


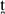 / (apico-alveolar and lamino-dental, respectively), show intermediate jaw positions, with differences between speakers. In terms of the kinematic measures examined (namely, variability in distance, duration and velocity of opening and closing movements), results show no consistent differences between English and Arrernte jaw movement.
/ (apico-alveolar and lamino-dental, respectively), show intermediate jaw positions, with differences between speakers. In terms of the kinematic measures examined (namely, variability in distance, duration and velocity of opening and closing movements), results show no consistent differences between English and Arrernte jaw movement.1 Introduction
Australian Aboriginal languages are renowned for their multiple place-of-articulation contrasts within the stop, nasal and lateral series (see Dixon Reference Dixon2002 for an overview). These multiple places of articulation include up to four coronal places of articulation: dental, alveolar, post-alveolar and alveo-palatal (henceforth simply ‘palatal’). The dental and palatal consonants are laminal, and the alveolar and post-alveolar consonants are apical. However, relatively few articulatory studies of these languages exist. The present study aims to bridge the gap between existing phonological descriptions of Australian languages and future articulatory work by providing preliminary data on the jaw, which is often said to be the carrier of speech; it focuses on jaw position for the different places of articulation in Central Arrernte (henceforth simply ‘Arrernte’), a central-Australian language spoken in and around the township of Alice Springs.
The point of departure for the present study is Keating, Lindblom, Lubker & Kreiman's (Reference Keating, Lindblom, Lubker and Kreiman1994) study of jaw height in Swedish and American English. This study looked at jaw height for the coronal consonants /s t d n l r/, the labial consonants /b f/, the velar /k/ and the glottal /h/.
Keating et al. found that in both languages, the coronal obstruents /s t d/ had the highest jaw positions, while the bilabial fricative /f/ had a slightly lower position than the coronal obstruents. The high jaw position for /s/ is considered to be due to the very precise tongue tip position required for fricative noise generation; a similarly high tongue position may also be necessary for the stops, which require generation of a noise burst. The relatively high jaw position for /f/ can be attributed to raising of the lower lip to the upper teeth (a passive articulator) to form fricative noise.
Of the supralaryngeal consonants, /k/ had the lowest jaw position overall in Keating et al.'s study, although /h/ had a lower jaw position than /k/. The low jaw position of /h/ is due to the fact that it is the voiceless equivalent of the adjacent vowel: as a result, of all the consonants, /h/ varies the most according to vowel context. The low jaw position for /k/ is perhaps due to the fact that raising of the tongue body does not require significant concomitant raising of the jaw.
The exact position in the jaw height hierarchy of the sonorant coronals /r n l/ varied between the two languages studied, but was generally intermediate between the coronal obstruents and the more back consonants. In the case of /l/, tongue body raising may not be required in conjunction with tongue tip raising due to laterality requirements, and hence the jaw is lower than for the obstruent coronals. However, Swedish /l/ had a lower jaw position than English /l/, the latter being more velarized. As for the rhotic, Swedish /r/ had a lower jaw position than English /r/, the former being trilled and the latter being an approximant [ʴ]. In the case of /n/, there is no need for a build-up of air pressure as there is for obstruents, and this too may lead to a lower jaw position. However, these various differences between the coronal sonorants were not statistically significant. Finally, the bilabial stop /b/ tended to pattern with the sonorant coronals; in this case, the lower and upper lips may work together to achieve closure, making active participation of the jaw less necessary.
In the present study, I focus on the place-of-articulation contrasts for the stop consonants in Arrernte. As may be inferred from the discussion of Keating et al.'s results above, the introduction of manner contrasts is a complicating factor, and beyond the scope of this preliminary study. More precisely, I am interested in how the various coronal stops of Arrernte pattern with respect to jaw position.
As already mentioned, coronals in Australian languages are divided into laminals (dental and palatal) and apicals (alveolars and post-alveolars); hence, the stop consonants studied here are lamino-dental /![]() /, apico-alveolar /t/, apico-post-alveolar /ʈ/, and lamino-palatal /c/. It is expected that the laminals (dental and palatal) will require a higher jaw position than the apicals, since the blade and body of the tongue as well as the tip need to be raised. It is possible that the apico-post-alveolar stop /ʈ/ in Arrernte will pattern similarly to the English /r/ (i.e. a slightly lower jaw position compared to the apico-alveolar stop /t/), since English /r/ can be categorized as an apico-post-alveolar approximant [ʴ].
