1 Motivation
Terminology is rapidly developing in many research and technological fields. It is very difficult to produce and maintain up-to-date terminology resources, especially for languages that are in need of many natural language processing (NLP) resources and tools. Such is the case for Serbian, for which terminological resources in many domains, if existing, tend to be obsolete.
The work presented in this paper is motivated by our assumption that existing NLP resources, methods, and tools can help in the development of terminology for Serbian. Since contemporary Serbian terminology in many domains is often strongly related to English terminology, for which many relevant and easily available lexical resources and tools exist (Ananiadou, McNaught and Thompson Reference Ananiadou, McNaught, Thompson, Rehm and Uszkoreit2012), we decided to use English resources, in order to facilitate the development of Serbian domain terminology.
Despite Serbian being an under-resourced language (Vitas et al. Reference Vitas, Popović, Krstev, Obradović, Pavlović Laźetić, Rehm and Uszkoreit2012), some important resources have been developed, such as aligned corpora, electronic dictionaries of simple, and multi-word units (MWUs), as well as shallow parsers. Since domain terminology is abundant with multi-word terms (MWTs),Footnote a and since they are predominantly noun phrases, shallow parsers for Serbian that extract such terms can help in producing aligned terminology.
In this paper, we will try to corroborate the following hypothesis:
On the basis of bilingual, aligned, domain-specific textual resources, a terminological list and/or a term extraction tool in a source language, and a system for the extraction of terminology-specific noun phrases (MWTs) in a target language, it is possible to compile a bilingual aligned terminological list.
This paper is organized as follows. In Section 2, we give a brief overview of previous related work. In Section 3, we name and describe lexical resources and tools that were used in our experiments. The design of the system and setting of experiments are explained in Section 4, followed by the evaluation of results and discussion in Section 5. More details about the classification are given in Section 6. Finally, we conclude and list plans for future work in Section 7.
2 Related work
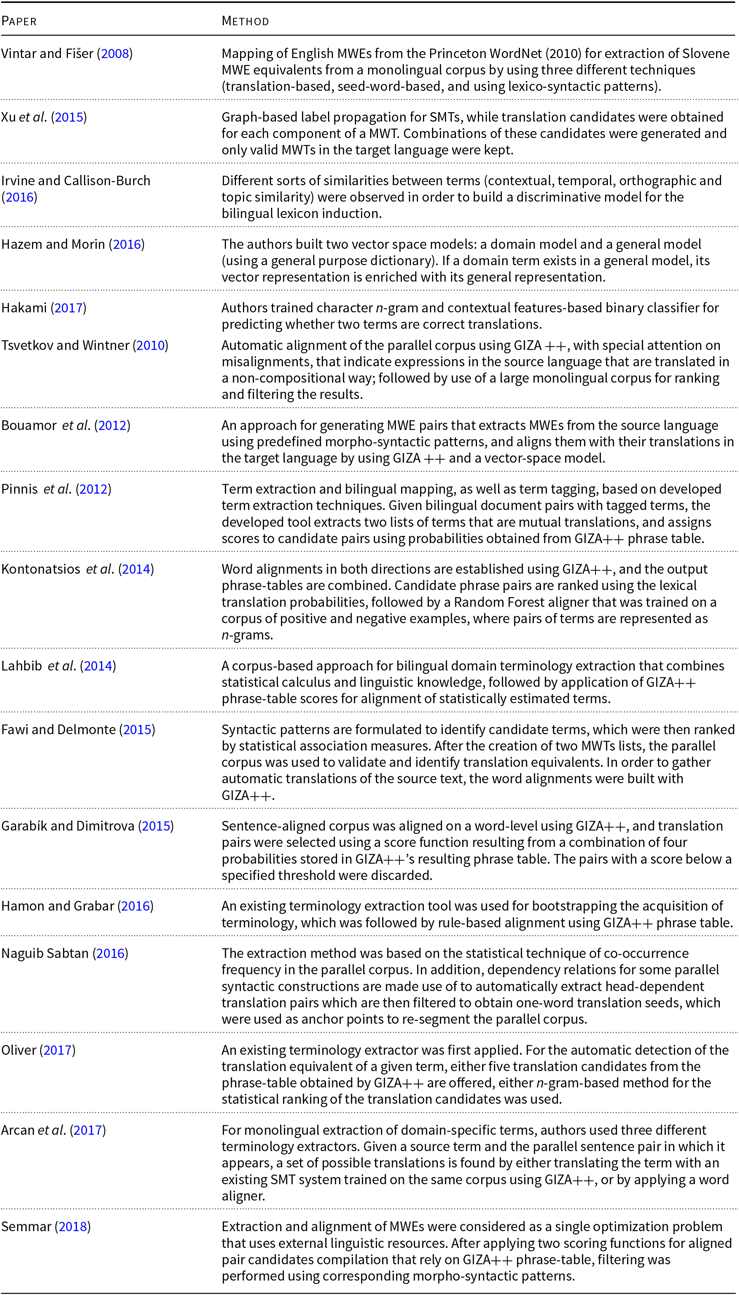
Over the past years, in order to compile bilingual lexica, researchers used various techniques for MWT extraction and alignment that differ in methodology, resources used, languages involved, and purpose for which they were built. In Table A1, given in the Appendix, a general overview of terminology extraction and alignment approaches are listed: languages for which terminology was compiled (Lang), types of used corpora (Corp: P for parallel and C for comparable), and to which domain they belonged (Domain), as well as the motivation for each of the conducted experiments (Aim: L for building bilingual terminology lists or T for improvement of an existing translation system).
A brief overview of alignment and extraction techniques applied in these works is given in Table A2 in the Appendix. Our method relies on the existence of a parallel sentence-aligned corpus. For word-level alignment of a sentence-aligned corpus, we used GIZA++ (Och and Ney Reference Och and Ney2000). It is safe to say that this tool is a benchmark for phrase-based approaches, as the majority of methods listed in Table A2 rely on it.
In order to compile a bilingual lexicon for a specific domain, we combine and compare several settings. Besides using only a parallel sentence-aligned corpus, we conducted an experiment where sentences from the corpus were extended with a bilingual list of inflected word forms from a general-purpose dictionary. Tsvetkov and Wintner (Reference Tsvetkov and Wintner2010) also used a bilingual list from a general-purpose dictionary, albeit for a different purpose, namely as an enhancement in the step where they identify terminology candidates, and not in order to extend the corpus. Hazem and Morin (2016) used an existing bilingual general-purpose dictionary for improving the vector space model representation for each term.
We compare different configurations for the extraction of domain terminology on both, source and target, sides.
