

1. INTRODUCTION
Relevance, in the broadest sense and according to the Oxford English Dictionary (OED), is a term used to describe “Connection with the subject or point at issue; relation to the matter in hand.”Footnote 3 In everyday language, it is used to describe the effectiveness of information in a given context as described by Saracevic.Footnote 4 In information retrieval (IR), the theory of relevance has several dimensions, including algorithmic relevance, topical relevance, cognitive relevance, situational relevance, motivational relevance, and, in particular for legal information retrieval, bibliographic relevance (as described by Van Opijnen and Santos in 2017).Footnote 5
The practice however, is that legal IR systems rely heavily on matching the text of the query with the text of the documents (algorithmic and topical relevance).Footnote 6 As BarryFootnote 7 pointed out, this may lead to poor user satisfaction.
Park suggested that users of (legal) IR systems have implicit criteria for the relevance/value judgments about documents presented to them.Footnote 8 This is supported by anecdotal evidence from employees of Legal Intelligence, one of two large legal content integration and information retrieval systems in the Netherlands. Users of the Legal Intelligence system have reported a preference for documents with certain characteristics over others, for example a preference for recent case law over older case law and case law from higher courts over case law from lower courts; sources which are considered authoritative (government publications) over blogs or news items, well-known authors over lesser-known authors, and/or the official version (case law or law) over reprints.
Van Opijnen and Santos describe a form of relevance that they call domain relevance, as “relevance of information objects within the legal domain itself (and hence not to ‘work task or problem at hand’).”Footnote 9 They relate domain relevance to the socio-cognitive relevance as defined by Cosijn and Ingwersen: “Socio-cognitive relevance is measured in terms of the relation between the situation, work task or problem at hand in a given socio-cultural context and the information objects, as perceived by one or several cognitive agents.”Footnote 10 Until now, the implicit criteria as mentioned by Park,Footnote 11 the domain relevance by Van Opijnen and Santos,Footnote 12 and anecdotal evidence from the Legal Intelligence users have not been connected to each other or studied systematically with users of legal IR systems.
Cosijn and Ingwersen stated that “It is interesting to note that some central aspects of socio-cognitive relevance are tangible.”Footnote 13 In this paper, we present the result of a user study investigating these tangible document characteristics (Saracevic's manifestations of relevanceFootnote 14) of domain relevance in legal IR, bridging that gap.
We focus on domain relevance because situational relevance and cognitive relevance are difficult to incorporate in legal IR systems, as the task and cognitive state of the users is usually not known. But if domain relevance is indeed shared between users, manifestations thereof may be used by legal IR systems to improve the relevance of their ranking, as suggested in the work of Cool et al from 1993.Footnote 15
The First International Workshop on Professional Search, held at SIGIR in 2018Footnote 16 described professional search as “professional search takes place in the work context, by specialists, and using specialist sources, often with controlled vocabularies.” This definition covers people from multiple domains, including librarians, scholars, lawyers and other knowledge work professionals. In the context of users of legal IR systems this includes professions such as lawyers, judges, government employees, legal information specialists and legal scholars. Experts in IR rather than law, such as professional support lawyers and information specialists, may, by the nature of their role, have a different perspective of relevance. A professional support lawyer (PSL) or information specialist retrieves information for a third person rather than themselves and will likely focus on completeness of the information, not being aware of the cognitive state of the client. A legal professional, however, searching for themselves will likely focus only on information that is new to them. From this different perspective, they may have a different perception of relevance.Footnote 17
In this paper we will distinguish three sub-groups of users: (a) legal information specialists; (b) legal scholars; and (c) legal practitioners. When referring to the overarching group of users, we will use the term legal professionals. Next to determining shared relevance factors between individual users, we will also investigate whether these different user sub-groups show agreement on domain relevance factors in the context of judging search results.
We conducted the study with users of the Legal IntelligenceFootnote 18 system, following Park, who argued that it is important to test with real users of the information retrieval system.Footnote 19 We address the following research questions: (1) To what extent can we demonstrate the existence and factors of domain relevance in the context of judgment of search results (document representation) in legal IR systems? (2) To what extent do legal information retrieval specialists, legal scholars and legal practitioners show agreement on relevance factors outside of a task context?
In answering these questions, this paper's contributions compared to previous work are: (1) we conducted a user study with professional users of a legal IR system to research the validity of the concept of domain relevance as described by Van Opijnen and Santos in 2017 in practice and its possible applications in legal IR systems;Footnote 20 (2) using a statistical analysis we demonstrate that sub-groups of users of legal IR systems (legal information specialists, legal scholars and legal professionals) show agreement on relevance factors outside of a task context, when judging search results (document representations) in legal IR.
2. BACKGROUND
Our research is done in the context of the theory of relevance as described by Saracevic in both 1975 and 1996.Footnote 21 He defines four research issues regarding relevance: the nature, manifestations, behavior and effects of relevance. Our research focuses on the manifestations of relevance; the different ways in which relevance manifests itself to users in legal IR systems. Saracevic also calls this “clue research”, “uncovering and classifying attributes or criteria that users concentrate on while making relevance inferences.”Footnote 22 These clues are described as attributes, criteria or factors of relevance, depending on the author. In the context of this paper, we will use the term ‘factors’.
Saracevic describes five types or spheres of relevance in which the manifestations can be grouped: algorithmic relevance, topical relevance, cognitive relevance, situational relevance and motivational/affective relevance.Footnote 23 Van Opijnen and Santos apply these spheres of relevance to the legal domain and developed a schema with six spheres of relevance, shown in figure 1.Footnote 24

Figure 1 Relevance schema of Van Opijnen and Santos.Footnote 27
Algorithmic relevance, sometimes called systemic relevance, is the degree to which the terms in the result match the terms in the query.Footnote 25 This dimension focuses solely on the relation between the query and the document, not on the user.
Topical relevance, which has also been referred to as ‘aboutness’,Footnote 26 moves beyond the query and the document, to the topic. An example would be that a query containing the term ‘trust’ in legal IR refers to a type of agreement involving three parties, rather than a belief that something or someone is good, and returning documents accordingly.
