1 Background
The phenomenon under examination in this paper is the glottalisation of coda stops. Glottalisation as defined here is the addition of glottal constriction to a coda oral stop, resulting in irregular, laryngealised phonation towards the end of the preceding voiced segment (Huffman Reference Huffman2005, Garellek Reference Garellek2015).Footnote 1 This phenomenon is most commonly associated with alveolar stops (Pierrehumbert Reference Pierrehumbert, Beals, Denton, Knippen, Melnar, Suzuki and Zeinfeld1994, Reference Pierrehumbert, Fujimura and Hirano1995; Tollfree Reference Tollfree1999; Seyfarth & Garellek Reference Garellek2015) although varieties of English differ according to the context and frequency of glottalisation used by speakers of the community. Previous studies have found glottalisation to be an important cue to coda stop voicelessness in many varieties of English, such as British English (BrE) (Roach Reference Roach1973), American English (AmE) (Pierrehumbert Reference Pierrehumbert, Fujimura and Hirano1995, Redi & Shattuck-Hufnagel Reference Redi and Shattuck-Hufnagel2001, Huffman Reference Huffman2005), and Scottish English (Gordeeva & Scobbie Reference Gordeeva and Scobbie2013). Some varieties exhibit place of articulation (POA) asymmetries in the degree of glottalisation, with alveolar stops more likely to be glottalised than bilabial or velar stops (Keyser & Stevens Reference Keyser and Stevens2006). Keyser & Stevens (Reference Keyser and Stevens2006) hypothesise, based on an EMA/intra-oral pressure study by Svirsky et al. (Reference Svirsky, Stevens, Matthies, Manzella, Perkell and Wilhelms-Tricarico1997), that voiceless bilabial and velar stops may be accompanied by an increase in tongue stiffness, which results in rapid inhibition of voicing. They suggest that alveolar stops, on the other hand, require increased flexibility of the tongue for their articulation allowing for greater expansion of the vocal tract, which in turn promotes maintenance of the transglottal pressure difference and thereby voicing. In other words, the suggestion is that the pressure above and below the glottis does not equalise as quickly for alveolar stops as it does for stops at other places of articulation, and hence voiceless alveolar stops may be prone to prolongation of voicing. Their hypothesis is that speakers employ glottalisation of alveolar stops as a mechanism to successfully extinguish voicing in the face of an undesirably expanding vocal tract (Keyser & Stevens Reference Keyser and Stevens2006) and they explain that this expansion (and hence maintenance of the transglottal pressure difference and resulting voicing prolongation) does not occur in labial and velar stop production, making glottalisation less necessary in these contexts. To the best of our knowledge this hypothesis is yet to be empirically tested. Keyser & Stevens (Reference Keyser and Stevens2006) concede that glottalisation of all three POAs may be necessary to enhance voicing contrasts compromised by reduced subglottal pressure in utterance final position. It should also be noted that bilabial and velar stops are nevertheless often glottalised in multiple varieties of English (see below) in both utterance final and non-utterance final position.
Although, as noted above, glottalisation as a cue to coda voicelessness is reported for many varieties of English, varieties differ according to which stops are glottalised and the frequency with which they are glottalised. In BrE, for example, glottalisation in conjunction with /t/ is well known (Milroy et al. Reference Milroy, Milroy, Hartley and Walshaw1994, Docherty et al. Reference Docherty, Foulkes, Milroy, Milroy and Walshaw1997). Glottal replacement of /t/, a similar and potentially related phenomenonFootnote 2 in which the oral stop is replaced or completely masked by a glottal stop, is also well attested (e.g. Roach Reference Roach1973, Wells Reference Wells1982, Docherty et al. Reference Docherty, Foulkes, Milroy, Milroy and Walshaw1997, Docherty & Foulkes Reference Docherty, Foulkes, Ohala, Hasegawa, Ohala, Granville and Bailey1999a) but will not be examined here. Similarly, we will not focus here on ejective realisations of stops (i.e. glottalic egressive stops), a phenomenon that is attested in Scottish English (Gordeeva & Scobbie Reference Gordeeva and Scobbie2013, McCarthy & Stuart-Smith Reference McCarthy and Stuart-Smith2013). However, glottalisation in BrE is not limited to alveolar stops; all of the voiceless stops /p t k/ as well as the voiceless affricate /ʧ/ can be glottalised (Roach Reference Roach1973), though variation exists among regional British dialects. In London and South-eastern English varieties /t/ is most frequently glottalised, with /p/ and /k/ glottalised less often (Wells Reference Wells1982, Tollfree Reference Tollfree1999, Schneider et al. Reference Schneider, Burridge, Kortmann, Mesthrie and Upton2004). In Tyneside English /p/ is more frequently glottalised than the other stops (Docherty et al. Reference Docherty, Foulkes, Milroy, Milroy and Walshaw1997, Watt & Milroy Reference Watt and Milroy1999; note that the timing of glottalisation in this variety differs from other British varieties, with the glottal gesture occurring prior to the oral gesture and masking the oral stop release – Wells Reference Wells1982, Docherty & Foulkes Reference Docherty and Foulkes1999b), and in Sandwell /t/ and /k/ are often glottalised, whereas /p/ is affected less frequently (Mathisen Reference Mathisen1999). In AmE glottalisation commonly occurs for /t/ and /p/, though it is reported to occur more frequently and in a greater range of contexts for /t/ than for /p/ (Pierrehumbert Reference Pierrehumbert, Beals, Denton, Knippen, Melnar, Suzuki and Zeinfeld1994, Huffman Reference Huffman2005, Seyfarth & Garellek Reference Garellek2015). Nevertheless, in perception AmE listeners have been found to associate glottalisation with both /t/ and /p/ (Chong & Garellek Reference Chong and Garellek2018).
Recent research has shown that glottalisation is also used in Australian English (AusE) voiceless stop codas. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018), in an analysis of monosyllabic words containing alveolar voiced and voiceless stop codas produced by 67 speakers from Sydney, found that 55% of the words containing voiceless codas exhibited glottalisation, whereas only 6% of the words ending in voiced codas contained glottalisation. Whether glottalisation functions in the same way in this variety for stops at other POAs remains an open question. In her paper on /t/ variation in AusE, Tollfree (Reference Tollfree2001) notes that in addition to /t/, glottalisation is also present for /k/ in some lexical items (such as the almost categorical presence for certain items such as like) and that it can also occasionally be found for /p/. However, no empirical evidence is available to support this observation.
A number of studies have highlighted links between glottalisation and social factors in different varieties of English. Glottalisation has been linked to different class affiliations. For example, in Tyneside English, Milroy et al. (Reference Milroy, Milroy, Hartley and Walshaw1994) found voiceless coda stop glottalisation to be associated with working class speakers, whereas middle class speakers tended to prefer glottal replacement. Similarly, word final glottalisationFootnote 3 has been found to serve as a marker of prestige in Cardiff English, where it was present in the speech of the middle class and those with middle class aspirations (Mees Reference Mees1987, Mees & Collins Reference Mees and Collins1999). On the other hand, intervocalic /t/ glottalisation was rarely used by middle class Cardiff English speakers, but commonly used by working class speakers (Mees Reference Mees, Coupland and Thomas1990). Tollfree (Reference Tollfree2001) found AusE speaking teenagers from lower socioeconomic backgrounds used glottalised variants of /t/ more frequently in pre-pausal contexts in conversational speaking style than teenagers from higher socioeconomic backgrounds (though this difference was reduced in more formal reading list style).
Some studies have suggested that in some varieties glottalisation is more common in male speech (e.g. Milroy et al. Reference Milroy, Milroy, Hartley and Walshaw1994,Footnote 4 Docherty, Hay & Walker Reference Docherty, Hay, Walker, Warren and Watson2006). Others have found it to be more common in the speech of females (e.g. Mees Reference Mees1987, Holmes Reference Holmes1995Footnote 5). In a study of primary school aged AusE speaking children, Tait & Tabain (Reference Tait, Tabain, Carignan and Tyler2016) found that girls produced more glottalised variants of /t/ than boys,Footnote 6 though they did not report any glottalised variants of stops at other POAs. Interestingly, in their study of glottalisation in AusE, Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) did not find evidence of gender differences in /t/ glottalisation. They did, however, find age differences; younger speakers employed glottalisation much more so than older speakers (71% in younger compared to 36% in older speakers). Paired with the fact that glottalisation has only been noted in the literature as being present in AusE since the late 1980s (Ingram Reference Ingram1989, Haslerud Reference Haslerud1995, Tollfree Reference Tollfree2001), this suggests a recent change to the variety. In the light of Tollfree’s (Reference Tollfree2001) findings discussed above, that glottalisation is more common for /t/ than for stops at other POAs, it is conceivable that the change may have originally affected alveolar stops, before progressing to the other POAs. If this is the case, we may expect to see differences according to gender for the POAs other than alveolar, as females are often the leaders of linguistic change (Cameron & Coates Reference Cameron, Coates, Cameron and Coates1989; Eckert Reference Eckert1989; Labov Reference Labov1990, Reference Labov2001).
There are a number of acoustic cues to the phonological voicing status of coda stops in English other than glottalisation: f0 is lower at the offset of vowels preceding voiced stops compared to voiceless stops; and there is often a voice bar present in the stop closure of voiced stop codas (House & Fairbanks Reference House and Fairbanks1953, Gruenenfelder & Pisoni Reference Gruenenfelder and Pisoni1980, Kohler Reference Kohler1982, Ohde Reference Ohde1984, Lisker Reference Lisker1986, Kingston & Diehl Reference Kingston and Diehl1994, Wright Reference Wright, Hayes, Kirchner and Steriade2004, Song, Demuth & Shattuck-Hufnagel Reference Song, Demuth and Shattuck-Hufnagel2012). Preceding vowel duration is a major cue to coda voicing (e.g. Klatt Reference Klatt1976, Lisker Reference Lisker1978, Port & Dalby Reference Port and Dalby1982, Fowler Reference Fowler1992). Recent research on AusE suggests that a trading relationship may exist between glottalisation and vowel duration as cues to coda stop voicing. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) found that in voiceless coda contexts younger speakers did not only utilise glottalisation more than older speakers, but they also made less use of preceding vowel duration. In addition, glottalisation affected high vowels less than non-high vowels (in both older and younger groups), with high vowels exhibiting greater coda voicing-related preceding vowel duration differences than non-high vowels. Furthermore, coda stop voicing affected inherently long vowels (e.g. /iː/beat vs. bead) more than inherently short vowels (e.g. /ɪ/ bit vs. bid). These findings were based on observations of stressed syllables only; questions remain about whether the same effects would be present in unstressed syllables, as coda voicing-related durational differences are expected to be already reduced in such unstressed environments (Klatt Reference Klatt1975, Crystal & House Reference Crystal and House1988b, Davis & van Summers Reference Davis and van Summers1989). In cases where the vowel duration cue to coda voicing has been minimised, the trading relationship would predict higher rates of glottalisation in voiceless stop contexts to offset the reduced effectiveness of the vowel duration cue and help to preserve the voicing contrast. Although word initial glottalisation, that is, glottal marking at the onset of a vowel initial word, has been found to be more common in stressed rather than unstressed syllables (Kohler Reference Kohler1994, Malisz, Żygis & Pompino-Marschall Reference Malisz, Żygis and Pompino-Marschall2013), we are not aware of similar findings for coda glottalisation.
