


Introduction
DSM-IV (APA, 1994) classifies personality disorders (PDs) as discrete entities such that an individual either has or does not have a particular PD. This categorical approach to diagnosis is clinically familiar and can facilitate communication between professionals. Categorical PD classifications, however, have significant limitations, including diagnostic overlap, high levels of co-morbidity, reliance on arbitrary thresholds, within-diagnosis heterogeneity and low inter-rater reliability (Trull & Durrett, Reference Trull and Durrett2005; Clark, Reference Clark2007; Kamphuis & Noordhof, Reference Kamphuis and Noordhof2009). The ability of dimensional systems to overcome these limitations has led many researchers to support a reconceptualization of PD in DSM-5 (Frances, Reference Frances1993; Trull & Durrett, Reference Trull and Durrett2005; Widiger & Samuel, Reference Widiger and Samuel2005; Widiger et al. Reference Widiger, Simonsen, Krueger, Livesley and Verheul2005; Clark, Reference Clark2007) that would allow all individuals to be characterized on a comprehensive set of PD-related dimensions (e.g. Harkness & McNulty, Reference Harkness, McNulty, Strack and Lorr1994; Harkness et al. Reference Harkness, McNulty and Ben-Porath1995; Widiger & Simonsen, Reference Widiger and Simonsen2005; Tackett et al. Reference Tackett, Silberschmidt, Krueger and Sponheim2008; Watson et al. Reference Watson, Clark and Chmielewski2008).
The promise and identification of prototypes
Its myriad conceptual strengths aside, the relatively major shift to a dimensional approach in clinical settings may prove challenging (Krueger et al. Reference Krueger, Skodol, Livesley, Shrout and Huang2007; Widiger & Trull, Reference Widiger and Trull2007), potentially preventing full realization of benefits offered by dimensional nosologies. One compelling way to integrate the unique strengths of categorical and dimensional models would be to identify empirically based prototypes of personality pathology, operationalizing prototypes as specific trait profiles using a dimensional classification system. This method would provide the benefits of a dimensional trait system in addition to, when a patient's profile was sufficiently similar to a given prototype, a categorical label to facilitate diagnosis, conceptualization and communication.
Previous research on personality types has identified some prototypes within normal (Block, Reference Block1971; Robins et al. Reference Robins, John, Caspi, Moffitt and Stouthamer Loeber1996; Asendorpf et al. Reference Asendorpf, Borkenau, Ostendorf and Van Aken2001; De Fruyt et al. Reference De Fruyt, Mervielde and Van Leeuwen2002; McCrae et al. Reference McCrae, Terracciano, Costa and Ozer2006; Ashton & Lee, Reference Ashton and Lee2009) and pathological personality systems, such as ‘code types’ on the Minnesota Multiphasic Personality Inventory (MMPI; Tellegen & Ben-Porath, Reference Tellegen and Ben-Porath1993), with varying degrees of replicability. However, increased understanding of the latent dimensional structure of PD and the development of novel statistical methods provide the opportunity to replace these earlier prototypes with ones derived using modern formal statistical modeling.
The identification of empirically derived prototypes
In the current research, we used methods based on finite mixture modeling (Fraley & Raftery, Reference Fraley and Raftery1998, Reference Fraley and Raftery2002; McLachlan & Peel, Reference McLachlan and Peel2000) that provide a model-based approach (using an information-theoretic fit index to compare models) to identifying prototypes formed by configurations of dimensions. Classic methods, including traditional cluster analysis, do not provide a model-based means of comparing models' fit (Lenzenweger et al. Reference Lenzenweger, Clarkin, Yeomans, Kernberg and Levy2008). Finite mixture modeling and related techniques have been used successfully for identification purposes ranging from landmine positions to breast cancer types (Fraley & Raftery, Reference Fraley and Raftery2002; Raftery & Dean, Reference Raftery and Dean2006), and also in the psychopathology and substance use literatures (e.g. Lenzenweger et al. Reference Lenzenweger, McLachlan and Rubin2007; Mun et al. Reference Mun, von Eye, Bates and Vaschillo2008a, Reference Mun, Windle and Schainkerb). However, their application to pathological personality has been limited to the latent structure of individual disorders such as psychopathy (Hicks et al. Reference Hicks, Markon, Patrick, Krueger and Newman2004; Skeem et al. Reference Skeem, Johansson, Andershed, Kerr and Louden2007; Andershed et al. Reference Andershed, Köhler, Louden and Hinrichs2008; Falkenbach et al. Reference Falkenbach, Poythress and Creevy2008) and borderline personality disorder (Lenzenweger et al. Reference Lenzenweger, Clarkin, Yeomans, Kernberg and Levy2008). The full universe of personality pathology has not been explored to search for prototypes using this approach.
