



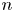

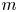


1. Introduction
Overview and objectives. Questions in technology, life sciences, and economics are often related to large systems of nodes connected via pairwise interactions which involve uncertainty due to unpredictable node behavior and missing data. Such uncertainties have been mathematically modeled and analyzed using random graph models of various complexity, including classical independently linked and uniform random graphs [Reference Frieze and Karoński20], stochastic block models and inhomogeneous Bernoulli graphs [Reference Abbe1,Reference Boguñá and Pastor-Satorras13,Reference Holland, Laskey and Leinhardt23], random graphs with given degree distributions [Reference Bollobás, Janson and Riordan14,Reference Molloy and Reed37], and generative models involving preferential attachment and rewiring mechanisms [Reference Albert and Barabási3,Reference Newman40]. While succeeding to obtain a good fit to degree distributions, most earlier models fail to capture second-order effects related to clustering and transitivity. Random intersection graphs [Reference Ball, Sirl and Trapman6,Reference Bloznelis7,Reference Britton, Deijfen, Lagerås and Lindholm16,Reference Godehardt and Jaworski21,Reference Karjalainen, van Leeuwaarden and Leskelä28,Reference Karoński, Scheinerman and Singer-Cohen29], spatial preferential attachment models [Reference Aiello, Bonato, Cooper, Janssen and Prałat2,Reference Jacob and Mörters24], and hyperbolic random geometric graphs [Reference Bode, Fountoulakis and Müller12,Reference Kiwi and Mitsche30,Reference Krioukov, Papadopoulos, Kitsak, Vahdat and Boguñá31] have been successful in extending the analysis to sparse graph models with tunable global clustering coefficient. Despite remarkable methodological advances obtained in the aforementioned articles and related literature, most models of sparse random graphs still appear somewhat rigid in what comes to modeling finer second-order properties, such as correlations of the degrees of adjacent nodes [Reference Newman39] and degree-dependent clustering coefficients [Reference Ángeles Serrano and Boguñá5,Reference Fountoulakis, van der Hoorn, Müller and Schepers19,Reference Vázquez, Pastor-Satorras and Vespignani47].
Main contributions. This article discusses a mathematical network model recently introduced in [Reference Bloznelis and Leskelä9] which is motivated by the structure of social networks composed of a large number of overlapping communities [Reference Breiger15]. The model is generated as a superposition of mutually independent Bernoulli random graphs  $G_1,\ldots , G_m$ of variable size (number of nodes) and strength (link probability), which can be interpreted as layers or communities. The node sets of the layers are random subsets of the underlying population of
$G_1,\ldots , G_m$ of variable size (number of nodes) and strength (link probability), which can be interpreted as layers or communities. The node sets of the layers are random subsets of the underlying population of  $n$ nodes. A key feature of the model is that the layer sizes and layer strengths are assumed to be correlated, which allows, for example, to model social networks with tunable frequencies of strong small communities and weak large communities. The main contribution of this article is a rigorous mathematical analysis (Theorem 1) of the bidegree distribution (joint degree distribution of adjacent nodes) of the model in a limiting regime where the number of nodes
$n$ nodes. A key feature of the model is that the layer sizes and layer strengths are assumed to be correlated, which allows, for example, to model social networks with tunable frequencies of strong small communities and weak large communities. The main contribution of this article is a rigorous mathematical analysis (Theorem 1) of the bidegree distribution (joint degree distribution of adjacent nodes) of the model in a limiting regime where the number of nodes  $n$ and the number of layers
$n$ and the number of layers  $m$ are large and of the same order of magnitude. We note that such a regime admits bidegree distributions with statistically dependent marginals. Moreover, power laws can be introduced by choosing suitable layer types (Theorem 2). The bidegree distribution yields compact mathematical formulas for the model assortativity (Theorem 3) and rank correlations (Theorem 4) of the adjacent node degrees. The latter theorem is suitable for modeling dependencies in heavy-tailed models with degrees having unbounded second moments. A proof outline of Theorem 1 was presented in the preliminary version [Reference Bloznelis, Karjalainen and Leskelä11]. We complete the proof with weaker assumptions in this paper. Theorem 2 and Lemmas 2 and 3, as well as the proofs for Lemmas 1 and 4, are new.
$m$ are large and of the same order of magnitude. We note that such a regime admits bidegree distributions with statistically dependent marginals. Moreover, power laws can be introduced by choosing suitable layer types (Theorem 2). The bidegree distribution yields compact mathematical formulas for the model assortativity (Theorem 3) and rank correlations (Theorem 4) of the adjacent node degrees. The latter theorem is suitable for modeling dependencies in heavy-tailed models with degrees having unbounded second moments. A proof outline of Theorem 1 was presented in the preliminary version [Reference Bloznelis, Karjalainen and Leskelä11]. We complete the proof with weaker assumptions in this paper. Theorem 2 and Lemmas 2 and 3, as well as the proofs for Lemmas 1 and 4, are new.
Related work. Degree distributions, clustering, and percolation analysis of the model are presented in [Reference Bloznelis and Leskelä9]. An analogous model where the node sets of the layers are deterministic has been studied in [Reference Yang and Leskovec49] in the context of overlapping community detection. Clustering coefficients and small subgraph frequencies for a special case with constant layer strengths have been analyzed in [Reference Gröhn, Karjalainen and Leskelä22,Reference Karjalainen and Leskelä27,Reference Karjalainen, van Leeuwaarden and Leskelä28,Reference Petti and Vempala41]. In the special case with unit layer strengths, the layers become cliques and the model reduces to the passive random intersection graph introduced in [Reference Godehardt and Jaworski21], with degree and clustering properties analyzed in [Reference Bloznelis7,Reference Kurauskas34]. A network model with similar features has been recently presented in [Reference Vadon, Komjáthy and van der Hofstad43]. Assortativity and bidegree distributions have earlier been analyzed in the context of random intersection graph models [Reference Bloznelis8,Reference Bloznelis, Jaworski and Kurauskas10], inhomogeneous Bernoulli graphs and their extensions [Reference Boguñá and Pastor-Satorras13,Reference Mahadevan, Krioukov, Fall and Vahdat35,Reference Sadeghi and Rinaldo42], preferential attachment models [Reference Krot and Prokhorenkova32,Reference van der Hofstad and Litvak44], and configuration models in [Reference van der Hofstad and Litvak44–Reference van der Hoorn and Litvak46]. Extremal properties of bidegree correlations in general graphs have been reported in [Reference Czabarka, É., Rauh, Sadeghi, Short and Székely17,Reference van der Hofstad and Litvak44].
1.1. Notations
Sets and numbers. The cardinality of a set  $A$ is denoted
$A$ is denoted  ${\lvert {A}\rvert }$. Ordered pairs are denoted by
${\lvert {A}\rvert }$. Ordered pairs are denoted by  $(i,j)$ and unordered pairs by
$(i,j)$ and unordered pairs by  $\{i,j\}$. Here
$\{i,j\}$. Here  $1(A)$ is defined to be one when statement
$1(A)$ is defined to be one when statement  $A$ is true, and zero otherwise. We denote
$A$ is true, and zero otherwise. We denote  $[n] = \{1,\ldots ,n\}$ and
$[n] = \{1,\ldots ,n\}$ and  $\mathbb {Z}_+ = \{0,1,2,\ldots \}$. The falling factorial is denoted
$\mathbb {Z}_+ = \{0,1,2,\ldots \}$. The falling factorial is denoted  $(x)_r = x(x-1) \cdots (x-r+1)$.
$(x)_r = x(x-1) \cdots (x-r+1)$.
Graphs. A graph is defined as a pair  $G = (V(G), E(G))$ where
$G = (V(G), E(G))$ where  $V(G)$ is the set of nodes, and
$V(G)$ is the set of nodes, and  $E(G)$ is the set of edges (unordered node pairs). Nodes
$E(G)$ is the set of edges (unordered node pairs). Nodes  $i$ and
$i$ and  $j$ are called adjacent if
$j$ are called adjacent if  $\{i,j\} \in E(G)$. The set of nodes adjacent to node
$\{i,j\} \in E(G)$. The set of nodes adjacent to node  $i$ is denoted
$i$ is denoted  $N_G(i) = \{j \in V(G): \{i,j\} \in E(G)\}$. The degree of
$N_G(i) = \{j \in V(G): \{i,j\} \in E(G)\}$. The degree of  $i$ is denoted
$i$ is denoted  $\deg _G(i) = {\lvert {N_G(i)}\rvert }$. The set of ordered pairs of adjacent nodes is denoted by
$\deg _G(i) = {\lvert {N_G(i)}\rvert }$. The set of ordered pairs of adjacent nodes is denoted by  ${E_\textrm {dir}} (G) = \{(i,j) \in V(G) \times V(G) : \{i,j \} \in E(G)\}$.
${E_\textrm {dir}} (G) = \{(i,j) \in V(G) \times V(G) : \{i,j \} \in E(G)\}$.
Probability. For a probability measure on a countable space, we denote  $f(x) = f(\{x\})$ and
$f(x) = f(\{x\})$ and  $\int \phi \, df = \sum \phi (x) f(x)$. The Dirac measure at
$\int \phi \, df = \sum \phi (x) f(x)$. The Dirac measure at  $x$ is denoted by
$x$ is denoted by  $\delta _x$. The binomial distribution is denoted by
$\delta _x$. The binomial distribution is denoted by  $\operatorname {Bin}(x,y)(s) = \binom {x}{s} (1-y)^{x-s} y^{s}$, and the Poisson distribution by
$\operatorname {Bin}(x,y)(s) = \binom {x}{s} (1-y)^{x-s} y^{s}$, and the Poisson distribution by  $\operatorname {Poi}(\lambda )(s) = e^{-\lambda } ({\lambda ^{s}}/{s!})$. The product and the convolution of probability measures
$\operatorname {Poi}(\lambda )(s) = e^{-\lambda } ({\lambda ^{s}}/{s!})$. The product and the convolution of probability measures  $f$ and
$f$ and  $g$ are denoted by
$g$ are denoted by  $f \otimes g$ and
$f \otimes g$ and  $f \ast g$, respectively.
$f \ast g$, respectively.
2. Assortativity and bidegree distributions
2.1. Empirical quantities
Let  $G$ be a graph with a finite node set and a nonempty link set. Here
$G$ be a graph with a finite node set and a nonempty link set. Here  $G$ is viewed as a nonrandom graph or a fixed sample of a random graph. The (empirical) degree distribution of
$G$ is viewed as a nonrandom graph or a fixed sample of a random graph. The (empirical) degree distribution of  $G$ is a probability measure on
$G$ is a probability measure on  $\mathbb {Z}_+$ defined by
$\mathbb {Z}_+$ defined by
 $$f_G(s)= \frac{1}{{\lvert{V(G)}\rvert}} \sum_{i \in V(G)} 1 ( \deg_G(i) = s ),$$
$$f_G(s)= \frac{1}{{\lvert{V(G)}\rvert}} \sum_{i \in V(G)} 1 ( \deg_G(i) = s ),$$and represents the probability distribution of the random variable  $\deg _G(I)$ where
$\deg _G(I)$ where  $I$ is a random variable obtained by sampling a node uniformly at random. The (empirical) bidegree distribution of
$I$ is a random variable obtained by sampling a node uniformly at random. The (empirical) bidegree distribution of  $G$ with a nonempty link set is a probability measure on
$G$ with a nonempty link set is a probability measure on  $\mathbb {Z}_+^{2}$ defined by
$\mathbb {Z}_+^{2}$ defined by
 $$f_G^{(2)}(s,t) = \frac{1}{2 {\lvert{E(G)}\rvert}} \sum_{(i,j) \in {E_\textrm{dir}} (G)} 1 ( \deg_G(i) = s, \, \deg_G(j) = t ).$$
$$f_G^{(2)}(s,t) = \frac{1}{2 {\lvert{E(G)}\rvert}} \sum_{(i,j) \in {E_\textrm{dir}} (G)} 1 ( \deg_G(i) = s, \, \deg_G(j) = t ).$$This is the joint probability distribution of the pair  $(\deg _G(I), \deg _G(J))$ obtained by sampling
$(\deg _G(I), \deg _G(J))$ obtained by sampling  $(I,J)$ uniformly at random from the set of all ordered node pairs adjacent in
$(I,J)$ uniformly at random from the set of all ordered node pairs adjacent in  $G$. A simple computation shows that both marginals of the bidegree distribution are equal to the size-biased degree distribution
$G$. A simple computation shows that both marginals of the bidegree distribution are equal to the size-biased degree distribution
 \begin{equation} f_G^{*}(s) = \frac{s f_G(s)}{\sum_t t f_G(t)}. \end{equation}
\begin{equation} f_G^{*}(s) = \frac{s f_G(s)}{\sum_t t f_G(t)}. \end{equation}The Pearson correlation coefficient of the bidegree distribution is called the (empirical) assortativity of graph  $G$ and can be written as
$G$ and can be written as
 $$\operatorname{Cor}_G(\deg_G(I), \deg_G(J)) = \frac{\sum_{s,t} st f_G^{(2)}(s,t) - ( \sum_s s f_G^{*}(s) )^{2}} {\sum_s s^{2} f_G^{*}(s) - (\sum_s s f_G^{*}(s))^{2}}.$$
$$\operatorname{Cor}_G(\deg_G(I), \deg_G(J)) = \frac{\sum_{s,t} st f_G^{(2)}(s,t) - ( \sum_s s f_G^{*}(s) )^{2}} {\sum_s s^{2} f_G^{*}(s) - (\sum_s s f_G^{*}(s))^{2}}.$$2.2. Model quantities
Let  $G$ be a random graph such that
$G$ be a random graph such that  $V(G)$ is nonrandom and finite, and
$V(G)$ is nonrandom and finite, and  $E(G)$ is nonempty with positive probability. The model degree distribution of
$E(G)$ is nonempty with positive probability. The model degree distribution of  $G$ is defined by
$G$ is defined by
 \begin{equation} f(s) = \mathbb{P}( \deg_G(I) = s ), \end{equation}
\begin{equation} f(s) = \mathbb{P}( \deg_G(I) = s ), \end{equation}where  $I$ is a random node in
$I$ is a random node in  $V(G)$, selected uniformly at random and independently of
$V(G)$, selected uniformly at random and independently of  $E(G)$. The model bidegree distribution is defined by
$E(G)$. The model bidegree distribution is defined by
 \begin{equation} f_2(s,t) = \mathbb{P} ( \deg_G(I) = s, \, \deg_G(J) = t \, \big| \, (I,J) \in {E_\textrm{dir}} (G)), \end{equation}
\begin{equation} f_2(s,t) = \mathbb{P} ( \deg_G(I) = s, \, \deg_G(J) = t \, \big| \, (I,J) \in {E_\textrm{dir}} (G)), \end{equation}where  $(I,J)$ is an ordered pair of distinct nodes of
$(I,J)$ is an ordered pair of distinct nodes of  $V(G)$, selected uniformly at random and independently of
$V(G)$, selected uniformly at random and independently of  $E(G)$. By simple computations one may verify that
$E(G)$. By simple computations one may verify that  $f_2(t,s) = f_2(s,t)$, and that both marginals of the model bidegree distribution are equal to the size-biased model degree distribution
$f_2(t,s) = f_2(s,t)$, and that both marginals of the model bidegree distribution are equal to the size-biased model degree distribution
 \begin{equation} f_1^{*}(s) = \frac{s f(s)}{\sum_t t f(t)}. \end{equation}
\begin{equation} f_1^{*}(s) = \frac{s f(s)}{\sum_t t f(t)}. \end{equation}The Pearson correlation coefficient of the model bidegree distribution is called the model assortativity and can be written as
 \begin{equation} \operatorname{Cor}^{*}(\deg_G(I), \deg_G(J)) = \frac{\mathbb{E}^{*} \deg_G(I) \deg_G(J)- (\mathbb{E}^{*} \deg_G(I) )^{2}}{\mathbb{E}^{*} \deg_G(I)^{2} - ( \mathbb{E}^{*} \deg_G(I) )^{2}}, \end{equation}
\begin{equation} \operatorname{Cor}^{*}(\deg_G(I), \deg_G(J)) = \frac{\mathbb{E}^{*} \deg_G(I) \deg_G(J)- (\mathbb{E}^{*} \deg_G(I) )^{2}}{\mathbb{E}^{*} \deg_G(I)^{2} - ( \mathbb{E}^{*} \deg_G(I) )^{2}}, \end{equation}where  $(I,J)$ is an ordered pair of distinct nodes of
$(I,J)$ is an ordered pair of distinct nodes of  $V(G)$ selected uniformly at random as above and
$V(G)$ selected uniformly at random as above and  $\mathbb {E}^{*}$ refers to the conditional expectation given the event
$\mathbb {E}^{*}$ refers to the conditional expectation given the event  $\{ (I,J) \in {E_\textrm {dir}} (G)\}$.
