_n \buildrel d\over{\longrightarrow} \zeta$
and thus the average local clustering converges:
 \begin{equation} \mathbb{E}\bigl[\zeta_n\bigr] \to \mathbb{E}[\zeta]. \end{equation}
\begin{equation} \mathbb{E}\bigl[\zeta_n\bigr] \to \mathbb{E}[\zeta]. \end{equation}
Analogously to Corollary 2.8, Corollary 2.9 is almost a direct consequence of Theorem 2.7. Pointwise convergence in probability of the empirical CDF follows directly; however, the convergence of the sup-norm requires a proof that we provide in Section 3.4.1. We note that in fact Corollary 2.9 still holds if we replace Assumption 2.2(C) by the conditions in Assumption 2.2(C1) and Remark 2.3(ii). The intuition behind Corollary 2.9 is that triangles typically arise within one community; that is, triangles containing edges from different communities make a negligible contribution as the model size grows. This is due to the ‘locally tree-like’ structure of the underlying BCM (see Proposition 3.2 below). We remark that under our general conditions, we cannot establish that the local clustering scales inversely with the degree (as in e.g. [Reference Bloznelis9, Reference Newman39]); however, the inverse degree serves as an upper bound for the clustering. In the following, we establish when the model has positive asymptotic clustering.
Corollary 2.10 (Condition for positive asymptotic clustering) Under the conditions of Corollary 2.9, the asymptotic average clustering
 $\mathbb{E}[\zeta]$
is positive if and only if
$\mathbb{E}[\zeta]$
is positive if and only if
 $\mathbb{P}\bigl(\Lambda_{}^{\mathscr{c}}\geq1\bigr)>0$
, with
$\mathbb{P}\bigl(\Lambda_{}^{\mathscr{c}}\geq1\bigr)>0$
, with
 $\Lambda_{}^{\mathscr{c}}$
from Remark 2.3(ii).
$\Lambda_{}^{\mathscr{c}}$
from Remark 2.3(ii).
Proof of Corollary 2.10. Note that
 $\mathbb{P}\bigl(\Lambda_{}^{\mathscr{c}}\geq1\bigr)>0$
happens exactly when the assigned communities are not
$\mathbb{P}\bigl(\Lambda_{}^{\mathscr{c}}\geq1\bigr)>0$
happens exactly when the assigned communities are not
 $\boldsymbol{\mu}$
-almost surely triangle-free with
$\boldsymbol{\mu}$
-almost surely triangle-free with
 $\boldsymbol{\mu}$
from Assumption 2.2(C); i.e.,
$\boldsymbol{\mu}$
from Assumption 2.2(C); i.e.,
 $\mu_H>0$
for at least one
$\mu_H>0$
for at least one
 $H\in\mathscr{H}$
such that H contains at least one triangle. Clearly, this is a necessary condition, but also sufficient, as it implies that any vertex has a positive probability to be part of a triangle and have bounded degree at the same time.
$H\in\mathscr{H}$
such that H contains at least one triangle. Clearly, this is a necessary condition, but also sufficient, as it implies that any vertex has a positive probability to be part of a triangle and have bounded degree at the same time.
![]()
Another measure of clustering is the so-called global clustering coefficient, defined as three times the total number of triangles in the graph divided by the total number of connected triples (paths of length 2, often called ‘wedges’); formally,
 \begin{equation} \textrm{Cl}_{\textrm{glob}}\,{:}\,{\raise-1.5pt{=}}\, \frac{3 \Delta^{\mathscr{p}}_{\textrm{total}}}{\sum_{v\in\mathscr{V}^{\mathscr{l}}} \binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}= \frac{\sum_{v\in\mathscr{V}^{\mathscr{l}}} \Delta^{\mathscr{p}}(v)}{\sum_{v\in\mathscr{V}^{\mathscr{l}}} \binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}. \end{equation}
\begin{equation} \textrm{Cl}_{\textrm{glob}}\,{:}\,{\raise-1.5pt{=}}\, \frac{3 \Delta^{\mathscr{p}}_{\textrm{total}}}{\sum_{v\in\mathscr{V}^{\mathscr{l}}} \binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}= \frac{\sum_{v\in\mathscr{V}^{\mathscr{l}}} \Delta^{\mathscr{p}}(v)}{\sum_{v\in\mathscr{V}^{\mathscr{l}}} \binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}. \end{equation}
Note the relation with the local clustering coefficient defined in (2.23) as the ratio of
 $\Delta^{\mathscr{p}}(v)$
and
$\Delta^{\mathscr{p}}(v)$
and
 $\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}$
; in (2.28), we instead consider the ratio of the sum of these quantities over all individuals. Also note that we can think of the global clustering coefficient as the ratio of the averages of
$\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}$
; in (2.28), we instead consider the ratio of the sum of these quantities over all individuals. Also note that we can think of the global clustering coefficient as the ratio of the averages of
 $\Delta^{\mathscr{p}}(v)$
and
$\Delta^{\mathscr{p}}(v)$
and
 $\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}$
,
$\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}$
,
 \begin{equation} \textrm{Cl}_{\textrm{glob}} = \frac{ \frac{1}{N_n} \sum_{v\in`\mathscr{V}^{\mathscr{l}}} \Delta^{\mathscr{p}}(v)}{ \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}, \end{equation}
\begin{equation} \textrm{Cl}_{\textrm{glob}} = \frac{ \frac{1}{N_n} \sum_{v\in`\mathscr{V}^{\mathscr{l}}} \Delta^{\mathscr{p}}(v)}{ \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}, \end{equation}
while the average local clustering is given by the average of the ratios of the same quantities,
 \begin{equation} \mathbb{E}\bigl[ \textrm{Cl}(V_n^{\mathscr{l}}) \;\big\vert\; \omega_n \bigr]= \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \textrm{Cl}(v)= \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \frac{\Delta^{\mathscr{p}}(v)}{\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}. \end{equation}
\begin{equation} \mathbb{E}\bigl[ \textrm{Cl}(V_n^{\mathscr{l}}) \;\big\vert\; \omega_n \bigr]= \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \textrm{Cl}(v)= \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \frac{\Delta^{\mathscr{p}}(v)}{\binom{\mathscr{p}\text{-}\textrm{deg}(v)}{2}}. \end{equation}
While the global clustering coefficient and average local clustering coefficient embrace similar concepts, their behaviors are different. By [Reference Kurauskas38, Corollary 4.4], in addition to LWC, convergence of the global clustering coefficient requires the stronger condition of
 \begin{equation*}\mathbb{E}\bigl[ (\mathscr{p}\text{-}\textrm{deg}(V_n^{\mathscr{l}}))^2 \;\big\vert\; \omega_n \bigr] = \mathbb{E}\bigl[ (D_n^{\mathscr{p}})^2 \;\big\vert\; \omega_n \bigr] \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}\bigl[ (D^{\mathscr{p}})^2 \bigr],\end{equation*}
\begin{equation*}\mathbb{E}\bigl[ (\mathscr{p}\text{-}\textrm{deg}(V_n^{\mathscr{l}}))^2 \;\big\vert\; \omega_n \bigr] = \mathbb{E}\bigl[ (D_n^{\mathscr{p}})^2 \;\big\vert\; \omega_n \bigr] \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}\bigl[ (D^{\mathscr{p}})^2 \bigr],\end{equation*}
which can be reduced to
 $\mathbb{E}\bigl[ (D_n^{\mathscr{l}})^2 \bigr] \to \mathbb{E}\bigl[ (D^{\mathscr{l}})^2 \bigr]$
and
$\mathbb{E}\bigl[ (D_n^{\mathscr{l}})^2 \bigr] \to \mathbb{E}\bigl[ (D^{\mathscr{l}})^2 \bigr]$
and
 $\mathbb{E}\bigl[ (D_n^{\mathscr{c}})^2 \bigr] \to \mathbb{E}\bigl[ (D^{\mathscr{c}})^2 \bigr]$
(by Corollary 2.8). Under these conditions,
$\mathbb{E}\bigl[ (D_n^{\mathscr{c}})^2 \bigr] \to \mathbb{E}\bigl[ (D^{\mathscr{c}})^2 \bigr]$
(by Corollary 2.8). Under these conditions,
 $\textrm{Cl}_{\textrm{glob}}$
converges in probability to the ratio of expectations of the numerator and denominator of
$\textrm{Cl}_{\textrm{glob}}$
converges in probability to the ratio of expectations of the numerator and denominator of
 $\zeta$
in (2.25), i.e.,
$\zeta$
in (2.25), i.e.,
 \begin{equation} \textrm{Cl}_{\textrm{glob}} \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}\biggl[ \sum_{i=1}^{D^{\mathscr{l}}} \Lambda_{{(i)}}^{\mathscr{c}} \biggr]\Big/ \mathbb{E}\biggl[ \binom{\sum_{i=1}^{D^{\mathscr{l}}} D_{(i)}^{\mathscr{c}}}{2} \biggr], \end{equation}
\begin{equation} \textrm{Cl}_{\textrm{glob}} \buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}\biggl[ \sum_{i=1}^{D^{\mathscr{l}}} \Lambda_{{(i)}}^{\mathscr{c}} \biggr]\Big/ \mathbb{E}\biggl[ \binom{\sum_{i=1}^{D^{\mathscr{l}}} D_{(i)}^{\mathscr{c}}}{2} \biggr], \end{equation}
which in general is different from the limiting average local clustering
 $\mathbb{E}[\zeta]$
.
$\mathbb{E}[\zeta]$
.
The overlapping structure. Next, we turn our attention to the overlapping structure of the communities, which is one of the main motivators for the RIGC model. By an overlap, we mean two or more communities having one or more individuals in common. From this definition, it is clear that the internal structure of the communities does not play a role in the overlapping structure; thus the following discussion applies to the RIG model as well. By the construction of the model, i.e. the inclusion of individuals in several communities, it is clear that overlaps are present. We will study first the number of overlaps, and later the typical size of the overlaps as well. Let us introduce some notation. For
 $v\in\mathscr{V}^{\mathscr{l}}$
and
$v\in\mathscr{V}^{\mathscr{l}}$
and
 $a\in\mathscr{V}^{\mathscr{r}}$
, we say that v is part of
$a\in\mathscr{V}^{\mathscr{r}}$
, we say that v is part of
 $\textrm{Com}_a$
and write
$\textrm{Com}_a$
and write
![]()
if
![]()
for some
 $j\in\textrm{Com}_a$
. Let us denote the size of the overlap between
$j\in\textrm{Com}_a$
. Let us denote the size of the overlap between
 $a,b\in\mathscr{V}^{\mathscr{r}}$
,
$a,b\in\mathscr{V}^{\mathscr{r}}$
,
 $a\neq b$
, by
$a\neq b$
, by
We define the set of communities overlapping with the community a as
 \begin{equation} \mathscr{N}(a) \,{:}\,{\raise-1.5pt{=}}\, \{b\in\mathscr{V}^{\mathscr{r}} \,:\, b\neq a, \mathscr{O}(a,b) \geq 1 \}. \end{equation}
\begin{equation} \mathscr{N}(a) \,{:}\,{\raise-1.5pt{=}}\, \{b\in\mathscr{V}^{\mathscr{r}} \,:\, b\neq a, \mathscr{O}(a,b) \geq 1 \}. \end{equation}
For
 $k\in\mathbb{Z}^+$
, we introduce the set of unordered pairs of (at least) k-fold overlapping communities:
$k\in\mathbb{Z}^+$
, we introduce the set of unordered pairs of (at least) k-fold overlapping communities:
 \begin{equation}\mathscr{L}_k = {\mathscr{L}^{(n)}_k} \,{:}\,{\raise-1.5pt{=}}\, \bigl\{ \{a,b\}:\, a,b\in\mathscr{V}^{\mathscr{r}}, a\neq b, \mathscr{O}(a,b) \geq k \bigr\}. \end{equation}
\begin{equation}\mathscr{L}_k = {\mathscr{L}^{(n)}_k} \,{:}\,{\raise-1.5pt{=}}\, \bigl\{ \{a,b\}:\, a,b\in\mathscr{V}^{\mathscr{r}}, a\neq b, \mathscr{O}(a,b) \geq k \bigr\}. \end{equation}
Note that
 $\mathscr{L}_k \supseteq \mathscr{L}_{k+1}$
for all
$\mathscr{L}_k \supseteq \mathscr{L}_{k+1}$
for all
 $k\in\mathbb{Z}^+$
and
$k\in\mathbb{Z}^+$
and
 $\mathscr{L}_1$
contains all overlapping pairs, regardless of the size of overlap they share. Recall that
$\mathscr{L}_1$
contains all overlapping pairs, regardless of the size of overlap they share. Recall that
 $V_n^{\mathscr{r}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
, and further recall that
$V_n^{\mathscr{r}}\sim\textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
, and further recall that
 $\mathbb{P}(\;\cdot \mid \omega_n)$
denotes the conditional probability with respect to
$\mathbb{P}(\;\cdot \mid \omega_n)$
denotes the conditional probability with respect to
 $\omega_n$
and
$\omega_n$
and
 $\mathbb{E}[\;\cdot \mid \omega_n]$
denotes the corresponding conditional expectation. We can now state our result on the number of overlaps.
$\mathbb{E}[\;\cdot \mid \omega_n]$
denotes the corresponding conditional expectation. We can now state our result on the number of overlaps.
Proposition 2.11. (Number of overlaps) Consider
 $\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under Assumption 2.2. In addition, assume that, as
$\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under Assumption 2.2. In addition, assume that, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} \mathbb{E}\bigl[(D_n^{\mathscr{l}})^2\bigr] \to \mathbb{E}\bigl[(D^{\mathscr{l}})^2\bigr]
< \infty. \end{equation}
\begin{equation} \mathbb{E}\bigl[(D_n^{\mathscr{l}})^2\bigr] \to \mathbb{E}\bigl[(D^{\mathscr{l}})^2\bigr]
< \infty. \end{equation}
Then, as
 $n\to\infty$
, the average number of communities overlapping with a ‘typical’ one converges:
$n\to\infty$
, the average number of communities overlapping with a ‘typical’ one converges:
 \begin{equation}\frac{ 2 \lvert{\mathscr{L}_1}\rvert}{M_n}= \mathbb{E}\bigl[ \lvert{\mathscr{N}(V_n^{\mathscr{r}})}\rvert \;\big\vert\; \omega_n \bigr]\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}[D^{\mathscr{r}}]\mathbb{E}[\widetilde D^{\mathscr{l}}]. \end{equation}
\begin{equation}\frac{ 2 \lvert{\mathscr{L}_1}\rvert}{M_n}= \mathbb{E}\bigl[ \lvert{\mathscr{N}(V_n^{\mathscr{r}})}\rvert \;\big\vert\; \omega_n \bigr]\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}[D^{\mathscr{r}}]\mathbb{E}[\widetilde D^{\mathscr{l}}]. \end{equation}
Note that (2.35) ensures that
 $\mathbb{E}[\widetilde D^{\mathscr{l}}]<\infty$
, so the right-hand side of (2.36) is finite. We prove Proposition 2.11 in Section 3.4.2 using LWC. Intuitively, (2.36) asserts that a typical community
$\mathbb{E}[\widetilde D^{\mathscr{l}}]<\infty$
, so the right-hand side of (2.36) is finite. We prove Proposition 2.11 in Section 3.4.2 using LWC. Intuitively, (2.36) asserts that a typical community
 $V_n^{\mathscr{r}}$
overlaps with constantly many others, and thus the number of overlapping pairs of communities is linear in the total number of communities.
