


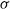
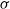
1. Introduction
In this paper we derive upper bounds for the Kolmogorov and Wasserstein distances between a mixture of normal distributions and a normal distribution with properly chosen parameter values. Here, a random variable X is said to have a mixture of normal distributions if there exists a
 $\sigma$
-algebra
$\sigma$
-algebra
 $\mathscr{G}$
such that the conditional distribution of X given
$\mathscr{G}$
such that the conditional distribution of X given
 $\mathscr{G}$
is normal. Also, for comparison and completeness, lower bounds for both distances are derived.
$\mathscr{G}$
is normal. Also, for comparison and completeness, lower bounds for both distances are derived.
To see why this is of interest, suppose that a random sequence
 $\{X_n;n=0,1,\ldots\}$
converges in distribution to a normal random variable Z. If
$\{X_n;n=0,1,\ldots\}$
converges in distribution to a normal random variable Z. If
 $\mathscr{L}\,(Z)$
is used instead of
$\mathscr{L}\,(Z)$
is used instead of
 $\mathscr{L}\,(X_n)$
for the (approximate) computation of the expectation
$\mathscr{L}\,(X_n)$
for the (approximate) computation of the expectation
 $\mathbb{E}(h(X_n))$
, where
$\mathbb{E}(h(X_n))$
, where
 $h\,:\,\mathbb{R}\to\mathbb{R}$
is a measurable function, an approximation error
$h\,:\,\mathbb{R}\to\mathbb{R}$
is a measurable function, an approximation error
 $\mathbb{E}(h(X_n))-\mathbb{E}(h(Z))$
is incurred, about which the limit theorem per se gives no information. In order to control this error, it is natural to use a metric on the space of probability measures on
$\mathbb{E}(h(X_n))-\mathbb{E}(h(Z))$
is incurred, about which the limit theorem per se gives no information. In order to control this error, it is natural to use a metric on the space of probability measures on
 $(\mathbb{R},\mathscr{R})$
, and try to bound the distance between
$(\mathbb{R},\mathscr{R})$
, and try to bound the distance between
 $\mathscr{L}\,(X_n)$
and
$\mathscr{L}\,(X_n)$
and
 $\mathscr{L}\,(Z)$
. A common choice is the Kolmogorov distance, which is defined for any two random variables X and Z with probability distributions
$\mathscr{L}\,(Z)$
. A common choice is the Kolmogorov distance, which is defined for any two random variables X and Z with probability distributions
 $\mu_1$
and
$\mu_1$
and
 $\mu_2$
by
$\mu_2$
by
 \begin{equation*}d_K(\mu_1,\mu_2) = \sup_{x\in\mathbb{R}}\bigl|\mathbb{P}(X\leq x)-\mathbb{P}(Z\leq x)\bigr|.\end{equation*}
\begin{equation*}d_K(\mu_1,\mu_2) = \sup_{x\in\mathbb{R}}\bigl|\mathbb{P}(X\leq x)-\mathbb{P}(Z\leq x)\bigr|.\end{equation*}
Another possibility is the Wasserstein distance, defined by
 \begin{equation*}d_W(\mu_1,\mu_2) = \sup_{h\in\mathcal{H}_1}\bigl|\mathbb{E}(h(X))-\mathbb{E}(h(Z))\bigr|,\end{equation*}
\begin{equation*}d_W(\mu_1,\mu_2) = \sup_{h\in\mathcal{H}_1}\bigl|\mathbb{E}(h(X))-\mathbb{E}(h(Z))\bigr|,\end{equation*}
where
 $\mathcal{H}_1$
is the class of Lipschitz functions with Lipschitz constant bounded by 1.
$\mathcal{H}_1$
is the class of Lipschitz functions with Lipschitz constant bounded by 1.
In Section 2, we derive bounds for both distances between the probability distribution of a random variable X which has a mixture of normal distributions, and a normally distributed random variable (Theorems 2.1 and 2.2). The bounds depend only on the first two moments of the first two conditional moments given the ‘mixing’
 $\sigma$
-algebra. The main tool used is Stein’s method, a powerful technique introduced in [Reference Stein20]. At the core of this method is a functional equation called the Stein equation,
$\sigma$
-algebra. The main tool used is Stein’s method, a powerful technique introduced in [Reference Stein20]. At the core of this method is a functional equation called the Stein equation,
 \begin{equation*}f^{\prime}(x) - xf(x) = I_{(-\infty,z]}(x) - \Phi(z) \qquad\forall x\in\mathbb{R},\end{equation*}
\begin{equation*}f^{\prime}(x) - xf(x) = I_{(-\infty,z]}(x) - \Phi(z) \qquad\forall x\in\mathbb{R},\end{equation*}
where
 $\Phi$
is the cumulative distribution function of the
$\Phi$
is the cumulative distribution function of the
 $\text{N}(0,1)$
distribution. By taking expectations with respect to
$\text{N}(0,1)$
distribution. By taking expectations with respect to
 $\mathscr{L}\,(X)$
on both sides, and using analytical properties of the solution function f, bounds can be obtained for the Kolmogorov distance between
$\mathscr{L}\,(X)$
on both sides, and using analytical properties of the solution function f, bounds can be obtained for the Kolmogorov distance between
 $\mathscr{L}\,(X)$
and
$\mathscr{L}\,(X)$
and
 $\text{N}(0,1)$
. While this is easiest if X is a sum of locally dependent random variables, the use of couplings and other special devices has made it possible to handle many other situations. There are also extensions of the method which allow for other approximating distributions to be used, such as Poisson and compound Poisson distributions and multivariate normal distributions. Since its introduction, the number of applications of the method has grown very large. For more details and many examples, see Barbour and Chen [Reference Barbour and Chen3, Reference Barbour and Chen4], and the references therein.
$\text{N}(0,1)$
. While this is easiest if X is a sum of locally dependent random variables, the use of couplings and other special devices has made it possible to handle many other situations. There are also extensions of the method which allow for other approximating distributions to be used, such as Poisson and compound Poisson distributions and multivariate normal distributions. Since its introduction, the number of applications of the method has grown very large. For more details and many examples, see Barbour and Chen [Reference Barbour and Chen3, Reference Barbour and Chen4], and the references therein.
In the second part of the paper we apply the obtained results to branching Ornstein–Uhlenbeck processes. A one-dimensional Ornstein–Uhlenbeck (OU) process is a stochastic process that follows a linear stochastic differential equation of the form
 \begin{equation}\textrm{d} X(t) = -\alpha X(t) \textrm{d} t + \sigma_{a} \textrm{d} W(t) \qquad\forall t\geq 0,\end{equation}
\begin{equation}\textrm{d} X(t) = -\alpha X(t) \textrm{d} t + \sigma_{a} \textrm{d} W(t) \qquad\forall t\geq 0,\end{equation}
where
 $\alpha,\sigma_a >0$
, and
$\alpha,\sigma_a >0$
, and
 $\{W(t);\ t\geq 0\}$
is a standard Wiener process. In the subfield of evolutionary biology called phylogenetic comparative methods, processes like (1.1) are used for modelling the evolution of phenotypic traits, such as body size, at the between-species level, in the following way: an Ornstein–Uhlenbeck process evolves on top of a possibly random phylogenetic tree, by which we mean a (random) directed acyclic graph with weights on edges that correspond to edge length, and nodes corresponding to the branching events in the tree; see Figure 1. In the Yule–Ornstein–Uhlenbeck (YOU) model, which we consider here, each speciation (i.e. branching) point is binary, and the edge lengths are independent exponentially distributed random variables. This so-called pure-birth tree is stopped just before the nth speciation event; i.e., it has n leaves (or tips). Without loss of generality we fix the birth rate to 1. Varying the birth rate will only have the effect of rescaling time and will not add anything substantial to our results.
$\{W(t);\ t\geq 0\}$
is a standard Wiener process. In the subfield of evolutionary biology called phylogenetic comparative methods, processes like (1.1) are used for modelling the evolution of phenotypic traits, such as body size, at the between-species level, in the following way: an Ornstein–Uhlenbeck process evolves on top of a possibly random phylogenetic tree, by which we mean a (random) directed acyclic graph with weights on edges that correspond to edge length, and nodes corresponding to the branching events in the tree; see Figure 1. In the Yule–Ornstein–Uhlenbeck (YOU) model, which we consider here, each speciation (i.e. branching) point is binary, and the edge lengths are independent exponentially distributed random variables. This so-called pure-birth tree is stopped just before the nth speciation event; i.e., it has n leaves (or tips). Without loss of generality we fix the birth rate to 1. Varying the birth rate will only have the effect of rescaling time and will not add anything substantial to our results.

Figure 1: Left: an example phylogenetic tree with 10 leaves, simulated using the R [17] package TreeSim [Reference Stadler19]. Right: an OU process with parameters
 $\alpha=1, \sigma_{a}=1/2, X(0)=-3$
evolving on top of this tree, simulated using the R package mvSLOUCH [Reference Bartoszek, Pienaar, Mostad, Andersson and Hansen9].
$\alpha=1, \sigma_{a}=1/2, X(0)=-3$
evolving on top of this tree, simulated using the R package mvSLOUCH [Reference Bartoszek, Pienaar, Mostad, Andersson and Hansen9].
In the YOU model, along each edge (i.e. branch) the process describing the phenotypic trait behaves as defined by (1.1). Then, at a speciation point the process splits into as many copies as there are descendant branches. At the start of each descendant branch the process starts with the value at which the ancestral branch ended (the starting value is the same for all descendant branches). From that point onward, on each descendant lineage the processes behave independently.
The YOU model can be further extended by allowing for jumps; see Bokma [Reference Bokma11]. A particular type of jump that can serve as a starting point for mathematical analysis is when a jump takes place just after a speciation event, independently on each descendant lineage, with a probability p that may depend on the speciation event; see Section 4 for more details.
In the context of evolutionary biology, the observed phenotypic data are the values of the process at the tips,
 $\{X_{i}\}_{i=1}^{n}$
. Of particular interest are central limit theorems for the sample average,
$\{X_{i}\}_{i=1}^{n}$
. Of particular interest are central limit theorems for the sample average,
 $\overline{X}_n$
, or more generally for functionals of the observed data (see e.g. Ren et al. [Reference Ren, Song and Zhang18], Adamczak and Miłoś [Reference Adamczak and Miłoś1], Bartoszek and Sagitov [Reference Bartoszek and Sagitov10], Ané et al. [Reference Ané, Ho and Roch2], Bartoszek [Reference Bartoszek8], and a multitude of other works). If the drift of the OU process is fast enough, then one can show convergence in distribution for
$\overline{X}_n$
, or more generally for functionals of the observed data (see e.g. Ren et al. [Reference Ren, Song and Zhang18], Adamczak and Miłoś [Reference Adamczak and Miłoś1], Bartoszek and Sagitov [Reference Bartoszek and Sagitov10], Ané et al. [Reference Ané, Ho and Roch2], Bartoszek [Reference Bartoszek8], and a multitude of other works). If the drift of the OU process is fast enough, then one can show convergence in distribution for
 $\overline{X}_n$
to a normal limit. However, if the drift is slow, then the dependencies induced by common ancestry persist and statements about the limit are more involved. The above was shown for the YOU model in [Reference Bartoszek and Sagitov10], while the YOU model with normally distributed jumps was considered in [Reference Bartoszek8]. In the slow drift regime one can show
$\overline{X}_n$
to a normal limit. However, if the drift is slow, then the dependencies induced by common ancestry persist and statements about the limit are more involved. The above was shown for the YOU model in [Reference Bartoszek and Sagitov10], while the YOU model with normally distributed jumps was considered in [Reference Bartoszek8]. In the slow drift regime one can show
 $L^{2}$
convergence (see e.g. [Reference Adamczak and Miłoś1], [Reference Bartoszek8], [Reference Bartoszek and Sagitov10]). However, so far there is no complete characterization of the limit in this case.
$L^{2}$
convergence (see e.g. [Reference Adamczak and Miłoś1], [Reference Bartoszek8], [Reference Bartoszek and Sagitov10]). However, so far there is no complete characterization of the limit in this case.
In Sections 3 and 4 of the present paper, we extend the central limit theorems for
 $\overline{X}_n$
by giving bounds for the Kolmogorov and Wasserstein distances between the distribution of
$\overline{X}_n$
by giving bounds for the Kolmogorov and Wasserstein distances between the distribution of
 $\overline{X}_n$
and properly chosen normal distributions (Theorems 3.1, 3.2, 4.1, and 4.2), which converge weakly to the limiting normal distributions of [Reference Bartoszek and Sagitov10] and [Reference Bartoszek8] as
$\overline{X}_n$
and properly chosen normal distributions (Theorems 3.1, 3.2, 4.1, and 4.2), which converge weakly to the limiting normal distributions of [Reference Bartoszek and Sagitov10] and [Reference Bartoszek8] as
 $n\to\infty$
. The key observation is that conditional on the tree (and the locations of jumps),
$n\to\infty$
. The key observation is that conditional on the tree (and the locations of jumps),
 $\overline{X}_n$
is a linear combination of normally distributed random variables, which makes it possible to apply Theorems 2.1 and 2.2. One needs to compute the first two moments of the conditional expectation and variance of
$\overline{X}_n$
is a linear combination of normally distributed random variables, which makes it possible to apply Theorems 2.1 and 2.2. One needs to compute the first two moments of the conditional expectation and variance of
 $\overline{X}_n$
, which requires a careful analysis of the random quantities involved, e.g., the heights in the tree and speciation events along lineages, but a considerable part of this work was done in [Reference Bartoszek and Sagitov10] and [Reference Bartoszek8] and can be reused here.
$\overline{X}_n$
, which requires a careful analysis of the random quantities involved, e.g., the heights in the tree and speciation events along lineages, but a considerable part of this work was done in [Reference Bartoszek and Sagitov10] and [Reference Bartoszek8] and can be reused here.
Lastly, in the appendix, for the sake of comparison and completeness, we state and prove lower bounds for both distances between the probability distribution of a random variable X which has a mixture of normal distributions, and a normally distributed random variable. The proof is based on ideas in Barbour and Hall [Reference Barbour and Hall5].
2. Normal approximation for mixtures of normal distributions
A metric
 $d(\cdot,\cdot)$
on the space of probability measures on a measurable space
$d(\cdot,\cdot)$
on the space of probability measures on a measurable space
 $(\Omega,\mathscr{F})$
is called an integral probability metric (see Müller [Reference Müller15]) if
$(\Omega,\mathscr{F})$
is called an integral probability metric (see Müller [Reference Müller15]) if
 \begin{equation} d(\mu_1,\mu_2) = \sup_{h\in\mathcal{H}}\left|\int h(x)d\mu_1(x) - \int h(x)d\mu_2(x)\right|,\end{equation}
\begin{equation} d(\mu_1,\mu_2) = \sup_{h\in\mathcal{H}}\left|\int h(x)d\mu_1(x) - \int h(x)d\mu_2(x)\right|,\end{equation}
where
 $\mathcal{H}$
is a class of measurable functions
$\mathcal{H}$
is a class of measurable functions
 $h\,:\,\Omega\to\mathbb{R}$
called the generating class. Our interest is in two integral probability metrics on the space of probability measures on
$h\,:\,\Omega\to\mathbb{R}$
called the generating class. Our interest is in two integral probability metrics on the space of probability measures on
 $(\mathbb{R},\mathscr{R})$
: the Kolmogorov distance
$(\mathbb{R},\mathscr{R})$
: the Kolmogorov distance
 $d_K$
, for which
$d_K$
, for which
 $\mathcal{H}$
is the set of indicator functions of half-lines,
$\mathcal{H}$
is the set of indicator functions of half-lines,
 $\mathcal{H}_0 = \{I_{(-\infty,z]}({\cdot});\ z\in\mathbb{R}\}$
, and the Wasserstein distance
$\mathcal{H}_0 = \{I_{(-\infty,z]}({\cdot});\ z\in\mathbb{R}\}$
, and the Wasserstein distance
 $d_W$
, for which
$d_W$
, for which
 $\mathcal{H}$
is the set
$\mathcal{H}$
is the set
 $\mathcal{H}_1$
of Lipschitz functions with Lipschitz constant bounded by 1. It is well known that for sequences of probability measures on
$\mathcal{H}_1$
of Lipschitz functions with Lipschitz constant bounded by 1. It is well known that for sequences of probability measures on
 $(\mathbb{R},\mathscr{R})$
, convergence in either distance implies the usual weak convergence; see Section 4 in [Reference Müller15].
$(\mathbb{R},\mathscr{R})$
, convergence in either distance implies the usual weak convergence; see Section 4 in [Reference Müller15].
Also, the Kolmogorov distance is scale-invariant (and location-invariant), in the sense that
 \begin{equation} d_K \left(\mathscr{L}\,(X),\mathscr{L}\,(Y)\right) = d_K\left(\mathscr{L}\left(\frac{X-\mu}{\sigma} \right),\mathscr{L}\left(\frac{Y-\mu}{\sigma} \right)\right) \qquad\forall \mu\in\mathbb{R},\sigma>0,\end{equation}
\begin{equation} d_K \left(\mathscr{L}\,(X),\mathscr{L}\,(Y)\right) = d_K\left(\mathscr{L}\left(\frac{X-\mu}{\sigma} \right),\mathscr{L}\left(\frac{Y-\mu}{\sigma} \right)\right) \qquad\forall \mu\in\mathbb{R},\sigma>0,\end{equation}
for any pair of random variables X and Y. This follows from (2.1) and the fact that
 \begin{equation*}\mathcal{H}_0 = \{I_{(-\infty,\sigma z+\mu]}({\cdot});\ z\in\mathbb{R}\} \qquad\forall \mu\in\mathbb{R},\sigma>0.\end{equation*}
\begin{equation*}\mathcal{H}_0 = \{I_{(-\infty,\sigma z+\mu]}({\cdot});\ z\in\mathbb{R}\} \qquad\forall \mu\in\mathbb{R},\sigma>0.\end{equation*}
The Wasserstein distance is not scale-invariant, but has the property
 \begin{equation} d_{\textrm{W}}\left(\mathscr{L}\,(X),\mathscr{L}\,(Y)\right) = \sigma d_{\textrm{W}}\left(\mathscr{L}\left(\frac{X-\mu}{\sigma}\right),\mathscr{L}\left(\frac{Y-\mu}{\sigma}\right)\right) \qquad\forall \mu\in\mathbb{R},\sigma>0,\end{equation}
\begin{equation} d_{\textrm{W}}\left(\mathscr{L}\,(X),\mathscr{L}\,(Y)\right) = \sigma d_{\textrm{W}}\left(\mathscr{L}\left(\frac{X-\mu}{\sigma}\right),\mathscr{L}\left(\frac{Y-\mu}{\sigma}\right)\right) \qquad\forall \mu\in\mathbb{R},\sigma>0,\end{equation}
which follows from (2.1) and the fact that for each
 $\mu\in\mathbb{R}$
,
$\mu\in\mathbb{R}$
,
 $\sigma>0$
, the mapping
$\sigma>0$
, the mapping
 $\xi\,:\,\mathcal{H}_1\to\mathcal{H}_1$
defined by
$\xi\,:\,\mathcal{H}_1\to\mathcal{H}_1$
defined by
 \begin{equation*}\xi h(x) = \sigma h\bigg(\frac{x - \mu}{\sigma}\bigg)\end{equation*}
\begin{equation*}\xi h(x) = \sigma h\bigg(\frac{x - \mu}{\sigma}\bigg)\end{equation*}
is a bijection.
Our main results are contained in Theorem 2.1 (Kolmogorov distance) and Theorem 2.2 (Wasserstein distance).
Theorem 2.1. Let X be a real-valued random variable such that
 $\mathbb{E}(X^2)<\infty$
, and let
$\mathbb{E}(X^2)<\infty$
, and let
 $\mathscr{G}$
be a
$\mathscr{G}$
be a
 $\sigma$
-algebra such that the regular conditional distribution of X given
$\sigma$
-algebra such that the regular conditional distribution of X given
 $\mathscr{G}$
is normal. Then
$\mathscr{G}$
is normal. Then
 \begin{equation*}d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mathbb{E}(X)}{\sqrt{\mathbb{E}(\mathbb{V}(X|\mathscr{G}))}}\biggr),\text{N}(0,1))\biggr) = d_K\bigl(\mathscr{L}\,(X),\text{N}\bigl(\mathbb{E}(X),\mathbb{E}(\mathbb{V}(X|\mathscr{G}))\bigr)\bigr)\end{equation*}
\begin{equation*}d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mathbb{E}(X)}{\sqrt{\mathbb{E}(\mathbb{V}(X|\mathscr{G}))}}\biggr),\text{N}(0,1))\biggr) = d_K\bigl(\mathscr{L}\,(X),\text{N}\bigl(\mathbb{E}(X),\mathbb{E}(\mathbb{V}(X|\mathscr{G}))\bigr)\bigr)\end{equation*}
 \begin{equation*}\leq \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}.\end{equation*}
\begin{equation*}\leq \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}.\end{equation*}
Proof. The following identity, called the Stein identity for the N(0,1) distribution, was originally derived in [Reference Stein20] (for more information, see Chen and Shao [Reference Chen, Shao, Barbour and Chen12] and the references therein): if Z is any real-valued random variable, then
 $Z\sim\text{N}(0,1)$
if and only if
$Z\sim\text{N}(0,1)$
if and only if
 \begin{equation} \mathbb{E}\bigl(f^{\prime}(Z) - Zf(Z)\bigr) = 0 \qquad\forall f\in\mathcal{C}_{bd},\end{equation}
\begin{equation} \mathbb{E}\bigl(f^{\prime}(Z) - Zf(Z)\bigr) = 0 \qquad\forall f\in\mathcal{C}_{bd},\end{equation}
where
 $\mathcal{C}_{bd}$
is the set of continuous, piecewise continuously differentiable functions
$\mathcal{C}_{bd}$
is the set of continuous, piecewise continuously differentiable functions
 $f\,:\,\mathbb{R}\to\mathbb{R}$
such that
$f\,:\,\mathbb{R}\to\mathbb{R}$
such that
 $\mathbb{E}(|f^{\prime}(Z_{0,1})|)<\infty$
if
$\mathbb{E}(|f^{\prime}(Z_{0,1})|)<\infty$
if
 $Z_{0,1}\sim\text{N}(0,1)$
.