The present study investigates glottalisation as a cue to coda voicing in unstressed syllables with reference to all three POAs in AusE to investigate dialect-specific distributional patterns and the potential progression of change. In this study we examine two separate datasets in two analyses. The first dataset contains productions from a cohort of young female university students from Sydney. These data enable an analysis of coda stops in unstressed contexts at all three English stop POAs and a comparison of voiced and voiceless stop codas. The second dataset contains productions extracted from the AusTalk (Burnham et al. Reference Burnham, Estival, Fazio, Viethen, Cox, Dale, Cassidy, Epps, Togneri, Wagner, Kinoshita, Göcke, Arciuli, Onslow, Lewis, Butcher, Hajek, Cosi, De Mori, Di Fabbrizio and Pieraccini2011) corpus. These data allow for an analysis of age and gender with respect to the implementation of glottalisation.
Based on the previous literature, our broad expectations are as follows:
-
Glottalisation will occur at all three POAs. The general patterns of glottalisation in AusE may be similar to those reported for London and South-eastern BrE; namely, that glottalisation will occur for voiceless stops at all three POAs to cue coda stop voicelessness, but will be more frequently associated with alveolar coda stops than stops at other POAs. This hypothesis is based on the close historical connection between London English and AusE (Cox & Palethorpe Reference Cox, Palethorpe and Hickey2012) and the fact that there are a number of similarities between the two dialects (Wells Reference Wells1982, Cochrane Reference Cochrane, Collins and Blair1989, Yallop Reference Yallop2001). This would also be in accord with comments in Tollfree (Reference Tollfree2001).
-
Reduced coda voicing-related vowel duration differences leads to increased glottalisation. Coda voicing-related preceding vowel duration effects will be reduced in unstressed syllable contexts, and therefore glottalisation, which is suggested to occur in a trading relationship with preceding vowel duration in the implementation of coda voicelessness (Penney et al. Reference Penney, Cox, Miles and Palethorpe2018), may occur at increased rates than has previously been reported for stressed syllables.
-
Younger speakers will produce glottalisation at higher rates than older speakers. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) showed that younger speakers were more likely to glottalise voiceless alveolar coda stops than older speakers and interpreted this as support for glottalisation being a recent change to AusE. If it is indeed a recent change and younger speakers are leading the change, then we may expect to see evidence of this not just in the alveolar POA, but across the entire range of voiceless stops. We also expect alveolars to exhibit increased rates of glottalisation relative to labials and velars indicating a progression of change.
-
Female speakers will glottalise at higher rates than male speakers.We may expect to find increased glottalisation in female speakers consistent with the idea that women are the leaders in linguistic changes (Cameron & Coates Reference Cameron, Coates, Cameron and Coates1989; Eckert Reference Eckert1989; Labov Reference Labov1990, Reference Labov2001). Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) did not find support for a gender effect in their study of glottalisation in alveolar POA in AusE; however, if there is evidence for a progression of change across POA we may expect to see gender effects for the other POAs.
2 Analysis 1: Young Sydney females
2.1 Method
2.1.1 Data
Recordings were made in a sound treated recording studio in the Department of Linguistics at Macquarie University, using an AKG C535 EB microphone, Cooledit 2000 audio capture software via an M-Audio delta66 soundcard to a Pentium 4 PC at 44.1 kHz sampling rate. Speakers read words from a computer monitor in a task containing 100 words in total. All 100 words were presented three times in random order. These data were originally collected for an experiment designed to examine the production of unstressed vowels. The word list included, among other forms, trochees with the form /(C)VɹɘC/, where the final consonant was either a voiced or voiceless stop at bilabial, alveolar or velar POA. Analyses from words of this type only will be reported here. Note that in English there are no instances of words in the /(C)VɹɘC/ form containing a voiced velar coda in word final position so this context is excluded from the analysis. As alveolar stops show a wide range of realisations in different contexts (e.g. /t d/ may be flapped intervocalically; /t/ may be realised as a glottal stop before nasals and laterals; /t d/ may be realised as unreleased stopsFootnote 7 preceding obstruents), we chose the prepausal context to maximise the occurrence of canonical, released realisations. Note, however, that examining this context does not preclude the presence of non-canonical stop variants in the data. We therefore also describe the non-canonically produced stop variants in the results section below. The words analysed here are Arab, carob, Europe, syrup, arid, Jarrod, ferret, parrot, barrack.Footnote 8 Two tokens were discarded due to mispronunciations. A total of 754 items (bilabial: 335; alveolar: 335; velar: 84) were examined (see Table A1 in the appendix for a list of tokens by word for this and subsequent analyses).
The selected items allow for the comparison between words containing final coda stops in each of the three POAs (e.g. syrup, parrot, barrack) as well as between voiced and voiceless final coda stops for the bilabial (e.g. carob, syrup) and alveolar (e.g. Jarrod, parrot) POA. The use of trochees enabled us to explore whether glottalisation may be maximally exploited in an environment in which the coda voicing-related preceding vowel duration differences may already be reduced. Note that for all of the words in this analysis a schwa vowel is used in the unstressed syllable as is common for words of this type in AusE; however, unstressed vowels preceding velar codas may be realised as phonetically higher than unstressed vowels in other contexts in AusE (Cox & Fletcher Reference Cox and Fletcher2017) and vowel height has been linked to rate of glottalisation, with high vowels showing less glottalisation than non-high vowels (Penney et al. Reference Penney, Cox, Miles and Palethorpe2018).
2.1.2 Speakers
Twenty-eight female AusE speakers (aged 18–38 years; mean age: 24 years; SD: 7) took part in this study. All were Macquarie University undergraduate students who received course credit for their participation. All were born in Australia and had at least one parent born in Australia. All had completed their high school education in Australia, with all but three having done so in Sydney. All non–Australian-born parents were born in an English speaking country and had English as an L1.
In this study we have opted for a design which will allow for a broad-based population-level analysis as opposed to a more focussed individual-level analysis (i.e. we have selected a relatively large sample of speakers from a homogeneous population who produce a restricted set of words repeated only three times). Our rationale for this design structure is that our focus is on patterns pertaining to this population of speakers. However, we acknowledge that individuals are likely to vary in their use of glottalisation so cross speaker variability will be reported below where appropriate.
2.1.3 Acoustic analysis
All /(C)VɹɘC/ tokens were first processed by the WebMAUS automatic aligner (Kisler, Reichel & Schiel Reference Kisler, Reichel and Schiel2017) utilising an AusE model. MAUS automatically returns Praat (Boersma & Weenink Reference Boersma and Weenink2015) textgrids with phonemic boundaries labelled. These were then checked and hand corrected where necessary. In addition, all textgrids were hand labelled for subsegmental components including:
-
the onset of a high energy periodic F2 signalling the onset of the initial (stressed) vowel
-
the cessation of high energy F2 signalling the end of the second (unstressed) vowel
-
the presence and duration of a voice bar in the stop closure
-
the release burst of the coda stop
-
the F3 trough signalling the target of the intervocalic rhotic (Espy-Wilson et al. Reference Espy-Wilson, Boyce, Jackson, Narayanan and Alwan2000, Foulkes & Docherty Reference Foulkes and Docherty2000, Hay & Maclagan Reference Hay and Maclagan2012, Cox et al. Reference Cox, Palethorpe, Buckley and Bentink2014, Yuen, Cox & Demuth Reference Yuen, Cox and Demuth2018)
-
the presence and duration of glottalisation
The presence and duration of glottalisation was identified through irregular pitch periods in the second half of the voiced /Vɹɘ/ sequence, visible as irregularity in the waveform and a sudden increase in the duration between periods in conjunction with irregularity in amplitude in the wideband spectrogram. We acknowledge that isolated words each represent a separate intonational phrase and therefore phrase final creak may be evident. We therefore established conservative criteria to ascertain whether irregularity should be considered due to glottalisation associated with the coda. Tokens in which irregularity extended throughout the voiced /Vɹɘ/ sequence were considered to be examples of phrase final creak or speaker specific creaky voice and were thus not included as examples of coda glottalisation for this study in line with Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018). Tokens in which irregularity began in the second half of the /Vɹɘ/ sequence (i.e. irregularity began after the F3 trough representing the target of the rhotic segment) but within 15 ms of the F3 trough were also considered examples of creaky voice rather than labelled as glottalised codas. In classifying the tokens in this manner we may have discarded some examples of glottalisation associated with final coda stops in which glottalisation began shortly after the target of the rhotic. It is also plausible that very short instances of phrase final creak occurring only at the end of the unstressed vowel may have been labelled as glottalised, though note that this would be the case for both voiced and voiceless coda contexts. Figure 1 illustrates an example of a labelled token containing coda glottalisation showing the waveform, spectrogram and textgrid tiers.
Figure 1. Example of a labelled file of the word parrot with coda glottalisation at the end of the voiced sequence. The glottalised portion is shown by labels glott – glott end. The closure period of the coda stop is shown by labels clo – coda.
We then calculated the duration of the final unstressed vowel. As it is difficult to effectively segment an intervocalic rhotic approximant from a neighbouring vowel, we measured duration from the F3 trough of the rhotic to the cessation of periodic F2 indicating offset of the vowel. We then measured F1 and F2 at the point equivalent to 75% of the duration of this segment, in order to obtain measurements of vowel height and backness. The point equating to 75% of the segment’s duration was selected in order to estimate the position where the formants had stabilised from the influence of the rhotic, though we note that unstressed schwa displays highly coarticulated characteristics (van Bergem Reference van Bergem1994, Fleming Reference Fleming and Minkova2009). High vowels are less affected by glottalisation than low vowels (Brunner & Żygis Reference Brunner, Żygis, Lee and Zee2011, Malisz et al. Reference Malisz, Żygis and Pompino-Marschall2013, Penney et al. Reference Penney, Cox, Miles and Palethorpe2018); in addition, as discussed above, in AusE unstressed vowels preceding velar and postalveolar codas (e.g. paddock, marriage) may be realised as phonetically higher than unstressed vowels in other contexts (Cox & Fletcher Reference Cox and Fletcher2017). Thus, formant measurements are an important variable in our analysis. Outliers were checked and hand corrected where necessary. Formant measures were then converted to the Bark scale using the vowels package (Kendall & Thomas Reference Kendall and Thomas2014) in R (R Core Team 2016).
Using the STRAIGHT pitch tracker (Kawahara, Masuda-Katsuse & de Cheveigné Reference Kawahara, Masuda-Katsuse and de Cheveigné1999) in VoiceSauce (Shue et al. Reference Shue, Keating, Vicenik, Yu, Lee and Zee2011), f0 was measured with a window size of 25 ms and a frame shift of 1 ms throughout the unstressed vowel (as segmented from the F3 trough associated with the preceding rhotic to the end of the vowel) and subsequently averaged into five equal subsections. The average f0 measure of the fifth subsection of the unstressed vowel was recorded as f0 at vowel offset.
