


Most research on the development of reading has been done in English. This raises questions about whether insights and models of reading skill and its development will generalize to other languages and writing systems. In fact, reading acquisition and use appear to be quantitatively and qualitatively different across writing systems, in ways that have prompted some theorists to propose that different cognitive architectures would be required to understand reading in different writing systems (Coltheart, Curtis, Atkins & Haller, Reference Coltheart, Curtis, Atkins and Haller1993; Coltheart, Rastle, Perry, Langdon & Ziegler, Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001; Frost, Reference Frost, Snowling and Hulme2005; Perfetti, Liu & Tan, Reference Perfetti, Liu and Tan2005). An alternative view is that these differences may be better understood in terms of statistical properties of the writing system (Ziegler & Goswami, Reference Ziegler and Goswami2005) and the impact these may have on the “division of labor” between semantic and phonological processing in reading (Seidenberg, Reference Seidenberg, Miller and Eimas1995). The models reported here apply the same basic architecture and learning rules to two very different writing systems – English and Chinese – in order to test these two possibilities. This is also a first-order question in the modeling of biliteracy for these two writing systems, because if the languages cannot be accommodated in a single functional architecture, it will have important consequences for the modeling of biliteracy in these two languages.
The difference between Chinese and English can be understood in terms of the statistical properties of spelling-to-sound and spelling-to-meaning mappings. Although English has something of an “outlier” writing system in mapping from print to sound (Malone, Reference Malone1925; Venezky, Reference Venezky1999), it has an alphabet of letters that correspond roughly to individual speech sounds (Venezky, Reference Venezky1970). In contrast, Chinese has an extremely “deep” orthography (Frost, Katz & Bentin, Reference Frost, Katz and Bentin1987) in that the pronunciation of a character cannot be computed sound-by-sound from its constituent parts (DeFrancis, Reference DeFrancis1989), although probabilistic cues to pronunciation do exist (Li & Kang, Reference Li and Kang1993; Zhu, Reference Zhu and Yuan1988) and are used by both children learning to read and adult readers (Lee, Tsai, Su, Tzeng & Hung, Reference Lee, Tsai, Su, Tzeng and Hung2005; Shu, Meng, Chen, Luan & Cao, Reference Shu, Meng, Chen, Luan and Cao2005). Chinese is sometimes characterized as a logographic system, in contrast to alphabetic systems, because of the morphemic (Leong, Reference Leong and Downing1973) or even morphosyllabic (e.g., DeFrancis, Reference DeFrancis1989; Mattingly, Reference Mattingly, Frost and Katz1992) mappings characters afford. Characters, as basic writing units, map onto morphemes – not phonemes – in the spoken language. Furthermore, Chinese characters typically contain a “semantic radical” that provides some probabilistic information that aids in the translation from orthography to semantics. Alphabetic writing systems rarely contain semantic information that is not somehow encoded phonologically. Even where there is ambiguity about spelling-to-sound for morphological forms (final -s and -ed in English), it cannot be said that these convey no phonological information at all, in the way that semantic components of Chinese characters do (see Frost, in press; Mirkovic, MacDonald & Seidenberg, Reference Mirkovic, MacDonald and Seidenberg2005, for discussion).
There is clear evidence among alphabetic orthographies that shallower systems are easier to learn than deeper ones, as reflected by both word and non-word performance in beginning readers (e.g., Ellis & Hooper, Reference Ellis and Hooper2001; Goswami, Gombert & de Barrera, Reference Goswami, Gombert and Barrera1998; Seymour, Aro & Erskine, Reference Seymour, Aro and Erskine2003). Differences between alphabetic orthographies and Chinese are starker still: the average English-reading child can recognize 3000–5000 words after the first grade (White, Graves & Slater, Reference White, Graves and Slater1990) whereas Chinese-reading children can typically read fewer than 800 characters with the same amount of schooling (Xing, Shu & Li, Reference Xing, Shu and Li2004). Thus, the overall consistency of mappings from units in the writing system to their phonological counterparts has clear effects on the rate at which reading skill can be acquired.
Another consequence of orthographic depth for the acquisition of reading is that related language skills (such as semantic and phonological processing) contribute differentially to reading success across writing systems. Shallow orthographies are characterized by weak effects of semantic variables in skilled reading (e.g., Bates, Burani, D'amico & Barca, Reference Bates, Burani, D'amico and Barca2001), and a limited contribution of semantic processing skills to the development of reading (McBride-Chang, Cho, Liu, Wagner, Shu, Zhou, Cheuk & Muse, Reference McBride-Chang, Cho, Liu, Wagner, Shu, Zhou, Cheuk and Muse2005; Saiegh-Haddad & Geva, Reference Saiegh-Haddad and Geva2008). In relatively “deep” orthographies, such as English, semantic knowledge plays some role in reading aloud, particularly in the reading of words whose spellings are highly atypical (Strain, Patterson & Seidenberg, Reference Strain, Patterson and Seidenberg1995, Reference Strain, Patterson and Seidenberg2002) and there is some evidence for a role of semantic processing abilities in beginning reading skill (Carlisle, Reference Carlisle2000, Reference Carlisle2003; Nation & Snowling, Reference Nation and Snowling1999). In part because print-to-sound cues are even less reliable in Chinese, the role of semantic processing in reading aloud is greater, and the contribution of semantics to the development of Chinese reading is particularly important (Shu, McBride-Chang, Wu & Liu, Reference Shu, McBride-Chang, Wu and Liu2006; Shu, Peng & McBride-Chang, Reference Shu, Peng and McBride-Chang2008).
