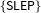One of the most fundamental questions in party politics is whether, and if so when, parties react to other parties. Advances in machine learning and the availability of highly granular textual data make progress on this question possible in a manner than was not previously feasible on a large scale. This paper develops a computational system, building upon recent advances in natural language processing, to analyze partisan debate and responsiveness with a broad potential utility for studying the dynamics of political competition across different scales and contexts. Hotly debated issues span all spheres of human activity, but politics is perhaps the sphere most defined by contentious debates, and much of it is now fully documented online and available for textual analysis. Text mining tools enable researchers to engage in the systematic analysis of text as data in an unprecedented manner, and political scientists have often been at the forefront of developing and applying such methods to analyze large-scale data collections of political texts.Footnote 1 This paper contributes to these developments by proposing a new sequential computational pipeline to predict action–reaction party dynamics.
1 Partisan Responsiveness
Game theoretic approaches to the study of party competition have offered many predictions about how parties should react to the moves of other parties on a given policy dimension, yet the empirical validation of these insights is surprisingly inconclusive. “We know very little,” writes one scholar, “about whether parties respond to policy shifts of rival parties” (Adams Reference Adams2012, p. 407). With few exceptions (Meguid Reference Meguid2008), most of the empirical studies that investigate partisan responsiveness focus on competition between mainstream parties or between the mainstream parties and smaller parties in their ideological families (Adams and Somer-Topcu Reference Adams and Somer-Topcu2009).
Do parties on opposite poles of the political spectrum react to each other’s agendas and thereby contribute to polarization? Political science as a discipline still knows relatively little about this fundamental issue and lacks tailored methods to analyze the dynamics of polarization originating from the interaction of political parties at the extreme poles of the political spectrum. In order to detect centrifugal tendencies in the party system, we focus directly on the most extreme poles of the party spectrum that drive polarization. The more common approach is to focus on interactions between parties that are ideologically related and spatially proximate (Katz and Mair Reference Katz and Mair1995; Arzheimer and Carter Reference Arzheimer and Carter2009; Abou-Chadi and Krause Reference Abou-Chadi and Krause2018, cf. Bustikova Reference Bustikova2014), whereas here we study parties that are ideologically and spatially opposite. Moreover, whereas responsiveness is typically examined from the perspective of the voter–party linkage (Klüver and Spoon Reference Klüver and Spoon2016), we analyze responsiveness at the level of political parties, which allows us to directly address the centrifugality of the party system. Voter’s attitudes can contribute to centrifugality, but political parties and politicians are the primary drivers of polarization (Arceneaux and Johnson Reference Arceneaux, Johnson, Thurber and Yoshinaka2015; Tucker et al. Reference Tucker, Guess, Barbera, Vaccari, Siegel, Sanovich, Stukal and Nyhan2018, p. 40).
Scholars have found that niche parties (radical right, ethnic, environmental and regionalist) are less responsive to the preferences of the general electorate and to other parties than are mainstream parties (Adams et al. Reference Adams, Clark, Ezrow and Glasgow2006; Spoon Reference Spoon2011). Empirical models of party competition that focus on the interactions of ideological “friends”—a mainstream party and its spatially nearby niche party—often ignore movements induced by ideological “foes.” By focusing on ideological foes, on more granular temporal dynamics and on more disaggregated issues, we demonstrate that niche “extreme” parties do react to their political rivals but only on selected topics, which suggests that their reactions may be strategic.
Niche parties are important vehicles of political polarization (Sartori Reference Sartori1976; Ignazi Reference Ignazi1992; Evans Reference Evans2002; Meguid Reference Meguid2008). The dynamic of responsiveness between two rival niche party families, studied in this paper, can enhance our understanding of the dynamics of multiparty systems of polarized pluralism (Sartori Reference Sartori1976). In such party systems, electoral advantage stems from centrifugal competition. If polar opposites are responding to each other’s provocations, polarization ensues because niche parties pull away from the center and stretch the ideological spectrum toward its extremes. If niche parties choose to respond to their polar opponent, they can have a harmful impact on the ability of the party system to rally around the center. By weakening centripetal competition, these dynamics contribute to volatility, fragmentation and de-alignment, and thereby undermine the ability of institutionalized mainstream parties to achieve moderation.
Small, niche parties are often overlooked because they appear marginal at the macro-electoral level and their supporters are missed by surveys. However, an advantage of text mining is that it allows us to capture the dynamics of responsiveness among small parties that often play an outsized role in party system polarization due to their focus on single issues and ideological purity. In the empirical case analyzed in this paper that focuses on radical right and ethnic parties in Slovakia, all major datasets on political parties, cross-national datasets and public opinion surveys ignore the second, more extreme, radical right party (Pospolitost́), which has transformed the landscape of Slovak politics by moving discourse to the extreme with a combative, militant style of politics. Major datasets also ignore the equally important Hungarian splinter movement that formed a new Hungarian ethnic party (Most-Híd), a division that has had a significant impact on both radical right mobilization and nation-wide political outcomes. The approach utilized here captures new, small, ascending parties (and factions) that have contributed in important ways to public discourse and to political polarization.
