



1. Introduction
Texts translated into a target language possess linguistic properties that are very different from comparable texts originally written in this language. These properties have been termed the “third code” (Frawley Reference Frawley and Frawley1984) or “translationese” (Gellerstam Reference Gellerstam, Wollin and Lindquist1986) in the literature. In fact, translationese has been shown to originate from two possible sources: one is assumed to be the translation process, which is independent of the source and target languages and results in “translation universals”, as argued by Baker (Reference Baker, Baker, Francis and Tognini-Bonelli1993, Reference Baker and Somers1996). These universals include simplification (translations tend to be simpler) and explicitation (translations are more explicit), among several others. The second source of differences concerns the assumption that translationese is bound to be influenced by the source language, from which the translations are produced. This is often referred to as the “law of interference” (Toury Reference Toury1995) or source language “shining through” (Teich Reference Teich2003).
Our work presented here investigates the hypothesis that translations constitute a separate language variety, different from other types of text in that language. In addition, we investigate the hypothesis that there is also interference from the source language, in which case we can consider translations from different source languages to be dialects of the translation variety (c.f. Koppel and Ordan Reference Koppel and Ordan2011). We use the term “dialect” rather loosely, to easily refer to the differences we see based on the source language of a translation. We are not trying to draw parallels to regional or social dialects.
The different characteristics of translationese and its dialects have been studied for decades (Toury Reference Toury, Holmes, Lambert and van den Broeck1978; Baker Reference Baker, Baker, Francis and Tognini-Bonelli1993; Laviosa-Braithwaite Reference Laviosa-Braithwaite1996; Mauranen and Kujamäki, 2004; Baroni and Bernardini Reference Baroni and Bernardini2005; Xiao Reference Xiao2010, among many others). Identifying them is not only of great interests to theoretical translation studies, but can also help improve the training of translators, the evaluation of translation quality, and the performance of language models in machine translation systems (Lembersky et al. Reference Lembersky, Ordan and Wintner2012). It is also the prerequisite for proposing and verifying any laws or universals with regard to translations. However, most of the existing translationese studies focus on Indo-European target languages, such as English (Laviosa-Braithwaite Reference Laviosa-Braithwaite1996; Olohan and Baker Reference Olohan and Baker2000), Spanish (Ilisei et al. Reference Ilisei, Inkpen, Pastor and Mitkov2010), German (Rubino et al. Reference Rubino, Lapshinova-Koltunski and van Genabith2016), or Russian (Kunilovskaya and Kutuzov Reference Kunilovskaya, Kutuzov, Menzel, Lapshinova-Koltunski and Kunz2017). However, if we assume that these characteristics are universal, then they need to be tested on a wide range of languages and also on multiple linguistic levels. In our current work, we focus on Chinese as the target language in translations. While there exist studies on Chinese, they only looked at translations from one source language, namely English (Xiao Reference Xiao2010; Xiao and Hu Reference Xiao and Hu2015; Hu et al. Reference Hu, Li and Kübler2018). As a result, they cannot be generalized to Chinese translations in general. More specifically, since only one source language was available, interference from different source languages could not be investigated and thus needs to be studied more thoroughly.
Therefore, in the research reported here, we first introduce a new corpus of translated Chinese, balanced with seven source languages from different language families, and then investigate three research questions: (1) What are the characteristics of Chinese translationese, both in general and with respect to different source languages? (2) Can we find differences not only at the lexical but also on the syntactic level? and (3) Based on the characteristics found in the previous questions, which of the proposed laws and universals can we corroborate based on our evidence from Chinese?
We use machine learning, classifying text into either translation or original text, in order to determine which characteristics reach a high level of accuracy. From a high accuracy, we can conclude that the respective characteristics are important differences between originals and translations or between different translation dialects. Note that this methodology allows us to investigate scenarios where combinations of features are important. This is much more difficult in count-based corpus studies. We have shown in previous work (Hu et al. Reference Hu, Li and Kübler2018) that a machine learning approach can reliably distinguish between translations and Chinese originals. In essence, the goal of this work is twofold: one goal is to determine empirically which featuresFootnote a can distinguish translated and non-translated Chinese as well as translations from different source languages. The other goal is more theoretical in nature, that is, we investigate whether Chinese translations can be described by the universal hypotheses proposed by Baker (Reference Baker, Baker, Francis and Tognini-Bonelli1993) and whether the law of interference is applicable.
The remainder of this article is structured as follows: Section 2 reviews the relevant literature in translation studies, focusing on the characteristics that have been investigated and on machine learning approaches, on which our work is based. Then, the new corpus is introduced (Section 3). Next, we perform machine learning experiments to distinguish translations from originals, with the goal of identifying and interpreting the discriminative features (Section 4). We will start with a range of features based on a previous study in English (Volansky et al. Reference Volansky, Ordan and Wintner2013) and the syntactic features from our previous work (Hu et al. Reference Hu, Li and Kübler2018). Then, new features will be introduced and tested. Finally, we compare our results with the study on English by Volansky et al. (Reference Volansky, Ordan and Wintner2013) and discuss implications for the universal hypothesis and the law of interference. Our findings are summarized in Section 5.
2. Related work
In this section, we will review relevant literature from two perspectives. The first angle is more linguistic in nature and revolves around the characteristics of translated text proposed over the decades, such as simplification and explicitation. Note that each category of features can be realized on different linguistic levels ranging from the most obvious and more easily accessible lexical level to the less obvious syntactic level. The second perspective is more computational in nature and concerns the methods and techniques for analyzing or utilizing these features. We will review studies that used frequency comparisons, focusing on the more recent machine learning research, which is the basis for our experimental work.
2.1 Features of translations
Over the years, research in translation studies has used the term “translationese” to describe the distinctive linguistic characteristics of translations that set them apart from both the source text and comparable text in the same target language (Gellerstam Reference Gellerstam, Wollin and Lindquist1986). Detailing what exactly those features are has been a major goal in corpus-based translation studies. Several high-level linguistic properties of translated text have been proposed, some of which are termed “translation universals” that are supposed to hold across all translations, regardless of source or target language (Baker Reference Baker, Baker, Francis and Tognini-Bonelli1993, Reference Baker1995, Reference Baker and Somers1996). For example, “explicitation” was first discussed by Blum-Kulka (Reference Blum-Kulka, House and Blum-Kulka1986), referring to the tendency that target text is usually rendered more explicit than the source text, as a result of the translation process. Later, explicitation was extended to describe the relation between translations and comparable original text (Baker Reference Baker, Baker, Francis and Tognini-Bonelli1993, Reference Baker1995). For example, in translations, pronouns are more likely to be spelled out, and connectives are often added to enhance cohesion and aid understanding. “Simplification” refers to the observation that translations are in general lexically and syntactically simpler and less ambiguous than original text (Baker Reference Baker, Baker, Francis and Tognini-Bonelli1993, Reference Baker and Somers1996). The “normalization” universal describes the tendency to conform to the “typical patterns” of the target language (Baker Reference Baker and Somers1996). Finally, there is “levelling out,” a “tendency of translated text to gravitate toward the center of a [linguistic] continuum” (Baker Reference Baker and Somers1996). An example is that in translated English, the type-token ratio (TTR) has a smaller standard deviation than original texts (Laviosa-Braithwaite Reference Laviosa-Braithwaite1996).
There are several other characteristics of translationese in the literature. One of them is “implicitation,” that is, the opposite of explicitation. Implicitation refers to the tendency of translators to make a text more implicit, by either leaving out connectives or using pronouns instead of the nouns in the source text. Implicitation may depend on the source–target language pair in question. For example, Cartoni et al. (Reference Cartoni, Zufferey, Meyer and Popescu-Belis2011) show that French-to-English translations use more clausal connectives than original English, but the opposite is true for English-to-French translations. There is evidence for implicitation in other languages as well; see Becher (Reference Becher2011) for German, Meyer and Webber (Reference Meyer and Webber2013) for French and German, and Ke (Reference Ke2005) for Chinese. However, this characteristic is difficult to operationalize. For this reason, we refrain from using it in our work.
All of the above-mentioned characteristics tend to focus on the discrepancies between translations and original text in the target language, therefore neglecting the influence from the source language. However, translations are by definition a product of the source text. Thus, it goes without saying that the source language plays an indispensable role in the creation of translationese. This is often referred to as the “law of interference” (Toury Reference Toury1995), which is also described as the phenomenon of the source language “shining through” (Teich Reference Teich2003). This effect has been demonstrated in empirical studies, for example, by Volansky et al. (Reference Volansky, Ordan and Wintner2013) and by Evert and Neumann (Reference Evert, Neumann, De Sutter, Lefer and Delaere2017).
To verify whether these proposed characteristics of translationese hold, be they universals or interference, researchers have traditionally used methods from corpus linguistics. For example, to study simplification, we can compare the measures of textual complexity such as TTR, mean sentence length, lexical density to see if there are statistically significant differences between a comparable corpus of translations and originals (Laviosa-Braithwaite Reference Laviosa-Braithwaite1996; Xiao Reference Xiao2010; Hu et al. Reference Hu, Xiao and Hardie2016). The same methodology also applies for explicitation. Scholars usually start with connectives and other function words, such as conjunctions and the complementizer that, which are considered signs of explicitness (Olohan and Baker Reference Olohan and Baker2000; Puurtinen Reference Puurtinen, Mauranen and Kujamäki2004; Chen Reference Chen2006). This line of work has produced fruitful yet mixed results. For example, studies on Hungarian (Pápai Reference Pápai, Mauranen and Kujamäki2004) and Chinese (Chen Reference Chen2006; Xiao Reference Xiao2010) found evidence supporting explicitation in translations via a comparison of frequencies, whereas a study on Finnish by Puurtinen (Reference Puurtinen, Mauranen and Kujamäki2004) reported “no clear overall tendency of either translated or original Finnish using connectives more frequently” in a corpus of translated and original children’s literature.
It should be noted that in a comparable corpus setting, where one has only access to (a) translations from a single source language, and (b) text originally written in the target language, there is no easy way of investigating the interference from the source language. To properly study source language interference, we usually either need both translated and source text to examine the translation process (as in the study by Blum-Kulka (Reference Blum-Kulka, House and Blum-Kulka1986)) or have translations from multiple source languages for comparison (as in the study by Volansky et al. Reference Volansky, Ordan and Wintner(2013)).
Starting from work by Baroni and Bernardini (Reference Baroni and Bernardini2005), however, a new paradigm in translation studies has gradually gained popularity. Instead of using occurrence counts of lexico-grammatical properties, the importance of linguistic characteristics is determined using them as features in machine learning tasks that classify text into translations and originals. Our study follows this line of work, and we will discuss relevant studies in the next section.
2.2 Classification between translated and original text
Baroni and Bernardini (Reference Baroni and Bernardini2005) use machine learning with features such as word or part-of-speech (POS) n-grams to classify journal articles on geopolitics that are either originally written in Italian or translated from English. They demonstrate that an ensemble of support vector machines can reach very high accuracy (86.7%), demonstrating convincingly that translationese is an experimentally verifiable phenomenon. They show that a machine learner can recognize linguistic differences between translations and originals with an accuracy that is higher than that of professional translators.
Similar classification tasks have been carried out for other Indo-European languages, for example, by Ilisei et al. (Reference Ilisei, Inkpen, Pastor and Mitkov2010) for Spanish medical and technical texts, by Ilisei and Inkpen (Reference Ilisei and Inkpen2011) for Romanian news text, by Rubino et al. (Reference Rubino, Lapshinova-Koltunski and van Genabith2016) for a mixed genre of German, and by many for English (Koppel and Ordan Reference Koppel and Ordan2011; Volansky et al. Reference Volansky, Ordan and Wintner2013; Rabinovich and Wintner Reference Rabinovich and Wintner2015; Rabinovich et al. Reference Rabinovich, Nisioi, Ordan and Wintner2016).
While some of these studies aim to explore classification under a more complex setting, for example, using a multi-genre, multi-source language corpus (Koppel and Ordan Reference Koppel and Ordan2011), employing unsupervised methods (Rabinovich and Wintner Reference Rabinovich and Wintner2015), others focus on examining the hypotheses reviewed above. In these studies, machine learning experiments serve as empirical evaluation of linguistic hypotheses. For example, Ilisei et al. (Reference Ilisei, Inkpen, Pastor and Mitkov2010) and Ilisei and Inkpen (Reference Ilisei and Inkpen2011) operationalize several simplification features, such as mean sentence length, parse tree depth, average senses per word, and show that adding these features improves the classification accuracy, providing support for the simplification hypothesis. They also show that there are syntactic differences in addition to lexical ones.
Of particular interest to our work is the study by Volansky et al. (Reference Volansky, Ordan and Wintner2013). They build classifiers to distinguish English original texts from translations into English aggregated from 10 source languages in the Europarl corpus (Koehn Reference Koehn2005). They categorize their features under four hypotheses: simplification, explicitation, normalization, and interference, with the goal of investigating the proposed translation universals and other characteristics. They not only cite the work of Baker (Reference Baker, Baker, Francis and Tognini-Bonelli1993) as the basis for their work but also include interference in their feature design.
More specifically, Volansky et al. (Reference Volansky, Ordan and Wintner2013) experiment with a number of simplification features. Different operationalizations of TTR achieve
 $>$
70% accuracy. Other features, such as lexical density, only reach an accuracy of 53%. Sentence length yields an accuracy of 65%, but this does not support the simplification hypothesis since 7 out of the 10 translations (from Italian, Portuguese, Spanish, etc.) have longer sentences than the English originals, contrary to the predictions of the simplification hypothesis. Overall, translations are 2.5 words longer than the originals.
$>$
70% accuracy. Other features, such as lexical density, only reach an accuracy of 53%. Sentence length yields an accuracy of 65%, but this does not support the simplification hypothesis since 7 out of the 10 translations (from Italian, Portuguese, Spanish, etc.) have longer sentences than the English originals, contrary to the predictions of the simplification hypothesis. Overall, translations are 2.5 words longer than the originals.
The interference features used by Volansky et al. (Reference Volansky, Ordan and Wintner2013) include POS n-grams, prefixes, and suffixes, among others. POS n-grams achieve a 90–98% accuracy, prefixes, and suffixes 80%. Crucially, Volansky et al. (Reference Volansky, Ordan and Wintner2013) analyze the POS trigrams and find that translations from all source languages have a much higher number of the trigram MD + VB + VVN (modal + verb base form + verb past participle, e.g., must be given) compared with English originals, with translations from Finnish at the top, followed by Swedish and Danish. The analysis of affix features again reveals that source language-specific prefixes are carried over to their English translations. For instance, mono- is more frequent in translations from Greek because of its Greek origin; the Latinate suffix -ible is more prominent in translations from Romance languages. These results not only prove the existence of interference but they also identify linguistic structures that distinguish translations from different source languages.
