


1 Introduction
Numerous languages exhibit contrastive breathy-voiced phonation either on obstruent consonants as in Hindi (e.g. Ohala Reference Ohala1983, Dixit Reference Dixit1989), Bengali (Khan Reference Khan2010a), and Maithili (Yadav Reference Yadav1984) or on vowels as in many Zapotec languages (e.g. Jones & Knudson Reference Jones, Knudson and Merrifield1977, Munro & Lopez Reference Munro, Lopez, Mendez, Garcia and Galant1999, Esposito Reference Esposito2010b). However, very few languages preserve this contrast across both obstruent consonants and vowels. While languages such as Suai (Abramson & Luangthongkum Reference Abramson and Luangthongkum2001), Jalapa Mazatec (Kirk, Ladefoged & Ladefoged Reference Kirk, Ladefoged, Ladefoged, Mattina and Montler1993), and Wa (Watkins Reference Watkins1999, Reference Watkins2002) contain both breathy vowels and voiceless aspirated consonants, languages that include both breathy vowels and breathy-voiced aspirated consonants (also known as breathy-aspirates) are exceptionally rare. This latter type appears to be limited to some Khoisan languages (e.g. !Xóõ, see Traill Reference Traill1985; Juǀ’hoansi, see Miller Reference Miller2007), White Hmong, and Gujarati. Languages such as these are particularly interesting because the breathiness on breathy-voiced aspirated stop consonants is typically realized not during the stop closure itself, but as a breathy-voiced release into the following vowel. Thus, both breathy vowels and prevocalic breathy-voiced aspirated stops involve breathy voicing during the vowel.
Previous research suggests that the voice quality of breathy vowels and breathy-voiced aspirated consonant releases should be similar from an articulatory standpoint. Ladefoged & Maddieson (Reference Ladefoged and Maddieson1996) define both breathy-voiced aspirated stops (which they refer to as ‘murmur’ following the terminology used in Ladefoged Reference Ladefoged1971) and breathy-voiced vowels in the same way; both involve vocal folds that vibrate without much contact and high rates of airflow. In comparing the Hindi minimal pair [bal] ‘hair’ and [bʱal] ‘forehead’, they observed breathy voicing for the first 100 ms following the stop release for the breathy-voiced aspirated stop [bʱ]. In their fiberoptic study of one speaker of Hindi, Kagaya & Hirose (Reference Kagaya and Hiroshi1975) observed that breathy-voiced aspirated consonants were largely identical to plain voiced stops up until the consonant release; after that point, glottal width increased, although not nearly to the extent seen in voiceless aspiration. This intermediate glottal width is key in maintaining voicing while allowing enough space for breathy airflow, further facilitated by the lack of supraglottal constriction. Kagaya & Hirose's acoustic analysis also indicates that breathy-voiced aspirated consonants in Hindi have a significantly lowered f0 at the consonant release relative to all other stop consonant types, consistent with findings in other non-tonal languages indicating a correlation between breathy vowels and lower f0 (see Pandit Reference Pandit1957, Dave Reference Dave1967, and Fischer-Jørgensen Reference Fischer-Jørgensen1967 for Gujarati; Wayland, Gargash & Jongman Reference Wayland, Gargash and Jongman1994 for Javanese). Furthermore, in a photo-electroglottographic study on plosives in Hindi, Dixit (Reference Dixit1989) found that the breathy-voiced aspirated consonants were produced by slack vocal folds, a moderately open glottis, a high rate of oral airflow, and a random distribution of noise. These four characteristics of breathy-voiced aspirated consonants are also properties of breathy vowels (see Gordon & Ladefoged Reference Gordon and Ladefoged2001). Fischer-Jørgensen (Reference Fischer-Jørgensen1967) also described breathy-voiced aspirated stops in Gujarati as similar to a breathy vowel, with the main difference being the degree of noise.
However, other descriptions suggest that breathy-voiced aspirated consonants and breathy vowels are distinct. Laver (Reference Laver1981) defines the phonation of breathy vowels as involving low muscular effort, thus producing a wide glottis, while he defines the phonation of whispered voice (in which he includes breathy-voiced aspirated consonants) as involving a manipulation of the arytenoids such that the vocal folds vibrate modally along their length but with a posterior gap through which air flows continuously. Esling & Harris (Reference Esling, Harris, Hardcastle and Beck2005), on the other hand, posit that the difference between whispery and breathy voice is not due to degree of glottal constriction, but rather due to an engagement of the aryepiglottic sphincter during whispery voice.
The current study examines acoustic and electroglottographic data collected from Gujarati and White Hmong to determine what properties reliably distinguish vowels following breathy-voiced aspirated consonant releases (e.g. [CʱV]) from phonemically breathy vowels (e.g. [C![]() ]), and to explore the phonetic and phonological properties shared between these structures in the two genetically-unrelated languages. Given that breathiness on consonants is typically realized as a breathy-voiced release into the following vowel, how are the two types of breathiness distinguished in CV sequences, if at all?
]), and to explore the phonetic and phonological properties shared between these structures in the two genetically-unrelated languages. Given that breathiness on consonants is typically realized as a breathy-voiced release into the following vowel, how are the two types of breathiness distinguished in CV sequences, if at all?
We hypothesize that the difference between these segments is likely one of timing and/or degree of breathiness. In terms of timing, we predict that the breathiness associated with breathy-voiced aspirated consonants is localized to the consonant release and thus produced at the onset of a following vowel, while the breathiness associated with breathy vowels is produced across a larger portion of the vowel, with language-specific distinctions in its exact localization. We also predict that post-aspirated vowels exhibit a different degree (i.e. more or less breathiness) of breathiness than breathy vowels.
2 Background
Phonation contrasts can be made using a variety of articulatory mechanisms, which produce an array of acoustic effects available to the listener for the perception of linguistic voice quality. To investigate these dimensions of phonation, we begin by reviewing the acoustic properties of phonation contrasts and continue with electroglottographic properties, the two types of measurements used in the current study. To minimize undue repetition, we restrict the following review to languages other than Gujarati and White Hmong; these two languages of interest are discussed in much greater detail in Section 2.3.
2.1 Acoustic properties of phonation
Often the most robust acoustic differences between phonation types can be seen in the spectrum; breathy phonation has a more sharply falling spectrum than modal phonation, while creaky phonation is often characterized as having a nearly flat spectrum. This steepness in the spectrum can be measured as spectral balance or spectral slope. Spectral balance is defined as the difference between the amplitude of the first harmonic (H1) from that of the second harmonic (H2), i.e. H1-H2, and has been used to measure phonation in languages as diverse as Jalapa Mazatec (Blankenship Reference Blankenship2002, Garellek & Keating Reference Garellek and Keating2010), !Xóõ (Bickley Reference Bickley1982), Chanthaburi Khmer (Wayland & Jongman Reference Wayland and Jongman2002), Green Mong (Andruski & Ratliff Reference Andruski and Ratliff2000), Takhian Thong Chong (DiCanio Reference DiCanio2009), and Santa Ana del Valle Zapotec (Esposito Reference Esposito2010b). Spectral slope is measured as the difference between the amplitude of the first harmonic (H1) and that of harmonics exciting higher formants, i.e. H1-A1, H1-A2, and H1-A3. H1-A1 has been shown to reliably distinguish phonation types in !Xóõ (Ladefoged Reference Ladefoged, Bless and Abbs1983) while H1-A2 distinguished phonation types in Krathing Chong (Blankenship Reference Blankenship2002). More commonly seen in the literature is H1-A3, which distinguishes phonation types in English (Stevens & Hanson Reference Stevens, Hanson, Fujimura and Hirano1995), Krathing Chong (Blankenship Reference Blankenship2002), Takhian Thong Chong (DiCanio Reference DiCanio2009), and Santa Ana del Valle Zapotec (Esposito Reference Esposito2010b). Esposito's (Reference Esposito2010a) cross-linguistic study also looked at small sets of data in Krathing Chong, Fuzhou, Green Mong, White Hmong, Mon, San Lucas Quiaviní Zapotec, Santa Ana del Valle Zapotec, Tlacolula Zapotec, Tamang, and !Xóõ, finding that spectral balance (i.e. H1-H2) and one or more of these three common measures of spectral tilt (i.e. H1-A1, H1-A2, H1-A3) differentiated phonation types in each language. In calculating spectral tilt or spectral balance, the amplitudes of harmonics can be corrected for the effects of the frequencies and bandwidths of adjacent formants (Hanson Reference Hanson1995); in this case, an asterisk (*) can be used to signify a corrected amplitude, e.g. H1*-A3*, a convention we adopt here.
