


Introduction
Most words are semantically ambiguous within one language (i.e., have more than a single meaning). For instance, the Spanish word muñeca has two distinct meanings (“doll” and “wrist” in English). This within-language feature can lead to multiple translations across languages (i.e., a form of cross-language ambiguity). Because languages differ in how they label concepts, it is often the case that one word is used in a certain language to refer to multiple meanings whereas another language uses different words for these distinct meanings. These are cases of multiple-translation words. In contrast, in other cases both languages label one or multiple meanings with a single word in each language (one-translation words). Translation ambiguity is a very frequent phenomenon because ambiguous words in one language rarely correspond to one word in another language (Degani & Tokowicz, Reference Degani and Tokowicz2010; Frenck-Mestre & Prince, Reference Frenck-Mestre and Prince1997). For instance, in a normative study, Prior, McWhinney and Kroll (Reference Prior, MacWhinney and Kroll2007) found that nearly half of the words included in their study had more than one translation between English and Spanish. Similarly, Tokowicz, Kroll, de Groot and Van Hell (Reference Tokowicz, Kroll, de Groot and Van Hell2002) found a 25 percent ratio of words with more than one translation between Dutch and English.
Previous studies have provided evidence of an advantage of one-translation words over multiple-translation words during translation. This disadvantage of multiple-translation words has been found using two different tasks. The effect was found using a translation recognition task by Sánchez-Casas, Suárez and Igoa (Reference Sánchez-Casas, Suárez and Igoa1992b) with Spanish–English bilinguals and by Laxén and Lavaur (Reference Laxén and Lavaur2010) with French–English bilinguals. In this task, participants are presented with a pair of words in different languages (sequentially or simultaneously), and they have to decide whether these two words are a correct translation pair or not. The results reported by these authors showed that participants were slower and less accurate when translation ambiguity was present in comparison with single-translation pairs. On the other hand, Tokowicz and Kroll (Reference Tokowicz and Kroll2007) examined multiple translations in an oral translation task in which English–Spanish bilingual participants were presented with one word in a given language and they had to orally produce its translation in the other language. Once again, a disadvantage in terms of response latency and error rates was obtained for words with more than one translation. The fact that it is harder to translate a word when it has more than one translation (i.e., when it is ambiguous across languages) than when it has a single translation, has been explained using the Distributed Representation Model (DRM, de Groot, Reference de Groot, Frost and Katz1992b). According to this model, activation will be determined by the proportion of nodes shared by the semantic representations of the translation word pair. The greater the proportion of semantic nodes shared by the two words, the higher the activation at this level and the faster the translation process will be. When there is a single correct translation this proportion will be maximal, and thus, the activation will also be maximal, whereas if the word is ambiguous and there are multiple-translation possibilities, each possible candidate will share only a part of its meaning with the word to be translated (see Figures 1 and 2). Thus, in this case the larger number of lexical-conceptual links of the ambiguous word will lead to a higher dissipation of activation hindering the translation process. When a translation-ambiguous word is presented for translation, a given amount of activation will be spread from the lexical entry of the Spanish word to the nodes that configure its meaning representation. For instance, if a participant reads or listens to a translation-ambiguous word like muñeca during a translation task, activation will be spread among a large number of nodes and each one of these nodes will be less active than in the case that the word has a single translation. Therefore, the translations of muñeca, nina “doll” and canell “wrist”, will receive less activation from the semantic level, being harder for the system to produce or recognize the correct translation.

Figure 1. Representation of a one-translation word between Spanish and Catalan according to the DRM. Adapted from de Groot (Reference de Groot, Frost and Katz1992b).

Figure 2. Representation of a word with multiple translations according to the DRM. Adapted from de Groot (Reference de Groot, Frost and Katz1992b).
Although the above-mentioned studies on number of translations differ in the version of the translation task used, both translation recognition and oral translation seem to be sensitive not only to cross-language ambiguity (multiple translations), but also to other experimental manipulations related to word meaning. Therefore, the two translation tasks are comparable (de Groot & Comijs, Reference de Groot and Comijs1995). Another difference between the reviewed studies of great relevance for the present study refers to the materials used. Although Laxén and Lavaur (Reference Laxén and Lavaur2010) and Tokowicz and Kroll (Reference Tokowicz and Kroll2007) used only non-cognate translations as experimental materials, Sánchez-Casas et al. (Reference Sánchez-Casas, Suárez and Igoa1992b) included also cognate translations (i.e., words that are similar in both form and meaning; e.g., papel–paper). In line with Laxén and Lavaur and Tokowicz and Kroll, Sánchez-Casas et al. found that the multiple-translation effect was reliable with non-cognate translations (e.g., hoja – sheet and leaf in English); however this was not the case for cognate translations (e.g., pipa – pipe and seed in English). That is, cognate words with more than one translation were not translated significantly more slowly than cognate words with a single translation. The advantage of cognates over non-cognates has been largely studied in psycholinguistics literature independently of ambiguity showing that cognates are recognized (e.g., Dijkstra, Grainger & Van Heuven, Reference Dijkstra, Grainger and Van Heuven1999; Dijkstra, Timmermans & Schriefers, Reference Dijkstra, Timmermans and Schriefers2000; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004), named (e.g., Costa, Caramazza & Sebastián-Gallés, Reference Costa, Caramazza and Sebastián-Gallés2002; Costa, Santesteban & Caño, Reference Costa, Santesteban and Caño2005), read aloud (de Groot, Borgwaldt, Bos & Van den Eijnden, Reference de Groot, Borgwaldt, Bos and Van den Eijnden2002) and translated (e.g., de Groot, Dannenburg & Van Hell, Reference de Groot, Dannenburg and Van Hell1994) faster than non-cognate words, and also produce more semantic and translation priming effects in a lexical decision task than