



To date, scholars have extensively examined what kinds of learners are cognitively adept at learning second language (L2) morprhosyntax. However, surprisingly little is known about the cognitive correlates of successful L2 pronunciation learning. In the context of 50 Japanese L2 learners in classroom settings, the current study examined the roles of three different kinds of foreign language aptitude (phonemic coding, associative memory, and sequence recognition) in three different aspects of their English /ɹ/ pronunciation acquisition (degree and rate of tongue retraction, labial, alveolar, and pharyngeal constrictions).
BACKGROUND
Foreign language aptitude
Many theories of second language acquisition (SLA) (e.g., Ellis, Reference Ellis2006, for useage-based accunts) share the fundamental view that adult L2 learners improve their proficiency as a function of increased language exposure and practice. At the same time, there is a great amount of empirical evidence that the final outcome of L2 proficiency after years of learning is subject to a great deal of individual variability; this is the case in English as a foreign language (EFL) classrooms, where access to the target language is limited to just a few hours of instruction a week and where learners are left without opportunities to meaningfully converse with other native and nonnative speakers (Muñoz, Reference Muñoz2014). In order to understand the underlying reasons for this variability, scholars have extensively examined a range of cognitive and perceptual abilities (i.e., measures of aptitude) that may contribute to determining the extent to which certain L2 learners can continuously enhance their L2 performance and eventually attain relatively advanced proficiency (see Li, Reference Li2015a; Skehan, Reference Skehan2015, for meta-analytic and narrative reviews).
Over the past 50 years, several aptitude frameworks have been conceptualized, tested, and refined. For example, Carroll and Sapon (Reference Carroll and Sapon1959) developed the Modern Language Aptitude Test (MLAT) to assess L2 learners’ intentional learning abilities for successful classroom L2 learning, including phonemic coding (the ability to associate sound strings with their corresponding symbols) and associative memory (the ability to associate letters with their corresponding objects). According to their validation reports (e.g., Carroll, Reference Carroll1962), it was found that students who obtained higher MLAT scores were likely to show better test performance and obtain higher final grades in their foreign language classes in the United States (see Alderson, Clapham, & Steel, Reference Alderson, Clapham and Steel1997).
Loosely building on the MLAT (Carroll & Sapon, Reference Carroll and Sapon1959), Meara (2005) developed the LLAMA, the aptitude test format that has been most widely used in SLA studies and adopted in the current study. The LLAMA is designed to measure various dimensions of L2 learners’ abilities to learn a new language using linguistic materials adapted from a British Columbian indigenous language. The LLAMA adopts the same measures as in the MLAT for assessing intentional learning abilities (i.e., phonemic coding and associative memory). These intentional test scores have been found to predict successful L2 morphosyntax learning especially when L2 learners receive explicit instruction/corrective feedback (e.g., Yalçin & Spada, Reference Yalçın and Spada2016; Yilmaz & Granena, Reference Yilmaz and Grañena2016)
Different from the traditional paradigm (e.g., MLAT), however, the LLAMA adopts a new task that is hypothesized to tap into one form of incidental learning ability (i.e., sequence recognition, the ability to remember novel linguistic patterns without awareness). L2 learners’ sequence recognition performance has been found to demonstrate strong associations with the degree of their learning success in certain contexts, where both intentional and incidental learning processes play a key role. These instances include the final quality of early bilinguals’ L2 morpshosyntax performance in naturalistic settings (Granena, Reference Granena2013), and the longitudinal development of classroom L2 learners’ oral proficiency when they engaged in both form-oriented and content-based instruction over time (Saito, Suzukida, & Sun, Reference Saito, Suzukida and Sun2018).
Aptitude effects on different stages of L2 learning
For the purpose of theory building on the cognitive individual differences in SLA, Skehan (Reference Skehan2016) proposed the acquisition-aptitude model, suggesting that different types of aptitude (e.g., phonemic coding, associative memory, and sequence recognition) are uniquely tied to different stages of L2 learning: (a) analyzing incoming input → (b) automatizing partially acquired knowledge → (c) attaining advanced-level use of the language. As such, Skehan argued that intentional language analysis, memory, and incidental learning abilities could differentially impact and relate to L2 learners’ performance, while each stage interconnects with the others in a complementary fashion.
In this model, L2 learners with higher auditory processing abilities (e.g., phonemic coding) are assumed to not only hold more information about unfamiliar sounds in their phonological buffer (i.e., short-term memory) but also analyze it in a prompt and timely fashion (i.e., executive control; Yilmaz & Koylu, Reference Yilmaz and Koylu2016). As L2 learners with greater associative memory can maintain and control larger amounts of information, they are assumed to pay attention to not only perceptually salient but also subtle and infrequent features in the L2 input, which is critical in the later stages of L2 learning (Schneiderman & Desmarai, Reference Schneiderman and Desmarais1988). To attain highly advanced L2 proficiency, however, L2 learners may need not only strong intentional but also solid incidental learning abilities to make the most of their L2 experience, as learners at this level may need to automatically detect novel sound, word, and grammar patterns during their exposure to the target language, regardless of the presence of awareness (e.g., sequence recognition; Granena, Reference Granena2013). Skehan’s model stressed that the interaction between aptitude and SLA (Phonemic Coding×Input Processing, Associative Memory×Automatization, Sequence Recognition×Lexicalization) could take place simultaneously (rather than independently), as all aspects of L2 learners’ developing system are essentially interwoven with each other.
