Text Analysis in Political Science
Text is an invaluable source of information about politics. Students of elections, campaigning, legislative behavior, party competition, issue agendas, and public policy use text as data to extract information from party manifestos, press releases, speeches, social media, laws, and other forms of political communication (e.g., Budge et al. Reference Budge, Klingemann, Volkens, Bara and Tanenbaum2001; Proksch and Slapin Reference Proksch and Slapin2010; Sagarzazu and Klüver Reference Sagarzazu and Klüver2015; Schwarz, Traber and Benoit Reference Schwarz, Traber and Benoit2015; Klüver and Sagarzazu Reference Klüver and Sagarzazu2016).
Advances in automated text analysis have made massive bodies of text accessible to social science research (Laver, Benoit and Garry Reference Laver, Benoit and Garry2003; Slapin and Proksch Reference Slapin and Proksch2008). Yet, computers have augmented rather than replaced human judgment of political text (Grimmer and Stewart Reference Grimmer and Stewart2013), which remains crucial in applications such as supervised learning (e.g., Esuli and Sebastiani Reference Esuli and Sebastiani2010; Nardulli, Althaus and Hayes Reference Nardulli, Althaus and Hayes2015) and ex post validation of automated approaches (e.g., Lowe and Benoit Reference Lowe and Benoit2013). The human mind is able to contextualize information in ways that are (at present) alien to machines,Footnote 1 yet human judgment is generally less reliable (Däubler et al. Reference Däubler, Benoit, Mikhaylov and Laver2012; Mikhaylov, Laver and Benoit Reference Mikhaylov, Laver and Benoit2012).
In this paper, we aim to test explicitly whether humans consider contextual factors when making judgments of political texts. We use an experiment where coders evaluate policy statements on immigration that we connect with party cues. The messages thus consist of two types of information: the actual content and the context in which it is presented. The results show that coders use heuristics from party labels and incorporate these priors into their coding decisions. In the conclusion, we discuss the consequences of these results for automated and human-based content analysis.
Heuristic Processing and Party Cues
Our argument draws on the concept of heuristic processing (Kam Reference Kam2005; Petersen et al. Reference Petersen, Skov, Serritzlew and Ramsøy2013; Bolsen, Druckman and Cook Reference Bolsen, Druckman and Cook2014; Fortunato and Stevenson Reference Fortunato and Stevenson2016). Heuristic processing means that individuals use contextual information to arrive at substantive evaluations (Eagly and Chaiken Reference Eagly and Chaiken1993). For instance, voters may resort to party cues as an information shortcut to form an opinion on a specific policy: “if you like the party, support the policy; if you dislike the party, reject the policy” (Petersen et al. Reference Petersen, Skov, Serritzlew and Ramsøy2013, 834). The difficult question of how to judge the policy is thus substituted for the easier question of whether one likes the policy’s sponsor.
Studies of party cues typically show that partisanship predicts support for a policy better than ideology or other factors (Cohen Reference Cohen2003; Goren, Federico and Kittilson Reference Goren, Federico and Kittilson2009; Nicholson Reference Nicholson2012; Druckman, Peterson and Slothuus Reference Druckman, Peterson and Slothuus2013). The work by Dancey and Sheagley (Reference Dancey and Sheagley2013) and Koch (Reference Koch2001) is particularly relevant for our purpose. These authors show that voters infer candidates’ positions largely from party labels. Thus, in the absence of better information, voters seem to fall back on party cues as a heuristic.
We argue that a similar process may be at work in the human coding of political text. Since such documents often contain complex or ambiguous language, identifying the best category for a statement can be a difficult task. As argued by Laver and Garry (Reference Laver and Garry2000), coders may therefore rely on party cues for their coding decisions:
An expert coder, by definition, comes to a text with prior knowledge of its context. Knowing a particular text to come from a left-wing party, for example, an expert coder might be more inclined to allocate certain text units to a left-wing coding category. The same coder might have allocated the same words in [a] different way if he or she had known that they came from a right-wing party. Inevitably, expert coding impounds the prior opinions of the coder about the text being coded, as well as its actual content (Laver and Garry Reference Laver and Garry2000, 626).
