The word superiority effect (WSE) is the superior recognition of a letter (e.g., L) when it appears in a word (salt) compared with a nonword (tsla). The WSE has been observed in many studies (Johnston, Reference Johnston1981; Reicher, Reference Reicher1969; Starrfelt, Petersen, & Vangkilde, Reference Starrfelt, Petersen and Vangkilde2013; Wheeler, Reference Wheeler1970). A similar pseudoword superiority effect also occurs: the recognition accuracy of a letter (T) is more accurate when it occurs in a pronounceable pseudoword (TOBLE) than in an unpronounceable nonword (TPBFE; Coch & Mitra, Reference Coch and Mitra2010; Grainger, Bouttevin, Truc, Bastien, & Ziegler, Reference Grainger, Bouttevin, Truc, Bastien and Ziegler2003). Thus, in alphabetic reading, there are influences on letter perception from both sublexical orthographic–phonological structures and whole words. Theoretically, the WSE occurs because word recognition is an interactive process in which higher level word knowledge interacts with letter knowledge to influence the perception of letters (McClelland & Rumelhart, Reference McClelland and Rumelhart1981).
The WSE also applies to Chinese, modified by the differences between alphabetic and Chinese writing. In written Chinese, a word consists of one or more characters; around 70% of words are two-character words (Lexicon of Common Words in Contemporary Chinese Research Team, 2009). For example, the two-character word 知识 (knowledge) consists of two characters, 知 and 识 (meaning: know and knowledge, respectively). Characters are spatially separated, but there is no additional space to mark a word boundary. This means that spaces are not cues to words, which can consist of one, two, three, or more characters. Typically, a character represents a morpheme with its own phonology and meaning, combining with other characters to provide the pronunciation and meaning of a word. Thus, word pronunciation and meaning are usually predictable from constituent characters.
Chinese word superiority thus is about the recognition of the constituent characters: A character is better recognized when it is part of a word than part of a nonword. The WSE that has been observed for skilled native Chinese readers can be illustrated by the following: the character 学 (learn) is more easily identified in a real two-character compound word 学生 (student) than in a nonword 学交 formed by two real characters (Cheng, Reference Cheng1981; Li & Pollatsek, Reference Li and Pollatsek2011; Mattingly & Xu, Reference Mattingly and Xu1994; Mok, Reference Mok2009; Shen & Li, Reference Shen and Li2012). Unlike alphabetic reading, the graphic-level unit (character) that benefits from being part of a word has meaning as well as a syllabic pronunciation. This raises the possibility that there is a meaning influence in Chinese WSE and evidence on the role of semantic transparency is consistent with this possibility (Mok, Reference Mok2009).
Relevant for the Chinese WSE is the fact that character frequency affects character recognition: a high-frequency character is recognized more quickly than a low-frequency character (Kuo et al., Reference Kuo, Yeh, Lee, Wu, Chou, Ho and … Hsieh2003; Liu & Perfetti, Reference Liu and Perfetti2003; Liu, Wu, & Chou, Reference Liu, Wu and Chou1996; Yan, Tian, Bai, & Rayner, Reference Yan, Tian, Bai and Rayner2006; Zhou, Marslen-Wilson, Taft, & Shu, Reference Zhou, Marslen-Wilson, Taft and Shu1999). Because the Chinese WSE reflects facilitation from the word level to the character level, the speed of character access would modify the size of the WSE. A high-frequency character would be quickly recognized on its own, with less time to be influenced by the slower developing word-level activation. In contrast, the slower recognition of a low-frequency character allows more time for word-level activation to spread to the character level. Thus, we predict a larger WSE for low-frequency characters than for high-frequency characters.
These considerations of character-level effects and word-level WSE raise the question of the relative knowledge a reader has about character and words. A reader may have relatively strong character knowledge, relatively strong word knowledge, or a balance of strong character and word knowledge. It is possible to address the strength of character and word knowledge within the WSE paradigm. First, we define the Chinese WSE as the difference in character recognition when the character is part of word and when it is part of a nonword. Second, we define the character frequency effect as the difference in recognition between a high-frequency character and a low-frequency character when they are part of a nonword. Thus, the dependence of WSE on character frequency is the size of the WSE when characters are high in frequency versus low in frequency, compared with the frequency effect defined in nonwords.
Using this approach to character-level and word-level effects, our aim was to investigate the dependence of WSE on character frequency for native Chinese speakers and learners of Chinese as a window on the trade-off between word-level and character-level knowledge. Native Chinese readers should have high knowledge at both the word and the character level. Learners of low proficiency may have more knowledge at one level or the other, and an imbalance in either would affect the pattern of the WSE, according to the assumptions of interaction between word and character levels.