The differential contribution of semantic and phonological processing across writing systems may also explain differences in the manifestation of reading disability across languages. In English, there is evidence for subtypes of developmental dyslexia: “phonological dyslexics” have specific difficulty with decoding and “surface dyslexics” have specific difficulty with atypically spelled words, but relatively spared performance on regular words and non-words (e.g., Manis, Seidenberg, Doi, McBride-Chang & Petersen, Reference Manis, Seidenberg, Doi, McBride-Chang and Petersen1996). These subtypes are often explained as resulting from distinct pre-existing deficits: in semantic processing for the developmental delay/surface dyslexics and phonological processing for the phonological dyslexics. The reading performance of children with developmental surface dyslexia is very similar to that of younger normal readers with respect to the relative difficulty of pseudowords, regular words and irregular-inconsistent words (Manis et al., Reference Manis, Seidenberg, Doi, McBride-Chang and Petersen1996). Their specific difficulty reading words with unusual spelling-to-sound correspondences may thus be associated either with semantic deficits or with a general delay in the development of reading skill (Nation & Snowling, Reference Nation and Snowling1998; Plaut, McClelland, Seidenberg & Patterson, Reference Plaut, McClelland, Seidenberg and Patterson1996). In contrast, developmental phonological dyslexia is associated with deficits in phonological processing (Stanovich & Siegel, Reference Stanovich and Siegel1994). In English, phonological dyslexics present with a reading impairment that is most pronounced for non-words, but, in milder cases, can leave exception word reading more or less intact (Castles & Coltheart, Reference Castles and Coltheart1993).
In Chinese, semantic and phonological processing deficits impact reading in different ways. Poor semantic processing is associated with difficulties reading all types of words, even those with more typical spelling-to-sound correspondences, although reading of atypically spelled words does suffer relatively more (Shu et al., Reference Shu, Meng, Chen, Luan and Cao2005). Children with phonological deficits are also impaired relative to age-matched controls on reading of all words, but the impairment is greater for words with typical spelling-to-sound correspondences, with the result that phonological dyslexics do not show the usual advantage for regular-consistent over irregular-inconsistent words (Shu et al., Reference Shu, Meng, Chen, Luan and Cao2005). In sum, there are gross differences between writing systems in the relative contribution of phonological and semantic processing abilities to the development of reading skill that appear to be driven largely by the consistency of print-to-sound mappings across languages. In previous studies, we have demonstrated that the same basic architecture and learning rules appropriate to English could model the acquisition and use of reading skill in Chinese, and simulate both effects that are directly analogous to English and effects that are specific to Chinese (Yang, McCandliss, Shu & Zevin, Reference Yang, McCandliss, Shu and Zevin2009).
Here, we simulate typical and disordered reading acquisition in English and Chinese by applying the same functional architecture (modified to represent the inputs and outputs for each language) and learning rules for both writing systems. The models implement the theory that reading is acquired via a process of statistical learning of mappings among spelling, sound and meaning, and test the hypothesis that differences in the patterns of typical and disordered reading development across writing systems may be explained in terms of differences in the statistical properties of the writing systems rather than by differences in functional architecture. In a second simulation, we model the simultaneous acquisition of Chinese and English, to examine whether the same learning trajectories and sequelae of pre-literate deficits would be observed across languages learned by the same individual. Simulation 2 addresses a first-order question in the modeling of Chinese/English biliteracy: Can English and Chinese are learned in the same set of mappings among orthography, phonology and semantics? Or do they require fundamentally different processing assumptions? Further, we can examine how the two languages interact when learned by the same system. It is possible that learning these two very different writing systems at the same time will lead to differences in how reading skill is acquired and used in both writing systems, but it is also possible that when both languages are learned at the same time, the outcome is equivalent to monolingual learning of each. Either outcome would have important consequences for understanding bilingualism and biliteracy in reading development.
Simulation 1: Modeling differential division of labor between Chinese and English in monolingual models
Here we examine development of typical and disordered reading in two parallel models implementing the same functional architecture for English and Chinese. Both models have feed-forward connections from an orthographic input layer to a phonological attractor network (Harm & Seidenberg, Reference Harm and Seidenberg1999), supplemented with a semantic input layer that functions mainly to provide a secondary source of input about word identity that is particularly useful for words with ambiguous spelling-to-sound mappings (Plaut et al., Reference Plaut, McClelland, Seidenberg and Patterson1996). Following Plaut (Reference Plaut1997), we used random bit patterns to capture this contribution of word-specific knowledge to generating a correct pronunciation. While this has the disadvantage of not providing a realistic representation of the similarity of the meanings of words within a language, it has the advantage of permitting us to use the same semantic patterns for both languages, thus allowing a direct investigation of the role of properties of the print-to-sound system on the division of labor.