Van Opijnen and Santos add bibliographical relevance to the list of Saracevic. Bibliographical relevance is the relation between the document searched for, and the document retrieved, also described as ‘isness’. This is especially relevant for the retrieval of known documents. What makes legal IR interesting, is that it is not only about finding information about something, but that there can be an important legal difference between two documents holding the same information. For example, the officially published version of a law in the United States Statutes at Large or the Official Journal of the European Union, and a reprint of that same law.Footnote 28
Van Opijnen and Santos, following Cosijn and Ingwersen,Footnote 29 do not include Saracevic's affective relevance in their schema, but add domain relevance. This is chosen as their representation of Cosijn and Ingwersen's socio-cognitive relevance, who describe it as “socio-cognitive relevance is measured in terms of the relation between the situation, work task or problem at hand in a given socio-cultural context and the information objects, as perceived by one or several cognitive agents. It encompasses the system, a group of individual users or agents, and the socio-organisational environment.”Footnote 30 Van Opijnen and Santos take this to mean “relevance of information objects within the legal domain itself (and hence not to ‘work task or problem at hand’)”.Footnote 31 They describe this as “the relation between the legal crowd and information objects” with “legal importance” as criterion for success.Footnote 32
Cognitive relevance focuses on the relation between the cognitive state and information need of the user and the document. It is unique to the user and the specific point in time, as it encompasses factors like informativeness, quality and novelty.Footnote 33
Situational relevance as described by Saracevic as “…relevance to a particular individual's situation – but to the situation as he sees it, not as others see it, nor as it really is.”Footnote 34 Van Opijnen and Santos describe it as the relation between the documents and the work task of the user. Situational relevance plays a role in domain-specific search, because relevance in specific domains depends on the expertise and context of the searcher as observed by Ingwersen and Järvelin.Footnote 35
Our research explores which document characteristics (Saracevic's manifestations of relevanceFootnote 36) reflect domain relevance when judging the relevance of search results in legal IR. This is inspired by the work of Cool et al from 1993,Footnote 37 so as to focus on factors of relevance that are “representable and usable in the support of information interaction/retrieval”; meaning that these factors can be used by the developers of legal IR systems to improve their ranking. It is also inspired by the work of TomsFootnote 38 with regard to relating relevance factors to spheres of relevance. It is likely that a relevance judgment based on document representations (in our research title and publisher curated summary) differs from the relevance judgment upon reading the entire document.Footnote 39 Because the document representation is what the user bases their judgement whether to open the document on, our research focuses on the document representation, and we use the term ‘perceived’ relevance.Footnote 40
Van Opijnen and Santos divide domain relevance into two sub-groups: (a) the legal importance of classes of information objects, and (b) the legal importance of individual information objects. An example of the legal importance of classes of information objects are the prevalence of the constitution over other types of laws, and verdicts from the Supreme Court which have more legal authority than verdicts from lower courts. The legal importance of individual information objects is more difficult to describe in manifestations of relevance, but can for example be established through citation analysis.
Prior research has identified relevance factors, manifestations of the spheres of relevance. Rieh and BelkinFootnote 41 addressed the user's perception of quality and authority as relevance factors. They identified seven different factors of information quality: source, content, format, presentation, currency, accuracy, and speed of loading; and two different levels of source authority: individual and institutional. Savolainen and Kari found in an exploratory study that specificity, topicality, familiarity, and variety were the four most mentioned factors in user-formulated relevance judgments, but there was a high number of individual factors mentioned by the participants.Footnote 42 This research has been expanded upon by Taylor in various articles.Footnote 43
Previous research on factors of relevance in the context of professional search has been done by, amongst others, Cuadra and KatterFootnote 44 and Rees and Schultz,Footnote 45 who examined judgements by expert reviewers. Barry, in 1994,Footnote 46 expanded on this research by inviting users (rather than expert reviewers) to submit a request for unknown or unfamiliar information,Footnote 47 for which she retrieved documents. The results lists were presented to the participants, who were asked to review whether they would or would not pursue the documents contained in the list. The study was done using an open-ended interview technique, to generate a complete overview of relevance factors. Barry identified 23 categories of relevance factors, grouped into seven classes:Footnote 48
• the information content of documents: depth/scope, objective accuracy/validity, tangibility, effectiveness, clarity, recency;
• the sources of documents: source quality, source reputation/visibility;
• the document as a physical entity: obtainability, cost;
• other information or sources within the environment: consensus, external verification, availability within the environment, personal availability;
• the user's situation: time constraints, relationship with author;
• the user's belief and preferences: subjective accuracy/validity, effectiveness;
• the user's previous experience and background: background/experience, ability to understand, content novelty, source novelty, stimulus document novelty;
Barry distinguishes between “tangible characteristics of documents”, subjective qualities and situational factors; Schamber, (in Barry and Schamber, 1998),Footnote 49 conducted structured time-line interviews with users searching for weather information. Schamber identified 22 categories of relevance factors, grouped into ten classes:
• accuracy;
• currency: time frame;
• specificity: summary/interpretation, variety/volume;
• geographic proximity;
• reliability: expertise, directly observed, source confidence, consistency;
• accessibility: availability, usability, affordability;
• verifiability: source agreement;
• clarity: verbal clarity, visual clarity;
• dynamism: interactivity, tracking/projection, zooming;
• presentation quality: human quality, nonweather information, permanence, presentation preference, entertainment value, choice of format.
As opposed to the work of Barry and Schamber, the aim of our research is not to generate a complete overview of relevance factors that may possibly be considered, but to determine whether it is possible to identify relevance factors that can be classified as domain relevance, requiring a level of agreement between different (groups of) users to establish the legal importance/wisdom of the legal crowd as described by Van Opijnen and Santos. Furthermore, we investigate relevance in the legal domain, as opposed to general academic search and weather information.
