


1 Introduction
The Old Northumbrian glosses to the Lindisfarne Gospels, the Durham Ritual and Rushworth² record the replacement of the inherited Old English present-tense marker -ð by -s as a change in progress. So, for example, ne is forðon tree god ðio doeð wæstma yfla ne tree yfla wyrcas wæstm god ‘for there is no good tree that creates evil fruit, nor an evil tree that creates good fruit’ at Lk 6.43, in the interlinear gloss to the Lindisfarne Gospels, illustrates how -s and -ð competed in the same environments in tenth-century Old Northumbrian (ONbr).Footnote 2
Much of the research addressing the proliferation of -s has attributed its spread to Norsification via either the transfer of Old Norse morphosyntactic structure (Keller Reference Keller and Keller1925; Samuels Reference Samuels and Eaton1985) or irregular sound change induced by second-language error (Kroch et al. Reference Kroch, Taylor, Ringe, Herring, van Reenen and Schoesle2000). Scholars positing an internally motivated explanation for the replacement process in ONbr focus on the distribution of the -s variant across the paradigm. The quantitative studies of Holmqvist (Reference Holmqvist1922: 13–15), Blakeley (Reference Blakeley1949/50) and Stein (Reference Stein, Kastovsky and Szwedek1986: 640) identify a person–number hierarchy whereby s-forms occurred more frequently in the plural environment than in the third-person singular, with a peak in the second-person plural. The higher incidence of -s in the second-person plural is seen by the aforementioned authors as indicative of -s generalizing under the influence of the second-person singular in etymological -s. A functional explanation is proposed by Berndt (Reference Berndt1956), who posits that the replacement of -ð by -s was the result of an evolutionary drive towards analytical structure. The availability of subject pronouns provided an analytical form to mark person and number that rendered verbal inflection redundant and thus both motivated and facilitated the levelling process (Berndt Reference Berndt1956: 51). Phonotactic considerations, similar to those that underlie the transition of -th to -s in Early Modern English (EModE) (Kytö Reference Kytö1993), also condition the process of change in ONbr; Blakeley (Reference Blakeley1949/50) demonstrates that higher frequencies of -s occur in verbs with stem-final dental segments /t, d, ð/, while vocalic stem-final segments, or those ending in the sibilant /s/, inhibit the occurrence of the -s ending.
The present reconsideration of the proliferation of -s in ONbr discusses evidence from a quantitative survey which benefits from the application of modern statistical methodology and addresses the issue using a multifactorial approach. Most crucially, the study analyses potentially relevant factors that remain unexplored in previous accounts. For instance, while the older literature has considered person and number as explanatory variables in conditioning variation between -s and -ð, the effect of subject type and adjacency on morphological variation in ONbr has hitherto been disregarded. This neglect is despite the fact that subject type and adjacency are crucial factors in determining the selection of verbal morphology in northern Middle English.
The verbal morphology of northern Middle English dialects, including Middle Scots, is characterised by a grammatical phenomenon generally referred to as the Northern Subject Rule (NSR). The NSR was a syntactic constraint that governed present-indicative plural verbal morphology in these dialects according to the type and position of the subject. A textbook description of the NSR would state that the present-indicative plural marker was -s, unless the verb had an immediately adjacent pronoun subject. If so, the marker was the reduced or zero ending (-e/-Ø), giving the following paradigm: thay kep(e) ‘they keep’, kep(e) we ‘do we keep’, þay haf(e) and makes ‘they have and make’, þay þat fastes, ‘they that fast’, and twa thynges makes ‘two things make’.
Given that this syntactically keyed agreement system with an -s versus -e/-Ø opposition does not exist in the tenth-century northern texts and there is no textual evidence of this pattern until the fourteenth century, the literature is heavily inclined in favour of an Early Middle English dating for the development of the NSR constraint (Isaac Reference Isaac and Tristam2003: 56–7; Pietsch Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005: 50; de Haas Reference Haas, Dossena, Dury and Gotti2008; de Haas & van Kemenade Reference Haas and van Kemenade2015). Benskin (Reference Benskin2011: 159) considers the possibility of origins in Early ONbr and suggests that the NSR could have developed ‘very early, even before the adoption of plural -s’. His close examination of present-tense marking in the Durham Ritual reveals that reduced verbal forms in -e/-a/-o occur with adjacent personal pronouns at a rate of 21 per cent (N = 24/115). Illustrative examples include ve agefe ~ exhibemus; gie gedoe ~ facitis and hia giclænsigo ~ castigant, all of which gloss Latin indicative plurals (Benskin Reference Benskin2011: 169 fn. 27).Footnote 3 De Haas's (Reference Haas, Dossena, Dury and Gotti2008) quantitative study of the frequency and distribution of reduced verbal forms with plural pronoun subjects in Lindisfarne shows that although -e/-a/-o forms do occur, both adjacent and non-adjacent pronominal subjects in the present indicative generally trigger endings in -s or -ð. Neither de Haas, nor Benskin, however, consider the possibility that the distribution of -s and -ð itself may have been conditioned by subject type and adjacency constraints. In other words, -s versus -ð, rather than -s versus -e/-Ø, displayed the same subject and adjacency effects found at the heart of the NSR. In the literature on the NSR, it is generally held that the constraint involves solely a syntactically conditioned opposition between an inflected -s form and an uninflected form (Poplack & Tagliamonte Reference Poplack and Tagliamonte1989: 58; King Reference King and Jones1997: 175; Pietsch Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005: 174). An alternative analysis has been posited by Benskin (Reference Benskin2011: 158), who views the NSR system as requiring an uninflected suffix but ‘independent of the suffix in -s’.
