


Introduction
The goal of music analysis is to advance our understanding of the cultural practice of musical expression, and the analysis of electronic music is no exception. Yet fundamental questions remain: What would a viable framework for the analysis of electronic music be? Are we seeking a parsimonious representation akin to Schenkerian analysis, using a graphic notational system rooted in Western art practices? If not traditional notation, do we still need to create a visual artefact from a sonic experience, such as an annotated spectrogram or another depiction of events over time, so that we can appease our eyes and hands with a representation supplanting a musical score? Or are we satisfied with using language alone? What constitutes a theory of electronic music? What methodologies advance our ability to answer these questions?
The goals of this chapter are to understand the elements of music as they manifest themselves in electronic music, introduce terminology and concepts associated with the analysis of electronic music, and explore techniques and methodologies through the analysis of a variety of works. Relevant research fields include the sciences (acoustics and mathematics), engineering (digital signal processing and time-frequency analysis), anthropology (the sociological and musicological interpretation of material culture), and psychology (psychoacoustics, music cognition and affective responses). The compositions selected are representative of different compositional approaches to electronic music and include examples from alternative rock, sonification, soundscapes and process music. Each piece referenced in this chapter has an accompanying published analysis so the reader can delve more deeply.
An Ontology of Electronic Music
Let’s begin with a phenomenological definition of electronic music. Simply put, electronic music is organised sound that uses electricity as essential materiality in either the creation of the composition, the realisation of the composition through performance, or both. Exercising this definition, pioneering works such as Lejaren Hiller and Leonard Isaacson’s Illiac Suite (1956) uses electricity to implement computer algorithms that result in the creation of the compositional material, but the result – a musical score – is performed by musicians. Four decades later, Heinrich Taube’s Aeolian Harp for piano and tape (2001) builds upon the mathematics of frequency modulation to derive the harmonic, melodic and timbral structures of the composition and applies it across multiple timescales. Contrast these works with those of internationally recognised DJ artist Ellen Allien from Germany or live-coding improviser Alexandra Cardenas from Colombia, and one quickly begins to understand and enjoy the evolution of the aesthetic, performative and technical diversity found in today’s electronic music.
The rise of technology and its application to music composition and performance suggest that we should broaden the questions that prompt analysis. New technologies such as multi-channel audio systems or music performed over networks beckons the question: Where is the sound coming from – is it intended for headphones or a 496-channel speaker array? Where are the musicians performing – are they on a traditional proscenium stage in a concert hall or are they on different continents? Are they in the real world in realtime or are they artificially intelligent characters on a virtual reality stage? How is the music created and performed? Does the music come from a computer program that is being manipulated by a composer in realtime, as in live coding? And most importantly, how do we perceive and understand it?
Historically, music theorists are concerned with the objective analysis of a musical artefact, usually some fixed form like a musical score or recording. An analysis is typically followed by an interpretation that contextualises the work within a repertoire. It is usually the musicologists who broaden the interpretation of a work and contextualise the cultural milieu in which it was created. But in electronic music, the cultural milieu of rapidly changing technologies in a fast-changing global culture is a factor in the creation and performance of the music. New technologies are created that spawn new compositions that use that technology, or the act of composition inspires the development of new technologies. These technological developments give rise to a burgeoning complexity of musical expression that include advances in microtonality (e.g., Andy Hasenpflug and Wendy Carlos), sophisticated diffusion systems for acousmatic multi-channel spatialisation (e.g., Rob Hamilton and Nina C. Young), networked music performance with real and virtual musicians (e.g., the SoundWIRE group at Stanford University or the DIAMOUSES framework at the Technological Educational Institute of Crete), textural density made perceptible by sophisticated audio engineering techniques (e.g., Aphex Twin and Björk), hacking/circuit bending (e.g., Reed Ghazala and Sarah Washington) and live coding (e.g., Alex McLean and Shelly Knotts).
In order to advance our understanding of electronic music, we must draw from a plurality of disciplines and methodologies. Theorists must understand the dynamic interplay of technology, creativity, material culture and socio-cultural norms in order to posit a comprehensive theory of the creation and performance of electronic music. This necessitates adopting methodologies from musicologists with a nod to engineers, computer scientists, sociologists and cultural anthropologists and others in order to appropriately contextualise the analysis of a musical work. An important touchpoint is the move towards empirical musicology (Clarke and Cook Reference Clarke and Cook2004), where scientific methodologies from the social and hard sciences are applied to the understanding of music.
The electronic music repertoire can be classified in many ways. For instance, we might posit various classes of electronic music, such as electronic dance music, live electronic music for the concert stage, telematic music that exists in cyberspace and acousmatic music that emanates exclusively from loudspeakers. Such classes are not necessarily mutually exclusive: a dance music track might be intended for Internet performance or a composition that employs circuit bending in its realisation could become an acousmatic work in its final form.
Within each of these classes are a myriad of styles. And as has been the case throughout music history, it’s not always possible to correlate style with any particular class. For example, comparing two 1968 electronic compositions reveals significant stylistic variation. The style of Wendy Carlos’ Switched on Bach is inherited from existing repertoire, re-orchestrated for the novel timbres of the synthesiser. On the other hand, the first version of David Tudor’s Rainforest transforms sound by transmitting acoustic energy through resonant materials, focusing our attention on the radiation of sound.
Classes may change in number, become fragmented into subclasses, be abandoned altogether or return after a period of being dormant. Without question, the proliferation of classes in electronic music has been spawned by a relationship between technology and material culture that is mutually recursive: technology has had a profound impact on human culture and human culture has influenced the development of technology. Take for instance the development of the mobile phone, prompted by the convenience of untethered social interaction using the human voice. This device not only fulfils its intended purpose, but also gives rise to mobile apps that extend the functionality of the device in unexpected ways. Not only can mobile phones be used to record, produce and perform music, they’ve also been employed as a communications platform for activists to organise or ways for citizen scientists to gather field data. This flexibility of purpose is precisely why composers with an insatiable appetite for new ways to extend musical expression are drawn to technology.
Since music is a time-based art, approaches to the analysis of electronic music spans a continuum of timescales: from the supra (when the work is situated in history), through the macro (larger scale structural divisions) and the meso (or phrase), to the micro (Roads Reference Roads2001). The supra timescale places a composition within the stylistic, technological, political, social and cultural norms of its time. Positioning a work on the supra timescale is key to understanding how and why an electronic work was created. The macro timescale reveals the overall structure of a composition, whether a continuously unfolding structure (through-composed) or a segmented musical structure, such as a binary or ternary form. The meso timescale is the expression of a musical thought that is grammatically analogous to a phrase or sentence. Musical phrases are often prosodic, characterised by the grammar of the composer, often culminating in a cadence, a moment of temporal repose. The micro timescale investigates the essential materiality of a timbre – its frequency and amplitude evolution over time.