3. METHODS
3.1 Study design
Previous studies addressing relevance factors conducted user observation studies with a thinking-aloud protocol or interviews, or a combination of both.Footnote 50 This research focuses on domain relevance. Based on the definition of Van Opijnen and Santos this encompasses two aspects: (1) a level of agreement between users, the ‘legal crowd’, and (2) it is not related to the task or problem at hand. An observation study with information needs submitted by the respondents is likely to also trigger responses related to situational and cognitive relevance. This is not desired in our case. And since observation studies are time consuming and therefore difficult to conduct with legal professionals, we decided to conduct a questionnaire.
The choice to use actual users rather than domain experts such as graduate students was influenced by Park.Footnote 51 A preliminary pilot questionnaire suggested that the target audience is not likely to complete a questionnaire that takes more than 12 minutes, because lawyers often bill per 6 minutes, and are unwilling to spend more than two billable units on a questionnaire. To ensure maximum response, we aimed to keep the questionnaire under 12 minutes.
3.1.1 Forced choice/relative relevance judgments
In the questionnaire respondents are shown an example queries and two search results and forced to make a choice between two options; a relative relevance judgment by indicating which of the two results they would like to see ranked higher than the other. We chose a method of forced choice/relative relevance scoring because research by Saracevic shows that the less a person knows about the subject, the more results they will mark as relevant (cognitive relevance), and that relative scoring (thereby limiting the effect of cognitive relevance) leads to more consistent results across respondents of different backgrounds than individual document scorings.Footnote 52
3.2 Participants
All users of the Legal Intelligence system were able to fill in the questionnaire. The questionnaire was made available online, so that respondents could fill it in at a moment convenient for them, to ensure maximum response. It was distributed to the national government and large law firms through their information specialists, and to all other users by a newsletter and a LinkedIn post. The questionnaire was brought to the attention of acquaintances who work in the legal field via email. We aimed for 50 responses, distributed over the different affiliation types, law area specialisms, and roles. The number of participants is more than in previous qualitative studies in professional search; for example, Schamber et al (in 1990) with 30 respondents,Footnote 53 Barry and Schamber (1998) with 18 respondents,Footnote 54 and Park (1993)Footnote 55 with 10 respondents. For our questionnaire type analysis (rather than the interviews of Schamber, Barry and Park), it is a feasible number.
3.2.1. Structure
The questionnaire consisted of three parts. The first part covered general questions regarding the legal field the respondent is active in, their function profile, and their level of expertise.
For each of the next two parts of the questionnaire, the respondents were shown an example search query. The respondents were first asked to indicate what information need they think the user is trying to fulfill by issuing this query. It is expected that because we use example queries rather than the users’ own information needs, respondents will focus on relevance factors from the algorithmic, bibliographical, topical and domain relevance spheres, rather than the cognitive and situational relevance spheres. This is in accordance with the aim of our research of finding relevance factors related to domain relevance. With this question we aimed to determine the extent to which cognitive and situational relevance played a role in the mind of the respondent.
Research has shown that the primitive/intuitive definition of relevance prevails when respondents are confronted with questions regarding relevance judgment.Footnote 56 For that reason, no formal definition of relevance was given in the questionnaire. In the introduction of the questionnaire some examples of factors were given.Footnote 57 To avoid leading the respondents, and to encourage respondents to consider all aspects from both results, these examples were not repeated alongside the questions.
3.3 Selection of stimuli
We manually selected two example queries from the query logs of the Legal Intelligence search engine (see appendix A). The example queries are shown to provide the context for the search results, and are broadly recognizable, so that all respondents will have an understanding of algorithmic, topical and bibliographical relevance of the search results (document representation) in relation to the query. To exclude query bias, all respondents are shown the same two queries.
The query along with two related search results, were shown as images from document representations as they are shown in the actual legal IR system. The interface of the pairwise choices is illustrated in figure 2.

Figure 2 A screenshot of the questionnaire. The example query is shown in the query field on top and the two search results (choices) are listed as ‘optie 1’ and ‘optie 2’ below the query.
3.3.1 Selection of search results
To make sure the forced choices/relative relevance judgments for the example queries encouraged critical thinking, we chose search results from the actual results list of the Legal Intelligence system. We chose two search results that differ on two of the relevance factors that are mentioned in the literature as relevance factors for (legal) IR (see section 2) that can be discerned from the information provided in the search result (document representation). We chose two search results where one has a higher score on the first factor and a lower on the second, and the other has a lower score on the first factor and a higher score on the second. The other factors are kept as similar as possible, given that the examples have to be chosen from actual search results. For the creation of these options, see appendix A.
By ensuring that the two search results differ on two factors while the other factors are as similar as possible, we aimed to avoid creating an ‘obvious’ choice and encourage users to describe their reasoning process.
3.3.2 Relevance factors
The factors used for the selection of the search results are selected from the literature (see section 2). We focus on factors of relevance that manifest themselves in the document representation (as shown on the result page), since the questionnaire does not include the document itself. To avoid bias by leading the respondents to answers demonstrating the existence of domain relevance and allow factors of algorithmic, topical and bibliographical relevance to be considered, these selection factors are not limited to expected factors of domain relevance, but encompass a broader scope of factors of relevance. In the setup of the questionnaire each possible relevance factor occurs multiple times (see appendix A). The factors used were:
• Recency:Footnote 58 it has been suggested that recent case law is more relevant than older case law (<2 years; 2–10 years; >10 years old), though recency can also be related to the specific period the case played in Van Opijnen and Santos,Footnote 59 in which case it would be situational relevance; Schamber's time frame factor;Footnote 60
• Legal hierarchy/importance:Footnote 61 case law from higher courts carries more weight than case law from lower courts (Supreme Court; courts of appeal; courts of first instance);
• Annotated:Footnote 62 annotated case law (providing context for the case) is more relevant than case law that is not annotated. Related to Schamber's factor of summary/interpretation;Footnote 63
• Source authority:Footnote 64 sources that are considered authoritative are preferred over other sources (government documents, leading publications; mid-range publications; blogs);
• Authority author:Footnote 65 documents written by well-known authors are considered more authoritative than other documents;
• Bibliographical relevance:Footnote 66 the official version (case law or law) is more relevant than reprints;
• Title relevance: results with search term in the title or summary are considered more relevant than results with the search term not in the title/summary (the visibility of algorithmic and topical relevance for respondents);
• Document type:Footnote 67 document types that pertain to the perceived information need are considered more relevant than other document types (depending on perceived information need expressed in the query as interpreted by respondent). Related to Schamber's presentation quality, especially the underlying factors of presentation; preference and choice of format.Footnote 68
The respondents were not informed for which relevance factors the paired results were chosen. The chosen factors were not mentioned explicitly in the questionnaire, to avoid leading respondents.
