In successful comprehension, listeners need to not only understand the words being said but also integrate what they hear into a shared model of the information established in the discourse. They need to understand how each new utterance relates to and updates that model, using the information structure (IS) of each utterance (e.g., see Calhoun, Reference Calhoun2010; Krifka, Reference Krifka2008). IS describes the way in which information is packaged in a discourse to serve the purpose of communication (Chafe, Reference Chafe and Li1976; Krifka, Reference Krifka2008). One key part of IS is focus, that is, the part of each utterance which updates an explicit or implicit “question-under-discussion” (QUD) in the immediate context (Roberts, Reference Roberts, Yoon and Kathol1996). For example, consider a context like (1) where a lost wallet has been found:
-
(1) Context: A young man lost his camera and wallet in the bus. The driver and a passenger found them.
-
(2) Who found the wallet?
-
(3) The passenger found the wallet (bold indicates prosodic prominence).
-
(4) * The passenger found the wallet.
The QUD is in (2). In response, the answer in (3), with prominence on passenger is appropriate, but (4), with prominence on wallet is not. The subject passenger is the focus, specifically a QUD-focus, as it answers or updates the QUD. Another function of focus is to indicate contextually relevant contrastive alternatives (Rooth, Reference Rooth1992), for example, the focus on passenger in (3) also implies there are other people who could have found the wallet, and these alternatives are relevant to the interpretation of the utterance. The two main functions of focus, reflected in the same word passenger, are best viewed as orthogonal to each other (Calhoun, Reference Calhoun2010; Vallduví, Reference Vallduví, Aloni and Dekker2016). Appropriate focus marking is important for coherence and efficient integration of information into the discourse model. Inappropriate focus marking has been shown to be a significant source of communication breakdown in L2 contexts (Jenkins, Reference Jenkins2002).
Along with prosodic prominence, as shown in (3), certain syntactic constructions (e.g., the it-cleft) are also key markers of IS in many languages (Féry & Ishihara, Reference Féry and Ishihara2016; Kügler & Calhoun, Reference Kügler, Calhoun, Gussenhoven and Chen2020). This poses challenges for L2 learners, as these cues are used differently, and with different weightings, in different languages. More generally, prosody is particularly challenging for L2 learners given the comparative difficulty in establishing relevant categories of prosodic structure and the pervasiveness of many-to-many mappings between form and function (e.g., see Mennen, Reference Mennen, Delais-Roussairie, Avanzi and Herment2015). There is little research on how L2 listeners use prosodic cues to process IS, although there is recent interest in this area (e.g., Chen & Lai, Reference Chen, Lai, Zonneveld, Quené and Heeren2011; Foltz, Reference Foltz2020; Ge et al., Reference Ge, Chen and Yip2020; Lee & Fraundorf, Reference Lee and Fraundorf2017). These studies have shown that learning speech cues to IS in L2 is challenging, especially as this is not usually explicitly taught in classrooms (Braun & Tagliapietra, Reference Braun and Tagliapietra2011; Trouvain et al., Reference Trouvain, Gut, Barry, Trouvain and Gut2007). Acquisition becomes even more complex when other cues are involved, such as syntactic cues. The interaction of multiple cues in IS processing remains unclear in L1 and L2.
Previous studies have found that L1 Mandarin and English listeners weight cues to focus differently, with prosodic cues being stronger than clefting in L1 Mandarin and the reverse in English (Calhoun et al., Reference Calhoun, Wollum and Kruse-Va’ai2021; Chen et al., Reference Chen, Chen and He2012; Greif & Skopeteas, Reference Greif and Skopeteas2021; Yan & Calhoun, Reference Yan and Calhoun2020). To the best of our knowledge, however, no research has investigated how these interact in L2 processing. In the current study, we attempt to fill in the research gap by looking at how Mandarin learners of English use prosodic and clefting cues to focus when processing their L1 (Mandarin) and L2 (English) using the same question-answer appropriateness rating task. We draw on Bates and MacWhinney’s (Reference Bates, MacWhinney, MacWhinney and Bates1989) Competition Model (CM) (see also Li & MacWhinney, Reference Li, MacWhinney and Chapelle2013) to investigate the relative strength of prosodic and clefting cues (see section “The role of prosody and clefting in the processing of focus in L1 and L2”). Given differences between the languages in the hierarchy of cue strength in signaling focus, Mandarin learners of English need to acquire new cue strengths in English. We also draw on Mennen’s (Reference Mennen, Delais-Roussairie, Avanzi and Herment2015) L2 intonation learning theory which establishes dimensions of prosodic differences between languages to predict difficulties in L2 intonation learning (see section “The role of prosody and clefting in the processing of focus in L1 and L2”).
In section “Focus marking”, we discuss how focus is marked by prosodic and clefting cues in Mandarin and English. In section “The role of prosody and clefting in the processing of focus in L1 and L2”, we review relevant existing L1 and L2 studies. In section “The current study”, we present two experiments examining the interacting effects of prosodic and clefting cues to focus by Mandarin listeners when processing their L1 and L2.
Focus marking
Prosodic focus marking
In Mandarin and English, the location of prosodic prominence is a primary cue to focus for listeners (e.g., Breen et al., Reference Breen, Fedorenko, Wagner and Gibson2010; Kügler & Calhoun, Reference Kügler, Calhoun, Gussenhoven and Chen2020; Lee et al., Reference Lee, Wang and Liberman2016). Prosodic prominence is realized with similar acoustic parameters in the two languages, typically a larger movement in F0, lengthened duration and increased intensity (Breen et al., Reference Breen, Fedorenko, Wagner and Gibson2010; Xu, Reference Xu1999). However, the details differ across the two languages. In English, utterance-level prosodic prominence is realized through pitch accenting. The focused word typically carries the nuclear pitch accent, that is, it is the most prominent in the intonational phrase (Calhoun, Reference Calhoun2010). In Figure 1, parents (top) and children (bottom) are foci, typically marked by H* or L+H* pitch accents in the ToBI system (Brugos et al., Reference Brugos, Shattuck-Hufnagel and Veilleux2006). These pitch accents are realized with a (steep) rise in pitch on the stressed syllable of the focused word. Focus is also marked by reduced pitch range in the post-focal region as in Figure 1. In addition, the duration for these two words is longer than their unfocused counterparts, as indicated by the word boundaries. In Mandarin, localized pitch movement has a distinctive function at the word level, marking lexical tones. Utterance-level prosodic prominence is realized by expansion of the pitch range (Xu, Reference Xu1999). Figure 2 shows expanded pitch range of the word 乘客 “passenger” when focused (top) compared to unfocused (bottom). Note that in both cases the lexical tone shape (rise-fall) is preserved: rising tone in the first syllable and falling tone in the second syllable.

Figure 1. Prosodic prominence on the subject (top) and object (bottom) (taken from the English stimuli in the current study).

Figure 2. Prosodic prominence on the subject (top) and object (bottom); numbers in the second layer show tones (taken from the Mandarin stimuli in the current study).
It is important to note that prosodic prominence can mark both QUD-focus and contrastive-focus in English and Mandarin (e.g., Breen et al., Reference Breen, Fedorenko, Wagner and Gibson2010; Chen & Braun, Reference Chen, Braun, Hoffmann and Mixdorff2006; Greif, Reference Greif2010). However, it remains debated whether different types of prosodic prominence (emphatic prominence/L+H* or normal prominence/H*) are associated with distinct categorical meanings, for example, H* signals new information (noncontrastive, QUD-focus), while L+H* signals contrastive information (contrastive focus) (Pierrehumbert & Hirschberg, Reference Pierrehumbert, Hirschberg, Cohen, Morgan and Pollack1990). Another line of studies showed that there may not be a clear distinction between the two accent types with regard to signaling contrast (Hedberg & Sosa, Reference Hedberg, Sosa, Lee, Gordon and Büring2008; Ladd & Schepman, Reference Ladd and Schepman2003). In particular, Rooth (Reference Rooth1992) made no distinction between different types of nuclear prominence—it is therefore assumed that any nuclear prominence can activate alternatives, that is, mark contrastive focus. Nevertheless, whether a focus has a contrastive reading is also affected by other factors like context: under a context that provides a contrastive interpretation (e.g., (1)), normal/noncontrastive prosodic prominence, such as an H* accent, may also render the focus contrastive.