We will use the term inter-temporal to describe music between timescales and intra-temporal to describe music within a timescale. It’s important to understand that inter-temporal and intra-temporal choices occur on a continuum, from the obvious (contributing to an objectivity in the analysis that is affirmed by others) to the interpretive (introducing subjectivity that may result in variability among analyses).
Theorists trained in the practice of Western music often define the elements of music as pitch, dynamics, rhythm and timbre. These elements have provided a theoretical framework that has endured over an expansive repertoire, though electronic music extends and problematises these elements. We know that pitch is our subjective response to the objective measurement of frequency and dynamics is our subjective designation that corresponds to the objective measurement of amplitude. The notion of rhythm, and relative rhythm in particular, comes from the historical lineage of mensural notation (Apel Reference Apel1961). With respect to the historical exploitation of these four elements of music, timbre is the last frontier.
Timbre is an important and vast field explored in electronic music and has evolved to become one of its defining attributes. Our ability to produce captivating timbres is due to the rise in technologies such as the synthesiser and computer, where the notion of what constitutes a musical instrument is itself open-ended. An oboe is a musical instrument, for example, but so too may be a radio or an electronic siren. Computer technology has emerged as the most flexible musical instrument of all time. Indeed, our understanding of timbre has increased dramatically since the advent of the computer. Because of advances in time-frequency analysis, we understand that we can now define timbre as the temporal evolution of frequency and amplitude (Risset and Wessel Reference Risset, Wessel and Deutsch1999).
Timbre is of seminal importance in a theory of electronic music because many composers use timbre as compositional material following Schaefferian theory. The centrality of timbre in electronic music has compelled our struggle to define it. Composer and theorist Denis Smalley uses the term spectromorphology to describe the temporal unfolding of sound spectra (Smalley Reference Smalley and Emmerson1986). This term conjoins three morphemes: spec – to look at or see (a spectrum), morph – shape, form, or structure, and ology, the study. Spectro is usually combined with another morpheme, such as gram, to create the word spectrogram. A spectrogram is a graph of a spectrum generated from the magnitude component of the Short-Time Fourier Transform (STFT) with time as the horizontal axis and frequency as the vertical axis (Adams Reference Adams and Simoni2006). Smalley’s definition of timbre is the ‘sonic physiognomy through which we identify sounds as emanating from a source, whether the source be actual, inferred or imagined’ (Smalley Reference Smalley1994). Teasing apart Smalley’s phrase sonic physiognomy, we arrive at a definition of timbre as the character or essential quality of a sound, where a listener may or may not be able to identify its origin.
We use the term sound object to label a timbral sound event that has an identifiable musical shape over time. A sound object may be measured for acoustical (objective) and psychoacoustical (subjective) properties that contribute to our ability to comprehend it and subsequently become a bearer of musical meaning. A sound object is a generalisation of the note in traditional music, without a necessary dependence on the attribute of pitch, and may be used as the building block of horizontal or vertical structures analogous to traditional melody and harmony respectively.
Simply put, the assertion that a note is something other than a sound object confuses our ability to define it. Instead, consider the epistemology of a note as a subset of a particular type of sound object: generally one that may exhibit a high degree of harmonicity and low degree of temporal evolution. The note subset chronologically precedes the sound object because the means to produce a note (e.g., traditional musical instruments) preceded the means to produce a sound object (e.g., electronic devices such as tape recorders or computers). On a supra timescale, the material culture that gave rise to the development of acoustic instruments preceded the material culture that gave rise to electronic instruments. Because in electronic music the sound object may be a structural extension of a note, the sound object advances musical semantics in ways that could not have been realised during the cultural milieu that gave rise to notes.
One of the salient compositional elements of Mortuos Plango, Vivos Voco, by British composer Jonathan Harvey, is the recording and subsequent manipulation of the great tenor bell of Winchester Cathedral. The recording of this bell is an identifiable sonic entity: a sound object. Exploration of this sound object on the micro timescale reveals that the macro formal structure of the composition is organised into eight sections that are influenced by the prolongation of the bell’s inharmonic spectrum. Software developed by Michael Clarke allows the theorist to interactively explore the bell’s timbre to heighten our understanding of the significance of this sound object in the realisation of this composition (Clarke Reference Clarke and Simoni2006).
Risset’s Computer Suite from Little Boy (1968) is associated with the dropping of the atomic bomb in 1945. There would be unequivocal agreement among theorists that this composition is Risset’s response to the historical events of World War II. There would also be unanimous agreement that the composition could not have been realised without Roger Shepard’s prior research in auditory illusions, which Risset implemented using the digital synthesis techniques developed at AT&T Bell Labs in the 1960s. The spectral envelope of the auditory illusion uses a Gaussian curve to control the amplitudes of ten component sinusoids that are separated by an octave (Patrício 2012). Risset provides perceptual clues to the macro formal structure by the titles of the three movements: Flight and Countdown, Fall and Contra-Apotheosis. The famous Shepard-Risset glissando is the hallmark of the second movement, functioning as a repeating sound object, and subsequently developed on the meso timescale.
Repertoire and Methodologies
How does one go about examining the timbre of a sound object on the micro timescale? Theorists have borrowed methodologies from engineers that allow for the visualization of audio signals that contribute to our understanding of timbre. There is a rich literature on the visualization of musical signals and the human perception of sound, or psychoacoustics (Adams Reference Adams and Simoni2006; Cook Reference Cook1999). A complete treatment of these topics, of paramount importance to the analysis of electronic music, is beyond the scope of this chapter. Suffice to say, there are essentially two different ways to view a sound file: in the time domain, with time as the x-axis and amplitude as the y-axis, or in the frequency domain, with frequency (Hz) as the x-axis and relative amplitude as the y-axis. The frequency domain is particularly useful in the analysis of timbre since it displays the frequency spectrum of a sound object at a moment in time. To show the spectral evolution of a sound file, such frequency plots are typically presented over x-axis time with frequency on the y-axis, and brightness on the 2-D plot denoting energy at a particular time and frequency, giving a spectrogram.
To illustrate these ways of enhancing our aural understanding of electronic music, we will closely examine the composition Mild und leise (1973) by American composer Paul Lansky. This eighteen-minute stereo composition was composed using an IBM 360/91, a third-generation mainframe computer that had 1 MB of RAM; the instructions to realise the sound were programmed on punch cards. Mild und leise is also the title of an aria in Tristan and Isolde (1859) by German composer Richard Wagner. Lansky’s Mild und leise is based on harmonic inversions of the Tristan chord, the leitmotif Wagner associated with the character Tristan.
