



Reading aloud involves more than using grapheme-to-phoneme conversion (GPC) rules. Stress assignment is a requirement for fluent reading aloud in alphabetic languages. Incorrect stress can convert a word into a pseudoword (e.g., in English: winDOW instead of WINdow) and stress is sometimes the only difference between some words (e.g., in English: DEsert vs. deSERT). In some languages stress is fixed, and thus it could be argued that stress assignment follows a simple rule (e.g., Polish, where words have penultimate stress). In other languages, stress is not fixed, and can vary across words. In many of those languages there is no orthographic mark that represents stress. However, in certain languages some (Spanish) or all (Greek) words have a stress mark (an acute accent) placed over the vowel in the stressed syllable that makes nonlexical stress assignment (i.e., without recovering the stress position from the mental lexicon) very easy. Therefore, these languages are ideal to study the role of nonlexical mechanisms for stress assignment. In this article, we focus on Spanish to study these mechanisms. In particular, we focus on the role of two nonlexical factors, such as the use of a stress pattern by default and the Spanish stress mark.
Stress Processing
Nonlexical mechanisms for stress assignment may be less relevant in languages without stress marks, as there is not any clear cue indicating the stress position in the word. Some research conducted in Italian, where words with stress on the antepenultimate or penultimate syllable (e.g., BIbita [drink], maTIta [pencil]) do not have stress marks, seems to confirm the main role of lexical information. In Italian, only words with final stress have a stress mark (e.g., veriTÁ [truth]), so stress assignment on the penultimate or antepenultimate syllable should be mainly lexical. Burani and Arduino (Reference Burani and Arduino2004) found that words with a high number of stress friends (i.e., words with the stress in the same position, the nucleus of the penultimate syllable, and the last syllable; Colombo, Reference Colombo1992) were read faster than words with a low number of stress friends. Previous research showed that in Italian naming words with penultimate stress was easier than naming words with antepenultimate stress (Colombo, Reference Colombo1991). These findings point to a nonlexical mechanism based on the most frequent stress (penultimate in Italian). However, Burani and Arduino (Reference Burani and Arduino2004) found that even words with antepenultimate stress could be read faster than words with penultimate stress when they had more stress friends. Therefore, lexical processing seems to be relevant in Italian.
In English there is no stress mark. Thus, similarly to Italian, stress assignment should be mainly lexical. Nevertheless, nonlexical stress assignment is still possible as there are other stress cues. One of these cues is a nonlexical mechanism consisting of stressing the first syllable by default, following the predominant stress pattern in English. However, Rastle and Coltheart (Reference Rastle and Coltheart2000) did not find evidence supporting this hypothesis. Words stressed on the first syllable were not named quicker (shorter RTs) or more accurately than words stressed on the last syllable. They found evidence of nonlexical stress assignment based on more complex rules than merely assigning the most frequent stress position to each word. In particular, Rastle and Coltheart (Reference Rastle and Coltheart2000) described a stress assignment algorithm based on the detection of affixes, integrated within the GPC rules. For example, if a prefix is detected, the GPC rules are applied to the remaining part of the word, and if no illegal cluster is found in the last two positions, the prefix pronunciation is recovered from the lexicon and the word is given final stress (the entire set of nonlexical stress rules is described in Rastle & Coltheart, Reference Rastle and Coltheart2000). This algorithm correctly predicted the stress position in a high percentage of cases (84%) when applied to pseudowords (Experiment 2), suggesting that it captures some of the nonlexical rules that may be used in reading aloud. If so, regular words, those that follow this algorithm, should be easier to read than irregular words. This is exactly what Rastle and Coltheart found for low-frequency (LF) words (Experiment 3), suggesting that stress is assigned through a nonlexical mechanism, at least for LF words. In line with these findings, Ktori, Tree, Mousikou, Coltheart, and Rastle (Reference Ktori, Tree, Mousikou, Coltheart and Rastle2015) reported that patients with surface dyslexia commit regularization errors and assign second-syllable stress to prefixed words. Therefore, although stress assignment may be mainly lexical, nonlexical mechanisms may still be playing a role, even in languages without stress marks.
