


When language is set to music or chanted, syllables are coordinated with a relatively isochronous metrical grid. This mapping, though not inflexible, is highly systematic, as reflected in singers’ preferences for certain possible maps over others. At the broadest level of generalization, preferred maps between text and music involve correspondences between analogous structures of language and music, such as the matching of prominence, constituency, tone and duration.Footnote 2 For example, prominent linguistic elements such as stressed syllables tend to align with metrically prominent events in music such as downbeats (Lerdahl & Jackendoff Reference Lerdahl and Jackendoff1983; Dell Reference Dell and Dominicy1989; Palmer & Kelly Reference Palmer and Kelly1992; Halle & Lerdahl Reference Halle and Lerdahl1993; Hayes & MacEachern Reference Hayes and MacEachern1998; Jackendoff & Lerdahl Reference Jackendoff and Lerdahl2006; Kiparsky Reference Kiparsky, Elan Dresher and Friedberg2006; Dell & Halle Reference Dell, Halle and Arleo2009; Hayes Reference Hayes, Inkelas and Hanson2009a, Reference Hayes2009b; Proto & Dell Reference Proto and Dell2013; Temperley & Temperley Reference Temperley and Temperley2013; Proto Reference Proto2015; Girardi & Plag Reference Girardi and Plag2019; Tan et al. Reference Tan, Lustig and Temperley2019; Kiparsky Reference Kiparsky2020). Second, linguistic constituency of various levels tends to align with analogous levels of musical phrasing (Halle Reference Halle2004; Patel Reference Patel2008; Starr & Shih Reference Starr and Shih2017). For example, intervals between attacks in music tend to scale with prosodic boundary strength. Third, linguistic pitch phenomena such as lexical tone and intonation often correspond with melodic contours (Devine & Stephens Reference Devine and Stephens1994; Wee Reference Wee2007; Schellenberg Reference Schellenberg2012; Villepastour Reference Villepastour, Lechleitner and Liebl2014; McPherson Reference McPherson2018, Reference McPherson2019; McPherson & Ryan Reference McPherson and Ryan2018; Ladd & Kirby Reference Ladd and Kirby2020).
A fourth dimension of correspondence between language and music in textsetting, and the focus of this article, is duration matching. A number of textsetting traditions distinguish heavy from light syllables, such that the former are allotted more grid space. In some cases, such correspondence is demonstrably independent of the other dimensions of correspondence just enumerated. In Ancient Greek music, for instance, heavy syllables – regardless of accent and position – are set to long notes in the music, while light syllables are set to short notes, an opposition in note value usually nowadays transcribed using quarter and eighth notes (West Reference West1992: 130–3; Hill Reference Hill2008; see, for instance, the Delphic hymns per West Reference West1992: 288–300). Similarly, a number of Afro-Asiatic languages exhibit living quantitative textsetting traditions in which heavy syllables are mapped onto more grid space than light syllables, including Bole (Schuh Reference Schuh2001), Hausa (Schuh Reference Schuh2011; Hayes & Schuh Reference Hayes and Schuh2019), Somali (Banti & Giannattasio Reference Banti, Giannattasio, Hayward and Lewis1996) and Tashlhiyt Berber (Dell & Elmedlaoui Reference Dell and Elmedlaoui2008, Reference Dell, Elmedlaoui and Newman2017; Dell Reference Dell, Cairns and Raimy2011). Of course, quantitative textsetting is not confined to Afro-Asiatic (e.g. Ross & Lehiste Reference Ross and Lehiste2011 on Estonian; Proto & Dell Reference Proto and Dell2013: 9–10 on Italian; Kiparsky Reference Kiparsky2020 on Urdu, among others); it is also found in English, as discussed presently. McPherson (Reference McPherson2021) analyzes a xylophone surrogate of Seenku (Mande) in which syllable weight is mapped onto musical articulation: heavy syllables such as CV are flammed (double-struck), unlike light syllables such as level-toned CV̆.Footnote 3
In English, too, textsetting is sensitive to weight, even when controlling for stress level and other factors. Consider the two lines in figure 1, the second a constructed comparandum (modified from Hayes & Kaun Reference Hayes and Kaun1996: 260). The lines exhibit identical stress profiles and constituencies. In both cases, the stressed syllables map onto the tallest grid columns, which mark strong metrical positions. The lines differ in the weights of the initial syllables of city and township, a difference reflected in the textsetting: light ci- is mapped onto one grid space (equivalent to an eighth note or quaver), while heavy town- occupies two spaces (a quarter note or crotchet). Hayes & Kaun (Reference Hayes and Kaun1996) refer to these two settings as short first and long first, respectively. To be sure, other settings are possible; indeed, it would not be unmetrical to set (a) long first or (b) short first. But the long-first setting is more frequent and more felicitous with a heavy syllable.Footnote 4
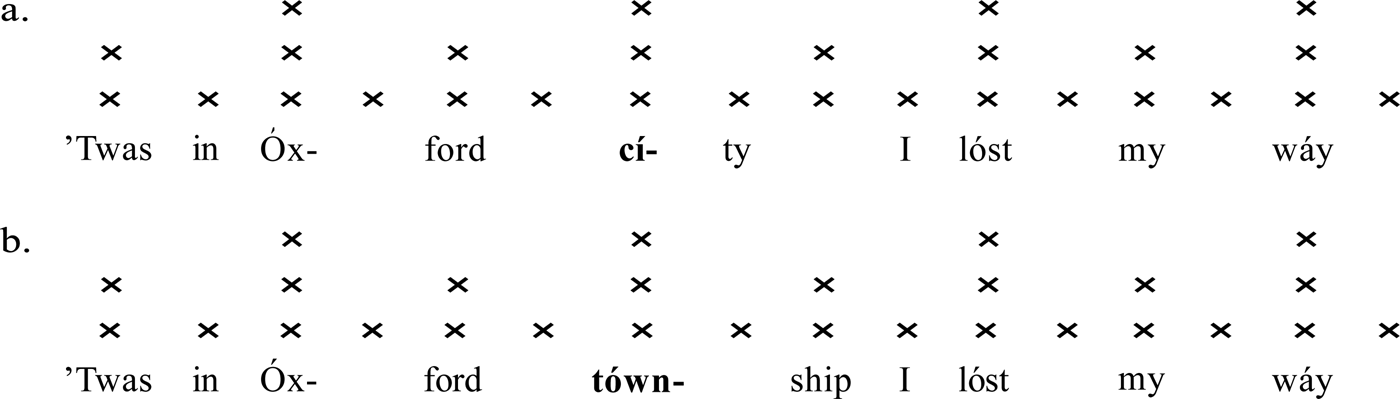
Figure 1. Possible settings of two lines differing only in syllable weight. While both settings (a–b) are possible for both lines, (b) is more likely if the boldface syllable is heavy.