$\{ (I,J) \in {E_\textrm {dir}} (G)\}$.
3. Random graph superposition model
A multilayer network model  $G_n$ with
$G_n$ with  $n$ nodes and
$n$ nodes and  $m$ layers of sizes
$m$ layers of sizes  $X_{n,k}$ and strengths
$X_{n,k}$ and strengths  $Y_{n,k}$,
$Y_{n,k}$,  $k=1,\ldots ,m$ is defined by: (i) sampling for each
$k=1,\ldots ,m$ is defined by: (i) sampling for each  $k$ a node set
$k$ a node set  $V(G_{n,k})$ uniformly at random from the subsets of
$V(G_{n,k})$ uniformly at random from the subsets of  $\{1,\ldots ,n\}$ of size
$\{1,\ldots ,n\}$ of size  $X_{n,k}$, (ii) linking each node pair in
$X_{n,k}$, (ii) linking each node pair in  $V(G_{n,k})$ independently with probability
$V(G_{n,k})$ independently with probability  $Y_{n,k}$, and (iii) aggregating the layers
$Y_{n,k}$, and (iii) aggregating the layers  $G_{n,k}$ by setting
$G_{n,k}$ by setting
 $$V(G_n) = \{1,\ldots,n\}$$
$$V(G_n) = \{1,\ldots,n\}$$and
 $$E(G_n) = E(G_{n,1}) \cup \cdots \cup E(G_{n,m}).$$
$$E(G_n) = E(G_{n,1}) \cup \cdots \cup E(G_{n,m}).$$The layers are assumed to be mutually independent, but the size and strength of a layer may be correlated. Formally, the model is defined by a list
 $$( (G_{n,1},X_{n,1},Y_{n,1}), \dots, (G_{n,m},X_{n,m},Y_{n,m}) )$$
$$( (G_{n,1},X_{n,1},Y_{n,1}), \dots, (G_{n,m},X_{n,m},Y_{n,m}) )$$of mutually independent random variables with values in  $\mathcal {G}_n \times \{0,\ldots ,n\} \times [0,1]$, where
$\mathcal {G}_n \times \{0,\ldots ,n\} \times [0,1]$, where  $\mathcal {G}_n$ denotes the set of undirected graphs with node set contained in
$\mathcal {G}_n$ denotes the set of undirected graphs with node set contained in  $\{1,\ldots ,n\}$. We assume that conditionally on
$\{1,\ldots ,n\}$. We assume that conditionally on  $(X_{n,k},Y_{n,k})$, the probability distribution of
$(X_{n,k},Y_{n,k})$, the probability distribution of  $V(G_{n,k})$ is uniform on the subsets of
$V(G_{n,k})$ is uniform on the subsets of  $\{1,\ldots ,n\}$ of size
$\{1,\ldots ,n\}$ of size  $X_{n,k}$, and conditionally on
$X_{n,k}$, and conditionally on  $(V(G_{n,k}), X_{n,k}, Y_{n,k})$, the probability distribution of
$(V(G_{n,k}), X_{n,k}, Y_{n,k})$, the probability distribution of  $E(G_{n,k})$ is such that each node pair of
$E(G_{n,k})$ is such that each node pair of  $V(G_{n,k})$ is linked with probability
$V(G_{n,k})$ is linked with probability  $Y_{n,k}$, independently of other node pairs. We obtain a rich class of generative probabilistic models when we assume that for every
$Y_{n,k}$, independently of other node pairs. We obtain a rich class of generative probabilistic models when we assume that for every  $m$ and
$m$ and  $n$ the layer types
$n$ the layer types  $(X_{n,1},Y_{n,1}), \dots , (X_{n,m}, Y_{n,m})$ are mutually independent and (identically) distributed according to a probability measure
$(X_{n,1},Y_{n,1}), \dots , (X_{n,m}, Y_{n,m})$ are mutually independent and (identically) distributed according to a probability measure  $P^{(n)}$ on
$P^{(n)}$ on  $\{0,\ldots ,n\} \times [0,1]$.
$\{0,\ldots ,n\} \times [0,1]$.
A large network is modeled as a sequence of network models of the above type indexed by the number of nodes  $n=1,2,\ldots$ so that the number of layers
$n=1,2,\ldots$ so that the number of layers  $m = m_n$ tends to infinity as
$m = m_n$ tends to infinity as  $n \to \infty$. To obtain a sparse network admitting tractable limiting formulas with rich expressive power, we shall focus on the sparse parameter regime where
$n \to \infty$. To obtain a sparse network admitting tractable limiting formulas with rich expressive power, we shall focus on the sparse parameter regime where  $m = \operatorname {\Theta }(n)$ and there exists a probability measure
$m = \operatorname {\Theta }(n)$ and there exists a probability measure  $P$ on
$P$ on  $\{0,1,\ldots \} \times [0,1]$ which approximates the layer type distribution according to
$\{0,1,\ldots \} \times [0,1]$ which approximates the layer type distribution according to  $P^{(n)} \to P$ weakly, together with the convergence of suitable cross moments
$P^{(n)} \to P$ weakly, together with the convergence of suitable cross moments  $P^{(n)}_{rs} \to P_{rs}$, where we use the shorthand notations
$P^{(n)}_{rs} \to P_{rs}$, where we use the shorthand notations
 $$P^{(n)}_{rs} = \mathbb{E}( (X_{n,k})_r \, Y_{n,k}^{s} ), \quad P_{rs} = \mathbb{E}( (X)_r Y^{s} ).$$
$$P^{(n)}_{rs} = \mathbb{E}( (X_{n,k})_r \, Y_{n,k}^{s} ), \quad P_{rs} = \mathbb{E}( (X)_r Y^{s} ).$$Here and below  $(X,Y)$ stands for a generic P-distributed random vector.
$(X,Y)$ stands for a generic P-distributed random vector.
Remark 1 We note that  $P^{(n)}_{10} = \mathbb {E} (X_{n,k})$ denotes the expected layer size in the model with scale parameter
$P^{(n)}_{10} = \mathbb {E} (X_{n,k})$ denotes the expected layer size in the model with scale parameter  $n$. To appreciate the relevance of other cross moments, we note that for any graph
$n$. To appreciate the relevance of other cross moments, we note that for any graph  $R$ with
$R$ with  $V(R) \subset \{1,\ldots ,n\}$,
$V(R) \subset \{1,\ldots ,n\}$,  ${\lvert {V(R)}\rvert }=r$ and
${\lvert {V(R)}\rvert }=r$ and  ${\lvert {E(R)}\rvert }=s$, the probability that
${\lvert {E(R)}\rvert }=s$, the probability that  $G_{n,k}$ contains
$G_{n,k}$ contains  $R$ as subgraph equals
$R$ as subgraph equals  $(n)_r^{-1} P^{(n)}_{rs}$, and the expected number of
$(n)_r^{-1} P^{(n)}_{rs}$, and the expected number of  $R$-isomorphic subgraphs in
$R$-isomorphic subgraphs in  $G_{n,k}$ equals
$G_{n,k}$ equals  $P^{(n)}_{rs}$ divided by the number of automorphisms of
$P^{(n)}_{rs}$ divided by the number of automorphisms of  $R$. Especially, the expected numbers of links, 2-stars, and 3-stars contained in any particular layer are given by
$R$. Especially, the expected numbers of links, 2-stars, and 3-stars contained in any particular layer are given by  $\frac 12 P^{(n)}_{21}$,
$\frac 12 P^{(n)}_{21}$,  $\frac 12 P^{(n)}_{32}$, and
$\frac 12 P^{(n)}_{32}$, and  $\frac 16 P^{(n)}_{43}$, respectively.
$\frac 16 P^{(n)}_{43}$, respectively.
When the number of layers is of the same order as the number of nodes  ${m}/{n} \to \mu \in (0,\infty )$,
${m}/{n} \to \mu \in (0,\infty )$,  $P^{(n)} \to P$ weakly, and
$P^{(n)} \to P$ weakly, and  $P^{(n)}_{10} \to P_{10} \in (0,\infty )$, we obtain a sparse network
$P^{(n)}_{10} \to P_{10} \in (0,\infty )$, we obtain a sparse network  $G_n$ with the model degree distribution (2) converging weakly [Reference Bloznelis and Leskelä9] to a compound Poisson distribution
$G_n$ with the model degree distribution (2) converging weakly [Reference Bloznelis and Leskelä9] to a compound Poisson distribution
 \begin{equation} \bar f_1 = \operatorname{CPoi}(\lambda, g) \end{equation}
\begin{equation} \bar f_1 = \operatorname{CPoi}(\lambda, g) \end{equation}with rate parameter  $\lambda = \mu P_{10}$ and increment distribution
$\lambda = \mu P_{10}$ and increment distribution
 \begin{equation} g(s) = \int_{\mathbb{Z}_+{\times} [0,1]} \operatorname{Bin}(x-1,y)(s) \frac{x P(dx,dy)}{P_{10}}, \quad s \in \mathbb{Z}_+. \end{equation}
\begin{equation} g(s) = \int_{\mathbb{Z}_+{\times} [0,1]} \operatorname{Bin}(x-1,y)(s) \frac{x P(dx,dy)}{P_{10}}, \quad s \in \mathbb{Z}_+. \end{equation}In other words, the limiting model degree distribution  $\bar f_1$ represents the law of
$\bar f_1$ represents the law of  $\sum _{k=1}^{\Lambda } H_k$, where
$\sum _{k=1}^{\Lambda } H_k$, where  $\Lambda ,H_1,H_2,\ldots$ are mutually independent random integers and such that
$\Lambda ,H_1,H_2,\ldots$ are mutually independent random integers and such that  $\operatorname {Law}(\Lambda ) = \operatorname {Poi}(\lambda )$ and
$\operatorname {Law}(\Lambda ) = \operatorname {Poi}(\lambda )$ and  $\operatorname {Law}(H_k) = g$.
$\operatorname {Law}(H_k) = g$.
4. Main results
4.1. Bidegree distribution
The result below characterizes the limiting bidegree distribution in the random Bernoulli graph superposition model. The limiting bidegree distribution can be represented as the joint law of random variables
 \begin{equation} (D_1^{*}, D_2^{*} ) = (1 + D_1 + D'_1, \, 1 + D_2 + D'_2 ), \end{equation}
\begin{equation} (D_1^{*}, D_2^{*} ) = (1 + D_1 + D'_1, \, 1 + D_2 + D'_2 ), \end{equation}where  $D_1$,
$D_1$,  $D_2$, and
$D_2$, and  $(D_1',D_2')$ are mutually independent and such that
$(D_1',D_2')$ are mutually independent and such that  $D_1$ and
$D_1$ and  $D_2$ follow the limiting degree distribution
$D_2$ follow the limiting degree distribution  $\bar f_1$ defined by (6).
$\bar f_1$ defined by (6).  $D_1'$ and
$D_1'$ and  $D_2'$ are defined with the help of an auxiliary random vector
$D_2'$ are defined with the help of an auxiliary random vector  $(X',Y')$ taking values in
$(X',Y')$ taking values in  $\mathbb {Z}_+ \times [0,1]$ and having the distribution
$\mathbb {Z}_+ \times [0,1]$ and having the distribution  ${(x)_2 y P(dx,dy)}/{P_{21}}$. Namely, given
${(x)_2 y P(dx,dy)}/{P_{21}}$. Namely, given  $(X',Y')$ the random variables
$(X',Y')$ the random variables  $D_1'$ and
$D_1'$ and  $D_2'$ are conditionally independent and both are
$D_2'$ are conditionally independent and both are  $\operatorname {Bin}(X'-2,Y')$-distributed. In order to explain the origin of
$\operatorname {Bin}(X'-2,Y')$-distributed. In order to explain the origin of  $(X',Y')$, we fix a vertex pair
$(X',Y')$, we fix a vertex pair  $\{i,j\}$ and number
$\{i,j\}$ and number  $k$. Then
$k$. Then  $(X',Y')$ represents the limit (in distribution) of the size and strength of the layer
$(X',Y')$ represents the limit (in distribution) of the size and strength of the layer  $G_{n,k}$ conditioned on the event that
$G_{n,k}$ conditioned on the event that  $\{i,j\}\in E(G_{n,k})$ (in this case, we say that the edge
$\{i,j\}\in E(G_{n,k})$ (in this case, we say that the edge  $\{i,j\}$ is produced by
$\{i,j\}$ is produced by  $G_{n,k}$). Typically, an edge
$G_{n,k}$). Typically, an edge  $\{i,j\}\in E(G_n)$ is produced by a single layer. The (limiting) numbers of neighbors of
$\{i,j\}\in E(G_n)$ is produced by a single layer. The (limiting) numbers of neighbors of  $i$ and
$i$ and  $j$ produced by this particular layer are represented by
$j$ produced by this particular layer are represented by  $D_1'$ and
$D_1'$ and  $D_2'$, while the numbers of neighbors produced by other layers are represented by
$D_2'$, while the numbers of neighbors produced by other layers are represented by  $D_1$ and
$D_1$ and  $D_2$.