Although ideological opposites seemingly compete on the same cultural dimension, they strategically highlight and suppress their reactions to some topics that their opponents raise. In the long run of an electoral cycle, the dynamics of counter-reactions can wash out, giving the false impression that niche parties are less responsive than mainstream parties, but this is at odds with the microdynamics highlighted in this analysis. The volatile nature of identity politics indicates that polarization is often driven by microbursts that can quickly escalate contestation and, subsequently, recede. Text mining allows us to disaggregate the identity dimension of party competition and, by looking at a multiplicity of topics, to identify with a high level of precision which topics elicit reactions and which are ignored.
This paper contributes to a growing literature using text mining to learn party positions from texts (e.g., treaties, legislative documents and speeches), typically represented as a numerical measure of distance. Building on ideas introduced in Monroe et al. (Reference Monroe, Colaresi and Quinn2008, pp. 376–82, 398–99) and Grimmer and Stewart (Reference Grimmer and Stewart2013, pp. 3–5), as well as other works on meme diffusion and the temporal characteristics of cascades through social communities (Leskovec et al. Reference Leskovec, Backstrom and Kleinberg2009), we use probabilistic topic modeling features and subject matter expertise to develop and assess a novel end-to-end computational pipeline to predict partisan responsiveness (Alashri et al. Reference Alashri, Alzahrani, Bustikova, Siroky and Davulcu2015). Our main methodological contribution is to introduce a new system for detecting, analyzing and predicting partisan responsiveness between political rivals, which we believe has potentially broad application across a variety of contexts and at different levels of analysis.
We first establish that parties from different (antagonistic) party families respond to each other’s actions and document the microdynamics of partisan responsiveness that occur within lengthy electoral cycles traditionally studied through the prism of party manifestos and expert surveys of party positions. We simultaneously detect topics that are ignored by the adversarial camps and, using country-specific knowledge, explain the strategic logic that leads party leadership to escalate selectively. We compare the SLEP (Sparse Learning with Effective Projection) classifier used in this paper (Liu et al. Reference Liu, Chen and Ye2009a) to a Naive Bayes classifier and to a Random Forest classifier. We show that SLEP performs very favorably.Footnote 2 We also compare our latent Dirichlet allocation (LDA) approach to a vector space baseline model and a word embedding model. Based on the F-measure, LDA offers the best model.
The next section formally defines the research objective and presents a full view under the hood of the methodology, followed by a discussion of the predictive results and substantive findings.
2 Predicting Partisan Responsiveness
All adversarial dyads create contentious frames, but not all frames and topics that one political camp raises resonate with the other camp, and sometimes an increase in attention to a topic by one camp is ignored by their political rivals. Given these assumptions, and a set of documents from each side’s websites, we first ask: do the documents form a spike around a topic during a particular time period? If so, we then ask whether proximate spikes from an opposing camp are related, and can we use this information to predict partisan responsiveness?
We focus on ideological adversaries: radical right parties, which advocate for the sovereign rule of the majority in “their” state, and ethnic parties, which stand for minority inclusion and are therefore often at odds with the radical right. In the context of this application to political parties, the proposed computational system is designed to conduct six sequential tasks (without loss of generality): (i) collect documents from political party websites and index them for fast retrieval and processing; (ii) identify key issues using theoretically derived scales and subject matter expertise; (iii) make issue-specific topic inference for each political camp; (iv) detect party-specific spikes that reflect increased attention to a specific issue and measure whether these spikes elicit a response from the opposing political camp (spike relatedness); (v) identify frames that discriminate between ignored/escalated spikes; (vi) train and test predictive models of partisan responsiveness. The result is a framework that can model how political discourse varies over time, detect topics that gain disproportionate attention from each camp and predict which topics solicit reactions from political rivals and which topics are ignored.
Once topical spikes from political opponents are detected and categorized using LDA (Blei et al. Reference Blei, Ng and Jordan2002), we exploit the terms that comprise the topics as features, together with a gradient descent approach known as SLEP (Liu et al. Reference Liu, Chen and Ye2009a), in order to identify discriminative frames and to predict partisan responsiveness. To assess the framework’s predictive accuracy, we use 10-fold cross-validation and 10,597 documents downloaded from the official websites of radical right and ethnic political parties in Slovakia, spanning a decade (2004–2014) of contentious politics. Using the F-measure, the classification accuracy for predicting partisan responsiveness (positive/escalated spikes) ranges from 80% to 89% and the classification accuracy for predicting the negative/ignored spikes (the lack of partisan responsiveness) ranges from 78% to 86%, depending on the topic and political camp. These results compare very favorably to experimentally tuned Naive Bayes and Random Forest classifiers.Footnote 3 Subject matter experts then validate and interpret the results.
Figure 1 offers a stylized overview of the system architecture. The numbers on the top left corner of each box represent the order in which these processes are executed. Each of the seven steps in the process is briefly described below, with additional details in the following sections.

Figure 1. System Architecture.
(1) Download documents, label by party, date and store in the database.
(2) Identify grid/group issues using the theoretical framework.
(3) Generate a ranked list of the top n-gram terms.
