


Introduction
For a long time, the debate in the literature about the nature of the bilingual memory centered on whether two languages access one common or two separate conceptual systems (see Francis, Reference Francis1999, Reference Francis, Kroll and DeGroot2005, for a review). However, converging evidence from different experimental paradigms (e.g., speeded translation, semantic priming, masked priming and long-term priming) has confirmed that translation equivalents tap shared semantic representations in bilingual memory, even though experiments with cross-language semantic associates produced mixed findings that were difficult to interpret (e.g., Kirsner, Smith, Lockhart, King and Jain, Reference Kirsner, Smith, Lockhart, King and Jain1984; Schwanenflugel and Rey, Reference Schwanenflugel and Rey1986; Williams, Reference Williams1994). For example, experiments using a semantic priming paradigm (Chen & Ng, Reference Chen and Ng1989; Jin, Reference Jin1990; Altarriba, Reference Altarriba and Harris1992; Keatley, Spinks and de Gelder, Reference Keatley, Spinks and de Gelder1994) and a masked priming paradigm (De Groot and Nas, Reference de Groot and Nas1991; Gollan, Forster and Frost, Reference Gollan, Forster and Frost1997; Grainger and Frenck-Mestre, Reference Grainger and Frenck-Mestre1998; Jiang, Reference Jiang1999; Jiang and Forster, Reference Jiang and Forster2001; Finkbeiner, Forster, Nicol and Nakumura, Reference Finkbeiner, Forster, Nicol and Nakamura2004; Basnight-Brown and Altarriba, Reference Basnight-Brown and Altarriba2007; Perea, Dunabeitia and Carreiras, Reference Perea, Dunabeitia and Carreiras2008) were extended to involve cross-language stimuli and, as a result, robust translation priming has been established as a reliable phenomenon. In particular, Altarriba and Mathis (Reference Altarriba and Mathis1997) showed that early language learners demonstrated a cross-language interference effect in a Stroop task, which suggests the existence of a direct connection from L2 to semantic representations without L1 mediation.Footnote 1 Similar results were obtained by Lee, Wee, Tzeng and Hung (Reference Lee, Wee, Tzeng, Hung and Harris1992) and Tzelgov, Henik and Leise (Reference Tzelgov, Henik and Leiser1990).
Translation priming asymmetry
Earlier studies of translation priming (e.g., Schwanenflugel and Rey, Reference Schwanenflugel and Rey1986; Grainger and Beauvillain, Reference Grainger and Beauvillain1988; Chen and Ng, Reference Chen and Ng1989; Jin, Reference Jin1990; Keatley et al., Reference Keatley, Spinks and de Gelder1994) used a lexical decision task (LDT), in which the prime was plainly visible, and the stimulus onset asynchrony (SOA) was at least 150 ms. The general findings revealed both translation and semantic facilitation effects. This would suggest that translation equivalents and semantically related words are somehow interconnected across languages. However, the main problem with using this type of priming paradigm is that participants would quickly realize that the target might be a translation of the prime, and hence might prepare for that eventuality by actually carrying out the necessary translation. Alternatively, there may be a post-access effect in which participants realize that the target was a translation of the prime, and this leads to a faster lexical decision response (e.g., Perea et al., Reference Perea, Dunabeitia and Carreiras2008). Therefore, the priming effect observed with a visible prime may not be an accurate indicator of the extent to which the representation of the prime automatically activates the representation of the target. For these reasons, a masked priming paradigm is preferred. In the standard masked priming paradigm (Forster and Davis, Reference Forster and Davis1984), a forward mask is followed by a briefly presented prime (40–60 ms), which is then immediately followed by the target. Under these conditions, the prime cannot be identified. In bilingual translation priming experiments the target is a word in one language and the prime is either the translation-equivalent word in the other language, or a completely unrelated word. In some experiments, the prime is followed by a backward mask so that participants have more time to process the prime, but are still unaware of the prime. Since participants are unaware of the prime, it is obvious that they would not be able to predict the target as the translation equivalent of the prime. Nor would they derive any benefit from a retrospective strategy, in which the relatedness of the target and the prime acts as a cue for the decision (Neely, Keefe and Ross, Reference Neely, Keefe and Ross1989). Thus, the claimed benefit of using this technique is that it is more sensitive to automatic processes, and less sensitive to strategic processes. A priming effect is observed when the primed target is responded to faster than the unprimed target, which is interpreted as indicating that the lexical entries in both languages are linked in some way (either at the lexical level or semantic level or both).
Another benefit of using this technique is that it provides the possibility of testing participants in one language (that of the target word) and manipulating the language of the prime without the participant's knowledge that the experiment is about their bilingualism. This bilingual paradigm is operating in a “monolingual mode” (e.g., Grosjean, Reference Grosjean1998, Reference Grosjean and Nicol2001), and thus accurately measures the automaticity of language processing.
Early work with this technique suggested that translation priming was restricted to cognate terms, i.e., words that are descended from the same form, for example, the Spanish–English translation equivalent rico–rich (de Groot and Nas, Reference de Groot and Nas1991; Sánchez-Casas, Davis and García-Albea, Reference Sánchez-Casas, Davis and García-Albea1992), but subsequent research with Hebrew–English and Chinese–English bilinguals showed that non-cognates also produced strong priming (Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999; Forster and Jiang, Reference Forster, Jiang and Nicol2001), suggesting that the difference in script might be a critical factor (Forster and Jiang, Reference Forster, Jiang and Nicol2001).
Importantly, one thing that seems clear from masked translation priming experiments using a lexical decision task is that words in L1 have a marked effect on the recognition of L2 words, but not vice versa (e.g., Keatly et al., 1994; Williams, Reference Williams1994; Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999). That is, an asymmetrical pattern of cross-language priming is observed: L1 can prime L2, but L2 cannot prime L1. This is not what one would expect if the two languages overlapped completely at the semantic level, which should produce equal amounts of priming in both directions, i.e., symmetry. This might suggest that bilinguals are unable to effectively process L2 primes within such a short time. However, this can't be true because L2–L2 repetition priming was reliably observed in both Chinese and Hebrew in lexical decision (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999).