The first phrase of Lansky’s Mild und leise is approximately 41 seconds and presents the unfolding of the Tristan chord in sonic events discretely assigned to each stereo channel. To demonstrate the time domain representation of a sound file, we will examine the first 21 seconds (Fig. 15.1).

In Fig. 15.1, the timescale in seconds is displayed horizontally across the top of the image. Since this is a stereo file, we see two x-axes: the top x-axis is the left channel and the lower x-axis is the right channel. Amplitude is measured on a linear scale of −1.0 to 1.0 for each channel along the channel’s x-axis. The image shows that sound is assigned exclusively to the right or left channel.
Musicians are well trained in interpreting events in the time domain. Conventional music notation is also a time-domain representation, with time as the x-axis and pitch notated on the staff on the y-axis. Since Lansky is using the opening of Mild und leise to reveal the pitch material of his Tristan-like chord, we can compare the time domain representation of the sound file with its corresponding music notation (Fig. 15.2).
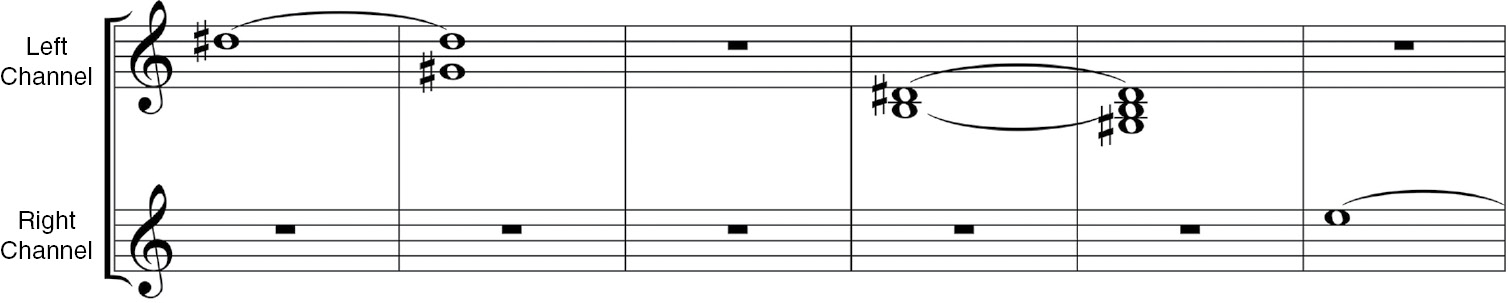
Figure 15.2 Music notation corresponding to the sonic material of Figure 15.1
A frequency domain snapshot, with frequency as the x-axis and relative amplitude measured on a linear scale from 0.0 to 1.0 as the y-axis, is useful when examining the spectral components of a sound object at a moment in time. Looking at the initial sound object of Mild und leise in the frequency domain, we see that its component frequencies are integer multiples of the fundamental frequency (Fig. 15.3).
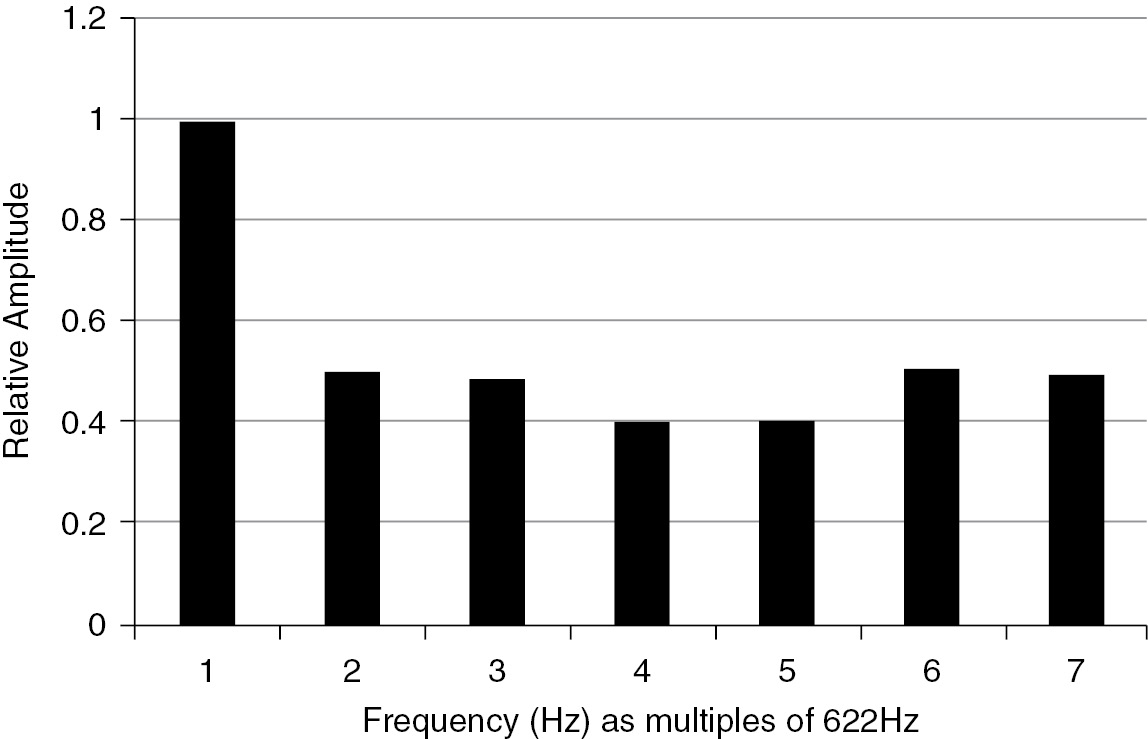
Another way to visualize sound is to use time-frequency analysis and create a spectrogram. Figure 15.4 is a spectrogram of the first 21 seconds of the left channel of Mild und leise (window size = 1024, Linear, scale dBV). We see energy at ~622 Hz (D#), with energy at integer multiples of thefundamental, indicating a timbre that exhibits harmonicity, consistent with our view of this sound object in the frequency domain. The degree of harmonicity gives the aural impression and thus function of a note that coincides with Lansky’s unfolding of the Tristan chord. When the second sound object enters at around 3 seconds, we see prominent energy at 415.3 Hz and an octave above 830.6 Hz while the G# at 622 Hz is sustained. Following, we see a fade in amplitude followed by about 2.5 seconds of silence. After the silence, we see the spectrogram increase in complexity as the sound objects combine to form a chordal structure. The spectrogram reveals and our ear confirms that the sound objects exhibit very little spectral evolution.