There are two factors that might affect the word representations of low-proficiency Chinese learners. First, learners of Chinese as a foreign language (CFL) have developed word representations in their first language. This word-level awareness may transfer to their approach to Chinese learning, at the expense of component characters. Second, teaching Chinese to CFL learners emphasizes the whole word over its constituent characters, especially at the beginning (Shi, Reference Shi2008; Zhang, Reference Zhang1992). For example, the word 学习 (meaning: study) has two constituent characters. Instead of an explanation of the individual characters 学 (meaning: learn) and 习 (meaning: study), the word 学习 is presented and learned as a whole. An imbalance in favor of whole words over characters may be particularly high for CFL learners at low proficiency levels, before they have had substantial exposure to characters. These observations lead to the hypothesis that CFL learners are more dependent on top-down lexical-level activation than bottom-up character activation. This hypothesis appears to have some support from previous studies, including eye-tracking studies that find that words, rather than characters, are the primary processing unit in both Chinese reading and learning for CFL learners (Bai et al., Reference Bai, Liang, Blythe, Zang, Yan and Liversedge2013; Shen et al., Reference Shen, Liversedge, Tian, Zang, Cui, Bai and … Rayner2012). When a space was inserted between words to make the word boundaries clear, the total sentence reading time of CFL learners from different backgrounds (English, Korean, and Japanese) was greatly shortened (Shen et al., Reference Shen, Liversedge, Tian, Zang, Cui, Bai and … Rayner2012). In addition, low-proficiency CFL learners show more efficiency in learning new words that appear in sentences with clear word boundaries marked by spaces, compared with the traditional format of no spacing between characters (Bai et al., Reference Bai, Liang, Blythe, Zang, Yan and Liversedge2013). The advantage of word units for low-proficiency CFL learners is further demonstrated by the fact that, with unlimited naming time, they make more errors to name a single character than when the character is part of a word (Chen, Reference Chen2015). This pattern mimics that of the WSE.
These considerations lead us to predict that CFL learners show a more general WSE effect that is independent of character frequency. In addition, we are interested in the role of language and writing system background on the Chinese WSE effect. Thai and Indonesian provide such a contrast. Indonesian is a nontonal language. Thai, however, is a tonal language in which each syllable is pronounced with one of five distinct tones; experience in a tonal language can support awareness of phonology, and thus reading, in a second language (Tong, He, & Deacon, Reference Tong, He and Deacon2017; Wang, Perfetti, & Liu, Reference Wang, Perfetti and Liu2005). In addition, like Chinese, written Thai, an alphasyllabary, combines consonant–vowel sequences as a unit and does not insert spaces between words. In contrast to Thai, Indonesian is an alphabetic writing system. Each word has its own space, and the word boundary is very clear. Thus, to test the generality of the WSE effect for CFL learners and to test for possible differences suggested by the word spacing conventions of their two writing systems, we replicate the WSE experiment with Thai and Indonesian Chinese learners.
We used the Reicher–Wheeler brief exposure, forced-choice paradigm to test the Chinese WSE in two studies, one with native Chinese and one with two groups of CFL learners. The key features of the paradigm are (a) the brief (round 50 ms) visual exposure of a letter (or character) string that is either a word or a nonword (the brief exposure prevents conscious perception and recoding of the string); and (b) following this brief exposure, the immediate presentation of two probe letters (or characters); the participant selects the one that appeared in the briefly presented string. When the letter (or character) string is a word, each of the two letters (or characters) would make a word, thus eliminating word-based guessing as an effective strategy. The relevant result for the WSE is that when the letter string is a word, the correct letter is more likely to be chosen.
In this study, a two-character real word or nonword was briefly presented near recognition threshold (around 50 ms, adjusted individually to maintain high accuracy levels without a ceiling or floor effect), followed by two probe characters. Participants chose the one that had appeared in the two-character word. By comparing character recognition accuracy in real words and nonwords, we assess the WSE (e.g., 学 in “学习”; 头 in “头有”); by comparing character recognition accuracy of high- and low-frequency characters within nonwords (e.g., 头 in “头有”;竹 in “竹咽”), we assess character frequency effects; by comparing the size of the WSE for high- and low-frequency characters, we assess the dependence of the WSE on character frequency.