Other spectral measures discussed in the voice quality literature include the difference in amplitude between the second and fourth harmonics (H2-H4), for measuring pathological voice quality (Kreiman, Gerratt & Antoñanzas-Barroso Reference Kreiman, Gerratt and Antoñanzas-Barroso2006), the average of H1-H2 compared to A1, for measuring non-contrastive voice quality in English (Stevens Reference Stevens and Fujimura1988), and formant amplitude differences such as A2-A3 in English (Klatt & Klatt Reference Klatt and Klatt1990). These are, however, not widely used in studies of linguistically contrastive voice quality.
Acoustic measures of the spectrum have been associated with various physiological characteristics. Holmberg et al. (Reference Holmberg, Hillman, Perkell, Guiod and Goldman1995) showed that H1-H2 correlated with the open quotient (OQ) of the glottal cycle, i.e. the portion of time the vocal folds are open per cycle. The larger the open quotient (i.e. the longer the vocal folds are apart), the greater the amplitude of the first harmonic over that of the second harmonic. Thus, the value (in dB) of H1-H2 is higher for breathy phonation than for modal or creaky phonation. Furthermore, Stevens (Reference Stevens1977) suggested that spectral tilt measures could be correlated with the abruptness of vocal fold closure. More abrupt vocal fold closure excites the higher harmonics; for breathy phonation, which typically involves less abrupt vocal fold closure, the higher harmonics are weakened, and thus spectral tilt measures are higher for breathy phonation than for modal or creaky phonation.
Depending on the language, dialect, vowel quality, tone, speaker sex or gender, and other factors, not all spectral measures will distinguish phonation types. In Mpi, for example, H1-H2 distinguishes phonation types on high tone vowels more reliably than on mid or low tone vowels (Blankenship Reference Blankenship2002). In Santa Ana del Valle Zapotec, H1-H2 successfully distinguishes breathy, modal, and creaky phonation in female speech but not in male speech (Esposito Reference Esposito2010b). Kreiman, Gerratt & Antoñanzas-Barroso (Reference Kreiman, Gerratt and Antoñanzas-Barroso2007) showed that f0 was positively correlated with H1*-H2* in non-disordered and pathological productions of the vowel [a], while Iseli, Shue & Alwan (Reference Iseli, Shue and Alwan2007) found that H1*-H2* was positively correlated with f0 only for speakers whose pitch was lower than 175 Hz.Footnote 1 Because females generally speak in a higher pitch than males, some of the sex-specific effects of H1*-H2* may be due to its complex relation to f0.
In addition to spectral measures, measures of noise and/or aperiodicity in the signal can also measure differences in voice quality. One such measure, cepstral peak prominence (CPP), has been used in English (Hillenbrand, Cleveland & Erickson Reference Hillenbrand, Cleveland and Erickson1994); Krathing Chong, Jalapa Mazatec, Mpi, and Tagalog (Blankenship Reference Blankenship2002); and for a small set of data from Krathing Chong, Fuzhou, Green Mong, White Hmong, Mon, San Lucas Quiaviní Zapotec, Santa Ana del Valle Zapotec, Tlacolula Zapotec, Tamang, and !Xóõ (Esposito Reference Esposito2010a).
2.2 Electroglottographic properties of phonation
When invasive methods of articulatory research are either unavailable or inappropriate, an electroglottograph (EGG) can be used as an indicator of the degree of contact between the vocal folds over time, which can in turn help describe and categorize phonation types. The EGG has been used to measure linguistic voice quality in Maa (Guion, Post & Payne Reference Guion, Post and Payne2004), Vietnamese (Michaud Reference Michaud2004), Santa Ana del Valle Zapotec (Esposito Reference Esposito2005), Tamang (Michaud & Mazaudon Reference Michaud and Mazaudon2006), Takhian Thong Chong (DiCanio Reference DiCanio2009), and Yi (Kuang Reference Kuang2010, Reference Kuang2011), and non-linguistic voice quality in speakers with and without voice disorders. For example, Childers & Lee (Reference Childers and Krishnamurthy1991) used EGG measures to determine the characteristics of the voice source during modal voice, vocal fry, falsetto, and breathy voice in both normal and pathologically disordered voices. They found that breathy phonation (as well as falsetto) was produced with a longer glottal pulse width, lower pulse skewing (the ratio of the opening phase to the closing phase), and less abrupt glottal closure than modal phonation. Using acoustic data, they also found that breathy phonation was produced with high turbulent noise, not seen in the other voice qualities.
The most common measure derived from the EGG is CQ, variously referred to as contact quotient, closed quotient, and closing quotient. CQ is a ratio of the portion of time the vocal folds are in a greater degree of contact over the total duration for a complete glottal cycle. In the current study, calculating the edges of this portion of this ‘greater degree of contact’ involves a hybrid method with a 25% threshold (see Rothenberg & Mahshie Reference Rothenberg and Mahshie1988, Orlikoff Reference Orlikoff1991, Howard Reference Howard1995, and Herbst & Ternström Reference Herbst and Ternström2006). This means that the beginning of the contact/closure phase (the portion with the ‘greater degree of contact’) is defined as the point at which the first derivative of the EGG (dEGG) is at its peak, and the end of the contact/closure phase is defined as the point 25% from the point of greatest opening (where 25% is calculated from the time from closure peak to opening peak). CQ is the inverse of the open quotient measure (OQ). Acoustic and electroglottographic studies of contrastive voice quality/register in Takhian Thong Chong (DiCanio Reference DiCanio2009) and White Hmong (Esposito, in press) compared OQ with H1-H2 and H1-A3, finding that OQ was more closely correlated with H1-H2 than with H1-A3, confirming Holmberg et al.'s (Reference Holmberg, Hillman, Perkell, Guiod and Goldman1995) study. Assuming a unidimensional model of phonation based on glottal opening (Ladefoged Reference Ladefoged1971, Gordon & Ladefoged Reference Gordon and Ladefoged2001), phonations with a wider opening (e.g. breathy voice) are expected to have lower CQ values than do phonations with greater vocal fold contact (e.g. modal voice, creaky voice).
The first derivative of the EGG, dEGG, is also useful in measuring voice quality. The peak positive value in the dEGG for each glottal pulse represents the amplitude of the increase in contact between the vocal folds; this value is variably referred to as Peak Increase in Contact (PIC; see Keating et al. Reference Keating, Esposito, Garellek, Khan and Kuang2010) or as dEGG Closure Peak Amplitude (DECPA; see Michaud Reference Michaud2004 for Mandarin, Naxi and Vietnamese; see Vũ-Ngọc, d'Alessandro & Michaud Reference Vũ-Ngọc, d'Alessandro and Michaud2005 for Vietnamese). In this way, DECPA can represent the speed of the vocal folds during the closing phase; phonations produced with faster glottal closure have greater DECPA values than phonations produced with slower glottal closure.Footnote 2 Of course, the vocal folds need not actually fully close to derive a DECPA value, as what is being measured is the increase in contact between the folds. It is not uncommon in breathy phonation and similar voice qualities for the folds to come into contact while still leaving a partially open glottis, allowing air to pass through.
