1. Introduction
Learning English as a non-native language is affected by several factors, such as the setting (English as a second language, ESL, or English as a foreign language, EFL), learner age (children or adults), curriculum (formal or informal), and the goal of learning English (academic purpose or survival English). Irrespective of these variables, grammar is the backbone of learning another language. Syntax is by and large characterized by a combinatorial system applied to the sentence. The combinatorial system in sentences, regardless of the modality of speaking or writing, largely defines the meaning of the message conveyed and understood. In the acquisition of the first language (L1), syntactic rules are acquired naturally and effortlessly upon adequate exposure and time. However, syntactic skills in a second language (L2), especially after puberty, Footnote 1 do not come naturally; as a result, effortful learning is required. In addition to this biological disadvantage involved in learning L2 at later ages, a consideration of L1 interference with and its influence on L2 learning is another aspect to take into account. One approach to unpacking and examining how L1 plays a role in learning L2 is a comparative study of performance patterns in adult learners of English to those of native speakers of English, because adults have stabilized linguistic skills. This study investigated how native adult speakers of Spanish who recognized written English words at the levels of third–fifth grade Footnote 2 formulated L2 English sentences when randomly ordered words were orally provided, compared to native English speakers who had matched word reading skills.
Given that the linguistic system of L1 affects L2 learning (Goldin-Meadow, Ozyurek, Sancar, & Mylander, Reference Goldin-Meadow, Ozyurek, Sancar, Mylander, Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Ozcaliskan2009; Pae, Schanding, Kwon, & Lee, Reference Pae, Schanding, Kwon and Lee2014), it would be useful to investigate how adult learners of English construct sentences using randomly presented words. Biber, Davies, Jones, and Tracy-Ventura (Reference Biber, Davies, Jones and Tracy-Ventura2006) note that the Spanish language has interesting cross-linguistic features that are both similar to and different from the English language. The similarities and dissimilarities offer an excellent opportunity to investigate the linguistic distance between these two languages and its impact on learning L2. The similarities reside at both phonemic and linguistic levels. On the phonemic level, Spanish and English are alphabetic languages in that multiple graphemes form a syllable, which is unlike syllabic languages such as Chinese and Japanese. On the linguistic level, although they share the same language family, Indo-European, the branch is different; that is, Spanish is a Romance language, while English is a Germanic language. Another difference lies in the syntactic level. In general, the word order scheme in Spanish is more flexible than that in English. First, subjects are not mandatory in sentences, unless emphasis is to be placed; e.g., Leo libros ‘I read books’; Yo leo libros ‘It is me who reads books, not you, not him’. Second, verb conjugation is frequently in accordance with the person and number of the omitted subject; e.g., (Yo) Compro manzana ‘(I) buy apples’; (Tú) Compras manzanas ‘(You) buy apples’; (Ellos) Compran manzanas ‘(They) buy apples’. Third, direct object pronouns come before verbs; e.g., Las compro ‘(I) them buy’; Lo leo ‘(I) it read’. Next, unlike English (i.e., typical adjective + noun order), adjectives usually come after a noun, denoting a distinctive or contrastive attribute of the noun, including nationality, place of origin, shape, substance, purpose, color; e.g., pintura metálica ‘metallic paint’, el año escolar ‘the school year’, una casa verde ‘a green house’ (Kattán-Ibarra & Pountain, Reference Kattán-Ibarra and Pountain2003). Finally, adjectives are frequently used as nouns in Spanish, which is hardly found in English; e.g., Saludé al viejo ‘I greeted the old man’ (Kattán-Ibarra & Pountain, Reference Kattán-Ibarra and Pountain2003). With respect to the typological difference, Spanish is a verb-framed language (Ibarretxe-Antunano, Reference Ibarretxe-Antunano, Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Ozcaliskan2009; Talmy, Reference Talmy and Shopen1985, Reference Talmy, Sutton, Johnson and Shields1991), whereas English is a satellite-framed language (Slobin, Reference Slobin, Shibatani and Thompson1996; see below for more information).
1.1. learning english as L2
Typical syntactic development includes the acquisition of the ability to form sentences with words and other smaller structural units. The capability of operating syntactic structures fluently in sentences is largely demonstrated by word order that is a necessary cue to sentence interpretation in English. A number of studies support the notion that the nature of the child’s syntactic processing system in L1 does not differ from that of adults, because the ability to fully rely on narrow syntax as a source of interpretation develops at an early age (i.e., 2–3 years of age) and matures over time (Akhtar, Reference Akhtar1999; Mannell & Friederici, Reference Mannel and Friederici2011; Vasilyeva, Waterfall, & Huttenlocher, Reference Vasilyeva, Waterfall and Huttenlocher2008). Syntactic development continues into early adulthood (20–29 years) and remains stable into middle age (40–49 years) and beyond (Nippold, Hesketh, Duthie, & Mansfield, Reference Nippold, Hesketh, Duthie and Mansfield2005).
How L2 learners acquire syntactic skills compared to L1 speakers is of great importance in understanding similarities and dissimilarities in L1 acquisition and L2 learning. Studies have shown that, in contrast to children’s successful mastery in L1 and L2, adult L2 learners frequently show variability in establishing an advanced proficiency skill level (see Bley-Vroman, Reference Bley-Vroman, Schachter and Gass1989, for the fundamental difference hypothesis; Hopp, Reference Hopp2012), and some learners show a stabilized L2 grammar in certain areas (Long, Reference Long, Doughty and Long2005).