/, apico-alveolar /t/, apico-post-alveolar /ʈ/, and lamino-palatal /c/. It is expected that the laminals (dental and palatal) will require a higher jaw position than the apicals, since the blade and body of the tongue as well as the tip need to be raised. It is possible that the apico-post-alveolar stop /ʈ/ in Arrernte will pattern similarly to the English /r/ (i.e. a slightly lower jaw position compared to the apico-alveolar stop /t/), since English /r/ can be categorized as an apico-post-alveolar approximant [ʴ].
In the remainder of the introduction, I provide a brief outline of relevant aspects of Arrernte phonology.
1.1 A brief outline of Arrernte phonology
Arrernte is notable for having few vowels and many consonants (Henderson & Dobson Reference Henderson and Dobson1993, Breen Reference Breen2001). Arrernte has an extensive system of coronal consonants, with four coronal places of articulation in each of the stop, nasal, pre-stopped nasal (e.g. /tn/) and lateral series. As mentioned above, the four coronal places of articulation are apico-alveolar, apico-post-alveolar (often called ‘retroflex’), lamino-dental and lamino-palatal. The stop, nasal and pre-stopped nasal series also have bilabial and velar places of articulation, giving a total of six places of articulation in each of these series. Therefore, the complete stop series is /p ![]() t ʈ c k/, respectively bilabial, (lamino-)dental, (apico-)alveolar, (apico-)post-alveolar, (lamino-)palatal and velar. Note that Arrernte, like the vast majority of Australian Aboriginal languages, does not have a voicing contrast in the stop series, and also does not have a fricative series. The remaining consonants in the language are glides (palatal, labial-velar and velar) and rhotics (alveolar trill and post-alveolar approximant). This study will focus only on the stop consonants.
t ʈ c k/, respectively bilabial, (lamino-)dental, (apico-)alveolar, (apico-)post-alveolar, (lamino-)palatal and velar. Note that Arrernte, like the vast majority of Australian Aboriginal languages, does not have a voicing contrast in the stop series, and also does not have a fricative series. The remaining consonants in the language are glides (palatal, labial-velar and velar) and rhotics (alveolar trill and post-alveolar approximant). This study will focus only on the stop consonants.
It is often argued that Arrernte has a three-vowel system, consisting of /i/, /ɐ/ and /ə/; however, in practice, the two central vowels /ɐ/ and /ə/ are by far the most frequent and carry the highest functional load, leading to the possibility of analysing Arrernte as a two-vowel system. A fourth vowel, /u/, may exist, but like /i/ it has an extremely low functional load and a restricted distribution. Despite the possible existence of the /u/ vowel, rounding is generally treated as a property of the consonant that is transferred onto the adjacent vowel(s) (and which may then spread further in the word).
One particularly salient aspect of Arrernte phonology is its apparent reliance on an underlying VC syllable structure (cf. Blevins Reference Blevins2001). Much evidence for such a structure lies in the language's reduplicative morphology, and in a word-game called ‘Rabbit Talk’ which is played by speakers (Breen & Pensalfini Reference Breen and Pensalfini1999). ‘Rabbit Talk’ involves the shifting around of syllables, and it is VC syllables that are moved in this game. There is also strong evidence for an underlying VC structure in the assignment of word ‘stress’, where the most prominent syllable in a word is the second VC syllable. However, whether this is word stress or post-lexically assigned prominence is unclear, since Arrernte prosody is not well understood. It is worth noting in this context that preliminary work by Rickard (Reference Rickard2006) suggests that Arrernte rhythm may pattern more like syllable-timed languages than stress-timed languages, suggesting that Arrernte is unlikely to have lexical word stress.
A recent acoustic study of formant transitions has shown that CV and VC transitions have comparable variability in Arrernte as well as in two other Aboriginal languages, Yanyuwa and Yindjibarndi; this is in contrast to English and other languages studied, where variability in transitions is much greater for VC than CV sequences (Tabain, Breen & Butcher Reference Tabain2004). It is worth noting, however, that these variability effects were purely in the frequency domain (i.e. F2 and F3 values at consonant edges, and formant locus equations), rather than in the temporal domain: the study did not find any effects on duration of CV vs. VC formant transitions.