A growing number of studies have investigated the intricate connections between different types of aptitude and multiple aspects of L2 morphosyntax learning. In the context of EFL students in Turkey, for example, Yalçin and Spada (Reference Yalçın and Spada2016) found that those with higher language analysis abilities (grammatical inferencing) demonstrated strong gains in the acquisition of a relatively easy structure (past progressive) after 4 hr of instruction. Comparatively, those with higher memory abilities (associative memory) successfully acquired the relatively difficult structure (passive). Similarly, Li (Reference Li2013, Reference Li2015b) found that language analysis abilities (grammatical sensitivity) were facilitative of L2 Chinese learners’ acquisition of a relatively easy structure (classifiers), especially when their instruction did not involve any metalinguistic explanation nor explicit correction. The current study was designed to conduct exploratory analyses with regard to the aptitude-acquisition interaction in the context of L2 pronunciation development.
Roles of aptitude in L2 pronunciation learning
Whereas much attention has been directed toward examining the role of aptitude in the learning of L2 morphosyntax, some studies have begun to delve into the cognitive individual differences in L2 phonological acquisition. For example, Darcy and her colleagues conducted a series of empirical studies showing that L2 learners’ vowel perception and production performance was associated with a range of cognitive abilities, such as working memory, attention control, and processing speed (Darcy, Park, & Yang, Reference Darcy, Park and Yang2015), and inhibitory control (Darcy, Mora, & Daidone, Reference Darcy, Mora and Daidone2016). In an intervention study, Li and DeKeyser (Reference Li and DeKeyser2017) demonstrated that musical talent (sensitivity to rhythm) mediated the effects of explicit instruction on American learners’ acquisition of L2 Mandarin lexical tones.
Moreover, these cognitive abilities are not necessarily specific to language learning behaviors per se, but rather amenable to many different areas of general skill acquisition (for further discussion on domain-specific vs. domain-general cognitive abilities, see Skehan, Reference Skehan2016). As reviewed earlier, aptitude is defined as a set of capacities directly related to intentional and incidental language learning (Carroll & Sapon, Reference Carroll and Sapon1959; Meara, 2005). In their synthesis of the L2 speech literature, Trofimovich, Kennedy, and Foote (Reference Trofimovich, Kennedy and Foote2015, p. 354) pointed out that “there has been little systematic research on the relationship between various subcomponents of language aptitude and L2 pronunciation learning.” To advance the agendas of L2 speech aptitude research in an interdisciplinary fashion, more studies are needed to elucidate the extent to which the existing aptitude frameworks in SLA are applicable to the attainment of L2 pronunciation proficiency in classroom settings.
Japanese learners’ English /ɹ/ acquisition
The current study focused on one of the most well-researched topics in the L2 pronunciation learning literature: the acquisition of English /ɹ/ by adult native Japanese speakers. American English /ɹ/ can be acoustically characterized by (a) lower third formant (F3; 1600–1900 Hz), (b) lower second formant (F2; 1300–1600 Hz), and (c) longer transitional duration of first formant (F1; 50–100 ms; Espy-Wilson, Reference Espy-Wilson1992; Espy-Wilson, Boyce, Jackson, Narayanan, & Alwan, Reference Espy-Wilson, Boyce, Jackson, Narayanan and Alwan2000; Flege, Takagi, & Mann, Reference Flege, Takagi and Mann1995; Hattori & Iverson, Reference Hattori and Iverson2009). Because English /ɹ/ is absent in the Japanese approximant categories (including only /w/ and /j/), inexperienced Japanese learners likely substitute the Japanese tap for English /ɹ/ in perception (Guion, Flege, Akahane-Yamada, & Pruitt, Reference Guion, Flege, Ahahane-Yamada and Pruitt2000) and production (Riney, Takada, & Ota, Reference Riney, Takada and Ota2000). Relative to English /ɹ/, the Japanese tap sound features higher F3 (2400–3000 Hz) and F2 (1700–2100 Hz) values, and shorter transition duration (5–20 ms; Hattori & Iverson, Reference Hattori and Iverson2009; Lotto, Sato, & Diehl, Reference Lotto, Sato and Diehl2004). Thus, the acquisition of English /ɹ/ pronunciation requires Japanese learners to make simultaneous constrictions in the labial, alveolar, and pharyngeal parts of vocal tract (for lower F3, <1900 Hz) while retracting tongue body (for lower F2, <1600 Hz) and prolonging the phonemic length (for longer transition duration, >50 ms).
Examining this specific instance of L2 learning allowed us to probe how adult L2 learners (with different aptitude profiles) can acquire various dimensions of pronunciation abilities that are differentially exploited in the first language (L1) phonetic system (i.e., existing, partially-used vs. novel cues).Footnote 1 According to our precursor studies (Saito & Brajot, Reference Saito and Brajot2013; Saito & Munro, Reference Saito and Munro2014), for example, adult Japanese learners tend to show different levels of difficulty in their English /ɹ/ development in the following order: Tongue retraction/lower F2→duration/longer F1 transition → labial, alveola, and pharyngeal constrictions/lower F3.