For the source side, we compare two cases. In the first case, we use an existing bilingual domain dictionary. The aim is to obtain translations of existing source terms on the target side and evaluate these obtained translations against the existing target terms from the dictionary.
A similar approach was proposed by Vintar and Fišer (2008). Their goal was to translate English terms from Princeton WordNet (2010) to Slovene in order to enrich the Slovene WordNet. Hakami and Bollegala (Reference Hakami and Bollegala2017) also used an existing list of source terms from the biomedical domain, which they later mapped to an existing list of terms on the target side. Kontonatsios et al. (2014) used the biomedical metathesaurus for the evaluation of their proposed method.
In the second case, we obtain source terminology using an existing term extractor. For this purpose, we compared several existing extraction tools for English, similarly to some other authors (Pinnis et al. Reference Pinnis, Ljubešić, Stefanescu, Skadina, Tadić and Gornostay2012; Hamon and Grabar Reference Hamon and Grabar2016; Oliver Reference Oliver2017; Arcan et al. Reference Arcan, Turchi, Tonelli and Buitelaar2017).
For the extraction of terminology on the target side, we apply morphological and statistical analysis. A similar approach was taken by other authors (Bouamor, Semmar and Zweigenbaum Reference Bouamor, Semmar, Zweigenbaum, Calzolari, Choukri, Declerck, Doan, Maegaard, Mariani, Moreno, Odijk and Piperidis2012; Lahbib, Bounhas and Elayeb Reference Lahbib, Bounhas, Elayeb, Meersman, Panetto, Dillon, Missikoff, Liu, Pastor, Cuzzocrea and Sellis2014; Fawi and Delmonte Reference Fawi and Delmonte2015; Hamon and Grabar Reference Hamon and Grabar2016; Sabtan Reference Sabtan and Muhammad2016; Semmar Reference Semmar2018).
To the best of our knowledge, a research where terminology extraction was performed, and later compared, using both an existing list of terms and a list of extracted terms, has not been reported so far.
The upper part of the Table A2 (the first five methods) lists the techniques that do not rely on the GIZA++ toolkit. In these approaches, authors either used only morpho- and lexico-syntactic patterns for terminology extraction and alignment, or approached these tasks as optimization problems, or even treated them as classification tasks.
In the final step, we apply a binary classifier on the obtained translation candidates, with an aim to determine good and bad translation pairs. A similar approach to classification of terms was proposed by Hakami and Bollegala (Reference Hakami and Bollegala2017). Authors represented each term using two types of features: character n-grams extracted from a term and contextual features. We examine performance of several binary classifiers, which are based on different lexical and syntactic features. These features are extracted from the resulting list of bilingual terminology that was previously manually evaluated.
3 Lexical resources and tools
In this section, we will present resources and tools used for preparing the input for our experiments (Subsections 3.1, 3.2, 3.3, 3.4, and 3.5), as well as the tools used in the processing steps (Subsection 3.6).
3.1 Aligned domain corpus
The English/Serbian textual resource was derived from the Journal for Digital Humanities INFOtheca,Footnote b which is published biannually in Open Access. Twelve issues with a total of 84 papers were included in the corpus. The papers were either written originally in Serbian and translated to English (61 articles, 73%) or vice versa (23 articles, 27%). Translations were done either by authors themselves, who were experts in the Library and Information Sciences (LIS) field but not trained translators, or by professional translators who had no specific expertise in LIS. All papers in both languages were proofread.
Papers published in this journal deal with various topics. The main topics are graphically represented in Figure 1 using the TreeCloud tool for visualization (Gambette and Véronis Reference Gambette, Véeronis, Locarek-Junge and Weihs2010).

Figure 1. Main corpus topics represented as Tree Clouds produced from article titles, keywords and abstracts.
The selected papers were aligned at the sentence level resulting in 14,710 aligned segments (Stanković et al. Reference Stanković, Krstev, Vitas, Vulović, Kitanović, Cal, Gorgan and Ugarte2017; Stanković et al. Reference Stanković, Krstev, Lazić and Vorkapić2015).Footnote c The Serbian part has 301,818 simple word forms (41,153 different), while the English part has 335,965 simple word forms (21,272 different). This means that the average frequency of a word form in the Serbian part is 7, while the average word form frequency in the English part is 15. The major reason for this difference is high inflection, which is a characteristic feature of Slavic languages, and which produces many different forms for each lemma. In this paper, we will refer to this resource as LIS-corpus.
3.2 Dictionary of library and information science
The Dictionary of Librarianship: English-Serbian and Serbian-English (in this text referred to as LIS-dict) (Kovačević, Begenišić and Injac-Malbasa Reference Kovačević and Begenišić2014) was developed by a group of authors from the National Library of Serbia and is available for searching at the Library website. The version of the dictionary that we used for our experiment has 12,592 different Serbian terms (out of which 9376, or 74%, were MWT), 11,857 different English terms (8575, or 72% MWT), generating a total of 17,872 distinct pairs. Among distinct pairs, both terms were MWTs in 10,574 (60%) cases, while in 1923 (11%) cases a Serbian MWT had a SWT equivalent in English, and in 1070 (6%) cases an English MWT had a SWT equivalent in Serbian. Both terms in a pair were SWTs in 4305 cases (24%). Among Serbian SWTs, 1378 (43%) were components of a MWT, while the same is true for 1245 (38%) English SWTs.
For the research presented in this paper, we used only those English/Serbian translation pairs where the Serbian term was a noun phrase MWT. Terms for which it could be automatically determined that they were not noun phrases were filtered out (for instance, vidi i “see also”).
3.3 The extraction of English terms
For the extraction of English MWTs, we used an open-source software tool, FlexiTerm (Spasić et al. Reference Spasić, Greenwood, Preece, Francis and Elwyn2013). It automatically recognizes MWTs from a domain-specific corpus, based on their structure, frequency, and collocations. Three other MWT extractors were considered for obtaining English MWTs: TextProFootnote d (Pianta, Girardi and Zanoli Reference Pianta, Girardi and Zanoli2008), TermSuiteFootnote e (Cram and Daille Reference Cram and Daille2016), and TermEx2.8.Footnote f Evaluation performed on the list of terms extracted by all four extractors and evaluated as potential MWU terms showed that FlexiTerm outperformed the other three. Namely, out of 3000 top ranked MWTs, FlexiTerm recognized 1719, TextPro 1,005, TermSuite 1162, and TermEx 289. The comparison between two top ranked extractors, FlexiTerm and TermSuite showed that these two tools extract 97.6%.