For Chinese, to our knowledge, our investigation (Hu et al. Reference Hu, Li and Kübler2018) is the only classification study, and no study has utilized translations from multiple source languages. Therefore, the interference effect has only been investigated for English-to-Chinese translations. The current study aims to fill the two gaps and set the baseline for text classification of original and translated Chinese. More interestingly, it will provide a direct comparison between English (Volansky et al. Reference Volansky, Ordan and Wintner2013) and Chinese translationese to see whether those hypotheses hold for a language from a language family different from the Indo-European languages that have been intensely investigated so far.
On the methodological side, we will experiment with syntactic features that have rarely been used in Chinese translation studies and focus on providing a detailed and meaningful linguistic interpretation. Syntactic features have been used in several studies on Indo-European translations. As described above, Ilisei and Inkpen (Reference Ilisei and Inkpen2011) use parse tree depth as an indicator for sentence complexity in Spanish. In another study, Rubino et al. (Reference Rubino, Lapshinova-Koltunski and van Genabith2016) compute surprisal, complexity, and distortion features based on flattened constituent parse trees, which are then used as features for their classifier. While Rubino et al. (Reference Rubino, Lapshinova-Koltunski and van Genabith2016) operationalize information density as surprisal, we use another information-theoretic measure—entropy—to measure information density and complexity, since Hale (Reference Hale2016) suggests that entropy is a better predictor in modeling human sentence processing. There are also other studies that look at syntactic features without using parse trees. For instance, Kunilovskaya and Kutuzov (Reference Kunilovskaya, Kutuzov, Menzel, Lapshinova-Koltunski and Kunz2017) use words, POS tags, and length features to detect unnaturalness (i.e., translationese) in English-to-Russian translations. Some studies in the edited volume by De Sutter et al. (Reference De Sutter, Lefer and Delaere2017) also investigate structural properties of translations, for example, phrasal verbs in English translations (Cappelle and Loock Reference Cappelle, Loock, De Sutter, Lefer and Delaere2017), noun + modifier, and modifier + noun combinations in Italian translations and interpretations (Ferraresi and Miličević Reference Ferraresi, Miličević, De Sutter, Lefer and Delaere2017). However, they all extract relevant structures by wordform matching, rather than by relying on parse trees. One innovation in our current study is to measure syntactic complexity by the entropy of various types of grammar rules and to use them as features for classification, as we will explain in the next section.
3. Methodology
In this section, we describe the features, dataset, and classifier in the current study. Our starting point constitutes the work by Volansky et al. (Reference Volansky, Ordan and Wintner2013) (and our previous work (Hu et al. Reference Hu, Li and Kübler2018)) in that we also use a machine learning approach to text classification as the method to measure the validity of the translation hypotheses. Volansky et al. (Reference Volansky, Ordan and Wintner2013) have based their work on the theoretical work by Baker (Reference Baker, Baker, Francis and Tognini-Bonelli1993, Reference Baker1995, Reference Baker and Somers1996) and Toury (Reference Toury1995), that is, they investigate (mostly) Baker’s translation universals and the law of interference. Following Volansky et al. (Reference Volansky, Ordan and Wintner2013), we first explore features representing the three universals used in their work. However, if we see differences between source languages with regard to those features, we can interpret those differences as support for the law of interference.
3.1 Features
The features used in this study are explained below. A complete list can be found in Appendix B. Some of the features are taken from Ilisei et al. (Reference Ilisei, Inkpen, Pastor and Mitkov2010) and Volansky et al. (Reference Volansky, Ordan and Wintner2013), with modifications suitable for Chinese. We add syntactic features and features specific to Chinese.
3.1.1 Explicitation features
Variants of cohesive markers. The most widely used type of features for explicitation consists of cohesive markers. We test a list of 160 cohesive markers from Chen (Reference Chen2006). We next experiment with features that measure the richness of the markers, that is, their total counts, TTR, and entropy.
Explicit naming. This is operationalized as the ratio of personal pronouns to proper nouns, based on the assumption that the more explicit the text, the more proper nouns, rather than pronouns, are used.
Single naming and mean multiple naming. Single naming counts the number of single-token pronouns, whereas mean multiple naming counts the average number of tokens in proper noun phrases (NPs), both with the hypothesis that more explicit texts are likely to elaborate on the proper nouns and have longer ones in general (e.g., by adding in translations the titles or positions of officials). The three naming features are taken from Volansky et al. (Reference Volansky, Ordan and Wintner2013).
3.1.2 Simplification features
TTR and lengths of linguistic units. Most of our lexical features are commonly used in stylometry studies (Grieve Reference Grieve2007): TTR, length of various linguistic units, etc. Here, we use the operationalization by Volansky et al. (Reference Volansky, Ordan and Wintner2013) when possible so that our results are directly comparable to theirs for English. We borrow two variants of TTR and add a character-based TTR measure since in Chinese, word segmentation is nontrivial and characters almost always constitute morphemes themselves, which can also serve as the building block of the lexicon. Mean word and sentence lengths are straightforward, with the hypothesis that translations are shorter because they should be simpler.
Lexical density. This is measured by the number of content words divided by the number of all tokens. We expect translations to have a lower proportion of content words.
Mean character/word rank. The mean rank of all characters/words from ranked frequency lists. A lower mean rank means the text uses more frequent words rather than rare words since they have lower rank. Translations are expected to have a lower mean rank.
Most of the above features are directly comparable to Volansky et al. (Reference Volansky, Ordan and Wintner2013). We also use several syntactic measures of complexity, inspired by previous research in translation (Ilisei et al. Reference Ilisei, Inkpen, Pastor and Mitkov2010), language acquisition (Chen et al. Reference Chen, Boston and Hale2009; Lu Reference Lu2010), and psycholinguistics (Lin Reference Lin2011; Kwon et al. Reference Kwon, Kluender, Kutas and Polinsky2013):
Constituent tree depth. The mean depth of all constituent trees (Ilisei et al. Reference Ilisei, Inkpen, Pastor and Mitkov2010).
Number of complex NPs per clause. Complex NPs include NPs involving adjectives, quantifier phrases, classifier phrases, etc., as modifiers, as well as conjoined NPsFootnote b. This is inspired by work by Lu (Reference Lu2010) who measured the complexity of learners’ English. Chinese originals are hypothesized to use more complex NPs.
Number of verb phrases (VPs) per clause. For VPs, it is difficult to operationalize the notion of complex VPs, thus we simply count all VPs, excluding the ones with copula 是 (Eng. be).
Number of relative clauses per clause. Previous studies have shown that translations in Chinese tend to use more complex relative clauses (Lin Reference Lin2011; Lin and Hu Reference Lin and Hu2018). Relative clauses in different languages are structurally distinctive, for example, pre-nominal in Chinese, Japanese, and Korean, post-nominal in many Indo-European languages (Kwon et al. Reference Kwon, Kluender, Kutas and Polinsky2013; Lin Reference Lin2018). Hence, we expect translations and originals to use them differently.
Entropy of grammar. Apart from structure counts, we also investigate the entropy of grammar rules. Entropy measures the uncertainty of a random variable (Shannon Reference Shannon1948). Here, we use it as an approximation of how scattered, diverse, or complex a grammar is. It has been used to measure syntactic complexity of child language (Chen et al. Reference Chen, Boston and Hale2009). For context-free grammar (CFG) rules, we calculate the entropy of the rules headed by each phrase (NP, VP, etc.)Footnote c:
 \begin{equation*}E(\textrm{XP}) = - \sum_{r \in \{ \textrm{rules headed by XP} \}} p(r) \cdot \log (p(r))\end{equation*}
\begin{equation*}E(\textrm{XP}) = - \sum_{r \in \{ \textrm{rules headed by XP} \}} p(r) \cdot \log (p(r))\end{equation*}
A high entropy for NP rules roughly means that there are diverse and complex ways of forming an NP. Note that there are 28 phrasal tags in the Chinese Penn Treebank (Xue et al. Reference Xue, Xia, Chiou and Palmer2005), on which our parser model is trained. Thus, we have 28 entropy features. In a related setting, we use the number of unique types of each XP-headed rule as features, which also gives us 28 features.
Previous studies only investigated certain syntactic features such as the ba and bei structures (Xiao and Hu Reference Xiao and Hu2015), without looking at syntactic complexity in a more general and principled manner. We are filling this gap by measuring the complexity of the grammar as a whole.
3.1.3 Normalization features
Repetitions. This feature counts the number of content words (nouns, verbs, adjectives, and adverbs) that occur more than once in a text chunk (Volansky et al. Reference Volansky, Ordan and Wintner2013). We also use a variant that counts only the number of re-occurring nouns. This feature operationalizes the tendency for translations to avoid repetitions (Ben-Ari Reference Ben-Ari1998).
Average pointwise mutual information (PMI). This is the mean PMI across all word bigrams (following Volansky et al. Reference Volansky, Ordan and Wintner2013). Note that the greater the PMI, the more likely it is that the bigram is a collocation. The normalization hypothesis states that translations tend to conform to conventions in the language, leading us to expect more collocations or fixed phrases. If the hypothesis is true, we would expect higher average PMI for translations.
We add several features that capture the unique linguistic properties in Chinese since translations tend to “exaggerate … typical grammatical structures, punctuation and collocational patterns or clichés” (Baker Reference Baker and Somers1996).
Aspect markers. Chinese lacks tense markers but does have three unique aspect markers (了 le, 过 guo and 着 zhe) which mark the perfective, experiential, and imperfective aspects, respectively. We use the normalized counts of these markers as features.
Measure words/classifiers. A measure word is required for all nouns in Chinese, and it is placed between a quantifier or demonstrative and the noun. We exclude measure words that are related to metric systems, such as 千克 kilogram, 磅 pound, since they differ between countries and would thus be predicitive in the machine learning task, but not with regard to translationese.
Sentence-final particles. Sentence-final particles (啊 a, 吗 ma, 吧 ba, etc.) express the emotion of speakers or the mood of the sentence (e.g., 吗 ma indicates interrogative mood). We again use the normalized counts of these particles as features.
4-character idioms. A unique type of idioms called chengyu (成语) is commonly used in Chinese. They mostly consist of four characters, usually with some historical reference. Assuming that they are highly discriminative for original Chinese, we use the normalized counts of the idioms from Xinhua DictionaryFootnote d.
ba -structure. The ba-structure is used to front the object and make it the focus of the sentence.
bei -structure. The bei-structure is the Chinese passive form. It has been shown that translated Chinese uses more bei-structure than the originals (Xiao and Hu Reference Xiao and Hu2015).
3.1.4 Interference features
n -grams. Word and character n-grams are used as upper bound in previous studies; POS n-grams have been shown to be effective in machine learning approaches (Volansky et al. Reference Volansky, Ordan and Wintner2013; Hu et al. Reference Hu, Li and Kübler2018).
We also use a set of syntactic features based on constituent parse trees. These features have been tested in our previous work (Hu et al. Reference Hu, Li and Kübler2018) and in Native Language Identification tasks (Swanson and Charniak Reference Swanson and Charniak2012; Bykh and Meurers Reference Bykh and Meurers2014; Malmasi and Dras Reference Malmasi and Dras2018). We assume that they capture translationese structures.
CFG rules. Counts of CFG rules.
3.2 Dataset
3.2.1 Sub-corpus of translated Chinese
Our translation corpus is based on the Chinese newspaper 《参考消息》 (Eng.: Reference News), published by the official news agency of the Chinese government, Xinhua News Agency. The newspaper was launched in the 1950s, initially meant to be an internal publication for government officials to read (translated) foreign news. Therefore, it only contains news reports and commentaries translated from non-Chinese sources, for example, The New York Times, Der Spiegel, Le Figaro. A large number of articles are translated from German, French, Russian, Japanese, and other languages.
In the current study, we use articles translated from seven source languages: German (DE), American English (EN), Spanish (ES), French (FR), Japanese (JP), Korean (KO), and Russian (RU). We take articles from about 10 sources per language, in a time span of 20 years (1980 to 1999), totaling roughly 400,000 tokens for each language (except for Korean, for which we only have 372,000 tokens). For German, English, French, Japanese, and Russian, we use articles longer than 400 tokens to ensure a good representation.
We have manually checked information of each non-English newspaper to make sure that they do not have an English version, or their English version is launched after 2000, so that the texts we use are indeed translated from the language in questionFootnote e.
We take the 400,000 tokens for each source language and split them into 200 chunks, each with roughly 2000 tokens, in order to match the chunk size in the corpora used by Volansky et al. (Reference Volansky, Ordan and Wintner2013) and Xiao (Reference Xiao2010). Article boundaries are discarded. That is, one chunk of text in English might include different articles, but all chunks are roughly equal in length.
3.2.2 Sub-corpus of original Chinese
To find a comparable corpus of original Chinese, we turn to the Chinese news published by the same news agency that publishes Reference News: Xinhua. The Chinese Gigaword project contains news articles from Xinhua originally written in Chinese, from 1991 to 2006 (Graff Reference Graff2007). We select an equal amount of tokens from each year between 1991 and 1999 to build our corpus of original Chinese. Only news of the type “story” are included to ensure that we have standard narrative texts. Other types include short summaries of news or advertisement.
We preprocess these texts in the same way as the translated Chinese. That is, we obtain 2,800,000 tokens of Xinhua News in total, which is roughly equivalent to number of all translations combined. They are then split into chunks of 2000 words, resulting in 1400 chunks. Hence, we have roughly the same number of chunks and words per chunk for translations and originals.
We have decided on these two sub-corpora for several reasons. First, both are in the news domain, which not only makes them comparable but also easier to process using a current NLP pipeline (segmentation, POS tagging, parsing etc.), since most models are trained on news data. In fact, the data in the Chinese Penn Treebank (Xue et al. Reference Xue, Xia, Chiou and Palmer2005), which is generally used to train the segmenters, POS taggers, and parsers, consist mostly of news texts from Xinhua. Second, as data from both sub-corpora are published by Xinhua, we assume that they have gone through similar editing processes. In this way, we exclude differences caused by editing policies as far as possible. Third, the translations in Reference News are of high quality. Reference News remains one of the most widely circulated newspapers in China today with a very good reputation. It has a rigid system of selecting translators, and the translations undergo thorough proofreading before publicationFootnote f.
3.3 Experimental setup
For the machine learning experiments, we use a binary task, classifying text chunks into translated or original Chinese. We use the support vector machine classifier (SMO) in WEKA (Hall et al. Reference Hall, Frank, Holmes, Pfahringer, Reutemann and Witten2009) with its default settings and 10-fold cross-validation (following Volansky et al. (Reference Volansky, Ordan and Wintner2013)). For feature extraction, we extend the implementation by Lutzky and StarFootnote g. The Stanford CoreNLP toolkit (Manning et al. Reference Manning, Surdeanu, Bauer, Finkel, Bethard and McClosky2014) and their default models are used for segmentation, POS tagging, and parsing of Chinese.
3.4 Visualization of results
Throughout the analysis section, we will make extensive use of the violin plot (e.g., Figure 1(a)). In such plots, the x-axis represents translations from the seven source languages (DE: German, EN: English, ES: Spanish, FR: French, JP: Japan, KO: Korean, and RU: Russian) and the original text in Chinese (XIN, short for Xinhua News Agency). The y-axis shows the (normalized) value of the feature in question. The dots in the plot indicate the mean of each value, and the shape of the violin visualizes the full distribution of the texts for that feature, where the thicker part shows that the values in that section have higher frequency, and the thinner part shows lower frequencies. This makes this representation more informative than box plots.