$D_2$.
The joint distribution of  $(D_1^{*}, D_2^{*})$ defined by (8) can be written as
$(D_1^{*}, D_2^{*})$ defined by (8) can be written as
 \begin{equation} \bar f_{2} = \delta_{(1,1)} \ast (\bar f_1 \otimes \bar f_1) \ast f'_{2} \end{equation}
\begin{equation} \bar f_{2} = \delta_{(1,1)} \ast (\bar f_1 \otimes \bar f_1) \ast f'_{2} \end{equation}where  $\ast$ refers to the convolution of probability measures on
$\ast$ refers to the convolution of probability measures on  $\mathbb {Z}_+^{2}$, and
$\mathbb {Z}_+^{2}$, and  $f'_{2}$ stands for the distribution of
$f'_{2}$ stands for the distribution of  $(D_1',D_2')$,
$(D_1',D_2')$,
 \begin{equation} f'_{2}(s,t) = \int_{\mathbb{Z}_+{\times} [0,1]} \operatorname{Bin}(x-2,y)(s) \operatorname{Bin}(x-2,y)(t) \frac{(x)_2 y P(dx,dy)}{P_{21}}. \end{equation}
\begin{equation} f'_{2}(s,t) = \int_{\mathbb{Z}_+{\times} [0,1]} \operatorname{Bin}(x-2,y)(s) \operatorname{Bin}(x-2,y)(t) \frac{(x)_2 y P(dx,dy)}{P_{21}}. \end{equation}The main intuition behind (8) and (9) is that the overlap of the edges that contribute to  $D_1$ and
$D_1$ and  $D_1'$ (or
$D_1'$ (or  $D_2$ and
$D_2$ and  $D_2'$) is negligible.
$D_2'$) is negligible.  $D_1$ and
$D_1$ and  $D_2$ represent the numbers of neighbors when the common layer is removed, and these numbers are asymptotically independent. Moreover, removing the common layer does not affect the asymptotic degree distribution
$D_2$ represent the numbers of neighbors when the common layer is removed, and these numbers are asymptotically independent. Moreover, removing the common layer does not affect the asymptotic degree distribution  $\bar f_1$. The edge between nodes
$\bar f_1$. The edge between nodes  $I$ and
$I$ and  $J$ in the definition (3) is represented by
$J$ in the definition (3) is represented by  $\delta _{(1,1)}$.
$\delta _{(1,1)}$.
Theorem 1 characterizes the large-scale limiting behavior of the bidegree distribution of  $G_n$,
$G_n$,
 $$f_{2,n}(s,t) = \mathbb{P}( \deg_{G_n}(1) = s, \deg_{G_n}(2) = t \, | \, (1,2) \in {E_\textrm{dir}} (G_n) ).$$
$$f_{2,n}(s,t) = \mathbb{P}( \deg_{G_n}(1) = s, \deg_{G_n}(2) = t \, | \, (1,2) \in {E_\textrm{dir}} (G_n) ).$$We note that the probability above is the same as in (3). Indeed, the probability distribution of  $G_n$ is invariant under permutation/relabeling of its nodes. Therefore, the random pair
$G_n$ is invariant under permutation/relabeling of its nodes. Therefore, the random pair  $(I,J)$ can be replaced in (3) by a nonrandom one.
$(I,J)$ can be replaced in (3) by a nonrandom one.
Theorem 1 Let  $m,n \to \infty$. Assume that
$m,n \to \infty$. Assume that  ${m}/{n} \to \mu \in (0,\infty )$, and that
${m}/{n} \to \mu \in (0,\infty )$, and that  $P^{(n)} \to P$ weakly for some probability measure
$P^{(n)} \to P$ weakly for some probability measure  $P$ on
$P$ on  $\mathbb {Z}_+ \times [0,1]$.
$\mathbb {Z}_+ \times [0,1]$.
(i) If
 $P^{(n)}_{rs} \to P_{rs} \in (0, \infty )$ for $rs=10,21$, then $f_{2,n} \to \bar f_2$ weakly, where the limiting bidegree distribution $\bar f_2$ is defined by (9).
$P^{(n)}_{rs} \to P_{rs} \in (0, \infty )$ for $rs=10,21$, then $f_{2,n} \to \bar f_2$ weakly, where the limiting bidegree distribution $\bar f_2$ is defined by (9).(ii) If in addition,
$P^{(n)}_{rs} \to P_{rs} < \infty$ for $rs = 32,43$, then $\int \phi \, d f_{2,n} \to \int \phi \, d \bar f_{2}$ for all $\phi : \mathbb {Z}_+^{2} \to \mathbb {R}$ such that ${\lvert {\phi (x,y)}\rvert } \le c(1 + x^{2} + y^{2})$ for some constant $c< \infty$.










The approximation (i) in the weak topology assumes that the mean layer size  $P^{(n)}_{10}$ and the mean number of edges
$P^{(n)}_{10}$ and the mean number of edges  $\frac 12 P^{(n)}_{21}$ per layer converge to nonzero finite limits. When in addition
$\frac 12 P^{(n)}_{21}$ per layer converge to nonzero finite limits. When in addition  $P^{(n)}_{32}$ and
$P^{(n)}_{32}$ and  $P^{(n)}_{43}$ converge to finite limits, we obtain a stronger approximation (ii) in the Wasserstein-2 metric ([Reference Villani48], Thm. 6.9), which is used to derive approximations for the model assortativity in Theorem 3.
$P^{(n)}_{43}$ converge to finite limits, we obtain a stronger approximation (ii) in the Wasserstein-2 metric ([Reference Villani48], Thm. 6.9), which is used to derive approximations for the model assortativity in Theorem 3.
We are particularly interested in network models featuring: (i) tunable power law degree distributions and (ii) tunable frequencies of strong small communities and weak large communities. To meet requirement (ii), we let the marginals  $X$ and
$X$ and  $Y$ of
$Y$ of  $P$ be negatively correlated. For simplicity, we will consider the case where the asymptotic community strength
$P$ be negatively correlated. For simplicity, we will consider the case where the asymptotic community strength  $Y$ is a negative power of the layer size
$Y$ is a negative power of the layer size  $X$. To meet requirement (i), we choose a suitable distribution for
$X$. To meet requirement (i), we choose a suitable distribution for  $X$. We mention that the asymptotic power law degree distribution and clustering properties in this setup were shown in [Reference Bloznelis and Leskelä9]. In Theorem 2 , we establish the first-order asymptotic of the limiting bidegree distribution
$X$. We mention that the asymptotic power law degree distribution and clustering properties in this setup were shown in [Reference Bloznelis and Leskelä9]. In Theorem 2 , we establish the first-order asymptotic of the limiting bidegree distribution  ${\bar f}_2(s,t)$ as
${\bar f}_2(s,t)$ as  $s,t\to +\infty$.
$s,t\to +\infty$.
Theorem 2 Denote by  $(D_1^{*}, D_2^{*})$ a random vector with the asymptotic bidegree distribution
$(D_1^{*}, D_2^{*})$ a random vector with the asymptotic bidegree distribution  ${\bar f}_2$. Assume that the limiting layer type distribution equals
${\bar f}_2$. Assume that the limiting layer type distribution equals  $P(dx,dy) = p(dx)\delta _{q(x)} (dy)$ with
$P(dx,dy) = p(dx)\delta _{q(x)} (dy)$ with
 $$p(x) = (a+o(1))x^{-\alpha} \quad \text{as } x\to \infty \quad \text{and} \quad q(x) = \min \{1, b x^{-\beta} \}$$
$$p(x) = (a+o(1))x^{-\alpha} \quad \text{as } x\to \infty \quad \text{and} \quad q(x) = \min \{1, b x^{-\beta} \}$$with exponents  $\alpha >2$,
$\alpha >2$,  $\beta \in (0,1)$,
$\beta \in (0,1)$,  $\alpha +\beta >3$ and constants
$\alpha +\beta >3$ and constants  $a,b > 0$. If
$a,b > 0$. If  $\beta =0$, then
$\beta =0$, then  $q(x)$ is a constant and we require
$q(x)$ is a constant and we require  $b<1$. Then as
$b<1$. Then as  $t \to \infty$,
$t \to \infty$,
 \begin{equation} \mathbb{P}(D_1^{*} = t) = (1+o(1))c' t^{-{(\alpha-2)}/{(1-\beta)}}, \end{equation}
\begin{equation} \mathbb{P}(D_1^{*} = t) = (1+o(1))c' t^{-{(\alpha-2)}/{(1-\beta)}}, \end{equation}where  $c' = ab^{{(\alpha -2)}/{(1-\beta )}} (1-\beta )^{-1} P_{21}^{-1}$. Denote
$c' = ab^{{(\alpha -2)}/{(1-\beta )}} (1-\beta )^{-1} P_{21}^{-1}$. Denote  $\delta _t=t^{1/2}\ln ^{4}(2+t)$. For
$\delta _t=t^{1/2}\ln ^{4}(2+t)$. For  $t_1,t_2\to +\infty$ such that
$t_1,t_2\to +\infty$ such that  $(t_2-t_1)/\delta _{t_2}\to +\infty$ we have
$(t_2-t_1)/\delta _{t_2}\to +\infty$ we have
 \begin{equation} \mathbb{P} ( D_1^{*} = t_1, D_2^{*} = t_2 ) = (1+o(1))c''(t_2-t_1)^{{-}1-{(\alpha-2)}/{(1-\beta)}} t_1^{-{(\alpha-2)}/{(1-\beta)}}, \end{equation}
\begin{equation} \mathbb{P} ( D_1^{*} = t_1, D_2^{*} = t_2 ) = (1+o(1))c''(t_2-t_1)^{{-}1-{(\alpha-2)}/{(1-\beta)}} t_1^{-{(\alpha-2)}/{(1-\beta)}}, \end{equation}where  $c' = \mu a^{2} b^{{2(\alpha -2)}/{(1-\beta )}} (1-\beta )^{-2} P_{21}^{-1}$.
$c' = \mu a^{2} b^{{2(\alpha -2)}/{(1-\beta )}} (1-\beta )^{-2} P_{21}^{-1}$.
The intuition behind this result is that the largest contribution to each degree  $D_i^{*} = 1+D_i+D_i'$,
$D_i^{*} = 1+D_i+D_i'$,  $i=1,2$, is made by the respective term
$i=1,2$, is made by the respective term  $D_i'$. In particular, the tail asymptotic (11) is that of the tail of
$D_i'$. In particular, the tail asymptotic (11) is that of the tail of  $D_i'$. Furthermore, the terms
$D_i'$. Furthermore, the terms  $D_1'$ and
$D_1'$ and  $D_2'$ are strongly correlated for large values
$D_2'$ are strongly correlated for large values  $t_1$,
$t_1$, $t_2$ and the distribution of
$t_2$ and the distribution of  $(D_1',D_2')$ concentrates around the diagonal. Indeed, this can be seen if we extrapolate (12) to the range
$(D_1',D_2')$ concentrates around the diagonal. Indeed, this can be seen if we extrapolate (12) to the range  $t_2-t_1=const$. Note, however, that this range is excluded by our technical condition
$t_2-t_1=const$. Note, however, that this range is excluded by our technical condition  $\delta _{t_2}=o(t_2-t_1)$.
$\delta _{t_2}=o(t_2-t_1)$.
4.2. Assortativity
The following result provides a formula of the limiting model assortativity which is well defined when the limiting degree distribution has a finite third moment. In the special case with unit strengths, this formula yields the corresponding result for passive random intersection graphs given in [Reference Bloznelis, Jaworski and Kurauskas10], Thm. 3.1.
Theorem 3 Let  $m,n \to \infty$. Assume that
$m,n \to \infty$. Assume that  ${m}/{n} \to \mu \in (0,\infty )$, and that
${m}/{n} \to \mu \in (0,\infty )$, and that  $P^{(n)}_{rs} \to P_{rs} < \infty$ for
$P^{(n)}_{rs} \to P_{rs} < \infty$ for  $rs = 10,21,32,43$, for some probability measure
$rs = 10,21,32,43$, for some probability measure  $P$ on
$P$ on  $\mathbb {Z}_+ \times [0,1]$ such that
$\mathbb {Z}_+ \times [0,1]$ such that  $P_{10}, P_{21}>0$. Then the model assortativity (5) converges according to
$P_{10}, P_{21}>0$. Then the model assortativity (5) converges according to
 $$\operatorname{Cor}^{*}(\deg_{G_n}(I), \deg_{G_n}(J)) \to \frac{P_{21}( P_{43} + P_{33}) - P_{32}^{2}} {P_{21}(P_{43} + P_{32}) - P_{32}^{2} + \mu P_{21}^{2} ( P_{21} + P_{32})}.$$
$$\operatorname{Cor}^{*}(\deg_{G_n}(I), \deg_{G_n}(J)) \to \frac{P_{21}( P_{43} + P_{33}) - P_{32}^{2}} {P_{21}(P_{43} + P_{32}) - P_{32}^{2} + \mu P_{21}^{2} ( P_{21} + P_{32})}.$$ The limiting assortativity is always nonnegative by the following result and the fact that  $P_{33} \leq P_{32}$.
$P_{33} \leq P_{32}$.