Butcher (Reference Butcher, Harrington and Tabain2006) has suggested that the planning unit for speakers of Aboriginal languages may be a VCV sequence, based on various articulatory and acoustic results in the literature (including the Tabain et al. Reference Tabain, Breen and Butcher2004 study just mentioned). For instance, in an articulatory study of focus realization in Warlpiri, a central-Australian language, it was found that duration differences, F0 peaks and supra-laryngeal expansion (namely, of tongue body movement) were all centred around the coda consonant, rather than the vowel (see Butcher & Harrington Reference Butcher and Harrington2003 for the acoustic data, and Butcher Reference Butcher, Harrington and Tabain2006 for the kinematic data on tongue movement). This is contrary to results for other languages in the world. Butcher argues that such a structure is best designed to preserve the place-of-articulation cues which are so important in Aboriginal languages, given their tendency to have multiple coronal places of articulation; he terms this the ‘place-of-articulation imperative’. However, he notes that there may be a tension between this structure and the universally preferred CV(C) structure, since the phonologies of some languages appear to be moving towards the latter structure. He suggests, given comparative historical evidence showing an earlier preference for words beginning with consonants, that alternation between CV(C) and VC(V) preferences may be cyclic over time.Footnote 1
It should be noted that grammars of Australian languages tend to describe sound structures in terms of the phonological word, (C)VC(C)V(C), where the consonant is preferably flanked by vowels on each side (cf. Hamilton Reference Hamilton1996, Baker & Harvey Reference Baker and Harvey2003). Hence, many aspects of Australian languages phonology (such as phonotactics and allomorphy) refer to the phonological word rather than the syllable. As a result, it is often not clear if a language prefers a CV syllable structure – as most languages in the world do – or a VC syllable structure.
The language examined here, Arrernte, is the strongest example of an Australian language with an underlying VC syllable structure, due to the various word-game, stress assignment and reduplicative morphology rules mentioned above. However, the articulatory basis to this phonological VC preference is not clear. Moreover, the acoustic phonetic data of Tabain et al. (Reference Tabain, Breen and Butcher2004) suggest that Arrernte and other Aboriginal languages make no difference between CV and VC transitions on a phonetic level.
Consequently, a secondary question asked in this study is whether or not this underlying VC structure, or the acoustic phonetic equivalence of CV and VC transitions, is in any way reflected in jaw movement in Arrernte. Many speech researchers have considered the jaw to form the basis of speech production (e.g. Kozhevnikov & Chistovich Reference Kozhevnikov and Chistovich1965 from a psycholinguistic point of view, and MacNeilage Reference MacNeilage1998 from a developmental and evolutionary point of view – but see Benner, Grenon & Esling Reference Benner, Grenon and Esling2008 for the alternative view that laryngeal control precedes jaw control in the developing infant), and others have noted the importance of jaw movements in speech control (e.g. Gracco Reference Gracco1994, Fujimura Reference Fujimura2000).
In order to explore the question of syllable structure, the Arrernte jaw data are compared with jaw data from Australian English, a language which has a clear preference for CV(C) syllable structures. The English data are also presented as a methodological point of comparison, since many aspects of the method in the present study are different from those of previous studies (see ‘Method’ section for more details).
2 Method
2.1 Speakers and recordings
Two native speakers of Arrernte (SJ and JT) and two native speakers of Australian English (LS and the author, MT) were recorded at the Speech, Hearing and Language Research Centre physiology studio at Macquarie University in Sydney. The Arrernte speakers were mother (SJ) and daughter (JT) teachers of Arrernte language in Alice Springs, and the English speakers were involved in speech research. A third speaker of Arrernte, who had come to Sydney for the recordings, was found to be insufficiently fluent in the language and was not recorded (a third English speaker who was recorded was male, and his results are not presented here due to possible male–female articulatory differences). The interpretation of the results presented below is therefore limited to two speakers per language.
The recordings were supervised by a technician. Speaker MT was also present at all recordings.
Articulatory (EMA) and acoustic data were recorded simultaneously and time-synchronized. The acoustic data were recorded directly onto a Unix machine at a sampling rate of 20 kHz. The EMA data were recorded at 200 Hz using a 10-channel Carstens system. These EMA data were also recorded directly to the Unix machine.
Two EMA sensors were placed on the tongue (one on the Tongue Back (TB) and one on the Tongue Tip (TT)); two sensors were placed on the vermilion borders of the lips (one on each of the Upper Lip (UL) and Lower Lip (LL)); and one sensor for the JawFootnote 2 was placed on the chin. A reference transducer was placed on the bridge of the nose. The tongue sensors were attached with Ketac bond, and the other sensors were attached with dental tape. The TT sensor was placed approximately 1 cm from the tip of the tongue, and the TB sensor was placed approximately 3–3.5 cm from the tip of the tongue.
Data from the reference sensor were smoothed using a Lowess filter – a regression-based filter which uses a first-degree polynomial fit – with the filter span set to 1 second. (A first-degree fit was chosen in this instance because head movement was observed to be linear over the time-span of the filter.) The reference sensor was then subtracted from the other sensors in order to correct for head movement. The data were then rotated to the measured occlusal plane of the speaker. Prior to kinematic labelling, the data from each measured articulator were smoothed using a Loess filter – a regression-based filter with a second-degree polynomial fit – with the filter span set to one-third the length of the analysis window. (A second-degree fit was chosen in this instance because the analysis window was likely to contain a turning point in the Jaw trajectory – see section 2.3 below, ‘Labelling and analysis’, for a description of the analysis window.) All of this signal processing, as well as the articulatory labelling procedure described below, were carried out using the R statistical package (R Development Core Team 2003).