Despite the wealth of research on content analysis of political texts, this idea has not yet been widely explored. The lone exception is a recent study on crowd-coding by Benoit et al. (Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016) who report small effects of anonymizing documents that are consistent with heuristic processing.
Data and Methods
In our experiment, ten coders classify 200 policy statements on immigration and migrant integration. In most advanced democracies this is a very polarizing issue for both parties and voters. We sample sentences on immigration from Austrian election manifestos produced between 1986 and 2013. The Austrian party system is particularly suited to analyzing positional competition on immigration, with a strong populist radical right party (the Austrian Freedom Party (FPÖ)) occupying the anti-immigration pole and the Green party espousing strong pro-immigration views. Two mainstream parties, the Social Democrats (SPÖ) and the People’s Party (ÖVP), take intermediate positions.Footnote 2
We derive policy statements on immigration and integration from party manifestos, and edit them to mask the original party authorship. We start out with content analysis data from the Austrian National Election Study (AUTNES) that splits manifesto text into standardized coding units, and classifies each unit into one of about 700 fine-grained issue categories (see Dolezal et al. Reference Dolezal, Ennser-Jedenastik, Müller and Winkler2016). We first identify all sentences that address immigration or the integration of migrants. We then exclude sentences that recount objective facts (e.g., immigration statistics), those where parties claim credit for their track record (e.g., past legislative accomplishments), and those containing attacks on rival parties, leaving a total of 889 sentences.
Next, we remove duplicates, bullet points, headings, tables of content, and statements that are unclear without the prior or the next sentence. We also discard pairs of antithetical statements (e.g., “Austria is a country of immigration” and “Austria is not a country of immigration”), because coders would be confused should the randomization put identical party labels on these statements. The remaining sample consists of 200 sentences (see the Online Appendix B).
Next, we remove all party labels, references to previous or subsequent sentences, or gender-sensitive language (used primarily by parties of the left). Finally, we manipulate the sentences to produce five experimental conditions: a version without a party cue (the control), and four versions with party cues for the Greens, the SPÖ, ÖVP, and FPÖ. Hence, the statement “We stand for a modern and objective immigration policy” (without party cue) is rephrased as “We [Greens/Social Democrats/Christian Democrats/Freedomites (‘Freiheitliche’)] stand for a modern and objective immigration policy.” For every sentence, each of the five conditions is randomly assigned to two coders. Thus, each coder receives 200 sentences with conditions varying randomly across statements. This design also ensures that each statement is coded twice under the same condition. In addition, we randomize the order of the sentences for each coder.
Ten student assistants with prior training and experience in coding political text were recruited for the experiment. We instructed them about our interest in party positions on immigration as expressed in the 200 sentences and advised them not to talk to each other about the task. In the introduction, we also gave examples for positive and negative messages toward immigration and multiculturalism. The actual coding question appeared below each policy statement: “Does this statement convey a positive or a negative stance on immigration and multiculturalism – or is the statement neutral or unclear, respectively?” Coders could then click on buttons to indicate their coding decision for a “positive,” a “neutral/unclear,” or a “negative” statement (see Online Appendix C). After the coding process was completed, we de-briefed the student assistants and provided feedback on the purpose of this experiment.