Two experiments investigated the WSE and its dependence on character frequency. Experiment 1 tested these effects for skilled native Chinese readers. Experiment 2 tested low-proficiency CFL learners, Thai–Chinese learners in Experiment 2a and Indonesian–Chinese learners in Experiment 2b. Based on the assumption that low-proficiency CFL learners have lower quality character representations even for higher frequency words, we would expect a general WSE effect regardless of the character frequency independent of native language (L1) backgrounds. Alternatively, readers’ adaptions to the L1 writing system might be transferred to Chinese. A relevant writing factor is the presence of spaces, which mark word boundaries in Indonesian. In reading Chinese, this could cause Indonesian learners to attend more to characters, which are separated by spaces in Chinese. On this assumption, characters would become a basic unit for Indonesian learners. This would lead to a reduced WSE effect for Indonesian–Chinese learners, compared with Thai learners, whose writing does not mark word boundaries with spaces. For the same reason, we might expect character recognition to be better for Indonesian learners, which would benefit low-frequency characters as well as high frequency.
EXPERIMENT 1
Method
Participants
Twenty-nine native Chinese undergraduates (average age 22.9, SD=2.3) from South China Normal University were recruited through advertisements and were paid for their participation in the experiment. There were 15 males and 14 females. All participants were right-handed with normal or corrected-to-normal vision. Each participant signed the consent form before the experiment. All the procedures were approved by the university ethics review board.
Stimuli
There were 96 pairs of stimuli. Each pair consists of a two-character word (“学习”, meaning: study) or a nonword (“头有”) and a probe (a nonword two-character string “学练” or “头春”). Half of the pairs were real words and their probes, and the other half pairs were nonwords and their probes. The task is to recognize the character in the probe, which was also in the previous word or nonword. For the real word pairs, the probe (学练: a nonword two-character string) includes a target character (学: learn) that was part of the two-character word (学习: study) and a foil character (练: practice). Critical for the logic of the WSE, the remaining character (习: study) of the two-character word (学习: study) can form a word with both the target character (学: learn) and the foil character (练, the word is 练习 “practice”). This design avoids a spurious correct report of the target character from an inference based on the other character of the word. Similarly, in the nonword pair, the target character (头: head) is part of a nonword (头有), and the remaining character (有: have) cannot be a word with the foil character (春: spring). All characters are in simplified Chinese.
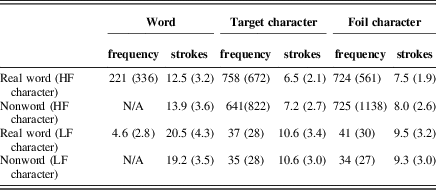
For 48 trials, the target character within the word or nonword was high frequency (e.g., 学: study; 700/million, Cai & Brysbaert, Reference Cai and Brysbaert2010); for the other 48 pairs, the target was low frequency (e.g., 皂: soap; 36/million). Target character frequencies for real words and nonword controls did not differ: high frequency, t (46)<1; low frequency, t (46)<1. The average number of strokes of the target character was 8.5 and did not differ across real words and nonwords: high frequency, t (46)<1; low frequency, t (46)<1. Finally, the frequency of the target character and the foil character did not differ: high frequency, t (47)<1; low frequency pairs, t (47)<1. More details of the stimuli were in Table 1.
Table 1 Characteristics of stimuli (standard deviations in parentheses)
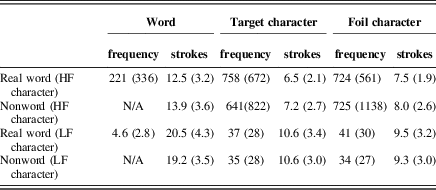
Note: HF and LF refer to high frequency and low frequency, respectively.
Although varying character frequency independent of word frequency would be the typical design, we chose a different strategy. To have a low-frequency character as part of a high-frequency word would have produced a large frequency disparity between the two characters. Furthermore, for most two-character words, two low-frequency characters cannot make a high-frequency word. If one character in a word were low, the other would be exceptionally high. Such a frequency disparity between two characters in a word would result in differential recognition of the characters. Accordingly, we chose to preserve the balance of character frequency within a word by having two high-frequency characters make up a high-frequency word and two low-frequency characters make up a low-frequency word (high-frequency words were 221/million and low-frequency words were 4.6/million). We avoided very low frequency words, which might have suppressed the word-level activation needed to observe a WSE. The materials were chosen from the textbooks of low-proficiency Chinese learners, making it likely that even low-frequency words were familiar to learners as well as native readers. These materials were the same across the two experiments.