non-cognate words (e.g., Davis, Sánchez-Casas, García-Albea, Ferré, Guasch & Molero, Reference Davis, Sánchez-Casas, García-Albea, Ferré, Guasch and Molero2010; García-Albea, Sánchez-Casas & Igoa, Reference García-Albea, Sánchez-Casas, Igoa and Hilert1998; Grainger & Frenck-Mestre, Reference Grainger and Frenck-Mestre1998). Thus, it may be that multiple-translations affect these two types of words differently. One possible explanation of the absence of the multiple-translation effect in cognate translations could be related to the greater form overlap of these words in comparison to non-cognate words. It might be that the translation responses of cognate words are performed more on the basis of their form similarity than their meaning overlap. In fact, it has been proposed that the locus of the cognate advantage can be at the sub-lexical form level (e.g., Dijkstra, Miwa, Brummelhuis, Sappelli & Baayen, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010). If formal similarity contributes to cognate translations to a greater extent than does meaning overlap, then access to the words’ semantic representations may be limited and the effect of having more than one translation would be reduced. However, there is some evidence that does not seem to be consistent with such an interpretation, at least in translation tasks. In particular, de Groot and colleagues carried out a series of experiments in which they studied the effect of several semantic variables (definition accuracy, imaginability, context availability, etc.) on the translation process of both cognate and non-cognate words (e.g., de Groot, Reference de Groot1992a; de Groot & Comijs, Reference de Groot and Comijs1995; de Groot et al., Reference de Groot, Dannenburg and Van Hell1994). In all the experiments, semantic variables were found to influence both cognate and non-cognate translation performance. Even more, such an influence did not seem to be modulated by form similarity. In particular, the results showed that when participants responded to a list of words only including cognate translations and formally unrelated fillers (conditions that could bias a form-based translation response), semantic effects were also observed in cognate words (de Groot & Comijs, Reference de Groot and Comijs1995). Finally, and of relevance here, the semantic effects were found to be of the same size in cognate words and in non-cognate words in the translation recognition task. Thus, it seems that cognate performance in this task is influenced by semantic variables and that the possibility that access to meaning is reduced by form similarity is not supported. Nevertheless, it is still possible that processes underlying cross-language ambiguity may differ from those of other semantic variables.
If one adopts the DRM to account for the multiple-translation effects, the findings reported by de Groot and colleagues we discussed above would be consistent with the predictions derived from this model regarding these cross-language ambiguity effects. As mentioned earlier, the DRM explains the multiple-translation effect by assuming that the smaller the degree of meaning overlap between the words, the fewer semantic nodes they will share at the semantic/conceptual representation level and, consequently, the more slowly words will be recognized as translations. If this assumption is correct, both cognate and non-cognate words should show the multiple-translations disadvantage because both types of translations may differ in the degree of semantic overlap between the two languages. Nevertheless, to our knowledge, Sánchez-Casas et al.'s (Reference Sánchez-Casas, Suárez and Igoa1992b) study is the only one that has investigated the issue of cross-language ambiguity in cognate and non-cognate translations. Thus, the first aim of the present study is to further examine the multiple-translation effect in these two types of translations. We used Catalan and Spanish, a language pair that has not been tested previously in translation ambiguity studies. These languages are orthographically very close and have a large number of cognates, and they constitute good candidates for exploring to what extent the number of translations effect is the same in these two languages as in less similar language pairs.
Another characteristic of words with multiple translations that is important to take into account is that they seldom have two balanced translation possibilities into the other language. Translation is often biased to one of the possible meanings which is the one provided spontaneously by the majority of people, the so-called dominant translation. Thus, given an ambiguous Catalan word such as set, participants will mostly translate it into Spanish as sed “thirst”, and less frequently will provide the alternative meaning siete “seven” as the first translation. Different word characteristics have been suggested as factors to determine the preference for one of the word's possible translations. For instance, participants may choose the translation that is more similar in form to the word to be translated (de Groot & Comijs, Reference de Groot and Comijs1995) or they may prefer the shorter and more frequent translation (e.g., Prior et al., Reference Prior, MacWhinney and Kroll2007). In the example mentioned above, participants may choose sed whose form is more similar to set than siete and it is also the shorter translation. For the purposes of this study, and regardless of what determines the participant's decision, we will consider the dominant translation the one given by most participants when asked to spontaneously translate the word, and the subordinate translations the ones given by fewer people. The role of translation probability has been investigated recently by Laxén and Lavaur (Reference Laxén and Lavaur2010) using a translation recognition task in which, in contrast to oral translation, it is possible to manipulate which word's translation is to be shown to the participants for performing translation recognition. The results of this study revealed that translation recognition for dominant translations was faster than for subordinate translations, indicating that dominance is a relevant variable in the translation process. Laxén and Lavaur tested only non-cognate translations, thus in addition to this study's aim to examine the multiple-translation effect both in cognates and non-cognates, a second aim was to examine the effect of dominance of translation in both cognates and non-cognates. Adopting the DRM, these authors explain the advantage of dominant over subordinate translations by suggesting that words will share more semantic nodes with their dominant translations than with any of the subordinate ones. Assuming such an explanation for the moment, no differences should be expected between cognate and non-cognate words regarding the effect of this variable. However, as we will argue in the discussion, it is not clear to us how the advantage for dominant translations can be explained in terms of number of shared nodes.