2.3 About the languages
2.3.1 Gujarati
Gujarati is an Indo-European language (Indo-Iranian branch, Central Indic group) spoken primarily in Gujarat state in India, with significant minority populations in other central-western Indian states including Maharashtra (with a large community in Mumbai), Rajasthan, Karnataka, and Madhya Pradesh, and in long-established immigrant communities throughout the UK, North America, East Africa, and elsewhere (Lewis Reference Lewis2009).
Like other Indic languages, Gujarati has a four-way contrast in voicing and aspiration in stops and affricates, including voiceless unaspirated, voiceless aspirated, modally-voiced unaspirated, and breathy-voiced aspirated consonants across five places of articulation: bilabial, dental, retroflex, alveolopalatal (affricate), and velar (Nair Reference Nair1979, Masica Reference Masica1993, Cardona & Suthar Reference Cardona, Suthar, Cardona and Jain2003).Footnote 3 In the vocalic inventory, the most conservative dialects show an eight-vowel system [ie ɛ a ə ɔ ou] in modal phonation, while other dialects (e.g. Saurashtra) show a six-vowel system [iea ə ou] (Firth Reference Firth1957: 231–232; Pandit Reference Pandit1961: 62–63). Gujarati also has a set of breathy vowels, most of which are modern reflexes of what were once sequences of vowels and breathy consonants (Pandit Reference Pandit1957: 169–170; Dave Reference Dave1967: 1–2; Fischer-Jørgensen Reference Fischer-Jørgensen1967: 73; Nair Reference Nair1979: 9; Masica Reference Masica1993: 120; Mistry Reference Mistry and Kaye1997: 666–669; Cardona & Suthar Reference Cardona, Suthar, Cardona and Jain2003: 665–666).Footnote 4 Breathy vowels that derive from such structures come in four types, based on their historical source sequence. One very common source is [əɦV]; breathy vowels [![]() ] are the modern reflex of what is historically and orthographically [əɦə əɦa əɦe əɦo əɦi əɦu], respectively (e.g. [b
] are the modern reflex of what is historically and orthographically [əɦə əɦa əɦe əɦo əɦi əɦu], respectively (e.g. [b![]() ɾ] ‘outside’, orthographically
ɾ] ‘outside’, orthographically ![]() 〈bəɦaɾə〉).
〈bəɦaɾə〉).
Less frequent sources of breathy vowels include [Vɦə], [#ɦ], and [VCʱ]. Historical and orthographic [Vɦə] is optionally rendered as a single breathy vowel in modern Gujarati, e.g. [ʋ![]() n] ~ [ʋaɦən] ‘vehicle’. In very casual speech, a third type of breathy vowel comes as the result of the optional lenition of word-initial [ɦ], as in [
n] ~ [ʋaɦən] ‘vehicle’. In very casual speech, a third type of breathy vowel comes as the result of the optional lenition of word-initial [ɦ], as in [![]() lːəɽ] ~ [ɦulːəɽ] ‘riot’. Lastly, post-vocalic breathy-voiced aspirated consonants [bʱ
lːəɽ] ~ [ɦulːəɽ] ‘riot’. Lastly, post-vocalic breathy-voiced aspirated consonants [bʱ![]() ʱ ɖʱ dʑʱ ɡʱ] optionally lose their aspiration in very casual speech, with their associated breathiness transferred to surrounding vowels; they can also be lenited to fricatives or approximants in these situations, e.g. [bə
ʱ ɖʱ dʑʱ ɡʱ] optionally lose their aspiration in very casual speech, with their associated breathiness transferred to surrounding vowels; they can also be lenited to fricatives or approximants in these situations, e.g. [bə![]() ʱ
ʱ![]() ] ~ [b
] ~ [b![]()
![]()
![]() ] ~ [b
] ~ [b![]() ð
ð![]() ] ‘whole’ (Firth Reference Firth1957: 235; Pandit Reference Pandit1957: 171; Mistry Reference Mistry and Kaye1997: 667; Cardona & Suthar Reference Cardona, Suthar, Cardona and Jain2003: 666).
] ‘whole’ (Firth Reference Firth1957: 235; Pandit Reference Pandit1957: 171; Mistry Reference Mistry and Kaye1997: 667; Cardona & Suthar Reference Cardona, Suthar, Cardona and Jain2003: 666).
Due to various sociolinguistic pressures, breathy vowels are often not produced as such in particular contexts. Pandit (Reference Pandit1957: 170), Dave (Reference Dave1967: 2), Nair (Reference Nair1979: 22), and Cardona & Suthar (Reference Cardona, Suthar, Cardona and Jain2003: 666) report that many speakers have merged the breathy vowels with their corresponding modal vowels in what is often described as an ‘educated’ speech register, producing [b![]() n] ‘sister’ as [bɛn]. Turner (Reference Turner1921: 529), Dave (Reference Dave1967: 4), Masica (Reference Masica1993: 120), and Cardona & Suthar (Reference Cardona, Suthar, Cardona and Jain2003: 665–666) also report that speakers are more likely to produce breathy vowels as disyllabic sequences reflecting their orthographic representation, especially in formal settings or when reading, e.g. producing [b
n] ‘sister’ as [bɛn]. Turner (Reference Turner1921: 529), Dave (Reference Dave1967: 4), Masica (Reference Masica1993: 120), and Cardona & Suthar (Reference Cardona, Suthar, Cardona and Jain2003: 665–666) also report that speakers are more likely to produce breathy vowels as disyllabic sequences reflecting their orthographic representation, especially in formal settings or when reading, e.g. producing [b![]() n] ‘sister’ as [bəɦen] or [bəɦɛn], orthographically
n] ‘sister’ as [bəɦen] or [bəɦɛn], orthographically ![]() 〈bəɦenə〉. Breathy vowels with a [əɦV] source are the least likely to be pronounced as a disyllabic sequence, but even words of this source have been reported to be produced in a spelling pronunciation (i.e. disyllabically) in studies such as Dave (Reference Dave1967: 4), where subjects were told to read words directly from a script.Footnote 5
〈bəɦenə〉. Breathy vowels with a [əɦV] source are the least likely to be pronounced as a disyllabic sequence, but even words of this source have been reported to be produced in a spelling pronunciation (i.e. disyllabically) in studies such as Dave (Reference Dave1967: 4), where subjects were told to read words directly from a script.Footnote 5
Due to well-known constraints on aspiration in Indic languages (i.e. Grassmann's Law, see Whitney Reference Whitney1889, Wackernagel Reference Wackernagel1896), Gujarati does not have monomorphemic sequences of breathy-voiced aspirated consonants and breathy vowels (i.e. *[Cʱ![]() ]); furthermore, the low frequency of breathy segments in borrowed words means that new additions to the lexicon are unlikely to change this characteristic of the language.
]); furthermore, the low frequency of breathy segments in borrowed words means that new additions to the lexicon are unlikely to change this characteristic of the language.