In the initial stages of L2 speech learning (e.g., first 6 months of immersion in naturalistic settings), Japanese learners tend to quickly acquire the interlanguage strategy (i.e., tongue retraction) of producing English /ɹ/ with lower F2 (<1600 Hz; Saito & Munro, Reference Saito and Munro2014). This is arguably because this distinction (lower vs. higher F2) is used in the Japanese approximant categories (differentiating /w/ and /j/). Although lower F2 (an index of tongue retraction) is not a primary acoustic correlate of listeners’ English /ɹ/ perception (for details, see below), this is the “interlanguage” strategy that Japanese learners likely adopt as a first step toward acquiring targetlike English /ɹ/ production.
After Japanese accumulate more L2 experience (a few years of immersion), they may obtain another interlanguage strategy (i.e., the ability to produce English /ɹ/ with sufficiently long length; F1 transition >50 ms; Saito & Brajot, Reference Saito and Brajot2013). This is possible when Japanese learners notice, activate, and integrate the length distinction that is used in the Japanese vowel categories (short vs. long vowels), but not in the Japanese approximant categories.
Finally, experienced Japanese learners demonstrate some evidence of F3 acquisition (<1900 Hz). This typically requires a great deal of intensive L2 use (e.g., 10+ years of length of residence in an L2 speaking environment; Flege et al., Reference Flege, Takagi and Mann1995) or/and focused training (e.g., 30+ hr of high variability phonetic training; Bradlow, Pisoni, Akahane-Yamada, & Tohkura, Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997). Producing English /ɹ/ with lower F3 (providing the most important acoustic information for English /ɹ/ perception) is considered the most difficult dimension, as the F3 acoustic representation and the relevant articulatory configuration (creating the labial, alveolar, and pharyngeal constrictions) is not actively used in the Japanese system (Iverson et al., Reference Iverson, Kuhl, Akahane-Yamada, Diesch, Tohkura, Kettermann and Siebert2003).
The suggested hierarchy of Japanese learners’ English /ɹ/ development also corresponds to the kinds of acoustic information native English listeners use while assessing the intelligibility and accuracy of Japanese learners’ English /ɹ/ production (e.g., Iverson et al., Reference Iverson, Kuhl, Akahane-Yamada, Diesch, Tohkura, Kettermann and Siebert2003; Saito & van Poeteren, Reference Saito and van Poeteren2018; Underbakke, Polka, Gottfried, & Strange, Reference Underbakke, Polka, Gottfried and Strange1988). When Japanese learners attempt to produce English /ɹ/ by using their initial interlanguage strategy (retracting tongue body), native English listeners may have much difficulty perceiving it as English /ɹ/ because they do not use lower F2 as a perceptual cue (Iverson et al., Reference Iverson, Kuhl, Akahane-Yamada, Diesch, Tohkura, Kettermann and Siebert2003). As their experience and proficiency increases, Japanese learners likely make efforts to produce English /ɹ/ not only with more tongue retraction but also with longer phonetic length (>50 ms). This interlanguage strategy helps native English listeners form a specific categorical perception of the sound (English /ɹ/ but not English /w/, /d/, nor /l/; Underbakke et al., Reference Underbakke, Polka, Gottfried and Strange1988). When it comes to native English listeners’ accuracy evaluation within the category (the extent to which Japanese learners’ English /ɹ/ pronunciation forms approximate native norms), they tend to use F3 information as a primary acoustic cue (Saito & van Poeteren, Reference Saito and van Poeteren2018).
To help native listeners perceive English /ɹ/ in an efficient and effective manner, it is reasonable to assume that Japanese learners acquire the three phonetic features at different points in time (lower F2→longer F1 transition → lower F3) vis-à-vis increased experience and proficiency.
Current Study
The current study took an exploratory approach toward examining the aptitude-acquisition link for a specific L2 sound (i.e., English /ɹ/) among a total of 50 sophomore college Japanese students with 7 years of EFL instruction and no experience overseas. In conjunction with the literature review presented above, three cognitive abilities (phonemic coding, associative memory, and sequence recognition) are hypothesized to reflect three different stages of acquisition (input processing, automatization, and lexicalization); and English /r/ acquisition comprises three stages of L2 speech learning according to different levels of difficulty (determined by the acoustic difference between the L1 and L2 systems; lower F2, longer F1 duration, and lower F3). Thus, the following three predictions were formulated to elucidate how different types of aptitude could be associated with different stages of English /ɹ/ development in FFL classrooms (phonemic coding for lower F2, associative memory for longer F1 duration, and sequence recognition for lower F3).
1. Phonemic coding, which is essential at the initial stage of L2 learning (noticing and understanding), will relate to the extent to which Japanese learners can master the relatively easy aspect of English /ɹ/ acquisition (F2 reduction).
2. As high-level associative memory allows L2 learners with abundant cognitive resources to process not only salient but also nonsalient features in input, it was predicted that this ability would demonstrate a strong association with Japanese learners’ acquisition of the medium-difficult dimension (longer duration).
3. Incidental learning aptitude, such as sequence cognition, was predicted to play a key role in the acquisition of the most difficult dimension (lower F3). This is arguably because L2 learners with this ability can maximize their L2 experience by processing the limited amount of input they receive in EFL settings intentionally as well as incidentally.