We use an ordered logistic regression to model the data-generating process. We let
 $$ y^{{\asterisk}} _{{ijk}} $$
denote coder k’s perception of sentence i with party label j. The perceived position of a sentence is determined by the content of the sentence (i), the party cue (j), and a coder effect (k). We thus estimate the policy position
$$ y^{{\asterisk}} _{{ijk}} $$
using
$$ y^{{\asterisk}} _{{ijk}} $$
denote coder k’s perception of sentence i with party label j. The perceived position of a sentence is determined by the content of the sentence (i), the party cue (j), and a coder effect (k). We thus estimate the policy position
$$ y^{{\asterisk}} _{{ijk}} $$
using
 $$y^{{\asterisk}} _{{ijk}} ={\rm party}\,{\rm cue}_{j} {\plus}{\rm content}_{i} {\plus}{\rm coder}_{k} {\plus}e_{{ijk}} .$$
$$y^{{\asterisk}} _{{ijk}} ={\rm party}\,{\rm cue}_{j} {\plus}{\rm content}_{i} {\plus}{\rm coder}_{k} {\plus}e_{{ijk}} .$$
Coders categorize statements as positive (1), neutral/unclear (0), or negative (−1), and we map the observed coding decisions (y) using
 $$y=\left\{ {\matrix{ {{\minus}1} & {{\rm if}\,y^{{\rm {\asterisk}}} \leq \mu _{1} } \cr {0{\rm }} & {{\rm if}\,\mu _{1} \lt y^{{\rm {\asterisk}}} \leq \mu _{2} } \cr {1{\rm }} & {{\rm if}\,\mu _{2} \lt y^{{\rm {\asterisk}}} } \cr } } \right.,$$
$$y=\left\{ {\matrix{ {{\minus}1} & {{\rm if}\,y^{{\rm {\asterisk}}} \leq \mu _{1} } \cr {0{\rm }} & {{\rm if}\,\mu _{1} \lt y^{{\rm {\asterisk}}} \leq \mu _{2} } \cr {1{\rm }} & {{\rm if}\,\mu _{2} \lt y^{{\rm {\asterisk}}} } \cr } } \right.,$$
where µ l are cut-off points between the three-ordered coding categories.
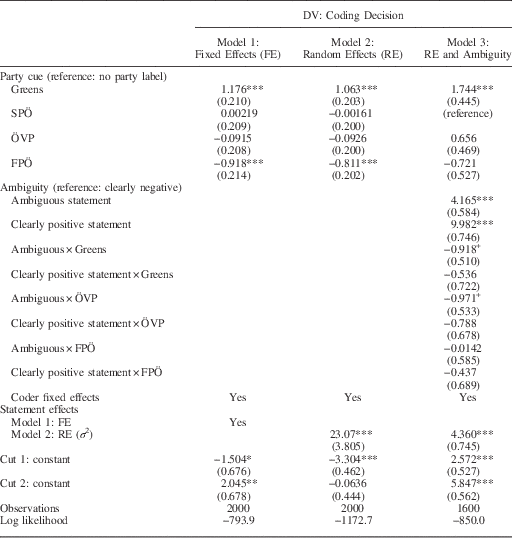
To measure the effect of party cues, we use indicator variables for the four party labels (Greens, SPÖ, ÖVP, and FPÖ). The statements without party label serve as our reference category. We control for content-related factors using either fixed (Model 1) or random effects (Model 2) on the sentence level. We also include fixed effects to capture coder effects.Footnote 3
Results
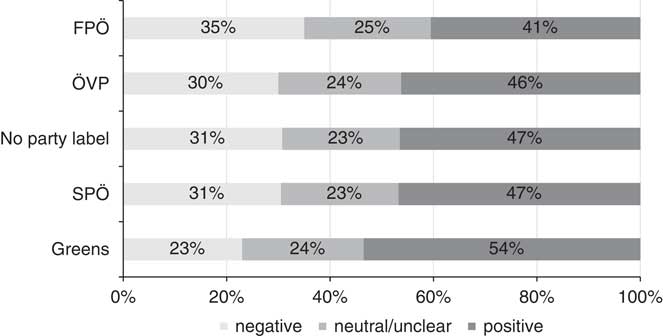
Figure 1 displays the percentage of statements coded as negative, neutral/unclear, and positive toward immigration for different party cues. In the no-label condition coders classify 31 percent of the sentences as negative and 47 percent as positive toward immigration (the remaining 23 percent are coded as “neutral/unclear” statements). While the shares are almost identical for the mainstream parties on the center-left (SPÖ) and the center-right (ÖVP), they differ substantially for the more extreme parties: only 23 percent of all statements with a Green party cue were coded as negative, whereas 54 percent were identified as positive statements on immigration. By contrast, the FPÖ cue produced 35 percent negative and 41 percent positive statements. Thus, especially for those parties with the strongest stances on immigration party cues did affect the coders’ decisions.