In an attempt to account for the morphological variation exhibited by the NSR, the present study views the rule as pertaining to syntactically conditioned variation between competing forms, rather than presupposing an exclusively inflected versus uninflected alternation. Such a perspective finds support in descriptions of variation between past be forms. Subject type is also an influential factor in determining variation between was and were (and is and are), not only in northern Middle English (Forsström Reference Forsström1948: 193–207) and Middle and Early Modern Scots (Montgomery Reference Montgomery, Fenton and McDonald1994: 91–2), but also in non-standard varieties of Present-day English (Chambers Reference Chambers and Kortmann2004; Tagliamonte Reference Tagliamonte, Filppula, Klemola and Paulasto2009).Footnote 4 Data taken from Middle English itself substantiates the view that the NSR is not dependent on an inflected–uninflected opposition.
The core syntactically conditioned pattern in the North was -s versus -e/-Ø, but even in the northern texts, such as the fourteenth-century Athelstan's Charter, -n also occurred as a variant of -s in nominal contexts (Fernández-Cuesta & Rodríguez-Ledesma Reference Fernández-Cuesta, Rodríguez-Ledesma and Mazzon2007: 126). In dialects outside the traditional northern boundaries in the Northwest and Northeast Midlands, and parts of the East Midlands, the selection of present-tense morphology adhered to the NSR but with different morphological material. De Haas (Reference Haas, Dossena, Dury and Gotti2008, Reference Haas2011) identifies a syntactically keyed alternation between -n and -s in the Lancashire copy of Anturs of Arther at the Tarnewathelan. In this text, plural pronoun subjects trigger verb forms ending in -e/-Ø or -n, as in thay byde ‘they wait’, but also thay droupun and daren ‘they droop and tremble’.Footnote 5 Full noun-phrase subjects trigger -s, as in byernes bannes the tyme ‘nobles curse the time’.
In his discussion of twentieth-century instances of the NSR taken from the Survey of English Dialects (Orton et al. Reference Orton, Barry, Dieth, Halliday, Tilling and (eds1962–71), Pietsch (Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005: 139–40) also finds that non-standard relic forms in -n and -s compete with each other in conformity with the NSR constraint in the Northwest Midlands area. Forms in -n occur with plural pronominal pronoun subjects, as in we callen it [SED: Db1], while full NP subjects trigger -s (-n occurs only once with a full NP subject out of a total of 335 -n tokens). Shorrocks (Reference Shorrocks1999: 114, quoted in Pietsch Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005: 140) finds the same syntactically conditioned alternation between -n and -s in modern northern dialect in Lancashire.
In parts of the East Midlands in Middle English, -ð as a variant of -s occurs with full NPs and non-adjacent subject pronouns, whereas adjacent subject pronouns require -n or its later derivative, the reduced or zero ending -e/-Ø (McIntosh Reference McIntosh, McIntosh and Laing1989; de Haas Reference Haas2011). De Haas (Reference Haas2011) finds insufficient evidence in the Bury Documents for a categorical East Midlands NSR system involving -th versus -e/-Ø/-n, although McIntosh (Reference McIntosh, McIntosh and Laing1989: 118) notes that the pattern is operative ‘[i]n the great majority of cases’ in Rosarium Theologie (MS Gonville and Caius College Cambridge 354/581).
Manifestations of the NSR in Middle English and twentieth-century rural varieties demonstrate that the surface realisations of the constraint display a considerable degree of morphological variation that do not solely involve a syntactically conditioned alternation between an uninflected and inflected form, namely -s. The surface morphology of the NSR varies diatopically as well as diachronically, but the syntactic configuration of the constraint remains stable.
Given that subject and adjacency effects appear to be triggered when morphological variants co-occur in the same environment, the aim of the present study was to ascertain whether subject type and adjacency constraints played a role in conditioning the distribution of -s and -ð in ONbr. It will be seen that earlier stages of northern English differentiated syntactically between pronominal and nominal subjects and that the distribution of ONbr verbal morphology constitutes the first attested manifestation of the subject and adjacency effects found at the crux of the NSR.
2 Methods and data
The methodological difficulties inherent in any study involving historical data are particularly pronounced in the case of Late ONbr; the only substantial material to survive from the period comprises interlinear glosses to Latin texts. Since the Latin original might potentially have had a skewing effect on the Old English translation, caveats apply when using glossarial translations as the basis for linguistic analysis. Furthermore, the collaborative approach to medieval text production, whereby the production of texts was more often than not a team effort involving several individuals, has important implications for our understanding of the language of the ONbr glosses, as it makes it very difficult to talk about homogeneous dialectal features.
The present study relies on the interlinear gloss to the Lindisfarne Gospels (London, British Library, Cotton Nero D. iv). The data are taken from the standard edition of Lindisfarne (Skeat Reference Skeat1871–87), collated with the facsimile edition of the manuscript (Kendrick et al. Reference Kendrick1960). This Latin Gospelbook was written at Lindisfarne Abbey in Northumbria in the early eighth century (see Ross et al. Reference Ross, Stanley and Brown1960; Brown Reference Brown2003). Some time around 950, an interlinear gloss in ONbr was added to the Latin, thus making the manuscript one of the few surviving substantial witnesses of early northern dialect.