Procedure
To accommodate the variable levels of individual perceptual thresholds, we designed a self-adaptive procedure to estimate stimulus onset asynchrony (SOA) for individual participants, based on a preliminary series of 40 practice trials. Each trial began with a “+“ fixation in the middle of the screen for 1000 ms followed by a two-character word. The duration of the word for each participant was determined by the participant’s accuracy in target character recognition. In the practice session, the 40 trials had an SOA of 50 ms. Adjustments to the experimental SOA were made based on each participant’s accuracy over the 40 practice trials: for accuracy less than 0.75, the SOA for the experimental trials was extended to 55 ms; between 0.75 and 0.85, the SOA remained at 50 ms; above 0.85, the SOA was shortened to 45 ms. Thus, each participant experienced the experimental trials at an SOA of 45–55 ms. Once experimental trials were under way, further adjustments were possible depending on the accuracy of 9 continuous trials: if the number of accurate trials was 6 or fewer, the SOA was extended by 5 ms. If the number of accurate trials was 8 or more, the SOA was shortened by 5 ms. If the number of accurate trials of was 7, the SOA did not change. In Experiment 1, the final average SOA of the two-character word across all participants was 43 ms with a SD of 5 ms. The range of average SOA was 40–57 ms for participants.
Trial sequence
Following fixation, the two-character word appeared for the variable SOA describe above and then replaced by a pattern ## mask for 500 ms. Two characters appeared with the pattern mask, one above the ## and the other below the ##. The location of the target character and its position in the two-character word (left or right) were counterbalanced. Participants had 3 s to choose which character had been in the word. If time expired, the next trial began. The experiment had 96 trials with a break for participants after 48 trials.
Results and discussion
The key results were as follows: (a) character recognition accuracy was significantly higher for real words than for nonwords, thus indicating a Chinese WSE; (b) in nonwords, character recognition was more accurate for high-frequency characters than for low-frequency character; and (c) the WSE depended on character frequency, larger for low-frequency characters than for high-frequency characters. The character recognition accuracies are shown in Table 2.
Table 2 Means and standard deviations (in parentheses) of character recognition accuracy and reaction time (RT) for native Chinese readers

To test the WSE and the character frequency effect (CFE), we analyzed the data using mixed-effects modeling (Baayen, Davidson, & Bates, Reference Baayen, Davidson and Bates2008) with character recognition accuracy as the dependent variable. Two participants were excluded because their character recognition accuracy was more than 2.5 SD below each participant’s mean, leaving 27 participants for the analysis.
The models were implemented in lme4 packages in R (Maechler & Bates, Reference Maechler and Bates2010). The base model included the variable we manipulated as the fixed effect and intercepts for participants and items as random effects. In the WSE modeling, the fixed factor is the word type (word vs. nonword) and the fixed factor for CFE modeling is the character frequency in nonwords (high frequency vs. low frequency). Model comparisons determined whether the best fit model included the random participant slope or random item slope for manipulated variable.Footnote 1
In the WSE modeling, neither random participant slopes nor item slopes significantly improved the model fit; thus, the best fit model for WSE was defined as the base model. The model testing confirmed that character recognition accuracy was higher in the real words than in the nonwords, a WSE; estimate=1.18, SE=0.23, z=5.17, p<.001.
Because the base model for CFE did not converge with random intercepts for both subjects and items, we used separate models, one with random intercepts for subjects and one for items. Both models showed that character recognition accuracy was significantly higher for high-frequency characters than for low-frequency characters, estimate=0.53, SE=0.19, z=2.81, p<.01 (random intercepts for subjects); estimate=0.52, SE=0.24, z=2.14, p<.05 (random intercepts for items).
Paired sampled T tests were used to test the dependence of WSE on character frequency. The size of the WSE, defined as the accuracy difference between real words and nonwords, was .04 for high- and .09 for low-frequency characters, t (26)=3.23, p<.01, r pb 2=.29. Thus, the WSE was larger for low frequency characters.
In order to test whether there was a trade-off between accuracy and reaction times, we also included the reaction times for character recognition in analysis.Footnote 2 Reaction times for character recognition were consistent with the accuracy. Higher character recognition accuracy was associated with shorter character recognition reaction times. The best fit model for WSE reaction times had word type as a fixed effect, and participant and item intercepts and participant slope for word type as random effects. There was a reaction time advantage for recognition of a character in real words compared with nonwords, estimate=–67.71, SE=20.31, t=–3.36, p<.001. The high character recognition accuracy in real words did not result in a cost to reaction times. Reaction times for a high-frequency character in nonwords were significant shorter than for a low-frequency character in nonwords, estimate=–114.11, SE=23.56, t=–4.84, p<.001. The best fit model for CFE reaction times had character frequency as a fixed effect, and participant and item intercepts as random effects.