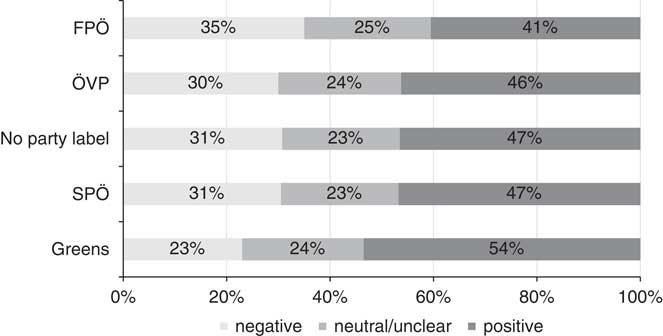
Fig. 1 Coding decisions by condition Note: There are 400 observations per condition, based on 200 statements, with each statement coded twice per party cue. FPÖ=Freedom Party; SPÖ=Social Democrats; ÖVP=People’s Party.
The same pattern appears in the ordered logistic regression model where the dependent variable is the coding decision (i.e., whether a statement is coded as negative, neutral/unclear, or positive). The key independent variables are the party cue indicators (using statements without party labels as the reference category). We control for coder effects using fixed (Model 1) and random effects (Model 2). Since the results are very similar, we focus our discussion on the random effects model.
The positive coefficient for the Green party label means that such statements are judged as more positive than statements without a party label. Similarly, coders evaluate statements attributed to the FPÖ as more negative than those with no party label. In contrast, party cues for both mainstream parties (SPÖ and ÖVP) yield very small effect sizes that are not statistically significant at conventional levels.
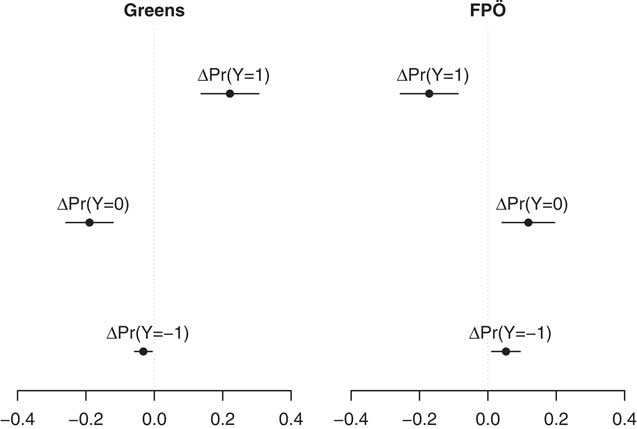
In terms of actual coding decisions, Figure 2 shows how a Green party label increases the probability of a statement being coded as positive (Y=1) by 22 percentage points, while it decreases the probability that coders use the “neutral” (Y=0) and “negative” (Y=−1) categories by 19 and 3 percentage points, respectively. Vice versa, an FPÖ label decreases the chances that a statement is coded as positive by 17 percentage points. In turn, coders are more likely to identify statements with the FPÖ label as neutral (plus 12 percentage points) or negative (plus 5 percentage points). While the effects for these two parties are thus substantial, we also note that there are no significant differences between policy statements with and without party cues for either mainstream party (SPÖ and ÖVP).