$V_n^{\mathscr{r}}$
overlaps with constantly many others, and thus the number of overlapping pairs of communities is linear in the total number of communities.
Next, we assert that the ‘typical’ overlap size is 1; we call this the single-overlap property. There are several ways to interpret what the ‘typical overlap’ means, leading to slightly different statements, as follows.
Theorem 2.12. (Single-overlap property) Consider
 $\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under Assumption 2.2. Then the single-overlap property holds, in the following ways:
$\textrm{RIGC}(\textbf{d}^{\mathscr{l}},\textbf{Com})$
under Assumption 2.2. Then the single-overlap property holds, in the following ways:
-
(i) Vertex perspective. For a uniform individual
$V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
, the communities that
$V_n^{\mathscr{l}}$
is part of w.h.p. overlap only at
$V_n^{\mathscr{l}}$
. Formally, as
$n\to\infty$
,(2.37) -
(ii) Community perspective. For a uniform community
$V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
, the communities that
$V_n^{\mathscr{r}}$
overlaps with w.h.p. share only a single individual with
$V_n^{\mathscr{r}}$
. Formally, as
$n\to\infty$
,
(2.38)
\begin{equation} \mathbb{P}\bigl( \exists b\in\mathscr{N}(V_n^{\mathscr{r}})\,:\, \mathscr{O}(V_n^{\mathscr{r}},b) \geq 2 \;\big\vert\; \omega_n \bigr) \buildrel {\mathbb{P}}\over{\longrightarrow} 0. \end{equation}
-
(iii) Global perspective. Assume additionally the condition (2.35), and let
$\{A_n,B_n\}\sim\textrm{Unif}[\mathscr{L}_1]$
denote a pair of communities chosen u.a.r. from among all distinct pairs of overlapping communities. Then w.h.p. their overlap is one individual. Formally, as
$n\to\infty$
,
(2.39)
\begin{equation}\mathbb{P}\bigl( \mathscr{O}(A_n,B_n) \geq 2 \mid \omega_n\bigr)= \lvert{ \mathscr{L}_2 }\rvert \big/ \lvert{ \mathscr{L}_1 }\rvert\buildrel {\mathbb{P}}\over{\longrightarrow} 0. \end{equation}












We complete the proof in Section 3.4.2 but discuss the statement now. The extra second moment condition (2.35) in Theorem 2.12(iii) suggests a substantial difference from Parts (2.12)–(2.12). Indeed, Parts (2.12)–(2.12) establish local properties and follow directly from LWC, which is not true for Part (2.12). The difficulty is in relating the choice of the pair
 $(A_n,B_n)\sim\textrm{Unif}\bigl[\mathscr{L}_1 \bigr]$
to the choice of a single uniform vertex (and further choices in its neighborhood). This problem is nontrivial and further regularity is required. Also note that Proposition 2.11 requires the same second moment condition for
$(A_n,B_n)\sim\textrm{Unif}\bigl[\mathscr{L}_1 \bigr]$
to the choice of a single uniform vertex (and further choices in its neighborhood). This problem is nontrivial and further regularity is required. Also note that Proposition 2.11 requires the same second moment condition for
 $\mathbb{E}[\widetilde D^{\mathscr{l}}]$
to be finite that is used in identifying the asymptotics for
$\mathbb{E}[\widetilde D^{\mathscr{l}}]$
to be finite that is used in identifying the asymptotics for
 $\lvert{ \mathscr{L}_1 }\rvert$
, that is, the denominator in (2.39). In the underlying BCM (see Definition 2.1),
$\lvert{ \mathscr{L}_1 }\rvert$
, that is, the denominator in (2.39). In the underlying BCM (see Definition 2.1),
 $\lvert{ \mathscr{L}_1 }\rvert$
is the number of pairs of communities that are at graph distance 2; however, the fluctuations of this quantity are an open problem in the case when the variance of the degrees diverges.
$\lvert{ \mathscr{L}_1 }\rvert$
is the number of pairs of communities that are at graph distance 2; however, the fluctuations of this quantity are an open problem in the case when the variance of the degrees diverges.
Relationship with the ‘passive’ random intersection graph. The overlapping structure may be represented as a graph on
 $\mathscr{V}^{\mathscr{r}}$
by adding an edge between a pair of communities for each individual they are both connected to. This leads to a ‘dual’ RIG, defined on the communities, that is sometimes referred to as the ‘passive model’ in the literature [Reference Godehardt and Jaworski26]. The sizes of the overlaps
$\mathscr{V}^{\mathscr{r}}$
by adding an edge between a pair of communities for each individual they are both connected to. This leads to a ‘dual’ RIG, defined on the communities, that is sometimes referred to as the ‘passive model’ in the literature [Reference Godehardt and Jaworski26]. The sizes of the overlaps
 $\mathscr{O}(a,b)$
and the number of overlapping pairs
$\mathscr{O}(a,b)$
and the number of overlapping pairs
 $\lvert{\mathscr{L}_1}\rvert$
can be seen as the edge multiplicities and total number of edges in the passive model, respectively; in particular,
$\lvert{\mathscr{L}_1}\rvert$
can be seen as the edge multiplicities and total number of edges in the passive model, respectively; in particular,
 $2\lvert{ \mathscr{L}_1 }\rvert/M_n$
gives the average degree. Note that in this regard, applying Theorem 2.12 with the roles of left-hand side and right-hand side reversed (and also replacing (2.35) by
$2\lvert{ \mathscr{L}_1 }\rvert/M_n$
gives the average degree. Note that in this regard, applying Theorem 2.12 with the roles of left-hand side and right-hand side reversed (and also replacing (2.35) by
 $\mathbb{E}[(D_n^{\mathscr{r}})^2]\to\mathbb{E}[(D^{\mathscr{r}})^2]<\infty$
in Theorem 2.12(ii)) provides some insight on the number of multi-edges in the ‘active’ RIG (with complete graph communities) on the
$\mathbb{E}[(D_n^{\mathscr{r}})^2]\to\mathbb{E}[(D^{\mathscr{r}})^2]<\infty$
in Theorem 2.12(ii)) provides some insight on the number of multi-edges in the ‘active’ RIG (with complete graph communities) on the
 $\mathscr{l}$
-vertices. In turn, this provides an upper bound for the number of multi-edges in the RIGC model as well, but obtaining a lower bound is nontrivial: since the communities are not complete graphs, the fact that two individuals are together in several communities does not necessarily mean that they are connected by multiple edges, and finer properties of the measure
$\mathscr{l}$
-vertices. In turn, this provides an upper bound for the number of multi-edges in the RIGC model as well, but obtaining a lower bound is nontrivial: since the communities are not complete graphs, the fact that two individuals are together in several communities does not necessarily mean that they are connected by multiple edges, and finer properties of the measure
 $\boldsymbol{\mu}$
(see Assumption 2.2(C)) come into play. It further complicates the situation that if we condition on having several communities that both individuals are part of, we also introduce a bias to the
$\boldsymbol{\mu}$
(see Assumption 2.2(C)) come into play. It further complicates the situation that if we condition on having several communities that both individuals are part of, we also introduce a bias to the
 $\mathscr{b}$
-degrees involved.
$\mathscr{b}$
-degrees involved.
2.4. Discussion on the random intersection graph with communities
In this section, we discuss the relationship of our model to other network models and shed light on possible applications and their limitations.
Parameter choices. Working with prescribed parameters provides a wide range of applicability. As Corollaries 2.8 and 2.9 suggest, the degree distribution and clustering of the RIGC model are tunable to match our observations of real-world networks; however, the choice of
 $\textbf{d}^{\mathscr{l}}$
and
$\textbf{d}^{\mathscr{l}}$
and
 $\textbf{Com}$
is hard to infer. One way of obtaining these parameters explicitly is through community-detection algorithms [Reference Fortunato22, Reference Fortunato and Hric23]. For theoretical research, one may be interested in generating the input parameters randomly; we give two examples of this. A simple idea is to use i.i.d. random variables with distribution
$\textbf{Com}$
is hard to infer. One way of obtaining these parameters explicitly is through community-detection algorithms [Reference Fortunato22, Reference Fortunato and Hric23]. For theoretical research, one may be interested in generating the input parameters randomly; we give two examples of this. A simple idea is to use i.i.d. random variables with distribution
 $D^{\mathscr{l}}$
and Com to generate the sequences
$D^{\mathscr{l}}$
and Com to generate the sequences
 $\textbf{d}^{\mathscr{l}}$
and
$\textbf{d}^{\mathscr{l}}$
and
 $\textbf{Com}$
, respectively. However, the parameters must satisfy (2.1). If both
$\textbf{Com}$
, respectively. However, the parameters must satisfy (2.1). If both
 $\textrm{Var}(D^{\mathscr{l}})<\infty$
and
$\textrm{Var}(D^{\mathscr{l}})<\infty$
and
 $\textrm{Var}(D^{\mathscr{r}})<\infty$
, we can use the algorithm proposed by Chen and Olvera-Cravioto in [Reference Chen and Olvera-Cravioto16] to generate the sequences
$\textrm{Var}(D^{\mathscr{r}})<\infty$
, we can use the algorithm proposed by Chen and Olvera-Cravioto in [Reference Chen and Olvera-Cravioto16] to generate the sequences
 $\textbf{d}^{\mathscr{l}}$
,
$\textbf{d}^{\mathscr{l}}$
,
 $\textbf{Com}$
in such a way that the sums of the
$\textbf{Com}$
in such a way that the sums of the
 $\mathscr{l}$
- and
$\mathscr{l}$
- and
 $\mathscr{r}$
-degrees are equal, while the entries are asymptotically independent. While the algorithm in [Reference Chen and Olvera-Cravioto16] was designed for the directed configuration model, it is straightforwardly applicable to the BCM.
$\mathscr{r}$
-degrees are equal, while the entries are asymptotically independent. While the algorithm in [Reference Chen and Olvera-Cravioto16] was designed for the directed configuration model, it is straightforwardly applicable to the BCM.
Our second example is generating a matching pair of
 $\textbf{d}^{\mathscr{l}}$
and
$\textbf{d}^{\mathscr{l}}$
and
 $\textbf{d}^{\mathscr{r}}$
in a dependent way through a bipartite version of the generalized random graph [Reference Britton, Deijfen and Martin-Löf15], or a Norros–Reittu model [Reference Norros and Reittu41]. Once
$\textbf{d}^{\mathscr{r}}$
in a dependent way through a bipartite version of the generalized random graph [Reference Britton, Deijfen and Martin-Löf15], or a Norros–Reittu model [Reference Norros and Reittu41]. Once
 $\textbf{d}^{\mathscr{r}}$
is given, we have to generate
$\textbf{d}^{\mathscr{r}}$
is given, we have to generate
 $\textbf{Com}$
in a compatible way, i.e., such that the community sizes are indeed the
$\textbf{Com}$
in a compatible way, i.e., such that the community sizes are indeed the
 $\mathscr{r}$
-degrees. Assumption 2.2(C) that there exists a family of conditional measures
$\mathscr{r}$
-degrees. Assumption 2.2(C) that there exists a family of conditional measures
 \begin{equation} \mu_{H \vert k} = \mathbb{P}\bigl(\textrm{Com}_a\simeq H \mid d_a^{\mathscr{r}} = \lvert{\textrm{Com}_a}\rvert = k\bigr),\quad \boldsymbol{\mu}_{\cdot\vert k} = (\mu_{H \vert k})_{H\in\mathscr{H}_k},\quad (\boldsymbol{\mu}_{\cdot \vert k})_{k\in\mathbb{Z}^+}, \end{equation}
\begin{equation} \mu_{H \vert k} = \mathbb{P}\bigl(\textrm{Com}_a\simeq H \mid d_a^{\mathscr{r}} = \lvert{\textrm{Com}_a}\rvert = k\bigr),\quad \boldsymbol{\mu}_{\cdot\vert k} = (\mu_{H \vert k})_{H\in\mathscr{H}_k},\quad (\boldsymbol{\mu}_{\cdot \vert k})_{k\in\mathbb{Z}^+}, \end{equation}
that describe the conditional distribution of community graphs for each given community size. In fact
 $\mu_{H \vert k} = \mu_H/q_k$
, with
$\mu_{H \vert k} = \mu_H/q_k$
, with
 $\boldsymbol{\mu}$
and
$\boldsymbol{\mu}$
and
 $\textbf{q}$
from Parts (C) and (C1), respectively, of Assumption 2.2. (We note that because of this relation, under Assumption 2.2(C1), the implication is reversible, i.e., the existence of
$\textbf{q}$
from Parts (C) and (C1), respectively, of Assumption 2.2. (We note that because of this relation, under Assumption 2.2(C1), the implication is reversible, i.e., the existence of
 $(\boldsymbol{\mu}_{\cdot \vert k})_{k\in\mathbb{Z}^+}$
implies Assumption 2.2(C).) Thus we can generate each
$(\boldsymbol{\mu}_{\cdot \vert k})_{k\in\mathbb{Z}^+}$
implies Assumption 2.2(C).) Thus we can generate each
 $\textrm{Com}_a$
according to the measure
$\textrm{Com}_a$
according to the measure
 $\boldsymbol{\mu}_{\cdot \vert d_a^{\mathscr{r}}}$
, all independently of each other.
$\boldsymbol{\mu}_{\cdot \vert d_a^{\mathscr{r}}}$
, all independently of each other.
Overlaps. The motivation behind RIGs is to generate overlapping communities, which is clearly satisfied by Proposition 2.11. However, Theorem 2.12 asserts the single-overlap property of the RIGC and RIG graphs, which limits the applicability of these models. For example, they may not be a good fit for scientific collaboration networks, where the same authors often collaborate on several papers and with several other collaborators. However, the RIGC may be used for social networks when the different communities of the same person tend to be separate: their family members, their colleagues, their sports club friends, etc., typically do not know each other.
On the other hand, the single-overlap property may be used to optimize community detection; for example, consider the C-finder algorithm based on the clique percolation method [Reference Derényi, Palla and Vicsek19, Reference Palla, Derényi, Farkas and Vicsek42], which we explain briefly. A k-clique in a graph is a complete subgraph on k vertices, and we call two k-cliques adjacent if they share
 $k-1$
vertices. A component in k-clique percolation is a maximal set of vertices that are connected through a chain of adjacent k-cliques. We remark that such components may overlap, as long as the intersection does not contain a
$k-1$
vertices. A component in k-clique percolation is a maximal set of vertices that are connected through a chain of adjacent k-cliques. We remark that such components may overlap, as long as the intersection does not contain a
 $(k-1)$
-clique; the simplest case is when the overlap has fewer than
$(k-1)$
-clique; the simplest case is when the overlap has fewer than
 $k-1$
vertices. The C-finder algorithm outputs such components as possibly overlapping communities in the network. Now suppose each community of the RIGC is 3-clique connected, i.e., built up from edge-adjacent triangles. Due to the single-overlap property of the RIGC, a typical community will be a component of 3-clique percolation by itself, i.e., no other communities will be 3-clique adjacent to it, allowing detection with great accuracy. Thus, such an RIGC works very well in conjunction with the C-finder algorithm, either in first generating the RIGC and then detecting its communities, or in running C-finder on the dataset for which one wishes to use the RIGC as a null model.