Acoustic studies of breathy phonation in Gujarati have been primarily focused on breathy vowels, and less so on breathy aspirated consonants. Fischer-Jørgensen (Reference Fischer-Jørgensen1967) examined various acoustic measures to determine what properties reliably distinguished breathy vowels from their modal counterparts. Spectral balance, as measured by the amplitude difference between the first and second harmonics (i.e. H1-H2), and three measures of spectral tilt, as measured by the amplitude difference between the first harmonic and the first, second, and fourth formants (i.e. H1-A1, H1-A2, and H1-A4, respectively), were all found to be more sharply falling in breathy vowels. Furthermore, a slightly lowered f0, lower overall intensity (as measured by RMS energy) were found to be characteristics of breathy vowels; aspiration noise was also found in some breathy productions, although this was assessed only visually. An earlier study by Pandit (Reference Pandit1957) also found both low f0 and an increase in aspiration noise at higher frequencies to be associated with breathy vowels, while a later study by Bickley (Reference Bickley1982) also confirmed that a higher H1-H2 value was a reliable indicator of breathiness. Dave (Reference Dave1967) focused on the formant structure of breathy vowels, finding that they are largely indistinguishable from modal vowels in vowel quality. In the acoustic component of Khan (Reference Khan2010b, Reference Khan2012), a study of ten Gujarati speakers’ voice quality, it was further confirmed that breathy vowels have a significantly steeper spectral balance (as measured by H1*-H2*) and spectral tilt (as measured by H1*-A3*) than their corresponding modal vowels, concurring with previous studies. Unlike previous studies of Gujarati, however, the data examined in Khan (Reference Khan2010b, Reference Khan2012) were collected in a more naturalistic setting (as was done for the current study), and the spectral measures were corrected for the effects of formant frequencies and bandwidths (Hanson Reference Hanson1995) using Iseli et al.'s (Reference Iseli, Shue and Alwan2007) algorithm, as indicated with the asterisk (*). Furthermore, Khan (Reference Khan2010b) found that the midpoints of breathy vowels had lower CPP values than modal vowels, as well as significantly steeper rises in intensity.
Perception studies of Gujarati breathy vowels largely concur with the main predictions of acoustic studies: while f0 and aspiration noise can have some influence on voice quality categorization, a high H1-H2 value is consistently found to be the strongest cues for breathy voice. In the listening component of her study, Fischer-Jørgensen (Reference Fischer-Jørgensen1967) determined that the perception of synthesized breathy vowels in Gujarati was largely dependent on the fundamental, which had a low frequency at the onset of the vowel but a high amplitude (H1) throughout (measured relative to the rest of the spectrum); other acoustic cues were determined to be less important for perception. In the perception component of Bickley's (Reference Bickley1982) study, it was found that Gujarati speakers rely solely on spectral balance (H1-H2) when categorizing the voice quality of synthesized vowels; aspiration noise did not appear to influence voice quality categorization. Furthermore, in a cross-linguistic study of the perception of linguistic voice quality by speakers of English, Spanish, and Gujarati, Esposito (Reference Esposito2010a) also found that Gujarati-speaking listeners rely primarily on H1-H2 differences when categorizing vowels excised from various non-Indic languages (i.e. Krathing Chong, Fuzhou, Green Mong, White Hmong, Mon, Santa Ana Del Valle Zapotec, San Lucas Quiaviní Zapotec, Tlacolula Zapotec, Tamang, and !Xóõ), even in cases where the phonation contrasts in those other languages were not made using differences in H1-H2. Considering this strong bias amongst Gujarati speakers to attend to H1-H2 differences when categorizing vowels, it follows that Gujarati speakers are in fact more sensitive to very small changes in H1-H2 than are speakers of other languages, a hypothesis supported in Kreiman, Gerratt & Khan's (Reference Kreiman, Gerratt and Khan2010) perception study of speakers of English, Thai, and Gujarati.
While the majority of studies of breathy phonation in Gujarati have focused on its acoustic properties and their perception by native speakers, a handful of articulatory studies can also be found in the literature. Fischer-Jørgensen's (Reference Fischer-Jørgensen1967) study incorporated two articulatory components on a subset of her subjects, including an EGG analysis of two speakers and an aerodynamic analysis of three speakers. She found that breathy vowels are produced with greater airflow and shorter closed phase and possibly a wider glottis. Modi (Reference Modi1987) used x-ray data of the word [k![]() ʋə
ʋə![]() ] ‘proverb’ to determine that breathy phonation in ‘murmur dialects’ such as Standard Gujarati involves a lowered and widened glottis. Most recently, the first large-scale EGG study of Gujarati vowels (Khan Reference Khan2010b, Reference Khan2012) found that breathy vowels have a significantly lower contact quotient (CQ) than corresponding modal vowels, signifying that breathy phonation involves a more open glottis than modal vowels. In a further cross-linguistic extension of the Khan (Reference Khan2010b, Reference Khan2012) study, Keating et al. (Reference Keating, Esposito, Garellek, Khan and Kuang2010) showed that this difference in CQ closely resembled the EGG properties of other languages with a phonemic distinction between modal and breathy vowels. To date, there has not been an EGG study of breathy-voiced aspirated consonants in Gujarati.
] ‘proverb’ to determine that breathy phonation in ‘murmur dialects’ such as Standard Gujarati involves a lowered and widened glottis. Most recently, the first large-scale EGG study of Gujarati vowels (Khan Reference Khan2010b, Reference Khan2012) found that breathy vowels have a significantly lower contact quotient (CQ) than corresponding modal vowels, signifying that breathy phonation involves a more open glottis than modal vowels. In a further cross-linguistic extension of the Khan (Reference Khan2010b, Reference Khan2012) study, Keating et al. (Reference Keating, Esposito, Garellek, Khan and Kuang2010) showed that this difference in CQ closely resembled the EGG properties of other languages with a phonemic distinction between modal and breathy vowels. To date, there has not been an EGG study of breathy-voiced aspirated consonants in Gujarati.
2.3.2 White Hmong
White Hmong is a Hmong-Mien language spoken in Laos, Thailand, and by a large immigrant community in the US. It contrasts seven tones: rising (45), mid (33), low (22), mid-rising (24), high-falling (52), low-falling (21), and falling (42). Two of the tones are associated with non-modal phonation: the low-falling tone (21) is creaky and the falling tone (42) is breathy.
In addition, White Hmong has a large consonant inventory which includes voiced, voiceless, and prenasalized plosives. A unique feature of White Hmong, that is not found in other varieties such as Green Mong, is a four-way stop contrast within the non-prenasalized alveolar place of articulation [ttʰ ddʱ]; the last consonant of that set, [dʱ], is characterized as a ‘whispery voiced alveolar stop, with optional aspiration’ in Jarkey (Reference Jarkey1987: 66). The voiced unaspirated and breathy-voiced aspirated alveolar stops [ddʱ] of White Hmong are modern reflexes of laterally-released velar stops in Proto-Western Hmong [klkɬ] (Mortensen Reference Mortensen2000: 14–15); these correspond to laterally-released alveolar/velar stops [tl ~ kltɬ ~ kɬ] in other Western Hmong dialects such as Green Mong (Golston & Yang Reference Golston, Yang and Féry2001; Mortensen Reference Mortensen2004: 3). There is a restriction on the co-occurrence of breathy-voiced aspirated [dʱ] and following vowels bearing the falling breathy tone (*[Cɦ![]() 42]) or the high-falling tone (*[CɦV 52]).
42]) or the high-falling tone (*[CɦV 52]).
Previous research on the acoustic and electroglottographic properties of phonation in White Hmong showed that the amplitude of the first harmonic (H1*) and derivative-EGG closure peak amplitude (DECPA) are the most successful measures of phonation in that they distinguish all three phonation types (i.e. breathy, modal, creaky), though not all at the same point in the vowel. Other measures distinguish at least two of the three phonation categories. Of particular interest to the current study are the measures that distinguish breathy from modal phonation. The amplitude of the first harmonic (H1*), the amplitude of the first harmonic minus the amplitude of the second harmonic (H1*-H2*) and closed quotient (CQ) distinguish breathy from modal phonation at the beginning of the vowel, while DECPA, H1*, H1*-H2*, and CQ distinguish these phonations at the middle of the vowel and CQ, at the end of the vowel (Esposito Reference Esposito2010c). An additional study, Keating et al. (Reference Keating, Esposito, Garellek, Khan and Kuang2010), found that CQ, DECPA (i.e. ‘PIC’), and H1*-H2* successfully distinguished the phonation types of White Hmong averaging across the entire vowel duration. To date, there have not been any studies on the perception of phonation by White Hmong listeners.