Figure 1. Explicitation features in translations and original Chinese (XIN). Black dots indicate the mean.
4. Results and discussion
We use machine learning to determine which types of linguistic information are highly distinctive for original Chinese or translations, that is, if we use certain features and reach a high accuracy, we can deduce that these features are distinctive. Our previous work (Hu et al. Reference Hu, Li and Kübler2018) has shown that only using word n-grams, we reach a perfect accuracy in classifying texts into Chinese originals or translations. For many other features, our classifier is able to distinguish translations from originals with high accuracy, even if the features have worked poorly for English as target language (Volansky et al. Reference Volansky, Ordan and Wintner2013). In the curent work, we see that translations are distributed based on their typological traits for a number of features. This means that the Japanese and Korean translations often pattern together, and translations from Indo-European languages are closer in many respects.
The following analysis of our results is structured along the four translations universals that also served as the basic structuring principle in the work by Volansky et al. (Reference Volansky, Ordan and Wintner2013). If we find features that allow a successful separation of translations and originals, we can assume that these features belong to the translation universals. If we find features that work for some languages but not others, we have candidates for the law of interference.
4.1 The explicitation hypothesis
The first hypothesis we look at is explicitation: translations are more explicit than the originals. We report the classification results in Table 1.
Table 1. Classification accuracy for our Chinese experiments in comparison to English (Volansky et al. Reference Volansky, Ordan and Wintner2013): Explicitation features

