Introduction
Tinnitus is an auditory perception that can be described as the experience of sound, in the ear or in the head, in the absence of external acoustic stimulation. Up to 18 per cent of the population in industrialised countries is affected by tinnitus.Reference Gopinath, McMahon, Rochtchina, Karpa and Mitchell1, Reference Coles2 The majority of tinnitus sufferers are only mildly affected. However, a proportion (between 0.5 and 3 per cent of the adult population) suffer severe, chronic tinnitus to an extent that can seriously affect their normal lives and produce mood disorders, anxiety, depression and altered sleep patterns.Reference Gopinath, McMahon, Rochtchina, Karpa and Mitchell1
Sound therapy is one of the approaches most frequently used in tinnitus treatment, either alone or combined with behavioural therapy and counselling.Reference Jastreboff3, Reference Phillips and McFerran4 Sound therapy involves exposing the patient to passive auditory stimulation, using various sounds, typically delivered via a table-top or ear-level sound generator. Treatment is usually performed for several hours daily, and is often recommended for at least 12 months.Reference Henry, Zaugg, Myers and Schechter5–Reference Jastreboff and Jastreboff7
Debate continues over the possible mechanisms underlying the beneficial effects of sound therapy for tinnitus patients.Reference Hiller and Haerkötter8, Reference Kroener-Herwig, Biesinger, Gerhards, Goebel, Verena Greimel and Hiller9 Recent studies have shown that sound therapy may induce long-lasting effects on the neural auditory pathways, which could lead to a decrease in tinnitus perception. One possible explanation is that auditory stimulation could reverse the neural plastic modifications thought to arise in the auditory pathways of tinnitus patients,Reference Noreña and Eggermont10, Reference Noreña and Eggermont11 e.g. reorganisation of the cortical tonotopic map, and increased spontaneous neural activity.Reference Eggermont and Roberts12, Reference Moller13 Another theory that may explain the beneficial effects of sound therapy on tinnitus patients is that listening to sounds can have direct and indirect effects on the limbic and parasympathetic systems,Reference Henry, Zaugg, Myers and Schechter5, Reference Brown, Martinez and Parsons14 which are involved in the mechanisms of tinnitus-associated distressReference Moller13 and which have also recently been described as possible key structures in the pathophysiology of tinnitus.Reference Rauschecker, Leaver and Mühlau15 Another theory, among the most recognised, is that sound therapy may induce an increase in the level of background neural activity in the auditory pathways, and thus decrease the contrast between ‘tinnitus-related’ neural activity and background neural activity, facilitating habituation to tinnitus.Reference Jastreboff and Jastreboff7
Sound therapy is widely used in tinnitus management, and has been found to provide beneficial effects and relief from tinnitus-related stress and anxiety.Reference Henry, Zaugg, Myers and Schechter5 A wide variety of sounds, protocols and devices have been used in tinnitus sound therapy, with settings fitted to the patient's specific needs and frequently changed according to the patient's preferences over time. Among the signals most frequently used in sound therapy are: (1) meaningless noise, such as white, wide-band or ‘pink’ noise; (2) recordings of natural sounds, such as rain, waterfalls, moving water or wind; and (3) complex synthetic signals, such as combinations of pure tones.
These therapeutic sounds act as maskers. Therefore, such sounds could, in principle, interfere with patients' everyday listening activities, e.g. following a conversation. To date, such side effects of sound therapy have not been quantitatively investigated, and it is not known whether different therapeutic sounds have different effects on patients' speech comprehension. In other words, it is not known whether the possible reduction in speech intelligibility experienced during sound therapy could be minimised by the choice of particular sounds.
Only one previous study, by Spitzer et al.,Reference Spitzer, Goldstein, Salzbrenner and Mueller16 has attempted to quantify the influence of sound therapy on speech intelligibility. This study used normal hearing listeners and measured the intelligibility of monosyllabic words in the presence of two different tinnitus maskers (Audiotone T570 and Starkey TM3), and also in the presence of additional background noise. The study reported no substantial decrease of intelligibility when speech was presented with the two sounds alone, but a significant decrease in intelligibility when speech was presented together with both sounds plus additional background noise. The authors concluded that the patient's ability to communicate effectively could be impaired during sound therapy, particularly in noisy environments.