Methods
Architecture
The same basic architecture (Figure 1) was used for two models: one for Chinese and one for English. Each model had an orthographic input layer designed to represent the spellings of words in the appropriate writing system, fully connected to a hidden layer with 100 units, which was in turn fully connected to a phonological output layer designed to represent the pronunciations of words in that language. The phonological output layer was fully connected both directly to itself and to 50 cleanup units, permitting the formation of attractor states, following Harm and Seidenberg (Reference Harm and Seidenberg1999). The English representations of orthography and phonology were adapted from the scheme of Harm and Seidenberg (Reference Harm and Seidenberg2004): 101 units were used to represent 10 slots of letters in the orthographic layer and 200 units were used for eight slots to represent phonemes in phonological layer. The Chinese orthographic representation consisted of 270 units based on a linguistic description of Chinese orthography including radicals, number of strokes and radical position, adapted from Xing et al. (Reference Xing, Shu and Li2004) by excluding slots that explicitly coded the location of the phonetic component (see Yang et al., Reference Yang, McCandliss, Shu and Zevin2009, for details). Ninety-two units were used to code each Chinese syllable, which includes five slots: one onset slot, three rime slots, and a fifth slot for tone. As in Zhao & Li's (Reference Zhao and Li2009) PatPho system, each phoneme slot was encoded with the same basic featural representation, but with a slightly different configuration for the two languages (e.g., Chinese has palatal and retroflex in addition to bilabial, alveolar and velar, used in the English models).

Figure 1. Architecture of the monolingual Model.
A second input layer was included to simulate the contribution of semantics in print-to-sound translation. Semantic patterns were 3000 random bit patterns clustered into 120 categories over 200 semantic features. Categories were created by generating a set of 120 prototypes, in which each feature had a probability of 0.1 of being active. Each prototype was then used to generate 25 exemplars by randomly selecting 10% of all features and resetting their probability of activation to 0.05, under the constraint that each exemplar differ from all other exemplars by at least three features. A subset of 2881 patterns was assigned randomly to the words in the English training corpus. A subset of 2689 patterns from the English training patterns were selected and randomly assigned to Chinese characters. In both versions of the model, the semantic input layer was connected to the output layer via 100 hidden units.
Training
Training was carried out in the same way for the English and Chinese versions of the model. We first pre-trained the phonological attractor net to an error threshold of 0.01, and the final weights (240K in Chinese and 60K in the English model) of phonological attractor net were embedded in the reading model. To avoid “catastrophic interference”, interleaved training (Hetherington & Seidenberg, Reference Hetherington and Seidenberg1989) on phonological processing and reading was adopted. Training mixed 10% “listening” trials, on which only the phonological attractor was trained, with 90% “reading” trials, on which the whole model was trained. A learning rate of 0.005 and momentum of 0.9 were used. Online learning was used with the continuous recurrent back-propagation algorithm (Pearlmutter, Reference Pearlmutter1995). Each word was selected according to the training probability transformed via square root compression.
The Chinese training corpus of 2689 characters consisted of 2390 characters from a set of naming norms (Liu, Shu & Li, Reference Liu, Shu and Li2007) and 299 additional items from phonetic families represented in the testing materials. Frequency estimates were taken from the Modern Chinese Frequency Dictionary (Language and Teaching Institute of Beijing Language College, 1986). The English training corpus consisted of 2881 monosyllabic words assigned frequencies taken from the Marcus, Santorini and Marcinkiewicz (Reference Marcus, Santorini and Marcinkiewicz1993) norms, which are based on 43 million tokens from The Wall Street Journal.
In both languages, two subtypes of developmental dyslexia were simulated by applying decay to either the hidden units from orthography to phonology (to simulate phonological dyslexia, hereafter PD) or the hidden units from semantics to phonology (to simulate surface dyslexia, hereafter SD). Decay on each weight ω was reduced in magnitude according to the formula Δω = −ω×σ, where σ was the decay constant. In order to simulate a wide range of deficit severity, 20 different decay values were used, varying from 0.25 × 10−5 to 5 × 10−5 in steps of 0.25 × 10−5. Unimpaired models were also run 20 times. Each run of the model used a different random seed for the initial randomization of weights and selection order of stimuli.
Testing
Naming accuracy was computed to test the model's performance. It was determined by applying a winner-take-all scoring system: for each slot on the output layer, we determined which phoneme was closest to the pattern on the output at the final time tick and reported this as the model's pronunciation.
Test items were drawn from studies of consistency, regularity and frequency effects in the two languages: the 120 Chinese test items were from Yang et al. (Reference Yang, McCandliss, Shu and Zevin2009), and the 144 English test items were those used by Plaut et al. (Reference Plaut, McClelland, Seidenberg and Patterson1996) from Taraban and McClelland (Reference Taraban and McClelland1987). In both languages, the items were sets of regular-consistent, regular-inconsistent and exception words matched for frequency, phonetic family size and other Chinese script properties, such as structure type, the number of strokes and radicals.
