


1. Introduction
Computer-mediated communication has been used in language teaching for the past thirty years. Previous research has focused on peer-to-peer videoconferencing (Develotte, Guichon & Kern, Reference Develotte, Guichon and Kern2008), the potential of the webcam for language instruction (Develotte, Guichon & Vincent, Reference Develotte, Guichon and Vincent2010) and describing multimodal online conversation (Lamy & Flewitt, Reference Lamy and Flewitt2011).
In foreign language learning, face-to-face communication facilitates mutual understanding. Desktop videoconferencing (DVC) is similar to face-to-face communication but takes place at a distance (Develotte, Kern & Lamy, Reference Develotte, Kern and Lamy2011). Nevertheless DVC communication is different from face-to-face as it involves more gestures and fewer words (Cosnier & Develotte, Reference Cosnier and Develotte2011). Hence, teaching through videoconferencing is potentially different from teaching face-to-face.
This paper focuses on tutoring practices of two populations of teachers, trainee teachers and experienced teachers. All the teachers participated in a project using the DVC platform, VISU, designed for delivering online language courses. VISU, implemented in 2010, combines videoconferencing features with writing and interaction tools. The prototype used for the experiment has three different ‘rooms’: the synchronous room – designed for interactions between the tutor and the students, the retrospection room – where sessions can be replayed, and the administrator/tutor's room – designed for tutors to enable them to set up online tasks and upload multimedia links. For the purposes of our research we analysed teachers’ use of webcams and tried to answer the following question: How does multimodal interaction and the polyfocality of attention affect interactive learning and teaching?
The study was conducted in an international context, the international project Le Français en (première) ligne Footnote 2, which allow learners (students) of French to interact with French speakers, and also allows students in the second year of their Master of Arts in Teaching French (University Lumière-Lyon 2) to design multimedia tasks for language learning.
This paper discusses the aforementioned research question of the webcam's effects on multimodal active learning and is divided into three parts. The first part introduces the context of the study and the subsequent two parts discuss the theoretical and methodological framework and present the results.
Our hypothesis is that in the DVC environment, the tutoring situation affects both experienced and inexperienced teachers and the way they teach.
We will emphasize the framing, the degree of use of the webcam, the spatial context, and tutors’ and learners’ gestures. Finally, we will present the qualitative findings of the study conducted on this multimodal corpus.
2. Context of the research
2.1 Le Français en (première) ligne
Le Français en (première) ligne (F1L) allows future teachers of French as a Foreign Language (FFL) to gain practical experience of Information and Communication Technology (ICT) and enables foreign students to get in touch with experts who are native speakers of the target language. Between 2009 and 2010, online interactions took place on the VISU platform developed by the Universities of Lyon 1, Lyon 2 and the TECFA from Geneva through the research program ITHACA, funded by the French National Research Agency.
2.2 VISU
VISUFootnote 3 offers three features: a space for preparing educational resources, a room for online interactions between students and tutors, and a retrospection room where interactions can be replayed for training and research purposes. The synchronous room provides tutors and learners with a collaborative videoconferencing space including several functionalities supported by a trace-based system – chat, multimedia activities, timeline, online users, and the possibility of writing personal notes (a marker) during online interactions. The retrospection room (fig. 1) provides tutors and researchers with real-time visualization of online interactions and real-time tracking visualization of tutors’ and students’ tracking data for analysis and evaluation purposes of multimodal interactions (chat, markers, online users, timeline).

Fig. 1 Screenshot of the retrospection room.
(1) online users; (2) tracking tools; (3) timeline; (4) marker; (5) rich marker; (6) interaction tracking tools; (7) learners; (8) tutor.
2.3 Participants
The participants in this experiment were eleven FFL tutors (eight trainee teachers and three experienced teachers) and 22 BA students from UC Berkeley (22 females in their 5th semester of learning French).
Participation was voluntary. The trainee teachers received 20 hours of training on how to use VISU in Lyon in their regular classroom. The experienced teachers received 45 minutes online instruction in January, one week before the online interaction took place.
The trainee tutors (N = 8, 6 females and 2 males) were second-year students on the Master of Arts in Teaching French as a Foreign Language course at the University Lumière- Lyon 2 and they delivered the online teaching from the same classroom lab. Seventy-five per cent of the trainee tutors, all of whom worked in the same language lab in Lyon, claimed they were comfortable using VISU before the online interaction commenced.
The experienced teachers (N = 3, 2 females and 1 male) had a Master of Arts in Teaching French as a Foreign Language and were based in different locations (France, Spain and Finland). Before the online interactions commenced, all of the experienced teachers reported that they were comfortable using VISU. It should be noted that these teachers, all of whom worked from home, had previous online tutoring experience and were experienced in the field of teaching/learning with ICT.
The trainee teachers designed the online tasks and registered instructional information on the platform two days before the interactions commenced. The subject areas were based on UC Berkeley's curriculum. The online sessions lasted 45 minutes and took place every Tuesday at 6pm CET/ 9am PST from January to March.
We identified three configurations of online tutoring: one tutor/ two learners, one tutor/one learner, two tutors/one learner (see figure 2).