If nonlexical mechanisms are used in languages without stress marks, it could be argued that these mechanisms would be even more relevant in languages with stress marks. In Spanish, the stress is orthographically marked in many words, and it should be a relevant source of information for stress assignment. However, previous research in Greek, another language with stress marks, suggests that the primary source of information for stress assignment might be lexical (Protopapas & Gerakaki, Reference Protopapas and Gerakaki2009; Protopapas, Gerakaki, & Alexandri, Reference Protopapas, Gerakaki and Alexandri2007). This does not mean that the stress mark is useless in Greek, as it still plays a role when reading pseudowords (Protopapas & Gerakaki, Reference Protopapas and Gerakaki2009; Protopapas et al., Reference Protopapas, Gerakaki and Alexandri2007). However, when reading words the lexical route is quicker because processing the stress mark has a cost (Protopapas, Reference Protopapas, Thomson and Jarmulowics2016). Having said that, Greek is highly different from Spanish. In modern Greek, all words should have the stress mark, whereas in Spanish the stress mark rather indicates an infrequent stress (e.g., antepenultimate) or an exception to some phonological rules or regularities. Therefore, the presence/absence of the stress mark is highly informative in Spanish, and it may be beneficial despite the processing costs. In line with this idea, evidence suggests that lexical stress may be used for visual word recognition in Spanish (Domínguez & Cuetos, Reference Domínguez and Cuetos2018) and that the stress mark may function as a cue for stress assignment in visual word recognition (Gutiérrez-Palma & Palma-Reyes, Reference Gutiérrez-Palma and Palma-Reyes2008). Similarly, Gutiérrez-Palma et al. (Reference Gutiérrez-Palma, Raya-García and Palma-Reyes2009) found evidence that stress assignment in pseudowords depended on the presence/absence of the stress mark, but only when pseudowords have no similar word. When pseudowords have similar words lexical information is more relevant. Therefore, there is evidence that the stress mark may play some role in stress assignment, but this role is probably more relevant in LF words.
Another possibility is that readers have learned some knowledge implicitly or have acquired some orthographic correlates to lexical stress. Implicit knowledge may facilitate word reading when word stress matches expected stress. Furthermore, implicit knowledge might interfere when the real and expected stress of the word do not match. Kelly, Morris, and Verrekia (Reference Kelly, Morris and Verrekia1998) tested this hypothesis in English by comparing words marked or not for final stress (e.g., with final double letters such as -ll or -ette). They found that marked words were read with fewer errors when they had final stress (e.g., CorNELL) than when they had first stress (e.g., PAlette). Although orthography does not include stress marks in English, there are some stress regularities that may influence stress assignment. These results suggest that orthographic stress regularities can be a relevant source of information for stress assignment. Therefore, clear and systematic orthographic stress cues, such as the stress mark, should be even more relevant.
Stress in Spanish
Statistics and rules about Spanish stress suggest that nonlexical mechanisms for stress assignment are viable in Spanish. A possibility is that readers may use a stress pattern by default. In Spanish, the most frequent stress pattern is the penultimate syllable because it accounts for about 64% of Spanish words (Morales-Front, Reference Morales-Font, Núñez, Colina and Bradley2014). Final stress is the next most frequent pattern, accounting for about 28% of Spanish words. Antepenultimate stress is very uncommon, and it is only present in about 8% of cases (Morales-Front, Reference Morales-Font, Núñez, Colina and Bradley2014). Given these statistics, penultimate stress could be considered as the default stress for Spanish.
Our second nonlexical factor is the stress mark. This is a highly informative cue that indicates some exceptions to general regularities and rules. Linguistics stress rules in Spanish state that final heavy syllables (i.e., with a complex rime) attract the stress (e.g., the syllable MAR in calaMAR [squid]), or that final light syllables (e.g., the syllable llo in caMEllo [camel]) should not be stressed (Harris, Reference Harris1983). Stress marks are used for words that do not follow these rules (e.g., alMÍbar [syrup]). These exceptions are reflected in the rules for spelling stress marks.
There are simple general rules for writing the stress mark in Spanish: (a) words with antepenultimate stress (e.g., CÁmara [camera]) have a stress mark; (b) words with penultimate stress have a stress mark when they end in a consonant other than “n” or “s” (e.g., ÁRbol [tree]); and (c) words with final stress have a stress mark when they end in a vowel or in “n” or “s” (e.g., ruBÍ [ruby], caJÓN [drawer]). Therefore, stress marks are quite informative and useful stress cues. The presence or absence of stress marks indicates whether a syllable is stressed or unstressed, allowing Spanish speakers to pronounce any single written word, even if it is an unknown word. Basically, it is enough to parse the stress mark (presence or absence) and the last few letters of the word. In the absence of a stress mark, the structure of the final syllable indicates the stress.