In both languages, sentence-final objects occupy the “default” focus position (Calhoun, Reference Calhoun2010; Ladd, Reference Ladd2008; Xu, Reference Xu2004). Subjects (and other non-sentence-final constituents) must carry phonetically strong prosodic marking to signal focus, with no prominence on the final object, while for final objects, “neutral” (non-emphatic) prominence is sufficient to signal focus. Further, objects have a default focus bias, that is, they may be processed as if they carry focus, even if they are not overtly focused marked at all (e.g., not accented, Carlson et al., Reference Carlson, Dickey, Frazier and Clifton2009; Yan & Calhoun, Reference Yan and Calhoun2020). Therefore, an asymmetry exists between subjects and objects in focus processing in both Mandarin and English (Chen et al., Reference Chen, Chen and He2012; Yan & Calhoun, Reference Yan and Calhoun2020).
Syntactic focus marking (clefting)
In English and Mandarin, focus can also be marked by certain syntactic constructions, such as clefts (e.g., it was … that in English and SHI….DE in Mandarin) (Lambrecht, Reference Lambrecht2001; Paul & Whitman, Reference Paul and Whitman2008), as in the following:

In both languages, the cleft head (e.g., passenger in (5a) and (6a)) is normally analyzed as being in focus. In English the head is always initial, immediately following it was, for example, passenger in (5a) and wallet in (5b). Mandarin has different positions for subject and object clefts. For subjects, SHI precedes the subject, as for 顾客 “passenger” in (6a), and DE precedes the object. DE in this position also indicates past tense (Chao, Reference Chao1968; Hole, Reference Hole2011; Paul & Whitman, Reference Paul and Whitman2008). For objects, SHI immediately precedes the verb, while DE precedes the object, as for 钱包 “wallet” in (6b) (Paul & Whitman, Reference Paul and Whitman2008). This pre-object 的 (DE) is largely restricted to Northern Mandarin speakers and may not be acceptable for Taiwan Mandarin and other southern varieties (Hole, Reference Hole2011; Paul & Whitman, Reference Paul and Whitman2008; Teng, Reference Teng1979), so the current study uses Northern Mandarin speakers.
SHI…DE clefts in Mandarin and it-clefts in English are said to carry an existential presupposition that canonical sentences do not have (e.g., Hedberg, Reference Hedberg, Hartmann and Veenstra2013; Lambrecht, Reference Lambrecht2001). For example, for (5a) and (6a), it is presupposed that someone (the passenger) found the wallet, and that there is an alternative set of people who could have. In order to be pragmatically appropriate, a context such as (1) (repeated as (7)) is usually needed, which introduces an entity that contrasts with the clefted element (Molnár, Reference Molnár, Molnár and Winkler2006). The contrasting entity can also be inferable from a set (e.g., passenger—people on a bus) (Calhoun et al., Reference Calhoun, Wollum and Kruse-Va’ai2021). In the current study, such a context was included (see section “Materials and design”).
-
(7) Context: A young man lost his camera and wallet in the bus. The driver and a passenger found them.
The clefted constituent is clearly therefore a contrastive focus. However, it is also usually a QUD-focus, in that it carries the asserted, or “question-answering” part of the proposition (Lambrecht, Reference Lambrecht2001). This is consistent with the experimental findings for English and Mandarin (Arnhold, Reference Arnhold2021; Calhoun et al., Reference Calhoun, Wollum and Kruse-Va’ai2021; Chen et al., Reference Chen, Chen and He2012) (see section “L1 studies”). It has also been claimed that another difference between the two types of focus marking, clefts and canonical word order sentences marked with prosodic prominence, is that clefts carry an exhaustive inference in both English and Mandarin (É Kiss, Reference É Kiss1998; Hole, Reference Hole2011; Krifka, Reference Krifka2008; Paul & Whitman, Reference Paul and Whitman2008). However, increasing experimental work in both languages is not consistent with this, unlike the exhaustive adverb only (e.g., Destruel et al., Reference Destruel, Velleman, Onea, Bumford, Xue, Beaver and Schwarz2013, Liu & Yang, Reference Liu, Yang, Köllner and Ziai2016; see overview in Onea, Reference Onea, Cummins and Katsos2019). Reviewing these studies, Onea (Reference Onea, Cummins and Katsos2019) concludes that it is probably the case that “clefts imply that no other true answer to that issue is more informative than the canonical inference” (p. 415), which may or may not lead to the interpretation of exhaustivity depending on the context.
There are other types of cleft constructions in both languages, but we use SHI…DE clefts in Mandarin and it-clefts in English, since both are claimed to be canonical cleft constructions in the respective languages (Hole, Reference Hole, Krifka and Musan2012; Liu & Kempson, Reference Liu and Kempson2018) and have been studied for their focus properties. They are similar in function and have been compared in previous studies on focus processing (e.g., Yan & Calhoun, Reference Yan and Calhoun2020).
In both languages, the cleft head normally carries the nuclear prominence, for example, 乘客 “passenger” in (5a) and (6a), so prosodic and clefting cues converge on the same word (which is both a QUD- and contrastive-focus). However, the nuclear prominence can fall on a different constituent, for example, the object 钱包 “wallet” in (8). In this case, prosodic and clefting cues mark QUD-focus on different constituents, that is, the two cues compete for focus assignment (both constituents are contrastive). Such “mismatch” constructions are attested in naturally occurring speech in both Mandarin and English (Delin & Oberlander, Reference Delin and Oberlander1995; Hedberg, Reference Hedberg, Hartmann and Veenstra2013; Hole, Reference Hole2011; Lambrecht, Reference Lambrecht2001; Prince, Reference Prince1978) and have recently been used in experimental studies of Mandarin, English, and Korean (Calhoun et al., Reference Calhoun, Wollum and Kruse-Va’ai2021; Kember et al., Reference Kember, Choi, Yu and Cutler2021; Yan & Calhoun, Reference Yan and Calhoun2019, Reference Yan and Calhoun2020).
-
(8) Mismatch subject clefts with prosodic prominence on the object

Despite their similarities, clefting cues to focus differ in Mandarin and English in the following ways. Firstly, the SHI…DE construction marks focus in Mandarin without word order alteration (other than the placement of SHI), while in English, clefts involve fronting (raising to a higher clause); this results in greater movement for the object, relative to its non-clefted position. Secondly, while subject clefts are more frequent than object clefts in both languages (Mandarin: Hedberg, Reference Hedberg1999; English: Roland et al., Reference Roland, Dick and Elmanc2007), this seems to be more marked in Mandarin, and object clefts may only mark object focus for Northern varieties of Mandarin (Paul & Whitman, Reference Paul and Whitman2008). These differences may affect their interpretation.
The role of prosody and clefting in the processing of focus in L1 and L2
L1 studies
In languages where prosodic prominence is a primary cue to focus, listeners use the position of prosodic prominence to identify the focus and distinguish focus types (e.g., Breen et al., Reference Breen, Fedorenko, Wagner and Gibson2010; Birch & Clifton, Reference Birch and Clifton1995; Clifton & Frazier, Reference Clifton and Frazier2016; Lee et al., Reference Lee, Wang and Liberman2016; Welby, Reference Welby2003). But there is much less research on what happens if there are multiple cues to focus in an utterance, particularly when these indicate focus on different words, for example, (8) above. In English, although prosodic prominence is a primary cue to focus in canonical order sentences, Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021) found listeners gave a higher weighting to the clefting cue (it-clefts) than prosodic prominence when the two cues signaled focus on different words. Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021) used a forced-choice task, in which participants had to choose between two possible questions for an utterance which was presented as an answer and which had prosodic and/or clefting cues on the subject and/or the object (the question and answer conditions were the same as those in the current study, see Table 1 in section “Materials and design”). They found that the preferences for choosing each question (subject question [SQ] or object question [OQ]) under different sentence conditions were as follows:
-
(9) SQ Preference: ScleftS≥canonS≥ScleftO
OQ Preference: OcleftO≥canonO≥OcleftS
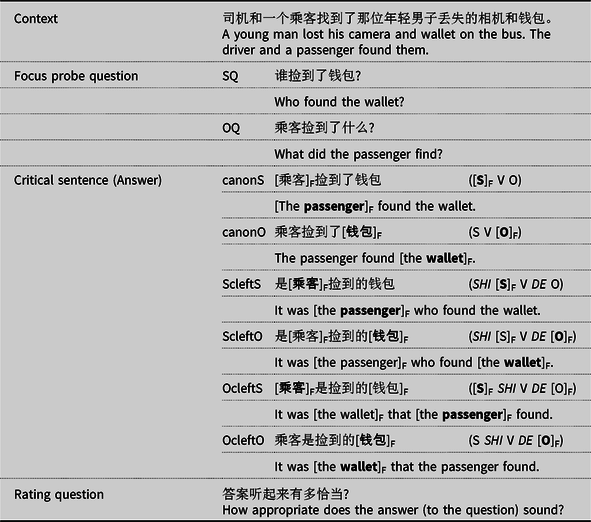
Table 1. Examples of test materials
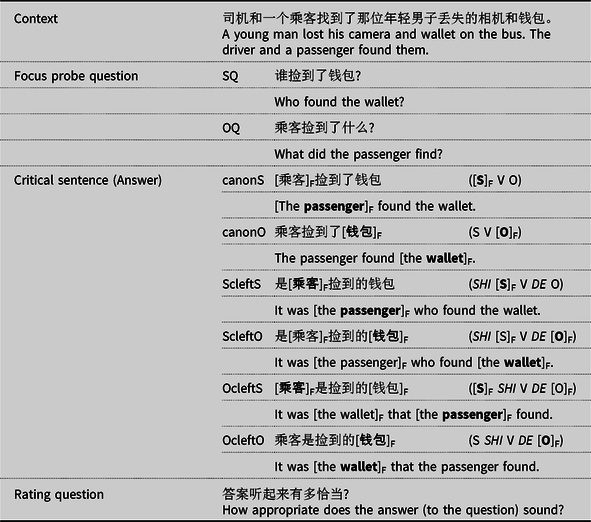
(canon = canonical order sentence; Scleft = subject cleft; Ocleft = object cleft; the capitalized S or O at the end of each label indicates whether prosodic prominence was on the subject or on the object, also see Table 1 in section “Materials and design” for detailed explanation of the labels. Note that in both cases ≥ indicates that the canonical sentences were not significantly different from either cleft, but these were significantly different from each other).
Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021) showed that prosodic prominence was a reliable cue to focus in canonical word order sentences. In cleft sentences where prosodic prominence and clefting cues aligned (ScleftS or OcleftO), the combined cue was key to listeners to interpret the focus position. However, when the two cues clashed (ScleftO or OcleftS), clefting was more important than prosodic prominence. For instance, “Who found the wallet?” was more likely to be chosen as a suitable question than “What did the passenger find?” for the answer “It was [the passenger]F that found [the wallet]F.” There were no differences in the effect of focus cues on subjects versus objects. Arnhold (Reference Arnhold2021) used a rating study (similar to the current study, see section “The current study”) where listeners rated how suitable an answer sentence (canonical word order vs. subject clefts with/without prominence on the subject) was to the question (broad focus question vs. subject focus question). It was found that for the broad focus question the two clefts were rated less suitable than the canonical word order sentences, and the cleft with subject focus was rated less suitable than the one with broad focus. This suggests both prosodic and clefting cues played an important role in interpreting focus given a preceding broad focus question.
In Mandarin, studies suggest that prosodic prominence in Mandarin is more effective than clefting in the processing of focal information (Chen et al., Reference Chen, Chen and He2012; Yan & Calhoun, Reference Yan and Calhoun2020). For example, Yan and Calhoun (Reference Yan and Calhoun2020) used a speeded “false alternative” rejection task, in which participants had to reject a “false alternative” question like (10) after hearing a sentence with the subject or object marked by prosodic prominence and/or clefting (as in (3)–(6), (8)) in Mandarin and English. They found that prosodic prominence facilitated the rejection of the false alternative (driver or camera) in both languages, with a stronger effect in Mandarin compared to English. Clefting played an inhibitory role in both languages. The results further showed that prosodic and clefting cues had a smaller effect on processing for objects than subjects, as focus was already cued by default position for objects (see section “Prosodic focus marking”).
-
(10) SQ: Did the driver find the wallet?
OQ: Did the passenger find the camera?
L2 studies
Before reviewing studies in L2, we present relevant L2 learning theories as a framework for evaluation of these findings. Few L2 learning theories explicitly address prosody. We concentrate on the L2 intonation learning theory (Mennen, Reference Mennen, Delais-Roussairie, Avanzi and Herment2015) and the CM (Bates & MacWhinney, Reference Bates, MacWhinney, MacWhinney and Bates1989) as the most useful for the current study.
L2 learning theories
Mennen’s L2 intonation learning theory (LILt) (2015) explicitly deals with intonation acquisition. Although the focus of the theory is on production, it has also been tested in perception studies (see section “L2 research on focus processing”). The theory predicts that L2 difficulties in learning intonation will depend on the types of differences between L1 and L2, due to L1 transfer. Four dimensions of differences (modified from Ladd, Reference Ladd1996) are presented in the model and discussed in relation to focus marking in English and Mandarin below.
The first is the “systemic dimension,” involving the inventories of phonological elements and their distributions in the two languages. English and Mandarin seem to differ on this dimension in that focus is marked by pitch accenting in English and pitch range expansion in Mandarin. However, previous perception studies (see above and Ip & Cutler, Reference Ip and Cutler2020; Yan et al., Reference Yan, Calhoun and Warren2022) have shown that these are functionally equivalent in processing the focus of an utterance. Therefore, we treat these as the same phonological element: nuclear (or utterance-level) prosodic prominence, in both languages. This places the difference on the second “realizational dimension” (the phonetic implementation of phonological elements: pitch accenting vs. pitch range expansion). We show below that this difference does not seem to matter in perception, at least for focus; however, it may be important in production. Therefore, it is predicted that the acquisition of prosodic prominence in perception may not be difficult for Mandarin learners of English due to the similar functionality of prosodic prominence in learners’ L1 and L2. The third “semantic dimension” (relating to the functions of the categorical elements or tunes) is particularly relevant for the current study. In our case, this concerns how prosodic prominence interacts with clefting as cues to focus in Mandarin and English. Although the model does not touch on how prosody interacts with other parts of the linguistic system, we predict difficulties for L2 learners if this interaction is functionally different to their L1 system. The languages seem to differ in the relative importance of prosodic and syntactic cues to focus. Based on LILt, we predict that the use of prosodic cues in English should not be problematic for Mandarin L2 listeners, but clefting may not provide as effective a cue to focus for Mandarin listeners in English. The fourth “frequency dimension” (the frequency of use of phonological elements) is not as easy to assess, because the relative frequencies of use of prosodic prominence and clefting as focus markers are not known (e.g., from corpora).
The CM (Bates & MacWhinney, Reference Bates, MacWhinney, MacWhinney and Bates1989), as applied to second language acquisition (Li & MacWhinney, Reference Li, MacWhinney and Chapelle2013), has been tested in much crosslinguistic research with both L1 and L2 (e.g., Chen et al., Reference Chen, Chen and He2012; Liu et al., Reference Liu, Bates and Li1992). Although it is not specifically directed toward L2 learning of prosody, it can be used to make relevant predictions for the current study as the model deals with cue weights in learners’ L1 and L2, which is the core of the current study. The weighting of various cues to signal meanings may differ between languages. The model suggests that while native speakers of a given language use the cue strength associated with that language, for learners of that language, the acquisition of cue-strength patterns is part of their learning and may exhibit different patterns depending on the L1–L2 relationship. In English and Mandarin, prosodic prominence and clefting, the two types of focus cues used in the current study, have different cue strengths. These cues converge or compete in the interpretation of focus. For example, in “It was the passenger who found the wallet,” both the prosodic and clefting cue converge on passenger as the focus. The cue strength is combined. By contrast, the two cues compete in “mismatch” clefts such as “It was the passenger who found the wallet.” The two cues indicate focus on different words, and this divergence creates a competition: prominence wins in Mandarin and clefting may win in English (e.g., Calhoun et al., Reference Calhoun, Wollum and Kruse-Va’ai2021; Chen et al., Reference Chen, Chen and He2012). In light of this variation in relative cue strength, when Mandarin learners interpret focus in their L2 English, they need to acquire new cue-strengths and L1 transfer is likely.
L2 research on focus processing
The use of prosodic cues to process focus in L2 speech is challenging, even for proficient learners (e.g., Braun & Tagliapietra, Reference Braun and Tagliapietra2011; Ge et al., Reference Ge, Chen and Yip2020; Lee & Fraundorf, Reference Lee and Fraundorf2017; van Maastricht et al., Reference van Maastricht, Krahmer and Swerts2016). For example, using a cross-modal lexical priming task, Braun and Tagliapietra (Reference Braun and Tagliapietra2011) looked at the effect of contrastive and noncontrastive prosodic prominence in priming contrastive alternatives in Dutch (L2) with advanced L1 German listeners. Contrastive prosodic prominence enhances the encoding of alternatives to the focused word but is marked by different intonation contours in Dutch and German. It was found that learners with high proficiency inferred alternatives after both intonation contours, suggesting acquisition of the L2 contour but also L1 transfer.