Mild und leise would have become an historical artefact representative of the third computer generation had it not been discovered by the British alternative rock band Radiohead, who extracted the first phrase of Lansky’s piece and used the sample as an ostinato for Idioteque on their album Kid A (2000). The sample that Radiohead used (with Lansky’s permission) begins at about thirteen and a half seconds and has a duration of eleven seconds at an estimated tempo of 68.7871 bpm (using beat detection software in the Digital Audio Workstation [DAW] Logic Pro X). Idioteque uses a tempo of crotchet = 137.6 bpm, twice that of the Lansky sample, and floats the sample above a 4/4 drum track. But Radiohead quotes four sound objects of Lansky to create a five-bar ostinato, an unusual rhythmic backdrop for rock that is typically grouped into four-bar units. Radiohead’s sample consists of the last four of the first five of Lansky’s sound objects; the band play these back from a keyboard during performance. Figure 15.5 shows the opening of Idioteque’s drum track (bars 1–7) with Lansky’s sample added to the same session (beginning at bar 8). By overlaying Lansky’s source sound file onto Radiohead’s Idioteque in a DAW, we can see how Lansky’s sample was integrated into the work.
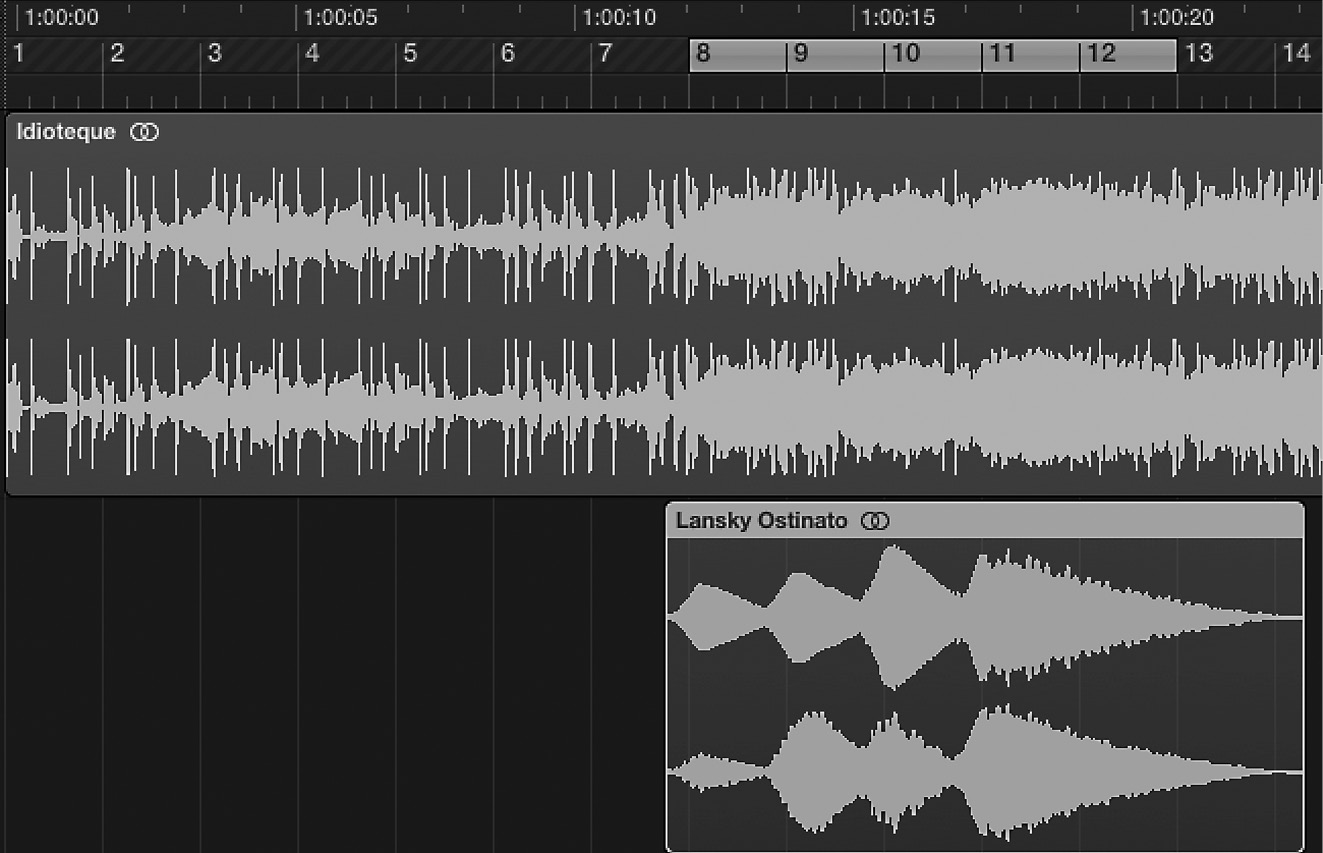
What is intriguing about Lansky’s Mild und leise and Radiohead’s Idioteque is that on the supra timescale, the two works are emblematic of two successive generations of computer technology. Lansky’s laborious compositional practice, requiring the use of punch cards, is in stark contrast to the comparatively sophisticated production capabilities of Radiohead. The band draws upon fourth generation computer technology with special purpose DAW software that takes advantage of human–computer interaction advances such as copy-paste, inconceivable during the creation of Mild und leise. The technologies used to create each of these works make an indelible mark on the macro formal organisation of the composition: in the case of Lanky, the paradigmatic use of punch cards resulted in discrete sonic events akin to notes whereas Radiohead’s sample-based ostinato arises from a musical heritage of loop-based compositions made popular with the advent of recording technologies. This remarkable juxtaposition of Wagner, Lansky and Radiohead is testimony to the accelerating globalisation of music: after the passing of over a century, a German composer, Richard Wagner, influences an American composer, Paul Lansky. Then, a mere twenty-eight years later, Lansky’s work is rediscovered and reinvented by Radiohead, extending Wagner’s influence to nearly 150 years. Radiohead’s contribution to alternative rock was their ability to infuse electronica and techno, Lansky’s inspiration was in the reinterpretation of Wagner, and Wagner pushed the boundaries of Western harmonic function.
Some composers have experimented with electricity itself in the creation of a musical work. For example, Christina Kubisch’s Electrical Walks (2003) audify electromagnetic radiation in realtime through custom headphones made by the composer (Ikeshiro Reference Ikeshiro2014). Audification is the process of transforming an analogue or digital time-domain signal into sound, maintaining a direct relationship (indexicality) between the signal and the sound. In Kubisch’s installation, each person who participates creates their own unique instantiation of the work by walking through the electromagnetic fields that are increasingly prevalent in cities. Guided walks that reveal interesting audifications have been developed worldwide in places such as New York City, Berlin and London. The micro temporal characteristics of the work are related to the composer’s choice in audifying the electromagnetic signals; the meso formal structure is influenced by the density of the electromagnetic signals that are audified; and the macro formal structure is unique depending on the path of each person who participates in the installation. This composition defies a single analysis because of the high degree of individualisation that accompanies each realisation of the work. As a result, the analysis could be approached by examining the composer’s conceptual design of the application of technology to the realisation of the composition. It is also possible to examine the audified walks of a number of individuals, searching for a statistical distribution that reveals the probability of certain events occurring on certain routes. Alternatively, it would be interesting to do a comparative study of the walks of two different listeners, comparing the actual sound produced during the walk with the listener’s perceptual response to the sound.