A grid representation such as in figure 1 shows only the alignment of syllables’ beginnings (or attacksFootnote 5) with metrical positions, not the alignment of syllables’ offsets. In other words, it does not make explicit how long notes are held within their allotted grid spaces. For example, town in (b) might fill both available timing slots, or the singer might pause slightly between town- and ship. This article, along with nearly all research in generative textsetting (e.g. Halle & Lerdahl Reference Halle and Lerdahl1993: 15; Hayes & Kaun Reference Hayes and Kaun1996: 245; Keshet Reference Keshet2006: 3–4; Dell & Halle Reference Dell, Halle and Arleo2009: 65), treats the alignment of attacks with the grid and the allotment of grid space between attacks, not the orthogonal question of how syllables are performed for a given setting.Footnote 6 As Hayes & Kaun (Reference Hayes and Kaun1996: 245) explain, ‘for rhythmic purposes it is not particularly crucial where a note ends’. In order to emphasize that it is grid space rather than note value that is being modeled, the present article employs the terms ‘quarter space’ and ‘eighth space’ rather than ‘quarter note’ or ‘eighth note’. (‘Space’ should not be confused with ‘empty space’, that is, a rest.) For instance, in figure 1, town- occupies a quarter space, regardless of how legato or staccato it is articulated. Both a quarter note and an eighth note followed by an eighth rest constitute quarter spaces.
Returning to the role of weight in English textsetting, Hayes & Kaun (Reference Hayes and Kaun1996: 263–7) demonstrate through textsetting experiments with ten participants (in addition to a set of original scores) that, first, non-word-final heavy syllables are significantly more likely than non-word-final light syllables to be set to quarter as opposed to eighth spaces (to use the present terminology). Although this first finding is compatible with both categorical and gradient weight, they go on to argue that textsetting is sensitive to gradient duration based on the behavior of word-final heavy syllables. As they note, the degree of lengthening of a phrase-final syllable correlates monotonically with the strength of the prosodic juncture that it precedes. For instance, the ultima of an intonation group tends to be more prolonged than the ultima of a phonological phrase that is not final in its intonation group. Likewise, in textsetting, Hayes & Kaun (Reference Hayes and Kaun1996) find that the juncture strength following a syllable correlates monotonically with the syllable's space apportionment. An interpretation of these results is that textsetting responds to the fine-grained, natural durations of syllables.
Halle (Reference Halle2004), however, discusses a consideration that potentially undermines this inference (see also Oehrle Reference Oehrle, Kiparsky and Youmans1989: 104–17 for a similar argument): space allocation might respond directly to juncture strength without being mediated by syllable duration. There is, after all, evidence for constituency matching in textsetting that is independent of syllable duration mapping. Indeed, in some cases, the need for direct constituency mapping is trivial. For instance, a sentence ending with a schwa might be followed by a measure of rest in the music. In this case, the musical phrasing corresponds with the linguistic phrasing, but the spacing cannot be attributed to the duration of the schwa. Halle (Reference Halle2004: 6) offers the example of oronyms, that is, phonetically near-identical phrases that differ in constituency (see also Oehrle Reference Oehrle, Kiparsky and Youmans1989: 104). For example, need in we need a decanter is more felicitously set to a quarter space than the same morpheme in we needed a cantor.Footnote 7 As another illustration (not Halle's) of the necessity of direct constituency mapping, consider fountain of youth versus tip of the hat in figure 2, in which tip is more felicitously set to a quarter space than foun-. Because tip is shorter than foun-, the bias in grouping must be due to constituency mapping rather than syllable duration. Thus, it is possible that Hayes & Kaun's (Reference Hayes and Kaun1996) final lengthening results are driven by constituency matching rather than natural syllable duration. That said, Hayes & Kaun (Reference Hayes and Kaun1996) present another test that is not susceptible to this confound: stressed, heavy syllables are significantly more likely to be set to short spaces as antepenults than as penults, a difference that they attribute to the gradient effect of polysyllabic shortening (Reference Hayes and Kaun1996: 297).

Figure 2. An illustration of the need for constituency matching independent of weight mapping. Despite the syllable foun- being greater in natural duration than the syllable tip, the former is more likely to be set to a shorter space in (a–d). Especially at a slow tempo, (a) is more felicitous than (b), and (d) more than (c).