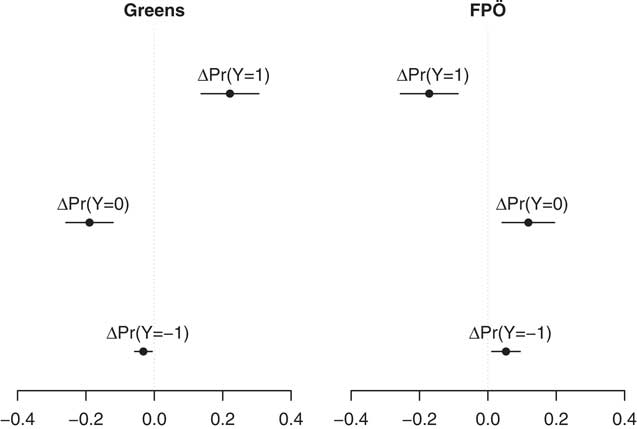
Fig. 2 Marginal effects of Green and Freedom Party (FPÖ) cues on coding decisions Note: Marginal effects of party cues compared to the no-label condition along with 95% confidence intervals. Estimates based on Model 2 in Table 1 with the remaining covariates at their observed values.
In addition to those direct effects, the effect of party cues may also be stronger for more ambiguous policy statements: coders have more leeway to follow party cues if a statement leaves room for interpretation. For example, a stance for a “modern and objective immigration policy” is arguably more open to interpretation than support for family reunification (positive) or immediate deportation of illegal immigrants (negative).
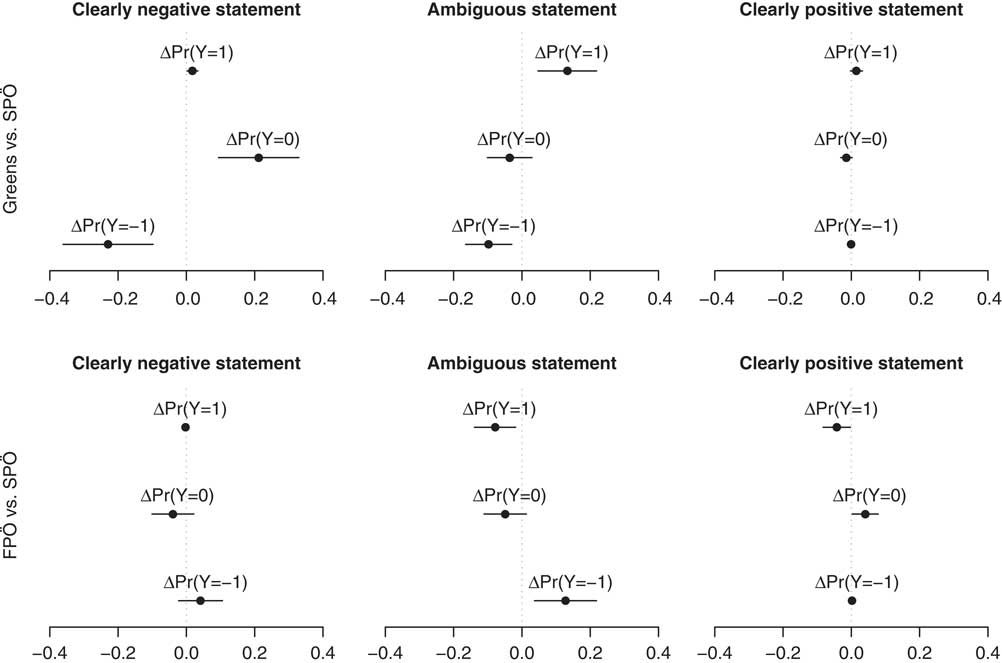
To test this expectation, we use coder agreement in the evaluations under the neutral condition (no party cue). We classify policy statements as clearly positive (negative), if both coders identified the statement as being positive (negative). All other statements (i.e., coders disagreeing in their judgment or both perceiving it to be “neutral/unclear”) are classified as ambiguous policy statements. We then interact this variable with the party cues to test whether cueing effects are stronger for ambiguous than for clear policy statements. Importantly, we exclude statements coded under the “neutral” condition from the analysis and use the SPÖ condition as the reference group instead.Footnote 4 The regression results based on the remaining 1600 observations are shown in Table 1 (Model 3). The marginal effect plots for the Greens and the FPÖ are shown in Figure 3.