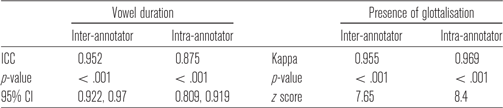
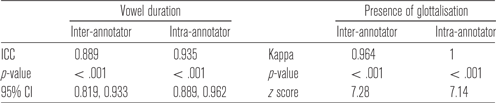
To ensure annotator reliability 10 per cent of the data were randomly selected and re-labelled. A second trained annotator also re-labelled 10 per cent of the data to assess inter-annotator reliability. Intra-class correlations and 95% confidence intervals were calculated for the continuous measure of vowel duration, using the irr package (Wolak, Fairbairn & Paulsen Reference Wolak, Fairbairn and Paulsen2012). For the categorical measure of the presence or absence of glottalisation a Cohen’s Kappa score was calculated. Table 1 contains the results for inter-annotator reliability and intra-annotator reliability. As can be seen, reliability was high in all cases.
Table 1: Intra-class correlation results for vowel duration and Cohen’s Kappa results for the presence of glottalisation.
2.1.4 Statistical analysis
We fitted a number of mixed models using the lme4 (Bates et al. Reference Bates, Maechler, Bolker and Walker2015) and lmertest (Kuznetsova, Brockhoff & Christensen Reference Kuznetsova, Brockhoff and Christensen2016) packages in R (R Core Team 2016). The following analyses were conducted:
-
Linear mixed effects modelling was used to conduct three separate analyses of the following dependent variables: vowel formants (either F1 or F2), coda voicing-related durational contrasts, and differences in fundamental frequency.
-
Logistic mixed effects modelling was used to conduct two separate analyses of the following dependent variables: glottalisation in voiced and voiceless codas, and glottalisation in voiceless codas.
The details of the dependent variables and fixed factors included in each of the models will be reported below. Unless otherwise specified, we included in each model random intercepts for speaker and repetition and random slopes for repetition by speaker. Where relevant (and noted below) random intercepts were included for word and random slopes were included for word by speaker. We initially included all fixed factors and their interactions, then pruned the models after carrying out model comparisons with the anova() function to remove non-significant terms that did not significantly improve the model, beginning with non-significant interactions. Using this approach we arrived at the most parsimonious model for each analysis. For significant effects (at an alpha level of p = .05) we report F-statistics for the linear mixed effects models and Chi-Square statistics for the logistic mixed effects models. Post-hoc analyses were carried out with Tukey HSD corrections for multiple comparisons.
2.2 Results
2.2.1 Analysis of vowel formants
We first analysed F1 and F2 of the unstressed vowels in all 754 tokens to identify whether the POA of the following stop had an effect on the height and fronting of the unstressed vowel. We fitted separate linear mixed effects models for F1 and F2, in which the respective formant measurement was the dependent variable (i.e. either F1 or F2 measured in Bark). In both models POA was a fixed factor. The syntax for each of the models was as follows: lmer(formant ~ poa + (1+repetition|speaker) + (1|repetition)).
Figure 2 illustrates the mean F1 and F2 in Bark for each POA for all voiced and voiceless tokens for all speakers. As can be seen, velar POA produced slightly more variation in F1 than the other POAs. However, the linear mixed effects model for F1 showed no significant effect of POA (F(2,696) = 2.226; p = .105). Figure 2 also shows that the bilabial POA had a clear effect of lowering F2, as is to be expected (Modarresi et al. Reference Modarresi, Sussman, Lindblom and Burlingame2005), and the linear mixed effects model for F2 confirmed POA had a significant effect (F(2,724) = 561.9; p < .0001). Post-hoc tests showed that F2 in each POA context differed significantly from each of the others (alveolar–labial: p < .0001; alveolar–velar: p = .004; labial–velar: p < .0001). Unstressed vowels were more retracted in the bilabial context and most fronted in the velar context, but POA did not have an effect on the height of unstressed vowels.
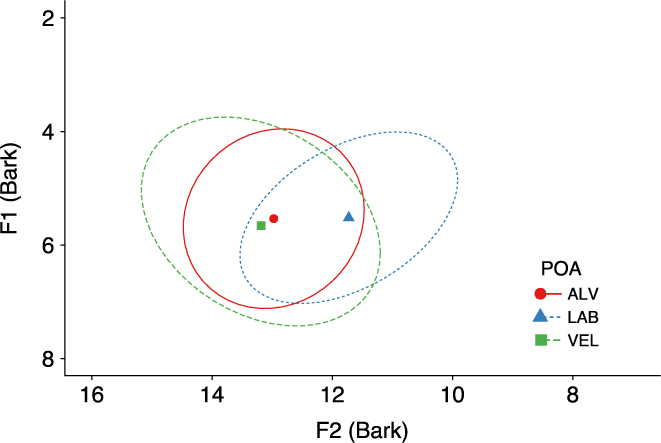
Figure 2. Mean F1 and F2 values (Bark) for unstressed vowels according to POA of following stop. Shapes represent centroids. Ellipses represent 95% confidence intervals.
2.2.2 Analysis of coda voicing-related durational contrast
Figure 3 displays the mean durations of the unstressed vowels (which included the transitional component from the trough of F3 of the rhotic) in both the voiced and voiceless coda contexts for alveolar and bilabial POAs. As can be seen, for each POA the unstressed vowels are longer in the voiced coda context (mean: 142 ms; SD: 30 ms) than the voiceless coda context (mean: 124 ms; SD: 33 ms), though the differences between voicing contexts are small.
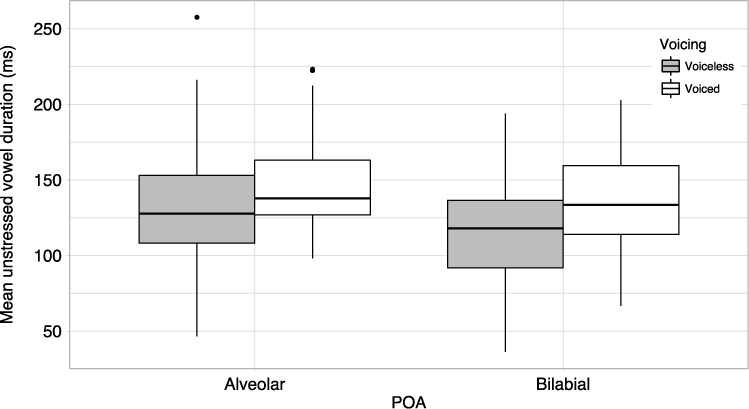
Figure 3. Mean duration (ms) of unstressed vowels (represented by the segment identified from the trough of F3 in the /ɹ/ to the offset of F2) in voiced and voiceless contexts at alveolar and bilabial POA. Boxes represent the middle 50% of unstressed vowel duration values; solid horizontal lines within the boxes represent the median; whiskers represent minimum and maximum values excluding outliers.
We fitted a linear mixed effects model in order to identify whether there was a coda voicing-related vowel duration difference between the voiced and voiceless coda contexts. For this model we included only words with bilabial and alveolar POAs to account for the lack of examples of words with a velar POA in the voiced coda set. We also removed two words from the data set that contained no onset consonant in the initial syllable, so that all of the items included in the analysis contained the same number of segments. This was necessary in order to avoid potential durational differences that may result from compression effects, whereby syllables containing a greater number of segments may lead to reduced vowel duration (Fowler Reference Fowler1983, Munhall et al. Reference Munhall, Fowler, Hawkins and Saltzman1992, Katz Reference Katz2012). Both of the items removed contained voiced coda stops: one bilabial (Arab) and one alveolar (arid). The words included in this analysis were therefore carob, Europe, syrup, Jarrod, ferret, parrot. A total of 503 tokens (bilabial: 251; alveolar: 252) were included. The duration of the unstressed vowel (represented by the segment identified from the trough of F3 in the /ɹ/ to the offset of F2) was the dependent variable. The voicing of the final coda stop and POA were included as fixed factors. An interaction term was originally included but this did not improve the model and hence it was removed from the final model. Random intercepts were included for speaker, repetition and word, and random slopes were included for repetition and word by speaker. The syntax for the most parsimonious model was as follows: lmer(duration ~ voicing + poa + (1+repetition+word|speaker) + (1|repetition) + (1|word)). The model showed a significant effect for coda voicing (F(1,4) = 21.613; p =.012), confirming that vowels were longer before voiced coda stops. There was also a significant effect for POA (F(1,4) = 16.136; p =.013), with longer vowels preceding alveolar stops (mean: 137 ms; SD: 33 ms) compared to bilabial stops (mean: 123 ms; SD: 32 ms). Unstressed vowels were longer in duration before voiced coda stops, and longer in duration before stops at alveolar POA.
2.2.3 Analysis of glottalisation in voiced and voiceless codas
Eighty-three per cent of voiceless coda tokens and 10% of voiced coda tokens exhibited glottalisation as determined by the presence of irregular voicing at the end of the final vowel and identified during the section of the word from the trough of F3 to the coda stop closure. 83% of the voiceless alveolar stops, 83% of the voiceless bilabial stops, and 82% of the voiceless velar stops were glottalised. In contrast, glottalisation was only present for 8% of the voiced alveolar stops, and 11% of the voiced bilabial stops. Recall that there were no items containing final voiced velar stops in the data set. Figure 4 illustrates the proportions of glottalised tokens in voiced and voiceless coda contexts for each of the POAs. In the voiceless context, nine of the 28 speakers produced glottalisation categorically, with the majority of the other speakers glottalising at least 80% of tokens. Only one speaker produced glottalisation in less than half of the tokens in the voiceless context. In the voiced context, 13 speakers produced glottalisation in at least one token, and one speaker glottalised more than 50% of tokens. Table A2 in the appendix provides details of the individual speakers’ rates of glottalisation in each voicing context.
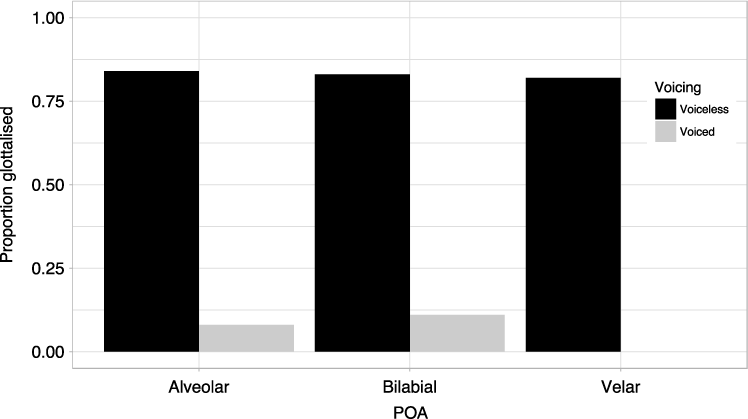
Figure 4. Proportion of items glottalised in each POA and coda voicing context. Note that there were no items containing voiced velar coda stops.
In order to investigate whether the voicing of the coda had an effect on the presence of glottalisation we fitted a logistic mixed effects model to a subset of the data comprising all words (voiced and voiceless contexts) with bilabial and alveolar codas. The presence of glottalisation was the dependent variable. POA and the phonological voicing status of the final coda stop were included as fixed factors, as was an interaction term between the factors, though this did not improve the model fit and was removed from the final model. Random intercepts were included for speaker, repetition, and word, and random slopes were included for repetition and word by speaker. The syntax for the most parsimonious model was as follows: glmer(glottalisation ~ poa + voicing + (1+repetition+word|speaker) + (1|repetition) + (1|word)). The words included in this analysis were Arab, carob, Europe, syrup, arid, Jarrod, ferret, parrot.A total of 670 tokens (bilabial: 335; alveolar: 335) were included.