All these regularities could be considered part of some type of nonlexical mechanism for stress assignment. It is possible to use penultimate stress as the default because it is the most frequent. If so, in Spanish words will be easier to read with penultimate stress than with the rare antepenultimate stress. Moreover, words with antepenultimate stress should be more difficult because those words have a stress mark; the processing of the stress mark requires time. Under certain circumstances, the cost of processing the mark may be higher than the benefit of locating the stress.
In this study, we focus on how nonlexical information can be used for stress assignment in Spanish. We manipulate the stress mark (present vs. absent) and the stress type (antepenultimate vs. penultimate), as well as other variables such as lexical frequency (high vs. low) and lexicality (words vs. pseudowords). Lexical frequency and lexicality were included to investigate stress effects when lexical information is less available (as in LF words) or absent (as in pseudowords). We predict that nonlexical mechanisms will influence stress assignment to a greater extent in LF words and pseudowords.
In Experiment 1 we compare words with antepenultimate stress to words with penultimate stress. We expect longer RTs in words with antepenultimate stress. This difficulty could be due to two factors. First, a nonlexical procedure based on the use of a stress by default. If this is the case, words with antepenultimate stress should be more difficult to read because antepenultimate stress is very infrequent. Second, stress marks may require time to be processed. If this is the case, words with antepenultimate stress should be more difficult to read because these words have a stress mark. To distinguish between these two possibilities, in Experiment 2 we present words and pseudowords in pure versus mixed stress blocks, following a priming procedure similar to the one Colombo and colleagues (Reference Colombo1992, 2009) used in Italian. If a priming effect is found (i.e., if reading is easier in pure blocks) this would be evidence that lexical stress has been partially accessed before naming the word. Therefore, differences between words with more and less frequent stress patterns should be smaller or even absent in pure blocks. However, if differences between words with antepenultimate and penultimate stress are due to the processing of the stress mark, they should still be present in both pure and mixed blocks. Therefore, no interaction should emerge even if reading is easier in pure blocks. Finally, in both experiments, differences due to stress marks should be found only if processing the stress mark has a cost that is higher than its benefit.
Experiment 1
Method
Participants
Thirty-eight psychology students (ages 18 to 30) from the universities of Oviedo and Jaén, all native speakers of Spanish, took part in this experiment. They read and signed an informed consent form and received academic credit for their participation.
Instruments
DMDX software (Forster & Forster, Reference Forster and Forster2003) was used to present stimuli and to sound-record participants’ vocal responses. Checkvocal software (Protopapas, Reference Protopapas2007) was used to analyze sound files and to determine RTs and vocal response accuracy.
Materials
Two hundred and thirty-eight stimuli were selected for this study (119 words and 119 pseudowords, all were three syllables). One hundred seventy stimuli (85 words and 85 pseudowords) were targets, and 68 (34 words and 34 pseudowords) were fillers.
Target words included 51 LF words (less than 10 occurrences per million), and 34 were medium and high-frequency (HF) words (more than 25 occurrences per million). LF words included 34 words with stress on the penultimate syllable (17 with a stress mark, e.g., alCÁzar [fortress], and 17 without a stress mark, e.g., caBAlla [mackerel]) and 17 words with stress on the antepenultimate syllable (e. g., CÉlula [cell]). All words with antepenultimate stress had stress marks because this is a spelling rule of the Spanish language.
HF words included 17 words with stress on the penultimate syllable but without a stress mark, and 17 with stress on the antepenultimate syllable. It was not possible to select a matched list of words with penultimate stress and with a stress mark. These types of words are very infrequent in Spanish, especially in the category of HF words.
Furthermore, 68 stimuli with stress on the final syllable were included as fillers to cover all types of words in Spanish. These stimuli were 34 words and 34 pseudowords, and half of them had a stress mark.
Within each frequency category, words were matched on their first phoneme or phoneme category, onset complexity (first syllable), length (phonemes and letters), lexical frequency, phonological neighborhood (number of neighbors and number of neighbors with more lexical frequent than the target), and phonological positional syllabic frequency (type and token). For this last index, only three-syllable words were considered as syllabic frequency effects (i.e., syllabic neighborhood effects) seem to be related to words with the same number of syllables (Chetail & Mathey, Reference Chetail and Mathey2011). Psycholinguistic indexes were obtained from Davis and Perea (Reference Davis and Perea2005).
