


1 Introduction
The Parallel Encoding and Target Approximation (PENTA) model of speech prosody was proposed as an attempt to improve the understanding of prosody by putting emphasis on two aspects of speech prosody that had not received sufficient attention, namely, communicative functions and articulatory mechanisms (Xu Reference Xu2005). The goal was to develop a framework that would explain how speech prosody works as a system of communication. More specifically, the framework to be developed should be able to describe how prosody can enable a rich repertoire of communicative functions to be simultaneously realised by an articulatory system, so that all the details of the surface prosody can be traced back to their proper sources. This was an ambitious goal, which could not be achieved in one fell swoop. Much subsequent work has therefore been done in terms of empirical testing, theoretical elaboration and computational modelling (Liu & Xu Reference Liu and Xu2005, Prom-on et al. Reference Prom-on, Xu and Thipakorn2009, Wang & Xu Reference Wang and Xu2011, Xu & Liu Reference Xu, Liu and Niebuhr2012, Liu et al. Reference Liu, Xu, Prom-on and Yu2013, Xu & Prom-on Reference Xu and Prom-on2014).
PENTA has received much scrutiny since its proposal, and one of the most comprehensive critiques is offered by Arvaniti & Ladd (Reference Arvaniti and Ladd2009). Arvaniti & Ladd contrast PENTA with the autosegmental-metrical theory of prosody (Pierrehumbert Reference Pierrehumbert1980, Beckman & Pierrehumbert Reference Beckman and Pierrehumbert1986, Pierrehumbert & Beckman Reference Pierrehumbert and Beckman1988, Gussenhoven Reference Gussenhoven2004, Ladd Reference Ladd2008), and argue that it is inadequate to explain the prosody of Greek wh-questions examined in their study. Such a direct theoretical comparison is welcome, as it provides an opportunity to explain PENTA in a way that is more directly relevant to phonology, as will be done in this paper. We will try to achieve this by offering not only an overview of the model, but also an illustration of how it can be applied in studying the prosody of specific languages. Along the way, we will also provide responses to Arvaniti & Ladd's specific criticisms. Finally, we will offer hypothetical interpretations of the prosody of Greek wh-questions based on data presented by Arvaniti & Ladd, with the caveat that the validity of all of our interpretations awaits rigorous empirical testing in future studies.
2 An outline of PENTA
2.1 Motivation and development
One of the greatest difficulties in studying prosody is what can be referred to as ‘the lack of reference problem’ (Pierrehumbert Reference Pierrehumbert1980, Reference Pierrehumbert and Horne2000, Xu Reference Xu2011a). That is, due to the general absence of orthographic representations of prosody other than punctuation, which itself may be due to a general difficulty in judging prosodic meanings by native speakers, there is little to fall back on when it comes to identifying prosodic units, whether in terms of their temporal location, scope, phonetic property or communicative function. For example, for the pitch track shown in Fig. 1, it is hard to determine what the relevant prosodic units are – F0 peaks and valleys, turning points, size of the F0 movements, temporal scope of a continuous movement, all of these, or none? The lack of reference problem makes it difficult to decide whether any of them should or should not be considered as the relevant units, and this difficulty lies at the heart of most of the theoretical disputes in speech prosody.

Figure 1 F0 track of You're going to Bloomingdales with Alan by a female American English speaker, with focus on Bloomingdales. Data from Liu et al. (2013).
The strategy adopted by autosegmental-metrical theory, as best explained by Pierrehumbert (Reference Pierrehumbert1980: 59), is to first focus on developing a formal structure of prosody by identifying which elements appear categorically distinct from each other in perception or in production. The result of such a form-first approach is the development of the autosegmental-metrical framework of prosody, which encompasses a rich inventory of phonological primitives that form the intonation systems of English (Pierrehumbert Reference Pierrehumbert1980, Ladd Reference Ladd2008), as well as many other languages (see the papers in Jun Reference Jun2005). Overall, although there are variations in theoretical details and methodological approaches among studies in the autosegmental-metrical tradition, the central question in this approach remains the same (Pierrehumbert Reference Pierrehumbert1980, Gussenhoven Reference Gussenhoven2004, Ladd Reference Ladd2008): what does the phonology of speech prosody look like?
The development of PENTA followed a different approach. It started with another question: how does prosody work as a communication system? Answering this question entails finding answers to two other essential questions: (i) what are the meanings that are conveyed by prosody?, and (ii) how does prosody encode these meanings in a way that allows easy decoding? In our search for answers, we took the bootstrapping strategy of always keeping one side of the function–form link relatively unambiguous while exploring the other side. In the first step, lexical tones, whose function and identity are relatively unambiguous, were experimentally examined to establish the basic mechanisms of tone production in connected speech, as summarised in Xu (Reference Xu2005, Reference Xu2011a). These studies established that even syllable-bound lexical tones do not show stable F0 properties in connected speech, but exhibit extensive surface variability according to tonal context (contrary to Arvaniti & Ladd's Reference Arvaniti and Ladd2009: 65 claim that PENTA assumes stable syllable-by-syllable specification of F0 contours for tones). It was further established that articulatory inertia and tone–syllable synchrony can account for a large portion of contextual tonal variability (Xu Reference Xu2005, Xu & Wang Reference Xu and Wang2001). Based on findings from tone research, non-lexical prosodic functions that could be experimentally controlled were then examined, with the tonally established articulatory mechanisms as the basis for separating F0 properties that are articulatorily obligatory and those that are functionally specified (Xu Reference Xu2005, 2011a). To enhance the robustness of this articulatory-functional approach, computational modelling tools were also developed as an additional, more rigorous means of hypothesis testing (Prom-on et al. Reference Prom-on, Xu and Thipakorn2009, Xu & Prom-on Reference Xu and Prom-on2014).
Thus the PENTA approach is based on two key positions. The first is that prosodic contrasts are defined functionally, rather than by formal categories. This position touches on the fundamental issue of the role of phonology as a level of abstract representation in speech prosody. In the PENTA model, representational units are contrastive not because they are distinct from each other, but because they serve to distinguish specific functional categories (or to represent functional dimensions if they are not categorical). While this is a standard principle in phonology, the special challenge of prosody, as mentioned above, has motivated an insistence on the primacy of function in the function–form relation, especially in case of uncertainty. For example, the long-standing autosegmental-metrical debate over whether LH* and H* are distinct phonological categories in English prosody (Ladd Reference Ladd2008) is a non-issue in the PENTA model, since there is thus far no consensus on what functions the two tone types serve to contrast. The second position is that PENTA considers articulatory mechanisms as essential, and incorporates them into the core of its theoretical framework. In this way a large portion of the surface prosodic patterns, e.g. in terms of alignment, scaling, etc., is attributed to obligatory articulatory processes rather than to phonology.
One thing that PENTA does share with autosegmental-metrical theory is the full recognition of arbitrary rules in prosody, just as in the segmental aspect of speech. In PENTA, this recognition, which is part of the basic assumption behind the encoding schemes, is motivated (Xu Reference Xu2005) by the well-known phenomenon of tone sandhi (Chen Reference Chen2000). That is, the surface forms of lexical tones often vary in ways that are quite arbitrary and language-specific, and cannot be explained by clear articulatory mechanisms. PENTA assumes that similar arbitrary rules also exist in prosody; on the basis of this assumption a number of target-assignment rules which are dependent on factors like the stress pattern of words, focus and modality have been recognised for American English (Liu et al. Reference Liu, Xu, Prom-on and Yu2013, Xu & Xu Reference Xu and Xu2005). Some of these will be illustrated in §3.2.
2.2 The conceptual framework
Figure 2 is a schematic diagram of PENTA in its most general form, i.e. representing not only prosody, but also other aspects of speech (Xu & Liu Reference Xu, Liu and Niebuhr2012). The leftmost block in the upper panel represents communicative functions that are conveyed by speech. The functions are arranged in a stack to indicate that they are parallel to one another, i.e. with no hierarchical relations, hence the key word parallel in the name of the model. The second block represents the encoding schemes associated with the communicative functions, i.e. the means to encode functional contrasts, whose schematisation here makes it clear that communicative functions do not directly control surface acoustics; rather, the two are linked through specific encoding schemes. It has always been assumed in the PENTA model, though not always made fully explicit in published work, that some of the encoding schemes are highly stylised and language-specific, while others are more gradient and universal. The third block in Fig. 2 represents the target approximation (TA) parameters that are linked to the encoding schemes. These parameters in turn control the TA process represented by the fourth block. It is this articulatory process that directly generates surface acoustics, including F0, as represented by the fourth block.Footnote 1 The TA model, as depicted in the lower panel, assumes that each syllable is assigned an underlying target that has not only a height (or position), but also a slope specification. The surface F0 is the result of asymptotic approximation of the target in full synchrony with the syllable. At the boundary between two adjacent syllables, the final articulatory state of the first syllable is transferred to the second syllable. Such transfer often results in a delay of the apparent alignment of an F0 turning point, as shown in the lower panel.