The results showed a significant effect for coda voicing (χ 2 = 41.226; p < .0001), confirming that glottalisation was less likely to occur in the voiced coda context for words ending in stops at both of these POAs. There was no significant effect found for POA (χ 2 = 1.780; p = .182). Glottalisation occurred at high rates in the voiceless coda context in both bilabial and alveolar contexts, but occurred only rarely in the voiced coda context.
2.2.4 Analysis of glottalisation in voiceless codas
We then fitted a logistic mixed effects model to another subset of the data containing all items in the voiceless coda context only. This enabled an analysis of potential differences in rates of glottalisation for words ending in stops at all three POAs. The presence of glottalisation was the dependent variable. POA of the final coda stop (bilabial, alveolar, velar) was the fixed factor.Footnote 9 The syntax for this model was as follows: glmer(glottalisation ~ poa + (1+repetition|speaker) + (1|repetition)). The words included in this analysis were Europe, syrup, ferret, parrot, barrack. Four hundred and nineteen tokens (bilabial: 167; alveolar: 168; velar: 84) were included in this analysis.
Unsurprisingly given the similar rates of glottalisation in the voiceless coda context, the analysis revealed no significant effect for POA (χ 2 = 0.204; p = .903), demonstrating that the presence of glottalisation was not dependent on the POA of the final coda stop. Glottalisation occurred at high rates in the voiceless coda context in all three POA contexts.
2.2.5 Comparison with stressed syllables
As the rates of glottalisation found in the voiceless coda context here (83%) are numerically higher than those previously reported for stressed syllables produced by a comparable cohort of speakers (i.e. the young speakers reported in Penney et al. Reference Penney, Cox, Miles and Palethorpe2018, who glottalised at a rate of 71%), we fitted a logistic mixed effects model to analyse whether these differences were statistically significant. We compared the data for unstressed syllables in the alveolar coda context with the data for stressed syllables produced by young female speakers (n = 17) included in Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018), which contained stressed CVC monosyllables with an alveolar coda. We examined only the young female speakers as they were analogous in age and gender to the speakers examined here. The young females in Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) produced glottalisation in 79% of the stressed tokens, a higher rate than the reported rate for the combined younger male and female speakers. The presence of glottalisation was the dependent variable, and whether the item was produced in a stressed or unstressed syllable was included as a fixed factor. The syntax for this model was as follows: glmer(glottalisation ~ stress + (1+repetition|speaker) + (1|repetition)). The words included in this analysis were ferret, parrot for the unstressed syllables, and heat, hit, heart, hut, hort, hot, hoot for the stressed syllables. 476 tokens (stressed: 308; unstressed: 168) were included in this analysis. The model showed that the difference in rates of glottalisation between stressed and unstressed contexts was not significant (χ 2 = 1.492; p = .222). Young female speakers glottalised at comparable rates in unstressed and stressed syllable contexts.
2.2.6 Analysis of differences in fundamental frequency
Table 2 lists the mean f0 for each POA in both voiced and voiceless contexts. The analysis of f0 at the offset of the unstressed vowel showed small differences in the expected direction between the voiced and voiceless coda contexts; f0 was slightly lower before voiced coda stops (mean = 200 Hz) than before voiceless coda stops (mean = 204 Hz). There was also a small difference in f0 between POAs, with f0 marginally lower before alveolar stops (mean = 201 Hz) than bilabial stops (mean = 203 Hz). In order to examine the relationship between f0 and coda voicing we fitted a linear mixed effects model to all of the items in the bilabial and alveolar POA contexts. The dependent variable was f0 at the offset of the unstressed vowel. POA of the final coda stop (bilabial, alveolar) and phonological coda voicing were included as fixed factors. An interaction term was also included but this did not improve the model fit and as such it was not included in the final model. We included random intercepts for speaker, repetition, and word. This was the maximal random effects structure to converge. The syntax for this model was as follows: lmer(f0 ~ voicing + POA + (1|speaker) + (1|repetition) + (1|word)). The words included in this analysis were Arab, carob, Europe, syrup, arid, Jarrod, ferret, parrot. Eight tokens were excluded from the analysis due to pitch tracking errors. Six hundred and sixty tokens (bilabial: 330; alveolar: 330) were included. We found no significant effect of either coda voicing (F(1,628) = 0.1079; p = .743) or POA (F(1,628) = 0.3527; p = .553) on f0; f0 at the offset of unstressed vowels was comparable preceding voiced and voiceless coda stops.
Table 2: Mean f0 (Hz) at vowel offset in voiced and voiceless coda contexts according to place of articulation of following coda stop.

2.2.7 Voice bar
The majority of tokens containing a voiced coda stop exhibited some prolonged voicing into the stop closure. In total, 321 tokens showed evidence of a voice bar: 312/335 (93%) of these were in the voiced coda context (alveolar: 155, bilabial: 157), with the remaining nine in the voiceless coda context (alveolar: 3, bilabial: 5, velar: 1). Of the tokens with a voice bar, 27 (9%) of these exhibited voicing throughout the entire closure.
Table 3: Number of non-canonical stop realisations according to coda voicing context. Brackets indicate number of tokens occurring in conjunction with glottalisation.
2.2.8 Non-canonical stop realisations
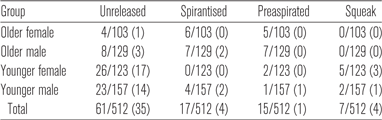
In addition to the glottalised productions, there were a number of other non-canonical realisations of coda stops present in the data (see Table 32 for a summary). First, 5% of the tokens (n = 40/754 produced by 12 speakers) contained coda stops which were unreleased. Glottalisation is often associated with unreleased stops (e.g. Kahn Reference Kahn1976, Selkirk Reference Selkirk, van der Hulst and Smith1982, Blevins Reference Blevins2006), and in 31 of the 40 tokens with unreleased stops, glottalisation was also present. In all but three of these glottalised unreleased stops, formant transitions were visible at the end of the unstressed vowel (i.e. a rising F2 preceding alveolar coda stops and a lowering F2 preceding bilabial coda stops), suggesting that an oral articulation was made for the stop even if there was no acoustic evidence for its release. The majority of unreleased stops had an alveolar POA (25/40), though there were also bilabial stops that were unreleased (15/40). Interestingly, none of the velar tokens contained unreleased stops. Velar stops have been reported to display unreleased variants less frequently than the other POAs (Crystal & House Reference Crystal and House1988a, Byrd Reference Byrd1993), and, although unreleased bilabial stops have been suggested to occur more frequently than unreleased alveolars (Byrd Reference Byrd1993), Crystal & House (Reference Crystal and House1988b) note that in unstressed syllables they tend to be released more frequently than the other POAs, which is consistent with the data examined here. There were also tokens in which the coda stop was spirantised; that is, produced with an incomplete occlusion resulting in turbulent (fricative) airflow through the closure period. This was the case in 4% of the tokens (n = 28/754 produced by 11 speakers). All but two of these were alveolar stops (with the other two bilabial stops), and spirantisation occurred in conjunction with glottalisation in 14 of the 28 tokens. Spirantisation of /t/ has been reported to be associated with female speakers with high socioeconomic status in AusE (Tollfree Reference Tollfree2001, Jones & McDougall Reference Jones and McDougall2009). In the analysis below, we compare whether differences are present between males and females, or between this cohort of speakers and the speakers in the AusTalk corpus more generally. A further 2% (n = 17/754 produced by six speakers) of the tokens exhibited preaspiration at vowel offset. Preaspiration is a period of voiceless aspiration that may occur at the end of a vowel preceding a voiceless obstruent (Helgason Reference Helgason2002, Nance & Stuart-Smith Reference Nance and Stuart-Smith2013). Occurrences of preaspiration were found at all POAs, but only one token preceded a bilabial, with eight tokens before both velar and alveolar coda stops. One speaker in particular was responsible for seven of the 17 examples. Glottalisation occurred in conjunction with preaspiration in over half of the tokens. Figure 5 shows an example of a token containing both preaspiration and glottalisation.
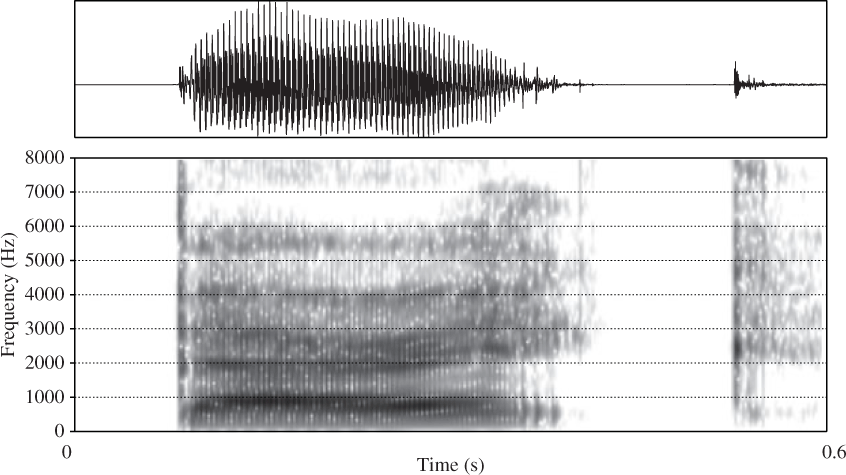
Figure 5. Spectrogram and waveform of the word barrack containing preaspiration and glottalisation at the end of the vowel.
Finally, 4% (n = 27/754 produced by 11 speakers) of the tokens contained glottal squeaks, which Redi & Shattuck-Hufnagel (Reference Redi and Shattuck-Hufnagel2001: 414) describe as ‘a sudden shift to relatively high sustained f0, which [is] usually very low amplitude’. These squeaks occurred for words at each POA (alveolar: 9; bilabial: 7; velar: 7), and, as has previously been suggested to be the case, they occurred almost exclusively in conjunction with glottalisation (Redi & Shattuck-Hufnagel Reference Redi and Shattuck-Hufnagel2001, Hejná, Palo & Moisik Reference Hejná, Palo and Moisik2016). There were four examples of squeaks that were not produced in conjunction with glottalisation; however, each of these tokens was produced in contexts with phrase final creak.Footnote 10 The squeaks were relatively short in duration (mean: 26 ms) and generally occurred closer to the left edge of the stop closure period than to the right edge (i.e. the release) (mean duration from closure: 20 ms; mean duration from release: 92 ms), with a mean f0 of 280 Hz. Figure 6 shows an example of a token containing a glottal squeak.
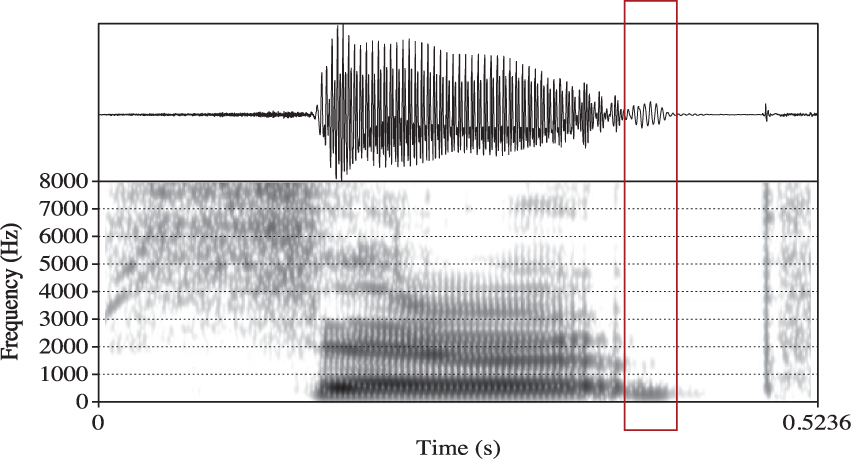
Figure 6. Spectrogram and waveform of the word syrup containing glottalisation and a glottal squeak at the end of the vowel. Red box shows the region of the glottal squeak, which has a mean f0 of 241 Hz. The preceding unstressed vowel has a mean f0 of 218 Hz prior to the onset of glottalisation.