$k-1$
vertices. The C-finder algorithm outputs such components as possibly overlapping communities in the network. Now suppose each community of the RIGC is 3-clique connected, i.e., built up from edge-adjacent triangles. Due to the single-overlap property of the RIGC, a typical community will be a component of 3-clique percolation by itself, i.e., no other communities will be 3-clique adjacent to it, allowing detection with great accuracy. Thus, such an RIGC works very well in conjunction with the C-finder algorithm, either in first generating the RIGC and then detecting its communities, or in running C-finder on the dataset for which one wishes to use the RIGC as a null model.
We believe that we can also use the clique percolation approach to make the RIGC a better fit than the traditional RIG for collaboration networks, in particular for scientific collaboration networks of authors and the papers they collaborate on. Rather than considering each paper as its own community, which leads to cliques with a typical overlap size larger than one, we can instead merge cliques with more than a single overlap into one community, which, in fact, uses the components of clique percolation as communities. Then we can think of each community as the collaboration network of a subcommunity of authors who often collaborate with one another, and the collaboration network as a network with hierarchical structure.
Multigraphs. The usual criticism that the configuration model receives is that it may produce a multigraph, and this happens w.h.p. in the case when the degrees have infinite (asymptotic) variance [Reference Van der Hofstad29, Chapter 7]. As the RIGC uses a BCM in its construction, we are bound to deal with multigraphs on the level of community memberships, and possibly on the level of the projection as well. One classical remedy is to condition the graph on simplicity; it is however outside the scope of this paper to study this conditional measure (which we conjecture is non-uniform) or to study whether the simplicity probability remains bounded away from 0 as the graph size grows. Another classical approach applied to the configuration model is erasure, and analogously, we can define the erased RIGC by removing self-loops and collapsing multi-edges into a simple edge, i.e., redefining the edge multiplicites from (2.2) as
 $X^{\prime}_{v,v}=0$
and
$X^{\prime}_{v,v}=0$
and
 $X^{\prime}_{v,w}=\mathbb{1}_{ \{X_{v,w}\geq1\} }$
. A different way of erasing would be to erase multiple edges in the underlying BCM, but note that such erasure does not ensure that the resulting RIGC is a simple graph; multi-edges may still arise from two individuals being part of two (or more) communities together. Hence erasing directly in RIGC is the natural/better choice. In this paper, however, we choose to study the RIGC as a multigraph, and argue that we do not see the effect of this in the local behavior; indeed, subject to Theorem 2.7, the local weak limit of the RIGC is simple (a distribution on rooted simple graphs). This means that a typical individual will w.h.p. not see a self-loop or multi-edge in its finite neighborhood. Based on this observation, our results extend to the erased RIGC without any modification.
$X^{\prime}_{v,w}=\mathbb{1}_{ \{X_{v,w}\geq1\} }$
. A different way of erasing would be to erase multiple edges in the underlying BCM, but note that such erasure does not ensure that the resulting RIGC is a simple graph; multi-edges may still arise from two individuals being part of two (or more) communities together. Hence erasing directly in RIGC is the natural/better choice. In this paper, however, we choose to study the RIGC as a multigraph, and argue that we do not see the effect of this in the local behavior; indeed, subject to Theorem 2.7, the local weak limit of the RIGC is simple (a distribution on rooted simple graphs). This means that a typical individual will w.h.p. not see a self-loop or multi-edge in its finite neighborhood. Based on this observation, our results extend to the erased RIGC without any modification.
3. Proofs
In this section, we prove the above results. For this purpose, we first provide a more detailed overview of the concept of LWC in Section 3.1. We then prove LWC for the RIGC as a consequence of the LWC of the underlying BCM, as has been done for other RIG models. Finally we include the proofs of our further results. For some of these results, we include a sketch of the proof here, and the more rigorous albeit tedious details can be found in an extended version of this paper [Reference Van der Hofstad, Komjáthy and Vadon31].
3.1. Preliminaries: marked graphs and local weak convergence
In order to prove our results, we first introduce the concepts that we rely on in our proof, the most central one being local weak convergence (LWC), a notion of convergence for sparse graph sequences. The usefulness of LWC comes from the fact that numerous properties of the finite graph(s) can be determined or approximated based on the limiting object alone [Reference Berger, Borgs, Chayes and Saberi6, Reference Garavaglia, van der Hofstad and Litvak24]. As its name suggests, LWC describes the graph from a local point of view; indeed, in Definition 2.6, we have defined LWC in probability in terms of convergence of frequencies of graph neighborhoods. We cover some of the theory behind the notion of LWC, in fact in a more general setting of marked graphs, which we also define shortly. The theory of LWC presented is partially based on [Reference Aldous and Steele1, Reference Benjamini, Lyons and Schramm4, Reference Benjamini and Schramm5] and [Reference Van der Hofstad30, Chapter 2], but generalized and tailored to our needs. We start by defining marked graphs.
Marked graphs. Marks provide a general framework for indicating additional information on the edges and/or vertices of a (multi)graph, such as edge weights, edge directions, graph coloring, etc. In our case, we use marks to include edge labels of the underlying BCM, as well as indicate the community graphs assigned to each
 $\mathscr{r}$
-vertex. We formally define marked (multi)graphs below. For simplicity, we will simply write graphs. Keep in mind that edges between the same pair of vertices receive marks separately and may have different marks.
$\mathscr{r}$
-vertex. We formally define marked (multi)graphs below. For simplicity, we will simply write graphs. Keep in mind that edges between the same pair of vertices receive marks separately and may have different marks.
Let
 $\mathscr{G}$
denote the set of all locally finite (multi)graphs on a countable (finite or countably infinite) vertex set. Let the set of marks
$\mathscr{G}$
denote the set of all locally finite (multi)graphs on a countable (finite or countably infinite) vertex set. Let the set of marks
 $\mathscr{M}$
be an arbitrary countable set that contains the special symbol
$\mathscr{M}$
be an arbitrary countable set that contains the special symbol
 $\varnothing$
, which is to be interpreted as ‘no mark’. A marked graph is a pair
$\varnothing$
, which is to be interpreted as ‘no mark’. A marked graph is a pair
 $(G,\Xi)$
, where
$(G,\Xi)$
, where
 $\Xi$
is the mark function that maps elements of G into
$\Xi$
is the mark function that maps elements of G into
 $\mathscr{M}$
; in particular, for
$\mathscr{M}$
; in particular, for
 $v\in\mathscr{V}(G)$
,
$v\in\mathscr{V}(G)$
,
 $\Xi(v) \in \mathscr{M}$
, and for
$\Xi(v) \in \mathscr{M}$
, and for
 $e\in\mathscr{E}(G)$
,
$e\in\mathscr{E}(G)$
,
 $\Xi(e) \in \mathscr{M}^2$
. It is common to associate two marks to each edge, with one mark associated to each endpoint, which is often interpreted as associating separate marks to the two directions of a bi-directed edge. Since we work with the BCM, it is more useful to think of the marks as being associated to the half-edges that form the edge. We denote the set of graphs with marks from the mark set
$\Xi(e) \in \mathscr{M}^2$
. It is common to associate two marks to each edge, with one mark associated to each endpoint, which is often interpreted as associating separate marks to the two directions of a bi-directed edge. Since we work with the BCM, it is more useful to think of the marks as being associated to the half-edges that form the edge. We denote the set of graphs with marks from the mark set
 $\mathscr{M}$
by
$\mathscr{M}$
by
 $\mathscr{G}(\mathscr{M})$
.
$\mathscr{G}(\mathscr{M})$
.
We remark that any graph in
 $\mathscr{G}$
(which we may refer to as the set of unmarked graphs, for clarity) can be turned into a marked graph by assigning the ‘no mark’ symbol
$\mathscr{G}$
(which we may refer to as the set of unmarked graphs, for clarity) can be turned into a marked graph by assigning the ‘no mark’ symbol
 $\varnothing$
to each vertex and half-edge; thus, results and definitions formulated for marked graphs apply straightforwardly to (unmarked) graphs.
$\varnothing$
to each vertex and half-edge; thus, results and definitions formulated for marked graphs apply straightforwardly to (unmarked) graphs.
Rooted marked graph, isomorphism, and r -neighborhood. We now generalize Definition 2.5 to marked graphs.
-
(i) Choose a vertex o in a marked graph
$(G,\Xi)$
to be distinguished as the root; if G is not connected, we restrict ourselves to the connected component of o, and denote the rooted marked graph by
$(G,\Xi,o)$
.


Denote the set of rooted marked graphs by
 $\mathscr{G}_o(\mathscr{M})$
. We call a random element of
$\mathscr{G}_o(\mathscr{M})$
. We call a random element of
 $\mathscr{G}_o(\mathscr{M})$
a random rooted marked graph.
$\mathscr{G}_o(\mathscr{M})$
a random rooted marked graph.
-
(ii) We say that the rooted marked graphs
$(G_1,\Xi_1,o_1)$
and
$(G_2,\Xi_2,o_2)$
are isomorphic, and denote this by
$(G_1,\Xi_1,o_1)\simeq(G_2,\Xi_2,o_2)$
, if there is a graph-isomorphism between them that also maps root to root and preserves marks. When there are multiple edges between the same pair of vertices, we require that there be the same number of edges with any given mark between the corresponding pairs of vertices in the two graphs. -
(iii) The (closed) ball
$B_r(G,\Xi,o)$
can be defined analogously to the unmarked graph ball (Definition 2.5(iv)), by restricting the mark function to the subgraph as well.




Distance and topology. We are now ready to define a metric on
 $\mathscr{G}_o(\mathscr{M})$
. For two elements
$\mathscr{G}_o(\mathscr{M})$
. For two elements
 $(G_1,\Xi_1,o_1), (G_2,\Xi_2,o_2)\in\mathscr{G}_o(\mathscr{M})$
, we define the largest radius r such that the r-neighborhoods of the roots are isomorphic:
$(G_1,\Xi_1,o_1), (G_2,\Xi_2,o_2)\in\mathscr{G}_o(\mathscr{M})$
, we define the largest radius r such that the r-neighborhoods of the roots are isomorphic:
 \begin{equation} r_{\textrm{max}}\,{:}\,{\raise-1.5pt{=}}\, \begin{cases}-1 & \text{if $\Xi_1(o_1)\neq\Xi_2(o_2)$},\\[4pt]
+\infty & \text{if $(G_1,\Xi_1,o_1)\simeq (G_2,\Xi_2,o_2)$},\\[4pt]
\sup\bigl\{ r\in\mathbb{N}\,:\, B_r(G_1,\Xi_1,o_1)\simeq B_r(G_2,\Xi_2,o_2) \bigr\} & \text{otherwise}.\end{cases}\end{equation}
\begin{equation} r_{\textrm{max}}\,{:}\,{\raise-1.5pt{=}}\, \begin{cases}-1 & \text{if $\Xi_1(o_1)\neq\Xi_2(o_2)$},\\[4pt]
+\infty & \text{if $(G_1,\Xi_1,o_1)\simeq (G_2,\Xi_2,o_2)$},\\[4pt]
\sup\bigl\{ r\in\mathbb{N}\,:\, B_r(G_1,\Xi_1,o_1)\simeq B_r(G_2,\Xi_2,o_2) \bigr\} & \text{otherwise}.\end{cases}\end{equation}
We then define the distance between the rooted marked graphs as
 \begin{equation} d_{\textrm{loc}}\bigl( (G_1,\Xi_1,o_1),(G_2,\Xi_2,o_2)\bigr) \,{:}\,{\raise-1.5pt{=}}\, 2^{-r_{\textrm{max}}} \in [0,2]. \end{equation}
\begin{equation} d_{\textrm{loc}}\bigl( (G_1,\Xi_1,o_1),(G_2,\Xi_2,o_2)\bigr) \,{:}\,{\raise-1.5pt{=}}\, 2^{-r_{\textrm{max}}} \in [0,2]. \end{equation}
The distance
 $d_{\textrm{loc}}$
is a metric on the isomorphism classes of
$d_{\textrm{loc}}$
is a metric on the isomorphism classes of
 $\mathscr{G}_o(\mathscr{M})$
, which turns this space into a Polish space, i.e., a complete, separable metric space (see [Reference Aldous and Steele1] or [Reference Van der Hofstad30, Theorem A.6]).
$\mathscr{G}_o(\mathscr{M})$
, which turns this space into a Polish space, i.e., a complete, separable metric space (see [Reference Aldous and Steele1] or [Reference Van der Hofstad30, Theorem A.6]).