Translation direction has also been a variable of interest in the study of word translation because it is often found that translation from L1 to L2 is performed more slowly than translation in the reverse direction (e.g., Kroll & Stewart, Reference Kroll and Stewart1994; Sánchez-Casas, Davis & García-Albea, Reference Sánchez-Casas, Davis and García-Albea1992a). With regard to the effect of number of translations, the previous studies that examined this variable using both translation directions do not specify the effect of multiple translations in each direction separately, with the exception of Experiment 2 in Laxén and Lavaur's study (Reference Laxén and Lavaur2010). In this experiment, the authors compared response times to different translation word pairs (one-translation words, multiple dominant translations and subordinate translations) in the two language directions, and found that the only difference that did not reach significance was that between one-translation words and dominant translations when the direction was from L1 to L2. Thus, overall, translation direction does not strongly modulate the effect of translation type. This evidence is consistent with the DRM's predictions because according to this model translation times will depend on the degree of semantic overlap between the words from the two languages, and this overlap will be the same regardless of the direction in which translation takes place. Nevertheless, there are some data from other paradigms that suggest that translation direction can be relevant. For instance, it has been generally found that the magnitude of both translation and semantic priming is greater from L1 to L2 than in the reverse direction (e.g., see Schoonbaert, Duyck, Brysbaert & Hartsuiker, Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009, for a review). Interestingly, this asymmetry disappears if the bilinguals are balanced and highly proficient in both languages (Davis et al. Reference Davis, Sánchez-Casas, García-Albea, Ferré, Guasch and Molero2010; Duñabeitia, Perea & Carreiras, Reference Duñabeitia, Perea and Carreiras2009; Perea, Duñabeitia & Carreiras, Reference Perea, Duñabeitia and Carreiras2008). Laxén and Lavaur's bilinguals were proficient in both languages but they were not balanced. Therefore, the third aim of our study was to examine the influence of translation direction on the pattern of results with multiple translations, using for the first time balanced bilinguals who are similar to those previously tested in the priming studies.
Although level of language proficiency has been a bilingual characteristic investigated in translation studies, language dominance is a variable that has been largely ignored. This is not surprising if one considers that most available studies have tested unbalanced bilinguals who were always more proficient in their dominant language, so the effect of the two variables could not have been separated. Moreover, the studies that have examined balanced bilinguals have focused on proficiency and not language dominance (e.g., Perea et al., Reference Perea, Duñabeitia and Carreiras2008; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2009). The bilinguals tested in the present study were balanced in terms of proficiency, rating themselves as being almost equally highly proficient in the two languages, but they differed in the language they preferred and used more frequently on a daily basis. The Catalan dominant group used more often Catalan than Spanish and the opposite was true for the Spanish dominant group. By studying the performance of this type of bilinguals in translation performance in the two language directions (Catalan–Spanish vs. Spanish–Catalan), it was possible to hold proficiency relatively constant while varying dominance established in terms of language use, and to determine if this variable had an effect on translation performance independently from that of proficiency.
A final variable that has been demonstrated to be relevant in translation processes is concreteness. There is evidence that concrete words are processed faster than abstract words (de Groot, Reference de Groot, Frost and Katz1992a, Reference de Groot, Schreuder and Weltens1993; de Groot et al., Reference de Groot, Dannenburg and Van Hell1994; Van Hell & de Groot, Reference Van Hell and de Groot1998) and that they produce semantic priming of a greater magnitude (e.g., Lozano & Sánchez-Casas, Reference Lozano and Sánchez-Casas2010; Schoonbaert et al., Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009). According to DRM, this advantage of concrete words can be explained by assuming that they would share more semantic nodes across languages than abstract words, because the former label objects in the physical world and they would be less culture-dependent and their semantic overlap would be greater than that of abstract words. Tokowicz and Kroll (Reference Tokowicz and Kroll2007) carried out a series of oral translation experiments in which they manipulated concreteness in words with a single or multiple translations. In addition to the finding that participants were faster and more accurate in their responses to one-translation words than to words with multiple translations, the authors reported an interaction of this variable with concreteness. In particular, they found that the multiple-translation effect emerged only in abstract but not in concrete words. More recently, however, Laxén and Lavaur (Reference Laxén and Lavaur2010) did not find any evidence of this interaction using non-cognate words, although in this case a translation recognition task was used. As in Laxén and Lavaur, in our study we used a translation recognition task, but it was not possible to include concreteness as a factor in the experimental design, due to material selection restrictions (i.e., it was not possible to choose materials based on concreteness while maintaining the design balanced in terms of number of translations and cognate status). Nevertheless concrete and abstract words were included among both cognate and non-cognate translation pairs as well as among both one- and multiple-translation pairs so that we could perform a post-hoc analysis to examine the influence of concreteness in the pattern of results.
In sum, the following experiment aimed to examine the role of number of translations on cognate and non-cognate words manipulating translation dominance in the case of multiple translations, and including both concrete and abstract words. In order to achieve this aim, highly proficient Spanish–Catalan bilinguals, dominant in either language, were tested on a translation recognition task in the two language directions (Spanish–Catalan and Catalan–Spanish).
Experimental study
Method
Participants
Forty second-year psychology students from the Rovira i Virgili University (Tarragona, Spain) participated in the investigation as part of a course requirement. The sample consisted of 32 women and 8 men aged from 20 to 25 years old. All of them were highly proficient Spanish–Catalan bilingual speakers. Half of the participants were Catalan dominants and the other half were Spanish dominants. Both groups acquired their second language early in age (0–3 years old), and they were exposed to the two languages on a daily basis.
