Introduction
Cross-language influences during visual word recognition are very well documented in the literature. Indeed, when bilinguals are reading in their second language (L2), their native language (L1) is also activated and vice versa. These cross-language influences are due to parallel activation of lexical candidates from both languages, which compete for selection (Dijkstra & van Heuven, Reference Dijkstra and van Heuven2012). The so-called cognate effect is one of the most robust experimental effects which has been considered as evidence for this parallel co-activation across-languages i.e., a differential processing for cognate words (translation equivalents that share form besides meaning; e.g., papel-paper in European Portuguese [EP] and English, respectively) vs. non-cognate words (translation equivalents which share only meaning; e.g., casa-house in EP and English, respectively). In addition to sharing meaning, cognate words also share form (i.e., they also present some level of orthographic and/or phonological overlap). As a consequence, the shared semantic representation receives more feed-forward activation (from simultaneously activated orthographic representations) compared to non-cognate words, which in turn feeds back and reinforces the form-meaning mapping, leading to facilitatory effects. However, although the majority of studies using different input modalities (e.g., visual and auditory), tasks (e.g., lexical decision, language decision, go/no-go, translation recognition, progressive demasking, sentence completion), paradigms (e.g., masked and unmasked priming), and techniques (e.g., eye-tracking, event-related potentials, pupillometry) have shown a cognate facilitation effect (CFE; e.g., Caramazza & Brones, Reference Caramazza and Brones1979; Cristoffanini, Kirsner & Milech, Reference Cristoffanini, Kirsner and Milech1986; de Groot & Nas, Reference de Groot and Nas1991; Dijkstra, Grainger & van Heuven, Reference Dijkstra, Grainger and van Heuven1999; Dijkstra, Timmermans & Schriefers, Reference Dijkstra, Timmermans and Schriefers2000b; Guasch, Ferré & Haro, Reference Guasch, Ferré and Haro2017; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004; Lemhöfer, Dijkstra, Schriefers, Baayen, Grainger & Zwitserlood, Reference Lemhöfer, Dijkstra, Schriefers, Baayen, Grainger and Zwitserlood2008; Midgley, Holcomb & Grainger, Reference Midgley, Holcomb and Grainger2011; van Hell & Dijkstra, Reference van Hell and Dijkstra2002; Soares, Oliveira, Comesaña & Costa, Reference Soares, Oliveira, Comesaña and Costa2018a; Soares, Oliveira, Ferreira, Comesaña, Macedo, Ferré, Acuña-Fariña, Hernández-Cabrera & Fraga, Reference Soares, Oliveira, Ferreira, Comesaña, Macedo, Ferré, Acuña-Fariña, Hernández-Cabrera and Fraga2019), recent studies have revealed that the CFE can vanish or can even be reversed if identical cognate words (i.e., cognates with complete orthographic overlap, e.g., piano in EP and English) are removed from the stimulus list (Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade & Fraga, Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012; Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015), or if the list contains non-target language words requiring a different response (Poort & Rodd, Reference Poort and Rodd2017; Vanlangendonck, Peeters, Rueschemeyer & Dijkstra, Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020). Thus, a thorough characterization of the representation and processing of cognate words in the bilingual mind requires an examination of how stimulus list composition influences cognate word recognition. This was precisely the aim of the present study, i.e., to further examine the effect the stimulus list composition has on the CFE by manipulating the number of identical cognates in the list while keeping task requirements constant.
Cognate word processing and stimulus list composition
The CFE supports the claim of a non-selective language access in bilinguals, which is a core assumption of models such as the BIA (Dijkstra & van Heuven, Reference Dijkstra, van Heuven, Grainger and Jacobs1998), BIA+ (Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002) or its recent extension, the Multilink (Dijkstra, Wahl, Buytenhuijs, van Halem, Aljibouri, de Korte & Rekké, Reference Dijkstra, Wahl, Buytenhuijs, van Halem, Aljibouri, de Korte and Rekké2019). According to these models, the languages known by bilinguals are represented in an integrated way in their minds, and the CFE arises from the form/semantic overlap between cognate and non-cognate words across those languages. Thus, when a given input word is presented, it would activate multiple word candidates as a function of their similarity to the input regardless of the language in use. In the case of cognates, two lexical representations (one for each language) would be activated and would send activation to the overlapping semantic representation, which, in turn, feeds back activation to the form level. As a result, the amount of activation they receive would be greater in comparison to non-cognates and processing is facilitated. Within this framework, it is further assumed that identical and non-identical cognates are differently represented and processed, as identical cognates are likely to share the same orthographic representation (e.g., piano in EP and American English) and two phonological representations (/pjɐnu/ and /piænoʊ/, respectively), while non-identical cognates present two orthographic and two phonological representations (e.g., papel - /pɐpɛl/ in EP and paper /peɪpəR/ in English). When the representations of a non-identical cognate become active, they compete with each other in the same way that other word candidates within and across languages do, through lateral inhibition. Higher competition delays processing: thus, explaining the reduced facilitation for non-identical cognates compared to identical cognates (Dijkstra, Miwa, Brummelhuis, Sappelli & Baayen, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010), especially when there are mismatches between orthography and phonology (e.g., dança [dɐ̃sɐ] - DANCE [dɑ:ns] > bomba [bõbɐ] - BOMB [bɒm]; although both pairs have the same degree of phonological overlap, the former has a lower degree of orthographic overlap; see Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015 for more details). The degree of competition seems to also vary as a function of variables that do not only depend on the internal representation of cognates. In particular, task demands and stimulus list composition seem to have an influence on how fast cognates are processed (Comesaña, Moreira, Valente, Hernández & Soares, Reference Comesaña, Moreira, Valente, Hernández and Soares2019; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Elston-Güttler, Gunter & Kotz, Reference Elston-Güttler, Gunter and Kotz2005; Hoversten & Traxler, Reference Hoversten and Traxler2020; Jared & Kroll, Reference Jared and Kroll2001; Schwartz & Kroll, Reference Schwartz and Kroll2006; van Hell & de Groot, Reference van Hell and de Groot2008; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020; Wu & Thierry, Reference Wu and Thierry2010).
The BIA+ model (and also the Multilink) allow characterizing modulations on word processing as either linguistic or non-linguistic due to the incorporation of two different systems: an identification system and a task/decision system. Only the task/decision system takes into consideration task requirements, the instructions given to the participants to perform the task, and the stimulus list composition. The identification system, on the other hand, is not influenced by non-linguistic contexts. As a consequence, top-down processes should not affect the early stages of bilingual visual word recognition or, with it, the relative activation level of each language. This postulate is not shared by its predecessor model (BIA, Dijkstra and van Heuven, Reference Dijkstra, van Heuven, Grainger and Jacobs1998). According to the BIA model, lexical selection of target words is directly influenced by feedback inhibition of the non-target words from language nodes that represent the language membership of an item. Hence, top-down effects over activation levels throughout the word recognition system are allowed in this model. Although language nodes still play a role within the architecture of BIA+ and Multilink, they no longer have feedback connections to the lexicon. Instead, inhibition of non-target lexical representations is said to take place by the separate task/decision system that operates on the output of the word identification system.