Furthermore, we performed ANOVAs separately for HF and LF words, to ensure that there were no significant differences in the psycholinguistic indexes (see Table 1); as expected, no significant differences were found. Therefore, within each frequency category, words with antepenultimate/penultimate stress and with/without stress marks, were equivalent. The entire list of words can be consulted in Appendix A.
Table 1. Psycholinguistic indexes in each condition, mean and (standard deviation)

Note: NP = number of phonemes, LF = lexical frequency, PSF1 = positional syllabic frequency (type and token, 1st syllable), PSFa = positional syllabic frequency (type and token, average 1st, 2nd, and 3rd syllables). PN = phonological neighbors, HPN = phonological neighbors of higher frequency. –Sm = without stress mark, +Sm = with stress mark.
The pseudowords were generated from these words and for the same conditions. To make sure that each pseudoword had at least a stress neighbor (Colombo, Reference Colombo1991), the penultimate syllable’s nucleus and last syllable remained while the beginnings of the words were exchanged. For example, for the words figura (figure) and minuto (minute), the endings of the words -ura and -uto were exchanged with the beginnings of the words fig- and min- making the pseudowords figuto and minura (see Appendix B). Following this procedure, pseudowords were matched on the first phoneme, onset complexity, and length (phoneme and letters), as they were derived from matched words. Moreover, as pseudowords had at least a stress neighbor it was considered more likely that they would be pronounced with the intended stress.
Procedure
A standard word-naming task was used. In each trial, a warning signal “*” was presented at the center of the computer screen (500 ms). It was followed by a blank screen (500 ms), and then by the target stimulus. RTs started immediately after target display. Target duration was fixed at 1500 ms regardless of the participant’s response, which was sound-recorded. The intertrial interval lasted 1500 ms.
Stimuli presentation was counterbalanced in two blocks. Half the participants first saw the word block and then the pseudoword block, and the other half saw the stimuli in reverse order. Before beginning each block, four practice trials were presented. Within each block there was a brief break of about 30 seconds on average. Stimuli were randomly presented. In total, there were 238 trials, and each experimental session lasted for about 15 minutes.
Results and Discussion
We collected 6,460 responses (170 stimuli × 38 participants) and we found 482 (7.46%) errors (naming errors, stress assignment errors, and no responses), 72 in words and 410 in pseudowords (see Table 2). Participants incorrectly placed the stress 273 times, 47 times in words and 226 in pseudowords; the misplacement occurred 78 times on the final syllable, 103 times on the penultimate syllable, and 71 times on the antepenultimate syllable. Naming errors, stress errors, and no responses were removed from the following analyses. RTs longer than 2 standard deviations (SDs) above the mean for each participant, in every stress stimulus type, were also removed. RTs and errors for each condition are presented in Table 2.
Table 2. Reaction times (ms) and errors (%) in experiment 1. Standard deviations in parentheses

Note: –Sm = without stress mark, +Sm = with stress mark.
RT analyses of variance (ANOVAs) were conducted with mixed effects analyses (Baayen, Reference Baayen2008) fit by REML using the R software (R Core Team, 2012), to estimate both fixed effects, that is, replicable effects of theoretical interest, and random effects, unexplained effects due to random variations between items or participants. Stepwise comparisons were performed from the most complex to the simplest model, and the one with the most complex adjustment and smallest Akaike Information Criteria (AIC; Akaike, Reference Akaike, Parzen, Tanabe and Kitagawa1974) and significant χ 2 test for the log-likelihood was retained. For the random factor structure, we followed a forward best-path procedure (Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013). F values from the ANOVAs of type III with Satterthwaite approximation for degrees of freedom are reported for fixed effects. When interactions were significant, t-test were performed and the p-values were adjusted using the Holm–Bonferroni method.
It should be noted that it was impossible to consider all the factors together, because, as reported in the materials section, we did not have stimuli at each level of the different categories. Therefore, we tried several models to explain the data.