$Z_{0,1}\sim\text{N}(0,1)$
.
Using (2.4), we shall first derive a similar Stein identity for the
 $\text{N}(\mu,\sigma^2)$
distribution, where
$\text{N}(\mu,\sigma^2)$
distribution, where
 $\mu\in\mathbb{R}$
and
$\mu\in\mathbb{R}$
and
 $\sigma\in(0,\infty)$
: if W is any real-valued random variable, then
$\sigma\in(0,\infty)$
: if W is any real-valued random variable, then
 $W\sim\text{N}(\mu,\sigma^2)$
if and only if
$W\sim\text{N}(\mu,\sigma^2)$
if and only if
 \begin{equation} \mathbb{E}\bigl(\sigma^2g^{\prime}(W) - (W-\mu)g(W)\bigr) = 0 \qquad\forall g\in\mathcal{C}_{bd}^{\mu,\sigma},\end{equation}
\begin{equation} \mathbb{E}\bigl(\sigma^2g^{\prime}(W) - (W-\mu)g(W)\bigr) = 0 \qquad\forall g\in\mathcal{C}_{bd}^{\mu,\sigma},\end{equation}
where
 $\mathcal{C}_{bd}^{\mu,\sigma}$
is the set of continuous, piecewise continuously differentiable functions
$\mathcal{C}_{bd}^{\mu,\sigma}$
is the set of continuous, piecewise continuously differentiable functions
 $g\,:\,\mathbb{R}\to\mathbb{R}$
such that
$g\,:\,\mathbb{R}\to\mathbb{R}$
such that
 $\mathbb{E}(|g^{\prime}(Z_{\mu,\sigma})|)<\infty$
if
$\mathbb{E}(|g^{\prime}(Z_{\mu,\sigma})|)<\infty$
if
 $Z_{\mu,\sigma}\sim\text{N}(\mu,\sigma^2)$
. To prove (2.5), we define the random variable Z by
$Z_{\mu,\sigma}\sim\text{N}(\mu,\sigma^2)$
. To prove (2.5), we define the random variable Z by
 $Z=\frac{1}{\sigma}(W-\mu)$
, and note that
$Z=\frac{1}{\sigma}(W-\mu)$
, and note that
 $Z\sim\text{N}(0,1)$
if and only if
$Z\sim\text{N}(0,1)$
if and only if
 $W\sim\text{N}(\mu,\sigma^2)$
. We also define the mapping
$W\sim\text{N}(\mu,\sigma^2)$
. We also define the mapping
 $T\,:\,\mathcal{C}_{bd}^{\mu,\sigma}\to\mathcal{C}_{bd}$
by
$T\,:\,\mathcal{C}_{bd}^{\mu,\sigma}\to\mathcal{C}_{bd}$
by
 $Tg(x) = \sigma g(\sigma x + \mu)$
. T is easily seen to be a bijection with inverse
$Tg(x) = \sigma g(\sigma x + \mu)$
. T is easily seen to be a bijection with inverse
 \begin{equation*}T^{-1}f(y) = \frac{1}{\sigma}f\bigg(\frac{y-\mu}{\sigma}\bigg).\end{equation*}
\begin{equation*}T^{-1}f(y) = \frac{1}{\sigma}f\bigg(\frac{y-\mu}{\sigma}\bigg).\end{equation*}
This yields
 \begin{align*}\sigma^2g^{\prime}(W) - (W-\mu)g(W) & = \sigma^2g^{\prime}(\sigma Z+\mu) - (\sigma Z+\mu-\mu)g(\sigma Z+\mu)\\[4pt]
& = [Tg]^{\prime}(Z) - Z [Tg](Z) \qquad\forall g\in\mathcal{C}_{bd}^{\mu,\sigma},
\end{align*}
\begin{align*}\sigma^2g^{\prime}(W) - (W-\mu)g(W) & = \sigma^2g^{\prime}(\sigma Z+\mu) - (\sigma Z+\mu-\mu)g(\sigma Z+\mu)\\[4pt]
& = [Tg]^{\prime}(Z) - Z [Tg](Z) \qquad\forall g\in\mathcal{C}_{bd}^{\mu,\sigma},
\end{align*}
which in combination with (2.4) gives (2.5).
We next consider the following functional equation, which we propose to call the Stein equation for the
 $\text{N}(\mu,\sigma^2)$
distribution. It arises in a natural way from (2.5):
$\text{N}(\mu,\sigma^2)$
distribution. It arises in a natural way from (2.5):
 \begin{equation} \sigma^2g^{\prime}(y) - (y-\mu)g(y) = I_{(-\infty,z]}\biggl(\frac{y-\mu}{\sigma}\biggr) - \Phi(z) \qquad\forall y\in\mathbb{R},\end{equation}
\begin{equation} \sigma^2g^{\prime}(y) - (y-\mu)g(y) = I_{(-\infty,z]}\biggl(\frac{y-\mu}{\sigma}\biggr) - \Phi(z) \qquad\forall y\in\mathbb{R},\end{equation}
where
 $z\in\mathbb{R}$
. For each fixed
$z\in\mathbb{R}$
. For each fixed
 $z\in\mathbb{R}$
, it is clear that a function
$z\in\mathbb{R}$
, it is clear that a function
 $g\in\mathcal{C}_{bd}^{\mu,\sigma}$
satisfies (2.6) if and only if the function
$g\in\mathcal{C}_{bd}^{\mu,\sigma}$
satisfies (2.6) if and only if the function
 $f = Tg\in\mathcal{C}_{bd}$
(defined above) satisfies the functional equation
$f = Tg\in\mathcal{C}_{bd}$
(defined above) satisfies the functional equation
 \begin{equation} f^{\prime}(x) - xf(x) = I_{(-\infty,z]}(x) - \Phi(z) \qquad\forall x\in\mathbb{R},\end{equation}
\begin{equation} f^{\prime}(x) - xf(x) = I_{(-\infty,z]}(x) - \Phi(z) \qquad\forall x\in\mathbb{R},\end{equation}
which is the classical Stein equation for the N(0,1) distribution. We obtain from Section 2.1 in [Reference Chen, Shao, Barbour and Chen12] that (2.7) has the solution
 $f = f_z$
, where
$f = f_z$
, where
 \begin{equation*}f_z(x) = e^{x^2/2}\int_{-\infty}^x\bigl[I_{(-\infty,z]}(u) - \Phi(z)\bigr]e^{-u^2/2}du\qquad\forall x\in\mathbb{R}.\end{equation*}
\begin{equation*}f_z(x) = e^{x^2/2}\int_{-\infty}^x\bigl[I_{(-\infty,z]}(u) - \Phi(z)\bigr]e^{-u^2/2}du\qquad\forall x\in\mathbb{R}.\end{equation*}
It is also shown in Section 2.2 in [Reference Chen, Shao, Barbour and Chen12] that
 $f_z$
is bounded, continuous, and continuously differentiable except at
$f_z$
is bounded, continuous, and continuously differentiable except at
 $x=z$
. Moreover,
$x=z$
. Moreover,
 $f_z$
satisfies
$f_z$
satisfies
 \begin{equation*}0<f_z(x)\leq \frac{\sqrt{2\pi}}{4} \quad\forall x\in\mathbb{R}; \qquad |f_z^{\prime}(x)|\leq 1 \quad\forall x\in\mathbb{R}.\end{equation*}
\begin{equation*}0<f_z(x)\leq \frac{\sqrt{2\pi}}{4} \quad\forall x\in\mathbb{R}; \qquad |f_z^{\prime}(x)|\leq 1 \quad\forall x\in\mathbb{R}.\end{equation*}
Therefore, the function
 $g_z = T^{-1}f_z$
, explicitly given by
$g_z = T^{-1}f_z$
, explicitly given by
 \begin{equation*}g_z(y)= \frac{1}{\sigma}f_z\bigg(\frac{y-\mu}{\sigma}\bigg),\end{equation*}
\begin{equation*}g_z(y)= \frac{1}{\sigma}f_z\bigg(\frac{y-\mu}{\sigma}\bigg),\end{equation*}
is a solution to (2.6). This function
 $g_z$
is bounded, continuous, and continuously differentiable except at
$g_z$
is bounded, continuous, and continuously differentiable except at
 $y=\sigma z+\mu$
, and satisfies
$y=\sigma z+\mu$
, and satisfies
 \begin{equation} 0<g_z(y)\leq \frac{\sqrt{2\pi}}{4\sigma} \quad\forall y\in\mathbb{R}; \qquad |g_z^{\prime}(y)| \leq \frac{1}{\sigma^2} \quad\forall y\in\mathbb{R}.\end{equation}
\begin{equation} 0<g_z(y)\leq \frac{\sqrt{2\pi}}{4\sigma} \quad\forall y\in\mathbb{R}; \qquad |g_z^{\prime}(y)| \leq \frac{1}{\sigma^2} \quad\forall y\in\mathbb{R}.\end{equation}
For the remainder of the proof, we define for convenience
 $\mathcal{C}_{bbd}$
as the set of bounded, continuous, piecewise continuously differentiable functions
$\mathcal{C}_{bbd}$
as the set of bounded, continuous, piecewise continuously differentiable functions
 $g\,:\,\mathbb{R}\to\mathbb{R}$
with bounded derivative. By definition,
$g\,:\,\mathbb{R}\to\mathbb{R}$
with bounded derivative. By definition,
 $\mathcal{C}_{bbd}\subset\mathcal{C}_{bd}^{\mu,\sigma}$
for each
$\mathcal{C}_{bbd}\subset\mathcal{C}_{bd}^{\mu,\sigma}$
for each
 $\mu\in\mathbb{R}$
,
$\mu\in\mathbb{R}$
,
 $\sigma\in(0,\infty)$
, and by (2.8),
$\sigma\in(0,\infty)$
, and by (2.8),
 $g_z\in\mathcal{C}_{bbd}$
for each
$g_z\in\mathcal{C}_{bbd}$
for each
 $z\in\mathbb{R}$
. Recalling that the random variable X has a conditionally normal distribution given
$z\in\mathbb{R}$
. Recalling that the random variable X has a conditionally normal distribution given
 $\mathscr{G}$
, we obtain from (2.5) that
$\mathscr{G}$
, we obtain from (2.5) that
 \begin{equation*}\mathbb{E}(\mathbb{V}(X|\mathscr{G}) g^{\prime}(X) - \bigl(X-\mathbb{E}(X|\mathscr{G})\bigr)g(X)\bigr|\mathscr{G}) = 0 \qquad\text{\textit{P}-almost surely}\qquad\forall g\in\mathcal{C}_{bbd}.\end{equation*}
\begin{equation*}\mathbb{E}(\mathbb{V}(X|\mathscr{G}) g^{\prime}(X) - \bigl(X-\mathbb{E}(X|\mathscr{G})\bigr)g(X)\bigr|\mathscr{G}) = 0 \qquad\text{\textit{P}-almost surely}\qquad\forall g\in\mathcal{C}_{bbd}.\end{equation*}
Taking expectations and rewriting, this gives
 \begin{equation} \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G}) g^{\prime}(X) + \mathbb{E}(X|\mathscr{G})g(X)\bigr) = \mathbb{E}\bigl(Xg(X)\bigr) \qquad\forall g\in\mathcal{C}_{bbd}.\end{equation}
\begin{equation} \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G}) g^{\prime}(X) + \mathbb{E}(X|\mathscr{G})g(X)\bigr) = \mathbb{E}\bigl(Xg(X)\bigr) \qquad\forall g\in\mathcal{C}_{bbd}.\end{equation}
From the definition of Kolmogorov distance and (2.2), it follows that for any
 $\mu\in\mathbb{R}$
and
$\mu\in\mathbb{R}$
and
 $\sigma\in(0,\infty)$
,
$\sigma\in(0,\infty)$
,
 \begin{equation*}d_K\bigl(\mathscr{L}\,(X),\text{N$(\mu,\sigma^2)$}\bigr) = d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N(0,1)}\biggr) = \sup_{z\in\mathbb{R}}\bigl|\mathbb{P}\biggl(\frac{X-\mu}{\sigma} \leq z\biggr) - \Phi(z)\bigr|,\end{equation*}
\begin{equation*}d_K\bigl(\mathscr{L}\,(X),\text{N$(\mu,\sigma^2)$}\bigr) = d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N(0,1)}\biggr) = \sup_{z\in\mathbb{R}}\bigl|\mathbb{P}\biggl(\frac{X-\mu}{\sigma} \leq z\biggr) - \Phi(z)\bigr|,\end{equation*}
 \begin{equation} \begin{split}\mathbb{P}\biggl(\frac{X-\mu}{\sigma} \leq z\biggr) - \Phi(z) &= \mathbb{E}\bigl(\sigma^2 g_z^{\prime}(X) - (X-\mu) g_z(X)\bigr)\\
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_z(X) + (\mu-\mathbb{E}(X|\mathscr{G})) g_z(X)\bigr) \qquad\forall z\in\mathbb{R}.\end{split}\end{equation}
\begin{equation} \begin{split}\mathbb{P}\biggl(\frac{X-\mu}{\sigma} \leq z\biggr) - \Phi(z) &= \mathbb{E}\bigl(\sigma^2 g_z^{\prime}(X) - (X-\mu) g_z(X)\bigr)\\
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_z(X) + (\mu-\mathbb{E}(X|\mathscr{G})) g_z(X)\bigr) \qquad\forall z\in\mathbb{R}.\end{split}\end{equation}
If we choose
 $\mu =\mathbb{E}(X)$
and
$\mu =\mathbb{E}(X)$
and
 $\sigma^2 = \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)$
, we get
$\sigma^2 = \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)$
, we get
 \begin{equation*}\bigl|\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_z(X)\bigr)\bigr| \leq \mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigr)\frac{1}{\sigma^2} \leq \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} \qquad\forall z\in\mathbb{R},\end{equation*}
\begin{equation*}\bigl|\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_z(X)\bigr)\bigr| \leq \mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigr)\frac{1}{\sigma^2} \leq \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} \qquad\forall z\in\mathbb{R},\end{equation*}
using (2.8) and Hölder’s inequality. For the second term on the right-hand side of (2.10), we will use a coupling similar to the one used in the proof of Theorem 1.C in Barbour et al. [Reference Barbour, Holst and Janson6]; the latter theorem deals with Poisson approximations for mixtures of Poisson distributions. First, letting the random variable
 $Y\sim\text{N}(\mu,\sigma^2)$
be independent of
$Y\sim\text{N}(\mu,\sigma^2)$
be independent of
 $\mathscr{G}$
, we can write
$\mathscr{G}$
, we can write
 \begin{align*}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G})) g_z(X)\bigr) & = \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))(g_z(X) - g_z(Y))\bigr)\\
& = \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_A\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr)\\
&\quad + \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_{A^c}\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr) \qquad\forall z\in\mathbb{R},
\end{align*}
\begin{align*}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G})) g_z(X)\bigr) & = \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))(g_z(X) - g_z(Y))\bigr)\\
& = \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_A\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr)\\
&\quad + \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_{A^c}\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr) \qquad\forall z\in\mathbb{R},
\end{align*}
where
 $A=\{\sigma^2 \leq\mathbb{V}(X|\mathscr{G})\}$
. For each
$A=\{\sigma^2 \leq\mathbb{V}(X|\mathscr{G})\}$
. For each
 $\omega\in A$
, we construct a probability space with two independent random variables
$\omega\in A$
, we construct a probability space with two independent random variables
 $Y_1\sim\text{N}(0,\sigma^2)$
and
$Y_1\sim\text{N}(0,\sigma^2)$
and
 $Y_2\sim\text{N}(0,\mathbb{V}(X|\mathscr{G})-\sigma^2)$
, so that
$Y_2\sim\text{N}(0,\mathbb{V}(X|\mathscr{G})-\sigma^2)$
, so that
 $\mathbb{E}(X|\mathscr{G}) + Y_1+Y_2\sim\text{N}(\mathbb{E}(X|\mathscr{G}),\mathbb{V}(X|\mathscr{G}))$
, and
$\mathbb{E}(X|\mathscr{G}) + Y_1+Y_2\sim\text{N}(\mathbb{E}(X|\mathscr{G}),\mathbb{V}(X|\mathscr{G}))$
, and
 $\mu + Y_1\sim\text{N}(\mu,\sigma^2)$
. Using this coupling, and the fact that
$\mu + Y_1\sim\text{N}(\mu,\sigma^2)$
. Using this coupling, and the fact that
 $\lVert g^{\prime}_z\rVert = \sup_{x\in\mathbb{R}}|g^{\prime}_z(x)| \leq \frac{1}{\sigma^2}$
, we obtain
$\lVert g^{\prime}_z\rVert = \sup_{x\in\mathbb{R}}|g^{\prime}_z(x)| \leq \frac{1}{\sigma^2}$
, we obtain
 \begin{align*}&\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_A\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr)\bigr|\\
&\quad =\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_A\mathbb{E}(g_z(\mathbb{E}(X|\mathscr{G}) + Y_1+Y_2) - g_z(\mu + Y_1)|\mathscr{G})\bigr)\bigr|\\
&\qquad \leq\mathbb{E}\bigl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr| I_A\lVert g^{\prime}_z\rVert \mathbb{E}(|\mu-\mathbb{E}(X|\mathscr{G}) - Y_2||\mathscr{G})\bigr)\\
&\qquad \leq\frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2I_A\bigr) + \frac{1}{\sigma^2}\mathbb{E}\bigl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|I_A\mathbb{E}(|Y_2||\mathscr{G})\bigr)\\
&\quad =\frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2I_A\bigr) + \frac{1}{\sigma^2}\mathbb{E}\biggl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|I_A\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|}\biggr)\qquad\forall z\in\mathbb{R}.\end{align*}
\begin{align*}&\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_A\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr)\bigr|\\
&\quad =\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_A\mathbb{E}(g_z(\mathbb{E}(X|\mathscr{G}) + Y_1+Y_2) - g_z(\mu + Y_1)|\mathscr{G})\bigr)\bigr|\\
&\qquad \leq\mathbb{E}\bigl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr| I_A\lVert g^{\prime}_z\rVert \mathbb{E}(|\mu-\mathbb{E}(X|\mathscr{G}) - Y_2||\mathscr{G})\bigr)\\
&\qquad \leq\frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2I_A\bigr) + \frac{1}{\sigma^2}\mathbb{E}\bigl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|I_A\mathbb{E}(|Y_2||\mathscr{G})\bigr)\\
&\quad =\frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2I_A\bigr) + \frac{1}{\sigma^2}\mathbb{E}\biggl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|I_A\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|}\biggr)\qquad\forall z\in\mathbb{R}.\end{align*}
Similarly, for each
 $\omega\in A^c$
, we construct a probability space with two independent random variables
$\omega\in A^c$
, we construct a probability space with two independent random variables
 $\widehat Y_1\sim\text{N}(0,\mathbb{V}(X|\mathscr{G}))$
and
$\widehat Y_1\sim\text{N}(0,\mathbb{V}(X|\mathscr{G}))$
and
 $\widehat Y_2\sim\text{N}(0,\sigma^2-\mathbb{V}(X|\mathscr{G}))$
, so that
$\widehat Y_2\sim\text{N}(0,\sigma^2-\mathbb{V}(X|\mathscr{G}))$
, so that
 $\mathbb{E}(X|\mathscr{G}) + \widehat Y_1\sim\text{N}(\mathbb{E}(X|\mathscr{G}),\mathbb{V}(X|\mathscr{G}))$
, and
$\mathbb{E}(X|\mathscr{G}) + \widehat Y_1\sim\text{N}(\mathbb{E}(X|\mathscr{G}),\mathbb{V}(X|\mathscr{G}))$
, and
 $\mu + \widehat Y_1 + \widehat Y_2\sim\text{N}(\mu,\sigma^2)$
. This gives, after some calculations,
$\mu + \widehat Y_1 + \widehat Y_2\sim\text{N}(\mu,\sigma^2)$
. This gives, after some calculations,
 \begin{align*}& \bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_{A^c}\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr)\bigr|\\[5pt]
& \quad \leq \frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2I_{A^c}\bigr) + \frac{1}{\sigma^2}\mathbb{E}\biggl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|I_{A^c}\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|}\biggr)\qquad\forall z\in\mathbb{R}.
