


1. Introduction
Urdu, the national language of Pakistan, and Hindi, the national language of India, jointly rank as the fourth most widely spoken language in the world (Lewis Reference Lewis2009). Urdu and Hindi are closely related in morphology and phonology, but use different scripts: Urdu is written in Perso-Arabic script and Hindi is written in Devanagari script. Interestingly, for social media and short messaging service (SMS) texts, a large number of Urdu and Hindi speakers use an informal form of these languages written in Roman script, Roman Urdu.
Since Roman Urdu does not have standardized spellings and is mostly used in informal communication, there exist many spelling variations for a word. For example, the Urdu word ![]() [life] is written as zindagi, zindagee, zindagy, zaindagee, and zndagi. The lack of standard spellings inflates the vocabulary of the language and causes sparsity problems. This results in poor performance of natural language processing (NLP) and text mining tasks, such as word segmentation (Durrani and Hussain Reference Durrani and Hussain2010), part-of-speech tagging (Sajjad and Schmid 2009), spell checking (Naseem and Hussain 2007), machine translation (Durrani et al. Reference Durrani and Hussain2010), and sentiment analysis (Paltoglou and Thelwall Reference Paltoglou and Thelwall2012). For example, neural machine translation models are generally trained on a limited vocabulary. Nonstandard spellings would result in a large number of words unknown to the model, which would result in poor translation quality.
[life] is written as zindagi, zindagee, zindagy, zaindagee, and zndagi. The lack of standard spellings inflates the vocabulary of the language and causes sparsity problems. This results in poor performance of natural language processing (NLP) and text mining tasks, such as word segmentation (Durrani and Hussain Reference Durrani and Hussain2010), part-of-speech tagging (Sajjad and Schmid 2009), spell checking (Naseem and Hussain 2007), machine translation (Durrani et al. Reference Durrani and Hussain2010), and sentiment analysis (Paltoglou and Thelwall Reference Paltoglou and Thelwall2012). For example, neural machine translation models are generally trained on a limited vocabulary. Nonstandard spellings would result in a large number of words unknown to the model, which would result in poor translation quality.
Our goal is to perform lexical normalization, which maps all spelling variations of a word to a unique form that corresponds to a single lexical entry. This reduces data sparseness and improves the performance of NLP and text mining applications.
One challenge of Roman Urdu normalization is lexical variations, which emerge through a variety of reasons, such as informal writing, inconsistent phonetic mapping, and non-unified transliteration. Compared to the lexical normalization of languages with a similar script like English, the problem is more complex than writing a language informally in the original script. For example, in English, the word thanks can be written colloquially as thanx or thx, where the shortening of words and sounds into fewer characters is done in the same script. During Urdu to Roman Urdu conversion, two processes happen at the same time. (1) Various Urdu characters phonetically map to one or more Latin characters. (2) The Perso-Arabic script is transliterated to Roman script. Since transliteration is a nondeterministic process, it also introduces spelling variations. Figure 1 shows an example of an Urdu word ![]() [boys] that can be transliterated into Roman Urdu in three different ways (larke, ladkay, or larkae) depending on the user’s preference. Lexical normalization of Roman Urdu aims to map transliteration variations of a word to one standard form.
[boys] that can be transliterated into Roman Urdu in three different ways (larke, ladkay, or larkae) depending on the user’s preference. Lexical normalization of Roman Urdu aims to map transliteration variations of a word to one standard form.
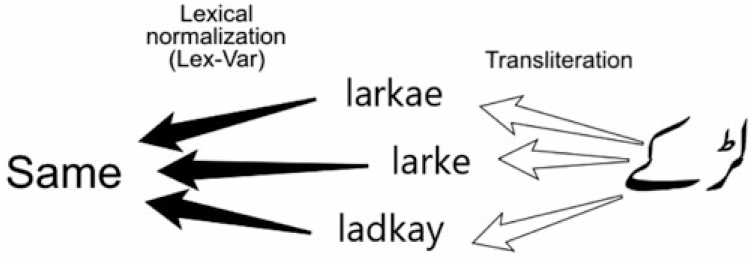
Figure 1. The lexicon can be varied due to informal writing, non-unified definition of transliteration, phonetic mapping, etc.
Another challenge is that Roman Urdu lacks a standard lexicon or labeled corpus for text normalization to use. Lexical normalization has been addressed for standardized or resource-rich languages like English (Gouws et al. Reference Gouws, Hovy and Metzler2011; Han et al. Reference Han, Cook and Baldwin2013; Jin Reference Jin2015). For such languages, the correct or the standard spelling of words is known, given the standard existence of the lexicon. Therefore, lexical normalization typically involves finding the best lexical entry for a given word that does not exist in the standard lexicon. Thus, the proposed approaches aim to find the best set of standard words for a given nonstandard word. On the other hand, Roman Urdu is an under-resourced language that does not have a standard lexicon. Therefore, it is not possible to distinguish between an in-lexicon and an out-of-lexicon word, and each word can potentially be a lexical variation of another. Lexical normalization of such languages is computationally more challenging than that of resource-rich languages.
Since we do not have a standard lexicon or labeled corpus for Roman Urdu lexical normalization, we cannot apply a supervised method. Therefore, we introduce an unsupervised clustering framework to capture lexical variations of words. In contrast to the English text normalization by Rangarajan Sridhar (Reference Rangarajan Sridhar2015), Sproat and Jaitly (Reference Sproat and Jaitly2017), our approach does not require prior knowledge on the number of lexical groups or group labels (standard spellings). Our method significantly outperforms the state-of-the-art Roman Urdu lexical normalization using rule-based transliteration (Ahmed Reference Ahmed2009).
In this work, we give a detailed presentation of our framework (Rafae et al. Reference Rafae, Qayyum, Uddin, Karim, Sajjad and Kamiran2015) with additional evaluation datasets, extended experimental evaluation, and analysis of errors. We develop an unsupervised feature-based clustering algorithm, Lex-Var, that discovers groups of words that are lexical variations of one another. Lex-Var ensures that each word has at least a specified minimum similarity with the cluster’s centroidal word. Our proposed framework incorporates phonetic, string, and contextual features of words in a similarity function that quantifies the relatedness among words. We develop knowledge-based and machine-learned features for this purpose. The knowledge-based features include UrduPhone for phonetic encoding, an edit distance variant for string similarity, and a sequence-based matching algorithm for contextual similarity. We also evaluate various learning strategies for string and contextual similarities such as weighted edit distance and word embeddings. For phonetic information, we develop UrduPhone, an encoding scheme for Roman Urdu derived from Soundex. Compared to other available techniques that are limited to English sounds, UrduPhone is tailored for Roman Urdu pronunciations. For string-based similarity features, we define a function based on a combination of the longest common subsequence and edit distance metric. For contextual information, we consider top-k frequently occurring previous and next words or word groups. Finally, we evaluate our framework extensively on four Roman Urdu datasets: two group-chat SMS datasets, one Web blog dataset, and one service-feedback SMS dataset and measure performance against a manually developed database of Roman Urdu variations. Our framework gives an F-measure gain of up to 15% as compared to baseline methods.
We make the following key contributions in this paper:
-
• We present a general framework for normalizing words in an under-resourced language that allows user-defined and machine-learned features for phonetic, string, and contextual similarity.
-
• We propose two different clustering frameworks including a k-medoids-based clustering (Lex-Var) and an agglomerative clustering (Hierarchical Lex-Var)
-
• We present the first detailed study of Roman Urdu normalization.
-
• We introduce UrduPhone for the phonetic encoding of Roman Urdu words.
-
• We perform an error analysis of the results, highlighting the challenges of normalizing an under-resourced and nonstandard language.
-
• We have provided the source code for our lexical normalization framework.Footnote a
The remainder of this article is organized as follows. In Section 2, we present our problem statement for the lexical normalization of an under-resourced language. In Section 3, we describe our clustering framework for the lexical normalization of an under-resourced language, including UrduPhone and Lex-Var. In Section 4, we describe the evaluation criterion for the lexical normalization of Roman Urdu, describe the research experiments, and present the results and the error analysis. Section 5 discusses the related work in the lexical normalization of informal language, and Section 6 concludes the paper.
2. Task definition
Roman Urdu is a transliterated form of the Urdu language written in Roman script. It does not have a standardized lexicon. That is, there is no standard spelling for words. Therefore, each word observed in a corpus can potentially be a variant of one or more of the other words appearing in the corpus. The goal of lexical normalization is to identify all spelling variations of a word in a given corpus. This challenging task involves normalizations associated with the following three issues: (1) different spellings for a given word (e.g., kaun and kon for the word [who]); (2) identically spelled words that are lexically different (e.g., bahar can be used for both [outside] and [spring]); and (3) spellings that match words in English (e.g., had [limit] for the English word had). The last issue arises because of code-switching between Roman Urdu and English, which is a common phenomenon in informal Urdu writing. People often write English phrases and sentences in Urdu conversations or switch language mid-sentence, for example, Hi everyone. Kese ha aap log? [Hi everyone. How are you people?]. In our work, we focus on finding common spelling variations of words (issue (1)), as this is the predominant issue in the lexical normalization of Roman Urdu and do not address issues (2) or (3) explicitly.
Regarding issue (1), we note that while Urdu speakers generally transliterate Urdu script into Roman script, they also will often move away from the transliteration in favor of a phonetically closer alternative. A commonly observed example is the replacement of one or more vowels with another set of the vowels that has a similar pronunciation (e.g., janeaey [to know] can also be written as janeey). Here, the final characters “aey” and “ey” give the same pronunciation. Another variation of the previous word is janiey. Now the character “i” is replacing the character “e”. In some cases, users will omit a vowel if it does not impact pronunciation, for example, mehnga [expensive] becomes mhnga and similarly bohut [very] becomes bht. Another common example of this type of omission occurs with nasalized vowels. For example, the Roman Urdu word kuton [dogs] is the transliteration of the Urdu word ![]() . But often, the final nasalized Urdu character
. But often, the final nasalized Urdu character ![]() is omitted during conversion, and the Roman Urdu word becomes [kuto]. A similar case is found for words like larko [boys], daikho [see], nahi [no] with final “n” omitted. We incorporate some of these characteristics in our encoding scheme UrduPhone (See Section 3.3.1 and Table 2 for more details on UrduPhone, its rules, and for complete steps to generate encoding).
is omitted during conversion, and the Roman Urdu word becomes [kuto]. A similar case is found for words like larko [boys], daikho [see], nahi [no] with final “n” omitted. We incorporate some of these characteristics in our encoding scheme UrduPhone (See Section 3.3.1 and Table 2 for more details on UrduPhone, its rules, and for complete steps to generate encoding).
We define the identification of lexical variations in an under-resourced language like Roman Urdu as follows: given words
 $w_i$
(
$w_i$
(
 $i = 1, \ldots, N$
) in a corpus, find the lexical groups
$i = 1, \ldots, N$
) in a corpus, find the lexical groups
 $\ell_j$
(
$\ell_j$
(
 $j = 1, \ldots, K$
) to which they belong. Each lexical group can contain one or more words corresponding to a single lexical entry and may represent different spelling variations of that entry in the corpus. In general, for a given corpus, the number of lexical groups K is not known since no standardized lexicon is available. Therefore, we estimate it using normalization.
$j = 1, \ldots, K$
) to which they belong. Each lexical group can contain one or more words corresponding to a single lexical entry and may represent different spelling variations of that entry in the corpus. In general, for a given corpus, the number of lexical groups K is not known since no standardized lexicon is available. Therefore, we estimate it using normalization.
Clustering is expensive in the specific case of Roman Urdu normalization. Considering an efficient algorithm like k-means clustering, the computational complexity of lexical normalization is O(NKT), where T is the number of iterations required for clustering. By comparison, for languages like English with standardized lexicons, each out-of-vocabulary (OOV or not in the dictionary) word can be a variant of one or more in-vocabulary (IV) words. The computational complexity of lexical normalization in English (given by
 $O(K(N-K))$
where K and
$O(K(N-K))$
where K and
 $(N-K)$
are the numbers of IV and OOV words, respectively) is computationally less expensive than the lexical normalization of Roman Urdu.
$(N-K)$
are the numbers of IV and OOV words, respectively) is computationally less expensive than the lexical normalization of Roman Urdu.
3. Method
In this section, we describe different components of our clustering framework. Section 3.1 formalizes our clustering framework including the algorithm developed. Section 3.2 defines a similarity function used in our clustering algorithm. In Section 3.3, we describe the features used in our system.
3.1 Clustering framework: Lex-Var
We develop a new clustering algorithm, Lex-Var, for discovering lexical variations in informal texts. This algorithm is a modified version of the k-medoids algorithm (Han 2005) and incorporates an assignment similarity threshold,
 $t>0$
, for controlling the number of clusters and their similarity spread. In particular, it ensures that all words in a group have a similarity greater than or equal to some threshold, t. It is important to note that the k-means algorithm cannot be used here because it requires that the means of numeric features describe the clustered objects. The standard k-medoids algorithm, on the other hand, uses the most centrally located object as a cluster’s representative.
$t>0$
, for controlling the number of clusters and their similarity spread. In particular, it ensures that all words in a group have a similarity greater than or equal to some threshold, t. It is important to note that the k-means algorithm cannot be used here because it requires that the means of numeric features describe the clustered objects. The standard k-medoids algorithm, on the other hand, uses the most centrally located object as a cluster’s representative.
Algorithm 1 gives the pseudo-code for Lex-Var. Lex-Var takes as input words (
 $\mathcal{W}$
) and outputs lexical groups (
$\mathcal{W}$
) and outputs lexical groups (
 $\mathcal{L}$
) for these words. UrduPhone segmentation of the words gives the initial clusters. Lex-Var iterates over two steps until it achieves convergence. The first step finds the centroidal word
$\mathcal{L}$
) for these words. UrduPhone segmentation of the words gives the initial clusters. Lex-Var iterates over two steps until it achieves convergence. The first step finds the centroidal word
 $c_i$
for cluster
$c_i$
for cluster
 $\ell_i$
as the word for which the sum of similarities of all other words in the cluster is maximal. In the second step, each non-centroidal word
$\ell_i$
as the word for which the sum of similarities of all other words in the cluster is maximal. In the second step, each non-centroidal word
 $w_i$
is assigned to cluster
$w_i$
is assigned to cluster
 $\ell_j$
if
$\ell_j$
if
 $S(w_i, c_j)$
(see Section 3.2) is maximal among all clusters and
$S(w_i, c_j)$
(see Section 3.2) is maximal among all clusters and
 $S(w_i, c_j) > t$
. If the latter condition is not satisfied (i.e.,
$S(w_i, c_j) > t$
. If the latter condition is not satisfied (i.e.,
 $S(w_i, c_j) \leq t$
), then instead of assigning word
$S(w_i, c_j) \leq t$
), then instead of assigning word
 $w_i$
to cluster
$w_i$
to cluster
 $\ell_j$
, it starts a new cluster. We repeat these two steps until a stop condition is satisfied (e.g., a fraction of words that change groups becomes less than a specified threshold). The computational complexity of Lex-Var is
$\ell_j$
, it starts a new cluster. We repeat these two steps until a stop condition is satisfied (e.g., a fraction of words that change groups becomes less than a specified threshold). The computational complexity of Lex-Var is
 $O((n^2 + N)KT)$
, where n is the maximum number of words in a cluster, which is typically less than N.
$O((n^2 + N)KT)$
, where n is the maximum number of words in a cluster, which is typically less than N.
Figure 2 shows the details of our clustering framework. The first row of boxes shows the workflow of the system, and the area in the dotted square includes the modules used in our clustering method. The filled arrows indicate the outputs of the algorithms, and the unfilled arrows show modules that apply submodules.