FlexiTerm performs term recognition in two steps: linguistic filtering is used to select term candidates followed by the calculation of a termhood, a frequency-based measure used as an evidence that qualifies a candidate as a term. In order to improve the quality of termhood calculation, which may be affected by the term variation phenomena, FlexiTerm uses a range of methods to neutralize the main sources of variation in terms. It manages the syntactic variation by processing candidates using a Bag-of-Words (BOW) representation. Orthographic and morphological variations are dealt with using stemming in combination with lexical and phonetic similarity measures.
This tool was originally evaluated on biomedical corpora, but we used it for MWT extraction in the domain of LIS. It was run with default settings and without additional dictionaries. In this paper, we will refer to this tool as Eng-TE.
3.4 The system for extraction of Serbian MWTs
The only system developed specifically for the extraction of MWTs from Serbian texts is a part of LeXimir (Stanković et al. Reference Stanković, Obradović, Krstev, Vitas, Jassem, Fuglewicz, Piasecki and Przepirkowski2011), a tool for management of lexical resources. However, we considered the use of two other extractors: FlexiTerm and TermSuite, described in the previous section and already used for the extraction of English terms. FlexiTerm is designed specifically for English, while for TermSuite several modules for different languages were developed: English, Spanish, German, French, and Russian (Cram and Daille Reference Cram and Daille2016), and we experimented with all of them. Evaluation performed on the list of terms extracted by all extractors and evaluated as potential MWU terms showed that LeXimir outperformed the other two. Namely, out of 3000 top ranked MWTs, LeXimir recognized 1604, TermSuite for Spanish 522 and FlexiTerm 513, while other TermSuite modules gave poor results. LeXimir recognized 93.5% of terms extracted by all extractors and positively evaluated–1715.
LeXimir consists of two modules. The first module of the extraction system is a rule-based system relying on e-dictionaries and local grammars that are implemented as finite-state transducers (Stanković et al. Reference Stanković, Krstev, Obradović, Lazić and Trtovac2016). In this research, the system was tuned to recognize 26 most frequent syntactic structures, which were previously identified by an analysis of several Serbian terminological dictionaries and the Serbian e-dictionary of MWUs. Some of these structures are A_N_Prep_N in naslovno polje na mikrofiÅ¡u “title field on a microfiche” or A_N_(A_N)gen in poslednja sveska serijske publikacije “last issue of the serial publication” where A stands for an adjective, N for a noun, and PREP for a preposition. Each of these components can be a single word or a MWU. Our system was used in a mode in which all possible MWTs in a word sequence are recognized, and not only the longest one. For instance, for the sequence naslovno polje na mikrofiu, the recognized terms would be: naslovno polje “title field”, polje na mikrofiu “field on a microfiche”, and the longest match would be naslovno polje na mikrofiu. The list of the most frequent classes is presented in (Krstev et al. Reference Krstev, Šandrih, Stanković, Mladenović, Chair, Choukri, Cieri, Declerck, Goggi, Hasida, Isahara, Maegaard, Mariani, Mazo, Moreno, Odijk, Piperidis and Tokunaga2018).
The second module of the extraction system uses MWTs from the LIS domain that were already incorporated in e-dictionaries–there are 3100 such entries. While the first module of the system is essential for retrieving new domain MWTs, the second one recognizes already established terms that need not conform to 26 syntactic structures covered by our local grammars. One such example is sistem klju u ruke “system key in hands (system off-the-shelf)” with a structure of a noun followed by a noun phrase in the nominative case, which, being rather rare, was not included in our term extraction system. In both cases, extracted MWTs have to be aligned with their English counterparts.
In order to neutralize differences between extracted MWTs that occur due to word inflection, we performed simple-word lemmatization within MWTs, that is, each word form from a MWT was replaced by a corresponding lemma from the Serbian morphological e-dictionaries (or lemmas, if several candidates existed), thus generating one or more MWTs, lemmatized word by word, for each extracted MWT. For instance, recognized forms naslovno polje, naslovna polja, naslovnim poljem, etc. were all normalized as naslovni polje.
In this paper, we will refer to this system as Serb-TE.
3.5 The bilingual list of inflected word forms
In order to improve the quality of the statistical machine alignment of chunks (described in Subsection 3.6), we have prepared a set of aligned and inflected English/Serbian single and multi-unit word forms. We used two bilingual lexical resources that we processed with the tool LeXimir. (a) Serbian Wordnet (SWN) (Krstev Reference Krstev2014),Footnote g which is aligned to the Princeton WordNet (PWN), and (b) a bilingual list containing general lexica with 10,551 English/Serbian entries. The production of the bilingual list of inflected forms was done in several steps:
1. First, a parallel list from SWN and PWN containing 75,766 aligned English/Serbian single and multi-word literals was compiled. This list was then merged with the bilingual list yielding a new list of 86,317 entries.
2. To each Serbian noun, verb, or adjective from the merged list, we assigned its inflected forms obtained from the Serbian morphological e-dictionaries (Krstev Reference Krstev2008). These inflected forms have various grammatical codes assigned to them, which were used in the final step.
3. A similar procedure was performed for English nouns, verbs, and adjectives from the bilingual list. In order to obtain inflected forms with grammatical categories, we used the English morphological dictionary from the Unitex distributionFootnote h and the MULTEX-East English lexicon.Footnote i
4. In the final step, Serbian and English inflected word forms were aligned taking into account corresponding grammatical codes, which were previously harmonized to the best possible extent. For example, the grammatical category codes for adjectives in the Serbian dictionary are a/b/c, for the positive/comparative/superlative forms. The Unitex English dictionary does not have a code for the positive, while the codes for the comparative and superlative are C and S, respectively. The second English dictionary followed the MULTEXT-EAST specification, using p/c/s as codes. Thus, the Serbian codes a/b/c were mapped to English codes ∈/C/S and p/c/s, respectively.
At the end of this procedure, we obtained a bilingual list of inflected forms having 426,357 entries. In this paper, we will refer to this resource as bi-list.
3.6 The alignment of chunks
For the purpose of word alignment, phrase extraction, and phrase scoring, we used GIZA++ (Och and Ney Reference Och and Ney2000; Koehn et al. Reference Koehn, Hoang, Birch, Callison-Burch, Federico, Bertoldi, Cowan, Shen, Moran and Zens2007). In order to discard as many aligned pairs that were not correct mutual translations as possible, two filtering steps were performed. Each pair of aligned chunks from the phrase table contained information about inverse and direct phrase translation probability. In the first filtering step, we discarded all aligned chunks that did not have at least one of these probabilities greater than 0.85, simultaneously eliminating character entities and punctuation.