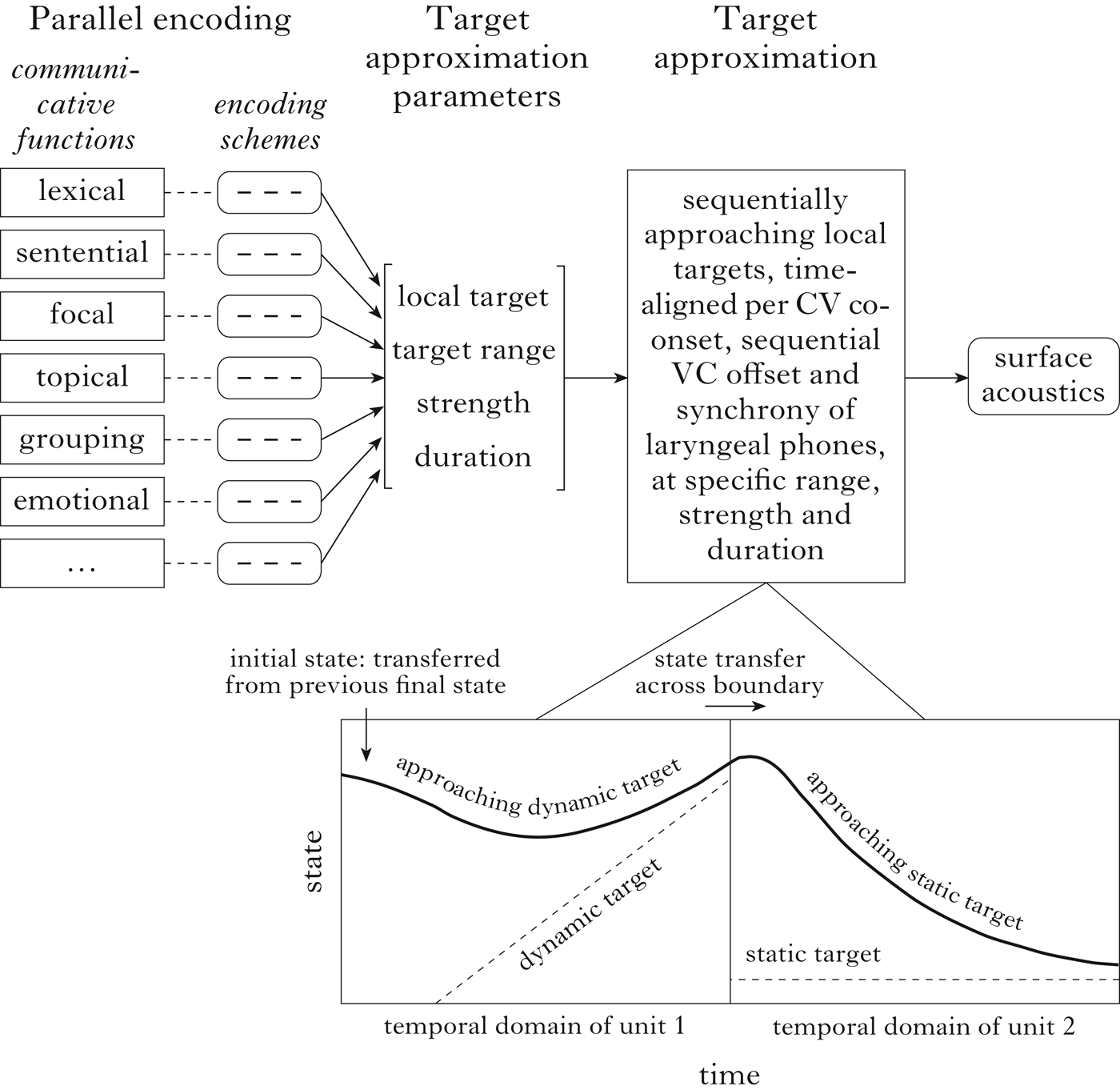
Figure 2 Upper panel: a schematic sketch of the PENTA model. Lower panel: the target-approximation component, which is an articulation process (Xu & Wang 2001, Xu 2005, Xu & Liu 2012).
There are many implications of PENTA that may not be immediately obvious from the descriptions given above, and this has often led to confusion about the model. It will thus be helpful to set out some of the most critical implications of PENTA, first in the brief list below, followed by further elaborations in the subsequent sections.
(i) Syllable-sized pitch targets are the prosodic primitives of PENTA, and as such bear the closest resemblance to tones in autosegmental-metrical theory. They differ from the autosegmental-metrical tones in that their link to surface F0 trajectories is via syllable-synchronised sequential target approximation. In contrast, linear or sagging interpolation between specified targets proposed by Pierrehumbert (Reference Pierrehumbert1980) is the mechanism assumed in autosegmental-metrical theory, as is made clear in Arvaniti & Ladd. In the PENTA model, as shown in Fig. 2, all targets are virtual, because they do not directly correspond to observable features such as turning points, elbows or plateaus.
(ii) There are no specifications for the temporal alignment of turning points or elbows. Rather, all observed alignments are assumed to be the result of syllable-synchronised realisation of underlying pitch targets.
(iii) For each syllable, a unique target is assigned as a result of the interaction of all the communicative functions involved (as indicated in Fig. 2 by the single arrow between the target approximation parameters block and the target approximation block vs. the multiple arrows between the parallel encoding block and the target approximation parameters block). Thus the encoding schemes of all the functions involved jointly determine a unique target of each syllable for a particular phonetic dimension. This integrated target therefore carries information about all the encoded functions.Footnote 2
(iv) In contrast to its explicit assumption about articulatory mechanisms, PENTA does not explicitly stipulate a predefined inventory of communicative functions or their encoding schemes for any language. Rather, it assumes that encoding schemes, whether language-specific or universal, or categorical or gradient, have to be established experimentally by directly controlling communicative functions.
(v) Despite the assumption of a direct link between encoding schemes and communicative functions, PENTA does not directly link communicative functions to surface prosody. Rather, it assumes that communicative functions are linked to surface prosody both through articulatory mechanisms that are universal and through encoding schemes that are either universal or language-specific.
(vi) PENTA has no phonetic implementation rules that are not based on explicit articulatory mechanisms. As will be discussed in §2.3, some of the phonetic implementation rules in autosegmental-metrical theory can be reinterpreted from the PENTA perspective as being morphophonological rather than phonetic. As such, they are treated as properties of relevant encoding schemes.
To summarise, the only obligatory melodic primitives in PENTA are the syllable-sized pitch targets. The phonetic characteristics of these targets include height, slope and rate of approximation. These characteristics can be used to describe their phonetic types, such as targets that are high or low, dynamic or static (having flat or non-flat slopes), or strong or weak (having a high or low rate of approximation). As a result, although PENTA does not stipulate an inventory of predefined phonological categories, once a particular function in a language is identified, it is possible to discuss the correspondence of the PENTA-based targets with categories predefined in other theories, such as H, H*, L, L* in autosegmental-metrical theory.
2.3 Recent new conceptual developments
There has recently been a further development in the conceptualisation of the encoding schemes in PENTA (Liu et al. Reference Liu, Xu, Prom-on and Yu2013). This was driven by the recognition that some of the encoding schemes of prosodic functions bear a strong resemblance to lexical morphemes, in three critical ways. First, like lexical morphemes, each of these encoding schemes consists of multiple prosodic components, which are meaningless by themselves, but act jointly to mark both intra- and inter-functional contrasts. Second, similar to lexical morphemes, an encoding scheme for a prosodic function may have allomorph-like variants, whose occurrence is conditioned by factors like location in sentence and interaction with other prosodic functions. Finally, similarly to lexical morphemes, these encoding schemes are language-specific, and their patterns may have historical origins.Footnote 3 These prosodic encoding schemes differ from lexical morphemes in that they contrast prosodic functions that carry postlexical meanings. It is therefore appropriate to refer to them collectively as prosodic morphemes.
One of the clearest examples of a prosodic morpheme is prosodic focus, whose function is to highlight one speech unit against the rest of the sentence. Empirical studies have shown that focus is realised not only with specific pitch patterns, but also with specific patterns of duration, intensity and even voice quality (Cooper et al. Reference Cooper, Eady and Mueller1985, Heldner Reference Heldner2003, de Jong Reference de Jong2004). Also, in many languages, focus is realised not only with prosodic patterns of the focused unit itself, but also with post-focus compression of pitch and intensity (see Xu et al. Reference Xu, Chen and Wang2012 for a review). Furthermore, post-focus compression has recently been found to be absent in many other languages (Xu et al. Reference Xu, Chen and Wang2012). It has been hypothesised that post-focus compression as a special way of encoding focus is a feature inherited from a proto-language (Xu Reference Xu, Lee and Zee2011b). Thus the encoding scheme of focus in languages like Mandarin and English are multi-componential, language-specific, and probably with historical etymologies – very similar to lexical morphemes.