Fig. 2 Screenshot: three configurations of online tutoring
3. Theoretical framework
The research protocol is based on an empirical method of collecting ecological data. A corpus of study is proposed to describe the tutoring practices in multimodal synchronous computer mediated communication.
The qualitative data analysis method is based on Computer-Mediated Discourse Analysis (Herring, Reference Herring2004) combined with recent French research on discourse and interaction analysis (Kerbrat-Orecchioni, Reference Kerbrat-Orecchioni2005; Cosnier, Reference Cosnier2008) and the degree of tutors’ involvement using webcams (Develotte, Guichon & Vincent, Reference Develotte, Guichon and Vincent2010). We conducted our analysis based on Cosnier's concept of “totext” which is described as a complex phenomenon of communication including symbols, co-verbals co-ordinators and extra communicative gestures. Cosnier shows that gestures and/or vocalizations have a quasi-linguistic form and conventional use and he classifies them into several categories (see figure 3):

Fig. 3 Gestural categories (Cosnier, 2002)
– co-verbal: phonogene (related to the productive activity of speech) or illustrative (related to the propositional content of speech);
– deictics: designating or symbolic reference;
– icons: the shapes of represented objects;
– ideographic or metaphorical: representing abstract objects;
– sticks or beats or intonation: in two movements of the head or hands, pragmatic markers;
– expressive: mainly facial expressions that connote the propositional content or which metacommunicatively mark the position of the speaker and/or his co-speaker;
– co-ordinators: ensure the co-pilot of the interaction (maintenance and passing tricks);
– phatic: activity of the speaker to verify or maintain contact primarily through the eyes, intonation and occasional physical contact;
– regulators: receptor activity in response to the previous (back channel): nods, smiles and short voco-verbalizations;
– extra communicative: adapters, games, praxis, etc.
We studied two key concepts, polyfocality and multimodality in the DVC environment. Multimodality supports communication with the user through verbal, nonverbal and paraverbal communication and the presence of different communication tools (Develotte, Guichon & Kern, Reference Develotte, Guichon and Kern2008). Polyfocality seems, in fact, to be part of the very ethos of new communication technologies (Jones, Reference Jones2004).
A researcher cannot neglect the pedagogical context in which exchanges take place (Mangenot, Reference Mangenot2007). The theoretical framework is both linguistic and pedagogical and in the manner of Kerbrat-Orecchioni (Reference Kerbrat-Orecchioni2005), in this study we also crossbred theories.
4. Methodology
4.1 Corpus of study
The main corpus consisted of a total of seven teaching sessions of 45 minutes each. We selected the 5th session in order to study stabilized tutoring practices and the use of different communication tools for a total of 7 hours, 7 minutes and 47 seconds of online interactions. Our analysis of the data, collected through the ecological method, is descriptive. Moreover, a series of semi-directed interviews were held with each online tutor and learner. Next, we compared our analysis of their use of webcams and their perceptions of the effects of these on multimodal interactive learning. This added another 15 hours and 45 minutes of interviews to our corpus of study.
4.2 Data analysis
We focused on multimodal interaction and the polyfocality of attention in three configurations of tutoring: one tutor and two learners, one tutor and one learner, and two tutors and one learner. We studied the following aspects: framing, the degree of use of the webcam, spatial context, tutors’ and learners’ gestures, and the tutors’ ethos and politeness in the DVC environment, including face-threatening and face-flattering acts. Politeness theory (Brown & Levinson, Reference Brown and Levinson1987; Goffman, Reference Goffman1973, Reference Goffman1974; Kerbrat-Orecchioni, Reference Kerbrat-Orecchioni2005) suggests that speech acts include compensatory strategies, which are a set of processes that enable interactants to preserve each other's face. Goffman (Reference Goffman1967: 66) describes face as:
the public self-image that every member wants to claim for himself.
Face Threatening Acts (FTAs) refer to:
acts and strategies which could harm or threaten the positive or negative face of one's interlocutors (Brown & Levinson, Reference Brown and Levinson1987 :61).
In her work on verbal interactions and speech in interaction, Kerbrat-Orecchioni revisited the concept of face and FTAs. Kerbrat-Orecchioni stresses anti-FTAs speech acts (Reference Kerbrat-Orecchioni1996), a concept that she changed to Face Flattering Acts (FFAs) (1997). FFAs are speech acts performed by the interactants that have the potential to preserve each other's face (Kerbrat-Orecchioni, Reference Kerbrat-Orecchioni1997).
5. Results
The results of the study reflect the differences between tutors and are intended to provide a preliminary understanding of the effectiveness of the use of webcams in the DVC environment. First, we will present a descriptive overview of framing in DVC, i.e., the position of the subject in the frame of the screen. Then we will elaborate on the degree of use of the webcam, and the effects of the spatial context on the interactions between tutors and learners. Finally, we will elaborate on tutors’ gestures occurring during the session along with their ethos and politeness in DVC. A series of interview extracts will illustrate learners’ perceptions of the multimodal learning environment.
5.1 Framing
The analysis shows several types of framing while tutors were using two types of webcams: external webcams and built-in webcams. Students used only built-in webcams.
5.2 Tutor's side
We present several types of framing in DVC in two configurations: external webcams and built-in webcams. The types of framing we analysed were classified into centred, lateral, shifting, lateral medium, extreme close-up and satellite close-up during double-tutoring (see figure 4).