For the second step, we provided a BoW representation for English terms from the LIS-dict, that is, from Eng-TE, and removed stop words from it, producing a list mainly populated with content words. Then, we lemmatized each token from the BoW using the Natural Language Toolkit (nltk) Python library and its WordNet interface. The same simple word lemmatization was applied to the English parts of the aligned chunks. Aligned chunks in which the English part did not have at least one lemmatized content word from the BoW list were eliminated.
Along with the original and lemmatized forms of chunks and their frequencies in the original phrase table, we also preserved the information about the alignment of content words, contained within phrase tables. This information helped us to make a backup of Serbian SWTs that are translated as English SWTs (dubbed SWT-chunk), which we use for elimination of incorrect translations in the post-processing step.
We decided to add bilingual lists to the corpus of aligned sentences, for training purposes. We first split the corpus of aligned sentences into three disjoint parts: the training (80%), the development (10%), and the test set (10%). The BLEU score (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002) was obtained for three different 3-gram language models. The first model was trained only on the training set of sentences and then tuned on the development test. This yielded a BLEU score of 24.78. The second model was trained on the training sentence set extended with the bilingual list containing the general lexica list and the parallel list from SWN and PWN. After tuning on the development set, the BLEU score for the test set increased to 24.93. The third model was extended with the full bi-list. After tuning, BLEU score increased to 26.21 on the test set.
In this paper, we will refer to this suite of tools as Align.
4 The design of the system
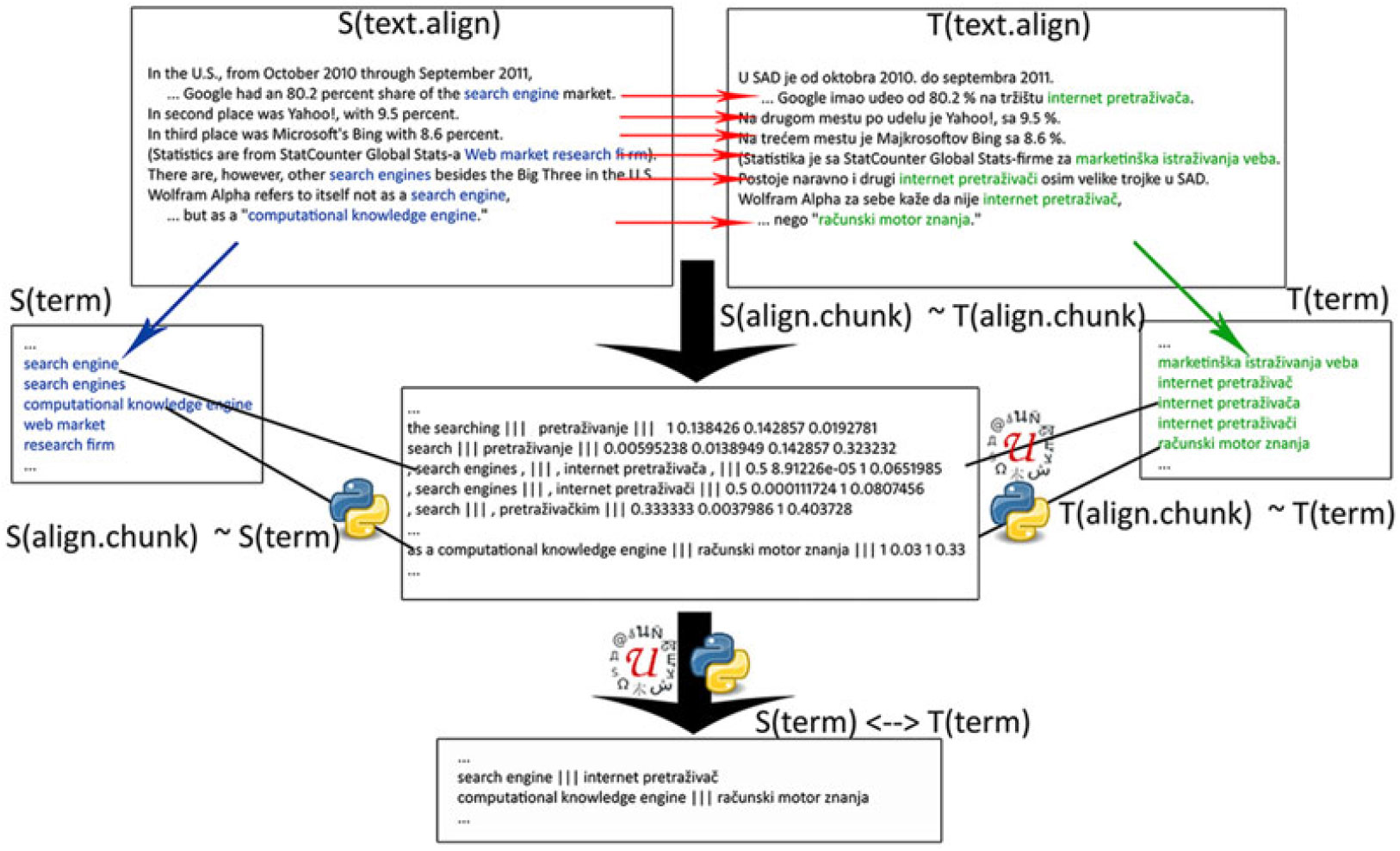
The conceptual design of our system is as follows:
1. Input:
i. A sentence-aligned domain-specific corpus involving a source and a target language. We will denote an entry in this corpus by S(text.align) ↔ T(text.align);
ii. A list of terms in the source language. This list can be either an external resource from the same domain or extracted from the text. We will denote an entry in this list by S(term);
iii. A list of terms in the target language. This list can be either an external resource from the same domain or obtained from the text. We will denote an entry in this list by T(term).
2. Processing:
i. Aligning bilingual chunks (possible translation equivalents) from the aligned corpus. We will denote aligned chunks by S(align.chunk) ↔ T(align.chunk);
ii. Initial filtering of the chunks so that only chunks in which the source part of the chunk matches a term in the list of domain terms in the source language remain: S(align.chunk) ∼ S(term), where the symbol ∼ denotes the relation “match” (explained later);
iii. Subsequent filtering of the chunks that remained after the initial filtering so that only chunks in which the target part of the chunk matches a term in the list of extracted MWTs in the target language remain: T(align.chunk) ∼ T(term);
3. The result:
i. A list of matching source and target terms S(term) ↔ T(term) obtained from the aligned chunks: (S(term) ∼ S(align.chunk)) ᐱ (T(term) ∼ T(align.chunk)) ᐱ (S(align.chunk) ↔ T(align.chunk)).