If the two languages of a bilingual share a common semantic system (at least for translation equivalents), one might ask how the asymmetry occurs. One might expect that the Revised Hierarchical Model (RHM) of bilingual representations (Kroll and Stewart, Reference Kroll and Stewart1994) could explain this priming asymmetry. The RHM assumes connections between L1 and L2 at the lexical level and a direct access from the form to the meaning (i.e., conceptual level) in both languages. According to this model, access to semantic information from L2 needs to be mediated by L1 at the initial stages of L2 learning. As L2 proficiency increases, a direct connection between L2 and the semantic system is established and L1 mediation is no longer useful in processing. Thus, an asymmetry is created in this model: L1 words have stronger connections to concepts than the newly learned L2 words (also see Kroll and Tokowicz, Reference Kroll, Tokowicz and Nicol2001, Reference Kroll, Tokowicz, Kroll and DeGroot2005). As suggested by Kroll and Tokowicz (Reference Kroll, Tokowicz and Nicol2001), the lexical asymmetry may arise in part from the differential reliance of L2 on L1, and may also be a result of the different mappings from a small L2 lexicon to a large L1 lexicon for which some L2 translation equivalents are absent. However, if there are strong lexical links between L2 words and their L1 translations (as the RHM proposes), then one would expect strong L2–L1 priming, which definitely is not the case. The alternative explanation might be that the relative speed of processing in L1 and L2 is responsible for the asymmetry. If L1 processing is unaffected by L2 primes because bilinguals process the L2 primes too slowly, the translation asymmetry in lexical decision seems obvious. In fact, Jiang (Reference Jiang1999) designed an experiment to explore this possibility by inserting a blank after the presentation of L2 primes before L1 recognition to ensure sufficient time for L2 processing. The results showed no priming from L2 to L1 in lexical decision and suggested that the absence of priming was not due to slower processing of L2 primes.
Task effects in translation priming
The most puzzling aspect of this asymmetry is its dependence on task. For example, Grainger and Frenck-Mestre (Reference Grainger and Frenck-Mestre1998) tested highly skilled English–French bilinguals in both lexical decision and semantic categorization using the masked priming paradigm. Non-cognate translation equivalents of English and French were selected to serve as primes and targets. Prime words were always presented in French (L2) and target words always in English (L1). The results showed that reaction times in semantic categorization and lexical decision tasks were similar. However, there was a robust translation priming effect in the semantic categorization task, but not in the lexical decision task. Grainger and Frenck-Mestre (Reference Grainger and Frenck-Mestre1998) proposed that this task effect followed logically from the fact that semantic categorization requires access to semantic information whereas lexical decision does not. They argued that the translation priming effects observed with the highly proficient bilinguals were mediated by semantic representations shared by translation equivalents and not by excitatory connections between distinct form representations. However, this explanation of the task effect does not account for the existence of L1–L2 priming in lexical decision. If lexical decision does not require access to semantic information, then why has L1–L2 translation priming been consistently observed in this task in several earlier studies?
The Sense Model
In a recent article, Finkbeiner et al. (Reference Finkbeiner, Forster, Nicol and Nakamura2004) attempted to explain this task effect by proposing a new model of translation priming: the Sense Model, which proposes that translation priming depends on the degree of overlap in the senses associated with the prime and target, and that a semantic categorization task accentuates this overlap.
The Sense Model starts with the assumption that most words are polysemous and that the range of senses that a word has differs across languages. Translation equivalents share one sense (typically, the dominant sense), but may differ in the remaining senses. For examples, the English word black and the Chinese word 黑 are translation equivalents, sharing the core sense (COLOR) in common; however, in English black can also be used to refer to a type of humor or a calamitous day on Wall Street, while in Chinese, 黑 can refer to those who are evil-minded or something that is secret. Thus, the senses of L1 and L2 words can extend well beyond the shared semantic sense that determines translation equivalence. Since bilinguals are normally more proficient in their L1 than L2, it follows that an L2 speaker would likely know fewer senses of L2 words compared with L1 words. This would result in a representational asymmetry between L1 and L2 at the semantic level.
According to the Sense Model, translation priming depends not only on the overlap in the semantic senses activated by the prime and the target, but on the ratio of primed to unprimed senses associated with the target. The representational asymmetry indicates that most, if not all, of the L2 senses are associated with L1, but not vice versa. In order to produce priming, it is necessary to activate a sufficient proportion of the target senses. Priming from L1 to L2 occurs because the L1 prime can activate a high proportion of the L2 target senses. However, priming from L2 to L1 is weaker because the L2 prime might activate only the dominant sense of the L1 target, and hence the ratio of primed to unprimed senses associated with the L1 target will be rather low, compared to that in the L1–L2 direction. This differential activation is assumed to affect the degree of priming in a lexical decision task. However, in a semantic categorization task, the category is assumed to act as a kind of filter which limits activation to just the category-relevant features of the target, thereby increasing the ratio of the primed senses to the unprimed senses in the case of L2–L1 priming (see Figure 1). Of course, a similar effect would not be expected in the L1–L2 direction because all of the L2 senses would be activated by the L1 prime in any case. However, in lexical decision, there is no category information, and therefore there is no filtering effect that could increase the ratio of primed to unprimed senses in the L2–L1 direction, therefore no priming is observed. We will refer to this explanation as the Category Restriction Hypothesis.
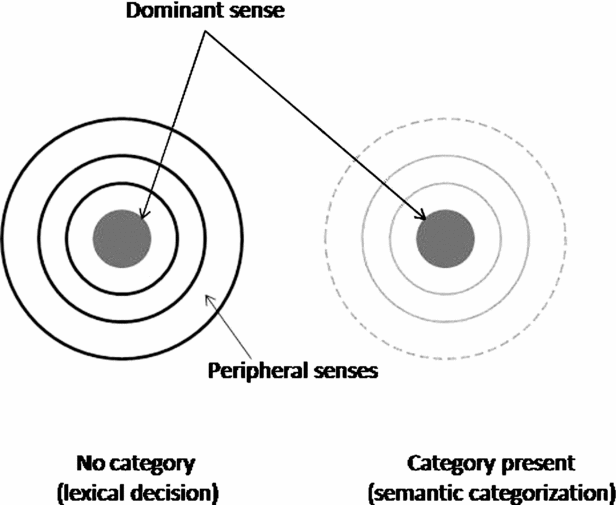
Figure 1. A schematic representation of the activation of the L1 target in a lexical decision task and a semantic categorization task. The dominant sense that determines translation equivalency is shared between L1 and L2, depicted by the dark grey circle. The non-dominant senses (peripheral senses, not shared between L1 and L2) are depicted by the white circles. Translation priming is assumed to depend on the proportion of target senses that are activated by the prime. In lexical decision, an L2 prime will only activate the dominant sense, leading to a small proportion of primed L1 target senses. But in semantic categorization, when the peripheral senses are suppressed by the category, the proportion of primed senses will be greater, leading to stronger priming.