In this paper, only data from the Jaw sensor will be reported.Footnote 3 However, it should be noted that a Jaw sensor placed on the chin, rather than on the lower gum, will show the influence of the mentalis and platysma muscles as well as simple jaw movement.
It should also be noted that only one reference sensor was used in the present study, rather than two (the second sensor usually being placed on the upper gum), making correction for head movement more difficult. In order to overcome this problem, the data were visually inspected for any noticeable changes in head position over time.
The placement of the Jaw sensor and the absence of the second reference sensor were necessary in the context of working with minority language speakers. Since approval to place sensors on the gums had not previously been given at Macquarie University, it was considered ethically problematic to use this technique on speakers of an Australian language (especially since a male technician was working with female speakers). This was therefore one known methodological problem which necessitated the recording of parallel English data as a point of comparison.
2.2 Stimuli
This study used the same word-lists, for both Arrernte and English, as those in the Tabain et al. (Reference Tabain, Breen and Butcher2004) study. The English word-list was designed to be as similar as possible to the Arrernte word-list. Stimuli in each word-list consisted of real words which contained target syllables in word-initial, word-medial and word-final positions. The syllables in the word-list consisted of all the consonants in the language (for Arrernte) or all the stop consonants in the language (for English), paired with all the phonotactically permissible (phonemically monophthong) vowels in the language.Footnote 4 A list of all the words used in the current study is given in the appendix. Note that this list does not contain all of the words produced by the speakers during the recording session, since only a particular subset of words was chosen for the current study (details follow). It should also be noted that of the Arrernte word-list, there were some words that speaker JT did not produce, and some words that speaker SJ did not produce. This was due to differences in familiarity with certain words.
In the current study, only consonants which were produced with both a preceding and a following monophthongal, non-high vowel were chosen; hence, no word-initial or word-final consonants were used, and no diphthongs or high vowels were adjacent to the consonants (diphthong-like movements can result in Arrernte following a rounded consonant). High vowels were avoided because the jaw position is usually high for these vowels, making the identification of separate consonant and vowel targets somewhat difficult. Diphthongs were avoided because there is no one articulatory target to identify.
For Arrernte, the consonants extracted were /p ![]() t ʈ c k/, and for English the consonants extracted were /p b t d k g/. Since Arrernte has no phonemic voice contrast, the stop consonants in this language may be voiced, voiceless or aspirated, depending on place of articulation and prosodic context. In order to make the English data more comparable to the Arrernte data, the six English stop consonants were collapsed into three according to place of articulation – namely bilabial, alveolar and velar. Hence, from here on, the voiceless symbol will be used to represent both the phonemically voiced and the phonemically voiceless stops of English (these collapsed stops may therefore be phonetically voiced, voiceless or aspirated): /p/ will refer to /p b/, /t/ will refer to /t d/, and /k/ will refer to /k g/.Footnote 5
t ʈ c k/, and for English the consonants extracted were /p b t d k g/. Since Arrernte has no phonemic voice contrast, the stop consonants in this language may be voiced, voiceless or aspirated, depending on place of articulation and prosodic context. In order to make the English data more comparable to the Arrernte data, the six English stop consonants were collapsed into three according to place of articulation – namely bilabial, alveolar and velar. Hence, from here on, the voiceless symbol will be used to represent both the phonemically voiced and the phonemically voiceless stops of English (these collapsed stops may therefore be phonetically voiced, voiceless or aspirated): /p/ will refer to /p b/, /t/ will refer to /t d/, and /k/ will refer to /k g/.Footnote 5
The monophthongal non-high vowels for Arrernte were /ə ɐ/; and for English, they were /ə ɜː ɐ ɐː e eː æ ɔ/.Footnote 6 For the purposes of this study, aspiration following a stop consonant was included as part of the vowel.
It is worth noting that the present study is based on lists of real words in the languages examined. This more natural variability contrasts with the strict environments on which previous studies of jaw movement have been based. For instance, the stimuli in Gracco (Reference Gracco1994) were sapapple, seepapple, sabapple, seebapple, samapple, seemapple, where the first vowel and the manner of the first bilabial consonant were the controlled variables. Although the present study was controlled to a certain extent, the variety of vowels and consonants included was much greater than in the Gracco (Reference Gracco1994) study. This more natural environment is also necessary given that most minority language speakers are reluctant to produce nonsense words in their language. Again, the English data recorded as a methodological point of comparison were designed to mimic the Arrernte word-list as closely as possible (even to the extent of having several words beginning with /r/, given that ‘retroflexion’ – i.e. an apico-post-alveolar articulation – is such an important part of Arrernte phonology).