Recently, Ge et al. (Reference Ge, Chen and Yip2020) investigated the mapping between focus and prosody in English sentences with only by advanced Cantonese and Dutch learners. Cantonese marks focus primarily with focus particles (Chao, Reference Chao1947), whereas English and Dutch use prosodic prominence. Ge et al. (Reference Ge, Chen and Yip2020) manipulated question (e.g., “I wonder what the fox is licking”Footnote 1 ) and answer types (e.g., “The fox is only licking the honey/licking the honey”) and found that Cantonese learners of English gave equal “make sense” ratings to appropriate prosody and to inappropriate prosody, while both English native speakers and Dutch learners of English gave higher “makes sense” ratings to answers with appropriate than inappropriate prosody. This can be explained by LILt as differences in the semantic dimension. Difficulties occurred when the use of prosodic cues to focus is different in L1 and L2, as was the case for Cantonese learners but not for Dutch learners. Ortega-Llebaria and Colantoni (Reference Ortega-Llebaria and Colantoni2014) investigated the mapping between focus, prosody, and syntax in English with advanced Mandarin and Spanish learners, finding that in the perception and production of English focus using prosodic prominence, Mandarin learners behaved similarly to English native speakers, but Spanish learners performed less accurately. This again shows L2 performance largely depended on the semantic function of the L2 cues in their L1, consistent with LILt.
Although the mapping between prosody and focus has been investigated in L2 studies, the mapping between clefting and focus has rarely been tested (but see Reichle & Birdsong, Reference Reichle and Birdsong2014 for an investigation in L2 proficiency effects using event-related potentials with L1 and L2 French speakers), let alone the interaction between prosodic and clefting cues. Due to the differences in the relative cue weightings in the two languages, it is valuable to examine how clefting cues are used in focus identification in English by Mandarin learners. The previous studies reviewed above have used moderate to high proficiency learners, yet find processing differences compared with L1 speakers, suggesting this is a challenging aspect of second language acquisition even for reasonably advanced learners.
The current study
The current study investigates which cue(s) (prosodic, clefting, or both) Mandarin learners of English use in their interpretation of focus in an untimed rating task in their L2, compared to L1. In the experiments, participants judged how appropriate an answer to a question sounded. The intended focus in the answer was marked by prosodic and/or clefting cues. Given the contexts in the experiment, the focus was a narrow QUD-focus, that is, the focused word answered the preceding question (see section “Focus marking”). Both subject and object focus conditions were used, as previous studies have found differences in the processing of subjects and objects in reaction time and accuracy tasks (though not rating tasks, see section “L1 studies”) and there are asymmetries between subject and object clefts (see section “Syntactic focus marking (clefting)”). We did not include a broad focus or “neutral” realization given the complexity of the design.
There were two groups of participants: near-monolingual Mandarin-speaking participants in their L1 (L1 experiment) and Mandarin learners of English (mid-to-high proficiency) in their L2 English (L2 experiment). Our study therefore focuses on intermediate-to-high level English learners. While proficiency is likely to affect performance on this task, we chose to look at these learners, as integration of multiple cues to focus is complex and likely to be challenging even for high proficiency learners. This may be too difficult for lower proficiency learners. Previous studies in this area have involved learners of similar proficiency levels to ours (see section “L2 research on focus processing”).
The L2 English materials were slightly simplified from those used in Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021) with L1 English speakers, using the same conditions. Some words in the materials in Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021) were replaced so that all words were among the 2000 most frequent words in BNC/COCA (Cobb, Reference Cobb2000), making sure that L2 learners knew them. This allowed us to compare our findings for L2 English speakers to those for L1 English speakers in Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021).
Research questions and predictions
Research questions
RQ1. Does prosodic prominence on the QUD focus result in higher appropriateness ratings than prosodic prominence in another location, and does this differ in L1 and L2?
RQ2. Relative to canonical word order, does consistent clefting on the QUD focus result in higher appropriateness ratings and inconsistent clefting in lower appropriateness ratings, and does this differ in L1 and L2?
RQ3. What are the relative weightings of prosodic and clefting cues in L1 and in L2?
Predictions
For RQ1, our prediction in both L1 and L2 is that prosodic prominence on the QUD focus will result in higher ratings than prosodic prominence in another location because of the key role of prominence in marking focus in both languages, as prosodic prominence cues to focus are used in a functionally equivalent way in learners’ L1 and L2 based on the first two dimensions in LILt (see section “L2 learning theories”). For RQ2, in both L1 and L2, based on the CM (see section “L2 learning theories”), we predict that compared to no clefting, consistent clefting will strengthen focus marking and result in higher ratings, while inconsistent clefting cues will result in lower ratings. For RQ3, we expect different cue-weighting in L1 and L2: when prosodic and clefting cues compete, prosodic cues will win over clefting in Mandarin, but clefting may win over prosodic cues in English based on previous studies (see section “L1 studies”). Therefore, in L2, based on the “semantic dimension” in LILt (see section “L2 learning theories”), it is expected that effective use of clefting cues will be difficult for Mandarin learners, due to L1 transfer. Also, due to the possible difference in relative cue strength in learners’ L1 and L2, the CM predicts that acquiring new cue strengths may pose challenges for L2 learners.
Method
Participants
Thirty-six native near-monolingual Mandarin speakers (32 females and 4 males; mean age = 24.6 [18–40], SD = 5.4) were recruited for the L1 experiment. We recruited L1 speakers who were similar to the L2 speakers specified below (in terms of demographics, education level, etc.). Given that some English education is compulsory in China, it is highly unlikely that this group would be fully monolingual. All of our L1 participants had completed compulsory education in China and had therefore learnt English for at least 6 years. Their average self-reported English proficiency level was 2.7 (SD = 0.6) on a scale of 1–6. They had not lived outside China for more than six consecutive months.
Another 36 native Mandarin speakers (35 females and one male; mean age = 21 [19–23], SD = 0.8) were recruited for the L2 experiment. They were third or fourth year English major students recruited from a university in China. Their average self-reported English proficiency level was 3.85/6 (SD = 0.6), which was significantly higher than that of the participants for the L1 experiment (t = 8.5, p <.001). This was slightly lower than 4.17/6 for Cantonese learners and 4.55/6 for Dutch learners, who were categorized as advanced learners in Ge et al. (Reference Ge, Chen and Yip2020), and slightly higher than 3.6/6 in Lee and Fraundorf (Reference Lee and Fraundorf2017) and 3.7/6 in Lee and Fraundorf (Reference Lee and Fraundorf2019) for Korean learners who were categorized as moderate to high proficiency learners. Like the L1 participants, none of the L2 participants had lived outside China for more than six consecutive months. All participants in both experiments reported themselves to have grown up in northern or central China (e.g., Henan, Hebei province) and could not speak any language other than their native language (Mandarin and/or a dialect) and English. They received supermarket vouchers in recognition of their participation. None of them reported hearing or reading difficulties.
A cloze test, developed for another L2 focus processing experiment by Lee and Fraundorf (Reference Lee and Fraundorf2019), was used to assess proficiency of the L2 group and was included as the proficiency factor in the data analysis (see section “Results”). The average cloze score was 31/40 (SD = 3) (as compared to 33.6 [SD = 2.91] in Lee & Fraundorf, Reference Lee and Fraundorf2019). The average age of starting to learn English was 10.7 (SD = 2). The means of self-reported English proficiency on a scale of 1–6 are listening: 3.4 (SD = 0.9), speaking: 3.5 (SD = 1), reading: 4.5 (SD = 0.8), and writing: 4 (SD = 0.7).
Materials and design
Forty-eight sets of Mandarin experimental materials for the L1 experiment and 60 sets of English materials for the L2 experiment were constructed. The Mandarin stimuli were adapted from Yan and Calhoun (Reference Yan and Calhoun2020) which used cross-modal lexical decision tasks to test the role of focus in speech processing in the two languages, where a lot of factors (e.g., frequency, the numbers of strokes and radicals of Mandarin characters) were controlled for. Each set of materials in the two languages includes a Context, Focus probe question, Critical sentence (Answer), and Rating question, as shown in Table 1 (see full list in the On-line Supplementary Materials available at https://osf.io/54hgr/). The context was designed to be short and plausible, while introducing either two sets of explicitly mentioned alternatives (e.g., passenger and wallet in Table 1) or a set which introduced inferable alternatives (e.g., man and woman can be implied by couple). The alternatives in the context made the cleft sentences pragmatically plausible (see section “Syntactic focus marking (clefting)”). All words in the English critical sentences were among the 2000 most frequent words in BNC/COCA (Cobb, Reference Cobb2000).
As Table 1 shows, there were two types of question: a SQ and an OQ. There were six sentence types for the answer, varying the position of prosodic prominence and the presence and type of clefting: canonS and canonO (canonical word order with contrastive prosodic prominence on the subject or the object noun), ScleftS and ScleftO (subject cleft with contrastive prosodic prominence on the subject or the object noun), and OcleftS and OcleftO (object cleft with contrastive prosodic prominence on the subject or the object noun). This resulted in 12 experimental conditions (2 question types × 6 sentence types).