The evidence supporting the Sense Model comes from Japanese–English bilinguals’ performance in lexical decision and semantic categorization (Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004). In this study, Japanese–English bilinguals were presented with items that were blocked according to semantic category and asked to decide whether the displayed item belonged to the indicated category or not. Each category consisted of the same number of exemplar and non-exemplar L1 targets. All the targets were preceded either by a masked translation prime or a control prime in L2. During the debriefing, all the participants denied any awareness of the English primes. The findings of this experiment revealed a significant L2–L1 priming effect of 19 ms. However, the same items used in a lexical decision task showed no priming. Thus, L2 primes appeared to activate their L1 translation counterparts in a semantic categorization task, but not in lexical decision. Furthermore, Finkbeiner et al. found that the same Japanese–English bilinguals showed L2–L2 repetition priming in lexical decision and concluded that L2 primes were processed effectively in lexical decision.
To date, the Sense Model is the only theory that is able to provide an account for the priming asymmetry and its dependence on task. However, there are four important aspects associated with the Sense Model that have never been empirically investigated. First, there is the assumption that the category in a semantic categorization task functions as a filter restricting the activation of the target semantics, unlike lexical decision; namely, the Category Restriction Hypothesis. Second, there is the possibility that a congruence effect might be contributing to priming in the semantic categorization task. That is, when subjects try to make a category decision on the targets, the same decision process could also have been carried out on the prime. If the prime elicits a different response to the target, a response conflict is generated. No such effect occurs on translation trials where both prime and target would elicit the same response (by definition). In fact, priming caused by implicit decision processes on the prime has been observed in the monolingual literature (Damian, Reference Damian2001; Davis, Kim and Sánchez-Casas, Reference Davis, Kim, Sánchez-Casas, Kinoshita and Lupker2003; Forster, Mohan and Hector, Reference Forster, Mohan, Hector, Kinoshita and Lupker2003; Forster, Reference Forster2004; Quinn and Kinoshita, Reference Quinn and Kinoshita2008). Third, previous studies (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004) have inserted a backward mask between the prime and target in order to allow more processing time for L2 primes. If the Sense Model is correct, this should not be necessary for L2–L1 priming if a semantic categorization task is used. Finally, it is of interest to find out whether just any task that requires access to word meaning can also produce L2–L1 priming, or whether some more specific requirement is involved.
To address the above-mentioned issues, the current paper will provide experimental evidence for the Sense Model's explanation of the task effect in masked translation priming. In Experiment 1, we consider whether L2–L1 priming is restricted to exemplars of the category, as required by the Sense Model. Second, in Experiment 2 we consider whether the effect is a genuine priming effect, or is a response congruence effect. Experiment 3 investigates whether L2–L1 priming can still survive in the conventional masked priming procedure without the 150 ms backward mask that has been used in previous studies. Finally, we take up the question of whether the increase in priming produced by the categorization task is simply a consequence of the fact that in order to respond, the semantic properties of the target words must be accessed, whereas this is not necessarily the case in a lexical decision task.
In the current study, we focus on late but proficient second-language learners to further examine these assumptions and possibilities in the semantic categorization task. The bilingual population recruited in the study has similar language experiences and proficiency as those in earlier masked priming studiesFootnote 2 (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004).
Experiment 1: The Category Restriction Hypothesis
The Category Restriction Hypothesis implies that L2–L1 priming should be observed for exemplars, but not for non-exemplars, because the category would not restrict the semantic senses of L1 targets that are non-exemplars. If translation priming is observed for non-exemplars as well as for exemplars, then some other explanation for the task effect must be found. This issue was not specifically addressed in Finkbeiner et al. (Reference Finkbeiner, Forster, Nicol and Nakamura2004).
Therefore, the purpose of the first experiment is: (1) to confirm the results predicted by the Sense Model, testing a different group of bilinguals (Chinese–English); and (2) to confirm that L2 to L1 priming is only observed for exemplars.
Method
Participants
Eighteen Chinese–English bilinguals were recruited from the University of Arizona for this experiment. All of them were native speakers of Chinese and had lived in the USA for at least one and a half years by the time of testing. Participants had learned English after acquiring their L1 and received a minimum of eight years of English instruction in China before they came to USA for undergraduate or graduate degrees. All the participants voluntarily participated in the study but were not paid for their participation.
Materials
It is necessary that participants have acquired all the L2 words employed in the translation priming experiment. Therefore, frequently used and taught L2 words were selected from Battig and Montague's (Reference Battig and Montague1969) category norms for verbal items by the first author (a native speaker of Chinese). Eventually, eight categories were selected: a part of a building, a family relative, a color, a unit of time, a four-footed animal, a profession, a part of the human body and a sport. In addition, the category a country name was selected for practice items.
Altogether, two hundred English words were selected from the nine categories. Their Chinese translation equivalents were then selected according to the first author's knowledge of Chinese. In order to ensure translation equivalency for each English–Chinese prime–target word pair, four Chinese–English bilinguals (from the same population as the participants in the experiment) were asked to translate the list of English words into their Chinese equivalents; another four were consulted to translate the same list of words from Chinese to English. Only those words that maintained translation consistency in both directions of translation by all of the consultants were considered for this study. The criterion for selection was based on Chinese–English bilinguals’ familiarity with both of the category norms and vocabulary in two languages, plus the translation consistency among these bilingual consultants. As a result, ten exemplars/words were selected for each category, and five exemplars/words were used for the practice category. In total, eighty-five cross-language word pairs were selected.
The English non-exemplars needed to meet four conditions: (1) they were frequently used and taught concrete nouns; (2) the non-dominant senses of these items were irrelevant to any of the tested categories; (3) within each category, the non-exemplars themselves needed to be semantically distinct from each other in order to avoid a possible congruence effect in the case that two or more non-exemplars happened to share certain semantic senses; and (4) the same degree of translation equivalency held between the Chinese and English translations of the non-exemplars. In accordance with the above requirements, the same procedure of normed translation in both directions was performed, and eighty-five items (the same number as for exemplars) were selected from twenty-seven categories (different from the above-mentioned nine categories) in Battig and Montague (Reference Battig and Montague1969) and distributed among the tested and practice categories so that each category had an equal number of exemplars and non-exemplars.