2.3 Labelling and analysis
The acoustic data were labelled by two paid labellers who were enrolled to do Ph.D.s on the phonetics of Australian Aboriginal languages. Acoustic data were segmented and labelled according to standard acoustic criteria. The articulatory data were labelled by MT (the author) as described in this section below. The acoustic and articulatory labelling and the analyses of the data were done using the EMU speech database system (http://emu.sourceforge.net/ – last accessed 15 August 2006; see also Cassidy & Harrington Reference Cassidy and Harrington1996) interfaced with the R statistical package (R Development Core Team 2003).
Articulatory labelling was also done by hand. An interactive program written in R presented the time-course of the Jaw sensor movement in the x–y plane for a given /V1CV2/ utterance (where both V1 and V2 are non-high vowels, and C is a stop consonant). This time-course extended from the acoustic onset of the vowel preceding the target consonant (and included any aspiration at the start of the vowel), to the acoustic offset of the vowel following the consonant. The articulatory labeller marked the articulatory targets for each vowel and the consonant, based on visually-identified velocity minima in the articulatory Jaw trajectory. The x- and y-targets presented below are extracted from these hand-labelled targets.
The labeller also marked the velocity maxima between the targets for V1 and C, and between the targets for C and V2, based on visual inspection. The tangential velocity results presented below are also taken from these hand-labelled points.
Figure 1 gives an example of a labelled utterance from Arrernte. The sequence ‘6 p @’ at the top of the figure denotes the phonemic sequence /ɐpə/. The acoustic onset and offset of the consonant are automatically marked as circles, and the start of the trajectory is automatically labelled by a cross and the letter S. Inverted triangles represent hand-labelled articulatory targets (deemed velocity minima) for the vowels and consonant, and upright triangles represent hand-labelled velocity maxima between the articulatory targets. It can be seen that in this particular example, the Jaw velocity maximum between the V1 target and the C coincides with the acoustic onset of the stop closure, and the Jaw target (velocity minimum) for the stop occurs just before the acoustic release of the stop.Footnote 7

Figure 1 Example of the articulatory labelling process. The plot shows a Jaw movement trajectory for the sequence /ɐpə/. The acoustic onset and offset of the consonant are automatically marked as large (empty) circles, and the start of the trajectory is marked by a cross and the letter S. Inverted filled triangles represent hand-labelled articulatory targets (deemed velocity minima) for the vowels and the consonant, and upright filled triangles represent hand-labelled velocity maxima between the articulatory targets. Each small circle represents an EMA sample at every 5 ms in time. Units on both the x- and y-axes are mm × 10−1 from the reference transducer; note, however, that system resolution is about 5 mm × 10−1.
The jaw closing movement into the consonant (i.e. from V1 to C) is considered to be a VC movement; and the opening movement from the consonant into the following vowel (i.e. from C to V2) is considered to be a CV movement. The measures presented below will be for Velocity, Duration and Distance. Velocity is the hand-labelled maximum velocity for the VC or CV sequence (in the x–y plane); Duration is the difference in time between the vowel target and the consonant target (also for both VC and CV); and Distance is the Euclidean distance (often called ‘magnitude’ in other studies) between the consonant target and the vowel target (also for both VC and CV). Note that the Euclidean distance measure (i.e. the shortest path between two points on the x–y plane) is not a measure of total path-length traversed by the jaw, which may be equal to or greater than the Euclidean distance presented here.
Hand-labelling of articulatory targets, rather than automatic labelling, was chosen for this study due to its partially exploratory nature. Although jaw movement in English and other European languages is comparatively well-studied, this is not the case for Arrernte and other Aboriginal languages which have multiple coronal places of articulation. In fact, the current study may be the first study of jaw movement in an Aboriginal language. Hence, it was deemed wiser to use a phonetically-informed human labeller, rather than an automatic labeller, in order to come to a better understanding of jaw movement in Arrernte, especially for the coronal consonants.
2.4 Statistical analysis
Differences in hand-labelled x and y targets for the six different consonants in Arrernte were tested using a univariate ANOVA in the SPSS statistical package. Since jaw movements in the x and y planes are correlated, the significance level for the main test was set at a relatively low .01, and for the post-hoc tests at .001.