One study, Fulop & Golston (Reference Fulop and Golston2008), examined vowels with breathy voice, modal voice, and after breathy-voiced aspirated stops (which they called ‘whispery voiced plosives’) as produced by two speakers of White Hmong. They measured the amplitude of the first harmonic minus the amplitude of the second (H1-H2) and third harmonics (H1-H3) as well as harmonicity during (i) the consonant release and (ii) the consonant closure phase. During the consonant release, all three measures distinguished all three vowels types. However, during the closure phase, H1-H3 and harmonicity failed to distinguish any of the phonations, while H1-H2 only distinguished the modal from the breathy vowels. Results support the idea that breathy vowels are distinct from vowels after breathy-voiced aspirated consonants. In addition, the higher harmonicity values for vowel after the breathy-voiced aspirated consonants supports Laver's definition for breathy aspiration/whispery phonation, which is posited to involve continuous airflow.
2.4 Previous work on consonant aspiration and vowel breathiness
Apart from the Fulop & Golston (Reference Fulop and Golston2008) mentioned above, previous research investigating vowel breathiness and consonant aspiration has compared breathy-voiced vowels to modal vowels following voiceless aspirated consonants (as opposed to vowels following breathy-voiced aspirated consonants). For example, Watkins (Reference Watkins1999) studied phonation in Wa and compared CQ values for breathy vowels to those produced after voiceless aspirated consonants for five timepoints within a vowel. Results showed that there were timing differences between the breathy vowels and the vowels after the aspirated consonants. Breathy vowels began with a higher CQ (i.e. more contact) than vowels after aspirated consonants. However, for the remainder of the vowel, breathy vowels have a lower CQ (i.e. less contact) than the vowels after the aspirated consonants. This trend continued until the last measured timepoint, when the two vowels types had roughly the same CQ. In addition, Garellek & Keating (Reference Keating, Esposito, Garellek, Khan and Kuang2010) found that Jalapa Mazatec breathy vowels and modal vowels after voiceless aspirated consonants shared similar values in H1*-H2*, H1*-A1*, H1*-A2*, and CPP.
3 Current study
3.1 Methods
3.1.1 Speakers
3.1.1.1 Gujarati
Ten native speakers of Gujarati (three male, seven female) were recorded at the Phonetics Laboratory at UCLA's Linguistics Department.Footnote 6 All but two subjects were in their 20s or 30s and had spent the majority of their lives in India, having only recently (<1 year) moved to the US at the time of the recording. Of the remaining two speakers, one was in her 50s and had lived in the US for 26 years, and another was in her 20s and had lived in the US for three years. All subjects were also fluent speakers of English as well as various Indic languages, most commonly Hindi and Marathi, although all reported their first language to be Gujarati. Native fluency in Gujarati was assessed by asking the potential subject questions regarding his or her place of origin and length of stay in the US. All subjects reported that they continued to speak Gujarati on a daily basis and all subjects were fully literate in Gujarati.
3.1.1.2 White Hmong
Twelve native speakers of White Hmong (six male, six female) were recorded at the Hmong American Partnership (St. Paul, Minnesota). Speakers ranged from 24 to 58 years of age and were born in Laos, Thailand, or the US, and resided in Minneapolis/St. Paul, Minnesota, at the time of the experiment. Eleven of the speakers spoke English in addition to White Hmong; the reported age of English onset ranged from 5 to 18 years of age. One speaker (Speaker 8) was a monolingual White Hmong speaker. Native fluency in White Hmong was assessed by asking the potential subjects questions regarding his or her place of origin and length of stay in the US. All speakers reported that they used White Hmong daily and all were fully literate in White Hmong.
Table 1 summarizes the background information on the speakers; gender, approximate age, country of birth, and number of years in the United States are given for both Gujarati and White Hmong subjects.
Table 1 Speakers, gender, approximate age, birthplace, and number of years in the US.

3.1.2 Speech materials
Both the Gujarati and White Hmong data sets consisted of three types of words, categorized by their target consonant–vowel (CV) sequence: (i) a voiced unaspirated consonant followed by a breathy vowel (i.e. [C![]() ], ‘Breathy V’); (ii) a breathy-voiced aspirated consonant followed by a modal vowel (i.e. [CʱV], ‘Breathy-aspirated C’); or (iii) a voiced unaspirated consonant followed by a modal vowel (i.e. [CV], ‘Modal’). For the sake of convenience, we use the term ‘post-aspirated vowel’ as equivalent to ‘modal vowel following a breathy-voiced aspirated consonant’ henceforth. The wordlist for both languages is presented in Table 2.
], ‘Breathy V’); (ii) a breathy-voiced aspirated consonant followed by a modal vowel (i.e. [CʱV], ‘Breathy-aspirated C’); or (iii) a voiced unaspirated consonant followed by a modal vowel (i.e. [CV], ‘Modal’). For the sake of convenience, we use the term ‘post-aspirated vowel’ as equivalent to ‘modal vowel following a breathy-voiced aspirated consonant’ henceforth. The wordlist for both languages is presented in Table 2.
Table 2 Gujarati and White Hmong wordlist. Gujarati words are written in the Gujarati alphasyllabary and White Hmong words are written in the Hmong Romanized Popular Alphabet. Words from both languages are transcribed in IPA under the orthographic representation, and glossed into English below the IPA transcription.
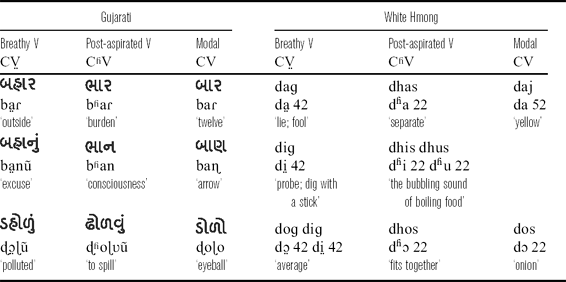
3.1.2.1 Gujarati
Gujarati words were elicited in the following method. First, the investigator revealed a flashcard displaying the target word written in Gujarati orthography (with an English translation below) for no more than two seconds. The speaker then had to create a sentence immediately beginning with the word. The recording was then started, and the speaker produced the sentence as many times as possible within a fixed ten-second window. To familiarize this method to the speakers, a flashcard displaying ![]() ‘dog’ ([ku
‘dog’ ([ku![]() ɾo]) was provided, after which, the investigator (acting as a subject) would create the sentence [ku
ɾo]) was provided, after which, the investigator (acting as a subject) would create the sentence [ku![]() ɾobʱaɡi ɡəjo] ‘The dog ran away’, as an example, and produce it as many times as possible in ten seconds as an illustration of the task. Later, measurements were taken (as explained below) of all repetitions of these target words, and these measurements were then averaged across repetitions of each word before proceeding with the statistical analysis.Footnote 7
ɾobʱaɡi ɡəjo] ‘The dog ran away’, as an example, and produce it as many times as possible in ten seconds as an illustration of the task. Later, measurements were taken (as explained below) of all repetitions of these target words, and these measurements were then averaged across repetitions of each word before proceeding with the statistical analysis.Footnote 7
By asking the subjects to produce the words in a sentence of their own creation and by keeping the orthographic representation hidden for the duration of the recording, it was possible to minimize the effects of spelling pronunciation (i.e. disyllabic pronunciation) associated with reading tasks in Gujarati, while the increased speech rate and use of familiar vocabulary items helped discourage the use of formal register (i.e. breathy–modal neutralization). Furthermore, of the four sources of breathiness in Gujarati (i.e. [əɦV], [Vɦə], [#ɦ], [VCʱ]), the last three are largely restricted to very casual, lenited speech, inappropriate for a laboratory setting; thus, all target words come from the more stable [əɦV] source.
3.1.2.2 White Hmong
All White Hmong words were uttered in the frame Rov hais ____ dua [ʈɔ24 hai22 ____duə33] ‘Say ____ again’. The onset consonants of the target words were limited to alveolars as that is the only place of articulation with non-prenasalized breathy-voiced aspirated consonants in White Hmong. Six of the words were monosyllabic; the other two words were disyllabic, in which only the first syllable was examined.
Because breathy vowels only occur on the falling tone (42), and breathy-voiced aspirated consonants cannot cooccur with the breathy-falling tone (42) or the high-falling tone (52), the tones examined in the current study include the high-falling tone (52) and the low tone (22) for modal consonant–vowel sequences, the low tone (22) for breathy-voiced aspirated consonants followed by modal vowels, and the falling tone (42) for the unaspirated consonants followed by breathy vowels.
3.1.3 Measurement
For both languages, simultaneous audio and electroglottographic recordings were made using a Glottal Enterprises two-channel electroglottograph and a head-mounted microphone. Acoustic and electroglottographic measurements were taken automatically using VoiceSauce (Iseli et al. Reference Iseli, Shue and Alwan2007, Shue, Keating & Vicenik Reference Shue, Keating and Vicenik2009) and EGGWorks (Tehrani Reference Tehrani2009), respectively. The acoustic and electroglottographic parameters along which the data were measured were chosen based on their reported success in distinguishing modal and breathy vowels in the most recent studies of Gujarati (Keating et al. Reference Keating, Esposito, Garellek, Khan and Kuang2010; Khan Reference Khan2010b, Reference Khan2012) and White Hmong (Esposito, in press, Keating et al. Reference Keating, Esposito, Garellek, Khan and Kuang2010).Footnote 8 The three acoustic parameters included H1*-H2*, H1*-A3*, and cepstral peak prominence (CPP) as defined in Hillenbrand et al. (Reference Hillenbrand, Cleveland and Erickson1994). Both spectral measures (i.e. H1*-H2* and H1*-A3*) were corrected for surrounding formant frequencies and bandwidths (Hanson Reference Hanson1995) using the Iseli et al. (Reference Iseli, Shue and Alwan2007) method. The two electroglottographic parameters included CQ – measured using the hybrid method with a 25% threshold as explained above – and DECPA, defined as the peak positive value for each glottal pulse in the first derivative of the electroglottographic signal.
Measurements were made by dividing each vowel into nine parts with equal duration and then averaging the value for a given measure within each part. Only the first five parts (essentially, the beginning and the middle of the vowel) were examined as we reasoned that the effects of breathy-voiced aspirated consonants would be localized to the beginning and, to a lesser extent, the middle of the vowel.Footnote 9 Because they are defined as the first five-ninths of the vowel's duration, these five timepoints are not of equal duration across tokens. They are in effect normalized for overall vowel duration.
3.2 Results
Separate ANOVAs and post-hoc pair-wise comparisons for each measure at each timepoint were used to determine if there was a significant (p ≤ .001) difference between the vowel types (i.e. breathy, post-aspirated, and modal). The current study is particularly concerned with comparing post-aspirated vowels to breathy and modal vowels. For a detailed analysis comparing breathy vowels to modal vowels, see Khan (Reference Khan2010b, Reference Khan2012) for Gujarati and Esposito (in press) for White Hmong.
3.2.1 Gujarati
The results of the acoustic and EGG measures across five timepoints for Gujarati are presented in Table 3. Only measures that show a significant difference between the phonation categories (i.e. post-aspirated vowels compared to either breathy or modal vowels) are given. Graphs of the average values for statistically successful measures (p ≤ .001) across five timepoints are presented in Figure 1. DECPA is not included in the graphs for Gujarati, as this measure was not statistically successful in distinguishing any two of the three categories.
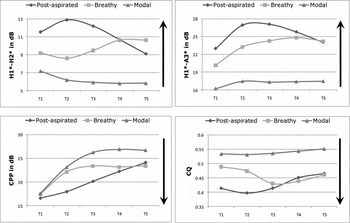
Figure 1 Graphs of the average H1*-H2* (dB), H1*-A3* (dB), CPP (dB), and CQ (unspecified units) values for vowels after breathy-voiced aspirated consonants (labeled ‘post-aspirated’ in the graphs above), breathy vowels, and modal vowels at each of the first five of nine timepoints (T1–T5) in Gujarati. For each graph, the arrow points in the direction of increased breathiness.
Table 3 Measures that distinguish vowels after breathy-voiced aspirated consonants from either breathy vowels or modal vowels at five timepoints (T1–T5) in Gujarati. All measures listed showed a statistically significant difference (p ≤ .001) between the two categories in question.

3.2.1.1 Results of acoustic measures
Spectral results indicate that breathy, modal, and post-aspirated vowels are not significantly different at the consonant release, but the three soon separate into distinct categories in the next few timepoints; by the midpoint of the vowel, however, breathy and post-aspirated vowels become indistinguishable in their spectral properties, while remaining distinct from modal vowels. Specifically, H1*-H2* is significantly higher in post-aspirated vowels than in breathy vowels at timepoints 2 and 3; the same measure also distinguishes both categories from modal vowels, which have the lowest H1*-H2* values in the set. By timepoint 4, however, breathy and post-aspirated vowels are no longer statistically distinct from each other, while they both remain significantly higher than modal vowels. In terms of overall changes in mean values, modal vowels exhibit a low H1*-H2* across all five timepoints, while post-aspirated vowels show a dynamic shape, reaching their highest H1*-H2* values at timepoint 2; breathy vowels are similar to post-aspirated vowels in terms of this dynamic shape, although with a delayed peak, exhibiting their highest H1*-H2* values at timepoints 4 and 5.
Like H1*-H2*, spectral tilt as measured by H1*-A3* is significantly higher (i.e. more steeply falling) in post-aspirated vowels than in breathy vowels at timepoints 2 and 3, while both categories exhibit a significantly steeper tilt than modal vowels across timepoints 3, 4, and 5. Like the overall changes in means of H1*-H2* values, modal vowels maintain a low, flat H1*-A3* value, while post-aspirated vowels reach their highest value at timepoints 2 and 3 and breathy vowels show a similar but delayed peak at timepoint 4.
As a measure of the strength of the signal over noise across the spectrum, CPP is expected to be lower in breathier phonations. Indeed, CPP measures are generally lower for post-aspirated vowels and higher for modal vowels, with an intermediate value for breathy vowels. However, the specifics are slightly different from the patterns seen in the measures of spectral tilt and spectral balance. All three categories show a rise in CPP across all five timepoints, both starting and ending with statistically non-distinct values at timepoints 1 and 5; however, the sharpness of their rises across the intermediate timepoints is different. At timepoint 2, both breathy and modal vowels sharply rise in CPP and are not distinguished from one another, while post-aspirated vowels show a shallower rise and are thus significantly lower in CPP than the other two categories. By timepoint 3, however, all three categories separate and are statistically distinct from one another, with post-aspirated vowels having the lowest CPP value (i.e. noisiest and/or least periodic) and modal vowels having the highest. The pattern is then reversed at timepoint 4, with breathy and post-aspirated vowels not distinguished but modal vowels continuing to exhibit a significantly higher value.
3.2.1.2 Results of electroglottographic measures
EGG data also reveal distinctions in the production of modal, breathy, and post-aspirated vowels in Gujarati. Post-aspirated vowels have a lower CQ than modal vowels at all timepoints, but are not statistically distinguished from breathy vowels at any timepoint. Post-aspirated vowels exhibit their lowest (i.e. breathiest) CQ value at timepoint 2. At timepoint 3, breathy vowels reach their lowest CQ value, essentially merging with the post-aspirated category. After timepoint 3, both categories gradually become less breathy but still significantly distinct from modal vowels, with the average CQ values of the breathy and post-aspirated vowels appearing indistinguishable from one another.
DECPA does not distinguish any two of the three categories in Gujarati following our use of p ≤ .001 as a benchmark for statistical significance; however, post-aspirated and modal vowels are distinguished in DECPA in the first timepoint, with post-aspirated vowels exhibiting the higher value, following a lower standard for significance (p = .005).
3.2.2 White Hmong
The results of the acoustic and EGG measures across five timepoints for White Hmong are presented in Table 4. Only measures that show a significant difference between the phonation categories are given. Individual graphs of the average values for CPP, H1*-H2*, CQ, and DECPA across five timepoints are presented in Figure 2. The results of H1*-A3* are not shown in the graphs because this measure does not significantly distinguish any two of the three categories in White Hmong.
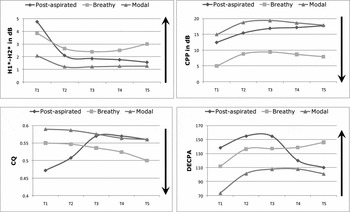
Figure 2 Graphs of the average H1*-H2* (dB), CPP (dB), CQ (unspecified units), and DECPA (unspecified units) values for vowels after aspirated consonants (labeled ‘post-aspirated’ in the graphs above), breathy vowels, and modal vowels in each of the first five of nine timepoints (T1–T5) in White Hmong. For each graph, the arrow points in the direction of increased breathiness.
Table 4 Measures that distinguish vowels after breathy-voiced aspirated consonants from either breathy vowels or modal vowels at five timepoints (T1–T5) in White Hmong. All measures listed showed a statistically significant difference (p ≤ .001) between the two categories in question.

3.2.2.1 Results of acoustic measures
On the measure H1*-H2*, vowels after breathy-voiced aspirated consonants were breathier than phonemically breathy vowels at the first timepoint. (That is, they had a significantly higher H1*-H2* value.) By point 2, however, the H1*-H2* value for the post-aspirated vowels is no longer significantly higher than that of breathy vowels. In fact, on points 2, 3, and 4, there is no significant difference between the post-aspirated and breathy vowels. However, by point 5, the average H1*-H2* value for the breathy vowels increases, while the value for the post-aspirated vowels decreases. These two vowel types are significantly different at this timepoint, with the post-aspirated vowels having a modal-like H1*-H2* value. The post-aspirated vowels and modal vowels are significantly different on the first two timepoints, when the post-aspirated vowels have a higher, breathy-like, H1*-H2* value. By point 3, when the H1*-H2* value drops for the post-aspirated vowels, this vowel type is no longer significantly different from modal vowels.
Like modal vowels, post-aspirated vowels have a significantly higher CPP (i.e. they are less noisy and/or more periodic) than breathy vowels throughout the five timepoints. In fact, there was no significant difference between the CPP values for modal vowels and post-aspirated vowels at any of the timepoints. Thus, along the CPP dimension, there are essentially two categories in White Hmong: breathy vowels and modal vowels, the latter category also including vowels preceded by breathy-voiced aspirated [dʱ].
3.2.2.2 Results of electroglottographic measures
Post-aspirated vowels have a significantly different CQ value from breathy vowels on all five timepoints and are significantly different from modal vowels on the first two timepoints. On points 1 and 2, the post-aspirated vowels have even less vocal fold contact than the breathy vowels. But, by timepoint 3, the CQ value of the post-aspirated vowels increases such that it is significantly higher than breathy phonation and no longer significantly different from modal phonation.
For DECPA, the post-aspirated vowels are significantly breathier than either breathy or modal phonation until point 4.Footnote 10 During points 4 and 5, the DECPA value for post-aspirated vowels drops and becomes more modal-like, becoming significantly lower than that of breathy vowels, but not significantly different from modal phonation.
4 Discussion
In the current study, we hypothesized that the difference between post-aspirated vowels – phonemically modal vowels following breathy-voiced aspirated stops ([ʱV]) – and phonemically breathy vowels ([![]() ]) would be manifested in the timing and/or degree of breathiness. Both timing and degree distinctions were found in both languages. Language-specific differences in the overall resemblance of post-aspirated vowels to other categories were also found, as well as differences in the reliability of specific acoustic and electroglottographic measures to distinguish categories. This section expands on these cross-linguistic comparisons, and explores possible explanations for the cross-linguistic differences.
]) would be manifested in the timing and/or degree of breathiness. Both timing and degree distinctions were found in both languages. Language-specific differences in the overall resemblance of post-aspirated vowels to other categories were also found, as well as differences in the reliability of specific acoustic and electroglottographic measures to distinguish categories. This section expands on these cross-linguistic comparisons, and explores possible explanations for the cross-linguistic differences.
We hypothesized that the breathiness associated with breathy-voiced aspirated consonants would be localized to the consonant release and thus produced at the onset of the following vowel, while the breathiness associated with breathy vowels would be produced across a larger portion of the vowel, with language-specific distinctions in the exact localization. Results confirmed this hypothesis. In both languages, there was a brief, early realization of breathy phonation (as indicated along multiple acoustic and EGG dimensions) after the breathy-voiced aspirated consonant; post-aspirated vowels generally began very breathy, but became more modal at the vowel midpoint, reflecting the fact that the breathiness is phonologically associated with the consonant and not with the vowel. The localization of breathy phonation in the breathy vowel, however, was more language-specific. In White Hmong, breathy vowels are uniformly breathy across the first half of their duration, while in Gujarati, breathy vowels start out with a more modal-like phonation, but become breathier by the midpoint. This dynamic realization of breathy vowels in Gujarati may be due to the historical source of vocalic breathiness in that language. Most breathy vowels in Gujarati derive from disyllabic sequences of vowels with intervocalic [ɦ]; thus, although truly disyllabic productions (e.g. [VɦV]) were not found in the current study (presumably due to the precautionary measures taken in the experimental setup), monophthongal breathy vowels in Gujarati may still exhibit the strongest breathiness near the midpoint, while still remaining breathier than modal vowels throughout the duration.
In addition to the difference in timing, we also hypothesized that post-aspirated vowels would show a different degree of breathiness than breathy vowels; however, the direction of magnitude was not inherently obvious from previous research. The results of our acoustic and electroglottographic analyses confirm that the two categories are distinguished by degree in both languages, clearly demonstrating that post-aspirated vowels begin with even greater breathiness than breathy vowels across various measures; in effect, the beginning of the post-aspirated vowel is breathier than that of a breathy vowel. This greater magnitude of breathiness in post-aspirated vowels is likely related to its short, early realization; given its association to the preceding consonant rather than to the vowel itself, the breathiness from breathy-voiced aspirated stops must be produced in a limited duration, and may thus require compensatory amplification to be reliably perceived by the listener.
The similarity of post-aspirated vowels to other categories was found to be language-specific. Post-aspirated vowels in both languages begin breathier and become more modal towards the vowel midpoint, but their overall resemblance to breathy or modal vowels differs. Along the various measures across the five timepoints, post-aspirated vowels were statistically more similar to breathy vowels in Gujarati, but statistically more similar to modal vowels in White Hmong. The strong similarity between modal vowels and post-aspirated vowels in White Hmong may be one of the reasons why Jarkey (Reference Jarkey1987) believed the aspiration associated with [dʱ] to be optional; the aspiration produced following the release of [dʱ] may simply be less salient in White Hmong due to its limited duration, typically not lasting beyond the first timepoint. Post-aspirated vowels in Gujarati, on the other hand, maintain their breathiness through the second or third timepoint (depending on the measure), and thus presumably have a more salient period of breathiness, more closely resembling breathy vowels.
In the absence of photographic data that would have been obtained through laryngoscopic or other invasive means in the current study, our findings on the articulation of breathy phonation in Gujarati and White Hmong breathy vowels and breathy-voiced aspirated stops are based on electroglottographic data as well as established correlations between acoustic outputs and source characteristics. For example, claims that breathy phonation involves a more open glottis are supported by the lower CQ values and higher H1*-H2* values in both breathy vowels and post-aspirated vowels across the two languages. Claims that breathy phonation involves a less abrupt glottal closure, however, require further investigation. The two measures related to the nature of the glottal closure are DECPA and H1*-A3*, which are expanded on below.