In summary, the results of Experiment 1 showed a WSE in word recognition for native Chinese readers. A character was more easily recognized in words than in nonwords. The results suggest that Chinese word processing is an interactive process in which word-level activation facilitates character recognition (Li & Pollatsek, Reference Li and Pollatsek2011; Li, Rayner, & Cave, Reference Li, Rayner and Cave2009; Mok, Reference Mok2009). However, the WSE depended on character frequency. For native Chinese readers, a high-frequency character is recognized on its own too quickly to benefit from top-down activation from the word level. In contrast, the slower access to a low-frequency character is facilitated by word-level activation, thus producing a larger WSE.
Experiment 2a and Experiment 2b tested the hypothesis that Chinese CFL learners would show a Chinese WSE, given the assumption of word-level focus in their learning. These experiments further allowed a comparison of two very different L1s with contrasting writing systems, the alphasyllabic Thai, which, like Chinese, omits word spaces, and the alphabetic word-spaced Indonesian.
EXPERIMENT 2A: L1 THAI LEARNERS OF CHINESE
Method
Participants
A total of 22 Thai–Chinese learners (13 males) with an average age of 21.6 years (SD=2.2) participated in the experiment. All participants were undergraduate students majoring in Chinese linguistics at the School of Foreign Languages, Sun Yat-sen University. All participants were recruited through advertisements and were paid for their participation. Each participant signed the consent form before the experiment. All the procedures were approved by the university ethics review board. The participants were right-handed with normal or corrected-to-normal vision. All participants reported that they are Thai native speakers and proficient in Thai. The participants were defined as low-proficiency CFL leaners, because they had passed the fourth level (the intermediate level with a vocabulary of 1,200 words) of the Chinese Proficiency Test (HSK) but not the sixth (the highest level with a knowledge of 5,000 words). The HSK is a standardized test of Chinese language proficiency for nonnative speakers that distinguishes six levels of proficiency. The sixth levels of HSK from first level to sixth level correspond, respectively, to A1, A2, B1, B2, C1, and C2 of the Common European Framework of Reference for Languages. No participant has passed Level 5 (the higher intermediate level with a vocabulary of 2,500).
Materials, design and procedure
The materials, design, and procedure were identical to Experiment 1. The average SOA of the two-character word was 54 ms and the range was from 42 to 59 ms with a 5-ms SD.
Results and discussion
Table 3 presents the mean accuracy in selecting the target character. The key results are as follows: (a) character accuracy for real words was higher than for nonwords, thus demonstrating the WSE for Thai-Chinese learners; (b) character recognition was more accurate for high-frequency characters than for low-frequency characters in nonwords; and (c) the WSE did not depend on character frequency. These conclusions are supported by the statistical tests reported below.
Table 3 Means and standard deviations (in parentheses) of character recognition accuracy and reaction time (RT) for Thai–Chinese learners

We use mixed-effects modeling as in Experiment 1. The best fit models for WSE and CFE both included the respective manipulated variable (word type for the WSE model and character frequency for the CFE model) as a fixed effect and random intercepts by subjects and items. Model testing showed a WSE for Thai–Chinese leaners. Character recognition accuracy in the real word condition was higher than in the nonword condition, estimate=0.44, SE=0.13, z=3.34, p<.001; character recognition accuracy was significantly higher for high-frequency characters than for low-frequency characters in nonwords, which indicated an effect of character frequency, estimate=0.41, SE=0.17, z=2.42, p<.05. The WSE size was 0.09 and 0.07, respectively, in the low- and high-frequency conditions, not significantly different, t (21)<1. The character recognition reaction times were included in modeling to test the time cost of character recognition. The best fit model for WSE reaction times had word type as a fixed effect, and participant and item intercepts as random effects. The mean reaction times for character recognition for non-words was longer than real words, but not significantly so, estimate=43.71, SE=25.30, t=1.73, p=.08. The best fit model for CFE reaction times had character frequency as a fixed effect, and participant and item intercepts and participant slope for character frequency as random effects. The character recognition reaction times for the high-frequency character in nonwords was significant shorter than for low-frequency character in nonwords, estimate=–79.92, SE=40.31, t=–1.98, p<.05.
The main result of Experiment 2a is evidence for a Chinese WSE for Thai–Chinese learners. Characters were identified on average 8% better in words than in nonwords and did not depend on character frequency. Its magnitude was comparable to the 9% shown by native Chinese readers (Experiment 1). However, their basic character accuracy was low (71% overall in nonwords) and frequency dependent, compared with 88% overall for the Chinese native speakers. Our interpretation is that these limited proficiency participants had relatively weak character knowledge combined with sufficiently developed word-level knowledge to allow activation from the word level to affect processing of the character level. If words rather than characters are the basic processing units for native Chinese readers (Rayner, Li, & Pollatsek, Reference Rayner, Li and Pollatsek2007), our evidence suggests the same is true for learners who are far below native Chinese in proficiency. This conclusion is consistent with evidence that CFL learners depend on words in Chinese reading (Shen et al., Reference Shen, Liversedge, Tian, Zang, Cui, Bai and … Rayner2012).
