

Measuring corruption has received extensive academic and policy attention due to the central role it plays in the quality of democracy, the provision of public goods, and economic growth. Some international organizations monitor corruption in their member countries or tie funding to corruption ratings. Recognizing the lack of reliable and actionable corruption indicators, repeated calls have been made to develop so-called second-generation governance indicators better suited to aiding policy making and hypothesis testing. However, only limited progress has been made thus far.Footnote 1
In order to address this lack of actionable corruption indices, we develop novel proxy measures of grand corruption that: (1) match a specific corruption definition, (2) derive from objective data, (3) allow for consistent temporal and cross-country comparisons on large samples and (4) can be validated using alternative corruption proxies.
We develop a measurement of grand corruption in public procurement, as it constitutes roughly 30 per cent of government spending in Organisation for Economic Co-operation and Development (OECD) countries, it is a data-rich area, and it is perceived to be a corrupt sector. Our domain-specific definition of corruption is: ‘The aim of corruption [in public procurement] is to steer the contract to the favoured bidder without detection. This is done in a number of ways, including avoiding competition through, for example, unjustified sole sourcing or direct contracting awards; or favouring a certain bidder by tailoring specifications, sharing inside information, etc.’.Footnote 2 This definition focuses attention on restricted and unfair access to public resources – that is, particularism.Footnote 3
LITERATURE ON MEASURING CORRUPTION
Available indicators are often inadequate for testing theories of grand corruption and developing effective solutions to it. Most corruption indicators derive from surveys of attitudes, perceptions and experiences of corruption among different stakeholders (for example, general population, firms, experts); reviews of institutional features designed to control corruption; and audits and investigations of individual cases.
The two most widely used perception and attitude surveys are the World Bank’s Control of CorruptionFootnote 4 and Transparency International’s Corruption Perceptions Index.Footnote 5 Both have received extensive criticism applicable to any similar survey.Footnote 6 Critics point out that perceptions may or may not be related to actual experience.Footnote 7 They can be driven by general sentiment reflecting, for example, prior economic growthFootnote 8 or recent media coverage of high-profile corruption cases.Footnote 9 Perceptions of grand corruption are even more unreliable than perceptions of everyday corruption, since experts and citizens have almost no direct experience of it. Since these indicators are typically produced from non-representative surveys, representativeness bias is likely to occur (that is, capturing the views of a particular group rather than the whole population), in addition to reflexivity bias (that is, respondents influenced by prior and future measurements) exaggerated by small samples.Footnote 10 Furthermore, many such indices vary surprisingly little over time in spite of apparently large changes in the underlying governance structures, which suggest that they are insensitive to change.Footnote 11 Surveys of experiences with low-level bribery, such as the Quality of Government Institute’s regional survey,Footnote 12 address some weaknesses of perception surveys, yet still suffer from others such as non- response or false response to sensitive questions about bribing. Most importantly, only a tiny fraction of the population has direct experience with grand corruption, which limits the use of this method.
While reviews of the institutions responsible for controlling corruptionFootnote 13 are crucial to understanding the determinants of corruption, by design, they do not directly measure corruption. Without a precisely measured outcome variable, they have to rely on untested theories of which institutional features work. Scientific analyses and audits of individual cases are highly reliable for establishing both petty and grand corruption; however, their narrow scope and lack of representativeness make them of limited use for comparative purposes. In addition, data from courts and law enforcement agencies typically cannot be compiled to create corruption indices because courts have little capacity to investigate a large number of cases and there is a high risk of capture in corrupt countries. An innovative exception to this general observation is Escresa and Picci, who exploit the independence of US courts from foreign corrupt groups in enforcing the Foreign Corrupt Practices Act.Footnote 14
Some authors, recognizing the need for further indicators, have developed objective corruption proxies that rely on directly observable behaviours that likely indicate corrupt behaviour.Footnote 15 These studies investigate corruption in various contexts such as elections and high-level politics or welfare services and redistributive programmes. However, many of these innovative indicators are context dependent and are prohibitively expensive to replicate over time and across countries.