Lemma 1 (Generalizes [Reference Bloznelis, Jaworski and Kurauskas10], Rem. 2)
For any probability distribution  $P$ on
$P$ on  $\mathbb {Z}_+ \times [0,1]$,
$\mathbb {Z}_+ \times [0,1]$,
 $$P_{32}^{2} \le P_{21} ( P_{43} + P_{33} ).$$
$$P_{32}^{2} \le P_{21} ( P_{43} + P_{33} ).$$4.3. Rank correlations
Assortativity modeled using Pearson's correlation of the bidegree distribution is ill-behaved for graph models where the limiting degree distribution has an infinite third moment [Reference van der Hofstad and Litvak44]. In such cases, rank correlation coefficients provide a robust alternative [Reference van der Hofstad and Litvak44–Reference van der Hoorn and Litvak46]. For a probability measure  $f$ on
$f$ on  $\mathbb {R}^{2}$ with nondegenerate marginals, Kendall's rank correlation [Reference Kruskal33,Reference Nešlehová38] is defined by
$\mathbb {R}^{2}$ with nondegenerate marginals, Kendall's rank correlation [Reference Kruskal33,Reference Nešlehová38] is defined by
 $$\rho_\textrm{Ken}(f) = \operatorname{Cor}( \operatorname{sgn}(U^{(1)}-Z^{(1)}), \, \operatorname{sgn}(U^{(2)}-Z^{(2)}) )$$
$$\rho_\textrm{Ken}(f) = \operatorname{Cor}( \operatorname{sgn}(U^{(1)}-Z^{(1)}), \, \operatorname{sgn}(U^{(2)}-Z^{(2)}) )$$where  $\operatorname {sgn}(x) = 1(x>0) - 1(x<0)$, and
$\operatorname {sgn}(x) = 1(x>0) - 1(x<0)$, and  $(U^{(1)},U^{(2)})$ and
$(U^{(1)},U^{(2)})$ and  $(Z^{(1)},Z^{(2)})$ are mutually independent and
$(Z^{(1)},Z^{(2)})$ are mutually independent and  $f$-distributed. Spearman's rank correlation is defined as
$f$-distributed. Spearman's rank correlation is defined as
 $$\rho_\textrm{Spe}(f) = \operatorname{Cor} (r_1(U^{(1)}), \, r_2(U^{(2)}) ),$$
$$\rho_\textrm{Spe}(f) = \operatorname{Cor} (r_1(U^{(1)}), \, r_2(U^{(2)}) ),$$where  $(U^{(1)},U^{(2)})$ is
$(U^{(1)},U^{(2)})$ is  $f$-distributed and
$f$-distributed and  $r_i(x) = \frac 12( f^{(i)}(-\infty ,x) + f^{(i)}(-\infty ,x] )$ with
$r_i(x) = \frac 12( f^{(i)}(-\infty ,x) + f^{(i)}(-\infty ,x] )$ with  $f^{(i)}$ denoting the
$f^{(i)}$ denoting the  $i$-th marginal distribution of
$i$-th marginal distribution of  $f$. There are several alternative definitions for Spearman's rank correlation corresponding to different tie-breaking conventions [Reference Amerise and Tarsitano4]. The above definition agrees with the commonly used mid-rank convention ([Reference Nešlehová38], Thms. 14 and 15).
$f$. There are several alternative definitions for Spearman's rank correlation corresponding to different tie-breaking conventions [Reference Amerise and Tarsitano4]. The above definition agrees with the commonly used mid-rank convention ([Reference Nešlehová38], Thms. 14 and 15).
Theorem 4 Let  $m,n\to +\infty$. Assume that
$m,n\to +\infty$. Assume that  ${m}/{n} \to \mu \in (0,\infty )$, and
${m}/{n} \to \mu \in (0,\infty )$, and  $P^{(n)} \to P$ weakly with
$P^{(n)} \to P$ weakly with  $P^{(n)}_{rs} \to P_{rs}$ for
$P^{(n)}_{rs} \to P_{rs}$ for  $rs=10,21$, where
$rs=10,21$, where  $0 < P_{rs} < \infty$. Then it holds that
$0 < P_{rs} < \infty$. Then it holds that
 $$\rho_\textrm{Ken}(f_{2,n}) \to \rho_\textrm{Ken}({\bar f}_2) \quad \text{and} \quad \rho_\textrm{Spe}(f_{2,n}) \to \rho_\textrm{Spe}({\bar f}_2),$$
$$\rho_\textrm{Ken}(f_{2,n}) \to \rho_\textrm{Ken}({\bar f}_2) \quad \text{and} \quad \rho_\textrm{Spe}(f_{2,n}) \to \rho_\textrm{Spe}({\bar f}_2),$$where the limiting bidegree distribution  ${\bar f}_2$ is defined by (9).
${\bar f}_2$ is defined by (9).
5. Discussion
This article describes degree correlations in a sparse network model introduced in [Reference Bloznelis and Leskelä9], constructed by a natural superposition mechanism with overlapping layers. The main contribution is a compact explicit description of the limiting model bidegree distribution (Theorem 1), fully characterized in terms of the limiting joint distribution  $P$ of layer sizes and layer strengths, and the limiting ratio
$P$ of layer sizes and layer strengths, and the limiting ratio  $\mu$ of the number of layers and the number of nodes. Some remarks deserve further attention.
$\mu$ of the number of layers and the number of nodes. Some remarks deserve further attention.
(i) In this work, we have studied the model bidegree distribution, whereas several earlier works [Reference van der Hofstad and Litvak44–Reference van der Hoorn and Litvak46] have focused on the convergence of the empirical bidegree distribution computed from a fixed random graph sample. Based on analogous studies on ergodic properties of clustering coefficient [Reference Karjalainen and Leskelä27,Reference Karjalainen, van Leeuwaarden and Leskelä28], we expect that both distributions converge to the same limit under mild regularity assumptions.
(ii) The freedom to tune the limiting joint distribution
$P$ of layer sizes and layer strengths yields a rich class of network models. As a concrete example, we studied the case where the layer strength is a deterministic function of layer size so that $Y = q(X)$. If layer sizes follow an approximate power law $\mathbb {P}(X=x) \propto x^{-\alpha }$, and $q(x) \propto x^{-\beta }$, then the limiting degree distribution follows a power law $\mathbb {P}(D_1 = t) \propto t^{-\delta }$ with $\delta = 1 + {(\alpha -2)}/{(1-\beta )}$ [Reference Bloznelis and Leskelä9]. Because the marginals of the limiting bidegree distribution are size-biased versions of the degree distribution, it follows that the marginals of $f_2$ are power laws with density exponent $\delta -1 = {(\alpha -2)}/{(1-\beta )}$. The dependence structure of the power-law random variables $D_1^{*}$ and $D_2^{*}$ is implicitly captured by (8). The same functional form of layer strengths has been also investigated in [Reference Yang and Leskovec49] for deterministic layer node sets.(iii) Fitting the model to real data sets is a problem of future research. A fully nonparametric approach to estimating
$P$ appears hard if not impossible, even though currently there are no (positive or negative) theoretical results regarding model identifiability. An alternative approach is to restrict to models where $P = P_\theta$ is parametrized by a small-dimensional parameter $\theta$, and develop estimators of $\theta$ using empirical small subgraph counts. Recent work in this direction includes [Reference Gröhn, Karjalainen and Leskelä22,Reference Karjalainen and Leskelä27,Reference Karjalainen, van Leeuwaarden and Leskelä28] for models with constant layer strength. Model fitting with deterministic (unknown) layer node sets has been studied in [Reference Yang and Leskovec49].














6. Proofs
6.1. Proof of Theorem 1$\mathbf {(i)}$

We start with some auxiliary results. Theorem 5 (shown in [Reference Bloznelis and Leskelä9]) establishes the asymptotic compound Poisson model degree distribution. Lemma 2 shows that the degrees of nodes 1 and 2 are asymptotically independent in a model where the layers larger than some  $M>0$ are removed. Lemma 3 shows that this asymptotic independence still holds when
$M>0$ are removed. Lemma 3 shows that this asymptotic independence still holds when  $M$ tends to infinity.
$M$ tends to infinity.
Theorem 5 ([Reference Bloznelis and Leskelä9], Thm. 3.1)
Let  $\mu >0$. Let
$\mu >0$. Let  $n,m\to +\infty$. Assume that
$n,m\to +\infty$. Assume that  $m/n \to \mu$. If
$m/n \to \mu$. If
(i)
$P^{(n)}$ converges weakly to some probability measure $P$ on $\mathbb {Z}_+ \times [0,1]$ and(ii)
$P^{(n)}_{10}$ converges to some number $P_{10} \in (0, \infty )$,





then the model degree distribution of  $G_n$ converges weakly to a compound Poisson distribution defined by
$G_n$ converges weakly to a compound Poisson distribution defined by
 $$\sum_{k=1}^{\Lambda} H_k,$$
$$\sum_{k=1}^{\Lambda} H_k,$$where  $\Lambda , H_1, H_2, \ldots$ are independent random variables with
$\Lambda , H_1, H_2, \ldots$ are independent random variables with  $\operatorname {Law}(\Lambda ) = \operatorname {Poi}(\mu P_{10})$ and
$\operatorname {Law}(\Lambda ) = \operatorname {Poi}(\mu P_{10})$ and  $\operatorname {Law}(H_k) = g$ with the probability mass function
$\operatorname {Law}(H_k) = g$ with the probability mass function
 $$g(s) = \int \operatorname{Bin}(x-1,y)(s) \frac{x P(dx,dy)}{P_{10}}, \quad s \in \mathbb{Z}_+.$$
$$g(s) = \int \operatorname{Bin}(x-1,y)(s) \frac{x P(dx,dy)}{P_{10}}, \quad s \in \mathbb{Z}_+.$$Lemma 2 (Independence with truncated communities) Assume the conditions of Theorem 5 hold. Fix  $s,t \in \mathbb {N}$, and
$s,t \in \mathbb {N}$, and  $M>0$ such that
$M>0$ such that  $\mathbb {P} ( X \leq M) > 0$. Let
$\mathbb {P} ( X \leq M) > 0$. Let  $K = \{k: X_{n,k} \leq M \}$ and define
$K = \{k: X_{n,k} \leq M \}$ and define  $\hat G = ([n], E(\hat G))$ with
$\hat G = ([n], E(\hat G))$ with
 $$E(\hat G) = \bigcup_{k \in K} E( G_{n,k}).$$
$$E(\hat G) = \bigcup_{k \in K} E( G_{n,k}).$$Let  $\hat d_i = \deg _{\hat G}(i)$. Then, as
$\hat d_i = \deg _{\hat G}(i)$. Then, as  $n \rightarrow \infty$,
$n \rightarrow \infty$,
 $$\mathbb{P} (\hat d_1 = s, \hat d_2 = t) = \mathbb{P} (\hat d_1 = s) \mathbb{P}(\hat d_2 = t) + o(1).$$
$$\mathbb{P} (\hat d_1 = s, \hat d_2 = t) = \mathbb{P} (\hat d_1 = s) \mathbb{P}(\hat d_2 = t) + o(1).$$Proof. We construct  $\hat G$ as follows. Let
$\hat G$ as follows. Let  $\hat G_{n,k}$ be independent layers with sizes and strengths
$\hat G_{n,k}$ be independent layers with sizes and strengths
 $$\hat X_{n,k} = X_{n,k} \mathbb{I}(X_{n,k} \leq M), \quad \hat Y_{n,k} = Y_{n,k} \mathbb{I}(X_{n,k} \leq M), \quad k = 1\ldots m.$$
$$\hat X_{n,k} = X_{n,k} \mathbb{I}(X_{n,k} \leq M), \quad \hat Y_{n,k} = Y_{n,k} \mathbb{I}(X_{n,k} \leq M), \quad k = 1\ldots m.$$We assume that  $n$ is large enough so that
$n$ is large enough so that  $\mathbb {P}(X_{n,k} \leq M) > 0$ and define the (random) edges as
$\mathbb {P}(X_{n,k} \leq M) > 0$ and define the (random) edges as  $E(\hat G) = \bigcup _{k=1}^{m} E(\hat G_{n,k})$. Denote by
$E(\hat G) = \bigcup _{k=1}^{m} E(\hat G_{n,k})$. Denote by  $Z_i$ the layers that contain node
$Z_i$ the layers that contain node  $i$:
$i$:
 $$Z_i = \{ k: \; i \in V(\hat G_{n,k}) \}, \quad i=1,2.$$
$$Z_i = \{ k: \; i \in V(\hat G_{n,k}) \}, \quad i=1,2.$$By Markov's inequality
 \begin{align} \mathbb{P} (|Z_1| > \ln m) & \le \frac{\mathbb{E} (|Z_1|)}{\ln m} = \mathbb{P} (1 \in V(\hat G_{n,1})) \frac{m}{\ln m} \nonumber\\ & = \mathbb{E} \left( \frac{ \hat X_{n,1}}{n} \right) \frac{m}{\ln m} \le \frac{mM}{n \ln m}. \end{align}
\begin{align} \mathbb{P} (|Z_1| > \ln m) & \le \frac{\mathbb{E} (|Z_1|)}{\ln m} = \mathbb{P} (1 \in V(\hat G_{n,1})) \frac{m}{\ln m} \nonumber\\ & = \mathbb{E} \left( \frac{ \hat X_{n,1}}{n} \right) \frac{m}{\ln m} \le \frac{mM}{n \ln m}. \end{align}Define the events
 $${\hat {\mathcal{T}}}_{1,2}= \{{\hat d}_1=s\} \cap \{{\hat d}_2=t \} \quad \text{and} \quad {\mathcal{E}}=\{Z_1 \cap Z_2 \neq \emptyset \}.$$
$${\hat {\mathcal{T}}}_{1,2}= \{{\hat d}_1=s\} \cap \{{\hat d}_2=t \} \quad \text{and} \quad {\mathcal{E}}=\{Z_1 \cap Z_2 \neq \emptyset \}.$$For  $z_1 = 1, \ldots , m$ we obtain