Learning English as an L2 or a foreign language (FL) involves learning a series of linguistic and syntactic features of English. Languages vary in the way in which semantic information is coded and expressed in sentences. According to Talmy’s (Reference Talmy and Shopen1985) theory of cross-linguistic typology, the way in which linguistic information (especially the semantic-to-surface relationship) is encoded in the verb or verbal phrase is different across languages. Verb-framed languages, such as French, Turkish, Spanish, Japanese, and Korean, encode semantic information about actions and directions in the main verb without particles, especially in the expression of path or direction of movement, while satellite-framed languages, such as English and German, use additional particles for the completion of intended meanings. In satellite-framed languages, the path or manner of motion can be expressed in a particle within a verbal clause. For example, the sentence The bottle floated into the cave encodes the Motion (non-agentive) in the main verb floated and the Path in the particle into (i.e., satellite) as a lexical bundle (Talmy, Reference Talmy and Shopen1985). In contrast, verb-framed languages have the Motion and Path conflated in the verb. For example, the sentence The bottle floated into the cave is expressed as La botella entró a la cueva’ ‘The bottle moved-in to the cave’; see Talmy, Reference Talmy and Shopen1985, p. 69). Other examples in English are the sentence the bird flew away , which can be expressed as ‘the bird exited flying’ without the use of a particle in the verb-framed language (slightly modified from Goldin-Meadow et al., Reference Goldin-Meadow, Ozyurek, Sancar, Mylander, Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Ozcaliskan2009, p. 29) and the sentence X ran out of the house, which can be expressed as ‘X exited the house running’ in Spanish (Filipovic, Reference Filipovic2013 p. 2). Talmy (Reference Talmy and Shopen1985) used the term ‘lexicalization doublets’ in English, in which a “single verb form can be used either with or without an inc[o]rporated idea of motion” (p. 64). Therefore, English tends to have predicates that are semantically denser and more varied than verb-framed languages, because the frequent encoding of multiple information is expressed using verb+satellite constructions (e.g., run up, run down, run into, run away, jump over, pull down to, chase away) (Hickmann, Hendriks, & Champaud, Reference Hickmann, Hendriks, Champaud, Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Ozcaliskan2009). This typological difference in the construction of lexical items in verb stems has not only been studied in children’s narratives (Berman & Slobin, Reference Berman and Slobin1994) and adults’ rhetorical style or literary translation (Slobin, Reference Slobin, Shibatani and Thompson1996), but has also been expanded to second language studies (Cadierno & Robinson, Reference Cadierno and Robinson2009; Cadierno & Ruiz, Reference Cadierno and Ruiz2006; Römer, O’Donnell, & Ellis, Reference Römer, O’Donnell and Ellis2014).
English verbs have a set of unique characteristics. Apart from twelve different verb tenses and three different aspect forms, as well as multiword verbs (e.g., phrasal verbs and prepositional verbs), there are four major forms of the verb, including the base (e.g., see), past (e.g., saw), past participle (e.g., seen), and present participle (e.g., seeing). English verbs can also be categorized into, at least, three categories: to-be verbs, intransitive verbs, and transitive verbs. To-be verbs can be used as the main verbs (e.g., am, is, are) of sentences or as auxiliary verbs (e.g., is studying, have been studying, is studied). As far as intransitive verbs are concerned, research shows that some intransitive verbs are particularly difficult for learners of English as an L2 (Kondo, Reference Kondo2005; Montrul, Reference Montrul2005; Oshita, Reference Oshita2001; Pae et al., Reference Pae, Schanding, Kwon and Lee2014; Sorace, Reference Sorace2000). Intransitive verbs have two subcategories of unergative verbs and unaccusative verbs. Unergative verbs describe the subject’s action and status without direct objects (e.g., smile, sit, run) because they imply volition on the part of the subjects. Unaccusative verbs often indicate a change of state (e.g., melt, freeze, happen) or a change of location (e.g., fall, move, arrive) with a lack of volition on the part of the subjects. Unaccusative verbs suggest that grammatical subjects are not the semantic actors of verbs but recipients of the actions of verbs in sentences. As a result, English learners, including native speakers of Spanish, tend to over-passivize this type of verbs (for detailed information, see Kondo, Reference Kondo2005; Montrul, Reference Montrul2005; Oshita, Reference Oshita2001; Pae et al., Reference Pae, Schanding, Kwon and Lee2014; Sorace, Reference Sorace2000). Oshita (Reference Oshita2001) has noted that over-passivization is usually observed in advanced learners of English.
Mostly because of these aforementioned features, verbs are considered to be one of the most difficult items among various grammatical points for English learners (Collins, Reference Collins2007; Folse, Reference Folse2009; Pinker, Reference Pinker1999). Another constraint in syntax is the sequencing of words in sentences. Word order problems in English typically occur at the beginning to low-intermediate levels. Errors in word order made by English learners are likely to stem from cross-linguistic influence. English is stricter than other languages in terms of word order, as other languages allow for more freedom in the arrangement of subjects, verbs, and objects (Folse, Reference Folse2009). For example, since verbs can at times come before subjects in Spanish, Spanish speakers are likely to say or write *Suddenly entered in the room a stranger.
1.2. research questions
If the ease or difficulty in making use of syntactic rules in L2 production depends on the proximity or distance between the L1 and L2 linguistic systems, it would be worthwhile to examine which syntactic feature facilitates or inhibits message construction, lexical activation, and morphosyntactic arrangement in the L2. This examination would allow us to better understand the operating principle that governs L2 learners’ sequencing of words for plausible sentences. To investigate these elements, two research questions were addressed in this study:
-
1. How do native speakers of Spanish formulate sentences in English when randomly ordered words are orally presented, in comparison to native speakers of English who had matched reading levels?