Where authoritative sources or authors are used in the examples, it was attempted to show sources and authors that are so generally known that respondents from other legal fields will likely recognize these names from their legal education, or can estimate it by the academic title of the author. It is assumed that the other factors used in the examples, such as whether a case is annotated, are valid for all legal fields.
Though the factors chosen to base the examples on are prominent in literature, they are by no means an exhaustive list. Nor do they have to be, since they are used as a tool to select good examples that encourage the respondent to think and describe their thought process. Respondents are given a free text field to give their own motivation for their choice.
Because of the time limit discovered during the pilot questionnaire, the number of queries is limited to two and it was not possible to show all possible combinations of factors. Each participant saw eleven pairs of search results spread over the two example queries. Because of the expected sample size, we presented all users with the same search results, to ensure enough data per question. Since the purpose of our research is to gather qualitative information to understand the factors that influence the perception of (domain) relevance, and the factors are inputted into the questions only to avoid an ‘obvious’ choice, the fact that not all combinations were tested does not limit the outcome of the research.
Likewise, because the research focuses on the factors that influence the choice, rather than the choice itself, there was no benefit in presenting the questions in a different order to different users.
3.4 Extracting and mapping relevance factors
Respondents could give a free text explanation for each of the forced choices. Often, these explanations contained one or more relevance factors, or a statement indicating the respondent had no preference. We manually aggregated and linked the free text explanations to the most similar relevance factors found in literature (see section 2), which include the factors used to select the options (see section 3.3.2), but also other factors mentioned by users.
-
Examples of the mapping include:
• Recency: ‘Newer’ or ‘Appears out of date’;
• Legal hierarchy: ‘Supreme Court higher than appeals courts’;
• Annotated: ‘Annotated case law is always relevant’;
• Authority: ‘Hartkamp is a well-known author’ or ‘If a verdict is reprinted in a journal it says something about the importance’;
• Bibliographical relevance: ‘Source instead of derivative’;
• Title relevance: ‘Doesn't show anything about the possible contents of the document’;
• Document type: ‘It's the law!’ or ‘explanatory memorandum not first thing to look at’;
• Level of depth: ‘General piece’ or ‘Good broad starting point’;
• Law area (topic): ‘Because it is civil law’;
• Usability: ‘More relevant information quickly’ or ‘Convenient source’;
• Document length: ‘Reports are often very long’ or ‘Option 2 would take more time to read’.
Some answers did not contain relevance factors. Either because none were given (eg. “duh”) or because the answer was too vague to extract relevance factors (eg ‘more relevant’). It was also possible for a single answer to mention multiple factors. An example is the response “Option 1 because it comes from a higher court. From option 2 the annotation is interesting.”Footnote 69 In four instances the respondent indicated “same answer as before.” In those instances, we looked at the response from the previous example and noted the same factor(s) as for the previous examples.
In the explanations, users regularly referenced authority, without mentioning whether they meant the authority of the source or the author.Footnote 70 This is related to Schamber's reliability factor, which covers both author and source.Footnote 71 Like Schamber we grouped the authority arguments. This led to a total of 11 main relevance factors which were mentioned at least once.
After the mapping, we counted for each participant the number of times each of the 11 relevance factors were mentioned. This counting was performed across all answers, since the individual questions were not of interest. This way we obtained a vector of 11 relevance factor frequencies for each participant.
Barry (in 1994),Footnote 72 Barry and Schamber (1998)Footnote 73 and Taylor et al. (2007)Footnote 74 group the relevance factors into types. Barry creates groups for factors pertaining to the information content, the user's background, the user's beliefs and preferences, other information in the environment, the sources of the document, the physical entity of the document, and the user's situation. Barry and Schamber also show an example of grouping into accuracy, currency, specificity, geographical proximity, reliability, accessibility, verifiability, clarity, dynamism, and presentation quality. These groups show similarities with the spheres of relevance, but are not the same.Footnote 75 To be able to see to what extent domain relevance can be demonstrated, and which relevance factors (manifestations) are related to it, we manually relate the found relevance factors to the six spheres of relevance mentioned in section 2.
Based on Van Opijnen and Santos, two conditions need to be met before relevance factors can be mapped to domain relevance (whether on information class level or individual document level): (1) there is a level of agreement between users, the ‘legal crowd’, and (2) the relevance factor is not related to the task or problem at hand as described in section 2. If respondents do not indicate a situational context for the example queries used in the questionnaire, the mapping of the relevance factors found to spheres of relevance can be done with the assumption that the method with which the data is gathered implies that factors mentioned are not related to task context. Similarly, since the query shown was an example rather than a query from the user themselves, the user is asked to take a step back from what they already know (their personal cognitive state). This means that factors like ‘novelty’ (whether the information is new to the user or not), which would be a factor of cognitive relevance, is less likely, as the user is not considering the information in relation to themselves, but to a hypothetical other user. Because the user is not relating their answers to themselves, but to this hypothetical other user, factors that would normally be grouped under cognitive relevance become a factor of domain relevance.
The mapping of the relevance factors is then done based on the schema shown in figure 3 using the following sequential steps:
• If the relevance factor is about the (perceived) ‘computational relationship between a query and information representation’:Footnote 76
◦ Then the relevance sphere is (perceived) algorithmic relevance.
• Else if the relevance factor is about the (perceived) ‘relationship between the ‘topic’ (concept, subject) of a request and the information objects’:Footnote 77
◦ Then the relevance sphere is topical relevance.