We used a detailed questionnaire to gather information about the linguistic history of the participants, including age of acquisition of the two languages, frequency of use, and proficiency in the various linguistic skills (i.e., listening, speaking, reading and writing). The two groups of bilinguals were established on the basis of the information from the questionnaire. Table 1 presents data regarding the participants’ level of proficiency in both languages as well as frequency-of-language-use. The data reported in the table represent mean scores and standard deviations for listening, reading, speaking, and writing. Participants used a scale from 1 (very low) to 7 (very high) to evaluate their proficiency in these skills. Similarly, the frequency-of-language-use scores in these four skills were also obtained using a seven-point scale on which 1 meant that only Catalan was used, 7 meant that they used only Spanish, and 4 meant that both languages were used with the same frequency.
Table 1. Proficiency and frequency-of-language-use scores in Spanish and Catalan for the different language skills provided by the Spanish and Catalan dominant groups. Standard deviations are presented in brackets.

As can be seen in Table 1, both bilingual groups were highly competent in both Spanish and Catalan. Proficiency in Spanish did not differ between the Spanish dominants and Catalan dominant participants, with the only difference that Catalan dominants rated themselves as being more proficient in speaking Catalan than Spanish dominants did (t 1(1,21.38) = 3.56; p < .05). As expected, Spanish dominants use Spanish more often than Catalan in all four skills (scores above 4), whereas Catalan dominants use Catalan more often than Spanish (scores below 3.5), except in reading where they read slightly more in Spanish than in Catalan (3.9). This is not surprising because University texts are generally written in Spanish. All comparisons between the two groups on the frequency-of-language-use variable were significant.
Materials
A total of 160 word pairs were selected as the critical items for the experiment. Each word pair consisted of a word in Spanish or in Catalan and its corresponding translation in the other language. For half of the 160 word pairs (80) the Spanish word was presented first followed by its translation in Catalan (e.g., cuchillo “knife” – ganivet), whereas for the other 80 word pairs, the order was reversed (Catalan–Spanish) (e.g., cop “hit” – golpe). In each of the two translation directions (Spanish–Catalan vs. Catalan–Spanish), 40 of the word pairs were cognate translations (e.g., regalo “present” – regal) and the other 40 were non-cognate translations (e.g., arena “sand” – sorra). Within each translation type (cognates vs. non-cognates), 20 of the word pairs had only one translation in the other language (from now on, one-translation items), and the other 20 had more than one translation (hereafter multiple-translation items). Because the task used in the experiment was translation recognition, it was necessary to determine which of the possible translations provided in the translation questionnaire was going to be presented in the case of multiple translations. Within the multiple-translation set (40), half of the words were presented with the dominant translation and the other half with one of their subordinate translations. Thus, each of these words appeared only with one of its translations (i.e., dominant or subordinate).
An additional 160 unrelated word pairs were included as filler items (i.e., “NO” responses), half of them (80) were used in the Spanish–Catalan direction (e.g., enchufe–teulada “socket”–“roof”) and the other half (80) in the Catalan–Spanish direction (e.g., angoixa–edición “anguish”–“edition”). Thus, overall 50 percent of the items were correct translations (“YES” responses), and the other 50 percent were unrelated pairs (“NO” responses).
Multiple-translation norms
In order to determine the number of translations of each word, we used the same procedure as Tokowicz et al. (Reference Tokowicz, Kroll, de Groot and Van Hell2002) and Prior et al. (Reference Prior, MacWhinney and Kroll2007). Initially, we selected a list of 109 Spanish words and 110 Catalan words using a Spanish–Catalan dictionary. We included both cognate and non-cognate translation pairs with one and multiple translations. A questionnaire including these two lists of words was prepared. Twenty-six participants (different from those who participated in the experiment) were asked to write down the first translation that came to their minds. Thus, each participant provided one translation for each of the words from the two lists. The words that received at least two different correct translations were classified as multiple-translation items, whereas the words translated in all cases with the same word into the other language were classified as one-translation items. Although this is a procedure typically used to select materials for oral translation, we considered it equally valid for the translation recognition task used in the present study.
Experimental conditions
All of the 160 translation pairs were used as critical items in the experiment. The manipulation of cognate status, number of translations and translation dominance resulted in six experimental conditions in each language direction (see Table 2 for examples of each of the translations). However, the last of these variables, translation dominance, affected only multiple-translation pairs so it was not included as a factor in the main ANOVA.
Table 2. Examples of one-translation and multiple-translation pairs including dominant and subordinate translations. The word pairs presented in the experiment are written in uppercase, and the alternative translation that was not presented is showed in lowercase in brackets.

Table 3 presents the mean length (in number of letters) and mean word frequency (expressed as the logarithm of the direct value) corresponding to items in each experimental condition for both language directions. Frequency of the Spanish words was taken from B-Pal (Davis & Perea, Reference Davis and Perea2005) and frequency of the Catalan words was taken from the dictionary of the Institut d'Estudis Catalans (Rafel, Reference Rafel1998). Since the size of the corpus from which frequency values were taken was different for Catalan and Spanish, the Catalan frequency values were transformed to the same scale of the Spanish ones in order to be directly comparable.
Table 3. Mean length (number of letters) and (log) mean frequency of the word pair in the two translation directions for each experimental condition. Standard deviations are presented in brackets. Data from the two words of the pair are given.

For the one-translation and the multiple-translation words, length and frequency were matched for the second word of the pair across the two conditions. It was not possible to match frequency between cognates and non-cognates since the multiple-translation cognates in our set of materials were systematically more frequent than the non-cognates. However, our main concern was to test whether the multiple-translation effect was present for cognates and non-cognates rather than study the cognate effect by itself. Length and frequency comparisons between one- and multiple-translation conditions within each translation type in each translation direction revealed only one significant difference in the case of length in cognates in the Catalan–Spanish direction (5.65 vs. 4.55 for one and multiple translations, respectively) (t(1,32.8) = 3.405; p < .01). The other comparisons did not show significant differences.