Fig. 4 Framing screenshots: six configurations of framings
5.2.1 Experienced teachers
The framing analysis shows a centred close-up framing during the online interactions on the tutors’ side. However, the framing is different depending on whether the tutor is using an external webcam or a built-in webcam. The external webcam offers the possibility of adjusting the tutor's depth of field, therefore enabling better monitoring of the tutor's facial expressions. One experienced teacher out of three orients his body towards the learner's screen showing clearly that he is speaking to her and is paying attention to her answers on the lateral close-up focus on learner framing. One tutor out of three adopts a lateral close-up position when consulting the lesson plan on the left side of her screen. All tutors are in the field of view of the webcam. The analysis shows that for all three tutors, the webcam's potential is integrated into their behaviour.
5.2.2 Trainee teachers
The analysis shows a shifting close-up framing for seven out of eight tutors. Some tutors move restlessly in their chairs during pedagogical instruction, while delivering the instructional script, answering students’ questions or commenting on their answers. For two out of the eight tutors, the shifting close-up is followed briefly by a centred close-up framing. While reading the lesson plan, the framing is lateral close-up for seven tutors. While using the webcam, seven tutors out of eight were in the field of view of the screen. The analysis shows that for only four tutors, the webcam's potential is integrated into their behaviour. Sometimes, during external distractions in the language lab in Lyon, tutors looked away from the screen. When the tutors are motionless and a person passes by, it appears as though the background moves. As a result, the learners’ eyes are drawn towards this movement.
5.2.3 Framing issues
● Extreme close-up, the case of single tutoring
One tutor out of eight shows only the forehead or half of his face during the online session in an extreme close-up. Half of his face is hidden from view. As a direct result, his student positions herself the same way in front of the webcam (see figure 5).

Fig. 5 Extreme close-up
In this case, during the online interactions the perceptions of smiles and laughs are based on the sounds that are emitted by the tutor. The tutor seems to neglect the webcam and chooses a monotonous tone. The tutor's mouth is hidden from view, therefore the learner focuses predominantly on the audio. It seems that seeing the tutor could be a support for understanding the discourse in the videoconferencing context as one of the learners says, in an interview, “gestures really helped, which is probably why the visual aid Versus talking to someone on the phone and actually seeing them—reading lips and makingexpressions and gestures…”; while another learner states “I really rely on watching people's mouths when they talk to me or hear them sometimes.”
● Satellite close-up, the case of double tutoring
In the case of double tutoring, the tutors share the webcam and choose to stay in the field of view of the webcam. This creates a framing which we called a satellite close-up; when one of the tutors moves, the webcam creates an effect of canted framing. This means that either the right or the left side of the frame is bigger/smaller or higher/lower than the other, creating an imbalanced effect (see figure 6).