-
2. What is the prominent syntactic feature in English that is difficult for native speakers of Spanish in sequencing words for a plausible sentence?
The above research questions were examined by comparing the performance of native speakers of Spanish to that of native speakers of English who were matched with word reading skills (3–5th grade equivalency). Since research has shown that learning L2 syntax is influenced by the linguistic template established in L1 (Hopp, Reference Hopp2006), it was hypothesized that the performance pattern between speakers of Spanish and English would be different in terms of accuracy and use of syntactic features. Given the intricacies of English verbs, it was also hypothesized that the verb would be the most difficult part of speech to correctly articulate among Spanish native speakers.
2. Method
2.1. participants
Participants in this study included 206 adults (70 Spanish-speaking learners of English, 136 native speakers of English) who attended adult literacy classes in Atlanta, Georgia, US, and who were involved in a larger intervention study. The two groups were matched with the reading level in which their isolated English word reading skills fell in the range between third- and fifth-grade levels. All Spanish-speaking participants were Hispanics and 73% of them were female. Of the 136 native English speakers, 71% were female, and 89% were African Americans, 7% Caucasians, and 4% other or mixed races. The mean age of the Spanish speakers was 32.53 years (SD = 9.33), while that of the English speakers was 33.02 years (SD = 14.41). The mean year of formal schooling in their native country or in the US for the Spanish speakers was 12.17 (SD = 3.83), while that of the English speakers was 10.10 (SD = 1.61).
2.2. measures
2.2.1. Letter/Word knowledge
The participants’ letter/word knowledge was assessed using the Letter–Word Identification subtest of the Woodcock Johnson Psycho-Educational Battery III (WJ-III; Woodcock, McGrew, & Mather, Reference Woodcock, McGrew and Mather2001). This test was used as a screening measure to determine eligibility for a large intervention study. The items require the test taker to orally identify words presented on an easel. According to the test manual, the median reliability coefficient in the adult age range was .94.
2.2.2. Syntactic knowledge
The participant’s expressive grammar knowledge was gauged using the Word Ordering subtest of the Test of Language Development–Intermediate (TOLD-I: 3; Hammill & Newcomer, Reference Hanmill and Newcomer1997). The participant was orally given three to seven randomly ordered words and asked to formulate feasible sentences using the stimuli provided. Since all the words were orally provided, neither reading nor contextual information was required to generate sentences. According to the test manual, vocabulary knowledge was controlled by using words that were below the third-grade level, and the influence of memory was minimized by limiting the number of words in the sequences to seven (Hammill & Newcomer, Reference Hanmill and Newcomer1997). The test-taker was asked to construct various types of sentences, including simple and compound sentences. The randomly presented words could form a declarative, imperative, or interrogative sentence. The ceiling was three consecutive errors, and testing was discontinued when the test-taker produced three incorrect responses in a row. According to the test manual, the coefficient alpha for Hispanics was .70, and that for African Americans was .88. The coefficient of test–retest reliability for the subtest was .92.
2.3. procedure
An initial screening took place in a remedial reading intervention program for adults who struggled with reading in English to determine eligibility for the research project. The Letter–Word Identification subtest of the WJ-III (Woodcock et al., Reference Woodcock, McGrew and Mather2001) was administered to qualify adult students for the study. The participants whose grade equivalency fell between the 3.0 and 5.9 levels (i.e., raw scores of 42 through 57) on the Letter–Word Identification subtest were selected for this study. Prior to testing the participants, examiners were guided by a psychometrician using a test administration protocol that included specific instructions for administering each of the assessments as well as extensive practices. In order to reduce human mistakes in data handling, double scoring and double entry were performed; that is, the psychometrician scored all the tests, and another trained scorer independently verified the scoring; all data were independently double-entered, the two entries were compared, and errors were corrected to produce a quality dataset.
2.4. coding scheme
A coding scheme Footnote 3 was developed for systematic analysis. In documenting the two groups’ performance pattern of sentence formulation, each response was coded in terms of (1) the quality of the constructed sentence, (2) the participant’s use of the stimulus, and (3) syntactic features involved in error production. In obtaining the scale score, a coding scheme was first developed by the first author and went through a couple of revision processes based on a face validity checking by another author. The first rater coded the whole set of items, and 25% of the items were coded by a second coder. The inter-rater agreement at the first round was 84%. A second round of inter-rater reliability coefficient, after resolving discrepancies, reached a satisfactory level of 95%.
The quality of the constructed sentence was coded using a 7-point scale, ranging from 0 (incorrect) to 6 (completely correct). A score of 6 was assigned if the participant correctly produced the target sentence using the stimulus. If a new sentence was produced by either adding new words or phrases or deleting words from the stimulus with the appropriate use of inflections, a score of 5 was assigned. A gradient scale score was given according to the degree of correctness of the response.
The participant’s operation of the stimuli was coded based on the number of words used in the response. For example, if more words than the number of words in the stimulus were used in the response, an entry of ‘addition’ was used; if fewer words were used, it was coded as ‘deletion’; if the same number of words was used, it was coded as either ‘substitution’ or ‘neutral’ depending on the nature of the response. For the cases of deletion and addition, the syntactic features were coded, including the part of speech and other sentential forms such as phrases and clauses.