The evidence in the literature regarding the locus of non-linguistic context effects (within or outside the lexicon) is mixed (see Hoversten & Traxler, Reference Hoversten and Traxler2020). Here, it is worth mentioning the studies in which these effects in lexical access were assessed through the manipulation of stimulus list composition. Although only few studies have manipulated this variable (Brenders, van Hell & Dijkstra, Reference Brenders, van Hell and Dijkstra2011; Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Dijkstra, Bruijn, Schriefers & Brinke, Reference Dijkstra, Bruijn, Schriefers, Brinke and Ten2000a; Poort & Rodd, Reference Poort and Rodd2017; Titone, Libben, Mercier, Whitford & Pivneva, Reference Titone, Libben, Mercier, Whitford and Pivneva2011; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020), they all report influences on cognate word processing, especially in the size and direction of the cognate effect. The underlying mechanisms put forward, however, vary across studies. Thus, whereas some authors consider mechanisms related to response competition (i.e., outside the lexicon; e.g., Poort & Rodd, Reference Poort and Rodd2017; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020), others point out mechanisms related to the cross-linguistic overlap of items or word language ambiguity, which modulate relative language activation during the early stages of word recognition (i.e., within the lexicon; e.g., Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015, 2016).
For example, Vanlangendonck et al. conducted two English (L2) lexical decision experiments with Dutch–English late bilinguals who had to decide whether or not a given string of letters was a real English word. Participants saw identical and non-identical cognates, interlingual homographs (words with an identical form across-languages, but a different meaning; e.g., vast which means fixed in Dutch), control words (non-cognates), and pseudowords. Crucially, in the second experiment, half of the pseudowords were replaced with Dutch words (requiring a “no” response). The results showed a CFE in the first experiment (restricted to identical cognates), which turned into inhibition in the second experiment. The authors explained the change in the direction of the cognate effect as a consequence of a response conflict. That is, in the first experiment, the fact that only L2 words were presented requiring a “yes” response (a “pure” stimulus list) facilitated the processing of identical and non-identical cognates (although only the effect for the former was significant) relative to control words due to their form overlap. However, in the second experiment, the inclusion of L1 words turned the “pure” list into a “mixed” list, with L2 words bounded to a “yes” response and L1 words bounded to a “no” response. This change increased response competition between cross-language competitors and led to the associated interference effect in cognate processing, especially for identical cognates since their two readings are ambiguous with respect to language membership. This explanation can account for the modulation of cognate effects in mixed lists but falls short of explaining modulations occurring in strictly “pure” lists conditions (i.e., when only L2 words were included in the stimulus list composition, as in Comesaña et al.'s Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015 study). Comesaña et al. carried out two lexical decision experiments with Catalan–Spanish bilinguals. They presented two lists: in each case, containing cognate words, non-cognate words and pseudowords. While one list contained an equal number of identical cognates and non-identical cognates, the other contained only non-identical cognates. The results showed that the time it took participants to recognize non-identical Catalan–Spanish cognates (e.g., dutxa-ducha [shower]) was modulated by the presence (Experiment 1) or absence (Experiment 2) of identical cognates in the experimental list. Indeed, a CFE was only observed in Experiment 1 and restricted to identical cognates (as in Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020; see also Guasch et al., Reference Guasch, Ferré and Haro2017, for converging pupillometric evidence). Non-identical cognate words were recognized slightly faster than non-cognates but the effect was not significant. In Experiment 2, the effect was reversed, as non-identical cognates were responded to more slowly as compared to non-cognates (20 ms of inhibition). Because in both cases, all words were bounded to “yes” responses, the mechanism of response competition does not seem a plausible explanation for the observed differences. Instead, the authors explain their findings in terms of earlier influences of stimulus list composition on relative language activation. Specifically, in the absence of language ambiguous words (i.e., identical cognates), there is less activation of non-target language lexical candidates. Thus, any advantage of shared semantic representations for cognate words is reduced. Furthermore, since non-identical cognates have two orthographic and two phonological representations, they are proportionally more affected by lateral inhibition than non-cognate words, leading to the observed null CFE or its reversal. These results seem to indicate that non-linguistic context (via the manipulation of stimulus list composition) affects lexical access at earlier stages than those proposed by the authors of BIA+ and Multilink models. Assuming this, the question that follows now is how many language ambiguous words are necessary for the effect to be reduced or reversed.
The present study
The aim of this work was to directly answer the above question. Specifically, to address how the characteristics of the stimuli composing the lists, regarding the number of identical and non-identical cognate words, affect the magnitude and the direction of the CFE. To this end, we manipulated the number of identical cognates in the experimental lists according to four different ratios: (i) 50% identical cognates and 50% non-identical cognates (as in the Experiment 1 of Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015); (ii) 25% identical cognates and 75% non-identical cognates, (iii) 12% identical cognates and 88% non-identical cognates; and (iv) 0% identical cognates and 100% non-identical cognates (as in the Experiment 2 of Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015).
Task requirements were the same across the lists and all real words were bounded to “yes” responses. Hence, any observed effects of the number of identical cognates on the CFE cannot be attributed to mechanisms at the response level. Instead, assuming an earlier effect of stimulus list composition on lexical access, as the BIA model holds, we expected to find any facilitatory cognate effects to gradually decrease (and potentially disappear) as the number of identical cognates decreases in the list. We recognize that a lexical decision task does not enable us to establish with precision how much earlier is the effect of stimulus list composition in the CFE. More sensitive paradigms or techniques would be ideal to examine its locus. Nevertheless, we can assure with our design that any observed effect cannot be attributed to response competition and, thus, it is necessarily earlier than the authors of Multilink model hold. The CFE would be greater in the first list (i.e., when half of the cognates are identical), and null in the list where there are no identical cognates, as previous studies have shown (see Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015 for more detail).
General Method
Ethics statement
The experiment was conducted with the approval of the Ethics Committee for Human Research of the Research Center on Psychology (CIPsi) at the University of Minho (Braga, Portugal). Written consent was obtained from all the participants.