Besides Hayes & Kaun (Reference Hayes and Kaun1996), few studies probe whether durational correspondence in textsetting is sensitive to natural duration. Girardi & Plag (Reference Girardi and Plag2019), for instance, find that note length in English textsetting correlates with both stress level and poetic-metrical strength, but they do not analyze syllable weight. Hayes (Reference Hayes2009b) and Keshet (Reference Keshet2006) employ a constraint Strong-is-Long, which penalizes short spaces after prominent beats in the music, but this constraint does not refer to syllable weight.Footnote 8 The converse constraint Long-is-Strong does invoke weight, but only binary weight (Hayes & Schuh Reference Hayes and Schuh2019). San & Turpin (Reference San and Turpin2021) employ Final-is-Long, which requires a measure-final syllable to span three positions, regardless of weight. Beyond English, most research on quantitative textsetting treats weight as categorical. For example, Hayes & Schuh (Reference Hayes and Schuh2019: 284–93) model the durations with which syllables are sung in Hausa, but the model takes as inputs only discrete moras and syllables, not natural duration. McPherson (Reference McPherson2021: 11–14) goes further, finding that performative duration in Seenku is affected by gradient prosodic effects such as phonetic closed-syllable shortening. Finally, Gilroy (Reference Gilroy2021) reports two experiments with 87 participants that test whether vowel tenseness and coda voicing influence textsetting in English. In one of the experiments (Reference Gilroy2021: 45– 51), both effects are significant. Because all the stimuli are monosyllables, the effects must be attributed to intra-heavy durational differences.
Natural duration, which might also be called intrinsic or inherent duration, refers to the timing of spoken language as independent from textsetting. With Hayes & Kaun (Reference Hayes and Kaun1996), Hayes & MacEachern (Reference Hayes and MacEachern1998) and Kiparsky (Reference Kiparsky, Elan Dresher and Friedberg2006), I assume a modular approach to textsetting, such that correspondence constraints have access to natural prosody, allowing natural prosody to influence the realization of language as sung or chanted, though textsetting imposes its own constraints, modifying that prosody (e.g. Hayes & Schuh Reference Hayes and Schuh2019: 284–93). Natural duration in principle subsumes all systematic aspects of timing in spoken language, including phonemic length, intrinsic segmental duration (e.g. duration correlating with vowel height), adjustments due to segmental context (e.g. vowel shortening in closed syllables), lengthening under stress, final lengthening, polysyllabic shortening, gradient compensatory effects, and so forth. It is an empirical question whether all these properties in fact influence textsetting. This article finds that at least some of them do, and therefore endorses the position that weight mapping for textsetting relates a continuous dimension (duration) to a categorical dimension (the discrete grid).
In order to probe the nature of weight mapping while avoiding any possible interference from constituency matching, the tests in this article focus on syllables in a fixed word-internal position, namely, the stressed initials of disyllables. Each test examines whether a given factor impacts the rate with which syllables are allocated quarter versus eighth spaces, a categorical distinction. Hayes & Kaun's (Reference Hayes and Kaun1996) claim that textsetting invokes natural duration is supported throughout. The present article newly documents several ways in which subcategorical weight affects textsetting, including intrinsic vowel duration (section 2), coda complexity (section 2), onset complexity (sections 3–4) and the compression of vowels after filled onsets (section 4). These findings also bear on the domain of weight, conventionally assumed to be the syllable. I argue, however, that weight must be assessed over p-center intervals (the spans between successive perceptual centers), as this motivates the array of onset effects documented in sections 3–4. Finally, in sections 5–6, I maintain that categorical weight cannot be dispensed with altogether: even though weight for textsetting is sensitive to natural duration, categories are more polarized than a linear effect of duration alone would predict. Grammars are thus hybrid, incorporating both categorical and gradient aspects of weight.
1 The corpus and annotation of grid spacing
As a large annotated corpus of contemporary English popular music, I use DALI 2 (Dataset of synchronised Audio, LyrIcs and notes; Meseguer-Brocal et al. Reference Meseguer-Brocal, Cohen-Hadria and Peeters2018). The anglophone portion of DALI 2, as employed here, comprises 5,913 songs from 2,020 artists, mostly American. Release dates range from 1938 to 2017 with a median of 2003. The songs are mostly mainstream releases, with pop, rock and alternative being the most frequent genres. The three artists with the most songs in the corpus are Glee Cast, the Beatles and Demi Lovato.
DALI 2 contains data based on song recordings, not scores. Among other features, it provides the start time of each syllable as well as the duration with which it is held, both with nominal millisecond precision (Simpson et al. Reference Simpson, Roma, Plumbley, Vincent, Yeredor, Koldovský and Tichavský2015; Meseguer-Brocal et al. Reference Meseguer-Brocal, Cohen-Hadria and Peeters2018). DALI 2 does not provide annotations for grid alignment or note value. I add annotations for grid space as follows. An inter-onset interval (IOI) measures the time elapsed between the starts of two successive syllables, including any intervening silence. In most songs, especially those with fixed tempos – drum machines are commonly used in pop recordings – IOIs cluster around certain recurrent values. For example, figure 3 shows the density distribution of IOIs in the song ‘I hate this part’ by the Pussycat Dolls. The peaks of the distribution fall near multiples of 266 ms, with the two tallest peaks corresponding to eighth and quarter spaces. Smaller peaks correspond to sixteenth spaces (0.5 × 266 ms), dotted quarter spaces (3 × 266 ms), half spaces (4 × 266 ms), and so forth. Variance around each peak – the width of the mound – reflects the singer not hitting the beat precisely due, for instance, to stylistic choices or changing tempo. Also contributing to variance is the fact that singers do not generally seek to align the beginnings of syllables with beats, but rather their p-centers, which are closer to the beginnings of nuclei (section 4).