2.5. analysis outline
Basic information of descriptive statistics was obtained to get the means and standard deviations of the variables used as well as t-test and chi-squared statistics. The Word Ordering subtest of the TOLD-I: 3 included 23 items. However, the first 15 items were analyzed in this study because the Spanish speakers reached the ceiling at item 15. According to the test manual, the ceiling rule included three items, meaning that the test-taker failed to produce correct responses on three items in a row; in this case, test administration was discontinued.
3. Results
3.1. preliminary analyses and descriptive statistics
The raw scores were used for analysis in part because the test did not provide standard scores for adults and non-native speakers. A preliminary data screening for missing data, score ranges, and scatterplots was performed before analyzing data to address the two research questions posed for this study. No noticeable outliers were observed. Since the sample size of the two groups was different, the assumption of homogeneity of variances was tested using Levene’s test. The Levene statistic values of the subtest used in this study were not significant (p > .05), indicating that the data did not violate the homogeneity-of-variance assumption. The mean of isolated English word reading score, measured using the WJ-III, of the Spanish L1 group was 51.09 (SD = 4.29, range = 43–57; grade equivalency = 4.5), while that of native English speakers was 49.57 (SD = 4.78, range = 42–57; grade equivalency = 4.1). Although the Spanish-speaking group’s word reading skills were slightly higher than those of their English-speaking counterpart, the two groups’ performance on the word reading test was not significantly different (p > .05). The mean score of syntactic skills measured using the Word Ordering subtest of the TOLD-I: 3 for the Spanish speakers was 3.81 (SD = 2.70, range = 0–15; age equivalency = 7.04). The mean of the syntactic skills for the native English speakers was 10.46 (SD = 4.40, range = 0–19; age equivalency = 8.79). The syntactic skills were significantly different between the Spanish-speaking participants and the English-speaking comparison group (t(204) = 11.56, p < .001).
3.2. research question 1: how do native speakers of spanish formulate sentences in english when randomly ordered words are orally presented, in comparison to native speakers of english?
The participants’ performance on each item was examined using the raw score. Figure 1 shows the performance pattern of the Spanish- and English-speaking groups. The two groups performed differently on the first 15 items examined (t(14) = 8.48, p < .001; d = 1.25). Considering that the test items were arranged by item difficulty, the performance of the Spanish-speaking group did not conform with the expected pattern, while that of the native English speakers comparatively showed consistency with the increasing level of item difficulty, except for item 8 (He made the bed). Given that item 8 showed a sharp drop from the gradually declining trend, the English-speaking participants seemed to perform differently from the normative group of the Word Ordering subtest of the TOLD-I: 3. The largest difference in the accuracy rate between the L1 and L2 groups was found in item 7 (game, who, the, won for Who won the game?), followed by item 3 (hard, rained, it for It rained hard) and item 4 (cake, eat, your for Eat your cake). The closest gap in the accuracy rate between the two groups was found in item 6 (there, who, is for Who is there?), followed by item 2 (your, is, name, what for What is your name?).

Fig. 1. Performance on each item by group.
3.2.1. Number of words used in formulating sentences
In addition to the raw score of the Sentence Ordering subtest of the TOLD-I; 3, whose scoring was based on the basal and ceiling rules, a scale score obtained based on the coding scheme developed for analysis was analyzed. Overall, the two groups performed differently (t(14) = 8.44, p < .001; d = 1.24). The t-value using the scale score was strikingly similar to that using the raw score that was scored using the protocol established by the publisher. Concerning the two groups’ performance on each item, the scale score showed significant differences on all items (all ps < .001 but item 2; item 2: t = 2.94, p = .004; d = 0.43), which was also consistent with the pattern found using the raw score. This suggests that the coding was valid and reliable.
In order to see if there was a systematic pattern when the participants produced responses that deviated from the target sentence, a more microscopic analysis was employed. As briefly stated earlier, this analysis used the number of words of the stimulus as a barometer to determine an ‘addition’ or ‘deletion’ of words when the participants formulated sentences using the isolated words provided. When only one word was substituted for another, a coding of ‘substitution’ was used. When the total number of words used in the response was equal to that of the stimulus but the deviation included more than one word, it was coded as ‘neutral’. While the native English speakers tended to add words or phrases beyond the stimulus words given (addition = 37%; deletion = 24%; substitution = 23%; neutrality = 16%), the Spanish-speaking group was more likely to delete words from what was provided than the other cases (addition = 22%; deletion = 36%; substitution = 30%; neutrality = 12%). The use of the number of words by the two groups was significantly different in the addition of extra words and deletion from the target stimulus only (F(3,11) = 4.01, p = .009; F(3,11) = 3.44, p = .045, respectively). Figure 2 presents the two groups’ tendency to formulate sentences by adding, deleting, substituting, or deviating within the same number of words as the stimulus.

Fig. 2. Making use of the stimulus words in sentence formulation, by group.