Algorithm 1 Lex-Var

Figure 2. Flow diagram for Lex-Var.
After preprocessing the text, we normalize each word in the vocabulary. First, we initialize the clustering using random clustering or UrduPhone clusters. Then, based on the initial clusters, we apply (Hierarchical) Lex-Var algorithm to predict clusters. Finally, we compute the F-Measure based on the gold standard clusters to evaluate our prediction.
The Lex-Var algorithm applies a modified version of the k-medoids clustering, which uses a similarity measure that further consists of different features, including UrduPhone, string learning, and contextual feature. The edit distance is a submodule of the string learning. We learn the substitution cost with various methods such as expectation–maximization (EM).
3.2 Similarity measure
We compute the similarity between two words
 $w_i$
and
$w_i$
and
 $w_j$
using the following similarity function:
$w_j$
using the following similarity function:
 \begin{equation}S(w_i, w_j) = \frac{ \sum_{f=1}^F \alpha^{(f)} \times \sigma_{ij}^{(f)}} {\sum_{f=1}^F \alpha^{(f)} }\end{equation}
\begin{equation}S(w_i, w_j) = \frac{ \sum_{f=1}^F \alpha^{(f)} \times \sigma_{ij}^{(f)}} {\sum_{f=1}^F \alpha^{(f)} }\end{equation}
Here,
 $\sigma_{ij}^{(f)} \in [0, 1]$
is the similarity contribution made by feature f. F is the total number of features. We will describe each feature in Section 3.3 in detail.
$\sigma_{ij}^{(f)} \in [0, 1]$
is the similarity contribution made by feature f. F is the total number of features. We will describe each feature in Section 3.3 in detail.
 $\alpha^{(f)} > 0$
is the weight of feature f. These weights are set to 1 by default and are automatically optimized in Sections 3.4 and 4.3.4. The similarity function returns a value in the interval [0, 1] with higher values signifying greater similarity.
$\alpha^{(f)} > 0$
is the weight of feature f. These weights are set to 1 by default and are automatically optimized in Sections 3.4 and 4.3.4. The similarity function returns a value in the interval [0, 1] with higher values signifying greater similarity.
Table 1. UrduPhone versus Soundex encodings