The robustness of prototypes and dimensions
Whether prototypes can supplement the utility of dimensional classification systems is an empirical question. The first step in addressing this issue is to determine whether prototypes exist in a given dimensional system; if so, they can be evaluated for external validity. For instance, do the prototypes differ in predictable ways on hypothetically related variables that were not used to define the prototypes? Another crucial test is whether the prototypes are robust; that is, replicable across different samples (Asendorpf et al. Reference Asendorpf, Borkenau, Ostendorf and Van Aken2001; De Fruyt et al. Reference De Fruyt, Mervielde and Van Leeuwen2002). Sample-dependent prototypes would not be universally recoverable in other samples and, although they could be meaningful (e.g. show reasonable correlation patterns with external validators), they also would be non-robust (see Turkheimer et al. Reference Turkheimer, Ford and Oltmanns2008).
The question of robustness is not limited solely to prototypes; the robustness of dimensional approaches can also be evaluated. For instance, it would be important to evaluate whether a proposed DSM-5 dimensional PD system was robust across samples. Similar to prototypes, if the latent dimensional structure of personality pathology, for example inter-relationships among traits, were not robust and instead differed across samples, its utility as a classification system would be severely limited.
The present study addressed four issues: (1) Are there distinct prototypes within a dimensional system for assessing pathological personality? If so, are these prototypes (2) meaningful (i.e. have convergent/discriminant external correlates) and (3) robust (i.e. replicable across samples)? (4) How does the robustness of underlying trait dimensions compare with that of prototypes in the same dataset?
Method
Participants
Participant data from 24 samples (see Appendix) were aggregated to form a sample of 8690 individuals (‘total sample’; Simms et al. Reference Simms, Turkheimer and Clark2007). The total sample was 52.9% female (sex data missing for three participants), and participant ages ranged from 17 to 85 years (mean=26.7, s.d.=10.47; 1% missing). Ethnicity data were missing for 16.4% of participants; of the remainder, 78.9% self-identified as Caucasian, 9.9% as African-American, and 11.2% as another race/ethnicity. Each of the 24 samples was drawn from one of four distinct populations (referred to hereafter as ‘subsamples’): clinical patients (25% of the total sample), college students (35.8%), community participants (9.3%), and military recruits (29.9%; 2026 individuals participated voluntarily during basic training, and 572 were veterans from the first Gulf War).
Measures
Schedule for Nonadaptive and Adaptive Personality (SNAP; Clark, Reference Clark1993)
The SNAP is a 375-item, true–false format, self-report measure of 15 personality trait dimensions spanning from normal to pathological range. Its scales have high internal consistency (median=0.81, range=0.77–0.92 across five clinical, student and community adult samples) and are stable (medians=0.86, 0.84; ranges=0.68–0.93 and 0.68–0.91) over short to moderate intervals (1 week to 4.5 months respectively; see Clark, Reference Clark1993; Clark et al.,in press). The latent factor structure of the SNAP has been investigated, and three factors have been found to account for the covariation among its 15 scales (Clark, Reference Clark1993). These factors are negative emotionality (primarily assessed by negative temperament, mistrust, manipulativeness, aggression, self-harm, eccentric perceptions, and dependency scales), positive emotionality (primarily assessed by positive temperament, exhibitionism, entitlement, and detachment scales), and disinhibition (primarily assessed by disinhibition, impulsivity, propriety, and workaholism scales). The SNAP has been validated against a wide range of external criteria (Morey et al. Reference Morey, Hopwood, Gunderson, Skodol, Shea, Yen, Stout, Zanarini, Grilo, Sanislow and McGlashan2007; Clark et al., in press). Missing item responses were infrequent for participants in the current study: 99.4% of the sample omitted responses to ⩽4 items (⩽1.1% of the SNAP item pool). Scale scores were computed by treating missing values as responses in the non-keyed direction. For more information on the means, variances and intercorrelations of the SNAP scales, readers may contact the corresponding author (N.R.E.).