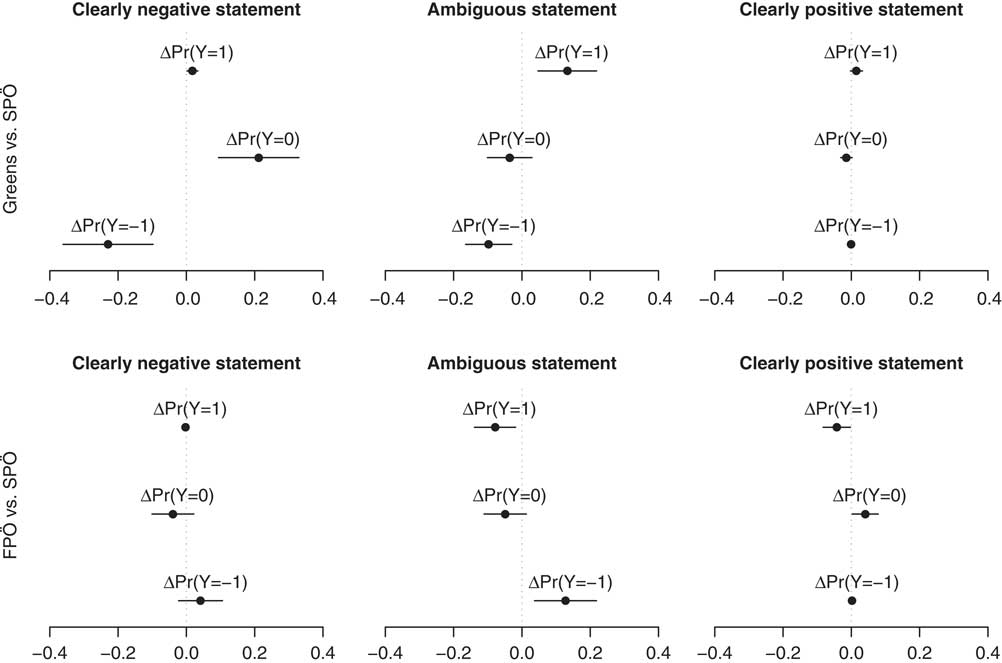
Fig. 3 Marginal effects for negative, ambiguous and positive statements Note: Marginal effects of party cues compared to the SPÖ condition along with 95% confidence intervals. Negative (positive) statements are those that both coders under the “neutral” prime unanimously identify as negative (positive) statements. All remaining statements are classified as ambiguous statements. Estimates based on Model 3 in Table 1 with the remaining covariates at their observed values. FPÖ=Freedom Party.
Table 1 The Impact of Party Cues on Coding Decisions
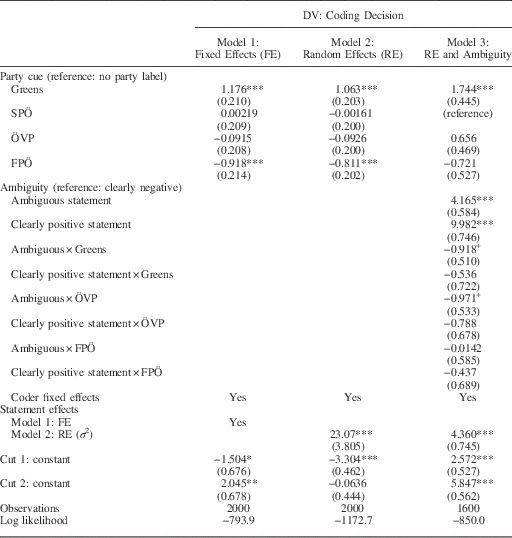
Note: Figures are coefficients from ordered logistic regression, with standard errors in parentheses; statement FE (Model 1) not shown.
DV=dependent variable; SPÖ=Social Democrats; ÖVP=People’s Party; FPÖ=Freedom Party.
+p<0.1, *p<0.05, **p<0.01, ***p<0.001.