3.3 Features
The similarity function in Equation (1) is instantiated with features representing each word. In this work, we use three features: phonetic, string, and contextual, which are computed based on rules or based on learning.
Table 2. UrduPhone homophone mappings in Roman Urdu
3.3.1 UrduPhone
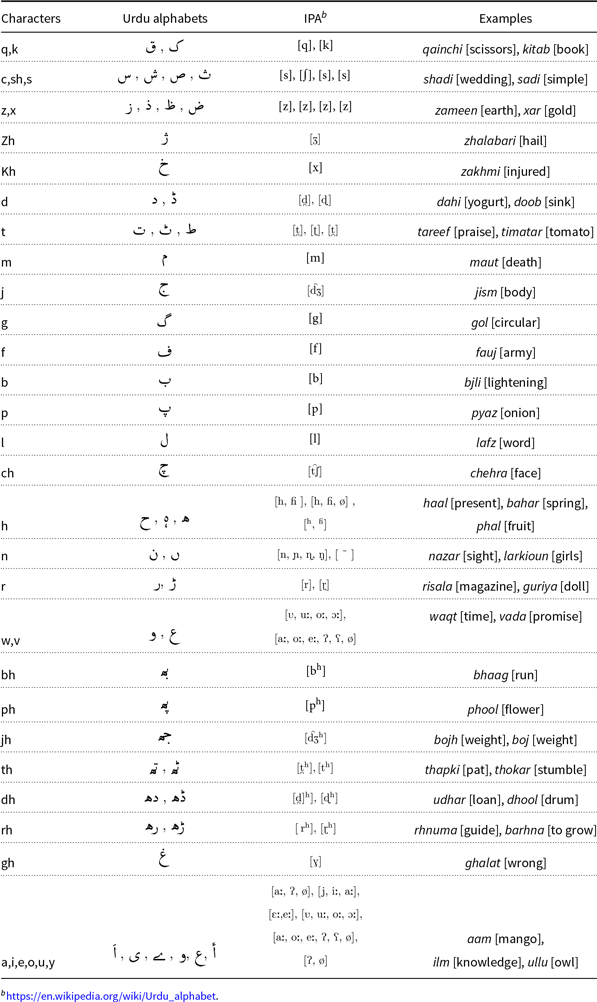
We propose a new phonetic encoding scheme, UrduPhone, tailored for Roman Urdu. Derived from Soundex (Knuth 1976; Hall and Dowling 1980), UrduPhone encodes consonants using similar sounds in Urdu and English. UrduPhone differs from Soundex in two ways:
-
(1) UrduPhone’s encoding of words contains six characters as opposed to four in Soundex. An increase in encoding length reduces the possibility of mapping semantically different words to one form. Soundex maps different words to a single encoding, which, due to the limited encoding length, can cause errors when trying to find correct lexical variations. See Table 1 for some examples of the differences. For example, mustaqbil [future] and mustaqil [constant] encode to one form, MSTQ, in Soundex but to two different forms using UrduPhone encoding. In a limited number of cases, UrduPhone increases ambiguity by mapping lexical variations of the same word into different encodings, as in the case of please and plx. Since these words share a similar context, these variations will map to one cluster with the addition of contextual information. This is also shown during our experiments.
-
(2) We introduce homophone-based groups, which are mapped differently in Soundex. There are several Urdu characters, which map to the same Roman form. For example, samar [reward], sabar [patience], and saib [apple], all start with different Urdu characters that have an identical Roman representation: s. We group together homophones such as w, v as in taweez, taveez [amulet] and z, x as in lolz, lolxx [laughter] or zara, xara [a bit]. One common characteristic with transliteration from Urdu to Roman script is the omission of the Roman character “h”. For example, the same Urdu word maps to both the Roman words samajh and samaj [to understand]. This is especially true in the case of digraphs representing Urdu aspirates such as dh, ph, th, rh, bh, jh, gh, zh, ch, and kh. A problem arises when the longest common subsequence in words (if “h” is omitted) causes overlaps such as (khabar [news], kabar [grave]) and (gari [car], ghari [watch]). Also, when sh comes at the end of a word, as in khawhish, khawhis [wish]; when “h” is omitted, the sound is mapped to the character s. Similarly, if there is a transcription error, such as dushman [enemy] becomes dusman, the UrduPhone encoding is identical. Here, the omission of “h” causes an overlap of the characters
 and .
and .

Algorithm 2 UrduPhone
The second column of Table 1 shows a few examples of Soundex encodings of Roman Urdu words. In some cases, Soundex maps two semantically different words to one code, which is undesirable in the task of lexical normalization. Table 2 shows a complete list of homophone-based mapping introduced in UrduPhone, and Algorithm 2 shows the process to encode a word into an UrduPhone encoding. Then, we compute the phonetic similarity of words
 $w_i$
and
$w_i$
and
 $w_j$
using Equation (2).
$w_j$
using Equation (2).
 \begin{align} \sigma_{ij}^{P} = \begin{cases} 1 & \text{if } UrduPhone(w_i)==UrduPhone(w_j) \\ 0 & \text{otherwise} \end{cases} \end{align}
\begin{align} \sigma_{ij}^{P} = \begin{cases} 1 & \text{if } UrduPhone(w_i)==UrduPhone(w_j) \\ 0 & \text{otherwise} \end{cases} \end{align}
3.3.2 Learning string similarity
The lexical variations of a word may have a number of overlapping subword units, for example, spelling variations of zindagi [life] include zindagee, zindagy, zaindagee, and zndagi with many overlapping subword units. To benefit from this overlap, we define a string similarity function as follows:
 \begin{equation}\sigma_{ij}^{S} = \frac{\mathit{lcs}(w_i, w_j) } {\min[\mathit{len}(w_i), \mathit{len}(w_j)] + \mathit{edist}(w_i, w_j)}\end{equation}
\begin{equation}\sigma_{ij}^{S} = \frac{\mathit{lcs}(w_i, w_j) } {\min[\mathit{len}(w_i), \mathit{len}(w_j)] + \mathit{edist}(w_i, w_j)}\end{equation}
Here,
 $\mathit{lcs}(w_i, w_j)$
is the length of the longest common subsequence in words
$\mathit{lcs}(w_i, w_j)$
is the length of the longest common subsequence in words
 $w_i$
and
$w_i$
and
 $w_j$
,
$w_j$
,
 $\mathit{len}(w_i)$
is the length of word
$\mathit{len}(w_i)$
is the length of word
 $w_i$
, and
$w_i$
, and
 $\mathit{edist}(w_i, w_j)$
is the edit distance between words
$\mathit{edist}(w_i, w_j)$
is the edit distance between words
 $w_i$
and
$w_i$
and
 $w_j$
.
$w_j$
.
Edit distance: The edit distance allows insertion, deletion, and substitution operations. We obtain the cost of edit distance operations in two ways:
Manually defined—In a naive approach, we consider the cost of every operation to be equal and set them to 1. We refer to this edit distance cost as edist
 $_{man}$
. This technique has a downside of considering all operations equally necessary, which is an erroneous assumption. For example, the substitution cost of a Roman character “a” to “e” should be less than the cost of “a” to “z” because both “a” and “ e” have related sounds in some contexts. It is possible to use these characters alternatively when transliterating from Perso-Arabic script to Roman Script.
$_{man}$
. This technique has a downside of considering all operations equally necessary, which is an erroneous assumption. For example, the substitution cost of a Roman character “a” to “e” should be less than the cost of “a” to “z” because both “a” and “ e” have related sounds in some contexts. It is possible to use these characters alternatively when transliterating from Perso-Arabic script to Roman Script.
Automatically learning edit distance cost—In this approach, we automatically learn the edit distance cost from the data. Consider a list of word pairs where one word is a lexical variation of another word. One can automatically learn the character alignments between them using an EM algorithm. The inverse character alignment probability serves as the cost for the edit distance operations.
In our case, we do not have a cleaned list of word pairs to learn character alignments automatically. Instead, we try to learn these character alignments from the noisy training data. To do this, we build a list of candidate word pairs by aligning every word to every other word in the corpus as a possible lexical variation. We split the words into characters and run the word-aligner GIZA++ (Och and Ney Reference Och and Ney2003). Here, the word-aligner considers every character as a word and every word as a sentence. We use the learned character alignments with one minus their probability as the cost for the edit distance function. We refer to this edit distance cost as edist
 $_{giza}$
.
$_{giza}$
.
Since the model learns the cost from the noisy data, likely, it is not a good representative of the accurate edit distance cost that would be learned from the cleaned data. In our alternative method, we automatically refine the list of candidate pairs and learn character alignments from it. In this approach, we consider the problem of lexical variations as a transliteration mining problem (Sajjad et al. 2011), where, given a list of candidate word pairs, the algorithm automatically extracts word pairs that are transliterations of each other. For this purpose, we use the unsupervised transliteration mining model of Sajjad et al. (2017), who define the modelFootnote c as a mixture of a transliteration submodel and a non-transliteration submodel. The transliteration submodel generates the source and target character sequences jointly and can model the dependencies between them. The non-transliteration model consists of two monolingual character sequence models that generate source and target strings independently of each other. The parameters of the transliteration submodel are uniformly initialized and then learned during EM training of the complete interpolated model. During the training process, the model penalizes character alignments that are less likely to be part of a transliteration pair and favors character alignments that are likely to be part of a transliteration pair.
We train the unsupervised transliteration miner on our candidate list of word pairs, similar to the GIZA++ training. Then, we learn the character alignments. We then use these character alignments with one minus their probability as the cost for the edit distance metric. We refer to this cost as edist
 $_{miner}$
.
$_{miner}$
.
3.3.3 Context information
We observe that nonstandard variants of a standard word have similar contexts. For example, truck and truk will be used in similar contexts, which might be very different from cat. We used this idea to define a contextual similarity measure between two words. We compare the top-k frequently occurring preceding (previous) and following (next) words’ features of the two words in the corpus. The previous and next word’s features can be each word’s ID, UrduPhone ID, or cluster/group ID (based on initial clustering of the words).
Let
 $a_1^i, a_2^i, \ldots, a_5^i$
and
$a_1^i, a_2^i, \ldots, a_5^i$
and
 $a_1^j, a_2^j, \ldots, a_5^j$
be the features (word IDs, UrduPhone IDs, or cluster IDs) for the top-5 frequently occurring words preceding word
$a_1^j, a_2^j, \ldots, a_5^j$
be the features (word IDs, UrduPhone IDs, or cluster IDs) for the top-5 frequently occurring words preceding word
 $w_i$
and
$w_i$
and
 $w_j$
, respectively. We use the similarity between the two words based on this context as defined by Hassan et al. (2009):
$w_j$
, respectively. We use the similarity between the two words based on this context as defined by Hassan et al. (2009):
 \begin{equation}\sigma_{ij}^{C} = \frac{\sum_{k=1}^5 \rho_k} {\sum_{k=1}^5 k}\end{equation}
\begin{equation}\sigma_{ij}^{C} = \frac{\sum_{k=1}^5 \rho_k} {\sum_{k=1}^5 k}\end{equation}
Here,
 $\rho_k$
is zero for any
$\rho_k$
is zero for any
 $a_k^i$
(i.e., the kth word in the context of
$a_k^i$
(i.e., the kth word in the context of
 $w_i$
) when there exists no match in
$w_i$
) when there exists no match in
 $a_*^j$
(i.e., in the context of word
$a_*^j$
(i.e., in the context of word
 $w_j$
). Otherwise,
$w_j$
). Otherwise,
 $\rho_k = 5 - \max[k, l] -1$
where
$\rho_k = 5 - \max[k, l] -1$
where
 $a_k^i = a_l^j$
and l is the highest rank (smallest integer) at which a previous match has not occurred. In other words, this measure is the normalized sum of rank-based weights for matches in the two sequences, with more importance given to those occurring in higher ranks. Note that contextual similarity can be computed even if the context sizes of the two words are different, an essential step as a word may not have five distinct words preceding it in the corpus.
$a_k^i = a_l^j$
and l is the highest rank (smallest integer) at which a previous match has not occurred. In other words, this measure is the normalized sum of rank-based weights for matches in the two sequences, with more importance given to those occurring in higher ranks. Note that contextual similarity can be computed even if the context sizes of the two words are different, an essential step as a word may not have five distinct words preceding it in the corpus.
We combine all the features using our similarity measure from Equation (1). The code for combining a set of features is in Algorithm 3.