The relation “match” (∼) is defined as follows: if a chunk is represented by an unordered set of distinct words obtained from the chunk after removal of stop words, the two chunks match if they are represented by the same set. For example, if one chunk is “information retrieval” and another one is “retrieval of information”, their corresponding set representations are {information, retrieval} and {retrieval, information}, respectively. Since these two sets are equal, we consider that these two chunks match. We used it for both sides of the aligned corpus.
In our experiments, the source language is English, and the target language is Serbian. For input and processing, we used resources and tools described in Section 3. As the aligned corpus (Input i), we used LIS-corpus alone, or augmented with bilingual pairs from the bi-list. For the extraction of English terms (Input ii), we used the English side of the dictionary LIS-dict in one series of experiments, and term extractor Eng-TE in the other, while the extraction of Serbian terms (Input iii) was done by Serb-TE. The alignment of bilingual chunks (Processing i) was done by Align. The visual presentation of this process is depicted in (Figure 2).

Figure 2. The overall design of the system for terminology extraction using monolingual and bilingual resources and tools.
The preparation of input data yielded the following results. When applying Eng-TE to the English side of LIS-corpus, 4835 terms were extracted; terms occurring two times or less were discarded, which reduced the list to 3169 terms that were used in the processing step ii. The same terms were later checked by the evaluator, an expert in the LIS field, and marked as LIS terms, terms from other domains or incorrect (not terms). After manual evaluation, 1442 English terms were annotated as correct, domain-specific terms and were used in the evaluation process, as explained in the next section.
Serbian terms were extracted by applying Serb-TE either to the Serbian part of the LIS-corpus or to the Serbian part of chunks derived from it. The results obtained applying Serb-TE to the source text from the corpus are as follows: the number of MWTs recognized by local grammars was 65,845, while the number of forms recognized in e-dictionaries was 2321, giving a total number of recognized forms of 68,166. However, given that some MWTs were extracted both by grammars and e-dictionaries, and, moreover, that some MWTs were extracted by more than one finite-state automata, the number of distinct MWTs was 57,168 (distinct lemmatized 49,632).
In the processing phase, the initial phrase table of aligned chunks, which is the result of alignment by GIZA++, contained 623,042 potential translation equivalents when only LIS-corpus was used as the input, that is, 1,662,253 when it was augmented with bi-list. The aligned chunks were then preprocessed, as explained in Subsection 3.6.
In our experiments, we combined each of the three following parameters, all related to the preparation of the input, with the other two, thus obtaining eight different experimental settings:
1. The list of domain terms for the source language (Input ii) is
(a) the source language part of LIS-dict including SWTs;
(b) the output of the extractor Eng-TE applied to the source language part of the aligned input corpus;
2. The input domain aligned corpus (Input i) consists of:
(a) the aligned corpus LIS-corpus;
(b) the aligned corpus LIS-corpus extended with the bilingual aligned pairs bi-list (LIS-corpus+);
3. The extraction of the set of MWTs in the target language by Serb-TE (Input iii) was done:
(a) on the target language part of the aligned chunks (chunk);
(b) on the target language part of the aligned input corpus (text).
The input preparation steps as well as processing consists of several components developed in C# and Python that are interconnected to work in a pipeline. It relies on existing tools for the extraction of English MWTs (Eng-TE) and Serbian MWEs (Serb-TE) implemented in LeXimir (Stanković et al. Reference Stanković, Krstev, Obradović, Lazić and Trtovac2016) and on GIZA++ for word alignment, while all other components are newly developed.
The summary of results obtained by our system for eight experiment settings is given in Table 1. We refer to the experiments using the labels introduced above.
Table 1. Numerical data that describe the results of term extraction system

The numbers in the columns represent the following results:
• Input and GIZA++ output results
A. Number of entry pairs in LIS-dict, that is, English terms extracted by Eng-TE;
B. Number of lines obtained from GIZA++ phrase table, after preprocessing steps;
C. Number of distinct, lemmatized Serbian MWTs extracted from the target language part of the aligned chunks (for chunk) or from the target language part of the aligned input corpus (for text).
• Additional filtering of results obtained by GIZA++:
I. Number of the aligned chunks after initial filtering using English terms (Processing ii): (S(align.chunk) ∼ S(term)), where the list of English terms depends on the choice of parameter 1 (the English part of LIS-dict or obtained from the corpus using Eng-TE for extraction).
II. Number of aligned chunks after subsequent filtering using Serbian terms (Processing iii): (S(term) ∼ S(align.chunk)) ᐱ (T(term) ∼ T(align.chunk)) ᐱ (S(align.chunk) ↔ T(align.chunk)).
III. Number of new term pairs after filtering, namely those that do not already exist in LIS-dict–these term pairs were obtained by selecting filtered chunks in which the Serbian part of the chunk does not match a term in the Serbian part of LIS-dict ((T(align.chunk) ≁ T(term.list))) (applicable only when LIS-dict is used in the experiment);
IV. Number of term pairs after filtering already existing in LIS-dict–these term pairs were obtained by selecting filtered chunks in which the Serbian part of the chunk matches a term in the Serbian part of (T(align.chunk) ∼ T(term.list)) (also applicable only for (LIS-dict) experiments);
Eval Data in this column represent the number of candidate bilingual term pairs obtained by the respective experiments. Before manual evaluation of these candidates, additional filtering was done, as follows:
— For experiments that used LIS-dict for Serbian term extraction, candidate pairs in which the Serbian part of the aligned chunk matched the Serbian part of a MWT from LIS-dict were removed, because these pairs were evaluated automatically by the dictionary through this match (their numbers are shown in column IV).
— For experiments where LIS-corpus+bi-list was used to expand the input corpus (LIS-corp+), the pairs that existed in bi-list, but did not occur in LIS-corpus were removed, because we did not want to take into consideration term pairs that we have forced into the corpus.
— For all experiments, a number of term pairs that could be only partially correct were removed. Namely, some English terms, mostly simple-word ones, were incorrectly aligned with Serbian MWTs that contain the translation of such English term(s) as a component. For instance, the English chunk containing the SWT “document” (for which the Serbian equivalent is dokument) was aligned to a number of Serbian chunks in which Serbian MWTs containing dokument as a component were detected: priprema dokumenta “document preparation”, svrha organizacije dokumenata “purpose of document organization”, drugi dokument “another document”, milion dokumenta “million documents”. For this filtering, we used SWT-chunk described in Subsection 3.6.