Differences in VC vs. CV movement with regard to Velocity, Duration and Distance were analysed using a modified paired t-test. These tests were carried out for both English and Arrernte speakers, in order to facilitate kinematic comparisons. Since the kinematic interest in this paper is in variability rather than in means, the standard paired t-test was modified so that it resembled the standard Levene test for homogeneity of variances (which is used with an ANOVA). This was done by subtracting the mean value of each condition from all of the values in that condition, and using the absolute value which remained (i.e. there were no negative values). The paired t-test was then conducted on these remaining absolute values.Footnote 8 For the initial tests, alpha was set at .05 for each measure for each speaker. Due to the low number of speakers and to the fact that this is an articulatory study, each speaker was treated separately in the statistics. Alpha was reduced to .01 for post-hoc tests according to place-of-articulation. These modified paired t-tests were conducted using the R statistical package.
3 Results
Table 1a gives the number of tokens for each consonant for each speaker. It can be seen that there are comparatively fewer tokens of the apicals than the laminals and peripherals. Table 1b shows the vowels preceding the target consonants, and table 1c shows the vowels following the target consonants. It can be seen that roughly half the English vowels are schwa, with most of the other vowels being low vowels. The Arrernte and English jaw data are therefore highly comparable in terms of vowel context, despite the fact that the vowel spaces of the two languages are very different.
Table 1a Number of tokens per consonant for each speaker of each language. Note that English only contains three stop places of articulation, whereas Arrernte contains six.

Table 1b Table of vowels preceding the target consonant.

Table 1c Table of vowels following the target consonant.

Figure 2 shows average Jaw trajectories for the four speakers studied here, and table 2 presents ANOVA results for the hand-labelled x and y consonant targets. Although the entire Jaw trajectory is presented in figure 2, targets may be identified as the points where the Jaw movement is noticeably slower (i.e. where the individual sample points are more tightly clustered). These targets are the focus of the first part of the presentation of results.

Figure 2 Plots of Jaw trajectories for the stop consonants of English and Arrernte. Data are presented separately for each speaker; speakers LS and MT are English speakers, and speakers JT and SJ are Arrernte speakers. Data are time-normalized and averaged across vowel contexts. The beginning of each trajectory, marked by the letter S, was taken at the acoustic onset of the consonant, and the end of each trajectory was taken at the acoustic endpoint of the consonant. Each averaged, time-normalized trajectory is plotted with 20 points equidistant in time. Units on both the x- and y-axes are mm × 10−1 from the reference transducer; note, however, that system resolution is about 5 mm × 10−1. In Arrernte figures, 〈th〉 = /![]() / and 〈rt〉 = /ʈ/.
/ and 〈rt〉 = /ʈ/.
Table 2 Results from main and post-hoc ANOVAs for consonant x and y Jaw targets for Arrernte speakers JT and SJ, and for English speakers LS and MT. Significance level is set at .01 for the main test and .001 for the post-hoc tests. > indicates that Jaw position is higher (y) or more back (x), and < indicates that Jaw position is lower (y) or more forward (x). Statistics are reported separately for each speaker.

*There was a trend for /t/ and /p/ to also be more forward than /k/.
It can be seen that, as expected, all of the speakers have a low Jaw position for /k/. English speaker MT has a significantly lower (and more back) Jaw position for /k/ than for both /p/ and /t/, whereas English speaker LS has a /t/ position between /p/ and /k/ in terms of height (but /t/ patterns with /p/ in being more front than /k/ for this speaker).
Arrernte speaker JT's /k/ is lower than all other consonants; for speaker SJ, it is (significantly) lower than only /c/ and /p/. /k/ is also more retracted than the laminal consonants for JT (but appears to pattern with the apicals and the bilabial for this speaker), and it is more retracted than the lamino-palatal and the bilabial for SJ.
Both of the Arrernte speakers, JT and SJ, have a very high Jaw position for the lamino-palatal /c/: for speaker JT, it is statistically higher and more forward than all other consonants except the lamino-dental /![]() / (in fact, the trajectories for /c/ and /
/ (in fact, the trajectories for /c/ and /![]() / partially overlap for speaker JT). Speaker JT also has a very forward Jaw position for /
/ partially overlap for speaker JT). Speaker JT also has a very forward Jaw position for /![]() /, with /
/, with /![]() / also being statistically higher than /k/ and /ʈ/ and more forward than all the other non-laminals. For speaker SJ, /c/ is higher than /k/ and /ʈ/, and /
/ also being statistically higher than /k/ and /ʈ/ and more forward than all the other non-laminals. For speaker SJ, /c/ is higher than /k/ and /ʈ/, and /![]() / is more forward than /k/.
/ is more forward than /k/.
For speaker JT, the apicals /t/ and /ʈ/ are statistically indistinguishable, though in backness they pattern with the peripherals /k/ and /p/ and are intermediate in height.