The definition of regularity in English and Chinese is slightly different. In English, regular words are those that can be pronounced correctly by rule (although there is some discrepancy between rule sets, due to disagreements about whether rules for units larger than single graphemes are considered, see e.g., Andrews & Scarratt, Reference Andrews and Scarratt1998; Zevin & Seidenberg, Reference Zevin and Seidenberg2006). In the current study, “regular” words are those with pronunciations consistent with the rule set of the Dual-Route Cascade model of word reading (Coltheart et al., Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001) which has a large number of multi-grapheme rules, but nonetheless counts many highly inconsistent items as “regular”. In Chinese, a character is considered regular if its pronunciation matches the pronunciation of its phonetic component when this occurs as a single character (see Peng & Yang, Reference Peng and Yang1997; Yang et al., Reference Yang, McCandliss, Shu and Zevin2009). In both languages, exception words or characters are just those that are not considered regular. Consistency is defined essentially the same way in both languages – completely consistent words share the pronunciation of some critical sub-lexical component with all of the words that contain that component – although the sub-lexical structures of the two languages are of course different. In English, regular inconsistent words were items such as DOLL and BROTH, that have exception words as neighbors (e.g., POLL and BOTH). In Chinese, consistency (like regularity) is defined at the level of the phonetic component. Characters that are regular but contain a phonetic component that is pronounced in different ways in different (exception) characters are regular and inconsistent. Simulations of surface and phonological dyslexia in Chinese children used the items from the original study (Shu et al., Reference Shu, Meng, Chen, Luan and Cao2005).
Results
Overall performance across languages, for typical and disordered reading models
Figure 2 shows the models’ accuracy over time for all items in the training set. For the typically developing model, on average, the English model reached 90% overall accuracy after 292K trials (SD = 10.1K) and the Chinese model reached 90% accuracy after 665K trials (SD = 15.7K). A 3 (Deficit: Typical, PD, SD) × 2 (Language: Chinese and English) ANOVA with maximum naming accuracy as the dependent variable revealed significant main effects of Deficit, F(2,114) = 187.93, MSE = .20, p < .01, and of Language, F(1,114) = 8.90, MSE = .01, p < .01, as well as an interaction between the two, F(2,114) = 119.08, MSE = .13, p < .01. The interaction arises because there was a greater effect of PD in the English model (81.0% accuracy) than in the Chinese model (89.4%), and the reverse pattern for SD, with a very modest effect in English (98.7% accuracy) but a large effect in Chinese (84.7%). Accuracy in the typical model was nearly perfect (> 99%) for both languages.

Figure 2. Learning trajectories of English and Chinese models show differential effects phonological (dashed line) and semantic (gray line) impairment across languages.
Reading deficits in English
To further investigate the patterns of reading disability resulting from particular patterns of deficit, we conducted a 2 (Regularity: regular-consistent, irregular-inconsistent) × 3 (Deficit: Typical, PD, SD) ANOVA analysis on maximum naming accuracy. The main effect of regularity was significant, F(1,57) = 54.91, MSE = .02, p < .01, as was the main effect of deficit, F(2,57) = 26.74, MSE = .05, p < .01, and the interaction of the two, F(2,57) = 14.41, MSE = .01, p < .01. As seen in Figure 3, regular-consistent words were read more accurately than irregular-inconsistent words, and the Typical model's overall performance (100%) was significantly better than the PD model (93.0%), p < .01, and marginally better than the SD model (97.7%), p = .056. The interaction between deficit and stimulus condition arose because performance on all items was impaired in the PD model, whereas the SD model was impaired only in irregular word reading. In the Typical model, all words were named accurately. Semantic impairment had no impact on the regular-consistent items (100% accuracy), but resulted in reduced accuracy for the irregular-inconsistent items (95.4%). In contrast, the PD model was impaired for both regular-consistent and irregular-inconsistent items (94.8% and 91.3% accuracy, respectively).

Figure 3. Learning trajectories for different stimulus types in the English model. Regular consistent items are impacted only by phonological impairment (dashed line) whereas both phonological and semantic impairment (gray line) impacted irregular-inconsistent items.
Poor nonword reading is a particular hallmark of phonological dyslexia in English, but the status of “non-character” reading in Chinese (i.e., whether it reflects normal reading processes or meta-linguistic guessing) is a topic of debate (Shu et al., Reference Shu, Meng, Chen, Luan and Cao2005; Weekes, Yin, Su & Chen, Reference Weekes, Yin, Su and Chen2006). Because of the higher degree of arbitrariness in spelling-to-sound mappings, it is hard to create non-characters in Chinese. We therefore tested nonword reading in a separate set of statistical tests for English. Nonword reading was strongly influenced by deficit, F(2,57) = 44.09, MSE = .06, p < .01. Post-hoc tests showed no effect of SD on nonword reading (86.2% accuracy, compared to 86.1% accuracy for the Typical model), p = .86, and a large effect of PD (77.0%), p < .01.