First, we tested the hypothesis that stress assignment may follow a stress pattern by default. If this hypothesis is correct, then words with penultimate stress would be read faster because the default stress would match the real word stress. This matching effect would not be found in pseudowords, as they do not have stored stress representations. Therefore, we analyzed the factor stress type (antepenultimate vs. penultimate) and its interaction with lexicality (words vs. pseudowords). In this analysis we only included LF words, and their derived pseudowords (see Appendix B). HF words were excluded because lexical stress could be more easily accessed for these words, and then the matching effect would be highly reduced. Therefore, pooling LF and LF words would have reduced the possibilities of finding a significant interaction between lexicality and stress type. The final model for this analysis had subjects and items as random factors, plus a random slope of lexicality over subjects (models with a more elaborate random factor structure failed to converge). According to this, the R code for the final model was: RT ~ lexicality * stress type + (1 + lexicality|subject) + (1|item). The value for the intercept was 547.22, SE = 11.53 and Median residual = .11. Pseudowords had higher RTs than LF words (Estimate = 87.58; SE = 8.96; p < .001), and stimuli with stress on the antepenultimate syllable took longer than stimuli with stress on the penultimate syllable (Estimate = 21.86; SE = 7.14; p < .01). The stress type by lexicality interaction was also significant (p < .05). Pairwise comparisons showed that the stress type effect only concerned the words, where the response was significantly faster in words with stress on the penultimate syllable than in words with stress on the antepenultimate syllable (Estimate = 22; SE = 7.15, p < .05).
Therefore, the stress type effect was significant only in words. We further examined whether this effect interacted with words’ lexical frequency. Stress matching might be less relevant for HF words, as lexical stress is supposed to be accessed very quick for these words. Then, lexical frequency (HF vs. LF words), and stress type (antepenultimate vs. penultimate syllable) fixed factors were studied. From these factors, the final model was: RT ~ lexical frequency + stress type + (1 + lexical frequency + stress type|subject) + (1 + lexical frequency|item). The value for the intercept was 504.601, SE = 10.231 and Median residual = .07. We observed that RTs depended on the lexical frequency (Estimate = 45.72; SE = 6.26, p < .001) and stress type (Estimate = 14.78; SE = 5.82, p < .05); shorter RTs emerged for HF words and for words with penultimate stress. However, the lexical frequency * stress type interaction was not significant.
These analyses show that HF or LF words with antepenultimate stress have longer RTs. However, this difference could be due to the stress mark, as all words with antepenultimate stress has a stress mark. To test this possibility, we only considered words with a stress mark, and we examined the stress type factor (i.e., words with antepenultimate stress vs. words with penultimate stress and stress mark). Only LF words were analyzed because no HF words with penultimate stress had a stress mark. No significant differences were found.
According to these results, the stress mark might be the relevant factor. We further analyzed this factor, and also its interaction with lexicality. If processing the stress mark has a cost it should be found in both words and pseudowords. For this analysis we included the conditions with and without a stress mark (i.e., LF words with penultimate stress and their derived pseudowords). The interaction lexicality * stress mark was not as significant as the final model was: RT ~ lexicality + stress mark + (1 + lexicality + stress mark|subject) + (1 + lexicality|item). The value for the intercept was 559.52, SE = 13.10 and Median residual = .09. From this analysis, we conclude that the presence of a stress mark increased the RTs (Estimate = 23.52, SE = 8.28, p < .001), and RTs were longer for pseudowords than words (Estimate = 88.03, SE = 10.27, p < .001).
Therefore, these analyses suggest that rather than a stress type effect there is a stress mark effect. If so, differences would be stronger if only stimuli with penultimate stress but without stress mark are compared to words with antepenultimate stress. Thus, we repeated the first analysis with LF words and their derived pseudowords, examining stress type and lexicality. The final model was RT ~ stress type * lexicality + (1| subject) + (1|item). The value for the intercept was 535.69, SE = 12.47 and Median residual = .12. We found a lexicality effect (Estimate = 86.44, SE = 4.40, p < .001), a stress type effect (Estimate = 33.96, SE = 6.58, p < .001), and a stress type by lexicality interaction (p < .05), as the difference determined by stress type effect was bigger in words (Estimate = 34.00, SE = 6.59, p < .001) than in pseudowords (Estimate = 21.29, SE = 6.73, p < .05). However, in both cases (words and pseudowords) RTs were higher for words with antepenultimate stress.
In this experiment, the main finding is that words with antepenultimate stress had longer RTs than words with penultimate stress. This result was obtained for both, HF and LF words, suggesting that even when lexical information is easily available (as in HF words) stress assignment is affected by nonlexical mechanisms. In Spanish, the most frequent stress is the penultimate, thus it is possible that this stress is assigned by default. If this nonlexical mechanism is used, words with penultimate stress would be easier to read. However, all words with antepenultimate stress have stress marks. The cost of processing the stress mark may be the main reason why words with antepenultimate stress were more difficult. According to this possibility, differences were only present when words with antepenultimate stress were compared to words with penultimate stress without a stress mark. The same result was found for pseudowords, although differences were higher for words than for pseudowords.