$z_1 = 1, \ldots , m$ we obtain
 \begin{align*} \mathbb{P} ({\mathcal{E}} \, \vert \, |Z_1| = z_1) & = \mathbb{P} \left(2 \in \left.\bigcup_{k \in Z_1} V(\hat G_{n,k}) \, \right| \, |Z_1| = z_1\right)\\ & \le z_1 \mathbb{P} (2 \in V(\hat G_{n,1}) \, \vert \, 1 \in V(\hat G_{n,1})) \\ & = z_1 \mathbb{E} \left( \binom{n-2}{ \hat X_{n,1} - 2} \binom{n-1}{\hat X_{n,1} - 1}^{{-}1} \right) \\ & = z_1 \mathbb{E} \left(\frac{ \hat X_{n,1} -1}{n-1}\right) < \frac{z_1 M}{n-1}, \end{align*}
\begin{align*} \mathbb{P} ({\mathcal{E}} \, \vert \, |Z_1| = z_1) & = \mathbb{P} \left(2 \in \left.\bigcup_{k \in Z_1} V(\hat G_{n,k}) \, \right| \, |Z_1| = z_1\right)\\ & \le z_1 \mathbb{P} (2 \in V(\hat G_{n,1}) \, \vert \, 1 \in V(\hat G_{n,1})) \\ & = z_1 \mathbb{E} \left( \binom{n-2}{ \hat X_{n,1} - 2} \binom{n-1}{\hat X_{n,1} - 1}^{{-}1} \right) \\ & = z_1 \mathbb{E} \left(\frac{ \hat X_{n,1} -1}{n-1}\right) < \frac{z_1 M}{n-1}, \end{align*}thus,
 \begin{align} \mathbb{P} ({\mathcal{E}}, \; |Z_1| \leq \ln m ) & \le \mathbb{P} ({\mathcal{E}} \, \vert \, |Z_1| \leq \ln m ) \nonumber\\ & \le \mathbb{P} (Z_1 \cap Z_2 \neq \emptyset \, \vert \, |Z_1| = \lfloor \ln m \rfloor) \nonumber\\ & \le \frac{M \ln m}{n-1}. \end{align}
\begin{align} \mathbb{P} ({\mathcal{E}}, \; |Z_1| \leq \ln m ) & \le \mathbb{P} ({\mathcal{E}} \, \vert \, |Z_1| \leq \ln m ) \nonumber\\ & \le \mathbb{P} (Z_1 \cap Z_2 \neq \emptyset \, \vert \, |Z_1| = \lfloor \ln m \rfloor) \nonumber\\ & \le \frac{M \ln m}{n-1}. \end{align}Since
 \begin{align*} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}) & = \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) + \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}, \; |Z_1| \leq \ln m)\\ & \quad + \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; |Z_1| > \ln m), \end{align*}
\begin{align*} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}) & = \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) + \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}, \; |Z_1| \leq \ln m)\\ & \quad + \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; |Z_1| > \ln m), \end{align*}it follows from (13) and (14) that
 \begin{equation} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}) = \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) + o(1). \end{equation}
\begin{equation} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}) = \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) + o(1). \end{equation}The latter probability is split into mutually exclusive events as
 \begin{equation} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) = \sum_{|A_1| \leq \left\lfloor {\ln m} \right\rfloor }\mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; Z_1 = A_1). \end{equation}
\begin{equation} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) = \sum_{|A_1| \leq \left\lfloor {\ln m} \right\rfloor }\mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; Z_1 = A_1). \end{equation}We now express  $\mathbb {P} ({\hat {\mathcal {T}}}_{1,2}, \; {\mathcal {E}}^{c}, \; Z_1 = A_1)$ as a product of two independent events. For a set
$\mathbb {P} ({\hat {\mathcal {T}}}_{1,2}, \; {\mathcal {E}}^{c}, \; Z_1 = A_1)$ as a product of two independent events. For a set  $A \subset [m]$, denote by
$A \subset [m]$, denote by  $G_{A}$ the superposition of
$G_{A}$ the superposition of  $\{\hat G_{n,k}: k \in A \}$. Observe that on the event
$\{\hat G_{n,k}: k \in A \}$. Observe that on the event  ${\mathcal {E}}^{c} \cap \{Z_1 = A_1 \}$ the degree of node 2 is determined by
${\mathcal {E}}^{c} \cap \{Z_1 = A_1 \}$ the degree of node 2 is determined by  $G_{A_1^{c}}$, and that the event
$G_{A_1^{c}}$, and that the event  $\{Z_1 = A_1 \}$ equals
$\{Z_1 = A_1 \}$ equals  $\{Z_1 \subset A_1\} \cap \{Z_1 \supset A_1 \}$. With these observations in mind, we rewrite the probability
$\{Z_1 \subset A_1\} \cap \{Z_1 \supset A_1 \}$. With these observations in mind, we rewrite the probability  $\mathbb {P} ({\hat {\mathcal {T}}}_{1,2}, \; {\mathcal {E}}^{c}, \; Z_1 = A_1)$ as
$\mathbb {P} ({\hat {\mathcal {T}}}_{1,2}, \; {\mathcal {E}}^{c}, \; Z_1 = A_1)$ as
 $$\mathbb{P} ( d_{G_{A_1}}(1) = s, \; d_{G_{A_1^{c}}}(2) = t, \; Z_2 \cap A_1 = \emptyset, \; Z_1 \subset A_1, \; Z_1 \supset A_1),$$
$$\mathbb{P} ( d_{G_{A_1}}(1) = s, \; d_{G_{A_1^{c}}}(2) = t, \; Z_2 \cap A_1 = \emptyset, \; Z_1 \subset A_1, \; Z_1 \supset A_1),$$where  $d_G(i) := \deg _G(i)$. The event
$d_G(i) := \deg _G(i)$. The event  $\{ d_{G_{A_1}}(1) = s \} \cap \{ Z_2 \cap A_1 = \emptyset \} \cap \{Z_1 \supset A_1 \}$ only depends on the layers
$\{ d_{G_{A_1}}(1) = s \} \cap \{ Z_2 \cap A_1 = \emptyset \} \cap \{Z_1 \supset A_1 \}$ only depends on the layers  $A_1$, and the event
$A_1$, and the event  $\{ d_{G_{A_1^{c}}}(2) = t \} \cap \{ Z_1 \subset A_1 \}$ only depends on the layers
$\{ d_{G_{A_1^{c}}}(2) = t \} \cap \{ Z_1 \subset A_1 \}$ only depends on the layers  $A_1^{c}$, so that the probability above equals
$A_1^{c}$, so that the probability above equals
 \begin{equation} \mathbb{P} ( d_{G_{A_1}}(1) = s, Z_2 \cap A_1 = \emptyset, Z_1 \supset A_1) \mathbb{P}( d_{G_{A_1^{c}}}(2) = t \,|\, Z_1 \subset A_1) \mathbb{P}(Z_1 \subset A_1). \end{equation}
\begin{equation} \mathbb{P} ( d_{G_{A_1}}(1) = s, Z_2 \cap A_1 = \emptyset, Z_1 \supset A_1) \mathbb{P}( d_{G_{A_1^{c}}}(2) = t \,|\, Z_1 \subset A_1) \mathbb{P}(Z_1 \subset A_1). \end{equation}We now employ a coupling argument to approximate the probability  $\mathbb {P}( d_{G_{A_1^{c}}}(2) = t \,|\, Z_1 \subset A_1)$. Introduce a random graph
$\mathbb {P}( d_{G_{A_1^{c}}}(2) = t \,|\, Z_1 \subset A_1)$. Introduce a random graph  $G^{*}$, which is a superposition of
$G^{*}$, which is a superposition of  $m$ i.i.d. layers
$m$ i.i.d. layers  $G^{*}_{n,k}$ with sizes and strengths
$G^{*}_{n,k}$ with sizes and strengths  $(X^{*}_{n,k}, Y^{*}_{n,k})$ following the distribution
$(X^{*}_{n,k}, Y^{*}_{n,k})$ following the distribution
 $$\mathbb{P}(X_{n,k}^{*} = x, Y_{n,k}^{*} \leq y) = \mathbb{P}(\hat X_{n,k} = x, \hat Y_{n,k} \leq y \, | \, 1 \not\in V(\hat G_{n,k})), \quad k=1,\ldots, m.$$
$$\mathbb{P}(X_{n,k}^{*} = x, Y_{n,k}^{*} \leq y) = \mathbb{P}(\hat X_{n,k} = x, \hat Y_{n,k} \leq y \, | \, 1 \not\in V(\hat G_{n,k})), \quad k=1,\ldots, m.$$The nodes of the layers,  $V(G^{*}_{n,k})$, are then chosen uniformly at random from the node set
$V(G^{*}_{n,k})$, are then chosen uniformly at random from the node set  $\{2, \ldots , n \}$, and the edges are generated independently with probabilities
$\{2, \ldots , n \}$, and the edges are generated independently with probabilities  $Y^{*}_{n,k}$. Define
$Y^{*}_{n,k}$. Define  $G^{*}_{A_1^{c}} = \{[n] \setminus \{1\}, \bigcup _{k\in A_1^{c}} E(G^{*}_{n,k})\}$. We approximate
$G^{*}_{A_1^{c}} = \{[n] \setminus \{1\}, \bigcup _{k\in A_1^{c}} E(G^{*}_{n,k})\}$. We approximate  $d_{G^{*}_{A_1^{c}}}(2)$ by
$d_{G^{*}_{A_1^{c}}}(2)$ by  $d_{G^{*}}(2)$ as follows. The union bound gives
$d_{G^{*}}(2)$ as follows. The union bound gives
 \begin{align*} \mathbb{P} (d_{G^{*}_{A_1^{c}}}(2) \neq d_{G^{*}}(2) ) & \leq \mathbb{P} \left( 2 \in \bigcup_{k \in A_1} V(G^{*}_{n,k}) \right) \\ & \leq (\ln m)\mathbb{P}( 2 \in V(G^{*}_{n,1})) \\ & \leq \frac{M \ln m }{n-1}, \end{align*}
\begin{align*} \mathbb{P} (d_{G^{*}_{A_1^{c}}}(2) \neq d_{G^{*}}(2) ) & \leq \mathbb{P} \left( 2 \in \bigcup_{k \in A_1} V(G^{*}_{n,k}) \right) \\ & \leq (\ln m)\mathbb{P}( 2 \in V(G^{*}_{n,1})) \\ & \leq \frac{M \ln m }{n-1}, \end{align*}and so,
 $$| \mathbb{P} (d_{G^{*}_{A_1^{c}}}(2) = r) - \mathbb{P}( d_{G^{*}}(2) = r) | \leq \frac{M \ln m }{n-1}, \quad \forall r=0,1,\ldots,$$
$$| \mathbb{P} (d_{G^{*}_{A_1^{c}}}(2) = r) - \mathbb{P}( d_{G^{*}}(2) = r) | \leq \frac{M \ln m }{n-1}, \quad \forall r=0,1,\ldots,$$which is  $o(1)$ as
$o(1)$ as  $n \to \infty$.
$n \to \infty$.
By construction, for  $k \in A_1^{c}$ the distribution of
$k \in A_1^{c}$ the distribution of  $G^{*}_{n,k}$ equals the conditional distribution of
$G^{*}_{n,k}$ equals the conditional distribution of  $\hat G_{n,k}$, given the event
$\hat G_{n,k}$, given the event  $\{Z_1 \subset A_1\}$. Thus,
$\{Z_1 \subset A_1\}$. Thus,  $\mathbb {P}( d_{G_{A_1^{c}}}(2) = t \,|\, Z_1 \subset A_1) = \mathbb {P} (d_{G^{*}_{A_1^{c}}}(2) = t)$, and the previous inequality gives
$\mathbb {P}( d_{G_{A_1^{c}}}(2) = t \,|\, Z_1 \subset A_1) = \mathbb {P} (d_{G^{*}_{A_1^{c}}}(2) = t)$, and the previous inequality gives
 $$\mathbb{P}( d_{G_{A_1^{c}}}(2) = t \,| \,Z_1 \subset A_1) = \mathbb{P}( d_{G^{*}}(2) = t) + o(1).$$
$$\mathbb{P}( d_{G_{A_1^{c}}}(2) = t \,| \,Z_1 \subset A_1) = \mathbb{P}( d_{G^{*}}(2) = t) + o(1).$$We insert this into (17), which together with (16) gives
 \begin{align*} & \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) \\ & \quad = \left(\mathbb{P}( d_{G^{*}}(2) = t) \sum_{|A_1| \leq \left\lfloor {\ln m} \right\rfloor } \mathbb{P} ( d_{G_{A_1}}(1) = s, Z_2 \cap A_1 = \emptyset, Z_1 = A_1)\right) + o(1), \end{align*}
\begin{align*} & \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}, \; {\mathcal{E}}^{c}, \; |Z_1| \leq \ln m) \\ & \quad = \left(\mathbb{P}( d_{G^{*}}(2) = t) \sum_{|A_1| \leq \left\lfloor {\ln m} \right\rfloor } \mathbb{P} ( d_{G_{A_1}}(1) = s, Z_2 \cap A_1 = \emptyset, Z_1 = A_1)\right) + o(1), \end{align*}where we have used the fact that the events  $\{ d_{G_{A_1}}(1) = s, Z_2 \cap A_1 = \emptyset , Z_1 \supset A_1\}$ and
$\{ d_{G_{A_1}}(1) = s, Z_2 \cap A_1 = \emptyset , Z_1 \supset A_1\}$ and  $\{Z_1 \subset A_1\}$ are independent. By using the mutual exclusivity of the events
$\{Z_1 \subset A_1\}$ are independent. By using the mutual exclusivity of the events  $\{Z_1 = A_1\}$ and the fact that
$\{Z_1 = A_1\}$ and the fact that  $d_{G_{A_1}}(1) = \hat d_1$ when
$d_{G_{A_1}}(1) = \hat d_1$ when  $Z_1=A_1$, the above expression simplifies to
$Z_1=A_1$, the above expression simplifies to
 \begin{equation} \mathbb{P}( d_{G^{*}}(2) = t) \mathbb{P} ( \hat d_1 = s, \; Z_2 \cap Z_1 = \emptyset, \; |Z_1| \leq \ln m) + o(1). \end{equation}
\begin{equation} \mathbb{P}( d_{G^{*}}(2) = t) \mathbb{P} ( \hat d_1 = s, \; Z_2 \cap Z_1 = \emptyset, \; |Z_1| \leq \ln m) + o(1). \end{equation}Returning back to (15), this yields
 \begin{align*} \mathbb{P}({\hat {\mathcal{T}}}_{1,2}) & = \mathbb{P}({\hat {\mathcal{T}}}_{1,2}, \mathcal{E}^{c}, |Z_1| \leq \ln m) + o(1) \\ & = \mathbb{P}( d_{G^{*}}(2) = t) \mathbb{P} ( \hat d_1 = s, \; Z_2 \cap Z_1 = \emptyset, \; |Z_1| \leq \ln m) + o(1) \\ & = \mathbb{P}( d_{G^{*}}(2) = t) \mathbb{P} ( \hat d_1 = s) + o(1). \end{align*}
\begin{align*} \mathbb{P}({\hat {\mathcal{T}}}_{1,2}) & = \mathbb{P}({\hat {\mathcal{T}}}_{1,2}, \mathcal{E}^{c}, |Z_1| \leq \ln m) + o(1) \\ & = \mathbb{P}( d_{G^{*}}(2) = t) \mathbb{P} ( \hat d_1 = s, \; Z_2 \cap Z_1 = \emptyset, \; |Z_1| \leq \ln m) + o(1) \\ & = \mathbb{P}( d_{G^{*}}(2) = t) \mathbb{P} ( \hat d_1 = s) + o(1). \end{align*}In the last step, we used (13) and (14).