Procedure
A translation recognition task was used in which the two words to be translated appeared sequentially on the screen. Participants were asked to decide whether the second word was a correct translation of the first word. Participants indicated their decision by pressing one of two response buttons, using their preferred hand for “YES” responses. As the participant pressed a foot-switch connected to the computer, a fixation point appeared on the screen for 500 ms. The fixation point was immediately followed by a Spanish or Catalan word displayed for 500 ms. Then the first word disappeared and a word in the other language (Catalan or Spanish) appeared for 500 ms. Both words were presented in uppercase. Reaction times were recorded to the nearest millisecond from the onset of the second word. The order of presentation of the items was randomized for each participant. The display of the stimuli and recording of reaction times and error percentages were controlled by the DmDX program (Forster & Forster, Reference Forster and Forster2003).
After responding to the items in one language direction, participants took a short break and then they responded to the items in the other language direction. Language direction order was counterbalanced. Both parts of the experiment were preceded by a practice block of eight items.
Results
The data corresponding to incorrect responses were discarded from the analysis. Response times that were more than two standard deviations above or below the mean for a given participant in all conditions were trimmed to the appropriate cutoff values in order to moderate the influence of outliers (this affected 4.2% of the data). Data from participants who had an error rate above 15% and any item with an error rate above 65% were removed from the analyses (this resulted in the exclusion of two participants and nine items). The mean response times and percentage of errors across the six experimental conditions are shown in the Table 4 for the Spanish–Catalan direction, and in the Table 5 for the Catalan–Spanish direction.
Table 4. Mean response times in milliseconds (RTs) and percentage of errors (%E) for both cognate and non-cognates as a function of number of translations and translation dominance in the Catalan–Spanish direction for both groups of participants.

Table 5. Mean response times in milliseconds (RT) and percentage of errors (%E) for both cognate and non-cognates as a function of number of translations and translation dominance in the Spanish-Catalan direction for both groups of participants.

We performed an analysis of variance (ANOVA) with data from the two translation-direction conditions on the response times and error data. These analyses included four factors with two levels each: cognate status (cognate vs. non-cognate), number of translations (one vs. multiple), translation direction (Spanish–Catalan vs. Catalan–Spanish), and language dominance (Spanish vs. Catalan). The first three factors were repeated measures in the analysis by participants and independent measures in the analysis by items. The fourth factor was between subjects in the analysis by participants and within subjects in the analysis by items.
Analyses on response times revealed that participants were faster performing translation recognition on cognates than on non-cognates (F 1(1,36) = 119.74; p < .01 and F 2(1,143) = 82.28; p < .01) and one-translation pairs than multiple-translation pairs (F 1(1,36) = 141.11; p < .01 and F 2(1,143) = 52.344; p < .01). Translation direction did not affect response times (F 1(1,36) = 1.73; p > .05 and F 2(1,143) < 1). The effect of language dominance was not significant by participants (F 1(1,36) < 1), but it reached significance by items (F 2(1,143) = 18.44; p < .01). No interactions reached significance. Error data analyses revealed a similar pattern of results: a significant effect of cognate status (F 1(1,36) = 42.83; p < .01 and F 2(1,143) = 28.52; p < .01) and multiple translations (F 1(1,36) = 33.02; p < .01 and F 2(1,143) = 41.13; p < .01), while translation direction was not significant (F 1(1,36) = 1.40; p > .05 and F 2(1,143); p < 1). Contrary to response times results a significant effect of language dominance was found (F 1(1,36) = 7.12; p < .05 and F 2(1,143) = 11.14; p < .01). Interactions between language dominance on the one hand and translation direction (F 1(1,36) = 24.27; p < .01 and F 2(1,143) = 4.581; p < .05) and cognate status (F 1(1,36) = 10.59; p < .01 and F 2(1,143) = 16.53; p < .01) on the other were significant. Two different three-way interactions were found between cognate status, translation direction and language dominance (F 1(1,36) = 31.79; p < .01 and F 2(1,143) = 6.32; p < .05); and between cognate status, number of translations and language dominance (F 1(1,36) = 5.86; p < .05 and F 2(1,143) = 5.12; p < .05). Moreover, the interaction between the four factors included in the analysis was significant too (F 1(1,36) = 19.05; p < .01 and F 2(1,143) = 5.54; p < .05).
Although the pattern of results is virtually the same for response times and accuracy, some differences can be observed. The main difference regards the role of language dominance on the pattern of effects. While response times were not affected by participants’ language dominance (Catalan or Spanish), participants committed a greater number of errors when they were Spanish dominants than when they were Catalan dominants. One possible factor that could contribute to the differences in the pattern of the accuracy data is that the Spanish dominant bilinguals may be slightly less balanced than the Catalan dominant ones. If this were the case, Catalan words may be less frequently used (i.e., less familiar) by the Spanish dominant group than the Spanish words by the Catalan dominant group, increasing the probability to make an error when making the decision during the translation recognition process.
To summarize, the results show that both cognate status and number of translations had a reliable effect on participants’ responses. On the one hand, translation recognition in cognate translations was faster and more accurate than in the non-cognate translations. However, it is important to note that cognates used as experimental materials were systematically more frequent than non-cognates, thus suggesting that the cognate effect may be confounded by a frequency difference between cognates and non-cognates. On the other hand, translation recognition for words with multiple translations was slower and less accurate than for words with a single translation. The lack of an interaction between these two factors indicates that multiple translations affect both cognate and non-cognate words similarly although the effect of multiple translations seems to be higher in non-cognates in comparison with cognates. Translation direction does not seem to have any effect on response times or error rates so that participants responded equally to materials in the Catalan–Spanish direction as they did to the Spanish–Catalan direction. Language dominance does not seem to affect response times but it seems to have an important role in accuracy data.