Algorithm 3 Similarity measure with weighted feature combination
3.4 Parameter optimization
The feature weights
 $\alpha^{(f)}$
used to measure word similarity in Equation (1) can be tuned to optimize prediction accuracy. For example, by changing the weights in our clustering framework (see Equation (1)), we can make contextual similarity more prominent (by increasing the weight
$\alpha^{(f)}$
used to measure word similarity in Equation (1) can be tuned to optimize prediction accuracy. For example, by changing the weights in our clustering framework (see Equation (1)), we can make contextual similarity more prominent (by increasing the weight
 $\alpha^{C}$
) so that words with the same UrduPhone encoding but different contexts are placed in separate clusters (see discussion in Section 4.4). But, we also test with other weight combinations and features, including using both word IDs and UrduPhone IDs to represent the top-5 most frequently occurring previous and next words (rather than just one representation as used in other experiments). We identify corresponding weights for contexts based on word IDs and UrduPhone IDs as
$\alpha^{C}$
) so that words with the same UrduPhone encoding but different contexts are placed in separate clusters (see discussion in Section 4.4). But, we also test with other weight combinations and features, including using both word IDs and UrduPhone IDs to represent the top-5 most frequently occurring previous and next words (rather than just one representation as used in other experiments). We identify corresponding weights for contexts based on word IDs and UrduPhone IDs as
 $\alpha^{C_1}$
and
$\alpha^{C_1}$
and
 $\alpha^{C_2}$
, respectively. The weights for the phonetic and the string features are
$\alpha^{C_2}$
, respectively. The weights for the phonetic and the string features are
 $\alpha^{P}$
and
$\alpha^{P}$
and
 $\alpha^{S}$
, respectively.
$\alpha^{S}$
, respectively.
We also optimize n variables to maximize an objective function using the Nelder–Mead method (Nelder and Mead 1965). We use the Nelder–Mead method to maximize the F-measure by optimizing the feature weights of our similarity function in Equation (1), as well as the hyperparameter, threshold t, in line 21 of Algorithm 1. We apply 10-fold cross-validation on the SMS (small) dataset (Table 9). We will describe the results in Section 4.3.4.
4. Experiments
In this section, we first describe our evaluation setup and the datasets used for the experiments. Later, we present the results.
4.1 Evaluation criteria
Since the lexical normalization of Roman Urdu is equivalent to a clustering task, we can adopt measures for evaluating clustering performance. We need a gold standard database defining the correct groupings of words for evaluation. This database contains groups of words such that all words in a given group are considered lexical variations of a lexical entry. In clustering terminology, words within a cluster are more similar than words across clusters. On the other hand, we typically use the accuracy (i.e., the proportion of OOV words that correctly match IV words) to evaluate the lexical normalization of a standardized language like English. This measure is appropriate because we know the IV words and can be compared to every OOV word.
Bagga and Baldwin (1998) discussed measures for evaluating clustering performance and recommend the use of BCubed precision, recall, and F-measure. These measures possess all four desirable characteristics for clustering evaluation (homogeneity, completeness, rag bag, and cluster size vs. the number of clusters—see Vilain et al. 1995 for details). In the context of the lexical normalization of nonstandard languages, they provide the additional benefit that they are computed for each word separately and then averaged for all words. For example, if a cluster contains all variants of a word and nothing else, then it is considered homogeneous and complete, and this is reflected in its performance measures. These measures are robust in the sense that incorporating small impurities in an otherwise pure cluster impacts the measures significantly (rag bag characteristic), and the trade-off between cluster size and the number of clusters is reflected appropriately. Other clustering evaluation measures do not possess all these characteristics and, in particular, commonly used measures like entropy and purity are not based on individual words.
Let
 $\mathcal{L} = \{\ell_{1},\cdots ,\ell_{K}\}$
be the set of output clusters and
$\mathcal{L} = \{\ell_{1},\cdots ,\ell_{K}\}$
be the set of output clusters and
 $\mathcal{L}^{\prime} = \{\ell_{1}^{\prime},\cdots ,\ell_{K}^\prime\}$
be the set of actual or correct clusters in the gold standard. We define correctness for word pair
$\mathcal{L}^{\prime} = \{\ell_{1}^{\prime},\cdots ,\ell_{K}^\prime\}$
be the set of actual or correct clusters in the gold standard. We define correctness for word pair
 $w_i$
and
$w_i$
and
 $w_j$
as
$w_j$
as
 \begin{equation}C(w_i,w_j) =\begin{cases}1 & \text{iff}(w_i \in \ell_m, w_j \in \ell_m)\text{ and }(w_i \in \ell_n^\prime, w_j \in \ell_n^\prime) \\0 & \text{otherwise}\end{cases}\end{equation}
\begin{equation}C(w_i,w_j) =\begin{cases}1 & \text{iff}(w_i \in \ell_m, w_j \in \ell_m)\text{ and }(w_i \in \ell_n^\prime, w_j \in \ell_n^\prime) \\0 & \text{otherwise}\end{cases}\end{equation}
In other words,
 $C(w_i, w_j)=1$
when words
$C(w_i, w_j)=1$
when words
 $w_i$
and
$w_i$
and
 $w_j$
appear in the same cluster (
$w_j$
appear in the same cluster (
 $\ell_m$
) of the clustering and the same cluster (
$\ell_m$
) of the clustering and the same cluster (
 $\ell_n^\prime$
) of the gold standard; otherwise,
$\ell_n^\prime$
) of the gold standard; otherwise,
 $C(w_i, w_j)=0$
. By definition,
$C(w_i, w_j)=0$
. By definition,
 $C(w_i, w_i)=1$
.
$C(w_i, w_i)=1$
.
The following expressions give the BCubed precision
 $P(w_i)$
and recall
$P(w_i)$
and recall
 $R(w_i)$
for a word
$R(w_i)$
for a word
 $w_i$
:
$w_i$
:
 \begin{equation}P(w_i) =\frac{\sum_{j=1}^{N} C(w_i,w_j) }{\left\vert{\ell_m}\right\vert}\end{equation}
\begin{equation}P(w_i) =\frac{\sum_{j=1}^{N} C(w_i,w_j) }{\left\vert{\ell_m}\right\vert}\end{equation}
 \begin{equation}R(w_i) =\frac{\sum_{j=1}^{N} C(w_i,w_j) }{\left\vert{\ell^\prime_m}\right\vert}\end{equation}
\begin{equation}R(w_i) =\frac{\sum_{j=1}^{N} C(w_i,w_j) }{\left\vert{\ell^\prime_m}\right\vert}\end{equation}
Here,
 $\ell_m$
and
$\ell_m$
and
 $\ell_m^\prime$
identify the cluster in the clustering and gold standard, respectively, that contain word
$\ell_m^\prime$
identify the cluster in the clustering and gold standard, respectively, that contain word
 $w_i$
. The summation for Equations (6) and (7) is over all the words j. Finally, we define the BCubed F-measure
$w_i$
. The summation for Equations (6) and (7) is over all the words j. Finally, we define the BCubed F-measure
 $F(w_i)$
of word
$F(w_i)$
of word
 $w_i$
in the usual manner as:
$w_i$
in the usual manner as:
 \begin{equation}F(w_i) = 2\times \frac{P(w_i)\times R(w_i)}{P(w_i)+R(w_i)}\end{equation}
\begin{equation}F(w_i) = 2\times \frac{P(w_i)\times R(w_i)}{P(w_i)+R(w_i)}\end{equation}
We compute the overall BCubed precision, recall, and F-measure of the clustering as the average of the respective values for each word. For example, we calculate the F-measure of the clustering as
 $\frac{\sum_{i=1}^N F(w_i)}{N}$
.
$\frac{\sum_{i=1}^N F(w_i)}{N}$
.
4.2 Datasets
We utilize four datasets in our experimental evaluation. The first and second datasets, SMS (small) and SMS (large), are obtained from Chopaal, an internet-based group SMS service.Footnote d These two versions are from two different time periods and do not overlap. The third dataset, Citizen Feedback Monitoring Program (CFMP) dataset, is a collection of SMS messages sent by citizens as feedback on the quality of government services (e.g., healthcare facilities, property registration).Footnote e The fourth dataset, Web dataset, is scraped from Roman Urdu websites on news,Footnote f poetry,Footnote g SMS,Footnote h and blogs.Footnote i Unless mentioned otherwise, the SMS (small) dataset is used for the experiment. All four datasets are preprocessed with the following steps: (1) remove single-word sentences; (2) add tags to URLs, email addresses, time, year, and numbers with at least four digits; (3) collapse more than two repeating groups to only two (e.g., hahahaha to haha); (4) replace punctuations with space; (5) replace multiple spaces with single space. For the SMS (small) and SMS (large) datasets, we carry out an additional step of removing group messaging commands.
We evaluate the performance of our framework against a manually annotated database of Roman Urdu variations developed by Khan and Karim (2012). This database, which we refer to as the “gold standard”, is developed from a sample of the SMS (small) dataset. It maps each word to a unique ID representing its standard or normal form. There are 61,000 distinct variations in the database, which map onto 22,700 unique IDs. The number of variations differs widely for different unique IDs. For example, mahabbat [love] has over 70 variations, such as muhabaat, muhabbat, and mhbt. The gold standard database also includes variations of English language words that are present in the dataset.
Table 3 shows statistics of the datasets in comparison with the evaluation gold standard database. The “Overlap with Gold Standard” means the number of words in the vocabulary of a dataset that also appear in the gold standard lexicon Khan and Karim (2012). The table also gives the number of words that appear in the gold standard and have at least (1) one preceding and at least one following word (context size
 $\geq$
1) and (2) five distinct preceding and following words in the dataset (context size
$\geq$
1) and (2) five distinct preceding and following words in the dataset (context size
 $\geq$
5). We evaluate these numbers of words for the respective datasets. The UrduPhone IDs of a dataset gives the number of distinct encodings of the evaluation words in the dataset (corresponding to the number of initial clusters).
$\geq$
5). We evaluate these numbers of words for the respective datasets. The UrduPhone IDs of a dataset gives the number of distinct encodings of the evaluation words in the dataset (corresponding to the number of initial clusters).
Table 3. Datasets and gold standard database statistics