Local weak convergence of deterministic graphs. Let
 $(G_n,\Xi_n)_{n\in\mathbb{N}}$
,
$(G_n,\Xi_n)_{n\in\mathbb{N}}$
,
 $(G_n,\Xi_n)\in\mathscr{G}(\mathscr{M})$
, be a sequence of (deterministic) finite marked graphs such that
$(G_n,\Xi_n)\in\mathscr{G}(\mathscr{M})$
, be a sequence of (deterministic) finite marked graphs such that
 $\lvert{G_n}\rvert\to\infty$
. For each n, let
$\lvert{G_n}\rvert\to\infty$
. For each n, let
 $U_n$
be a vertex of
$U_n$
be a vertex of
 $G_n$
chosen u.a.r., and consider the measures defined by
$G_n$
chosen u.a.r., and consider the measures defined by
 $(G_n,\Xi_n,U_n)$
on
$(G_n,\Xi_n,U_n)$
on
 $(\mathscr{G}_o(\mathscr{M}),d_{\textrm{loc}})$
. We will define the LWC of
$(\mathscr{G}_o(\mathscr{M}),d_{\textrm{loc}})$
. We will define the LWC of
 $(G_n,\Xi_n)_{n\in\mathbb{N}}$
as the weak convergence of the above measures, which can be defined in the standard way. Let
$(G_n,\Xi_n)_{n\in\mathbb{N}}$
as the weak convergence of the above measures, which can be defined in the standard way. Let
 $(\mathbb{R},d_{\textrm{eucl}})$
denote the Polish space of the real numbers equipped with the Euclidean distance, and introduce the set of test functionals
$(\mathbb{R},d_{\textrm{eucl}})$
denote the Polish space of the real numbers equipped with the Euclidean distance, and introduce the set of test functionals
 \begin{equation} \Phi = \{\varphi\,:\,\mathscr{G}_o(\mathscr{M})\to\mathbb{R} \,:\, \varphi \text{ is bounded and continuous} \}. \end{equation}
\begin{equation} \Phi = \{\varphi\,:\,\mathscr{G}_o(\mathscr{M})\to\mathbb{R} \,:\, \varphi \text{ is bounded and continuous} \}. \end{equation}
We remark that a special case of continuous functionals are those that only depend on a finite neighborhood of the root. We say that
 $(G_n,\Xi_n,U_n)_{n\in\mathbb{N}}$
converges in the LWC sense to a (possibly random) element
$(G_n,\Xi_n,U_n)_{n\in\mathbb{N}}$
converges in the LWC sense to a (possibly random) element
 $(G,\Xi,o) \in \mathscr{G}_o(\mathscr{M})$
, denoted by
$(G,\Xi,o) \in \mathscr{G}_o(\mathscr{M})$
, denoted by
 $(G_n,\Xi_n,U_n) \buildrel \text{loc}\over{\longrightarrow} (G,\Xi,o)$
, if for all
$(G_n,\Xi_n,U_n) \buildrel \text{loc}\over{\longrightarrow} (G,\Xi,o)$
, if for all
 $\varphi\in\Phi$
, as
$\varphi\in\Phi$
, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} \mathbb{E}\bigl[ \varphi(G_n,\Xi_n,U_n) \bigr]\to \mathbb{E}\bigl[ \varphi(G,\Xi,o) \bigr]. \end{equation}
\begin{equation} \mathbb{E}\bigl[ \varphi(G_n,\Xi_n,U_n) \bigr]\to \mathbb{E}\bigl[ \varphi(G,\Xi,o) \bigr]. \end{equation}
This statement is equivalent (see e.g. [Reference Van der Hofstad30, Theorem 2.6]) to the convergence of neighborhood counts; that is, the following statement is an equivalent definition of LWC: for any
 $r\in\mathbb{N}$
and any fixed
$r\in\mathbb{N}$
and any fixed
 $(G',\Xi',o')\in\mathscr{G}_o(\mathscr{M})$
, as
$(G',\Xi',o')\in\mathscr{G}_o(\mathscr{M})$
, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation}\mathbb{P}\bigl( B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o') \bigr)\to \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr). \end{equation}
\begin{equation}\mathbb{P}\bigl( B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o') \bigr)\to \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr). \end{equation}
Local weak convergence of random graphs. We now generalize Definition 2.6 for marked graphs (simultaneously generalizing (3.5) for random graphs). Let
 $(G_n,\Xi_n)_{n\in\mathbb{N}}$
,
$(G_n,\Xi_n)_{n\in\mathbb{N}}$
,
 $(G_n,\Xi_n)\in\mathscr{G}_o(\mathscr{M})$
, be a sequence of (finite) random marked graphs such that
$(G_n,\Xi_n)\in\mathscr{G}_o(\mathscr{M})$
, be a sequence of (finite) random marked graphs such that
 $\lvert{G_n}\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} \infty$
, and let
$\lvert{G_n}\rvert \buildrel {\mathbb{P}}\over{\longrightarrow} \infty$
, and let
 $U_n \mid (G_n,\Xi_n) \sim \textrm{Unif}[\mathscr{V}(G_n)]$
be a uniformly chosen vertex. Let
$U_n \mid (G_n,\Xi_n) \sim \textrm{Unif}[\mathscr{V}(G_n)]$
be a uniformly chosen vertex. Let
 $\mathbb{P}\bigl(\,\cdot \;\big\vert\; (G_n,\Xi_n)\bigr)$
denote conditional probability with respect to the marked graph (i.e., the free variable is
$\mathbb{P}\bigl(\,\cdot \;\big\vert\; (G_n,\Xi_n)\bigr)$
denote conditional probability with respect to the marked graph (i.e., the free variable is
 $U_n$
). We say that
$U_n$
). We say that
 $(G_n,\Xi_n,U_n)_{n\in\mathbb{N}}$
converges in probability in the local weak sense to a (possibly) random element
$(G_n,\Xi_n,U_n)_{n\in\mathbb{N}}$
converges in probability in the local weak sense to a (possibly) random element
 $(G,\Xi,o)\in\mathscr{G}_o(\mathscr{M})$
, and write
$(G,\Xi,o)\in\mathscr{G}_o(\mathscr{M})$
, and write
 $(G_n,\Xi_n,U_n)\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}(G,\Xi,o)$
, if the empirical neighborhood counts converge in probability, i.e., if for any fixed
$(G_n,\Xi_n,U_n)\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}(G,\Xi,o)$
, if the empirical neighborhood counts converge in probability, i.e., if for any fixed
 $r\in\mathbb{N}$
and fixed
$r\in\mathbb{N}$
and fixed
 $(G',\Xi',o')\in\mathscr{G}_o(\mathscr{M})$
, as
$(G',\Xi',o')\in\mathscr{G}_o(\mathscr{M})$
, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{align}\mathbb{P}\bigl( B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o') \;\big\vert\; (G_n,\Xi_n) \bigr)&\,{:}\,{\raise-1.5pt{=}}\, \frac{1}{\lvert{G_n}\rvert} \sum_{u\in\mathscr{V}(G_n)}\!\! \mathbb{1}_{\{B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o')\}} \nonumber\\
&\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr). \end{align}
\begin{align}\mathbb{P}\bigl( B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o') \;\big\vert\; (G_n,\Xi_n) \bigr)&\,{:}\,{\raise-1.5pt{=}}\, \frac{1}{\lvert{G_n}\rvert} \sum_{u\in\mathscr{V}(G_n)}\!\! \mathbb{1}_{\{B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o')\}} \nonumber\\
&\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr). \end{align}
We can also generalize (3.4) for an equivalent definition (again, see e.g. [Reference Van der Hofstad30, Theorem 2.12] for a proof of the equivalence) of LWC in probability. Let
 $\mathbb{E}\bigl[ \,\cdot \;\big\vert\; (G_n,\Xi_n) \bigr]$
denote conditional expectation corresponding to the conditional probability measure
$\mathbb{E}\bigl[ \,\cdot \;\big\vert\; (G_n,\Xi_n) \bigr]$
denote conditional expectation corresponding to the conditional probability measure
 $\mathbb{P}\bigl(\,\cdot \;\big\vert\; (G_n,\Xi_n)\bigr)$
. Then
$\mathbb{P}\bigl(\,\cdot \;\big\vert\; (G_n,\Xi_n)\bigr)$
. Then
 $(G_n,\Xi_n,U_n) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (G,\Xi,o)$
exactly when for all test functionals
$(G_n,\Xi_n,U_n) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (G,\Xi,o)$
exactly when for all test functionals
 $\varphi \in \Phi$
(see (3.3)),
$\varphi \in \Phi$
(see (3.3)),
 \begin{equation} \mathbb{E}\bigl[ \varphi\bigl(B_r(G_n,\Xi_n,U_n)\bigr) \;\big\vert\; (G_n,\Xi_n) \bigr]\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}\bigl[ \varphi\bigl(B_r(G,\Xi,o)\bigr) \bigr]. \end{equation}
\begin{equation} \mathbb{E}\bigl[ \varphi\bigl(B_r(G_n,\Xi_n,U_n)\bigr) \;\big\vert\; (G_n,\Xi_n) \bigr]\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{E}\bigl[ \varphi\bigl(B_r(G,\Xi,o)\bigr) \bigr]. \end{equation}
Extensions. We remark that there exist other notions of LWC for random graphs. Almost sure LWC can be defined by replacing the convergence in probability by almost sure convergence in (3.6). LWC in distribution is defined as
 \begin{equation} \mathbb{P}\bigl( B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o') \bigr)\to \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr), \end{equation}
\begin{equation} \mathbb{P}\bigl( B_r(G_n,\Xi_n,U_n) \simeq B_r(G',\Xi',o') \bigr)\to \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr), \end{equation}
where we note the lack of conditioning on the left-hand side. In this paper, we use LWC in probability, as it is not too restrictive while being strong enough to imply asymptotic independence of the neighborhoods of two uniformly chosen vertices. Such asymptotic independence is not guaranteed by LWC in distribution; see e.g. [Reference Van der Hofstad30, Section 2.3.1] for a discussion of the differences between these notions.
Remark 3.1 (Different root distributions) In certain cases, it is meaningful and interesting to study the convergence of subgraph counts around a vertex
 $W_n$
chosen according to a non-uniform distribution, for example size-biased by degree or chosen within a (large enough) subset of vertices. Our motivation is to restrict the choice of the root to one partition of the BCM. In the following, for a random vertex
$W_n$
chosen according to a non-uniform distribution, for example size-biased by degree or chosen within a (large enough) subset of vertices. Our motivation is to restrict the choice of the root to one partition of the BCM. In the following, for a random vertex
 $W_n$
with an arbitrary distribution on
$W_n$
with an arbitrary distribution on
 $\mathscr{V}(G_n)$
, we shall write
$\mathscr{V}(G_n)$
, we shall write
 $(G_n,\Xi_n,W_n) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (G,\Xi,o)$
to mean that the neighborhood counts around
$(G_n,\Xi_n,W_n) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (G,\Xi,o)$
to mean that the neighborhood counts around
 $W_n$
converge, i.e., for all
$W_n$
converge, i.e., for all
 $r\in\mathbb{N}$
and all
$r\in\mathbb{N}$
and all
 $(G',\Xi',o')\in\mathscr{G}_o(\mathscr{M})$
, as
$(G',\Xi',o')\in\mathscr{G}_o(\mathscr{M})$
, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} \mathbb{P}\bigl( B_r(G_n,\Xi_n,W_n) \simeq B_r(G',\Xi',o') \;\big\vert\; (G_n,\Xi_n) \bigr)\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr). \end{equation}
\begin{equation} \mathbb{P}\bigl( B_r(G_n,\Xi_n,W_n) \simeq B_r(G',\Xi',o') \;\big\vert\; (G_n,\Xi_n) \bigr)\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl(B_r(G,\Xi,o) \simeq B_r(G',\Xi',o')\bigr). \end{equation}
3.2. Local weak convergence of the underlying bipartite configuration model
Analogously to classical RIGs, we approach LWC of the RIGC via the LWC of the underlying BCM; see Definition 2.1 in Section 2.1. Without the community graphs assigned to each community and the edge labels encoding the assigned community roles, the LWC of the BCM follows from known results that we recall shortly. To formally state the LWC of the BCM, we first define the limiting object.
Recall
 $D^{\mathscr{l}}$
and
$D^{\mathscr{l}}$
and
 $D^{\mathscr{r}}$
from Parts (A) and (C1), respectively, of Assumption 2.2, and also recall (1.1). We define a discrete-time branching process
$D^{\mathscr{r}}$
from Parts (A) and (C1), respectively, of Assumption 2.2, and also recall (1.1). We define a discrete-time branching process
 $\textrm{BP}_{\mathscr{l}}$
with a single root
$\textrm{BP}_{\mathscr{l}}$
with a single root
 $\underline{0}$
in generation 0. The offspring of any two individuals are independent but not identically distributed. The root has offspring
$\underline{0}$
in generation 0. The offspring of any two individuals are independent but not identically distributed. The root has offspring
 $D^{\mathscr{l}}$
, every other individual in even generations has offspring distributed as
$D^{\mathscr{l}}$
, every other individual in even generations has offspring distributed as
 $\widetilde D^{\mathscr{l}}$
, and every individual in odd generations has offspring distributed as
$\widetilde D^{\mathscr{l}}$
, and every individual in odd generations has offspring distributed as
 $\widetilde D^{\mathscr{r}}$
. We denote the resulting family tree by
$\widetilde D^{\mathscr{r}}$
. We denote the resulting family tree by
 $(\textrm{BP}_{\mathscr{l}},\underline{0})$
, which we think of as a rooted (unmarked) tree: the family tree is obtained by adding edges between each individual and all its offspring. Then we have the following result.
$(\textrm{BP}_{\mathscr{l}},\underline{0})$
, which we think of as a rooted (unmarked) tree: the family tree is obtained by adding edges between each individual and all its offspring. Then we have the following result.
Proposition 3.2 Consider
 $\textrm{BCM}_n = (\textrm{BCM}(\textbf{d}^{\mathscr{l}},\textbf{d}^{\mathscr{r}})$
under Assumption 2.2 (A,B,C1,D) and recall
$\textrm{BCM}_n = (\textrm{BCM}(\textbf{d}^{\mathscr{l}},\textbf{d}^{\mathscr{r}})$
under Assumption 2.2 (A,B,C1,D) and recall
 $V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
. Then, in the generalized meaning of the notion
$V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
. Then, in the generalized meaning of the notion
 $\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
from Remark 3.1,
$\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
from Remark 3.1,
 \begin{equation} (\textrm{BCM}_n,V_n^{\mathscr{l}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{l}},\underline{0}). \end{equation}
\begin{equation} (\textrm{BCM}_n,V_n^{\mathscr{l}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{l}},\underline{0}). \end{equation}
Proof. The statement follows from the proof of [Reference Kurauskas38, Theorem 3.1(iv)].
![]()
The referenced proof uses a very precise coupling argument of a breadth-first search exploration of the graph and an appropriate branching process. In an extended version of this paper [Reference Van der Hofstad, Komjáthy and Vadon31], we provide our alternative proof, in which we apply a first and second moment method to the neighborhood counts.
By symmetry, a statement analogous to Proposition 3.2 holds for
 $V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
. Define the branching process
$V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
. Define the branching process
 $\textrm{BP}_{\mathscr{r}}$
analogously to
$\textrm{BP}_{\mathscr{r}}$
analogously to
 $\textrm{BP}_{\mathscr{l}}$
, with the roles of
$\textrm{BP}_{\mathscr{l}}$
, with the roles of
 $\mathscr{l}$
and
$\mathscr{l}$
and
 $\mathscr{r}$
reversed. That is, the root
$\mathscr{r}$
reversed. That is, the root
 $\underline{0}$
has offspring
$\underline{0}$
has offspring
 $D^{\mathscr{r}}$
, every other vertex in even generations has offspring
$D^{\mathscr{r}}$
, every other vertex in even generations has offspring
 $\widetilde D^{\mathscr{r}}$
, and every vertex in odd generations has offspring
$\widetilde D^{\mathscr{r}}$
, and every vertex in odd generations has offspring
 $\widetilde D^{\mathscr{l}}$
. Then
$\widetilde D^{\mathscr{l}}$
. Then
 \begin{equation} (\textrm{BCM}_n,V_n^{\mathscr{r}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{r}},\underline{0}), \end{equation}
\begin{equation} (\textrm{BCM}_n,V_n^{\mathscr{r}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{r}},\underline{0}), \end{equation}
where
 $\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
is again meant in the generalized sense of Remark 3.1. From (3.10) and (3.11), we can also obtain the local weak limit of the BCM with a uniform root
$\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
is again meant in the generalized sense of Remark 3.1. From (3.10) and (3.11), we can also obtain the local weak limit of the BCM with a uniform root
 $V_n^{\mathscr{b}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}} \cup \mathscr{V}^{\mathscr{r}}]$
. We define a mixing variable
$V_n^{\mathscr{b}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}} \cup \mathscr{V}^{\mathscr{r}}]$
. We define a mixing variable
 $\mathscr{s}$
and a mixture of BP family trees
$\mathscr{s}$
and a mixture of BP family trees
 $\textrm{BP}_{\mathscr{s}}$
as follows:
$\textrm{BP}_{\mathscr{s}}$
as follows:
 \begin{align} \mathbb{P}(\mathscr{s} = \mathscr{l}) = 1/(1+\gamma), \quad \mathbb{P}(\mathscr{s} = \mathscr{r}) = \gamma/(1+\gamma), \end{align}
\begin{align} \mathbb{P}(\mathscr{s} = \mathscr{l}) = 1/(1+\gamma), \quad \mathbb{P}(\mathscr{s} = \mathscr{r}) = \gamma/(1+\gamma), \end{align}
 \begin{align}(\textrm{BP}_{\mathscr{s}},\underline{0}) \buildrel d\over{=} \mathbb{1}_{\{ \mathscr{s} = \mathscr{l} \}} (\textrm{BP}_{\mathscr{l}},\underline{0}) + \mathbb{1}_{\{ \mathscr{s} = \mathscr{r} \}} (\textrm{BP}_{\mathscr{r}},\underline{0}).\end{align}
\begin{align}(\textrm{BP}_{\mathscr{s}},\underline{0}) \buildrel d\over{=} \mathbb{1}_{\{ \mathscr{s} = \mathscr{l} \}} (\textrm{BP}_{\mathscr{l}},\underline{0}) + \mathbb{1}_{\{ \mathscr{s} = \mathscr{r} \}} (\textrm{BP}_{\mathscr{r}},\underline{0}).\end{align}
Then, by (3.10), (3.11), Definition 2.6, and Remark 3.1,
 \begin{equation} (\textrm{BCM}_n,V_n^{\mathscr{b}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{s}},\underline{0}), \end{equation}
\begin{equation} (\textrm{BCM}_n,V_n^{\mathscr{b}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{s}},\underline{0}), \end{equation}
where
 $\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
now applies in the original sense of Definition 2.6.