Studies that focus on corruption in public procurement are more closely associated with our approach. For example, Golden and Picci propose a new measure of corruption based on the difference between the quantity of infrastructure and the related public spending in twenty regions in Italy.Footnote 16 Our proxies are inspired by authors using red flags in public procurement as proxy measures for corruption such as the use of exceptional procedure typesFootnote 17 or single bidding.Footnote 18
DATA
The data derive from public procurement announcements in 2009–14 in the EU-27 (excluding Malta) and Norway. Announcements appear in the Tenders Electronic Daily (TED), which is the online version of the ‘Supplement to the Official Journal of the EU’, dedicated to European public procurement.Footnote 19 The data represent a complete database of all public procurement procedures conducted under the EU Public Procurement Directives in the EU-27 plus Norway regardless of the funding source (for example, national, EU funded). All government contracts above given value thresholdsFootnote 20 have to follow transparency and procedural rules of the Directives, with a few exceptions (for example, some defence contracts). Since all countries’ public procurement legislation is within the framework of the Directives, national datasets are directly comparable.Footnote 21 The regulation of government contracting in World Trade Organization member states and a global Open Contracting Data Standard suggest that similar datasets can be constructed globally.Footnote 22
Procuring organizations enter the data into standard reporting forms following a common EU reporting guide. While the EU’s Publications Office checks these data, there is a non-negligible amount of missing or nonsensical data. The database used in this article is from the European Commission – DG GROWTHFootnote 23 which conducted further data quality checks and enhancements. TED contains variables appearing in (1) calls for tenders such as product specification, application deadline or assessment criteria and (2) contract award notices such as name of the winner, awarded contract value or date of contract signature. For every observed tender, we have information from contract award announcements as publication is always mandatory, while information from calls for tenders may not be published under specific circumstances.
The TED database contains over 2.8 million contracts, 2.3 million of which are used in the analysis. We excluded the following: (1) one country with too few observations (Malta), (2) contracts below mandatory reporting thresholds and (3) contracts on non-competitive markets.Footnote 24
MEASUREMENT MODEL
This section outlines the measurement logic; full technical details, including regression specifications, are available in Annex A.
The measurement model approximates our corruption definition, according to which corruption takes place when public officials circumvent legally prescribed principles of open and fair competition when designing and running tenders in order to recurrently award government contracts to connected companies. Thus, it is possible to identify the output and input sides of the corruption process: lack of bidders for government contracts (output) and means of fixing the procedural rules for limiting competition (inputs). Corruption proxies are obtained by measuring the degree of unjustified restriction of competition in public procurement. Such corruption indicators signal the risk of corruption rather than actual corruption. They are expected to be correlated with corrupt exchanges rather than perfectly matching them.
Such proxy indicators signal corruption only if competition is expected in the absence of corruption. Hence, markets that are non-competitive under non-corrupt circumstances had to be excluded (for example, markets for specialized services). Small markets (defined by product group and location) with a low number of potential bidders were excluded, constituting 8 per cent of contracts, underlining that the vast majority concern widely supplied products.
The simplest indication of restricted competition reflecting our corruption definition is when only one bid is submitted for a tender in a competitive market (output side).Footnote 25 This typically allows awarding contracts above market prices and extracting corrupt rents. Recurrent single-bidder tenders between a buyer and a supplier facilitate the development of the interpersonal trust that underpins corrupt contracting. Thus while individual instances of single bidding may be explained by a number of non-corrupt reasons (for example, known most productive bidder), recurrent or extensively used single-bidder contracts in a public organization or region are more likely to signal corruption and restricted access. Hence, the incidence of single-bidder contracts (that is, contracts awarded in procurement tenders in which only one bid was submitted) is the most basic corruption proxy proposed.
The more complex indication of corruption also incorporates characteristics of the tendering process that are determined by the public officials who are conducting the tender and contributing to competition restriction (input side). This composite indicator, which we call the Corruption Risk Index (CRI), is a simple arithmetic average of individual risk indicators, scaled between 0 (lowest observed corruption risk) and 1 (highest observed corruption risk).