Table 4. Details of experiments’ settings

4.3 Experimental results and analysis
We conduct different experiments to evaluate the performance of our clustering framework for lexical normalization of Roman Urdu. We test different combinations of features (UrduPhone, string, and/or, context) and different representations of contextual information (UrduPhone IDs or word IDs). We also establish two baseline methods for comparisons.
Table 4 gives the details of each experiment’s setting. Exps. 1 and 2 are baselines corresponding to segmentation using UrduPhone encoding and string similarity-based clustering (with initial random clusters equal to the number of UrduPhone segments), respectively. The remaining experiments utilize different combinations of features (string, phonetic, and context) in our clustering framework. Here, for string-based features, we used manually defined edit distance rules.Footnote j The initial clustering in these experiments is given by segmentation via UrduPhone encoding. In Exp. 3 no contextual information is utilized, while in Exp. 4 and Exp. 5 the context is defined by the top-5 most frequently occurring previous and next words (context size
 $\geq$
5) represented by their UrduPhone IDs and word IDs, respectively. In Exps. 2–5, we select the similarity threshold t such that the number of discovered clusters is as close as possible to the number of actual clusters in the gold standard for each dataset. This is done to make the results comparable across different settings. During our experiments, we observed that a threshold within a range of 0.25–0.3 was optimal for smaller datasets, including Web and CFMP, and 0.4–0.45 gave the best performance for larger datasets, including SMS (small) and SMS (large). However, we also tried to find the optimum threshold value using the Nelder–Mead method (see Table 9), which maximizes the F-measure.
$\geq$
5) represented by their UrduPhone IDs and word IDs, respectively. In Exps. 2–5, we select the similarity threshold t such that the number of discovered clusters is as close as possible to the number of actual clusters in the gold standard for each dataset. This is done to make the results comparable across different settings. During our experiments, we observed that a threshold within a range of 0.25–0.3 was optimal for smaller datasets, including Web and CFMP, and 0.4–0.45 gave the best performance for larger datasets, including SMS (small) and SMS (large). However, we also tried to find the optimum threshold value using the Nelder–Mead method (see Table 9), which maximizes the F-measure.
Figure 3(a), (b), (c), and (d) show performance results on SMS (small), SMS (large), CFMP, and Web datasets, respectively. The x-axes in these figures show the experiment IDs from Table 4, while the left y-axes give the BCubed precision, recall, and F-measure, and the right y-axes describe the difference between the number of predicted and actual clusters.

Figure 3. Performance results for experiments in Table 4. (a) SMS (small) dataset. (b) SMS (large) dataset. (c) CFMP dataset. (d) Web dataset.
The baseline experiment of segmentation via UrduPhone encoding (Exp. 1) produces a high recall and a low precision value. This is because UrduPhone tends to group more words in a single cluster, which decreases the total number of clusters and results in an overall low F-measure. The second baseline of string-based clustering (Exp. 2) gives similar values for precision and recall since the average number of clusters is closer to that of the gold standard. Although the F-measure increases over Exp. 1, string-based similarity alone does not result in sound clustering.
Combining the string and phonetic features in our clustering framework (Exp. 3) results in an increase in precision and recall values as well as a marked increase in F-measure from the baselines (e.g., there is an increase of 9% for the SMS (small) dataset, see Figure 3(a)). When contextual information is added (via UrduPhone IDs in Exp. 4 and word IDs in Exp. 5), precision, recall, and F-measure values increase further. For example, for the SMS (small) dataset, the F-measure increases from 77.4% to 79.7% (2% gain) and from 77.4% to 80.3% (3% gain) from Exp. 3 to Exp. 4, and Exp. 5, respectively.
The higher performance values obtained for the CFMP and Web datasets (Figure 3(c) and (d)) are due to fewer variations in these datasets, as evidenced by their fewer numbers of unique words in comparison to the SMS datasets.
Overall, our clustering framework using string, phonetic, and contextual features shows a significant F-measure gain when compared to baselines Exps. 1 and 2. We obtain the best performances when we use UrduPhone and string similarity, and when the context is defined using word IDs (Exp. 5).
4.3.1 UrduPhone
We compare UrduPhone with Soundex and its variantsFootnote k for lexical normalization of Roman Urdu. All the phonetic encoding algorithms are used to group/segment words based on their encoding and then evaluated against the gold standard. Table 5 shows the results of this experiment on the SMS (small) dataset.
We observe that UrduPhone outperforms Soundex, Caverphone, and Metaphone, while NYSIIS’s F-measure is comparable to that of UrduPhone. NYSIIS produces a large number of single-word clusters (4376 have only 1 word out of 6550 groups), which negatively impacts its recall. UrduPhone produces fewer clusters (and fewer one-word clusters), giving high recall. This property of UrduPhone is desirable for initial clustering in our clustering framework, as Lex-Var can split them but cannot collapse them. The bold values in Tables 5 and 8 are the best results for the corresponding columns.
We also test our clustering framework by replacing UrduPhone with NYSIIS as the phonetic algorithm. In Exp. 5 on the SMS (small) dataset, we find that the F-measure increases by only 5% over the NYSIIS baseline (Table 5), which is lower than the F-measure achieved with UrduPhone (Figure 3(a)).
Table 5. Comparison of UrduPhone with other algorithms on the SMS (small) dataset. Single clusters are clusters with one word only. Actual clusters = 7589