By contrast, SJ has a very low Jaw position for the apico-post-alveolar /ʈ/ (significantly lower than the palatal and bilabial); her /ʈ/ is similar to /k/ in position. Speaker SJ's lamino-palatal /c/ and the bilabial /p/ have very high Jaw positions (similar to speaker JT), being significantly higher than the velar and post-alveolar.
It should be noted that some of speaker SJ's productions of the apico-post-alveolar /ʈ/ were of a particular variant observed in some speakers of the language, namely, a strong palatalization before the stop proper, i.e. /ɐʈɐ/ is produced as [ɐjtɐ] or [ɐjʈɐ], with the ‘retroflex’ quality of the apical consonant not always being clear.Footnote 9 However, not all of SJ's productions of /ʈ/ were pre-palatalized; as a result, this speaker's post-alveolar data should be treated with caution.
Figure 3 shows mean and standard error bars for the Velocity, Duration and Distance measures for each consonant for each speaker. Tables 3a and 3b present the statistical significance results, both main (table 3a) and post-hoc (table 3b), for these measures. As can be seen, there is no consistent result across speakers, and most statistical tests show no significant difference between the VC and CV contexts. Perhaps the one exception is the bilabial /p/, where one Arrernte (JT) and one English (MT) speaker showed greater variability in Velocity in the VC context, and Arrernte speaker SJ showed greater variability in Duration and Distance in the VC context. By contrast, speaker MT showed lesser variability in Duration in the VC context.

Figure 3 Error bars showing mean ±2 standard errors for Velocity, Duration and Distance measures of the Jaw closing (VC) and opening (CV) movements. Velocity measures are in cm/sec, Duration measures are in milliseconds, and Distance measures are in mm × 10−1. Statistically significant results are circled (see table 2). Speakers LS and MT are English speakers, and speakers JT and SJ are Arrernte speakers. In Arrernte figures, 〈th〉 = /![]() / and 〈rt〉 = /ʈ/.
/ and 〈rt〉 = /ʈ/.
Table 3a Significance results and confidence intervals for the kinematic measures of Velocity, Duration and Distance. Statistics are reported separately for each speaker, and arranged by language. Significance level is set at .05 based on a modified paired t-test (see text for details). > indicates that VC has significantly greater variability than CV, < indicates that VC has significantly lesser variability than CV, and = indicates that there is no significant difference in variability.

Table 3b Post-hoc significance results according to place of articulation. One asterisk indicates that p < .01; two asterisks denote that p < .001; and three asterisks denote that p < .0001. > indicates that VC has significantly greater variability than CV, and < indicates that VC has significantly lesser variability than CV. (a) Arrernte, (b) English.

The only other consonants to show post-hoc effects were the apical /t/ and /ʈ/. Arrernte speaker JT showed effects on both Velocity and Duration for these consonants: for /ʈ/ the variability was greater in the VC context than in the CV context, but for /t/ the opposite was true. English speaker LS also showed greater variability in the VC context for Duration of /t/ movement.
It is perhaps worth noting that there were four effects overall on Velocity and four on Distance, but only two on Duration. This is consistent with the results of Tabain et al. (Reference Tabain, Breen and Butcher2004), where effects on the duration measure were very weak compared to the formant measures.
4 Discussion
The present results echo the results from Keating et al. (Reference Keating, Lindblom, Lubker and Kreiman1994) by having the lowest jaw position for /k/, and relatively higher jaw positions for the coronals. In particular, the palatal /c/ had an extremely high jaw position; this is perhaps a reflection of the large amount of tongue body raising required for the production of this consonant (Recasens Reference Recasens, Hardcastle and Hewlett1999).
By contrast, the apico-post-alveolar /ʈ/ had a relatively low jaw position, as may have been predicted by the relatively low jaw position for English /r/ – [ʴ] in Keating et al.'s study. Presumably, the jaw lowers in order to allow the tongue tip/blade to retract into the pre-palatal/post-alveolar region; from this region, it may then move forward into the alveolar region during stop closure (see Tabain, to appear, for electropalatographic data on the apico-post-alveolar; see also Ladefoged & Maddieson Reference Ladefoged and Maddieson1996 for discussion of retroflexes).
Contrary to expectations, the laminal consonants did not show a consistently higher tongue position than the apicals, since the (lamino-)dental /![]() / did not have a higher position than the (apico-)alveolar /t/. One may temporarily conclude that the requirements for stop closure and burst release are such that a relatively high jaw position is required for any stop formed in the alveolar region, regardless of its active articulator. If this hypothesis is true, differences between laminals and apicals would become apparent in the production of nasals and laterals, where the careful control of air pressure build-up for release is not required.