Participants
Japanese EFL students
The 50 sophomore EFL students (range=18–19 years; 23 males, 27 females) were recruited from various social sciences and humanities programs (business, marketing, economics, and psychology) at a large university located in downtown Tokyo. The participants were carefully selected to ensure that they had relatively homogeneous EFL backgrounds according to the following criteria. First, they were native speakers of Japanese (both of their parents must have been L1 Japanese speakers). Second, they started learning English from Grade 7, that is, they had 7 years of EFL education prior to entering the university.Footnote 2 Third, they had never been abroad at the time of the project. In this regard, we assumed that individual differences in their L2 pronunciation performance could be accounted for by their supposedly different aptitude profiles but not by their relatively similar experience.Footnote 3
Preliminary analyses of the same participants’ general oral proficiency (elicited from a picture cartoon task) and aptitude scores (based on LLAMA-B, D, E, and F) were reported in Saito (Reference Saito2017). In the current study, the same participants engaged in three different tasks (word reading, sentence reading, and timed picture description), where their abilities to pronounce English /ɹ/ in particular were tested at both controlled and spontaneous speech levels. Subsequently, the three different aspects of their English /ɹ/ pronunciation (F3, F2, and duration) were acoustically analyzed and linked to their relevant aptitude profiles of phonemic coding (LLAMA-E), associative memory (LLAMA-B), and sequence recognition (LLAMA-D). Within the first 4 weeks of the first semester in Year 2, the participants came for individual data collection sessions, which comprised an interview (to survey their bio and previous EFL experience), speech recording (to examine their English /ɹ/ pronunciation), and aptitude test (to survey their explicit and incidental pronunciation learning abilities). The entire session lasted for approximately 1 hr.
Native baselines
In addition, to provide baseline data for English /ɹ/ production, a total of 10 native speakers of English were also recruited (5 males, 5 females) from a university in Vancouver, Canada (M age =25.2 years). They were considered to be “monolinguals,” given that they reported little familiarity/use of other foreign languages on a daily basis.
Measuring aptitude profile
To measure the participants’ aptitude, three subcomponents of the LLAMA aptitude test—LLAMA-D (sequence recognition), LLAMA-B (associative memory), and LLAMA-E (phonemic coding)—were adopted in the current study for the following reasons. According to Skehan’s (Reference Skehan2016) taxonomy on L2 aptitude tests, the LLAMA is considered as domain specific. The test consists of linguistic materials and tasks that simulate various kinds of L2 learning experiences when participants aim to acquire a new, unfamiliar language. The methodological decision here distinguished the current study from the previous aptitude and speech studies using nonverbal materials (e.g., Darcy et al., Reference Darcy, Park and Yang2015).
In addition, the three tasks in the LLAMA (sequence recognition, associative memory, and phonemic coding) correspond to different cognitive abilities particularly relevant to L2 pronunciation learning (i.e., phonemic coding for input processing; associative memory for automatization; and sequence recognition for lexicalization; Skehan, Reference Skehan2016).
Finally, the LLAMA enables us to highlight two different modes of participants’ L2 learning processes: explicit versus incidental. From a methodological point of view, the three subtests (LLAMA-D, B, E) differ in terms of the absence/presence of the practice phase, where participants explicitly study the test materials. In this regard, the LLAMA-D was presumed to tap into incidental sound learning ability, and the LLAMA-B and LLAMA-E into intentional sound learning ability. To avoid activating the participants’ awareness, they engaged in the subtests in the following order: LLAMA-D→LLAMA-B→LLAMA-E.
∙ LLAMA-D . First, the participants listened to 10 sound strings as a part of a sound check (instructed to do so in order to avoid invoking any “intention” to memorize or analyze new sounds). They were then immediately asked to proceed to the testing phase,Footnote 4 where they listened to 30 new sound strings, and answered whether they had heard each item during the first listening. Their scores were recorded out of 75 points.
∙ LLAMA-B . Different from the LLAMA-D, in this subtest the participants were explicitly asked to remember a combination of five to six letters for 20 imaginary objects (i.e., associative memory) within 2 min so as to prepare for the testing phase afterward (recollection of learned items). Their scores were recorded out of 100 points.
∙ LLAMA-E . In this subtest, participants were given 2 min to identify and remember the relationship between 24 unfamiliar sounds and symbols (one syllable per symbol). Subsequently, their understanding/memory of sound–symbol correspondence was tested while listening to 20 combinations of two-sound strings. Their scores for the LLAMA-E were recorded out of 100 points.
Measuring English /ɹ/ pronunciation
The same English /ɹ/ analysis procedure in the precursor research (for the details, see Saito & Brajot, Reference Saito and Brajot2013) was adopted. The participants engaged in three different tasks—timed picture description (TPD), sentence reading (SR), and word reading (WR)—that require different processing abilities (spontaneous vs. controlled). Afterward, the participants’ English /ɹ/ tokens (four tokens [read, rain, rock, and road] from TPD; eight tokens [read, rain, red, race, run, Ryan, road, and wrong] from SR; and eight tokens [read, room, root, red, race, rough, ram, and right] from WR) were acoustically analyzed according to F2, F1 transition, and F3, each of which served as an index for the degree and rate of tongue retraction and labial/alveolar/pharyngeal constrictions.
Stimuli
All 20 target words included /ɹ/ in the word-initial position (n=8 for WR, n=8 for SR, and n=4 for TPD) and were consonant–vowel–consonant (CVC) singletons except “Ryan” in SR (CVVC). Given that Japanese learners tend to have more difficulty in producing word-initial /ɹ/ preceding front vowels (e.g., read and rain) than central and back vowels (rock and road; Flege et al., Reference Flege, Takagi and Mann1995), the following vowel condition was carefully controlled in each task (50% for singletons with front vowels and 50% for singletons with central and back vowels). The test tokens are summarized in Table 1.