Figure 3. Distribution of inter-onset intervals (IOIs) in the Pussycat Dolls’ ‘I hate this part’. The two highest peaks correspond to eighth and quarter spaces, with shading indicating accepted ranges.
To annotate quarter and eighth spaces for the whole music corpus, a density curve like the one in figure 3 is generated for each song. The two tallest peaks are retrieved. If the peak on the left is approximately half (45% to 55%) the duration of the peak on the right, these two maxima are taken to represent median eighth and quarter spaces, respectively. If no such ratio is evident, the song is excluded, leaving 2,371 usable songs in the corpus. Each usable song's spaces are then classified as eighth, quarter, or other, allowing some variance around the median (±25% the duration of the eighth) to accommodate inexact syllable-beat alignment. In figure 3, these bands are shaded. Space categories are distributed as follows: 46% eighth, 24% quarter and 30% other (excluded).
The distribution of IOIs in the songs used in this study, which exhibit relatively rigid grids, contrasts sharply with the distribution of IOIs in English as naturally spoken. Figure 4 depicts the latter, based on the first speaker in the Buckeye corpus of conversational English (Pitt et al. Reference Pitt, Dilley, Johnson, Kiesling, Raymond, Hume and Fosler-Lussier2007). In natural speech, IOIs are unimodally distributed. The contrast between figures 3 and 4 makes explicit that the regularly spaced peaks found in the musical corpus are due to the demands of textsetting, not the mechanics of natural speech. Singing, with its more rigid grid, discretizes the distribution: natural duration is shoehorned into categories corresponding to regular grid spaces.

Figure 4. Distribution of IOIs in natural English speech
One caveat about this methodology is that the labels ‘quarter’ and ‘eighth’ are somewhat arbitrary absent sheet music. What stops us from treating the two tallest peaks in figure 3 as, say, quarter and half spaces? For one thing, quarter and eighth notes predominate in the genre. For another, if the peak at 266 ms corresponded to a quarter note, the beats per minute would be a genre-defying 226. Finally, and most importantly, the labels are not critical to the tests that follow. What matters is that the target spaces are categories standing in a 1:2 timing relation. Indeed, this point holds implicitly of any study of a primarily oral genre, in which transcriptions are largely post hoc, including the English folk songs analyzed by Hayes & Kaun (Reference Hayes and Kaun1996), Hayes & MacEachern (Reference Hayes and MacEachern1998) and Kiparsky (Reference Kiparsky, Elan Dresher and Friedberg2006).Footnote 9 ‘Quarter’ and ‘eighth’ in this article might also be labeled ‘long’ and ‘short’.
A second caveat is that, as discussed above, grid space values do not encode how long notes are held. In most instances, note value and grid space are the same. However, for a note before a rest, grid space exceeds note value. For example, a quarter note before three beats of rest occupies a whole-measure space. In the tests below, this divergence between note values and grid spaces is unimportant, for two reasons. First, nearly all the tests consider only non-word-final syllables. In the present corpus, word-internal pauses are rare, meaning that note value and grid space are nearly always equivalent for the syllables in question. Second, the tests consider only quarter and eighth spaces, effectively excluding notes at the ends of musical phrases, which often precede rests. At any rate, grid space is not intended to be a proxy for note value. As discussed, rhythm is instantiated principally by the timing of attacks, not the timing of offsets.
2 Beyond binary weight
All else being equal, heavy syllables tend to be mapped onto larger grid spaces than light syllables. With this first test, I confirm this tendency while controlling for stress level and position in the word by considering only stressed initials of disyllables. The division between light and heavy syllables is nuanced in English (Moore-Cantwell Reference Moore-Cantwell2021), but for present purposes, I follow Olejarczuk & Kapatsinski (Reference Olejarczuk and Kapatsinski2018: 385) in treating syllables ending with monophthongs except /i, u/ as light and those ending with /i, u/, codas, diphthongs and syllabic consonants (including the rhotic) as heavy. In DALI 2, heavy syllables as initials of disyllables are mapped onto quarter (i.e. long) as opposed eighth (i.e. short) spaces 42% of the time, a rate almost twice that of light syllables in the same context (24%) and a significant difference (Fisher's exact test p < 0.0001). The result is the same regardless of how less securely long or short vowels such as /i, u, ɑ, ɔ, ɝ/ are classified.
Beyond binary weight, natural duration influences textsetting. For example, take vowel identity in stressed initials of words of the form CV́CVC0.Footnote 10 Figure 5 shows the rate at which vowels in this context are mapped onto quarter versus eighth spaces. On the one hand, the distinction between heavy and light syllables (or tense and lax vowels, as in Gilroy Reference Gilroy2021) is once again in evidence. Long vowels, which render open syllables heavy, are consistently more quarter space-aligned than short vowels. On the other hand, a role for gradience is obvious. Within each weight class, phonetically long vowels are increasingly likely to be mapped onto quarter spaces. Although some vowels, such as /æ/, vary substantially by dialect, some generalizations about vowel duration are stable across dialects, including /ɪ, ʊ/ being the shortest of the short and /aʊ, ɔɪ/ being the longest of the long (Umeda Reference Umeda1975; Jacewicz et al. Reference Jacewicz, Fox and Salmons2007). These trends are reflected as such in figure 5 and cannot be motivated The dashed divider is a commonly assumed cutoff for light versus heavy CV syllables. by a textsetting model that invokes only binary weight. Indeed, given the apparently seamless transition from light to heavy syllables, figure 5 creates the impression that textsetting might ignore binary weight altogether, heeding only natural duration. Nevertheless, the question of whether both categoricity and gradience are motivated requires statistical scrutiny, to which I return in section 5.