Naming features. Figure 1(a) shows the value of explicit naming for all seven translations, as well as the originals (XIN). As this feature is operationalized as the ratio of personal pronouns to proper nouns, the higher the value, the more personal pronouns are used compared to proper nouns. The 69.20% accuracy (from Table 1) indicates that this feature is discriminative to a certain extent. Crucially, this argues against the explicitation assumption, which would expect translations to be more explicit, that is, to use more proper nouns.
Figure 1(a) shows that translations from all Indo-European languages use more pronouns than translations from Japanese and Korean. Translations from the latter languages use fewer personal pronouns: their means (indicated by the dot) are lower, and the mass of their violin plots is skewed toward 0. We assume that this behavior is based on similar characteristics of the source and target language rather than resulting from explicitation: Japanese and Korean are similar to Chinese in that their pronouns can be dropped—given enough context—in both subject and object positions. Indo-European languages, in contrast, generally do not allow dropped pronouns, thus it would require a higher cognitive load to decide when to correctly drop the pronouns than to simply keep them in the translations from Indo-European languagesFootnote h.
The single naming feature achieves an accuracy just above chance (57.61%). Mean multiple naming performs better, with 65.25%. Figure 1(b) shows that the original Chinese texts have the longest proper NPs in general. This again argues against explicitation, which assumes that the translations will add additional information about proper nouns, resulting in longer proper name phrases. This may be attributed to the writing style of Xinhua Chinese news, which tends to add titles or positions of officials in the news, for example, 中共 中央总书记、国家主席、中央军委主席江泽民 (Eng.: Jiang Zemin, General Secretary of the Central Committee of the Chinese Communist Party, President of P. R. China, and the Chairman of the Central Military Committee). This is an extreme example, but similar cases are not uncommon in Xinhua news.
Cohesive features. These are usually the main features in translation studies on explicitation. If we use all 160 cohesive markers used by Chen (Reference Chen2006: Appendix), we reach an accuracy of 96.55%. If we only use the five most discriminative features, selected via Gain Ratio, we reach 92.00%. The high accuracy shows that cohesive markers are very discriminative. Figure 2 shows the top 10 markers, and we see that translations use them more frequently than originals. This is in line with previous studies on Chinese (e.g., Xiao Reference Xiao2010), which found an overuse of cohesive markers across all genres.
There are other interesting patterns with respect to individual translations. For example, translations from English use 但是 (Eng.: but) most frequently, whereas translations from Japanese overuse 据说 (Eng.: it is said that). Korean and Japanese translations overuse 所以 (Eng.: so/therefore) but seem to have fewer 因为 (Eng.: because) compared to other translations.
We now have a closer look at adversative conjunctions: when we use all adversative conjunctions in Chinese (但,但是,然而,可是,不过) (Eng.: but, yet, however) as features, the accuracy is 86.86%. The analysis, however, shows no consistent pattern of English translations overusing all adversative conjunctions, but overall, translations do use more adversatives than the originals. As for the extremely frequent use of 据说 (Eng.: it is said that) in Japanese translations, this may be caused by interference from the commonly used Japanese hearsay marker (そうです), which indicates that the speaker has heard the information from other sources and is not confident of its validityFootnote i.