2.3 Analysis 1: Discussion
The analysis of glottalisation according to coda stop voicing for alveolar and bilabial POAs suggests that glottalisation is employed as a cue to coda stop voicelessness in word final unstressed syllables containing schwa. This supports the hypothesis that, in line with findings for other varieties of English such as BrE and AmE (Roach Reference Roach1973,Wells Reference Wells1982, Pierrehumbert Reference Pierrehumbert, Beals, Denton, Knippen, Melnar, Suzuki and Zeinfeld1994, Huffman Reference Huffman2005, Seyfarth & Garellek Reference Garellek2015), glottalisation cues coda stop voicelessness generally in AusE, rather than specifically for alveolar stops. Future work comparing voiced and voiceless stops in an extended set of environments including both voiced and voiceless velar coda stops will be required to confirm the suggestion that glottalisation as a cue to voicelessness holds for all three POAs.
We hypothesised that /t/ would exhibit more glottalisation than the other voiceless stops; however, all three POAs demonstrated similar proportions of glottalised tokens and POA did not affect the likelihood of glottalisation occurring. This is in contrast to London English and to AmE, as in both varieties /t/ is more frequently glottalised than the other voiceless stops (Wells Reference Wells1982, Pierrehumbert Reference Pierrehumbert, Beals, Denton, Knippen, Melnar, Suzuki and Zeinfeld1994, Tollfree Reference Tollfree1999, Huffman Reference Huffman2005). Although glottalisation of velar and bilabial stops has previously been reported for AusE (Tollfree Reference Tollfree2001), it was suggested to occur less frequently for /k/ and only occasionally for /p/. This differs from the pattern shown in our results; however, it must be remembered that the environment examined here was different from the other studies, as we have exclusively examined unstressed syllables in isolated words.
We hypothesised that coda voicing-related vowel duration differences would be reduced in the unstressed environment and that, as a consequence, higher rates of glottalisation may be present compared to what has previously been reported for stressed contexts. We found a mean unstressed vowel duration difference of 18 ms, which was measured from the F3 trough of the preceding rhotic and as such incorporates part of the consonant. Although the difference was smaller than what has been previously reported for young female AusE speakers in stressed contexts, our analysis found that unstressed vowels were nevertheless significantly longer preceding voiced coda stops than before voiceless coda stops. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) found a mean vowel duration difference of 46 ms (24 ms when only short vowels were considered) between voiced and voiceless coda contexts in stressed syllables. Recall also that Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) showed that coda voicing-related vowel duration differences were reduced in their young speakers compared to older speakers. So while coda voicing-related durational differences may be reduced in the unstressed environment, they do not appear to be markedly more so than in the stressed environment. In addition, although we found numerically higher rates of glottalisation than those reported in Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) for stressed monosyllables, this difference was not found to be significant when compared to young female speakers in the stressed syllable context. In both stressed and unstressed contexts young female speakers exhibited high rates of glottalisation preceding voiceless codas.
Additional support for the idea that glottalisation may help to preserve the voicing contrast comes from the analysis of f0 above. Although we found small differences in f0 in the expected direction for voiced and voiceless stops, these differences were not found to be significant in our model, lending further support to the idea that glottalisation is taking on more of the ‘heavy lifting’ to maintain the coda voicing contrast in this environment. Note, however, that we observed at least some prolonged voicing in the closure period for the majority of voiced stops (though only relatively few tokens exhibited full voicing throughout closure). Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) also found a voice bar to be frequently present in voiced coda contexts in their data and suggest that glottalisation and voice bar may serve as complementary cues to coda stop voicing, at least in laboratory speech. The results presented here support this suggestion of complementarity.
Previous research has suggested that glottalisation is less likely to occur in high vowel contexts (Brunner & Żygis Reference Brunner, Żygis, Lee and Zee2011, Malisz et al. Reference Malisz, Żygis and Pompino-Marschall2013, Penney et al. Reference Penney, Cox, Miles and Palethorpe2018). Although there were examples of raised unstressed vowel realisations in the data, particularly in the velar coda context, we found no relationship between F1 and the presence of glottalisation. This is not surprising, given that the F1 variance in the unstressed vowels was minimal, as shown by the lack of significant effect of POA on F1 in the analysis of formants above. It is possible that examination of unstressed vowels that display more extreme height differences may produce different results.
Analysis 1 has shown that glottalisation occurs in conjunction with voiceless stops in unstressed syllables at all three POAs in AusE, at a level that is comparable to rates of glottalisation in stressed syllables in an alveolar coda context. We also found that the coda voicing-related vowel duration differences are reduced in unstressed contexts, although a significant difference in vowel duration between voiced and voiceless coda contexts remains. It should of course be borne in mind that this analysis is based on analysis of data in a very narrow, controlled environment; accordingly, it is not clear to what extent these results may be generalisable to other contexts. In addition, this analysis examined only young, female speakers. The following analysis is an extension to a different cohort, made up of both male and female speakers from different age groups, in order to examine more closely whether and to what extent glottalisation in unstressed syllables is affected by the factors of age and gender.
3 Analysis 2: Older and younger Sydney speakers from the AusTalk corpus
3.1 Method
3.1.1 Data
Data for Analysis 2 were extracted from AusTalk (Burnham et al. Reference Burnham, Estival, Fazio, Viethen, Cox, Dale, Cassidy, Epps, Togneri, Wagner, Kinoshita, Göcke, Arciuli, Onslow, Lewis, Butcher, Hajek, Cosi, De Mori, Di Fabbrizio and Pieraccini2011), which is a large corpus of AusE speech that was collected at multiple locations using standardised equipment and procedures between 2011 and 2015. It comprises audio and visual data from 973 speakers aged from 18 to 83 years from a range of regional and social backgrounds. The audio data used for the current analysis were sampled at 44.1 kHz via an AudioTechnica headworn AT892c microphone through an M-Audio FastTrackUltra8R digital recording interface. Specific details about the recording process, setup, equipment and hardware can be found in Burnham et al. (Reference Burnham, Estival, Fazio, Viethen, Cox, Dale, Cassidy, Epps, Togneri, Wagner, Kinoshita, Göcke, Arciuli, Onslow, Lewis, Butcher, Hajek, Cosi, De Mori, Di Fabbrizio and Pieraccini2011). Each speaker was recorded in both standardised and spontaneous speech tasks (Burnham et al. Reference Burnham, Estival, Fazio, Viethen, Cox, Dale, Cassidy, Epps, Togneri, Wagner, Kinoshita, Göcke, Arciuli, Onslow, Lewis, Butcher, Hajek, Cosi, De Mori, Di Fabbrizio and Pieraccini2011, Cassidy, Estival & Cox Reference Cassidy, Estival, Cox, Ide and Pustejovsky2017). One of the standardised tasks was a word list task, in which 322 isolated words were read in random order from a computer screen. For the present analysis trochees with the form /(C)VɹɘC/ with final voiceless coda stops at bilabial, alveolar or velar POA were extracted from the word list recordings. The words analysed here are syrup, parrot, barrack. Most speakers attended three sessions, and so produced three repetitions of each word; however, for some speakers only two tokens could be extracted. As in Analysis 1 above, the selected items will enable us to analyse potential differences in rates of glottalisation for words ending in stops at all three POAs. A total of 512 items (bilabial: 174; alveolar: 170; velar: 168) were examined.
3.1.2 Speakers
Data for this analysis were extracted for 61 speakers in two age groups: an older group aged above 55 years (n = 27, 12 female, 15 male; mean age: 65; SD: 8) and a younger group aged between 18 and 35 years (n = 34, 16 female, 18 male; mean age: 25; SD: 5). All of the speakers were born in and had completed their entire school education in Sydney. The inclusion of an older and a younger group will allow us to compare potential differences between the age groups in the implementation of voicing, particularly as glottalisation has been suggested to be a recent development in AusE (Penney et al. Reference Penney, Cox, Miles and Palethorpe2018). Hence, we may expect to find differences between older and younger speakers, particularly if there has been a progression of change across POA. Furthermore, the inclusion of male and female speakers in both age groups will enable us to examine whether differences related to gender play a role in the how glottalisation is employed.
As in Analysis 1, this design allows for a broad-based population-level analysis rather than a more focussed individual-level analysis. However, as individuals are likely to vary in their use of glottalisation cross speaker variability will be reported below as appropriate.
3.1.3 Acoustic analysis
All tokens in the data set were acoustically analysed using the same methods as described in the acoustic analysis section from Analysis 1 above. Vowel formants were also measured as outlined above; however, as this data set contains productions from both male and female speakers, normalisation of the formant measurements was also necessary to account for physiological differences between genders. The data were Lobanov normalised using the vowels package (Kendall & Thomas Reference Kendall and Thomas2014) in R (R Core Team 2016).
As in Analysis 1 above, 10 per cent of the data were randomly selected and relabelled by the first author to assess intra-annotator reliability. A second trained annotator also re-labelled 10 per cent of the data to assess inter-annotator reliability. Using the irr package (Wolak et al. Reference Wolak, Fairbairn and Paulsen2012), Intra-class correlations and 95% confidence intervals were calculated for vowel duration. For the categorical measure of the presence or absence of glottalisation a Cohen’s Kappa score was calculated. Table 4 contains the results for inter-annotator reliability and intra-annotator reliability, and shows that reliability was high in all cases.
Table 4: Intra-class correlation results for vowel duration and Cohen’s Kappa results for the presence of glottalisation.
3.1.4 Statistical analysis
As in Analysis 1 above, we fitted mixed models to the data using the lme4 package (Bates et al. Reference Bates, Maechler, Bolker and Walker2015) in R (R Core Team 2016). The following analyses were conducted:
-
Linear mixed effects modelling was used to conduct an analysis of vowel formants, with the relevant formant (i.e. either F1 or F2) as the dependent variable.
-
Logistic mixed effects modelling was used to conduct an analysis of glottalisation in voiceless codas, with the presence of glottalisation as the dependent variable.
As in Analysis 1, we included random intercepts for speaker and repetition and random slopes for repetition by speaker in each model. We initially included all fixed factors and their interactions, then pruned the models after carrying out model comparisons with the anova() function to remove terms that did not significantly improve the model, beginning with non-significant interactions. Post-hoc analyses were carried out with Tukey HSD corrections for multiple comparisons. Full details and the syntax of the most parsimonious model for each analysis will be reported below.