Figure 5. The percentage of the time that CV syllables (as stressed initials of disyllables) are mapped onto quarter as opposed to eighth spaces, by vowel. Error bars are Wilson scores. The dashed divider is a commonly assumed cutoff for light versus heavy CV syllables.
Additional evidence for the insufficiency of binary weight can be found in coda complexity. Consider once again stressed initials of disyllables, now relaxing the frame to ignore margin complexity: C0V́C0VC0. As figure 6 reveals, with each consonant added to the coda, quarter maps increasingly predominate eighth maps. For instance, among syllables with long vowels (right panel), which are all categorically heavy, both contrasts in the chain Ø < C < CC are significant, as reinforced by the Wilson intervals. These contrasts add to the contrasts among open syllables in figure 5, which are subsumed by Ø in figure 6.

Figure 6. The percentage of quarter and eighth spaces that are quarter spaces as a function of coda size in syllables with short vowels (left) and long vowels (right)
3 Syllables versus intervals in textsetting
The previous section established that the metrical categorization of syllables is not solely a function of binary weight. This section turns to the domain of weight, which is conventionally assumed to be the syllable or rime. An alternative possibility is that weight reflects the total vowel-to-vowel interval (Steriade Reference Steriade2008, Reference Steriade2012, Reference Steriade, Bowler, Duncan, Major and Torrence2019: 174–6; Hirsch Reference Hirsch, Kingston, Moore-Cantwell, Pater and Staubs2014; Ryan Reference Ryan2016: 725–6; Lunden Reference Lunden2017). As an illustration, in the word pregnancy, the syllables are [pɹɛg, nən, si], while the intervals are [ɛgn, əns, i], as in figure 7 (cf. Meyer et al. Reference Meyer, Dentel and Seifart2012: 688).
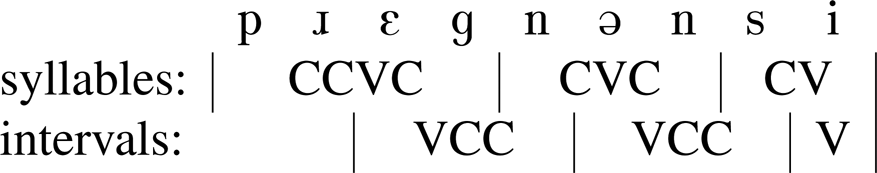
Figure 7. Syllable versus vowel-to-vowel interval parses of pregnancy. Under both approaches, the word comprises three spans.
Insofar as syllable weight is based on the rime, the beginning of the weight domain is the same for syllables and intervals, being the beginning of the vowel/nucleus. The main difference between the proposals concerns the right edge of the domain: with syllables, only some intervocalic consonants are parsed into the preceding vowel's domain, namely, those that can be syllabified as (parts of) codas, whereas with intervals, all intervocalic consonants are parsed into the preceding vowel's domain, regardless of phonotactics. Several arguments for intervals have been put forth (cited above), though the evidence is not clearcut (see Ryan Reference Ryan2016: 725–6 for a synopsis). As one argument, intervals are claimed to account better for the domain of durational invariance: the duration of a vowel trades not just with the duration of its coda, but also with that of the following onset. In this section, I present four statistical tests pitting syllables against intervals as domains of weight for English textsetting. All four favor intervals.
First, I examine grid space allocation as a function of onset size of the following syllable, limiting the data to stressed, non-word-final syllables. As figure 8 shows, even while holding the first (stressed) syllable's rime shape constant, each consonant added to the onset of the following syllable increases the first syllable's propensity to be mapped onto a quarter space. This result is expected with intervals, where the whole interlude counts towards the weight of the first vowel's span, but not with syllables. Indeed, syllables make the opposite prediction: as consonants are added to the following onset, the preceding syllable tends to be compressed, and would therefore be expected to be, if anything, lighter.Footnote 11 Syllable divisions here follow CELEX (Baayen et al. Reference Baayen, Piepenbrock and Gulikers1993). Depending on one's theory of English syllabification, one might take issue with certain syllabifications provided by CELEX. For example, where CELEX provides [ɛk.stɹə], one might instead consider [ɛks.tɹə] or ambisyllabicity. CELEX uses onset maximization, as is widely employed for English (Kahn Reference Kahn1976; Selkirk Reference Selkirk, van der Hulst and Smith1982). Other dictionaries use other schemes (Bartlett et al. Reference Bartlett, Kondrak and Cherry2009: 313–14). This test therefore favors intervals over syllables with onset maximization, but does not rule out other possible syllabification algorithms. The remaining three tests are more tightly controlled so as not to be ambivalent in this way.

Figure 8. Percentage of quarter as opposed to eighth maps as a function of the size of the trailing onset (onset of the following syllable), grouped by the rime type of the preceding syllable. Only the three most frequent rime types are shown.