An important methodological issue in Lindisfarne is whether the text of the gloss can be treated as a single, homogenous linguistic piece.Footnote 6 It is worth considering this matter here in some detail. The glossator of the Lindisfarne Gospels has traditionally been identified as Aldred (Ross et al. Reference Ross, Stanley and Brown1960: 24), a member of the St Cuthbert community, who appears to take credit for the gloss in the colophon added to fo. 259r of the manuscript. The remarkable linguistic variation manifest in Lindisfarne, however, led Brunner (Reference Brunner1947/8: 52) to suggest that either other scribes were involved in writing the gloss or that Aldred's translation was informed by several older sources. Given the palaeographical evidence in favour of considering the gloss to be the work of a single hand (Ross et al. Reference Ross, Stanley and Brown1960), the heterogeneity of the gloss's language is now generally viewed as attributable to Aldred's reliance on pre-existing vernacular translations of the Gospels (Brown Reference Brown2003; van Bergen Reference Bergen2008; Cole Reference Cole, Cuesta and Sanz2016).
Brunner's (Reference Brunner1947/8) study identifies the importance of assessing the distribution of linguistic variants in Lindisfarne as a diagnostic for establishing demarcations in the script. Her detailed survey of several variant forms in Lindisfarne shows that certain variants are either confined to, or are dominant in, specific parts of the text, with a clear demarcation at Mk 5.40.Footnote 7 Older studies on Lindisfarne tended to divide the data taken from the gloss strictly according to gospel (Holmqvist Reference Holmqvist1922; Ross Reference Ross1934; Berndt Reference Berndt1956). Since Brunner (Reference Brunner1947/8), however, the custom has been to follow her methodology and divide the whole gloss into 64 (arbitrarily determined) sections of equal length (see Blakeley Reference Blakeley1949/50) or to subdivide the data at the point where Brunner found a marked change in linguistic properties around Mk 5.40 (see van Bergen Reference Bergen2008).
The distribution of -s and -ð across the different sections of the gloss was first examined by Blakeley (Reference Blakeley1949/50) whose methodological point of departure was Brunner's division of the gloss. Blakeley's consideration of the effect of person and number on the distribution of -s and -ð across these sub-sections leads him to divide the gloss into four sections: section 1 (Mt Pref. – Mt 26.16); section 2 (Mt 26.17 – Mk 5.40); section 3 (Mk 5.41 – Lk Pref. *2.9); section 4 (Lk Pref. *2.10–end, so essentially Luke and John). Blakeley considers the person and number categories third singular, third plural and second plural.Footnote 8 No consideration is given to the effect of subject type and the first plural environment is excluded from the analysis.
For the data analysis in the present study, every instance of a plural and third-singular present form with an -s or -ð ending was extracted from all four Gospels, including the forms found in the prefaces. The initial corpus consisted of 3,053 present indicative and imperative tokens with -s or -ð endings. Following Brunner's (Reference Brunner1947/8) methodology, the data were then divided into 64 (arbitrarily determined) equal sections to determine the general distribution of -s and -ð across the text. My findings parallel those of Blakeley but with one crucial difference; they also identify a break around Jn 3.14–4.47, which justifies a five-way partitioning of the data: section 1 (Mt Pref. – Mt 26.16) 81% -s (N = 794/975); section 2 (Mt 26.17 – Mk 5.40) 28% -s (N = 55/194); section 3 (Mk 5.41 – Lk Pref. *2.9) 58% -s (N = 185/318); section 4 (Lk Pref. *2.10 – Jn 3.13) 22% (N = 209/947); section 5 (Jn 3.14 – end) 42% (N = 261/619). Differences in the occurrence of -s across these five sections are statistically significant at the < 0.001 level. The analysis of the distribution of -s across the whole gloss indicates a clear demarcation towards the end of Matthew at Mt 26.16, in line with Blakeley's findings. At this point of the narrative, the consistently high rate of -s usage (81 per cent) found throughout Matthew drops sharply between Mt 26.17–Mk 5.40. There is then a rise in -s usage between Mk 5.41–Lk Pref. *2.9, followed by a further drop and a rise once again in the last part of the gloss. The demarcation identified around the beginning of John's Gospel finds support in a number of studies that have highlighted the uniqueness of John's Gospel (Elliott & Ross Reference Elliott and Ross1972; van Gelderen Reference Gelderen2000: 58; van Bergen Reference Bergen2008; Kotake Reference Kotake, Amano, Ogura and Ohkado2008).
The demarcations in the text corroborate the view that Aldred made use of other sources in composing the gloss and suggest that the data do not reflect a homogeneous northern dialect, let alone an idiolect. Carrying out individual logistic regression analyses on each section, however, was not deemed viable given the nature of the multivariate statistical methodology employed. Firstly, including near-invariant data in a logistic regression analysis is problematic, and it is generally deemed good practice to exclude invariant and near-invariant contexts (Guy Reference Guy and Ferrara1988). Section 1 was therefore excluded from the data analysis in order to control for the near-invariant effect of the data up to Mt 26.16. Secondly, partitioning the data into five sections created datasets that were problematically small. Small datasets do not lend themselves to logistic regression analysis; for instance, in sections 2 and 3, certain subject types were under-represented. Collapsing sections 2–5 was therefore felt justified in order to test for subject effects that might not emerge in smaller data samples and to avoid the problematic ramifications brought about by small cells during a multivariate analysis (see Guy Reference Guy and Ferrara1988: 129–32 on the problems of low cell counts).
The present study is, in part, an attempt to readdress the limitations of previous monofactorial approaches to the issue of -s/-ð variation that analysed one variable at a time. Controlling simultaneously for the effects of all relevant variables is essential if one is to ensure that the effect of a given variable is genuine and not the by-product of other variables. The treatment of the data is therefore a compromise (with the appropriate caveats), which sets the benefits of using multivariate analysis against the need to recognise that the dataset under analysis cannot be understood as representing a homogeneous northern dialect or the idiolect of a single individual.