We complete the proof by showing that  $\mathbb {P}(d_{G^{*}}(2) = t)- \mathbb {P} ( {\hat d}_2 = t)=o(1)$. To this aim, we employ Theorem 5. Set
$\mathbb {P}(d_{G^{*}}(2) = t)- \mathbb {P} ( {\hat d}_2 = t)=o(1)$. To this aim, we employ Theorem 5. Set  $({\hat X}, {\hat Y}) = (X{\mathbb {I}}(X\le M), Y{\mathbb {I}}(X\le M))$, where
$({\hat X}, {\hat Y}) = (X{\mathbb {I}}(X\le M), Y{\mathbb {I}}(X\le M))$, where  $(X,Y) \sim P$. Note that
$(X,Y) \sim P$. Note that  $(X^{*}_1, Y^{*}_1)$ converges in distribution and in
$(X^{*}_1, Y^{*}_1)$ converges in distribution and in  ${\mathcal {L}}_1$ to
${\mathcal {L}}_1$ to  $(\hat X, \hat Y)$: indeed,
$(\hat X, \hat Y)$: indeed,
 \begin{align*} \mathbb{P}(X^{*}_{n,1} = x, Y^{*}_{n,1} \leq y) & = \mathbb{P}(\hat X_{n,1} = x, \hat Y_{n,1} \leq y \, | \, 1 \not\in (\hat G_{n,1}))\\ & = \frac{\mathbb{P}(1 \not\in V(\hat G_{n,1}) \,|\, \hat X_{n,1} = x, \hat Y_{n,1} \leq y ) \mathbb{P} ( \hat X_{n,1} = x, \hat Y_{n,1} \leq y)}{\mathbb{P}(1 \not\in V(\hat G_{n,1}) )}\\ & = \frac{\binom{n-1}{x}\binom{n}{x}^{{-}1} \mathbb{P} ( \hat X_{n,1} = x, \hat Y_{n,1} \leq y)}{\mathbb{E} ( \binom{n-1}{\hat X_{n,1}} \binom{n}{\hat X_{n,1}}^{{-}1} )}\\ & = \frac{1- n^{{-}1} x}{1- n^{{-}1} \mathbb{E} (\hat X_{n,1}) } \mathbb{P} ( \hat X_{n,1} = x, \hat Y_{n,1} \leq y) \\ & \to \mathbb{P}(\hat X = x, \hat Y \leq y). \end{align*}
\begin{align*} \mathbb{P}(X^{*}_{n,1} = x, Y^{*}_{n,1} \leq y) & = \mathbb{P}(\hat X_{n,1} = x, \hat Y_{n,1} \leq y \, | \, 1 \not\in (\hat G_{n,1}))\\ & = \frac{\mathbb{P}(1 \not\in V(\hat G_{n,1}) \,|\, \hat X_{n,1} = x, \hat Y_{n,1} \leq y ) \mathbb{P} ( \hat X_{n,1} = x, \hat Y_{n,1} \leq y)}{\mathbb{P}(1 \not\in V(\hat G_{n,1}) )}\\ & = \frac{\binom{n-1}{x}\binom{n}{x}^{{-}1} \mathbb{P} ( \hat X_{n,1} = x, \hat Y_{n,1} \leq y)}{\mathbb{E} ( \binom{n-1}{\hat X_{n,1}} \binom{n}{\hat X_{n,1}}^{{-}1} )}\\ & = \frac{1- n^{{-}1} x}{1- n^{{-}1} \mathbb{E} (\hat X_{n,1}) } \mathbb{P} ( \hat X_{n,1} = x, \hat Y_{n,1} \leq y) \\ & \to \mathbb{P}(\hat X = x, \hat Y \leq y). \end{align*}Thus, by Theorem 5,  $d_{G^{*}}(2)$ converges to the same distribution as
$d_{G^{*}}(2)$ converges to the same distribution as  $\hat d_2$, and so
$\hat d_2$, and so
 \begin{equation} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}) = \mathbb{P}( \hat d_1 = s)\mathbb{P} ( \hat d_2 = t) + o(1). \end{equation}
\begin{equation} \mathbb{P} ({\hat {\mathcal{T}}}_{1,2}) = \mathbb{P}( \hat d_1 = s)\mathbb{P} ( \hat d_2 = t) + o(1). \end{equation}Lemma 3 (M to infinity) Assume (i) and (ii) of Theorem 5, and that  $m/n \to \mu$. Define
$m/n \to \mu$. Define  $\hat d_1, \hat d_2$ as in Lemma 2. Denote
$\hat d_1, \hat d_2$ as in Lemma 2. Denote  $D_i = D_{n,i} = \deg _{G_n}(i)$. As
$D_i = D_{n,i} = \deg _{G_n}(i)$. As  $M \rightarrow \infty$,
$M \rightarrow \infty$,
 \begin{equation} \sup_n | \mathbb{P} (D_1 = s, D_2 = t) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t)| \rightarrow 0, \end{equation}
\begin{equation} \sup_n | \mathbb{P} (D_1 = s, D_2 = t) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t)| \rightarrow 0, \end{equation}and especially, as  $n \rightarrow \infty$,
$n \rightarrow \infty$,
 \begin{equation} \mathbb{P} (D_1 = s, D_2 = t) - \mathbb{P}(D_1=s)\mathbb{P}(D_2=t)\rightarrow 0. \end{equation}
\begin{equation} \mathbb{P} (D_1 = s, D_2 = t) - \mathbb{P}(D_1=s)\mathbb{P}(D_2=t)\rightarrow 0. \end{equation}Proof. From the assumptions, it follows that  $X_{n,1}$,
$X_{n,1}$,  $n=1,\ldots$ are uniformly integrable, hence
$n=1,\ldots$ are uniformly integrable, hence
 \begin{equation} \lim_{M\to+\infty} \sup_n \mathbb{E} (X_{n,1} \mathbb{I} (X_{n,1}>M) )=0. \end{equation}
\begin{equation} \lim_{M\to+\infty} \sup_n \mathbb{E} (X_{n,1} \mathbb{I} (X_{n,1}>M) )=0. \end{equation}Denote  ${\mathcal {T}}_{1,2} = \{D_1 = s, D_2 = t\}$. We approximate the probability of this event by the corresponding probability in the truncated model:
${\mathcal {T}}_{1,2} = \{D_1 = s, D_2 = t\}$. We approximate the probability of this event by the corresponding probability in the truncated model:
 \begin{equation} | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | \le \mathbb{P} (D_1 \neq \hat d_1) + \mathbb{P} (D_2 \neq \hat d_2). \end{equation}
\begin{equation} | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | \le \mathbb{P} (D_1 \neq \hat d_1) + \mathbb{P} (D_2 \neq \hat d_2). \end{equation}The event  $\{ D_1 \neq \hat d_1\}$ occurs when removing the layers larger than
$\{ D_1 \neq \hat d_1\}$ occurs when removing the layers larger than  $M$ also removes an edge between node 1 and another node. Since this can only happen if there exists a layer
$M$ also removes an edge between node 1 and another node. Since this can only happen if there exists a layer  $i$ such that
$i$ such that  $1 \in V(G_{n,i})$ and
$1 \in V(G_{n,i})$ and  $X_{n,i} > M$, the union bound gives
$X_{n,i} > M$, the union bound gives
 \begin{align*} \mathbb{P} (D_1 \neq \hat d_1) & \le \mathbb{P} \left( \bigcup_{i=1}^{m} \{1 \in V(G_{n,i}), X_{n,i} > M \} \right) \\ & \le \sum_{i=1}^{m} \mathbb{P} (1 \in V(G_{n,i}), X_{n,i} > M), \end{align*}
\begin{align*} \mathbb{P} (D_1 \neq \hat d_1) & \le \mathbb{P} \left( \bigcup_{i=1}^{m} \{1 \in V(G_{n,i}), X_{n,i} > M \} \right) \\ & \le \sum_{i=1}^{m} \mathbb{P} (1 \in V(G_{n,i}), X_{n,i} > M), \end{align*}and by the law of total probability
 \begin{align*} \mathbb{P} (1 \in V(G_{n,i}), X_{n,i} > M ) & = \mathbb{E} (\mathbb{P} (1 \in V(G_{n,i}), X_{n,i} > M \,| \, X_{n,i} )) \\ & = \mathbb{E} (\mathbb{P} (1 \in V(G_{n,i}) \,|\, X_{n,i}) \, \mathbb{I} (X_{n,i}>M) ) \\ & = \mathbb{E} \left( \frac{X_{n,i}}{n} \mathbb{I} (X_{n,i}>M) \right). \end{align*}
\begin{align*} \mathbb{P} (1 \in V(G_{n,i}), X_{n,i} > M ) & = \mathbb{E} (\mathbb{P} (1 \in V(G_{n,i}), X_{n,i} > M \,| \, X_{n,i} )) \\ & = \mathbb{E} (\mathbb{P} (1 \in V(G_{n,i}) \,|\, X_{n,i}) \, \mathbb{I} (X_{n,i}>M) ) \\ & = \mathbb{E} \left( \frac{X_{n,i}}{n} \mathbb{I} (X_{n,i}>M) \right). \end{align*}Putting this back to (23) gives
 $$| \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | \le 2 \frac{m}{n} \mathbb{E} ( X_{n,1} \mathbb{I} ( X_{n,1} > M)).$$
$$| \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | \le 2 \frac{m}{n} \mathbb{E} ( X_{n,1} \mathbb{I} ( X_{n,1} > M)).$$We similarly obtain
 \begin{equation} \sup_{k\geq 0} | \mathbb{P} (D_1 = k) - \mathbb{P} (\hat d_1 = k) | \le \mathbb{P}(D_1 \neq \hat d_1) \le \frac{m}{n} \mathbb{E} ( X_{n,1} \mathbb{I}(X_{n,1} > M) ). \end{equation}
\begin{equation} \sup_{k\geq 0} | \mathbb{P} (D_1 = k) - \mathbb{P} (\hat d_1 = k) | \le \mathbb{P}(D_1 \neq \hat d_1) \le \frac{m}{n} \mathbb{E} ( X_{n,1} \mathbb{I}(X_{n,1} > M) ). \end{equation}It follows from (22) and the boundedness of  $m/n$ that for any
$m/n$ that for any  $\varepsilon >0$ there exists
$\varepsilon >0$ there exists  $M_\varepsilon$ such that
$M_\varepsilon$ such that  $\forall M > M_\varepsilon$
$\forall M > M_\varepsilon$
 \begin{equation} \begin{aligned} | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | & \le \varepsilon, \quad \forall s,t \geq 0,\\ | \mathbb{P} (D_1 = k) - \mathbb{P} (\hat d_1 = k) | & \le \varepsilon, \quad \forall k \geq 0. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | & \le \varepsilon, \quad \forall s,t \geq 0,\\ | \mathbb{P} (D_1 = k) - \mathbb{P} (\hat d_1 = k) | & \le \varepsilon, \quad \forall k \geq 0. \end{aligned} \end{equation}Finally, we write
 \begin{align*} | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s) \mathbb{P}(\hat d_2 = t) | & \le | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | \\ & \quad + | \mathbb{P} (\hat d_1 = s, \hat d_2 = t) -\mathbb{P} (\hat d_1 = s) \mathbb{P}(\hat d_2 = t) |. \end{align*}
\begin{align*} | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s) \mathbb{P}(\hat d_2 = t) | & \le | \mathbb{P} ({\mathcal{T}}_{1,2}) - \mathbb{P} (\hat d_1 = s, \hat d_2 = t) | \\ & \quad + | \mathbb{P} (\hat d_1 = s, \hat d_2 = t) -\mathbb{P} (\hat d_1 = s) \mathbb{P}(\hat d_2 = t) |. \end{align*}The first term on the right-hand side is at most  $2\varepsilon$ by the above calculation, and the second term is
$2\varepsilon$ by the above calculation, and the second term is  $o(1)$ by Lemma 2. Hence (20) follows. Claim (21) follows from (20), (25).
$o(1)$ by Lemma 2. Hence (20) follows. Claim (21) follows from (20), (25).
We now introduce some notation. Recall that the bidegree distribution of  $G_n$ is given by
$G_n$ is given by
 $$f_{2,n}(s,t) = \mathbb{P}( \deg_{G_n}(1) = s, \deg_{G_n}(2) = t \,| \, \{1,2\} \in E(G_n) ).$$
$$f_{2,n}(s,t) = \mathbb{P}( \deg_{G_n}(1) = s, \deg_{G_n}(2) = t \,| \, \{1,2\} \in E(G_n) ).$$For  $A \subset [m]$, denote by
$A \subset [m]$, denote by  $G_{n,A}$ the graph with
$G_{n,A}$ the graph with  $V(G_{n,A}) = [n]$ and
$V(G_{n,A}) = [n]$ and  $E(G_{n,A}) = \bigcup _{k \in A} E(G_{n,k})$. Denote
$E(G_{n,A}) = \bigcup _{k \in A} E(G_{n,k})$. Denote  $D_i =\deg _{G_n}(i)$. We note that for any
$D_i =\deg _{G_n}(i)$. We note that for any  $k$,
$k$,
 $$D_i= D_{i,k} + \tilde D_{i,k} - \hat D_{i,k},$$
$$D_i= D_{i,k} + \tilde D_{i,k} - \hat D_{i,k},$$where  $D_{i,k}$ and
$D_{i,k}$ and  $\tilde D_{i,k}$ are the degrees produced by layer
$\tilde D_{i,k}$ are the degrees produced by layer  $k$ and by the layers other than
$k$ and by the layers other than  $k$, i.e.,
$k$, i.e.,
 $$D_{i,k} = \deg_{G_{n,k}}(i), \quad \tilde D_{i,k} = \deg_{G_{n, [m]\setminus \{k\}}}(i).$$
$$D_{i,k} = \deg_{G_{n,k}}(i), \quad \tilde D_{i,k} = \deg_{G_{n, [m]\setminus \{k\}}}(i).$$Furthermore,  $\hat D_{i,k}$ stands for the number of neighbors produced by the layer
$\hat D_{i,k}$ stands for the number of neighbors produced by the layer  $k$ and at least one other layer,
$k$ and at least one other layer,
 $$\hat D_{i,k} = \deg_{G_{n,k} \cap G_{n, [m]\setminus \{k\}}}(i).$$
$$\hat D_{i,k} = \deg_{G_{n,k} \cap G_{n, [m]\setminus \{k\}}}(i).$$Denote the event  $\mathcal {E}_k = \{ \{1,2 \} \in E(G_{n,k})\}$ and
$\mathcal {E}_k = \{ \{1,2 \} \in E(G_{n,k})\}$ and
 \begin{align*} f_n(s) & = \mathbb{P}(D_i = s), \\ \tilde f_{2,n}(s,t) & = \mathbb{P}( \tilde D_{1,k} =s, \tilde D_{2,k} = t), \\ f'_{2,n}(s,t) & = \mathbb{P}( D_{1,k} =s, D_{2,k} = t \, | \, \mathcal{E}_k ). \end{align*}
\begin{align*} f_n(s) & = \mathbb{P}(D_i = s), \\ \tilde f_{2,n}(s,t) & = \mathbb{P}( \tilde D_{1,k} =s, \tilde D_{2,k} = t), \\ f'_{2,n}(s,t) & = \mathbb{P}( D_{1,k} =s, D_{2,k} = t \, | \, \mathcal{E}_k ). \end{align*}Throughout the proof of Theorem 1(i) , we write  $X_i = X_{n,i}$ and
$X_i = X_{n,i}$ and  $Y_i = Y_{n,i}$.