In Spitzer and colleagues' study, the presentation levels of words, sounds and background noise were fixed (i.e. pre-determined) and speech intelligibility was thus measured at a fixed signal-to-noise ratio. In terms of psychometric function, measuring speech intelligibility at a fixed signal-to-noise ratio means estimating only one sample of the psychometric curve. Conversely, measuring speech intelligibility as a function of the signal-to-noise ratio would allow estimation of the whole psychometric curve, and thus enable characterisation of all speech intelligibility dynamics in the presence of different competing signals (from near-perfect performance to chance).Reference Klein17 Thus, to identify possible differences in speech intelligibility with the use of different sounds (or different settings), measures of the whole psychometric curve are in principle more accurate and robust than measures of speech intelligibility at a fixed signal-to-noise ratio.
Moreover, as the patient can usually modify the volume of sound therapy during treatment, assessment of the whole psychometric curve allows characterisation of the influence of therapeutic sounds on speech intelligibility for a wide range of stimulation levels. In many cases, sound therapy is delivered at low volume levels and thus may not impair speech intelligibility (e.g. tinnitus retraining therapy stimulation levels are below 20 dB SL (i.e. 20 dB above the patient's hearing threshold)).Reference Jastreboff and Jastreboff7 However, it is also true that patients are usually free to modify the sound therapy volume during treatment (particularly with the use of table-top sound generators), and in many cases the levels of therapeutic sounds are neither predictable (a priori) nor monitored.
Thus, in the present study we compared different sound therapy signals without specifying a particular stimulation level; rather, we compared the influence of different signals on speech intelligibility over a wide range of stimulation levels (i.e. over a wide range of signal-to-noise ratios).
The present study aimed to measure, in a group of normal hearing subjects, the psychometric curves for speech intelligibility in the presence of the following sound therapy signals: wide-band noise; a recording of moving water; and a combination of tones.
Materials and methods
Speech intelligibility in the presence of sound therapy signals was measured by performing a speech-in-noise test in a group of normal-hearing subjects, using the three different sound therapy signals as the ‘noise’. We then estimated and compared psychometric curves for speech intelligibility in the presence of the three different sound therapy signals. A detailed description of our subjects, procedures and data analysis is given below.
Subjects
Participants comprised 10 otologically normal hearing18 young adults (age range 22–32 years; mean age 24 years; three men and seven women) with pure tone thresholds not exceeding 20 dB HL at each audiometric frequency in the range 125–8000 Hz. Subjects' mean pure tone thresholds were lower than 10 dB HL at each of the tested frequencies.
Speech-in-noise test
The speech-in-noise test was based on consonants, and involved a three-alternative, forced-choice paradigm in which the three alternatives were displayed on a touch-sensitive computer screen. All subjects were instructed to use the touch-sensitive screen to select the perceived consonant from among three alternatives, or to guess if they were not sure. Subjects received no feedback on the accuracy of their responses during the test procedure.
Consonants were used because they are key elements in understanding speech in noise,Reference Li and Loizou19 and also because of their minimal redundancy, lack of semantic content and reportedly low test–retest variability.Reference Dubno and Dirks20 A set of 16 /aCa/ consonants was used (e.g. /aPa/, /aDa/), spoken by a male native Italian speaker, with the stress falling on the first vowel. The touch-sensitive screen displayed the spoken consonant together with two incorrect alternatives, which differed from the spoken consonant with respect to voicing, manner and place of articulation (e.g. the spoken consonant /aTa/ was combined with the two incorrect alternatives /aVa/ and /aMa/). The set of spoken consonants and the corresponding sets of displayed alternatives were part of the standard speech material used in clinical speech audiometry in Italy. The long-term mean speech spectrum for Italian spoken by a male native speaker is shown in Figure 1.

Fig. 1 Long-term mean speech spectrum of Italian spoken by a male native speaker.
Each subject performed the speech-in-noise test three times, using each of the following three sound therapy signals as background noise.
The first signal type was wide-band noise, generated by filtering steady-state, unmodulated white noise with the same long-term mean spectrum as male Italian speech.