\end{align*}
\begin{align*}& \bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))I_{A^c}\mathbb{E}(g_z(X) - g_z(Y)|\mathscr{G})\bigr)\bigr|\\[5pt]
& \quad \leq \frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2I_{A^c}\bigr) + \frac{1}{\sigma^2}\mathbb{E}\biggl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|I_{A^c}\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|}\biggr)\qquad\forall z\in\mathbb{R}.
\end{align*}
Combining these two bounds, for the second term on the right-hand side of (2.10) we get
 \begin{align*}&\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G})) g_z(X)\bigr)\bigr|\\
&\quad\leq \frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) + \frac{1}{\sigma^2}\mathbb{E}\biggl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|}\biggr)\\[4pt]
&\quad\leq \frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) + \frac{1}{\sigma^2}\sqrt{\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}\sqrt{\frac{2}{\pi}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigr)}\\[4pt]
&\quad\leq \frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\qquad\forall z\in\mathbb{R}.\end{align*}
\begin{align*}&\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G})) g_z(X)\bigr)\bigr|\\
&\quad\leq \frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) + \frac{1}{\sigma^2}\mathbb{E}\biggl(\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|}\biggr)\\[4pt]
&\quad\leq \frac{1}{\sigma^2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) + \frac{1}{\sigma^2}\sqrt{\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}\sqrt{\frac{2}{\pi}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigr)}\\[4pt]
&\quad\leq \frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\qquad\forall z\in\mathbb{R}.\end{align*}
Remark 2.1. In the case when
 $\mathbb{E}(X|\mathscr{G})\equiv m$
and
$\mathbb{E}(X|\mathscr{G})\equiv m$
and
 $\mathbb{V}(X|\mathscr{G})\equiv \tau^2$
for deterministic constants
$\mathbb{V}(X|\mathscr{G})\equiv \tau^2$
for deterministic constants
 $m\in\mathbb{R}$
and
$m\in\mathbb{R}$
and
 $\tau>0$
, meaning that
$\tau>0$
, meaning that
 $X\sim\text{N}(m,\tau^2)$
independently of
$X\sim\text{N}(m,\tau^2)$
independently of
 $\mathscr{G}$
, we obtain from (2.10) and (2.8) that
$\mathscr{G}$
, we obtain from (2.10) and (2.8) that
 \begin{equation*}d_K\bigl(\text{N$(m,\tau^2)$},\text{N$(\mu,\sigma^2)$}\bigr)\leq \frac{1}{\sigma^2}|\sigma^2-\tau^2| + \frac{\sqrt{2\pi}}{4\sigma}|\mu-m|.\end{equation*}
\begin{equation*}d_K\bigl(\text{N$(m,\tau^2)$},\text{N$(\mu,\sigma^2)$}\bigr)\leq \frac{1}{\sigma^2}|\sigma^2-\tau^2| + \frac{\sqrt{2\pi}}{4\sigma}|\mu-m|.\end{equation*}
Turning to Theorem 2.2, we define
 $\mathcal{H}_2$
as the set of all real-valued absolutely continuous functions on
$\mathcal{H}_2$
as the set of all real-valued absolutely continuous functions on
 $(\mathbb{R},\mathscr{R})$
, by which we mean all functions
$(\mathbb{R},\mathscr{R})$
, by which we mean all functions
 $h\,:\,\mathbb{R}\to\mathbb{R}$
such that h has a derivative almost everywhere, h
′ is Lebesgue integrable on every compact interval, and
$h\,:\,\mathbb{R}\to\mathbb{R}$
such that h has a derivative almost everywhere, h
′ is Lebesgue integrable on every compact interval, and
 \begin{equation*}h(b) - h(a) = \int_a^b h^{\prime}(u)du \qquad\forall -\infty<a\leq b<\infty.\end{equation*}
\begin{equation*}h(b) - h(a) = \int_a^b h^{\prime}(u)du \qquad\forall -\infty<a\leq b<\infty.\end{equation*}
It is well known that any Lipschitz continuous function
 $h\,:\,\mathbb{R}\to\mathbb{R}$
is absolutely continuous, and that
$h\,:\,\mathbb{R}\to\mathbb{R}$
is absolutely continuous, and that
 $|h^{\prime}(x)|\leq K$
, where K is the Lipschitz constant, for all
$|h^{\prime}(x)|\leq K$
, where K is the Lipschitz constant, for all
 $x\in\mathbb{R}$
where h
′(x) is defined. Moreover, as stated above, the Wasserstein distance on the space of probability measures on
$x\in\mathbb{R}$
where h
′(x) is defined. Moreover, as stated above, the Wasserstein distance on the space of probability measures on
 $(\mathbb{R},\mathscr{R})$
is defined by
$(\mathbb{R},\mathscr{R})$
is defined by
 \begin{equation*}d_W\bigl(\mu_1,\mu_2\bigr) = \sup_{h\in\mathcal{H}_1}\bigl|\int h(x)d\mu_1(x) - \int h(x)d\mu_2(x)\bigr|,\end{equation*}
\begin{equation*}d_W\bigl(\mu_1,\mu_2\bigr) = \sup_{h\in\mathcal{H}_1}\bigl|\int h(x)d\mu_1(x) - \int h(x)d\mu_2(x)\bigr|,\end{equation*}
where
 $\mathcal{H}_1$
is the set of all Lipschitz continuous functions with Lipschitz constant bounded by 1.
$\mathcal{H}_1$
is the set of all Lipschitz continuous functions with Lipschitz constant bounded by 1.
Theorem 2.2. Let X be a real-valued random variable such that
 $\mathbb{E}(X^2)<\infty$
, and let
$\mathbb{E}(X^2)<\infty$
, and let
 $\mathscr{G}$
be a
$\mathscr{G}$
be a
 $\sigma$
-algebra such that the regular conditional distribution of X given
$\sigma$
-algebra such that the regular conditional distribution of X given
 $\mathscr{G}$
is normal. Then
$\mathscr{G}$
is normal. Then
 \begin{align*}d_W\biggl(\mathscr{L}\,\biggl(\frac{X-\mathbb{E}(X)}{\sqrt{\mathbb{E}(\mathbb{V}(X|\mathscr{G}))}}\biggr),\text{N}(0,1))\biggr) \leq & \sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}}\\[4pt]
&+ \frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}.\end{align*}
\begin{align*}d_W\biggl(\mathscr{L}\,\biggl(\frac{X-\mathbb{E}(X)}{\sqrt{\mathbb{E}(\mathbb{V}(X|\mathscr{G}))}}\biggr),\text{N}(0,1))\biggr) \leq & \sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}}\\[4pt]
&+ \frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}.\end{align*}
Proof. The first part of the proof is the same as for Theorem 2.1. However, as a Stein equation for the
 $\text{N}(\mu,\sigma^2)$
distribution, instead of (2.6) we use
$\text{N}(\mu,\sigma^2)$
distribution, instead of (2.6) we use
 \begin{equation} \sigma^2g^{\prime}(y) - (y-\mu)g(y) = h\biggl(\frac{y-\mu}{\sigma}\biggr) - \mathbb{E}(h(Z_{0,1})) \qquad\forall y\in\mathbb{R},\end{equation}
\begin{equation} \sigma^2g^{\prime}(y) - (y-\mu)g(y) = h\biggl(\frac{y-\mu}{\sigma}\biggr) - \mathbb{E}(h(Z_{0,1})) \qquad\forall y\in\mathbb{R},\end{equation}
where
 $h\in\mathcal{H}_1$
, and
$h\in\mathcal{H}_1$
, and
 $Z_{0,1}\sim\text{N}(0,1)$
. For each
$Z_{0,1}\sim\text{N}(0,1)$
. For each
 $h\in\mathcal{H}_1$
, it is clear that a function
$h\in\mathcal{H}_1$
, it is clear that a function
 $g\in\mathcal{C}_{bd}^{\mu,\sigma}$
satisfies (2.11) if and only if the function
$g\in\mathcal{C}_{bd}^{\mu,\sigma}$
satisfies (2.11) if and only if the function
 $f = Tg\in\mathcal{C}_{bd}$
(defined in the proof of Theorem 2.1) satisfies the functional equation
$f = Tg\in\mathcal{C}_{bd}$
(defined in the proof of Theorem 2.1) satisfies the functional equation
 \begin{equation} f^{\prime}(x) - xf(x) = h(x) - \mathbb{E}(h(Z_{0,1})) \qquad\forall x\in\mathbb{R}.\end{equation}
\begin{equation} f^{\prime}(x) - xf(x) = h(x) - \mathbb{E}(h(Z_{0,1})) \qquad\forall x\in\mathbb{R}.\end{equation}
It is shown in [Reference Chen, Shao, Barbour and Chen12] that (2.12) has the solution
 $f = f_h$
, where
$f = f_h$
, where
 \begin{equation*}f_h(x) = e^{x^2/2}\int_{-\infty}^x\bigl[h(u) - \mathbb{E}(h(Z_{0,1}))\bigr]e^{-u^2/2}du\qquad\forall x\in\mathbb{R}.\end{equation*}
\begin{equation*}f_h(x) = e^{x^2/2}\int_{-\infty}^x\bigl[h(u) - \mathbb{E}(h(Z_{0,1}))\bigr]e^{-u^2/2}du\qquad\forall x\in\mathbb{R}.\end{equation*}
Moreover, for each
 $h\in\mathcal{H}_1$
,
$h\in\mathcal{H}_1$
,
 $f_h$
is bounded, has an absolutely continuous derivative, and satisfies
$f_h$
is bounded, has an absolutely continuous derivative, and satisfies
 \begin{align*}\lVert f_h\rVert & \leq \min\biggl(\sqrt{\frac{\pi}{2}}\lVert h-\mathbb{E}(h(Z))\rVert,2\lVert h^{\prime}\rVert\biggr);\\[5pt]
\lVert f^{\prime}_h\rVert &\leq \min\bigl(2\lVert h-\mathbb{E}(h(Z))\rVert,4\lVert h^{\prime}\rVert\bigr); \qquad\lVert f^{\prime\prime}_h\rVert\leq 2\lVert h^{\prime}\rVert,\end{align*}
\begin{align*}\lVert f_h\rVert & \leq \min\biggl(\sqrt{\frac{\pi}{2}}\lVert h-\mathbb{E}(h(Z))\rVert,2\lVert h^{\prime}\rVert\biggr);\\[5pt]
\lVert f^{\prime}_h\rVert &\leq \min\bigl(2\lVert h-\mathbb{E}(h(Z))\rVert,4\lVert h^{\prime}\rVert\bigr); \qquad\lVert f^{\prime\prime}_h\rVert\leq 2\lVert h^{\prime}\rVert,\end{align*}
where
 $\lVert\cdot\rVert$
denotes the (essential) supremum. Therefore, the function
$\lVert\cdot\rVert$
denotes the (essential) supremum. Therefore, the function
 $g_h = T^{-1}f_h$
, explicitly given by
$g_h = T^{-1}f_h$
, explicitly given by
 \begin{equation*}g_h(y)= \frac{1}{\sigma}f_h\bigg(\frac{y-\mu}{\sigma}\bigg),\end{equation*}
\begin{equation*}g_h(y)= \frac{1}{\sigma}f_h\bigg(\frac{y-\mu}{\sigma}\bigg),\end{equation*}
is a solution to (2.11) which is bounded, has an absolutely continuous derivative, and satisfies
 \begin{equation} \begin{split}\lVert g_h\rVert & \leq \frac{1}{\sigma}\min\biggl(\sqrt{\frac{\pi}{2}}\lVert h-\mathbb{E}(h(Z))\rVert,2\lVert h^{\prime}\rVert\biggr);\\[4pt]
\lVert g^{\prime}_h\rVert &\leq \frac{1}{\sigma^2}\min\bigl(2\lVert h-\mathbb{E}(h(Z))\rVert,4\lVert h^{\prime}\rVert\bigr); \qquad \lVert g^{\prime\prime}_h\rVert\leq \frac{2}{\sigma^3}\lVert h^{\prime}\rVert.\end{split}\end{equation}
\begin{equation} \begin{split}\lVert g_h\rVert & \leq \frac{1}{\sigma}\min\biggl(\sqrt{\frac{\pi}{2}}\lVert h-\mathbb{E}(h(Z))\rVert,2\lVert h^{\prime}\rVert\biggr);\\[4pt]
\lVert g^{\prime}_h\rVert &\leq \frac{1}{\sigma^2}\min\bigl(2\lVert h-\mathbb{E}(h(Z))\rVert,4\lVert h^{\prime}\rVert\bigr); \qquad \lVert g^{\prime\prime}_h\rVert\leq \frac{2}{\sigma^3}\lVert h^{\prime}\rVert.\end{split}\end{equation}
As in the proof of Theorem 2.1, we define
 $\mathcal{C}_{bbd}$
as the set of bounded, piecewise continuously differentiable functions
$\mathcal{C}_{bbd}$
as the set of bounded, piecewise continuously differentiable functions
 $g\,:\,\mathbb{R}\to\mathbb{R}$
with bounded derivative. By (2.13),
$g\,:\,\mathbb{R}\to\mathbb{R}$
with bounded derivative. By (2.13),
 $g_h\in\mathcal{C}_{bbd}$
for each
$g_h\in\mathcal{C}_{bbd}$
for each
 $h\in\mathcal{H}_1$
. As before, we obtain
$h\in\mathcal{H}_1$
. As before, we obtain
 \begin{equation} \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G}) g^{\prime}(X) + \mathbb{E}(X|\mathscr{G})g(X)\bigr) = \mathbb{E}\bigl(Xg(X)\bigr) \qquad\forall g\in\mathcal{C}_{bbd}.\end{equation}
\begin{equation} \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G}) g^{\prime}(X) + \mathbb{E}(X|\mathscr{G})g(X)\bigr) = \mathbb{E}\bigl(Xg(X)\bigr) \qquad\forall g\in\mathcal{C}_{bbd}.\end{equation}
By definition, the Wasserstein distance can be expressed as follows:
 \begin{equation*}d_W\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N(0,1)}\biggr) = \sup_{h\in\mathcal{H}_1}\bigl|\mathbb{E}h\biggl(\frac{X-\mu}{\sigma}\biggr) - \mathbb{E}(h(Z_{0,1}))\bigr|,\end{equation*}
\begin{equation*}d_W\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N(0,1)}\biggr) = \sup_{h\in\mathcal{H}_1}\bigl|\mathbb{E}h\biggl(\frac{X-\mu}{\sigma}\biggr) - \mathbb{E}(h(Z_{0,1}))\bigr|,\end{equation*}
where, using (2.11) and (2.14),
 \begin{equation} \begin{split}\mathbb{E}\biggl(h\bigg(\frac{X-\mu}{\sigma}\bigg)\biggr) - \mathbb{E}(h(Z_{0,1})) &= \mathbb{E}\bigl(\sigma^2 g_{h}^{\prime}(X) - (X-\mu) g_{h}(X)\bigr)\\
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g_{h}^{\prime}(X) + (\mu-\mathbb{E}(X|\mathscr{G}))) g_{h}(X)\bigr)\qquad\forall h\in\mathcal{H}_1.\end{split}\end{equation}
\begin{equation} \begin{split}\mathbb{E}\biggl(h\bigg(\frac{X-\mu}{\sigma}\bigg)\biggr) - \mathbb{E}(h(Z_{0,1})) &= \mathbb{E}\bigl(\sigma^2 g_{h}^{\prime}(X) - (X-\mu) g_{h}(X)\bigr)\\
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g_{h}^{\prime}(X) + (\mu-\mathbb{E}(X|\mathscr{G}))) g_{h}(X)\bigr)\qquad\forall h\in\mathcal{H}_1.\end{split}\end{equation}
If we choose
 $\mu =\mathbb{E}(X)$
and
$\mu =\mathbb{E}(X)$
and
 $\sigma^2 = \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)$
, the second term on the right-hand side of (2.15) can be handled in the same way as in the proof of Theorem 2.1, yielding the bound
$\sigma^2 = \mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)$
, the second term on the right-hand side of (2.15) can be handled in the same way as in the proof of Theorem 2.1, yielding the bound
 \begin{equation*}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G})) g_h(X)\bigr) \leq 4\frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + 4\sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\quad\forall h\in\mathcal{H}_1.\end{equation*}
\begin{equation*}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G})) g_h(X)\bigr) \leq 4\frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)} + 4\sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\quad\forall h\in\mathcal{H}_1.\end{equation*}
For the first term on the right-hand side of (2.15), letting the random variable
 $Y\sim\text{N}(\mu,\sigma^2)$
be independent of
$Y\sim\text{N}(\mu,\sigma^2)$
be independent of
 $\mathscr{G}$
, we can write
$\mathscr{G}$
, we can write
 \begin{align*}\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_h(X)\bigr) & = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))(g^{\prime}_h(X) - g^{\prime}_h(Y))\bigr)\\[4pt]
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))I_A\mathbb{E}(g^{\prime}_h(X) - g^{\prime}_h(Y)|\mathscr{G})\bigr)\\[4pt]
& \quad + \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))I_{A^c}\mathbb{E}(g^{\prime}_h(X) - g^{\prime}_h(Y)|\mathscr{G})\bigr) \qquad\forall h\in\mathcal{H}_1,
\end{align*}
\begin{align*}\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_h(X)\bigr) & = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))(g^{\prime}_h(X) - g^{\prime}_h(Y))\bigr)\\[4pt]
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))I_A\mathbb{E}(g^{\prime}_h(X) - g^{\prime}_h(Y)|\mathscr{G})\bigr)\\[4pt]
& \quad + \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))I_{A^c}\mathbb{E}(g^{\prime}_h(X) - g^{\prime}_h(Y)|\mathscr{G})\bigr) \qquad\forall h\in\mathcal{H}_1,
\end{align*}
where
 $A=\{\sigma^2 \leq\mathbb{V}(X|\mathscr{G})\}$
. We can now use exactly the same coupling as for the second term on the right-hand side of (2.15), together with the fact that
$A=\{\sigma^2 \leq\mathbb{V}(X|\mathscr{G})\}$
. We can now use exactly the same coupling as for the second term on the right-hand side of (2.15), together with the fact that
 $\lVert g^{\prime\prime}_z\rVert \leq \frac{2}{\sigma^3}$
, to obtain, after some calculations,
$\lVert g^{\prime\prime}_z\rVert \leq \frac{2}{\sigma^3}$
, to obtain, after some calculations,
 \begin{align*} & \bigl|\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_h(X)\bigr)\bigr|\\[4pt]
&\quad\leq \frac{2}{\sigma^3}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigr)} + \frac{2}{\sigma^3}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|\bigr)\\[4pt]
&\quad\leq \sqrt{\frac{2}{\pi}}\frac{2}{\sigma^3}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|^{3/2}\bigr) + \frac{2}{\sigma^3}\sqrt{\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}\sqrt{\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))^2\bigr)}\\[4pt]
&\quad\leq 2\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}} + \frac{2\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}}\qquad\forall h\in\mathcal{H}_1.
\end{align*}
\begin{align*} & \bigl|\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}_h(X)\bigr)\bigr|\\[4pt]
&\quad\leq \frac{2}{\sigma^3}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\sqrt{\frac{2}{\pi}\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigr)} + \frac{2}{\sigma^3}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|\bigl|\mu-\mathbb{E}(X|\mathscr{G})\bigr|\bigr)\\[4pt]
&\quad\leq \sqrt{\frac{2}{\pi}}\frac{2}{\sigma^3}\mathbb{E}\bigl(\bigl|\sigma^2-\mathbb{V}(X|\mathscr{G})\bigr|^{3/2}\bigr) + \frac{2}{\sigma^3}\sqrt{\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}\sqrt{\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))^2\bigr)}\\[4pt]
&\quad\leq 2\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}} + \frac{2\sqrt{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}}\qquad\forall h\in\mathcal{H}_1.
\end{align*}
Remark 2.2. In the case when
 $\mathbb{E}(X|\mathscr{G})\equiv m$
and
$\mathbb{E}(X|\mathscr{G})\equiv m$
and
 $\mathbb{V}(X|\mathscr{G})\equiv \tau^2$
for deterministic constants
$\mathbb{V}(X|\mathscr{G})\equiv \tau^2$
for deterministic constants
 $m\in\mathbb{R}$
and
$m\in\mathbb{R}$
and
 $\tau>0$
, from (2.15) and (2.13) we obtain
$\tau>0$
, from (2.15) and (2.13) we obtain
 \begin{equation*}d_W\bigl(\text{N$(m,\tau^2)$},\text{N$(\mu,\sigma^2)$}\bigr) \leq \frac{4}{\sigma^2}|\sigma^2-\tau^2| + \frac{2}{\sigma}|\mu-m|.\end{equation*}
\begin{equation*}d_W\bigl(\text{N$(m,\tau^2)$},\text{N$(\mu,\sigma^2)$}\bigr) \leq \frac{4}{\sigma^2}|\sigma^2-\tau^2| + \frac{2}{\sigma}|\mu-m|.\end{equation*}
Finally, we point out that it is possible to derive lower bounds for the Kolmogorov and Wasserstein distances under the same assumptions as in Theorems 2.1 and 2.2. Using ideas introduced in [Reference Barbour and Hall5] (see also Chapter 3 in [Reference Barbour, Holst and Janson6]), we state and derive lower bounds in the appendix (Theorem A.1; the bounds for the two distances are identical apart from a constant factor). It can be seen from Theorem A.1 that under mild conditions on the asymptotics of the higher order moments
 $\mathbb{E}((\mu-\mathbb{E}(X|\mathscr{G}))^4)$
and
$\mathbb{E}((\mu-\mathbb{E}(X|\mathscr{G}))^4)$
and
 $\mathbb{E}(|\mathbb{V}(X|\mathscr{G})-\sigma^2|(\mu-\mathbb{E}(X|\mathscr{G}))^2)$
, the upper bounds in Theorems 2.1 and 2.2 leave little room for improvement. In particular, the term
$\mathbb{E}(|\mathbb{V}(X|\mathscr{G})-\sigma^2|(\mu-\mathbb{E}(X|\mathscr{G}))^2)$
, the upper bounds in Theorems 2.1 and 2.2 leave little room for improvement. In particular, the term
 \begin{equation*}\frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\end{equation*}
\begin{equation*}\frac{\mathbb{V}\bigl(\mathbb{E}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\end{equation*}
cannot be replaced by another that converges faster to 0. However, the lower bound would allow for
 \begin{equation*}\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}}\end{equation*}
\begin{equation*}\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)^{3/2}}\end{equation*}
to be replaced by
 \begin{equation*}\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\end{equation*}
\begin{equation*}\frac{\mathbb{V}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}{\mathbb{E}\bigl(\mathbb{V}(X|\mathscr{G})\bigr)}\end{equation*}
(times some constant) in the first term, should this turn out to be possible.