$Y_i = Y_{n,i}$.
We summarize the proof strategy as follows. We show that the probability of the event
 $$\mathcal{E}_k \cap (\{\hat D_{1,k} > 0 \} \cup \{ \hat D_{2,k} > 0\})$$
$$\mathcal{E}_k \cap (\{\hat D_{1,k} > 0 \} \cup \{ \hat D_{2,k} > 0\})$$is negligible (Eq. (29)). Furthermore, for every  $k=1,\ldots , m$, on the event
$k=1,\ldots , m$, on the event  $\mathcal {E}_k$, we have
$\mathcal {E}_k$, we have  $D_1 \approx D_{1,k} + \tilde D_{1,k}$ and
$D_1 \approx D_{1,k} + \tilde D_{1,k}$ and  $D_2 \approx D_{2,k} + \tilde D_{2,k}$ for large
$D_2 \approx D_{2,k} + \tilde D_{2,k}$ for large  $n$. This together with Theorem 5 and Lemma 3 allows us to approximate
$n$. This together with Theorem 5 and Lemma 3 allows us to approximate  $f_{2,n} \approx (f_n \otimes f_n) \ast f'_{2,n}$ (Eqs. (30) and (31)). In the last part of the proof, we verify that
$f_{2,n} \approx (f_n \otimes f_n) \ast f'_{2,n}$ (Eqs. (30) and (31)). In the last part of the proof, we verify that  $f'_{2,n}(s,t) \approx f_2'(s-1,t-1)$, which together with the previous approximation and
$f'_{2,n}(s,t) \approx f_2'(s-1,t-1)$, which together with the previous approximation and  $f_n \otimes f_n \approx \bar f_1 \otimes \bar f_1$ gives the result,
$f_n \otimes f_n \approx \bar f_1 \otimes \bar f_1$ gives the result,  $f_{2,n} \approx \delta _{(1,1)} \ast (\bar f_1 \otimes \bar f_1) \ast f_2'$.
$f_{2,n} \approx \delta _{(1,1)} \ast (\bar f_1 \otimes \bar f_1) \ast f_2'$.
Proof of Theorem 1(i). First note that  $\mathbb {P}( \{1,2\} \in E(G_n)) = \mathbb {P}(\bigcup _{k=1}^{m} \mathcal {E}_k)$ and
$\mathbb {P}( \{1,2\} \in E(G_n)) = \mathbb {P}(\bigcup _{k=1}^{m} \mathcal {E}_k)$ and
 $$\sum_{k=1}^{m} \mathbb{P} (\mathcal{E}_k) - \sum_{k< l} \mathbb{P} (\mathcal{E}_k \cap \mathcal{E}_l) \le \mathbb{P} \left(\bigcup_{k=1}^{m} \mathcal{E}_k\right) \le \sum_{k=1}^{m} \mathbb{P} (\mathcal{E}_k),$$
$$\sum_{k=1}^{m} \mathbb{P} (\mathcal{E}_k) - \sum_{k< l} \mathbb{P} (\mathcal{E}_k \cap \mathcal{E}_l) \le \mathbb{P} \left(\bigcup_{k=1}^{m} \mathcal{E}_k\right) \le \sum_{k=1}^{m} \mathbb{P} (\mathcal{E}_k),$$and since the layers are i.i.d.,
 $$\sum_{k< l} \mathbb{P} (\mathcal{E}_k \cap \mathcal{E}_l) = \frac{1}{2}(m)_2 (P_{21}^{(n)} (n)_2^{{-}1})^{2},$$
$$\sum_{k< l} \mathbb{P} (\mathcal{E}_k \cap \mathcal{E}_l) = \frac{1}{2}(m)_2 (P_{21}^{(n)} (n)_2^{{-}1})^{2},$$and so
 \begin{equation} \mathbb{P}( \{1,2 \} \in E(G_n)) = \mathbb{P} \left(\bigcup_{k=1}^{m} \mathcal{E}_k\right) = \sum_{k=1}^{m} \mathbb{P} (\mathcal{E}_k) + O(n^{{-}2}) = m\mathbb{P}(\mathcal{E}_1) + O(n^{{-}2}), \end{equation}
\begin{equation} \mathbb{P}( \{1,2 \} \in E(G_n)) = \mathbb{P} \left(\bigcup_{k=1}^{m} \mathcal{E}_k\right) = \sum_{k=1}^{m} \mathbb{P} (\mathcal{E}_k) + O(n^{{-}2}) = m\mathbb{P}(\mathcal{E}_1) + O(n^{{-}2}), \end{equation}where we used the fact that  $m/n$ is bounded. We similarly approximate
$m/n$ is bounded. We similarly approximate
 \begin{align} & f_{2,n}(s,t) \, \mathbb{P}( \{1,2\} \in E(G_n) ) \nonumber\\ & \quad = \mathbb{P}\left(D_1=s, D_2=t, \bigcup_k \mathcal{E}_k \right) \nonumber\\ & \quad = m \mathbb{P}( D_1=s, D_2=t, \mathcal{E}_1 ) + O(n^{{-}2}) \nonumber\\ & \quad = m \mathbb{P}( D_{1,1} + \tilde D_{1,1} - \hat D_{1,1}=s, \, D_{2,1} + \tilde D_{2,1} - \hat D_{2,1}=t, \, \mathcal{E}_1) + O(n^{{-}2}). \end{align}
\begin{align} & f_{2,n}(s,t) \, \mathbb{P}( \{1,2\} \in E(G_n) ) \nonumber\\ & \quad = \mathbb{P}\left(D_1=s, D_2=t, \bigcup_k \mathcal{E}_k \right) \nonumber\\ & \quad = m \mathbb{P}( D_1=s, D_2=t, \mathcal{E}_1 ) + O(n^{{-}2}) \nonumber\\ & \quad = m \mathbb{P}( D_{1,1} + \tilde D_{1,1} - \hat D_{1,1}=s, \, D_{2,1} + \tilde D_{2,1} - \hat D_{2,1}=t, \, \mathcal{E}_1) + O(n^{{-}2}). \end{align} Next, we show that on the event  $\mathcal {E}_1$ the probability that
$\mathcal {E}_1$ the probability that  $\hat D_{1,1}>0$ or
$\hat D_{1,1}>0$ or  $\hat D_{2,1}>0$ is negligible. Recall that
$\hat D_{2,1}>0$ is negligible. Recall that  $X_1$ and
$X_1$ and  $Y_1$ denote the size and strength of layer 1. The union bound gives
$Y_1$ denote the size and strength of layer 1. The union bound gives
 \begin{align*} & \mathbb{P}(\mathcal{E}_1 \cap (\{\hat D_{1,1} > 0 \} \cup \{ \hat D_{2,1} > 0\}) \, | \, V(G_{n,1}), X_1, Y_1) \\ & \quad \le 2 \mathbb{P}(\mathcal{E}_1 \cap \{\hat D_{1,1} > 0 \} \, | \, V(G_{n,1}), X_1, Y_1)\\ & \quad \le 2 \mathbb{P}\left(\mathcal{E}_1 \cap \left.\left( \bigcup_{k=2}^{m} \bigcup_{j \in V(G_{n,1})} \{ \{1,j \} \in E(G_{n,k}) \} \right) \right| V(G_{n,1}), X_1, Y_1\right)\\ & \quad \le 2 \sum_{k=2}^{m} \sum_{j \in V(G_{n,1})} \mathbb{P}(\mathcal{E}_1 \cap \{ \{1,j \} \in E(G_{n,k}) \} \, | \, V(G_{n,1}), X_1, Y_1). \end{align*}
\begin{align*} & \mathbb{P}(\mathcal{E}_1 \cap (\{\hat D_{1,1} > 0 \} \cup \{ \hat D_{2,1} > 0\}) \, | \, V(G_{n,1}), X_1, Y_1) \\ & \quad \le 2 \mathbb{P}(\mathcal{E}_1 \cap \{\hat D_{1,1} > 0 \} \, | \, V(G_{n,1}), X_1, Y_1)\\ & \quad \le 2 \mathbb{P}\left(\mathcal{E}_1 \cap \left.\left( \bigcup_{k=2}^{m} \bigcup_{j \in V(G_{n,1})} \{ \{1,j \} \in E(G_{n,k}) \} \right) \right| V(G_{n,1}), X_1, Y_1\right)\\ & \quad \le 2 \sum_{k=2}^{m} \sum_{j \in V(G_{n,1})} \mathbb{P}(\mathcal{E}_1 \cap \{ \{1,j \} \in E(G_{n,k}) \} \, | \, V(G_{n,1}), X_1, Y_1). \end{align*}Since the layers are i.i.d., this equals
 \begin{align*} & 2(m-1)(X_1-1) \, \mathbb{P}(\mathcal{E}_1 \, | \, V(G_{n,1}), X_1, Y_1) \, \mathbb{P}( \{1,j\} \in E(G_{n,2}) | V(G_{n,1}), X_1, Y_1)\\ & \quad = 2(m-1)(X_1-1) ( \mathbb{I} (\{ 1,2 \} \subset V(G_{n,1}) ) Y_1 ) \, \mathbb{E} \left(\frac{(X_2)_2}{(n)_2} Y_2 \right). \end{align*}
\begin{align*} & 2(m-1)(X_1-1) \, \mathbb{P}(\mathcal{E}_1 \, | \, V(G_{n,1}), X_1, Y_1) \, \mathbb{P}( \{1,j\} \in E(G_{n,2}) | V(G_{n,1}), X_1, Y_1)\\ & \quad = 2(m-1)(X_1-1) ( \mathbb{I} (\{ 1,2 \} \subset V(G_{n,1}) ) Y_1 ) \, \mathbb{E} \left(\frac{(X_2)_2}{(n)_2} Y_2 \right). \end{align*}Taking  $\mathbb {E}(\ldots \,| \, X_1,Y_1)$ of the above gives
$\mathbb {E}(\ldots \,| \, X_1,Y_1)$ of the above gives
 \begin{align} & \mathbb{P}(\mathcal{E}_1 \cap (\{\hat D_{1,1} > 0 \} \cup \{ \hat D_{2,1} > 0\}) \, | \, X_1, Y_1) \nonumber\\ & \quad \le 2(m-1)(X_1-1) Y_1 \frac{(X_1)_2 }{(n)_2} \mathbb{E} \left(\frac{(X_2)_2}{(n)_2} Y_2 \right). \end{align}
\begin{align} & \mathbb{P}(\mathcal{E}_1 \cap (\{\hat D_{1,1} > 0 \} \cup \{ \hat D_{2,1} > 0\}) \, | \, X_1, Y_1) \nonumber\\ & \quad \le 2(m-1)(X_1-1) Y_1 \frac{(X_1)_2 }{(n)_2} \mathbb{E} \left(\frac{(X_2)_2}{(n)_2} Y_2 \right). \end{align}We now use the simple identity
 $$(X_1)_2 Y_1 = (X_1)_2 Y_1 \mathbb{I} ((X_1)_2 Y_1 < n^{1/2}) + (X_1)_2 Y_1 \mathbb{I} ((X_1)_2 Y_1 \geq n^{1/2}).$$
$$(X_1)_2 Y_1 = (X_1)_2 Y_1 \mathbb{I} ((X_1)_2 Y_1 < n^{1/2}) + (X_1)_2 Y_1 \mathbb{I} ((X_1)_2 Y_1 \geq n^{1/2}).$$Together with  $X_1 \leq n$ this yields
$X_1 \leq n$ this yields
 $$(X_1)_2 Y_1 / n \le n^{{-}1/2} + X_1 Y_1 \, \mathbb{I}((X_1)_2 Y_1 \geq n^{1/2}),$$
$$(X_1)_2 Y_1 / n \le n^{{-}1/2} + X_1 Y_1 \, \mathbb{I}((X_1)_2 Y_1 \geq n^{1/2}),$$and it follows that
 $$\mathbb{E}( (X_1-1) Y_1 (X_1)_2 / n ) \le \mathbb{E}( (X_1-1) n^{{-}1/2} ) + \mathbb{E}((X_1)_2 Y_1 \, \mathbb{I}((X_1)_2 Y_1 \geq n^{1/2})).$$
$$\mathbb{E}( (X_1-1) Y_1 (X_1)_2 / n ) \le \mathbb{E}( (X_1-1) n^{{-}1/2} ) + \mathbb{E}((X_1)_2 Y_1 \, \mathbb{I}((X_1)_2 Y_1 \geq n^{1/2})).$$The first term goes to zero by  $P_{10}^{(n)} \to P_{10}$. Since it was assumed that
$P_{10}^{(n)} \to P_{10}$. Since it was assumed that  $P^{(n)}$ converges weakly and
$P^{(n)}$ converges weakly and  $P_{21}^{(n)} \to P_{21}$, it follows that
$P_{21}^{(n)} \to P_{21}$, it follows that  $(X_1)_2 Y_1$ is uniformly integrable, so the second term also goes to zero. Thus,
$(X_1)_2 Y_1$ is uniformly integrable, so the second term also goes to zero. Thus,  $\mathbb {E}( (X_1-1) Y_1 (X_1)_2 / (n)_2 ) = o(n^{-1})$, and so (28) gives
$\mathbb {E}( (X_1-1) Y_1 (X_1)_2 / (n)_2 ) = o(n^{-1})$, and so (28) gives
 \begin{align} \mathbb{P}(\mathcal{E}_1 \cap (\{\hat D_{1,1} > 0 \} \cup \{ \hat D_{2,1} > 0\})) & \le 2(m-1) \mathbb{E} \left (\frac{(X_2)_2}{(n)_2} Y_2 \right)o(n^{{-}1})\nonumber\\ & = o(n^{{-}2}). \end{align}
\begin{align} \mathbb{P}(\mathcal{E}_1 \cap (\{\hat D_{1,1} > 0 \} \cup \{ \hat D_{2,1} > 0\})) & \le 2(m-1) \mathbb{E} \left (\frac{(X_2)_2}{(n)_2} Y_2 \right)o(n^{{-}1})\nonumber\\ & = o(n^{{-}2}). \end{align}Returning to (27), it follows that
 \begin{align} & f_{2,n}(s,t) \, \mathbb{P}( \{1,2\} \in E(G_n) ) \nonumber\\ & \quad = m \mathbb{P}( D_{1,1} + \tilde D_{1,1} =s, \, D_{2,1} + \tilde D_{2,1} = t, \, \mathcal{E}_1) +o(n^{{-}1}) \nonumber\\ & \quad = m \sum_{s_1 \le s} \sum_{t_1 \le t} \tilde f_{2,n}(s_1,t_1) \, \mathbb{P}( D_{1,1} =s-s_1, D_{2,1} = t - t_1, \, \mathcal{E}_1 ) + o(n^{{-}1}) \nonumber\\ & \quad = m \mathbb{P}(\mathcal{E}_1) \sum_{s_1 \le s} \sum_{t_1 \le t} \tilde f_{2,n}(s_1,t_1) f_{2,n}'(s-s_1,t-t_1) + o(n^{{-}1}) \nonumber\\ & \quad = \mathbb{P}( \{1,2\} \in E(G_n) ) \sum_{s_1 \le s} \sum_{t_1 \le t} \tilde f_{2,n}(s_1,t_1) \, f_{2,n}'(s-s_1,t-t_1) + o(n^{{-}1}), \end{align}
\begin{align} & f_{2,n}(s,t) \, \mathbb{P}( \{1,2\} \in E(G_n) ) \nonumber\\ & \quad = m \mathbb{P}( D_{1,1} + \tilde D_{1,1} =s, \, D_{2,1} + \tilde D_{2,1} = t, \, \mathcal{E}_1) +o(n^{{-}1}) \nonumber\\ & \quad = m \sum_{s_1 \le s} \sum_{t_1 \le t} \tilde f_{2,n}(s_1,t_1) \, \mathbb{P}( D_{1,1} =s-s_1, D_{2,1} = t - t_1, \, \mathcal{E}_1 ) + o(n^{{-}1}) \nonumber\\ & \quad = m \mathbb{P}(\mathcal{E}_1) \sum_{s_1 \le s} \sum_{t_1 \le t} \tilde f_{2,n}(s_1,t_1) f_{2,n}'(s-s_1,t-t_1) + o(n^{{-}1}) \nonumber\\ & \quad = \mathbb{P}( \{1,2\} \in E(G_n) ) \sum_{s_1 \le s} \sum_{t_1 \le t} \tilde f_{2,n}(s_1,t_1) \, f_{2,n}'(s-s_1,t-t_1) + o(n^{{-}1}), \end{align}where we have used (29) and the fact that  $m/n$ is bounded. In the last step, we invoked (26).