Aftershock by Natasha Barrett and Kathleen Mair (Barrett and Mair Reference Barrett and Mair2014) consists of a visually immersive three-dimensional sonification of fracturing and sliding events inside rock formations as they are stressed. Sonification is a more general class of electronic music from audification in that the composer selects parameters from one of more data sets and chooses how to map those data onto musical elements. Barrett and Mair use geophysical source material that is recorded using ultrasonic transducers distributed throughout a rock formation. By collecting data in this way, they create a composition that is representative of the time-variant changes in the state of the rock. Both aesthetic and scientific decisions are made during the process of sonification and often go hand-in-hand. In the case of Aftershock, decisions of mapping, scaling and data reduction were made collaboratively between the composer and scientist so that the geophysical properties were manifested in the emergence of art. Analysis of works deploying sonification should explore the technical and aesthetic choices made by the composer, resulting in the specific mapping of parameters as a vehicle to advancing our understanding of the phenomenon being sonified.
Acoustic ecology is the practice of observing the totality of the sonic field in which we find ourselves. Several composers have explored this phenomenon through the exploration of a class of electronic music known as soundscapes. Hildegard Westerkamp, in her Kit Beach Soundwalk (1989), juxtaposes the sound of feeding barnacles with the noise of a city (Kolber Reference Kolber2002). The composition explores scales of loudness, where the tiny stochastic sounds made by feeding barnacles sharply contrast with the loud sounds made by human life in a city. The composer extends the compositional practice of musique concrète by using technological interventions that heighten our aural awareness of sonic scale. For example, Westerkamp alters the background noise of the city at 1′42″ and at 3′07″ through the use of band-pass filters, in order to enhance our ability to hear the barnacles over the din of the city. The composer’s interest in the application of band-pass filters, a technique used in subtractive synthesis, suggests that removing aspects of a composition either through subtractive synthesis or by muting tracks in a DAW may assist in advancing our understanding of a composition. For example, if we had access to the DAW in which Westerkamp created the work, we could selectively listen and analyse components by muting sound tracks, filtering sounds to enhance spectral components of the sound, or extract sounds and create spectrograms.
Throughout history, composers have been inspired by mathematics in the realisation of musical compositions – from the time of Pythagoras and the Greek monochord, to the mathematical relationships in J. S. Bach’s Musical Offering, to the influence of pitch-class set theory in the music of George Crumb. Composers have had a special interest in the Golden Section – the division of a line into two parts so that the smaller part is to the larger part as the larger part is to the sum of both parts. The composition A Study in White (1987) by Japanese composer Joji Yuasa is in two movements: The Sea Darkens and I’ve lost it. The Sea Darkens is based on a haiku written by seventeenth-century poet Bashō spoken in Japanese by a female voice with the English translation spoken by a male voice. The 6′27″ composition features a number of synthesis techniques that are used to modify the speech, masking its intelligibility with white noise, phase vocoding, time stretching, cross synthesis, and band-pass filtering. The composition is in two distinct sections, the first section drawing to a close at 2′28″, punctuated by a cadence comprised of 12″ of silence. The second section begins at 2′40″. The macro formal structure is divided by the Inverse Golden Section (the smaller part) for section I, and the Golden Section (the larger part) for section II. Within each section, the Inverse Golden Section and Golden Section are again evident. Each section has a similar timbral arc in that each begins with the salient use of white noise (high degree of inharmonicity) that over time, transforms into more pitched material (a higher degree of harmonicity). The first section draws to a close with the simultaneous use of noise with pitched bands separated in frequency. In contrast, the second section ends with the temporal separation of noise and noisy pitched bands. In the second section beginning at 3′19″, the spoken word for ‘white’ in English produces an upward glissando. In contrast, the Japanese word fragment shiro (for shiroshi) that translates to white is treated with a downward glissando. This remarkable timbral structure is revealed in the spectrogram as a glissando of noise bands that evolves into primarily pitched material at around 5′46″. The theorist analysing this work makes extensive use of spectrograms which greatly aid in the visualization of the intra temporal organisation of the composition (Twombly Reference Twombly and Licata2002).
The Multimedia Content Description Interface, also known as the MPEG-7 Standard, contains metadata organised as hierarchical descriptors about multimedia content, including audio. Several researchers have employed the MPEG-7 Standard to the analysis of music. In one study, researchers were motivated to automatically extract a thumbnail of a composition, often referred to as a hook or refrain. They calculated the audio spectrum descriptor of the MPEG-7 Standard every 10 milliseconds, stored the calculations in a time series, and used the series to generate a succession of matrices that could be compared, looking for similarities. A comparative analysis of the similarity matrices of Metallica or Boney M show that it is feasible to automatically generate the time location of the refrain (Wellhausen and Höynck Reference Wellhausen and Höynck2003).
In another application of the MPEG-7 Standard, researchers used the audio descriptors intensity and spectral flatness (Bailes and Dean Reference Bailes and Dean2012). Intensity is measured as the unweighted sound pressure level (SPL) in dB and spectral flatness is the ratio of the geometric mean to the arithmetic mean of the power spectrum. Their study employed both non-musicians and musicians as test subjects, tasked with discerning the macro formal structure of four different electronic works in realtime. Results point to intensity as a greater indicator of musical structure than spectral flatness. Since the MPEG-7 Standard is well documented, it could be explored as a methodology that assists in the automatic identification of musical structure, as is the case with similarity matrices or intensity.
Borrowing from psychology, another approach to the analysis of electronic music is to employ a cognitive–affective model that explores the relationship between a listener’s cognitive and affective responses to music over multiple listenings. A cognitive response is a listener’s objective observation of the music and an affective response is a listener’s emotional response to the music. Research suggests that the likelihood of an affective response increases when a listener is able to derive meaning from their experience with the music or by their familiarity with it (Brentar, Neuendorf and Armstrong Reference Brentar, Neuendorf and Armstrong1994).