Table 1 N=20 English /ɹ/ tokens in the controlled and spontaneous production tests in relation to following vowel conditions

Procedure
First, the participants engaged in TPD. To elicit participants’ spontaneous use of English /ɹ/, they described seven pictures with 5 s of planning time for each photo. While the first three photos served as distractors (to reduce task familiarity effects), the remaining four photos were used for the main analysis. Three key words were given for each photo that the participants had to use while completing the task; one of the key words was a target word. For example, one picture portrayed a table in the driveway under the rain (key words: table, driveway, and rain). The purpose of this picture was to elicit learners’ spontaneous production of /ɹ/ in rain.
Second, participants read five target sentences together with three distracter sentences. A total of eight target words including word-initial /ɹ/ were embedded in the target sentences. In this SR task, the participants’ abilities to pronounce English /ɹ/ under more controlled conditions (than TPD) were tested. The target sentences were as follows:
∙ He will read my paper by the time I arrive there.
∙ She left her red bicycle on the side of the road.
∙ The race was cancelled because of the rain.
∙ I can correct all wrong sentences tonight.
∙ Ryan does not like to run in the snow.
Third, participants read a list of 25 individual words containing eight target words (read, room, root, red, race, rough, ram, and right) and 17 distracters (see Appendix A). Different from TPD (where participants’ priority lied in conveying intended message), they were asked to pronounce each word as accurately as possible (with their focus on accurate pronunciation forms).
Individual recording sessions took place in a soundproof booth at the Japanese university (for the Japanese EFL participants) and at a university-level school in Vancouver (for the native baselines). To avoid any confusion/misunderstanding in the oral test procedure for the Japanese participants, all instructions were delivered in Japanese by a research assistant (a native speaker of Japanese). All speech tokens were recorded by way of a Marantz PMD 660 and Roland-05, set at 44.1 kHz sampling rate and 16-bit quantization.
Acoustic analysis
In conjunction with the procedure for the acoustic analysis of natural English /ɹ/ tokens used in Flege et al. (Reference Flege, Takagi and Mann1995) and Hattori and Iverson (Reference Hattori and Iverson2009), two spectral (F3 and F2) and temporal (F1 transition) aspects of English /ɹ/ production was analyzed through a linear predictive coding routine in Praat (Boersma & Weenik, Reference Boersma and Weenink2017). For WR, word onset was identified by looking at both the wave forms and spectrographic representation of each token. Then, a cursor was placed on the point where both F2 and F3 were clearly observed. For TPD, a cursor was placed on the local minimum of F3 (dip) to get the F2 and F3 values. The length of English /ɹ/ was measured by measuring the beginning and end of F1 transition.
Normalization
To normalize anatomical differences among the participants (e.g., vocal tract length), their raw F2 and F3 values were adjusted following Lee, Guion, and Harada’s (Reference Lee, Guion and Harada2006) procedure (for details, see also Saito & Brajot, Reference Saito and Brajot2013; Saito & Munro, Reference Saito and Munro2014).
RESULTS
Aptitude scores
The participants’ scores on the LLAMA-D, LLAMA-B, and LLAMA-E are summarized in Table 2. To examine the construct validity of the LLAMA test, the independence/dependence of the participants’ scores were checked via correlation analyses. According to the results of the Kolmogorov–Smirnov goodness-of-fit tests, all the aptitude scores followed the normal distribution (p>.05).
Table 2 Descriptive statistics of aptitude test scores by 50 Japanese students

The participants’ LLAMA-D, LLAMA-B, and LLAMA-E scores were submitted to Pearson correlation analyses with alpha set to p<.017 (Bonferroni corrected). The three aptitude subtest scores were not significantly related to each other (r=.05, p=.70 for LLAMA-D vs. LLAMA-B; r=–.06, p=.67 for LLAMA-D vs. LLAMA-E; r=.20, p=.14 for LLAMA-B vs. LLAMA-E). As conceptualized by Meara (2005), these subtest scores could thus be considered to tap into three different dimensions of the participants’ cognitive abilities for language learning: (a) sequence recognition ability (LLAMA-D), associative memory ability (LLAMA-B), and phonemic coding ability (LLAMA-E).
English /ɹ/ proficiency
According to the descriptive results (see Table 3), the Japanese students’ /ɹ/ performance was substantially different from the native baselines in all the acoustic dimensions (F2, F1 transition duration, and F3). The Kolmogorov–Smirnov goodness-of-fit tests confirmed the normal distribution of the participants’ F2, F1 transition duration and F3 values (p>.05). As for the task dimensions, the results of one-way analysis of variance showed that the acoustic dimensions of their pronunciation forms did not significantly differ between WR, SR, and TPD in terms of F2, F (2, 110)=1.988, p=.101, duration, F (2, 110)=1.638, p=.119, and F3, F (2, 110)=2.434, p=.092. The results indicated that the Japanese participants’ English /ɹ/ performance was comparable whether it was elicited via the controlled or spontaneous tasks (WR, SR vs. TPD).