Materials
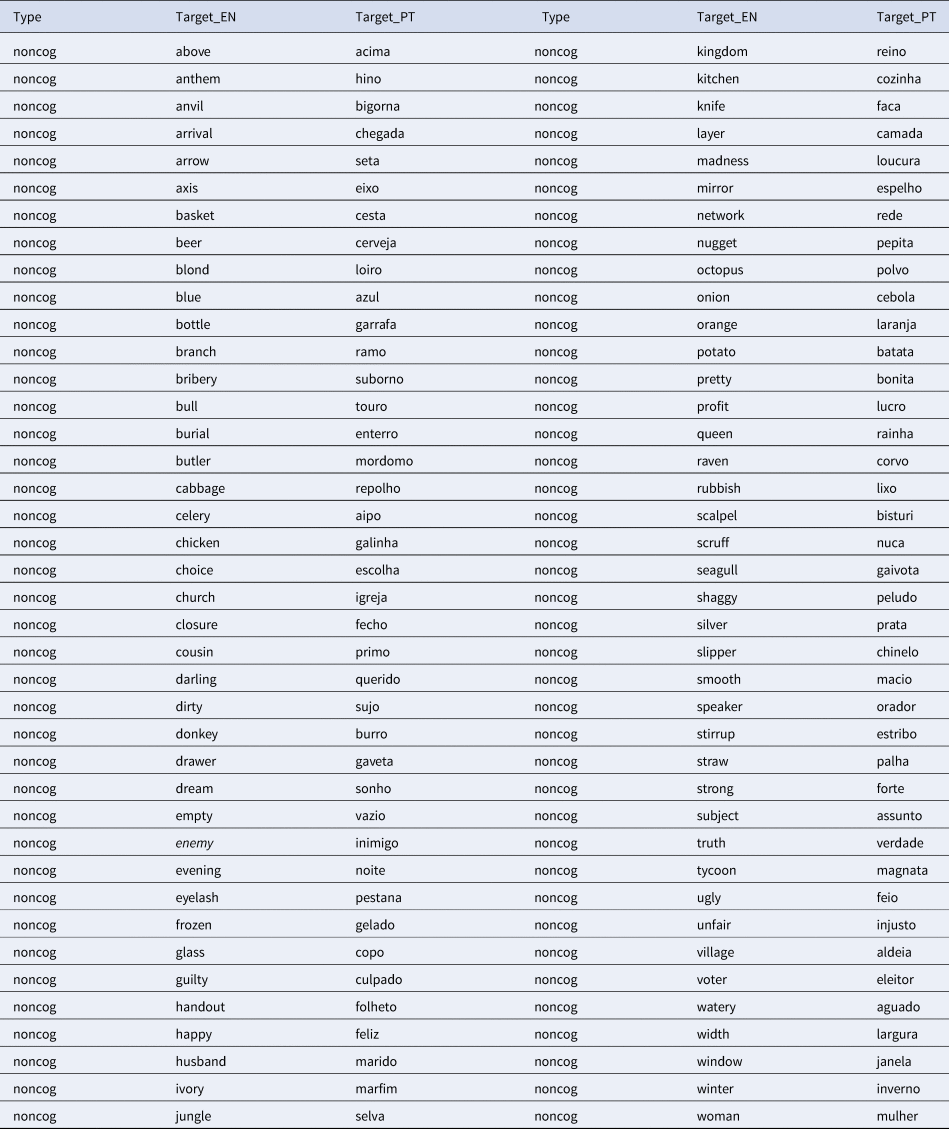
The materials consisted of four stimulus lists with 160 EP-English word pairs in each list/experiment (half cognates and half non-cognates). Stimulus lists were created by gradually decreasing the number of identical cognates within the lists. This resulted in four different ratios of identical vs. non-identical cognates: 50-50; 25-75; 12-88; and 0-100, respectively. The four experimental lists shared a varying number of common words ranging from a minimum of 56% up to 88% of shared words (see the stimuli for the four lists in the Appendix). Thus, identical cognates from List 1 that were not included in the other lists were replaced with non-identical cognates with similar values of frequency and length. Also, some non-cognate words were changed to guarantee the perfect match.
In each list, English cognates and non-cognates were matched in logarithmic word frequency and length in number of letters (all ps > .14; see Table 1 for mean and std). Frequency measures and data for length were obtained from the N-Watch database (Davis, Reference Davis2005). Also, when considering EP words, there were no differences between cognates and non-cognates in each list regarding the logarithmic frequency and length values (all ps > .13, see Table 1). These values were taken from the Procura-PALavras lexical database (P-PAL; Soares, Iriarte, de Almeida, Simões, Costa, Machado, França, Comesaña, Rauber, Rato & Perea, Reference Soares, Iriarte, de Almeida, Simões, Costa, Machado, França, Comesaña, Rauber, Rato and Perea2018b). In addition, there were no differences in logarithmic frequency and length across lists for both English and EP words (all ps > .28, see Table 1).
Table 1. Mean values of log frequency, length, and O and P NLD (standard errors are in round parentheses range is in square parentheses).

Note: EN and EP stand for English and European Portuguese, respectively; NLD_O and NLD_P stand for the Normalized Levenshtein Distance between English and EP translations regarding orthography and phonology, respectively. Values are reported for noncognates (NCG) and cognates (CG). Cognates are further split into non-identical cognates (CG_NI) and identical cognates (CG_Iden).
The degree of orthographic (O) similarity was calculated based on the Normalized Levenshtein Distance (NLD) with values ranging from 0 (no overlap) to 1 (total overlap). Non-identical cognates were selected such that orthographic similarity was maximized while also matching identical cognates on factors word length, phonological & orthographic neighbours and logarithmic frequency. The minimum cut-off in orthographic similarity was 0.43 for non-identical cognates and the maximum cut-off was 0.34 for noncognates with only few word pairs close to the cut-off boundaries. Table 1 contains both mean and range of orthographic similarity for the different lists and per condition. As expected, there were statistically significant differences in orthographic similarity between cognate and non-cognate words, as well as between identical and non-identical cognates within all lists (all ps < .001). Importantly, neither identical, non-identical cognates nor noncognates differed across lists in terms of their orthographic overlap (all ps > 0.4). For phonological (P) similarity, we relied on the analysis of the degree of overlap of the phonemic transcriptions. Those transcriptions were used to compute the NLD between pairs of words. Each phoneme was characterized according to a set of standard binary distinctive features. Thus, only those features that are necessary to minimally distinguish the sounds of EP and American English were included: syllabic, sonorant, consonantal, continuant, delayed release, lateral, nasal, voice, anterior, coronal, distributed, high, back, low, mid, and stress. In the computation of P similarity between a given pair of phonemes, the algorithm took into account the feature values that were shared by the two phonemes (see Gooskens & Heeringa, Reference Gooskens and Heeringa2004, for a similar approach). As was the case with O similarity, P similarity varied from 0 to 1. As expected, there were statistically significant differences between cognate and non-cognate words within all lists (all ps < .001). Overall, no differences were found regarding the degree of P overlap either between identical and non-identical cognates in each list or across lists (all ps > .372).
In addition to the cognate and non-cognate experimental words, we created 160 pseudowords per list using the Wuggy software (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010) for the purposes of the lexical decision task.