The resulting corpus spanned from Mt 26.17 to the end of the Gospels and comprised 2,078 present-indicative and imperative tokens with -s or -ð endings. Statistical analyses were carried out using Rbrul (Johnson Reference Johnson2009a, Reference Johnson2009b), a derivative of the open-source statistical programme R (R Development Core Team 2009).
To determine whether there were signs in ONbr of the same type of syntactically keyed agreement system which was later operative in northern Middle English, grammatical context was included in a series of logistic regression analyses alongside other linguistic factors that have proved important in previous accounts of variation.Footnote 9 The explanatory variable grammatical context reflected both the grammatical category of the subject (i.e. personal pronoun, demonstrative pronoun, full NP, null subject, etc.) and its person and number. Levels comprised: 3sg personal pronoun (he, hiu), 1pl personal pronoun (we), 2pl personal pronoun (gie),Footnote 10 3pl personal pronoun (hia), demonstrative pronoun,Footnote 11 indefinite pronoun,Footnote 12 noun phrase (sg), noun phrase (pl), null 3sg subject, null 3pl subject, NP + relative cl. (3sg), NP + relative cl. (3pl), and null imperative (pl). Other factors included morphosyntactic priming, polarity, lexical item and phonological factors such as stem ending and following segment (these will not be considered here in detail; see Cole Reference Cole2014 for discussion).
A further important methodological consideration when dealing with glossarial material is the degree to which the observed linguistic phenomena might have been influenced by the original Latin text (see van Bergen Reference Bergen2008 and Benskin Reference Benskin2011 for discussion). Benskin (Reference Benskin2011: 170) discusses the potential correlation between the demands of atomistic glossing, which dictate the use of explicit consonantal forms to render Latin verbal morphology explicitly in Old English, and the low incidence of reduced verbal forms in Lindisfarne. In the case of variation between -s and -ð, the glossator's preference for -s in the first- and second-person plural may have been influenced by Latin verbal forms in -s, e.g. gelefes gie ~ credetis at Jn 5.47. My analysis thus registers the potential influence of a Latin priming effect.Footnote 13
3 Results
3.1 Grammatical context effects
The logistic regression analyses selected morphosyntactic priming, lexical item, stem ending and grammatical context as crucial factors in determining the distribution of competing variants. following segment, latin and polarity were not selected as significant.
The detailed results of the multivariate analysis for grammatical context are provided in table 1. In the plural environment, there is a propensity for the personal-pronoun subjects gie, hia and we to favour -s (with factor weights of 0.70, 0.67 and 0.63, respectively). This is in contrast to null subjects and heavy subjects, such as full NPs and NP + relative clause subjects, which favour the inherited variant -ð.
Table 1. Effects of grammatical context on the probability of -s (as opposed to -ð) in plural and third-person singular environments in Lindisfarne (N = 2078)
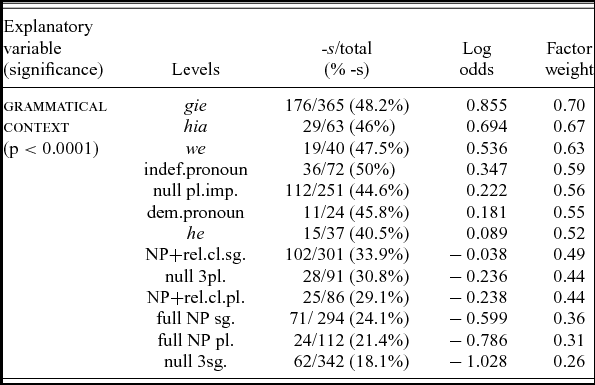
Of particular interest is the sharp difference in behaviour between the third-person plural personal pronoun hia and plural noun phrase subjects at 0.67 and 0.31, respectively. This contrast is precisely the patterning we would expect in an NSR system. The results in table 1 also reveal that an NP/Pro constraint, involving he vs full singular NP, exists in the third-person singular environment, with the personal pronoun subject he favouring the occurrence of -s significantly more so than singular full NP subjects (χ2 4.591 p < 0.05). These findings establish an NP/Pro constraint in both the plural and singular environments and concur with findings by Bailey et al. (Reference Bailey, Maynor and Cukor-Avila1989) for varieties of EModE and those of Cukor-Avila (Reference Cukor-Avila and Schneider1997) and Schneider & Montgomery (Reference Schneider and Montgomery2001) for non-standard varieties of American English (see fn. 4).
The results also indicate that indefinite pronouns and demonstrative pronouns pattern very differently from full noun phrase subjects, but similarly to personal pronoun subjects. Indefinite and demonstrative pronouns are twice as likely to trigger verbal endings in -s as full NP subjects and, at 0.59 and 0.55, respectively, have much higher factor weights. The parallel in morphosyntactic behaviour between demonstrative pronouns and personal pronouns is perhaps not surprising in that demonstratives could be used independently with an anaphoric function in Old English (see Mitchell Reference Mitchell1985: §344), as in ða god geseas ~ ipsi deum uidebunt ‘they/those will see God’ (Mt 5.8), taken from the gloss. In Lindisfarne, the demonstrative pronouns ðis, ðes, ðe and ða, ðas and the personal pronouns he and hia all occur as glosses for Latin demonstratives. Double glosses, involving both a personal and demonstrative pronoun, also frequently occur, for instance ðe onfoes ł he onfoeð ~ accipiet ‘he receives’ (Mt 10.41), hea ł ða ~ illi (Mt 2.5), which further illustrates the apparent interchangeability of demonstrative and personal pronouns in Old English.