Each critical sentence appeared in all 12 conditions, giving a total of 576 experimental stimuli for the L1 experiment and 720 for the L2 experiment. Twelve lists of stimuli were constructed in a Latin square design so that each sentence was in a different condition in each list. Each participant saw one list.
A further 24 filler trials for the L1 experiment and 20 fillers for the L2 experiment were constructed. There were fewer fillers in the L2 experiment so as not to make it too long for participants. The focus probe questions in the fillers asked about different parts of the answer such as adverbial (e.g., “When did the scholar visit this city?”). The answers in the filler trials had different sentence structures from the test items, such as subject-verb and subject-adverbial-verb-object, with varied locations of prosodic prominence.
Recording and acoustic analysis
For each language, the focus probe questions (see Table 1) were recorded by a male native speaker and the critical sentences (see Table 1) by a female native speaker. The English speakers had North American varieties, which would be familiar to most Chinese learners of English. All speakers were given instructions about how to read the sentences. Recordings were made in a soundproof room via a head-mounted microphone directly to a computer hard drive using Praat (Boersma & Weenink, Reference Boersma and Weenink2018) (Mandarin: sampling rate: 32000 Hz; bit rate: 512 kbps, bit depth: 16; English: sampling rate: 44100 Hz; bit rate: 705 kbps; bit depth: 16) (see Figure 1 for English examples of canonS and canonO, and Figure 2 for Mandarin examples of canonS and canonO, Figure 3 for examples of ScleftO and ScleftS in Mandarin and English, and Figure 4 for examples of OcleftO and OcleftS in Mandarin and English). The intensity of all sentences was re-scaled to 50 dB. Contrastive prosodic prominence (or emphatic stress) was used in the answer sentences in the experiments, as we wanted stimuli to unambiguously mark prosodic focus on either the subject or the object, and a “neutral” prominence (or normal stress) could leave the focus ambiguous.

Figure 3. Example pitch tracks for the stimuli in the subject cleft conditions, with stress on the object (ScleftO, left) then subject (ScleftS, right). Mandarin is at the top, English bottom.

Figure 4. Example pitch tracks for the stimuli in the object cleft conditions, with stress on the object (OcleftO, left) then subject (OcleftS, right). Mandarin is at the top, English bottom.
To confirm that the critical sentences did indeed differ according to the intended position of the prosodic prominence, the Mandarin sentences were automatically segmented (with manual corrections) at the word level using the Montreal Forced Aligner (McAuliffe et al., Reference McAuliffe, Socolof, Mihuc, Wagner and Sonderegger2017) and the English critical sentences using Munich automatic segmentation (MAUS) (Kisler et al., Reference Kisler, Reichel and Schiel2017). Then acoustic measurements were obtained for the subject and object nouns. The measures were duration, mean F0, and mean intensity (see On-line Supplementary Material). As focus is marked through pitch range expansion in Mandarin, F0 range (max F0 – min F0) was also calculated for Mandarin. The differences between each word (subject and object) in each condition, and between the same word in each prominence condition (e.g., subject in canonS vs. canonO), confirmed the materials have the intended prominence locations in both languages. Statistical tests confirming these findings are available in the On-line Supplementary Materials.
Procedure
The L1 and L2 experiments were administered using OpenSesame v. 3.1 (Mathôt et al., Reference Mathôt, Schreij and Theeuwes2012) in a quiet computer room. Participants listened to the stimuli over closed-ear headphones. Participants received written instructions on the computer screen. As Figure 5 shows, participants first saw a context and were instructed to press any key to proceed when they had read it, with no time limit. They then heard a dialogue consisting of a question in the male voice followed after 500 ms by an answer in the female voice. The screen was blank with a black background while the audio played. After that, they were prompted by a message on the screen to judge the appropriateness of the answer to the question, using a scale from 1 to 7. Only the endpoints (1 一点儿也不恰当 [not appropriate at all] and 7 极其恰当 [extremely appropriate]) were labeled. They indicated their judgment using the appropriate key on the keyboard, within 6 s. After either a key press or 6 s the experiment moved to the next trial. Trial order was randomized for each participant. Participants were told that they could take a break if they wanted whenever they saw the screen showing the context.

Figure 5. Procedure of the experiments.
Six practice trials were played in a fixed order before the main experiment. These followed the same format as the main experiment. Demographic information was collected using a paper form at the end. The cloze test was then administered to measure L2 participants’ English proficiency for the L2 experiment participants. The entire Mandarin experiment lasted approximately 20 min and the English experiment 30 min.
Data cleaning and analysis
The rating responses (1–7) were recorded and analyzed. For the L1 experiment, 50 of 1728 (48 from each of the 36 participants) test trials were unanswered (2.9%). The remaining 1678 test trials were used in the following analysis. For the L2 experiment, all 2160 test trials were used in the analysis.
As the dependent variable (ratings) was ordinal, cumulative link mixed models were fitted using the ordinal package (Christensen, Reference Christensen2015) in R (R Core Team, 2018). Because the L1 and L2 experiments involved different languages and groups of participants, it would not be appropriate to include both sets of data in one model. Therefore, we carried out two separate analyses. For the L1 experiment, the initial model included key experimental predictors: prosodic prominence position (subject, object), syntactic type (canonical, subject cleft, object cleft), and question type (subject, object) and their interactions. For the L2 experiment, we further included the values from the cloze test. This measure was a continuous variable in the four-way interaction (syntax*prosodic prominence*question type*proficiencyFootnote 2 ), in lower-level interactions, and as a simple effect. Random effects included intercepts for participants and items, and by-participant and by-item random slopes for the interactions between the key experimental factors as well as for their simple effects.
In each case, the initial model was simplified by removing the random slopes that had the lowest variance scores until the model converged. The R function anova was used to eliminate non-significant random slopes by comparison of models with and without one slope, and the Anova.clmm function in the RVAideMemoire package (Hervé, Reference Hervé2015) to eliminate non-significant fixed effects.
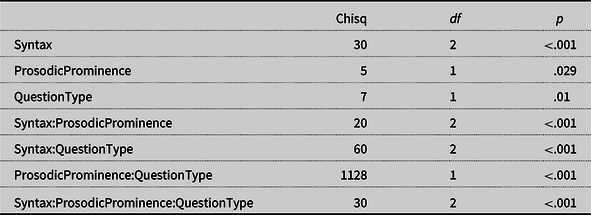
Results
L1 interpretation of focus
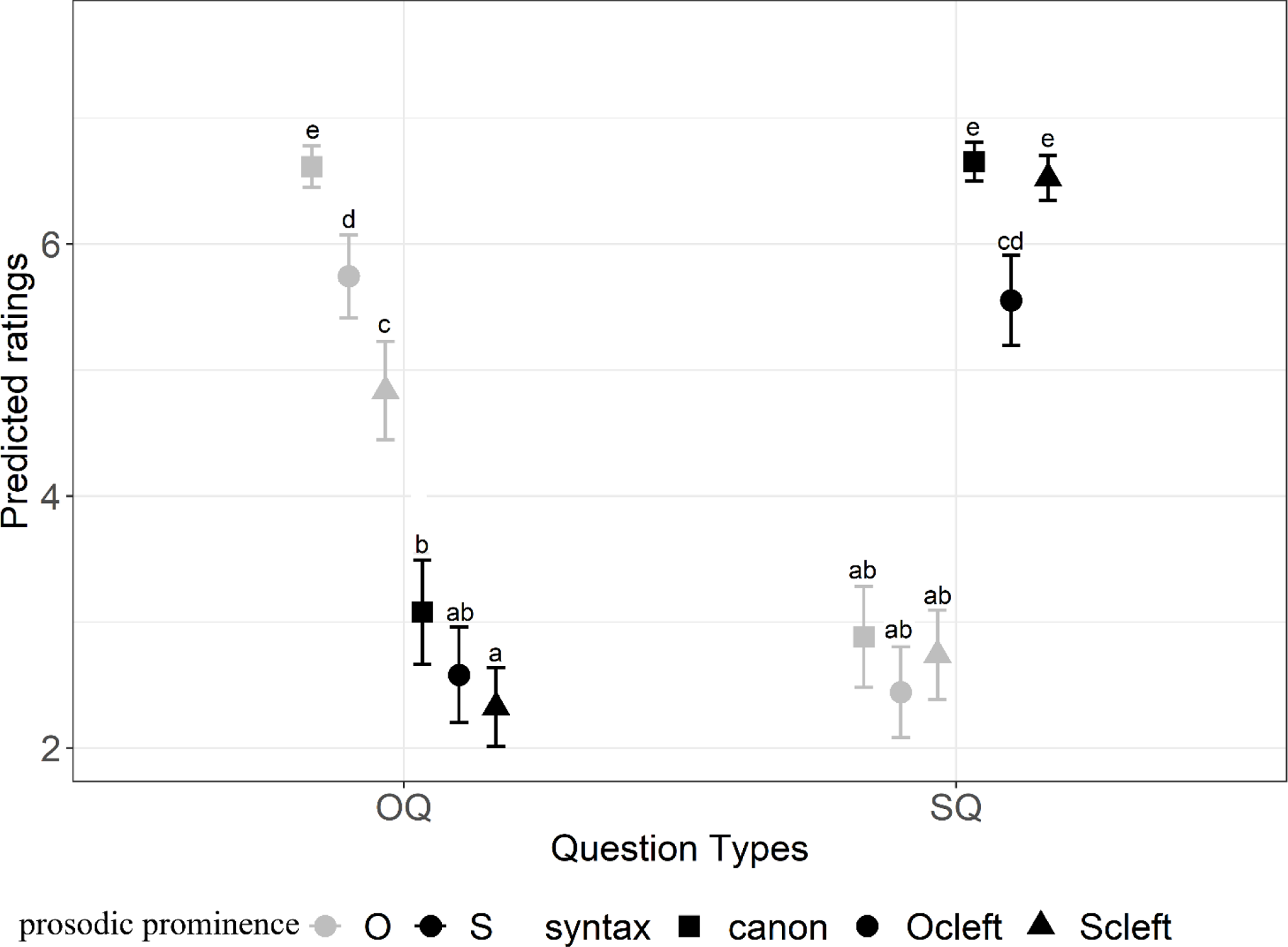
Table 2 shows the significance of variables in the final model for L1 (the analysis code, data, and the results of the fixed effects are summarized in the On-line Supplementary Materials). Predicted ratings were calculated from the model and plotted using the ggplot2 package (Wickham et al., Reference Wickham, Chang and Wickham2016) in Figure 6.