Procedure
The same procedure was applied for all the four experiments. Participants were tested individually in separate soundproof booths and randomly assigned to one of the four stimulus list conditions. Participants were asked to decide as quickly and accurately as possible whether the string of letters presented on the computer screen corresponded or not to a real word in English (i.e., to perform a lexical decision task). Participants indicated their decisions by pressing one of two response buttons (“M” for “yes” and “Z” for “no”) of the keyboard. The experiment was run using the DMDX software (Forster & Forster, Reference Forster and Forster2003). Prior to the experiment, there was a practice block consisting of 16 randomized trials (eight words plus eight pseudowords) to familiarize participants with the task. The practice block included identical cognates in those experiments, where the experimental stimulus list included cognates as well. Each trial started with a fixation cross at the center of the screen. After 500 ms, the fixation cross was replaced by the target stimulus presented in uppercase, which remained on the screen until participants responded or until 2,500 ms had elapsed. The experimental session consisted of 320 trials presented in randomized order. There were breaks during each session after every 80 trials. Participants decided when to continue after a break by pressing the space bar of the keyboard. The whole session lasted around 45 minutes to be completed.
Prior to the experiment, participants filled in the Language History Questionnaire (LHQ, Li, Zhang, Tsai & Puls, Reference Li, Zhang, Tsai and Puls2013) and, at the end of the lexical decision task, they performed three tests evaluating their lexical and spelling knowledge in the English language, in order to assess their L2 proficiency and to guarantee the homogeneity of the sample. In the LHQ, they were asked to provide the age at which they began to learn each of their languages and to estimate their proficiency on a 7-point Likert scale (1 = very poor, 7 = native-like) regarding reading, writing, speaking, and listening skills. In the first test administered at the end of the lexical decision task, participants performed a recognition task on all the 160 experimental items to ensure they knew their meaning. In the second test, participants were asked to translate 150 EP words into English (see Casalis, Commissaire & Duncan, Reference Casalis, Commissaire and Duncan2015 for more details about this test), and, in the last test, they were asked to choose the correct spelling out of two different spellings for a total of 20 pairs of words. The 20 English words were nouns, adjectives or adverbs, from four to fifteen-letters long, with a mean frequency of 29.6 and few orthographic neighbors (M = 1.05). These values were taken from the N-Watch database (Davis, Reference Davis2005).
We recorded a sample of 95 participants (26, 24, 23 and 22 participants for Lists 1 to 4 respectively). Of those 95 participants, we excluded the data from 23 participants in order to guarantee homogeneity in their language proficiency. Data from five of those participants were excluded, because their native language was not European Portuguese and data from an additional 11 participants were excluded because they scored less than 50% in any of the English language proficiency tests. The data from the remaining seven participants were excluded in order to balance proficiency levels of the population samples across lists. After exclusion, the data obtained from the LHQ and from the three language tests showed no differences between groups of participants across the four experimental list conditions (all ps > .14; see Table 2). Considering the results of the different tasks used to evaluate their proficiency, we can state that the final sample had intermediate to high L2 proficiency.
Table 2. Mean age of acquisition and mean of L2 proficiency (7-point Likert scale) based on the LHQ and average performance (percentage correct) on the three background tests per experiment (standard errors are in parentheses).

Note: AoA stands for Age of Acquisition; L2 stands for second language.
Experiment 1 (50-50 Condition)
Participants
Eighteen EP (L1)–English (L2) undergraduate students from the University of Minho (Braga, Portugal) participated in the experiment, in exchange for academic credits (all of them signed an informed consent). They were unbalanced bilinguals (14 females) with ages ranging from 19 to 38 years (M = 23.8; SD = 4.5). All of them reported having normal or corrected-to-normal vision.
Materials
The materials consisted of 160 English words (132 nouns): 80 cognates (40 identical and 40 non-identical) and 80 non-cognates plus 160 pseudowords. For more detail see General Method.
Results
Words with an error rate greater than 40% were excluded from the analyses (this amounted to 17 words in total, i.e., 16 words from the non-cognate condition and one from the non-identical cognate condition). In order to maintain the proportion of words across conditions, the 15 cognate words with lower accuracy rates were also eliminated (eight identical cognates and seven non-identical cognates). Those 15 cognate words were chosen such that overall frequency and length of words was still comparable across conditions. Thus, of the 160 presented words, only 128 (64 cognates [32 identical and 32 non-identical] and 64 non-cognates) were considered in the analyses. Individual trials corresponding to incorrect responses (5.34%), as well as extreme reaction times -RTs- (below 250 ms or above 2,000 ms) were also not considered (0.61%). Moreover, RTs that were more than 2 standard deviations (SDs) above or below participants’ means were also removed (5.47%). Rejection of individual trials did not lead to imbalance in the amount of items across conditions. Mean RTs and percentage of error per condition are presented in Table 3.
Table 3. Mean reaction times (in ms) and mean percentage of error for the Identical, Non-identical cognate conditions as well as for the cognate and non-cognate condition (standard errors are in parentheses).

Note: CG_Iden, CG_NI, CG and NCG stand for identical cognate, non-identical cognate cognate and non-cognate words. N stands for the total number of trials for all the items and participants.
Linear mixed models (for RT data) and logit mixed models (for accuracy data) with random intercept for subjects and items were run using R software (Bates, Machler & Bolker, Reference Bates, Machler and Bolker2011). The factors cognate (cognate vs. non-cognate) and word type (identical cognates, non-identical cognates, and non-cognates) entered as fixed factors in the models. Note that, for each experiment, we first ran a model with the factor cognate, and, in the cases that a cognate facilitation effect was observed, we ran a second analysis, with word type as a factor, to see whether the effect was restricted to identical cognate words. In each model, in a first approach, we included random slopes for participants either for the cognate or word type factors (note they were both within-participants, but between-items, factors). As the results were virtually the same and the fit of the models were very similar (comparing the models fit, all the p's were greater than .05), we opted to report the simpler models (with random intercepts for participants and items; see Barr, Levy, Scheepers & Tily, Reference Barr, Levy, Scheepers and Tily2013). Only the independent variables manipulated in the study were included as predictors, as variables such as word frequency and word length were controlled for across conditions (see General Method section). Data were not averaged prior to the analyses. For the effects that reached statistical significance, the second degree of freedom of the F statistic was approximated with Satterthwaite's method (see Satterthwaite, Reference Satterthwaite1941; and Khuri, Mathew & Sinha, Reference Khuri, Mathew and Sinha1998 for a review). The p-values were adjusted with Hochberg's method (see Benjamini & Hochberg, Reference Benjamini and Hochberg1995, and Hochberg, Reference Hochberg1988 for details) for all the post-hoc comparisons equal or below .05.
The models comparing cognate and non-cognate words revealed a cognate facilitation effect in both RTs and accuracy. Participants responded on average 38 ms faster to cognate words than to non-cognate words (662 and 700 ms, respectively), F(1, 122.19) = 14.509, p < .001, and made fewer errors when responding to cognates compared to non-cognates (2.6 and 8.1, respectively), χ2(1) = 9.8371, p = .002.