Figure 2. Normalized counts of the 10 most discriminating cohesive markers in translations and original Chinese (XIN).
We also look at other operationalizations of cohesive markers: total counts, TTR, and the entropy of these markers. The high accuracies (see Table 1) suggest that they are all good indicators of translations. A closer look shows that translations use about 50 cohesive markers per 2000-token chunk, whereas the originals use only half, about 25 per chunk.
When we compare the results of cohesive markers between Chinese in our work and English (Volansky et al. Reference Volansky, Ordan and Wintner2013) in Table 1, we observe that using only five Chinese markers performs much better than a list of 40 in English (92% vs. 81%). One possible reason is the difference in experimental settings: while we use translations from seven source languages, the English study uses 10, possibly making it more difficult to find shared features among all 10 translations into Chinese. Additionally, all the languages in the English study are Indo-European languages, whereas in our experiment, Chinese is very different from any of the source languages, which makes it easier to identify the translations. We see the discrepancy in classification accuracy throughout our study.
Another major reason is that all source and target languages in the study by Volansky et al. (Reference Volansky, Ordan and Wintner2013) belong to the Indo-European family; since they are more closely related, they will not differ as much in their ways of realizing cohesion. However, Chinese has a very different mechanism to express cohesion, which in most cases depends solely on the context with no surface cohesive markers at all. This has been noticed early on by Wang (Reference Wang1943, Reference Wang1944) and is a major topic in all translation courses in Chinese. To give an example (from Zhu (Reference Zhu1985)), 买不起别买- (Eng. literally: cannot afford don’t buy; meaning: if you cannot afford it, don’t buy it) is perfectly grammatical and natural in Chinese, but would be ungrammatical in English unless the dropped pronouns and subjunction if are present in the sentence. Therefore, the overuse of cohesive markers in translations in this study may have two sources: one is the tendency to make translations more explicit, which is also the case for English as target language (Volansky et al. Reference Volansky, Ordan and Wintner2013) and potentially other languages (Pápai Reference Pápai, Mauranen and Kujamäki2004), confirming the explicitation universal. The other source is interference from the source languages which use more cohesive markers than Chinese, and as a result are likely to have more such markers in their translations.
Examining this interpretation more thoroughly would require parallel corpora where the translation process can be studied, which we leave for future work. Yet, as described by Blum-Kulka (Reference Blum-Kulka, House and Blum-Kulka1986: 34), to examine explicitation properly, we need to tease apart the two sources of overused cohesive markers. In an ideal setting, the source language and target language should have similar preferences for the explicitness of cohesion, for example, in close cousins such as Spanish and Portuguese, so that differences in frequency can only be the result of the translation process, thus corroborating explicitation.
To summarize, if we measure the explicitness of a text by the frequency of cohesive markers, then translations into Chinese are generally more explicit than the Chinese originals. In fact, five cohesive markers provide enough information for the classifier to distinguish between originals and translations correctly in more than 90% of the cases. However, the use of pronouns and proper nouns in our case is potentially affected by the properties of the source and target languages and by writing styles. Consequently, we find interference rather than explicitation.
4.2 The simplification hypothesis
To test the simplification hypothesis, we perform classification tasks first using commonly used lexical features and then syntactic features, which have rarely been explored before. The results are shown in Table 2.
Table 2. Classification accuracy for our Chinese experiments in comparison to English (Volansky et al. Reference Volansky, Ordan and Wintner2013): Simplification features

4.2.1 Lexical simplification
Word-based TTR reaches an accuracy of 72.15% (see Table 2). Figure 3 shows that all translations have lower TTR rates compared to the Chinese originals. Japanese and Korean again pattern together, with the lowest TTR among all translations. This supports the simplification hypothesis in that translations have lower lexical diversity. However, translations and originals are nearly indistinguishable when using character-based TTR, and the results are close to chance.

Figure 3. Lexical simplification features in translations and original Chinese (XIN).
Figure 3 also shows that lexical density is lower in translations from Indo-European languages, that is, they use more function words. It is interesting that Japanese and Korean translations pattern with Chinese originals, sharing a higher lexical density. Thus, lexical density seems to be dependent on the source language, which refutes the claim of a universal feature. Again, these results argue for interference rather than for simplification.
Other measures such as mean word length and mean sentence length suggest that translations use shorter words and sentences in general, lending support to the simplification hypothesis. Their accuracies are all above 70% (see Table 2). In fact, the Chinese originals have longer words and sentences than all translations, without exception (see Figure 3). This is different from the study on English (Volansky et al. Reference Volansky, Ordan and Wintner2013), where the English originals rank 8th in sentence length among the 10 translations. The result for mean character rank suggests that the Chinese originals are more likely to have rare characters, that is, characters that are ranked very low on a frequency list. This result is in line with results by Xiao and Hu (Reference Xiao and Hu2015), who found the same tendency for all four genres they investigated.
Therefore, apart from character-based TTR, all features for lexical complexity and length of linguistic units do support the simplification hypothesis. For many features, we see that the accuracy in our experiment is roughly 10% higher than in the English study.
Feature values of N most frequent characters are shown in Figure 4. Note that the ranking is based on a Chinese corpus (Da Reference Da2004) of 200 million charactersFootnote j. It is interesting that using only the top five characters reaches above 93% accuracy (Table 2). We see that for 的 (particle DE), 是 (copula, Eng.: be), and 不 (Eng.: not/no), the translations consistently use them more often than the originals. This is in line with previous studies (He Reference He2008; Xiao Reference Xiao2010; Hu et al. Reference Hu, Li and Kübler2018) and can be interpreted as translations preferring very frequent words, that is, they try to conform to the norms of the target language (Baker Reference Baker and Somers1996).

Figure 4. Five most frequent characters in translations and original Chinese (XIN).
For the character (Eng.: one), we observe that Japanese and Korean pattern together, with similar values to original Chinese. This is another case of source language interference, resulting most likely from the fact that is the standard translation for indefinite articles from Indo-European languages. Chinese, as well as Japanese and Korean, does not have articles. While it is possible to use a pseudo-indefinite article (), this is dispreferred in original Chinese. For instance, 他是好人 (Eng.: He is nice guy) is preferred over 是一个好人 (Eng.: He is one + classifier nice guy). However, translators tend to opt for the cognitively easier solution to keep the articles. In fact, having such redundant articles has long been identified as an influence from Indo-European languages (Wang Reference Wang1943, Reference Wang1958) and as a characteristic of so-called Europeanized or translation-flavored Chinese (He Reference He2008). Our results provide solid empirical evidence that Europeanized Chinese is a more appropriate description since not all translations overuse the articles. Translations from languages that also lack articles do not overuse themFootnote k.
4.2.2 Syntactic simplification
The results of the syntactic simplification features are shown in the second part of Table 2.
Count-based features. Recall that the first three features are simple counts of complex NPs, VPs, and relative clauses per clause. Among them, the count of VPs performs the best, achieving 83.05% accuracy. The other two reach accuracies of around 70%. These results demonstrate that the three features have some discriminative power in distinguishing translations and originals. A closer look at their distribution in Figure 5 shows that overall, Chinese originals use more complex NPs (excluding relative clauses) than the translations, suggesting greater complexity. This would support the simplification hypothesis. However, if we look at relative clauses, which inevitably form complex NPs, the reverse is true. That is, translations from all the source languages tend to have more relative clauses. This seems to be truly universal despite obvious differences in the source languages. One explanation could be that this is a case of explicitation, assuming that the translators make complex NPs more explicit by “spelling them out” in the translation. An example of this would be the complex NP “a very complex idea” being translated into “an idea that is very complex.” However, to test this hypothesis, we would need access to the original texts in the source languages.