5 Evaluation and analysis of results
In order to assess the efficiency of our approach, we have first evaluated all extracted pairs manually. We assigned to each pair a label, from a set of labels, which were different for different source language extraction methods:
For extraction from the English part of LIS-dict, we used labels: LIS–if the extracted pair is correct, that is, the Serbian part of the pair is a MWT that is the translation equivalent of the English term, for example, personal digital assistant ≡ lini digitalni pomonik; NOK–if the extracted pair is not correct, for example, user analysis ≢ analiza navika korisnika (it should be analiza korisnika).
For the extraction by the English term extractor Eng-TE, we used labels: LIS–if the extracted pair is correct and the extracted terms belong to the LIS domain, for example, social networking tool ≡ alat za drutveno umrea-avanje; T–if the extracted pair is correct and the extracted terms belong to some other domain, for example, knowledge society ≡ drutvo znanja; OK–if the extracted pair contains translational equivalents, but does not represent a term, for example, numerous applications ≡ brojne aplikacije; NOK–if the extracted pair does not contain translational equivalents, for example, morphological process ≢ analiza leksema (it should be morfoloki proces); X–if Eng-TE extracted neither a term nor a complete noun phrase, for example, web into library.
When choosing the label LIS for the (LIS-dict) parameter setting, or LIS, T and OK for (Eng-TE) parameter setting the evaluator took the following approach: the Serbian term in the pair is a correct noun phrase and it is a translation equivalent of the English term in the same pair. It does not necessarily mean that a terminologist, specialist for the domain, would recommend it. For instance, fabrika biblioteka would be a preferable term for “factory library”, but we labeled as correct biblioteka fabrike as well.
The evaluation results are summarized in Table 2. They show that precision (P) is almost always better when the Serbian term extractor is applied to the target language part of the aligned input corpus (column text vs. column chunk, the only exceptions, almost insignificant, can be found in the Eng-TE/LIS-corp+ setting). The results also show that the use of additional bilingual pairs reduces precision for Eng-TE; however, the number of retrieved pairs as well as the number of acceptable pairs raises significantly (column LIS-corp vs. column LIS-corp+). We observe that when LIS-dict is used for extraction, the ratio of pairs already present in the dictionary (LIS-dict) and all positively evaluated pairs (LIS-dict+LIS) is rather stable, ranging from 44.40% for the LIS-corp+/chunk setting to 48.73% for the LIS-corp/text setting.
Table 2. Evaluation results for eight experiments: number of pairs per labels and the precision measure per combinations of labels

Evaluation results showed that a number of new term pairs were retrieved. When LIS-dict was used for English term extraction, 364 English terms from the dictionary were linked to new Serbian translations yielding 428 new term pairs. One example is the term “library staff” for which equivalent terms from the dictionary were slubenici biblioteke and zaposleni u biblioteci, while our procedure added three more: biblioteko osoblje, osoblje biblioteke, and biblioteki radnici. Likewise, 109 Serbian terms from the dictionary were linked to new English terms, yielding the same number of new translation pairs. For instance, biblioteko osoblje was the translation of “library personnel” in the dictionary, while our procedure linked it also to “library staff”. In some cases, new pairs were obtained that were not synonymous: for instance, the English term “capital” had three Serbian translations in the dictionary: kapital (referring to economics), verzal and veliko slovo (referring to upper-case letters), while our procedure added one more glavni grad (referring to a capital city). Among all term pairs retrieved using Eng-TE for extraction, 538 were supported by LIS-dict, while among all term pairs retrieved using LIS-dict for extraction, 168 were also retrieved with Eng-TE. Note that these numbers differ, since pairs from LIS-dict that supported Eng-TE were not necessarily retrieved by LIS-dict as well.
Our next aim was to estimate the recall of our system, since it was not feasible to calculate it exactly. To that end, we have tried to estimate the overall number of pairs of equivalent terms in our corpus (the unknown set positive), by following these steps:
1. First, we extracted English terms from the English part of LIS-corpus, assuming that the English term probably has the Serbian term equivalent in the Serbian part of the corpus. For the experiments that used LIS-dict for extraction, we used the English part of the dictionary. For the experiments that used the English term extractor Eng-TE, we used the union of two sets. The first set contained all terms extracted from the English part of our aligned corpus that occurred with a frequency ≥ 3 and that the human evaluator, an expert in the LIS field, evaluated as LIS terms, or terms from some other, close domain. The second set contained all distinct English terms occurring in the evaluated pairs. We will denote the union of the two sets by term_text and its size by s_term_text (the first estimation of the size of the set positive).
2. Next, we had to make an adjustment of the number of SWTs in the set obtained in the previous step. The adjustment was done only for experiments that used LIS-dict for extraction, as Eng-TE extracts only MWTs and acronyms. LIS-dict contains a number of SWTs, of which not many appear in our positively evaluated set, since we only took into consideration pairs in which the Serbian term is a MWT. We reduced the size of the term_text set so that the contribution of SWTs in it corresponds to the contribution of English SWTs in the evaluated set of pairs, in terms of their percentage share. Thus, we obtained the adjusted size of the set positive, which we will denote by s_term_text_adj.
3. Finally, we have calculated the number of pairs of equivalent terms covered by extracted English terms, separately for two methods of extraction. To that end, we have calculated the average number of pairs per one English term in our positively evaluated set. We have also calculated two adjustment parameters, one for LIS-dict settings and another for Eng-TE settings. These parameters were obtained as the ratio of all different term pairs and all different English terms in all four experiments related to the chosen extraction method. We applied these parameters to the adjusted size s_term_text_adj of the positive sets obtained in previous steps; thus, we obtained the estimated size of the sets of all pairs of equivalent terms in our corpus s_positive = tp + fn.
In Table 3, we present the results obtained by applying these steps, and the calculated precision, recall and F 1 score. We consider R and F 1 scores as relative since they depend on the source language (English) extraction–the comprehensiveness of LIS-dict and successfulness of Eng-TE.
Table 3. The calculation of the set of equivalent pairs, precision P, recall R, and F 1 score

When calculating these measures, as well as for subsequent results presented in this section, we treated as true positives all those pairs that were marked as LIS, T, and OK. It should be noted that it was sometimes difficult for evaluators to distinguish between LIS and T marks, and that the evaluator of Eng-TE terms and the evaluator of the extracted pairs often disagreed. We considered all of LIS, T, and OK marked pairs as successfully paired terms.Footnote j For both extraction methods, the best results were obtained with LIS-corp+/text settings–the only exception is the precision which is highest for the Eng-TE/LIS-corp/text. Better results for settings using additional bilingual pairs (LIS-corp+) are expected since significantly more aligned chunks were obtained with their usage (column B in Table 1). The application of Srp-TE to the whole Serbian text (text) yielded more extracted terms then its application to Serbian chunks (chunk) (column C in Table 1) because their application was not impeded by chunk boundaries. The subsequent use of the loose match function produced additional hits among which many were false (see Figure 3); nevertheless, the correct hits prevail as the raise in the precision for all experiment settings using text shows.