Table 2. ANOVA table of the final model for ratings for L1

Note. Model: Syntax*ProsodicProminence*QuestionType + (1|Item) + (1 + Syntax|Participant)

Figure 6. The predicted ratings from cumulative link mixed model for each condition for L1. Gray and black indicate the location of prosodic prominence, and different shapes indicate the different syntactic types.
A compact letter display (CLD) was produced using the CLD function in the multcompView package (Graves et al., Reference Graves, Piepho and Selzer2019) and added to Figure 6. This function produces all pairwise comparisons of least-squares means with Tukey adjustment (see the estimates, standard errors, z, and p values in the On-line Supplementary Material). The difference between two conditions is not significant (p ≥ .05) when they share at least one letter. For example, the first two conditions in the figure have different letter labels (e and d) showing that they were significantly different from each other, while the first two conditions in black share the label b and were therefore not significantly different.
Figure 6 shows the following preferences of each answer type for SQ and OQ in the L1 experiment:
-
(11) SQ: canonS = ScleftS > OcleftS > canonO = ScleftO = OcleftO
OQ: canonO > OcleftO > ScleftO > canonS ≥ OcleftS ≥ ScleftS
(Note that in both cases ≥ indicates that object clefts with prosodic prominence on the subject (OcleftS) were not significantly different from either canonical sentences with prosodic prominence on the subject (canonS) or subject clefts with prosodic prominence on the subject (ScleftS), but canonS and ScleftS were significantly different from each other).
As Figure 6 shows, sentences with prosodic prominence on the intended focus were all rated relatively high (>4) and sentences with no prominence on the intended focus were all relatively low (<4) regardless of whether there was a clefting cue and whether it was consistent or not. This clearly shows that prosodic prominence is an effective focus cue in Mandarin for all three syntactic types (canonical, subject clefts, and object clefts).
With prominence on the focus (grey for OQ, black for SQ in the figure), adding clefting cues, whether consistent or inconsistent, is generally dispreferred (compare circles and triangles with squares): consistent clefting cues resulted in lower ratings for object clefts; inconsistent clefting cues resulted in lower ratings for both subject and object clefts. With no prominence on the focus (black for OQ, grey for SQ), adding clefting cues, whether consistent or inconsistent, mostly played little role: when the question was about the subject and prominence was on the object, ratings for object and subject clefts were not significantly different from canonical sentences. When the question was about the object and prominence was on the subject, subject clefts, but not object clefts, differed significantly from canonical sentences, while the cleft types did not differ from each other.
It is possible that the ratings of sentence types differ from one another regardless of focus marking due to their naturalness or acceptability (compare, for instance, OcleftO and OcleftS). The results showed that under the same sentence condition, changing the question type resulted in a significant change of ratings for all sentence types. For all sentence types, ratings were higher when the prosodic prominence in the sentence matched the intended focus regardless of whether clefting cues were consistent. This shows the importance of prosodic prominence as focus cues in L1 Mandarin.
L2 interpretation of focus
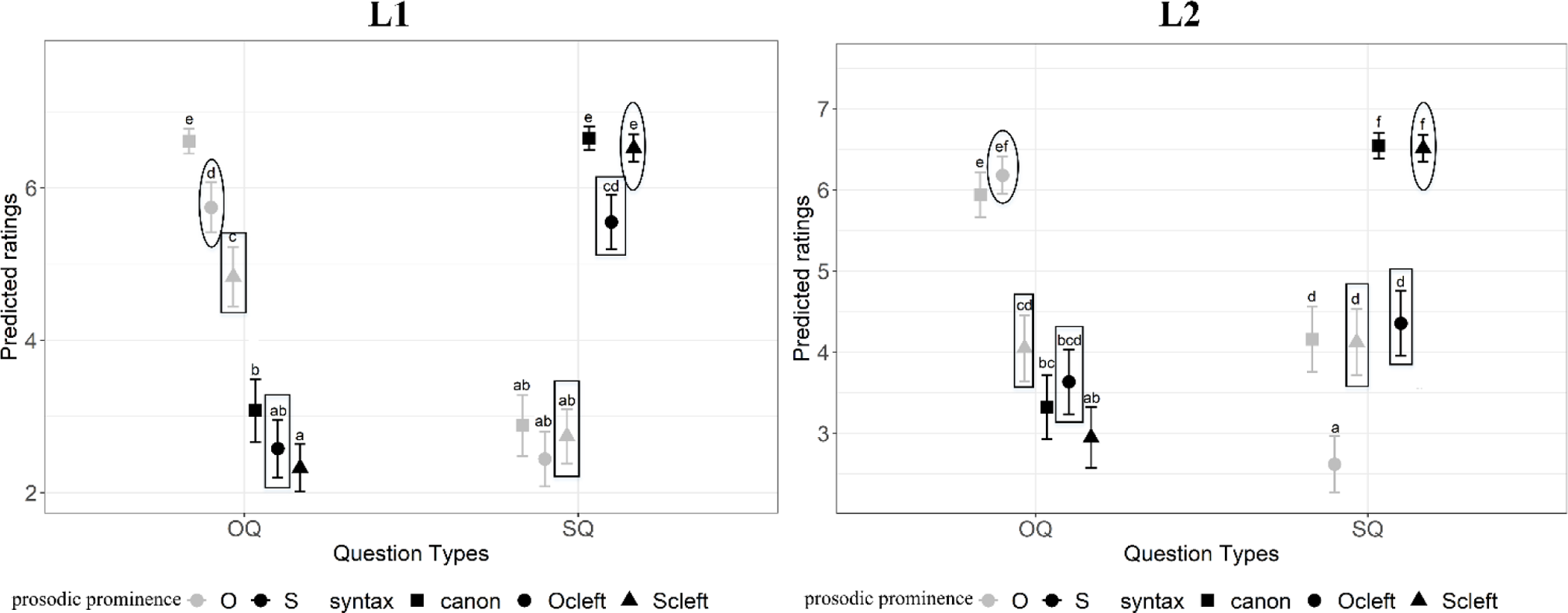
Table 3 presents the significance of variables in the final model for L2 (the results of the fixed effects are summarized in the On-line Supplementary Materials).
Table 3. ANOVA table of the final model for ratings for L2
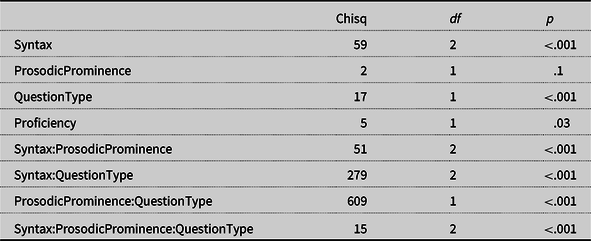
Note. Model: Syntax*ProsodicProminence*QuestionType + Proficiency + (1|Item) + (1|Participant).