Commonalities between the morphosyntactic behaviour of personal, demonstrative and indefinite pronouns bolster van Bergen's (Reference Bergen2003) hypothesis that demonstrative and indefinite pronouns behave similarly to personal pronouns in Old English and should not be classed as nominals. Recent generative studies corroborate this argument for demonstrative pronouns. Van Kemenade & Los (Reference Kemenade, Los, van Kemenade and Los2006) and van Kemenade (Reference Kemenade, Hinterhölzl and Petrova2009) show that independently used demonstrative pronoun subjects share commonalities with nominative pronouns in Old English in that they both typically occupy the highest subject position in the clausal configuration.Footnote 14
The results also indicate that third-person null subjects in ONbr behave similarly to full NP and NP + relative clause subject types in favouring the -ð variant. Commonalities in morphosyntactic behaviour between these subject types display a remarkable diachronic stability, with later varieties of northern English, including Scots and present-day Northumbrian dialects, exhibiting a similar concord pattern.
Montgomery's (Reference Montgomery, Fenton and McDonald1994) diachronic survey of subject-verb concord in Scots provides evidence that full NP subjects, non-adjacent pronoun subjects and null subjects also pattern similarly in fourteenth- to seventeenth-century Scots. Adjacent pronoun subjects in both the plural and first-person singular environments favour -Ø, while NP subjects and non-adjacent pronoun subjects favour -s, as in (1). Montgomery also notes how verb forms with no overt subject (at least in the first-person singular) also trigger verbal -s forms, as (2) illustrates.
(1) I have spokyn with my lord Maxwell and hes deleverit your lordship wrytinge
(The Scottish Correspondence of Mary Lorraine, 15 [Montgomery Reference Montgomery, Fenton and McDonald1994: 83])
(2) [I] committis zow to God his halle protectioun, [I] rests [,] Zour loving mother at power
(Memorials of the Montgomeries, 184 [Montgomery Reference Montgomery, Fenton and McDonald1994: 89])
Sentences (3) and (4), recorded in the Knaresborough Workhouse Daybook (García Bermejo & Montgomery Reference García-Bermejo Giner and Montgomery2003), indicate that similar syntactically keyed agreement is found in eighteenth-century Yorkshire dialect.
(3) I have gotton 18 pound of worsit spun this week but desines to make an Advance. (García Bermejo & Montgomery Reference García-Bermejo Giner and Montgomery2003: 32)
(4) [I] knows not what she would be at. (García Bermejo & Montgomery Reference García-Bermejo Giner and Montgomery2003: 33)
Cole's (Reference Cole2008) analysis of the retention of the NSR in contemporary northern dialect in the Tyneside region, based on NECTE (Corrigan et al. Reference Corrigan, Beal and Moisl2001–5), shows that full NP and NP + relative clause subjects favour was forms, and that was is also licensed if the subject pronoun is absent. Pronominal they, on the other hand, favours were. Examples of this distribution pattern are given in (5)–(9).
(5) I worked with these women which I thought was old then . . . to me they were old.
(6) My parents was thinking of getting a shop . . . they were also thinking of moving.
(7) . . . barracks which was occupied by soldiers in those days.
(8) [They] was the first bombs.
(9) You know [they] was like innocent times.
The morphosyntactic alignment in behaviour between full NP, NP + relative clause and null subjects displayed in the later northern varieties discussed above is a commonality shared with ONbr that highlights the diachronic stability of the agreement constraint.
3.2 Subject type, person and number effects
The levels analysed in the previous section for the explanatory variable grammatical context reflect both the grammatical category of the subject and its person and number. In order to test for the separate and individual effect of subject type, person and number on the occurrence of -s, analyses were also carried out in which the relevant categories were split into three separate explanatory variables, subject type, person and number, and tested alongside other relevant variables.
The multiple regression analyses are striking in that they indicate that subject type and person both exert a statistically significant conditioning effect on the occurrence of -s at the p < 0.001 level, but number was not selected as significant. Recall that an NP/Pro constraint operated in both the third-singular and plural environments. These results suggest that agreement in the ONbr datatset under scrutiny relies essentially on a pronominal–non-pronominal contrast, in addition to person, but not number features.
The results of the logistic regression analysis for subject type and person are outlined in table 2, and the percentages are represented graphically in figures 1 and 2. The differing morphosyntactic behaviour of personal, demonstrative and indefinite pronouns, in contrast with full NP subjects, is readily observable; consistently higher percentages of -s occur with pronoun subjects than with full NP subject types.