All of the above being taken into consideration, 170 Chinese–English word pairs (including both exemplars and non-exemplars) were selected and distributed into the stated nine categories. An additional 170 English words were selected from the CELEX database (Baayen, Piepenbrock and Gulikers, Reference Baayen, Piepenbrock and Gulikers1995) to serve as control/unrelated primes. These were unrelated to their targets, but matched with the critical primes (English translations) for frequency and word length.
None of the Chinese targets shared cognate status with their English primes. All targets were presented in simplified Chinese characters of size 12 and font SimSun (The experimental materials (Appendix 1, 2 and 3) are available on the Journal's website as Supplementary Materials accompanying the present article; see journals.cambridge.org/bil, vol 13 (3).).
Design and procedure
Usually, semantic categorization tasks are carried out in a blocked fashion such that all of the exemplars and an equal number of non-exemplars appear together (Frenck-Mestre and Bueno, Reference Frenck-Mestre and Bueno1999; Bueno and Frenck-Mestre, Reference Bueno and Frenck-Mestre2002; Forster and Hector, Reference Forster and Hector2002; Forster et al., Reference Forster, Mohan, Hector, Kinoshita and Lupker2003). Grainger and Frenck-Mestre (Reference Grainger and Frenck-Mestre1998) and Finkbeiner et al. (Reference Finkbeiner, Forster, Nicol and Nakamura2004) also used this procedure. Following this procedure, items in the present experiments were blocked according to semantic category. The practice category was presented prior to the other eight tested categories.
Each trial consisted of the following sequence (adapted from Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004): the trial started with a 500 ms forward mask (########), followed by an English prime (translation or control) in lowercase letters for 50 ms, followed by a backward mask (&&&&&&&&) for 150 ms and then the Chinese target word for 500 ms. The purpose of including the backward mask was to ensure enough time for the participants to process the L2 primes (cf. Jiang, Reference Jiang1999). It is important to note that the backward mask (&&&&) differed from the forward mask (####) so as to limit the visibility of the prime. This presentation sequence prevented the participants from being aware of the existence of the prime. No participant reported seeing the English words preceding the Chinese targets, and all were surprised during the debriefing to learn that any English word had been presented.
Within each category, there were four conditions: (1) five exemplar targets with translation equivalent primes; (2) five exemplar targets with control primes; (3) five non-exemplar targets with translation equivalent primes; and (4) five non-exemplar targets with control primes. Two counterbalanced lists were constructed so that the exemplar preceded by its translation prime on List A was preceded by its control prime on List B and vice versa. The same method was applied to non-exemplar items as well. No target word or prime word was repeated within lists. Half the participants were assigned to List A, and half were assigned to List B. Except for the initial practice category, all the other categories and all the items within each category were presented in a random sequence.
Participants were tested by the first author. They were asked to read written instructions in Chinese before they performed the task. No mention was made of the possible existence of the primes, nor the fact that their knowledge of English might be involved in the experiment. Prior to the presentation of targets within each category, they were given the category information on the computer screen and asked to decide whether the following presented targets belonged to the indicated category or not by pressing either a “YES” button or a “NO” button as quickly as possible. This stimulus presentation and timing of responses was controlled by the DMDX package developed at the University of Arizona by J. C. Forster (Forster and Forster, Reference Forster and Forster2003).
Results and discussion
In analyzing the results of this experiment and all subsequent experiments, data from trials on which an error occurred were discarded and outliers were treated by setting them equal to cutoffs established at two standard deviations above or below the mean for each participant. Subjects who made errors on more than 25% of the trials would have been excluded from the analysis, but none made more than 25% errors. As shown in Table 1, mean response time for exemplars was 591 ms in the translation prime condition and 611 ms in the control condition, yielding a translation priming effect of 20 ms. A two-way ANOVA by both participant and item analysis showed that this effect for the exemplars was significant (F 1(1,16) = 11.57, p = .004; F 2(1,156) = 6.08, p = .015). However, the translation priming for the non-exemplars was in the wrong direction (−2 ms), and was not significant (all Fs < 1). There were no significant effects for errors.
Table 1. Mean semantic categorization times (RT) (in milliseconds) and error rates (ER) (in percentages) for both exemplars and non-exemplars from L2 to L1 (Experiment 1).

The findings of Experiment 1 confirm that a masked translation priming effect in the L2–L1 direction can be obtained in a semantic categorization task, as shown originally by Grainger and Frenck-Mestre (Reference Grainger and Frenck-Mestre1998) and Finkbeiner et al. (Reference Finkbeiner, Forster, Nicol and Nakamura2004). In addition, no priming was observed for non-exemplars, as predicted by the Category Restriction Hypothesis, which assumes that the category acts as a context that filters out the irrelevant senses in L2–L1 processing so as to increase the ratio of primed to unprimed senses. Such an effect would not occur for non-exemplars since the category is not relevant to non-exemplars. Therefore, the proportion of primed to unprimed senses in the target word remains too low to support priming, and hence there is no priming, as in a lexical decision task where there is no context effect.
Experiment 2: Controlling for response congruence
According to Dehaene, Naccache, Le Clec'H, Koechlin, Mueller et al. (Reference Dehaene, Naccache, Le Clec'H, Koechlin, Mueller and Dehaene-Lambertz1998), responses to the target stimulus in a semantic categorization experiment can be influenced by implicit categorization responses to the prime, even though the prime is masked. In a number categorization task, Dehaene et al. required subjects to decide whether a target number was bigger or smaller than 5. Prior to the target, a masked number was presented. When the masked prime and target both fell on the same side of 5 (congruent trials), responses to the target were faster than when they fell on opposite sides (incongruent trials). In addition, both electrical and hemodynamic measures of brain activity indicated that subjects were in fact covertly classifying the masked primes. In a masked translation priming experiment, such an effect could easily be misinterpreted as translation priming since, on related trials, both the prime and the target would elicit the same categorization response, but on control trials they would typically elicit a different response, since unrelated control primes would usually be non-exemplars of the category. If the target was an exemplar, the translation prime would also be an exemplar (by definition), and hence this would be a congruent situation. However, if the control prime was a non-exemplar, then this would be an incongruent situation, which would lead to slower responses. However, no such effect would occur when the target was a non-exemplar, because the translation prime and the control prime would both be non-exemplars. If the prime was in fact an exemplar, then a response congruence effect would be observed for exemplar targets, as shown by Forster et al. (Reference Forster2004, Experiment 3).