Fig. 6 Satellite close-up
The negative space between the tutors is the first element that catches the students’ eyes. However, the fact that both tutors are active and have many facial expressions mitigates the above issue. In such a case, the student's eyes follow the tutors’ movements. While not explicitly targeting the satellite close-up, there are a number of questions that arise when observing the tutors’ choice: Are they knowingly choosing the satellite framing rather than the centred close-up framing? Do they want to see each other on the screen and monitor each other? Are they not paying attention to their seating positions because they are preoccupied with trying to monitor online interactions?
5.3 Learner's side
The tutors did not give the learners instructions on how to use the webcam. However, the learners’ framing is centred close-up: 20 out of 22 students appear in portrait view (medium shot) and have an upright posture (see figure 7).

Fig. 7 Portrait view
Nevertheless, three of the trainee tutors’ students show some variations of bad framing during online interactions. Figure 7 shows a student crouching, while the tutor's framing is a shifting close-up. Half of the student's face disappears. In addition to poor lighting, the student repeatedly removes the headset during the interactions due to background noise (see figure 8).

Fig. 8 Bad framing, learner's side
Figure 9 shows the direct result of an extreme close-up on the tutor's side. During the online session, the learner attempts to position herself in the webcam's field of view (see figure 9), especially during the co-verbal gestures that will be discussed later (see figure 10).

Fig. 9 Bad framing, student's side

Fig. 10 Student's side: co-verbal gesture and attempt at close-up
5.4 Degree of use of the webcam
We followed Develotte, Guichon and Vincent's (Reference Develotte, Guichon and Vincent2010) typology in relation to the degrees of use of the webcam (see figure 11):

Fig. 11 Degree of use of the webcam (Develotte, Guichon & Vincent, 2010)
– Degree 0: the trainee teacher does not appear on the video window, she is standing outside the camera focus or it is not possible to use the video medium
– Degree 1: the trainee teacher is not looking at the computer screen
– Degree 2: the trainee teacher is looking at the open video window on the computer screen
– Degree 3: the trainee teacher is looking at the open video window on the computer screen and she uses facial expressions and/or gestures to back up her message
– Degree 4: the trainee teacher is looking straight into the webcam, giving her interlocutor the impression that she is looking directly at her.
Tutors or learners are in the field of view of the webcam, and sometimes when they are distracted by various factors in their surroundings, they look away from the screen.
The analysis shows degree 1 for nine tutors out of eleven during external distractions. We found four configurations during occurrences when tutors and learners looked away from the screen: a third person interrupted the flow of the online interactions, the tutor addressed another person in the language lab, the tutor looked at a person out of the view of the webcam and the tutors looked at each other while double tutoring.
The webcam's potential is less integrated into the trainee teachers’ pedagogical practices. However, the experienced teachers look at the screens and the faces of the students while addressing them. They have degree 3 and 4 webcam use.
Four trainee tutors out of eight have degree 4, mainly involuntary, during a centred close-up framing.
5.5 Spatial context
During online interactions, six trainee teachers out of eight and four students out of twenty left the conversation abruptly but briefly. We found three configurations:
– Intervention of a third person: the tutor or the student leaves the conversation when addressed by a person in their physical environment (see Figure 12). Figure 12 shows a person in the UC Berkeley's language lab talking to the student. The student removes her headset, followed by the tutor's question: “What's going on?”

Fig. 12 Spatial context – The student abruptly leaves the online interaction
We also observed that during the pedagogical instruction, one of the experienced teachers looks at a person present in her living room, out of view of the webcam, and smiles at him/her.
– Excessive immobility (figure 13): In the case of excessive facial and physical immobility and extreme close-up, when another person passes behind the tutor, the student's eyes are attracted by the external scene.

Fig. 13 Spatial context – Excessive immobility
– Shared headset (figure 14): In the case of double tutoring, tutors share the same headset. When they pass it to each other their eyes leave the screen and they leave the conversation briefly.
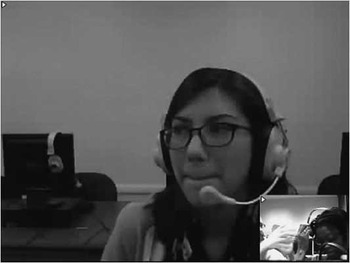
Fig. 14 Spatial context – Shared headset
5.6 Tutors’ gestures
5.6.1 Symbolic gestures
Overall, we observed very few symbolic gestures such as a gesture of the hand to say “goodbye” accompanied by a smile or gestures to applaud the learner. During one of the online tasks, two tutors out of eleven (a trainee teacher and an experienced teacher) asked students to remove the headset and they mimed the gesture through the webcam.
5.6.2 Co-verbal gestures
With regard to co-verbal gestures, we observed, for example, iconic gestures of the hands to explain words like “gloves”, or when tutors encouraged students (figure 15). Co-verbal gestures are accompanied by facial expressions and movement of the eyes and mouth. It seems that iconic gestures helped learners make sense of words and topics, as a learner explains referring to an experienced teacher: “her hands were pretty animated. Her face was really animated.” The same learner further states: “I used my hands a lot,” followed by her colleague stating the same experience: “I talked with my hands like, small, big.”