Second, consider words of the shape C0V́V(C)VC0, where V́V is a stressed long vowel or diphthong, such that the initial syllable is always heavy.Footnote 12 Intervals predict that the initial of C0V́V(C)VC0 should be heavier when the medial consonant is present: V́VC > V́V. This prediction is correct: When the consonant is present, the initial span is mapped onto quarter spaces 41% of the time, versus 33% when it is absent (Fisher's exact test p < 0.0001). This difference cannot be explained by syllables. More specifically, with syllables, there are two conceivable explanations for the difference, neither of which turns out to be viable. First, if C0V́V were durationally longer in C0V́V(C)VC0 when the medial consonant was present, one could claim that the duration of the first syllable was driving the effect. However, the opposite is true. Based on the Buckeye corpus, C0V́V is shorter in C0V́V(C)VC0 when the medial consonant is present (mean 172 when present versus 198 ms, t = −11.6, p < 0.0001). A second potential defense of syllables begins with the assumption that an intervocalic consonant can be syllabified as a coda. (If one is not willing to make this assumption, this second defense is unavailable.) For C0V́VCVC0, such a parse is most plausible when C0V́VC is a root and VC0 is either an inflectional suffix (e.g. -ing) or the second member of a compound (e.g. weekend). Bearing this in mind, I divide all C0V́VCVC0 words into two groups. The first group (n = 5,523) comprises words ending with a VC0 inflectional affix or compound member.Footnote 13 The second group (n = 6,806) comprises the remaining C0V́VCVC0 words. Words of the first group are more likely to be syllabified as VC.V than words of the second group. Nevertheless, the two groups exhibit essentially the same rate of quarter maps, at 41.3% and 40.8%, respectively (Fisher's exact test p = 0.61). This means that the observed difference between C0V́VCVC0 and C0V́V.VC0 cannot be attributed to a subset of the former being syllabified with a medial coda. Syllables have no way out.
As a third test, consider words of the shape C0V́C0.C1(C2)VC0, where C1 is a plosive and C2 is a liquid, excluding sequences tl and dl as well as words ending with -less. Intervals, unlike syllables, predict that the addition of C2 should contribute to the weight of the first span. The prediction is correct. The initial span of this frame is quarter-set 49% of the time when the following syllable starts with a plosive-liquid cluster, versus 33% of the time when it starts with only a plosive (Fisher's exact test p < 0.0001).
Finally, consider the duration of the single intervocalic consonant in the frame C0V́CVC0. As an estimate of the natural duration of each consonant in this context, I take its mean duration as the medial consonant of C0V́CVC0 in the Buckeye corpus. Means thus obtained range from 30 ms for [ɾ] to 129 ms for [ ʃ ]. In a logistic regression with grid mapping (quarter versus eighth) of the initial syllable as the dependent variable and intervocalic consonant duration and vowel quality (14 levels) as independent variables, consonant duration is positive and significant (t = 3.3, p < 0.001). This outcome is expected with intervals, since the intervocalic consonant is always grouped with the preceding vowel. It is unexpected with syllables, where either the consonant serves uniformly as the onset of the following syllable, or, if one admits VC.V parses, is not expected to vary systematically in its coda versus onset status as a function of its intrinsic duration. In fact, the outlook for syllables is grimmer still, since vowels tend to shorten before longer consonants in the frame VCV (Farnetani & Kori Reference Farnetani and Kori1986; Fant & Kruckenberg Reference Fant and Kruckenberg1989; McCrary Reference McCrary2004). Thus, if textsetting were sensitive to the durations of syllables, one would expect the effect to go in the opposite direction, with V1 behaving as lighter before a longer intervocalic consonant.
4 Onsets and the p-center interval
Having established that the vowel-to-vowel interval better characterizes the domain of weight for textsetting than does the syllable or rime, this section turns to the role of leading onsets. Under traditional views of both the syllable and the interval, the onset preceding a vowel – that is, the span's leading onset – is not expected to affect the weight of the span. Under syllables, this expectation follows from rime-based weight (Halle & Vergnaud Reference Halle and Vergnaud1987) or onsets not serving as heads of moras (Hyman Reference Hyman1985). Similarly, under intervals as characterized by Steriade (Reference Steriade2008, Reference Steriade2012, Reference Steriade, Bowler, Duncan, Major and Torrence2019: 174–6) and others, the interval begins with the vowel. Thus, an onset is either grouped with the preceding vowel's span or, if no vowel precedes, is extraprosodic. In short, intervals predict onsets to affect weight, but only trailing onsets, not leading ones.Footnote 14
Nevertheless, evidence has been mounting from across languages and weight-sensitive phenomena that leading onsets can contribute to weight, and not simply in ways that can be attributed to modulations of the following vowel (Ryan Reference Ryan2011b, Reference Ryan2014, Reference Ryan2016: 726–8, Reference Ryan2019; cf. Gordon Reference Gordon2005). For example, they influence stress placement in English, with increasingly long onsets increasingly attracting stress (Ryan Reference Ryan2014). (Note that onset length negatively correlates with the duration of the following vowel; thus, a rime or vowel-to-vowel interval is shorter, not longer, following a longer onset.) In this section, I demonstrate that leading onsets affect weight in textsetting.
As before, consider words of the form C0V́C0VC0. As shown in figure 9, as initial onset size increases, so does the incidence of quarter settings. This is confirmed by a logistic regression including predictors for onset size (four levels), categorical weight (two levels), vowel identity (14 levels), and the interaction of onset size and categorical weight. Regardless of whether categorical weight is computed using syllables or intervals,Footnote 15 the onset factor is significant (t = 6.0 and t = 7.2, respectively, both p < 0.0001). The one exception to the trend, as apparent in figure 9, is the contrast between null and simple onsets, with the former patterning as heavier. This reversal can be attributed to the duration of the vowel: vowels are significantly longer after null onsets than after simple onsets in English (Fowler Reference Fowler1983; van Santen Reference van Santen1992; Clements & Hertz Reference Clements, Hertz, Lavoie and Ham1996; Katz Reference Katz2010). For example, in words of the shape (C)V́C0VC0 in the Buckeye corpus, the initial vowel is on average 21% longer after a null onset. Given the sensitivity to vowel duration seen previously in figure 5, it is not surprising that an increase of this magnitude is felt. This increased vowel duration may or may not be further augmented by the prothetic glottal stop that often accompanies a stressed, word-initial vowel in English.Footnote 16

Figure 9. The percentage of the time that initial syllables of words of the shape C0V́C0VC0 are mapped onto quarter as opposed to eighth spaces as a function of initial onset size. As discussed, the trend-defying uptick for null onsets is expected with natural duration mapping.