Five-Factor Model (FFM)
The FFM conceptualizes the five primary domains of personality as neuroticism, extraversion, agreeableness, conscientiousness, and openness to experience. FFM domain data were available for 803 individuals who completed the self-report NEO Personality Inventory – Revised (NEO PI-R) and an additional 245 participants who completed the NEO Five-Factor Inventory (NEO-FFI; Costa & McCrae, Reference Costa and McCrae1992). The subset of NEO-PI-R items that constitute the NEO-FFI were used to generate domain scores for persons who completed the NEO-PI-R, yielding analogous FFM domain scores for 1048 individuals.
MMPI-2 Restructured Clinical (RC) scales (Tellegen et al. Reference Tellegen, Ben-Porath, McNulty, Arbisi, Graham and Kaemmer2003)
The RC scales (n=1006) remove the common variance (‘demoralization’) shared among all MMPI-2 clinical scales, yielding a demoralization (RCd) scale and eight relatively ‘pure’ scales: somatic complaints (RC1), low positive emotions (RC2), cynicism (RC3), antisocial behavior (RC4), ideas of persecution (RC6), dysfunctional negative emotions (RC7), aberrant experiences (RC8), and hypomanic activation (RC9). (MMPI-2 clinical scales 5 and 0 do not have analogous RC scales.) The psychometric properties, including internal consistency and test–retest stability, of the RC scales are strong and have been reported elsewhere (Tellegen et al. Reference Tellegen, Ben-Porath, McNulty, Arbisi, Graham and Kaemmer2003; Simms et al. Reference Simms, Casillas, Clark, Watson and Doebbeling2005).
Data analysis
Model-based cluster analysis
To determine whether distinct clusters (prototypes) of individuals in multivariate space are defined by the personality dimensions of the SNAP, we used a model-based clustering form of finite mixture modeling. This analysis, implemented in the MCLUST software package (version 3.1-1; Fraley & Raftery, Reference Fraley and Raftery2008) in the statistical language R, uses hierarchical clustering and expectation–maximization methods to determine the best-fitting cluster solution for the data. Model-based clustering fits a specified set of models to the data; these models differ in the number of clusters fit to the data (one to nine clusters) and in the characteristics of each cluster (volume, shape, and orientation in multivariate space). In addition to selecting the optimal number of clusters, model-based clustering estimates the optimal characteristics of volume, shape, and orientation for each cluster. Space limitations preclude a full treatment of the statistical foundations of this method, which have been discussed at length elsewhere (Fraley & Raftery, Reference Fraley and Raftery1998, Reference Fraley and Raftery2002; Raftery & Dean, Reference Raftery and Dean2006) and depicted visually (Hicks et al. Reference Hicks, Markon, Patrick, Krueger and Newman2004). In brief, the volume of each cluster indexes how homogeneous cluster members are on the variables that define the space. The larger the volume, the more widely dispersed cluster members are from the cluster's center point. The shape of each cluster can be either spherical or elliptical, and it indexes the relative dispersion of individuals along the variables that define the cluster.Footnote 1 Footnote † Elliptical shape indicates that individuals are dispersed more widely on some variables than on others. Finally, orientation refers to the positions of clusters in multivariate space, relative to the axes that define that space. Orientation indicates the magnitude and directionality of variables’ inter-relationships within each cluster.
The optimal cluster solution is selected using the Bayesian Information Criterion (BIC; Raftery, Reference Raftery1995), which balances model fit and parsimony, and allows for the comparison of non-nested models. The larger (in our case, the less negative and closer to zero) the value of BIC, the better the model under consideration balances fit and parsimony. Differences of 10 in two models' BIC values indicate that the odds are 150:1 that the model with the more favorable BIC value has a better fit; thus, Raftery (Reference Raftery1995) defines a BIC value difference of 10 to represent ‘very strong’ evidence in favor of the model with the more favorable BIC. This reliance on a formal fit index to select the optimal model differentiates model-based clustering from other, more heuristic methods, such as k-means cluster analysis, which often lack statistically grounded means of ascertaining the optimal number of clusters (Raftery & Dean, Reference Raftery and Dean2006).