• Else if the relevance factor is about the ‘relationship between a request and the bibliographic closeness of the information objects’ (document ‘isness’):Footnote 78
◦ Then the relevance sphere is bibliographical relevance.
• Else:
◦ The relevance sphere is domain relevance.
For factors mapped to domain relevance according to the steps above, we will report additional information: (a) whether it constitutes domain relevance on the document class level or on the individual document level,Footnote 79 and (b) whether it would have been classified under situational, cognitive or domain relevance had the user given this answer in relation to a personal task. For this additional information we will use the following definitions:
• If the relevance factor is about ‘the relation between the information needs of a user and the information objects’:Footnote 80
◦ Then the relevance sphere is cognitive relevance.
• If the relevance factor is about ‘the relationship between the problem or task of the user and the information objects’:Footnote 81
◦ Then the relevance sphere is situational relevance.
• If the relevance factor is about ‘the relevance of information objects within the legal domain itself’:Footnote 82
◦ Then the relevance sphere is domain relevance.
Using these grouped and mapped factors, in the format of counts in the vector of 11 relevance factor frequencies for each participant, we conduct a statistical analysis.

Figure 3 An adaptation to the relevance schema of Van Opijnen and Santos to reflect the method using a perceived information request and the lack of cognitive and situational relevance.
3.5 Statistical analysis
To test whether sub-groups of users of legal IR systems differ on the factors of relevance they consider, we first grouped every respondent who reported their function or job title as legal information specialist, librarian, professional support lawyer or a function in knowledge management as legal information specialists. Next, those who reported their job title as scholar were grouped as legal scholars. All other job titles were grouped as legal practitioners.
We then calculated inter- and intra-group dissimilarity, and performed a permutational multivariate analysis of variance (PERMANOVA).Footnote 83 Classical MANOVA assumes multivariate normality, which is unrealistic given that our data consists of relevance factor frequencies. PERMANOVA is a semiparametric alternative to MANOVA that does not assume multivariate normality.Footnote 84 Briefly, the PERMANOVA procedure with one predictor variable is as follows: (1). Calculate a suitable measure of dissimilarity for each pair of respondents; (2). Calculate sums of squares attributed to differences among the groups (SSA), and differences within each group (SSW); (3). Calculate the pseudo-F statistic F = (SSA/SSW) ⋅ [(N −д)/(д − 1)], where N is the sample size and д the number of groups; (4). Perform a permutation test to obtain a p-value. PERMANOVA thus compares dissimilarities between individuals in different groups (SSA) with dissimilarities between individuals in the same group (SSW); if the ratio between the two quantities is sufficiently large, the null hypothesis of no difference between the groups will be rejected. The approach for situations with more than one predictor variable is similar, with sums of squares attributed to each variable; for a detailed description of the PERMANOVA method we refer to M.J. Anderson's article from 2017 relating to “permutational multivariate analysis of variance.”Footnote 85 As a suitable dissimilarity measure we used the cosine dissimilarity (one minus the cosine similarity), which is commonly used for judging the dissimilarity of documents when they are represented as word frequency vectors.Footnote 86 Cosine dissimilarity also allows for respondents who habitually provide more factors per explanation than others. It considers the relative frequency of mentions of a factor for that respondent, not the absolute value. In the same way as it normalizes for document length when measuring text similarity, it compensates for the different amounts of factors respondents provide per question.Footnote 87
4. RESULTS
A total of 43 respondents completed the questionnaire. The respondents came from a range of areas of legal expertise, function types, organization types and years of work experience, as shown in Table 1. There were 11 query-answer pairs, leading to (43 ∗ 11 =) 473 choices made. In 28 instances (6%), the respondent indicated they had no preference for one option or the other. In 90 instances (19%), there was no (clear) explanation.
Table 1 Breakdown of respondents.

Respondents were asked to indicate what information they thought the user was trying to find with this query. This question was asked for two reasons: (1) to verify that the query is broadly recognizable, and (2) to verify that users interpret the example query without situational context, and do not for example imagine a situational context in their mind. Though users sometimes interpreted the query to be aimed at a specific information type (e.g. a lawFootnote 88 or case lawFootnote 89), none of them described a situational context (eg. They want to hire an expert witness for their case and want to know how expensive that will be, or “I have a contract that I want to get out of with retroactive effect and I want to know how to do that and what the consequences will be”). This is also reflected in the fact that out of the 86 responses given to these interpretation questions, the word ‘I’ was only used twice, which also affirms our assumption that situational and cognitive relevance can be precluded, as discussed in section 3.4.
The respondents often mention relevance factors when selecting a search result that were not part of the factors for which the corresponding search results were chosen. It therefore seems that the factors behind the selection of the examples were not so obvious in the presented questions that they lead respondents in their answers. On average, respondents are split 31:12 over the choices. The highest agreement reached for a choice was a division of 40:3, and the lowest agreement was 20:23. This suggests that the method used to select the search results invited critical thinking.
The relevance factors mentioned in the motivations of the respondents are listed, analyzed and discussed in the next subsection.
4.1 Relevance factors
All mentioned factors are listed in Table 2. As described in section 3.4, and based on the responses given by the respondents to the query interpretation question, when mapping relevance factors to spheres of relevance, we exclude mapping to situational and cognitive relevance. Because respondents were not asked to assign a weight to the factors in the outcome of their choice or whether it was the determining factor, the raw count of the factor does not indicate its importance, only how often it was mentioned.
Table 2 Relevance factors sorted by number of mentions in the free text field. An asterisk (*) indicates that the factor was not one of the factors used to select example results (listed in Section 3) but added by participants.