The second signal type was a recording of moving water, taken from a commercially available compact disk21 prepared for use in sound therapy.
The third signal type was a combination of tone pips: a series of pure tones with frequencies in the 0.5–8 kHz range and with 1/64 octave frequency spacing, each of 100 ms duration and with a mean inter-stimulus interval of 10 ms, presented in random order. The generic tone pip tp f at frequency f was generated using the formula:
where env(t) is a 100 ms flat envelope with a 5 ms rise and linear fall ramp, and A f is a weighting factor that equalises tone pips at the same sensation level across frequency, and is shaped according to the individual audiogram.Reference Noreña and Eggermont10, Reference Noreña and Eggermont11, Reference Noreña and Chery-Croze22
Figure 2 shows the waveforms of the wide-band noise, moving water and tone pip sound signals. The three signals were sampled at 44.1 kHz with 24 bit resolution. The signal-to-noise ratio was defined as the ratio of the root-mean-square value of the spoken consonant to the root-mean-square value of the sound therapy signal. During the speech-in-noise test, the output level of the spoken consonants was kept fixed at 60 dB HL, whereas the signal-to-noise ratio was adjusted (i.e. increased or decreased) by modifying the root-mean-square of the sound therapy signal (i.e. by decreasing or increasing its level).

Fig. 2 Waveforms of the three sound therapy signals: wide-band noise WN, (top panel), moving water recording MW, (centre panel) and tone pips TP, (bottom panel). S = seconds
The speech-in-noise test was based on an adaptive procedure: the first consonant was presented at +6 dB signal-to-noise ratio (this signal-to-noise ratio was found to provide perfect recognition of consonants in normal hearing adults),Reference Assmann, Summerfield, Greenberg, Ainsworth, Popper and Fay23 and the signal-to-noise ratio was then adjusted following the subject's response. A one-up/three-down ‘staircase’ for test progression was used, employing 2 dB steps: the signal-to-noise ratio was decreased by 2 dB after three correct responses, and increased by 2 dB after one incorrect response. We used this one-up/three-down test progression staircase because it has been shown to maximise test efficiency and convergence rate for three-alternative, forced-choice recognition tasks.Reference Kollmeier, Gilkey and Sieben24 Test progression was stopped after 20 reversals in signal-to-noise ratio value.
Equipment
The speech-in-noise test was administered using a personal computer with a professional soundcard (RME HDSP9632, 24 bit resolution, sampling frequency 44.1 kHz, total harmonic distortion <0.00063 per cent, frequency response flat 1 Hz to 21.1 kHz, signal-to-noise ratio 112 dB A; RME, Germany) connected to the RCA (Radio Corporation of American) analogue input of an audiometer (Amplaid 177 + ; Amplifon, Milan, Italy) with TDH49 headphones (TDH, Telephonics, New York, NY, USA) in a Peltor circumaural headset (Aearo, Indianapolis, IN, USA). The test equipment was calibrated at the beginning of the test session and thereafter as required, using the audiometer's standard calibration procedures with a standard calibration signal (a 1000 Hz tone).
The touch-sensitive screen was an LCD Viper 10.4 inch (resolution 800 × 600 pixel, brightness 350 cd/m2, contrast ratio 250:1, touch panel five wire resistive, resolution 4096 × 4096, response time <10 ms) connected to the personal computer.
Subjects performed the speech-in-noise test seated in a sound-proof booth (attenuation ranging from −23 dB SPL at 125 Hz to −40 dB SPL at 5 kHz).
Matlab-based software and a user interface (R2007b, version 7.5.0.342, MathWorks™, Natick, MA, USA) were used to automatically adjust the signal-to-noise ratio during the test procedure, to deliver the stimuli, to display the alternatives on the screen, and to record and analyse the subject's responses.