(4) Subject matter experts map issues onto theoretically informed scales.
(5) Infer latent topics for each issue and party or camp.
(6) Detect spikes of documents and label them as escalated or ignored.
(7) Use the results from step 6 as inputs for the prediction model.
In step 1, we wrote a set of scripts to download all documents from the websites of radical right parties and ethnic political parties in Slovakia from the beginning of the 2004 calendar year to March 16, 2014. Next, we preprocessed the data to extract text and article dates.Footnote 4 Then, we implemented the following methodology:
∙ Run a simple term frequency–inverse document frequency (TF–IDF) (Hartigan and Wong Reference Hartigan and Wong1979) on the entire corpus to generate a large candidate list of terms (after removing stopwords) for inclusion. This measure identifies the importance of a word to a document based on its presence in a document (TF) and its rarity at the corpus level (IDF). Select the top T n-gram terms (1–3 grams).
∙ Subject matter experts scan the list of n-grams ranked by frequency and select relevant keywords indicating hotly debated grid/group issues that capture views on group exclusion and state authority.
∙ For each issue:
– Select the documents that mention the issue based on given keywords;
– Run the Mallet algorithm (McCallum Reference McCallum2002) over each political party’s corpus to get their LDA’s latent topics, 100 topics each with 20 keywords (Blei et al. Reference Blei, Ng and Jordan2002);
– Detect and label the spikes from each party as escalated or ignored by the other camp based on the three-sigma rule (Pukelsheim Reference Pukelsheim1994);
– Use latent topics and a feature selection algorithm to determine issue-specific discriminative escalated versus ignored frames;
– Use discriminative frames to train a sparse-learning classifier (SLEP) to predict partisan responsiveness.
Next, we describe these steps in greater detail.
2.1 Text Processing and LDA Topic Inference for Each Camp
We selected parties that were on the opposing poles of the political spectrum: two radical right parties and two ethnic parties. We first collected all the documents, generated a ranked list of n-gram keywords and placed the most frequent n-grams on the top of the list.Footnote 5 Using the ranked list of n-gram keywords, experts identified grid/group issues (topics) using a classification scheme derived from general social theory (Douglas Reference Douglas1970; Douglas and Wildavsky Reference Douglas and Wildavsky1982).Footnote 6
The grid–group approach to the study of politics has been used to study mass political beliefs (Coughlin and Lockhart Reference Coughlin and Lockhart1998), the determinants of dimension dominance (Rehm and Kitschelt Reference Rehm, Kitschelt, Manow, Palier and Schwander2018), party alignments in Western Europe (Rehm and Kitschelt Reference Rehm, Kitschelt, Beramendi, Hausermann, Kitschelt and Kriesi2015), complex political orientations beyond the traditional left–right scale (Grendstad Reference Grendstad2003) and radical right parties (Bustikova and Kitschelt Reference Bustikova and Kitschelt2009). As a classification system, it places political orientations into four categories using the two axes of grid and group: hierarchy, egalitarianism, individualism and fatalism. It offers a more nuanced analytical tool for party classification than the left–right placement and is more versatile than the commonly used traditional versus libertarian distinction used in the Chapel Hill Expert Survey. It does not collapse identity onto one dimension and therefore can account for the fact that ethnic inclusion does not necessarily imply social liberalism.Footnote 7
Since our analysis investigates the responsiveness of polar opposites on the so-called “second” axis of party competition (cultural issues as opposed to economic issues), any spike in issues that the party discusses implies both an increase in salience and polarization (Spies and Franzmann Reference Spies and Franzmann2011). To capture different aspects of polarization and more granular action–reaction dynamics, the identity axis needs to be disaggregated. Grid–group allows the analyst to classify attitudes toward state authority as separate from ethnic issues.
We utilize LDA, one of the most popular topic inference algorithms (Blei et al. Reference Blei, Ng and Jordan2002). It assumes that documents represent a mixture of topics, where a topic is a probability distribution over words. In other words, it uses a “bag of words” approach to perform statistical topic modeling and to uncover hidden structures in large text corpora.Footnote 8 In our analysis, LDA outperformed two competitive alternatives: vector space and word embedding models.Footnote 9 After identifying the grid–group issues using ranked weighted TF–IDF terms, we applied LDA separately on ethnic and radical right parties’ corpora to discover their party-specific latent topics. For each grid–group issue, we determine when an issue is salient for one party (i.e., the issue-specific document volume crosses the threshold and constitutes a spike, as discussed below) and when that leads the other party to respond (with a temporally proximate and topically related spike).