Although the main factor responsible for these differences seems to be the stress mark, the interaction between lexicality and stress type was significant. This interaction is not expected if the stress mark is the only relevant factor. The reason why stress processing differences are higher in words may be that the penultimate stress is also assigned by default. If so, because of the cost of processing of the stress mark, a lexical mismatch would be present in words with antepenultimate stress. This lexical mismatch would not be present in pseudowords as they do not have any lexical stress representation. Nevertheless, stress marks seem to be more relevant, as differences disappeared when words with antepenultimate stress were compared to words with penultimate stress and with a stress mark.
As a whole, these results suggest that the main factor responsible for these differences is the presence/absence of the stress mark. This hypothesis is further explored in the next experiment.
Experiment 2
To test the hypothesis that processing stress marks involves extra time, in this experiment we present words and pseudowords in pure (all stimuli with the same stress) versus mixed blocks. If words with antepenultimate stress are more difficult because the antepenultimate stress is very infrequent, then the differences should be reduced (or even disappear) in pure blocks (where stress priming is expected) compared to mixed blocks. On the contrary, if differences are due to stress marks, no interaction between stress type and block type should emerge. Similar effects are expected in the pure blocks because stress marks should be processed every time, as it is placed on a different letter for each word.
Method
Participants
Twenty-eight psychology students (aged 18 to 28) from the University of Oviedo, all native speakers of Spanish, participated in this experiment. They received and signed an informed consent form and obtained academic credits for their participation. None of these students participated in the previous experiment.
Instruments
As in the first experiment, DMDX software (Forster & Forster, Reference Forster and Forster2003) was used to present the stimuli and record participants’ vocal responses. Checkvocal software (Protopapas, Reference Protopapas2007) was employed to analyze sound files and determine RTs and accuracy.
Materials
Sixty-eight stimuli from the previous experiment were included in Experiment 2. Thirty-four were LF words, 17 had stress on the antepenultimate syllable (e.g., CÉlula [cell]) and 17 had stress on the penultimate syllable without a stress mark (e.g., caBAlla [mackerel]). The remaining 34 stimuli were pseudowords (derived from LF words), with the same stress pattern as the real words.
Procedure
Stimuli were grouped into eight blocks of 17 items, four blocks for words and four for pseudowords. Half of them consisted of words or pseudowords with the same stress (e.g., 17 words with stress on the antepenultimate syllable), that is, pure blocks. The other four were mixed blocks comprising of stimuli (words or pseudowords) with different kinds of stress. Thus, we had two pure blocks of words, two pure blocks of pseudowords, two mixed blocks of words, and two mixed blocks of pseudowords.
A word-naming task was performed; participants had to read aloud the words or pseudowords as quickly as possible. The stimuli were presented after a warning signal “*” at the center of the computer screen (500 ms), followed by a blank screen (500 ms) and the target stimulus. The RT was counted immediately after the target display. Target duration was fixed to 1500 ms regardless of the participant’s response, which was sound-recorded. The intertrial interval duration was 1500 ms.
We counterbalanced block presentation. Half the participants saw the pure blocks first and the other half the mixed ones first. We also counterbalanced stress type. Within each block there was a brief break of about 30 seconds on average. Stimuli were presented in random order within each block, stimulus order was different for every participant. Before beginning the experimental presentation, four practice trials were presented. In total, experimental duration was approximately 15 minutes.
Results and Discussion
We collected 1,904 responses (68 stimuli × 28 participants) and we found 206 (10.81%) errors (naming errors, stress assignment errors, and no responses): 32 (1.06%) in words and 174 (9.13%) in pseudowords; 89 (4.67 %) in pure blocks and 117 (6.14%) in mixed blocks.
We analyzed RTs using mixed-effects modeling (R Core Team, 2012), to estimate both fixed effects (lexicality, block, and stress type) and random effects (item and subject), unexplained effects due to random variation between items or between participants (Baayen, Reference Baayen2008). Naming errors, stress errors, and no responses were removed from the analyses. We also removed RTs longer than 2 SDs above the mean (for each participant in every block). RTs and errors for each condition are presented in Table 3.