3.2 Results
3.2.1 Analysis of vowel formants
As in Analysis 1, we first examined the F1 and F2 measurements of the unstressed vowels in all 512 tokens to identify whether the POA of the following stop had an effect on the vowels’ phonetic height and fronting. We were also interested in whether this differed according to age group and/or gender. Figure 7 illustrates the mean F1 and F2 in Bark (converted from the Lobanov normalised measurements) for each POA for all tokens produced by the speakers according to age group and gender. We fitted linear mixed effects models separately for F1 and F2. In each model the relevant formant measurement (i.e. F1 or F2) was the dependent variable, with POA, age group, gender and their interactions included as fixed factors. The syntax for the most parsimonious F1 model was: lmer(F1 ~ (poa + age group + gender)^ 3 + (1+repetition|speaker) + (1|repetition)). The syntax for the most parsimonious F2 model was: lmer(F2 ~ (poa + age group + gender)^2 + (1+repetition|speaker) + (1|repetition)).
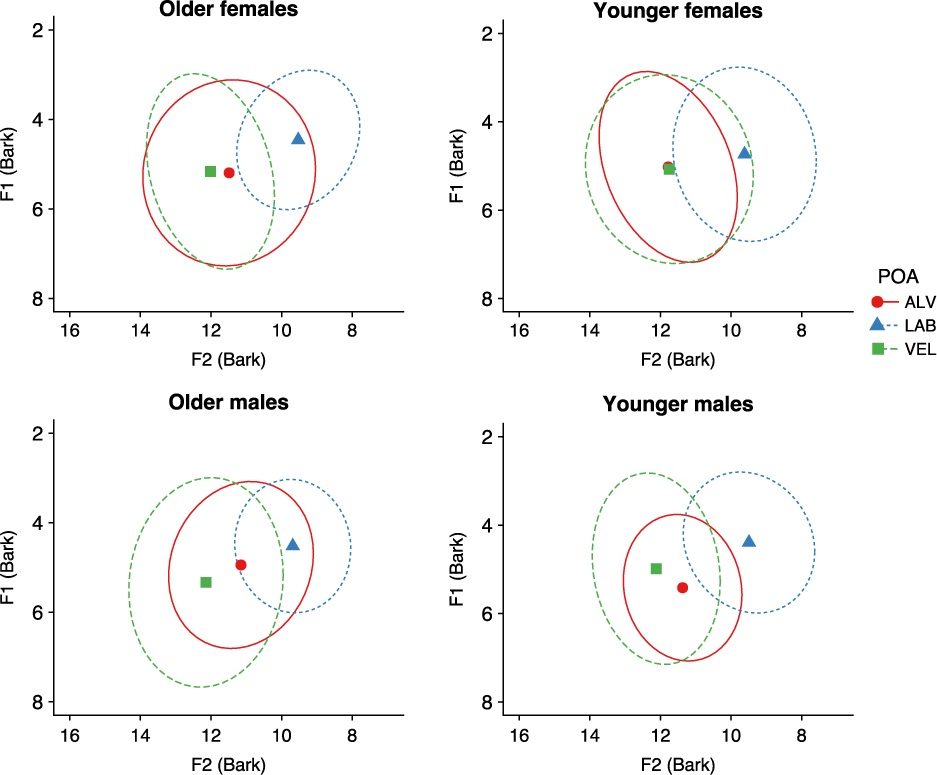
Figure 7. Mean F1 and F2 values (Bark) for unstressed vowels according to POA of following stop. Upper panels represent female speakers; lower panels represent male speakers. Left panels represent older speakers; right panels represent younger speakers. Shapes represent centroids. Ellipses represent 95% confidence intervals.
In the analysis of F1 data we a found significant effect for POA (F(2,444) = 37.614; p < .0001); in general, unstressed vowels before bilabial stops were produced with lower F1 (i.e. phonetically higher realisations) than those before stops at the other POAs. There was also a significant three way interaction between POA, age group, and gender (F(2,444) = 5.936; p = .003). Post hoc analyses showed that within each age and gender group all of the differences were related to the bilabial POA, which was significantly phonetically higher than alveolar and velar POAs for the older females (alveolar–bilabial: p = .005; bilabial–velar: p = .006) and the younger males (alveolar–bilabial: p = <.0001; bilabial–velar: p = .018), and than velar POA for the older males (p = .001). For the younger females there were no significant differences between the POAs.
The F2 analysis also showed a significant effect of POA (F(2,502) = 419.612; p < .0001), as well as a significant two way interaction between POA and gender (F(2,502) = 8.373; p = .003). In general, the bilabial context showed lower F2 values than the other POAs, as expected (Modarresi et al. Reference Modarresi, Sussman, Lindblom and Burlingame2005). Post hoc analyses showed significant differences in F2 between the male and female speakers before the alveolar POA (p = .011), with the male speakers showing lower F2 (i.e. more retracted productions) than the female speakers in this context. The male speakers showed significant differences between all three POAs (all p < .0001). In contrast, the female speakers showed significant differences between the bilabial and alveolar and between the bilabial and velar contexts (both p < .0001), but not between alveolar and velar.
To summarise, unstressed vowels were more retracted in the bilabial contexts for all groups, and higher in the bilabial context for all but the younger females. In addition, the male speakers produced more retracted unstressed vowels in the alveolar context compared to the female speakers.
3.2.2 Analysis of glottalisation in voiceless codas
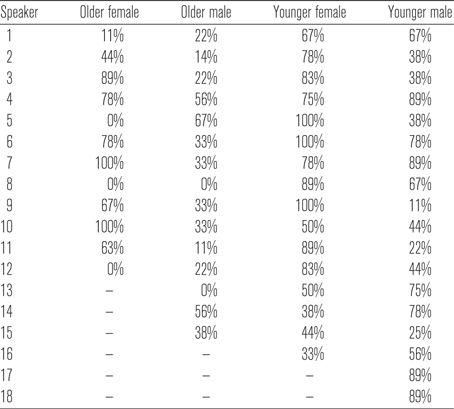
In total, 60% of the alveolar stops, 51% of the bilabial stops, and 51% of the velar coda stops were glottalised. Twenty of the 28 female speakers glottalised at least 50% of tokens, with five of the female speakers categorically producing glottalisation (three from the younger group and two from the older group). Three of the female speakers (all from the older age group) produced no glottalisation. Thirteen of the 33 male speakers produced glottalisation in at least 50% of tokens, none produced glottalisation categorically, and two of the male speakers (both from the older age group) produced no glottalisation. Table A3 in the appendix provides details of the individual speakers’ rates of glottalisation according to age group and gender. We fitted a logistic mixed effects model to all of the data (recall that this data set contained only items in the voiceless coda context) to analyse potential differences in rates of glottalisation for words ending in voiceless stops at all three POAs, as well as differences related to gender and to age group. The presence of glottalisation was the dependent variable. The POA of the final coda stop (bilabial, alveolar, velar), age group, gender and their interactions were included as fixed factors.Footnote 11 The syntax for the most parsimonious model was as follows: glmer(glottalisation ~ (poa + age group + gender)^2 + (1+repetition| speaker) + (1| repetition)). The model showed significant effects for age group (χ 2 = 12.254; p = .001) and for gender (χ 2 = 10.502; p = .001), as well as a significant interaction between POA and age group (χ 2 = 6.174; p = .047).
The significant effect for age group reveals that glottalisation was employed more frequently by the younger speakers (younger speakers 64%, older speakers 41% glottalised tokens). The gender effect shows that the male and female speakers utilised glottalisation differently (females 65%, males 46% glottalised tokens). Both of these effects support the suggestion that glottalisation is a recent change to AusE (Penney et al. Reference Penney, Cox, Miles and Palethorpe2018) and may indicate a change being led by young women.
The significant interaction between POA and age group indicates that the two age groups vary in the incidence of glottalisation at different stop POAs. Figure 8 illustrates the proportion of glottalised tokens within each POA for older and younger speakers. As can be seen, in each POA the younger speakers produced more glottalised tokens than the older speakers. However, the younger speakers show a preference for glottalisation in the alveolar context (74% glottalised), followed by bilabial (64% glottalised), with the velar context showing the least amount of glottalisation (55% glottalised). Older speakers do not exhibit this same preference for POA; instead, they glottalised at similar rates in both the velar (46% glottalised) and alveolar (43% glottalised) contexts, and least in the bilabial context (35% glottalised). Post hoc analyses showed that within each age group there were no significant differences between POAs. However, they also showed that the older and younger speakers differed significantly from each other in the alveolar (p = .007) and bilabial (p = .008) contexts, but did not differ in the velar context.
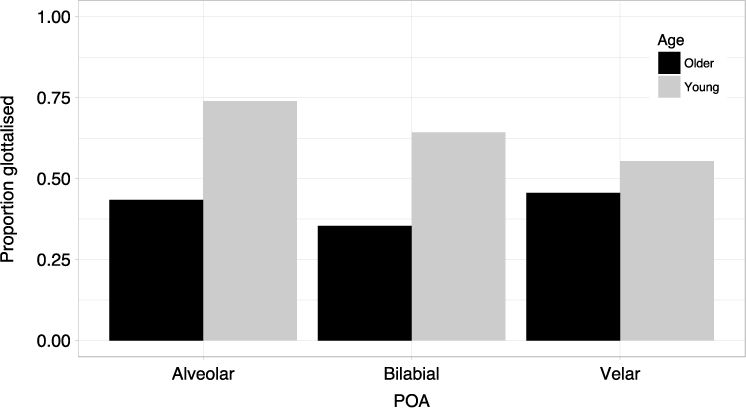
Figure 8. Proportion of tokens glottalised in each POA according to age group.
To summarise, female speakers produced glottalisation at higher rates than male speakers, and younger speakers produced glottalisation at higher rates than older speakers, particularly in the alveolar and bilabial coda contexts.
3.2.3 Comparison with stressed syllables
As in Analysis 1, we then conducted a comparison between these data and the data from the stressed syllable context reported in Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018), which used the same cohort of speakers (n =67; younger female: 17; younger male: 19; older female: 14; older male: 17). As only alveolar contexts were included in the stressed context data, we included only the unstressed syllables in the alveolar context in this comparison. We fitted a logistic mixed effects model with the dependent variable presence of glottalisation, and fixed factors stress (i.e. whether the item was produced in a stressed or unstressed syllable), age group, and gender. Interactions between the fixed factors were also included but these did not improve the model fit and they were not included in the final model. The syntax for the most parsimonious model was as follows: glmer(glottalisation ~ stress + age + gender + (1+repetition| speaker) + (1| repetition)). The words included in this analysis were parrot for the unstressed syllables, and heat, hit, heart, hut, hort, hot, hoot for the stressed syllables. 1418 tokens (stressed: 1248; unstressed: 170) were included in this analysis. We found significant effects for age group (χ 2 = 41.422; p < .0001), showing that younger speakers glottalised more than older speakers in both contexts, and for gender (χ 2 = 6.814; p = .009), demonstrating that the female speakers glottalised more than the male speakers. As in Analysis 1, we found no effect of stress (χ 2 = 0.725; p = .394), suggesting that rates of glottalisation were comparable across age and gender groups in both stressed and unstressed environments.
3.2.4 Comparison with Analysis 1
As the rates of glottalisation found in Analysis 2 were numerically smaller than those found in Analysis 1 above, we carried out a further comparison to test whether there was a statistical difference between the two cohorts of speakers. To enable a comparison with the speakers in Analysis 1 (n = 28), we examined only the productions of the young female speakers included in Analysis 2 (n = 16). Figure 9 shows the proportion of glottalised tokens containing a voiceless coda stop at each POA according to the respective data set. As can be seen, the speakers in Analysis 1 glottalised at essentially the same rate in each POA, while the speakers from Analysis 2 glottalised slightly less in the bilabial and velar contexts than they did in the alveolar context. We fitted a logistic mixed effects model to the data with presence of glottalisation as the dependent variable and fixed factors POA and data set (i.e. Analysis 1 or 2). An interaction between the fixed factors was also included but this did not improve the model fit and was removed from the final model. The syntax for the most parsimonious model was as follows: glmer(glottalisation ~ poa + corpus + (1+repetition| speaker) + (1| repetition)).