2.2 Detecting Spikes, Similarity and Escalation
We utilize the 68-95-99.7 rule for spike detection (Pukelsheim Reference Pukelsheim1994), also known as the three-sigma rule, which states that in a normal distribution nearly all values lie within three standard deviations (
 $\unicode[STIX]{x1D70E}$
) of the mean (
$\unicode[STIX]{x1D70E}$
) of the mean (
 $\unicode[STIX]{x1D707}$
). We utilize a fixed-sized sliding window (experimentally determined as 20 weeks) to compute a running average
$\unicode[STIX]{x1D707}$
). We utilize a fixed-sized sliding window (experimentally determined as 20 weeks) to compute a running average
 $\unicode[STIX]{x1D707}(20)$
and a standard deviation
$\unicode[STIX]{x1D707}(20)$
and a standard deviation
 $\unicode[STIX]{x1D70E}$
for each issue’s weekly volume distribution from each camp. We designate a weekly volume as a spike if the weekly document volume matching an issue exceeds (
$\unicode[STIX]{x1D70E}$
for each issue’s weekly volume distribution from each camp. We designate a weekly volume as a spike if the weekly document volume matching an issue exceeds (
 $\unicode[STIX]{x1D707}(20)+2\unicode[STIX]{x1D70E}$
). We tuned this sliding window to 20 weeks because it showed the best performance. When smaller windows (5 weeks, 10 weeks and 15 weeks) are applied, the resultant spikes are noisy. When larger windows are applied (25 weeks, 30 weeks and 35 weeks), the resultant spikes are sparse.
$\unicode[STIX]{x1D707}(20)+2\unicode[STIX]{x1D70E}$
). We tuned this sliding window to 20 weeks because it showed the best performance. When smaller windows (5 weeks, 10 weeks and 15 weeks) are applied, the resultant spikes are noisy. When larger windows are applied (25 weeks, 30 weeks and 35 weeks), the resultant spikes are sparse.
Spikes are categorized into two categories: (1) “escalated” spikes that trigger a reaction from the other camp or (2) “ignored” spikes that lead to no response—based on the relatedness (goodness of fit) of each topic distribution inferred by LDA in consecutive spikes from opposing camps. Spike categorization (escalated/ignored) is a result of shared topics between two consecutive spikes from opposing camps. By matching up consecutive spikes, we capture partisan debates, defined as “formal discussions on a set of related topics in which opposing perspectives and arguments are put forward.”Footnote
10
To measure the “relatedness” of topics between a pair of consecutive spikes from opposing camps, we utilize the Kullback–Leibler (KL) divergence between LDA topic distributions of consecutive spikes (Kullback and Leibler Reference Kullback and Leibler1951) and then convert it to a similarity measure, scaled between 0 and 1. The KL divergence of the probability distributions
 $E$
,
$E$
,
 $R$
on a finite set
$R$
on a finite set
 $X$
is defined asFootnote
11
$X$
is defined asFootnote
11
 $$\begin{eqnarray}D(E,R)=\mathop{\sum }_{x\in X}E(x)\log \frac{E(x)}{R(x)}.\end{eqnarray}$$
$$\begin{eqnarray}D(E,R)=\mathop{\sum }_{x\in X}E(x)\log \frac{E(x)}{R(x)}.\end{eqnarray}$$
Given two consecutive spikes from opposing camps, ethnic party spike
 $S_{E}$
and radical right party spike
$S_{E}$
and radical right party spike
 $S_{R}$
, we first identify latent topics of each spike with their distributions within the documents:
$S_{R}$
, we first identify latent topics of each spike with their distributions within the documents:
 $E$
is the distributions of
$E$
is the distributions of
 $S_{E}$
topics and
$S_{E}$
topics and
 $R$
is the distributions of
$R$
is the distributions of
 $S_{R}$
topics. For example, when comparing two consecutive spikes related to the issue of “Minorities”—one spike with topics from the ethnic camp such as “minority languages, schools, …etc” versus the following spike from other camp with topics “gypsy problem, schools, …etc”—we measure the distributions of topics in these two spikes with respect to the number of documents matching the “Minorities” topic. We then measure the divergence of topic distributions using the symmetric form of KL divergence (Seghouane and Amari, Reference Seghouane and Amari2007) that measures the divergence of the probability distributions
$S_{R}$
topics. For example, when comparing two consecutive spikes related to the issue of “Minorities”—one spike with topics from the ethnic camp such as “minority languages, schools, …etc” versus the following spike from other camp with topics “gypsy problem, schools, …etc”—we measure the distributions of topics in these two spikes with respect to the number of documents matching the “Minorities” topic. We then measure the divergence of topic distributions using the symmetric form of KL divergence (Seghouane and Amari, Reference Seghouane and Amari2007) that measures the divergence of the probability distributions
 $E$
,
$E$
,
 $R$
on a finite set
$R$
on a finite set
 $X$
of topics as follows:
$X$
of topics as follows:
 $$\begin{eqnarray}D(E,R)=\mathop{\sum }_{x\in X}\bigg((E(x)-R(x))\log \frac{E(x)}{R(x)}\bigg).\end{eqnarray}$$
$$\begin{eqnarray}D(E,R)=\mathop{\sum }_{x\in X}\bigg((E(x)-R(x))\log \frac{E(x)}{R(x)}\bigg).\end{eqnarray}$$
We normalize this measure with respect to the sum of distributions to be between [0,1] and convert it to a similarity measure as follows:
 $$\begin{eqnarray}Sim(S_{E},S_{R})=1-D_{\mathit{normalized}}(E,R),\end{eqnarray}$$
$$\begin{eqnarray}Sim(S_{E},S_{R})=1-D_{\mathit{normalized}}(E,R),\end{eqnarray}$$
where
 $Sim(S_{E},S_{E})=1$
means the two distributions of topics across the two spikes are identical. If the similarity of topic distributions between the two consecutive spikes from opposing camps exceeds a certain threshold, then we label the first spike as “escalated”; otherwise, it is considered “ignored.”Footnote
12
$Sim(S_{E},S_{E})=1$
means the two distributions of topics across the two spikes are identical. If the similarity of topic distributions between the two consecutive spikes from opposing camps exceeds a certain threshold, then we label the first spike as “escalated”; otherwise, it is considered “ignored.”Footnote
12
LDA is used twice. The first time, LDA is applied on the overall corpus (both radical and ethnic corpus) to measure the relatedness of spikes. The second time, LDA is used separately on the radical corpus (radical right parties) and on the ethnic corpus (ethnic parties) to determine issue-specific frames to be exploited as features for the predictive model.