Another example can be found in American English, where the underlying pitch target of a stressed syllable varies depending on whether the syllable is word-final or non-final, whether the word is focused and whether the sentence is a statement or yes-no question (Liu et al. Reference Liu, Xu, Prom-on and Yu2013), as can be seen in Fig. 3. Figure 3 also shows that the F0 of the post-focus syllables varies markedly, depending on whether the sentence is a statement or question. In particular, post-focus F0 in a question is raised well above the reference level, i.e. the pre-focus F0. This pattern, however, is absent in Mandarin (Liu et al. Reference Liu, Xu, Prom-on and Yu2013), as can be seen in Fig. 4. Such a cross-linguistic typological difference is again similar to the behaviour of lexical morphemes, although more research is needed to further explore this phenomenon.
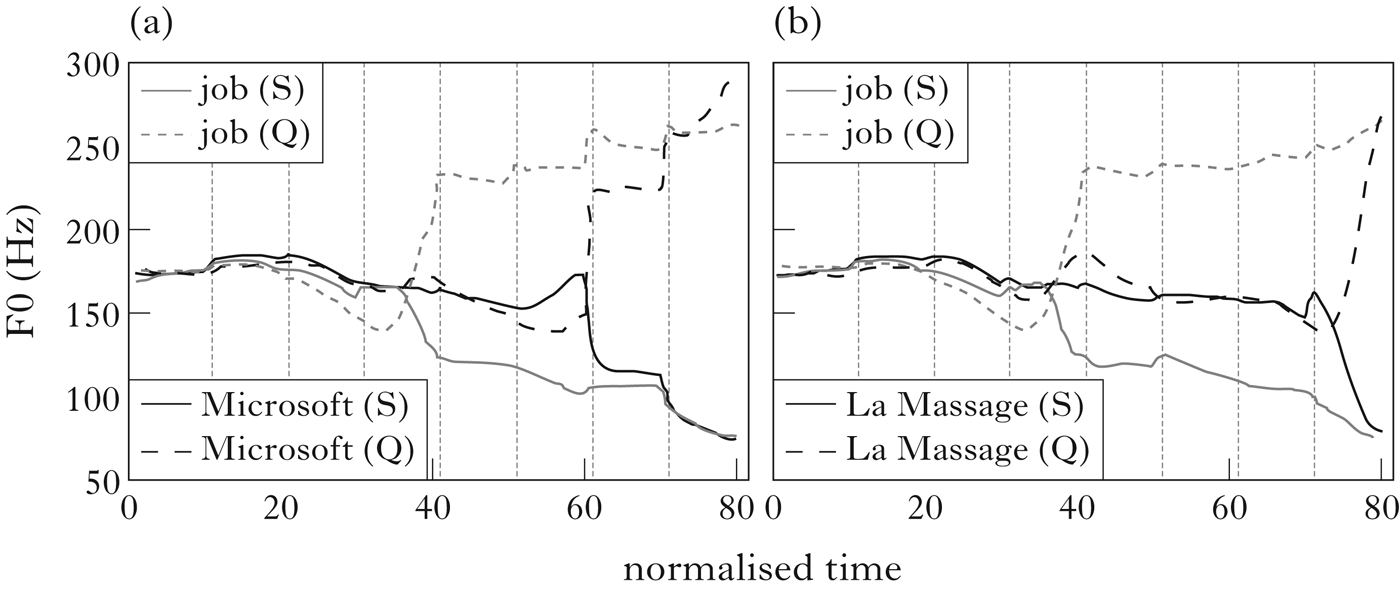
Figure 3 Mean F0 contours of focused words in statements (S) and questions (Q) of two American English sentences: (a) You want a job with Microsoft; (b) You want a job with La Massage. Data from Liu et al. (2013).

Figure 4 Mean F0 contours of the Mandarin sentence Zhāng Wēi dānxīn Xiāo Yīng kāichē fāyūn ‘Zhang Wei is concerned that Xiao Ying may get dizzy when driving’, spoken as either a statement (black lines; S) or a question (grey lines; Q). H denotes High tone. In (a), focus is on the sentence-initial word (solid lines) or there is no narrow focus (dashed lines). In (b), focus is either sentence-medial (solid lines) or sentence-final (dashed lines). Adapted from Liu & Xu (2005).
The notion of prosodic morpheme is an alternative to the tonal morpheme proposed by Pierrehumbert & Hirschberg (Reference Pierrehumbert, Hirschberg, Cohen, Morgan and Pollack1990). As discussed in detail in Liu et al. (Reference Liu, Xu, Prom-on and Yu2013), many of the morpheme-like meanings proposed by Pierrehumbert & Hirschberg for the phonological intonational components are similar to those associated with prosodic functions like focus and modality. But the multi-componential coding of the prosodic functions demonstrated by empirical studies show that it is these functions, rather than the pitch accents, phrase accents and boundary tones, that bear the most resemblance to lexical morphemes. Furthermore, some proposed phonetic implementation rules in autosegmental-metrical theory (Pierrehumbert Reference Pierrehumbert1980, Pierrehumbert & Hirschberg Reference Pierrehumbert, Hirschberg, Cohen, Morgan and Pollack1990) are part of the morpheme-like characteristics of focus and modality. For example, the upstep rule in English, which is said to raise the portion of F0 corresponding to a high boundary tone H% relative to the preceding H- phrase accent, is shown to be part of a continuous upshift of post-focus pitch range to mark a question (Fig. 3). Thus this extra raising is morphophonological, i.e. being part of a prosodic morpheme, rather than being a phonetic implementation rule.
2.4 A quantitative realisation
Like most other theoretical intonation models (O'Connor & Arnold Reference O'Connor and Arnold1973, Pierrehumbert Reference Pierrehumbert1980, Bolinger Reference Bolinger1986, 't Hart et al. Reference Hart, Collier and Cohen1990), PENTA was qualitative at the time of its proposal (Xu Reference Xu2005). As such, it could be employed in qualitative description and explanation of speech data, hypothesis testing and making qualitative predictions, but could not be used to make numerical predictions about intonation. An early effort was made to quantify the TA model (Xu et al. Reference Xu, Xu, Luo, Ohala, Hasegawa, Ohala, Granville and Bailey1999), followed by a much improved implementation in the form of the quantitative target approximation (qTA) model, which also enabled full testing of PENTA (Prom-on et al. Reference Prom-on, Xu and Thipakorn2009). The development of qTA followed a number of principles. The first was that there should be as few free parameters as possible, and every free parameter should be meaningful, i.e. usable by one or more encoding schemes. The second principle was that all the critical components of TA described in §2.2 should be quantitatively implemented, so as to faithfully realise the theoretical model. The third principle was that the model parameters should be learnable from real speech data, so as to enable full-fledged numerical testing of the predictive power of the theoretical model.
In qTA, the F0 of each syllable is represented by a third-order critically damped linear system driven by a pitch target, as shown in (1), where the first term represents the pitch target as a straight line with slope m and height b. The second term represents the natural response of the system, in which the transient coefficients, c1, c2 and c3, are calculated based on the initial F0 dynamic state and pitch target of the current syllable. As such they are not free parameters. Parameter λ represents the strength of the F0 movement toward the target. qTA realises the state transfer between adjacent syllables by taking the final F0 state of the preceding syllable in terms of its final F0, f0(0), velocity, f0′(0), and acceleration, f0″(0), as the initial F0 dynamic state of the current syllable.
-
(1)

With this initial state the three transient coefficients are computed with the formulas in (2).
-
(2)

Thus, for each syllable, qTA has only three free parameters: m, b and λ. m and b specify the form of the pitch target, with positive and negative values of m indicating rising and falling targets, and positive and negative values of b indicating raised and lowered pitch targets relative to the speaker's average F0. λ indicates how rapidly a pitch target is approached, with higher values representing faster target approximation. qTA therefore provides a faithful numerical representation of all the critical aspects of the theoretical TA model.
The development of the TA model and its qTA implementation were inspired by empirical findings about tonal dynamics (Xu & Wang Reference Xu and Wang2001, Prom-on et al. Reference Prom-on, Xu and Thipakorn2009), and were independent of other models, although similarities to a number of existing quantitative models became clear post facto. Despite the similarities, however, at least three key features remain unique to qTA on close examination: (i) unitary dynamic targets (which are different from contour targets, as in the Stem-ML (Kochanski & Shih Reference Kochanski and Shih2003) and SFC (Bailly & Holm Reference Bailly and Holm2005) models), (ii) unidirectional sequential target approximation, i.e. no overlap of movements, as in the task-dynamic model (Saltzman & Munhall Reference Saltzman and Munhall1989), or return phase in a movement, as in the Fujisaki model (e.g. Fujisaki Reference Fujisaki and MacNeilage1983), (iii) high-order state transfer across target approximation movements, a feature not found in any other model except VocalTractLab, which adopts the same idea and makes the transfer order even higher (Birkholz et al. Reference Birkholz, Kroger and Neuschaefer-Rube2011).