Fig. 15 Tutor encourages the student: “bravo”
5.6.3 Coordinator gestures
We observed two types of coordinators: regulators and phatic coordinators.
Regulators included many nods, learners’ gestures of approval and understanding of the instruction. Regulators have the function of showing the tutors’ approval of responses, of expressing encouragement through smiles and encouraging words, of rewarding the correct answer with praise, and of expressing congratulations. One learner explains that she was comfortable with asking questions to the tutor as the tutor's words were encouraging: “she'd say ‘oh you expressed yourself very well,’ which was nice to hear.”
We observed phatic gestures where one of the tutors needed help during the online interactions. He spoke to someone in the language lab without informing the learner and he resumed the conversation with the learner by saying “hello” as in a phone call.
5.6.4 Extra-communicative gestures
Tutors and students accompany their discourse with extra-communicative gestures. An extra- communicative gesture does not possess any semiotic meaning and does not convey information. Extra-communicative gestures are auto-centred gestures. We noted some examples, as seen in figure 16.
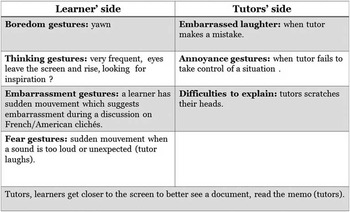
Fig. 16 Extra-communicative gestures
Tutors use adaptors, such as touching a part of their face or scratching parts of their body when they have difficulty explaining a word (figure 17).