Table 2. Effects of subject type and person on the probability of -s (as opposed to -ð) in plural and third-person singular environments in Lindisfarne (N = 2078)


Figure 1. Incidence (%) of -s ending according to subject type in Lindisfarne

Figure 2. Incidence (%) of -s ending according to person in Lindisfarne
As previously mentioned, older surveys of ONbr verb inflection have highlighted the differentiated distribution of -s across the various persons and numbers (see Holmqvist Reference Holmqvist1922: 13–14, fn. 7; Blakeley Reference Blakeley1949/50; Stein Reference Stein, Kastovsky and Szwedek1986: 640). These studies effectively establish the following hierarchy for the effect of person and number: second plural > first plural > third plural > third singular. Higher rates of -s occur in the second-person plural environment, in contrast with the relatively inhibitive effect of the third person, especially the third-person singular. These findings are replicated to an extent by the present study in that second- and first-person contexts appear to favour -s more so than third-person contexts. Nevertheless, the role played by subject type in conditioning the occurrence of -s highlights a crucial flaw in the handling of the data upon which the traditional person–number constraint hierarchy is based. Stein (Reference Stein, Kastovsky and Szwedek1986) differentiates the imperative plural and the second-person indicative plural but in line with older studies (Berndt Reference Berndt1956; Holmqvist Reference Holmqvist1922) makes no such categorial distinction in the third-person data. The result is that the first- and second-person plural codes comprise solely personal pronouns, i.e. a ‘favouring’ subject type, whereas in the third-person context, personal pronoun subjects are conflated with ‘disfavouring’ non-pronominal subject types. In other words, older studies have assumed homogeneity in the behaviour of different subject types across the third-person and, in doing so, have masked the effect of subject type and skewed the results for person. When the data are reduced to encompass a single subject type – personal pronoun subjects alone – in which present-tense -s markings across the different persons are comparable, the special prominence of the second person reported in the literature does not exist. The figures in table 3 demonstrate the strikingly similar incidence in -s usage across plural and singular contexts and the three persons for the pronoun subjects we, gie, hia and he. No statistically significant difference in behaviour is detected between we/gie against hia (χ² 0.092, p = 0.761), nor we/gie/hia versus he (χ² 0.725, p = 0.394).
Table 3. Distribution of -s endings across we, gie, hia and he in Lindisfarne (N = 493)

The findings of the present study demonstrate that the third person is not a disfavouring environment per se. The inclusion of subject types such as NP and null subjects in the count for the third person in older quantitative studies artificially deflates the overall incidence of -s in this context and effectively obscures the preference for third-person personal (and demonstrative and indefinite) pronouns to trigger -s.
A final issue that requires addressing is the potential for a Latin priming effect. Linguistic phenomena observed in Old English data taken from word-for-word glosses of Latin manuscripts run the risk of having been influenced entirely, or in part, by the Latin original. The above analysis registered the presence of a potential Latin prime but found no such effect. The Lindisfarne glossator shows no preference for -s over -ð in first- and second-person environments where the corresponding Latin verb ending in -s might have had a priming effect on the OE, e.g. gelefes gie ~ credetis Jn 5.47. When rates of ONbr -s among first- and second-person plural glosses of Latin verb forms ending in -s were compared across the same personal pronoun subject type with rates of -s found in the third-person plural, singular and imperative gie, whose corresponding Latin forms would not involve -s, i.e. when verbal inflection that could have been influenced by the Latin original was compared with verbal inflection where Latin could not have functioned as a prime, no statistically significant difference in behaviour was found (χ² 2.396, p = 0.121).
3.3 Adjacency effects
In addition to investigating the effect of subject type in the glosses, this study also set out to examine whether an adjacency effect conditioned the selection of verbal morphology in plural pronominal environments in ONbr, as it did in northern Middle English. The dataset for this analysis relied on 467 plural pronoun subject contexts extracted from the original corpus of 2,078 present-indicative and imperative tokens with -s or -ð endings. In line with the results of the quantitative analysis of -s/-ð, which highlight the similarities in morphosyntactic behaviour between personal and demonstrative pronouns in Old English, the plural demonstrative pronoun subjects ðas and ða were included in the code for third person together with the personal pronoun hia. Imperative gie tokens also formed part of the analysis since the distribution of plural imperative morphology in Middle English also exhibited an adjacency effect (Laing 2013: LAEME 4.4.4.7). adjacency was tested in logistic regression analyses alongside the following explanatory variables: person, polarity, stem ending and morphosyntactic priming (see Cole Reference Cole2014 for detailed discussion). The potential effect of subject verb inversion was also considered, in other words, whether verb forms occurred in ante- or post-pronominal position. In Old English when a plural pronoun subject immediately followed the verb the consonantal suffix was lost, e.g. wyrca we, as opposed to we wyrcas. The effect of inversion on the choice of verbal morphology is also witnessed in northern Middle English (Brunner Reference Brunner1970: §68) and in present-day varieties of northern English (Shorrocks Reference Shorrocks1999; Pietsch Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005). As a high degree of multicollinearity was detected between the codes for adjacency and inversion, these factor groups could not be tested simultaneously.Footnote 15 A chi-square evaluation showed that word order had no statistically significant effect on the use of suffixal -s (p = 0.250, χ2 1.322). A preliminary statistical analysis including person, inversion, polarity, stem ending and morphosyntactic priming confirmed this; inversion was not selected as significant, so it was removed as a variable from the analysis.
Non-adjacent contexts whereby the pronoun subject is not immediately adjacent to the verb comprise three broad subgroups in the gloss. They include verbs separated from their pronoun subjects by intervening elements, as in gie uutudlice cuoeðas ~ uos autem dicitis ‘you indeed say’ (Mk 7.11) and hia ne habbað ~ non habent ‘they have not’ (Lk 14.14). Non-adjacent contexts also comprise the second verbal element of coordinated VPs, such as ge geseas 7 ne geseað ~ uidebitis et non uidebitis ‘you will see and not perceive’ (Mt 13.14). Another non-adjacent context peculiar to the gloss is that involving multiple glosses. The glossator frequently provides alternative glosses for a single Latin lemma, separated by ł, the abbreviation for Latin vel ‘or’, thus hia saueð ł sauas ~ seminantur ‘they sow’ at Mk 4.18. In these cases, the verbal element not in immediate proximity to the pronoun subject was regarded as non-adjacent.Footnote 16
The logistic regression analysis selected stem ending at the p < 0.0001 level and morphosyntactic priming at the p < 0.001 level as the most influential factors, followed by adjacency at the p < 0.05 level. person and polarity were not selected as significant. The results for adjacency are summarised in table 4. The results indicate that adjacency plays a role in conditioning the occurrence of -s, whereby adjacent pronouns favour -s at 0.59, while non-adjacent pronoun environments disfavour -s at 0.41 and prefer -ð.