Table 3 Descriptive results of English /ɹ/ production by Japanese students (n=50) and native baselines (n=10)
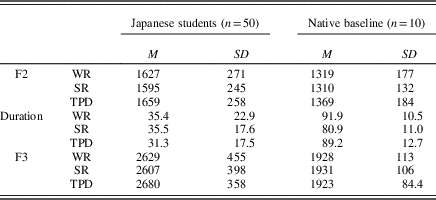
Note: WR, word reading. SR, sentence reading. TPD, timed picture description.
To count how many Japanese participants’ performance could be considered within the range of English /ɹ/, the nativelikeness analysis was adopted from many naturalistic L2 ultimate attainment studies (e.g., Abrahamson, Reference Abrahamsson2012). Following the commonly used procedure of the analysis, certain Japanese learners could be regarded as having reached “near-nativelike” proficiency if their performance fell within 2 SD of the native baseline group’s average scores. Accordingly, the number of such Japanese students who reached the native threshold of English /ɹ/ was counted for all the acoustic dimensions (F2, duration, and F3) at WR, SR, and TPD, respectively.
As summarized in Table 4, approximately half of the participants (42%–56%) acquired the nativelike F2 representation for English /ɹ/. However, the ratio of such successful English /ɹ/ performance was relatively low in the acquisition of duration (2%–14%) and F3 (2%–18%). The results indicated that 7 years of EFL education led many Japanese learners to master the easy aspect of English /ɹ/ acquisition (F2). However, much individual variability was present as to the difficult aspect of English /ɹ/ acquisition (duration, and F3).
Table 4 Number of Japanese students who fell within the range of nativelike English /ɹ/

Note: aAll the participants whose performance was below/above the threshold could be considered “nativelike” for each category (F2, duration, and F3). WR, word reading. SR, sentence reading. TPD, timed picture description
Aptitude–proficiency link
To provide a general picture of how each dimension of the participants’ English /ɹ/ pronunciation (F2, F1 transition duration, and F3) was associated with their sequence recognition (LLAMA-D), associative memory (LLAMA-B), and phonemic coding (LLAMA-E), a set of Pearson correlation analyses were performed. The size of the associations was also considered in consultation with Plonsky and Oswald’s (Reference Plonsky and Oswald2014) field-specific benchmarks (r=.25 for small, .40 for medium, .60 for large).
As shown in Table 5, the results identified significant correlations between the participants’ F2 performance at WR and LLAMA-E (p=.019). In addition, LLAMA-B was marginally related to the participants’ duration at WR (p=.052), and significantly correlated with their F2 and F3 performance at WR (p=.027, .046). The strength of the significant/marginal contrasts here (r=|.277 to –.312|) were considered small to medium (Plonsky & Oswald, Reference Plonsky and Oswald2014).
Table 5 Correlations between the participants’ English /ɹ/ performance and aptitude scores

Note: *indicates statistical significance at p<.05. †indicates marginal significance at p<.10.
To further probe the predictive power of the participants’ different aptitude scores (sequence recognition, associative memory, and phonemic coding) for three different aspects of their English /ɹ/ performance (F2, F1 duration, and F3), a set of stepwise multiple regression analyses were performed with each acoustic dimension of English /ɹ/ as a dependent variable relative to three different aptitude scores as independent variables. As summarized in Table 6, LLAMA-E scores explained 10.9% of the variance in the F2 performance; and LLAMA-B accounted for 8.0% of the variance in the F3 performance. According to Plonsky and Oswald’s (Reference Plonsky and Oswald2014) benchmark (R 2=.06 for small, .16 for medium, .36 for large), the amount of explained variance in these models could be considered relatively “small to medium” (.06<R 2<.16).
Table 6 Results of multiple regression analyses using the aptitude scores as predictors of English /ɹ/ pronunciation performance

Note: WR, word reading. SR, sentence reading. TPD, timed picture description. LLAMA-B for associative/rote memory. LLAMA-E for phonemic coding.
DISCUSSION
In the context of 50 second-year college Japanese students with relatively homogeneous EFL backgrounds (i.e., 7 years of EFL education and no experience abroad), the current study examined the extent to which individual variability in English /ɹ/ pronunciation attainment could be explained by three different components of aptitude—sequence recognition (LLAMA-D), associative memory (LLAMA-B), and phonemic coding (LLAMA-E). In keeping with Skehan’s (Reference Skehan2016) proposal, these aptitude factors were hypothesized to facilitate different stages of L2 acquisition (phonemic coding for initial, associative memory for middle, and sequence recognition for advanced; Skehan, Reference Skehan2016). Furthermore, the participants’ English /ɹ/ performance was scrutinized according to different acoustic/task dimensions that were assumed to reflect different amounts of learning difficulty (lower F2 for tongue retraction<longer duration for prolonged phonemic length<lower F3 for labial, alveolar, and pharyngeal constrictions) and processing abilities (WR<SR<TPD).
First and foremost, the results of the acoustic analyses showed a great deal of individual variability in the Japanese participants’ English /ɹ/ performance after 7 years of EFL education. Whereas many of them (40%–60%) successfully attained nativelike proficiency for the relatively easy aspect of English /ɹ/ acquisition (F2<1700 Hz), very few (<20%) did so for the relatively difficult aspect of English /ɹ/ acquisition (duration>50 ms, F3<2100 Hz). This was consistent with major L2 speech learning theories (e.g., Flege, Reference Flege2003, for speech learning model), which equally state that this specific L1–L2 context (the acquisition of English /ɹ/ by adult Japanese learners) could be considered as one of the most difficult instances of sound learning. Furthermore, the available research evidence has thus far suggested that L2 pronunciation development is a slow, gradual phenomenon (requiring more than 10 years of immersion for acquiring all aspects of English /ɹ/ pronunciation; see Ingvalson, McClelland, & Holt, Reference Ingvalson, McClelland and Holt2011). Taken together with what was found in the current study, it is logical to speculate that 7 years of EFL education alone may not be sufficient for Japanese students to lead to robust pronunciation development for all the acoustic dimensions of English, especially without any immersion through study abroad (Riney & Flege, Reference Riney and Flege1998).