Figure 5. Syntactic features for simplification in translations and original Chinese (XIN).
We also see in Figure 5 that translations tend to use more VPs than the originals. Note that the VPs in this operationalization do not include the copula.
Entropy-based features. First, we see that entropy-based features work quite well. If the entropies of CFG rules headed by each phrase (NP, VP, etc.) are used as features, we achieve 89.27% accuracy. If we only use the number of types of CFG rules for each phrase, we achieve 93.25%. Our assumption is that if originals have higher entropy and more types than translations, we can say that originals are syntactically more complex than translations. However, when we look into CFG rules headed by different phrases, the opposite is true. For most of the major phrases, such as ADJP, CP, DP, PP, and VP, the originals exhibit a significantly lower entropy (see left of Table 3). The distributions in the number of rule types are the same as their entropies, except for LCP. Only four phrases exhibit a higher entropy in the originals: CLP, LCP, NP, and QP. Two of them are, in fact, structures specific to Chinese: CLP is the classifier phrase unique to Chinese (as well as Japanese and Korean). LCP is a localizer phrase, which is a discontinuous prepositional phrase of the form “P + NP + localizer”, also unique to Chinese.
Table 3. Comparison of entropies of CFG rules. Upper half: H(O) < H(T); lower half H(O) > H(T). ***: p < 0.001. O: originals. T: translations
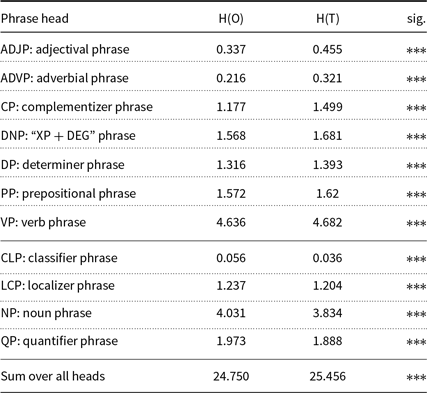
The sum of entropies of CFG rules over all phrasal heads in Table 3 is also higher in translations (25.456
 $>$
24.750). Based on this entropy, it seems reasonable to conclude that translations are generally more complex and diverse in terms of syntactic structure, contrary to the simplification hypothesis.
$>$
24.750). Based on this entropy, it seems reasonable to conclude that translations are generally more complex and diverse in terms of syntactic structure, contrary to the simplification hypothesis.
Therefore, our results based on entropy-related measures suggest that the simplification hypothesis may be too simplified to capture the whole picture. A case-by-case analysis is required here. Originals have more diverse ways of creating specific phrases such as NP and QP. Other phrases such as ADJP, ADVP, PP, and VP, however, have a more complex distribution in the grammar of translations. If we look at the bigger picture, in most cases, translation have a more complex and more unpredictable grammar, thus contradicting the simplification hypothesis.
To summarize, we find that many of the simplification features work well in our classification tasks. A closer look at the lexical features reveals that Chinese originals are indeed more complex than the translations from multiple source languages. Our syntactic features, however, suggest a more complicated picture. There is no conclusive evidence that all translations are syntactically simpler than originals. Originals have more complex NPs, but their grammar is generally less complex than that of translations. Future studies need to find more fine-grained ways of looking at syntactic complexity.
4.3 The normalization hypothesis
The normalization hypothesis states that translations are likely to exaggerate characteristics unique in the target language.
The repetitions feature is able to distinguish translations from originals 68.66% of the time (see Table 4), which is considerably higher than the corresponding 55% in the English setting. Figure 6 shows the distribution of two normalization features. We see once again that Japanese and Korean pattern together, close to the Chinese originals. Thus avoiding repetitions, as discussed by Ben-Ari (Reference Ben-Ari1998), is likely to be source language specific rather than universal since translations from Japanese and Korean clearly use similar numbers of repetition as the originals. If only the repetitions of nouns are considered, then the accuracy reaches 74.48%, with original Chinese having the highest number of noun repetitions. This supports the repetition avoidance assumption in translations, but there is potentially a confound, which is the particular anaphora reference strategy in Chinese. Traditionally, when the antecedent is an inanimate NP, Chinese speakers would prefer to repeat the whole NP rather than to use a pronoun “it” to refer to it (Lv Reference Lv1942; Wang Reference Wang1943; Chen Reference Chen1987). Hence, the more frequent noun repetition in original Chinese. However, while translating from Indo-European languages where “it” is routinely used to refer to inanimate objects, translators gradually start to follow suit, which results in fewer noun repetitions and an overuse of “it” (see (He Reference He2008, ch. 4) for a detailed corpus analysis and discussion). Considering the prevalence of NP repetition as a strategy for anaphora reference in Chinese, as reported in previous studies, we assume that this feature is more likely to model a specific feature of the target language, rather than showing normalization.
Table 4. Classification accuracy for our Chinese experiments in comparison to English (Volansky et al. Reference Volansky, Ordan and Wintner2013): Normalization features


Figure 6. Normalization features in translations and original Chinese (XIN).
The average PMI measures the degree of collocation usage in one text chunk. A higher average PMI indicates more collocations, with the initial assumption that translations tend to have more collocations, conforming to the conventions of the target language. However, this is not supported by our results, as shown in Figure 6. The originals have a higher average PMI than all translations, which is in line with the English study where originals are found to have “far more associated bigrams” (Volansky et al. Reference Volansky, Ordan and Wintner2013).
The three aspect markers reach an accuracy of 66.19%. The perfective marker 了, most frequent and hardest to acquire for language learners, seems to be used differently in all translations, with no clear pattern. For the imperfective marker 着, we observe that the Korean translations and the Chinese originals have the lowest counts. For the experiential marker 过, the Japanese translation and the Chinese original use it least frequently. Again, the results are contrary to the normalization hypothesis: for a target language-specific grammatical property, translations do not overuse or “exaggerate” it.
Using 114 measure words as features reaches a very high accuracy of 91.13%. Figure 7 shows the distribution of the 10 highest ranked measure words. We observe that the translations and the originals use them rather differently, which is why the experiments reach such a high accuracy. For instance, Japanese and Korean translations use the lowest number of 个 (Eng.: item); the Chinese originals have the lowest number of 种 (Eng.: type/kind), but the highest number of 项 (Eng.: item); and Japanese, Korean, and Russian translations use fewer 位 (Eng.: person). Thus, it seems that translations overuse some of the measure words, but not all of them. The characteristics of the source language also play a role here, as we see the different distributions in different translations. Compared with translations from seven source languages individually, originals have more measure words than six of them. In fact, only translations from Spanish use more measure words than originals (68.20 vs. 65.60 per chunk). This shows that most translations are underusing measure words rather than exaggerating this feature.

Figure 7. The 10 most frequent measure words (classifiers) plus their noun types (e.g., 个 (Eng.: item) means that “ 5个apple” is grammatical since apple is an item).

Figure 8. The top 5 sentence-final particle features with their functions.
With 17 sentence-final particles as features, the accuracy is well above chance level, at 70.76%. Again, we examine the top features, illustrated in Figure 8. It is clear that all translations make more use of particles that denote questions: 呢 (ne) and 吗 (ma). This is an interesting discovery, with two possible scenarios: (1) The source texts of all translations use more questions than the originals; (2) In the translation process, declarative sentences in the source text are rendered as rhetorical questions. An example for the second scenario would be: “This is a nice book” translated as “Isn’t this a nice book?.”
After a quick search in a randomly chosen sample of 200 sentences with 呢 (out of 1020 in total in all translations), we found that only 39 out of the 200 sentences with 呢 can count as rhetorical questions. That is, the particle 呢 is indeed used in questions most of the time. This seems to suggest that translations tend to have more questions than the originals, potentially due to the style of news writing in different languages.
Next, we look at ba and bei structures. These two features have similar classification accuracy, only slightly above chance. The feature distributions in Figure 9 demonstrate no clear pattern. However, independent-samples t-tests show that for the ba-structure, the normalized frequency in the originals (M = 0.0417) is significantly lower than that of the average of all translations combined (M = 0.0512); t(2737.2) = –8.0933, p = 8.639e–16. The same is true for the bei-structure, where the difference between the originals (M = 0.0300) and the translations (M = 0.0356) is again significant; t(2776.1) = –5.3462, p = 9.711e–08.