Participants with lower proficiency tend to give higher ratings (β = −0.2, SD = 0.1, z = −2). The predicted ratings were calculated from the model and plotted using ggplot in Figure 7 with CLD (see the estimates, standard errors, z, and p values in the On-line Supplementary Materials). The range of L2 listeners’ ratings was generally comparable with those for the L1 participants.
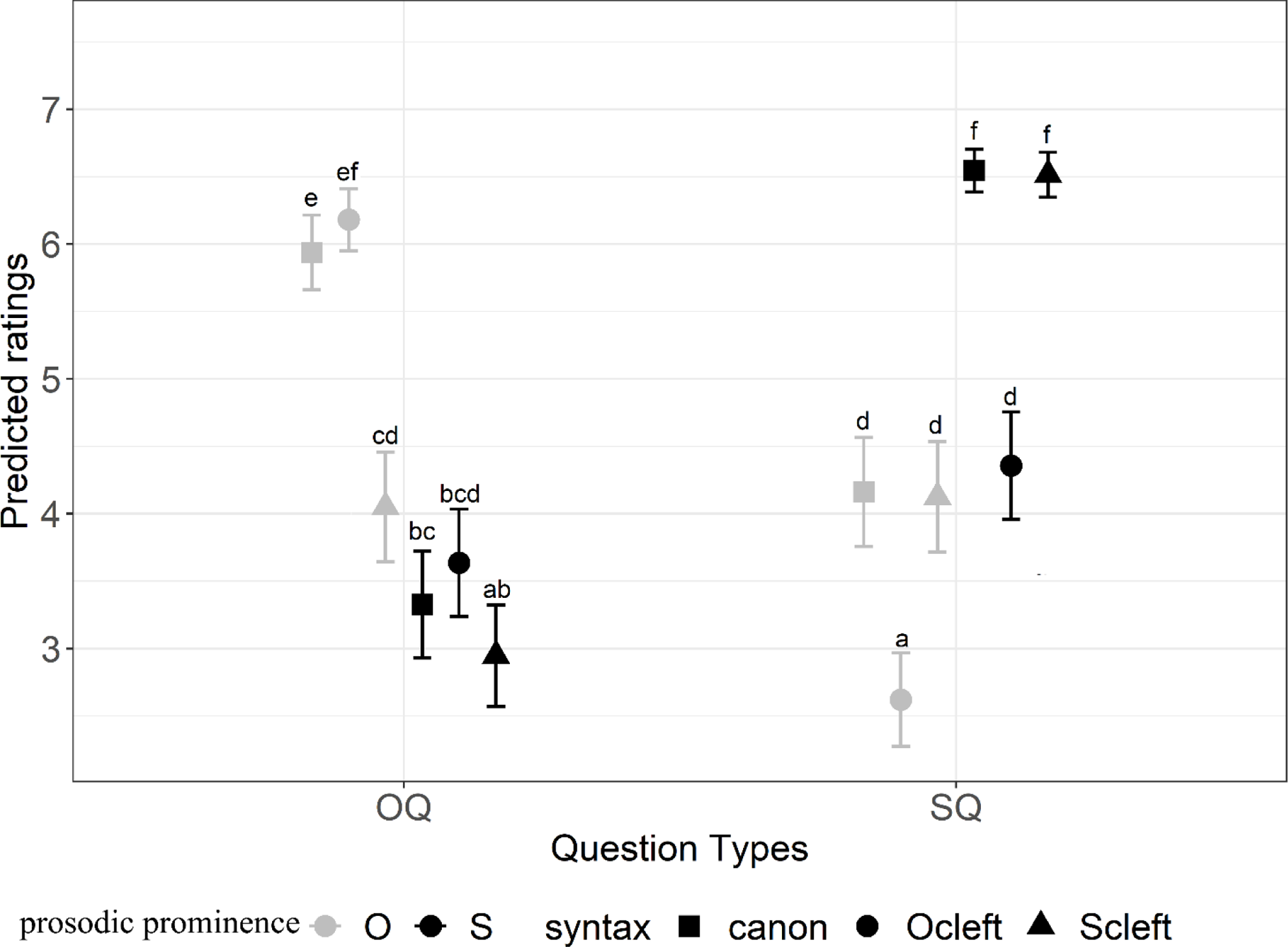
Figure 7. The predicted ratings from cumulative link mixed model for each condition for L2. Gray and black indicate the location of prosodic prominence, and different shapes indicate the different syntactic types.
Figure 7 shows the following preferences of each answer type for SQ and OQ in the L2 experiment:
-
(12) SQ: canonS = ScleftS > OcleftS = canonO = ScleftO > OcleftO
OQ: OcleftO = canonO > ScleftO ≥ OcleftS = canonS ≥ ScleftS
(Note that in both cases ≥ indicates that object clefts with prosodic prominence on the subject (OcleftS) were not significantly different from subject clefts with prosodic prominence on the object (ScleftO), and that canonical sentences with prosodic prominence on the subject (canonS) or subject clefts with prosodic prominence on the subject (ScleftS), but ScleftO and ScleftS were significantly different from each other).
As Figure 7 shows, the sentences with prosodic prominence on the focus and consistent clefting cues were rated relatively high (conditions labeled with ef and f, ratings ≥ 6). Sentences with no prominence on the focus or inconsistent clefting were judged around the midpoint of the rating scale 4 or lower. This pattern is different from that for Mandarin (see Figure 6) and shows that while prosodic prominence was the main factor in the L1, both prosodic prominence and clefting are important cues to focus for L2 learners.
With prominence on the focus (grey for OQ, black for SQ in the figure), consistent clefting resulted in statistically the same ratings as were obtained for canonical sentences, but inconsistent clefting resulted in lower ratings. With no prominence on the focus (black for OQ, grey for SQ), consistent clefting cues again resulted in statistically the same ratings as for canonical sentences, but now inconsistent clefting cues only resulted in lower ratings if they indicated focus on the object (the first two datapoints for SQ in Figure 7, labeled with d and a).
When prosodic prominence did not match clefting cues (the “mismatch” sentences ScleftO and OcleftS), the ratings were not significantly different from each other, neither within nor between question types (they all share the letter d and were all clustered around the midpoint of the rating scale).
Under the same sentence condition, changing the question type resulted in a significant change of ratings for the canonical sentences and head-stressed clefts, but not for the “mismatch” sentences. The similar ratings to the “mismatch” sentences may suggest that Mandarin learners of English assign equal weighting of prosodic prominence and clefting as cues to focus in English.
Discussion
During speech processing, listeners use various cues to search for important information as part of achieving successful communication. We investigated how L1 Mandarin L2 English listeners of intermediate-to-high proficiency use focus cues in English that are weighed similarly (prosodic cues) and differently (clefting cues) from their L1. We have shown that the role of prosodic prominence as a cue to focus is paramount in L1, but that prosodic and clefting cues are weighted equally in L2. The study suggests that the weighting of cues to focus varies across L1 and L2, contributing to the small body of literature showing cross-linguistic differences in this area. We elaborate on the role of prosodic and clefting cues in L1 and L2 below.
Effect of prosodic prominence
As expected, prosodic prominence was used consistently by Mandarin listeners in rating how appropriate an answer sounds to a question in their L1 and in L2 English. This is consistent with what Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021) found for L1 English speakers. This is because prosodic prominence plays an important role in both Mandarin and English and is in line with the predictions in section “Predictions”, based on LILt (see section “L2 learning theories”). This suggests that although the phonetic implementation of prosodic focus in the two languages is different, it operates as a functionally equivalent resource of “prosodic prominence”, that is, abstract “prominence” transfers straightforwardly from L1 to L2, at least in perception.
As discussed in section “The role of prosody and clefting in the processing of focus in L1 and L2”, in reaction time tasks prosodic cues interact with positional cues, for example, sentence-final objects show processing advantages associated with focus regardless of whether they are prosodically prominent. We did not find any such additional effect of position for objects when focus was marked by prosodic prominence in L1 or L2. In L1, the ratings for canonical word order sentences with prominence on the focus were almost identical (near 7), that is, canonS—SQ and canonO—OQ. In L2, the rating for canonS—SQ (f) was even higher than canonO—OQ (e), the opposite of the expected effect of default focus position. It may be, though, that positional effects would be found in canonical sentences with normal rather than emphatic stress on the object.
However, for L2 listeners, when focus was not marked with prosodic prominence, we found an interesting positional effect that was different to that found in previous L1 studies. For SQs, the ratings for ScleftO and canonO were around the midpoint of the rating scale (= 4). But in their L1, the corresponding ratings were very low, as shown in Figure 8 (note this comparison is indirect as different participants and materials were used in the two experiments). The same was not true for OQs (OcleftS and canonS under OQ), which were rated relatively low in both languages. Note that this effect is different from the positional bias found for L1 listeners in previous studies, where objects were processed as focused even if they were not prominent (equivalent to canonS under OQ). This suggests that L2 listeners are more accepting of “default” prosody in responses (i.e., prominence on the object), even where it is not appropriate in the discourse context (i.e., a QUD about the subject).