In another experiment, we analyze the effect of encoding length on the performance of the algorithm. We use the SMS (small) dataset to generate UrduPhone encodings of different sizes and cluster the words accordingly. Figure 4 summarizes the results. We see an increase in F-measure with an increase in encoding length until length seven and eight, where we achieve similar performance.
Table 2 defines the UrduPhone rules based on well-known techniques used for phonetic encoding schemes (dropping vowels) and on common knowledge of how people write Roman Urdu. As an additional experiment, we try to learn these rules from some datasets and use them to define our encoding scheme. We call this approach UrduPhone
 $_{prob}$
. Jiampojamarn et al. (2007) propose an alignment toolFootnote l based on the initial work of Ristad and Yianilos (1998). Instead of mapping each grapheme to a single phoneme, their method creates a many-to-many mapping. We use an Urdu script, and Roman Urdu transliteration parallel corpus scraped from the internet.Footnote m Unlike the Roman Urdu words in our experiment dataset, these have more standardized spellings. We use a maximum length of two as a parameter for training the model. Our output is probabilities of Roman Urdu characters mapping to Urdu script characters or to null.
$_{prob}$
. Jiampojamarn et al. (2007) propose an alignment toolFootnote l based on the initial work of Ristad and Yianilos (1998). Instead of mapping each grapheme to a single phoneme, their method creates a many-to-many mapping. We use an Urdu script, and Roman Urdu transliteration parallel corpus scraped from the internet.Footnote m Unlike the Roman Urdu words in our experiment dataset, these have more standardized spellings. We use a maximum length of two as a parameter for training the model. Our output is probabilities of Roman Urdu characters mapping to Urdu script characters or to null.
We use the maximum probability mapping rules to define our UrduPhone
 $_{prob}$
encodings. We experimented with using UrduPhone
$_{prob}$
encodings. We experimented with using UrduPhone
 $_{prob}$
as the feature in our system and also in combination with other string and context features. Table 6 shows the results.
$_{prob}$
as the feature in our system and also in combination with other string and context features. Table 6 shows the results.
Table 6. Experiments using UrduPhone, learning rules from Urdu-Roman Urdu transliteration corpus


Figure 4. Effect of varying UrduPhone encoding length on SMS (small) dataset (Exp 5).
4.3.2 String similarity
In Section 3.3.2, using the SMS (small) dataset, we compare the performance of three methods used to calculate edit distance cost—manually defined (edist
 $_{man}$
), automatically learned using GIZA++ (edist
$_{man}$
), automatically learned using GIZA++ (edist
 $_{giza}$
), and automatically learned using unsupervised transliteration mining (edist
$_{giza}$
), and automatically learned using unsupervised transliteration mining (edist
 $_{miner}$
).Footnote n
$_{miner}$
).Footnote n
For each word in our vocabulary, we found the 100 closest pairs, where closeness is defined by our similarity function as described in Equation (1) using UrduPhone, edist
 $_{man}$
for the string similarity, and context of previous and next word IDs as the feature set. We created a list of candidate word pairs by pairing every word with every other word in the cluster of 100 closest words. We take each Roman Urdu word as a sequence of Roman characters and its original Urdu script as a sequence of Urdu characters. We learn the alignment between the above two character sequences in two different ways. First, we apply GIZA++ and learn the alignment with the EM algorithm. Second, we implemented an unsupervised transliteration mining tool, details see Sajjad et al. (2017). Here, GIZA++ considers every word pair in the list of candidate pairs as a correct word pair to learn character alignments, whereas the transliteration mining tool penalizes the pairs that are less likely to be transliterations of each other during the training process. Since our list of candidate pairs is a mix of correct and incorrect pairs, the character alignments learned by the transliteration miner are likely to be better. The edit distance cost for each pair of characters can be computed from character alignments as
$_{man}$
for the string similarity, and context of previous and next word IDs as the feature set. We created a list of candidate word pairs by pairing every word with every other word in the cluster of 100 closest words. We take each Roman Urdu word as a sequence of Roman characters and its original Urdu script as a sequence of Urdu characters. We learn the alignment between the above two character sequences in two different ways. First, we apply GIZA++ and learn the alignment with the EM algorithm. Second, we implemented an unsupervised transliteration mining tool, details see Sajjad et al. (2017). Here, GIZA++ considers every word pair in the list of candidate pairs as a correct word pair to learn character alignments, whereas the transliteration mining tool penalizes the pairs that are less likely to be transliterations of each other during the training process. Since our list of candidate pairs is a mix of correct and incorrect pairs, the character alignments learned by the transliteration miner are likely to be better. The edit distance cost for each pair of characters can be computed from character alignments as
 $cost(char_i,char_j) = |1-P(char_i,char_j)|$
. Our string similarity function uses these edit distance costs instead of manually defined costs. Table 7 reports the results for both of these experiments using the SMS (small) dataset. The F-measure of the cost learned by the miner and GIZA++ is competitive with the manually defined cost. edist
$cost(char_i,char_j) = |1-P(char_i,char_j)|$
. Our string similarity function uses these edit distance costs instead of manually defined costs. Table 7 reports the results for both of these experiments using the SMS (small) dataset. The F-measure of the cost learned by the miner and GIZA++ is competitive with the manually defined cost. edist
 $_{giza}$
is affected by the noise in the data, which can be seen in its low precision compared to other methods. edist
$_{giza}$
is affected by the noise in the data, which can be seen in its low precision compared to other methods. edist
 $_{miner}$
achieved the highest precision, though it has the lowest recall.
$_{miner}$
achieved the highest precision, though it has the lowest recall.
Table 7. Varying edit distance cost for SMS (small) dataset. Learning character pair alignment probabilities

4.3.3 Context size
The experiments presented in the previous section used a context of top-5 frequently occurring previous and next words. Here, we study the effect of varying context size on the performance of our clustering framework. Table 8 shows the F-measure for all experiments with two different context sizes on the SMS (small) dataset. Decreasing the minimum context list size to 1 increases the number of words to evaluate; therefore, results are reported for all experiments with context size between 1 and 5, even though Exps. 1–3 do not use contextual information. Decreasing the minimum context list size to 1 also explains the lower performance values for these experiments as compared to those with context size of at least 5.
We see that context size of 1–5 (including words with contexts defined by at least 1–5 top previous/next words) is less effective in lexical normalization and sometimes even negatively impacts performance. For example, for the SMS (small) and CFMP datasets, Exp. 3 (no contextual information) performs better than Exp. 4 and Exp. 5 due to the noisy nature of shorter contexts.
For further analysis, we carried out experiments where we changed the context length from 1 to 5; an approach that differs from the previous experiments in which we used context size
 $=5$
and
$=5$
and
 $\geq 1$
. Figure 5 describes the results of the tests carried out on the SMS (small) dataset. We see a significant increase in performance when context size changes from 2 to 3. After 3, there is a slight performance increase. The best F-measure is from a context size of 4 and 5.
$\geq 1$
. Figure 5 describes the results of the tests carried out on the SMS (small) dataset. We see a significant increase in performance when context size changes from 2 to 3. After 3, there is a slight performance increase. The best F-measure is from a context size of 4 and 5.
Table 8. Performance (F-measure) with two different context sizes. Details of the experiments are given in Table 4

Table 9. Performance with different weights for features (Exp. 5 on SMS (small) dataset).
 $\alpha^P$
= weight of phonetic feature,
$\alpha^P$
= weight of phonetic feature,
 $\alpha^S$
= weight of string feature,
$\alpha^S$
= weight of string feature,
 $\alpha^{C_1}$
= weight of context using word ID,
$\alpha^{C_1}$
= weight of context using word ID,
 $\alpha^{C_2}$
= weight of context using UrduPhone ID
$\alpha^{C_2}$
= weight of context using UrduPhone ID