However, unlike native Chinese readers, the Thai–Chinese learners did not show a dependency of WSE on character frequency. We interpret this as evidence that characters that are nominally high frequency had not been learned enough to be rapidly recognized on their own and thus were able to benefit from activation from the word level.
EXPERIMENT 2B: L1 INDONESIAN LEARNERS OF CHINESE
Method
Participants
A total of 22 Indonesian learners (5 males) from Sun Yat-sen University, average age 20.9 (SD=1.6), were paid for their participation in the experiment. All the participants were right-handed with normal or corrected-to-normal vision. The participants are all from Indonesia and native Indonesian speakers. All of them are reported proficient in Indonesian. All participants had passed the fourth level of the HSK but not fifth or the sixth. All participants were recruited through advertisements and were paid for their participation. Each participant signed the consent form before the experiment. All the procedures were approved by the university ethics review board.
Material, design and procedure
Materials, design, and procedure were the same as Experiment 1. The average SOA of the two-character word was 51 ms, range 40–60 ms with a 6-ms SD.
Results and discussion
The key results were (a) a WSE effect: character accuracy in the real word condition was higher than in the nonword condition; (b) no CFE: accuracies for high-frequency characters and low-frequency characters in nonwords did not differ; and (c) the WSE did not depend on character frequency. Results are shown in Table 4 and statistics supporting the conclusions follow.
Table 4 Means and standard deviations (in parentheses) of character recognition accuracy and reaction time (RT) for Indonesian–Chinese learners

The best fit models for WSE and CFE both included respective manipulated variable (word type for the WSE model and character frequency for the CFE model) as a fixed effect and random intercepts by subjects and items. The mixed-effect modeling indicated a WSE: characters in real words were recognized more accurately than in nonwords, estimate=0.72, SE=0.17, z=4.24, p<.001. There was no CFE for Indonesian–Chinese learners, who showed no difference between high- and low-frequency characters in nonwords, estimate=0.27, SE=0.20, z=1.34, p=.18. The WSE size was comparable for low-frequency characters and high-frequency characters, 0.12 and 0.11, respectively, t (21)<1. Character recognition reaction times in the real word condition were significantly shorter than in the nonword condition, estimate=–52.43, SE=26.21, t=–2.00, p<.05. The best fit model for WSE reaction times had word type as a fixed effect, and participant and item intercepts as random effects. Character recognition reaction times for high-frequency characters were significant shorter than for low-frequency characters, estimate=–95.49, SE=–41.63, t=–2.29, p<.05. The best fit model for CFE reaction times had character frequency as a fixed effect, and participant and item intercepts and participant slope for character frequency as random effects.
The results of Experiment 2b showed a WSE effect for Indonesian learners of Chinese, the same result as with the Thai L1 learners of Experiment 2a. Further, for both language groups, the WSE and CFE did not interact.
Combined analyses of Experiment 1, Experiment 2a, and Experiment 2b
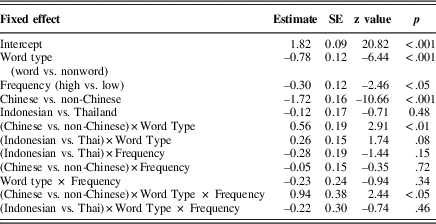
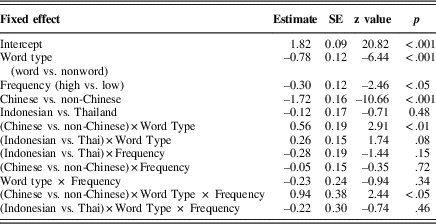
To test an effect of language background on character recognition accuracy, we combined data from all three experiments in a single logistic mixed-effects model. The model included three fixed effects (all contrast-coded) comprising two within-participants experimental factors: word type (word vs. nonword) and character frequency (high- vs. low-frequency character), and one between-participants language background factor (Chinese native speakers, Indonesian–Chinese Learners vs. Thai–Chinese learners) and their interactions. Intercepts for participants and items were included as random effects. Random slopes were not included in the model because they did not improve model fit. This modeling procedure produces estimates of the main effects analogous to those obtained in an analysis of variance (i.e., based on the mean differences between different levels of a variable; Cohen, Cohen, West, & Aiken, Reference Cohen, Cohen, West and Aiken2002). Table 5 summarizes the results: there was significant main effect of word type (WSE), z=–6.44, p<.001; character recognition accuracy was higher in the real words than in nonwords. Character recognition accuracy was also significantly higher for high-frequency characters than for low-frequency characters, z=–2.46, p<.05. Language background also produced a significant effect. Chinese native speakers were more accurate in character recognition than were the two groups of nonnative Chinese learners (z=–10.66, p<.001), who did not differ (z=–0.71, p=.48). Of specific interest was the interaction among word type, character frequency, and language background. Chinese native speakers showed a different WSE pattern than nonnative Chinese speakers (z=2.44, p<.05), who did not differ significantly (z=–0.74, p=.46). This interaction reflects the fact that the WSE (the word–nonword difference) was affected by character frequency more for the native Chinese speakers than for the two Chinese L2 groups.