The response congruence effect implies that the primes are semantically interpreted. This conclusion has been challenged by Damian (Reference Damian2001), who pointed out that with a limited number of stimuli (the digits 1–4 and 6–9), the masked primes would have been presented many times as targets on previous trials. This pairing of a visible target with the appropriate motor response could form a low-level S–R association, so that when that target number was subsequently presented as a masked prime, an implicit response tendency would be generated, which could be responsible for the congruence effect. Damian showed that when a larger range of stimuli was used, so that no target was ever repeated as a masked prime, no congruence effect was observed. If Damian's argument is correct, then there is no problem in designing suitable items for a translation priming experiment, since the primes have never been presented before as targets. But if Dehaene et al. are correct, and primes are categorized on the basis of their semantic properties, then the items in a translation priming experiment have to be designed so that the prime has the same status with respect to the category as the target.
Experiment 2 was therefore designed to determine whether the robust priming effect from L2 to L1 in semantic categorization was partially attributable to a congruence effect. To control for a possible congruence effect, another condition was added to the design of Experiment 1, in which the control prime was a category member. Therefore, three prime conditions were created: translation (the prime is the translation of the target), congruent (the prime is an exemplar of the category) and unrelated (the prime is unrelated to the target, but not an exemplar). If there is a genuine translation effect, then the translation primes should produce faster responses than the congruent primes, and if there is no difference between the congruent and control conditions, then one can infer that there is no congruence effect. One might argue that the congruent condition is really a semantically related condition, and that any difference between this condition and the unrelated control condition might reflect semantic priming, not a congruence effect. However, semantic priming effects with masked primes are very weak with short prime durations (50 ms and below, e.g., Rastle, Davis, Marslen-Wilson and Tyler, Reference Rastle, Davis, Marslen-Wilson and Tyler2000), even when there is a very close relationship between the prime and the target. The translation prime was the best candidate for the target in terms of semantic overlap, but the congruent/exemplar prime (e.g., CAMEL) was not closely related to the target (e.g., DOG) semantically even though it belonged to the same category (e.g., ANIMAL).
Method
Participants
Twenty-four Chinese–English bilinguals were recruited for this experiment at the University of Arizona. They were recruited from the same population of students as in Experiment 1.
Materials and design
The item selection followed the same procedure as in Experiment 1. In addition, it was determined that all the selected items were included in the cross-linguistic database (English and Chinese) obtained from a study of category norms (Yoon et al., Reference Yoon, Feinberg, Hu, Gutchess, Hedden, Chen, Jing, Cui and Park2004). This was to confirm that the items used in the study were the most representative/familiar category members in both cultures.
The frequently used and taught L2 words comprised the following ten categories: a part of building, an article of clothing, a vegetable, a unit of time, a four-legged animal, a profession, a part of the human body, a sport, a type of science and a kind of fruit. Within each category, there were nine exemplars and nine non-exemplars. Additionally, an extra category of a country name consisting of six exemplars and six non-exemplars was selected for practice prior to the real test. Taken together, 192 translation pairs (an equal number of exemplars and non-exemplars) were selected and distributed into eleven categories including the practice one.
Three conditions were created in each category (e.g., A Part of Building) for both exemplars and non-exemplars: Chinese target words were preceded by: (1) English translation primes (i.e., translation condition: e.g., room–房 间); (2) English exemplar primes (i.e., congruent condition: e.g., office–房 间); or (3) English unrelated primes (i.e., unrelated condition: e.g., good–房 间). For the congruent and unrelated conditions, 192 exemplar primes (but not translation equivalents of the targets) and 192 unrelated primes were selected, respectively, matching with translation primes for frequency and word length. Three counterbalanced lists were constructed so that the target preceded by its translation prime on List A was preceded by an exemplar prime on List B and an unrelated prime on List C.
Again, items were blocked and randomly presented within each category. Following the practice category, the order of presentation of the other categories was randomized.
Procedure
The testing procedure was the same as Experiment 1.
Results and discussion
As shown in Table 2, for exemplars, the mean response time in the translation prime condition was 619 ms, compared with a mean of 633 ms in the congruent control condition, and a mean of 630 ms in the incongruent control condition. The effect of prime type was significant (F 1(2,42) = 3.44, p = 0.042; F 2(2,174) = 5.11, p = 0.007), and this effect was obviously due entirely to the translation condition. There were no significant differences in the error rates (both Fs < 1). This result indicates that there is no congruence effect (–3 ms), and hence the translation priming observed here, and in Experiment 1, cannot be attributed to a congruence effect. Finally, planned comparisons for exemplars showed that translation priming (compared with the congruent unrelated condition) was significant in both subject and item analyses (F 1(1,21) = 5.05, p = 0.036; F 2(1,87) = 6.32, p = 0.014).
Table 2. Mean semantic categorization times (RT) (in milliseconds) and error rates (ER) (in percentages) for both exemplars and non-exemplars from L2 to L1 (Experiment 2).
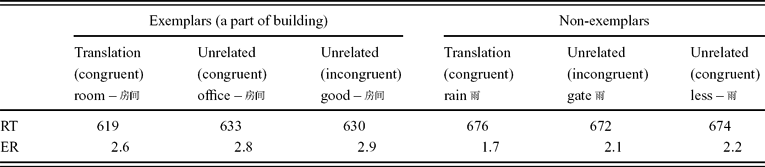
As in Experiment 1, there was no translation priming effect for non-exemplars (–4 ms, both Fs < 1). There were no significant differences in errors. Thus, the findings revealed reliable L2–L1 translation priming for exemplars but not for non-exemplars when the variable of congruence was controlled, confirming the Category Restriction Hypothesis proposed by the Sense Model.Footnote 3
The absence of any cross-language congruence effect is interesting, because such effects have been reported in several within-language experiments (e.g., Damian, Reference Damian2001; Forster et al., Reference Forster, Mohan, Hector, Kinoshita and Lupker2003; Forster, Reference Forster2004; Quinn and Kinoshita, Reference Quinn and Kinoshita2008). One possible explanation might be that the task set established by the instructions was to categorize words in a particular script, namely Chinese. Since the prime was in an alphabetic script, no attempt would have been made to categorize it, and hence no congruence effect occurred. Nevertheless, activation of the semantic properties of the prime could still have taken place. That is, the script difference between L1 and L2 can eliminate the implicit decision process (categorization) on the primes but the semantic properties of the primes are nevertheless activated.