Given that the amount of successful L2 pronunciation learning may widely vary regardless of learners’ EFL experience factors, the question has now become: to what degree can such individual variability in classroom L2 pronunciation learning be explained by factors related to aptitude? As predicted earlier, the results identified explicit learning aptitude—phonemic coding, associative memory—as a significant affecting factor for the participants’ English /ɹ/ acquisition. Whereas those with higher phonemic coding abilities appeared to demonstrate better performance in the relatively easy dimension of English /ɹ/ pronunciation (lower F2), those with greater associative memory tended to demonstrate more advanced performance, especially in the relatively difficult dimension of English /ɹ/ pronunciation (longer transition duration and lower F3). In line with the field-specific benchmark, suggested by Plonsky and Oswald (Reference Plonsky and Oswald2014), the magnitude of the associations could be considered “small to medium.”
Extending Skehan’s (Reference Skehan2016) acquisition-aptitude framework (which has evolved in L2 morphosyntax studies), the findings here indicated a multifaceted relationship between different constructs of aptitude and different stages of L2 pronunciation development.
Phonemic coding
Some scholars have shown that phonemic coding could be linked to global constructs of L2 pronunciation learning (e.g., Granena & Long, 2013, for foreign accentedness). To our knowledge, the current study was the very first attempt to examine the role of phonemic coding ability in the specific instance of L2 segmental acquisition with different levels of learning difficulty (i.e., Japanese learners’ F2, F3, and duration of English /ɹ/ pronunciation).
Phonemic coding ability, which requires both analysis (identifying the underlying patterns between sound strings to alphabets with diacritics) and memory (remembering sound–symbol correspondence) aspects of cognition may allow L2 learners to briefly hold onto incoming input and make it available for quick and immediate phonetic analysis. When exposed to a new target sound (English /ɹ/), such talented L2 learners may quickly notice, understand, and adjust to the already existing acoustic (lower F2) and articulatory (tongue retraction) parameters in the L1 Japanese phonetic system (where F2 is used to differentiate between /w/ and /j/). However, phonemic coding did not show significant correlations with the acquisition of the relatively difficult aspects of English /ɹ/ learning: phonemic lengthening and F3 reduction.
Associative memory
In the previous literature, it has been shown that Japanese learners tend to work on various aspects of English /ɹ/ production over an extensive period of time in naturalistic settings (length of residence >10 years). To achieve this demanding goal under classroom conditions, where input is relatively limited, Japanese learners may need more robust memory abilities, such as associative memory, to promote the acquisition of the phonetic cues absent in the L1 Japanese phonetic system, and to enhance the intelligibility and accuracy of English /ɹ/ pronunciation. Associative memory is hypothesized to help L2 learners better perceive and produce the target sound. Such talented learners can store larger amounts of visual, written, and sound information, which will, as a result, free up more cognitive resources available for more detailed, deeper analyses of the partially existing cues (longer phonemic length), as well as new cues (lower F3 for labial, alveolar, and pharyngeal constrictions).
Our findings on the relationship between associative memory and the later stage of L2 speech learning are in line with the previous aptitude literature, which has shown that L2 learners with greater associative memory likely attain advanced L2 proficiency in terms of grammaticality judgments (Linck et al., Reference Linck, Hughes, Campbell, Silbert, Tare, Jackson and Doughty2013) and reading and listening skills (Schneiderman & Desmarai, Reference Schneiderman and Desmarais1988). As for L2 speech learning, Silbert et al. (Reference Silbert, Smith, Jackson, Campbell, Hughes and Tare2015) examined and confirmed the strong relationship between associative memory and perception of nonnative contrasts.
For theoretical relevance, the findings can also be interpreted with reference to the influencing working memory model in cognitive psychology (e.g., Baddeley, Reference Baddeley2003). There has been a recent paradigm shift in the field of SLA toward integrating working memory model into a component of foreign language aptitude (e.g., Linck, Osthus, Koeth, & Bunting, Reference Linck, Osthus, Koeth and Bunting2014). According to Li’s (Reference Li2016) meta-analysis, the construct of the “short-term store” component of working memory significantly overlapped with the construct of associative memory (whereas the “executive control” component of working memory was closely tied to the construct of phonemic coding). This is arguably because of the fact that tasks measuring both associative memory (paired associates) and phonological short-term memory (nonword repetition and nonword/digit span) are similar in nature (i.e., storing and rehearsing new verbal/nonlinguistic information in phonological code but without entailing much processing).