Table 4. Effects of adjacency on the probability of -s (as opposed to -ð) for plural pronominal environments in Lindisfarne (N = 467)

The effect of morphosyntactic priming, which was found to be influential in determining the distribution of -s, would theoretically bias a speaker towards reusing a linguistic form, in this case the same inflectional ending. In other words, morphosyntactic priming has the reverse effect to the NSR constraint, which triggers differential inflections (Ans van Kemenade p.c.). The tension between the two constraints would be felt most strongly in cases where the glossator provides alternative verbal forms separated by ‘vel’ or in the case of contexts involving coordinated VPs of the type gie ongeattas hine 7 geseað hine ~ cognoscitis eum et uidistis ‘you know him and have seen him’ (Jn 14.7). In this particular example, non-adjacency would have the effect of triggering -ð, whereas priming would bias the speaker towards reusing -s and producing gie ongeattas hine 7 geseas hine. Given the strong morphosyntactic priming effect found in the glosses (see Cole Reference Cole2014), it is perhaps all the more remarkable that adjacency emerges as a robust syntactic effect in determining the direction of variation.
Tables 5 summarises the effect of subject type and adjacency on the distribution of -s and -ð endings in the core NSR plural environment. The dataset for this analysis relied on 755 plural tokens comprising full NP, NP + relative clause and null subjects, labelled ‘other’, and adjacent and non-adjacent first-, second- and third-person plural pronoun subjects extracted from the original corpus of 2,078 tokens. This gave a dataset of 755 tokens. The factor group subject type was included in a multivariate analysis alongside morphosyntactic priming, polarity, stem ending. All of the factors groups were selected as having a significant effect on the occurrence of -s at the p < 0.0001 level. polarity was also selected as having an effect at the p < 0.05 level.
Table 5. Effects of subject type on the probability of -s (as opposed to -ð) for plural environments in Lindisfarne (N = 755)

As can be seen from table 5, the following pattern emerges: adjacent pronoun subjects favour -s, while all other subject types including non-adjacent pronouns favour -ð. The constraint hierarchy – though not categorical – is nevertheless statistically significant. Furthermore, it is identical to that found in northern Middle English and later northern varieties and demonstrates that the syntactic NSR system operated in early northern dialects but with different morphological endings.
4 Discussion
Syntactic conditioning involving subject type and adjacency constraints alone does not explain the distribution of competing verbal morphology in ONbr as it does in northern Middle English. Other factors including phonological and lexical conditioning, and morphosyntactic priming, also govern the distribution of -ð/-s (see Cole Reference Cole2014). Nor are the effects of subject type and adjacency categorical. Caution is also required in too readily drawing conclusions about the grammar of ONbr based on a single witness. Yet the results of the present study indicate that the syntactic configuration at the crux of the NSR was already a feature of Late ONbr and constitute a crucial contribution to the study of the early history of the NSR. The study also debunks the well-ingrained conviction that -s spread into the second-person plural and other persons of the plural before the third-person singular. Moreover, the findings refute the suggestion that the linguistic factors conditioning variation between -ð and -s in ONbr were in any sense random or ‘unclear’ (see de Haas & van Kemenade Reference Haas and van Kemenade2015: 52). ONbr has been shown to differentiate syntactically between pronominal and nominal subjects and the effects of subject type and adjacency are statistically significant. Nor is the Early Middle English dating generally attributed to the emergence of the effects at the crux of the NSR (Isaac Reference Isaac and Tristam2003; Pietsch Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005; de Haas Reference Haas, Dossena, Dury and Gotti2008; de Haas & van Kemenade Reference Haas and van Kemenade2015) sustainable in view of the ONbr concord system.
The tenth-century dating of the subject-type constraint posited by the present study would initially appear to militate in favour of the proposition that the NSR was the result of Brittonic substratum influence on northern English (Hamp Reference Hamp1975/6; Klemola Reference Klemola and Tristram2000; de Haas Reference Haas, Dossena, Dury and Gotti2008; Benskin Reference Benskin2011). Benskin (Reference Benskin2011) offers a refined account of the typological similarities between northern Middle English and Middle Welsh verb agreement that form the basis of the so-called ‘Celtic hypothesis’. He identifies a fundamental parallel between the Middle Welsh concord system and the northern Middle English pattern. In Middle Welsh, the plural and third-person singular environments shared the same suffix, except when verbal forms co-occurred with adjacent plural personal pronouns, in which case a co-variant plural suffix was used. In other words, adjacent plural personal pronoun subjects blocked the suffix shared by the third-person singular and plural environments. Plural and third-person singular environments in ONbr also shared a suffix, in this case -ð, and ONbr also had a reduced co-variant plural suffix in -e, e.g. doe as opposed to doeð. According to Benskin, the Brittonic system provided the model for the reanalysis of the Brittonic suffixal alternation using ONbr morphology; the ONbr -ð suffix shared by the third-person singular and plural environments was used with all subject types, except with adjacent plural personal pronoun subjects. As this environment barred the suffix shared by plural and third-person singular environments, the co-variant ONbr plural suffix in -e was used with adjacent plural pronoun subjects. Benskin accounts for the -s versus -e/-Ø pattern of northern Middle English by suggesting that as -ð was replaced by -s, the new suffix inherited the grammatical constraints to which the older -ð suffix was already subject (Benskin Reference Benskin2011: 172–3).