Once the model that best balances fit and parsimony is selected, every individual is assigned to membership in the cluster that yields the highest probability of group membership. Thus, each cluster membership assignment is probabilistic and associated with a degree of uncertainty (calculated as one minus the probability of the most likely cluster assignment; Fraley & Raftery, Reference Fraley and Raftery2002) that can range from near zero uncertainty (almost complete assignment certainty) to near one (almost complete uncertainty). Assignment of cluster membership permits external validation of the clusters by examining variables on which the participants were assessed that were not used to estimate the cluster solution.
Exploratory factor analysis
Exploratory factor analysis was conducted in Mplus 5.2 (Muthén & Muthén, Reference Muthén and Muthén2009). These analyses used a maximum likelihood estimator (MLR) that produces robust estimates even when assumptions of traditional maximum likelihood factor analysis are violated. The Mplus default of oblique geomin rotation was applied, as previous research has indicated that it tends to recover factor structure well compared to many other rotations (Browne, Reference Browne2001). To determine the appropriate number of factors for extraction, we used three methods: (1) the scree test, (2) parallel analysis, and (3) substantive factor interpretability (see Brown, Reference Brown2006).
Results
Total sample cluster solution
The BIC values for each model fit to the 15 SNAP scales are presented in Table 1. The best-fitting model (BIC=−679235) consisted of seven ellipsoidal clusters of individuals that differed in terms of their orientations and volumes. This model fit the data much better than did the second best-fitting model (BIC=−679363). These results indicate that seven distinct groups of individuals exist in the multivariate space defined by the SNAP in this sample.Footnote 2 Assignments of individuals to their most probable cluster were associated with relatively low levels of uncertainty (Table 2), ranging from 0.13 (cluster 6) to 0.23 (cluster 7). Clusters ranged in the number and gender of individuals assigned to them, and χ2 analysis indicated that clusters differed significantly (p<0.001) with regard to the representation of each subsample (see Table 2).
Table 1. Bayesian Information Criterion (BIC) values for fitted models

Numerical table entries represent BIC values, with the value indicating the best model fit in bold. The 10 models are ordered by parsimony, with model 1 being the most parsimonious. Most models involved clusters shaped as spheres, ellipses, or a combination of both (i.e. ‘Varies’); Models 3–6 had diagonal distributions only. Volume could be equal (i.e. all clusters have the same volume) or variable across clusters. Orientation could be equal or variable across clusters. ‘Axes’ means orientation parallel to coordinate axes. n.a. means orientation not estimated due to spherical shape. Dashed lines indicate models that could not be estimated in this analysis. All BIC values have been rounded to the nearest whole number.
Table 2. Clusters' SNAP scale T score means (standard deviations), demographics, and uncertainties
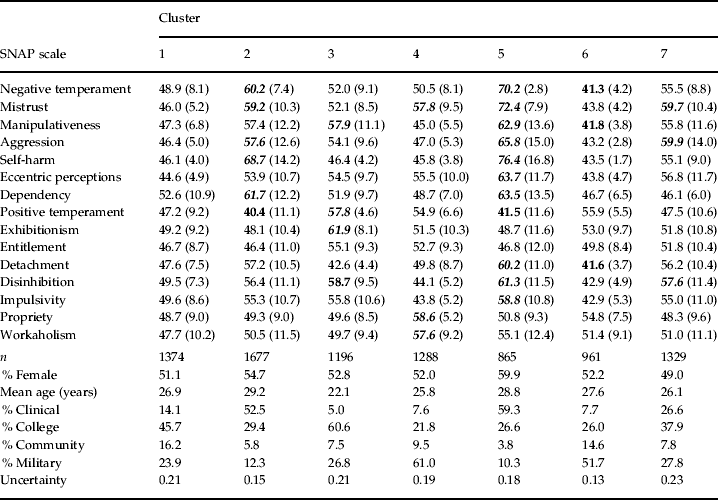
The Schedule for Nonadaptive and Adaptive Personality (SNAP) scale means that are more extreme than three-quarters standard deviation from the T score mean (i.e. <42.5 or >57.5) are bolded; those bolded that are T score >57.5 are also italicized.
‘% Clinical’ indicates the percentage of a cluster's membership made up of members of the clinical subsample, and so on.