3.2.2. Sentence types
Next, for an analysis of whether or not the two groups performed differently on the sentence types (i.e., declarative, imperative, interrogative, or flexible), the two groups’ performance was examined by sentence type. There were six items that could be constructed one way or another. These items were labeled as flexible choices. For example, the stimulus of party, fun, was, the could be constructed as either a declarative sentence (The party was fun) or an interrogative sentence (Was the party fun?). Figure 3 displays the aspect of performance by sentence type for the two groups. The two groups performed significantly differently on the sentence type (F(1,22) = 19.23, p < .001). The performance of the Spanish speakers was significantly lower than that of their native English counterparts. Despite the between-group difference, the pattern of the two groups’ performance was notably similar. The within-group differences in the four types of sentences (i.e., each group’s performance on declarative, imperative, interrogative, or flexible sentence) were not significantly different. The mean difference was greatest in the imperative sentences (mean difference = 48.19), while the difference in the interrogative sentences (mean difference = 33.25) showed the smallest mean difference. The declarative and imperative sentences were more difficult than the interrogative sentences for both groups. Items that allowed for an option of either a declarative or imperative sentence were the easiest for the two groups.

Fig. 3. The accuracy rate by sentence type.
3.3. research question 2: what is the prominent syntactic feature in english that is difficult for native speakers of spanish in sequencing words for a plausible sentence?
3.3.1. Grammatical features analyzed
Given that there were significant differences in the two groups’ performance on the measure, grammatical features in incorrect responses were analyzed. The grammatical feature analyzed included part of speech, to-infinitive, contraction use, and sentential units (i.e., phrases, clauses, and sentences). The chi-squared statistics showed that each group demonstrated significantly different frequencies of misuse in the grammatical features (X 2(4, N = 70) = 160.80, p < .001 for the Spanish speakers; X 2(4, N = 136) = 222.60, p < .001 for the English speakers). When the cases of adding additional words, deleting words, and substituting words were aggregated, the verb-related additions and deletions were the greatest. However, the difference in verb use between the two groups was not very remarkable. The greatest gap in the use between the two groups was observed in to-infinitives, followed by adverbs and articles. The Spanish-speaking learners of English were more likely to misuse the to-infinitives than their English-speaking counterparts, whereas the native English speakers were more inclined to misuse adverbs and articles than their Spanish-speaking counterparts. Table 1 shows the percentage of the use in each category by group when the participants formulated sentences using the randomly arranged three to seven words provided.
table 1. The tendency (%) to misuse grammatical features by adding, deleting, and substituting the stimulus words, by group

note: a indicates that the rate of misusage (%) is greater in native English speakers than in their Spanish-speaking counterparts.
Since the information presented in Figure 3 was aggregated, a separate examination was conducted for the cases of words added to or deleted from the stimulus. Figures 4 and 5 display the manner of grammatical feature usage by the two groups. Verbs were consistently a dominant feature for both Spanish- and English-speaking participants. With respect to addition, the Spanish speakers tended to incorrectly add verb-related words, followed by pronouns, significantly more than their English-speaking counterparts. For example, they unnecessarily added a to-be verb, as seen in *It is rain hard or *It is rained hard for It rained hard, as well as *Who is the game won? or *Who is won the game? for Who won the game? They also substituted pronouns for definite articles, as they produced *He made his bed for He made the bed. In contrast, the native English speakers were more likely to incorrectly add adverbs (or particles) and full sentences beyond the stimulus, as seen in *The rain came down hard for It rained hard and *Can I eat some of your cake? for Eat your cake. When it came to deletion, the Spanish-speaking group was more likely to drop to from the to-infinitive form and also misuse verbs at the same rate. For instance, they tended to produce *Are you ready go? for Are you ready to go? or *You are ready go for You are ready to go. The native English speakers were most likely to drop verbs, as in *You ready to go, followed by pronouns (e.g., What’s the name? for What is your name?; see Figures 4 and 5).

Fig. 4. Grammatical features misused when words or phrases were added to the stimulus, by group.

Fig. 5. Grammatical features misused when words or phrases were deleted from the stimulus, by group.
Concerning substituting words for other words, the Spanish-speaking group substituted adjectives and verbs most dominantly, while the native English speakers substituted words comparatively evenly across parts of speech, though verbs were the highest, followed by articles. Figure 6 shows a comparison of the two groups in terms of substitutions.

Fig. 6. Grammatical features misused when words or phrases were substituted for the stimulus, by group.
3.2.2. The verb
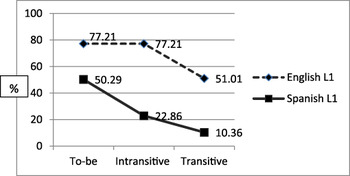
Given that the verb was the most conspicuously misused in this study through addition, deletion, and substitution, special attention was paid to the verb characteristics. The verb type was examined by categorizing the main verb as to-be verbs (e.g., are, is, was), intransitive verbs (e.g., rain, go), or transitive verbs (e.g., forget, make). The two groups showed a significant difference in the performance on the verb types of to-be verbs, intransitive verbs, and transitive verbs (F(1,24) = 26.02, p < .001). As a whole, the two groups performed differently on the type of verb (F(2,24) = 9.94, p = .001). When each group’s performance on the type of verb was examined, the native English speakers did not show a significant difference in the three types of verb forms (p > .05). However, the Spanish-speaking group showed a significant difference in their performance on the verb types (F(2,12) = 7.45, p = .008). Tukey’s post-hoc analysis showed that the performance between to-be verbs and transitive verbs was significantly different. The to-be verb was the easiest, followed by the intransitive verb that did not require an object in a sentence. The transitive verb that required an object in a sentence to complete the meaning of the verb was the most difficult verb form for both groups to formulate. The mean difference between the two groups was greatest in the intransitive verbs (54%), followed by transitive verbs (41%) and to-be verbs (27%). Figure 7 displays the two groups’ performance on the verb types.

Fig. 7. The accuracy rate by verb type.