Based on qualitative interviews with public procurement actors, a media review, and a review of the academic and policy literature, we identified a long list of potential ‘red flags’ of corruption and associated corruption techniques. ‘Red flags’ are differentiated from ‘green flags’ using statistical techniques to avoid an over-reliance on a small number of known examples disregarding the diversity of public procurement markets. Thus we implemented binary logistic regressions to model the input–output relationships between single bidding and other corruption ‘red flags’, also containing a wide set of control variables (for example, buyer sector). Those indicators were identified as valid ‘red flags’, which were significant and substantive predictors of single bidding. For continuous variables such as advertisement period length (days) we defined ‘red flag’ categories using cut-points in order to capture the non-linear character of corruption, while maximizing predictive power.
This process led to the following CRI components in addition to single bidding (descriptive statistics and exact definitions available in Annexes B and D):
1. A simple way to fix tenders is to avoid publishing the call for tenders in the official public procurement journal, as this makes it harder for non-connected competitors to prepare bids. This is only relevant in non-open procedures where publication is voluntary.
2. While open competition is relatively hard to avoid in some procedure types such as open tender, others such as invitation tenders are by default less competitive; hence using less open and transparent procedure types can indicate the deliberate limitation of competition.
3. A too-short advertisement period (number of days between publishing a tender and the submission deadline) can inhibit non-connected bidders in preparing adequate bids while the buyer informally notifies the favoured bidder about the opportunity ahead of time. Alternatively, the advertisement period may become lengthy due to legal challenge, which may also signal corruption risks.
4. Subjective, hard-to-quantify evaluation criteria (for example, the quality of company organigram) rather than quantitative or price-related criteria allow rigged assessment procedures as they create room for discretion and limit accountability mechanisms. Alternatively, price-only criteria can also be abused for corruption when the connected firm bids with the lowest price knowing that the quality will not be monitored.
5. If the time used to decide on the submitted bids is excessively short or lengthy, it can signal corruption risks. Snap decisions may reflect pre-mediated assessment, while long decision periods and a corresponding legal challenge suggest the outright violation of laws.
The strength of the single-bidder indicator is that it is very simple and easily interpreted. However, it is also more prone to gaming by corrupt actors such as including fake bidders to give the appearance of competition. For justified purchases of highly specific products, or when the most productive supplier is known, single bidding may overestimate the corruption risks, even though defining very specific purchases to match the specific characteristics of connected bidders is a major form of corrupt contracting.
The strength of the composite indicator approach is that it represents a more complete monitoring of the corrupt contracting process, while it also explicitly tries to abstract from diverse market realities to capture underlying corruption techniques. It allows ‘red flag’ definitions to change from context to context in order to capture similar levels of risk, irrespective of the detailed forms of corruption techniques used (for example, non-corrupt competitive conditions imply tighter submission deadlines in the Netherlands than in Greece, hence corrupt behaviour would reflect deviations from slightly different normal benchmarks). This flexibility in corruption indices aims to assure that the same level of risk is associated with a similar level of actual corruption when comparing countries. As corruption techniques are likely to change over time, tracking multiple corruption strategies in a single composite score is most likely to remain consistent. Both of these characteristics underpin its usefulness for international and time-series comparative research. The main weakness of CRI is that it can only detect a subset of corruption strategies, arguably the simplest ones, and therefore it cannot capture sophisticated types such as corruption combined with inter-bidder collusion. As long as the simplest strategies are the cheapest, they likely represent the most widespread forms of corrupt behaviour. However, more sophisticated corruption techniques are more likely to be used when monitoring institutions are stronger, which implies that the level of corruption may be underestimated in less corrupt countries. Further research should expand on the set of red flags tracked and evaluate the interaction between monitoring institutions, regulatory complexity and corruption sophistication in order to more precisely estimate corruption.