Each of the seven clusters was defined by the average score of the cluster's members on the 15 SNAP scales.Footnote 3 The means of the 15 SNAP scale scores, transformed into T scores, are presented for each cluster in Table 2.Footnote 4 Using a standard of an elevation of at least three-quarters of one standard deviation from the sample mean, the clusters showed interpretable features. Cluster 1 members reported levels of personality pathology completely within the average range. Cluster 2 was defined by elevated self-harm, dependency, negative temperament, mistrust, and aggression, in addition to decreased positive temperament. Cluster 3 membership was associated with elevated exhibitionism, disinhibition, manipulativeness, and positive temperament. Cluster 4 was marked by elevations of propriety, mistrust, and workaholism. Cluster 5 was associated with a wide variety of pathological personality functioning, with elevated self-harm, mistrust, negative temperament, aggression, eccentric perceptions, dependency, manipulativeness, disinhibition, detachment, and impulsivity, in addition to decreased positive temperament. Cluster 6 showed decreased levels of negative temperament, detachment, and manipulativeness. Finally, Cluster 7 showed elevated aggression, mistrust, and disinhibition.
External validation of total sample solution
It was next necessary to determine whether these clusters differ from one another in terms of variables exogenous to the cluster solution (i.e. have external validity), which we did by examining the average profile of each cluster on both normal (FFM) and pathological (MMPI-2 RC scales) personality measures. FFM domain and RC scale scores were averaged for all members of each cluster separately. Two seven-group MANOVAs comparing the clusters on the FFM domains and the RC scales respectively indicated omnibus differences; for the FFM scales [F(30, 4150)=46.23, p<0.001, Wilk's λ=0.316] and for the RC scales [F(54, 5057.7)=28.88, p<0.001, Wilk's λ=0.254]. We then tested, using Tukey's post-hoc tests, which of these domain/scale averages differed significantly across clusters, and significant differences between some clusters were found for each personality domain/scale. The FFM/RC scale T scores for each cluster are presented in Table 3; domain/scale scores with different superscript letters differ significantly (p<0.05) from one another.
Table 3. Five-Factor Model (FFM) domain (n=1048) and MMPI-2 RC scale (n=1006) means (standard deviations) for each cluster (in T scores)

MMPI, Minnesota Multiphasic Personality Inventory; RC, Restructured Clinical.
Means for each trait/scale that share the same superscript letter do not differ significantly from one another, but do differ significantly from traits with which they do not share a superscript letter. Lower groups of means have lower (i.e. closer to ‘a’) superscript letters.
These results, for both normal and pathological personality, showed many interpretable convergent and discriminant relationships with the clusters. (Openness did not seem to be highly important in describing differences among prototypes; cf. Samuel & Widiger, Reference Samuel and Widiger2008.) For instance, members of cluster 5, which showed the most pathological SNAP profile, reported the highest levels of neuroticism, which relates to various forms of internalizing psychopathology (Hettema et al. Reference Hettema, Neale, Myers, Prescott and Kendler2006; Lahey, Reference Lahey2009; Eaton et al. Reference Eaton, South, Krueger, Millon, Krueger and Simonsen2010), and also the lowest levels of extraversion, openness, agreeableness, and conscientiousness; a highly pathological constellation of traits. On the RC scales, with the exception of hypomanic activation, these individuals reported significantly higher levels of RC scale pathology than any other cluster; four of their RC scale scores had a T score >70. Results such as these suggest that the clusters show clinically meaningful differences on non-SNAP measures of normal personality and psychopathology.
Subsample solutions
The seven clusters we identified balanced fit and parsimony well, had interpretable SNAP profiles, and showed external validity with FFM and RC scale variables. We next addressed whether these clusters were robust by examining whether the same cluster solution emerged across different samples. The characteristics of our total sample provided the opportunity to evaluate this issue because it was composed of individuals drawn from four distinguishable populations, as described earlier. We tested the latent clustering of individuals in each subsample separately to determine whether the resulting solutions mirrored that of the total sample or each other.