4. Discussion
This study investigated how native speakers of Spanish orally formulated sentences in English as an L2 using a set of randomly ordered words orally provided by the examiner. As indicated earlier, the effects of vocabulary skills and memory were minimized because the words used were (1) below the third-grade level and (2) in the range of three to seven words per sentence. The goal was to elucidate specific aspects of syntactic features that influenced their sentence formulation, in comparison to native English speakers with similar reading levels. For this purpose, adults’ syntactic skills were analyzed, because adults have already established stabilized linguistic skills. As expected, different patterns of performance on syntactic skills were observed. This suggests a potential difference involved in the acquisition of L1 and L2, as well as a cross-linguistic influence on L2 learning. Further explorations demonstrated systematic differences between the two groups. The results of this study allow us to not only tap into a cross-linguistic influence on L2 sentence formulation, but also shed light on pedagogical implications so that challenging grammatical items can be effectively targeted in L2 instruction.
Overall, the Spanish-speaking group tended to delete words from the stimulus. This tendency might have stemmed from a limited ability of articulation in the L2. Although it might be natural to delete some of the words provided with a limited command of English, the pattern of deletion was different across syntactic features. In contrast, the native speakers of English tended to construct a new meaning by adding words or phrases to the stimulus. It was interesting that the English-speaking group added more words to construct new expressions rather than effectively using the stimulus words provided. Since they had a full command of oral English as an L1, a fragment of the stimulus words might have served as a cue to elicit other related or unrelated words in constructing sentences as they would like. Given that the native English speakers were struggling readers who read at between third- and fifth-grade levels, their tendency to generate new sentences by adding more words might be related to compensatory skills that struggling readers have developed over time to repair their limited reading skills.
Concerning the sentence type to be formulated, the L2 group showed a similar pattern of performance to that of the L1 group in a global way despite the L2 group’s lower performance than their L1 counterparts. The participants seemed to take advantage of options they had when either a declarative sentence or an interrogative sentence could be constructed using the stimulus words. Both groups performed best with the cases that allowed for the options, followed by interrogative sentences. The interrogative pronouns (e.g., what, who) and interrogative adverbs (e.g., where) in the stimuli might have served as a prompt that signaled interrogative sentences to be constructed. Interestingly, both groups performed the poorest on declarative sentences. This finding can be explained by the greater degrees of freedom that declarative sentences have in expression than the other two types of sentences, as interrogative and imperatives sentences have more restricted syntactic rules (i.e., interrogative sentences begin with interrogative pronouns, interrogative adverbs, or auxiliary verbs; imperative sentences begin with verb roots) than declarative or descriptive sentences.
Among the grammatical features examined, verbs were most misused by both groups. However, the aspect of misuse was different across the two groups. Specifically, the Spanish-speaking group was more likely to add verbs to the stimuli, while the English speakers showed a tendency to delete verbs. It should be noted that the tendency of adding verbs was striking in comparison to their tendency of deleting words from the stimulus in general. The tendency of adding verbs may have to do with the fact that Spanish speakers are inclined to place verbs before subjects, as seen in *Suddenly entered in the room a stranger (Folse, Reference Folse2009). Folse also notes that Spanish-speaking learners of English persistently omit subjects, as in I like cats. *Are very good pets. This phenomenon was found in the current study as well, as in *Picked some flowers for They picked some flowers and *Made the bed for He made the bed. Since English sticks to the SVO order, subject omission is rarely observed in English speakers. Another explanation of this finding is related to the typological differences of the language systems. As indicated earlier, Spanish is a verb-framed language (Ibarretxe-Antunano, Reference Ibarretxe-Antunano, Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Ozcaliskan2009; Talmy, Reference Talmy and Shopen1985, Reference Talmy, Sutton, Johnson and Shields1991). Since the Spanish language tends to include conflated Motion and Path information within the verb in the sentence (Talmy, Reference Talmy and Shopen1985), Spanish speakers may have a predilection to pay more attention to verbs than other part-of-speech items and place their intention in the verb; accordingly, they tend to overuse or emphasize the verb. In contrast, English speakers assign particles along with verbs in order to convey the action of the subject in the sentence. When the insertion of prepositions and adverbs shown by the native English speakers was examined, this claim seemed to be valid because there were more preposition and adverb additions by the English speakers than their Spanish-speaking counterparts. This finding partly supports the theory of cross-linguistic typology (i.e., verb-framed language vs. satellite-framed language) posed by Talmy (Reference Talmy and Shopen1985).
Another item that was added by the Spanish-speaking participants was articles, including definite and indefinite articles. The Spanish language has more articles than English. In Spanish, articles are used before nouns to indicate gender (masculine, feminine, or neutral), number (singular, plural), and whether or not the subsequent noun is specifically identifiable by the reader/listener (definite, indefinite). A definite article is used whenever the definite article the is used in English. There are more cases of the definite article being used in Spanish than in English. There are five definite articles, as follows: la (singular feminine), el (singular masculine), lo (neuter), las (plural feminine), and los (plural masculine). There are also more indefinite articles in Spanish with different uses, depending on number and gender: una (singular feminine), un (singular masculine), unas (plural feminine), and unos (plural masculine) (Kattán-Ibarra & Pountain, Reference Kattán-Ibarra and Pountain2003). The tendency to add more articles in the Spanish-speaking participants seems to be a direct L1 influence on L2 sentence construction. Specifically, many Spanish-speaking participants added or substituted a word with the definite article the in many cases, as follows: *What is the name yours? for What is your name?, *The rain is hard for It rained hard, *Eat the cake for Eat your cake, *They picked the flower for They picked some flowers (note that inaccuracy in the measure was based on the deviation from the stimulus, not on the correct form of syntax).