$\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
now applies in the original sense of Definition 2.6.
3.3. Local weak convergence of the random intersection graph with communities
In this section, we prove the LWC of the RIGC. We start by constructing the limiting object
 $(\textrm{CP},o)$
. The notation is inspired by the fact that
$(\textrm{CP},o)$
. The notation is inspired by the fact that
 $(\textrm{CP},o)$
is the ‘community projection’ (see Section 2.1) of a random rooted marked tree
$(\textrm{CP},o)$
is the ‘community projection’ (see Section 2.1) of a random rooted marked tree
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
defined below, in the same way that the RIGC is the ‘community projection’ of the underlying BCM. It is then not surprising that
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
defined below, in the same way that the RIGC is the ‘community projection’ of the underlying BCM. It is then not surprising that
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
is the local weak limit of the underlying BCM, including the community graphs, which we represent as a marked graph (formally introduced below). The limiting object
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
is the local weak limit of the underlying BCM, including the community graphs, which we represent as a marked graph (formally introduced below). The limiting object
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
is obtained from the BP family tree
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
is obtained from the BP family tree
 $(\textrm{BP}_{\mathscr{l}},\underline{0})$
, introduced in Section 3.2, by equipping it with a mark function
$(\textrm{BP}_{\mathscr{l}},\underline{0})$
, introduced in Section 3.2, by equipping it with a mark function
 $\Xi^{\mathscr{p}}$
defined shortly. In the following, we give a formal definition of these objects, starting with the marked graph representation of the underlying BCM.
$\Xi^{\mathscr{p}}$
defined shortly. In the following, we give a formal definition of these objects, starting with the marked graph representation of the underlying BCM.
The underlying BCM as a marked graph. We introduce the mark function
 $\Xi^{\mathscr{c}}$
on BCM to represent the community graphs and the assignment of community roles. Recall the set of possible community graphs
$\Xi^{\mathscr{c}}$
on BCM to represent the community graphs and the assignment of community roles. Recall the set of possible community graphs
 $\mathscr{H}$
and the ‘no mark’ symbol
$\mathscr{H}$
and the ‘no mark’ symbol
 $\varnothing$
. Let the set of marks be
$\varnothing$
. Let the set of marks be
 $\mathscr{M}^{\mathscr{p}} \,{:}\,{\raise-1.5pt{=}}\, \mathscr{H}\cup\mathbb{Z}^+\cup\{\varnothing,\mathscr{l}\}$
. We mark each
$\mathscr{M}^{\mathscr{p}} \,{:}\,{\raise-1.5pt{=}}\, \mathscr{H}\cup\mathbb{Z}^+\cup\{\varnothing,\mathscr{l}\}$
. We mark each
 $v\in\mathscr{V}^{\mathscr{l}}$
by
$v\in\mathscr{V}^{\mathscr{l}}$
by
 $\mathscr{l} \,=\!:\, \Xi^{\mathscr{c}}(v)$
and each
$\mathscr{l} \,=\!:\, \Xi^{\mathscr{c}}(v)$
and each
 $a\in\mathscr{V}^{\mathscr{r}}$
by its community graph
$a\in\mathscr{V}^{\mathscr{r}}$
by its community graph
 $\textrm{Com}_a \,=\!:\, \Xi^{\mathscr{c}}(a)$
. Recall that an edge of the underlying BCM formed by
$\textrm{Com}_a \,=\!:\, \Xi^{\mathscr{c}}(a)$
. Recall that an edge of the underlying BCM formed by
 $\mathscr{l}$
-half-edge (v,i) and
$\mathscr{l}$
-half-edge (v,i) and
 $\mathscr{r}$
-half-edge (a,l) is labeled by (i,l); we also mark this edge by the tuple (i,l). We refer to
$\mathscr{r}$
-half-edge (a,l) is labeled by (i,l); we also mark this edge by the tuple (i,l). We refer to
 $(\textrm{BCM},\Xi^{\mathscr{c}})$
as the community-marked BCM, and we note that it encodes all information necessary for constructing the RIGC. Indeed, the community graphs are given as the marks of
$(\textrm{BCM},\Xi^{\mathscr{c}})$
as the community-marked BCM, and we note that it encodes all information necessary for constructing the RIGC. Indeed, the community graphs are given as the marks of
 $\mathscr{r}$
-vertices, and edge-marks encode the assigned community roles: if
$\mathscr{r}$
-vertices, and edge-marks encode the assigned community roles: if
 $\mathscr{l}$
-vertex v is connected to
$\mathscr{l}$
-vertex v is connected to
 $\mathscr{r}$
-vertex a by an edge marked (i,l), we know that v takes on the community role of the vertex with label l in
$\mathscr{r}$
-vertex a by an edge marked (i,l), we know that v takes on the community role of the vertex with label l in
 $\textrm{Com}_a$
. Thus the community projection operator of Section 2.1 can be naturally redefined as
$\textrm{Com}_a$
. Thus the community projection operator of Section 2.1 can be naturally redefined as
 $\widehat{\mathscr{P}}\,:\, (\textrm{BCM},\Xi^{\mathscr{c}}) \mapsto \textrm{RIGC}$
. For some
$\widehat{\mathscr{P}}\,:\, (\textrm{BCM},\Xi^{\mathscr{c}}) \mapsto \textrm{RIGC}$
. For some
 $v\in\mathscr{V}^{\mathscr{l}}$
, we write
$v\in\mathscr{V}^{\mathscr{l}}$
, we write
 $\widehat{\mathscr{P}}\,:\, (\textrm{BCM},\Xi^{\mathscr{c}},v) \mapsto (\textrm{RIGC},v)$
for the rooted version of the projection.
$\widehat{\mathscr{P}}\,:\, (\textrm{BCM},\Xi^{\mathscr{c}},v) \mapsto (\textrm{RIGC},v)$
for the rooted version of the projection.
The local weak limit of the underlying BCM. We now introduce the marked BP family tree
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
. Recall
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
. Recall
 $(\textrm{BP}_{\mathscr{l}},\underline{0})$
from Section 3.2; conditionally on this (possibly infinite) BP family tree, we now define the random mark function
$(\textrm{BP}_{\mathscr{l}},\underline{0})$
from Section 3.2; conditionally on this (possibly infinite) BP family tree, we now define the random mark function
 $\Xi^{\mathscr{p}}$
, using the set of marks
$\Xi^{\mathscr{p}}$
, using the set of marks
 $\mathscr{M}^{\mathscr{p}}$
from above. We mark vertices in even generations by
$\mathscr{M}^{\mathscr{p}}$
from above. We mark vertices in even generations by
 $\mathscr{l}$
and vertices in odd generations by a random
$\mathscr{l}$
and vertices in odd generations by a random
 $H\in\mathscr{H}$
, determined as follows. Recall the family of conditional measures
$H\in\mathscr{H}$
, determined as follows. Recall the family of conditional measures
 $(\boldsymbol{\mu}_{\cdot \,\vert\, k})_{k\in\mathbb{Z}^+}$
from (2.40), and let us denote the degree of
$(\boldsymbol{\mu}_{\cdot \,\vert\, k})_{k\in\mathbb{Z}^+}$
from (2.40), and let us denote the degree of
 $a \in \mathscr{V}(\textrm{BP}_{\mathscr{l}})$
by
$a \in \mathscr{V}(\textrm{BP}_{\mathscr{l}})$
by
 $d_a$
. Independently of everything else, we mark a according to the measure
$d_a$
. Independently of everything else, we mark a according to the measure
 $\boldsymbol{\mu}_{\cdot \,\vert\, d_a}$
. This determines the marks on the vertices of
$\boldsymbol{\mu}_{\cdot \,\vert\, d_a}$
. This determines the marks on the vertices of
 $\textrm{BP}_{\mathscr{l}}$
. Now we describe the marks on the edges of
$\textrm{BP}_{\mathscr{l}}$
. Now we describe the marks on the edges of
 $\textrm{BP}_{\mathscr{l}}$
. We mark each edge e by a random tuple
$\textrm{BP}_{\mathscr{l}}$
. We mark each edge e by a random tuple
 $(i,l)\in(\mathbb{Z}^+)^2$
, and we determine i and l separately. (In particular, the two numbers in each tuple marking an edge are independent of each other, but are not independent of everything else.) Denote the endpoint of e in an even generation by v and the endpoint in an odd generation by a, where v and a intuitively correspond to an
$(i,l)\in(\mathbb{Z}^+)^2$
, and we determine i and l separately. (In particular, the two numbers in each tuple marking an edge are independent of each other, but are not independent of everything else.) Denote the endpoint of e in an even generation by v and the endpoint in an odd generation by a, where v and a intuitively correspond to an
 $\mathscr{l}$
- and
$\mathscr{l}$
- and
 $\mathscr{r}$
-vertex, respectively. We think of i and l as the marks of the
$\mathscr{r}$
-vertex, respectively. We think of i and l as the marks of the
 $\mathscr{l}$
- and
$\mathscr{l}$
- and
 $\mathscr{r}$
-half-edges incident to v and a, respectively. For any vertex u, we mark families of half-edges incident to u in a dependent way, so that each mark in
$\mathscr{r}$
-half-edges incident to v and a, respectively. For any vertex u, we mark families of half-edges incident to u in a dependent way, so that each mark in
 $[d_u]$
is used once, but independently of all other families. For
$[d_u]$
is used once, but independently of all other families. For
 $u \neq \underline{0}$
, we first mark the half-edge that is part of the edge connecting u to its parent, by a uniformly chosen mark
$u \neq \underline{0}$
, we first mark the half-edge that is part of the edge connecting u to its parent, by a uniformly chosen mark
 $K\sim\textrm{Unif}[d_u]$
. Since
$K\sim\textrm{Unif}[d_u]$
. Since
 $(\textrm{BP}_{\mathscr{l}},\underline{0})$
is a BP family tree, we may assume the children of each individual are ordered, which provides an ordering for those half-edges incident to u that are part of edges connecting u to its children. We mark these half-edges by the remaining marks
$(\textrm{BP}_{\mathscr{l}},\underline{0})$
is a BP family tree, we may assume the children of each individual are ordered, which provides an ordering for those half-edges incident to u that are part of edges connecting u to its children. We mark these half-edges by the remaining marks
 $[d_u] \setminus \{K\}$
in increasing order. For the root
$[d_u] \setminus \{K\}$
in increasing order. For the root
 $\underline{0}$
, we mark all its half-edges by
$\underline{0}$
, we mark all its half-edges by
 $[d_{\underline{0}}]$
in increasing order, analogously.
$[d_{\underline{0}}]$
in increasing order, analogously.
This defines the law of
 $\Xi^{\mathscr{p}}$
conditionally on
$\Xi^{\mathscr{p}}$
conditionally on
 $(\textrm{BP}_{\mathscr{l}},\underline{0})$
, and consequently the joint law
$(\textrm{BP}_{\mathscr{l}},\underline{0})$
, and consequently the joint law
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
.
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
.
Proposition 3.3 Consider the underlying BCM represented as a marked graph
 $(\textrm{BCM}_n,\Xi^{\mathscr{c}})$
under Assumption 2.2, and recall that
$(\textrm{BCM}_n,\Xi^{\mathscr{c}})$
under Assumption 2.2, and recall that
 $V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
. Then, in the generalized sense of
$V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
. Then, in the generalized sense of
 $\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
from Remark 3.1,
$\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}$
from Remark 3.1,
 \begin{equation} (\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}). \end{equation}
\begin{equation} (\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}). \end{equation}
Proof. The statement follows analogously to Proposition 3.2, by generalizing the proof of [Reference Kurauskas38, Theorem 3.1(iv)]. The breadth-first search exploration of the marked graph can be coupled to the marked branching process, by extending the coupling of the degrees to include the marks. More specifically, we have to couple the following three quantities in the BP to the corresponding ones in the graph exploration:
 $D^{\mathscr{l}}$
for the root; the joint distribution of
$D^{\mathscr{l}}$
for the root; the joint distribution of
 $\widetilde D^{\mathscr{l}}$
and K for other vertices in even generations; the joint distribution of
$\widetilde D^{\mathscr{l}}$
and K for other vertices in even generations; the joint distribution of
 $\widetilde D^{\mathscr{r}}$
, H, and K for vertices in odd generations. By the empirical convergence assumed in Assumption 2.2, the error of this coupling vanishes as
$\widetilde D^{\mathscr{r}}$
, H, and K for vertices in odd generations. By the empirical convergence assumed in Assumption 2.2, the error of this coupling vanishes as
 $n\to\infty$
. We omit further details.
$n\to\infty$
. We omit further details.
![]()
The local weak limit of the RIGC. Recall that in representing the underlying BCM as a marked graph, we also reinterpreted the community projection
 $\widehat{\mathscr{P}}\,:\, (\textrm{BCM},\Xi^{\mathscr{c}},v) \mapsto (\textrm{RIGC},v)$
acting on a rooted, suitably marked bipartite graph. (Note that this operation is well-defined even when this bipartite graph is infinite, as each community graph is inserted by a local operation.) Hence we can define
$\widehat{\mathscr{P}}\,:\, (\textrm{BCM},\Xi^{\mathscr{c}},v) \mapsto (\textrm{RIGC},v)$
acting on a rooted, suitably marked bipartite graph. (Note that this operation is well-defined even when this bipartite graph is infinite, as each community graph is inserted by a local operation.) Hence we can define
 $(\textrm{CP},o)$
as the community-projection
$(\textrm{CP},o)$
as the community-projection
 $\widehat{\mathscr{P}}$
of
$\widehat{\mathscr{P}}$
of
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
defined above, analogously to random clique trees in [Reference Kurauskas38]. It follows from the construction that
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
defined above, analogously to random clique trees in [Reference Kurauskas38]. It follows from the construction that
 $(\textrm{CP},o)$
is a simple, locally finite rooted graph with countable (possibly infinite) vertex set
$(\textrm{CP},o)$
is a simple, locally finite rooted graph with countable (possibly infinite) vertex set
 $\mathscr{V}(\textrm{CP}) = \{v\in\textrm{BP}_{\mathscr{l}}, \text{v is in an even generation}\}$
. We obtain the following insight on the overlapping structure of the communities: each vertex
$\mathscr{V}(\textrm{CP}) = \{v\in\textrm{BP}_{\mathscr{l}}, \text{v is in an even generation}\}$
. We obtain the following insight on the overlapping structure of the communities: each vertex
 $v \in \mathscr{V}(\textrm{CP})$
is part of exactly
$v \in \mathscr{V}(\textrm{CP})$
is part of exactly
 $d_v$
communities; however, by the tree structure of
$d_v$
communities; however, by the tree structure of
 $\textrm{BP}_{\mathscr{l}}$
, any two of these communities share only v as a common vertex, i.e., the proposed local weak limit CP has the single-overlap property.
$\textrm{BP}_{\mathscr{l}}$
, any two of these communities share only v as a common vertex, i.e., the proposed local weak limit CP has the single-overlap property.