2.5 Why is there a pitch target for every syllable?
One of the most questioned aspects of PENTA is its assumption of a pitch-target specification for each syllable in any language. This might appear to be an overgeneralisation from a tone language, and gives the impression of overfitting for languages that are not lexically tonal. In English and Greek, for example, many syllables appear unspecified for pitch because of their high F0 variability, absence of prominent peaks or valleys, and lack of stress. It therefore seems natural to assume, as does autosegmental-metrical theory, that ‘not every syllable has to have a specification for pitch’ (Arvaniti & Ladd Reference Arvaniti and Ladd2009: 48). Similar ‘sparse tonal specification’ assumptions can be found in other models as well (e.g. Fujisaki Reference Fujisaki and MacNeilage1983, Hirst Reference Hirst2005).
PENTA's imperative for pitch target for each syllable comes from its core assumption about speech articulation, as represented by the TA model shown in Fig. 2. That is, the F0 contour of every syllable comes from a single mechanism: articulatory approximation of an underlying pitch target in synchrony with the syllable. Thus there is no other way of generating an F0 contour for a syllable than assigning it an underlying pitch target. It is possible, however, to allow a single pitch target to be assigned to a string of unstressed syllables, as in the Fujisaki model. There are two reasons why we choose not to do so. The first is our assumption that the syllable, as a basic coarticulatory unit, is produced with all its underlying targets fully specified, whether consonantal, vocalic or tonal, and the process of articulation is to realise all of them simultaneously through target approximation within a time structure provided by the syllable (Xu & Liu Reference Xu and Liu2006, 2012). In other words, because all the targets, including the pitch target, have to be articulated in coordination at the syllable level, it is impossible for surface F0 contours to be generated separately and then added to the syllable. The second reason is that there is evidence, as will be discussed later, that not only stressed syllables but also unstressed syllables are assigned function-based contrastive pitch targets. For example, Xu & Xu (Reference Xu and Xu2005) found that when an initial-stressed word in English was focused, any unstressed syllables were assigned post-focus targets, i.e. with actively lowered pitch. But an unstressed syllable is also assigned a low strength, which is consistent with its weak stress status. As found in both acoustic analysis (Xu & Xu Reference Xu and Xu2005, Chen & Xu Reference Chen and Xu2006) and computational modelling (Liu et al. Reference Liu, Xu, Prom-on and Yu2013, Xu & Prom-on Reference Xu and Prom-on2014), such low strength can account for the high variability (and hence an apparent lack of target) of the pitch of the unstressed syllables in English and the neutral tone in Mandarin. Also, as will be shown later, similar differential strength assignments can, at least hypothetically, account for the alignment patterns in Greek wh-questions reported by Arvaniti & Ladd.
As further support, there is evidence that computational models with F0 specifications for every syllable generate synthetic prosody with better numerical and perceptual quality than those that have non-syllabic pitch specifications (Sun Reference Sun2002, Raidt et al. Reference Raidt, Bailly, Holm, Mixdorff, Bel and Marlien2004). Sun (Reference Sun2002), in particular, found that the three-target model (Black & Hunt Reference Black and Hunt1996), which simply uses three F0 points for each syllable, generated better synthetic prosody than did the Tilt model (Taylor Reference Taylor2000), which uses a sophisticated algorithm to represent the detailed shape of F0 peaks, when both models were trained on the same corpus.
Finally, in terms of economy of representation, the assumption of one target per syllable may not be as uneconomical as it appears. This is because, although each syllable needs to be assigned a target, the target can be the same for all syllables with the same functional status in terms of lexical tone, lexical stress, focus, modality (i.e. question vs. statement), boundary marking, etc. Such economy of representation is helped by PENTA's assumption of full synchrony of pitch targets with the syllable, which eliminates the need for parameters that represent the temporal alignment of onset and offset of prosodic units relative to segments, as is obligatory in models that assume flexible timing (Pierrehumbert Reference Pierrehumbert1981, Fujisaki Reference Fujisaki and MacNeilage1983).Footnote 4 As will be shown in greater detail in §3, only a small number of target parameters are needed to represent lexical tone, lexical stress, focus and modality in English, Mandarin and Thai. With these parameters, the intonation of all utterances in the corpora of the three languages was predictively synthesised with high accuracy in terms of root mean square errors and correlations when compared to the natural F0 contours (Prom-on et al. Reference Prom-on, Xu and Thipakorn2009, Prom-on & Xu Reference Prom-on and Xu2012).
3 Encoding schemes and their parametric representations
The above outline of PENTA, though more detailed than in previous publications, still leaves some ambiguities about the model, especially in terms of the nature of the encoding scheme and its relation to phonological representation. For further clarification, we would like to start by reiterating the core tenet of PENTA, mentioned at the beginning of §1, which is to develop a model that can explain exactly how speech works as a communication system. Based on this, we need to understand not only how meanings are encoded, but also how the coding is done in production and perception, how it can be learned in acquisition and how it may change over time. In other words, we need to know how this system operates. From an operational perspective, encoding schemes are the link between the meanings to be conveyed and the articulatory processes with which they are represented, in a way that allows effective transmission to the listener. A major task in the PENTA approach is therefore to identify the encoding schemes of various communicative functions. Empirical studies following this approach have shown that many meanings are conveyed by morpheme-like encoding schemes, as mentioned earlier. But some other meanings, e.g. emotion, attitude, etc., are conveyed by encoding schemes that are less stylistic, more universal, and likely shared with other animals (Xu, Kelly & Smillie Reference Xu, Kelly, Smillie, Hancil and Hirst2013, Xu, Lee et al. Reference Xu, Lee, Wu, Liu and Birkholz2013). The notion of encoding scheme therefore covers both types of meanings.
The assumption that encoding schemes need to be empirically discovered means that, in principle, the repertoire of encoding schemes in PENTA is an open set. But there are also clear constraints that significantly limit the size of the repertoire. These may come from very diverse sources, however. One major source is articulatory mechanisms, some of which are built into PENTA. For example, articulatory inertia makes it impossible for F0 movements to go beyond the maximum speed of pitch change, which would exclude pitch targets whose slope is too steep. Also, syllable-synchronised target approximation means that the timing of underlying targets relative to the syllable is largely fixed. Diachronic changes are another source of constraints. For example, the cross-linguistic distribution of post-focus compression found in recent research, as discussed in §2.3, has led to the Nostratic origin of post-focus compression hypothesis, which makes strong predictions about the existence of post-focus compression in all languages (Xu Reference Xu, Lee and Zee2011b). Finally, findings about emotional expressions in speech have pointed to the bio-informational principles of vocal coding that humans presumably share with other animals (Xu, Kelly & Smillie Reference Xu, Kelly, Smillie, Hancil and Hirst2013, Xu, Lee et al. Reference Xu, Lee, Wu, Liu and Birkholz2013). This again offers strong predictions about emotion-related encoding schemes. Given the diversity of the sources of constraint, PENTA is a framework that groups together mechanisms that are independent of one another, but treats all of them as indispensable parts of the speech-communication process.
More importantly, the recognition of the articulatory mechanisms has also shed new light on the issue of mental representation of prosody. Given the basic tenet of the PENTA approach as mentioned above, it is imperative that the assumed mental representation is operational. This means, first, that the representation should be sufficiently abstract so as not to require too much memory space. Second, it also needs to be able to account for fully continuous surface forms, leaving as few details unexplained as possible. Third, it should allow full gradience, so as to adequately represent individual and dialectal variation. Finally, it needs to be learnable with testable computational algorithms. The solution found in the PENTA approach, as a result mainly of the efforts to develop a computational realisation of the theoretical model, is a parametric representation in the form of underlying target, as opposed to symbolic representations that directly correspond to phonological units. Here the parametric representation is interpretable only on the basis of specific articulatory mechanisms that can be simulated with a computational model. For PENTA, qTA, introduced in §2.4, is such a model. Using data from English and Mandarin as examples, the next two sections will briefly show how parametric representations operate in PENTA.
3.1 Computational modelling tools
Since qTA was first proposed, computational tools have been developed to enable its conceptual exploration and quantitative testing. So far, four tools have been developed. qTA_demo1, mentioned by Arvaniti & Ladd (Reference Arvaniti and Ladd2009: 65), and qTA_demo2 are web-based interactive Java programs that demonstrate how the qTA model works.Footnote 5 Their interactive features make them convenient tools for a quick impromptu test of an idea or a prediction based on the TA model (as can be seen in Fig. 8, to be discussed later).