When it came to the verb types, transitive verbs and intransitive verbs were more difficult than to-be verbs for the Spanish-speaking group. To-be verbs are the most inflected verb in English, as they have eight different forms (i.e., am, is, are, was, were, being, been, be). Folse (Reference Folse2009) indicates that learners of English internalize the forms of be well, especially am, are, and is. As a result, they end up overusing or overgeneralizing the form of ‘subject + be’ even when a different main verb is needed, as seen in *I am drive this kind of car because it is get really good mileage (p. 49). Likewise, the Spanish-speaking participants produced double verbs in this study. As indicated earlier, they produced sentences such as *It is rain hard or *It is rained hard for It rained hard, and *Who is the game won? or *Who is won the game? for Who won the game? Another interpretation would be that the participants struggled with tenses. Footnote 4 This claim was validated with cases of *What was your name? for What is your name?, and *Who there was for Who is there?
Regarding verbs with and without direct objects, there seemed to have some confusion about the use and non-use of direct objects with transitive and intransitive verbs in the Spanish speakers. For instance, the Spanish participants produced *I cake you for Eat your cake and *The girl sees for See the girl. In this line, Folse (Reference Folse2009) notes that some learners of English formulate a sentence like *I enjoyed very much, where an object is in need. The demarcation of transitive and intransitive verbs seemed to be blurry for the Spanish participants in this study. The largest gap between the two groups was found in the performance of intransitive verbs, especially when a verb can be used as either transitively or intransitively (e.g., win, break, roll). As indicated earlier, some cases of over-passivization or overuse of the form of to-be were detected, as seen in *It is rained hard and *Who is won the game? Although the tendency of over-passivization or overuse of the form of to-be is likely to be observed in advanced English learners (Montrul, Reference Montrul2005; Oshita, Reference Oshita2001; Pae et al., Reference Pae, Schanding, Kwon and Lee2014), the findings of this study suggest that beginners are not immune to that problem, either.
Another grammatical feature apparent in the Spanish-speaking group is that they deleted items from the stimulus words to-infinitives. An infinitive phrase is a verb phrase with or without the particle to. In English, when a verb is introduced by the particle to, it is called a full infinitive or a to-infinitive, while when a verb on its own is used as an infinitive form, it is called a bare infinitive. The participants produced the sentence *You are ready go when it was supposed to be You are ready to go. The deletion of the to-infinitive might have resulted from a cross-linguistic influence in that Spanish infinitives work a little differently from English infinitives. Unlike English, in which the particle to is typically used before the verb, with the exception of bare infinitives, Spanish infinitives comprise only one word, with three different conjugations attached to the root of a verb depending on the endings (-ar, -er, and –ir, as in hablar , correr , and compartir ). They serve as a base for a conjugation, as a noun, or can be used after conjugated verbs (Liceras, Valenzuela, & Diaz, Reference Liceras, Valenzuela and Diaz1999). Another explanation for this type of errors would be simply one of general acquisition problems. Footnote 5
When the test items were examined, one of the findings showed that the sentence He made the bed was one of the difficult items for both L1 and L2 groups. The phrase make the bed is a lexical bundle of collocations. It seems that low-performing speakers of English also have problems in collocational expressions. One explanation is that the word make is simply polysemous with multiple meanings. The word make has forty-two meanings that can be expressed in sentences (Folse, Reference Folse2009). Conceptually speaking, the sentence *He did [or arranged] the bed would make more sense than He made the bed to speakers of other languages, because the sentence does not involve the creation of something, as the core meaning of the word make indicates. Similarly the word do can be used to express twenty-eight different meanings. The usage of do and make seems to be particularly difficult for Spanish speakers because the Spanish word hacer means ‘do’ or ‘make’ (Folse, Reference Folse2009). Therefore, learning an individual English word with no context would be nebulous for learners of English.
In a similar vein, the Spanish speakers did a comparatively poor job on the sentence it rained hard. The word hard is also polysemous in that it can be used as either an adjective (e.g., It is a hard task) or an adverb (i.e., She works hard ). Some participants treated the word hard as an adjective, as seen in *The rain is hard or *Rain is hard. In addition, the Spanish-speaking group was more likely to omit the impersonal subject it when it had no determinate subject, as seen in *Outside was cold and dark for It was cold and dark outside or It was dark and cold outside. In the sentence It was cold and dark outside, the pronoun it does not refer to anything specific but is non-referential or impersonal. In English, the non-referential subjects it or there are used to fill the subject position of a sentence to talk about the weather, temperature, time, days of the week, and holidays, distance, and the environment (Cowan, Reference Cowan2008). In Spanish, however, impersonal or non-referential subjects are typically not used, although subjects or pronouns are occasionally omitted. Hence, the error of the missing non-referential pronoun it in the sentence seems to be another example of a cross-linguistic influence resulting from subject-dropping or pronoun-dropping and/or ‘Spanish word order combinability’. Footnote 6 It appears that a solid understanding of the impersonal or non-referential pronoun has not been established in the native speakers of Spanish who participated in this study.