We now prove the LWC.
Proof of Theorem 2.7. We show that Theorem 2.7 follows from Proposition 3.3. For some
 $r\in\mathbb{N}$
and
$r\in\mathbb{N}$
and
 $v\in\mathscr{V}^{\mathscr{l}}$
, consider the neighborhood
$v\in\mathscr{V}^{\mathscr{l}}$
, consider the neighborhood
 $B_r(\textrm{RIGC},v)$
(see Definition 2.5). We first argue that this neighborhood is fully determined by
$B_r(\textrm{RIGC},v)$
(see Definition 2.5). We first argue that this neighborhood is fully determined by
 $B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},v)$
. We show that any vertex in
$B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},v)$
. We show that any vertex in
 $B_r(\textrm{RIGC},v)$
and any community containing an edge in
$B_r(\textrm{RIGC},v)$
and any community containing an edge in
 $B_r(\textrm{RIGC},v)$
is at distance at most
$B_r(\textrm{RIGC},v)$
is at distance at most
 $2r+1$
from v in the underlying BCM. Consider a vertex u or an edge e in
$2r+1$
from v in the underlying BCM. Consider a vertex u or an edge e in
 $B_r(\textrm{RIGC},v)$
, and construct the shortest possible chain of incident edges and vertices connecting it to v: either
$B_r(\textrm{RIGC},v)$
, and construct the shortest possible chain of incident edges and vertices connecting it to v: either
 $v=v_0,e_0,v_1,e_1,\ldots,e_{k-1},v_k=u$
, or
$v=v_0,e_0,v_1,e_1,\ldots,e_{k-1},v_k=u$
, or
 $v=v_0,e_0,v_1,e_1,\ldots,e_{k-1},v_k,e_k=e$
. (The length of a chain is the total number of elements in it.) The chain is the longest possible when we consider an edge e between vertices that are both at distance r from v. In this case, the shortest chain is
$v=v_0,e_0,v_1,e_1,\ldots,e_{k-1},v_k,e_k=e$
. (The length of a chain is the total number of elements in it.) The chain is the longest possible when we consider an edge e between vertices that are both at distance r from v. In this case, the shortest chain is
 $v=v_0,e_0,v_1,e_1,\ldots,e_{k-1},v_r,e_r=e$
, with length
$v=v_0,e_0,v_1,e_1,\ldots,e_{k-1},v_r,e_r=e$
, with length
 $2r+2$
. Let
$2r+2$
. Let
 $a_i$
denote the community that
$a_i$
denote the community that
 $e_i$
is part of; then the endpoints
$e_i$
is part of; then the endpoints
 $v_i$
and
$v_i$
and
 $v_{i+1}$
must be members of community
$v_{i+1}$
must be members of community
 $a_i$
. Hence, in the underlying BCM,
$a_i$
. Hence, in the underlying BCM,
 $v_i$
and
$v_i$
and
 $v_{i+1}$
are both neighbors of
$v_{i+1}$
are both neighbors of
 $a_i$
. That is, vertices that are neighbors in the RIGC are second neighbors in the BCM. Hence we have a (not necessarily self-avoiding) path
$a_i$
. That is, vertices that are neighbors in the RIGC are second neighbors in the BCM. Hence we have a (not necessarily self-avoiding) path
 $v=v_0,a_0,v_1,a_1,\ldots,a_{k-1},v_k=u$
or
$v=v_0,a_0,v_1,a_1,\ldots,a_{k-1},v_k=u$
or
 $v=v_0,a_0,v_1,a_1,\ldots,a_{k-1},v_k,a_k \ni e_k$
in the underlying BCM. Because of the correspondence between
$v=v_0,a_0,v_1,a_1,\ldots,a_{k-1},v_k,a_k \ni e_k$
in the underlying BCM. Because of the correspondence between
 $e_i$
and
$e_i$
and
 $a_i$
, the number of
$a_i$
, the number of
 $\mathscr{b}$
-vertices in the path in the BCM is the same as the length of the chain in the RIGC. We have already established that this length is at most
$\mathscr{b}$
-vertices in the path in the BCM is the same as the length of the chain in the RIGC. We have already established that this length is at most
 $2r+2$
; hence the number of edges along the path in the BCM, i.e., the graph distance between its endpoints, is at most
$2r+2$
; hence the number of edges along the path in the BCM, i.e., the graph distance between its endpoints, is at most
 $2r+1$
. This implies that, indeed,
$2r+1$
. This implies that, indeed,
 $B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},v)$
fully determines
$B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},v)$
fully determines
 $B_r(\textrm{RIGC},v)$
.
$B_r(\textrm{RIGC},v)$
.
From now on, we consider the graph sequences
 $\textrm{BCM}_n$
and
$\textrm{BCM}_n$
and
 $\textrm{RIGC}_n$
, and we use a tightness argument to prove that the convergence of neighborhood frequencies of
$\textrm{RIGC}_n$
, and we use a tightness argument to prove that the convergence of neighborhood frequencies of
 $B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}})$
implies the convergence of neighborhood frequencies of
$B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}})$
implies the convergence of neighborhood frequencies of
 $B_r(\textrm{RIGC},V_n^{\mathscr{l}})$
. We now establish this tightness and an appropriate truncation, so that we can rely on a finite subset of possible neighborhoods in our proof. Theorem 3.3 implies that degrees are tight in the random graph sequence
$B_r(\textrm{RIGC},V_n^{\mathscr{l}})$
. We now establish this tightness and an appropriate truncation, so that we can rely on a finite subset of possible neighborhoods in our proof. Theorem 3.3 implies that degrees are tight in the random graph sequence
 $B_{r}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}})$
, as follows. Recall the limit
$B_{r}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}})$
, as follows. Recall the limit
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
from Section 3.2. By construction, all degrees in
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
from Section 3.2. By construction, all degrees in
 $\textrm{BP}_{\mathscr{l}}$
are distributed as either
$\textrm{BP}_{\mathscr{l}}$
are distributed as either
 $D^{\mathscr{l}}$
,
$D^{\mathscr{l}}$
,
 $\widetilde D^{\mathscr{l}}$
, or
$\widetilde D^{\mathscr{l}}$
, or
 $\widetilde D^{\mathscr{r}}$
(see (1.1) and Assumption 2.2(A,C1)). By Assumption 2.2, these random variables are almost surely finite; hence the maximal degree in
$\widetilde D^{\mathscr{r}}$
(see (1.1) and Assumption 2.2(A,C1)). By Assumption 2.2, these random variables are almost surely finite; hence the maximal degree in
 $B_r(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
is almost surely finite. Note that for any
$B_r(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
is almost surely finite. Note that for any
 $K\in\mathbb{Z}^+$
, the functional
$K\in\mathbb{Z}^+$
, the functional
 $\mathbb{1}_{\{ \text{maximal degree in r-ball} > K \}}$
is bounded and continuous in the metric space
$\mathbb{1}_{\{ \text{maximal degree in r-ball} > K \}}$
is bounded and continuous in the metric space
 $(\mathscr{G}_o,d_{\textrm{loc}})$
(see Section 3.1). Thus by (3.4) and Proposition 3.3,
$(\mathscr{G}_o,d_{\textrm{loc}})$
(see Section 3.1). Thus by (3.4) and Proposition 3.3,
 \begin{equation} \begin{aligned} &\mathbb{P}\bigl( \max \bigl\{ \mathscr{b}\text{-}\textrm{deg}(v) \,:\, v \in B_{r}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \bigr\} > K \;\big\vert\; \omega_n \bigr) \\&\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl( \max \bigl\{ \mathscr{b}\text{-}\textrm{deg}(v) \,:\, v \in B_r(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \bigr\} > K \bigr), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\mathbb{P}\bigl( \max \bigl\{ \mathscr{b}\text{-}\textrm{deg}(v) \,:\, v \in B_{r}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \bigr\} > K \;\big\vert\; \omega_n \bigr) \\&\buildrel {\mathbb{P}}\over{\longrightarrow} \mathbb{P}\bigl( \max \bigl\{ \mathscr{b}\text{-}\textrm{deg}(v) \,:\, v \in B_r(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \bigr\} > K \bigr), \end{aligned} \end{equation}
where the right-hand side vanishes as
 $K\to\infty$
, as we have shown that the maximal degree in the r-ball is almost surely finite. Hence for any
$K\to\infty$
, as we have shown that the maximal degree in the r-ball is almost surely finite. Hence for any
 $\varepsilon>0$
, there exists
$\varepsilon>0$
, there exists
 $K=K(\varepsilon,r)\in\mathbb{Z}^+$
such that
$K=K(\varepsilon,r)\in\mathbb{Z}^+$
such that
 \begin{align} \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \} > K \bigr)
< \varepsilon/6, \end{align}
\begin{align} \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \} > K \bigr)
< \varepsilon/6, \end{align}
 \begin{align} \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \} > K \;\big\vert\; \omega_n \bigr)
< \varepsilon/3 \quad \text{w.h.p.}\end{align}
\begin{align} \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \} > K \;\big\vert\; \omega_n \bigr)
< \varepsilon/3 \quad \text{w.h.p.}\end{align}
Consider some
 $(H,o) \in \mathscr{G}_o$
that is a possible outcome of
$(H,o) \in \mathscr{G}_o$
that is a possible outcome of
 $B_r(\textrm{RIGC},V_n^{\mathscr{l}})$
. Denote by
$B_r(\textrm{RIGC},V_n^{\mathscr{l}})$
. Denote by
 $\mathscr{X}$
the set of all possible outcomes
$\mathscr{X}$
the set of all possible outcomes
 $(G,\Xi_G,o)$
of the random graph
$(G,\Xi_G,o)$
of the random graph
 $B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}})$
. Further, denote by
$B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}})$
. Further, denote by
 $\mathscr{Y}$
the subset of all
$\mathscr{Y}$
the subset of all
 $(G,\Xi_G,o) \in \mathscr{X}$
such that the r-ball in their
$(G,\Xi_G,o) \in \mathscr{X}$
such that the r-ball in their
 $\widehat{\mathscr{P}}$
-projection is (H,o). That is,
$\widehat{\mathscr{P}}$
-projection is (H,o). That is,
 $B_r(\textrm{RIGC},V_n^{\mathscr{l}}) \simeq (H,o)$
exactly when
$B_r(\textrm{RIGC},V_n^{\mathscr{l}}) \simeq (H,o)$
exactly when
 $B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o)$
for some
$B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o)$
for some
 $(G,\Xi_G,o) \in \mathscr{Y}$
. Similarly,
$(G,\Xi_G,o) \in \mathscr{Y}$
. Similarly,
 $B_r(\textrm{CP},o) \simeq (H,o)$
exactly when
$B_r(\textrm{CP},o) \simeq (H,o)$
exactly when
 $B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o)$
for some
$B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o)$
for some
 $(G,\Xi_G,o) \in \mathscr{Y}$
. Thus, to prove Theorem 2.7, it is sufficient to show that
$(G,\Xi_G,o) \in \mathscr{Y}$
. Thus, to prove Theorem 2.7, it is sufficient to show that
 \begin{equation} \begin{aligned} &\sum_{(G,\Xi_G,o) \in \mathscr{Y}} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\&\buildrel {\mathbb{P}}\over{\longrightarrow} \sum_{(G,\Xi_G,o) \in \mathscr{Y}} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr).\end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\sum_{(G,\Xi_G,o) \in \mathscr{Y}} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\&\buildrel {\mathbb{P}}\over{\longrightarrow} \sum_{(G,\Xi_G,o) \in \mathscr{Y}} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr).\end{aligned} \end{equation}
We prove this using the above truncation. With
 $K=K(\varepsilon,r)$
above, denote the subset of elements in
$K=K(\varepsilon,r)$
above, denote the subset of elements in
 $\mathscr{Y}$
where the maximal degree is at most K by
$\mathscr{Y}$
where the maximal degree is at most K by
 \begin{equation} \mathscr{Y}({\leq} K) \,{:}\,{\raise-1.5pt{=}}\, \Bigl\{ (G,\Xi_G,o)\,:\, \max\{\mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in(G,\Xi_G,o)\} \leq K \Bigr\}, \end{equation}
\begin{equation} \mathscr{Y}({\leq} K) \,{:}\,{\raise-1.5pt{=}}\, \Bigl\{ (G,\Xi_G,o)\,:\, \max\{\mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in(G,\Xi_G,o)\} \leq K \Bigr\}, \end{equation}
and let
 $\mathscr{Y}({>}K) \,{:}\,{\raise-1.5pt{=}}\, \mathscr{Y} \setminus \mathscr{Y}({\leq} K)$
. Define
$\mathscr{Y}({>}K) \,{:}\,{\raise-1.5pt{=}}\, \mathscr{Y} \setminus \mathscr{Y}({\leq} K)$
. Define
 $\mathscr{X}({\leq}K)$
and
$\mathscr{X}({\leq}K)$
and
 $\mathscr{X}({>}K)$
analogously: all elements of
$\mathscr{X}({>}K)$
analogously: all elements of
 $\mathscr{X}$
where the maximal degree is at most K and larger than K, respectively. Note that
$\mathscr{X}$
where the maximal degree is at most K and larger than K, respectively. Note that
 $\mathscr{Y}({\leq}K) \subseteq \mathscr{X}({\leq}K)$
is finite; hence by Proposition 3.3, the sum over this finite set converges:
$\mathscr{Y}({\leq}K) \subseteq \mathscr{X}({\leq}K)$
is finite; hence by Proposition 3.3, the sum over this finite set converges:
 \begin{equation} \begin{aligned} &\sum_{(G,\Xi_G,o) \in \mathscr{Y}({\leq}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\[4pt]
&\buildrel {\mathbb{P}}\over{\longrightarrow} \sum_{(G,\Xi_G,o) \in \mathscr{Y}({\leq}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr).\end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\sum_{(G,\Xi_G,o) \in \mathscr{Y}({\leq}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\[4pt]
&\buildrel {\mathbb{P}}\over{\longrightarrow} \sum_{(G,\Xi_G,o) \in \mathscr{Y}({\leq}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr).\end{aligned} \end{equation}
We bound the tail of the left-hand side of (3.17) as
 \begin{equation} \begin{aligned} &\sum_{(G,\Xi_G,o) \in \mathscr{Y}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\[4pt]
&\leq \sum_{(G,\Xi_G,o) \in \mathscr{X}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\[4pt]
&= \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \} > K \;\big\vert\; \omega_n \bigr)
< \varepsilon/3 \quad \text{w.h.p.},\end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\sum_{(G,\Xi_G,o) \in \mathscr{Y}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\[4pt]
&\leq \sum_{(G,\Xi_G,o) \in \mathscr{X}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BCM},\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \simeq (G,\Xi_G,o) \;\Big\vert\; \omega_n \Bigr) \\[4pt]
&= \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BCM}_n,\Xi^{\mathscr{c}},V_n^{\mathscr{l}}) \} > K \;\big\vert\; \omega_n \bigr)
< \varepsilon/3 \quad \text{w.h.p.},\end{aligned} \end{equation}
by (3.16b). Analogously, the tail of the right-hand side of (3.17) can be bounded as
 \begin{equation} \begin{aligned}&\sum_{(G,\Xi_G,o) \in \mathscr{Y}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr) \\[4pt]
&\leq \sum_{(G,\Xi_G,o) \in \mathscr{X}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr) \\[4pt]
&= \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \} > K \bigr)
< \varepsilon/6, \end{aligned} \end{equation}
\begin{equation} \begin{aligned}&\sum_{(G,\Xi_G,o) \in \mathscr{Y}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr) \\[4pt]
&\leq \sum_{(G,\Xi_G,o) \in \mathscr{X}({>}K)} \mathbb{P} \Bigl( B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \simeq (G,\Xi_G,o) \Bigr) \\[4pt]
&= \mathbb{P}\bigl( \max \{ \mathscr{b}\text{-}\textrm{deg}(v)\,:\, v\in B_{2r+1}(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0}) \} > K \bigr)
< \varepsilon/6, \end{aligned} \end{equation}
by (3.16a). Note that (3.19) implies that the difference between the finite sums is at most
 $\varepsilon/2$
w.h.p. Combining this observation with (3.20) and (3.21) via the triangle inequality implies that (3.17) holds. Since we have previously reduced Theorem 2.7 to this statement, this concludes the proof of Theorem 2.7.