Reading deficits in Chinese
In parallel with the analysis of the English model, we conducted a 2 (Regularity: regular-consistent, irregular-inconsistent) × 3 (Deficit: Typical, PD, SD) ANOVA with maximum accuracy as the dependent variable in Chinese. The main effect of regularity was significant, F(1,57) = 124.23, MSE = .11, p < .01, as was the main effect of deficit, F(2,57) = 111.93, MSE = .17, p < .01, and the interaction of the two, F(2,57) = 96.12, MSE = .09, p < .01. As seen in Figure 4, regular-consistent words were read more accurately than irregular-inconsistent words, and the Typical model's overall performance was significantly better than both the PD model, p < .01 than the SD model p < .01. The interaction between deficit and stimulus condition arose because performance on the word classes was differentially impacted by semantic and phonological impairments. In the Typical model, all words were named accurately (100%). Semantic impairment influenced the naming accuracy more for irregular-inconsistent (79.75%) than regular-consistent (96.5%) words, t(19) = 12.67, p < .01. In contrast, the PD model performed equally poorly on both regular-consistent (90.5%) and irregular-inconsistent (89.0%) words, t(19) = 1.55, p = .14.
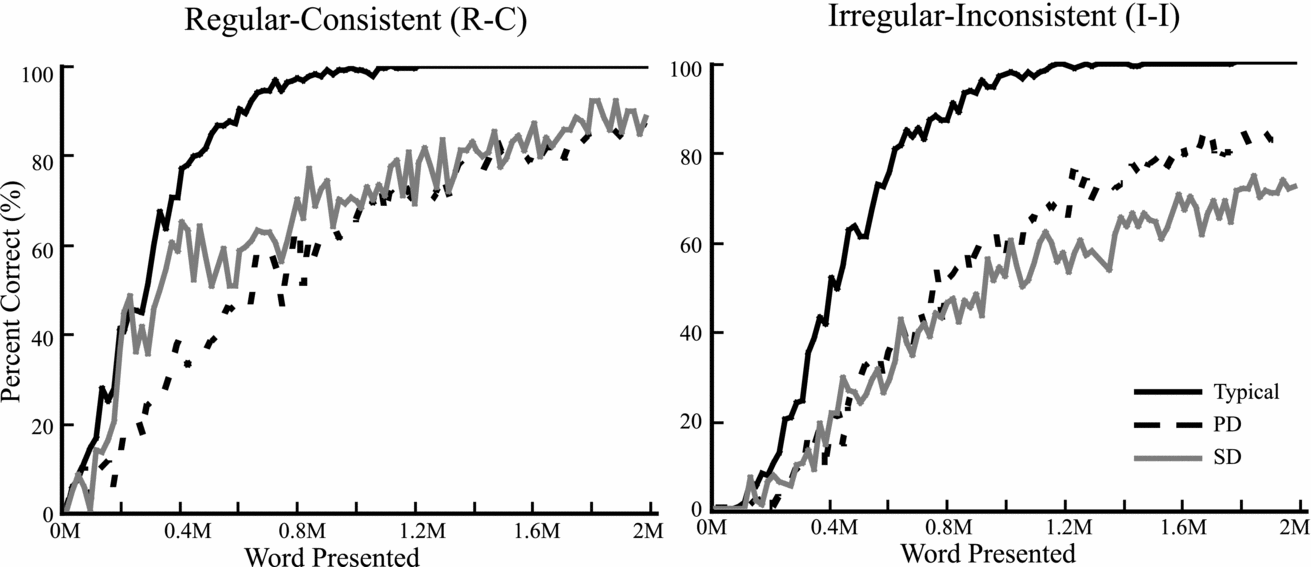
Figure 4. Learning trajectories for different stimulus types in the Chinese model. Both regular-consistent and irregular-inconsistent items are impacted by both phonological (dashed line) and semantic (gray line) impairments.
Simulating three cases of Chinese dyslexia
Shu et al. (Reference Shu, Meng, Chen, Luan and Cao2005) reported three cases of developmental dyslexia in Chinese, along with data on the children's phonological and semantic processing abilities. One case, Child L (age 9:0, male), was classified as surface dyslexic because of his relatively specific impairment on exception words. The two remaining cases (J, 10:8, and Q, 12:2, both male) were phonological dyslexics. One important feature of this study is that semantic and phonological processing skills were also tested independently. Child L's reading impairment was accompanied by frank impairments in morphological awareness, a meta-linguistic task used to assess semantic processing in Chinese readers (McBride-Chang, Shu, Zhou, Wat & Wagner, Reference McBride-Chang, Shu, Zhou, Wat and Wagner2003), but his performance on phonological awareness tasks was within normal range, whereas J and Q showed the converse pattern.