Having replicated the typical cognate facilitation effect, the following question we asked was whether the facilitation was restricted to identical cognate words. Mean reaction times and percentage of error per condition are presented in Table 3.
The analyses revealed a significant main effect of word type both in RTs (F(2, 120.09) = 17.976, p < .001) and accuracy data (χ2(2) = 13.896, p < .001), as expected. This effect showed that participants were faster at recognizing identical cognates over non-cognates (630 ms vs. 700 ms, respectively, p < .001), and also over non-identical cognate words (630 ms vs. 695 ms, respectively, p = .059). The difference between non-identical cognates and non-cognates was not significant (695 ms vs. 700 ms, p = .444).
The effect in the percentage of errors was quite similar to the effect found in the latency data. The main effect of word type reached significance, as participants made fewer errors with identical cognates than with non-cognates (1.2 and 8.1, respectively, p < .001). However, the difference between identical and non-identical cognates was only marginally significant (1.2 vs. 4.0; p = .052). The difference between non-identical cognates and non-cognates failed to reach statistical significance (4.0 vs. 8.1; p = .141).
Experiment 2 (25-75 condition)
Participants
Eighteen EP (L1)–English (L2) unbalanced bilinguals (17 females) from the same population as the participants from the Experiment 1 took part in the experiment. Their ages ranged from 18 to 35 years (M = 22.5; SD = 5.6). They had normal or corrected-to-normal vision and received course credits for their participation as in the Experiment 1.
Materials
The materials consisted of 160 English words (140 nouns): 80 cognates (20 identical and 60 non-identical) and 80 non-cognates. In addition, 160 pseudowords were presented. For more details see the General Method section.
Results
Words with an error rate greater than 40% were not considered in the analyses (22 words – 16 from the non-cognate condition and six from the non-identical cognate condition). In order to maintain the proportion of words across conditions, 10 more cognate words were eliminated. Those 10 cognate words were chosen such that overall frequency and length of words was still comparable across conditions. Thus, of the 160 presented words, only 128 (64 cognates [16 identical cognates; 48 non-identical cognates] and 64 non-cognates) were considered in the analyses. Individual trials corresponding to incorrect responses (4.90%), as well as extreme values (below 250 ms or above 2,000 ms) were also not considered (0.26%). Moreover, RT that were more than 2 SDs above or below the mean for each participant in all conditions were removed (4.77%). Rejection of individual trials did not lead to imbalance in the number of items across conditions.
The analyses done in this second experiment were the same as those in the previous one. The lmm for comparison between cognate and non-cognate words in latency data revealed a significant cognate effect CFE of 23 ms (670 and 693 ms, for cognates and non-cognates respectively; F(1, 121.56) = 4.2183; p = .042). In terms of accuracy, however, the difference between the errors committed for cognate and non-cognate conditions did not reach statistical significance, χ2(1) = 2.1626; p = .141).
The lmm conducted with the factor word type (identical, non-identical, and non-cognate) showed, in the latency data, a significant main effect of word type, F(2, 120.27) = 4.5426, p = .013. This effect showed facilitation for identical cognates over non-cognates (645 ms vs. 693 ms, respectively, p = .001), and that the difference between non-identical cognates over non-cognates failed to reach statistical significance (p = .273). The difference between identical and non-identical cognates was marginally significant (644 ms vs. 678 ms, p = .062). The results in the percentage of errors fail to show significant effects, χ2(2) = 3.1167; p = .211). Mean RTs and percentage of errors per condition are presented in the Table 3.
Experiment 3 (12-88 condition)
Participants
Eighteen European Portuguese (L1)–English (L2) unbalanced bilinguals (16 females) from the same population as participants from Experiments 1 and 2 took part in the experiment. Their ages ranged from 18 to 25 years (M = 20.7; SD = 1.7). They had normal or corrected-to-normal vision and received course credits for their participation.
Materials
The materials consisted of 160 English words (137 nouns): 80 cognates (10 identical and 70 non-identical) and 80 non-cognates. It also had 160 pseudowords. For more details see the General Method section.
Results
Words with an error rate greater than 40% were not considered in the analyses (25 words – 16 from the non-cognate condition, nine from the non-identical cognate condition). In order to maintain the original proportion across conditions, seven more words were eliminated (2 identical cognates and five non-identical cognates). Those seven words were chosen such that overall frequency and length of words was still comparable across conditions. Thus, 128 (64 cognates [eight identical + 56 non-identical] and 64 non-cognates) out of 160 words were considered in the analyses. Individual trials corresponding to incorrect responses (8.07%), as well as extreme values (below 250 ms or above 2,000 ms) were also not considered (0.65%). Moreover, RTs that were more than 2 SDs above or below the mean for each participant in all conditions were removed (5.12%). Rejection of individual trials did not lead to an imbalance in the number of items across conditions.
The results of the lmm in the latency data failed to show the typical cognate facilitation effect: F(1, 119.27) = 1.4101, p = .237, as no differences were observed between cognate and non-cognate words (707 and 715 ms, respectively). The same was observed in accuracy data, as no significant differences between cognates and non-cognates were observed (8.3 and 7.9, respectively; χ2(1) = 0.2431, p = .622).
The lmm with the factor word type (identical, non-identical cognates and non-cognates) was not conducted because the effect of cognate was not significant. See the mean RTs and percentage of errors per condition in Table 3.
Experiment 4 (0-100 condition)
Participants
Eighteen EP (L1)–English (L2) unbalanced bilinguals (16 females) with ages ranging from 17 to 32 years (M = 23.6; SD = 4.2) took part in the experiment. They were recruited from the same population as Experiments 1, 2, and 3. They had normal or corrected-to-normal vision and received course credits for their participation.
Materials
The materials consisted of 160 English words (135 nouns): 80 non-identical cognates and 80 non-cognates. It also had 160 pseudowords.
Results
Words with an error rate greater than 40% were not considered in the analyses (25 words – 16 from the non-cognate condition and nine from the cognate condition). In order to maintain the original proportion across conditions, seven more cognate words were eliminated. Those seven cognate words were chosen such that overall frequency and length of words was still comparable across conditions. Thus, of the 160 presented words, only 128 (64 non-identical cognates and 64 non-cognates) were considered in the results. Individual trials corresponding to incorrect responses (4.51%), as well as extreme values (below 250 ms or above 2,000 ms; 0.39%) were also not considered. Moreover, reaction times that were more than 2 SDs above or below the mean for each participant in all conditions were removed (4.99%). Rejection of individual trials did not lead to imbalance in the number of items across conditions. Reaction times and percentage of error per condition are presented in Table 3.