The other two tools, PENTAtrainer1 (Xu & Prom-on Reference Xu and Prom-on2010–14) and PENTAtrainer2 (Xu & Prom-on Reference Xu and Prom-on2014), are data-driven modelling programs.Footnote 6 Both use machine learning algorithms to automatically extract target parameters from real speech data through analysis-by-synthesis. These learning algorithms test each candidate target by putting it into the qTA function to generate continuous F0 contours that are then compared to the natural contours. The goodness of fit between the synthetic and original contours is used as the criterion in the selection of the targets (Prom-On et al. Reference Prom-on, Xu and Thipakorn2009, Prom-on & Xu Reference Prom-on and Xu2012). The quality of the F0 generation is assessed by three means: (i) root mean square errors, which measures the discrepancy of the synthetic contours from the original contours in terms of point-by-point height difference, (ii) Pearson's r, which assesses how closely the overall shape of the synthetic contours correlates with that of the original contours, and (iii) perceptual evaluation in terms of category identification (e.g. tone, focus, etc.) and naturalness.
Critically, both trainers allow predictive synthesis of F0 contours using categorical parameters learned from training. They differ only in terms of how function-specific targets are obtained. PENTAtrainer1 takes a two-phase approach. In Phase 1, an optimal target is obtained for each syllable of each utterance by comparing the performance of all possible combinations of the three target parameters (b, m, λ in (1)). The parameter set that achieves the best fit to the F0 contour of a specific syllable (i.e. with the smallest sum square errors) is selected as its pitch target. An example of such resynthesis is shown in Fig. 5, where the short dashed lines are the learned targets. The F0 contours generated with these learned targets (solid lines) seem to fit the original F0 contours (dotted lines) quite well. In Phase 2, categorical targets are obtained by averaging over the parameters of all the syllables in the corpus that belong to the same categorical combination, e.g. all the on-focus H tones that occur at the beginning of a sentence (Prom-on et al. Reference Prom-on, Xu and Thipakorn2009). This approach can be referred to as categorisation by averaging. As found in Prom-on et al. (Reference Prom-on, Xu and Thipakorn2009) and Liu et al. (Reference Liu, Xu, Prom-on and Yu2013), good predictive results can be obtained for both English and Mandarin.

Figure 5 Original (dotted) vs. resynthesised (solid) F0 contours of the English utterance You're going to Bloomingdales with Alan shown in Fig. 1. Adapted from a synthesis by PENTAtrainer1 (http://www.homepages.ucl.ac.uk/~uclyyix/PENTAtrainer1/).
The categorisation by averaging strategy employed in PENTAtrainer1, despite its reasonable performance, cannot satisfactorily estimate all qTA parameters. In particular, locally estimated parameters may not be globally optimal. For example, in some cases, the rate of target approximation (λ) may not be adequately estimated if there is severe target undershoot. Besides, the simple exhaustive search implemented in PENTAtrainer1 is inefficient, and probably biologically unrealistic as a learning algorithm. These problems are addressed by PENTAtrainer2, in which function-specific targets are learned directly from an entire corpus that has been functionally annotated (Prom-on & Xu Reference Prom-on and Xu2012, Xu & Prom-on Reference Xu and Prom-on2014). This is achieved with simulated annealing, an optimisation algorithm that performs stochastic parameter sampling to avoid local minima in parameter estimation. Figure 6 shows an example of an annotated utterance (top) and natural F0 and synthetic contours (bottom), where the latter is generated with categorical target parameters learned from an entire corpus.

Figure 6 A schematic representation of PENTAtrainer2 interfaces (http://www. homepages.ucl.ac.uk/~uclyyix/PENTAtrainer2/) for the Mandarin sentence tā MĂI māma men de la ma ‘Did he BUY what mother has?’, with focus on mai3. The annotation interface (top) allows users to mark temporal scope of functional units. Here and below, the annotated functions are lexical tone (H=High, L=Low, N=neutral), focus (pre=pre-focus, on=on-focus and post=post-focus) and sentence modality (S=statement, Q=question). Vertical lines are set to coincide with syllable boundaries. The temporal scope of a functional region covers syllables with identical labels. The output interface (bottom) displays learned pitch targets (dashed lines), as well as synthetic (dotted lines) and natural (solid lines) F0 contours, and allows users to play the utterance with either synthetic or natural prosody (Prom-on & Xu 2012).
In Xu & Prom-on (Reference Xu and Prom-on2014), good overall numerical results were achieved with PENTAtrainer2 for English (the same dataset tested with PENTAtrainer1 in Liu et al. Reference Liu, Xu, Prom-on and Yu2013), Mandarin and Thai. In Prom-on et al. (Reference Prom-on, Xu and Thipakorn2009), which applied categorisation by averaging, the perceptual identification rates for tone in Mandarin and focus in both Mandarin and English were found to be similar for synthetic and natural speech. Just as importantly, synthetic prosody (in terms of F0 and duration) was heard to be just as natural as natural prosody for English, and only slightly worse for Mandarin.
Interestingly, the total number of function-specific parameters learned from the speech corpora and used in the predictive synthesis was very small. In Xu & Prom-on (Reference Xu and Prom-on2014), 78 parameters (i.e. 26 for each of the b, m and λ values) were used for 960 English sentences (consisting of 8640 syllables), 84 parameters for 1280 Mandarin sentences (consisting of 10240 syllables) and 30 parameters for 2500 Thai disyllabic phrases. The number of function-specific parameters roughly equals the number of parameters per target×the number of simulated functions×the number of function-internal categories – non-existing category combinations. This suggests that a high level of abstraction can be achieved with PENTA-based computational approaches. The abstraction level is comparable to other models, e.g. five parameters per Standard Chinese tone in the Fujisaki model (Fujisaki Reference Fujisaki and MacNeilage1983) and four parameters per intonational event in the Tilt model (Taylor Reference Taylor2000).
3.2 Modelling encoding schemes of English prosody: an illustration
The application of the computational tools described above allows us to model some of the major prosodic encoding schemes in English and Mandarin. Figure 7 provides a summary illustration with modelling data on English from Xu & Prom-on (Reference Xu and Prom-on2014). Each graph shows the original F0 of an American English utterance, pitch targets learned by PENTAtrainer2 and synthetic F0 contours generated with the learned targets. The sentences were spoken with either sentence-medial or sentence-final focus, either as statements or as questions. As can be seen, the encoding schemes of focus and modality in American English exhibit allomorphic patterns that are best described in terms of their interactions both with each other and with lexical stress.

Figure 7 Original (dashed) and synthetic (dotted) F0 contours of the sentence You want a job with Microsoft, spoken by a male American English speaker as either a statement (a, b) or a question (c, d), with focus on either job (b, d) or Microsoft (a, c). Also displayed are the pitch targets (straight dashed lines) learned by PENTAtrainer2, based on the functional annotations shown at the bottom of each graph (stress: u=unstressed, s=non-final stressed, s0=final stressed; syllable position (n=non-final, sf=semifinal, f=sentencefinal). All graphs are adapted from screenshots of the demo window of the synthesis tool in the PENTAtrainer2 package (http://www.homepages. ucl.ac.uk/~uclyyix/PENTAtrainer2/). Data from Xu & Prom-on (2014).
(i) Focus is characterised by a robust post-focus pitch range shift, with the direction of the shift dependent on modality: downward in a statement (Fig. 7a, b), but upward in a question (Fig. 7c, d). The resulting post-focus plateaus correspond to the L- and H- phrase accents in the autosegmental-metrical model, but from the PENTA perspective they are allomorphic components of the focus and modality encoding schemes (or prosodic morphemes), rather than autonomous prosodic units in their own right.
(ii) Both focus and modality also interact with lexical stress and stress structure of the word, by determining the micro-properties of the targets. For on-focus word-final stressed syllables, the target slope falls in a statement, but rises in a question (job in Fig. 7b, d). For on-focus, non-final stressed syllables, the target slope rises in both statements and questions, at least for this speaker (Mi- in Fig. 7a, c).
(iii) In both statements and questions, targets are higher in stressed syllables than in unstressed syllables, but the differences are much smaller in questions.
In comparison with the F0 contours in Fig. 4, we can see that the variations due to cross-functional interactions in English are rather different from those in Mandarin. While English shows a robust post-focus upshift in questions, Mandarin shows a post-focus downshift even in questions, except that the size of the downshift is smaller than in statements. Again unlike English, the direction of the target slopes of Mandarin tones does not change from statements to questions, presumably due to the existence of a lexical tonal constraint. These cross-linguistic differences in the encoding schemes of similar prosodic functions show that they are highly language-specific, and that their exact forms cannot be predicted solely on functional grounds.