In a controlled longitudinal study of trained musicians, listeners were exposed to twentieth-century acoustic and electronic music (Simoni Reference Simoni, McLean and Dean2016). On the first listening, the listeners were told nothing about the music and were asked to write down their observations using a modified Think-Aloud Protocol. With each successive listening, listeners were given additional information about the compositions and again, wrote their observations. After learning the title, reading the programme notes, receiving a theoretical overview to the compositional approach, and in one case discussing the composition with the composer, compositions that initially elicited a majority of cognitive responses accompanied by unfavourable affective responses were transformed to a majority of favourable affective responses. The electronic composition that evoked the most positive affective response after multiple listenings was Mara Helmuth’s soundscape composition, Abandoned Lake in Maine (1997). This through-composed work uses the sounds of recorded loons to draw the listener into a virtual acousmatic soundscape. The sounds of the loons are processed using granular synthesis, yet the resultant processed sounds retain a high degree of similarity to the actual sound of a loon.
Alvin Lucier’s I am sitting in a room (1970) for voice and electromagnetic tape is a sensational example of the macro formal structure unfolding over time as the result of a compositional process. This class of music, known as process music, operates when the resultant music is simply the output of a process (not necessarily computer based). Other composers with works which may be categorized as process music include Morton Feldman, Annea Lockwood, Steve Reich, Terry Riley, Karlheinz Stockhausen and La Monte Young. Historically, I am sitting in a room is situated on a supra timescale marked by the invention of the microphone, tape recorder and loudspeaker – the input and output technologies that are required to create the composition. The score of the composition includes an equipment list accompanied by an explanation of the recursive process that should be used to realise the composition. Lucier’s version of the composition consists of four sentences of instructions that reveal the recursive process and thus the macro formal structure of the composition:
I am sitting in a room, different from the one you are in now.
I am recording the sound of my speaking voice and I am going to play it back into the room again and again until the resonant frequencies of the room reinforce themselves so that any semblance of my speech, with perhaps the exception of rhythm, is destroyed.
What you will hear, then, are the natural resonant frequencies of the room articulated by speech. I regard this activity not so much as a demonstration of a physical fact, but more as a way to smooth out any irregularities my speech might have.
Lucier gives no specific directions on the duration of the recording, the acoustical or physical attributes of the space where the recording should be made, or the text that should form the basis of the composition. The number of times the person who realises the composition engages in the recursive process determines the macro formal structure of the composition. The source material as well as the acoustic characteristics of where the recording is made determines the timbral characteristics of the composition.
Given the freedom in the realisation of the composition, there could be an infinite number of realisations and thus recordings of I am sitting in a room. A recording was initially released in 1970 on LP as part of ‘Source: Music of the Avant Garde’ featuring the voice of the composer (Lucier 1970) and re-released on CD in 2008 by Pogus Productions. Another version was released by Lovely Music, initially on LP in 1981 and re-released on CD in 1990. The Source version consists of fifteen iterations of the composer speaking the instructions cited above with an overall duration of approximately twenty-three minutes. The Lovely Music version consists of thirty-two iterations of the text spoken by the composer spanning approximately forty-five minutes. A version attributed to Source and readily available on Spotify has a duration of 16:19 and consists of eleven iterations of Lucier’s spoken text.
Because there are multiple versions of the recording, each using the same text and speech of the composer but recorded in different spaces and disseminated on different formats, it is enjoyable to conduct a comparative timbral analysis. A comprehensive analysis of the Lovely Music version was completed by Benjamin Broening (Reference Broening and Simoni2006). In this version of the composition, the macro formal structure is obvious: thirty-two iterations of the four sentences spoken by the composer, each iteration lasting approximately ninety seconds. The inter-temporality between the meso and macro formal timescales can therefore be measured in absolute duration. What’s less obvious, when considering an intra-temporal analysis on the micro timescale, is the perceptible degree to which each iteration reveals the sonic effect of the room on speech intelligibility. Broening offers a spectrogram of the first ten iterations of the Lovely Music version, which reveals the gradual resonant frequencies of the room increasing in amplitude around 92 Hz (approximately F) and two octaves above and 116 Hz (approximately B-flat) and two octaves above.
A comparative analysis of the Source recording displays the emergence of different resonant frequencies. Using public domain software called Sonic Visualizer (Cannam 2015), a spectrogram was generated of the tenth iteration of the Source version.1 Using Sonic Visualizer it is possible to zoom into either the x-axis (time), y-axis (frequency) or both axes. This particular spectrogram (Fig. 15.6) has a duration of approximately ninety seconds, just like each iteration of the Lovely Music version. The frequency range of the tenth iteration spans from 43Hz to 15202 Hz. The fundamental of Lucier’s spoken voice is approximately 129 Hz, with some variability in timbre due to the phonemes of the speech and his delivery of the text. The frequency resolution of the spoken text could be improved if the size of the Hamming window included more samples, such as 2048 or 4096, which would reduce temporal accuracy. The spectrogram shows that a prominent resonance has emerged at approximately 1,850 Hz with that resonance reinforced at integer multiples of the octave: 3,700 Hz, 5,500 Hz, 7,440 Hz, 9,250 Hz, 11,100 Hz and finally 12,950 Hz. The resonances produced in the Source recording are in contrast to the Lovely Music recording where the room does not contribute as much of the high-frequency content as the recursive process unfolds. If a listener isolates the tenth iteration, in the Lovely Music version and compares it with the tenth iteration of the Source version, it’s possible to conduct a comparative analysis of the speech intelligibility of both versions.

Even with Lucier’s lingering at the end of some speech fragments, his emphasis of certain phonemes, and his stuttering, the intelligibility of his speech is impeccable in the recording of his voice. As the composition progresses, Lucier’s speech intelligibility is eroded by the resonant frequencies of the room. Whether considering the Lovely Music or Source recording, there is a remarkable transformation from the semantic meaning of his speech to the semantic meaning of sound: speech becomes music. As intelligibility decreases, the listener’s focus shifts from the meaning of the words to the sound objects that emerge from the processing of the speech. Characteristics of each phoneme, such as its amplitude envelope, become temporal boundaries in the designation of each sound object.
Since the composer’s recorded speech is the same in both the Source and Lovely Music recordings, the variables that contribute to the different timbral characteristics of the recording are the type of microphone used, the position of the microphone in relation to the source, the tape deck, the choice of loudspeaker, the position of the loudspeaker in the room, and of course, the room itself. In the analysis of electronic music, it is important to consider all of the instruments used to realise the composition, especially if it exists solely in a recorded form. In this regard, the microphone, the loudspeakers, and the placement of these instruments are as much a part of the realisation of the composition as the music itself. I am sitting in a room makes the point that the components used to create the recording – the microphone, the tape recorder, and the loudspeaker – are as compositionally significant as the traditional acoustic instrument a composer may select during symphonic orchestration.