Because the pattern of results was virtually the same for both groups, we opted to collapse the variable language dominance and present the results considering participants as one group. Figures 3 and 4 present mean response times and percentage of errors for each language direction, as a function of cognate status and number of translations collapsed across the two dominant groups.

Figure 3. Response times (RTs) as a function of number of translations and translation status in both directions. The four bars of each direction correspond to the mean RT for each experimental condition.

Figure 4. Percentage of errors in both translation directions, as a function of number of translations and translation status. The four bars of each group correspond to the mean accuracy data for each experimental condition.
Dominance of the translation
As commented above, within the multiple-translation pairs, in half of the trials the dominant translation was presented whereas in the other half one of the subordinate translations appeared. Because this distinction affects only half of the materials, we did not include this variable as a factor in the ANOVA. Instead, we conducted planned comparisons to examine the effect of this variable. Considering that the pattern of results of the two participants’ groups was virtually identical in the two translation directions, comparisons were made collapsing language dominance and translation direction.
When comparing response times of one-translation words with those of multiple dominant translations, the difference was significant both in cognates (t 1(1,37) = 5.80; p < .01 and t 2(1,60) = 3.66; p < .01), and in non-cognates (t 1(1,37) = 7.89; p < .01 and t 2(1,58) = 3.51; p < .01). Comparisons between one-translation and multiple subordinate words were significant in both cognates (t 1(1,37) = 8.45; p < .01 but t 2(1,56) = 5.42; p < .01) and non-cognates (t 1(1,37) = 10.77; p < .01 and t 2(1,49) = 5.83; p < .01). Finally, comparisons between multiple dominant and subordinate words reached statistical significance in cognates (t 1(1,37) = 4.39; p < .01 but t 2(1,38) = 1.98; p = .055) and non-cognates (t 1(1,37) = 5.57; p < .01 and t 2(1,29) = 2.25; p < .05).
Error data analyses showed a similar pattern of results. When looking into error rates participants committed the same amount of errors when performing translation recognition for one-translation and multiple dominant translations within cognate translations (t 1(1,37) = 1.42; p > .05 and t 2(1,60) = 1.70; p > .05) but they were less accurate with non-cognates (t 1(1,37) = 4.20; p < .01 and t 2(1,58) = 2.40; p < .05). Participants were more prone to commit errors when performing translation recognition for multiple subordinate translations than for one-translation words in both cognates (t 1(1,37) = 8.02; p < .01 and t 2(1,56) = 7.00; p < .01) and non-cognates (t 1(1,37) = 5.55; p < .01 and t 2(1,49) = 4.46; p < .01). Differences between dominant and subordinate multiple translations were significant in cognates (t 1(1,37) = 7.55; p < .01 and t 2(1,38) = 4.74; p < .01), but in non-cognates they only reached statistical significance in the analysis by participants (t 1(1,37) = 3.15; p < .01 but t 2(1,29) = 1.70; p > .05).
Planned comparisons on translation dominance showed that the multiple-translation disadvantage on response times arises even when comparing one-translation pairs with multiple dominant ones. The effect is even more obvious when comparing one-translation pairs with the multiple subordinate translations, as expected. Moreover, the comparisons between response times to dominant and subordinate translations were significant, thus indicating that translation recognition was slowed down when participants responded to the subordinate translations. Similarly to response time data the accuracy data seem to point out the relevance of translation dominance. Participants committed more errors during translation recognition in multiple dominant translations than to one-translation words (except in cognates). Moreover, the difference between dominant and subordinate multiple-translation pairs was significant (except for the analysis by items for the non-cognates).
Concreteness
Although, as commented above, we could not systematically manipulate concreteness of our items due to material selection restrictions, we performed a post-hoc analysis to examine the possible influence of this variable in the pattern of results. We obtained concreteness values for the words included in the experiment as experimental items by means of a questionnaire in which 22 participants (different from the participants who took part in the experiment and from those who completed the translation questionnaire) evaluated the concreteness of these words on a scale from 1 to 7 (on which 7 indicated the highest concreteness). The average score of the 22 participants for each word was considered as the concreteness value for that word.
Previous evidence has shown that concreteness and number of translations do not independently affect translation performance. In a normative study, Tokowicz et al. (Reference Tokowicz, Kroll, de Groot and Van Hell2002) reported a correlation between these two variables suggesting that abstract words tend to have more translations than concrete words. More recently, using an oral production task, Tokowicz and Kroll (Reference Tokowicz and Kroll2007) found that concreteness interacted with number of translations, so that only abstract words showed the multiple-translation effect. On the basis of these findings, these authors suggest the possibility that these two variables might have been confounded in the materials’ selection of previous studies. In order to determine whether concreteness was modulating the multiple-translation effect obtained in our translation response times, an analysis of covariance (ANCOVA) was performed with the mean response times. Cognate status (cognate or non-cognate) and number of translations (one or multiple) were entered as classification variables, and the concreteness value for each word was entered as covariate. A preliminary analysis evaluating the homogeneity-of-regression assumption indicated that the relationship between the covariate (concreteness) and the dependent variable (response times) did not differ significantly as a function of cognate status (F(1,150) < 1) and number of translations (F(1,150) = 1.11; p > .05). The analyses revealed that the effect of multiple translations remained significant (F(1,150) = 55.51; p < .01), as well as the cognate status effect (F(1,150) = 89.47; p < .01). Moreover, in line with previous studies, the analyses also showed that concrete words were responded to faster than abstract words (F(1,150) = 4.54; p < .05). These results suggest that none of the reported effects in the present study seem to be attributable to concreteness.