The results of the present study pose a serious impediment for the mechanics of the substratum syntax transfer as proposed by Benskin. The -s suffix does not pattern like -ð in ONbr. Rather than the -s suffix inheriting the syntactic constraints that applied to -ð and favouring non-pronominal plural environments, as expected under Benskin's analysis, these are precisely the contexts that disfavour the -s suffix; -s is significantly more common in adjacent pronominal plural environments, precisely the environment that bars the shared third-person singular and plural suffix in Brittonic. The distributional system, as recorded by the gloss, is the diametric opposite to the system Benskin's hypothesis requires. By the Middle English period, the distribution of northern verbal morphology had indeed fallen into alignment with that of Middle Welsh: -s eventually went to completion in all third-person singular environments regardless of subject type and in all non-pronominal plural environments. But the story told by the gloss would necessarily force the rather unlikely conclusion that there was an interim period in which the distribution of ONbr present-indicative verbal morphology bore scarce resemblance to the Brittonic system, before it once again emerged in accordance with the Brittonic system several centuries after the conjectured period of contact. Such a chronological incongruence suggests that the surface similarity between the two systems is not related and developed independently.
The language contact situation that arose in the North during the Old English period between speakers of Brittonic and Old English, and indeed Old English and Old Norse, was instrumental in determining the reconfiguration of the Old Northumbrian system, but the effects of contact phenomena in triggering language change need not necessarily involve structural borrowing. Contact scenarios are well known to be conducive to the type of linguistic simplification that -s levelling constitutes (Trudgill Reference Trudgill2010: 30–5). The emergence of a subject-type concord system is best understood as an endogenous response to a breakdown in the original system based on number and person marking brought about by levelling, rather than as the product of systemic transfer.
The distribution of -ð/-s in ONbr corroborates Pietsch's (Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005) contention that the emergence of subject effects is likely in linguistic scenarios where levelling has led to the inherited agreement system based on grammatical person and number becoming opaque. In situations of extreme person–number neutralisation, a system based on a distinction between pronominal and non-pronominal subjects may ‘become cognitively more salient in processing than the person–number distinction’ (Pietsch Reference Pietsch, Kortmann, Herrmann, Pietsch and Wagner2005: 198). Processes of morphological restructuring have been identified in similar linguistic scenarios in Modern English. The breakdown in person–number agreement caused by processes of was and were levelling has led to morphological restructuring involving an alternative agreement system based on a positive–negative polarity distinction in some varieties of British and American English. Speakers tend to generalise was in positive contexts and weren't in negative contexts (see Schilling-Estes & Wolfram Reference Schilling-Estes and Wolfram1994; Wolfram & Schilling-Estes Reference Wolfram, Schilling-Estes and Schneider1996; Anderwald Reference Anderwald2001).
Assessing the Old Northumbrian data within a broader framework of diachronic variation also contributes to the ongoing debate as to whether NSR-like patterns found in varieties of EModE and non-standard varieties of Present-day English are the results of diffusion or are motivated by language-internal factors.Footnote 17 Schendl (Reference Schendl and Britton1996: 152–3) attributes the low-frequency subject-type constraint found in Early Modern London English to migration into London from the North and the Midlands. In explaining the prevalence of NSR-type concord in non-standard varieties of American English, diffusionist accounts suggest that the subject-type concord system reached North America via the immigration of Irish and British settlers whose speech had the constraint (Montgomery et al. Reference Montgomery, Fuller and DeMarse1993; Montgomery & Fuller Reference Montgomery, Fuller and Schneider1996; Poplack & Tagliamonte Reference Poplack and Tagliamonte2001).
The diachronic stability and geographical scope of the constraints found at the crux of the rule, together with their prevalence in varieties isolated from northern contact, challenges the view that subject effects on variation must necessarily be the result of diffusion. Northern input may explain some of the modern varieties in question, but subject effects have also been shown to operate in processes of deregularisation where external input cannot be held responsible for the observed agreement system. See Godfrey & Tagliamonte (Reference Godfrey and Tagliamonte1999) for an analysis of deregularisation in Devon English that identifies subject-type effects and Schreier (Reference Schreier2002) for Tristan da Cunha English. Indeed, the same effects are found to condition the levelling of suffixal -r in the present-indicative paradigm of Early Modern Swedish (Larsson Reference Larsson1988). All of this suggests that the term ‘Northern Subject Rule’ may in fact be a misnomer for a syntactic constraint whose effects are prevalent far beyond northern boundaries. An alternative explanation points to independent language-internal trends, whereby there exists a predisposition within many varieties of English for the morphological variation occasioned by levelling to be conditioned by competing agreement systems, one based on person and number and the other on subject type and adjacency. The pattern and strength of this tendency need not manifest themselves identically in varieties; the trend will vary according to the influences of the local setting and the varying impact of standardisation, becoming rule-like processes in some varieties and little more than tendencies in others (see Tagliamonte Reference Tagliamonte, Filppula, Klemola and Paulasto2009: 127). The results of the present study show that an agreement system based on subject type and adjacency, regardless of the surface morphological realisation, is a persistent and pervasive feature in the history of English and can be traced back to some of the earliest attested processes of levelling and variation in the English language.