REGRESSION RESULTS
The binary logistic regression model described above was implemented in six specifications to show the independent effect of each ‘red flag’ on single bidding (Models 1–5) and their combined effect (Model 6) (Table 1). Descriptive statistics of the dependent variable, Single Bidding, are available in Annex C. These highlight the wide variation in single-bidding practice across Europe.
Table 1 Binary Logistic Regression Results on Contract Level, 2009–14
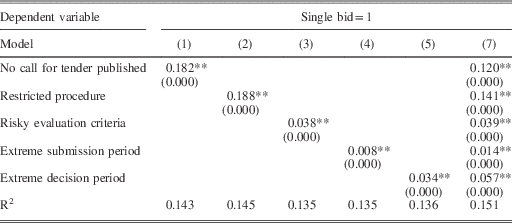
Note: EU-27+Norway, average marginal effects reported (N=1,306,025). All regressions contain control variables: Buyer Sector, Buyer Type, Year, Product Market, Contract Value, Country. p-values in parentheses; *p<0.05, **p<0.01
The hypothesized relationships between single bidding and corruption techniques are supported by the estimation results. In a database encompassing enormous diversity across twenty-eight countries and six years in 2.3 million contracts, our simple regression models perform well by explaining 13–15 per cent of the variance in single bidding.
Not publishing the call for tenders in the official journal (TED) increases the average probability of only receiving a single bid in every regression by 12–18 per cent, which is one of the strongest impacts across all models. Non-open procedure types carry a higher corruption risk than open procedures in terms of the probability of a single bid in all our models: they are associated with a 14–19 per cent higher single-bid probability. Evaluation criteria behave as expected, with both price-only and the excessive use of non-quantitative criteria carrying corruption risks: risky criteria are associated with a 4 per cent higher probability of single bidding across the different models compared to the reference category. Extremely short or lengthy advertisement periods are associated with approximately a 1 per cent higher probability of a single bid received across the different models compared to the normal or typical advertisement periods (that is, typically legally mandated periods of about 40–50 days). Extremely short or long decision periods are estimated to increase the probability of single bidding by 3–6 per cent compared to typical decision periods. While some of these average estimated effects seem small, they only reflect the Europe-wide relationship; the ‘red flag’ impacts are considerably stronger in some countries than in others.
Based on these regression results and theory, we could identify ‘red flags’ of corruption: single bidding and further components of the CRI. For simplicity, each ‘red flag’ is weighted equally, making CRI a simple arithmetic average of its components. Additivity reflects the interchangeability of different corruption techniques used to achieve corrupt deals, as well as the fact that more ‘red flags’ signal a contracting process that is more in line with our corruption model – that is, it makes corruption more likely to occur. Nevertheless, it is once again highlighted that sophisticated corrupt actors may only need to use one of the measured corruption techniques to render a procedure corrupt, making the composite score a lower-bound estimate of the true corruption risks. Component weights are normed so that CRI falls between 0 and 1 (that is, weights were set at 1/6). Such a simple weighting allows easy interpretability of changes in CRI scores: changes can be thought of in terms of additional ‘red flags’.
VALIDATING THE CORRUPTION PROXIES
The validity of single-bidder and CRI indicators stems from their correspondence with the definition of high-level corruption in public procurement and the fitted regression models. Analysis of their association with micro-level objective corruption proxies, and with widely used survey-based macro-level corruption indicators, further bolsters their validity by suggesting that they proxy for corruption rather than for other phenomena such as low administrative capacity. The main results are discussed here, and additional validity tables can be found in Annex B.
We test validity using two micro-level objective risk indicators: procurement suppliers’ country of origin and contract prices. We expect a contract to represent a higher risk of corruption if it is awarded to a company registered in a tax haven, as secrecy makes it easier to hide corrupt money.Footnote 26 As expected, across EU-27 plus Norway there is a marked and significant difference in corruption risks of contracts won by foreign companies registered in tax havens versus those that are not: 0.28 versus 0.26 for single bidding, and 0.34 versus 0.31 for CRI (Ncontract=28,642).