2.3 Models
We experimented with three methods: a baseline vector space model, a word embedding model and an LDA model.
2.3.1 Baseline Vector Space Model
In our baseline model (vector space model), we directly modeled the similarity approach by using the cosine similarity over spikes’ frequent keyword vector representation of
 $E$
and
$E$
and
 $R$
, without requiring a lower dimensional space representation of the data, for example, inferring topic distribution LDA or word embedding document to vector as follows:
$R$
, without requiring a lower dimensional space representation of the data, for example, inferring topic distribution LDA or word embedding document to vector as follows:
 $$\begin{eqnarray}Sim(S_{E},S_{R})=Cosine(E,R)=\frac{E\cdot R}{\Vert E\Vert _{2}\cdot \Vert R\Vert _{2}}.\end{eqnarray}$$
$$\begin{eqnarray}Sim(S_{E},S_{R})=Cosine(E,R)=\frac{E\cdot R}{\Vert E\Vert _{2}\cdot \Vert R\Vert _{2}}.\end{eqnarray}$$
The similarity measure is a sparse vector representation of frequent keywords. We computed all distances between consecutive spikes using Equation (4) and, by thresholding, determined the labels of spikes whose measure is larger than or equal to the mean, indicating an “escalated” spike from the opposing camp; otherwise, they are labeled as “ignored.”
2.3.2 Word Embedding Model
Word embedding utilizes neural networks to encode the context into a denser, lower dimensional space. It is a highly effective method of capturing semantic relations where each document is represented by a real number vector such that similar documents are closer to one another than dissimilar documents in a geometric space. We employed the Paragraph Vector Distributed Bag of Words (PV-DBOW) proposed by Mikolov et al. (Reference Mikolov, Chen, Corrado and Dean2013) and Le and Mikolov (Reference Le and Mikolov2014) to infer the real number vector of a document (a.k.a. doc2vector). After training the PV-DBOW model over our corpus, we infer vectors for each spike and computed all distances using Equation (4).Footnote 13
2.3.3 LDA Model
The LDA model can be viewed as a three-level Bayesian probabilistic model to learn distributions of topics over documents and words. After training an LDA model, we infer topic distribution for each spike’s topics. Then, we determine the labels of spikes based on the KL measure, which captures the divergence of distributions between two consecutive spikes (Equation (3)).
2.4 Framing Analysis and Predicting Escalation
During a debate on a particular topic, both radical right parties and ethnic parties discuss different perspectives.Footnote 14 Once escalated and ignored spikes from one camp are determined, we use a sparse-learning framework (Liu et al., Reference Liu, Chen and Ye2009a), with the aim of selecting a subset of discriminating features that can identify and classify contentious (escalatory) spikes as opposed to ignored ones. The following steps describe our algorithm:
(1) For each key grid–group issue, run LDA to get latent topics for one camp. Footnote 15
(2) Filter the frame
 $\times$
spike matrix to include only the top 2,000 terms representing frames from one camp (100 topics (or topic dimensions) each with top 20 terms inferred).