3. The Yule–Ornstein–Uhlenbeck model
In order to apply the results in Section 2 to the YOU model, we first need to condition on an appropriate
 $\sigma$
-algebra, and then obtain formulæ, along with their asymptotic behaviours, for the means and variances of the conditional means and variances. Since the OU process is Gaussian, conditionally on the phylogeny the values of the traits at the n leaves will have an n-dimensional Gaussian distribution. Hence, the natural
$\sigma$
-algebra, and then obtain formulæ, along with their asymptotic behaviours, for the means and variances of the conditional means and variances. Since the OU process is Gaussian, conditionally on the phylogeny the values of the traits at the n leaves will have an n-dimensional Gaussian distribution. Hence, the natural
 $\sigma$
-algebra to condition on is the
$\sigma$
-algebra to condition on is the
 $\sigma$
-algebra generated by the pure-birth tree. For a tree with n leaves, we denote this
$\sigma$
-algebra generated by the pure-birth tree. For a tree with n leaves, we denote this
 $\sigma$
-algebra by
$\sigma$
-algebra by
 $\mathcal{Y}_{n}$
. Moreover, we use the following notation:
$\mathcal{Y}_{n}$
. Moreover, we use the following notation:
 $\Gamma({\cdot})$
is the gamma function,
$\Gamma({\cdot})$
is the gamma function,
 $H_n = 1 + \frac{1}{2} + \ldots + \frac{1}{n}$
, and
$H_n = 1 + \frac{1}{2} + \ldots + \frac{1}{n}$
, and
 \begin{equation*}b_{n,x} = \frac{1}{1+x}\cdot\frac{2}{2+x}\cdot \ldots \cdot\frac{n}{n+x}=\frac{\Gamma(n+1) \Gamma(x+1)}{\Gamma(n+x+1)},\qquad x \gt -1.\end{equation*}
\begin{equation*}b_{n,x} = \frac{1}{1+x}\cdot\frac{2}{2+x}\cdot \ldots \cdot\frac{n}{n+x}=\frac{\Gamma(n+1) \Gamma(x+1)}{\Gamma(n+x+1)},\qquad x \gt -1.\end{equation*}
Theorem 3.1. Consider the YOU model with
 $\alpha \ge 1/2$
. Let
$\alpha \ge 1/2$
. Let
 $\overline{X}_{n}$
be the average value of the traits at the n leaves, let
$\overline{X}_{n}$
be the average value of the traits at the n leaves, let
 \begin{equation*}\overline{Y}_{n} = \overline{X}_{n}\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}},\end{equation*}
\begin{equation*}\overline{Y}_{n} = \overline{X}_{n}\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}},\end{equation*}
and let
 \begin{equation*}\delta = X(0)\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}}.\end{equation*}
\begin{equation*}\delta = X(0)\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}}.\end{equation*}
Let also
 $\mu_n = \mathbb{E}(\overline{Y}_{n})$
and
$\mu_n = \mathbb{E}(\overline{Y}_{n})$
and
 $\sigma_n^2 = \mathbb{E}(\mathbb{V}(\overline{Y}_{n}|\mathscr{G}))$
.
$\sigma_n^2 = \mathbb{E}(\mathbb{V}(\overline{Y}_{n}|\mathscr{G}))$
.
-
(i) If
 $\alpha=\frac{1}{2}$
, then
as
\begin{equation*}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)= \text{O}(\ln^{-1} n)\end{equation*}
$n\to\infty$
, where
$\mu_n = \delta b_{n,1/2}$
and
Moreover,
\begin{equation*}\sigma_n^2 = \frac{1}{n} + \left(1-\frac{1}{n} \right)\left(\frac{2}{n-1}(H_n-1)-\frac{1}{n-1}\right) - b_{n,1}.\end{equation*}
$(\frac{n}{\ln n})^{1/2}\,\mu_n\to 0$
and
$\frac{n}{\ln n}\,\sigma_n^2\to 2$
as
$n\to\infty$
, so
$(\frac{n}{\ln n})^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,2)$
as
$n\to\infty$
.
$\alpha=\frac{1}{2}$
, then
as
\begin{equation*}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)= \text{O}(\ln^{-1} n)\end{equation*}
$n\to\infty$
, where
$\mu_n = \delta b_{n,1/2}$
and
Moreover,
\begin{equation*}\sigma_n^2 = \frac{1}{n} + \left(1-\frac{1}{n} \right)\left(\frac{2}{n-1}(H_n-1)-\frac{1}{n-1}\right) - b_{n,1}.\end{equation*}
$(\frac{n}{\ln n})^{1/2}\,\mu_n\to 0$
and
$\frac{n}{\ln n}\,\sigma_n^2\to 2$
as
$n\to\infty$
, so
$(\frac{n}{\ln n})^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,2)$
as
$n\to\infty$
.
-
(ii) If
$\alpha>\frac{1}{2}$
, then
as
\begin{equation*}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right) = \begin{cases}\text{O}\big(n^{-2\alpha+1}\big),&\text{$\frac{1}{2}<\alpha<\frac{3}{4}$,}\\[4pt]
\text{O}\big(\frac{\ln^{1/2}n}{n^{1/2}}\big),&\text{$\alpha=\frac{3}{4}$,}\\[4pt]
\text{O}(n^{-1/2}),&\text{$\alpha>\frac{3}{4}$,}\end{cases}\end{equation*}
$n\to\infty$
, where
$\mu_n = \delta b_{n,\alpha}$
, and
Moreover,
\begin{equation*}\sigma_n^2 = \frac{1}{n} + \left(1-\frac{1}{n}\right)\left(\frac{2 - (n+1)(2\alpha + 1)b_{n,2\alpha}}{(n-1)(2\alpha-1)}\right) - b_{n,2\alpha}.\end{equation*}
$n^{1/2}\,\mu_n\to 0$
and
$n\sigma_n^2\to\frac{2\alpha+1}{2\alpha-1}$
as
$n\to\infty$
, so
$n^{1/2}\,\;\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,\frac{2\alpha+1}{2\alpha-1})$
as
$n\to\infty$
.




















Theorem 3.2. Consider the YOU model with
 $\alpha \ge 1/2$
, with the same notation as in Theorem 3.1.
$\alpha \ge 1/2$
, with the same notation as in Theorem 3.1.
-
(i) If
$\alpha=\frac{1}{2}$
, then
as
\begin{equation*}d_{W}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)= \text{O}(\ln^{-1} n)\end{equation*}
$n\to\infty$
.
-
(ii) If
$\alpha>\frac{1}{2}$
, then
$d_{W}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right) =
\left\{\begin{array}{l@{\quad}l}\text{O}\big(n^{-2\alpha+1}\big),& \frac{1}{2}\lt \alpha \lt \frac{3}{4},\\[4pt]
\text{O}\big(\frac{\ln^{1/4}n}{n^{1/2}}\big),& \alpha = \frac{3}{4},\\[4pt]
\text{O}\big(n^{-\min(\alpha-1/4,3/4)}\big),& \alpha > \frac{3}{4},\end{array}\right.$
as
$n\to\infty$
.






Proof of Theorems 3.1–3.2. As explained above, the phylogeny is modelled by a pure-birth tree, in which each speciation point is binary, and the edge lengths are independent exponentially distributed random variables with the same rate parameter, called the birth rate. Without loss of generality we take 1 as the birth rate. Then the time between the kth and
 $(k+1)$
th speciation event, denoted by
$(k+1)$
th speciation event, denoted by
 $T_{k+1}$
, is exponentially distributed with rate
$T_{k+1}$
, is exponentially distributed with rate
 $(k+1)$
, as the minimum of
$(k+1)$
, as the minimum of
 $(k+1)$
independent rate-1 exponentially distributed random variables; see Figure 2.
$(k+1)$
independent rate-1 exponentially distributed random variables; see Figure 2.

Figure 2: A pure-birth (Yule) tree with the various time components marked on it. A branching OU process, which might also have a jump just after each speciation event (i.e. branching point), evolves on top of the tree. In this example we assume that a jump only takes place just after the first speciation event. The values of
 $\mathbf{1}_{1}$
,
$\mathbf{1}_{1}$
,
 $\mathbf{1}_{2}$
,
$\mathbf{1}_{2}$
,
 $\mathbf{1}_{3}$
,
$\mathbf{1}_{3}$
,
 $\mathbf{1}_{4}$
,
$\mathbf{1}_{4}$
,
 $Z_{1}$
,
$Z_{1}$
,
 $Z_{2}$
, and
$Z_{2}$
, and
 $Z_{3}$
refer to the situation where node A is randomly sampled. The
$Z_{3}$
refer to the situation where node A is randomly sampled. The
 $\mathbf{1}_{i}$
random variables tell us if the ith speciation event is on the selected lineage, while the
$\mathbf{1}_{i}$
random variables tell us if the ith speciation event is on the selected lineage, while the
 $Z_{i}$
variables tell us if a jump took place on the lineage just after the ith speciation event. As the third speciation event does not lie on the lineage to node A,
$Z_{i}$
variables tell us if a jump took place on the lineage just after the ith speciation event. As the third speciation event does not lie on the lineage to node A,
 $Z_{3}$
is undefined. The values of
$Z_{3}$
is undefined. The values of
 $\tilde{\mathbf{1}}_{1}$
,
$\tilde{\mathbf{1}}_{1}$
,
 $\tilde{Z}_{1}$
, and
$\tilde{Z}_{1}$
, and
 $\tau^{(n)}$
refer to the situation where the pair of nodes (A,C) was randomly sampled. As jumps take place after speciation events, the only common jump possibility for this pair is at speciation node 1. Hence
$\tau^{(n)}$
refer to the situation where the pair of nodes (A,C) was randomly sampled. As jumps take place after speciation events, the only common jump possibility for this pair is at speciation node 1. Hence
 $\tilde{\mathbf{1}}_{i}$
,
$\tilde{\mathbf{1}}_{i}$
,
 $\tilde{Z}_{i}$
for
$\tilde{Z}_{i}$
for
 $i>1$
are undefined.
$i>1$
are undefined.
There are two key random components to consider: the height of the tree
 $(U_{n})$
and the time from the present backwards to the coalescence of a random pair (out of
$(U_{n})$
and the time from the present backwards to the coalescence of a random pair (out of
 $\binom{n}{2}$
possible pairs) of tip species
$\binom{n}{2}$
possible pairs) of tip species
 $(\tau^{(n)})$
. These random variables are illustrated in Figure 2, but see also Figure A.8 in [Reference Bartoszek7] and Figures 1 and 5 in [Reference Bartoszek8].
$(\tau^{(n)})$
. These random variables are illustrated in Figure 2, but see also Figure A.8 in [Reference Bartoszek7] and Figures 1 and 5 in [Reference Bartoszek8].
In order to study the properties of the OU (and, in the next section, OU+jumps) process evolving on a tree, we need expressions for the Laplace transforms of the above random objects that contribute to the mean and variance of the average of the tip values,
 $\overline{X}_{n}$
. In [Reference Bartoszek and Sagitov10] the following formulæ, including the asymptotic behaviour as
$\overline{X}_{n}$
. In [Reference Bartoszek and Sagitov10] the following formulæ, including the asymptotic behaviour as
 $n\to\infty$
, are derived (see Lemmata 3 and 4 in [Reference Bartoszek and Sagitov10]):
$n\to\infty$
, are derived (see Lemmata 3 and 4 in [Reference Bartoszek and Sagitov10]):
 \begin{equation}\begin{array}{ll}\mathbb{E}\left( {e^{-xU_n}} \right) &= b_{n,x}\sim \Gamma(x+1)n^{-x}, \\[5pt]
\mathbb{V}\left( {e^{-xU_n}} \right) &= b_{n,2x}-b_{n,x}^2\sim (\Gamma(2x+1)-\Gamma(x+1)^{2})n^{-2x},\end{array}\end{equation}
\begin{equation}\begin{array}{ll}\mathbb{E}\left( {e^{-xU_n}} \right) &= b_{n,x}\sim \Gamma(x+1)n^{-x}, \\[5pt]
\mathbb{V}\left( {e^{-xU_n}} \right) &= b_{n,2x}-b_{n,x}^2\sim (\Gamma(2x+1)-\Gamma(x+1)^{2})n^{-2x},\end{array}\end{equation}
 \begin{equation}\mathbb{E}\big( {e^{-y\tau^{(n)}}} \big) =
\left\{
\begin{array}{l@{\quad}l@{\quad}l}
\frac{2}{n-1}(H_{n}-1)-\frac{1}{n+1} &\sim\ \ 2n^{-1}\ln n,& y=1,\\[8pt]
\frac{2-(n+1)(y+1)b_{n,y}}{(n-1)(y-1)} &\sim\ \ \frac{2}{y-1}n^{-1},& y \gt 1,\end{array}\right.\end{equation}
\begin{equation}\mathbb{E}\big( {e^{-y\tau^{(n)}}} \big) =
\left\{
\begin{array}{l@{\quad}l@{\quad}l}
\frac{2}{n-1}(H_{n}-1)-\frac{1}{n+1} &\sim\ \ 2n^{-1}\ln n,& y=1,\\[8pt]
\frac{2-(n+1)(y+1)b_{n,y}}{(n-1)(y-1)} &\sim\ \ \frac{2}{y-1}n^{-1},& y \gt 1,\end{array}\right.\end{equation}
 \begin{equation} \mathbb{E}\big( {e^{-xU_n-y\tau^{(n)}}} \big) \sim
\left\{\begin{array}{l@{\quad}l}
2\Gamma(x+1)n^{-x-1}\ln n,& y=1,\\[8pt]
\frac{2\Gamma(x+1)}{y-1} n^{-x-1},& y\gt 1.\end{array}\right.\end{equation}
\begin{equation} \mathbb{E}\big( {e^{-xU_n-y\tau^{(n)}}} \big) \sim
\left\{\begin{array}{l@{\quad}l}
2\Gamma(x+1)n^{-x-1}\ln n,& y=1,\\[8pt]
\frac{2\Gamma(x+1)}{y-1} n^{-x-1},& y\gt 1.\end{array}\right.\end{equation}
The variance of the conditional expectation is derived in Lemma 5.1 in [Reference Bartoszek8] and Lemma 11 in [Reference Bartoszek and Sagitov10]:
 \begin{equation}\mathbb{V}\left( {\mathbb{E}\left( { {e^{-y\tau^{(n)}}} \vert \mathcal{Y}_{n}} \right)} \right) =\left\{\begin{array}{c@{\quad}c}O(n^{-2y}) & 0 < y
< \frac{3}{2}, \\[7pt]
O(n^{-3}\ln n) & y =\frac{3}{2}, \\[7pt]
O(n^{-3}) & y>\frac{3}{2}.\end{array}\right.\end{equation}
\begin{equation}\mathbb{V}\left( {\mathbb{E}\left( { {e^{-y\tau^{(n)}}} \vert \mathcal{Y}_{n}} \right)} \right) =\left\{\begin{array}{c@{\quad}c}O(n^{-2y}) & 0 < y
< \frac{3}{2}, \\[7pt]
O(n^{-3}\ln n) & y =\frac{3}{2}, \\[7pt]
O(n^{-3}) & y>\frac{3}{2}.\end{array}\right.\end{equation}
We furthermore have
 \begin{equation}\begin{array}{ll}\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &=\delta e^{-\alpha U_{n}}, \\[5pt]
\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &= n^{-1}+(1-n^{-1})\mathbb{E}\left( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \right) - e^{-2\alpha U_{n}},\end{array}\end{equation}
\begin{equation}\begin{array}{ll}\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &=\delta e^{-\alpha U_{n}}, \\[5pt]
\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &= n^{-1}+(1-n^{-1})\mathbb{E}\left( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \right) - e^{-2\alpha U_{n}},\end{array}\end{equation}
 \begin{equation}\begin{array}{ll}\mathbb{E}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) = n^{-1} + &(1-n^{-1})\mathbb{E}\big( {e^{-2\alpha \tau^{(n)}}} \big) - \mathbb{E}\big( {e^{-2\alpha U_{n}}} \big)\\[4pt]
& \sim \left\{\begin{array}{c@{\quad}c}2n^{-1}\ln n, & \alpha=1/2,\\[7pt]
\frac{2\alpha+1}{2\alpha-1}n^{-1},& \alpha>1/2\end{array}\right.\end{array}\end{equation}
\begin{equation}\begin{array}{ll}\mathbb{E}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) = n^{-1} + &(1-n^{-1})\mathbb{E}\big( {e^{-2\alpha \tau^{(n)}}} \big) - \mathbb{E}\big( {e^{-2\alpha U_{n}}} \big)\\[4pt]
& \sim \left\{\begin{array}{c@{\quad}c}2n^{-1}\ln n, & \alpha=1/2,\\[7pt]
\frac{2\alpha+1}{2\alpha-1}n^{-1},& \alpha>1/2\end{array}\right.\end{array}\end{equation}
(Lemma 8 in [Reference Bartoszek and Sagitov10]) and
 \begin{equation} \mathbb{V}\left( {\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) = \mathbb{V}\left( {\delta e^{-\alpha U_{n}}} \right) \sim \delta^{2}(\Gamma(2\alpha+1)-\Gamma(\alpha+1)^{2})n^{-2\alpha}\end{equation}
\begin{equation} \mathbb{V}\left( {\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) = \mathbb{V}\left( {\delta e^{-\alpha U_{n}}} \right) \sim \delta^{2}(\Gamma(2\alpha+1)-\Gamma(\alpha+1)^{2})n^{-2\alpha}\end{equation}
(Lemma 4 in [Reference Bartoszek and Sagitov10]). It remains to consider
 $\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
. Using (3.5), we obtain
$\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
. Using (3.5), we obtain
 \begin{align*}\mathbb{V}\big( {\mathbb{V}\big( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \big)} \big) = \, & \mathbb{V}\big( {(1-n^{-1})\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big) - e^{-2\alpha U_{n}}} \big)\\[5pt]
= \, & (1-n^{-1})^{2}\mathbb{V}\big( {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)} \big) + \mathbb{V}\big( {e^{-2\alpha U_{n}}} \big)\\[5pt]
& -2(1-n^{-1})\mathbb{C}\big( { {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)},{e^{-2\alpha U_{n}}}} \big)\\[5pt]
= \, & (1-n^{-1})^{2}\mathbb{V}\big( {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)} \big) + \mathbb{V}\big( {e^{-2\alpha U_{n}}} \big)\\[5pt]
& -2(1-n^{-1})\big(\mathbb{E}\big( {e^{-2\alpha(\tau^{(n)}+U_{n})}} \big)-\mathbb{E}\big( {e^{-2\alpha \tau^{(n)}}} \big)\mathbb{E}\big( {e^{-2\alpha U_{n}}} \big)\big).\end{align*}
\begin{align*}\mathbb{V}\big( {\mathbb{V}\big( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \big)} \big) = \, & \mathbb{V}\big( {(1-n^{-1})\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big) - e^{-2\alpha U_{n}}} \big)\\[5pt]
= \, & (1-n^{-1})^{2}\mathbb{V}\big( {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)} \big) + \mathbb{V}\big( {e^{-2\alpha U_{n}}} \big)\\[5pt]
& -2(1-n^{-1})\mathbb{C}\big( { {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)},{e^{-2\alpha U_{n}}}} \big)\\[5pt]
= \, & (1-n^{-1})^{2}\mathbb{V}\big( {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)} \big) + \mathbb{V}\big( {e^{-2\alpha U_{n}}} \big)\\[5pt]
& -2(1-n^{-1})\big(\mathbb{E}\big( {e^{-2\alpha(\tau^{(n)}+U_{n})}} \big)-\mathbb{E}\big( {e^{-2\alpha \tau^{(n)}}} \big)\mathbb{E}\big( {e^{-2\alpha U_{n}}} \big)\big).\end{align*}
We consider the
 $\alpha \ge 1/2$
regime. As normality of the limiting distribution was not shown for
$\alpha \ge 1/2$
regime. As normality of the limiting distribution was not shown for
 $\alpha <1/2$
in [Reference Bartoszek and Sagitov10] (and should not be expected; see Remark 3.1 below), there will be no gain from presenting long formulæ for that case. Using (3.1), (3.2), and (3.3) (see also Lemmata 3 and 4 in [Reference Bartoszek and Sagitov10] and Lemma 5.1 in [Reference Bartoszek8]), and, when considering
$\alpha <1/2$
in [Reference Bartoszek and Sagitov10] (and should not be expected; see Remark 3.1 below), there will be no gain from presenting long formulæ for that case. Using (3.1), (3.2), and (3.3) (see also Lemmata 3 and 4 in [Reference Bartoszek and Sagitov10] and Lemma 5.1 in [Reference Bartoszek8]), and, when considering
 $\mathbb{V}\left( {\mathbb{E}\left( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \right)} \right)$
, using the approximation for large n
$\mathbb{V}\left( {\mathbb{E}\left( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \right)} \right)$
, using the approximation for large n
 \begin{equation}\sum\limits_{i=k}^{n}i^{r} \sim\left \{\begin{array}{l@{\quad}l}\frac{1}{r+1} (n^{r+1}-k^{r+1}), & r > -1, \\[5pt]
\ln n, & r = -1, \\[5pt]
\frac{1}{r+1} (k^{r+1} - n^{r+1}), & r
< -1\end{array}\right.\end{equation}
\begin{equation}\sum\limits_{i=k}^{n}i^{r} \sim\left \{\begin{array}{l@{\quad}l}\frac{1}{r+1} (n^{r+1}-k^{r+1}), & r > -1, \\[5pt]
\ln n, & r = -1, \\[5pt]
\frac{1}{r+1} (k^{r+1} - n^{r+1}), & r
< -1\end{array}\right.\end{equation}
coming from
 \begin{equation*}\int\limits_{k+1}^{n-1} x^{r} \textrm{d} x \le \sum\limits_{i=k}^{n}i^{r} \le \int\limits_{k-1}^{n+1} x^{r} \textrm{d} x,\end{equation*}
\begin{equation*}\int\limits_{k+1}^{n-1} x^{r} \textrm{d} x \le \sum\limits_{i=k}^{n}i^{r} \le \int\limits_{k-1}^{n+1} x^{r} \textrm{d} x,\end{equation*}
we obtain the following asymptotic behaviour as
 $n\to\infty$
:
$n\to\infty$
:
 \begin{equation}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right)\sim\left\{\begin{array}{l@{\quad}l}8\zeta_{2}n^{-2} + (\Gamma(3)-\Gamma(2))^{2}n^{-2},& \alpha = \frac{1}{2}, \\
\\
\begin{split}
&\frac{32\alpha^{2}}{2-2\alpha}\zeta_{4-4\alpha}n^{-4\alpha}\\[5pt]
&+ (\Gamma(4\alpha+1)-\Gamma(2\alpha+1))^{2}n^{-4\alpha},\end{split} & \frac{1}{2} < \alpha < \frac{3}{4}, \\ \\36n^{-3}\ln n,& \alpha = \frac{3}{4}, \\ \\\frac{32\alpha^{2}}{(2\alpha-1)(4\alpha-3)(4\alpha-2)}n^{-3},& \frac{3}{4} < \alpha < 1, \\ \\16n^{-3},& \alpha = 1, \\\\\frac{32\alpha^{2}}{(4\alpha-3)(4\alpha-2)(2\alpha-1)}n^{-3},& 1