In general, the empirical results support the expectation that party cue effects are larger for more ambiguous policy statements. For most conditions with clearly negative or clearly positive party labels, the marginal effects of Green or FPÖ party labels are small and often statistically insignificant. The sole exception are clearly negative (i.e., anti-immigration) statements with a Green party label (upper left panel in Figure 3). Coders are much less likely to classify these statements as negative (−23 percentage points) and (mostly) use the “neutral/unclear” category instead. In contrast, the marginal effects are more pronounced for ambiguous policy statements. Adding a Green party label instead of an SPÖ party cue increases the probability to code these statements as positive toward immigration by 13 percentage points, and decreases the probability to code the same statement as negative by 10 percentage points. The reverse pattern holds for the FPÖ: compared to a SPÖ party cue, the FPÖ label increases the probability that coders evaluate a statement as negative by 13 percentage points, while the probability of coding the statement as “positive” decreases by 8 percentage points.
Concluding Remarks
Our results show that coders use party cues as contextual information to interpret policy statements. Moreover, the effect of party cues differs across parties: they have the strongest effect for the most extreme parties, but equal zero for centrist mainstream parties.
These findings have implications for how we evaluate the validity of estimates derived from text as data. Computerized approaches based on the “bag of words” assumption usually aim to de-contextualize the information given in texts. In particular, party names and labels are often excluded in the data pre-processing. Estimates based on these approaches are more reliable, and arguably capture the actual content expressed in the text better than those involving human judgment. At the same time, they also ignore the context in which these statements are made. In contrast, our results support Laver and Garry’s (Reference Laver and Garry2000, 626) claim that human coders use prior knowledge to contextualize information provided in the text.Footnote 5 This contextual information might improve the validity of the (position) estimates.
Of course, whether contextualization actually does improve data validity or whether it rather biases the results is a question that very much depends on the nature of the coders’ priors. The validity of the estimates should increase if human priors are “correct,” meaning that they are based on actual knowledge about party policy or if human readers can decipher coded language in political text. In contrast, coder priors from party labels harm the validity if they are based on uninformed heuristics or affective party evaluations. In any case, the drawback of contextualization is that these estimates are usually less reliable (as judgments differ across individuals).
Our findings also imply that position estimates of extreme parties generated by manual coding may be biased toward the extremes if no additional safeguards are put in place.Footnote 6 If coders know the author of a political text, they are more likely to use coding categories that fit prior information about that party. This results in a centrifugal effect that counteracts the centripetal tendencies caused by unreliable coding processes in manual coding of political texts (Mikhaylov, Laver and Benoit Reference Mikhaylov, Laver and Benoit2012).
Our findings also speak to more substantive research questions. For example, parties may aim to avoid clear (positional) statements and “blur” their policy positions instead (Rovny 2012; Rovny Reference Rovny2013). Our results indicate that the effect of party cues on the coders’ perceptions of policy statements is more influential for these ambiguous policy statements. This finding is also in line with recent research showing that moderate policy positions are often considered as being more ambiguous than extreme ones (Bräuninger and Giger Reference Bräuninger and Giger2016).
There are various avenues for future research. Perhaps the most crucial question relates to the external validity of our findings: do we over- or under-estimate the party cue effects that may exist in “real” coding processes? On the one hand, our estimates are rather conservative because we draw on a sample of experienced coders who are trained to adhere to fine-grained coding schemes, and thus should rely less on contextual information from party cues. On the other hand, we used a non-random sample of policy statements on immigration and the share of more ambiguous statements may be over-represented in this sample. As party cue effects tend to be stronger for more ambiguous policy statements, we might therefore over-estimate the potential consequences of party cues for the perceived (coded) party policy stances. Similarly, it would be interesting to study how our findings travel to other issue dimensions. For example, party cue effects may be weaker on less polarized issue dimensions, or when parties have no strong policy reputations.
Acknowledgement
We would like to thank the FWF (Austrian Science Fund) for their support under grant number S10903-G11. We are indebted to our student assistants for their assistance and support in this coding experiment.