$\times$
spike matrix to include only the top 2,000 terms representing frames from one camp (100 topics (or topic dimensions) each with top 20 terms inferred).(3) Formulate the problem as a logit model streamlined by the SLEP framework (Liu et al., Reference Liu, Chen and Ye2009a) to predict escalated versus ignored spikes. Formally,

 $$\begin{eqnarray}\mathbf{min}_{x}\mathop{\sum }_{i=1}^{m}w_{i}\log (1+\exp (-y_{i}(x^{t}a_{i}+c)))+\unicode[STIX]{x1D706}\Vert x\Vert _{1},\end{eqnarray}$$
$$\begin{eqnarray}\mathbf{min}_{x}\mathop{\sum }_{i=1}^{m}w_{i}\log (1+\exp (-y_{i}(x^{t}a_{i}+c)))+\unicode[STIX]{x1D706}\Vert x\Vert _{1},\end{eqnarray}$$
where
 $a_{i}$
is the vector representation of the
$a_{i}$
is the vector representation of the
 $i$
th spike,
$i$
th spike,
 $w_{i}$
is the weight assigned to the
$w_{i}$
is the weight assigned to the
 $i$
th spike (
$i$
th spike (
 $w_{i}=1/m$
by default),
$w_{i}=1/m$
by default),
 $A=[a_{1},a_{2},\ldots ,a_{m}]$
is the frame
$A=[a_{1},a_{2},\ldots ,a_{m}]$
is the frame
 $\times$
spike matrix,
$\times$
spike matrix,
 $y_{i}$
is the polarity of each spike (+1 for an escalated spike and -1 for an ignored spike),
$y_{i}$
is the polarity of each spike (+1 for an escalated spike and -1 for an ignored spike),
 $x_{j}$
, the
$x_{j}$
, the
 $j$
th element of
$j$
th element of
 $x$
, is the unknown weight for each frame, (
$x$
, is the unknown weight for each frame, (
 $\unicode[STIX]{x1D706}>0$
) is a regularization parameter that controls the sparsity of the solution and
$\unicode[STIX]{x1D706}>0$
) is a regularization parameter that controls the sparsity of the solution and
 $|x|_{1}=\sum |x_{i}|$
is the 1-norm of the
$|x|_{1}=\sum |x_{i}|$
is the 1-norm of the
 $x$
vector.
$x$
vector.
The sparse-learning approach (SLEP) relies on a gradient descent algorithm to solve the above convex and nonsmooth optimization problem (Liu et al., Reference Liu, Ji and Ye2009b). The frames with nonzero values on the sparse
 $x$
vector yield the discriminant factors for classifying a spike as escalated or ignored based on their polarity (positive or negative). Frames with positive polarity correspond to escalated frames and those with negative polarity to ignored frames.
$x$
vector yield the discriminant factors for classifying a spike as escalated or ignored based on their polarity (positive or negative). Frames with positive polarity correspond to escalated frames and those with negative polarity to ignored frames.
3 Analysis
3.1 The Data Corpus
The corpus comprises 10,597 news and opinion articles downloaded from the official websites of radical right and ethnic political parties in Slovakia from 2004 and 2014. From the ethnic camp, we downloaded all documents from Most-Híd (http://www.most-hid.sk) and from SMK—Party of the Hungarian Coalition (http://www.mkp.sk). From the radical right camp, we downloaded all documents from the SNS—Slovak National Party (http://www.sns.sk) and Slovenská Pospolitost́—The Slovak Brotherhood (https://pospolitost.wordpress.com). The document volume is roughly equal between the two camps.
While the method has broad potential applications for studying a diverse set of cases and topics, a word is in order about why this party system serves as an interesting and important case study to introduce this approach to predicting partisan responsiveness. First, the radical right parties and the ethnic parties in Slovakia are both relatively large compared to some “niche parties” in other countries; so they are politically relevant for coalition formation.
Second, the political space in Slovakia has been characterized by a high degree of variation in the extent to which it is polarized on issues of national identity, and this variability allows us to track a truly dynamic process of contestation. Finally, over the past two decades, the political scene in Slovakia has been quite stable in terms of the actors that anchor both political poles. This provides consistency over time in the analysis since the actors are identifiable with transparent profiles and reputations that have been established over a relatively long time period (Gyárfášová et al. Reference Gyárfášová2015; Baboš, Világi, and Oravcová Reference Baboš, Világi and Oravcová2016; Kluknavská and Smolík Reference Kluknavská and Smolík2016; Guasti and Mansfeldová Reference Guasti and Mansfeldová2018).

Figure 2. Contentious Frames Analyzer Tool. Zoom on the period from the middle of July 2013 to the middle of March 2014. Below the main plot is a secondary plot that shows the entire time period from 2004 to 2014. Users can simply slide the window to the time period of interest and the main plot will zoom in on this period and identify ignored and escalated spikes for a given topic, which can be selected on the right (Minorities, Nation, Language, Interstate (Relations), Economics, EU/Enlargement), and for a given actor in the dyad (ethnic or radical right party), which can be selected below the main plot: Ethnic eliciting Radical reaction prediction (left) or Radical eliciting Ethnic reaction prediction (right).
Figure 2 displays spikes of attention over time to one topic (in this case, “Language”), by both camps (radical spikes are red and ethnic spikes are blue), and shows that the adversaries mobilize in bursts.Footnote 16 It also shows whether a spike from one camp is ignored or reacted to by the other camp in the form of a new spike on the same topic. The bottom panel in Figure 2 shows (in gray) the overall volume of contentious frames (2008–2011) during a period of intense debate over a very restrictive language law, adopted in September 2009 with the help of the SNS, and the ensuing efforts of ethnic parties to soften its negative impact on Hungarians. Finally, Figure 2 illustrates the volume of documents generated by radical (red line) and ethnic (blue line) political party outlets in Slovakia over the entire 10-year period (between 2004 and 2014) that we analyze.
Not all topics resonate within the dyad. The “predictions” panel on the right of Figure 2 shows a timeline (using alphabetic annotations) that corresponds to ethnic party spikes and predictions about whether they will lead to “escalation” as a result of the radical right parties responding. Green labels indicate a “hit” (correct prediction) and red labels indicate a “miss” (incorrect prediction) by the classifier. In the screenshot displayed, which covers from July 2013 to March 2014, the classifier correctly hits 9 of out 10 spikes.