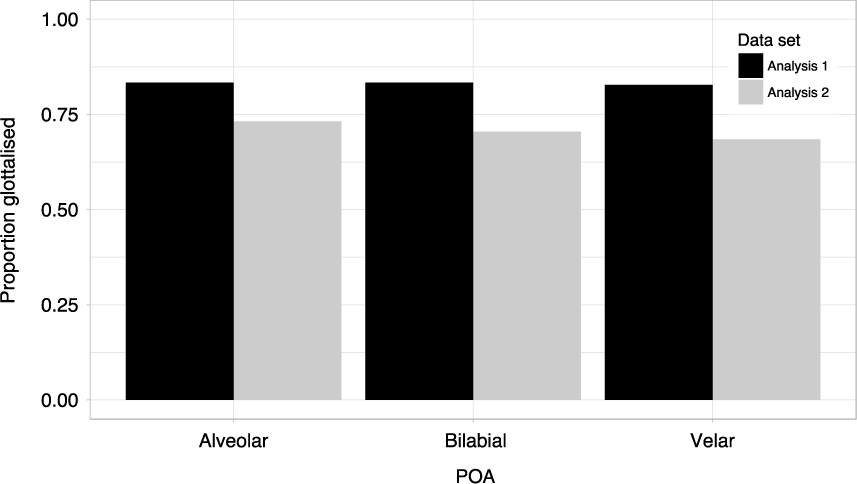
Figure 9. Proportion of glottalised tokens with voiceless coda stops according to POA for young female speakers in two data sets.
The results showed no significant effect for POA (χ 2 = 0.172; p = .918). Overall, the speakers from Analysis 1 glottalised more frequently than the speakers from Analysis 2 (83% compared to 71%), with a trend towards significance for data set (χ 2 = 3.223; p = .073). Despite the differences, in both sets glottalisation was produced at each POA at very high rates by the young female speakers.
Table 5: Number of non-canonical stop realisations according to age group and gender. Brackets indicate number of tokens occurring in conjunction with glottalisation.
3.2.5 Non-canonical stop realisations
As in Analysis 1, there were a number of non-canonical stop realisations represented in the data; these are summarised in Table 5. Twelve per cent of the tokens (n = 61/512 produced by 24 speakers) contained unreleased coda stops (i.e. they showed no evidence of a release burst). Of these unreleased stops, more than half were also glottalised. Formant transitions at the end of the unstressed vowel were observable for all but three of these glottalised unreleased stops, indicating that although no release was visible the vast majority of cases nevertheless involved a supralaryngeal articulation. In the younger speakers, the majority of the unreleased stops had alveolar POA, though unreleased bilabial tokens also occurred; unreleased velar tokens were rare (alveolar: 29; bilabial: 18; velar: 2). In the older speakers, bilabials were more often unreleased than alveolars, and there were no unreleased velar tokens (alveolar: 3; bilabial: 9). The small number of unreleased velar stops is consistent with Analysis 1 above and with previous literature which suggests velar stops are released more frequently than stops at the other POAs (Crystal & House Reference Crystal and House1988a, Byrd Reference Byrd1993). There were also some examples of spirantised stops, though these accounted for only 3% of all tokens (n = 17/512 produced by 11 speakers). As was found in Analysis 1, spirantisation occurred almost exclusively in the alveolar context though there were two occurrences in conjunction with velar stops. Glottalisation was also present in four of the spirantised tokens. The majority of the spirantised stops were produced by males (11/17), and those that were produced by females were produced by older females. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) also found that male speakers used spirantisation more than females. These results contrast with previous research based on speakers from Melbourne, which found spirantisation of /t/ (fricated /t/) to be associated with female speakers (Jones & McDougall Reference Jones and McDougall2009, Loakes & McDougall Reference Loakes and McDougall2010), possibly suggesting a regional difference.
Another 3% of the tokens (n = 15/512 produced by eight speakers) contained preaspiration. The majority of these were produced by older speakers, and they occurred in alveolar contexts, though there were two examples for velar stops. In contrast to Analysis 1, where half of the 17 preaspirated stops were also glottalised, only one preaspirated token occurred in conjunction with glottalisation. Glottal squeaks were rare in this data set, accounting for only 1% of the data (n = 7/512 produced by five speakers). As in Analysis 1, each glottal squeak occurred in conjunction with either glottalisation or phrase final creak. Five of the seven squeaks were found in the alveolar context; there was also one squeak observed in each of the bilabial and velar contexts. A single female produced three of the squeaks, with the remaining squeaks each produced by a different speaker. The squeaks found here exhibited similar characteristics to those described in Analysis 1; they were short in duration (mean: 21 ms) and occurred shortly after the stop closure period began (mean duration from closure: 30 ms; mean duration from release: 66 ms). The squeaks in this Analysis had a mean f0 of 295 Hz (female: 301 Hz; male: 281 Hz).
3.3 Analysis 2: Discussion
One of our hypotheses was that younger speakers would produce glottalisation in unstressed syllables at higher rates than the older speakers (previously found for alveolar stops in stressed syllables), which would be consistent with a recent change to AusE. As stated above, glottalisation has been noted in the AusE literature since the late 1980s (Ingram Reference Ingram1989, Haslerud Reference Haslerud1995, Tollfree Reference Tollfree2001), whereas prior to this it was considered to be absent from the variety (Wells Reference Wells1982, Trudgill Reference Trudgill1986). The results presented support the hypothesis and show that younger speakers are significantly more likely to glottalise than older speakers in the unstressed syllable context examined here. In addition, the results provide additional support for the claim that glottalisation is a recent change to AusE (Penney et al. Reference Penney, Cox, Miles and Palethorpe2018), with younger speakers leading the change. Of course, real time analysis would be required to discount the possibility that the age-related differences are due to age grading effects (Bailey Reference Bailey, Chambers, Trudgill and Schilling-Estes2002); likewise, an examination of historical data may be able to shed more light on the processes of how and when this change entered the variety.
The results also demonstrate that female speakers produced glottalisation more frequently than male speakers. While previous studies have found gender effects related to glottalisation in other varieties of English (Holmes (Reference Holmes1995), Mees (Reference Mees1987, Reference Mees and Collins1990), and Redi & Shattuck-Hufnagel (Reference Redi and Shattuck-Hufnagel2001) all found females exhibited more glottalisation than males, though Milroy et al. (Reference Milroy, Milroy, Hartley and Walshaw1994) found the opposite), this has not previously been shown to be the case in AusE. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) found no evidence of a gender effect; however, their analysis examined glottalisation associated with alveolar coda stops in stressed syllables only. In the present study, we explored glottalisation in unstressed syllables for all three English stop POAs. We might speculate that the gender difference could be due to the different stress contexts, though we found that rates of glottalisation were similar between stressed and unstressed syllables for alveolar stops. Perhaps the difference is rather due to our examination of a greater number of contexts; though we did not find an interaction between gender and POA, Figure 9 shows that the younger speakers produced numerically less glottalisation in the non-alveolar contexts, which may suggest that the relevant gender differences lie within the non-alveolar POAs. Figure A1 in the appendix also shows that the differences between males and females are greater in the non-alveolar contexts. The gender effect that we found may be interpreted as supporting the notion that women are the drivers of this change to AusE. This would not be surprising, given that women are often at the forefront of sociophonetic change and have been shown to adopt new features sooner than men (Labov Reference Labov1990). Of course, other explanations may also be possible; for example, it may be that females glottalise more frequently than males for physiological reasons. For example, women may make greater use of a raised larynx as a strategy to reduce transglottal pressure difference in order to cease voicing but this suggestion requires empirical examination. Such a strategy may introduce a bias for glottalisation (Moisik Reference Moisik2013).
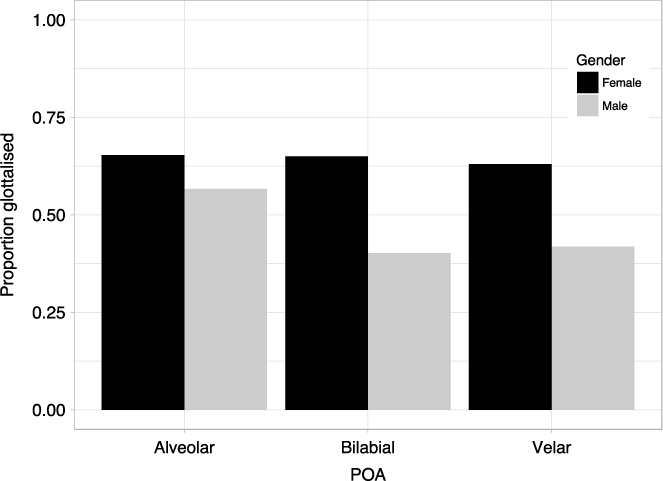
Figure A1. Proportion of tokens glottalised in each POA according to gender.
Analysis 2 adds further support to the finding in Analysis 1 that glottalisation is employed for voiceless coda stops at all three POAs in unstressed syllables in this variety of English. Glottalisation was present in at least half of all tokens examined at each POA suggesting that glottalisation is an important cue for voiceless coda stops in unstressed syllables, regardless of POA. We hypothesised that /t/ would exhibit more glottalisation than the other voiceless stops; although in Analysis 2 we found glottalisation to be numerically more frequent for alveolar stops compared to the other POAs in the younger group, we found no significant differences in rates of glottalisation according to POA within either age group. As in Analysis 1 above, this finding contrasts with the pattern of /t/ being most frequently glottalised in other varieties of English, such as London English (Wells Reference Wells1982, Tollfree Reference Tollfree1999) and AmE (Pierrehumbert Reference Pierrehumbert, Beals, Denton, Knippen, Melnar, Suzuki and Zeinfeld1994, Huffman Reference Huffman2005, Seyfarth & Garellek Reference Garellek2015). Tollfree (Reference Tollfree2001) suggests that glottalisation is frequently present for /k/ for particular lexical items, and occasionally present for /p/ in AusE. Based on this, we anticipated evidence of a progression of change from alveolar to the other POAs. We did find that the younger speakers differed significantly from the older speakers in the alveolar and bilabial contexts, but not in the velar context. The alveolar and bilabial were also the contexts that showed the highest proportions of glottalisation for the younger speakers. This may indicate some marginal support for a progression of change. Alternatively, the difference in findings may be due to the unstressed context investigated here.
As in Analysis 1 above, we found no evidence of an effect of unstressed vowel height on the presence of glottalisation, which is not altogether surprising as all of the tokens contained a schwa. We also hypothesised that increased rates of glottalisation may be present in unstressed syllables compared to stressed syllable codas, given vowel duration cues may be reduced in such contexts (Klatt Reference Klatt1975, Crystal & House Reference Crystal and House1988b, Davis & van Summers Reference Davis and van Summers1989). The younger speakers in Analysis 2 produced glottalisation in unstressed syllables containing coda /t/ at a comparable rate to that reported for stressed syllables in Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018), with a slight increase in the unstressed context (unstressed: 74%; stressed: 71%). The older speakers in this analysis produced glottalisation at higher rates than has been reported for stressed syllables (unstressed: 43%; stressed: 36%). However, as in Analysis 1 above, the comparison of glottalisation of coda /t/ in stressed and unstressed syllables showed no difference for any of the age or gender groups, suggesting that rates of glottalisation, though slightly increased, were statistically comparable between the two contexts.