Note also that the match between the synthetic and original F0 contours in Fig. 7 is not nearly as good as that in Fig. 5. This is partly because the synthesis here is predictive, based on categorical parameters learned from all the utterances by a speaker in a corpus, as opposed to resynthesis in Fig. 5 (by PENTAtrainer1), but partly also because there is still room for further adjustments in the functional annotations. For example, since the relative position of unstressed syllables within an initial-stressed word is not annotated in this simulation, the pitch targets of the unstressed syllables are the same, regardless of their positions in the word. As a result, the synthetic F0 in -crosoft does not show final upstep in Fig. 7d. Thus, even if the major characteristics of the encoding schemes have been identified, their detailed properties are still an object of continuous empirical investigations.
3.3 Model-based parametric representations
The modelling tools and the illustration of their application in the previous sections have demonstrated the plausibility of qTA-based parametric representations. These targets are functionally defined, since each of them corresponds to a unique combination of a set of functions, as shown in Fig. 6. These targets are abstract, as each of them is specified by only three parameters, but can correspond to a countless number of contextual variants. This one-to-many correspondence (Xu & Prom-on Reference Xu and Prom-on2014) is achieved on the basis of a specific mechanistic model, namely qTA. These targets are also gradient, since all three parameters are numeric rather than symbolic. The target values are data-driven, since they are learned from real speech data. Table I displays these properties, and shows which of them are shared by symbolic representations. As can be seen, only abstractness is unquestionably shared by the two types of representations. Although it is possible to obtain autosegmental-metrical-style representations in a data-driven manner (Lee et al. Reference Lee, Xu and Prom-on2014), the predictive power of doing so is as yet unknown.
Table I Comparison of PENTA-based parametric and autosegmental-metrical-style symbolic representations.

Model-based parametric representations may also offer a solution to a well-known puzzle in phonology, namely tone sandhi (Chen Reference Chen2000). For example, Mandarin Tone 3 is changed to Tone 2 when followed by another Tone 3: T3→T2 /—T3. With PENTAtrainer2 this rule can be operationalised as the result of an interaction between two functions: lexical tonal contrast and boundary marking. That is, the pitch target to be implemented in articulation is jointly determined by the morphemic tone of the current syllable, the morphemic tone of the next syllable and the strength of the boundary between the two syllables. Such functional interaction may allow T3 to develop a pitch-target variant that happens to be similar to that of another tone, e.g. T2. But the two need not be identical, since the functional combinations are not the same. Xu & Prom-on (Reference Xu and Prom-on2014) found that the best modelling result was obtained when the sandhi T3 was allowed to learn its own target, rather than when it was forced to use the T2 target. This result is consistent with the empirical finding of subtle yet consistent differences between the original and sandhi-derived T2 in Mandarin (Xu Reference Xu1997, Peng Reference Peng2000). Thus the obligatoriness of associating a unique target to each functional combination may have led to the development of tone sandhi in the first place. But further research along these lines is needed.
Finally, computational modelling of parametric representations may allow the exploration of mechanisms of speech acquisition. For example, it is known that both young songbirds and human children need to hear themselves during a critical practice stage of song or speech learning (Doupe & Kuhl Reference Doupe and Kuhl1999), but why this is the case is still unclear (Nick Reference Nick2014). The analysis-by-synthesis applied in the PENTA trainers uses qTA to repeatedly generate continuous surface trajectories, and compares them to the training speech data. The ease with which near-optimal targets (i.e. those capable of predictively generating naturalistic contextual and cross-speaker variants; Prom-on et al. Reference Prom-on, Xu and Thipakorn2009, Xu & Prom-on Reference Xu and Prom-on2014) are learned in this way suggests the importance of using one's own articulators to generate the acoustic signal during the practice period.
4 Hypothetical interpretations of Greek wh-question prosody
Because the present paper is prompted by Arvaniti & Ladd's criticism of PENTA based on their Greek data, we offer a PENTA-based interpretation of what Arvaniti & Ladd report about Greek wh-question prosody. We are not in a position to offer a full PENTA account of the Greek wh-question prosody, due to lack of experimental data on Greek, so the interpretations presented below can only be speculative, and are subject to future empirical verification.
4.1 Overall interpretation
Our overall interpretation of Greek wh-question intonation is illustrated in Fig. 8, which displays functional annotations corresponding to hypothetical underlying pitch targets and qTA-simulated F0 contours of two sentences from Arvaniti & Ladd, based on data presented in their paper. Overall, Greek wh-questions appear to involve a prosodic focus on the wh-word, which raises its pitch target(s) (the first syllable in Fig. 8a and the first three syllables in Fig. 8b), but lowers the pitch targets of all subsequent syllables. The raised on-focus pitch targets result in an early F0 peak, but the slope of the on-ramp of the peak depends on the lexical stress of the syllable: steeper if it is stressed (a), but shallower if it is unstressed (b). The lowered post-focus pitch targets result in an F0 drop immediately after the wh-word, but the rate of the drop also depends on the lexical stress of the post-focus syllable: faster if it is stressed (a), slower if it is unstressed (b). The post-focus lowering also results in a low plateau after a post-focus stressed syllable (a). Within either the on-focus or post-focus region, the pitch target is slightly higher for a stressed than for an unstressed syllable. This is, however, purely hypothetical for Greek, and based on findings for English (Xu & Xu Reference Xu and Xu2005, Prom-on et al. Reference Prom-on, Xu and Thipakorn2009, Liu et al. Reference Liu, Xu, Prom-on and Yu2013, Xu & Prom-on Reference Xu and Prom-on2014), because there is not sufficient information about stress-related target height available in the data reported by Arvaniti & Ladd. The sentence-final rise, which involves a shallow rising target if the final syllable is unstressed (a), or a steep rising target if the final syllable is stressed (b), is associated with the interrogative modality of the wh-question. Overall, from the PENTA perspective, the functional equivalence of Greek wh-questions exists at multiple levels: focus shows a consistent pattern of raised on-focus pitch and lowered post-focus pitch; question modality shows a consistent sentence-final rise (or even a progressive rise throughout the sentence, if Greek is similar to Mandarin: Liu & Xu Reference Liu and Xu2005); lexical stress shows (hypothetically) consistent higher vs. lower pitch targets. Each of these functional equivalences is shared by all the wh-question sentences presented by Arvaniti & Ladd, regardless of their length or lexical composition.
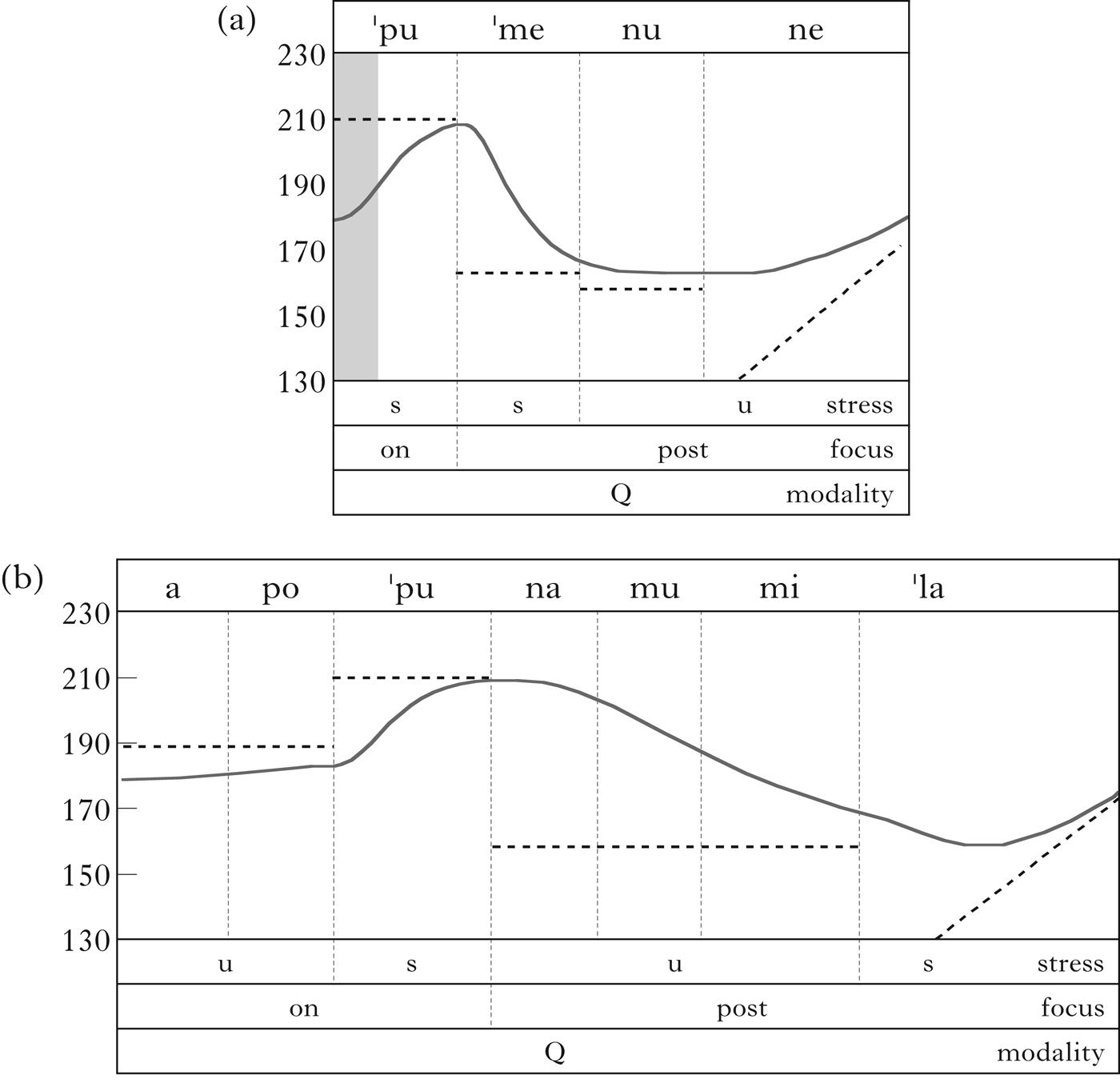
Figure 8 F0 contours, simulated using qTA_demo1, of (a) Greek ['pu 'menune] ‘Where are they staying?’ and (b) [apo'pu na mu mi'la] ‘Where could s/he be talking to me from?’, resulting from qTA realisation of underlying pitch targets (dashed lines), which are hypothetically set for the functions annotated in the bottom tiers. The vertical bar at the left edge of (a) illustrates the ‘truncation’ effect of a voiceless consonant.