Estimation of psychometric curves
The speech-in-noise test procedure described above enabled assessment of the full range of speech intelligibility dynamics, from perfect performance (i.e. at +6 dB signal-to-noise ratio) to near-chance performance (i.e. at the lowest signal-to-noise ratio values reached by the test progression staircase). Data collected using the test progression staircase were used to estimate the psychometric curves for each of the three different sound therapy signals, for each subject. The procedure for estimation of the psychometric curves is briefly summarised below; a detailed description has been published elsewhere.Reference Wichmann and Hill25, Reference Treutwein26
Firstly, at each of the signal-to-noise ratios considered during the test progression staircase, the proportion of correct responses was calculated for each subject.Reference Klein17 This proportion indicated, for each subject, the psychometric curve sample corresponding to the respective signal-to-noise ratio. (For example, see Figure 3 for an estimation of the psychometric curve sample at −10 dB signal-to-noise ratio.)

Fig. 3 Estimation of one subject's psychometric curve, from data collected using the test progression ‘staircase’ procedure. (a) Sequence of signal-to-noise ratio (SNR) values recorded during test progression staircase. (b) Corresponding samples of the psychometric curve (square plot points) as a function of the signal-to-noise ratio and, superimposed, the psychometric curve (Φ(μ,σ); continuous line) estimated by fitting data with the cumulative normal function reported in the box.
Then, the psychometric curve samples thus obtained were fitted with a cumulative normal function Φ(μ,σ), with mean μ and standard deviation σ (see Figure 3), by using probit transformationReference Finney27 and weighted linear regression.Reference Treutwein26
Finally, goodness of fit was assessed using the Kolmogorov–Smirnov test for normality, at a level of significance equal to 0.05.
Estimation of threshold and slope
Two parameters which characterise psychometric curves – threshold and slope – were estimated from data collected using the speech-in-noise test, and compared for the three sound therapy signals.
Threshold was defined as the signal-to-noise ratio value where speech intelligibility was equal to 79.4 per cent, and was estimated (consistent with Leek)Reference Leek28 as the mean of the signal-to-noise ratio values at all the midpoints of the ascending runs in the one-up/three-down test progression staircase. To minimise estimation bias, we discarded the first three reversals, and thus averaged an even number of runs.Reference Leek28
Slope was defined as the steepness of the psychometric curve at its point of inflection, and was estimated (consistent with Strasburger)Reference Strasburger29 using the following formula:
where y 1 and y N are the first sample (i.e. at the lowest signal-to-noise ratio) and the last sample (i.e. at the highest signal-to-noise ratio) of the psychometric curve, and σ is the standard deviation of the cumulative normal function Φ(μ,σ) which best fits the data.
Results
Figure 4 shows the mean speech intelligibility values in the presence of the three sound therapy signals, as a function of signal-to-noise ratio, in the 10 subjects.

Fig. 4 Mean psychometric curves (−1 standard deviation) for speech intelligibility, for the 10 subjects, in the presence of wide-band noise (WN), moving water recording (MW) and tone pips (TP).
Overall, it can be observed that the psychometric curves were different for the three different sound therapy signals. For a given signal-to-noise ratio, the mean speech intelligibility was lower for the wide-band noise than for the moving water or tone pip noises (Figure 4). For example, at a signal-to-noise ratio of −10 dB, the mean speech intelligibility was 62 per cent with the wide-band noise, 85 per cent with the moving water recording and 96 per cent with the tone pips. Thus, in order to reach a given level of speech intelligibility, it was necessary to use higher signal-to-noise ratio values for the wide-band noise than for the moving water recording or the tone pips. For example, to obtain a speech intelligibility of at least 80 per cent, it was necessary to use a signal-to-noise ratio of at least −4 dB for the wide-band noise, at least −12 dB for the moving water recording and at least −14 dB for the tone pips. Similarly, to reach near-perfect speech intelligibility (i.e. higher than 95 per cent) it was necessary to use a signal-to-noise ratio of at least 2 dB for the wide-band noise, whereas for the moving water recording and tone pips values as low as −6 and −10 dB were sufficient, respectively.
The psychometric curves obtained for the moving water recording and the tone pips were shifted towards lower signal-to-noise ratio values, compared with the psychometric curves obtained for the wide-band noise: the lowest signal-to-noise ratio values reached by the test progression staircase were −20 dB for the moving water recording and −22 dB for the tone pips, compared with −12 dB for the wide-band noise. The lowest speech intelligibility values were 50, 40 and 38 per cent, for the wide-band noise, moving water recording and tone pips, respectively.