General discussion
The main aim of the present study was to examine the effect of multiple translations on translation recognition performance using cognate and non-cognate translation pairs. The results showed that translation recognition was slower and less accurate for words with more than one translation in the other language than for words with a single translation in the other language and this difference was observed in both cognates and non-cognates, regardless of the participants’ language dominance and translation direction. Moreover, data on translation dominance revealed that the translation recognition of dominant translation pairs was faster and less prone to errors than subordinate ones.
Regarding the multiple-translation effect, our pattern of results is in line with previous studies that have used both translation recognition (Laxén & Lavaur, Reference Laxén and Lavaur2010; Sánchez-Casas et al., Reference Sánchez-Casas, Suárez and Igoa1992b) and oral translation tasks (Tokowicz & Kroll, Reference Tokowicz and Kroll2007). As mentioned earlier, within the framework of the DRM (de Groot, Reference de Groot, Frost and Katz1992b) this difference can be explained in terms of number of shared semantic nodes between the representations of the words involved in the translation pair. When a word in one language is always translated in another language by the same word (i.e., one-translation cases), the proportion of shared nodes between the meaning representations of the two words will be maximal. On the contrary, when a word has more than one translation in another language, the semantic representation of the first word will share only part of its meaning with each of its possible translations. Thus, the proportion of shared semantic nodes will always be lower for multiple-translation pairs than for one-translation pairs. Additionally, the ambiguous word would have a more complex semantic representation expressed in a larger number of nodes, one subset for each different meaning, and the activation received from the conceptual to the lexical level would be spread over a larger number of nodes. For instance, the Spanish word silla shares its complete meaning with the Catalan word cadira “chair”, as one is the unique translation of the other. By contrast, the Spanish word muñeca can be translated into Catalan both by nina “doll” and canell “wrist”. If we assume that meaning is represented as a set of semantic nodes, silla and cadira will share all their nodes, facilitating the translation recognition process. On the contrary, in the case of muñeca, the meaning of each possible translation will be represented as a subset of semantic nodes so that the activation will be distributed over a larger number of nodes hindering the translation recognition process. At the same time, the proportion of shared nodes between the meaning of the ambiguous word muñeca and each one of its translations will be lower than in the one-translation cases.
In contrast, the presence of a multiple-translation effect in both cognate and non-cognate words is not consistent with the only study that has compared the two types of words. In Sánchez-Casas et al.'s (Reference Sánchez-Casas, Suárez and Igoa1992b) study a reliable number of translations effect was found for non-cognate but not for cognate words, whereas we have now found evidence of this effect for both types of translations. However, it is important to note that there was a trend in Sánchez-Casas et al.'s study for cognates with multiple translations to be recognized more slowly than unambiguous cognates although the difference did not reach statistical significance. Similarly, there is a trend in the present study suggesting that the magnitude of the multiple-translation effect may be higher for non-cognates than for cognates. At this point, it is not clear to us why the results from the two studies are not the same. However, there are methodological differences across the studies that may be important to consider in further research in order to provide an answer to this question. For instance, the type of bilinguals (more balanced in our case), the material used (Sánchez-Casas et al.'s multiple-translation words were all ambiguous in each language of the bilingual, whereas this was not always true in our multiple-translation set), or the language pairs tested (in contrast to Spanish and English, Catalan and Spanish are both Romance languages with a high degree of orthographic and phonological similarity and they are in very close contact in everyday life).
In relation to the influence of the variable translation dominance, our results also showed that translation recognition was performed faster and more accurately for one-translation pairs than for dominant and subordinate ones in both cognate and non-cognate words, supporting the conclusion that cognates and non-cognates behave similarly in this task. More importantly, translation recognition was faster for dominant pairs than for subordinate pairs. This pattern of results is in the same line as that reported by Laxén and Lavaur (Reference Laxén and Lavaur2010), the only study to our knowledge that examined the effect of dominance of translation. In the two studies, the fastest and most accurate responses were given to one-translation pairs and the responses to multiple-translation pairs were modulated by translation dominance.
In order to account for the role of translation dominance in translation within the framework of the DRM, Laxén and Lavaur (Reference Laxén and Lavaur2010) have suggested that dominant translations would share more semantic nodes than subordinate ones with their translation equivalent. This suggestion is based on the proposal that translation response times and accuracy depend on the degree of semantic overlap (i.e., number of shared nodes). That is, the more nodes shared by the representations of two words, the greater the activation at the semantic level. As mentioned in the introduction, a proposal in these terms implies that the more translations a word has, the less the semantic overlap between each of them and its translation. However, it is unclear why a word would share more nodes with its dominant translation than with each of its subordinate translations. The dominance of the translation is established on the basis of the preference of participants choosing one or another possible translation. For instance, if we take the Catalan ambiguous word set, the Spanish translation given as dominant is sed “thirst” whereas the subordinate translation is siete “seven”. According to Laxén and Lavaur, this preference (which is reflected in faster and more accurate response times for the dominant translation, set–sed) would be due to the greater number of semantic nodes shared by set and sed in comparison to set and siete (see Figure 5). If such an interpretation was true, and sed and siete are correct translations of set, it would be necessary to determine why the semantic overlap (number of nodes) is not the same in both cases. An alternative explanation within the framework of the DRM would be to consider the translation dominance effect as a frequency effect; that is, the dominant translation is determined by the frequency with which one word is translated into the other (see Figure 6). Because words’ meanings are suggested to be represented as a set of semantic nodes in a connectionist-like network (e.g., McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Plaut, Reference Plaut1997; Seidenberg & McClelland, Reference Seidenberg and McClelland1989), it could be the case that links from the lexical level to these nodes are more or less strong depending upon the frequency with which this link has been activated. In other words, translation dominance might be explained in terms of lexical-to-semantic connection strength rather than in terms of number of shared nodes at the semantic level. De Groot (Reference de Groot, Frost and Katz1992b) already stated in the original formulation of the DRM that it is very unlikely that every semantic effect might be explained in terms of proportion of overlapping semantic nodes. Alternatively, this author proposed that the locus of some semantic effects will be found in the connections between the lexical and the semantic level instead of in the number of nodes involved.