The pitch targets, represented by the dashed lines, which are purely hypothetical in Fig. 8, can be obtained by applying PENTAtrainer1 or PENTAtrainer2 to the real data. As noted above, the annotations below the F0 contours illustrate the PENTA-style functional annotations specified in the caption.
In addition to the global patterns, Fig. 8 also shows micro-patterns related to alignment, scaling, etc., which are a major concern in Arvaniti & Ladd (Reference Arvaniti and Ladd2009). Here we can see that they are mostly due to interactions between focus, modality and lexical stress. The details of these interactions, as will be discussed in the following sections, can be accounted for by articulatory mechanisms of pitch production, as captured by the qTA model in PENTA.
4.2 Tonal crowding, alignment and scaling: a PENTA perspective
In Arvaniti & Ladd (Reference Arvaniti and Ladd2009), local variations are described in terms of alignment and scaling of F0 peaks and elbows. These patterns are accounted for by tonal crowding, which is said to occur whenever two or more tones are associated with the same tone-bearing unit or with adjacent units. The evidential basis of tonal crowding is that certain observed F0 patterns vary when the phonologically specified tones are close to each other, but remain stable once those tones are two or more syllables apart. From the PENTA perspective, these tonal adjustments can be accounted for by the articulatory-functional mechanism outlined in §2.2, which involves no freedom of underlying tonal alignment, and no direct scaling as an F0 adjustment mechanism in its own right. As is shown in Fig. 8 and below, variations in both alignment and scaling can nevertheless be generated by the qTA model once the underlying pitch targets are given based on specific communicative functions.
4.2.1 Alignment of NH as on-focus F0 peak
NH (nuclear H) measures the location of the early F0 peak in a wh-question. Arvaniti & Ladd show that its location is earlier when the wh-word has final stress and the following word has initial stress than when there are intervening unstressed syllables, but there is no further variation according to the number of intervening unstressed syllables. Also, when the interstress interval was zero, ‘the peak appeared much earlier in short than in long questions, and in fact aligned with the nuclear vowel itself; in contrast, in long questions, in which the pressure on NH comes only from the following L1 [see §4.2.2 for a definition of L1], the peak co-occurred with the onset consonant of the postnuclear syllable’ (2009: 58). Arvaniti & Ladd attribute these patterns to the crowding of the NH and the upcoming L, which is severe only when the L is immediately adjacent to NH.
Our interpretation, based on the TA model in PENTA and empirical data from English and Mandarin (Liu et al. Reference Liu, Xu, Prom-on and Yu2013) can be seen in Fig. 8. In (a), the first post-focus syllable [me] is lexically stressed, and so its target strength is high. As a result, the rising momentum generated by approaching the on-focus high target is quickly reversed, leading to an F0 peak very close to the syllable boundary. In contrast, in (b), the first post-focus syllable is unstressed, and thus has weak target strength. As a result, it takes longer for the on-focus rising momentum to be reversed, leading to an F0 peak that is aligned further to the right of the syllable boundary. As mentioned in §2.4, evidence of such stress-related articulatory strength is found in both acoustic analysis and computational modelling for English and Mandarin. In addition, because there is no anticipatory mechanism in qTA, lexical stress of syllables further to the right would not have any more impact on the peak alignment. Thus the NH alignment reported by Arvaniti & Ladd can be accounted for by PENTA using qTA simulation without any explicit specification of F0 peak alignment or assumption of tonal crowding.
4.2.2 Alignment of L1 as post-focus F0 elbow
L1 refers to an elbow ‘defined as the point that showed a clear change in slope between the fall after the nuclear peak and the low plateau’ (Arvaniti & Ladd Reference Arvaniti and Ladd2009: 55). Overall, L1 is described as exhibiting stress-seeking behaviour: it ‘typically co-occurs with the first stressed syllable after the nucleus, thereby ensuring that this syllable has low F0 to the extent that tonal crowding permits’ (2009: 67). From a PENTA point of view, this is directly related to the NH alignment discussed above, and thus explainable by the same mechanism. That is, as seen in Fig. 8, due to focus, F0 is lowered immediately after the stressed syllable of the wh-word, regardless of whether the first post-focal syllable is stressed. On the other hand, as also seen in Fig. 8, the speed at which this lowering is realised depends on the stress level of the post-focus syllable. It is faster if the post-focus syllable is stressed (a), but slower if it is unstressed (b). Similar stress-dependent post-focus F0 falling speed has been found for English (Xu & Xu Reference Xu and Xu2005). In other words, the ‘stress-seeking’ behaviour observed in Arvaniti & Ladd, as well as other autosegmental-metrical-based studies (Pierrehumbert & Beckman Reference Pierrehumbert and Beckman1988, Grice et al. Reference Grice, Ladd and Arvaniti2000, Gussenhoven Reference Gussenhoven2000), can be accounted for in PENTA as being due to the greater articulatory strength given to stressed syllables than to unstressed syllables, even when they are both post-focus.
4.2.3 Alignment of L2 as F0 elbow of final rise
L2 refers to the later elbow with respect to the final vowel in a wh-question, ‘defined as the point that showed a clear upward inflection between the low plateau and the utterance-final rise’ (Arvaniti & Ladd Reference Arvaniti and Ladd2009: 55). They found that ‘in both short and long questions, L2 occurred after the onset of the final vowel, when this vowel was stressed, but slightly before it, when stress was on the antepenult; in the latter case, L2 co-occurred with the consonant of the question's last syllable’ (2009: 61). More specifically, ‘while L2 co-occurred with the onset of the final vowel when the last word was stressed either on the penult or the antepenult, it occurred half-way through the final vowel when this vowel was stressed’ (2009: 61–62).
These patterns are again likely related to target strength due to lexical stress. That is, the target strength of sentence-final syllables is dependent on lexical stress, being higher in stressed syllables and lower in unstressed syllables. The impact of this difference can again be seen in Fig. 8. Both sentences have a sentence-final rising target associated with the question modality. The sentence in (a) shows a continuous shallow final rise, due to the low strength in its unstressed final syllable. The sentence in (b), in contrast, shows a dip in the middle of the syllable before the final rise, due to the high strength of its stressed final syllable. This dip, which is also seen in Fig. 1a in Arvaniti & Ladd (Reference Arvaniti and Ladd2009) for the Greek sentence [ɸpi ɸzi] ‘Where does s/he live?’ with sentence-final stress, is likely to have led to the difference in the manually marked L2 alignment in Arvaniti & Ladd. But the simulation in Fig. 8 shows that the real source of the difference is in the property of the pitch targets, not in their underlying alignment.