Within each subsample, an identical model-based clustering analysis to that described earlier was conducted. The optimal cluster solutions, selected by BIC, in the clinical patient, college student, community participant, and military recruit subsamples were respectively two-, three-, two-, and two-cluster solutions with variable volume, shape, and orientation. In each subsample, the seven-cluster model from the total sample was tested, and its fit was markedly worse than the optimal solutions (e.g. in the clinical patient subsample, BIC=−176792 v. −179045). The SNAP scale means for the subsamples' clusters are presented in Table 4. Examination of these results yields three conclusions: (1) the total sample seven-cluster solution did not emerge, or fit well, in any of the subsamples; (2) importantly, the clusters that emerged in the four subsamples, even taken together, did not recreate the total sample seven-cluster solution (which they would have if each subsample contained a subset of the seven clusters); and (3) the clusters that emerged in each of the subsamples did not match the clusters that emerged in the other subsamples, which they might have in the samples that are, for example, of similar ages, such as the college students and military recruits. However, the only truly similar group to emerge was a relatively non-pathological group in the college and community sample. These results suggest, therefore, that the prototypes of personality pathology that emerged were sample dependent and thus not robust.
Table 4. SNAP scale means (standard deviations) for each cluster in the four subsamples (in T scores)

Schedule for Nonadaptive and Adaptive Personality (SNAP) means that are more extreme than three-quarters standard deviation from T score mean (i.e. <42.5 or >57.5) are bolded; those bolded that are T score >57.5 are also italicized.
Factor structure of the SNAP across samples
We next tested whether the factor structure of the SNAP, and thus the relationships among its latent dimensions, was robust by conducting exploratory factor analyses within each of the subsamples. Examination of scree plots and parallel analyses within each subsample indicated that a three- or four-factor solution was optimal. For all four subsamples, the three-factor solution was easily interpretable as representing negative emotionality, positive emotionality, and disinhibition factors. The factor loading patterns that emerged in each subsample are reported in Table 5, with loadings corresponding with Clark's (Reference Clark1993) three-factor structure highlighted. Each factor had several scales with large loadings in expected directions. The four-factor solutions also produced relatively clear negative emotionality, positive emotionality, and disinhibition factors, but the fourth factor tended to be difficult to interpret, having very few scales with high factor loadings and, in all four subsamples, being defined by only a single scale with a loading of absolute magnitude >0.60. This lack of sizable loadings and difficult interpretability indicated that factor four was an overextraction. Thus, we took the scree plot, parallel analysis, and interpretability results as strong evidence that a three-factor solution was optimal in each subsample.
Table 5. Factor loadings for each SNAP scale in the clinical, college, community, and military subsamples

The results are from maximum likelihood exploratory factor analysis extracting three factors with oblique geomin rotation and a robust estimator (MLR). Loadings are rounded to two decimal places, and Schedule for Nonadaptive and Adaptive Personality (SNAP) factor structure identified by Clark (Reference Clark1993) is bolded.
How similar were the patterns of the three factors' loadings across the four subsamples? To address this question, we calculated a coefficient of congruence (Burt, Reference Burt1948; Tucker, Reference Tucker1951; Abdi, Reference Abdi and Salkind2007) for each factor within each pair of subsamples. Thus, we compared the loadings of the clinical subsample's first factor with the loadings of the college subsamples' first factor; we then compared the similarity of the second, and then third, factors across these two subsamples. We continued the process until all pair-wise subsample factors had been examined for congruence, which resulted in 18 factor congruences; six combinations each for negative emotionality, positive emotionality, and disinhibition factor. The coefficient of congruence ranges from −1 to 1, where −1 represents a completely inverse pattern of loadings for two factors, 0 represents no association between two factors' loadings, and 1 indicates complete similarity between the loadings of two factors. All 18 of our coefficients of congruence ranged from 0.98 to 0.99. This result shows nearly perfect agreement between the patterns of loadings across the subsamples for each factor, indicating that a highly similar factor structure underlies the SNAP scales within each subsample.
Discussion
Are there distinct prototypes within a dimensional system for assessing pathological personality?