If we take the stance that associative memory is possibly linked to phonological short-term memory, the findings of the study (i.e., the role of associative memory in the relatively difficult aspects of English /ɹ/ acquisition) would provide further empirical evidence to the strong memory effects on high-level L2 acquisition, reported in a wide range of SLA studies to date. For example, L2 learners with greater phonological short-term memory likely attain more nativelike lexicogrammar performance as a result of study abroad (O’Brien, Segalowitz, Collentine, & Freed, Reference O’Brien, Segalowitz, Collentine and Freed2006) and long-term immersion (Foster, Bolibaugh, & Kotula, Reference Foster, Bolibaugh and Kotula2014). By conducting an intervention study with a pretest and posttest design, Révész (Reference Révész2012) demonstrated that the impact of instruction (recasts) on L2 oral proficiency development (the accurate use of past/present progressive) was significantly correlated with participants’ phonological short-term memory (but not with their executive control). Echoing the SLA/working memory literature (see Kormos, Reference Kormos2013, for a detailed review), the current study supports a tentative conclusion that solid phonological memory could be instrumental to advanced-level L2 speech attainment, because it is hypothesized to equip learners with strong storage functions that they need so as to best utilize, process, and analyze every L2 input that they have explicitly engaged in.
Roles of incidental learning aptitude
Finally, it is important to remember that the participants’ incidental aptitude (sequence recognition) was not associated with their English /ɹ/ performance, and that the link between explicit aptitude (phonemic coding and associative memory) and all the significant aptitude–proficiency associations were limited to the controlled task condition (word reading). The lack of any significant role for incidental aptitude (sequence recognition) hints that incidental learning could be minimally beneficial in classroom settings, where the nature of L2 learning is predominantly explicit (e.g., grammar translation and form-focused exercise activities). Under such L2 learning environments, as shown earlier, L2 learners seemingly benefit from those components of aptitude that impact explicit and intentional learning in an effective and efficient manner. Similarly, the explicit aptitude effects found in the controlled task (WR) rather than the spontaneous task (TPD) also indicate that such aptitude can predict L2 learners’ performance when they can fully focus on phonetic forms without paying much attention to the content of message (controlled processing), a typical characteristic of many form-oriented EFL classrooms.
Future directions
Given that the current study took a first step toward conceptualizing an aptitude framework for L2 pronunciation development in classroom settings, the interpretations of the data set presented here need to be considered as tentative at best. Given the theoretical and practical value of the topic, several issues worthy of future investigation need to be addressed. Although the study found that the two explicit aptitude factors explained approximately 10% of variance in the participants’ L2 pronunciation attainment, it would be intriguing to replicate the findings by adopting a more comprehensive set of aptitude measures that are designed to tap into explicit and implicit learning abilities (with and without awareness), and domain-specific and domain-general abilities (associated with language learning and applicable to any general skill acquisition) in both the receptive and the productive modes (cf. Saito, Sun, & Tierney, Reference Saito, Sun and Tierney2018, for explicit and implicit sensitivity to segmental and suprasegmental sensitivity)
Furthermore, the current study assumed that the participants had relatively homogeneous EFL backgrounds at the time of the project (7 years of EFL experience without any experience abroad). Although the participants’ aptitude scores were moderately associated with their English /ɹ/ pronunciation, there is some possibility that the findings here could have been confounded with their potentially different EFL backgrounds (e.g., those who attained better English /ɹ/ pronunciation may have had not only higher aptitude scores but also spent more time in practicing the L2). On the one hand, it has been extensively shown that adult L2 learners can demonstrate some improvement (e.g., their pronunciation forms being more intelligible) after receiving a great amount of L2 input under EFL conditions (5–6 years of classroom experience; Simon & D’Hulster, Reference Simon and D’Hulster2012).
On the other hand, few studies have thus far examined precisely how many hours and what kind(s) of L2 instruction are needed to enhance the rate and ultimate attainment of L2 pronunciation. While tracking the longitudinal development of L2 oral proficiency by Japanese EFL students, Saito and Hanzawa (Reference Saito and Hanzawa2018) showed that the effects of classroom experience on Japanese EFL students’ change could be limited to fluency (rather than segmental) aspects of L2 speech. In terms of Japanese learners’ English /ɹ/ acquisition, Riney and Flege’s (Reference Riney and Flege1998) longitudinal study similarly demonstrated that the mere exposure to L2 instruction alone may not result in tangible improvement, suggesting that some learner-internal factors beyond experience (e.g., aptitude) may predict the incidence of successful L2 speech learning in foreign language classrooms. To this end, future research is strongly called for with a view of expounding the complex relationship between EFL experience, aptitude, and individual differences vis-à-vis the context of L2 segmental development and attainment (cf. Nagle, Reference Nagle2017).
Finally, the current study, which used a cross-sectional data set, does not allow us to discuss any causal relationship between aptitude and proficiency. As a remedy, more longitudinal work is needed to further examine the extent to which L2 learners with special aptitude profiles (associative memory, phonemic coding, and phonological short-term memory) can actually enhance various dimensions of L2 speech, when they engage in various kind of practice activities over an extensive period of time (e.g., O’Brien et al., Reference O’Brien, Segalowitz, Collentine and Freed2006).
APPENDIX A
DISTRACTER ITEMS IN WORD READING
man, book, desk, tall, bus, music, Tom, ship, chair, map, mom, sip, subway, yellow, think, feet, cap
ACKNOWLEDGMENTS
The current study was partially funded by the Grant-in-Aid for Scientific Research in Japan and Birkbeck College Additional Research Support Grant. I am grateful to the journal editor, Rachel Hayes-Harb, and Applied Psycholinguistics reviewers for providing constructive comments on earlier versions of this paper.