Table 5 Summary of the fixed effects in the logistic mixed-effects models of character recognition accuracy
GENERAL DISCUSSION
Across experiments, we found the WSE occurs in Chinese for both native readers and adult learners of Chinese as a foreign language. Using the Reicher–Wheeler paradigm, the experiments found that a character was better recognized when it was part of a word than when it was part of a nonword. This consistent WSE is explained within the framework of interactive activation, in which higher word-level representations (a two-character word) and their lower level constituents (a single character) interact through bidirectional activation (McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Reicher, Reference Reicher1969; Wheeler, Reference Wheeler1970). The WSE occurs when the word level receives sufficient activation to increase activation of its constituent characters, thus influencing their recognition (Mok, Reference Mok2009; Shen & Li, Reference Shen and Li2012).
Although Chinese differs from alphabetic writing in many aspects, this interaction across levels of lexical representation (word and letter or word and character) may be universal across writing systems (Mok, Reference Mok2009; McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Reicher, Reference Reicher1969; Shen & Li, Reference Shen and Li2012; Wheeler, Reference Wheeler1970). Nevertheless, although the mechanism (interactive activation) may be general, it is possible that the information sources it uses are not the same across languages. In English, letter perception operates at the orthographic level (letter identity), and its enhancement in the WSE occurs through orthographic–phonological structures rather than meaning. This is evidenced by the fact that the WSE occurs for wordlike pseudowords as well as for real words. Furthermore, because an individual letter is not directly connected to meaning, the alphabetic WSE uses form information, not meaning. In Chinese, the WSE may arise not only through orthographic form but also through meaning links between the character and the word. For example, the word电脑 (diàn nǎo: computer) consists of two characters: 电 (diàn: electronic) and 脑 (nǎo: brain). Thus, an effect of the word meaning computer on the perception of a character meaning electronic has both a form component (the character) and a meaning component (the contribution of the character meaning to the word meaning).
Thus, in general, we can describe the WSE for Chinese two-character words as reflecting a compound of form and meaning connections between word and character. The meaning contribution may be affected by the semantic transparency of the word’s characters, which has been found to influence word recognition in other paradigms (Zhou & Marslen-Wilson, Reference Zhou and Marslen-Wilson2009; Zhou, Marslen-Wilson, Taft, & Shu, Reference Zhou, Marslen-Wilson, Taft and Shu1999). More specifically for the WSE effect, a study by Mok (Reference Mok2009) compared the WSE for transparent constituent characters with opaque constituent characters in the words. For example, in the partially opaque word 坏蛋 (meaning: scoundrel), the two constituent characters have the meanings of “bad” and “egg,” respectively. Mok (Reference Mok2009) found that the WSE effect was greater for the transparent constituent character 坏 (“bad”) than for the semantically opaque constituent 蛋 (“egg”). This result implies a meaning connection between the character and the whole word that added to the WSE.
The present studies found that the frequency of the constituent character constrains WSE more for native Chinese readers, who showed a larger WSE for low-frequency characters, than for low-proficiency learners of Chinese. In general, character access is affected by character frequency for skilled Chinese readers (Kuo et al., Reference Kuo, Yeh, Lee, Wu, Chou, Ho and … Hsieh2003; Liu & Perfetti, Reference Liu and Perfetti2003; Liu et al., Reference Liu, Wu and Chou1996; Yan et al., Reference Yan, Tian, Bai and Rayner2006; Zhou et al., Reference Zhou, Marslen-Wilson, Taft and Shu1999). Identifying a low-frequency character needs more cognitive resources for visuo-orthographic analysis, phonological retrieval, and semantic retrieval because of the lower quality representation for a low-frequency character (Kuo et al., Reference Kuo, Yeh, Lee, Wu, Chou, Ho and … Hsieh2003). Because native Chinese readers, with literacy experience, develop high-quality representations of characters as well as words, they show a WSE only when the characters are relatively low in frequency, which allows a benefit from the activation of the whole word.