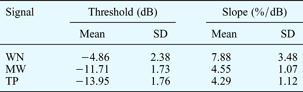
Table I shows means and standard deviations for the threshold and slope of the psychometric curves obtained for the three sound therapy signals. The threshold was higher for the wide-band noise (nearly −5 dB), and lower for the moving water recording (nearly −12 dB) and the tone pips (nearly −14 dB).
Table I Psychometric curve parameters for the Three sound therapy signals

SD = standard deviation; WN = wide-band noise; MW = moving water recording; TP = tone pips
The Kolmogorov-Smirnov test for normalityReference Lilliefors30 revealed that threshold and slope were normally distributed, so parametric analysis of variance (ANOVA) was performed. Differences in threshold and slope for the three different signals were assessed by means of repeated measures (i.e. within-subject) ANOVA, with post-hoc paired samples t-tests with Bonferroni correction. A p value lower than 0.05 was considered significant.
Statistical analysis revealed that all the observed differences in threshold between the different sound therapy signals were significant. Slope was higher for the wide-band noise (nearly 8 per cent/dB) and lower for the moving water recording and tone pips (nearly 4 ÷ 4.5 per cent/dB). Statistical analysis indicated that the mean slope value obtained for the wide-band noise was significantly higher than that obtained for the other two sound therapy signals (p = 0.005); the slight difference in slope value for the moving water recording versus the tone pips (i.e. 4.55 vs 4.29 per cent/dB) was not significant (p = 0.499).
Discussion
Overall, these findings indicate that speech intelligibility is differently influenced by the three sound therapy signals investigated, i.e. wide-band noise, a recording of moving water and a combination of tone pips. The psychometric curves obtained in the presence of the three signals were markedly different (Figure 4). At any given signal-to-noise ratio, speech intelligibility was lower for the wide-band noise than for the other two signals, suggesting that, at a given level of stimulation, wide-band noise had a greater influence on speech intelligibility than either the moving water recording or the tone pips. Accordingly, to reach a given level of speech intelligibility, higher signal-to-noise ratio values were needed for the wide-band noise than for the other two signals. In particular, the psychometric curve threshold was significantly higher for the wide-band noise (i.e. −4.86 dB) than for the moving water recording (i.e. −11.71 dB) or the tone pips (i.e. −13.95 dB).
We also observed that the psychometric curves obtained for both the moving water recording and the tone pips were shifted towards lower signal-to-noise ratio values, compared with those obtained for the wide-band noise. For both the moving water recording and the tone pips, the dynamic range for speech intelligibility varied from −22 to +6 dB signal-to-noise ratio; this was broader than the dynamic range obtained for the wide-band noise (i.e. −12 to +6 dB signal-to-noise ratio). Accordingly, we found that the slope of the psychometric curves was significantly lower (i.e. the curve was flatter) for the moving water recording and tone pips (i.e. 4 ÷ 4.5 per cent/dB), and significantly greater (i.e. the curve was steeper) for the wide-band noise (i.e. 8 per cent/dB). Considering that the slope parameter measures the rate at which speech intelligibility decreases for a given decrease in signal-to-noise ratio, the steeper slope observed for the wide-band noise indicated that, for a given increase in signal level, the intelligibility of speech deteriorated more rapidly in the presence of wide-band noise and more slowly in the presence of the moving water recording and the tone pips.
From a practical point of view, considering that the patient is usually free to modify the volume of sound therapy during treatment, the observed difference in slope would suggest that the use of a moving water recording or tone pips may provide the patient with a higher degree of flexibility, as regards changing the sound therapy stimulation level, compared with the use of wide-band noise. This is because, for a given increase in the volume of sound stimulation, the intelligibility of speech deteriorated more slowly for the moving water recording and tone pips than for the wide-band noise.
Overall, the analysis of psychometric curves indicated that speech intelligibility in normal hearing subjects was more affected by the use of wide-band noise than by the other two sound therapy signals, and that tone pips had the least effect on speech intelligibility. This latter finding is in line with the results of Licklider and Guttman,Reference Licklider and Guttman31 who compared the masking effects of pink noise versus a combination of pure tones, and found that the effect of the combination of pure tones (containing up to 40 components) was less than that of pink noise of the same frequency range and power.