The presented approach is the first one developed for bilingual English/Serbian term extraction, and therefore we could not compare our results with some previous research. The results of a similar research, involving a language closely related to Serbian, in which authors used TerminologyAligner tool to obtain translation equivalents of terms tagged in a bilingual English/Croatian corpus were R = 13.49%, P = 54.88%, and F 1 = 21.66% (Pinnis et al. 2012); however, one should note that they used a comparable, not an aligned corpus.
In Tables 4 and 5, we present data that offer an insight into the diversity of extracted term pairs, when different parameter settings are used. We grouped results by the major parameter, the method of term extraction in the source language LIS-dict versus Eng-TE. In these tables, only positively evaluated pairs were taken into consideration. The results in Table 4 show that our extraction system fared much better when Eng-TE was used for source language term extraction, regardless of the choice of other parameters, ((1206/2248) ∗ 100 = 53.65%), than when LIS-dict was used ((244/902) ∗ 100 = 27.05%). We have not compared results obtained with different settings of the first parameter (LIS-dict vs. Eng-TE), since comparison of all different term pairs extracted using these two parameters (902 vs. 2,248, “at least 1” line in Table 4) showed very low overlap–only 488 common pairs.
Results presented in Table 5 show that none of the sets of term pairs that are obtained by varying three parameters is a true subset of some other set, that is, each set contains some term pairs that distinguish it from other sets.

Figure 3. The distribution of four most important sources of false pairings for various settings.
Table 4. An overlap between results obtained by the use of LIS-dict and extractor FlexiTerm

Table 5. The number of common term pairs between sets obtained by varying three parameters

In this table, the percentage of common terms is calculated in relation to the total number of terms in the set given in the column header; the similarity of sets (SIM) is calculated using the Dice measure. It can be observed that the highest similarity between sets is obtained when Eng-TE is used for term extraction, the input corpus is enhanced by the set of aligned pairs (LIS-corp+), with either choices of the third parameter–the method of extracting target terms (the framed results in Table 5). The use of parameters Eng-TE/LIS-corp+ extracts the highest number of pairings, and thus the third parameter does not contribute much. The lowest similarity between sets is obtained when LIS-dict is used for term extraction, Serbian terms are extracted from the target part of LIS-corpus (text), with either choices of the second parameter–corpus with and without additional bilingual pairs, which is understandable since addition of these pairs introduced many new pairings, as previously explained (the underlined and italic results in Table 5). The application of the match function (chunk vs. text) produced less variability when terms are extracted (Eng-TE) than when they are compared with the dictionary (LIS-dict), because the form of terms from the dictionary is more strict than the form of those extracted, and thus the way the match function is applied to extracted terms is less significant.
Finally, we analyzed pairs that were marked by the evaluator as NOK, in order to find the main sources of false pairings, and the results are presented in Figure 3.
The main reason for rejecting a term pair was that the Serbian term is longer than it should be (label “long” in the figure legend), for instance, cena meubiblioteke pozajmice ↔ “interlibrary loan” (it should be meubiblioteka pozajmica). The other frequently occurring reasons are:
The match function that we used for comparing extracted terms and aligned chunks was in some cases too loose (label “match”). For instance, dokument iz kolekcije “document from a collection” has the same set representation as kolekcija dokumenata (the correct translation of “document collection”) and was thus offered as a translation. However, in such cases, the correct pairs were often also offered, kolekcija dokumenata and zbirka dokumenata in this case.
Translations in texts within LIS-corpus were incorrect, imprecise, or did not use a corresponding term (label “transl”). An example of an incorrect translation is “Unstructured Information Management Architecture”, which was translated in the text as nestrukturirana aplikacija za upravljanje informacijama (a literal translation for “Unstructured Application for Information Management”, instead of the proper translation arhitektura za upravljanje nestrukturiranim informacijama): an example of imprecise translation occurred for “lexical resource”, which was translated as jeziki resurs (literally “language resource”) instead as leksiki resurs. In the Serbian text “(wide) accessibility” was not translated by a term, but rather by iri i laki pristup (literally, “wider and easier access”).
In a number of cases, chunks were not correctly linked, which resulted in false parings, for instance, korien koncept (literally “used concept”) was linked with “natural language” (label “connect”).
The remaining sources of false parings resulted from Serbian terms being shorter than they should be, for instance, autorsko pravo ↔ “copyright law” (it should be zakon o autorskim pravima) or when Serbian and English terms overlapped in scope, for instance imenovani entitet → “entity recognition” (it should be prepoznavanje imenovanih entiteta ↔ “named entity recognition”). In a few cases, the English term was not a noun phrase and thus could not be captured by Serb-TE, for instance “on subscription”.
6 Classifier
After manual evaluation of the compiled list of bilingual MWTs, we decided to consider the possibility for automatic validation of candidate pairs in the future. The idea was to develop a sequence of steps to be added at the end of the previously described procedure, which would separate correct from incorrect translation pairs. To that end, we trained a machine learning classifier with two classes: OK for pairs that represent correct translations (positive class), and NOK for the pairs that do not (negative class).
Information on the set of experiments (LIS-dict or Eng-TE) in which the pair was generated was assigned to each pair, as an additional feature, and after that, all pairs were joined into a single dataset, and all duplicates were eliminated. Eventually, 5602 pairs were used as samples for the classifier: 2071 from LIS-dict (out of which 1583 were not obtained by Eng-TE), 3531 from Eng-TE (out of which 3043 were not obtained by LIS-dict), and 488 pairs obtained by both LIS-dict and Eng-TE.
Pairs evaluated as OK, BI, T, as well as term pairs that already existed in LIS-dict, represented in column IV of Table 1, were classified as positive (i.e., they are considered to be good translations), while pairs evaluated as NOK or X were classified as belonging to the negative class. Eventually, this resulted in a dataset with 3150 positive and 2452 negative pairs.
We wanted to examine the influence of several lexical and syntactic features on the outcome of the validation. Features were extracted from the quadruple: (T(align.chunk), T(align.chunk) lemmatized word by word, T(term) and S(term)). The first step was to perform Part-of-Speech tagging of each component of the MWT, regardless of the language. Unitex was used for POS-tagging of Serbian chunks and terms, and the POS-tagger included in the Python’s nltk module was used for English terms. English was tagged using the universal tagset:Footnote k ADJ, ADP, ADV, CONJ, DET, NOUN, NUM, PRT, PRON, VERB, and X, while the tagset that Unitex uses for Serbian consists of: N, A, V, ADV, PREP, CONJ, PAR, INT, NUM, and PRO.