Figure 9. ba- and bei-structures.
As a result, it becomes challenging to interpret the classification results and the t-tests results meaningfully. The results from the t-tests indicate that it is extremely unlikely that the translations and the originals are drawn from the same population. It cannot tell us whether we can reliably distinguish the two classes based solely on one feature. In this sense, the classification accuracy can be considered a more “conservative” measure for the features since a much greater difference is needed to achieve good classification accuracy. Consequently, we need to keep in mind that the significant features in previous t-test-based studies may not be good features in a classification task. Also, a classifier is able to make use of the complicated distribution of multiple features so as to classify new data, which is beyond the capability of statistical tests.
When looking at the Chinese idioms chengyu, the total count of all idioms only gives an accuracy of 54.45%, slightly above chance. The t-test again shows a significant difference between translations (M = 0.0039) and originals (M = 0.0033), p = 5.847e–12. Thus, we conclude that translations use significantly more idioms, supporting the normalization hypothesis, but the difference is not large enough for a classifier to reliably distinguish translations from originals.
Nevertheless, translations and originals do use the idioms quite differently, indicated by the 81.30% accuracy of treating each idiom as a single feature. Appendix D shows the 20 most frequent idioms and their frequencies in the two varieties. For example, in the originals, the most frequent two idioms are political slogans of the government: 艰苦奋斗 (Eng.: work hard) and 实事求是 (Eng.: seek truth from facts). The most frequent idioms in the translations are 引人注目 (Eng.: eye-catching), 成千上万 (Eng.: thousands of), 无论如何 (Eng.: anyways/no matter what), 众所周知 (Eng.: as is known to all), and 有朝一日 (Eng.: some day). When we look at the idiom usage in specific translations, we again find that it is dependent on the source language. For example, Japanese translations use more 引人注目 (Eng.: eye-catching) than any other translations or the originals. French translations overuse 无论如何 (Eng.: anyways); Spanish translations overuse 成千上万 (Eng.: thousands of). These are interesting observations to be further explored when we have access to the source texts.
4.4 The interference hypothesis
The classification results of interference features are presented in Table 5.
Table 5. Classification accuracy for our Chinese experiments in comparison to English (Volansky et al. Reference Volansky, Ordan and Wintner2013): Interference features

4.4.1 n-grams
Character and word n-grams work extremely well in this task, in line with previous studies (Volansky et al. Reference Volansky, Ordan and Wintner2013; Hu et al. Reference Hu, Li and Kübler2018). However, looking at the 100 features ranked highest by Gain Ratio, we notice that many of these features are content characters/words. For example, out of the 10 most discriminating characters for the originals, 2 are Chinese family names (Liu and Yang). Among the top word unigrams, many are names of Chinese governmental bodies. POS trigrams also perform very well, close to character and word unigrams. Since many of the interesting structures shown in POS trigrams are also captured by CFG rule features, we will leave feature analysis to the next section.
4.4.2 CFG rules
CFG rules as features capture the syntactic structures of the texts, without any topic-related information, unlike word or character n-grams. As shown in Table 5, with only the five highest ranked features, we reach an accuracy of 94.11%. Note that the translations are based on seven source languages, which means that our syntactic features must be consistent across all translations to reach such a high accuracy.
Before we present a detailed feature analysis, we want to point out that a comparison between the features in this study and in our previous work (Hu et al. Reference Hu, Li and Kübler2018) can be very fruitful: 99% of the translations examined in Hu et al. (Reference Hu, Li and Kübler2018) are translated from English, but in multiple genres: news, fiction, general prose, and science. Therefore, if a translation feature is found to be important in both studies, there is a good chance that it is a robust feature across source languages and genres. Such features will be truly “universal” for Chinese translations, and we will focus on analyzing these features, in addition to high ranking features.
Rules typical for originals. We start with the three features that are typical for originals, which were the most important in this and our previous study (Hu et al. Reference Hu, Li and Kübler2018: Table 5). They are underlined in Table 6a, with graphical illustrations in Appendix E.
Table 6. CFG rules ranked by Gain Ratio. O: original. T: translation.

(a) Top 20 CFG rules, underlined rules correspond to rules by Hu et al. (2018)
(b) Top rules headed by NP
First, there are two VP rules: VP
 $\rightarrow$
VP PU VP PU VP (3 VPs) and VP
$\rightarrow$
VP PU VP PU VP PU VP (4 VPs). After searching for sentences with such structures, we found multiple predicates connected by either the comma , or “ˎ”, the unique punctuation in ChineseFootnote l. Indeed, parallel VPs within one sentence is characteristic of Chinese writing. We found one example with five VP predicates in a Chinese original: “各级人民法院要 (VP认真学习…), (VP联系实际…), (VP制定措施), (VP落到实处), (VP抓出成效)” (Eng.: courts at all levels must (VPstudy … carefully), (VP integrate theory with practice), (VPmake plans), (VP take actions), (VP be effective)). Note that these predicates do not have to be in chronological order in Chinese or have an explicit conjunction.
$\rightarrow$
VP PU VP PU VP (3 VPs) and VP
$\rightarrow$
VP PU VP PU VP PU VP (4 VPs). After searching for sentences with such structures, we found multiple predicates connected by either the comma , or “ˎ”, the unique punctuation in ChineseFootnote l. Indeed, parallel VPs within one sentence is characteristic of Chinese writing. We found one example with five VP predicates in a Chinese original: “各级人民法院要 (VP认真学习…), (VP联系实际…), (VP制定措施), (VP落到实处), (VP抓出成效)” (Eng.: courts at all levels must (VPstudy … carefully), (VP integrate theory with practice), (VPmake plans), (VP take actions), (VP be effective)). Note that these predicates do not have to be in chronological order in Chinese or have an explicit conjunction.
The same is true for NPs. For example, we have discussed the rule NP
$\rightarrow$
NN PU NN in Table 6a previously (Hu et al. Reference Hu, Li and Kübler2018). Here it should suffice to say that Chinese originals prefer using the punctuation (PU) “ˎ” to conjoin common nouns (NN), whereas the translations prefer the conjunction 和 (Eng.: and).
In summary, these three rules are consistent for the Chinese originals, but they are clearly not typical of Chinese translationese. If structures that are carried over from source languages to the target language showcase interference, then these rules show the opposite.
Next, we turn to the top rule in the originals, VP
$\rightarrow$
VV NP QP and VP. We find structures such as:
-
• ( VP ( VV 产) ( NP 钢) ( QP 771.05 万吨))
( VP ( VV produced) ( NP steel) ( QP 7.7105 million tons)
Eng.: produced 7.7105 million tons of steel
-
• ( VP ( VV 节约) ( NP 运输成本) ( QP 40多万元))
( VP ( VV saved) ( NP transportation costs) ( QP 400,000 more RMB)
Eng.: saved more than 400,000 RMB transportation costs
In English, German, Spanish, and French, the NP and QP are usually ordered differently, as VV QP NP. In fact, the “VV QP NP” order is also acceptable in Chinese for the second example above, but Chinese news emphasizing the amount of savings would prefer the “VV NP QP” order to put the final emphasis on QP, giving the flavor of idiomatic Chinese. To our knowledge, this has not been reported in any previous studies. Note that since this rule abstracts to the phrase level, no n-gram features will be able to detect it.
Rules typical for translations. Again, we first look for features that occur across all languages, in this study and in our previous work (Hu et al. Reference Hu, Li and Kübler2018) (underlined in Table 6a). ADVP
$\rightarrow$
CS indicates a higher frequency of subordinating conjunctions in translations. CP
$\rightarrow$
ADVP IP in effect captures the same structure, as a search in the trees shows that 98% of the ADVPs serve as subordinating conjunctions, making the CP a subordinating clause. NP
$\rightarrow$
DNP NP matches an NP with a preceding noun modifier DNP (which is of the form “XP + particle DE 的”), more frequently used in translations. This suggests that NPs in translations are more likely to be modified by nouns, with the particle 的 as the marker (for a detailed discussion see (Hu et al. Reference Hu, Li and Kübler2018)).
We can also focus on a subset of CFG rules, for example, those headed by NP. Using only NP-headed rules as features means that the classifier will only have information about the internal structure of NPs to distinguish Chinese originals and translations. We reach an accuracy of over 95% using only 30 features. This suggests that the structure of NPs alone is enough for the classifier to make reliable decisions. The top ranking features are shown in Table 6b. Here, we focus on the rules typical for translations, with their distributions illustrated in Figure 10. We first see that for five out of the seven rules, Japanese and Korean translations again pattern together with the originals, suggesting that the Japanese and Korean translations tend to have NPs that are structured similarly to original Chinese texts.
One interesting rule in Figure 10 is NP
$\rightarrow$
PN PN, where a NP is composed of two consecutive pronouns. A search in the parse trees finds mostly a personal pronoun followed by a reflexive pronoun, for example, 我们自己 (literally: we self; Eng.: we ourselves), 他本人 (literally: he self, Eng.: he himself). This has not been reported in previous literature and indicates that either Indo-European texts favor such a structure, or translators overuse it in the translation process, which can be verified in the future with a parallel corpus.
The three features at the bottom of Figure 10 are very similar in that they all have two modifiers preceding the head NP, where the second modifier (DNP/CP) ends with the particle DE 的. When searching for NP
$\rightarrow$
QP DNP NP and NP
$\rightarrow$
QP CP NP, we find that the quantifier in QP is very often the word “one,” forming the structure (
NP
(
QP
“one” classifier) (DNP/CP) (NP)), for example, (
NP
(
QP
一种) (
DNP
新型的) (
NP
关系)) (Eng.: (
NP
(
QP
one classifier) (
DNP
new) (
NP
relationship))). This is parallel to the “articles” in Chinese (briefly discussed in Section 4.2.1). Recall that Japanese, Korean, Russian, and Chinese do not have articles and that indefinite articles are usually translated into Chinese as “one + classifier + NP.” If there were an interference phenomenon, we would expect translations from article-less languages to have fewer such structures with “one” as the quantifier; translations from languages with articles should have more “one + modifier + NP”. To verify this, we calculate the proportion of structures where the quantifier is “one” to those with other quantifiers (“two” or “many”, or others)Footnote m, with results shown in Table 7.
Table 7 Quantifier in: (
 ${}_{\textrm{NP}}$
(
${}_{\textrm{NP}}$
(
 ${}_{\textrm{QP}}$
quantifier classifier) (DNP/CP) (NP)). DNP: an NP modifier. CP: relative clause. XIN: original Chinese
${}_{\textrm{QP}}$
quantifier classifier) (DNP/CP) (NP)). DNP: an NP modifier. CP: relative clause. XIN: original Chinese