Another item that showed a big difference between the two groups’ performance in terms of the accuracy rate had to do with a phrasal verb (i.e., take out) as in the sentence Don’t forget to take out the cat or Don’t forget to take the cat out. As briefly indicated earlier, phrasal verbs and prepositional verbs are one of the more difficult grammar items learners of English face. This also has to do with Talmy’s (Reference Talmy and Shopen1985) typological difference in which Spanish encodes the motion in the main verb, while English uses particles along with the main verb to assign the meaning of motion in a sentence.
In summary, the results of this study highlight the crucial role of verbs in sentence construction in both native English and Spanish speakers. As Pinker (Reference Pinker1999) notes, the verb is the main ingredient of language and serves as an anchor to which other words are secured in sentences. This study also partially supports the theory of cross-linguistic typology (Talmy, Reference Talmy and Shopen1985), in that native English speakers and Spanish speakers are likely to use different lexicalization patterns that are specific to their L1s.
4.1. pedagogical implications
Adult learners of English have unique learning disadvantages compared to children. First, they have fewer clock hours involved in English learning than children who are voluntarily and involuntarily exposed to English in schools. Second, they have already passed the critical period (Snow & Hoefnagel-Höhle, Reference Snow and Hoefnagel-Höhle1978) for language learning. Despite criticism, the Critical Period Hypothesis that learners before puberty have biological advantages in learning another language is generally accepted. Third, many adult learners of English have full-time work and family obligations and can only attend English classes for a few hours each week in the evening. As a result, they are not exposed to lengthy formal English learning opportunities. Given these learning constraints, lesson plans that are conducive to adult learners of English are necessary to accelerate adults’ learning of English. Considering the fast-growing number of Spanish-speaking immigrants in the US, lesson plans that specifically target the most challenging grammar points would help speed up Spanish speakers’ learning of English as an L2. The findings of this study provide empirical evidence, inform teachers of Spanish-speaking adult learners of English in regard to which grammatical points to target in the adult classroom, and help teachers develop evidence-based curriculum or lesson plans.
Although how to teach English grammar has been a steady topic of debate in English language teaching, what to teach to facilitate the speed of English learning has been relatively under-discussed. Moreover, how L2 learners make use of randomly arranged stimulus words in sentence formulation has not been examined. Since this study provides empirical evidence on sentence formulation by native Spanish-speaking learners of English as an L2, the findings of this study suggest pedagogical themes that need to be addressed in ESL or EFL classrooms to effectively target grammatical points that are difficult in learning English as an L2.
Although there are criticisms surrounding grammar teaching, the intricacies and complexities of English verbs may be better tackled with direct grammar instruction than simply hoping that learners will get the concept on their own via implicit learning or simple exposure to an L2 environment. Given some adult learners’ stabilized L2 grammar shown in L2 English learning (Bley-Vroman, Reference Bley-Vroman, Schachter and Gass1989; Long, Reference Long, Doughty and Long2005), targeting student-specific direct instruction that teases apart each layer and its function would be helpful. Specifically, models of explicit instruction focusing on verbs, multiword verbs (i.e., prepositional verbs and phrasal verbs), unaccusative verbs, and polysemous verbs would enhance learners’ syntactic skills in English. Given the overuse of articles in English sentences by the Spanish speakers, the over-application of L1 linguistic features may need to be suppressed in L2 English. The lack of the to-infinitive in Spanish should also be addressed in explicit instruction and lesson plans. Finally, tenses are related to verbs. Spanish has verb tenses that look similar to those in English, but their usage is different. For example, the sentence *Tomorrow, I accompany you if you want is feasible in Spanish (Folse, Reference Folse2009, p. 74), although a modal verb (i.e., will) that indicates future is required in English. Phrasal verbs and prepositional verbs are other targets to be amplified in lesson plans for adult learners of English.
4.2. future directions
Although this study provides a comprehensive analysis of the performance patterns of Spanish-speaking learners of English, compared to those of native English speakers, a few limitations need to be addressed. The limitations are also closely related to future directions. First, this study included participants who read English words between third- and fifth-grade equivalency levels. An inclusion of more advanced readers would not only allow for a better understanding of the linguistic profiles of sentence formulation in English as an L2, but would also shed light on a syntactic growth pattern from beginning to advanced levels. It is suggested that more research be conducted in subsequent studies to corroborate the findings of this study. A study with different L1 groups would also extend the findings of this study. Second, the L2 oral proficiency of the Spanish-speaking participants was not considered in this study, although their L2 word reading level was identified and matched with the comparison group. A future study that includes participants’ L2 oral proficiency levels would substantiate and corroborate the results of this study. Third, it would be interesting to analyze elicited sentence formulation in free, spontaneous speech responding to an open-ended question posed by the examiner in order to examine whether the constraint placed in the prescribed stimuli used in this study made a difference in the use of correct syntax in the L2. An examination of free speech samples beyond controlled situations would allow for a fine comparison to the results of this study. Fourth, the instrument used to measure syntactic skills is normed on ages 8–18 because of a lack of measures that are normed on adults. Studies that utilize supplementary measures, along with the TOLD-I: 3 assessment tool, are needed to validate the findings of this study. Next, this study used oral production of sentence formulation. A comparative study including written narratives or essays would broaden the understanding of sentence construction upon presentation of stimulus words. An identification of similarities and dissimilarities in oral and written production would also provide valuable information about the aspect of modality in the area of L2 acquisition. Last, although the usage of verbs was extensively analyzed, the morphological marking of verbs was not examined in this study. The way verbs mark morphological inflections, such as tense, aspect, or third person -s, would provide a broader and deeper understanding of verb usage by learners of English as an L2 or FL.