Another explanation could be related to the relative language proficiency of L1 and L2. If participants’ L1 is more dominant, it is reasonable to think that lexical access to L1 is faster than L2. Thus, it is possible that the time allowed for processing primes was sufficient for semantic activation to benefit L1 target recognition, but not sufficient for categorization. Therefore, translation priming was observed, but no congruence effect. To test this hypothesis, one could investigate whether a congruence effect is obtained in the reverse direction (L1–L2) in semantic categorization. If the congruence effect is still absent in the L1–L2 direction, then it would appear that the script might be critically involved. This explanation would be supported if congruence effects were observed in an experiment where targets were a mixture of L1 and L2 words, so that the task list was to categorize either type of words.
One other methodological issue that requires further discussion is the inclusion of an interpolated mask between the prime and target in Experiments 1 and 2. This procedure was adopted in previous translation priming experiments (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Grainger and Frenck-Mestre, Reference Grainger and Frenck-Mestre1998; Jiang, Reference Jiang1999; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004). This issue was first raised by Gollan et al. (Reference Gollan, Forster and Frost1997), who argued that the absence of L2–L1 priming could be due to the relative speeds of processing of the two languages, the idea being that the L1 target word might generate a response before the L2 prime processing finished. In order to guard against this possibility, an interpolated mask was introduced, even though Jiang (Reference Jiang1999) failed to find L2–L1 priming in lexical decision with such a mask. Clearly, extra time for L2 processing is not relevant to priming in lexical decision. However, it is unclear whether the interpolated mask is required in semantic categorization. Experiment 3 was designed to investigate this issue.
Experiment 3: The role of the backward mask in priming
In earlier studies, it was thought that maybe the reason no L2–L1 priming was observed in lexical decision was because there was insufficient time for the L2 prime to be processed. However, inserting a backward mask between the prime and the target had no effect (Jiang, Reference Jiang1999). Subsequent work with a semantic categorization task revealed L2–L1 priming, but the practice of including a backward mask was continued, making it unclear whether this procedure was really necessary. From the point of view of the Sense Model, it is the category that is responsible for priming, and therefore the backward mask should not be necessary.
Method
Participants
Twenty-four Chinese–English bilinguals were recruited from the same subject pool as in Experiments 1 and 2. All the participants were paid to participate in the study.
Materials
The materials were the same as in Experiment 2.
Design and procedure
The test procedure was the same as for Experiment 2, except that the 150 ms backward mask was removed.
Results and discussion
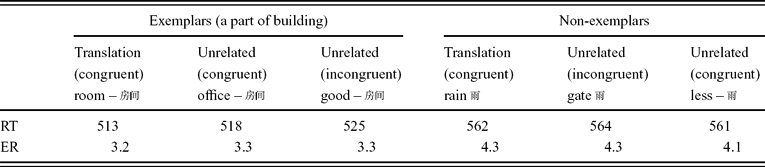
As shown in Table 3, mean response times were 513 ms in the translation prime condition, which was significantly faster than the unrelated condition (525 ms) by both subject and item analyses (F 1(1,21) = 17.27, p <.01; F 2(1,87) = 6.25, p = 0.01). When compared to the congruent condition (518 ms), the translation effect was significant in the subject analysis, but not in the item analysis (F 1(1,21) = 4.47, p = 0.047; F 2(1,87) = 1.01, p = 0.317). A separate analysis of the congruent and unrelated conditions showed no congruence effect from L2 to L1 (F 1(1,21) = 2.85, p = 0.11; F 2(1,87) = 1.39, p = 0.24). In addition, the mean error rate was 3.3% and did not differ significantly between conditions for exemplars. The non-exemplars did not show any advantage for translation primes (562 ms) compared with the exemplar controls (564 ms), nor unrelated primes (561 ms) (F 1(2,42) = 0.21, p = 0.81, F 2(2,174) = 0.46, p = 0.63). The mean error rate was 4.2% and did not differ significantly between conditions for non-exemplars.
Table 3. Mean semantic categorization times (RT) (in milliseconds) and error rates (ER) (in percentages) for both exemplars and non-exemplars from L2 to L1 without the backward mask (Experiment 3).
These results confirm the findings of Experiment 2 for both exemplars and non-exemplars, further demonstrating that the L2–L1 translation effect is not simply a response congruence effect.Footnote 4 Equally importantly, the results provide evidence that the backward mask is not a critical factor in L2–L1 priming. Again, the Sense Model is supported. Also, it should be noted that it seems likely that processing of the prime continues even after it has been replaced by the target, otherwise we would have to conclude that the meaning of the prime can be extracted within 50 ms, whereas evidence from eye-tracking and ERP experiments suggests that 150 ms is a more likely estimate (Sereno and Rayner, Reference Sereno and Rayner2003). Thus the relevant variable is probably the prime duration (which should be long enough to initiate lexical access of the prime), not the interval of time between the prime and the target.
One further aspect of the results is worth attention. That is, without the backward mask, the mean reaction times across three conditions for both exemplars and non-exemplars decreased by 108 ms for exemplars and 112 ms for non-exemplars, respectively, compared with the results for Experiment 2. Given that Experiments 2 and 3 were run with a similar group of participants and the same stimuli, it seems that the effect of the backward mask is to slow down the response to the targets. How this interference might have affected the processing of L2 primes is unclear.