$\varepsilon/2$
w.h.p. Combining this observation with (3.20) and (3.21) via the triangle inequality implies that (3.17) holds. Since we have previously reduced Theorem 2.7 to this statement, this concludes the proof of Theorem 2.7.
![]()
3.4. Proofs of further results on the random intersection graph with communities
We now provide the proofs of our results on the local properties of the RIGC model as consequences of LWC. Namely, we prove the convergence of the degree and local clustering coefficient and study the overlapping structure in Sections 3.4.1 and 3.4.2, respectively.
3.4.1 Degrees and clustering
Recall the definition of
 $(\textrm{CP},o)$
, the local weak limit of the RIGC, as the
$(\textrm{CP},o)$
, the local weak limit of the RIGC, as the
 $\widehat{\mathscr{P}}$
-projection of
$\widehat{\mathscr{P}}$
-projection of
 $(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
from Section 3.3. By this construction, it is clear that
$(\textrm{BP}_{\mathscr{l}},\Xi^{\mathscr{p}},\underline{0})$
from Section 3.3. By this construction, it is clear that
 $D^{\mathscr{p}}$
(see (2.20)) and
$D^{\mathscr{p}}$
(see (2.20)) and
 $\zeta$
(see (2.25)) respectively describe the degree and local clustering coefficient of
$\zeta$
(see (2.25)) respectively describe the degree and local clustering coefficient of
 $o \in \textrm{CP}$
. Further recall the empirical degree
$o \in \textrm{CP}$
. Further recall the empirical degree
 $D_n^{\mathscr{p}}$
(see (2.11)–(2.12)) and empirical local clustering
$D_n^{\mathscr{p}}$
(see (2.11)–(2.12)) and empirical local clustering
 $\zeta_n$
(see (2.24)–(2.25)). Since
$\zeta_n$
(see (2.24)–(2.25)). Since
 \begin{equation*}(\textrm{RIGC}_n,V_n^{\mathscr{l}})\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}(\textrm{CP},o),\end{equation*}
\begin{equation*}(\textrm{RIGC}_n,V_n^{\mathscr{l}})\buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow}(\textrm{CP},o),\end{equation*}
it is intuitive that
 $D_n^{\mathscr{p}}\buildrel d\over{\longrightarrow} D^{\mathscr{p}}$
and
$D_n^{\mathscr{p}}\buildrel d\over{\longrightarrow} D^{\mathscr{p}}$
and
 $\zeta_n \buildrel d\over{\longrightarrow} \zeta$
. We complete the formal proof of the stronger statements (2.21) and (2.26) below.
$\zeta_n \buildrel d\over{\longrightarrow} \zeta$
. We complete the formal proof of the stronger statements (2.21) and (2.26) below.
Proof of Corollaries 2.8 and 2.9. We show that pointwise convergence of the empirical CDFs follows directly from Theorem 2.7, by the following reasoning. Recall that
 $\mathbb{P}(\,\cdot \mid \omega_n)$
denotes conditional probability with respect to
$\mathbb{P}(\,\cdot \mid \omega_n)$
denotes conditional probability with respect to
 $\omega_n$
and
$\omega_n$
and
 $\mathbb{E}[\,\cdot \mid \omega_n]$
denotes the corresponding conditional expectation. Further, denote by
$\mathbb{E}[\,\cdot \mid \omega_n]$
denotes the corresponding conditional expectation. Further, denote by
 $\mathbb{P}_o$
and
$\mathbb{P}_o$
and
 $\mathbb{E}_o$
the probability measure of
$\mathbb{E}_o$
the probability measure of
 $(\textrm{CP},o)$
and the corresponding expectation. For arbitrary fixed
$(\textrm{CP},o)$
and the corresponding expectation. For arbitrary fixed
 $x\in\mathbb{R}$
, we define the functionals
$x\in\mathbb{R}$
, we define the functionals
 \begin{equation} \varphi_x, \psi_x\,:\, \mathscr{G}_o\to\{0,1\},\quad \varphi_x(G,o) \,{:}\,{\raise-1.5pt{=}}\, \mathbb{1}_{\{\deg(o)\leq x\}},\quad \psi_x(G,o)\,{:}\,{\raise-1.5pt{=}}\, \mathbb{1}_{\{\textrm{Cl}(o)\leq x\}}. \end{equation}
\begin{equation} \varphi_x, \psi_x\,:\, \mathscr{G}_o\to\{0,1\},\quad \varphi_x(G,o) \,{:}\,{\raise-1.5pt{=}}\, \mathbb{1}_{\{\deg(o)\leq x\}},\quad \psi_x(G,o)\,{:}\,{\raise-1.5pt{=}}\, \mathbb{1}_{\{\textrm{Cl}(o)\leq x\}}. \end{equation}
Clearly, both functionals are bounded and only depend on a finite neighborhood of o; thus they are continuous in the metric space
 $(\mathscr{G}_o,d_{\textrm{loc}})$
(see Section 3.1). Note that we can express the (empirical) CDFs from (2.12), (2.20), (2.24), and (2.25), respectively, as
$(\mathscr{G}_o,d_{\textrm{loc}})$
(see Section 3.1). Note that we can express the (empirical) CDFs from (2.12), (2.20), (2.24), and (2.25), respectively, as
 \begin{equation}\begin{aligned} F_n^{\mathscr{p}}(x) &= \mathbb{E}\bigl[ \varphi_x(\textrm{RIGC}_n,V_n^{\mathscr{l}}) \;\big\vert\; \omega_n \bigr],& F^{\mathscr{p}}(x) &= \mathbb{E}_o \bigl[ \varphi_x(\textrm{CP},o) \bigr], \\[4pt]
F_n^\zeta(x) &= \mathbb{E}\bigl[ \psi_x(\textrm{RIGC}_n,V_n^{\mathscr{l}}) \;\big\vert\; \omega_n \bigr],& F^\zeta(x) &= \mathbb{E}_o \bigl[ \psi_x(\textrm{CP},o) \bigr].\end{aligned}\end{equation}
\begin{equation}\begin{aligned} F_n^{\mathscr{p}}(x) &= \mathbb{E}\bigl[ \varphi_x(\textrm{RIGC}_n,V_n^{\mathscr{l}}) \;\big\vert\; \omega_n \bigr],& F^{\mathscr{p}}(x) &= \mathbb{E}_o \bigl[ \varphi_x(\textrm{CP},o) \bigr], \\[4pt]
F_n^\zeta(x) &= \mathbb{E}\bigl[ \psi_x(\textrm{RIGC}_n,V_n^{\mathscr{l}}) \;\big\vert\; \omega_n \bigr],& F^\zeta(x) &= \mathbb{E}_o \bigl[ \psi_x(\textrm{CP},o) \bigr].\end{aligned}\end{equation}
Theorem 2.7 asserts that
 $(\textrm{RIGC}_n,V_n^{\mathscr{l}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{CP},o)$
; thus, using the equivalent definition of LWC in probability (3.7), for any fixed
$(\textrm{RIGC}_n,V_n^{\mathscr{l}}) \buildrel {\mathbb{P}\text{-loc}}\over{\longrightarrow} (\textrm{CP},o)$
; thus, using the equivalent definition of LWC in probability (3.7), for any fixed
 $x\in\mathbb{R}$
, as
$x\in\mathbb{R}$
, as
 $n\to\infty$
,
$n\to\infty$
,
 \begin{equation} F_n^{\mathscr{p}}(x) \buildrel {\mathbb{P}}\over{\longrightarrow} F^{\mathscr{p}}(x),\quad F_n^\zeta(x) \buildrel {\mathbb{P}}\over{\longrightarrow} F^\zeta(x). \end{equation}
\begin{equation} F_n^{\mathscr{p}}(x) \buildrel {\mathbb{P}}\over{\longrightarrow} F^{\mathscr{p}}(x),\quad F_n^\zeta(x) \buildrel {\mathbb{P}}\over{\longrightarrow} F^\zeta(x). \end{equation}
That is, indeed, the empirical CDF of degrees and local clustering coefficient converge in probability pointwise. This can be strengthened to the convergence in sup-norm in (2.21) and (2.26) by a truncation argument. The details can be found in the extended version of this paper [Reference Van der Hofstad, Komjáthy and Vadon31].
![]()
3.4.2. The overlapping structure
In this section, we prove Proposition 2.11 and Theorem 2.12 on the typical number and size of overlaps in the RIGC model. Theorem 2.12(i)–(ii) follows easily from Theorem 2.7 by counting 4-cycles through the root. For a detailed argument, we refer the interested reader to the extended version of this paper [Reference Van der Hofstad, Komjáthy and Vadon31]. We do provide the proof of Proposition 2.11 and Theorem 2.12(iii), which rely on the additional second moment condition (2.35) and require a slightly different approach. We make use of the following notation. Recall that
 $V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
,
$V_n^{\mathscr{l}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}]$
,
 $V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
, and
$V_n^{\mathscr{r}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{r}}]$
, and
 $V_n^{\mathscr{b}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}\cup\mathscr{V}^{\mathscr{r}}]$
. Further recall that
$V_n^{\mathscr{b}} \sim \textrm{Unif}[\mathscr{V}^{\mathscr{l}}\cup\mathscr{V}^{\mathscr{r}}]$
. Further recall that
 $\mathbb{P}(\,\cdot \mid \omega_n)$
denotes conditional probability with respect to
$\mathbb{P}(\,\cdot \mid \omega_n)$
denotes conditional probability with respect to
 $\omega_n$
(i.e., conditionally on the graph realization), and
$\omega_n$
(i.e., conditionally on the graph realization), and
 $\mathbb{E}[\,\cdot \mid \omega_n]$
denotes the corresponding conditional expectation (i.e., partial average over the choice of the uniform vertex).
$\mathbb{E}[\,\cdot \mid \omega_n]$
denotes the corresponding conditional expectation (i.e., partial average over the choice of the uniform vertex).
Sketch of proof of Proposition 2.11. As before, we reduce Proposition 2.11 to LWC. Thus, we define the functional
 $\varphi$
on
$\varphi$
on
 $\mathscr{G}_o$
(see Section 3.1 for the notation) that counts the number of vertices at graph distance 2 from the root; i.e., for
$\mathscr{G}_o$
(see Section 3.1 for the notation) that counts the number of vertices at graph distance 2 from the root; i.e., for
 $(G,o)\in\mathscr{G}_o$
,
$(G,o)\in\mathscr{G}_o$
,
 \begin{equation} \varphi(G,o) \,{:}\,{\raise-1.5pt{=}}\, \lvert{\partial B_2(G,o)}\rvert. \end{equation}
\begin{equation} \varphi(G,o) \,{:}\,{\raise-1.5pt{=}}\, \lvert{\partial B_2(G,o)}\rvert. \end{equation}
Recall (2.32)–(2.33). We can rewrite the left-hand side of (2.36) as
 \begin{equation} \begin{split} \frac{2 \lvert{ \mathscr{L}_1 }\rvert}{M_n}= \mathbb{E}\bigl[ \lvert{\mathscr{N}(V_n^{\mathscr{r}})}\rvert \;\big\vert\; \omega_n \bigr]= \mathbb{E} \bigl[ \varphi(\textrm{BCM}_n,V_n^{\mathscr{r}}) \;\big\vert\; \omega_n \bigr]. \end{split} \end{equation}
\begin{equation} \begin{split} \frac{2 \lvert{ \mathscr{L}_1 }\rvert}{M_n}= \mathbb{E}\bigl[ \lvert{\mathscr{N}(V_n^{\mathscr{r}})}\rvert \;\big\vert\; \omega_n \bigr]= \mathbb{E} \bigl[ \varphi(\textrm{BCM}_n,V_n^{\mathscr{r}}) \;\big\vert\; \omega_n \bigr]. \end{split} \end{equation}
Recall
 $(\textrm{BP}_{\mathscr{r}},\underline{0})$
from Section 3.2 and note that
$(\textrm{BP}_{\mathscr{r}},\underline{0})$
from Section 3.2 and note that
 \begin{equation} \mathbb{E}\bigl[ \varphi(\textrm{BP}_{\mathscr{r}},\underline{0}) \bigr] = \mathbb{E}[D^{\mathscr{r}}] \mathbb{E}[\widetilde D^{\mathscr{l}}], \end{equation}
\begin{equation} \mathbb{E}\bigl[ \varphi(\textrm{BP}_{\mathscr{r}},\underline{0}) \bigr] = \mathbb{E}[D^{\mathscr{r}}] \mathbb{E}[\widetilde D^{\mathscr{l}}], \end{equation}
which is exactly the proposed limit of (3.26). The proof can now be completed by applying Proposition 3.3 and (3.4) as before; however, some technical difficulties arise. Namely, the functional
 $\varphi$
is not bounded, so a truncation argument is necessary. The technicalities of this truncation argument are included in the extended version of this paper [Reference Van der Hofstad, Komjáthy and Vadon31]. This concludes the proof of Proposition 2.11.
$\varphi$
is not bounded, so a truncation argument is necessary. The technicalities of this truncation argument are included in the extended version of this paper [Reference Van der Hofstad, Komjáthy and Vadon31]. This concludes the proof of Proposition 2.11.