The significantly different effects on speech intelligibility of the three sound therapy signals here observed are due to the different acoustic characteristics of these signals, i.e. their different spectral and temporal features.
Wide-band noise is a steady-state noise with a flat (i.e. unmodulated) temporal envelope and a broad-band spectrum that overlaps the frequency spectrum of speech. Thus, in principle the masking effect of wide-band noise on speech would be evenly distributed over all the frequency components and all the temporal features of speech. If, for example, the speech level is kept fixed and the wide-band noise level is increased (decreasing the signal-to-noise ratio), the broad spectrum of wide-band noise will tend to mask the whole speech spectrum, and the flat envelope of wide-band noise will tend to uniformly cover the whole speech waveform, thus causing a rapid deterioration in speech intelligibility.
• Sound therapy is a common tinnitus treatment, alone or combined with behavioural therapy and counselling
• Such sound therapy may affect patients' speech understanding; this effect is little understood
• This study assessed the effect of three different sound therapy signals on speech intelligibility, at varying stimulation levels
• At the same stimulation level, speech intelligibility was lower for wide-band noise than for a moving water recording or a combination of pure tones
• For a given stimulation level increase, the wide-band noise hindered speech intelligibility most rapidly, and the tone combination least rapidly
On the other hand, both the moving water recording and the tone pips are non-stationary signals, and their frequency spectra generally did not overlap with the speech frequency spectrum. Rather, the frequency spectra of moving water and tone pips comprised a high proportion of harmonics, generated either naturally, by the movement of water (for the moving water recording), or synthetically, by the summation of pure tones (for the tone pips). Moreover, as explained in the Materials and Methods section, the tone pips had no spectral component below 0.5 kHz, and their masking effect on the low-frequency components of speech was thus weaker. Therefore, when listening to speech in the presence of the moving water recording or the tone pips, the masking effect will not be evenly distributed across the acoustic characteristics of speech because some of the spectral and temporal features of speech can easily emerge above the spectral and temporal features of these two sound therapy signals. The average listener can thus take advantage of the temporal fluctuations and spectral harmonicity of the moving water recording and the tone pips, and can perceive some speech features and thus ‘glimpse’ the target speech. In particular, during periods when the temporal envelope of the masker decreases, the listener can easily access the fine temporal structure and acoustic landmarks of consonants (e.g. the closing and release of stop consonants), which are crucial to speech understanding in noise.Reference Li and Loizou19, Reference Assmann, Summerfield, Greenberg, Ainsworth, Popper and Fay23
Conclusion
The present study showed that, for a given stimulation level, the use of different signals for tinnitus sound therapy can have significantly different effects on the intelligibility of speech during treatment. In particular, the patient's ability to comprehend speech may be better preserved during sound therapy using natural sound recordings (e.g. moving water) or synthetic combinations of tones (i.e. generally speaking, sounds rich in harmonic content and temporal fluctuations), compared with steady-state, broad-band signals. In other words, our findings indicate that the use of signals rich in harmonic content and temporal fluctuations may give patients a greater degree of flexibility, as regards changing their sound therapy stimulation level, without impairing speech understanding.
In future studies, it will be important to explore a wider set of sounds and a wider range of sound therapy settings, in order to investigate further the effects of sound therapy upon the patient's ability concurrently to understand speech or to follow a conversation. For this purpose, the use of objective measures, such as the speech intelligibility indexReference Rhebergen, Lyzenga, Dreschler and Festen32 and the speech transmission index,Reference Ma, Hu and Loizou33 would be particularly helpful in predicting speech intelligibility in a variety of noisy conditions, either steady-state or fluctuating. Such systematic investigation of changes in speech intelligibility in the presence of different sound therapy settings could provide clinically useful suggestions and possible new criteria with which to better define optimal sound therapy protocols. Such clinical information could give patients more treatment flexibility and, also, maximise their listening and comprehending abilities during concurrent tinnitus sound therapy.
Acknowledgement
This work was partially supported by the Fondazione Ascolta e Vivi, as part of the project ‘Advanced methods and models for the investigation of the human hearing function in tinnitus’ (February 2006 to February 2009).