Experiment 4: Categorizing with an ad hoc category
An obvious difference between semantic categorization and lexical decision is that semantic access is essential for semantic categorization, but not for lexical decision. It has been argued that this is the reason why the semantic task is more sensitive to translation priming (Grainger and Frenck-Mestre, Reference Grainger and Frenck-Mestre1998; de Groot, Reference de Groot and Cook2002). This argument was also adopted in long-term priming studies. For example, Zeelenberg and Pecher (Reference Zeelenberg and Pecher2003) concluded that long-term cross-language repetition priming depended on tasks that required access to conceptual knowledge (e.g., semantic categorization). Obviously, it is important to pursue the same question in masked translation priming. If a conceptual task is critical for producing L2–L1 priming, then any categorization task that requires conceptual level processing should increase the effectiveness of masked L2 primes. The following experiment was designed to test this possibility.
One way to achieve this is to ask participants to categorize words according to the physical properties of the objects they refer to, e.g., “Is it bigger than a brick?”. Such a category is completely ad hoc in the sense that it is an arbitrary classification that would never have been learned by any speaker of the language. In order to answer this question for each word, participants need to first access the lexical entry to determine the referent and then recover the conceptual properties associated with that entry. Only then can they make a decision about its relative size. If this type of ad hoc categorization can produce L2–L1 priming, the implication is that explicit conceptual level processing is all that is required to produce L2–L1 priming. If there is no observed priming, then one can conclude that the type of category is the key to L2–L1 priming. This is compatible with the Sense Model, since the ad hoc “bigger than a brick” category is unlikely to have any filtering effect.
Method
Participants
Fourteen Chinese–English bilinguals, who were from the same population of students as in Experiment 1–3, were recruited for this experiment at the University of Arizona. All the participants were paid to participate in the study.
Materials and design
The Chinese–English word pairs were selected by the same procedure used in Experiment 1. Two Chinese–English bilinguals were asked to provide translation equivalents from English to Chinese; another two did the reverse direction. The items that matched in both directions were used as test items.
Ninety-six Chinese–English word pairs were used in all. Half of these referred to objects that were clearly larger than a brickFootnote 5 (e.g., airplane, ladder, hospital, kitchen), and half referred to objects smaller than a brick (e.g., earring, lipstick, napkin, cucumber). In order to test the priming effect in both directions (L1–L2 and L2–L1), half of the items were presented as English targets preceded by masked Chinese primes and the other half presented as Chinese targets preceded by masked English primes. In both L1–L2 and L2–L1 stimulus presentation, two conditions were manipulated: the targets were preceded by either translation primes or unrelated primes.
Two lists of counterbalanced materials were constructed so that each target word was observed in both the translation and unrelated conditions with both directions (L1–L2 and L2–L1). Each list was presented as four blocks of equal numbers of items, including two blocks of Chinese target words and the other two blocks of English target words. Items were randomized within each block. Half the participants were tested on the L1–L2 items first, followed by the L2–L1 items, and half were tested in the reverse order. The control primes were always different words but were matched with their translation primes in length and frequency. In addition, ten practice trials were constructed preceding the real test in each direction of presentation (L1–L2 or L2–L1).
Procedure
The method of presentation was exactly the same as in Experiment 1 for the Chinese targets preceded by English primes (L2–L1 direction), including the 150 ms backward mask. The presentation of the L1–L2 items was slightly different in that there was no backward mask between the prime and target, because previous research with L1 primes has shown that it is unnecessary (e.g., Jiang, Reference Jiang1998, Reference Jiang1999; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004), and there is the added problem that the prime starts to become visible to L1 readers. Therefore, this experiment adopted the same L1 to L2 priming procedure as in Jiang's studies (1999): each trial started with the 500 ms forward mask (贔贔贔贔贔贔), followed by a Chinese prime (translation or control) for 50 ms, and then the English target word in lower case for 500 ms. The forward mask component 贔 was a very low frequency Chinese character. Using a Chinese character as a forward mask ensures better masking for a Chinese prime. None of the participants reported that they knew this character, and none reported being able to see the prime.
Participants read the instructions in Chinese before doing the experiment. They were asked to respond “Yes” to the word if the object referred to was bigger than a brick; otherwise they were to respond “No”.
Results and discussion
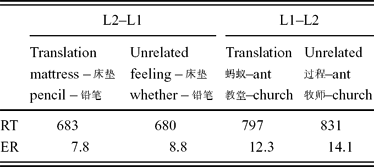
The mean classification times and error rates for English and Chinese targets are shown in Table 4. There was a significant effect of 34 ms for L1–L2 priming (F 1(1,14) = 5.65, p = 0.035; F 2(1, 48) = 10.02, p = 0.003). However, there was no priming in the reverse L2–L1 direction (–3 ms). There were no significant effects for errors.Footnote 6
Table 4. Mean categorization times (RT) (in milliseconds) and error rates (ER) (in percentages) for all items (English targets and Chinese targets) in Experiment 4.
What is crucial in this experiment is failing to find L2–L1 priming in a semantic categorization task that uses an ad hoc category. It therefore seems clear that the category plays a more critical role in translation priming than merely forcing participants to take meaning into account. The fact that a significant L1–L2 priming effect was found also shows that the failure of L2–L1 priming cannot be attributed to excessive noise in the data produced by the nature of the task. It should be noted that this result is still consistent with the Sense Model, since it is assumed that most or all of the L2 senses would be activated by the L1 translation prime.
General discussion
The main findings are straightforward: (1) proficient Chinese–English bilinguals show L2–L1 translation priming in a semantic categorization task, but for exemplars only, as predicted by the Sense Model; (2) this effect occurs when the possibility of a response congruence effect is eliminated; (3) however, there is no L2–L1 translation priming when an ad hoc category is used, which confirms the critical element in priming: the type of category; and (4) L2–L1 translation priming survives in semantic categorization even without the interpolated mask between the prime and target.
The main contribution of the Sense Model is its account of the asymmetry of masked translation priming and its dependence on the task; effects that have been consistently observed in the bilingual masked priming literature. Most researchers have explained the priming asymmetry in a lexical decision task as a result of lack of L2 proficiency (e.g., Keatley et al., Reference Keatley, Spinks and de Gelder1994; Kroll and Stewart, Reference Kroll and Stewart1994; Gollan et al., Reference Gollan, Forster and Frost1997), but some evidence suggests that even highly proficient bilinguals demonstrate priming asymmetry in lexical decision (e.g., Dudsic, Reference Dudsic2000). The influential RHM gives emphasis to L2 proficiency as important in determining how lexical and semantic representations are connected and suggests that L2 speakers may rely on L2–L1 lexical links rather than L2 links to concepts. However, this claim has been challenged by empirical data that showed L2 semantic effects even with very beginning second language learners (e.g., Altarriba and Mathis, Reference Altarriba and Mathis1997). Additionally, the proficiency account is problematic: if bilinguals are proficient enough to produce within-L2 priming in lexical decision (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999) and L2–L1 priming in semantic categorization (e.g., Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004; Experiments 1–3 in this paper), why are they not proficient enough to produce L2–L1 priming in lexical decision? In other words, why is proficiency relevant only to lexical decision?