In Closing
This chapter has demonstrated that a framework for the analysis of electronic music requires a flexible and integrated multidisciplinary approach that borrows from a range of disciplines. We have observed that methodologies employed across the sciences, engineering, mathematics and psychology can support our goal of advancing our understanding of the cultural practice of musical expression. The selection of which methodological approach yields the greatest musical insight is related to the essence of the compositional process in which the music was created. The choice of which methodology to use is guided by our experience with electronic music, in turn igniting our curiosity to discover its structural essence across multiple timescales.
As the repertoire continues to increase in complexity, we need not only to strengthen the relationship between and among disciplinary methodologies, but also to be open to considering what other disciplines and their concomitant methodologies enhance our understanding of electronic music. But methodologies are just a means toward an end, a springboard toward heightened understanding. As methodologies increase the sophistication of our phenomenological understanding, we still rely on language to communicate this understanding to each other. Since many consider music to be a language, music theory is meta-language: a language about a language. The complexity of thought conveyed in this language is related to the intricacies of musical expression and the depth of our analytical inquiry. After all, we engage in the analysis of electronic music because we strive to ennoble our understanding of the cultural practice of human communication through musical expression.
Note
1 The analysis parameters used to generate this spectrogram were: x-axis and y-axis linear interpolation, Hamming window of 1024 samples, and scale dBV.
Éliane Radigue
As many musicians of my generation, my first contact with electronic sounds was through the ‘accidents’ of feedback effects, the so called ‘Larsen effect’ between a microphone and a loudspeaker. The challenge of the game was to tame it, keeping it on the edge of its limits, where feedback just appears before blowing up or disappearing. Moving the microphone slowly on this virtual line allowed slight changes within sustained tones.
The other way to create sonic material was practising re-injection between two tape recorders, controlling the process through light touches on potentiometers whether reading or recording, producing mainly different beats, very fast or slower higher or lower pitches.
This is how I came to constitute the basic vocabulary I was attracted to work with.
My first contact with a ‘real synthesiser’ was at NYU at the end of 1970. Naturally, I looked to produce these kind of sounds and of course it was much easier to control their slow evolution with the Buchla.
I’ve never been fond of technology, it was just a necessary means to produce the sounds I was looking for, and to better control slow changes within these sounds.
I came back to Paris with an ARP 2500. It was a real love affair for several years with a very good assistant: my cat remained very quiet when we were purring together, protesting as soon as I made a wrong move with my potentiometers. I had a real physical relationship with the ARP as soon as I could forget the burden of technic and achieve the kind of symbiosis that any musician has with their instrument, whether acoustical or electronic.
Daniel Miller
I started Mute Records inspired by electronic music and punk, influenced by many artists who’ve come and gone, as well as some who’ve remained well known. In some ways, punk didn’t go far enough: learning three chords still seemed like too much, when you could press down one synth key and hear an amazing sound. In the early to mid 70s you might aspire to be able to afford the instruments Kraftwerk could, but we had to make do with tape loops and distortion effects. The cheaper synths came later on in the decade (and especially in the early 80s), kickstarting the punk synth pop ethos.
Making records effectively in the bedroom in 1978, I somehow managed to get a 7-inch single and distribute it, and this DIY approach became the initial basis for Mute. Over the years I’ve often told artists who’ve approached Mute ‘why don’t you release it yourself?’ Nowadays we’re saturated in recordings, available online, and in fact I’m perfectly happy with that; it was something we all hoped would happen back when we were first trying to release material ourselves! There might be a lot of crap, but at least people have the opportunity. Yet Mute still has a role to play; not just as a seal of quality, but because we can support artists with our expertise in distribution and product, and because some artists actually like working with A&R.
In the future, we’ll keep progressing in the endless search for music, whether made with computer or one-hundred-piece orchestra, as long as humans remain involved. We may even consider signing machine musicians if their creators have imbued them with enough human passion. Whilst I’m personally curious to explore releases of generative music, there probably won’t be so much impact as some might hope from such algorithmic music. As people already have access to so much music, generative works only add to the problem of having too many choices.
The role of electronic music is no longer so distinct; the lines are completely blurred when everyone is recording using computers, and can apply however many effects. My personal position in defining electronic music is simply to state ‘everything has to start with a sine wave’. If in my studio I had every orchestral sample, every drum hit, and every kind of synthesis in the world, I’d never begin with a preset, but keep this precept in mind.
Ikue Mori
I started my musical life as a drummer, then worked with drum machines live, and now use a laptop. My focus has always been on improvisation: live spontaneous playing and interaction with other players. I want to maximise combinations of sounds, colours and textures while also using some pre-programmed beats and melodies.
Coming from an improvising background, I am keenly aware of the interplay between what is controlled and what is unpredictable. For example, I constantly change the loop point or pitch so that a pattern is unrecognisable every time it is played. Adding this option opens up more possibilities of creating a live improvised flow.
I don’t use samples or field recordings, but find inspiration in nature and environmental sounds and try to create imaginary electronic landscapes: sounds that can be transformed and moved organically to evoke visual images without using an actual image.
Chris Carter and Cosey Fanni Tutti
Of the many forms our electronic music making takes we can certainly say that amongst a certain strata we are best known for our experimental work in our band Throbbing Gristle. Of course we have also been producing and performing all kinds of other electronic music for more than forty years as Chris & Cosey and latterly as Carter Tutti.
When we started out, back in the 1970s, the independent music scene in the UK was rife with new bands experimenting with electronics in music and the experimental music landscape was akin to the Wild West, with vast horizons of potential and seemingly everything or anything being possible to realise and release. The reason for this outpouring of untapped electronic creativity was the new-found affordability and accessibility of electronic instruments and recording equipment. Prior to the 70s electronic music was primarily produced by academics and composers or those wealthy enough to be able to invest in what was then an expensive pursuit as the vast majority of synthesisers and recording equipment were until then expensive investments and often only available if you had the financial backing of a major record company, a university or college, or were producing or performing best-selling records … of which there were relatively few then. But music manufacturers, especially those in Japan, began producing relatively affordable synthesisers, effects and recording equipment for the blossoming ‘home studio’ and semi-pro performing market. Of course this was great for everyone producing music on a budget, not just electronic musicians, but the savvy electronic music scene immediately saw the potential of this wonderfully relentless wave of affordable new products and so began the inevitable democratisation of electronic music. It would no longer be a dry academic pursuit emanating from sound labs, or institutions producing quirky sound effects albums for TV and film. Young ‘underground’ bands and musicians brimming with ideas could experiment with electronics to their heart’s content and release their ideas to the world without ever having set foot inside a recording studio.
Running parallel to that new trend in producing electronic music on a budget was an even more affordable approach – the DIY method. A niche sub-underground movement which was more about building your own equipment, or hacking and modifying existing equipment to suit your own needs. From our own experience this was also a more collaborative method, with people sharing ideas, concepts and techniques and lending equipment to each other. But the aim was the same … to perform and produce experimental electronic music without restriction.