Figure 5. Representation of dominance of translation in terms of number of shared nodes as proposed in Laxén and Lavaur (Reference Laxén and Lavaur2010). As can be seen, the dominant translation shares four of six semantic nodes whereas the subordinate translation only shares two semantic nodes. Adapted from DRM (de Groot, Reference de Groot, Frost and Katz1992b).
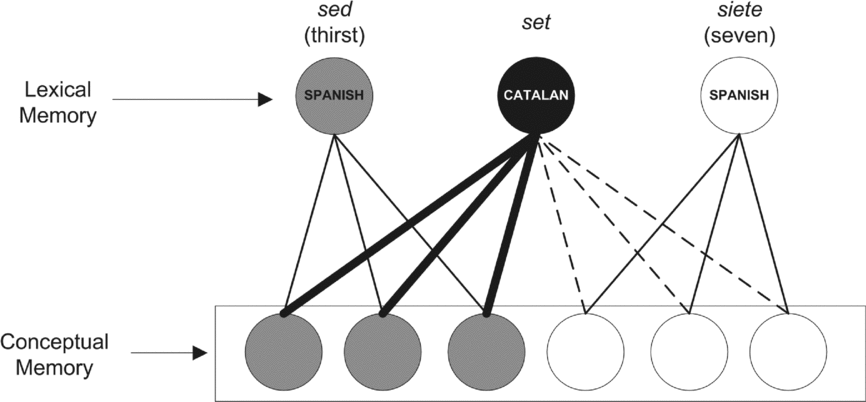
Figure 6. Representation of dominance of translation in terms of connection strength as proposed in the present study. Both translation possibilities share the same number of nodes, but connections from lexical to semantic level are stronger in the dominant than in the subordinate translations, as is represented by the stronger lines in the figure. Adapted from DRM (de Groot, Reference de Groot, Frost and Katz1992b).
One of the novel aspects of this study in comparison to previous ones was to test participants who were highly proficient in both Catalan and Spanish and used both languages on a daily basis. Although they can be considered as balanced bilinguals in terms of proficiency, they are dominant in one of the languages. As the results have clearly shown, our participants’ translation performance is the same regardless of translation direction (L1–L2 vs. L2–L1) and language dominance (Spanish or Catalan). This pattern of results seems to suggest that language dominance in terms of language use per se is not relevant for word translation when proficiency is high in both languages and participants are immersed in a completely bilingual environment.
Finally, another interesting finding concerns the effect of concreteness. As mentioned previously, concrete concepts label physical objects in the word and tend to be less culture-dependent than abstract concepts, leading concrete concepts to have fewer translations. Evidence supporting the idea that concrete and abstract words differ with respect to number of translations has been reported by Tokowicz and colleagues. In their normative study, Tokowicz et al. (Reference Tokowicz, Kroll, de Groot and Van Hell2002) found that the more abstract a word was, the more translations it had. Using an oral translation task, Tokowicz and Kroll (Reference Tokowicz and Kroll2007) reported that number of translations only slowed down translation performance in the case of abstract words. On the basis of these findings, these authors have suggested the possibility that the effect of number of translations may be a consequence of the concreteness status of the word and that these two variables are not independent. However, the pattern of results is not the same when the translation recognition task is used. Laxén and Lavaur (Reference Laxén and Lavaur2010) found that the number of translations effect was present both in concrete and abstract words, and this is also the case in the present study, where we did not find evidence that concreteness affected number of translations effect. Nevertheless, it should be noted that the failure to find an interaction between these variables does not imply that they are not related, as Tokowicz et al.'s (2002) normative data suggest. On the other hand, although the evidence suggests that oral and translation recognition tasks are both sensitive to semantic manipulations (e.g., de Groot & Comijs, Reference de Groot and Comijs1995), the processes underlying the two tasks are not the same. Although the two tasks require participants to manage competition between possible translations as well as to inhibit the ones that are no longer relevant, they differ in important respects. For instance, while the translation recognition task includes an additional decision stage, where participants must compare the suggested translation displayed on the screen (second word) with the possible translations that the previously presented word (first word) activated, the oral translation task does not involve any decision process, but it requires participants to search for and select a single word to be produced as an appropriate translation. Further research needs to be carried out to explore how these and other differences might determine how and when variables such as concreteness and translation dominance can affect translation of ambiguous words.
Conclusion
The present study shows that both number of translations and translation dominance influence bilingual performance in translation recognition, and that such an influence is not modulated by cognate status, language dominance or translation direction. In principle, this set of findings can be accounted for within the framework of the DRM, by assuming that the overlap at the semantic representation level is smaller with multiple-translation words and that the frequency of use of one or the other translation (i.e., translation dominance) changes connection weights among nodes. Further experiments need to be performed to examine why concreteness affects oral translation and translation recognition tasks differently.