To solve this problem, the Sense Model attributes the minimal or null L2–L1 priming to the relative poverty of L2 lexical semantics rather than the weaker connection of L2 to concepts. Note that second language learners who learn L2 after L1 acquisition would usually learn L2 words through their L1 equivalents. It seems likely that these bilinguals would only acquire the dominant sense shared by L1 and L2, even though their L2 proficiency level could be high by different measures. This would guarantee that the L2 senses would be a subset of the L1 senses, which is what the Sense Model attributes the priming asymmetry to. Most previous masked priming studies (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004) employed this type of bilingual population. Therefore, the relative poverty of L2 senses is highly possible.
An equally important assumption of the Sense Model is that lexical decision times are sensitive to the proportion of semantic senses activated for a given target by the prime. This assumption is perhaps more difficult to defend. The implication is that a lexical decision response cannot be made until all of the senses of the word have been activated, and hence there can be no priming at a semantic or conceptual level unless the prime manages to activate all, or a very large proportion of, the senses of the target word. The proposal that lexical decision might depend on semantic activation is not difficult to accept, given the increasing number of findings indicating clear effects of variables such as imageability, number of semantic neighbors and semantic “richness” on lexical decision times (e.g., Pexman, Holyk and Monfils, Reference Pexman, Holyk and Monfils2003; Siakaluk, Buchanan and Westbury, Reference Siakaluk, Buchanan and Westbury2003; Bastiaansen, Oostenveld, Jensen and Hagoort, Reference Bastiaansen, Oostenveld, Jensen and Hagoort2008; Pexman, Hargreaves, Siakaluk, Bodner and Pope Reference Pexman, Hargreaves, Siakaluk, Bodner and Pope2008), but whether these semantic effects are of the right type to support the Sense Model interpretation of asymmetric translation priming is another matter. An obvious direction for future research is to see whether L2–L1 priming in lexical decision depends on the semantic properties of the target.
This general approach is supported by recent evidence from Finkbeiner (Reference Finkbeiner2002) and Rodd, Gaskell and Marslen-Wilson (Reference Rodd, Gaskell and Marslen-Wilson2002). What has generally been reported in the literature is faster lexical decision times for ambiguous words than unambiguous words. However, Rodd et al. challenged this conclusion and argued that the ambiguity advantage is actually a sense benefit. They found that lexical decision times were slightly slower for ambiguous words with multiple unrelated meanings (e.g., bark) than for unambiguous words, but decision times for words with many related senses (e.g., burn) were significantly faster than for words with few senses (e.g., bone). These results suggest that competition among the multiple meanings of ambiguous words slowed down recognition, but that rich semantic representations (i.e., senses) associated with words facilitated recognition. Similar findings were reported by Finkbeiner et al. (Reference Finkbeiner, Forster, Nicol and Nakamura2004), showing that lexical decision times were faster for many-sense words (fifteen or more) than for few-sense words (one or two) selected from WordNet (Fellbaum, Reference Fellbaum1998). All these findings suggest that lexical decision times are sensitive to the number of semantic senses associated with the target word. If this is the case, then it is not too surprising that cross-language translation priming should be related to the proportion of the target senses that are pre-activated by the prime.
How does the Sense Model fare with other translation effects? For example, could it explain the asymmetry when participants are asked explicitly to translate from one language to the other? With this task, forward translation (L1–L2) is slower than backward translation (L2–L1) (e.g., Kroll and Stewart, Reference Kroll and Stewart1994). In L1–L2 translation, bilingual participants need to activate the semantic senses of L1 and then use the dominant sense to select the L2 form for production. However, in determining the dominant sense from all the competing L1 senses, processing takes time and effort. In the reverse direction of translation, L2 recognition will automatically activate the dominant sense that will be associated with L1; therefore, producing L1 does not involve any competition. As a result, the process of backward translation might require less effort and time.
As discussed before, the Sense Model applies only to a subset of bilinguals: those who have learned L2 after acquiring L1. One might think that bilinguals who learn their two languages simultaneously in the same context should develop the full range of senses in either language independently. Thus, there might not be the kind of representational asymmetry for this group of bilinguals. In fact, this argument is supported by recent results reported by Perea at al. (2008). They found that Basque–Spanish speakers showed the same amount of priming in both directions – Basque to Spanish and Spanish to Basque – using a lexical decision task with masked primes. Perea at al. claimed that the failure of early experiments (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004) to observe L2–L1 priming was due to the nature of the participants, who learned L2 as a second or foreign language, unlike those who grew up in a natural bilingual environment and used two languages on a daily basis. This leads us to think that it might be the nature of L2 lexical development that causes the difference in priming. If bilinguals learn two languages in a natural bilingual environment where they have balanced exposure to two languages (e.g., speaking one language at home and speaking the other language at work or school), compared to proficient second language learners who learn L2 only in a classroom setting in an L1 cultural environment, their lexical development can be conceivably more balanced. That is, using both languages daily in similar contexts can lead to greater sense overlap in their lexical semantics, and the range of senses of L1 and L2 will be more similar. According to the Sense Model, the ratio of primed to unprimed senses would then be similar in either language direction. As a result, these balanced bilinguals might show early and automatic translation priming effects in lexical decision, like the ones in Perea et al. (Reference Perea, Dunabeitia and Carreiras2008).
Conclusion
The Sense Model introduces the notion of asymmetrical lexical semantic representations between L1 and L2 in bilingual memory, which causes the translation asymmetry in lexical decision. To account for the symmetric priming in semantic categorization, the Sense Model claims that the category serves as a filter to eliminate the representational asymmetry. We tested these assumptions in the current experiments by investigating whether the translation effect only occurred to exemplars (Experiment 1), ruling out the possibility of congruence effect (Experiments 2 and 3), and the role of the category information in translation priming (Experiment 4). All of the results provide strong support for the assumptions of the Sense Model.