The results failed to show the typical CFE, as no differences were observed between cognate and non-cognate words both in latency data (655 and 655 ms, respectively), F(1, 120.18) = 0.0418, p = .838, and accuracy data (4.5 and 4.5, respectively), χ2(1) = 0.0171, p = .896). These results are consistent with the results observed by Comesaña et al. (Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015) using the same procedure and stimulus lists composition (i.e., without identical cognates).
In order to rule out general differences across Experiments 1 to 4 to drive any of the observed patterns so far, we re-analyzed the data considering the experimental list as a factor. For that purpose, we ran lmm with the factors word type (cognate, non-cognate) and experimental list (50-50, 25-75, 12-88, 0-100) as fixed factors in the models.
The results failed to show a main effect of experimental list in both RTs and accuracy data (all ps > .270), as expected. Similarly expected was the significance of the main word type effect in the RTs, F(1, 190.1) = 9.8234, p = .002. However, this effect was not significant in the accuracy data, χ2(1) = 2.3468, p = .126). Surprisingly, the results also failed to show an interaction between word type and experimental list both in RTs (F(3, 7827.8) = 0.9654, p = .408) and accuracy (χ2(3) = 6.2406, p = .101).
Discussion
In the present study, we investigated the effect of stimulus list composition on the CFE. By varying the ratio of identical and non-identical cognates across four experimental lists, we were able to analyze the impact of stimulus list composition on the direction and magnitude of the cognate effect. Overall, the results show that cognate facilitation decreases and eventually disappears with the decreasing number of identical cognates in the experimental lists. In Experiments 1 and 2, both comprising a substantial amount of identical cognates, we observed a significant CFE, as previous studies did, supporting a bilingual non-selective lexical access (e.g., Caramazza & Brones, Reference Caramazza and Brones1979; Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Cristoffanini et al., Reference Cristoffanini, Kirsner and Milech1986; de Groot & Nas, Reference de Groot and Nas1991; Dijkstra et al., Reference Dijkstra, Grainger and van Heuven1999, Reference Dijkstra, Timmermans and Schriefers2000b; Guasch et al., Reference Guasch, Ferré and Haro2017; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004; Lemhöfer et al., Reference Lemhöfer, Dijkstra, Schriefers, Baayen, Grainger and Zwitserlood2008; Midgley et al., Reference Midgley, Holcomb and Grainger2011; van Hell & Dijkstra, Reference van Hell and Dijkstra2002). In both experiments, significant facilitatory effects were restricted to identical cognates. Importantly, identical cognates were processed significantly faster than non-identical cognates in both experiments even when the latter only differed in one or two letters.
This finding of facilitatory effects being restricted to identical cognates replicates what was found in Comesaña et al.'s study (Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015), and is in accordance with other lexical decision studies (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020) that similarly reported a sudden drop in reaction times for identical cognates relative to non-identical cognates which varied in just one letter (see Figure 1).

Figure 1. The average reaction times per item against degree of orthographic similarity per experiment
Hence, our findings further support the assumption that identical and non-identical cognates are processed differently. This is consistent with the tenets of BIA+ and Multilink models, which suggest that the different cognate types rely on distinct lexical representations. Specifically, while identical cognates have a shared orthographic representation, non-identical cognates have two distinct orthographic representations, which compete for selection. As a result, a non-identical cognate's lexical activation is inhibited by stronger lateral inhibition. Notably, in Experiment 2, the magnitude of the CFE on reaction times was already reduced to almost half in comparison to the one observed in Experiment 1 (from 38 to 23 ms). This finding reinforces the idea of a dynamically modulated non-target language activation within the lexicon as a consequence of variations in the stimulus list composition. Importantly, despite the smaller CFE, the overall pattern of responses when considering the speed and accuracy of participants is similar to the one observed in the first experiment (see Tables 2 and 3). Furthermore, the facilitative effects of cognate words completely disappeared when there were no (Experiment 4) or only very few (Experiment 3) identical cognates in the lists. Thus, our data add to previous literature reporting null-findings or even inhibitory effects for cognate words during L2 word recognition (e.g., Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Schwartz, Kroll & Diaz, Reference Schwartz, Kroll and Diaz2007; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020). Note that, although we do not replicate the complete reversal of the cognate effect as reported by Comesaña et al. (Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015), this is likely due to the difference in phonological overlap between the studies. Whereas Comesaña et al. presented cognate words across highly similar languages (Catalan–Spanish), we presented English–Portuguese cognates that by nature share fewer phonological features. Therefore, compared to Comesaña et al's study, our non-identical cognates were likely less affected by lateral inhibition due to phonological overlap. In fact, Comesaña et al. show that their observed inhibitory effect on non-identical cognates was significantly weaker for those with lower phonological overlap.
The fact that we only observed a CFE when a substantial number of identical cognates (50% in Experiment 1 and 25% in Experiment 2) were presented supports the idea that the facilitation effect is mainly driven by identical cognates. Although there are some studies similarly reducing the proportion of identical cognates in the list that had found facilitatory effects for cognate words, they have not controlled for the effect of phonological overlap (e.g., Costa, Caramazza & Sebastian-Galles, Reference Costa, Caramazza and Sebastian-Galles2000; Yudes, Macizo & Bajo, Reference Yudes, Macizo and Bajo2010). In previous studies in which this variable was manipulated and/or controlled for, the cognate effect was absent (e.g., Schwartz et al., Reference Schwartz, Kroll and Diaz2007) or one of inhibition (Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015), which can at least partially explain the contradictory results observed in the literature.