< \alpha,\end{array}\right.\end{equation}
\begin{equation}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right)\sim\left\{\begin{array}{l@{\quad}l}8\zeta_{2}n^{-2} + (\Gamma(3)-\Gamma(2))^{2}n^{-2},& \alpha = \frac{1}{2}, \\
\\
\begin{split}
&\frac{32\alpha^{2}}{2-2\alpha}\zeta_{4-4\alpha}n^{-4\alpha}\\[5pt]
&+ (\Gamma(4\alpha+1)-\Gamma(2\alpha+1))^{2}n^{-4\alpha},\end{split} & \frac{1}{2} < \alpha < \frac{3}{4}, \\ \\36n^{-3}\ln n,& \alpha = \frac{3}{4}, \\ \\\frac{32\alpha^{2}}{(2\alpha-1)(4\alpha-3)(4\alpha-2)}n^{-3},& \frac{3}{4} < \alpha < 1, \\ \\16n^{-3},& \alpha = 1, \\\\\frac{32\alpha^{2}}{(4\alpha-3)(4\alpha-2)(2\alpha-1)}n^{-3},& 1
< \alpha,\end{array}\right.\end{equation}
where
 $\zeta_{r}$
is the Riemann zeta function,
$\zeta_{r}$
is the Riemann zeta function,
 \begin{equation*}\zeta_{r}=\sum\limits_{k=1}^{\infty} k^{-r}.\end{equation*}
\begin{equation*}\zeta_{r}=\sum\limits_{k=1}^{\infty} k^{-r}.\end{equation*}
Denote now the leading constant of
 $\mathbb{E}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
$\mathbb{E}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
 $C^{EV}_{a,b}$
, that of
$C^{EV}_{a,b}$
, that of
 $\mathbb{V}(\mathbb{E}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
$\mathbb{V}(\mathbb{E}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
 $C^{VE}$
, and that of
$C^{VE}$
, and that of
 $\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
$\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
 $C^{VV}_{a,b}$
, where a and b are the endpoints of the interval to which
$C^{VV}_{a,b}$
, where a and b are the endpoints of the interval to which
 $\alpha$
belongs. If
$\alpha$
belongs. If
 $a=b$
, then we just write
$a=b$
, then we just write
 $C^{VV}_{a}$
. In our notation we drop the dependence of the constant on
$C^{VV}_{a}$
. In our notation we drop the dependence of the constant on
 $\alpha$
and X(0), treating it as implied. For
$\alpha$
and X(0), treating it as implied. For
 $\alpha=\frac{1}{2}$
, Theorem 2.1 gives
$\alpha=\frac{1}{2}$
, Theorem 2.1 gives
 \begin{equation} \begin{array}{l}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)\\[15pt]
\quad\le \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\\[15pt]
\quad\lesssim\frac{\sqrt{C^{VV}_{1/2}}}{C^{EV}_{1/2}}\ln^{-1}n+\frac{C^{VE}}{C^{EV}_{1/2}}\ln^{-1}n+\sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}(C^{VV}_{1/2})^{1/4}}{C^{EV}_{1/2}}\ln^{-1}n,\end{array}\end{equation}
\begin{equation} \begin{array}{l}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)\\[15pt]
\quad\le \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\\[15pt]
\quad\lesssim\frac{\sqrt{C^{VV}_{1/2}}}{C^{EV}_{1/2}}\ln^{-1}n+\frac{C^{VE}}{C^{EV}_{1/2}}\ln^{-1}n+\sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}(C^{VV}_{1/2})^{1/4}}{C^{EV}_{1/2}}\ln^{-1}n,\end{array}\end{equation}
where
 $\mu_n$
and
$\mu_n$
and
 $\sigma_n^2$
, as well as their asymptotic behaviour as
$\sigma_n^2$
, as well as their asymptotic behaviour as
 $n\to\infty$
, can be obtained from (3.1), (3.2), (3.5), and (3.6). It follows immediately from (2.2) and Remark 2.1 that
$n\to\infty$
, can be obtained from (3.1), (3.2), (3.5), and (3.6). It follows immediately from (2.2) and Remark 2.1 that
 $(\frac{n}{\ln n})^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,2)$
as
$(\frac{n}{\ln n})^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,2)$
as
 $n\to\infty$
. Analogously, for
$n\to\infty$
. Analogously, for
 $\alpha>\frac{1}{2}$
, Theorem 2.1 gives
$\alpha>\frac{1}{2}$
, Theorem 2.1 gives
 \begin{equation} \begin{array}{l}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)\\[9pt]
\lesssim\left\{\begin{array}{l@{\quad}l}\frac{\sqrt{C^{VV}_{1/2,3/4}}}{C^{EV}_{1/2,\infty}}n^{-2\alpha+1}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha+1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1/2,3/4}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-2\alpha+1},& \frac{1}{2} < \alpha < \frac{3}{4}, \\\\
\frac{\sqrt{C^{VV}_{3/4}}}{C^{EV}_{1/2,\infty}}\frac{\ln^{1/2}n}{n^{1/2}}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{3/4}\big)^{1/4}}{C^{EV}_{1/2,\infty}}\frac{\ln^{1/4}n}{n^{1/2}},& \alpha = \frac{3}{4}, \\\\
\frac{\sqrt{C^{VV}_{3/4,1}}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha + 1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{3/4,1}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-\alpha+1/4},& \frac{3}{4} < \alpha < 1, \\\\
\frac{\sqrt{C^{VV}_{1}}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-3/4},& \alpha = 1, \\\\
\frac{\sqrt{C^{VV}_{1,\infty}}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha + 1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1,\infty}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-\alpha+1/4},& 1
< \alpha.\end{array}\right.\end{array}\end{equation}
\begin{equation} \begin{array}{l}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)\\[9pt]
\lesssim\left\{\begin{array}{l@{\quad}l}\frac{\sqrt{C^{VV}_{1/2,3/4}}}{C^{EV}_{1/2,\infty}}n^{-2\alpha+1}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha+1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1/2,3/4}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-2\alpha+1},& \frac{1}{2} < \alpha < \frac{3}{4}, \\\\
\frac{\sqrt{C^{VV}_{3/4}}}{C^{EV}_{1/2,\infty}}\frac{\ln^{1/2}n}{n^{1/2}}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{3/4}\big)^{1/4}}{C^{EV}_{1/2,\infty}}\frac{\ln^{1/4}n}{n^{1/2}},& \alpha = \frac{3}{4}, \\\\
\frac{\sqrt{C^{VV}_{3/4,1}}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha + 1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{3/4,1}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-\alpha+1/4},& \frac{3}{4} < \alpha < 1, \\\\
\frac{\sqrt{C^{VV}_{1}}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-3/4},& \alpha = 1, \\\\
\frac{\sqrt{C^{VV}_{1,\infty}}}{C^{EV}_{1/2,\infty}}n^{-1/2}+ \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha + 1}+ \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1,\infty}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-\alpha+1/4},& 1
< \alpha.\end{array}\right.\end{array}\end{equation}
We obtain
 $\mu_n$
and
$\mu_n$
and
 $\sigma_n^2$
, their asymptotic behaviour as
$\sigma_n^2$
, their asymptotic behaviour as
 $n\to\infty$
, and the fact that
$n\to\infty$
, and the fact that
 $n^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,\frac{2\alpha+1}{2\alpha-1})$
as
$n^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}(0,\frac{2\alpha+1}{2\alpha-1})$
as
 $n\to\infty$
, just as in the previous case.
$n\to\infty$
, just as in the previous case.
For the Wasserstein distance, the first term on the right-hand side of (3.10) should be replaced by
 \begin{equation} \begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[18pt]
\lesssim \sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2}\big)^{3/4}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-3/2}n + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2}}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-3/2}n,\end{array}\end{equation}
\begin{equation} \begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[18pt]
\lesssim \sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2}\big)^{3/4}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-3/2}n + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2}}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-3/2}n,\end{array}\end{equation}
and the first term on the right-hand side of (3.11) should be replaced by
 \begin{equation}\begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[15pt]
\lesssim\left\{\begin{array}{ll}\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2,3/4}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3\alpha + 3/2} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2,3/4}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3\alpha + 3/2},& \frac{1}{2} < \alpha < \frac{3}{4}, \\[14pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{3/4}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}\frac{\ln^{3/4}n}{n^{3/4}} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{3/4}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/4}}\frac{\ln^{1/2}n}{n^{3/4}},& \alpha = \frac{3}{4}, \\[15pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{3/4,1}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3/4} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{3/4,1}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-\alpha},& \frac{3}{4} < \alpha < 1, \\[15pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3/4} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-1},& \alpha = 1, \\[15pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1,\infty}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3/4} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1,\infty}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-\alpha},& 1
< \alpha.\end{array}\right.\end{array}\end{equation}
\begin{equation}\begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[15pt]
\lesssim\left\{\begin{array}{ll}\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2,3/4}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3\alpha + 3/2} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2,3/4}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3\alpha + 3/2},& \frac{1}{2} < \alpha < \frac{3}{4}, \\[14pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{3/4}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}\frac{\ln^{3/4}n}{n^{3/4}} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{3/4}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/4}}\frac{\ln^{1/2}n}{n^{3/4}},& \alpha = \frac{3}{4}, \\[15pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{3/4,1}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3/4} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{3/4,1}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-\alpha},& \frac{3}{4} < \alpha < 1, \\[15pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3/4} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-1},& \alpha = 1, \\[15pt]
\sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1,\infty}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-3/4} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1,\infty}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-\alpha},& 1
< \alpha.\end{array}\right.\end{array}\end{equation}
We illustrate the bounds from (3.10) and (3.11) and those for the YOU model with jumps (the YOUj model) in Figure 3.

Figure 3: Top: illustration of the bounds from (3.10) and (3.11). For the graph we chose
 $\sigma_{a}^{2}=1$
and
$\sigma_{a}^{2}=1$
and
 $X(0)=(2\alpha)^{-1/2}$
. Bottom: illustration of the bounds on the Kolmogorov distance for the YOUj model. For the graphs we chose
$X(0)=(2\alpha)^{-1/2}$
. Bottom: illustration of the bounds on the Kolmogorov distance for the YOUj model. For the graphs we chose
 $X(0)=(2\alpha)^{-1/2}$
,
$X(0)=(2\alpha)^{-1/2}$
,
 $p=1/2$
, and
$p=1/2$
, and
 $\sigma_{a}^{2}=\sigma_{c}^{2}=1$
. For
$\sigma_{a}^{2}=\sigma_{c}^{2}=1$
. For
 $\alpha=1/2$
we use the bound of (4.11), while for
$\alpha=1/2$
we use the bound of (4.11), while for
 $\alpha>1/2$
we are in the non-convergent regime, so the bounds come from explicitly calculating the asymptotic constant in (4.13).
$\alpha>1/2$
we are in the non-convergent regime, so the bounds come from explicitly calculating the asymptotic constant in (4.13).
Remark 3.1. The theorems presented in this section do not give information about the case
 $\alpha < 1/2$
. However, one can strongly suspect that the limit will not be normal in this case. By considering higher moments of the limiting distribution, Remark
$\alpha < 1/2$
. However, one can strongly suspect that the limit will not be normal in this case. By considering higher moments of the limiting distribution, Remark
 $3.14$
of [Reference Adamczak and Miłoś1] showed that when the YOU model is stopped at a fixed time (the number of tips being random) for
$3.14$
of [Reference Adamczak and Miłoś1] showed that when the YOU model is stopped at a fixed time (the number of tips being random) for
 $\alpha < 1/2$
, the limit is not normal. Unfortunately, when stopping just before the nth speciation event, the approach in [Reference Bartoszek and Sagitov10] does not allow for easy derivation of the higher moments in order to reach the same conclusion as in [Reference Adamczak and Miłoś1].
$\alpha < 1/2$
, the limit is not normal. Unfortunately, when stopping just before the nth speciation event, the approach in [Reference Bartoszek and Sagitov10] does not allow for easy derivation of the higher moments in order to reach the same conclusion as in [Reference Adamczak and Miłoś1].
4. The Yule–Ornstein–Uhlenbeck model with jumps
The new feature of the YOUj model, as compared to the YOU model, is that a normally distributed jump with mean 0 may or may not take place in the trait value immediately after a speciation event. The jumps occur independently of one another and of the OU process, but the probability of a jump, and the variance of the jump, may depend on the number of the speciation event: with speciation event number
 $i=1,\ldots,n$
, we associate a jump probability
$i=1,\ldots,n$
, we associate a jump probability
 $p_{i}$
and jump variance
$p_{i}$
and jump variance
 $\sigma_{c,i}^{2}$
. If the jump probabilities and variances are constant, we write
$\sigma_{c,i}^{2}$
. If the jump probabilities and variances are constant, we write
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
.
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
.
The key problem is that one needs to keep careful track of the jumps that take place at speciation events and of how the ‘mean-reversion’ of the OU process part causes their effect to be smoothed out along a lineage. We keep the notation defined in Section 3, except that we now denote by
 $\mathcal{Y}_{n}$
the
$\mathcal{Y}_{n}$
the
 $\sigma$
-algebra that contains information on the whole Yule tree and on the jump locations, i.e. the speciation events after which jumps have taken place. We now introduce the concept of convergence with density 1.
$\sigma$
-algebra that contains information on the whole Yule tree and on the jump locations, i.e. the speciation events after which jumps have taken place. We now introduce the concept of convergence with density 1.
Definition 4.1. A subset
 $E \subset \mathbb{N}$
of positive integers is said to have density 0 (see e.g. Petersen [Reference Petersen16]) if
$E \subset \mathbb{N}$
of positive integers is said to have density 0 (see e.g. Petersen [Reference Petersen16]) if
 \begin{equation*}\lim\limits_{n \to \infty}\frac{1}{n}\sum\limits_{k=0}^{n-1}I_{E}(k) =0,\end{equation*}
\begin{equation*}\lim\limits_{n \to \infty}\frac{1}{n}\sum\limits_{k=0}^{n-1}I_{E}(k) =0,\end{equation*}
where
 $I_{E}({\cdot})$
is the indicator function of the set E.
$I_{E}({\cdot})$
is the indicator function of the set E.
Definition 4.2. A sequence
 $a_{n}$
converges to 0 with density 1 if there exists a subset
$a_{n}$
converges to 0 with density 1 if there exists a subset
 $E\subset \mathbb{N}$
of density 0 such that
$E\subset \mathbb{N}$
of density 0 such that
 \begin{equation*}\lim\limits_{n \to \infty,n \notin E}a_{n} =0.\end{equation*}
\begin{equation*}\lim\limits_{n \to \infty,n \notin E}a_{n} =0.\end{equation*}
Theorem 4.1. Consider the YOUj model with
 $\alpha \ge 1/2$
. Let
$\alpha \ge 1/2$
. Let
 $\overline{X}_{n}$
be the average value of the traits at the n leaves, let
$\overline{X}_{n}$
be the average value of the traits at the n leaves, let
 \begin{equation*}\overline{Y}_{n} = \overline{X}_{n}\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}},\end{equation*}
\begin{equation*}\overline{Y}_{n} = \overline{X}_{n}\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}},\end{equation*}
and let
 \begin{equation*}\delta = X(0)\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}}.\end{equation*}
\begin{equation*}\delta = X(0)\sqrt{\frac{2\alpha}{\sigma_{a}^{2}}}.\end{equation*}
Let also
 $\mu_n = \mathbb{E}(\overline{Y}_{n})$
and
$\mu_n = \mathbb{E}(\overline{Y}_{n})$
and
 $\sigma_n^2=\mathbb{E}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right)$
.
$\sigma_n^2=\mathbb{E}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right)$
.
-
(i) If
$\alpha=1/2$
, and
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, then
as
\begin{equation*}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right) = \text{O}\big(\ln^{-\frac{1}{2}} n\big)\end{equation*}
$n\to\infty$
, where
$\mu_n = \delta b_{n,\alpha}$
. Moreover,
$(\frac{n}{\ln n})^{1/2}\,\mu_n\to 0$
and
as
\begin{equation*}\frac{n}{\ln n}\sigma_n^2\to 2+\frac{4p}{\sigma_a^{2}}\sigma_{c}^{2}\end{equation*}
$n\to\infty$
, so
as
\begin{equation*}\bigg(\frac{n}{\ln n}\bigg)^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}\bigg(0,2+\frac{4p}{\sigma_a^{2}}\sigma_{c}^{2}\bigg)\end{equation*}
$n\to\infty$
.
-
(ii) If
$\alpha>1/2$
, and
$(p_i,\sigma_{c,i}^{2})\equiv (1,\sigma_{c}^{2})$
, then the asymptotics as
$n\to\infty$
for
is the same as in Theorem 3.1(ii), and
\begin{equation*}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)\end{equation*}
$\mu_n = \delta b_{n,\alpha}$
. Moreover,
$n^{1/2}\,\mu_n\to 0$
and
as
\begin{equation*}n\sigma_n^2\to\frac{2\alpha+1}{2\alpha-1}\bigg(1 + \frac{2p}{\sigma_a^{2}}\sigma_{c}^{2}\bigg)\end{equation*}
$n\to\infty$
, so
as
\begin{equation*}n^{1/2}\,\overline{Y}_{n}\ \xrightarrow{\ d\ }\ \text{N}\bigg(0,\frac{2\alpha+1}{2\alpha-1}\bigg(1 + \frac{2p}{\sigma_a^{2}}\sigma_{c}^{2}\bigg)\bigg)\end{equation*}
$n\to\infty$
.
-
(iii) If
$\alpha>1/2$
, and the sequence
$p_{n}\sigma_{c,n}^{4}$
is bounded and converges to 0 with density 1, then
as
\begin{equation*}d_{K}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right) \to 0\end{equation*}
$n\to\infty$
.
























Theorem 4.2. Consider the YOUj model with
 $\alpha \ge 1/2$
, with the same notation as in Theorem 4.1.
$\alpha \ge 1/2$
, with the same notation as in Theorem 4.1.