4.2.4 Scaling, truncation and virtual targets
The above discussion has shown that the alignment of NH, L1 and L2 reported by Arvaniti & Ladd can be accounted for by PENTA in terms of the interaction of lexical stress with focus and question intonation. With regard to scaling, Arvaniti & Ladd did not find significant effects of tonal crowding. We note, however, that such lack of variability has much to do with the way scaling is defined, which in Arvaniti & Ladd is in terms of only the F0 peak on the wh-word and elbow of post-focus F0 drop and sentence-final F0 rise. From the perspective of target approximation, this lack of variability is not really surprising. As can be seen in the simulations in Fig. 8, this is because the time pressure is not high enough to trigger a significant undershoot for those particular measurements. For NH, there is no real leftward push from the first post-focus syllable, whether the latter is stressed or unstressed. For L1 and L2, the lack of systematic variability could also be due to a large variance in the measurement, given that visual identification of elbows is unlikely to be highly consistent. If, on the other hand, scaling refers to the degree of target undershoot in each syllable, its effect can be clearly seen in most of the unstressed syllables in Fig. 8.
Arvaniti & Ladd also report that sentences that start with a stressed syllable have higher initial F0 than those starting with an unstressed syllable. They attribute this to a truncation mechanism, by which a stressed syllable truncates a virtual L target that occurs at the left edge of every sentence in Greek. From the simulated F0 contours in Fig. 8, however, it is difficult to see how this truncation mechanism can work. If the proposed virtual target is located at the left edge of a sentence, the stressed syllable must be at its right. Given such a target sequence, if there is any remnant of the L after the truncation, it should be still at the leftmost edge, based on the target-interpolation mechanism of the autosegmental-metrical theory, thus keeping the lowest initial F0 unchanged. With the target-interpolation model, variation of initial F0 due to stress of the sentence-initial syllable can occur only if the virtual L is fully replaced by the tone of the stressed syllable.
From the PENTA perspective, the idea of an utterance-initial virtual pitch is actually rather plausible, because there is already evidence for it in empirical data on tones produced in isolation (Xu Reference Xu1997), as shown in Fig. 9. We can see that different tones have different onset F0. However, the early portions of all the tones seem to point back to a common origin in the middle of the pitch range. It is therefore possible that speakers start their laryngeal target approximation before the onset of phonation. Such a delayed voice onset is easily implementable in PENTA, by imposing a fixed time delay relative to the onset of pitch target approximation. But note that such an onset delay would ‘truncate’ the initial F0 from the left, rather than from the right as suggested by Arvaniti & Ladd, and would be applied regardless of whether the initial syllable is stressed.
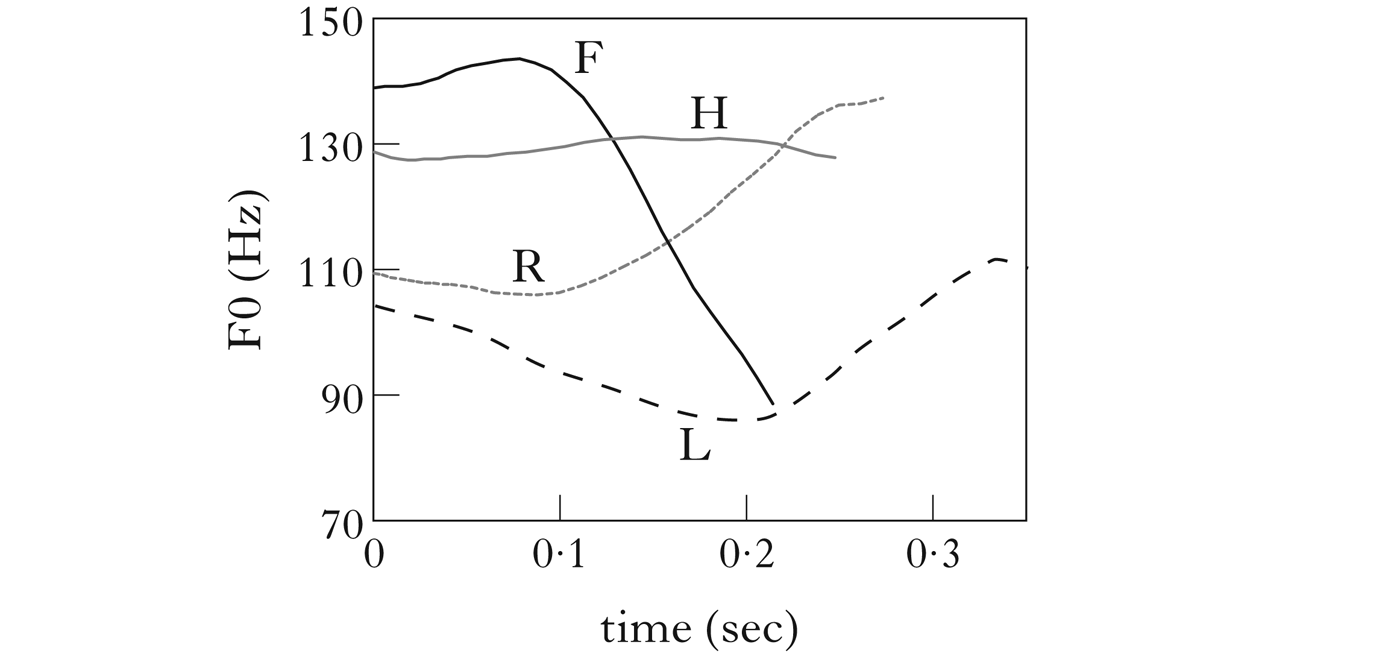
Figure 9 Mean F0 contours of Mandarin falling, rising high and low tones in the syllable [ma] spoken in isolation by 8 speakers (averaged over seven repetitions by eight speakers). Data from Xu (1997).
Furthermore, because in Arvaniti & Ladd the wh-word with initial stress, [ɸpi], starts with a voiceless consonant, while the wh-word without initial stress, [apoɸpi], starts with a vowel, an F0 contour with a rising onset is likely to start higher in the former case, as shown in Fig. 10. That is, a voiceless consonant perturbs the F0 contour of a syllable in two ways, raising the onset F0 very briefly, and ‘truncating’ an otherwise continuous F0 movement, as can be clearly seen when compared to the F0 of a sonorant onset (Xu & Xu Reference Xu and Xu2003). Such a ‘truncation’ mechanism has already been implemented in the PENTA trainers and is tested in Xu & Prom-on (Reference Xu and Prom-on2014).

Figure 10 Effects of voiceless consonants on the F0 contours of Mandarin rising and falling tones produced after high and low tones. Each curve is an average across five repetitions, two carrier sentences and seven female speakers. All curves are aligned to the syllable offset. Data from Xu & Xu (2003).
5 Concluding remarks
We have presented an overview of PENTA as a framework for conceptually and computationally linking communicative meanings to fine-grained prosodic details, based on an articulatory-functional view of speech communication. In this framework a rich repertoire of communicative functions is simultaneously realised through an articulatory encoding process, so that all the details of the surface prosody can be traced back to their respective sources. As such, PENTA has addressed the major criteria advocated by Arvaniti & Ladd for a complete theory of intonation, namely abstraction, generalisation, prediction and accounting for detail.
Abstraction is addressed in PENTA by defining prosodic categories primarily in terms of communicative functions, while treating the underlying phonetic forms of the functional categories as a matter of empirical discovery. It is further achieved by the ability of the articulatory mechanisms simulated by qTA, with which an invariant (hence abstract) pitch target can generate an unlimited number of contextual variants (Xu & Prom-on Reference Xu and Prom-on2014).
Generalisation is addressed in PENTA by treating the basic articulatory mechanisms of pitch production, as well as the core principle of encoding multiple layers of information in parallel, as universal, while allowing the phonetic details of the encoding schemes to be discovered through empirical studies.
Prediction is addressed in the PENTA approach at two levels. At the phonetic level, we have developed computational algorithms capable of learning function-specific pitch targets from natural speech and using the learned parametric representations to synthesise F0 contours that closely match those of natural utterances, either by the same speaker or by different speakers. At the functional level, prediction is addressed by always looking for the proper sources of the encoding schemes. Some of the sources are historical, and are thus responsible for language-specific variations; some are biological or bio-informational, hence are behind encoding properties that are not only universal among human languages, but are also shared with other animal communication systems (Xu, Kelly & Smillie Reference Xu, Kelly, Smillie, Hancil and Hirst2013, Xu, Lee et al. Reference Xu, Lee, Wu, Liu and Birkholz2013).
Accounting for detail is addressed in PENTA by developing analysis and modelling tools that are capable of processing many aspects of prosodic events, and by trying to link them to underlying sources in terms of either articulation or functional encoding. A substantial number of details in surface prosody have already been accounted for, including various alignment and scaling patterns, as discussed in this paper. More importantly, the quality of these accounts can be assessed in numerical terms through computational modelling, which makes it possible for even highly theoretical debates to be conducted with the help of detailed quantitative comparisons.