The BIA+ and Multilink models provide a mechanism of response competition as the cause of variations in the size and direction of the cognate effect as a function of stimulus list composition. However, response competition cannot account for the present results since language-specific response requirements were held constant across all experiments. According to the authors of the models, no effects of local language context such as effects of stimulus list composition during word identification are expected (with the exception of linguistic sentence context), since word recognition processes are thought to be strongly driven by input modulations. Any effect is, hence, explained via control processes of a separate task/decision system that would arise outside of the lexicon (at the response level), specifically through inhibition of competing language task schemas. This explanation can account for findings observed during tasks for which items from the target and the non-target language were bound to different responses (“yes” for words from the target language and “no” for words from the non-target language). In the present research, as there was only a unique response associated to all real words (“yes” response), no competition should occur on the response level. One may think, however, that even in the absence of response competition, the presence of identical cognates in the lists may have reduced task difficulty and would lead participants to adjust their decision criteria. In that case, the overall reaction times and error rates should decrease as the number of identical cognates in the lists increases. The data in the present research do not support this explanation since response times and accuracy to cognates and non-cognate words as a whole were similar across experiments (bear in mind that we kept all properties of the lists the same and replaced identical words by non-identical words as well as selected control words to keep all the conditions matched on frequency, word length, etc). Indeed, the percentage of common words across lists was high (from 56% to 88%), which minimizes the effect of possible confounding effects of words exchange (see all items per experiment in the Appendix). Our findings fit better with the tenets of the earlier BIA model and its role for language nodes as language filters depending on non-linguistic factors. According to this model, top-down inhibition mechanisms enable the context to affect the word identification system by inhibiting irrelevant language representations through the so-called language nodes. The model is also further corroborated by recent studies arguing for a less categorical view of bilingual language control in which the degree of activation of two languages may dynamically vary as a function of experimental factors (Hoversten & Traxler, Reference Hoversten and Traxler2020). Further evidence for such a view comes from studies in which global language context (i.e., the environment before starting the experiment) was manipulated (Elston-Güttler et al., Reference Elston-Güttler, Gunter and Kotz2005; Elston-Güttler & Gunter, Reference Elston-Güttler and Gunter2009; Hoversten & Traxler, Reference Hoversten and Traxler2016, 2020). For instance, Hoversten and Traxler (Reference Hoversten and Traxler2020) carried out two eye-tracking experiments with Spanish–English bilinguals in an attempt to examine the relative influence of top-down language control and bottom-up input during the reading of L2 and L1 semantically low-constraint sentences. Half of the sentences were presented in the L2 and the other half in the L1 in two separated blocks. Global language context was created by greeting participants in each block's target language, as well as testing proficiency in that language prior to each block. Stimuli contained either a small proportion of pseudowords or single word code switches into the alternate language. Importantly, code switches were either presented as a para-foveal preview (covertly) or overtly (the monolingual language context being either strengthened or disrupted, respectively). Only when code switches were presented overtly, did they disrupt reading. This disruptive force was initially less strong as compared to pseudowords. However, it further decreased with more exposure to language switches. In the words of the authors, it seemed as participants zoomed out of the target language with increasing exposure to language switches. Conversely, when code switches were presented covertly (creating a monolingual context), code-switched words were treated like pseudowords throughout the experiment indicating that participants remained zoomed in to the target language. Hence, the authors conclude that participants were less committed to the target language when there was a more bilingual language context. The results of this and other studies (e.g., Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Elston-Güttler & Gunter, Reference Elston-Güttler and Gunter2009; Hoversten & Traxler, Reference Hoversten and Traxler2016; Wu & Thierry, Reference Wu and Thierry2010), together with the present results, provide evidence for the flexible adjustment of the degree of accessibility of each language during reading as a function of linguistic and non-linguistic factors.
Further evidence comes from studies using electrophysiological techniques such as event-related brain potentials (ERPs) and magnetoencephalography (e.g., Chauncey, Grainger & Holcomb, Reference Chauncey, Grainger and Holcomb2008; Comesaña, Ferré, Demestre, Valente, Gonçalves & van Heuven, Reference Comesaña, Ferré, Demestre, Valente, Gonçalves and van Heuven2021, in preparation; Pellika, Helenius, Mäkelä & Lehtonen, Reference Pellika, Helenius, Mäkelä and Lehtonen2015; Yudes et al., Reference Yudes, Macizo and Bajo2010). For example, Comesaña et al. (2021, in preparation) replicated the findings by Comesaña et al. (Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015) with Catalan–Spanish bilinguals and extended them to ERP data. Two lexical decision experiments in Spanish were conducted. In the first one, there was a similar proportion of identical to non-identical cognates; whereas in the second experiment only non-identical cognates were presented. The degree of O and P overlap in cognate words was manipulated. Four groups of cognates were created as a function of their form overlap: O + P+, O + P-, O-P+, and O-P-. In accordance with Comesaña et al. (Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015), they found a differential processing for cognate words depending on their degree of form overlap as well as the stimulus list composition. Indeed, while the typical cognate facilitation effect appeared in several temporal windows in Experiment 1 (120-150 ms, 300-500 ms, and 500-800 ms), in Experiment 2 it was restricted to a single temporal window (200-250 ms) and even reversed in the last temporal window (500-800 ms). Importantly, differences in cognate processing across experiments appeared in early temporal windows (120-150 ms), revealing that the effect of phonology was restricted to cognates from Experiment 2 (P- larger negativities than P+). These differences remained during later time windows (300-500 and 500-800 ms) and showed up in the behavioral data as well. In the study of Yudes et al. (Reference Yudes, Macizo and Bajo2010), greater effects of cognate words were observed in tasks in which words from both languages were required (e.g., translation tasks) in comparison to other purely monolingual tasks such as association decision in which participants had to decide whether or not pairs of words from a given language were related in meaning. Although, in this case, task requirements were explicitly manipulated and any difference in the results’ pattern could be attributed to differences in task schemas, it serves us to infer that both processes (those occurring at the level of response and those occurring within the lexicon) influence the degree of cross-language activation.
In order to implement dynamic top-down inhibition on the lexicon depending on language activation, the original feedback connections between language nodes and lexical level would need to be re-instantiated as originally suggested by the BIA model. Previously the authors of the BIA+/Multilink model have argued that the influence of language membership is relatively small, and hence will only be available after word identification (Dijkstra et al., Reference Dijkstra and van Heuven2002). However, this ignored a potentially cumulative effect of language membership. For example, upon activation of a non-target language item, the corresponding language node would be activated and in turn lead to inhibition of lexical items from the other language(s). This inhibition slowly degrades as only target language items are presented subsequently. However, with many language-ambiguous items, inhibition through language nodes would be constantly reinforced before degrading back to baseline and hence multiple language-ambiguous items will have a cumulative effect leading to an overall increase in non-target language facilitation. A cumulative effect of language membership would also explain the temporal effects by Hoversten and Traxler (Reference Hoversten and Traxler2020) mentioned earlier. Importantly, the inhibition through language nodes will not be all or nothing but will dynamically modulate the activation strength of the lexical items and do so in interaction with other lexical factors. This is why studies that varied additional lexical factors such as frequency, but did not specifically manipulate or model the potential cumulative effect of repeated non-target language item activation (e.g., Dijsktra et al., Reference Dijkstra, Timmermans and Schriefers2000b), do not suffice as evidence against the effect of language membership.
To conclude, the current study provides evidence for top-down influences on cognate processing which cannot be explained by increases in response conflict or adjustments in decision criteria. Thus, current leading computational models of bilingual visual word recognition such as BIA+ and Multilink should be amended to account for these results.
Acknowledgements
This research was conducted at Psychology Research Centre (UID/PSI/01662/2013), University of Minho and funded by the FCT (Foundation for Science and Technology) through the state budget, with reference IF / 00784/2013 / CP1158 / CT0013. This has also been partially supported by the FCT and the Portuguese Ministry of Science, Technology and Higher Education through national funds and co-financed by FEDER through COMPETE2020 under the PT2020 Partnership Agreement (POCI-01-0145-FEDER-007653). We would like to thank Andreia Rauber for their help with the phonological analysis of the experimental words.