-
(i) If
$\alpha=1/2$
, and
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, then
as
\begin{equation*}d_{W}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right) = \text{O}(\ln^{-3/4} n)\end{equation*}
$n\to\infty$
.
-
(ii) If
$\alpha>1/2$
, and
$(p_i,\sigma_{c,i}^{2})\equiv (1,\sigma_{c}^{2})$
, then the asymptotics as
$n\to\infty$
for
is the same as in Theorem 3.2(ii).
\begin{equation*}d_{W}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right)\end{equation*}
-
(iii) If
$\alpha>1/2$
, and the sequence
$p_{n}\sigma_{c,n}^{4}$
is bounded and converges to 0 with density 1, then
as
\begin{equation*}d_{W}\left(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\right) \to 0\end{equation*}
$n\to\infty$
.












Proof of Theorems 4.1 and 4.2. In addition to the random quantities defined in Section 3, we have to consider two more random components of the tree, the speciation events on a random lineage (out of n possible ones), and the speciation events common to (i.e. on the path from the origin of the tree to the most recent common ancestor of) a random pair of tip species (out of
 $\binom{n}{2}$
possible pairs). We define
$\binom{n}{2}$
possible pairs). We define
 $\mathbf{1}_{i}$
as a binary random variable indicating that the tree’s ith speciation event is present on our randomly chosen lineage,
$\mathbf{1}_{i}$
as a binary random variable indicating that the tree’s ith speciation event is present on our randomly chosen lineage,
 $\tilde{\mathbf{1}}_{i}$
as a binary random variable indicating that the tree’s ith speciation event is present on the path from the root to the most recent common ancestor of our randomly sampled pair of tips,
$\tilde{\mathbf{1}}_{i}$
as a binary random variable indicating that the tree’s ith speciation event is present on the path from the root to the most recent common ancestor of our randomly sampled pair of tips,
 $Z_{i}$
as a binary random variable indicating that a jump took place just after the tree’s ith speciation event on our randomly chosen lineage, and
$Z_{i}$
as a binary random variable indicating that a jump took place just after the tree’s ith speciation event on our randomly chosen lineage, and
 $\tilde{Z}_{i}$
as a binary random variable indicating that a jump took place just after the tree’s ith speciation event on the path from the root to the most recent common ancestor of our randomly sampled pair of tips. For illustration of these random variables see Figure 2.
$\tilde{Z}_{i}$
as a binary random variable indicating that a jump took place just after the tree’s ith speciation event on the path from the root to the most recent common ancestor of our randomly sampled pair of tips. For illustration of these random variables see Figure 2.
Furthermore, we define the two following sequences of random variables:
 \begin{equation*}\phi^{\ast}_{i}\,:=\,Z_{i}e^{-2\alpha(T_{n}+\ldots+T_{i+1})}\mathbb{E}\left( { {\mathbf{1}_{i}} \vert \mathcal{Y}_{n}} \right); \quad\phi_{i}\,:=\,\tilde{Z}_{i}\tilde{\mathbf{1}}_{i}e^{-2\alpha(T_{n}+\ldots+T_{i+1})} \qquad\forall i=1,\ldots,n-1.\end{equation*}
\begin{equation*}\phi^{\ast}_{i}\,:=\,Z_{i}e^{-2\alpha(T_{n}+\ldots+T_{i+1})}\mathbb{E}\left( { {\mathbf{1}_{i}} \vert \mathcal{Y}_{n}} \right); \quad\phi_{i}\,:=\,\tilde{Z}_{i}\tilde{\mathbf{1}}_{i}e^{-2\alpha(T_{n}+\ldots+T_{i+1})} \qquad\forall i=1,\ldots,n-1.\end{equation*}
We can recognize that
 $\phi^{\ast}_{i}$
and
$\phi^{\ast}_{i}$
and
 $\phi_{i}$
capture how the effect of each (potential) jump will be modified before the end of the randomly selected lineage is reached. The first quantifies the effects that jumps will have on a randomly selected tip species, while the second quantifies the effects that jumps will have on the covariance between a random pair of tip species. Intuitively speaking, a random event at distance (in time) t away from the point of interest is under the OU process discounted by a factor of
$\phi_{i}$
capture how the effect of each (potential) jump will be modified before the end of the randomly selected lineage is reached. The first quantifies the effects that jumps will have on a randomly selected tip species, while the second quantifies the effects that jumps will have on the covariance between a random pair of tip species. Intuitively speaking, a random event at distance (in time) t away from the point of interest is under the OU process discounted by a factor of
 $e^{-\alpha t}$
, implying that the contribution of its variance will be discounted by
$e^{-\alpha t}$
, implying that the contribution of its variance will be discounted by
 $e^{-2\alpha t}$
.
$e^{-2\alpha t}$
.
Recall that with each speciation event,
 $i=1,\ldots,n$
, we associate the jump probability
$i=1,\ldots,n$
, we associate the jump probability
 $p_{i}$
and jump variance
$p_{i}$
and jump variance
 $\sigma_{c,i}^{2}$
, and that the jumps are normally distributed with mean 0. In the case when
$\sigma_{c,i}^{2}$
, and that the jumps are normally distributed with mean 0. In the case when
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, we have the following (the
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, we have the following (the
 $\alpha \ge 1/2$
regime in the proof of Theorem
$\alpha \ge 1/2$
regime in the proof of Theorem
 $3.2$
in [Reference Bartoszek7]):
$3.2$
in [Reference Bartoszek7]):
 \begin{equation}\mathbb{E}\left( {\sum\limits_{i=1}^{n-1}\phi^{\ast}_{i}} \right) =\frac{2p}{2\alpha}(1-(1+2\alpha)b_{n,2\alpha})\sim \frac{2p}{2\alpha}(1-\Gamma(2+2\alpha)n^{-2\alpha}),\end{equation}
\begin{equation}\mathbb{E}\left( {\sum\limits_{i=1}^{n-1}\phi^{\ast}_{i}} \right) =\frac{2p}{2\alpha}(1-(1+2\alpha)b_{n,2\alpha})\sim \frac{2p}{2\alpha}(1-\Gamma(2+2\alpha)n^{-2\alpha}),\end{equation}
 \begin{equation}\mathbb{E}\left( {\sum\limits_{i=1}^{n-1}\phi_{i}} \right) =\left\{\begin{array}{c@{\quad}l@{\quad}l}\frac{4p}{n-1}\Big(H_{n}-\frac{5n-1}{2(n+1)}\Big) &\sim\ \ 4pn^{-1}\ln n, & \alpha =1/2,\\[12pt]
\dfrac{2p}{2\alpha}\dfrac{(2-(2\alpha+1)(2\alpha n -2\alpha+2)b_{n,2\alpha})}{(n-1)(2\alpha-1)} &\sim\ \ \dfrac{4p}{2\alpha(2\alpha-1)}n^{-1}, & \alpha >1/2.\end{array}\right.\end{equation}
\begin{equation}\mathbb{E}\left( {\sum\limits_{i=1}^{n-1}\phi_{i}} \right) =\left\{\begin{array}{c@{\quad}l@{\quad}l}\frac{4p}{n-1}\Big(H_{n}-\frac{5n-1}{2(n+1)}\Big) &\sim\ \ 4pn^{-1}\ln n, & \alpha =1/2,\\[12pt]
\dfrac{2p}{2\alpha}\dfrac{(2-(2\alpha+1)(2\alpha n -2\alpha+2)b_{n,2\alpha})}{(n-1)(2\alpha-1)} &\sim\ \ \dfrac{4p}{2\alpha(2\alpha-1)}n^{-1}, & \alpha >1/2.\end{array}\right.\end{equation}
In the case when
 $p_{n}\sigma_{c,n}^{4}\to 0$
with density 1 as
$p_{n}\sigma_{c,n}^{4}\to 0$
with density 1 as
 $n\to\infty$
, we have the following, by Corollaries
$n\to\infty$
, we have the following, by Corollaries
 $5.4$
and
$5.4$
and
 $5.7$
in [Reference Bartoszek8]: as
$5.7$
in [Reference Bartoszek8]: as
 $n\to\infty$
, for
$n\to\infty$
, for
 $\alpha=1/2$
,
$\alpha=1/2$
,
 \begin{equation}\begin{array}{l}(n\ln^{-1} n) \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi^{\ast}_{i}} \right) \to 0,\qquad (n^{2}\ln^{-1} n) \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}} \right) \to 0,\end{array}\end{equation}
\begin{equation}\begin{array}{l}(n\ln^{-1} n) \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi^{\ast}_{i}} \right) \to 0,\qquad (n^{2}\ln^{-1} n) \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}} \right) \to 0,\end{array}\end{equation}
and for
 $\alpha>1/2$
,
$\alpha>1/2$
,
 \begin{equation}\begin{array}{l}n \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi^{\ast}_{i}} \right) \to 0,\qquad n^{2} \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}} \right) \to 0.\end{array}\end{equation}
\begin{equation}\begin{array}{l}n \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi^{\ast}_{i}} \right) \to 0,\qquad n^{2} \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}} \right) \to 0.\end{array}\end{equation}
For the conditional mean and variance of
 $\overline{Y}_{n}$
, the following formulæ are provided in [Reference Bartoszek8], Lemma 6.1:
$\overline{Y}_{n}$
, the following formulæ are provided in [Reference Bartoszek8], Lemma 6.1:
 \begin{equation}\begin{array}{ll}\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &=\delta e^{-\alpha U_{n}}, \\[4pt]
\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &= n^{-1}+\big(1-n^{-1}\big)\mathbb{E}\bigg( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \bigg) - e^{-2\alpha U_{n}}\\[4pt]
&\quad +\,n^{-1}\frac{2\alpha}{\sigma_a^{2}}\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi^{\ast}_{i}+\big(1-n^{-1}\big)\frac{2\alpha}{\sigma_a^{2}}\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}.\end{array}\end{equation}
\begin{equation}\begin{array}{ll}\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &=\delta e^{-\alpha U_{n}}, \\[4pt]
\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right) &= n^{-1}+\big(1-n^{-1}\big)\mathbb{E}\bigg( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \bigg) - e^{-2\alpha U_{n}}\\[4pt]
&\quad +\,n^{-1}\frac{2\alpha}{\sigma_a^{2}}\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi^{\ast}_{i}+\big(1-n^{-1}\big)\frac{2\alpha}{\sigma_a^{2}}\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}.\end{array}\end{equation}
In the case when
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, using (3.6), (4.1), and (4.2) we obtain
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, using (3.6), (4.1), and (4.2) we obtain
 \begin{equation}\mathbb{E}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) \sim\left\{\begin{array}{c@{\quad}c}2\left(1+\frac{2p}{\sigma_a^{2}}\sigma_{c}^{2}\right)n^{-1}\ln n, & \alpha=1/2, \\[12pt]
\frac{2\alpha+1}{2\alpha-1}\left(1 + \frac{2p}{\sigma_a^{2}}\sigma_{c}^{2}\right)n^{-1}, & \alpha >1/2,\end{array}\right.\end{equation}
\begin{equation}\mathbb{E}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) \sim\left\{\begin{array}{c@{\quad}c}2\left(1+\frac{2p}{\sigma_a^{2}}\sigma_{c}^{2}\right)n^{-1}\ln n, & \alpha=1/2, \\[12pt]
\frac{2\alpha+1}{2\alpha-1}\left(1 + \frac{2p}{\sigma_a^{2}}\sigma_{c}^{2}\right)n^{-1}, & \alpha >1/2,\end{array}\right.\end{equation}
and as in (3.7), we get
 \begin{equation*}\mathbb{V}\left( {\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) = \mathbb{V}\left( {\delta e^{-\alpha U_{n}}} \right) \sim \delta^{2}(\Gamma(2\alpha+1)-\Gamma(\alpha+1)^{2})n^{-2\alpha}.\end{equation*}
\begin{equation*}\mathbb{V}\left( {\mathbb{E}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) = \mathbb{V}\left( {\delta e^{-\alpha U_{n}}} \right) \sim \delta^{2}(\Gamma(2\alpha+1)-\Gamma(\alpha+1)^{2})n^{-2\alpha}.\end{equation*}
It remains to consider
 $\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
. We will use Cauchy–Schwarz to obtain an upper bound
$\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
. We will use Cauchy–Schwarz to obtain an upper bound
 \begin{equation}\begin{array}{ll}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) & \,\le 4\left(\mathbb{V}\left( {\mathbb{E}\left( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \right)} \right) +\mathbb{V}\big( {e^{-2\alpha U_{n}}} \big)\right. \\[8pt]
& \quad\left.+\, n^{-2}\bigg(\frac{2\alpha}{\sigma_a^{2}}\bigg)^{2}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^2\phi^{\ast}_{i}} \right)+\bigg(\frac{2\alpha}{\sigma_a^{2}}\bigg)^{2}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^2\phi_{i}} \right)\right).\end{array}\end{equation}
\begin{equation}\begin{array}{ll}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) & \,\le 4\left(\mathbb{V}\left( {\mathbb{E}\left( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \right)} \right) +\mathbb{V}\big( {e^{-2\alpha U_{n}}} \big)\right. \\[8pt]
& \quad\left.+\, n^{-2}\bigg(\frac{2\alpha}{\sigma_a^{2}}\bigg)^{2}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^2\phi^{\ast}_{i}} \right)+\bigg(\frac{2\alpha}{\sigma_a^{2}}\bigg)^{2}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^2\phi_{i}} \right)\right).\end{array}\end{equation}
As before, we first consider the case when
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
. We look at
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
. We look at
 $\mathbb{V}\Big( {\sum\limits_{i=1}^{n-1}\phi^{\ast}_{i}} \Big)$
and consider in more detail the elements I, II, and III in the proof of Lemma 5.3 in [Reference Bartoszek8], to obtain
$\mathbb{V}\Big( {\sum\limits_{i=1}^{n-1}\phi^{\ast}_{i}} \Big)$
and consider in more detail the elements I, II, and III in the proof of Lemma 5.3 in [Reference Bartoszek8], to obtain
 \begin{equation}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\phi^{\ast}_{i}} \right) \sim\left\{\begin{array}{c@{\quad}c}n^{-1}\ln n, & \alpha = 1/4,\\[5pt]
\frac{4p^{2}}{4\alpha-1}n^{-1}, & \alpha> 1/4.\end{array}\right.\end{equation}
\begin{equation}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\phi^{\ast}_{i}} \right) \sim\left\{\begin{array}{c@{\quad}c}n^{-1}\ln n, & \alpha = 1/4,\\[5pt]
\frac{4p^{2}}{4\alpha-1}n^{-1}, & \alpha> 1/4.\end{array}\right.\end{equation}
In the same fashion, for
 $\mathbb{V}\Big( {\sum\limits_{i=1}^{n-1}\phi_{i}} \Big)$
we consider in more detail the element III in the proof of Lemma 5.5 in [Reference Bartoszek8], and using (3.8) we obtain
$\mathbb{V}\Big( {\sum\limits_{i=1}^{n-1}\phi_{i}} \Big)$
we consider in more detail the element III in the proof of Lemma 5.5 in [Reference Bartoszek8], and using (3.8) we obtain
 \begin{equation}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\phi_{i}} \right) \sim\left\{\begin{array}{c@{\quad}c}16p(1-p)n^{-2}\ln n, & \alpha =1/2,\\[9pt]
\frac{32p(1-p)}{(4\alpha)(4\alpha-1)(4\alpha-2)}n^{-2}, & \alpha>1/2.\end{array}\right.\end{equation}
\begin{equation}\mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\phi_{i}} \right) \sim\left\{\begin{array}{c@{\quad}c}16p(1-p)n^{-2}\ln n, & \alpha =1/2,\\[9pt]
\frac{32p(1-p)}{(4\alpha)(4\alpha-1)(4\alpha-2)}n^{-2}, & \alpha>1/2.\end{array}\right.\end{equation}
The other elements I, II, IV, and V for
 $\alpha \ge 1/2$
converge faster to 0; hence they do not contribute to the leading asymptotic behaviour. Using (3.1), (3.4), (4.8), and (4.9), we obtain the bound
$\alpha \ge 1/2$
converge faster to 0; hence they do not contribute to the leading asymptotic behaviour. Using (3.1), (3.4), (4.8), and (4.9), we obtain the bound
 \begin{equation}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) \lesssim\left\{\begin{array}{c@{\quad}c}4\big(\frac{2\alpha}{\sigma_a^{2}}\big)^{2}\sigma_{c}^{4}16p(1-p)n^{-2}\ln n, & \alpha=1/2, \\[9pt]
4\big(\frac{2\alpha}{\sigma_a^{2}}\big)^{2}\sigma_{c}^{4}\frac{32p(1-p)}{(4\alpha)(4\alpha-1)(4\alpha-2)}n^{-2}, & \alpha>1/2 .\end{array}\right.\end{equation}
\begin{equation}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right) \lesssim\left\{\begin{array}{c@{\quad}c}4\big(\frac{2\alpha}{\sigma_a^{2}}\big)^{2}\sigma_{c}^{4}16p(1-p)n^{-2}\ln n, & \alpha=1/2, \\[9pt]
4\big(\frac{2\alpha}{\sigma_a^{2}}\big)^{2}\sigma_{c}^{4}\frac{32p(1-p)}{(4\alpha)(4\alpha-1)(4\alpha-2)}n^{-2}, & \alpha>1/2 .\end{array}\right.\end{equation}
Just as in Section 3, we denote the leading constant of
 $\mathbb{E}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
$\mathbb{E}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
 $C^{EV}_{a,b}$
, that of
$C^{EV}_{a,b}$
, that of
 $\mathbb{V}(\mathbb{E}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
$\mathbb{V}(\mathbb{E}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
 $C^{VE}$
, and that of
$C^{VE}$
, and that of
 $\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
$\mathbb{V}(\mathbb{V}(\overline{Y}_{n} \vert \mathcal{Y}_{n}))$
by
 $C^{VV}_{a,b}$
, where a and b are the endpoints of the interval to which
$C^{VV}_{a,b}$
, where a and b are the endpoints of the interval to which
 $\alpha$
belongs. If
$\alpha$
belongs. If
 $a=b$
, then we just write
$a=b$
, then we just write
 $C^{VV}_{a}$
. If
$C^{VV}_{a}$
. If
 $\alpha=1/2$
and
$\alpha=1/2$
and
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, Theorem 2.1 gives
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, Theorem 2.1 gives
 \begin{equation} \begin{array}{l}d_{K}\biggl(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\biggr)\\[8pt]
\quad\le \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\\[13pt]
\quad\lesssim\frac{\sqrt{C^{VV}_{1/2}}}{C^{EV}_{1/2}}\ln^{-1/2}n+\frac{C^{VE}}{C^{EV}_{1/2}}\ln^{-1}n+\sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1/2}\big)^{1/4}}{C^{EV}_{1/2}}\ln^{-3/4}n,\end{array}\end{equation}
\begin{equation} \begin{array}{l}d_{K}\biggl(\mathcal{L}\left(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\right),\textrm{N}(0,1)\biggr)\\[8pt]
\quad\le \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\\[13pt]
\quad\lesssim\frac{\sqrt{C^{VV}_{1/2}}}{C^{EV}_{1/2}}\ln^{-1/2}n+\frac{C^{VE}}{C^{EV}_{1/2}}\ln^{-1}n+\sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1/2}\big)^{1/4}}{C^{EV}_{1/2}}\ln^{-3/4}n,\end{array}\end{equation}
where
 $\mu_n$
and
$\mu_n$
and
 $\sigma_n^2$
, as well as their asymptotic behaviour as
$\sigma_n^2$
, as well as their asymptotic behaviour as
 $n\to\infty$
, can be obtained from (3.1), (4.5), and (4.6). Just as in Section 3, it follows that
$n\to\infty$
, can be obtained from (3.1), (4.5), and (4.6). Just as in Section 3, it follows that
 \begin{equation*}\Bigl(\frac{n}{\ln n}\Bigr)^{1/2}\overline{Y}_n\ \xrightarrow{\ d\ }\ \text{N}\bigg(0,2+\frac{4p}{\sigma_a^{2}}\sigma_{c}^{2}\bigg)\end{equation*}
\begin{equation*}\Bigl(\frac{n}{\ln n}\Bigr)^{1/2}\overline{Y}_n\ \xrightarrow{\ d\ }\ \text{N}\bigg(0,2+\frac{4p}{\sigma_a^{2}}\sigma_{c}^{2}\bigg)\end{equation*}
as
 $n\to\infty$
. For the Wasserstein distance, the first term on the right-hand side of (4.11) should be replaced by
$n\to\infty$
. For the Wasserstein distance, the first term on the right-hand side of (4.11) should be replaced by
 \begin{equation} \begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[13pt]
\quad\lesssim \sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2}\big)^{3/4}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-3/4}n + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2}}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-1}n.\end{array}\end{equation}
\begin{equation} \begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[13pt]
\quad\lesssim \sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2}\big)^{3/4}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-3/4}n + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2}}}{\big(C^{EV}_{1/2}\big)^{3/2}}\ln^{-1}n.\end{array}\end{equation}
If
 $\alpha>1/2$
and
$\alpha>1/2$
and
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, where
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
, where
 $p<1$
, Theorem 2.1 gives
$p<1$
, Theorem 2.1 gives
 \begin{equation} \begin{array}{l}d_{K}\biggl(\mathcal{L}\bigg(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\bigg),\textrm{N}(0,1)\biggr)\\[8pt]
\quad \le \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\\[13pt]
\quad\lesssim\frac{\sqrt{C^{VV}_{1/2,\infty}}}{C^{EV}_{1/2,\infty}} + \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha + 1} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1/2,\infty}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-\alpha + 1/2}.\end{array}\end{equation}
\begin{equation} \begin{array}{l}d_{K}\biggl(\mathcal{L}\bigg(\frac{\overline{Y}_{n}-\mu_n}{\sigma_n}\bigg),\textrm{N}(0,1)\biggr)\\[8pt]
\quad \le \frac{\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \frac{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{1/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\\[13pt]
\quad\lesssim\frac{\sqrt{C^{VV}_{1/2,\infty}}}{C^{EV}_{1/2,\infty}} + \frac{C^{VE}}{C^{EV}_{1/2,\infty}}n^{-2\alpha + 1} + \sqrt{\frac{2}{\pi}}\frac{\sqrt{C^{VE}}\big(C^{VV}_{1/2,\infty}\big)^{1/4}}{C^{EV}_{1/2,\infty}}n^{-\alpha + 1/2}.\end{array}\end{equation}
The bound does not converge to 0 as
 $n\to\infty$
. The same is true for the Wasserstein distance, where the first term on the right-hand side of (4.13) should be replaced by
$n\to\infty$
. The same is true for the Wasserstein distance, where the first term on the right-hand side of (4.13) should be replaced by
 \begin{equation} \begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[13pt]
\lesssim \sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2,\infty}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2,\infty}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-\alpha + 1/2}.\end{array}\end{equation}
\begin{equation} \begin{array}{l}\sqrt{\frac{2}{\pi}}\,\frac{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/4}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}} + \frac{\sqrt{\mathbb{V}\bigl(\mathbb{E}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}\sqrt{\mathbb{V}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)}}{\mathbb{E}\bigl(\mathbb{V}(\overline{Y}_{n}|\mathcal{Y}_n)\bigr)^{3/2}}\\[13pt]
\lesssim \sqrt{\frac{2}{\pi}}\,\frac{\big(C^{VV}_{1/2,\infty}\big)^{3/4}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}} + \frac{\sqrt{C^{VE}}\sqrt{C^{VV}_{1/2,\infty}}}{\big(C^{EV}_{1/2,\infty}\big)^{3/2}}n^{-\alpha + 1/2}.\end{array}\end{equation}
However, if
 $p=1$
, the leading term in (4.7) vanishes, which implies the convergence to 0 in Theorem 4.1(ii). In order to obtain the rate of convergence, we need to look at lower-order terms. They turn out to be the same as for
$p=1$
, the leading term in (4.7) vanishes, which implies the convergence to 0 in Theorem 4.1(ii). In order to obtain the rate of convergence, we need to look at lower-order terms. They turn out to be the same as for
 \begin{equation*}\mathbb{V}\big( {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)} \big),\end{equation*}
\begin{equation*}\mathbb{V}\big( {\mathbb{E}\big( { {e^{-2\alpha \tau^{(n)}}} \vert \mathcal{Y}_{n}} \big)} \big),\end{equation*}
since in the
 $\alpha\ge 1/2$
regime all the other terms converge to 0 just as fast (Parts I, IV, and V of Lemma 5.5 in [Reference Bartoszek8]) or faster (cf. Lemmata 5.3 and 5.5 in [Reference Bartoszek8]). Using the convergence rates presented in (3.4), (3.7), and (4.6), we obtain Theorem 4.1(ii) and Theorem 4.2(ii).