/ did not have a higher position than the (apico-)alveolar /t/. One may temporarily conclude that the requirements for stop closure and burst release are such that a relatively high jaw position is required for any stop formed in the alveolar region, regardless of its active articulator. If this hypothesis is true, differences between laminals and apicals would become apparent in the production of nasals and laterals, where the careful control of air pressure build-up for release is not required.
It should be pointed out that the position of the bilabial /p/ is relatively higher in the present study than in Keating et al.'s study. This difference is most likely due to the fact that the Jaw sensor was placed on the chin in the present study, and on the lower gums in the Keating et al. study. As mentioned above, the chin sensor will combine jaw movement with lower lip movement, and hence may form a distorted picture of jaw movement in labial consonants.
The present results also show that there is no consistent difference in variability between opening and closing jaw movements for any of the kinematic measures examined. This was true for both English, which clearly has a preference for CV structures, and for Arrernte, which phonologically has a preference for VC structures.
It is worth noting that the one consonant which did show an effect across speakers and measures was the bilabial stop, which generally (with one exception, the Duration measure for MT) showed greater variability in VC closing movement than in CV opening movement. This is the consonant which relies most heavily on the jaw to achieve stop closure (indeed, in the present study, jaw movement was measured from the chin, which is even more likely to show effects of lip closure).
As mentioned above, the effect of different consonant manners of articulation has not been considered in the present study: as recent articulatory studies by Mooshammer, Hoole & Geumann (Reference Mooshammer, Hoole and Geumann2006) and Recasens & Espinosa (Reference Recasens and Espinosa2006) have shown, even within the same place of articulation (alveolar in the case of the Mooshammer et al. study, and palatal in the case of the Recasens & Espinosa study), articulatory strategies, including jaw movement, can vary greatly according to manner requirements. The extension of the present study to nasal and lateral manners of articulation for all of these places of articulation is a necessary first step to understanding the effects of place of articulation on jaw movement.
Another important extension of the present work is to consider how jaw movement for Arrernte consonants is coordinated with movement of the active articulator (e.g. the lips for /p/ or the tongue tip for /t/). Since numerous articulatory studies of inter-articulator coordination have shown more stable CV articulation than VC articulation, differences in timing may become apparent between English and Arrernte (see Tuller & Kelso Reference Tuller, Kelso and Jeannerod1990 for laryngeal–bilabial coordination; Kochetov Reference Kochetov, Goldstein, Whalen and Best2006 for lip–tongue coordination in Russian; and also Turk Reference Turk and Keating1994, Byrd Reference Byrd1996 and Krakow Reference Krakow1999 for reviews).
Future work may also investigate the relationship between jaw movement and Arrernte prosody (once this is better understood), since rhythmic and melodic structures tend to have an important influence on jaw movement (e.g. Stone Reference Stone1981; Erickson Reference Erickson1998; Tabain Reference Tabain2003, and references therein).
A further possible extension of the present study is to see just how much influence the vowel context has on jaw consonant movements in an Aboriginal language such as Arrernte. It is possible that in Arrernte, which has only three vowel phonemes, /i ɐ ə/, but many consonant contrasts, vowels do not influence jaw targets as much as they do in English and Swedish (Keating et al. Reference Keating, Lindblom, Lubker and Kreiman1994), which have many vowel contrasts but fewer consonant contrasts. Although the effects of phoneme inventory size on acoustic output have been considered (e.g. Manuel Reference Manuel1990), studies of comparable effects on articulation are relatively few.
Acknowledgements
I would like to thank Richard Beare, Gavan Breen and Kristine Rickard for assistance with various stages of the project, and my speakers (Janet Turner and Sabella Turner for Arrernte, and Lisa Stephenson for English) for their time. An earlier version of this work was presented at the 11th Australasian Speech Science and Technology Conference in Auckland, New Zealand, in December 2006. This research was supported by the Australian Research Council (F00105978 and DP0663825 to myself), and by the National Institutes of Health (DC00403 to Catherine Best). I am grateful to four anonymous reviewers and to the editors for their comments on previous versions of this paper.
Appendix: Lists of English and Arrernte words used in the present study
English words
Stop consonants in VCV environments (where V is a non-high vowel) are shown in bold. Note that Australian English is non-rhotic.

Arrernte words with English equivalents
Stop consonants in VCV environments (where V is a non-high vowel) are shown in bold. Note that the realization of word-initial and word-final vowels (whether phonemic or not) is highly variable in Arrernte – as a result, some words which may appear consonant-initial are produced with an initial vowel, and some words which may appear consonant-final are produced with a final vowel.
A note on Arrernte orthography:









