


1 Introduction
An actor's success depends on the extent to which they can convincingly portray an identity other than their own. Actors have many tools at their disposal to this end, both visual and behavioural; one of these tools is their use of language, for example, by speaking a different dialect from their own (see, e.g., Hodson Reference Hodson2014). Such performance in a second dialect may not always be on target, but while, for example, Bell & Gibson (Reference Bell and Gibson2011: 569) acknowledge that inaccuracies may be accidental, their focus is on strategic inaccuracies that add an extra layer to the performance. For many second-dialect performances, however, and indeed for many audiences, inaccuracies need not be layered and a successful linguistic performance hinges purely on hitting the target.
Reviews and online comments often praise or criticise the accuracy of a (staged) second-dialect performance. The second-dialect performances of Hugh Laurie, as Dr Gregory House in House, and David Tennant, as the Tenth Doctor in Doctor Who, are generally seen as highly accurate and successful. But if accuracy and inaccuracy can be strategic, it is important to understand how they behave when they are merely accidental.
This article reports on a two-part study of American English second-dialect performance by three Australian actors. An acoustic analysis of the short vowel systems in their first and second dialects is presented in section 3; a listener acceptability experiment on the American English performance data is presented in section 4. The results from the acoustic analysis and the holistic acceptability experiment are then compared (section 5) and contextualised in the field of second-dialect acquisition and performance.
2 Background
2.1 Second dialects in performance
The sociolinguistic literature has paid considerable attention to the use of dialect in performance. This includes dialect performance in music (Trudgill Reference Trudgill1983; Beal Reference Beal2009; Coupland Reference Coupland2011), on the radio (Coupland Reference Coupland2001) and in film (Hodson Reference Hodson2014; Bucholtz Reference Bucholtz2011). Often, a dialect is performed because it is felt to be appropriate for the context (e.g. the American English accent in early songs by the Beatles; Trudgill Reference Trudgill1983), because it conveys a form of authenticity (as in, e.g., the Arctic Monkeys songs; Beal Reference Beal2009) or because it evokes a particular ‘feel’ (Welsh-accented radio broadcasts (Coupland Reference Coupland2001) or New Zealand advertisements (Bell Reference Bell1992)). Studies of dialect performance, then, tend to investigate questions related to this authenticity – including the effect of more or less successful performance. The question of success in performance leads to further questions about how dialect performance relates to (second-) dialect acquisition.
The question of authenticity is not straightforward, and what is seen as authentic is based on subjective greyscale judgements on multiple parameters (Hodson Reference Hodson2014: 224–30). While it may be argued that a performance is inherently deauthenticating (see Coupland Reference Coupland2009: 284), this need not be the case. Coupland (Reference Coupland2009: 294) discusses how the Artic Monkeys ‘successfully perform authenticity’, and how ‘speakers’ agentive control of a repertoire of meaningful feature[s] and styles’ can be seen as performance (authenticity that is performed); Bucholtz (Reference Bucholtz2003: 408), Coupland (Reference Coupland2009: 298) and Hodson (Reference Hodson2014: 235) claim that authenticity ultimately is constructed within the context of the performance. Although accuracy of the dialect performance is often seen as a measure of success and of authenticity, this context-based construction means that ‘“accuracy” is irrelevant’ (Coupland Reference Coupland2009: 298).
What makes authenticity an even murkier issue in the current study is that the performed dialect is not a non-standard variety, as is often the case. Like David Tennant's Doctor Who, performed in a second-dialect version of Standard Southern British English, the performed General American English accents constitute a standard variety of English. And indeed, Coupland's measures of authenticity can apply to Standard English as much as they can to non-standard English (Hodson Reference Hodson2014: 225–6). In popular perception, however, this type of dialect performance is about ‘losing’ rather than ‘putting on’ an accent; it is about no longer being perceived as a linguistic Other and becoming invisible (or inaudible).
2.2 Acquisition and performance
If an actor performs in a second dialect, they need at some level to have acquired that dialect. This raises the question of whether actors’ second-dialect acquisition differs in any way from acquisition outside a performance context, or whether the two can be seen as equivalent. Siegel (Reference Siegel2010: 64–6) is quite adamant that D2 performance is separate from naturalistic D2 acquisition, and that studies of second-dialect performance do not inform our knowledge of SDA. And of course, many factors that are relevant in SDA are neutralised in D2 performance – predominantly social factors, but perhaps also linguistic ones. But to avoid throwing out the baby with the bath water, it is worth exploring where the differences lie between acquisition and performance, and discussing where the value of performance data may lie for studies of second-dialect acquisition.
One difference between performance and acquisition lies in the type of knowledge or competence required. Performance, according to Siegel (Reference Siegel2010: 219), ‘requires only explicit knowledge or conscious awareness of some of the features of the D2, and the ability to imitate them accurately’. This means that performance data give no evidence of ‘automatic processing of underlying mental computational procedures’ (Reference Siegel2010: 74), the implicit competence that is evidence of true acquisition. And indeed, Siegel's discussion of dialect coaching (Reference Siegel2010: 196) describes very explicit methods of learning: awareness raising, guided listening and imitation, starting with ‘signature sounds’ (what we might call stereotypes) and progressing to less obvious differences between the D1 and the D2. We also see predominantly conscious, cognitive learning in Trudgill's (Reference Trudgill1983: 145–58) discussion of second-dialect performance according to Le Page's ‘acts of identity’ model (Le Page & Tabouret-Keller Reference Le Page and Tabouret-Keller1985), in which success (read: accuracy) is determined by:
1. the extent to which we are able to identify our model group;
2. the extent to which we have sufficient access to [the model groups] and sufficient analytical ability to work out the rules of their behavior;
3. the strength of various (possibly conflicting) motivations towards one or another model and towards retaining our own sense of our unique identity;
4. our ability to modify our behaviour (probably lessening as we get older).
Implicit learning, which Siegel appears to view as true acquisition of a D2, is described as a subconscious, automatic process, in which learners are not aware of their own learning – even if the process is not quite implicit or subconscious at every level (Dörnyei Reference Dörnyei2009: 138). Some explicit knowledge does seem to be required, however: a learner is thought to only be able to acquire a feature if they are to some extent aware of it (the noticing hypothesis; Dörnyei Reference Dörnyei2009: 164) and most SDA studies fail to clearly distinguish the two types of processes (Siegel Reference Siegel2010: 74). In an SDA context, Nycz (Reference Nycz and Babel2016) has shown that awareness of D2 features is not a necessary requirement for dialect change, but that it does influence the process: speakers showed enhanced levels of adoption or rejection of a D2 feature they were aware of compared to a feature that had not been noticed.
All in all, the difference in learning styles between learning for performance and true acquisition looks to be quantitative rather than qualitative, with performance typically showing more explicit and acquisition showing more implicit learning methods, but neither necessarily relying exclusively on one or the other.
Another important difference between second-dialect performance and acquisition is motivation. In acquisition, there is often an integrative motivation. Canadian learners of D2 New York English, for example, ‘deliberately manipulat[ed] their use of salient dialect features’ in order to show or hide their Canadian identity (Nycz Reference Nycz and Babel2016: 70). The motivation for second-dialect performance is often more instrumental: a character's identity does not necessarily influence an actor's identity. Even though the ‘acts of identity’ model mentions motivation in the context of identity, this is probably to be interpreted loosely. The use of American English by the Beatles (Trudgill Reference Trudgill1983) was not to convey a personal identity as Americans, but a professional and therefore more instrumental identity as pop musicians with little bearing on who they were as individuals. Identity, therefore, is likely to be a more important motivational factor in acquisition than in performance.
2.3 Measuring success in SDA and performance
Acquisition and performance also differ in what constitutes ‘success’. Successful performance is often judged holistically (Hodson Reference Hodson2014: 228), even though raters may be able to point at specific linguistic features or at non-linguistic features such as the rater's awareness of the performance actually being in a second dialect (Hodson Reference Hodson2014: 231–3). Similarity to real-world dialects plays a role, but is not the determining factor in the success of a performance (Hodson Reference Hodson2014: 236). Studies of second-dialect acquisition, by contrast, have a much more particular measure of success, comparing learners’ use of specific D2 features to native speakers of the second dialect, or charting the loss of D1 features. Often, the features investigated are the ‘signature sounds’ that dialect coaching focuses on: the loss of t-flapping (Chambers Reference Chambers1992) and the acquisition of t-glottaling (Tagliamonte & Molfenter Reference Tagliamonte and Molfenter2007) by Canadian learners of England English; the loss of Canadian raising (Nycz Reference Nycz2013a, Reference Nycz and Babel2016) or the acquisition of the Philadelphia split-trap pattern (Payne Reference Payne1976, Reference Payne and Labov1980). Here, similarity to real-world dialects is in fact the determining factor. Of course, quantitative comparison of the use of stereotypical features also occurs in studies of performance; see Trudgill (Reference Trudgill1983), which focuses on specific features of American English (dubbed the ‘USA-5 model’ by Simpson Reference Simpson1999).
2.4 The value of performance data
It is clear, then, that second-dialect performance and acquisition cannot simply be equated. Performance is likely to involve relatively more explicit learning (speech coaching) and a different, more instrumental motivation than ‘real’ second-dialect acquisition. These are not either/or questions, however: motivations can be multiple, and explicitly learned skills can be internalised and thereby become more implicit (Dörnyei Reference Dörnyei2009: 151–8). Optimistically, we can state that training for performance constitutes the maximum of what can be acquired naturalistically. The instrumental motivation is not counteracted by a desire to retain a personal identity, and we can study what is trained, rather than the inevitably smaller set of skills that are internalised and retained.
Another clear value of performance data is that much of it is in the public domain, and therefore readily available and accessible. This applies not only to the performed second-dialect data, but often also to actors’ first-dialect data, e.g. from other work or non-performed speech. Given these advantages of second-dialect performance data, it is worth asking what this can tell us about what is maximally possible in second-dialect acquisition, and about how such success is measured.
2.5 Factors influencing success in SDA
Compared to second-language acquisition, the literature on second-dialect acquisition in naturalistic settings is extremely small. Siegel (Reference Siegel2010) aims to give a comprehensive overview and arrives at only seventeen studies published in English, many also on SDA in English. More recently, the field has been advanced by Nycz (Reference Nycz2013a, Reference Nycz2013b, Reference Nycz2015, Reference Nycz and Babel2016). These studies give a range of different results, but it is clear that the success of SDA varies depending on individual and linguistic factors, and that SDA goes hand in hand with an increase in variability.
An individual factor that is often believed to constrain a person's ability to acquire a second dialect is the age at which they start learning the dialect: age of acquisition. The idea that pre-adolescents can acquire a faithful copy of the speech they hear around them, while post-adolescents cannot is fundamental to Labov's (Reference Labov2007) distinction between ‘transmission’ and ‘diffusion’: the latter, which has an element of SDA in it, often introduces changes to the original input. Labov (Reference Labov2007: 383) is explicit about this issue when he writes that ‘it would be helpful to know more about the limitations on children's ability to learn new dialects and on adults’ inability to learn them’. Work on age of acquisition within SDA, however, is much less categorical than Labov's assertion. Younger learners do appear more successful at SDA than older learners (e.g. Payne Reference Payne1976, Reference Payne and Labov1980; Chambers Reference Chambers1992; Tagliamonte & Molfenter Reference Tagliamonte and Molfenter2007; Siegel Reference Siegel2010: 84–92), but the role of adolescence as a watershed period between ability and non-ability of successful SDA is much less clear; there is even some evidence that the latest age at which successful SDA can be expected is as young as 7 (Siegel Reference Siegel2010: 92). Studies that show successful SDA after age 14 all focus on lexicon and morphology only (Kerswill Reference Kerswill1994; Ivars Reference Ivars and Nordberg1994; Omdal Reference Omdal and Nordberg1994). The overall evidence for the influence of age of acquisition on success in SDA suggests that someone who starts acquiring a D2 before adulthood will learn some things, but not necessarily consistently.
Linguistic factors, too, influence success in second-dialect acquisition. Chambers (Reference Chambers1992) formulates eight generalisations, or ‘principles’, on these linguistic factors. The generalisations deal predominantly with linguistic level and rule complexity; the three principles that are relevant to the current study on pronunciation are given below:
3. Simple phonological rules progress faster than complex ones.
5. In the earliest stages of acquisition, both categorical rules and variable rules of the new dialect result in variability in the acquirers.
7. Eliminating old rules occurs more rapidly than acquiring new ones.
Rule complexity appears to be the clearest linguistic predictor of success (Principle 3). A phonological rule, here, is to be understood as a generalisation of what a learner has to do to produce D2 output from the original D1 forms (or from a generative point of view, underlying D1 representations). Chambers does not give a clear metric for rule complexity, but from the examples he discusses, we can distinguish at least three types:
a. categorical substitution of phonemes;
b. change of distribution of phonemes;
c. phonemic split.
The easiest type is when a learner must categorically substitute each instance of a D1 sound with a different D2 sound. A Northern English learner of Standard Southern British English must acquire a more diphthongised face vowel [eɪ] instead of their D1 realisation [eː]. (For the sake of argument, these realisations are stereotypical generalisations and gloss over any variation that may exist in the D1 and D2.) Because the distribution of this vowel is identical in both accents, this is a relatively simple rule.
A more complicated type of rule is when a learner must change the distribution of two sound categories that exist in both the D1 and D2, but have different distributions. Both Northern English and SSBE have /æ/ and /ɑː/ phonemes, but the example learner would have to change the distribution of trap=bath /æ/ vs palm /ɑː/ to trap /æ/ vs bath=palm /ɑː/. This is a more difficult rule, because the substitution /æ/ > /ɑː/ only applies in some cases, but not in others.
Finally, the most complex type of rule is when a learner must acquire a D2 phonological split of a D1 phoneme. An example here is the split of Northern English strut=foot /ʊ/ into strut /ʌ/ vs foot /ʊ/. This is similar to the previous type, but the extra complication is that /ʌ/ is a new phoneme for the learner, not a pre-existing one as /ɑː/ was.
The easier processes can generally be expected to be acquired more successfully, although this is not a hard and fast rule.
Chambers's Principle 7 holds that it is easier to eliminate old (D1) rules than to acquire new (D2) rules. This may be the case for some of the allophonic and phonotactic rules in his study (t-flapping and rhoticity), but other examples are less convincing. Chambers sees ‘low vowel merger’ (lot=thought) as a D1 rule that his speakers of Canadian English have to undo, but ‘vowel backing’ (trap≠bath) as a new D2 rule to be acquired. On lot=thought, Chambers (Reference Chambers1992: 696) explicitly says that ‘[p]olylectally, the C[anadian] E[nglish] merger is innovative,’ but surely we must assume that SDA happens in a historical linguistic vacuum — and to a synchronic acquirer of a second dialect, ‘low vowel merger’ and ‘vowel backing’ are essentially the same: acquisition of a new phoneme and redistribution of a set words over this new phoneme and the single pre-existing phoneme that was previously used in all these words. Unlike t-flapping and rhoticity, the figures for these two phonological splits in Chambers (Reference Chambers1992) are not meaningfully different, suggesting that we do indeed need to look at the process of acquisition synchronically. (Compare also Nycz's (Reference Nycz2015: 470) comment on the role of theoretical analysis in SDA.)
Finally, Principle 5 holds that SDA leads to variability in the acquirer whether or not the D2 is variable on a specific point. This is not surprising, as acquisition is inherently characterised by variable success at all stages of the acquisition process (Larsen-Freeman Reference Larsen-Freeman1997). In the case of phonetic variables, where no two realisations of a phoneme will share the exact same acoustic properties (formant frequencies, duration, voice onset time, etc.), this means that we should expect considerable variation in SDA — and it is not clear whether this variation derives from the D1, the D2 or the acquisition process. (This is not to say that variation, including social constraints on variation, cannot be acquired successfully; see Tagliamonte & Molfenter Reference Tagliamonte and Molfenter2007.).
In the context of accommodation, believed to be a major mechanism in SDA (Siegel Reference Siegel2010: 70–3), three different patterns have been identified by Bigham (Reference Bigham2010) for how speakers deal with D1 and D2 variation. These are visualised in figure 1. Some learners showed a larger range of variation compared to their D1 to include a larger number of D2-typical realisations not possible in the D1. Other learners appeared to have restricted their D1 variation to include only those realisations that are also acceptable in the D2. Finally, some learners shifted all their realisations in the direction of the D2 while maintaining a similar range of variation. The different outcomes are likely to be the result of different, possibly subconscious, acquisition strategies, but arguably only the latter outcome, shift, constitutes true acquisition of the D2.

Figure 1. Schematic representation of three learner strategies for the acquisition of vowels in a second dialect
3 Phonetic study
3.1 Methods
3.1.1 Informants
The speakers in the phonetic study are three young Australian actors: Tom Green, Dena Kaplan and Tim Pocock. All three had roles in the Australian television series Dance Academy (ABC 2010–13), and the American television series Camp (NBC 2013). Dance Academy follows a group of young dancers at a Sydney ballet school. The Australian setting is prominent in the show, with frequent images of iconic Sydney cityscapes; the actors use Australian English in this show. Camp, which revolves around young (trainee) staff at a summer camp, is clearly set in the United States, even though the show was recorded in Australia. There are numerous American cultural and place name references, cars drive on the right, and the actors use American English. In terms of second-dialect performance, then, Australian English is the actors’ D1 and American English is their D2.
Unlike the majority of dialect performance discussed in the literature, the performed (second) dialect in Camp is not a non-standard variety of English. The target appears to be a standard American English designed not to add an extra layer, but to convey normality to an American audience despite an Australian cast.
Green (b. 1991) was born in Australia and grew up there, and the majority of his work is Australian, although Camp was not his first American production; he also plays a role in an internet-based American series. Kaplan (b. 1989) was born in South Africa and moved to Australia at age 7. Her role in Camp is her first American role. Pocock's (b. 1985) dialectal history, finally, is a bit more diverse, having grown up in South Africa and Ireland before moving to Australia. As with the others, the majority of his work is Australian, but Pocock has a previous North American role in the 2009 movie X-Men Origins: Wolverine.Footnote 1
Although two of the three informants can be argued not to have Australian English as their D1, for the purposes of this article it is unproblematic to regard it as such nonetheless. The measurements for Kaplan and Pocock's D1 performance show no meaningful differences from those for Green, and also auditorily they use Australian, not South African or any other English. In both Australian and American English, the actors use a ‘general’ rather than a ‘broad’ or specific regional accent (Wells Reference Wells1982: 470, 594). The actors received guidance on their American English accents from a speech coach.Footnote 2 From their biographies, the actors’ work in Australian and American English does not appear to have been concurrent.
3.1.2 Audio quality
The source of the data used in this study was digital recordings of Dance Academy and Camp in the .mp4 file format. This is a lossy form of digital compression, meaning that not all acoustic information that would be available in an uncompressed format (.wav) is retained in the audio file. Lossless extraction of the audio track from the .mp4 file to .wav allows for acoustic analysis, but the loss of data in the initial lossy conversion will still have an influence. De Decker & Nycz (Reference De Decker and Nycz2011) have shown that different recording devices and formats do affect formant measurements. However, within-device and within-format comparison is unproblematic, especially for the first two formants, which are least affected by audio conversion. The third and higher formants show greater deviations, and De Decker & Nycz (Reference De Decker and Nycz2011: 54) advise against using these measurements.
3.1.3 Data selection and coding
This study focuses on the actors’ pronunciation of short vowels. Previous SDA research on this pair of dialects, albeit with the D1 and D2 roles reversed, focused primarily on the more salient long vowels and diphthongs goat, fleece, face and price in addition to kit and rhoticity (Foreman Reference Foreman, Allen and Henderson2000; Siegel Reference Siegel2010: 34–6), but as successful second-dialect acquisition presumably means attaining accuracy in both salient and non-salient variables, the short vowel system should give an insight into what is possible to acquire. The short vowels were also chosen because the acoustic study originally served as a teaching tool, and working with long vowels and diphthongs would be too difficult for students of this level.
All normally stressed tokens of short vowels uttered by the three actors were isolated from eight second-season episodes of Dance Academy and five episodes of Camp.Footnote 3 To avoid breaking effects, tokens before /l/ and /r/ were excluded, also if the liquid was in the onset of the following syllable. Tokens obscured by background noise or music were not included in the data set. An overview of the number of tokens for each speaker in each lexical set is given in table 1. The first and second formants of all tokens were measured manually in Praat (v. 5.3.04, Boersma & Weernink Reference Boersma and Weenink2012) at peak intensity using default settings.
Table 1. Number of tokens for each speaker, per lexical set

It is clear that numbers are only sufficient to discuss the actors’ performance in the kit, dress, trap, strut and lot lexical sets. The lower token counts in the other sets do allow us to make impressionistic judgements about (i) the acquisition of a different distribution of phonemes in the lot, cloth and thought lexical sets in American English, and (ii) the possible retention of the trap/bath differentiation from the actors’ D1 when speaking their D2 (see below). The infrequent foot vowel will be ignored in the remainder of this article.
3.1.4 Defining the D2 target
The measure of success in this phonetic study is the similarity of D2 realisations to D2 native-speaker performance. Table 2 (visualised in figure 2) gives reference values for the first and second formants of the five vowels in the accents of three relevant areas: the Midwestern United States (Hillenbrand et al. Reference Hillenbrand, Getty, Clark and Wheeler1995), Southern California (Hagiwara Reference Hagiwara1997) and Sydney, Australia (Cox Reference Cox2006). The Midwestern US accent roughly represents a non-local ‘General American’, while the Californian data may be relevant as Kaplan's character in Camp attends Stanford University. The (adolescent) data for Sydney clearly function as a baseline D1 reference. Given the inter- and, especially, intra-speaker variability in formant values, it is not fruitful to formulate (normalised) D2 target values for F1 and F2, but the reference figures do give a clear general idea of how the speakers need to change their speech in order to sound more D2-like. For the five vowels in question, this involves the following changes:
Table 2. Reference formant values, in Hz, for five short vowels in two accents of American English (Hillenbrand et al. Reference Hillenbrand, Getty, Clark and Wheeler1995; Hagiwara Reference Hagiwara1997) and Australian English (Cox Reference Cox2006)


Figure 2. Reference formant values, in Hz, for five short vowels in two accents of American English (Hillenbrand et al. Reference Hillenbrand, Getty, Clark and Wheeler1995; Hagiwara Reference Hagiwara1997) and Australian English (Cox Reference Cox2006). Male speakers on the left, female speakers on the right
kit AmE kit is lower and further back than its AusE counterpart. The AmE realisation is similar to AusE dress.
dress Also dress is lower and further back in AmE than in AusE, but the lowering and backing required stops well short of AusE trap.
trap The changes necessary for trap are more complicated. Midwestern US trap is higher and more fronted than the AusE vowel, which is stereotypically thought of as raised, but the Californian vowel is further back and (for female speakers only) considerably lower. trap raising appears to be spreading from New England to other varieties of AmE (Clopper et al., Reference Clopper, Pisoni and de Jong2005); in California, however, trap is raised only before nasals, but is lowered and backed in all other contexts (Eckert Reference Eckert2008; Podesva Reference Podesva2011). In other words, the direction and complexity of the necessary change depend on the exact identity of the D2. Simultaneously, in AusE, the stereotypically high front vowels are currently lowering in a drag chain led by trap (Cox & Palethorpe Reference Cox and Palethorpe2008). There is some evidence, though inconclusive, that variables undergoing change in the D1 are more salient, and therefore easier to acquire in the D2 (Siegel Reference Siegel2010: 121).
strut The AmE strut vowel is raised compared to AusE, and is equivalent in height to AusE lot. The two American reference accents do not give clear information on whether strut is slightly further front or slightly further back than the AusE vowel.
lot AmE lot is lower and further front than in AusE, and can more or less be equated with AusE strut. (Although F3 is not taken into account in this study, the speakers would need to unround their lot vowel, suggesting an AmE lot target very similar to AusE strut.)
All these concern simple substitutions of a D1 realisation by a D2 realisation and, although the phonetic near-identity of some D2 phonemes with different D1 phonemes may be a complicating factor, there is little to suggest that the actors should be unsuccessful in producing the altered sounds. We may therefore expect a relatively high measure of success. This is different, however, when it comes to the distributional differences between Australian and American English, for which we unfortunately have rather patchy D2 performance data (see table 3).
Table 3. Lexical incidence of phonemes in five lexical sets in Australian and American English (based on Wells Reference Wells1982)

The first of these differences concerns the trap and bath lexical sets. These are distinguished in Australian English, with the exception of a subset of bath labelled dance by Wells (Reference Wells1982), which patterns with (and is coded here as) trap; American English does not distinguish the sets. As this change involves a merger for those with D1 Australian English, it is not expected that the actors will have difficulty accurately pronouncing the bath set. A possible complicating factor, the sameness in Australian English of bath and start, is unlikely to be problematic, as there is a clear orthographic cue <r> identifying the start words.
The second difference is more difficult to acquire, as it involves a redistribution of lexical sets across phonemes. In Australian English, lot and cloth use the same vowel, while thought is different; in American English, cloth is identical with thought while lot is different. In large areas of the United States and Canada, however, thought/cloth and lot are undergoing or have undergone a merger, so that all three are /ɑ/. From an acquisitional perspective, this is clearly the easier choice.
3.2 Results
The average measurements for the three speakers in both accents are given in tables 4, 5 and 6, visualised in figures 3, 4 and 5. The tables and figures allow us to determine what kinds of changes the speakers have made to their speech in their D2; the standard deviations (ellipses in the figures) are a measure of variability in production.Footnote 4 An overview of these types of changes is given in table 7.
Table 4. Mean first and second formant frequencies (in Hz, standard deviations in brackets) for Tom Green's performance in Australian and American English

Table 5. Mean first and second formant frequencies (in Hz, standard deviations in brackets) for Dena Kaplan's performance in Australian and American English

Table 6. Mean first and second formant frequencies (in Hz, standard deviations in brackets) for Tim Pocock's performance in Australian and American English


Figure 3. Mean first and second formant frequencies (in Hz) for Tom Green's performance in Australian and American English. Ellipses are drawn at one standard deviation from the means.
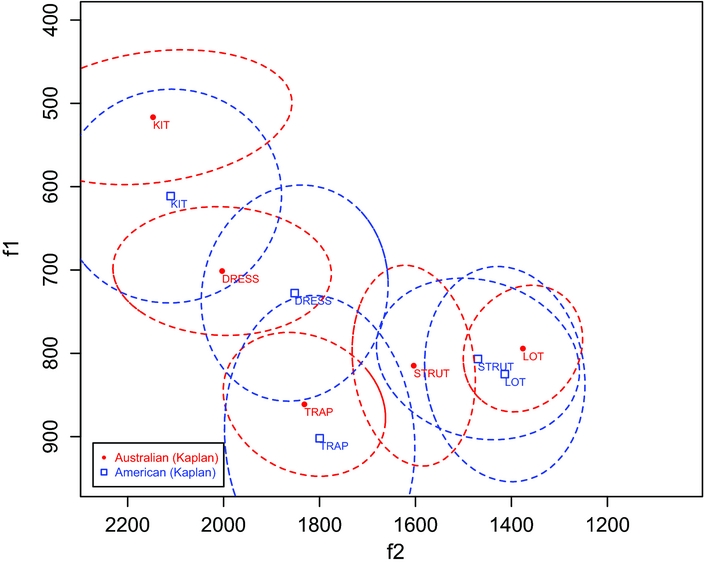
Figure 4. Mean first and second formant frequencies (in Hz) for Dena Kaplan's performance in Australian and American English. Ellipses are drawn at one standard deviation from the means.

Figure 5. Mean first and second formant frequencies (in Hz) for Tim Pocock's performance in Australian and American English. Ellipses are drawn at one standard deviation from the means.
Table 7. Overview of changes made to vowel pronunciation apparent from the results

All three speakers have changed all five vowels in the expected direction, and in that sense have done what is necessary for an AmE performance. The degrees of difference, however, differ between speakers. Green's mean formant values in the D2 remain relatively close to those in the D1, with the exception of lot. Kaplan makes much clearer changes, but is less stable in her AmE as the standard deviations for her D2 vowels are much larger than those for her D1 vowels. Pocock shows a more stable D2 that also visually is more clearly distinguished from his D1.
Figures 6, 7 and 8 allow us to examine the phonological changes the speakers have to apply in an American English accent, although some of the speakers have very few tokens for the relevant lexical sets and the conclusions are necessarily tentative. The first of the phonological changes is the (synchronic, acquisitional) merger of the trap and bath lexical sets, and (in the case of a Californian English target) the introduction of allophonic raising of /æ/ before nasals. These data are presented in the left panels of the relevant figures. It is clear that all three speakers have successfully merged the trap and bath sets, but evidence for the allophonic raising pattern is less clear. Kaplan's data cannot give evidence for the pattern, as all trap and bath tokens in her data were pre-nasal. Green appears to have an incipient nasal pattern: although the high and front realisations are always pre-nasal, not all pre-nasal /æ/ tokens are high and front. Pocock does show a clear nasal pattern, although he only employs the front–back dimension, and not the height dimension as well.

Figure 6. Tom Green's realisations of the bath and trap lexical sets (left) and the cloth, lot and thought lexical sets (right) in American English

Figure 7. Dena Kaplan's realisations of the bath and trap lexical sets (left) and the cloth, lot and thought lexical sets (right) in American English.

Figure 8. Tim Pocock's realisations of the bath and trap lexical sets (left) and the cloth, lot and thought lexical sets (right) in American English
The other phonological change concerns the lot, cloth and thought lexical sets, shown in the right panels of figures 6, 7 and 8. Here especially, low token counts obscure the picture somewhat. Green's American English appears to have the innovative three-way merger between these sets. Kaplan and Pocock's American English performances do so, too, but a bit less clearly. In Kaplan's data, the more fronted realisations are lot, perhaps showing the traditional American pattern. Pocock's data, on the other hand, show that if anything, thought may be a bit further back than the other two sets, which is more in line with his D1 Australian English pattern.
3.3 Discussion
These results suggest that the three actors differ in their success at performing in American English. Based on the direction of changes made and the relative size of standard deviations in the D2 compared to the D1, Pocock seems to be most successful of the three in his American English performance. While Green is consistent in his D2 speech, he has not changed much from his D1; Kaplan does clearly make the required changes, but her D2 is much less consistent. In terms of Bigham's accommodation types (table 7), the speakers show different patterns. Where Kaplan seems to rely predominantly on strategies resulting in expansion, Pocock uses a range of strategies that may ultimately allow for greater success. The accommodation types do not appear to pattern according to vowel category. We would need a much clearer idea of the range of variation in the target accent to be able to say what strategy would be the best choice. This would most likely be a different strategy for different vowels, and given inter-individual variation even in the D1, also for different speakers.
The expected difference in acquisition between phonetic and phonological changes is borne out by the data. The merger of trap and bath, expected to be easy to acquire, was indeed acquired without any problems, while the change in distribution of vowels over the lot, cloth and thought sets was acquired much more variably. The split of a phoneme, as is required with the nasal pattern in /æ/, is thought to be most difficult but is acquired with reasonable success, to the extent that the data allow us to investigate this.
4 Foreign accent rating
If the acoustic study shows moderately successful second-dialect performance by the three Australian actors, at least in the short vowel system, the next question is whether their performance is acceptably American for their predominantly American audience. To investigate this, a foreign accent rating (FAR) experiment was performed in which American native-speaker judges rated the actors’ Americanness.
4.1 Methods
The FAR followed the methodology presented in Schmid & Hopp (Reference Schmid and Hopp2014: 369–74). Six short (10–15 seconds) fragments of American-accented speech – two for each speaker – were selected as test items. The fragments had to show a relatively uninterrupted stretch of speech by a single speaker (short interruptions by others were removed from the audio file) and a minimum of background noise. The fragments were not controlled for the presence of the five vowels investigated in the acoustic study. Six similarly selected fragments of actors that are native speakers of American English (table 8) functioned as controls. Focusing on American-accented speech and excluding Australian-accented speech from the FAR resulted in a relatively narrow range of accents across test and control items, so that the results would not be distorted by low ratings for clearly non-American accents. This was done as the focus in this article is on the accuracy and acceptability of these performed D2s qua second-dialect acquisition. In the television series, by contrast, a single actor continued to use his (broad) Australian English D1. This had the effect that the other actors’ D2 American English are assessed as more acceptably American, as they are explicitly contrasted with an accent that is very clearly not American. This suggestion to the audience is even stronger as the Australian-speaking character was the (somewhat unsympathetic) leader of a competing summer camp, meaning that Australian English becomes explicitly ‘othered’ vis-à-vis even imperfect American English accents.
Table 8. Distractor items in the foreign accent rating

The fragments were presented in a fixed order in a single audio file, with each fragment being introduced by a number spoken by a female voice in an American English accent and a five-second pause between each fragment. The instruction to survey participants explicitly mentioned variation in accents of English and named American English as an identifying characteristic of most Americans. Exactly what constitutes an American English accent, however, was left to the participants to decide. For each fragment, raters were asked to answer two multiple-choice questions:
• Do you think Speaker [. . .] is American?
– yes
– no
• How certain are you of your answer?
– very certain
– reasonably certain
– not certain at all
The answers to these questions were converted into a 6-point Likert scale, where 1 is ‘definitely not American’ and 6 is ‘definitely American’. The advantage of this method over direct judgements on a Likert scale is that it forces judges to make a decision instead of choosing one of the middle options on the scale (see Schmid et al. Reference Schmid, Gilbers and Nota2014: 374).
As Hodson (Reference Hodson2014: 231) suggests, knowledge of actor background may influence judgements of their performed accents. The question as it was phrased in the FAR does suggest that some speakers may not be American, but offer no further information. If the task was to identify the Australians speaking a second-dialect version of American English, the judgements might have been different.
Respondents were also asked about their own linguistic backgrounds, in particular about their exposure to varieties other than American English, and whether they could identify the speakers in the judgement task.
4.2 Results
The FAR was distributed via social media in November 2014 using the ‘friend-of-a-friend’ approach. After removing incomplete responses, responses from judges who spent a considerable time outside the USA, and responses from judges who indicated that they recognised one of the speakers (even if they identified the speaker incorrectly), a total of 154 responses remained. The means of their responses, with standard deviations, are given in table 9.
Table 9. Mean scores with standard deviations in the Foreign Accent Rating
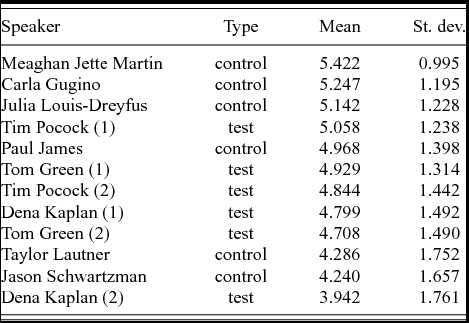
It is immediately obvious from the table that the ratings for the Australian test items were not as high as those for the American controls. This is not a hard and fast rule, however: it was especially the female Americans (D1) that received high ratings, while two of the male Americans (D1) scored a good deal lower than most of the Australian (D2) test items. The second fragment from Kaplan was rated especially poorly. With the exclusion of that fragment, however, the test items from the Australian actors had mean scores between 4.708 and 5.058, meaning that they were classified as ‘American’ with reasonable certainty. It is also possible to establish a hierarchy of relative success: Pocock performs best, followed by Green and Kaplan.
Judges were more in agreement about speakers who did sound American than about speakers who sounded less so: the standard deviations for the higher scores are much smaller than those for the lower scores. This negative correlation (ρ = –0.963) between means and standard deviations is highly significant (p = 4.9 × 10–7), but standard deviations are likely to be smaller at the extremes of the scale than in the middle.
4.3 Discussion
Two findings stand out from the FAR. Firstly, the Australian speakers of American English were found, on average, to sound less American than the American speakers. A FAR is a holistic rating, and this was not a carefully controlled matched-guise experiment. It is not clear what features, if any, respondents used to come to their assessment of the Americanness of the clips. In this sense, a FAR is a black box similar to the responsive aspect of accommodation (Coupland Reference Coupland1984: 50–1). Hayes-Harb & Hacking (Reference Hayes-Harb and Hacking2015) show on the basis of interviews with accent judges that although they use phonetic information (such as segments, rhythm, stress, fluency and intonation) in their judgements, they also comment on imagined social types with no explicit link to phonetic information. While the hierarchy of the actors’ judged Americanness (Pocock, Green, Kaplan) matches that of their acoustic accuracy, it is not certain that the accent judges attended to any or all of the short vowels from the acoustic study.Footnote 5
The other finding is that the ratings for the American speaker controls are very clearly gendered.Footnote 6 Earlier work on American English suggests female voices are perceived as more standard (northern) than an equivalent male voice (Plichta & Preston Reference Plichta and Preston2005: 121, 123), but while this might explain why the female controls are rated as ‘better’ than the male controls, it does not explain why Pocock and Green are rated higher than Kaplan. Alternatively, what it means to ‘sound American’ may differ for men and women; if that is the case, Pocock and Green are judged much more similar to the male target(s) than Kaplan is to the female target(s), and the hierarchy of success is even more extreme.
5 General discussion and conclusion
This article has presented an analysis of second-dialect performance by three Australian actors. It was suggested that this analysis can give a realistic impression of what is possible in second-dialect acquisition, as this type of performance mitigates a number of factors that may stand in the way of acquisition: issues of access, analysis and motivation. The acoustic analysis of five short vowels shows that the actors changed their mean vowel productions in the required direction, but resulting in different patterns of variation. Although there is no quantifiable measure of success in the absence of a clearly defined target, the actors appear reasonably successful at second-dialect performance at the phonetic and, to perhaps a slightly lesser degree, at the phonological level. A subjective, holistic assessment of their success in a foreign-accent rating did suggest the actors were found out as non-Americans – or at least as not stereotypically American. Some of the male American speakers used as controls, however, scored even lower on the FAR, and it is uncertain what the judges considered to be an American accent and whether (some of) the features they responded to were the same as those investigated in the acoustic study.
All in all, this study suggests that, at least on the surface, second-dialect performance is similar to second-dialect acquisition in terms of the outcomes of changes made to vowel pronunciation. Given the practical challenges related to longitudinal phonetic studies of second-dialect acquisition — issues of access and being able to control for factors influencing the process — performance may be a very useful proxy for studies of the limits and the mechanisms of accent change. Second-dialect performance is frequent, controlled, and in any case the performances are mediated and therefore much more readily available than data from naturalistic SDA.
The study raises two other points for further research into accuracy and acceptability of second-dialect acquisition and performance. Firstly, acoustic accuracy on a range of features may not be a reliable measure of success, because these features may not be salient or meaningful for listeners’ judgements. Secondly, it is not evident in what way detailed (acoustic) and holistic (acceptability judgement) measurements of the degree of an acquirer's or performer's success are related. In this study, discrepancies between both measures are probably for a large part due to subjective judges attending to a range of different accent features, which may or may not include features from the acoustic study. While many studies of second-dialect acquisition (Siegel Reference Siegel2010) have focused on acoustic accuracy, subjective success is perhaps more important in real-life acquisition as the goal there is highly motivated by a desire for acceptance by the community. It therefore seems prudent to include both types of measures of success in future studies of second-dialect acquisition and performance.

