$\alpha\ge 1/2$
regime all the other terms converge to 0 just as fast (Parts I, IV, and V of Lemma 5.5 in [Reference Bartoszek8]) or faster (cf. Lemmata 5.3 and 5.5 in [Reference Bartoszek8]). Using the convergence rates presented in (3.4), (3.7), and (4.6), we obtain Theorem 4.1(ii) and Theorem 4.2(ii).
Finally, if the sequence
 $p_{n}\sigma_{c,n}^{4}$
is bounded and converges to 0 with density 1, then by (4.4) we obtain
$p_{n}\sigma_{c,n}^{4}$
is bounded and converges to 0 with density 1, then by (4.4) we obtain
 \begin{equation*}\begin{array}{l}n^2 \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}} \right) \to 0\quad\text{as $n\to\infty$,}\end{array}\end{equation*}
\begin{equation*}\begin{array}{l}n^2 \mathbb{V}\left( {\sum\limits_{i=1}^{n-1}\sigma_{c,i}^{2}\phi_{i}} \right) \to 0\quad\text{as $n\to\infty$,}\end{array}\end{equation*}
which implies that
 $n^{2}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right)\to 0$
as
$n^{2}\mathbb{V}\left( {\mathbb{V}\left( { {\overline{Y}_{n}} \vert \mathcal{Y}_{n}} \right)} \right)\to 0$
as
 $n\to\infty$
, by (4.7). This in turn entails convergence of both distances to 0 as
$n\to\infty$
, by (4.7). This in turn entails convergence of both distances to 0 as
 $n\to\infty$
, but without any information on the rate. This proves Theorem 4.1(iii) and Theorem 4.2(iii).
$n\to\infty$
, but without any information on the rate. This proves Theorem 4.1(iii) and Theorem 4.2(iii).
Remark 4.1. In the original arXiv preprint (identifier arXiv:1602.05189) for [Reference Bartoszek8], it was stated that convergence to normality in the
 $\alpha \ge 1/2$
regime will only take place if
$\alpha \ge 1/2$
regime will only take place if
 $\sigma_{c,n}^{4}p_{n} \to 0$
with density 1 and is bounded. However, in (4.11) above we can see that in the critical case,
$\sigma_{c,n}^{4}p_{n} \to 0$
with density 1 and is bounded. However, in (4.11) above we can see that in the critical case,
 $\alpha=1/2$
, convergence to normality will hold even if
$\alpha=1/2$
, convergence to normality will hold even if
 $(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
.
$(p_i,\sigma_{c,i}^{2})\equiv (p,\sigma_{c}^{2})$
.
Remark 4.2. The condition
 $p_{n}\sigma_{c,n}^{4} \to 0$
with density 1 in Theorem 4.1 can be slightly relaxed. Essentially the same results (with possibly different bounds) will hold if
$p_{n}\sigma_{c,n}^{4} \to 0$
with density 1 in Theorem 4.1 can be slightly relaxed. Essentially the same results (with possibly different bounds) will hold if
 $(1-p_{n})p_{n}\sigma_{c,n}^{4} \to 0$
with density 1 with additional assumptions on the jump effects on a randomly chosen lineage and for a random pair of sampled lineages (see Theorem
$(1-p_{n})p_{n}\sigma_{c,n}^{4} \to 0$
with density 1 with additional assumptions on the jump effects on a randomly chosen lineage and for a random pair of sampled lineages (see Theorem
 $4.6$
in [Reference Bartoszek8]). However, introducing this here would require a significant amount of additional heavy notation, for no gain in the actual application of Stein’s method to the YOUj model.
$4.6$
in [Reference Bartoszek8]). However, introducing this here would require a significant amount of additional heavy notation, for no gain in the actual application of Stein’s method to the YOUj model.
Appendix
Theorem A.1. Let X be a real-valued random variable such that
 $\mathbb{E}(X^2)<\infty$
, and let
$\mathbb{E}(X^2)<\infty$
, and let
 $\mathscr{G}$
be a
$\mathscr{G}$
be a
 $\sigma$
-algebra such that the regular conditional distribution of X given
$\sigma$
-algebra such that the regular conditional distribution of X given
 $\mathscr{G}$
is normal. Define
$\mathscr{G}$
is normal. Define
 $\mu=\mathbb{E}(X)$
,
$\mu=\mathbb{E}(X)$
,
 $\sigma^2 = \mathbb{E}(\mathbb{V}(X|\mathscr{G}))$
, and
$\sigma^2 = \mathbb{E}(\mathbb{V}(X|\mathscr{G}))$
, and
 \begin{equation*}\kappa(x) = (\sigma^2-x)\biggl(\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{3/2} - \frac{1}{2^{3/2}}\biggr) \qquad\forall x\geq 0.\end{equation*}
\begin{equation*}\kappa(x) = (\sigma^2-x)\biggl(\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{3/2} - \frac{1}{2^{3/2}}\biggr) \qquad\forall x\geq 0.\end{equation*}
If the asymptotic behaviour of X is such that
 $\sigma^{-2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^4\bigr)$
and
$\sigma^{-2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^4\bigr)$
and
 $\sigma^{-2}\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converge to 0 faster than
$\sigma^{-2}\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converge to 0 faster than
 $\mathbb{V}(\mathbb{E}(X|\mathscr{G}))\Bigl[ = \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)\Bigr]$
, and
$\mathbb{V}(\mathbb{E}(X|\mathscr{G}))\Bigl[ = \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)\Bigr]$
, and
 $\sigma^{-2}\mathbb{E}\bigl(|\sigma^2-\mathbb{V}(X|\mathscr{G})|(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converges to 0 faster than
$\sigma^{-2}\mathbb{E}\bigl(|\sigma^2-\mathbb{V}(X|\mathscr{G})|(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converges to 0 faster than
 $\mathbb{E}(\kappa(\mathbb{V}(X|\mathscr{G})))$
, then
$\mathbb{E}(\kappa(\mathbb{V}(X|\mathscr{G})))$
, then
 \begin{equation*}d\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr) \geq \frac{\bigl||T_1(X)| - |T_2(X)|\bigr|}{C\sigma^2},\end{equation*}
\begin{equation*}d\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr) \geq \frac{\bigl||T_1(X)| - |T_2(X)|\bigr|}{C\sigma^2},\end{equation*}
where
-
(i) either
$d=d_K$
and
$C = \int_{-\infty}^\infty|2x^3-5x|e^{-x^2/2}dx$
, or
$d=d_W$
and
$C = \max_{x\in\mathbb{R}}|2x^3-5x|e^{-x^2/2}$
; -
(ii)
$|T_1(X)| \asymp \mathbb{V}(\mathbb{E}(X|\mathscr{G}))$
and
$|T_2(X)| \sim \mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr)$
.






Moreover,
 $\mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr) \leq \frac{27}{8}\sigma^{-2}\mathbb{E}((\sigma^2-\mathbb{V}(X|\mathscr{G}))^2)$
.
$\mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr) \leq \frac{27}{8}\sigma^{-2}\mathbb{E}((\sigma^2-\mathbb{V}(X|\mathscr{G}))^2)$
.
Proof. Inspired by the approach of Sections 3.2–3.3 in [Reference Barbour, Holst and Janson6], we define the function
 $g\,:\,\mathbb{R}\to\mathbb{R}$
as follows:
$g\,:\,\mathbb{R}\to\mathbb{R}$
as follows:
 \begin{equation*}g(y) = (y-\mu)\exp\biggl(-\frac{(y-\mu)^2}{2\sigma^2}\biggr) \qquad\forall y\in\mathbb{R}.\end{equation*}
\begin{equation*}g(y) = (y-\mu)\exp\biggl(-\frac{(y-\mu)^2}{2\sigma^2}\biggr) \qquad\forall y\in\mathbb{R}.\end{equation*}
It is easily seen that g is bounded and has a bounded and continuous derivative. Define
 $h\,:\,\mathbb{R}\to\mathbb{R}$
by
$h\,:\,\mathbb{R}\to\mathbb{R}$
by
 $h(x) = \sigma^2g^{\prime}(\sigma x + \mu) - \sigma xg(\sigma x + \mu)$
for each
$h(x) = \sigma^2g^{\prime}(\sigma x + \mu) - \sigma xg(\sigma x + \mu)$
for each
 $x\in\mathbb{R}$
. This gives
$x\in\mathbb{R}$
. This gives
 \begin{equation} \mathbb{E}\bigl(\sigma^2g^{\prime}(X) - (X-\mu)g(X)\bigr) = \mathbb{E}\bigg(h\bigg(\frac{X-\mu}{\sigma}\bigg)\bigg) - \mathbb{E}\bigg(h\bigg(\frac{Z-\mu}{\sigma}\bigg)\bigg),\end{equation}
\begin{equation} \mathbb{E}\bigl(\sigma^2g^{\prime}(X) - (X-\mu)g(X)\bigr) = \mathbb{E}\bigg(h\bigg(\frac{X-\mu}{\sigma}\bigg)\bigg) - \mathbb{E}\bigg(h\bigg(\frac{Z-\mu}{\sigma}\bigg)\bigg),\end{equation}
where
 $Z\sim\text{N}(\mu,\sigma^2)$
. By the Stein identity (2.5), the second term on the right-hand side in (A.1) is 0, and using Fubini’s theorem, the right-hand side can be rewritten as
$Z\sim\text{N}(\mu,\sigma^2)$
. By the Stein identity (2.5), the second term on the right-hand side in (A.1) is 0, and using Fubini’s theorem, the right-hand side can be rewritten as
 \begin{align*} \mathbb{E}\bigg(h\bigg(\frac{X-\mu}{\sigma}\bigg)\bigg) - \mathbb{E}\bigg(h\bigg(\frac{Z-\mu}{\sigma}\bigg)\bigg) & = \int_{-\infty}^\infty h\bigg(\frac{x-\mu}{\sigma}\bigg)dF_X(x) - \int_{-\infty}^\infty h\bigg(\frac{x-\mu}{\sigma}\bigg)dF_Z(x)\\[8pt]
&= \int_{-\infty}^\infty \int_{-\infty}^x\frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)dy\,dF_X(x)\\[5pt]
&\quad - \int_{-\infty}^\infty \int_{-\infty}^x\frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)dy\,dF_Z(x)\\[8pt]
&= \int_{-\infty}^\infty \frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\mathbb{P}(X>y)dy\\[5pt]
&\quad - \int_{-\infty}^\infty\frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\mathbb{P}(Z>y)dy,
\end{align*}
\begin{align*} \mathbb{E}\bigg(h\bigg(\frac{X-\mu}{\sigma}\bigg)\bigg) - \mathbb{E}\bigg(h\bigg(\frac{Z-\mu}{\sigma}\bigg)\bigg) & = \int_{-\infty}^\infty h\bigg(\frac{x-\mu}{\sigma}\bigg)dF_X(x) - \int_{-\infty}^\infty h\bigg(\frac{x-\mu}{\sigma}\bigg)dF_Z(x)\\[8pt]
&= \int_{-\infty}^\infty \int_{-\infty}^x\frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)dy\,dF_X(x)\\[5pt]
&\quad - \int_{-\infty}^\infty \int_{-\infty}^x\frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)dy\,dF_Z(x)\\[8pt]
&= \int_{-\infty}^\infty \frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\mathbb{P}(X>y)dy\\[5pt]
&\quad - \int_{-\infty}^\infty\frac{1}{\sigma}h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\mathbb{P}(Z>y)dy,
\end{align*}
implying that
 \begin{align*}\bigl|\mathbb{E}\bigg(h\bigg(\frac{X-\mu}{\sigma}\bigg)\bigg) & - \mathbb{E}\bigg(h\bigg(\frac{Z-\mu}{\sigma}\bigg)\bigg)\bigr| \leq \int_{-\infty}^\infty \frac{1}{\sigma}\bigl|h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\bigr|\,\bigl|\mathbb{P}(X>y)-\mathbb{P}(Z>y)\bigr|dy\\[5pt]
& \leq d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr)\int_{-\infty}^\infty \frac{1}{\sigma}\bigl|h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\bigr|dy\\[5pt]
& = d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1)\bigg)\biggr)\int_{-\infty}^\infty|h^{\prime}(x)|dx.
\end{align*}
\begin{align*}\bigl|\mathbb{E}\bigg(h\bigg(\frac{X-\mu}{\sigma}\bigg)\bigg) & - \mathbb{E}\bigg(h\bigg(\frac{Z-\mu}{\sigma}\bigg)\bigg)\bigr| \leq \int_{-\infty}^\infty \frac{1}{\sigma}\bigl|h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\bigr|\,\bigl|\mathbb{P}(X>y)-\mathbb{P}(Z>y)\bigr|dy\\[5pt]
& \leq d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr)\int_{-\infty}^\infty \frac{1}{\sigma}\bigl|h^{\prime}\bigg(\frac{y-\mu}{\sigma}\bigg)\bigr|dy\\[5pt]
& = d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1)\bigg)\biggr)\int_{-\infty}^\infty|h^{\prime}(x)|dx.