Fig. 17 Tutor side – extra-communicative gesture
Common adaptors used by students and tutors are gestures of thinking (e.g., resting their heads on their hands and looking pensive, or scratching their heads) and gestures of their eyes (e.g., looking away from the screen when it is difficult to explain a word). Praxis gestures arise when a document is being shared (e.g., tutors and students get closer to the screen to see the document better).
5.7 Tutors’ ethos
In DVC, mimogestuality and framing are important factors that influence the image that the tutors give of themselves to the learners. The study of the tutors’ ethos showed that experienced teachers effectively used the webcam, framing and calculated gestures. Trainee teachers were building up a tutoring ethos based on the webcam's potential. However, some appeared too focused on their own image while others seemed to neglect the benefits of using the webcam.
5.8 Politeness in the multimodal learning environment
Politeness in DVC has special rituals constrained by the tools. Eye to eye contact is simulated (Develotte, Guichon & Vincent, Reference Develotte, Guichon and Vincent2010) and during self-reflective moments, the eyes leave the screen and tutors and students adopt a position similar to Rodin's The Thinker. It seems that in DVC, this posture, associated with a lack of attention in face-to-face communication, results in the listener appearing to be more attentive. Experienced and trainee teachers reinforce the ending of online interactions by ample gestures of the hand to say “goodbye”. However, when a conversation ends abruptly, it gives the impression that the person is being shut out of the virtual environment and this may be perceived as being impolite.
The Face Flattering Acts are exaggerated (e.g., “bravo” accompanied by a hand gesture positioned in front of the webcam).
The Face Threatening Acts noticeable via the webcam result in less gestural supervision (e.g., yawning, gestures of annoyance, etc.). This raises the question that perhaps tutors and students tend to forget the presence of the webcam. On the other hand, noticeable audio Face Threatening Acts are regulated (e.g., coughing and the gesture of hiding the microphone).
6. Discussion
The study was intended as a descriptive analysis of the use of DVC in language teaching and learning. The analysis of the use of webcams showed six types of framing on the tutors’ side. The results indicate that some framing issues on the learner's side appear as a mirror effect of the tutor's bad framing. The integration of the webcam into pedagogical instructions can benefit students’ comprehension and familiarity with a language. Experienced teachers effectively channelled information through the webcam in order to engage learners in making sense of discourse and knowledge construction. In addition, single and double tutoring have an effect on interactive learning and teaching. For example, in the case of double tutoring, while using the same DVC, two tutors have to share the screen, the headset and the task of giving instructions. The study showed that during short conversation practices, the two tutors tend to have confidential exchanges, which result in the student feeling left out from the discussion. Finally, body orientation and exaggerated gestures are important as they guide students and help them discover new words by creating an interactive environment.
In DVC, oral discourse, intonation and knowing how to effectively use the webcam are part of the tutoring ethos. Also, mimogestuality and framing are important in influencing the image that tutors want to give of themselves to students. Therefore, we propose to add to Develotte, Guichon and Vincent's (Reference Develotte, Guichon and Vincent2010) typology (different degrees of the use of webcam), our analysis that takes into account the actors’ framing during online interactions.
However, for students, it is not very easy to perceive the webcam's potential in DVC. Overall, they have a fixed posture and are focused but they do not demonstrate sufficient mimogestuality to communicate. Awareness of one's image and its potential to communicate more effectively is one of the essential abilities learners should practise in order to maximise their experience of learning through DVC.
7. Limitations of the study
This study, which focuses on multimodality and polyfocality, provides a descriptive analysis of framing, tutors’ gestures, their ethos and politeness in DVC. However, an in-depth exploration of participants’ uses of different online tools and platforms outside VISU in terms of user experience, user perceptions and preferences could benefit both teacher training and interaction design. When asked if previous online experience helped her during the online sessions on VISU, an experienced teacher acknowledged that “experience plays an important role” but “we are not necessarily familiar with the tool, and the last session I felt it was more fluid, so it is the fact that we needed to get used to the interface of VISU.”
Further research is needed to replicate this study with a larger sample of participants in order to examine tutors’ and learners’ profiles when analysing interactions with DVC tools. One tutor, who used to teach through the telephone, said in the interview: “the video, it's clear, it's a change, all my courses are without video, and then the chat, I used the chat a lot.” The same tutor explains her extensive use of chat in teaching: “we need time to structure a little bit more, and it is my way to work, after all students which I have had online, only spoken language can also hinder some students.” Then she compares VISU with the platform she uses to deliver other online courses: “on WISIQ we share an interactive board with the student to build concepts together.” This type of study could help in developing awareness of different kinds of audience.
One tutor illustrates the limits of the DVC in an interview: “we are forced to be very close to the screen and it blocks some of the gestures which are close to the face, and therefore this part of the communication is blocked by the camera.” Tutoring strategies should be expanded to acquire better understanding of the effectiveness of using DVC for language teaching.
8. Conclusion and perspectives
The purpose of this study was to conduct a detailed analysis of the effects of the webcam on interactive learning. We highlighted some recommendations that may be worth noting for teacher training purposes. Analysis shows that experienced teachers and trainee teachers used the audio, video and text features of the platform differently. The tutoring practices display transferable semio-pedagogical skills from one platform to another in the case of the experienced teachers. Seven types of framing in DVC were identified. It is interesting to note that bad framing on the tutor's side has a mirror effect on the learner's side. The complexity of VISU setup requires training for teachers to adjust to the communication tools in order to convey the meaning of the task to be carried out. However, the mimogestuality is constrained by the framing. This particular learning environment has its limitations and possibly needs to improve its communication tools. It is hoped that such research may enhance interaction design, as tools mediate how users interact with each other and their design affects the user's experience with the tools.
The analysis also shows that, through the use of DVC, experienced teachers were able to project a more effective tutoring ethos than some trainee tutors. Thus, trainee tutors, if they happen to develop an ethos closer to learners, sometimes lose control of their role and of their image. It seems that tutoring by DVC cannot be improvised and the more the communication is synchronous and visual, the greater quality of online tutoring. Appropriate training not only for better management of the tools, but also regarding the role of the tutor in DVC, is essential to enhancing the quality of online tutoring. Moreover, language tutors using these new devices do not have a pre-constructed ethos, therefore they should build it into their discourse and become the arbiter of the interaction.
This type of study can be applicable to DVC environments across other educational domains in order to enhance tutors’ engagement with students in learning as well as interacting with one another. Another study will be conducted in order to observe whether participants adjust their behavior when interacting with each other by webcam over seven sessions. We will also conduct further analysis a sub-corpus showing how multimodal interactions and the use of the tools in DVC may support the quality of learning, lead to better dialogues and foster productive online interactions.
We conclude by inviting further research on the benefits of using webcams in language teaching and learning.
Acknowledgements
The authors wish to express their gratitude to Pr. Dr. Christine Develotte, Rahul Dhakal Timilsina and Rakesh Bhanot for their helpful comments on earlier drafts of this paper. We greatly appreciate the insightful comments and feedback from the reviewers.

