Subject matter experts selected the key issues shown in Table 2 and mapped them onto the group (nationalism) and grid (state authority) dimensions. Focusing on these six topics, the framework categorizes spikes as either escalated or ignored for both radical right parties and for ethnic parties and then uses this information to predict partisan responsiveness. To determine whether a pair of consecutive spikes on one of these six topics is related, the mean similarity for each grid/group issue was used as the threshold. If the similarity between a spike (from one camp) and the following spike (from the other camp) exceeds the mean similarity for an issue, then the first spike is labeled escalated and otherwise it is labeled ignored.
Table 1. Number of Analyzed Documents.

Ethnic parties are: SMK—Strana mad’arskej koalície, Party of the Hungarian Coalition (now Strana mad’arskej komunity) and Most-Híd—Bridge).
Radical right parties are: SNS—Slovenská národná strana, Slovak National Party and Slovenská Pospolitost´, Slovak Brotherhood.
Table 2. Group (Nationalism) and Grid (State Authority) Issues.

To illustrate, Figure 3 shows the similarity measure (
 $y$
-axis) for ethnic party spikes, for each of the six grid/group issues (
$y$
-axis) for ethnic party spikes, for each of the six grid/group issues (
 $x$
-axis). Dots represent spikes and boxes show the means (which vary between 0.35 and 0.45), along with the first and third quartiles, with whiskers for the 95% confidence intervals on the similarity measure. Once spikes from each camp are detected and categorized, the terms that comprise the topics are used as features for the SLEP classifier (Liu, Reference Liu, Ji and Ye2009b) to identify discriminative frames. Using 10-fold cross-validation (McLachlan, Reference Mclachlan, Do and Ambroise2004), we calculated the precision, recall and F-measure (Perry, Reference Perry, Kent and Berry1955).
$x$
-axis). Dots represent spikes and boxes show the means (which vary between 0.35 and 0.45), along with the first and third quartiles, with whiskers for the 95% confidence intervals on the similarity measure. Once spikes from each camp are detected and categorized, the terms that comprise the topics are used as features for the SLEP classifier (Liu, Reference Liu, Ji and Ye2009b) to identify discriminative frames. Using 10-fold cross-validation (McLachlan, Reference Mclachlan, Do and Ambroise2004), we calculated the precision, recall and F-measure (Perry, Reference Perry, Kent and Berry1955).
3.2 Model Performance and Frame Detections Based on the LDA Model
Table 3 displays the performance of the vector space model, the word embedding model and LDA. In this table, the LDA model outperformed the other two models (F-measure).Footnote 17 Using the same set of LDA-based features, the SLEP classifier outperforms both the Naive Bayes and Random Forest classifiers in terms of the overall F-measure, which is consistently higher for SLEP than for either alternative classifier across all escalated and ignored topics.Footnote 18

Figure 3. Similarity Measures for Ethnic Spikes.
Table 3. F-measures of Three Models.

Figure 4 shows the “language” topics over which ethnic parties and radical parties fight (e.g., languag(e) Slovak, Hungarian school, minor(ity) nation, human right, educ(ational) minist(ry)). The Venn diagram shows two intersected circles, where the first circle belongs to the first spikes with top terms and the second circle represents the spikes from the other party. The intersecting area represents the common terms. Language education emerges as an intrinsic focal point spurring debate, in this case, prompted by ethnic parties and followed by a spike from radical right parties.

Figure 4. Intersecting Topics.
Table 4. Contentious Frames.

3.3 Contentious Frames and Polarization in Slovakia
To assess which topics are contentious and polarize public discourse and which topics are ignored, we turn to the intersecting topics and “contentious frames” identified in Figure 4 and Table 4, which lists issue-specific frames used by each camp that tended to elicit reactions from the other camp. We then compare these with the “ignored frames” in Table 5.
The left column of Table 4 depicts the Hungarian–Slovak political cleavage over language and Hungarian minority rights rather clearly. This is consistent with decade-old fights over the status of the Hungarian minority, particularly its language rights (Bútora Reference Bútora2007; Haughton and Ryba Reference Haughton and Ryba2008; Mesežnikov, Gyárfášová, and Smilov Reference Mesežnikov, Gyárfášová and Smilov2008; Deegan Krause and Haughton Reference Deegan Krause and Haughton2009). Radical parties tend to escalate on language policies: they respond strongly when ethnic parties talk about the “language law,” “minority language” and “mother tongue.”
Slovakia is home to two ethnic minorities: politically mobilized Hungarians and demobilized, impoverished Roma. The computational results show that radical parties and (Hungarian) ethnic parties react differently to Roma issues. While radicals respond to frames that advance the rights of the Hungarian speakers, the reverse is not true: if radicals challenge the right of Hungarians to be politically accommodated, ethnic parties do not escalate. Instead, ethnic parties escalate if radical right parties launch attacks on Roma: a different ethnic group and when they invoke the legacy of interwar fascism associated with an independent Slovak state. Ethnic parties also respond when the radical right parties discuss “protection of the republic,” “white race” and the “Gypsy (Roma) problem.” The historical dimension associated with attempts to whitewash the fascist legacy of Jozef Tiso, who collaborated with the Nazis, is most evident in the frames “Nation,” “Language” and “Minority.”