\end{align*}
We therefore get the following lower bound for the Kolmogorov distance:
 \begin{equation} d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr) \geq \frac{\bigl|\mathbb{E}(\sigma^2g^{\prime}(X) - (X-\mu)g(X))\bigr|}{\int_{-\infty}^\infty|h^{\prime}(x)|dx}.\end{equation}
\begin{equation} d_K\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr) \geq \frac{\bigl|\mathbb{E}(\sigma^2g^{\prime}(X) - (X-\mu)g(X))\bigr|}{\int_{-\infty}^\infty|h^{\prime}(x)|dx}.\end{equation}
From the definition and (A.1), we get a very similar lower bound for the Wasserstein distance:
 \begin{equation*}d_W\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr) \geq \frac{\bigl|\mathbb{E}(\sigma^2g^{\prime}(X) - (X-\mu)g(X))\bigr|}{\max_{x\in\mathbb{R}}|2x^3-5x|e^{-x^2/2}}.\end{equation*}
\begin{equation*}d_W\biggl(\mathscr{L}\,\biggl(\frac{X-\mu}{\sigma}\biggr),\text{N}(0,1))\biggr) \geq \frac{\bigl|\mathbb{E}(\sigma^2g^{\prime}(X) - (X-\mu)g(X))\bigr|}{\max_{x\in\mathbb{R}}|2x^3-5x|e^{-x^2/2}}.\end{equation*}
We next observe that
 \begin{equation*}g^{\prime}(y) = \biggl(1-\frac{(y-\mu)^2}{\sigma^2}\biggr)\exp\bigg(-\frac{(y-\mu)^2}{2\sigma^2}\bigg)\end{equation*}
\begin{equation*}g^{\prime}(y) = \biggl(1-\frac{(y-\mu)^2}{\sigma^2}\biggr)\exp\bigg(-\frac{(y-\mu)^2}{2\sigma^2}\bigg)\end{equation*}
and
 \begin{equation*}g^{\prime\prime}(y) = \biggl(\frac{(y-\mu)^3}{\sigma^4}-\frac{3(y-\mu)}{\sigma^2}\biggr)\exp\bigg(-\frac{(y-\mu)^2}{2\sigma^2}\bigg) \qquad\forall y\in\mathbb{R},\end{equation*}
\begin{equation*}g^{\prime\prime}(y) = \biggl(\frac{(y-\mu)^3}{\sigma^4}-\frac{3(y-\mu)}{\sigma^2}\biggr)\exp\bigg(-\frac{(y-\mu)^2}{2\sigma^2}\bigg) \qquad\forall y\in\mathbb{R},\end{equation*}
which in turn implies that
 \begin{align*}g(\sigma x +\mu) & = \sigma xe^{-x^2/2},\\[5pt]
g^{\prime}(\sigma x +\mu) & = (1-x^2)e^{-x^2/2},\end{align*}
\begin{align*}g(\sigma x +\mu) & = \sigma xe^{-x^2/2},\\[5pt]
g^{\prime}(\sigma x +\mu) & = (1-x^2)e^{-x^2/2},\end{align*}
and
 \begin{equation*}g^{\prime\prime}(\sigma x +\mu) = \sigma^{-1}(x^3-3x)e^{-x^2/2}\end{equation*}
\begin{equation*}g^{\prime\prime}(\sigma x +\mu) = \sigma^{-1}(x^3-3x)e^{-x^2/2}\end{equation*}
for each
 $x\in\mathbb{R}$
. From this we get
$x\in\mathbb{R}$
. From this we get
 \begin{equation*}h(x)= \bigl(\sigma^2(1-x^2) - \sigma^2 x^2\bigr)e^{-x^2/2} = \sigma^2(1-2x^2)e^{-x^2/2}\end{equation*}
\begin{equation*}h(x)= \bigl(\sigma^2(1-x^2) - \sigma^2 x^2\bigr)e^{-x^2/2} = \sigma^2(1-2x^2)e^{-x^2/2}\end{equation*}
and
 \begin{equation*}h^{\prime}(x) = \sigma^2\bigl(-4x -x +2x^3\bigr)e^{-x^2/2} = \sigma^2(2x^3-5x)e^{-x^2/2} \qquad\forall x\in\mathbb{R}.\end{equation*}
\begin{equation*}h^{\prime}(x) = \sigma^2\bigl(-4x -x +2x^3\bigr)e^{-x^2/2} = \sigma^2(2x^3-5x)e^{-x^2/2} \qquad\forall x\in\mathbb{R}.\end{equation*}
It remains to find a lower bound for the numerator in (A.2). Using (2.9), we first write
 \begin{align*}\mathbb{E}\bigl(\sigma^2 g^{\prime}(X) - (X-\mu) g(X)\bigr) & = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}(X) + (\mu-\mathbb{E}(X|\mathscr{G})) g(X)\bigr)\\[5pt]
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))\mathbb{E}(g^{\prime}(X)|\mathscr{G}) + (\mu-\mathbb{E}(X|\mathscr{G}))\mathbb{E}(g(X)|\mathscr{G})\bigr).\end{align*}
\begin{align*}\mathbb{E}\bigl(\sigma^2 g^{\prime}(X) - (X-\mu) g(X)\bigr) & = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G})) g^{\prime}(X) + (\mu-\mathbb{E}(X|\mathscr{G})) g(X)\bigr)\\[5pt]
& = \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))\mathbb{E}(g^{\prime}(X)|\mathscr{G}) + (\mu-\mathbb{E}(X|\mathscr{G}))\mathbb{E}(g(X)|\mathscr{G})\bigr).\end{align*}
After some straightforward computations, we get
 \begin{equation*}\mathbb{E}(g(X)|\mathscr{G}) = \int_{-\infty}^\infty (y-\mu)\exp\biggl(-\frac{(y-\mu)^2}{2\sigma^2}\biggr)\frac{1}{\sqrt{2\pi\mathbb{V}(X|\mathscr{G})}}\exp\biggl(-\frac{(y-\mathbb{E}(X|\mathscr{G}))^2}{2\mathbb{V}(X|\mathscr{G})}\biggr)dy\end{equation*}
\begin{equation*}\mathbb{E}(g(X)|\mathscr{G}) = \int_{-\infty}^\infty (y-\mu)\exp\biggl(-\frac{(y-\mu)^2}{2\sigma^2}\biggr)\frac{1}{\sqrt{2\pi\mathbb{V}(X|\mathscr{G})}}\exp\biggl(-\frac{(y-\mathbb{E}(X|\mathscr{G}))^2}{2\mathbb{V}(X|\mathscr{G})}\biggr)dy\end{equation*}
 \begin{align} = \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)(\mathbb{E}(X|\mathscr{G})-\mu),\end{align}
\begin{align} = \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)(\mathbb{E}(X|\mathscr{G})-\mu),\end{align}
and multiplying (A.3) by
 $\mu-\mathbb{E}(X|\mathscr{G})$
, we obtain
$\mu-\mathbb{E}(X|\mathscr{G})$
, we obtain
 \begin{align*}
&(\mu-\mathbb{E}(X|\mathscr{G}))\mathbb{E}(g(X)|\mathscr{G})\\
&= -\biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)(\mu-\mathbb{E}(X|\mathscr{G}))^2,\end{align*}
\begin{align*}
&(\mu-\mathbb{E}(X|\mathscr{G}))\mathbb{E}(g(X)|\mathscr{G})\\
&= -\biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)(\mu-\mathbb{E}(X|\mathscr{G}))^2,\end{align*}
an expression which is nonpositive. Furthermore, by convexity,
 \begin{equation} \biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{3/2} \geq \frac{1}{2^{3/2}}\biggl(1 - \frac{3}{4\sigma^2}(x-\sigma^2)\biggr) \qquad\forall x>-\sigma^2,\end{equation}
\begin{equation} \biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{3/2} \geq \frac{1}{2^{3/2}}\biggl(1 - \frac{3}{4\sigma^2}(x-\sigma^2)\biggr) \qquad\forall x>-\sigma^2,\end{equation}
where the right-hand side is the tangent line at
 $x=\sigma^2$
. It follows that if
$x=\sigma^2$
. It follows that if
 $\mathbb{V}(X|\mathscr{G})\geq \sigma^2$
, then
$\mathbb{V}(X|\mathscr{G})\geq \sigma^2$
, then
 \begin{align*}1 &\geq \frac{1}{2^{3/2}} \geq \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
&\geq \frac{1}{2^{3/2}}\biggl(1 - \frac{3(\mathbb{V}(X|\mathscr{G})-\sigma^2)_+}{4\sigma^2} - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{4\sigma^2}\biggr)\end{align*}
\begin{align*}1 &\geq \frac{1}{2^{3/2}} \geq \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
&\geq \frac{1}{2^{3/2}}\biggl(1 - \frac{3(\mathbb{V}(X|\mathscr{G})-\sigma^2)_+}{4\sigma^2} - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{4\sigma^2}\biggr)\end{align*}
(compare the proof of Lemma 3.2.1 in [Reference Barbour, Holst and Janson6]), while if
 $\mathbb{V}(X|\mathscr{G})\leq \sigma^2$
, then
$\mathbb{V}(X|\mathscr{G})\leq \sigma^2$
, then
 \begin{align*}1 & \geq \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
&\geq \frac{1}{2^{3/2}}\biggl(1 + \frac{3(\sigma^2-\mathbb{V}(X|\mathscr{G}))_+}{4\sigma^2} - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}\\[4pt]
&- \frac{3(\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2}{8\sigma^4}\biggr) \geq \frac{1}{2^{3/2}}\biggl(1 - \frac{7(\mu-\mathbb{E}(X|\mathscr{G}))^2}{8\sigma^2}\biggr).\end{align*}
\begin{align*}1 & \geq \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
&\geq \frac{1}{2^{3/2}}\biggl(1 + \frac{3(\sigma^2-\mathbb{V}(X|\mathscr{G}))_+}{4\sigma^2} - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}\\[4pt]
&- \frac{3(\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2}{8\sigma^4}\biggr) \geq \frac{1}{2^{3/2}}\biggl(1 - \frac{7(\mu-\mathbb{E}(X|\mathscr{G}))^2}{8\sigma^2}\biggr).\end{align*}
Multiplying by
 $\mu-\mathbb{E}(X|\mathscr{G})$
and taking expectations in the last two sets of inequalities, we get
$\mu-\mathbb{E}(X|\mathscr{G})$
and taking expectations in the last two sets of inequalities, we get
 \begin{equation} \begin{split}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) &\geq \bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))g(X)\bigr)\bigr|\\[8pt]
&\geq \frac{1}{2^{3/2}}\biggl(\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) - \frac{7\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^4\bigr)}{8\sigma^2}\\[8pt]
&\quad -\frac{3\mathbb{E}\bigl((\mathbb{V}(X|\mathscr{G}) - \sigma^2)_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{4\sigma^2}\biggr).\end{split}\end{equation}
\begin{equation} \begin{split}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) &\geq \bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))g(X)\bigr)\bigr|\\[8pt]
&\geq \frac{1}{2^{3/2}}\biggl(\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr) - \frac{7\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^4\bigr)}{8\sigma^2}\\[8pt]
&\quad -\frac{3\mathbb{E}\bigl((\mathbb{V}(X|\mathscr{G}) - \sigma^2)_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{4\sigma^2}\biggr).\end{split}\end{equation}
From this it follows that if the asymptotic behaviour of X is such that
 $\sigma^{-2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^4\bigr)$
and
$\sigma^{-2}\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^4\bigr)$
and
 $\sigma^{-2}\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converge to 0 faster than
$\sigma^{-2}\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converge to 0 faster than
 $\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
, it holds that
$\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
, it holds that
 $\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))g(X)\bigr)\bigr| \asymp \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
.
$\bigl|\mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))g(X)\bigr)\bigr| \asymp \mathbb{E}\bigl((\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
.
Similarly, after some computations, we obtain
 \begin{equation*}\mathbb{E}(g^{\prime}(X)|\mathscr{G}) = \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr),\end{equation*}
\begin{equation*}\mathbb{E}(g^{\prime}(X)|\mathscr{G}) = \biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2}\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr),\end{equation*}
and subtracting with
 $\mathbb{E}(g^{\prime}(Z)) = \frac{1}{2^{3/2}}$
leads to
$\mathbb{E}(g^{\prime}(Z)) = \frac{1}{2^{3/2}}$
leads to
 \begin{align*}\mathbb{E}(g^{\prime}(X)|\mathscr{G})- \frac{1}{2^{3/2}} \,=\, & \biggl(\biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2} - \frac{1}{2^{3/2}}\biggr)\\[4pt]
& \times\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
& + \frac{1}{2^{3/2}}\biggl(\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr) - 1\biggr).\end{align*}
\begin{align*}\mathbb{E}(g^{\prime}(X)|\mathscr{G})- \frac{1}{2^{3/2}} \,=\, & \biggl(\biggl(\frac{\sigma^2}{\sigma^2 +\mathbb{V}(X|\mathscr{G})}\biggr)^{3/2} - \frac{1}{2^{3/2}}\biggr)\\[4pt]
& \times\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
& + \frac{1}{2^{3/2}}\biggl(\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr) - 1\biggr).\end{align*}
Multiplying by
 $\sigma^2-\mathbb{V}(X|\mathscr{G})$
and using the function
$\sigma^2-\mathbb{V}(X|\mathscr{G})$
and using the function
 $\kappa$
defined in Theorem A.1, we get
$\kappa$
defined in Theorem A.1, we get
 \begin{equation} \begin{split} & (\sigma^2 -\mathbb{V}(X|\mathscr{G}))\biggl(\mathbb{E}(g^{\prime}(X)|\mathscr{G})- \frac{1}{2^{3/2}}\biggr)\\[5pt]
&\quad = \kappa(\mathbb{V}(X|\mathscr{G}))\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[5pt]
&\qquad + \frac{1}{2^{3/2}}(\sigma^2-\mathbb{V}(X|\mathscr{G}))\biggl(\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr) - 1\biggr).\end{split}\end{equation}
\begin{equation} \begin{split} & (\sigma^2 -\mathbb{V}(X|\mathscr{G}))\biggl(\mathbb{E}(g^{\prime}(X)|\mathscr{G})- \frac{1}{2^{3/2}}\biggr)\\[5pt]
&\quad = \kappa(\mathbb{V}(X|\mathscr{G}))\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[5pt]
&\qquad + \frac{1}{2^{3/2}}(\sigma^2-\mathbb{V}(X|\mathscr{G}))\biggl(\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr) - 1\biggr).\end{split}\end{equation}
We observe that
 $\kappa(\sigma^2) = 0$
, and that
$\kappa(\sigma^2) = 0$
, and that
 \begin{equation*}\kappa^{\prime}(x) = -\biggl(\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{3/2} - \frac{1}{2^{3/2}}\biggr) - (\sigma^2-x)\frac{3}{2\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2} \qquad\forall x> 0,\end{equation*}
\begin{equation*}\kappa^{\prime}(x) = -\biggl(\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{3/2} - \frac{1}{2^{3/2}}\biggr) - (\sigma^2-x)\frac{3}{2\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2} \qquad\forall x> 0,\end{equation*}
so
 $\kappa^{\prime}(x)<0$
for
$\kappa^{\prime}(x)<0$
for
 $x\in(0,\sigma^2)$
,
$x\in(0,\sigma^2)$
,
 $\kappa^{\prime}(\sigma^2)=0$
, and
$\kappa^{\prime}(\sigma^2)=0$
, and
 $\kappa^{\prime}(x)>0$
for
$\kappa^{\prime}(x)>0$
for
 $x>\sigma^2$
. Moreover, by (A.4),
$x>\sigma^2$
. Moreover, by (A.4),
 \begin{equation*}\kappa(x) \geq \frac{1}{2^{3/2}}\frac{3}{4\sigma^2}(\sigma^2 - x)^2 \qquad\forall x\leq \sigma^2,\end{equation*}
\begin{equation*}\kappa(x) \geq \frac{1}{2^{3/2}}\frac{3}{4\sigma^2}(\sigma^2 - x)^2 \qquad\forall x\leq \sigma^2,\end{equation*}
and
 $\kappa^{\prime}(x)\to\frac{1}{2^{3/2}}$
as
$\kappa^{\prime}(x)\to\frac{1}{2^{3/2}}$
as
 $x\to\infty$
. Next,
$x\to\infty$
. Next,
 \begin{align*}\kappa^{\prime\prime}(x) & = \frac{3}{\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2} + (\sigma^2-x)\frac{15}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2}\\[5pt]
&= \frac{3}{\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2}\biggl(1 + \frac{5}{4}\biggl(\frac{\sigma^2 - x}{\sigma^2 + x}\biggr)\biggr) = \frac{15}{2\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2}\biggl(\frac{\sigma^2}{\sigma^2 + x} - \frac{1}{10}\biggr)\quad\forall x> 0,\end{align*}
\begin{align*}\kappa^{\prime\prime}(x) & = \frac{3}{\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2} + (\sigma^2-x)\frac{15}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2}\\[5pt]
&= \frac{3}{\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2}\biggl(1 + \frac{5}{4}\biggl(\frac{\sigma^2 - x}{\sigma^2 + x}\biggr)\biggr) = \frac{15}{2\sigma^2}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{5/2}\biggl(\frac{\sigma^2}{\sigma^2 + x} - \frac{1}{10}\biggr)\quad\forall x> 0,\end{align*}
and
 \begin{align*}& \kappa^{\prime\prime\prime}(x) = -\frac{45}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2} - (\sigma^2-x)\frac{105}{8\sigma^6}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{9/2}\\[4pt]
&= -\frac{15}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2}\biggl(3 + \frac{7}{2}\biggl(\frac{\sigma^2 - x}{\sigma^2 + x}\biggr)\biggr) = -\frac{105}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2}\biggl(\frac{\sigma^2}{\sigma^2 + x} - \frac{1}{14}\biggr)\quad\forall x> 0,\end{align*}
\begin{align*}& \kappa^{\prime\prime\prime}(x) = -\frac{45}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2} - (\sigma^2-x)\frac{105}{8\sigma^6}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{9/2}\\[4pt]
&= -\frac{15}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2}\biggl(3 + \frac{7}{2}\biggl(\frac{\sigma^2 - x}{\sigma^2 + x}\biggr)\biggr) = -\frac{105}{4\sigma^4}\biggl(\frac{\sigma^2}{\sigma^2 + x}\biggr)^{7/2}\biggl(\frac{\sigma^2}{\sigma^2 + x} - \frac{1}{14}\biggr)\quad\forall x> 0,\end{align*}
implying that
 $\kappa^{\prime\prime}(x)>0$
for
$\kappa^{\prime\prime}(x)>0$
for
 $x\in(0,9\sigma^2)$
,
$x\in(0,9\sigma^2)$
,
 $\kappa^{\prime\prime}(9\sigma^2)=0$
, and
$\kappa^{\prime\prime}(9\sigma^2)=0$
, and
 $\kappa^{\prime\prime}(x)<0$
for
$\kappa^{\prime\prime}(x)<0$
for
 $x>9\sigma^2$
. Moreover,
$x>9\sigma^2$
. Moreover,
 $\kappa^{\prime\prime}(x)$
is strictly decreasing for
$\kappa^{\prime\prime}(x)$
is strictly decreasing for
 $x\in[0,13\sigma^2)$
. This means that for
$x\in[0,13\sigma^2)$
. This means that for
 $\delta>0$
small enough, for any
$\delta>0$
small enough, for any
 $x_0\in(9\sigma^2-\delta,9\sigma^2)$
it holds that
$x_0\in(9\sigma^2-\delta,9\sigma^2)$
it holds that
 $\kappa^{\prime\prime}(x_0)>0$
and
$\kappa^{\prime\prime}(x_0)>0$
and
 $\kappa^{\prime}(x_0)>\frac{1}{2^{3/2}}$
. It therefore holds that
$\kappa^{\prime}(x_0)>\frac{1}{2^{3/2}}$
. It therefore holds that
 $\kappa(x) \geq \frac{1}{2}\kappa^{\prime\prime}(x_0)(\sigma^2-x)^2$
for
$\kappa(x) \geq \frac{1}{2}\kappa^{\prime\prime}(x_0)(\sigma^2-x)^2$
for
 $x\in[0,x_0]$
, and
$x\in[0,x_0]$
, and
 \begin{equation*}\kappa(x) \geq \frac{1}{2}\kappa^{\prime\prime}(x_0)(\sigma^2-x_0)^2 + \frac{1}{2^{3/2}}(x-x_0)\end{equation*}
\begin{equation*}\kappa(x) \geq \frac{1}{2}\kappa^{\prime\prime}(x_0)(\sigma^2-x_0)^2 + \frac{1}{2^{3/2}}(x-x_0)\end{equation*}
for
 $x\geq x_0$
. It also follows from the preceding that
$x\geq x_0$
. It also follows from the preceding that
 \begin{equation*}\kappa(x) \leq \frac{1}{2}\kappa^{\prime\prime}(0)(\sigma^2-x)^2 = \frac{27}{8\sigma^2}(\sigma^2-x)^2\end{equation*}
\begin{equation*}\kappa(x) \leq \frac{1}{2}\kappa^{\prime\prime}(0)(\sigma^2-x)^2 = \frac{27}{8\sigma^2}(\sigma^2-x)^2\end{equation*}
for
 $x\geq 0$
.
$x\geq 0$
.
Using now the fact, observed in Section 3.2 in [Reference Barbour, Holst and Janson6], that
 $1\geq (1-2u)e^{-u} \geq 1-3u$
for all
$1\geq (1-2u)e^{-u} \geq 1-3u$
for all
 $u\geq 0$
, we obtain
$u\geq 0$
, we obtain
 \begin{align*}\kappa(\mathbb{V}(X|\mathscr{G})) & \geq \kappa(\mathbb{V}(X|\mathscr{G}))\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
&\geq \kappa(\mathbb{V}(X|\mathscr{G}))\biggl(1 - \frac{3(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}\biggr),\end{align*}
\begin{align*}\kappa(\mathbb{V}(X|\mathscr{G})) & \geq \kappa(\mathbb{V}(X|\mathscr{G}))\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr)\\[4pt]
&\geq \kappa(\mathbb{V}(X|\mathscr{G}))\biggl(1 - \frac{3(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}\biggr),\end{align*}
and, furthermore,
 \begin{align*}& (\sigma^2-\mathbb{V}(X|\mathscr{G}))_+\biggl|\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr) - 1\biggr|\\[4pt]
&\quad\leq \frac{3(\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}.\end{align*}
\begin{align*}& (\sigma^2-\mathbb{V}(X|\mathscr{G}))_+\biggl|\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\biggl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\biggr) - 1\biggr|\\[4pt]
&\quad\leq \frac{3(\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}.\end{align*}
Also,
 \begin{align*}& (\mathbb{V}(X|\mathscr{G})-\sigma^2)_+\biggl|\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\bigl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\bigr) - 1\biggr|\\[5pt]
&\leq \frac{3(\mathbb{V}(X|\mathscr{G})-\sigma^2)_+(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}.\end{align*}
\begin{align*}& (\mathbb{V}(X|\mathscr{G})-\sigma^2)_+\biggl|\biggl(1 - \frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{\sigma^2+\mathbb{V}(X|\mathscr{G})}\biggr)\exp\bigl(-\frac{(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2(\sigma^2+\mathbb{V}(X|\mathscr{G}))}\bigr) - 1\biggr|\\[5pt]
&\leq \frac{3(\mathbb{V}(X|\mathscr{G})-\sigma^2)_+(\mu-\mathbb{E}(X|\mathscr{G}))^2}{2\sigma^2}.\end{align*}
Taking expectations in (A.6) and using the last three sets of inequalities, we get
 \begin{align*}\mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr) + & \frac{3\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{2^{5/2}\sigma^2}\geq \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))\mathbb{E}(g^{\prime}(X)|\mathscr{G})\bigr)\\ &\geq \mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr) - \frac{3\mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{2\sigma^2}\\ & \qquad - \frac{3\mathbb{E}\bigl((\mathbb{V}(X|\mathscr{G})- \sigma^2)_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{2^{5/2}\sigma^2}.\end{align*}
\begin{align*}\mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr) + & \frac{3\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{2^{5/2}\sigma^2}\geq \mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))\mathbb{E}(g^{\prime}(X)|\mathscr{G})\bigr)\\ &\geq \mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr) - \frac{3\mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{2\sigma^2}\\ & \qquad - \frac{3\mathbb{E}\bigl((\mathbb{V}(X|\mathscr{G})- \sigma^2)_+(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)}{2^{5/2}\sigma^2}.\end{align*}
From this it follows that if the asymptotic behaviour of X is such that
 $\sigma^{-2}\mathbb{E}\bigl(|\sigma^2-\mathbb{V}(X|\mathscr{G})|(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converges to 0 faster than
$\sigma^{-2}\mathbb{E}\bigl(|\sigma^2-\mathbb{V}(X|\mathscr{G})|(\mu-\mathbb{E}(X|\mathscr{G}))^2\bigr)$
converges to 0 faster than
 $\mathbb{E}(\kappa(\mathbb{V}(X|\mathscr{G})))$
(note also that
$\mathbb{E}(\kappa(\mathbb{V}(X|\mathscr{G})))$
(note also that
 $\kappa(\mathbb{V}(X|\mathscr{G})) \leq |\sigma^2-\mathbb{V}(X|\mathscr{G})|)$
, it holds that
$\kappa(\mathbb{V}(X|\mathscr{G})) \leq |\sigma^2-\mathbb{V}(X|\mathscr{G})|)$
, it holds that
 \begin{equation*}\bigl|\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))\mathbb{E}(g^{\prime}(X)|\mathscr{G})\bigr)\bigr|\sim \mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr).\end{equation*}
\begin{equation*}\bigl|\mathbb{E}\bigl((\sigma^2-\mathbb{V}(X|\mathscr{G}))\mathbb{E}(g^{\prime}(X)|\mathscr{G})\bigr)\bigr|\sim \mathbb{E}\bigl(\kappa(\mathbb{V}(X|\mathscr{G}))\bigr).\end{equation*}
Acknowledgements
We wish to thank an anonymous referee for a number of insightful comments. K. B. is supported by Grant No. 2017−04951 from the Swedish Research Council (Vetenskapsrådet).



