As mentioned in section “L2 studies”, prosody is not normally taught explicitly in classrooms. Although it seems that Mandarin speakers were able to make use of prosodic cues to focus in the current listening study, problems still exist in production and in other aspects of intonation learning (see section “L2 learning theories” on the second dimension of LILt). For example, Mandarin speakers face some difficulties in disambiguating “neutral’ broad focus and sentence-final object focus in English in production (Wayland et al., Reference Wayland, Guerra, Chen and Zhu2019), which likely involves learning differences in phonetic realization. Therefore, some targeted intonation teaching would help learners better produce and comprehend L2 speech. Such teaching is likely to be useful for all second language learners as both closely related and unrelated languages may differ in their mapping between focus and prosody (e.g., German-Dutch in Braun & Tagliapietra, Reference Braun and Tagliapietra2011; English-Cantonese in Ge et al., Reference Ge, Chen and Yip2020).
Effect of clefting
In relation to the role of clefting and the relative roles of prosodic and clefting cues to focus, the results showed that although clefting cues played a role in both L1 and L2, this was generally inhibitory or neutral rather than facilitatory. In both the L1 and L2, when prosodic and clefting cues to focus were consistent with one another and with the question type (ScleftS for SQ and OcleftO for OQ, indicated in ellipses in Figure 8) the answers were given high ratings. However, consistent clefting did not result in higher ratings than canonical sentences with prominence on the focus, for example, canonS and ScleftS were rated equally highly to the SQ. This is consistent with Arnhold’s (Reference Arnhold2021) rating study on L1 English and also Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021), based on question preferences. Based on the CM, when the two cues converged on the same word, the cue strength is strongest, and the answer was therefore rated as highly acceptable (approximately 7) in both their L1 and L2, compared to when the cues diverged (i.e., ScleftO and OcleftS). However, the combination of the two cues is not any stronger than the prosodic cue alone. It is possible there may be a ceiling effect that obscures any “benefit” that the additional clefting cue might add.
For object focus in Mandarin, OcleftO sentences were rated slightly lower than the corresponding canonical sentences (canonO). This may be because the relative rarity of object SHI…DE clefts might make OcleftO somewhat less acceptable, compared to canonO (see section “Syntactic focus marking (clefting)”). However, the ratings for OQ-OcleftO were still high (around 6), indicating that object clefts were still broadly acceptable for native listeners, and that they were more acceptable than the “mismatch” sentences (e.g., OQ-ScleftO) (<3), as shown in Figure 6. In English, having a consistent clefting cue did not lower the appropriateness rating (canonO = OcleftO) (>6), showing differences between L1 and L2.
When the prosodic and clefting cues clashed (the “mismatch” sentences indicated in rectangles in Figure 8), we saw a different relative cue-weighting of prosodic and clefting cues in L1 and L2. Prosodic cues were clearly favored over clefting cues for L1 Mandarin listeners (e.g., SQ > OQ for OcleftS; OQ > SQ for ScleftO). This indicates that prosodic prominence is more important as a cue to focus than clefting in Mandarin. Note that the current study only investigated SHI…DE clefts. This does not necessarily mean that all syntactic focus cues are less effective. Pseudo-clefts are more commonly used structures to mark object focus in Mandarin, and they have a dedicated sentence-final focus position for both subject and object clefts. It would be valuable to investigate pseudo-clefts in future studies to see if they play a stronger role than SHI…DE in the identification of focus due to the salient position of focus.
In L2, there was no significant difference in the ratings of the “mismatch” sentences (ScleftO and OcleftS) for either question type (i.e., they all share letter d in the right-hand panel of Figure 8). This is different to Calhoun et al. (Reference Calhoun, Wollum and Kruse-Va’ai2021), which showed English listeners weighted cleft cues more highly than prosodic cues in such structures to perceive focus in response to a wh-question (e.g., participants chose SQs as appropriate for ScleftO sentences). Listeners were therefore weighting clefting cues more strongly in L2 than in L1, but still not in a native-like way. This is consistent with LILt, which predicts difficulties where there are differences in the “semantic dimension,” in this case the relative importance of clefting in Mandarin and English focus. While the model did not specifically discuss the interaction with other linguistic systems, we have shown that applying the theory in this way successfully predicted the difficulty. In addition, based on the CM which predicts that L2 learners need to acquire new patterns of cue-strengths, we could see evidence of learning, in that the Mandarin listeners had learnt that clefting cues are weighted more highly in English (when the two cues clash) than in their L1. However, the relative difficulty of integrating these cues (or resolving the competition between them) ultimately made these structures ambiguous as to whether they marked subject or object focus for these L2 listeners. These results have shown that there is a negative transfer to L2 of cue strengths that derive from Mandarin listeners’ L1 pattern of cue strengths (i.e., the fact that in their L1 the prosodic cue wins the competition when prosodic and clefting cues place focus on different words in an utterance). The CM is not specifically directed toward L2 learning of cue competition between prosody and clefting, but the theory can be applied in this way.
In this paper, we have looked at learners whose L1 is Mandarin, where clefting seems to be a less important marker of focus than prosodic prominence. It would be valuable to look at learners with other L1s, especially those in which clefting is as or more important than prosodic cues to focus such as Korean (Kember et al., Reference Kember, Choi, Yu and Cutler2021), or where prosodic prominence is an optional marker of focus such as Yucatec Maya (Kügler & Skopeteas, Reference Kügler and Skopeteas2006). To our knowledge, there are no such studies; however, we predict that for L2 English learners with such L1s, syntactic focus marking cues will be more important than prosodic in the L2, and they will find it relatively harder to make effective use of prosodic cues (similar to the findings of Ge et al. Reference Ge, Chen and Yip2020). In addition, it would be particularly interesting to look at L2 learners with L1s like Russian, where prosodic and syntactic cues seem to be equally important in the perception of prominence, and these cues interact with each other in a complex way (Luchkina & Cole, Reference Luchkina and Cole2021). Regarding LILt, such learners should find it relatively straight-forward to effectively use clefting and prominence cues to focus in English, since they both have that semantic function in their L1. However, regarding the CM, difficulties may arise in acquiring the particular patterns of cue strength that differ between their L1 and L2. In general, we predict that the importance of different focus markers in the L1 will be linked to learners’ performance in their L2, rather than particular types of focus marker (prominence, clefts, etc.) being inherently more or less difficult for L2 learners to acquire.
In this study, we recruited learners in a relatively narrow proficiency range: intermediate-to-high. As expected, therefore, while we included proficiency as a control factor in the L2 experiment model, it did not interact with prosodic prominence, syntax or question type; although we did find a general effect of proficiency, in that participants with lower proficiency tend to give higher ratings. In future research, it would be interesting to look at the learning trajectory by including learners from a wider range of proficiencies, as L2 proficiency is an important factor in the comprehension of focus in L2 (Akker & Cutler, Reference Akker and Cutler2003; Braun & Tagliapietra, Reference Braun and Tagliapietra2011; Lee & Fraundorf, Reference Lee and Fraundorf2017). Previous L2 studies based on the CM have predicted that L2 proficiency is an influential factor which determines the developmental direction of cue use as well as transfer patterns (differentiation, forward transfer, backward transfer, and amalgamation, see Li & MacWhinney, Reference Li, MacWhinney and Chapelle2013). Future studies could investigate learners with different levels of L2 proficiency to shed light on the acquisition of cue-focus mappings.
Conclusion
This paper has presented an investigation of the role of prosodic and clefting cues to focus by Mandarin listeners in their L1 and L2. We have shown that prosodic prominence cues to focus are used in a functionally equivalent way in L1 and L2, similar to native speakers in both languages. However, L2 listeners found it more difficult to integrate the relatively higher-weighted clefting cues in English. In future work, this method could be extended to different prosodic conditions (e.g., “neutral” broad focus), to different clefting types (e.g., pseudo-clefts), and to learners with different levels of L2 proficiency. It would also be good in future work to test the relative importance and use of different cues to focus for learners from a wider variety of L1s and to increase our understanding of how use of focus cues in the L1 and L2 relate to each other.
Acknowledgements
The authors thank Associate Editor Dr. Amanda Huensch and three anonymous reviewers for insightful comments on earlier drafts of this paper. The authors also thank all participants for taking part in this study. The study was supported by The National Social Science Fund of China (21CYY014).
Conflict of interest
The author(s) declare none.