In the previous section (section 3), medial onsets were shown to contribute to the weight of the interval initiated by the preceding vowel. I now test whether they also contribute to the weight of the following interval. Consider the onset of the ultima of words of the form C0VC0VC0. As figure 10 reveals, the same effect of onset size that is found for word-initial onsets obtains also for word-medial onsets, both for unstressed (left panel) and stressed (right panel) ultimas. The slight reversal from null to simple similarly recapitulates figure 9. Logistic models, as above, confirm the significance of the trend observed in figure 10 (t = 6.2 and t = 6.3, both p < 0.0001).

Figure 10. The percentage of the time that final syllables of C0VC0VC0 words are mapped onto quarter as opposed to eighth spaces as a function of final onset size, paneled by the stress level of the ultima.
Thus, a leading onset contributes to the weight of its span in textsetting, an effect predicted neither by rime-based weight nor by vowel-to-vowel intervals. Given that intervals were found in section 3 to be superior to syllables for modeling weight in textsetting – only intervals capture trailing onset effects — the question is how to reconcile intervals with leading onset effects. One logically possible explanation that does not work is to invoke the effect of onset complexity on the duration of the following vowel. If vowels were longer after longer onsets, an explanation of onset weight would be available without modifying the vowel-to-vowel span. However, as footnote 16 points out, vowels are progressively shorter, not longer, after progressively longer onsets.
A viable solution is a modification to interval theory that I have elsewhere termed the p- center interval (Ryan Reference Ryan2016: 727, Reference Ryan2019: 239). The p-center, or perceptual center (Morton et al. Reference Morton, Marcus and Frankish1976), refers to the time point in a syllable at which the beat is felt, or, from a production standpoint, the target of alignment between tactus and syllable. Even in the absence of an overt grid, p-centers are targets for isochrony. For example, in reciting a list of monosyllables, p-centers are targeted for even spacing. As has long been recognized (e.g. List Reference List1974: 368), when entraining syllables with an isochronous grid, singers do not generally attempt to align the beginnings of syllables with beats. Rather, the target for isochrony is closer to the beginning of the vowel.Footnote 17 For instance, Bravi (Reference Bravi and Russo2016) examines the alignment of syllables with beats in nonsense Italian songs containing only the syllables ma or pa, finding that the point of alignment is closer to the left edge of the vowel than that of the consonant (Reference Bravi and Russo2016: 444–5). Likewise, Seifart et al. (Reference Seifart, Meyer, Grawunder and Dentel2018) find that the drum strikes used to imitate the tone and rhythm of the Amazonian language Bora approximate the intervals between vowels rather than syllables. McPherson (Reference McPherson2021) finds the same for the xylophone surrogate of Seenku.
Nevertheless, the p-center cannot be identified precisely with the beginning of the vowel (or nucleus): the target deviates from the vowel edge depending on the constitution of the syllable. For one thing, adding consonants or duration to the onset tends to shift p-centers leftwards relative to the vowel (Cooper et al. Reference Cooper, Whalen and Fowler1986; Villing Reference Villing2010).Footnote 18 For example, the p-center anticipates the vowel more in spa more than ba (Port Reference Port and Gareth Gaskell2007: 509). Specifically, the p-center is on average 24 ms earlier relative to the vowel in spa than in ba in the Harvard-Haskins Database of Regularly Timed Speech (Patel et al. Reference Patel, Löfqvist and Naito1999). This offset is considerably less than the difference in duration between the two onsets. Marcus (Reference Marcus1981: 253) regresses on the durations of the onset and rime to predict p-center placement, finding both to be significant, but with substantially different coefficients. Ryan (Reference Ryan2014: 329) shows that p-centers steadily drift leftwards relative to the vowel as onset complexity increases in English; see also Šturm & Volín (Reference Šturm and Volín2016) on Czech and Barbosa et al. (Reference Barbosa, Arantes, Meireles and Vieira2005) on Brazilian Portuguese. Franich (Reference Franich2018) finds that prenasalized syllables exhibit earlier p-centers in Medumba (Bantu).
In sum, the p-center is an event (or probability distribution over events) that approximates the beginning of the vowel, but incorporates some (not all) of the duration of the onset, at least for longer onsets.Footnote 19 The p-center interval is therefore a good candidate for the domain of weight in textsetting. On the one hand, it allows for trailing onset effects (section 3): The span between p-centers includes not just a rime, but a portion of the following onset. On the other hand, it allows for leading onset effects (this section): in the presence of a longer onset, the p-center is realized slightly earlier, expanding the domain of weight. This approach is thus superior to the three alternatives of vowel-to-vowel intervals (which fail to capture leading onset effects), whole-syllable weight (which fails to capture trailing onset effects) and rime-based weight (which captures neither leading nor trailing onset effects).
5 On the coexistence of categoricity and gradience in weight mapping for textsetting
While weight mapping for textsetting is sensitive to natural duration, that does not preclude it from also being sensitive to categorical weight. Indeed, this section presents two tests whose results suggest that textsetting invokes both duration and categorical weight. First, consider once again the effect of vowels’ intrinsic durations on grid space allocation. Figure 11 is based on the stressed vowels of CV́CVC0 words. As before, duration correlates with grid space: the longer the vowel, the more likely it is to be set to a quarter as opposed to an eighth space. But the figure now also separates vowels by categorical weight (as defined in section 2), revealing that long and short vowels (i.e. vowels that render CV syllables heavy or light, respectively) are more polarized than duration alone would predict. Intrinsic duration is estimated using the Buckeye corpus, taking only stressed, initial vowels in CV́CVC0 words. The independent effect of categorical weight is supported by logistic regression. A model with predictors for both categorical weight and duration significantly outperforms the subset model with duration alone (ΔAIC = −475; p < .0001). Categorical weight and duration have roughly similar effect sizes, with scaled coefficients of 0.32 and 0.21, respectively. Their interaction is non-significant (p = .38), meaning that duration has a similar effect within each category.