Simulation of case studies was undertaken by identifying a point in training at which the appropriate model (SD for Child L, PD for J and Q) achieved the same overall accuracy (on all test items) as the case being simulated. Data from all three are shown in Figure 5. The SD model attained overall performance of 44% after an average of 364K (SD = 58K) trials. At this point in training, the SD model's ability to read words was strongly influenced by stimulus regularity – 61.25% accuracy for regular items vs. 50.63% for irregular, t(19) = 7.64, p < .01.

Figure 5. Simulations of three case studies. Child L has semantic deficits, and shows a strong regularity effect, whereas children J and Q have phonological deficits and show no regularity effect.
A diagnostic feature of phonological dyslexia in Chinese is the lack of a regularity effect, seen in both of the cases under consideration here. Child J's overall accuracy was 49%, which the PD model reached after 433K (SD = 88K) trials. At this point in training, the model exhibited no effect of regularity with 59.1% and 58.1% accuracy for regular and irregular characters, respectively, t(19) = 1.00, p = .33. Child Q's overall accuracy was 73%, which the PD model reached after 910K (SD = 192K) trials. At this point in training, the model did not show evidence for a regularity effect – 79.8% and 78.6% accuracy for regular and irregular items, t(19) = 1.58, p = .13.
Discussion
When the same functional architecture is trained to read English and Chinese, distinct patterns of typical and atypical development are observed across languages. Gross differences in the rate of learning of the two writing systems are clearly captured by the models, as are differences in the patterns of deficits observed in reading disability. Specifically, the same constitutive deficits (in phonological and semantic processing) have distinct effects that are language-specific, suggesting that these patterns are driven by statistical properties of the writing systems themselves, and not by differences in the basic architecture of reading across languages.
In both English and Chinese, phonological deficits have relatively broad effects, and are a key factor in predicting reading disability (McBride-Chang & Zhong, Reference McBride-Chang, Zhong, Li, Tan, Bates and Tzeng2006; Snowling, Reference Snowling2000; Vellutino & Fletcher, Reference Vellutino, Fletcher, Margaret and Snowling2005). This is captured in the overall pattern of effects in the two models. Further, language-specific features of phonological dyslexia are also observed. In English, children with phonological difficulties have particular difficulty with nonword pronunciation (Castles & Coltheart, Reference Castles and Coltheart1993; Manis et al., Reference Manis, Seidenberg, Doi, McBride-Chang and Petersen1996; Temple & Marshall, Reference Temple and Marshall1983). This was also found in the English model. In contrast, nonword reading is a difficult task for even skilled Chinese readers, and is rarely tested in development, but there is a specific pattern that is a hallmark of phonological dyslexia – the reduced size of the regularity effect observed by Shu et al. (Reference Shu, Meng, Chen, Luan and Cao2005). This effect was also captured in the model.
Semantic deficits had strikingly different effects across writing systems. In English, semantic support is mainly necessary for irregular-inconsistent items, and deficits in semantic processing have relatively specific effects on these items (Castles & Coltheart, Reference Castles and Coltheart1993, Reference Castles and Coltheart1996; Manis et al., Reference Manis, Seidenberg, Doi, McBride-Chang and Petersen1996). In Chinese, in contrast, effects of semantic deficits are quite general, impacting both regular-consistent and irregular-inconsistent items nearly equally. Again, this is consistent with case observations from Shu et al. (Reference Shu, Meng, Chen, Luan and Cao2005), and is also generally consistent with the relatively strong correlation of morphological awareness with reading ability (Ku & Anderson, Reference Ku and Anderson2003; McBride-Chang, Cho et al., Reference McBride-Chang, Cho, Liu, Wagner, Shu, Zhou, Cheuk and Muse2005).
Simulation 2: Modeling Chinese–English bilingualism
Although they shared many features, the models in Simulation 1 differed in important ways, because their phonological and orthographic representations were language-specific. Here we explore whether the same model, when trained to read both English and Chinese will show similar patterns of results to parallel models described in Simulation 1. We did this by training a single model with a single phonological output attractor, a single semantic system, and two orthographic input layers, one for each language.
Methods
Architecture
The architecture of the bilingual model (Figure 6) was modified from Simulation 1 to two orthographic layers as its input: one for Chinese and one for English. The orthographic representations themselves were the same as in Simulation 1, as was the semantic representation. In order to represent Chinese and English syllables in the same phonological layer, the number of units used to represent phonology was increased to accommodate the larger number of contrasts. Eight phoneme slots were used to encode the CCCVVVCC structure of syllables both for Chinese and English (where C is a consonant and V is a vowel). Like Zhao and Li's (Reference Zhao and Li2009) PatPho system, a set of 37 phonological features were used to describe each phoneme: 20 features were used for consonants including two for voiced or not, ten for place and eight for manner of articulation (see Table 1); 17 features were used for vowels including seven for height, five for backness, three for roundedness and two for long or short. All features were binary, taking values of 0 or 1. The 37 features per phoneme over eight phoneme slots yielded a total of 296 features. Including extra four features added to represent five tones in Chinese syllables, the number of features on the phonological layer was increased to 300 features.