Holly Herndon
I am a composer and performer interested in the laptop as an intimate and performative instrument, often incorporating the processed voice.
My work responds to my surroundings, firmly placed in the present, with an eye towards the future. I disregard the separation of art and popular music styles, which I present in a variety of contexts.
I am concept driven, finding ways in which the production of the work imbues the underlying idea, which is often extra-musical. I experiment not only with music, but also with how it is distributed, presented, performed and documented, as these components change dramatically with the Internet.
Collaboration is a key part of my practice, as I find the notion of the ‘lone genius’ deceptive and limiting. My best work occurs when I release some control, reconciling my ideas with those of other musicians, theorists, designers, artists, dancers, technologists, philosophers, and more.
Vince Clarke
What I love about using synthesisers to make music is their unpredictability. Most older analogue synths, and now newer Eurorack modular systems, do not have the capacity to store sounds. This means that it is nearly impossible to create the exact same sound twice, and this is where the fun begins. I may start off with the intention to patch a brass-like sound only to end up with something completely other-worldly. Newer preset keyboards and samplers allow the user to create incredible emulations of real instruments at the touch of a button, but for me, the process of scrolling through endless sound menus is not nearly as interesting as patching cords, twiddling knobs and adjusting sliders.
Synthesisers and sequencers have given me the means to compose and record music that would have otherwise been stuck inside my head forever. If I have an idea, I can instantly program it, bypassing the time needed to master a traditional musical instrument. However, if the actual idea is crap, then all the technology in the world won’t turn that idea into a good song. Most people remember songs rather than the fact that the bass sound comes from an Oberheim Expander.
Ralf Hütter
Electronic music functioning over the last years. Of course with the arrival of digital and computer programs and laptop computers now for the first time we are very closely related to the atmosphere in the late sixties in Dusseldorf when I started with my partner Florian. Because they are part of our music, we are part of our music, we are part of the venue, the surround sound is the next step in this direction and at the same time implementation of our ambitions. We were travelling with tons of analogue devices and kilometres of wires but finally nothing has worked as it should definitely. In this century we use the tools that we dreamed of during last three decades of the century; in fact we have been able to put everything together. Its about the whole the whole music of Kraftwerk since the seventies autobahn the endless journey the timing of the composition resulting from the technical possibilities of the vinyl longplaying record europe endless and the final sequence endless endless
Hasnizam Abdul Wahid
Our performing arts in Malaysia reflect a long tradition of communication as well as direct interaction between a performer and audience. The Wayang Kulit traditional shadow puppet plays demonstrate that multimedia performances are not something new in the Malaysian context. At present, the enhancement of an art performance with technology, either through creative hardware hacking or interactive programming, is increasingly a popular practice. Local arts, from traditional folklores to traditional musical instruments, are being gradually explored alongside new technologies, and decontextualised with admiration, thought and respect.
The opportunity to work with researchers from various disciplines, such as biology, social science and more, inspires me to explore the immense rainforest as well as the people of the island of Borneo where I reside. The central point of my composition is to explore the exotic, its surroundings, and ‘tell a story through sound’, away from urban city sounds and moving into the concept of biomusic.
The vast culture and multicultural ethnicity of the people are also perfected by the beautiful soundscape of the rainforest. I have always been fond of exploring the Malaysian biophony, geophony as well as anthrophony because, through these materials I exhibit the micro, macro and diverse timbres created by nature and its colony.
Elsa Justel
The Acousmatic Versus the World Wide Web
Electroacoustic music was born as a revelation and stimulus for creative spirits in search of new resources and compositional forms. Schaeffer’s ideas disseminated throughout the musical world providing new creative avenues and establishing the bases of a new sonic culture. These ideas brought with them a new way of listening that favours pure hearing, stimulates imagination, and enriches the musical experience with new artistic values linked to matter, energy and space.
In this context, new sound diffusion systems appeared with the aim of extending the perceptual field and creating immersive environments. Acousmatic material gained a new lease of life with the availability of new multichannel audio formats. Yet such work requires an adequate physical space, namely, the concert hall.
The advent of digital media and later the World Wide Web, brought with them a new dissemination paradigm that offered greater visibility and accessibility to electroacoustic production. Unfortunately, online media often result in poorer sound quality and fewer chances for acousmatic listening. Further, the live concert experience is weakened by a vast array of listening contexts. The idea of the musical ‘work’ also seems to be dissolving, substituted by a collective process of continuous transformation, which results, at times, in residual and contingent audio derived from a naïve manipulation of music technology.
A dichotomy arises, one that pits Acousmatics against the World Wide Web as a medium.
I do not wish to play down the advantages of the WWW and those offered by similar interactive media in their role to diffuse music throughout the planet, yet I believe that knowledge obtained from acousmatic practice deserves careful attention. New generations of electroacoustic composers will need comprehensive support to prevent acousmatic practice from disappearing, and avoid becoming mere subjects manipulated by an all-powerful media-dominated world.
Beatriz Ferreyra
Does Acousmatic Music Have a Future?
With the present music technology boom, does what we have called electroacoustic or acousmatic music have any future? This is especially troublesome in relation to new aesthetic trends in live electronics, improvisation and installation work, among many others. Frequently, these practices allow for a false sense of musical achievement, given the ease with which sound events can be triggered on stage; further, the manipulation of sound alone frequently constitutes the performance itself. At times I wonder if this is the result of ignoring how much deeper one can delve into the transformation of sound, given enough dedication and time.
In this context, the creation of acousmatic music is often considered old fashioned by some composers, who may not be entirely familiar with the history of electronic music or have a solid music education. Their view undervalues, in my opinion, the approach that electroacoustic composers have employed since the 50s towards recorded sound: the meticulous craftmanship of sound that went on in private and in the studio, before appearing in the concert hall.
On stage, our generation aimed to produce elaborate music in a live context. We were concerned with structure, agency and emotion. We aspired to the quality of through-composed music, not just producing a collection of pleasant sounds. This approach should enrich the current practice of live electronic performance and composition, not simply be discarded as a thing of the past.
I believe that acousmatic composition is still in its ‘teens’, as it were, and with the potential to go much further thanks to the current rate of development of music technology. Acousmatic music, at just under seventy years of existence is still very young when you compare it to the centuries old evolution of classical and popular music.
We are not at the end of the acousmatic adventure, since we will continue to develop technology and new ideas. We will continue to find new ways of listening and engaging emotionally, and new ways to conceive of acousmatic music without limitations. In the fluidity of a sonic world open to anything that can make a sound, we accept infinite possibilities for construction. We dare to look for new clues without denying the unfamiliar or becoming victims of fashionable trends.