One may assume that DECPA, the peak positive value in the first derivative of the EGG signal, should be higher when the vocal folds approximate one another (i.e. in the closure phase) more quickly, but surprisingly, it was found to be higher in both types of breathy sequences in White Hmong. (The measure was not reliable in distinguishing phonation categories in Gujarati.) A higher DECPA was also found for lax phonation (a phonation similar to breathy) in Yi (Keating et al. Reference Keating, Esposito, Garellek, Khan and Kuang2010; Kuang Reference Kuang2010, 2012) and in an additional study on White Hmong (Esposito, in press). A visual inspection of the EGG signal for the White Hmong data collected for the current study confirms that breathy phonation is characterized by a longer open quotient and shorter closing quotient (although it is presumed the glottis may not be completely closed in breathy phonation), with a very sharp transition between the two. Keating et al. (Reference Kreiman, Gerratt and Khan2010: 93) suggests that the higher DECPA values for breathy/lax phonation is due to a principle of ‘the further, the faster’; the greater degree of glottal opening in breathy phonation might require the vocal folds to move more quickly to return to a (semi-)closed state. It may be that this shortening of the transition to the closure phrase makes it possible for White Hmong speakers to elongate their open phase without elongating the entire glottal pulse, which would in turn significantly lower the pitch in this lexical tone language. In Gujarati, on the other hand, the longer open phase presumably comes about through a longer overall glottal pulse, generating the lower f0 long established as a property of Gujarati breathiness (Pandit Reference Pandit1957, Dave Reference Dave1967, Fischer-Jørgensen Reference Fischer-Jørgensen1967) while not significantly affecting the DECPA.
Because of the strengthening of the fundamental and the weakening of higher harmonics due to the less-abruptly closed glottis in breathy voice, H1*-A3* is often cited as an acoustic correlate of the abruptness of glottal closure (Stevens Reference Stevens1977). Indeed, this measure successfully distinguishes both types of breathy phonation from modal phonation in Gujarati in the expected direction (although this was not the case in Fischer-Jørgensen's Reference Fischer-Jørgensen1967 study using uncorrected spectral measures), but it is not a useful measure in White Hmong. It is unclear why H1*-A3* is unsuccessful in White Hmong, although one possibility would be that the higher frequency aperiodic noise generated in White Hmong breathy phonation is loud enough to boost the value of A3* to a level not significantly distinct from that of modal phonation. Indeed, the authors’ intuitions would characterize the breathy vowels of White Hmong as far noisier than those of Gujarati.
5 Conclusions and directions for further study
Despite their geographical and genetic distance, Gujarati and White Hmong have both independently generated a cross-linguistically unusual contrast between breathy and modal phonation in both voiced stop consonants ([C] vs. [Cʱ]) and vowels ([V] vs. [![]() ]), a distinction so rare that it is not even shared by closely related languages such as Hindi or Green Mong. Both Gujarati and White Hmong have derived CV sequences in which phonetic breathiness can be associated phonologically to the consonant ([CʱV]) or to the vowel ([C
]), a distinction so rare that it is not even shared by closely related languages such as Hindi or Green Mong. Both Gujarati and White Hmong have derived CV sequences in which phonetic breathiness can be associated phonologically to the consonant ([CʱV]) or to the vowel ([C![]() ]) – but not to both (*[Cʱ
]) – but not to both (*[Cʱ![]() ]), due to similar phonotactic restrictions in both languages. Both acoustically and articulatorily, these two types of sequences (i.e. [CʱV] and [C
]), due to similar phonotactic restrictions in both languages. Both acoustically and articulatorily, these two types of sequences (i.e. [CʱV] and [C![]() ]) are distinguishable within the first half of the vowel: in both languages, breathiness associated with stops is characterized by a short period of extreme breathiness concentrated at the onset of the consonant into the vowel, while breathiness associated with vowels is characterized by a less extreme production of breathiness, spread more evenly across the first half of the vowel (with some dynamic behavior in Gujarati). Naturally, the phonetic details are more language-specific, with some acoustic and electroglottographic measures being better indicators of breathiness in one language over the other (e.g. H1*-A3* in Gujarati, DECPA in White Hmong), and with vowels following breathy-voiced aspirated consonants ([ʱV]) more closely resembling phonemically breathy vowels ([
]) are distinguishable within the first half of the vowel: in both languages, breathiness associated with stops is characterized by a short period of extreme breathiness concentrated at the onset of the consonant into the vowel, while breathiness associated with vowels is characterized by a less extreme production of breathiness, spread more evenly across the first half of the vowel (with some dynamic behavior in Gujarati). Naturally, the phonetic details are more language-specific, with some acoustic and electroglottographic measures being better indicators of breathiness in one language over the other (e.g. H1*-A3* in Gujarati, DECPA in White Hmong), and with vowels following breathy-voiced aspirated consonants ([ʱV]) more closely resembling phonemically breathy vowels ([![]() ]) in Gujarati while they more closely resemble phonemically modal vowels ([V]) in White Hmong.
]) in Gujarati while they more closely resemble phonemically modal vowels ([V]) in White Hmong.
The results of the present study show that timing and degree of breathiness are reliable in distinguishing breathy vowels from post-aspirated vowels. The question arises: If presented with breathiness in a CV sequence, can listeners rely on either timing or degree of breathiness alone to determine the segment to which the breathiness is phonologically associated (i.e. [CʱV] or [C![]() ]), if they perceive the breathiness at all? There are secondary cues to distinguishing these segments in both languages. In White Hmong, all breathy vowels bear the falling tone 42, so f0 could play a vital role in the perception of breathiness, while in Gujarati, duration could play an important role in distinguishing these segments in that most breathy vowels in that language derive from disyllables and can be produced as such in certain registers, while post-aspirated vowels are not derived from such sequences. A follow-up to the current study would be a perception experiment where speakers are asked to identify and/or discriminate between [CʱV] and [C
]), if they perceive the breathiness at all? There are secondary cues to distinguishing these segments in both languages. In White Hmong, all breathy vowels bear the falling tone 42, so f0 could play a vital role in the perception of breathiness, while in Gujarati, duration could play an important role in distinguishing these segments in that most breathy vowels in that language derive from disyllables and can be produced as such in certain registers, while post-aspirated vowels are not derived from such sequences. A follow-up to the current study would be a perception experiment where speakers are asked to identify and/or discriminate between [CʱV] and [C![]() ] sequences (and possibly modal [CV] as another option). This future extension would allow us to determine how both cross-linguistic and language-specific cues assist native speakers of these two typologically rare languages in perceiving breathy voice and determining its segmental association in ambiguous contexts.
] sequences (and possibly modal [CV] as another option). This future extension would allow us to determine how both cross-linguistic and language-specific cues assist native speakers of these two typologically rare languages in perceiving breathy voice and determining its segmental association in ambiguous contexts.
Acknowledgments
This study is supported by NSF grant BCS-0720304 for a project entitled ‘Production and Perception of Linguistic Voice Quality’ (Principal Investigators: Patricia A. Keating, Abeer Alwan, Jody Kreiman, and Christina M. Esposito; 2007–2012), exploring aspects of phonation in various languages. The authors would like to thank (i) our consultants for their participation, (ii) Victoria Thatte, Ramesh Goud, and Ranjan Goud for their input, (iii) the staff and clients at the Hmong American Partnership, the members of the Immanuel Hmong Lutheran Church, Eric Bestrom, Claire Moore-Cantwell, Alice Ware, and Oleh Zaychenko for their assistance, and (iv) John H. Esling, Adrian P. Simpson, Ewa Jaworska, and three anonymous reviewers for their valuable comments and suggestions.