Figure 5. Effect of varying context size on SMS (small) dataset (Exp. 5).
4.3.4 Parameters: Feature weights and clustering threshold
Feature weights As discussed in Section 3.4, we test the impact of changing the weights in our clustering framework (see Equation (1)). We assumed that all features have equal weights in experiments presented in Section 4.3. Then, we change the feature weights to emphasize different features. The increased weights caused words to break their initial UrduPhone clusters in favor of better contextual similarity, but the overall performance did not change. We tried several combinations, including using both the contexts (i.e., word IDs and UrduPhone IDs).
Table 9 shows the performance of our clustering framework on the SMS (small) dataset with different feature weight combinations. As a comparison, we show results for Exp. 5 (context represented by word IDs only) and have the following observations with respect to F-Measure. (1) F-measure does not improve when using both word IDs and UrduPhone IDs to represent the context. (2) F-measure degrades when removing the phonetic similarity feature. (3) F-measure achieves the highest value when we set a higher weight to phonetic and contextual similarity than to string similarity.
We also use the Nelder–Mead method to maximize the F-measure by optimizing the feature weights of our similarity function in Equation (1), as well as the threshold mentioned in line 21 of Algorithm 1 on cross-validation set (see Section 3.4). The average F-measure is slightly better than what we observed with manual selection of weights in Exp. 5 (described in Table 4).
Clustering threshold We analyze the performance of Exp. 5 (best setting) for the SMS (small) dataset with varying threshold t (Figure 6). The value of t controls the number of clusters smoothly, and precision increases with this number while F-measure reaches a peak when the number of predicted groups is close to that of the gold standard.
4.3.5 Comparison with other clustering methods and variations
In addition to our k-medoids-based Lex-Var clustering method, we propose using agglomerative hierarchical clustering (Hierarchical Lex-Var) as our clustering framework for lexical normalization. To reduce the search complexity at each merge decision, we form (once) and search within the 10 most similar words for each word (neighborhood). At each merge decision, we merge the two most similar words and/or groups (if either word is part of a group) in their respective neighborhoods. Algorithm 4 describes the Hierarchical Lex-Var Clustering algorithm. We tested with a neighborhood size of 10 and 100. The results are mentioned in Table 10.

Algorithm 4 Hierarchical Lex-Var

Figure 6. Effect of varying threshold t on SMS (small) dataset (Exp. 5).
Hierarchical Lex-Var, when used instead of Lex-Var, results in slightly better performance. However, it is significantly slower than Lex-Var. Even with our neighborhood-based optimization, hierarchical clustering takes hours to converge, while our Lex-Var algorithm converges in minutes when processing the SMS (small) dataset.

Algorithm 5 2-skip-1-gram
Table 10. Performance of Hierarchical Lex-Var on SMS (small) dataset

Additionally, we compare our clustering framework with other clustering methods as independent approaches. We also test with variations in similarity features of our clustering framework. We report the following experiments:
-
1. Rule-based transliteration: Each word in the vocabulary was transliterated based on the method by Ahmed (2009). The final words were mapped to an Urdu word dictionary of around 150,000 words.Footnote o Each Urdu word acted as a cluster label.
-
2. Brown clustering: Brown clustering is a hierarchical clustering method for grouping words based on their contextual usage in a corpus (Brown et al. 1992). We use this as an independent approach for the lexical normalization of Roman Urdu.
-
3. Word2Vec clustering: Word2Vec represents words appearing in a corpus by fixed-length vectors that capture their contextual usage in the corpus (Mikolov et al. 2013). The Word2Vec model is generated using the gensimFootnote p python package to learn vectors for each Roman word. For learning the word vectors, we used the minimum count of 5, dimension size of 100, and 10 iterations. Words are clustered using k-means clustering on word vectors, and we report the performance for lexical normalization of Roman Urdu.
-
4. 2-skip-1-grams: In our clustering framework for lexical normalization, we use the 2-skip-1-gram approach with Jaccard coefficient (Jin 2015) to compute string similarity (rather than our string similarity function (Equation (3))). Algorithm 5 shows the 2-skip-1-gram algorithm.
-
5. 2-skip-1-gram + string feature:We use both 2-skip-1-gram and our string similarity functions for computing string similarity in our clustering framework for lexical normalization
-
6. “h” omitted UrduPhone: We use a modified version of UrduPhone in our clustering framework for lexical normalization. The modified version discards aspirated characters in the encoding. For example, encoding for mujhay [me] becomes identical to that for mujay [me] to handle “h” omission.
-
7. Word2Vec vectors (50): We generate Word2Vec vectors of size 50. We use the cosine similarity of these vectors instead of the contextual similarity described in Equation (4).
-
8. Word2Vec vectors (100): We increase the size of Word2Vec vectors to 100.
-
9. Word2Vec words: Word2Vec vectors are used to find the 10 most similar words for each word. These neighboring words define the context of each word, and contextual similarity is computed using Equation (4). We use our clustering framework for lexical normalization.
-
10. Word IDs + Word2Vec words: We use two contextual features: top-5 frequently occurring previous/next words represented by word IDs (like in Exp. 5) and top-10 most-similar words according to Word2Vec (as above).
Table 11 summarizes the results. Exp. 1 is a rule-based lexical normalization method. Exps. 2 and 3 are independent clustering methods for lexical normalization. We also modify string features (Exps. 4 and 5), phonetic features (Exp. 6), and contextual features (Exps. 7, 8, 9, and 10), respectively, in our clustering framework.
Table 11. Performance of other clustering methods and variations in our framework on SMS (small) dataset

We can make the following observations from these experiments. (1) Rule-based transliteration performs slightly lower than our clustering method (2) Brown clustering and Word2Vec clustering are unsuitable for lexical normalization as evidenced by their poor performance. (3) Word2Vec-based context (either Word2Vec vectors or similar words) and 2-skip-1-gram-based string features do not outperform our context and string features. One possible reason for the low performance of Brown clustering and Word2Vec could be the small size of the training data. These algorithms require a huge amount of data to learn.
4.3.6 Lexical normalization of English text
To test the robustness of our dataset for other languages, we experimented with an English dataset provided by Derczynski et al. (2013) and used in the W-NUT 2015 task.Footnote q The gold standard we used is the lexical normalization dictionary provided by the University of Melbourne.Footnote r The dataset has more than 160,000 messages containing 60,000 unique words. After preprocessing (the same preprocessing steps as for the Roman Urdu datasets), we get a 2700 word-overlap with the gold standard. For the phonetic encoding, we tested with Soundex and UrduPhone.
Table 12 summarizes the results along with the best results for the Roman Urdu dataset from Table 4. We observe an F-measure of more than 90% with both encoding schemes, with UrduPhone performing better than Soundex. This difference in performance is presumably due to the extended encoding size in UrduPhone, which makes it possible to keep more information about the original word.
Table 12. Performance of Lex-Var on English dataset. We used Soundex and UrduPhone encodings as phonetic features