From the pairs with matching POS-tags, a total of 178 features were extracted. Namely, for each of the 4 components from the quadruple, 31 features were extracted, yielding a total of 124 features. Components from the quadruple were then observed in pairs (6 different combinations), with 9 features extracted from each pair, yielding 54 features in total. We refer to the 31 features that were extracted from single MWT as “single” features, and the 9 features that were extracted observing the pair as “joint” ones. These 40 features are listed and described in Table A3, given in the Appendix. Within the T column (Type), numerical features are denoted as N, while categorical features are denoted as C.
After feature extraction, all categorical features were automatically encoded to consistent numerical values. We tried out several supervised classification methods: Naive Bayes (NB) (Rish Reference Rish2001), Logistic Regression (LR) (Hosmer, Lemeshow and Sturdivant Reference Hosmer, Lemeshow and Sturdivant2013), Linear and Radial Basis Function Support Vector Machines (SVM and RBF SVM) (Joachims Reference Joachims1998), Random Forests (RF) (Liaw and Wiener Reference Liaw and Wiener2002), and Gradient Boosting (GB) (Friedman Reference Friedman2001). These binary classifiers were trained and evaluated in fivefold cross-validation (CV) settings, using standard classification evaluation metrics: accuracy, F1, precision, and recall. The results are displayed in Table 6.
Table 6. Evaluation of different types of classifiers in a fivefold CV setting

Best accuracy (78.49%), F 1 score (82.09%), and recall (87.65%) were obtained with RBF SVM classifier, while RF classifier had the best precision (79.73%). At the end of our procedure, we opted for the RBF SVM classifier, since it achieved better F1 score and accuracy in comparison to other trained models.
In Table 7, we display the results of fivefold CV RBF SVM classifier, obtained on pairs from experiments LIS-dict (2071 samples) and Eng-TE (3531 samples), separately. Except for the accuracy, other classification metrics gave better results for the experiment that used Eng-TE. The number of samples in this case was greater, which may explain better precision, recall, and F 1 score, since classifiers are prone to over-fitting on smaller datasets (resulting in greater accuracy).
Table 7. Comparison of classification metrics on datasets comprised of pairs obtained from experiments that used LIS-dict and Eng-TE, separately

Ten features with highest influence on the classification outcome, according to the GB classifier trained on the whole training set, are displayed in Figure 4. Features that have the most influence are the ones related to S(term) (regardless of whether it comes from LIS-dict or is extracted by Eng-TE): POS-tag of the word at the second position in the MWT, number of different characters, total number of characters, and total number of tokens.
Among the top five influential features is also the POS-tag of the word at the third position of the extracted Serbian MWU. The feature that indicates the origin of the pair is ranked as the 109th by relevance for this classifier.
Ten features having the highest Pearson’s correlation coefficients with the target label, examined on the whole training set using Weka tool (Eibe, Hall and Witten Reference Eibe, Hall and Witten2016), are displayed in Figure 5. The earlier mentioned features that strongly influenced the GB classifier appeared among those most correlated with the target label.

Figure 4. Feature importance for GB classifier in a fivefold CV setting.
It is interesting to take a look at other features that are correlated with the target label, but did not influence the GB classifier, such as the origin feature (source) and percent of lexical diversity of the S(term). We determined Pearson’s correlation coefficients of the source feature with other features. The features that had the highest correlations were all related to S(term): number of tokens (0.465), number of characters (0.391), number of different characters (0.389), POS-tag at the second position (0.319), and percent of lexical diversity (−0.312). Since feature selection is a part of GB algorithm, a possible explanation for the fact that the source feature did not show up among the most influential ones is its high correlation with other influential features.

Figure 5. Pearson’s correlation based feature selection.
We compared all features, taking into account the origin of the candidate pair. The average, minimum, and maximum values of almost all features were consistent, regardless of the origin of the pair. The only exceptions were the maximum number of characters for T(term) (both the original and lemmatized; 62 characters for the pairs obtained after the experiment that used Eng-TE and 45 for the pairs obtained from the experiment that used LIS-dict), and the average number of characters in S(term) (12.532 for the case of LIS-dict and 17.197 for the case of Eng-TE). We concluded that Eng-TE yielded somewhat longer English terms, which sometimes resulted in pairing with longer Serbian MWUs.
The goal was to build a language-independent method for the validation of the list of pairs compiled from the presented procedure. Results obtained on this dataset are satisfactory, given that they are obtained on a modest number of samples, and that the method did not use any external language resources (e.g., dictionaries for the validation of translations). We conclude that it is safe to add the predicted class (positive, i.e., OK, negative, i.e., NOK) to each pair in the final list, as a suggestion when deciding if a pair should be entered into a bilingual lexicon or not.
7 Conclusion
With approaches outlined in this paper, we wanted to achieve two goals: (a) to evaluate our system for the extraction of bilingual MWTs that uses different settings; (b) to build a classifier that would automatically separate correct term pairs produced by our system. As an additional result, we enriched the Dictionary of LIS with 2474 term pairs. Additionally, we wrapped the procedure into a web service, integrated it with other applications, and developed a user friendly interface.Footnote l
Our results show that for both methods of term extraction from the English part of the aligned corpus, the best results were achieved when corpus was enhanced with additional bilingual pairs, and when extraction of Serbian terms was performed on the Serbian part of the aligned corpus, instead of aligned chunks. Thus, we will continue to experiment with these settings. Moreover, we will enrich bi-list with newly produced pairs. Our experiments also show that both methods of extraction produce some different pairs of equivalent terms. In our future work, we will use not only both methods, when a dictionary for a source language is available, but also terms obtained from several different extractors.
We will continue to develop our system and improve its components. The most imminent tasks include: (a) the improvement of the Serb-TE in order to eliminate recognitions that in many cases led to the production of incorrect pairs; (b) experiments with new parameters, such as the recognition of longest matches versus all matches; (c) experiments with different, more strict, “match” relations between terms and extracted chunks. Our most important future research will concentrate on developing methods for reliable distinction between domain-specific terms and free noun phrases.
In the future, we will apply the same approach to other domains–mining, electrical energy, and management–for which aligned domain corpora have already been prepared. Needless to say, the enrichment of sentence-aligned domain-specific corpora, bilingual word lists, and monolingual dictionaries of MWTs is the long-term activity.
Appendix
Table A1. General overview of the related work

Table A2. Overview of the proposed techniques in the related work

Table A3. Description of the extracted features