Our results indicated the presence of seven distinct clusters of individuals, some of which seemed to be PD prototypes whereas others may have represented prototypes for mental health or resilience, within the multivariate space defined by the SNAP dimensions. Such clusters could have significant implications for application of dimensional pathological personality systems. For instance, if DSM-5 does mark the change to a dimensional classification system for PD (Trull & Durrett, Reference Trull and Durrett2005; Widiger & Simonsen, Reference Widiger and Simonsen2005), prototypes could unify dimensions and categories as complementary approaches (e.g. John & Robins, Reference John and Robins1994; Robins et al. Reference Robins, John, Caspi, Moffitt and Stouthamer Loeber1996). For instance, if patients' dimensional profiles are sufficiently similar to a predefined prototype, they could be conceptualized both in terms of the extremity of their trait scores and the diagnostic group of individuals whom they resemble. These results indicate that the identification of such prototypes can be done in a mathematically sophisticated way rather than solely by clinical theory or heuristic clustering methods; however, testing specific theory-based hypotheses about prototypes (e.g. those proposed for DSM-5) would be a worthwhile direction for future research. Such empirically derived prototypes have the potential to bridge the gap between dimensional nosologies and simple communicative diagnosis of an individual patient. To realize this potential, though, the prototypes need to be both meaningful and robust.
Are these prototypes meaningful?
To address this question, we focused on external validity. FFM domains and MMPI-2 RC scales revealed notable differences between the seven clusters we identified that coincided with the conceptualization of the clusters based on interpretation of their SNAP scale profiles. That these normal personality and psychopathology data were exogenous to the original cluster analysis, and showed interpretable patterns of convergence and discrimination across clusters, was evidence that the clusters of individuals had meaningful external correlates and were not simply mathematically identified groups with no real-world significance. Any inferences drawn from the associations with external variables, however, should be tempered by the fact that we did not generate specific a priori hypotheses about these relationships.
Are these prototypes robust?
Although the clusters seemed to represent meaningful differences between groups of people, their utility would be limited if they were sample dependent. In other terms, there must be replicable zones of rarity of observations in the multivariate structure of the data for clusters to have the ontological status of ‘distinguishable types of people’. To determine cluster robustness, we examined the cluster structure within each of the dataset's four subsamples. Each subsample yielded fewer clusters of individuals, and these clusters did not replicate, or combine to become, those of the total sample, nor were solutions isomorphic between subsamples. That is, the total sample solution was not simply the ‘sum’ of the subsample solutions; the subsample solutions, taken together, did not reproduce the seven clusters seen in the total sample. Moreover, within all four subsamples, the seven-cluster solution from the total sample showed very poor fit compared with the best-fitting solutions.
The prototypes were thus not robust across samples, even though they related differentially and predictably to external variables, indicating that they represented latent groupings that showed external validity. In this way, it seems that the clusters, both the original seven and those identified in the subsamples, are meaningful but non-robust (see Turkheimer et al. Reference Turkheimer, Ford and Oltmanns2008). This non-replicability of cluster solutions suggests that the emergent clusters in the total sample and each subsample are sample dependent, and thus non-robust in the sense that a replicable cluster solution could not be identified. Even though we could not identify robust prototypes, there may exist prototype-like combinations of traits that contribute to the prediction of important criteria (e.g. by representing particularly maladaptive trait constellations, similar to MMPI ‘code types’; Tellegen & Ben-Porath, Reference Tellegen and Ben-Porath1993). Additional research along these lines would be valuable to determine the extent to which this phenomenon generalizes to other samples, measures, and constructs (e.g. Asendorpf et al. Reference Asendorpf, Borkenau, Ostendorf and Van Aken2001; De Fruyt et al. Reference De Fruyt, Mervielde and Van Leeuwen2002).
How does the robustness of underlying trait dimensions compare with that of prototypes?
Unlike the latent group structure, the latent factor structure was highly robust across subsamples. This finding indicates that, in terms of organizing constructs, dimensions work well and are replicable. To the extent that a particular dimension has validity (which the SNAP dimensions have shown in previous research; e.g. Clark, Reference Clark1993; Fiedler et al. Reference Fiedler, Oltmanns and Turkheimer2004), dimensional structures underlying pathological personality are both meaningful and robust. That is, although samples may differ on their standings on these dimensions relative to one another (e.g. higher levels of negative temperament in clinical patients compared with college students), the dimensions that underlie this variation are organized similarly and thus provide a means to connect different samples on the same continuous variables. Stated another way, dimensional solutions are dependent primarily upon the variables included; cluster solutions are dependent on both the variables included and the population(s) sampled (see De Fruyt et al. Reference De Fruyt, Mervielde and Van Leeuwen2002). A key future direction would compare fit and validity of latent dimensional, model-based clustering, and hybrid solutions (e.g. Lubke & Muthén, Reference Lubke and Muthén2007; Muthén, Reference Muthén2006) once appropriate methods (e.g. model-based clustering in Mplus) have been developed to facilitate direct comparisons.