Scholars of Slovak politics know that radical right parties attack both Hungarians and Roma, but the computational results also reveal that ethnic Hungarian parties are more likely to respond to radical frames that are not related to the rights of Hungarians but rather to Roma, and to historical frames. If ethnic parties escalate on issues of Roma and interwar legacies, they frame radicals as fascists and xenophobes, and thereby diminish radicals as credible adversaries that can be engaged to debate policy. This may explain why ethnic parties stay quiet when radical right parties question policies that expand their (language) rights.
Table 5. Ignored Frames.

Turning to the frames that were largely ignored by the other side of the political spectrum in Table 5, we see that radical right parties did not respond when topics were discussed in cultural terms but rather did so when these topics were discussed in policy terms. Under the issue “Minority,” for example, radicals did not respond to the frames “cultural minorities,” “theater” and “cultural activities.” Although these frames may suggest concessions to minorities, they fall short of recognition as a “national minority,” which implies language rights as well as political and economic power-sharing. Similarly, ethnic parties ignored radical frames under the issues of “Nation,” “Language” and “Minority” that focused on religion (“Pope Benedict,” “Jan Hus,” “church provinces” and “Slovak Church”).
Tables 4 and 5 underscore the fact that the key issues of contention between radical right parties and ethnic political parties are almost exclusively related to three main issues: (1) rights of Hungarians as a national minority, (2) hostility toward Roma, an ethnic underclass and (3) an interwar fascist legacy: a historical cleavage that concerns the Nazi collaboration of the first independent Slovak state during World War II. The computational and qualitative text analysis advances understanding of party politics with a new approach to highlighting the issue-specific causes of political mobilization and polarization. It reveals that radical right parties mobilize when their adversaries discuss minority rights, whereas the ethnic parties respond to adversarial frames that evolve around racism and historical autocratic regime legacies. In sum, parties on the opposing poles of the political spectrum respond to each other and selectively react to each other’s polarizing frames.
4 Conclusion
The computation approach introduced in this paper has a broad potential applicability for studying ideological positioning and partisan debates in political science, at different scales and contexts of political competition. Using this framework, scholars can parse, analyze and generate predictions about practically any interesting “debate” between “camps” that produces a large corpus of time-stamped text. While any form of documented debate is a fair game, political debates are particularly ripe for this type of approach because they are frequently both contentious and consequential.
With the growth of online content, political scientists now have more information at their disposal than they can humanly process and understand. Manual processing of such information is time-consuming, costly and does not scale well. This article enriches computational political science by harnessing unstructured data into temporal and topical dimensions for automated analysis to better understand and predict partisan responsiveness. It develops and assesses a new computational tool to discover and predict contentious and ignored frames for each political camp. Using radical right party and ethnic party website content from 2004 to 2014 in Slovakia, the model has an average accuracy (F-measure) for escalated ethnic spikes of 84.7% and an average accuracy for escalated radical spikes of 83.3%. This approach outperforms Random Forest and Naive Bayes classifiers. Using LDA boosts performance over vector space and word embedding models. A qualitative analysis of the contentious and ignored frames yields additional substantive insights and shows that ethnic parties respond more to xenophobic and historical frames, whereas radical right parties react more to frames about minority accommodation. We have also shown that parties on the very opposite poles of the ideological spectrum react to each other’s frames and thereby contribute to political polarization.
Although considerable progress has been made in automating content analysis, scholars have also become increasingly aware of its limitations. Grimmer and Stewart (Reference Grimmer and Stewart2013) present several issues that scholars applying content analysis models should recognize and engage. First, scholars should acknowledge the complexity of the language and that many quantitative models are incapable of handling language complexity as humans do. Automated content analysis methods will not replace humans, but these methods can magnify our abilities. Here, the automated analysis of partisan responsiveness serves as a complement, rather than a substitute, to subject matter expertise. All the quantitative results in the paper are validated qualitatively by subject matter experts. Second, since there is no global method for automated content analysis, each research problem, along with its data, has to have its own methodology. Although there are general principles and algorithms, there is no “Plug and Play” solution to various research questions. As a result, validating the outputs of content analysis models is a core requirement. One venerable validation approach entails having subject area experts examine the results.
We believe this study represents an important contribution to political science, yet we also wish to highlight several limitations and directions for future research. First, we analyzed the content of official party websites but not other outlets, such as newspapers and social media. Incorporating data from these sources could expand the range of actors and frames, leading to a more comprehensive understanding of partisan dynamics and higher predictive accuracy. Moreover, these sources could identify emerging trends in real time. Second, more work is needed examining the role of external events, such as elections and protests. Despite these limits, we are hopeful that this approach to understanding partisan responsiveness and polarization will facilitate and inspire additional usage, research and insights into how topic modeling can improve our understanding of party politics and our ability to predict party dynamics.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2019.18.