4 General discussion
Taken together, the two analyses here demonstrate that glottalisation occurs for voiceless stops at all three POAs in AusE utterance final unstressed syllable codas. Therefore, it seems that glottalisation serves as a cue to coda voicelessness generally for stops at each POA, and is not specifically related to alveolar stops. In contrast to other varieties of English such as London English and AmE, where glottalisation occurs most frequently with alveolar stops, we found no significant differences in rates of glottalisation between the POAs. It may be possible that glottalisation initially occurred for alveolars in AusE but has now spread to the other stops as well. Glottalisation of /t/ has been noted in the AusE literature since the late 1980s (Ingram Reference Ingram1989, Haslerud Reference Haslerud1995), whereas the only mention of glottalisation of /pk/ prior to this paper was in Tollfree (Reference Tollfree2001), where glottalisation of non-alveolar stops was suggested to be less common. In Analysis 2 we found that the younger speakers differed from the older speakers for /t/ and /p/, and these contexts were also those that were numerically most frequently glottalised in the younger speakers. Taken together with Tollfree’s findings, this may provide some limited support for a progression from alveolar to stops at other POAs.
Analysis 2 showed that younger speakers were more likely to glottalise than older speakers for stops at all three POAs. This is in accord with previous findings and supports the idea that glottalisation is a recent change to AusE, though alternative explanations may also be possible (e.g. age grading, physiological differences between older and younger speakers). In addition, glottalisation occurred at high rates for stops at each POA in the younger female speakers in both of the analyses. Combined with the finding from Analysis 2 that females glottalised more than males, these results may support the idea that glottalisation is a recent change led by young female speakers. Tait & Tabain (Reference Tait, Tabain, Carignan and Tyler2016) also found glottalisation to be more common in female than male primary school-aged children, perhaps indicating an early onset of a gender difference.
Unsurprisingly given the unstressed context analysed here, we found that preceding unstressed vowel height did not have an effect on the presence of glottalisation. Vowel height has previously been linked to glottalisation, with high vowels less likely to be glottalised (Brunner & Zygis Reference Brunner, Żygis, Lee and Zee2011, Malisz et al. Reference Malisz, Żygis and Pompino-Marschall2013, Penney et al. Reference Penney, Cox, Miles and Palethorpe2018). In our examination of unstressed syllables we did not find a height effect, although our data were restricted to schwa contexts and, hence, minimal height variance is to be expected.
In both of the analyses we found that glottalisation in unstressed syllables occurred at comparable rates to stressed syllables. Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) found evidence of a trading relationship between glottalisation and vowel duration, whereby rates of glottalisation increased in combination with decreased coda voicing-related vowel duration differences. Such a trading relationship would predict increased glottalisation in unstressed contexts, if vowel duration differences were reduced compared to stressed contexts. In Analysis 1 we found a reduced vowel duration difference between voiced and voiceless coda contexts compared to stressed contexts, though a small but significant difference was maintained. The high rates of glottalisation observed in conjunction with reduced coda-voicing related vowel duration differences lends supports the idea that glottalisation may assist in maintaining the phonological coda voicing contrast if the vowel duration cue is minimised. This is further supported by the f0 analysis, which found that differences between the voiced and voiceless coda contexts appear to have been minimised in the data examined here. As all of the tokens examined were produced as single words, and hence all were in utterance final position, this finding is also partially in accord with Keyser & Stevens (Reference Keyser and Stevens2006), who suggest that voiceless stops at all three POAs may show glottalisation in final position to enhance the voicing contrast. Note, however, that they posit that glottalisation may be necessary as subglottal pressure is reduced in final position and hence may not support voicing in the stop closure period thereby undermining the voicing contrast. We found a voice bar in the majority of voiced coda stops, suggesting that this particular cue was not reduced in our data, though, as noted above, the vowel duration and f0 cues were reduced.
We found some evidence of differential rates of glottalisation between the young female speakers in Analysis 1 and 2, despite these speakers being matched for age and gender. Although these differences were not found to be significant in our modelling, it is possible that further variation may exist in the community and may be attributable to social factors that we have not accounted for in our analysis, such as differences in socioeconomic status, regional (area specific) variation, or differing ethno-cultural affiliations. Tollfree (Reference Tollfree2001) found differences in rates of glottalisation of /t/ related to socioeconomic status in conversational speech of AusE teenagers, and Cox & Palethorpe (Reference Cox, Palethorpe, Mannell and Robert-Ribes1998, Reference Cox, Palethorpe, Lee and Zee2011) have shown differences between speakers from different regions of Sydney and between those with different ethno-cultural backgrounds. It is also possible that individual differences may play a role.
In both analyses speakers produced a range of non-canonical stop realisations including unreleased stops which were often associated with glottalisation. Previous research has found that glottalisation often co-occurs with unreleased stops (Kahn Reference Kahn1976, Selkirk Reference Selkirk, van der Hulst and Smith1982, Blevins Reference Blevins2006), and it has been suggested that glottalisation may promote perception of the stop’s POA through increasing the amplitude of the formants where transitions occur (Garellek Reference Garellek2011). Spirantised stops were also present in both analyses: in Analysis 1 there were examples of spirantised stop realisations produced by the young females; in Analysis 2, the young females were not responsible for any of the spirantised stops which were instead produced by males. Previous research on speakers from Melbourne has linked spirantisation to female speakers, particularly females from high socio-economic backgrounds (Tollfree Reference Tollfree2001, Jones & McDougall Reference Jones and McDougall2009, Loakes & McDougall Reference Loakes and McDougall2010), though Penney et al. (Reference Penney, Cox, Miles and Palethorpe2018) also found that male speakers produced spirantised realisations more frequently than female speakers in their data from Sydney. Spirantisation is perhaps related to individual speaker differences rather than gender.
Tokens exhibiting preaspiration were also present in each of the analyses. In Analysis 2 these were mainly produced by older speakers and did not occur with glottalisation. Curiously, however, in Analysis 1 over half of the cases preaspiration occurred in conjunction with glottalisation. Although it might seem that preaspiration and glottalisation may be very separate strategies for achieving voicelessness: the former through glottal abduction, and the latter through glottal adduction, it may be possible that in cases where the two strategies are combined, preaspiration occurs when the vocal folds are abducted following the final glottal closure associated with glottalisation (before the oral closure is made). However, Figure 5 seems to suggest that, rather than occurring in sequence, these two phenomena overlap, as can be seen by the aperiodic energy associated with the aspiration occurring at the same time as the irregular voicing due to glottalisation. This may be explained by models of laryngeal activity that consider the entire larynx, rather than focussing solely on the glottis, such as those posited by Edmondson & Esling (Reference Edmondson and Esling2006) and Moisik & Esling (Reference Moisik and Esling2011). According to this view, glottalisation may be achieved through epilaryngeal constriction (i.e. ventricular incursion), which could take place at the same time as the vocal folds are abducted, resulting in preaspiration.Footnote 12
Finally, both data sets contained examples of glottal squeaks. Interestingly, squeaks were produced exclusively by young speakers in each of the analyses. In Analysis 2, more squeaks were produced by female speakers, though the female speakers in Analysis 1 produced more squeaks than the females in Analysis 2. Redi & Shattuck-Hufnagel (Reference Redi and Shattuck-Hufnagel2001) and Hejná et al. (Reference Hejná, Palo and Moisik2016) suggest that squeaks are more likely to be produced by female speakers, and are speaker specific; that is, certain (mostly female) speakers tend to produce squeaks in conjunction with glottalisation, but they are not necessary in order to produce glottalisation. Eleven of the 28 speakers in Analysis 1 did produce at least one squeak, which to our knowledge is a higher proportion than has previously been reported (and, indeed, is higher than in Analysis 2). Why this might be so is uncertain; however, it does suggest future examination of glottal squeaks in AusE speakers may reveal interesting patterns of individual stop realisation.
It should again be pointed out that this examination was based on small sets of data collected in highly controlled contexts, and therefore the interpretations offered in this paper may not be generalisable to other, less restricted contexts. Accordingly, in our future work we plan to explore glottalisation in a greater variety of contexts and with speakers from a wider range of social backgrounds. In addition, it would be interesting to extend this research to examine when children begin to use glottalisation as a cue to coda voicing. This may help to determine whether glottalisation has a primarily social or physiological basis if prepubescent boys and girls whose anatomical structures are not yet differentiated use glottalisation differently. Future work may also further explore the suggestion that glottalisation is a recent change to AusE, by analysing archival data collected at different time points since the 1980s.
5 Conclusion
This study has shown that glottalisation occurs in conjunction with coda voiceless stops at each POA in utterance final unstressed syllables in single words in AusE. Glottalisation was shown to occur at high rates in unstressed contexts, in conjunction a reduction in the use of vowel duration as a cue to coda voicing. In the face of a reduced vowel duration cue to coda stop voicing glottalisation may be utilised to cue voicelessness. Younger speakers used glottalisation more than older speakers, and females were more likely to glottalise than males, both results supporting previous suggestions of a recent change. Further research is needed to examine whether the patterns found here are replicated in unscripted speech. In addition, an analysis of the links between production and perception will further our understanding of potential trading relationships between cues to coda stop voicing.
Acknowledgments
This research was supported in part by an Australian Government Research Training Program scholarship to the first author. Parts of this research were presented at the 2017 Australian Linguistic Society annual conference at the University of Sydney, and the fifth New Ways of Analyzing Variation – Asia Pacific conference (NWAV–AP5) at the University of Queensland; we thank audience members for their comments and questions. In addition, we would like to thank Steve Cassidy for assistance with AusTalk, Kelly Miles for additional annotation, and members of the MQ phonetics lab for their feedback. We also thank Amalia Arvaniti, Gerry Docherty, and two anonymous reviewers for their insightful comments and suggestions.
Appendix A. Additional material
Table A1 Number of tokens by word in each analysis.
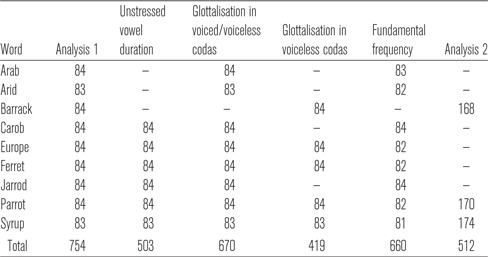
Table A2 Rates of glottalisation per speaker in Analysis 1 according to voicing context.
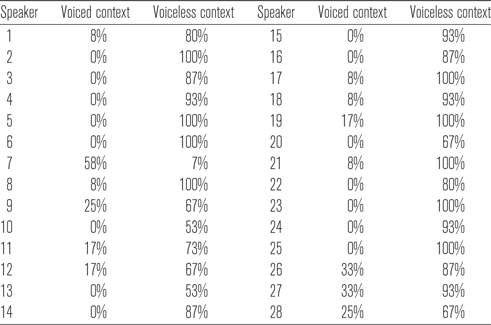
Table A3 Rates of glottalisation per speaker in Analysis 2 according to age group and gender.