Figure 10. Top translation-dominant CFG rules headed by NP.
It is obvious that for languages that do have articles, that is, German, English, Spanish, and French, there are more structures using “one” as the quantifier. The opposite is true for Japanese, Korean, and Russian (underlined in Table 7), suggesting source language interference. Our results confirm previous observations (Wang Reference Wang1958; He Reference He2008) by not only looking at frequencies of “one” (Figure 4) but also at its frequencies in complex NPs that involve another modifier. Most importantly, the multiple source languages used in this study allow us to connect the observation to typological differences among all source languages, that is, languages with articles versus languages without articles. This clearly demonstrates the interference effect and indicates that it may be traced back to the typological properties of the source languages.
In summary, with regard to interference, we have seen in previous sections that each source language has its distinctive, favored cohesive markers and idioms. In this section, we discover features in typologically distinct language groups, for example, languages with indefinite articles. Finally, there are also structures with higher frequencies across all translations such as the rule NP
$\rightarrow$
DNP NP. In this sense, interference is at work simultaneously at multiple levels, sometimes for individual source languages, sometimes for language groups, and others for translationese as a whole.
5. Conclusion
In the work reported here, we have investigated the characteristics of translations into Chinese along with text originally written in Chinese. Our corpus consists of original Chinese texts from Xinhua and translations from seven languages into Chinese, also published by Xinhua.
Our methodology is based on a machine learning approach that classifies texts into originals and translations. Looking at the classifier’s accuracy when given specific characteristics allows us to determine how discriminative these characteristics are. We have shown that translated Chinese texts differ from non-translated ones, thus constituting a variety that is different from original Chinese. Some of these differences originate from universal tendencies in translations while others are a result of source language interference. The latter phenomenon creates different “dialects” of translated Chinese, depending on the properties of the source language.
Our approach is novel in several aspects: we look at translations into Chinese rather than into English, adding valuable empirical results from a non-Indo-European target language; we look at a typologically diverse group of source languages, complementing previous studies on Chinese. Additionally, we use a finer grained metric than pure counts or frequencies: we use a machine learning approach, which allows us to integrate syntactic features. Since the number of these features is high, a purely count-based approach cannot accommodate such features very well.
In terms of the four specific hypotheses, we find evidence supporting the explicitation hypothesis, as shown in the discriminative power of cohesive markers and their overuse in translations. Simplification is generally supported by the lexical features, different from the findings for English (Volansky et al. Reference Volansky, Ordan and Wintner2013). However, the grammar of translations has a higher entropy than the grammar for originals, which contradicts the simplification hypothesis. As for normalization, we do not find an overall tendency of translations “exaggerating” uniquely Chinese features. In fact, translations have a lower average PMI, indicating fewer collocations. They do use significantly more ba-/bei- structures and idioms, but these features only yield at-chance accuracy in classification. Finally, interference is manifested in many places throughout our study. For example, (1) the overuse of pronouns in translations from non-pro-drop languages, (2) the higher frequency of quantifier phrases involving “one” in translations from languages with articles, and (3) the patterning together of Korean and Japanese translations. These are all cases of interference from specific source languages. Some of these effects are at the lexical level while others are syntactic in nature. Thus, we can confirm that interference is a major force, and it creates multiple dialects of translationese. Another important finding is that our accuracies on Chinese are in most cases (considerably) higher than those on English (Volansky et al. Reference Volansky, Ordan and Wintner2013), except for single naming and TTR. Since we have very similar experimental settings and an almost identical implementation, this is unlikely due to chance. It suggests that how well a feature performs in classification is closely related to the distance between the source languages and the target language. When they are very distant as in our experiment, classification becomes an easier task. We therefore need empirical evidence from a wider variety of languages before deciding which features are “universal” among all translations. Our analysis of Chinese is an initial step in this direction toward building general theories of translations, and our method can be easily extended to other languagesFootnote n.
Finally, our study suggests a number of new challenges. The first concerns the question of how to reconcile results from different methodologies such as t-tests and classification accuracies. Is a statistically significant difference between translations and originals enough to identify translationese features? If classification accuracy is considered, what accuracy is required for a feature to be accepted as discriminative? Second, after the advent of large scale corpora, translation studies have gradually shifted their focus from the relation between translations and their source text (e.g., Blum-Kulka Reference Blum-Kulka, House and Blum-Kulka1986) to textual, stylistic properties of translations per se (Baker Reference Baker, Baker, Francis and Tognini-Bonelli1993). In our study, we see a need to go back to the source texts again to uncover the ultimate source of translationese. In an ideal setting, a corpus needs to be composed of three types of texts: source texts, target texts, and comparable texts originally written in the target language. This structure guarantees that we can gain a deeper understanding of translationese and the source from which it originates.
Acknowledgements
The authors thank Ruoze Huang, Chien-Jer Charles Lin, Jingyi Guo, Yueqi Zhu, and the computational linguistics colloquium at Indiana University for helpful discussions. The authors are grateful for the comments and suggestions from Aini Li and our two anonymous reviewers. The authors also thank Noam Ordan for providing information about the implementation for the study on English. The first author is partly funded by China Scholarship Council.
A Text distribution in our multi-source language corpus
Data sources for each source language. Only showing sources with more than 50 texts for ES. All KO newspapers are included, but they are not listed here because there are too many

B Summary of features

C Tregex patterns
-
• Complex NP: NP [ <<JJ|QP|ADJP|CLP|DNP|DP|<< (NP $++ NP !$+ CC) ]
-
• VP: VP > IP !< VC
-
• Relative clause: CP>(NP|QP|DP|PRN|LCP)<(DEC|DEG)
-
• “one” + classifier + DNP/CP + NP: NP <1 (QP<1(CD<-/[1−−]/)) <2 (DNP|CP) <3 NP
-
• all QP + DNP/CP + NP: NP <1 QP <2 (DNP|CP) <3 NP
D Most frequent idioms (Chengyu)

E Top 20 syntax features




