Table 3. Reaction times (ms) and errors (%) in experiment 2. Standard deviations in parentheses

Note: –Sm = without stress mark.
We tested different models, the final model was RT ~ block + lexicality + stress type + (1|item) + (1+ lexicality|subject). The value for the intercept was 487.22, SE = 9.00, and Median residual = .11. The results suggest that block, lexicality, and stress type are factors determining RTs. First, pseudowords had higher RTs than words (Estimate = 82.25, SE = 9.74, p < .001). Second, stimuli with stress on the antepenultimate syllable took longer than stimuli with stress on the penultimate syllable (Estimate = 12.99, SE = 4.50, p < .001). Third, RTs were lower for the pure blocks showing a stress priming effect (Estimate = 18.22, SE = 4.55, p < .001). However, we did not find any significant interactions; the effect of stress type was the same in words and pseudowords, and it was independent of block type.
In this experiment, we presented words in pure versus mixed stress blocks. We hypothesized that differences between words with antepenultimate stress and words with penultimate stress would be smaller in the pure blocks. We found that words with antepenultimate stress had longer RTs, even though the block manipulation was effective as we found a stress priming effect (i.e., RTs were shorter in the pure blocks). Therefore, these results support the idea that stress type differences are due to the presence of the stress mark in words with antepenultimate stress, pointing to the same conclusion as Experiment 1.
General Discussion
This study focused on stress processing in Spanish, in particular on two factors that may affect stress assignment such as the frequency of the stress type and the presence/absence of the stress mark. The results showed that words with stress on the antepenultimate syllable were read significantly slower (i.e., longer RTs) than words with stress on the penultimate syllable, regardless of the lexical frequency. In addition, the presence of a stress mark implied a cost for words with penultimate syllable stress, as we found a stress mark effect in this type of word. Finally, we found that these results were independent of priming because the same results were obtained in the pure and mixed blocks.
In this study we have hypothesized that stress processing differences could be due to stress type or to the presence of a stress mark. Concerning the stress type, if stress assignment is mainly lexical, frequent stress patterns (e.g., penultimate in Spanish) should be accessed more easily. Moreover, it is also possible that stress assignment follows a nonlexical mechanism based on a default stress pattern. This default stress in Spanish is probably the penultimate stress, which should be easier to assign through this nonlexical route. If stress type is important, when less frequent stress patterns (e.g., antepenultimate) are primed, stress processing differences should be smaller or even disappear. However, results in Experiment 2 do not follow this prediction. Although reading was easier in pure blocks, showing a priming effect, words with antepenultimate stress were still more difficult. These differences suggest that the presence of the stress mark may be the main relevant factor.
In Experiment 1 the interaction between lexicality and stress type was significant, suggesting that the cost of processing the stress mark may not be the only relevant factor. If a stress pattern (e.g., penultimate) is assigned by default, a lexical mismatch would be present in words with antepenultimate stress, but not in pseudowords. This lexical mismatch may explain why stress processing differences were higher in words. However, the stress mark seems to be more relevant than the lexical mismatch, as no differences were found when words with antepenultimate stress were compared to words with penultimate stress and stress marks.
As a whole, these data suggest that the main factor responsible for the stress processing differences is the stress mark, which is present in all words with antepenultimate stress. Results from Experiment 1 show that stress processing differences are observed only when words with antepenultimate stress are compared to words without stress marks. Moreover, in Experiment 2 these differences are still present in pure blocks (in both, words and pseudowords), despite of the fact that a stress priming effect was found. Therefore, the presence of stress marks seems to have a cost that is higher than its benefit (Protopapas, Reference Protopapas, Thomson and Jarmulowics2016).
The cost of processing stress marks is probably not due to the time to decode a single letter, as the stress mark does not refer to a single segment but to the words’ metrical representation (i.e., syllables and lexical stress). Therefore, many other decoding operations (e.g., letters to phonemes and phonemes to syllables) are required before the stress mark can be fully processed (Protopapas, Reference Protopapas, Thomson and Jarmulowics2016). The presence of the stress mark might cause all these processes to start automatically, which requires extra time and has a cost. However, this processing has not any benefit because the primary source for stress assignment is lexical. As a consequence, the stress mark would have a more relevant role when other sources of information (e.g., lexical) are not available. This is what our results suggest, and it might be extended to other orthographies that also include a stress mark, such as Greek or Italian. Accordingly, previous results in Greek show that the stress mark plays a more relevant role when reading pseudowords than when reading words (Protopapas & Gerakaki, Reference Protopapas and Gerakaki2009). To our knowledge, no similar research has been conducted in Italian.