Aside from the factors mentioned used to select the examples, which are described in the Section 3, respondents mentioned four factors in their considerations of which documents they wish to see ranked higher: (1). the level of depth or detail of a document, described by BarryFootnote 90 as depth/scope and by Schamber as specificity;Footnote 91 (2). the law area of the document, as determined through the title, source or author; (3). the usability of the document,Footnote 92 described in the factors of Barry as effectiveness;Footnote 93 (4). the length of the document, related to what Barry describes as time constraintsFootnote 94 and Schamber as variety/volume.Footnote 95
4.1.1 Title Relevance
The title relevance is a factor of perceived algorithmic relevance, because it covers the (perceived) relationship between the query and the document representation.Footnote 96 Though all results shown were actual results returned by the Legal Intelligence system, and therefore deemed to be algorithmicly relevant, users mentioned the presence or absence of the query terms in the snippet as factor to prefer one result over the other. We therefore call this ‘perceived’ algorithmic relevance. In the work of Schamber this might be considered a factor of ‘presentation quality’.Footnote 97
It is not surprising that the perceived algorithmic relevance is the most often named factor. Both Park and Saracevic also describe this as a major factor in the perception of relevance in relation to professional search.Footnote 98 This is likely because snippets play a role in understanding the algorithmic relevance of search results.Footnote 99
4.1.2 Document Type
Document type constitutes a factor of domain relevance on the document class level. In a different context than this research, it would likely constitute a factor of cognitive relevance, since it deals with the relationship between the information need of the user and the information objects.Footnote 100 Though we have excluded that respondents perceived cognitive relevance in the example query, this focus on information type lingers, as is demonstrated by the fact that the factor of document type was already visible in the question regarding the interpretation of the query. Responses include references to a law or case law.
4.1.3 Recency
Recency is a factor of domain relevance, which can be argued to be both on document class and individual document level. While anecdotal evidence suggests that in general newer documents are considered more relevant than older documents, this may differ if the legal professional is dealing with a case from the past. In a different context than this research this would be a factor of either cognitive relevance (newer information is more likely to be novel for the user and thus more likely to solve an information need of the user) or situational relevance (if they are working on a case from a particular period recency becomes a factor dealing with the relationship between the task of the user and the information object).Footnote 101
4.1.4 Level of Depth
The level of depth or detail of a document is a factor of domain relevance on the individual document level. In a different context than this research this factor would be considered to relate to cognitive relevance. Depending on the familiarity of the user on the subject, they will be looking for a high-level document (introduction to a subject they are not yet familiar with), or a very detailed document. It therefore deals with the relationship between the information need of the user and the information object.Footnote 102
4.1.5 Legal Hierarchy
The legal hierarchy is a factor of domain relevance on the document class level. Given the legal status represented by this factor (e.g. in case of appeals), this factor would also be mapped to domain relevance in situations other than this questionnaire.
4.1.6 Law Area (Topic)
The factor of the law area (topic) is a factor of (perceived) topical relevance. Respondents indicate that they are only interested in results that relate to a specific area of law.Footnote 103 It therefore deals with the relationship between the (perceived) topic of the request and the information objects,Footnote 104 and suggests that the respondent considers topical relevance to be delimited by law area.
4.1.7 Authority/Credibility
The factor of authority/credibility is a factor of domain relevance on the individual document level. In a context other than this questionnaire it would most likely be related to the sphere of situational relevance. It is often considered in relation to the persuasiveness/citability of the document, and would therefore likely be related to the work task of the user rather than their cognitive state.Footnote 105
4.1.8 Usability
The factor of usability is a factor of domain relevance on the individual document level. In other instances than this research it would most likely be related to situational relevance, as usability relates to the underlying motivation for information retrieval.Footnote 106 It shows overlap with citability.
4.1.9 Bibliographical Relevance
The factor of bibliographical relevance is related to the sphere of bibliographical relevance, as it concerns the ‘isness’ of the document; or, as described by Van Opijnen and Santos “the relationship between a request and the bibliographic closeness of the information objects”.Footnote 107
4.1.10 Annotated
The factor of whether a document is annotated, or not, is a factor of domain relevance on the document class level. Annotations provide context for the reader, and this is considered preferred in general (though individual annotations may be considered irrelevant because of a (perceived) lack of quality). In a different context the factor of annotated would be considered a factor of cognitive relevance, as it regards the relationship between the information need of the user and the information object.Footnote 108
4.1.11 Document Length
The factor of document length is a factor of domain relevance, likely on the document class level. In other situations this factor would likely be mapped to situational relevance, as it relates to the task of the user and the amount of available time and completeness required.Footnote 109 However, the mentioning of this factor in the questionnaire, even when there is no task and therefore no time constraint (note that the users did not have access to the document, only to the snippet shown on the result page), suggests that legal professionals prefer not to read very long reports in general.Footnote 110
4.2 Differences between user sub-groups
Table 3 shows the total frequencies of each factor, aggregated per sub-group. At a first glance there appear to be small differences in the factors mentioned between legal practitioners, legal scholars, and legal information specialists. Practitioners mentioned the length of the document as a factor, which the information specialists and scholars did not. The factor of usability is also named relatively more often by practitioners than other sub-groups. The group of information specialists appear to mention the level of depth less than other sub-groups. Whereas the group of legal scholars mention legal hierarchy and authority less than the other sub-groups.
Table 3 Relevance factors sorted by the number of mentions in the free text field, according to function type.

To further analyze the differences between the groups, we visualize the differences between respondents at an individual level using the cosine dissimilarities between them. The dissimilarities are visualized in two dimensions in Figure 4. It can be observed that the different groups are not well-separated in the two dimensional space, and the observed distances between the group centroids are small compared to the observed distances within each group.