For low-proficiency CFL learners, for both L1 backgrounds tested here, the WSE did not depend on character frequency. The WSE effect ranged from 7% to 12% across the two language backgrounds and across the two levels of character frequency. One explanation for this centers on the conclusion that, although words and characters are both functional units in reading, the whole word plays a more important role for CFL learners (Bai et al., Reference Bai, Liang, Blythe, Zang, Yan and Liversedge2013; Chen, Reference Chen2015; Shen et al., Reference Shen, Liversedge, Tian, Zang, Cui, Bai and … Rayner2012). The importance of the word as a perceptual unit is quite general in Chinese reading, beyond CFL learners. Eye tracking evidence (Li et al., Reference Li, Rayner and Cave2009; Li & Pollatsek, Reference Li and Pollatsek2011) suggests that words, more than characters, are the primary orthographic unit in Chinese reading. Thus, the difference between native Chinese readers and nonnative Chinese learners is the relative functionality of the word and character. The low-proficiency CFL learners have a greater dependence on word knowledge in identifying characters (Bai et al., Reference Bai, Liang, Blythe, Zang, Yan and Liversedge2013; Shen et al., Reference Shen, Liversedge, Tian, Zang, Cui, Bai and … Rayner2012) and need more time to reach the threshold of the character processing compared with native Chinese readers (Liu, Wang, & Perfetti, Reference Liu, Wang and Perfetti2007). Liu et al. (Reference Liu, Wang and Perfetti2007) found low-proficiency Chinese L2 leaners needed an SOA of 500 ms for orthographic priming (Liu et al., Reference Liu, Wang and Perfetti2007) while another study with the same procedure found orthographic character priming for native Chinese readers with an SOA 43 ms (Perfetti & Tan, Reference Perfetti and Tan1998). We see a related difference in the present study, where SOAs were determined for individual participants by an adaptive procedure. Low-proficiency CFL learners required longer SOAs (54 ms for Thai–Chinese learners and 51 ms for Indonesian–Chinese learners) compared with native Chinese readers (43 ms).
It is very likely that the functional, as opposed to the nominal, character frequency differences were not the same for native and CFL learners. For native Chinese readers who have abundant knowledge of characters, a low-frequency character is functionally much higher (more familiar) than it is for the CFL learners, perhaps more comparable to a CFL learner’s high-frequency character. Although this group difference in exposure should apply also for high-frequency characters, the impact of the difference is reduced. The relation between objective frequency and identification is nonlinear, such that frequency differences become less functional at high levels.
One reason for the relatively lower character knowledge (relative to word knowledge) for CLF learners may be that CFL instruction emphasizes words over characters. This reflects the practical assumption that the word is the basic semantic unit that can be used in isolation. However, this emphasis may reduce the attainment of high-quality character representations, thus allowing word-level knowledge to dominate character recognition. The strong WSE we observed for CFL learners in the present study suggests that more character practice would be useful to establish high-quality character representations. The fact that the WSE was found for both low-proficiency Thai and Indonesian Chinese learners indicates the generality of interactive activation between the character and word levels in Chinese. Consistent with the present study, Chen, Zhong, and Leng (Reference Chen, Zhong and Leng2017) found that Korean–Chinese learners showed the same WSE for high- and low-frequency characters.
As to differences between the Thai and Indonesian L1 groups, their WSEs were not reliably different, although the WSE effect for Indonesian L1 (0.115) was slightly and nonsignificantly larger than for Thai participants (0.08). A difference was observed in the effect of character frequency when nonwords were presented. The Thai L1 group, but not the Indonesian L1 group, showed a frequency effect favoring high-frequency characters. This pattern of results is mixed support, at best, for the idea that transfer of space cues from L1 would increase the reader’s use of character units, as opposed to word units, in Chinese.
In summary, three experiments found a WSE in Chinese for native readers and CFL learners from different L1 backgrounds. The WSE effect depended on character frequency for skilled native Chinese readers more than for CFL learners. The results thus demonstrate the general importance of word-level knowledge in Chinese reading across skill levels, while also suggesting that character knowledge, which is central to skilled reading, may develop more slowly in CFL learners, at least when teaching emphasizes words over characters.
APPENDIX A
Table A.1 High character frequency stimuli

Table A.2 . Low character frequency stimuli

ACKNOWLEDGMENTS
This research was supported by China National Social Science Foundation Grant 15CYY020 (to L.C.).