Montserrat Comesaña is the corresponding author
Appendix (Stimuli used in each experiment. In blue the common words across experiments)
Experiment 1
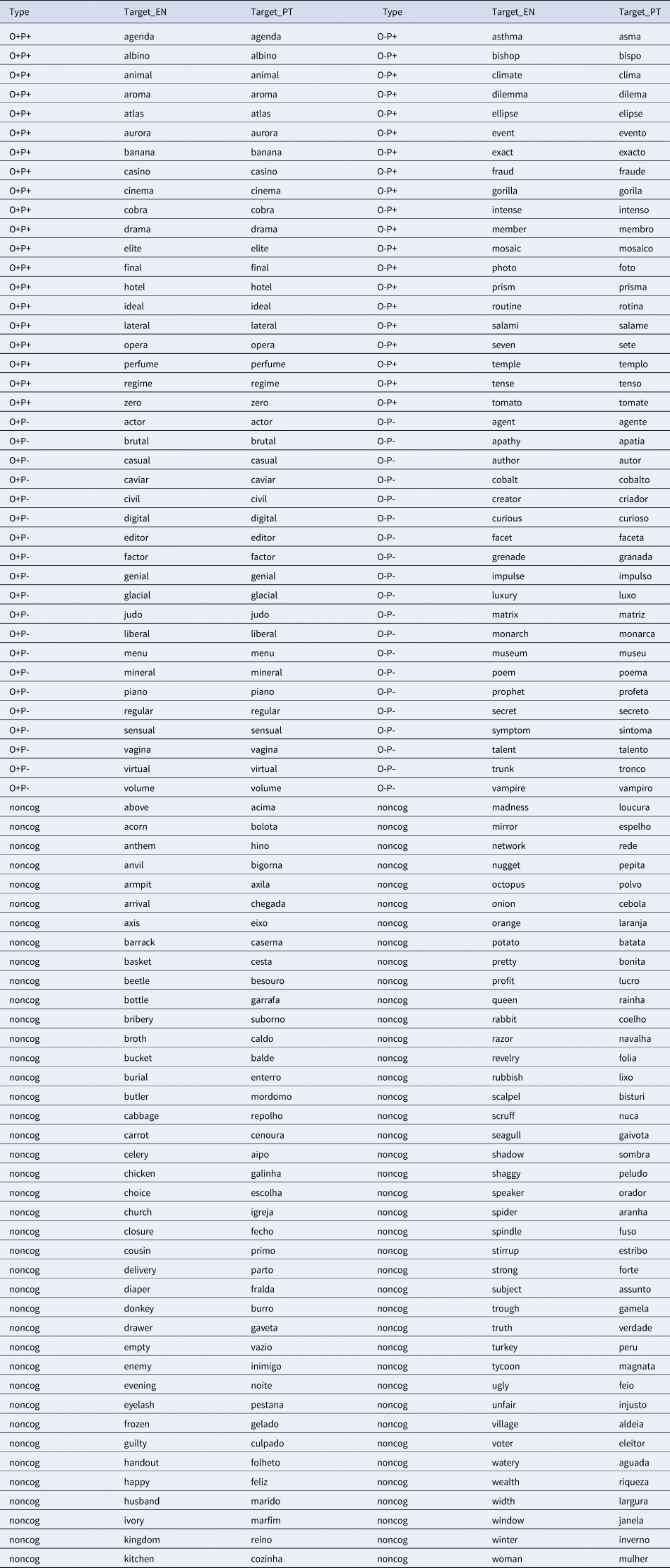
Experiment 2


Experiment 3
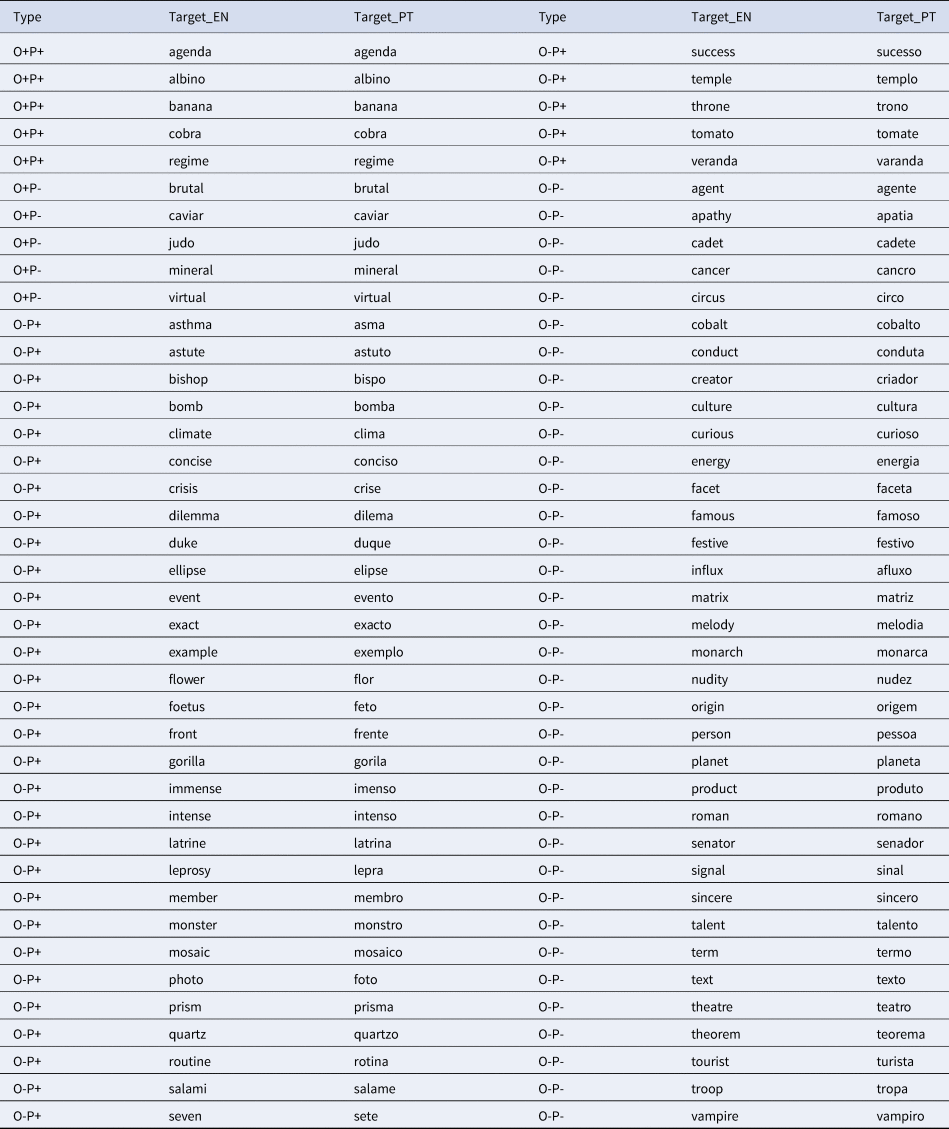

Experiment 4