We also expect corruption to drive prices up. Although reliable unit prices are not available across many sectors, we can employ an alternative indicator of price: the ratio of the actual contract value to the initially estimated contract value.Footnote 27 As expected, both single-bidder contracts and a higher CRI are associated with higher prices. Single-bidder contracts have 9–9.6 per cent higher prices than multiple-bidder contracts. Contracts with one additional red flag (that is, 1/6 CRI points higher) are 2.5–2.7 per cent more pricey after controlling for major confounding factors (Table 2). To complement the full population estimations with more reliable, but small sample price information, we manually collected unit price information from procurement announcements for new computed tomography (CT) scanners and new highway and road construction. Both tests support validity.
Table 2 Linear Regressions Explaining Relative Contract Value and Unit Prices, 2009–2014
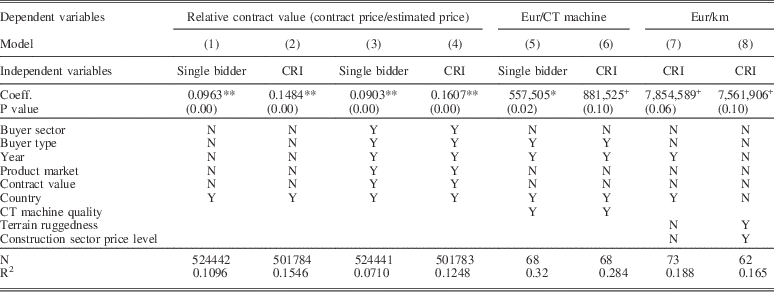
Note: EU-27+Norway. Each regression contains constant; relative contract values equal to or smaller than 1. p-value in parentheses; +p<0.1, *p<0.05, **p<0.01
While corruption perceptions are considered to be too sticky and biased to adequately capture changes in corruption, they are more reliable for comparing levels of corruption across countries for a longer time period.Footnote 28 Hence, correlating levels of subjective and objective corruption indicators by country can provide a further validity test. The 2009–13 country average single-bidder and CRI indicators correlate as expected with widely used perception-based corruption indicators such as Transparency International’s Corruption Perception Index (coefficients are around 0.6). A 2013 Eurobarometer survey of bidding companies’ experience of corruption across the EU provides the most directly comparable survey-based indicator of corruption in public procurement (Standard Eurobarometer 79). Higher values indicate a higher reported experience of corruption, hence moderate positive linear correlation coefficients (0.56–0.62) also support indicator validity.
CONCLUSIONS
This article developed two objective proxies of high-level corruption: a simple indicator (single bidding) and a complex indicator (CRI). Both indicators have been validated by their direct fit with our corruption definition, an empirical model of corrupt rent extraction and a range of external validity tests.
The great advantage of our approach is that a large amount of data is already available for research across high-, middle- and low-income countries, starting from about 2008. Such data are generated on a daily basis by national procurement systems adding to databases automatically on a real-time basis at no additional cost. As the proposed corruption risk indicators are calculated on the transaction level, they also allow us to move away from country-level analysis to look into regions, sectors, organizations or individuals’ behaviour, which has long been thought to be necessary for advancing the field. Such large volumes of internationally comparative micro-level data open up a new horizon for comparative research on corruption and the quality of institutions more broadly. Subsequent research could benefit from using corruption proxies that avoid the biases of subjective indicators and the context-bound nature of most objective indices. Using corruption proxies that are sensitive to change allows us to better assess interventions and to test theories of institutional change such as the impact of increasing salaries on corruption or electoral accountability and corruption at the municipal level.
The proposed corruption proxies can also be used to understand which anticorruption measures are effective. For example, they can be used to evaluate single regulatory or organizational changes such as tightening reporting requirements or introducing organizational integrity management. They could also help oversight bodies decide where to spend their limited resources for conducting audits. Corruption proxies can also be made available to citizens, NGOs and journalists to hold governments accountable.
In order to increase the reliability and validity of corruption risk measurement, further research could identify and measure additional corruption risk techniques as more data become available; it could also use more advanced analytics to differentiate justified instances of competition restriction (such as product specificity) from unjustified cases of favouritism.