4.4 Error analysis
To gain a better understanding of our clustering framework, we analyze the output of different experiments with examples of correct and incorrect lexical normalization. While lexical normalization based on UrduPhone mappings (Exp. 1) is a good starting point for finding word variations, it produces some erroneous groupings. We summarize these groupings as follows:
-
1. Words that differ only in their vowels are in the same cluster:
-
• takiya [pillow], tikka [grilled meat], take
-
• khalish [pain], khuloos [sincerity]
-
• baatain [conversations], button
-
• doosra [another], desire
-
• separate, spirit, support
-
-
2. Same words having different consonants map to different groups:
-
• mujhse, mujse meaning [from me]
-
• kuto, kuton meaning [dogs]
-
• whose, whoze
-
• skool, school
-
-
3. Words whose abbreviations or short forms do not have the same UrduPhone mapping:
-
• government, govt
-
• private, pvt
-
• because, coz
-
• forward, fwd
-
Exps. 4 and 5 can separate words initially clustered incorrectly (group 1) (e.g., baatain [conversations] and button, spirit and support) due to contextual information and similarity differentiating the variations. Despite using phonetic variations in combination with contextual feature, we see incorrect clusterings in the two experiments. We can divide these inaccuracies into several groups.
-
1. Words that have different UrduPhone mappings but are in fact the same. These are not clustered in the final outcome.
-
• [mujy] and [mujhy] meaning [me]
-
• [oper] and [uper] meaning [up]
-
• [prob] and [problem]
-
• [mornin] and [morng]
-
• [number] and [numbers]
-
• [please] and [plx,plz]
-
-
2. Words that have the same UrduPhone mapping and are lexical variants but are not clustered in the same group:
-
• [tareeka] and [tareka] meaning [way]
-
• [zamaane] and [zamany] meaning [times]
-
• [msg] and [message]
-
• [morng] and [morning]
-
• [cmplete,complet,complete] and [cmplt]
-
-
3. Words that are different but have the same UrduPhone mapping and are clustered together:
-
• maalik [owner], malika [queen], malaika [angels]
-
• nishaan [vestige], nishana [target]
-
• tareka [way], tariq [a common name meaning “a night visitor”]
-
• what, white
-
• waiter, water
-
A closer look at the examples reveals that some words that have the same UrduPhone mapping and should cluster together are found in separate groups (group 2). This result is due to low context similarity between the words, which causes them not to group (e.g., tareeka and tareka meaning [way] have a contextual similarity of 0.23, even though they have the same UrduPhone mapping).
Another prominent issue is that words in separate clusters in UrduPhone remain separated in the output of Exps. 4 and 5 (groups 2 and 3). This observation highlights the point that our experiments do not perform well at handling abbreviations (e.g., prob and problem), plurals (e.g., number and numbers), and some phonetic substitutes (e.g., please and plx). Our framework separates Roman Urdu words that can be written with an additional consonant (e.g., mujy and mujhy meaning [me]). It also maps words that start with a different vowel (e.g., oper and uper meaning [up]).
To tackle the issue of low contextual similarity not overcoming the difference in UrduPhone mapping, we doubled the weight assigned to the context feature. This adjustment produces almost no change in overall performance when compared to standard (Exps. 4 and 5). However, this adjustment causes more words with different UrduPhone mappings to be clustered together, usually incorrectly:
-
• acha [okay], nahaya [bathe], sucha [truthful]
-
• maalom [know], manzor [approve]
-
• chalang [jump], thapar [slap]
-
• darzi [tailor], pathar [stone]
-
• azmaya [to try], sharminda [ashamed]
Furthermore, as the same UrduPhone mappings do not restrict the clusters, this variation produces interesting combinations. The words in the groups below, although not lexical variants of each other, have strong contextual similarity and sometimes can even be replaced (for the other) in the sentence.
-
• admi [man], larkay [boys], larki [girl]
-
• kufr [to unbelieve in God], shirk [to associate partners with God]
-
• shak [suspicion], yaqeen [certainty]
-
• loves, likes
-
• private, pvt
-
• cud, may, would
-
• tue, tuesday, wed
-
• blocked, kicked
-
• gov, government
5. Previous work
Normalization of informal text messages and tweets has been a research topic of interest (Sproat et al. 2001; Kaufmann and Kalita 2010; Clark and Araki 2011; Wei et al. 2011; Pinto et al. 2012; Ling et al. 2013; Sidarenka et al. 2013; Roy et al. 2013; Chrupała 2014; Desai and Narvekar 2015), with the vast majority of the work limited to English and other resource-rich languages. Our work focuses on Roman Urdu, an under-resourced language, that does not have a gold standard corpus with standard word forms. We restrict our task to finding lexical variations in informal text, a challenging problem because every word is a possible variation of every other word in the corpus. Additionally, the spelling variation problem of Roman Urdu inherits inconsistencies that occur due to the transliteration of Urdu words from Perso-Arabic script to Roman script. In our work, we model these inconsistencies separately and in combination with other features.
Researchers have used phonetic, string, and contextual knowledge to find lexical variations in informal text.Footnote s Pinto et al. (2012), Han et al. (2012), Zhang et al. (2015) used phonetic-based methods to find lexical variations.
Contractor et al. (2010) used string edit distance based on the longest common subsequence ratio and edit distance of Consonant Skeletons (Prochasson et al. 2007) of the IV–OOV words. Gouws et al. (2011) used a sizable English corpus to extract candidate lexical variations and rescore them based on lexical similarity. We also use lexical similarity as a feature in our clustering framework but do not have a reference to a Roman Urdu corpus with standard word forms. Jin (2015) also generated an OOV–IV list using the Jaccard index (Levandowsky and Winter 1971) between k-skip-n-grams of string s and standard word forms. As we do not have these in Roman Urdu, we consider every word as a possible lexical variation of every other word in the corpus. Similar to Jin (2015), we use k-skip-n-grams in our additional experiments and find that they perform slightly worse than our algorithm. Chrupała (2014) used conditional random field (Lafferty 2001) to learn the sequence of edits from labeled data.
Han et al. (2012) used word similarity and word context to enhance performance by initially extracting OOV–IV pairs using contextual similarity and then re-ranking them based on string and phonetic distances. In contrast, we define a similarity function that considers all three features together to find lexical variations of a word. Unlike previous approaches, we have a small corpus from which to extract contextually similar word pairs. Also, there is no standard Roman Urdu dictionary that can be used to annotate words as either IV or OOV. Li and Liu (2014) defined similarity measure as a combination of the longest common subsequence, term frequency, and inner product of word embeddings. We use the longest common subsequence as part of the string similarity feature. In our additional experiments, we test with a cosine similarity of word embeddings (Table 10). Li and Liu (2014) used a combination of string similarity and vector-based similarity to generate a candidate list, which was re-ranked using a character-level machine translation model (Pennell and Liu 2011) and Jazzy Spell Checker,Footnote t etc. Yang and Eisenstein (2013) used an unsupervised approach that learns string edit distance, lexical, and contextual features using a log-linear model and sequential Monte Carlo approximation.
Singh et al. (2018), Costa Bertaglia and Volpe Nunes (2016) used word embeddings to find similar standard and nonstandard words for text normalization. Chrupała (2014) used character-level neural text embeddings (Chrupała 2013) as added information from unlabeled data for better performance. Rangarajan Sridhar et al. (2014) used deep neural networks to learn distributed word representations. We experimented with word embeddings as a feature in our similarity measure in the supplementary experiments in Table 11.
Hassan and Menezes (2013) used a 5-gram language model to create a contextual similarity lattice and applied Markov random walk for lexicon generation. Their approach uses a linear combination of contextual feature and string similarity (longest common subsequence ratio and edit distance), which is very similar to our approach. However, unlike Hassan and Menezes (2013), we assume that every Roman Urdu word is a noisy word and thus cannot separate nodes of the graph into standard and nonstandard forms. Sproat and Jaitly (2017) used a recurrent neural network to normalize text. Pennell and Liu (2011), Li and Liu (2014) used a character-level machine translation system for the normalization task. Lusetti et al. (2018) used an encoder–decoder architecture where different levels of granularity were used for the target-side language model, for example, characters and words. Wang and Ng (2013) used a beam-search decoder with integrated normalization operations, such as missing word recovery and punctuation correction to normalize nonstandard words. Our work, however, is limited to grouping the lexical variations of Roman Urdu words. However, we do not have any labeled data or parallel data available to build such a translation system. Our proposed method is robust since it learns from user data, and it groups abbreviations and their complete forms together in one cluster.
Almeida et al. (2016) used a standard English dictionary and an informal English dictionary to normalize words to their root forms. In our case, we do not use a standard dictionary as one does not exist for Roman Urdu words. Ling et al. (2013) automatically learned normalization rules using a parallel corpus of informal text. Irvine et al. (2012) used manually prepared training data to build an automatic normalization system for the Roman Urdu script. Unlike Irvine et al. (2012), we propose an unsupervised approach, which does not require labeled data. Additionally, our approach to the Roman Urdu normalization problem does not require us to have a corresponding Urdu script form for each Roman word.
Phonetic encoding schemes There have been several sound-based encoding schemes used in the literature to group similar sounding words together. Here, we summarized a few of the schemes in the context of lexical normalization.
The Soundex algorithm (Knuth 1973; Hall and Dowling 1980) encodes the first letter and the following three consonants of a word with consonants having a similar place of articulation sharing the same code. The NYSIIS method (Taft 1970), designed by the New York Police for American names, employ more sophisticated encoding rules based on multi-character n-grams and relative vowel positioning. The Metaphone algorithm (Philips 1990), developed in 1990 as a Soundex variant, incorporates English pronunciation rules for phonetic encoding of words. Other, more recent variations include Caverphone (Wang 2009) and Double MetaphoneFootnote u; they include complex grammatical rules for phonetic encoding of words. The Double Metaphone algorithm also differs from others in that it generates up to two encodings for each word—one reflects the basic version of the word’s pronunciation, and the other reflects an alternative pronunciation based on other languages. This is particularly useful when comparing foreign names with their anglicized versions. For example, the names Catherine and Katrina have a common code KTRN. Previous algorithms like Metaphone and Soundex do not provide such a capability.
Most of these schemes are designed for English and European languages and are not sufficiently expressive, especially for lexical normalization or when applied to another family of languages.
We propose a method to find lexical variations in Roman Urdu that uses string edit distance like Contractor et al. (2010), sound-based encoding like Pinto et al. (2012), and contextual information like Han et al. (2012) combined in a discriminative framework. In contrast to previous work, our method does not use a resource of standard word forms to find lexical variations.
6. Conclusion and future work
Roman Urdu is a transliterated form of the Urdu language written in Roman script, used in informal communication in social media and SMS texts. It does not have a standard lexicon, which results in an extensive use of lexical variations that hamper automatic processing. Our framework for lexical normalization of Roman Urdu is an unsupervised model meant to address this important issue. Our clustering framework incorporates customized phonetic encoding, string-based matching, and contextual similarity. We conducted an extensive evaluation of our framework on four real-world datasets. We used manually generated gold standard containing Roman Urdu lexical variations with their standard forms (Khan and Karim 2012). We show that our framework effectively discovers lexical variations in Roman Urdu corpora with significant improvement over the baseline methods.
Our work brings us one step closer to automatically generate a normalized Roman Urdu corpus. We can cluster spelling variations of a word and then map them to the most frequent form and can use this corpus to develop NLP applications. In the future, we would like to extrinsically evaluate our normalization procedure on several NLP tasks, such as POS tagging and machine translation.
Acknowledgment
This research was partially funded by the National Science Foundation (NSF) Award No. 1747728 and the National Science Foundation of China (NSFC) Award No. 61672524.



