Table 1. Phonetic features for consonants in Chinese and English.

Note: Where symbols appear in pairs, the one to the right represents a voiced consonant. Symbols shaded in light grey represent phonemes that occur only in Chinese, symbols shaded in dark grey represent phonemes that occur only in English, and unshaded symbols represent phonemes present in both languages.

Figure 6. Architecture of the bilingual model.
Training and testing
Training was carried out in the same way as in the monolingual models. The learning rate, momentum, and learning algorithm of model, as well as the training materials were the same as in Simulation 1. We trained the reading model directly without pre-training the phonological attractor net. Simultaneous bilingualism was modeled by interleaved training on both languages, with an equal likelihood of training on either language on each trial. Twenty runs of normal model were trained with a different random seed for the initial randomization of weights and selection order of stimuli. As in Simulation 1, two types of decay were applied to either the hidden units from orthography to phonology (PD) or the hidden units from semantics to phonology (SD). Decay on each weight ω was reduced in magnitude according to the formula Δω = −ω×σ, where σ was the decay constant. Different decay values for each of twenty runs (both for PD and SD model) were used, varying from 0.25 × 10−5 to 5 × 10−5 in steps of 0.25 × 10−5.
Testing also followed the same procedures as in Simulation 1.
Results
The model learned English more rapidly than Chinese, achieving 90% accuracy in 600K trials for Chinese, but only after 300K trials in English, t(19) = 112.45, p < .01. Further, semantic and phonological deficits had different effects on performance across languages, as revealed by a 3 (Deficit: Typical, Phonological, Semantic) × 2 (Language: English, Chinese) ANOVA with maximum accuracy as the dependent variable, and iterative runs of the model as a random variable. Main effects were observed for both deficit, F(2,38) = 111.57, p < .01, and language, F(1,19) = 5.73, p < .05, with an interaction between these two factors, F(2,38) = 96.29, p < .01. The interaction arose because the effect of phonological deficits was greater for English (59.0% accuracy) than Chinese (71.7%) overall, whereas the effect of semantic deficits was greater in Chinese (90.1%) than English (98.8%).
Figure 7 shows the differential effect of impairments on stimulus types. In English, the effect of semantic impairments was specific to irregular inconsistent items (accuracy for these items was 97.3%, compared to 99.96% for regular consistent items). In contrast, semantic deficits impacted both types of items in Chinese (88.3% accuracy for irregular-inconsistent, 95.3% accuracy for regular-consistent). Phonological deficits impacted both types of items in both languages. In English, the phonologically impaired model nonetheless read regular-consistent items more accurately than irregular items (76.2% vs. 65.7%, t(19) = 13.48, p < .01). In contrast, the model's performance in Chinese was impacted more equally for regular-consistent (73.5%) and irregular-inconsistent (70.3%), although the regularity effect was significant at this point in training, t(19) = 3.22, p < .01. Finally, we tested nonword reading for English only, and found substantial deficits for the phonologically impaired model (22.1% accuracy, vs. 59.7% in the typical model, t(19) = 9.07, p < .01). A modest (57.3%) but significant effect of semantic impairment was also found, t(19) = 3.18, p < .01.

Figure 7. Deficits in bilingual model showed differential effect of impairments on stimulus types.
Discussion
The pattern of results observed in a single model trained on both English and Chinese generally replicated the results from two models with the same architecture trained on each language separately. The results further support the view that differences between languages in typical and atypical patterns of learning can be explained without assuming differences in functional architecture between the languages. In particular, simulated deficits in the same set of hidden units had distinct effects on reading outcomes in English and Chinese.
General discussion
The simulations presented here capture differences between two very different writing systems in the rate of acquisition as well as the differential sequelae of pre-existing deficits in phonological and semantic processing over the course of reading development. They also represent the first computational simulations of specific cases of developmental dyslexia in Chinese. That the same architecture and learning rules give rise to different outcomes across writing systems suggests that differences in typical and atypical reading development can be understood as resulting from statistical properties of the mapping from spelling to sound inherent to specific writing systems (Ziegler & Goswami, Reference Ziegler and Goswami2005), rather than structural differences in the reading system itself. This is in contrast to previous models of reading in Chinese, in particular Perfetti et al. (Reference Perfetti, Liu and Tan2005), in which it is assumed that there is no sub-lexical spelling-to-sound conversion in Chinese. In such models, phonological and semantic activation from print are mediated by lexical representations only (cf. models of alphabetic reading, which are equipped with an “assembled phonology” routine that permits sub lexical spelling-to-sound conversion). While it is possible in principle that such basic architectural differences could emerge as a result of statistical differences between the writing systems, it is difficult to characterize the results of the current simulations in those terms. Further, in Simulation 2, the same implemented model showed distinct patterns of typical and disordered reading ability across languages. This is the first simulation to address the acquisition of reading skill in a shared architecture for two languages, and is an important first step toward modeling the acquisition of biliteracy, because it addresses the first-order question of whether reading in the two languages can be learned within the same basic processing and learning architecture.