Although stress processing is costly, according to the present results it could be argued that models of reading aloud should incorporate stress as part of the phonological sublexical processing. Most models could easily incorporate the stress mark. According to the dual route theory (e.g., Rastle & Coltheart, Reference Rastle and Coltheart2000) phonological stress could be assigned by an algorithm that uses the stress mark as part of the GPC rules. According to connectionist models (Arciuli et al., Reference Arciuli, Monagan and Seva2010; Perry et al., Reference Perry, Ziegler and Zorzi2010), it is possible to include stress marks nodes linked to stress nodes representing the stress patterns. Finally, the stress mark could be considered as evidence to estimate (following the Bayes theory) the probability of a certain stress pattern (Jouravlev & Lupker, Reference Jouravlev and Lupker2015). Whatever the theoretical approach, the present study suggests some type of stress mark sublexical processing should be considered.
If processing stress marks has a cost and stress assignment is mainly lexical (Protopapas, Reference Protopapas, Thomson and Jarmulowics2016), then what is the role of stress marks? Do stress marks in no way influence stress processing? This possibility is very unlikely as stress marks are highly informative in Spanish (see the Stress in Spanish section). Moreover, there is evidence that lexical stress may be used for visual word recognition in Spanish (Domínguez & Cuetos, Reference Domínguez and Cuetos2018; Gutiérrez-Palma & Palma-Reyes, Reference Gutiérrez-Palma and Palma-Reyes2008), and for reading aloud (Gutiérrez-Palma et al., Reference Gutiérrez-Palma, Raya-García and Palma-Reyes2009). The present results clearly indicate that stress marks are processed when reading aloud, which is necessary to be used for nonlexical stress assignment. However, the cost of processing stress marks suggests that stress assignment is mainly lexical, even in a language with clear stress cues such as Spanish. This finding is consistent with previous research in Greek (Protopapas, Reference Protopapas, Thomson and Jarmulowics2016), another language with stress marks.
Limitations and Future Directions
A limitation of the present study is that the design does not allow us to determine the relative influence of the different sources of information for stress assignment. Findings suggest that stress marks start the nonlexical processing, but that the primary source for stress assignment is lexical. For this reason, stress mark processing does not benefit from it. To test this hypothesis, future research might use pseudowords, and manipulate the presence/absence and the position of the stress mark, that is, no stress mark (e.g., camula), as in the word it was derived from (e.g., cámula), or in a different position (e.g., camulá). Moreover, future studies can also manipulate the resemblance to real words of pseudowords. This design has already been used in Greek by Protopapas and Gerakaki et al. (Reference Protopapas and Gerakaki2009), and provides indexes of lexical, stress mark, and stress by default processing. This procedure could be easily adapted to Spanish to investigate the role of stress marks as a function of the availability of lexical information.
Conclusions
The present results suggest that word naming in Spanish is harder in words with antepenultimate stress. This result seems to be due to the time necessary for processing the stress mark, which is present in all words with antepenultimate stress. Therefore, the use of orthographic cues to lexical stress may be considered as part of word processing in reading aloud, at least in a language such as Spanish where stress marks are related to some exceptions in general stress rules.
Acknowledgments
This study was funded by grants PSI2011-29155 and PSI2015-64174P from the Ministry of Economy and Competitiveness, Spanish Government. We would also like to thank Sara Incera and Inés Antón-Mendez for their help in reviewing the English academic writing of this article.
APPENDIX A
Words
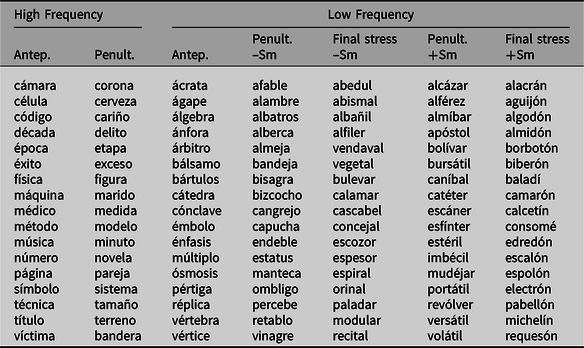
Note: –Sm = without stress mark, +Sm = with stress mark.
APPENDIX B
Pseudowords

Note: –Sm = without stress mark, +Sm = with stress mark.