Proof of Theorem 2.12(iii). Recall
 $\mathscr{O}(a,b)$
and
$\mathscr{O}(a,b)$
and
 $\mathscr{L}_k$
from (2.32)–(2.34). By Proposition 2.11,
$\mathscr{L}_k$
from (2.32)–(2.34). By Proposition 2.11,
 $\lvert{\mathscr{L}_1}\rvert$
is of order
$\lvert{\mathscr{L}_1}\rvert$
is of order
 $M_n$
; thus, to show that
$M_n$
; thus, to show that
 $\lvert{\mathscr{L}_2}\rvert/\lvert{\mathscr{L}_1}\rvert = o_{\mathbb{P}}(1)$
, it is sufficient to prove that
$\lvert{\mathscr{L}_2}\rvert/\lvert{\mathscr{L}_1}\rvert = o_{\mathbb{P}}(1)$
, it is sufficient to prove that
 $\lvert{\mathscr{L}_2}\rvert = o_{\mathbb{P}}(M_n)$
, which we carry out via a first moment method. We compute
$\lvert{\mathscr{L}_2}\rvert = o_{\mathbb{P}}(M_n)$
, which we carry out via a first moment method. We compute
 \begin{equation} 2\, \mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr]= \mathbb{E}\Bigl[ \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b}} \mathbb{1}_{\{\mathscr{O}(a,b)\geq 2\}} \Bigr]= \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr). \end{equation}
\begin{equation} 2\, \mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr]= \mathbb{E}\Bigl[ \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b}} \mathbb{1}_{\{\mathscr{O}(a,b)\geq 2\}} \Bigr]= \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr). \end{equation}
With some K to be chosen later, we split the sum
 \begin{equation} \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr)= \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}\leq K}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr)+ \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}> K}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr). \end{equation}
\begin{equation} \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr)= \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}\leq K}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr)+ \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}> K}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr). \end{equation}
We start by bounding the first term. Recall that
![]()
denotes the event that v takes a community role in
 $\textrm{Com}_a$
. For individuals
$\textrm{Com}_a$
. For individuals
 $v_1,\ldots,v_k$
and communities
$v_1,\ldots,v_k$
and communities
 $a_1,\ldots,a_l$
, denote the event that all k individuals are in all l communities by
$a_1,\ldots,a_l$
, denote the event that all k individuals are in all l communities by
Further recall
 $d_v^{\mathscr{l}}$
and
$d_v^{\mathscr{l}}$
and
 $d_a^{\mathscr{r}}$
from Section 2.1 and
$d_a^{\mathscr{r}}$
from Section 2.1 and
 $\mathscr{h}_n$
from (2.1). By the union bound, we obtain
$\mathscr{h}_n$
from (2.1). By the union bound, we obtain

by counting the suitable versus the available choices of half-edges. Using (1.1), (2.3), and the fact that
 $\mathscr{h}_n = \mathbb{E}[D_n^{\mathscr{l}}] N_n$
by Remark 2.3(i), we have
$\mathscr{h}_n = \mathbb{E}[D_n^{\mathscr{l}}] N_n$
by Remark 2.3(i), we have
 \begin{equation} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \frac{d_v^{\mathscr{l}}(d_v^{\mathscr{l}}-1)}{\mathscr{h}_n}= \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \frac{d_v^{\mathscr{l}}(d_v^{\mathscr{l}}-1)}{\mathbb{E}[D_n^{\mathscr{l}}]}= \frac{\mathbb{E}\bigl[ D_n^{\mathscr{l}} (D_n^{\mathscr{l}}-1) \bigr]}{\mathbb{E}[D_n^{\mathscr{l}}]}= \mathbb{E}\bigl[ \widetilde D_n^{\mathscr{l}} \bigr]. \end{equation}
\begin{equation} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \frac{d_v^{\mathscr{l}}(d_v^{\mathscr{l}}-1)}{\mathscr{h}_n}= \frac{1}{N_n} \sum_{v\in\mathscr{V}^{\mathscr{l}}} \frac{d_v^{\mathscr{l}}(d_v^{\mathscr{l}}-1)}{\mathbb{E}[D_n^{\mathscr{l}}]}= \frac{\mathbb{E}\bigl[ D_n^{\mathscr{l}} (D_n^{\mathscr{l}}-1) \bigr]}{\mathbb{E}[D_n^{\mathscr{l}}]}= \mathbb{E}\bigl[ \widetilde D_n^{\mathscr{l}} \bigr]. \end{equation}
Since
 $\mathscr{h}_n\to\infty$
as
$\mathscr{h}_n\to\infty$
as
 $n\to\infty$
, we have that
$n\to\infty$
, we have that
 $2\mathscr{h}_n(\mathscr{h}_n-1)(\mathscr{h}_n-2)(\mathscr{h}_n-3) \geq \mathscr{h}_n^4$
for n large enough; thus, combining (3.31)–(3.32), we obtain
$2\mathscr{h}_n(\mathscr{h}_n-1)(\mathscr{h}_n-2)(\mathscr{h}_n-3) \geq \mathscr{h}_n^4$
for n large enough; thus, combining (3.31)–(3.32), we obtain
 \begin{equation} \begin{aligned} \mathbb{P}\bigl( \mathscr{O}(a,b) \geq 2 \bigr)&\leq \frac{d_a^{\mathscr{r}}(d_a^{\mathscr{r}}-1)d_b^{\mathscr{r}}(d_b^{\mathscr{r}}-1)}{\mathscr{h}_n^2}\sum_{v,w\in\mathscr{V}^{\mathscr{l}}} \frac{d_v^{\mathscr{l}}(d_v^{\mathscr{l}}-1)}{\mathscr{h}_n}\frac{d_w^{\mathscr{l}}(d_w^{\mathscr{l}}-1)}{\mathscr{h}_n} \\&\leq \frac{d_a^{\mathscr{r}}(d_a^{\mathscr{r}}-1)d_b^{\mathscr{r}}(d_b^{\mathscr{r}}-1)}{\mathscr{h}_n^2} \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2.\end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathbb{P}\bigl( \mathscr{O}(a,b) \geq 2 \bigr)&\leq \frac{d_a^{\mathscr{r}}(d_a^{\mathscr{r}}-1)d_b^{\mathscr{r}}(d_b^{\mathscr{r}}-1)}{\mathscr{h}_n^2}\sum_{v,w\in\mathscr{V}^{\mathscr{l}}} \frac{d_v^{\mathscr{l}}(d_v^{\mathscr{l}}-1)}{\mathscr{h}_n}\frac{d_w^{\mathscr{l}}(d_w^{\mathscr{l}}-1)}{\mathscr{h}_n} \\&\leq \frac{d_a^{\mathscr{r}}(d_a^{\mathscr{r}}-1)d_b^{\mathscr{r}}(d_b^{\mathscr{r}}-1)}{\mathscr{h}_n^2} \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2.\end{aligned} \end{equation}
Then, using the condition
 $d_a^{\mathscr{r}} \leq K$
, the definition of
$d_a^{\mathscr{r}} \leq K$
, the definition of
 $d_{\textrm{max}}^{\mathscr{r}}$
from Remark 2.3(iii), and the fact that
$d_{\textrm{max}}^{\mathscr{r}}$
from Remark 2.3(iii), and the fact that
 $\mathscr{h}_n = \sum_{b\in\mathscr{V}^{\mathscr{r}}} d_b^{\mathscr{r}}$
by definition, we have
$\mathscr{h}_n = \sum_{b\in\mathscr{V}^{\mathscr{r}}} d_b^{\mathscr{r}}$
by definition, we have
 \begin{equation} \begin{aligned} \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}\leq K}} \mathbb{P}\bigl( \mathscr{O}(a,b) \geq 2 \bigr)&\leq \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}\leq K}} \frac{d_a^{\mathscr{r}}(d_a^{\mathscr{r}}-1)d_b^{\mathscr{r}}(d_b^{\mathscr{r}}-1)}{\mathscr{h}_n^2} \\[5pt]
&
< \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 M_n \sum_{b\in\mathscr{V}^{\mathscr{r}}} \frac{d_b^{\mathscr{r}}(d_{\textrm{max}}^{\mathscr{r}}-1)}{\mathscr{h}_n^2}\leq \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 M_n \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n}. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}\leq K}} \mathbb{P}\bigl( \mathscr{O}(a,b) \geq 2 \bigr)&\leq \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}\leq K}} \frac{d_a^{\mathscr{r}}(d_a^{\mathscr{r}}-1)d_b^{\mathscr{r}}(d_b^{\mathscr{r}}-1)}{\mathscr{h}_n^2} \\[5pt]
&
< \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 M_n \sum_{b\in\mathscr{V}^{\mathscr{r}}} \frac{d_b^{\mathscr{r}}(d_{\textrm{max}}^{\mathscr{r}}-1)}{\mathscr{h}_n^2}\leq \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 M_n \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n}. \end{aligned} \end{equation}
We continue by bounding the second term in (3.29), where
 $d_a^{\mathscr{r}}>K$
. Using Markov’s inequality, we obtain an alternative bound for the probability
$d_a^{\mathscr{r}}>K$
. Using Markov’s inequality, we obtain an alternative bound for the probability
 \begin{equation} \mathbb{P}\bigl( \mathscr{O}(a,b) \geq 2 \bigr) \leq \mathbb{E}\bigl[ \mathscr{O}(a,b) \bigr]/2. \end{equation}
\begin{equation} \mathbb{P}\bigl( \mathscr{O}(a,b) \geq 2 \bigr) \leq \mathbb{E}\bigl[ \mathscr{O}(a,b) \bigr]/2. \end{equation}
Taking expectation in (2.32) and again using (3.32), we have

Combining (3.35)–(3.36), and using that
 $\sum_{b\in\mathscr{V}^{\mathscr{r}}}d_b^{\mathscr{r}} = \mathscr{h}_n \leq 2(\mathscr{h}_n-1)$
for n large enough, we get
$\sum_{b\in\mathscr{V}^{\mathscr{r}}}d_b^{\mathscr{r}} = \mathscr{h}_n \leq 2(\mathscr{h}_n-1)$
for n large enough, we get
 \begin{equation} \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}> K}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr)\leq \frac{\mathbb{E}[\widetilde D_n^{\mathscr{l}}]}{2} \sum_{b\in\mathscr{V}^{\mathscr{r}}} \frac{d_b^{\mathscr{r}}}{\mathscr{h}_n-1} \sum_{\substack{a\in\mathscr{V}^{\mathscr{r}}\\d_a^{\mathscr{r}}> K}} d_a^{\mathscr{r}}\leq \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \sum_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}} \mathbb{1}_{\{d_a^{\mathscr{r}}>K\}}. \end{equation}
\begin{equation} \sum_{\substack{a,b\in\mathscr{V}^{\mathscr{r}}\\a\neq b\\d_a^{\mathscr{r}}> K}} \mathbb{P}\bigl( \mathscr{O}(a,b)\geq2 \bigr)\leq \frac{\mathbb{E}[\widetilde D_n^{\mathscr{l}}]}{2} \sum_{b\in\mathscr{V}^{\mathscr{r}}} \frac{d_b^{\mathscr{r}}}{\mathscr{h}_n-1} \sum_{\substack{a\in\mathscr{V}^{\mathscr{r}}\\d_a^{\mathscr{r}}> K}} d_a^{\mathscr{r}}\leq \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \sum_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}} \mathbb{1}_{\{d_a^{\mathscr{r}}>K\}}. \end{equation}
Combining (3.29), (3.34), and (3.37), we have
 \begin{equation} \begin{aligned} \frac{2\, \mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr]}{M_n}&\leq \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n}+ \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \frac{1}{M_n} \sum_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}} \mathbb{1}_{\{d_a^{\mathscr{r}}>K\}} \\&= \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n}+ \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \mathbb{E}[D_n^{\mathscr{r}} \mathbb{1}_{\{D_n^{\mathscr{r}}>K\}}]. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \frac{2\, \mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr]}{M_n}&\leq \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n}+ \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \frac{1}{M_n} \sum_{a\in\mathscr{V}^{\mathscr{r}}} d_a^{\mathscr{r}} \mathbb{1}_{\{d_a^{\mathscr{r}}>K\}} \\&= \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n}+ \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \mathbb{E}[D_n^{\mathscr{r}} \mathbb{1}_{\{D_n^{\mathscr{r}}>K\}}]. \end{aligned} \end{equation}
We show that
 $\mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr] / M_n \to 0$
by showing that it can be made arbitrarily small for n large enough. Fix an arbitrary
$\mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr] / M_n \to 0$
by showing that it can be made arbitrarily small for n large enough. Fix an arbitrary
 $\varepsilon>0$
; we will choose first K, then n, so that the obtained upper bound is smaller than
$\varepsilon>0$
; we will choose first K, then n, so that the obtained upper bound is smaller than
 $\varepsilon$
. Under the second moment condition (2.35),
$\varepsilon$
. Under the second moment condition (2.35),
 $\mathbb{E}[\widetilde D_n^{\mathscr{l}}] \to \mathbb{E}[\widetilde D^{\mathscr{l}}] < \infty$
; thus
$\mathbb{E}[\widetilde D_n^{\mathscr{l}}] \to \mathbb{E}[\widetilde D^{\mathscr{l}}] < \infty$
; thus
 $(\mathbb{E}[\widetilde D_n^{\mathscr{l}}])_{n\in\mathbb{N}}$
is bounded. By Assumption 2.2(D),
$(\mathbb{E}[\widetilde D_n^{\mathscr{l}}])_{n\in\mathbb{N}}$
is bounded. By Assumption 2.2(D),
 $(D_n^{\mathscr{r}})_{n\in\mathbb{N}}$
is uniformly integrable; thus we can choose
$(D_n^{\mathscr{r}})_{n\in\mathbb{N}}$
is uniformly integrable; thus we can choose
 $K=K(\varepsilon)$
large enough so that for all n large enough,
$K=K(\varepsilon)$
large enough so that for all n large enough,
 \begin{equation} \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \mathbb{E}[D_n^{\mathscr{r}} \mathbb{1}_{\{D_n^{\mathscr{r}}>K\}}] \leq \varepsilon. \end{equation}
\begin{equation} \mathbb{E}[\widetilde D_n^{\mathscr{l}}] \mathbb{E}[D_n^{\mathscr{r}} \mathbb{1}_{\{D_n^{\mathscr{r}}>K\}}] \leq \varepsilon. \end{equation}
Again using that
 $(\mathbb{E}[\widetilde D_n^{\mathscr{l}}])_{n\in\mathbb{N}}$
is bounded, and further that K is now fixed and
$(\mathbb{E}[\widetilde D_n^{\mathscr{l}}])_{n\in\mathbb{N}}$
is bounded, and further that K is now fixed and
 $d_{\textrm{max}}^{\mathscr{r}}/\mathscr{h}_n\to0$
by Remark 2.3(iii), we conclude that for n large enough,
$d_{\textrm{max}}^{\mathscr{r}}/\mathscr{h}_n\to0$
by Remark 2.3(iii), we conclude that for n large enough,
 \begin{equation} \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n} \leq \varepsilon. \end{equation}
\begin{equation} \bigl(\mathbb{E}[\widetilde D_n^{\mathscr{l}}]\bigr)^2 K^2 \frac{d_{\textrm{max}}^{\mathscr{r}}}{\mathscr{h}_n} \leq \varepsilon. \end{equation}
Therefore, for n large enough,
 $\mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr]/M_n \leq \varepsilon$
, which is equivalent to
$\mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr]/M_n \leq \varepsilon$
, which is equivalent to
 $\mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr] = o(M_n)$
. By Markov’s inequality,
$\mathbb{E}\bigl[ \lvert{\mathscr{L}_2}\rvert \bigr] = o(M_n)$
. By Markov’s inequality,
 $\lvert{\mathscr{L}_2}\rvert = o_{\mathbb{P}}(M_n)$
, which combined with Proposition 2.11 implies
$\lvert{\mathscr{L}_2}\rvert = o_{\mathbb{P}}(M_n)$
, which combined with Proposition 2.11 implies
 $\lvert{\mathscr{L}_2}\rvert/\lvert{\mathscr{L}_1}\rvert = o_{\mathbb{P}}(1)$
. This concludes the proof of Theorem 2.12(iii).
$\lvert{\mathscr{L}_2}\rvert/\lvert{\mathscr{L}_1}\rvert = o_{\mathbb{P}}(1)$
. This concludes the proof of Theorem 2.12(iii).
![]()
Acknowledgements
This work is supported by the Netherlands Organisation for Scientific Research (NWO) through the VICI grant 639.033.806 (R. v. d. H.), the VENI grant 639.031.447 (J. K.), the Gravitation Networks grant 024.002.003 (R. v. d. H.), and the TOP grant 613.001.451 (V. V.). V. V. thanks Lorenzo Federico and Clara Stegehuis for helpful discussions throughout the project.