When print-to-sound mappings are generally systematic, as in English, the contribution of semantic processing to reading aloud is limited largely to the pronunciation of the words that benefit least from regularities in the print-to-sound mapping (Strain et al., Reference Strain, Patterson and Seidenberg1995, Reference Strain, Patterson and Seidenberg2002). The mappings from print to sound in Chinese are much less reliable overall, with the result that the confluence of semantic and phonological processing is important to processing even words with relatively consistent mappings. These differences in the division of labor between phonological and semantic contributions to reading play out as differences in the manifestation of reading disability in the two writing systems. In English, semantic deficits have a relatively modest effect on reading in general, causing a highly selective impairment on exception words, whereas phonological impairments are more general and severe, and are marked by particular difficulty with generalization to nonwords. This disparity in the sequelae of phonological and semantic impairments has been exhaustively discussed in the current framework (Harm & Seidenberg, Reference Harm and Seidenberg2004). The division of labor for Chinese is more equitable, and therefore both semantic and phonological impairments have widespread effects (McBride-Chang, Cho et al., Reference McBride-Chang, Cho, Liu, Wagner, Shu, Zhou, Cheuk and Muse2005; Shu et al., Reference Shu, McBride-Chang, Wu and Liu2006; Toyoda & Scrimgeour, Reference Toyoda and Scrimgeour2009).
We have simulated differences between writing systems in the contribution of semantics to reading aloud, but a full account of the development of literacy across languages will require consideration of other factors. For example, mappings from print to meaning are actually much more systematic for Chinese characters than for monomorphemic words in English. This is likely to have consequences for reading development, and may be related to the finding that morphological awareness contributes more strongly to reading skill in Chinese than in other languages (McBride-Chang, Cho et al., Reference McBride-Chang, Cho, Liu, Wagner, Shu, Zhou, Cheuk and Muse2005). The current model uses a simplified random-bit semantic representation designed to capture only the fact that semantics can serve as an additional source of support for arriving at a pronunciation in the naming task. This was sufficient to model differential contributions of semantics and phonology to reading aloud, but mappings from spelling to meaning, and their impact on development across languages have begun to be studied behaviorally (Carlisle, Reference Carlisle2000, Reference Carlisle2003; Ku & Anderson, Reference Ku and Anderson2003; McBride-Chang et al., Reference McBride-Chang, Shu, Zhou, Wat and Wagner2003; McBride-Chang, Wagner, Muse, Chow & Shu, Reference McBride-Chang, Wagner, Muse, Chow and Shu2005) and would require a more elaborate model (e.g., with a similar architecture to Harm & Seidenberg, Reference Harm and Seidenberg2004) to simulate. The greater orthographic complexity of Chinese may also contribute to differences between languages. Ho, Chan, Chung, Lee and Tsang (Reference Ho, Chan, Chung, Lee and Tsang2007) describe orthographic processing deficits that may be directly related to reading disability, and these will be important to incorporate in a full account of reading acquisition across writing systems. Further, one major difference in patterns of brain activity during reading across writing systems – robust activation in the middle frontal gyrus for Chinese, which is not observed for alphabet languages – has been attributed to the increased demands on spatial processing involved in identifying Chinese characters (Bolger, Perfetti & Schneider, Reference Bolger, Perfetti and Schneider2005; Tan, Laird, Li & Fox, Reference Tan, Laird, Li and Fox2005). One challenge for future modeling will be to incorporate an account of how orthographic knowledge emerges from more general aspects of visual processing (e.g., Polk & Farah, Reference Polk and Farah1997, Reference Polk and Farah1998).
In sum, the current simulations reflect an important step in cross-language modeling of the development of typical and disordered reading, and the modeling of biliteracy. The model instantiates two principles that have emerged from the study of reading acquisition, that the grain size of spelling-to-sound mappings determines the functional units that emerge in the spelling-to-sound system (Ziegler & Goswami, Reference Ziegler and Goswami2005), and that the “division of labor” between phonological and semantic contributions to the development of reading depends on the reliability of mappings among print, sound and meaning (Harm & Seidenberg, Reference Harm and Seidenberg2004; Seidenberg, Reference Seidenberg1993). As demonstrated in prior work (Yang et al., Reference Yang, McCandliss, Shu and Zevin2009; Zevin & Seidenberg, Reference Zevin and Seidenberg2006), the model's simulation of consistency effects depends on its ability to identify the appropriate grain sizes at which spelling-to-sound mappings exhibit regularities. Rather than assume a priori that a particular grain size should be privileged in the acquisition and use of these regularities, the model arrives at an appropriate level of description for each language as a result of the statistical structure of the input (Frost, in press). Similarly, the division of labor between phonological and semantic processes in reading plays out very differently in the two languages, even within the context of the same implemented model in Simulation 2. Specifically, the impact of semantic impairments is much greater and more general in Chinese than in English. Thus, the models presented here elucidate how these two principles can interact to produce different developmental trajectories across writing systems within a universal functional architecture.