Figure 11. Categorical weight and intrinsic segmental duration exert independent effects, based on stressed, initial CV syllables in disyllables
A second, more omnibus test supports the same conclusion. Consider initial, stressed intervals of the more inclusive frame C0V́C0VC0. For each vowel-to-vowel interval V́C0 in this context, I compute the percentage of the time that it is mapped onto quarter as opposed to eighth spaces, as well as the mean duration of that interval in the same word context in Buckeye.Footnote 20 I exclude any interval that is unattested or attested only once in either corpus. As figure 12 illustrates, duration correlates gradiently with quarter settings among both heavy and light intervals. Moreover, there is a significant additive effect of category membership (ΔAIC=−522; p < .0001). As usual, light versus heavy is operationalized for intervals in terms of timing slots, such that any interval with three or more slots is heavy. Once again, categorical weight and duration have roughly similar effect sizes, with scaled coefficients of 0.26 and 0.35, respectively. Additionally, the interaction of categorical weight and duration is now significant (p < .0001), with the effect of duration being greater among light syllables. This is, perhaps, to be expected, given that each millisecond added has a proportionally smaller impact on a heavy syllable.

Figure 12. Quarter as opposed to eighth settings as a function of the mean duration of the interval, split by categorical weight
6 Conclusion
In the setting of text to music, Hayes & Kaun (Reference Hayes and Kaun1996) posit that the mapping of syllables to a discrete metrical grid is based on the phonetic durations of those syllables: ‘Reflect the natural phonetic durations of syllables in the number of metrical beats they receive’ (Reference Hayes and Kaun1996: 260). As discussed, most of their evidence for weight as a continuous as opposed to categorical variable derives from the correlation of grid space with final lengthening, evidence that is subject to another possible analysis: independent of syllable weight, textsetting is known to match linguistic constituency (Oehrle Reference Oehrle, Kiparsky and Youmans1989; Halle Reference Halle2004; above, figure 2). The larger gaps after higher-level constituents (sites of greater final lengthening) might be due to the parallelism of linguistic constituency and musical phrasing (Halle Reference Halle2004).
That said, the present study supports Hayes & Kaun's (Reference Hayes and Kaun1996) conclusion through several tests that avoid this confound by controlling for constituency, taking only the stressed initials of disyllables. Moreover, I expand the repertoire of phonetic factors known to influence textsetting, adding vowel height,Footnote 21 coda size, leading onset size, trailing onset size, and vowel lengthening after a null onset. Furthermore, onset effects reveal that weight is based not on the rime, syllable, or vowel-to-vowel interval, but rather on the p-center interval. P-centers approximate the beginnings of vowels, but are perturbed by properties of onsets and other factors. P-center intervals are only a slight modification of vowel-to-vowel intervals, but one that permits the incorporation of leading onset effects of the type documented in section 4. The role of p-centers as points of alignment between syllables and beats has long been recognized. Given this role, it is perhaps not surprising that p-centers should also serve to delimit the domain of weight for textsetting, as proposed here.
Finally, while textsetting is based in part on natural duration, I argue that there remains a role for categorical weight. In particular, syllables/intervals are more polarized in textsetting than durational differences alone would predict. A grammatical model with both categorical and gradient weight as factors significantly outperforms one with gradient weight alone.Footnote 22 Indeed, Ryan (Reference Ryan2011a: 440–6) postulates the same need for hybridity in metrics.Footnote 23 For example, in the Finnish Kalevala epic, heavy and light syllables behave as nearly categorically distinct; however, a cline of weight is evident within heavy syllables. Categoricity is also supported by several textsetting traditions in which syllable weight translates more or less directly to metrical grid positions (e.g. Ancient Greek, Hausa and others cited in the introduction). I therefore maintain that weight mapping for textsetting has both categorical and gradient aspects, as can be implemented by the combination of categorical correspondence (say, Heavy-is-Long: ‘a heavy interval must be allocated at least a quarter measure’) and gradient correspondence (say, Heavier-is-Long: ‘for every interval mapped onto an eighth measure, assign a penalty equivalent to that interval's natural duration’). While these constraints are merely sketches inviting further development, this combined-constraint approach is essentially what was implemented by the logistic models in section 5.
Another area of ongoing research concerns the degree of phonetic detail to which the textsetting grammar has access. This article supports the position that at least some phonetic detail is available (e.g. the intrinsic durations of vowels), building on phonetic effects in textsetting posited by other studies (e.g. polysyllabic shortening in Hayes & Kaun Reference Hayes and Kaun1996, prevoiceless compression in Gilroy Reference Gilroy2021). But numerous aspects of prosody and segmental timing are yet to be probed. More generally, what is at issue is how textsetting grammars operationalize natural duration. One simple hypothesis is that the grammar has access to all systematic phonetic detail in the spoken language. However, it may turn out that some aspects of spoken language timing are not taken into account when allocating discrete grid space to syllables. For example, timing in spoken language is sensitive to factors such as word frequency, contextual predictability and speech rate, to name a few; textsetting may or may not respond to such factors. Weight mapping is rich, but how rich?