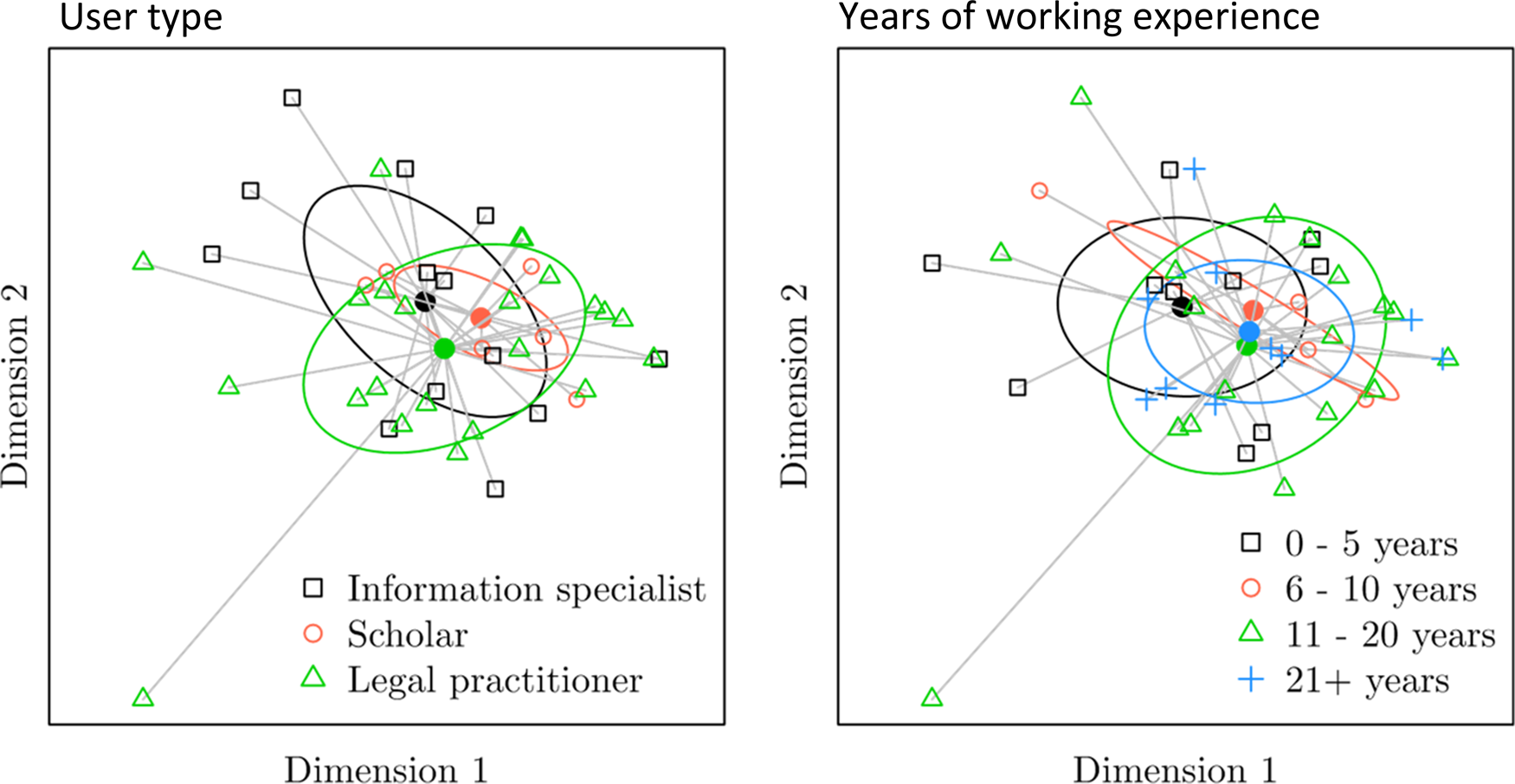
Figure 4 The dissimilarities between respondents visualized in two dimensions using principle coordinates analysis (PCoA). Left: Labeled as legal information specialist, legal scholar or legal practitioner. Right: Labeled by years of working experience. The connected dot in the center of each group represents the group centroid; the ellipses represent one standard deviation around each centroid.
To test whether the differences between legal information specialists, legal scholars, and legal practitioners are statistically significant, we performed a PERMANOVA. We included two predictor variables in our analysis. The primary predictor variable of interest was whether someone is a legal professional, scholar, or an information specialist. Years of working experience (0–5 years, 6–10 years, 11–20 years, 21+ years) was added as an additional variable to correct for possible existing differences in years of working experience between the user subgroups in our sample. One respondent was excluded from the analysis because they did not provide an explanation for any of the questions, leading to a total sample size of 42 (23 legal practitioners and 13 information specialists, and 6 scholars). All permutation tests were performed using 10,000 permutations.
PERMANOVA is somewhat sensitive to heterogeneity of multivariate dispersions, meaning that significant results may be caused by different variation within each group, rather than differences between the groups.Footnote 111 Therefore, we first performed a permutation test for homogeneity of multivariate dispersionsFootnote 112 for the user subgroups (pseudo F = 1.43, p = 0.248) and for years of working experience (pseudo F = 0.076, p = 0.976). Neither test was significant, thus providing no evidence of different variation within each group.
The PERMANOVA results can be observed in Table 4. Note that the test for the interaction is conditioned on the main effects, and each tests for a main effect is conditioned on the other main effect. The interaction effect was not significant (p = 0.892). The difference in the user subgroups was not significant (p = 0.243), nor was the main effect of years of working experience (p = 0.344).
Table 4 PERMANOVA results.

5. DISCUSSION
5.1 Implications
5.1.1 Relevance factors
Legal IR systems appear to focus on algorithmic and topical relevance, while the results of this research show that users (when judging search results outside of the context of a particular worktask) have agreement on other manifestations of relevance that are visible in document representations and could be used in ranking algorithms – such as the factors of recency, whether a document is annotated or not, legal hierarchy and bibliographical relevance, that can easily be recognised by IR systems to enhance their ranking. Incorporating the lessons learned from this research could enhance the user experience.
It is interesting to note that document type is the second most mentioned consideration for the respondent's relevance choices. This suggests that when users of legal IR systems are searching for something, they know what type of document they are likely to find the information in. Similarly, the level of depth respondents are looking for (fourth most reported argument) influences what document types they open. These factors appear to be related to the sphere of cognitive relevance (the relation between the information need and the document), making it more challenging to incorporate these factors in ranking algorithms.
The mentioning of document length by two respondents separate of each other, in regards to a different question, and in the absence of a situational task, suggests that legal professionals might prefer not to read very long reports. Though the number of respondents is too small to reach strong conclusions, it is interesting, as anecdotal evidence suggests that this might be different in certain situations (eg. when trying to bury the opposing party in work or when that particular document is very pertinent to a certain task) suggesting that while there is some general consensus on the preference of shorter documents, situational relevance might be stronger than domain relevance.