Implications for prototypes in diagnostic systems
We have shown that model-based clustering can be used to resolve clusters of individuals based on their normal and pathological personality traits, but even these sophisticated techniques are highly sample dependent. Thus, a cluster model generated in one sample will not necessarily be the optimal model in another sample. However, model-based clustering can converge on solutions that represent robust disease categories in nature. For instance, Fraley & Raftery (Reference Fraley and Raftery1998) analyzed data for plasma glucose and insulin response to oral glucose and degree of insulin resistance. The method identified correctly three classes of individuals (those without diabetes, with chemical diabetes, and those with overt diabetes) with a much lower error rate (12%) than traditional methods (36–47%). That no robust convergence was seen in our data using an approach shown to be successful in identifying discrete disease entities suggests that there may be no generalizable prototypes of personality pathology. If official classification systems (e.g. DSM-5) were derived from research using this methodology to generate diagnostic PD prototypes, several questions would need to be addressed to ensure appropriate generalizability: What is the appropriate sample to use in the generation of diagnostic prototypes? Should research focus on a clinical or epidemiological sample?
The answer to these questions rests with the aim of the analysis. Researchers interested in personality pathology clusters in the USA might use a representative nationwide sample, whereas for clinicians interested in clusters of individuals in an urban out-patient clinic, the appropriate sample might be the clinic's patients. The degree to which clusters from other samples would be appropriate in a particular location is unclear, and future research is necessary to resolve it. This issue mirrors the notion that local norms can be more informative than broader sample norms (see Crocker & Algina, Reference Crocker and Algina2006). Insofar as the aim is to develop a nosology composed of generalizable (‘real’) disorders, however, our results suggest that efforts to identify discrete forms of personality pathology will continue to be as unsuccessful as they have been historically.
It could be argued that nosological prototype generation should focus on clinical samples. The lack of prototype robustness across subsamples might then seem to be largely irrelevant to determining useful clinical prototypes. However, two points deserve mention. First, when the clinical subsample was used to ascertain pathological personality prototypes, the results were not compelling: only two clusters emerged, seemingly representing personality pathology and a lack of personality pathology. Second, examination of multiple clinical samples would probably yield a poor level of robustness of the emergent prototypes. A sample of individuals with eating disorders might generate different prototypes from a sample of depressed individuals; prototypes emerging from a psychiatric hospital sample might not replicate prototypes from a community mental health center.
Implications for dimensions in diagnostic systems
Unlike the prototypes, the dimensional structures underlying personality pathology showed robustness across samples, suggesting that dimensions represent a more generalizable and stable means of conceptualizing PD than do particular PD prototypes. Such dimensional structures unify individuals in a common, invariant framework. In addition, this latent structure seems to underlie variation across diverse samples, thus making it simultaneously more easily applicable to a group of individuals than previously derived prototypes, and more amenable to generalization of research findings. These results are highly congruent with research supporting the fundamentally dimensional nature of personality pathology and the need to pursue a dimensional, empirically derived nosology for DSM-5 (Frances, Reference Frances1993; Trull & Durrett, Reference Trull and Durrett2005; Widiger & Samuel, Reference Widiger and Samuel2005; Widiger & Simonsen, Reference Widiger and Simonsen2005; Clark, Reference Clark2007) rather than continue efforts to identify discrete, robust PD diagnoses.
Acknowledgments
Data collection was supported, in part, by grants from the University of Minnesota Press. The current study expands upon a preliminary analysis presented in a book chapter (Krueger et al., in press). That chapter outlined an unelaborated set of PD prototypes with the aim of illustrating the method of finite mixture modeling, with no data presented pertaining to the external validity or replicability/robustness of the identified prototypes, or to the replicability of dimensional structures in the same data set in contrast to the prototypes.
Appendix
Description of samples included in the total dataset (n=8690)

Declaration of Interest
L. A. Clark is the author of the Schedule for Nonadaptive and Adaptive Personality (SNAP). L. A. Clark and L. J. Simms are authors of the Manual for the Schedule for Nonadaptive and Adaptive Personality-Second Edition (SNAP-2).