Though not an aim of this research, it is interesting to note that the most reported relevance factor, whether the word is in the title or summary of the result, suggests that simple changes in the user interface might already improve the perception of the quality of the ranking for users, without actually changing the ranking itself. An IR system will only return documents that are algorithmically relevant – in the sense of containing query terms – but the results suggest that the respondents find it challenging to perceive the relevance of a document if they do not see the search terms in the title or the summary. By showing snippets (where the section of the document where the query terms are found is shown), rather than publisher curated summaries as is currently the case in the system and examples used for our research, users will be able to see the query terms in context. This type of document representation will likely enable users to better estimate the relevance of the document.
5.1.2 User subgroups
In this study the observed differences between legal information specialists, legal scholars, and legal practitioners, in terms of the factors they consider in judging the relevance of legal documents, were not found to be statistically significant. At this moment there is no reason to treat these sub-groups differently in legal IR systems.
5.2 Limitations of the study
Our research focuses on relevance factors that are visible as document characteristics. The chosen method excludes situational relevance.Footnote 113 The relevance factors found are therefore not an exhaustive list of relevance factors for the legal domain. Because the method focuses on a forced choice between two options, diversity of document types in the ranking is not reflected in the research. Similarly, factors related to obtainability are not covered.
Our research is conducted with Dutch legal professionals using Dutch legal examples. However, this confirms the cross-jurisdictional framework of Van Opijnen and Santos.Footnote 114 Given the national nature of the legal domain, it is however interesting to conduct further research in other countries to determine whether other legal jurisdictions may provide further insights into the factors related to domain relevance.
In our statistical analysis we investigated the difference between information specialists, legal scholars, and legal practitioners, corrected for pre-existing differences in number of years of working experience. It is possible that the sub-groups of users in our sample differ on other characteristics. For example, we know that the respondents come from a wide variety of law areas (Table 1). However, due to our modest sample size it was not feasible to include this in the analysis as well.
6. CONCLUSIONS
With regards to research question 1: to what extent can we demonstrate the existence and factors of domain relevance in the context of judgment of search results (document representation) in legal IR systems?
Based on Van Opijnen and Santos's work of 2017, domain relevance requires two aspects: (1). a level of agreement between users, the ‘legal crowd’, and (2). it is not related to the task or problem at hand. Since respondents do not indicate a situational context for the example queries used in the questionnaire, the method with which the data is gathered means that factors mentioned are not related to task context, satisfying the second requirement. The first requirement is satisfied by the number of respondents mentioning the same factors. Based on the factors mentioned by the respondents, we can conclude that document type, recency, level of depth, legal hierarchy, authority, usability and whether a document is annotated are factors of domain relevance when outside of a task context.
The results confirm the existence of domain relevance as described in the theoretical framework by Van Opijnen and Santos, and the factors related to domain relevance confirm the anecdotal evidence given by Legal Intelligence users.
With regard to research question 2: To what extent do legal information retrieval specialists, legal scholars and legal practitioners show agreement on relevance factors outside of a task context? Despite small differences in reported factors, we did not find evidence to conclude that legal information specialists, legal scholars, and legal practitioners differ significantly in terms of the factors they consider in judging the relevance of legal documents outside of a task context.
At this moment there is no reason to treat these sub-groups differently in legal IR systems. In the near future we will use these findings, in particular the factors of domain relevance on document class level that can be established through document representations, to extend our research into improvements for ranking algorithms in legal information retrieval systems.
7. ACKNOWLEDGEMENTS
The authors wish to thank the employees of Legal Intelligence, in particular Dr. T.E. de Greef and Mr. S. Beaufort, for their cooperation in this research and the distribution of the questionnaire to the users of the system. The authors wish to thank Dr. M. van Opijnen for his feedback on an earlier version of this paper.
APPENDIX: COMPOSITION OF SEARCH RESULTS
Documents and positions as retrieved from Leiden Law School data set.
For the hierarchy level of the court, the newness of the document, and the authority of the source a three-point scale is used. For all other factors the presence or absence of the factor in the result is shown.
A.1 Example query 1: ‘Tarieven deskundigenonderzoek’ Translated: ‘Fees expert witnesses’
Total number of results: 4945
Question 1:
Option 1: Recency (1), Legal hierarchy (3)
Option 2: Recency (2), Legal hierarchy (2)
Question 2:
Option 1: Title relevance (y), Recency (3)
Option 2: Title relevance (n), Recency (1)
Question 3:
Option 1: Legal hierarchy (1), Bibliographical relevance (n)
Option 2: Legal hierarchy (2), Bibliographical relevance (y)
Question 4:
Option 1: Source authority (1, Asser, T&C), Title relevance (n)
Option 2: Source authority (3, blog, news), Title relevance (y)
Question 5:
Option 1: Source authority (1, Asser, T&C), Document type (n)
Option 2: Source authority (2, mid), Document type (y)
Question 6:
Option 1: Source authority (2, mid), Authority author (n)
Option 2: Source authority (3, blog, news), Authority author (y)
Question 7:
Option 1: Document type (y), Bibliographical relevance (n)
Option 2: Document type (n), Bibliographical relevance (y)
A.2 Example query 2: ‘vernietiging overeenkomst terugwerkende kracht’ Translated: ‘voidable contract retroactive effect’
Total number of results: 1325
Question 1:
Option 1: Recency (2), Annotated (n)
Option 2: Recency (3), Annotated (y)
Question 2:
Option 1: Source authority (2, mid), Authority author (n)
Option 2: Source authority (3, blog, news), Authority author (y)
Question 3:
Option 1: Legal hierarchy (1), Annotated (n)
Option 2: Legal hierarchy (3), Annotated (y)
Question 4:
Option 1: Authority author (y), Recency (3)
Option 2: Authority author (n), Recency (1)