$m/n$ is bounded. In the last step, we invoked (26).
We now apply Lemma 3 to approximate the term  $\tilde f_{2,n}(s_1,t_1)$, which represents the joint degree distribution in the model with
$\tilde f_{2,n}(s_1,t_1)$, which represents the joint degree distribution in the model with  $m-1$ layers. First, observe that the conditions in Lemma 3,
$m-1$ layers. First, observe that the conditions in Lemma 3,  $P^{(n)} \to P$ weakly and
$P^{(n)} \to P$ weakly and  $P_{10}^{(n)} \to P_{10} \in (0,\infty )$, are satisfied by our assumptions. Secondly, since
$P_{10}^{(n)} \to P_{10} \in (0,\infty )$, are satisfied by our assumptions. Secondly, since  $m/n \to \mu$, also
$m/n \to \mu$, also  $(m-1)/n \to \mu$. Thus, we can apply (21) (with
$(m-1)/n \to \mu$. Thus, we can apply (21) (with  $\tilde f_{2,n}(s_1,t_1)$ in place of
$\tilde f_{2,n}(s_1,t_1)$ in place of  $\mathbb {P}(D_1=s,D_2=t)$, and similarly
$\mathbb {P}(D_1=s,D_2=t)$, and similarly  $\mathbb {P}(\tilde D_{1,k} = s_1)$,
$\mathbb {P}(\tilde D_{1,k} = s_1)$,  $\mathbb {P}(\tilde D_{2,k} = t_1)$ in place of
$\mathbb {P}(\tilde D_{2,k} = t_1)$ in place of  $\mathbb {P}(D_1=s)$,
$\mathbb {P}(D_1=s)$,  $\mathbb {P}(D_2=t)$), and obtain
$\mathbb {P}(D_2=t)$), and obtain
 $$\tilde f_{2,n}(s_1,t_1) - \mathbb{P}( \tilde D_{1,k} =s_1) \mathbb{P}( \tilde D_{2,k} = t_1) \to 0.$$
$$\tilde f_{2,n}(s_1,t_1) - \mathbb{P}( \tilde D_{1,k} =s_1) \mathbb{P}( \tilde D_{2,k} = t_1) \to 0.$$Next, we approximate  $\mathbb {P}( \tilde D_{1,k} =s_1)$ and
$\mathbb {P}( \tilde D_{1,k} =s_1)$ and  $\mathbb {P}( \tilde D_{2,k} =t_1)$. Namely, by Theorem 5, the asymptotic degree distribution only depends on
$\mathbb {P}( \tilde D_{2,k} =t_1)$. Namely, by Theorem 5, the asymptotic degree distribution only depends on  $\mu$ and the limiting type distribution
$\mu$ and the limiting type distribution  $P$, and in particular, replacing
$P$, and in particular, replacing  $m$ by
$m$ by  $m-1$ does not change these limits. Hence,
$m-1$ does not change these limits. Hence,  $\mathbb {P}( \tilde D_{1,k} =s_1)$ and
$\mathbb {P}( \tilde D_{1,k} =s_1)$ and  $f_n(s_1)$ converge to the same number,
$f_n(s_1)$ converge to the same number,
 $$\mathbb{P}( \tilde D_{1,k} = s_1) - f_n(s_1) \to 0 \quad \text{and} \quad \mathbb{P}( \tilde D_{2,k} = t_1) - f_n(t_1) \to 0,$$
$$\mathbb{P}( \tilde D_{1,k} = s_1) - f_n(s_1) \to 0 \quad \text{and} \quad \mathbb{P}( \tilde D_{2,k} = t_1) - f_n(t_1) \to 0,$$which gives the approximation
 \begin{align*} & f_{2,n}(s,t) \mathbb{P}( \{1,2\} \in E(G_n)) \\ & \quad = \mathbb{P}( \{1,2 \} \in E(G_n) ) \sum_{s_1 \le s} \sum_{t_1 \le t} ( f_{n}(s_1) f_n(t_1) \, f_{2,n}'(s-s_1,t-t_1) + o(1) ) + o(n^{{-}1}), \end{align*}
\begin{align*} & f_{2,n}(s,t) \mathbb{P}( \{1,2\} \in E(G_n)) \\ & \quad = \mathbb{P}( \{1,2 \} \in E(G_n) ) \sum_{s_1 \le s} \sum_{t_1 \le t} ( f_{n}(s_1) f_n(t_1) \, f_{2,n}'(s-s_1,t-t_1) + o(1) ) + o(n^{{-}1}), \end{align*}where we note that since  $s$ and
$s$ and  $t$ do not depend on
$t$ do not depend on  $n$, the double sum equals
$n$, the double sum equals  $(f_n \otimes f_n) \ast f'_{2,n}) (s,t) + o(1)$. Furthermore, the identity
$(f_n \otimes f_n) \ast f'_{2,n}) (s,t) + o(1)$. Furthermore, the identity  $\mathbb {P}(\mathcal {E}_1) = {P_{21}^{(n)}}/{(n)_2}$ together with (26) gives
$\mathbb {P}(\mathcal {E}_1) = {P_{21}^{(n)}}/{(n)_2}$ together with (26) gives  $\mathbb {P}( \{1,2 \} \in E(G_n)) = ({P_{21}^{(n)}}/{(n)_2}) m+O(n^{-2}) = \operatorname {\Theta }(n^{-1})$. As a consequence, dividing by
$\mathbb {P}( \{1,2 \} \in E(G_n)) = ({P_{21}^{(n)}}/{(n)_2}) m+O(n^{-2}) = \operatorname {\Theta }(n^{-1})$. As a consequence, dividing by  $\mathbb {P}( \{1,2 \} \in E(G_n))$ yields
$\mathbb {P}( \{1,2 \} \in E(G_n))$ yields
 \begin{equation} {\lvert{ f_{2,n}(s,t) - ((f_n \otimes f_n) \ast f'_{2,n}) (s,t) }\rvert} \to 0 \end{equation}
\begin{equation} {\lvert{ f_{2,n}(s,t) - ((f_n \otimes f_n) \ast f'_{2,n}) (s,t) }\rvert} \to 0 \end{equation}for any  $s,t \in \mathbb {Z}_+$, with
$s,t \in \mathbb {Z}_+$, with  $\ast$ denoting the convolution of probability measures on the additive group
$\ast$ denoting the convolution of probability measures on the additive group  $\mathbb {Z}^{2}$. We know that
$\mathbb {Z}^{2}$. We know that  $f_n \to \bar f_1$ weakly where
$f_n \to \bar f_1$ weakly where  $\bar f_1$ is the limiting model degree distribution in (6). Therefore,
$\bar f_1$ is the limiting model degree distribution in (6). Therefore,  $f_n \otimes f_n \to \bar f_1 \otimes \bar f_1$ weakly as probability measures on
$f_n \otimes f_n \to \bar f_1 \otimes \bar f_1$ weakly as probability measures on  $\mathbb {Z}_+^{2}$.
$\mathbb {Z}_+^{2}$.
Let us investigate the limit of  $f'_{2,n}$. We note that given
$f'_{2,n}$. We note that given  $(X_k,Y_k)$ and the event
$(X_k,Y_k)$ and the event  $\mathcal {E}_k = \{ \{1,2\} \in E(G_{n,k})\}$, the random variables
$\mathcal {E}_k = \{ \{1,2\} \in E(G_{n,k})\}$, the random variables  $D_{1,k}$ and
$D_{1,k}$ and  $D_{2,k}$ are independent, and both distributed according to
$D_{2,k}$ are independent, and both distributed according to  $1 + \operatorname {Bin}(X_k-2,Y_k)$. Hence
$1 + \operatorname {Bin}(X_k-2,Y_k)$. Hence
 \begin{align*} & \mathbb{P}( D_{1,k} =s, D_{2,k} = t, \mathcal{E}_k \, | \, X_k, Y_k) \\ & \quad = \mathbb{P}( \mathcal{E}_k \, | \, X_k, Y_k) \, \mathbb{P}( D_{1,k} =s, D_{2,k} = t \, | \, \mathcal{E}_k, X_k, Y_k) \\ & \quad = \frac{(X_k)_2}{(n)_2} Y_k \, \operatorname{Bin}(X_k-2, Y_k)(s-1) \operatorname{Bin}(X_k-2,Y_k)(t-1). \end{align*}
\begin{align*} & \mathbb{P}( D_{1,k} =s, D_{2,k} = t, \mathcal{E}_k \, | \, X_k, Y_k) \\ & \quad = \mathbb{P}( \mathcal{E}_k \, | \, X_k, Y_k) \, \mathbb{P}( D_{1,k} =s, D_{2,k} = t \, | \, \mathcal{E}_k, X_k, Y_k) \\ & \quad = \frac{(X_k)_2}{(n)_2} Y_k \, \operatorname{Bin}(X_k-2, Y_k)(s-1) \operatorname{Bin}(X_k-2,Y_k)(t-1). \end{align*}By taking expectations above, and dividing the outcome by  $\mathbb {P}(\mathcal {E}_k) = \mathbb {E} ( ({(X_k)_2}/{(n)_2}) Y_k )= (n)_2^{-1} P^{(n)}_{21}$, it follows that
$\mathbb {P}(\mathcal {E}_k) = \mathbb {E} ( ({(X_k)_2}/{(n)_2}) Y_k )= (n)_2^{-1} P^{(n)}_{21}$, it follows that
 $$f'_{2,n}(s,t) = \int \operatorname{Bin}(x-2,y)(s-1) \operatorname{Bin}(x-2,y)(t-1) \frac{(x)_2 y P^{(n)}(dx,dy)}{P^{(n)}_{21}} .$$
$$f'_{2,n}(s,t) = \int \operatorname{Bin}(x-2,y)(s-1) \operatorname{Bin}(x-2,y)(t-1) \frac{(x)_2 y P^{(n)}(dx,dy)}{P^{(n)}_{21}} .$$When  $P^{(n)} \to P$ weakly and
$P^{(n)} \to P$ weakly and  $P^{(n)}_{21} \to P_{21} \in (0,\infty )$, it follows that
$P^{(n)}_{21} \to P_{21} \in (0,\infty )$, it follows that  $f'_{2,n}(s,t) \to f'_{2}(s-1,t-1)$ pointwise on
$f'_{2,n}(s,t) \to f'_{2}(s-1,t-1)$ pointwise on  $\mathbb {Z}_+^{2}$, where
$\mathbb {Z}_+^{2}$, where  $f'_2$ is defined by (10). Hence
$f'_2$ is defined by (10). Hence
 $$(f_n \otimes f_n) \ast f'_{2,n} \to \delta_{(1,1)} \ast (\bar f_1 \otimes \bar f_1) \ast f'_{2}$$
$$(f_n \otimes f_n) \ast f'_{2,n} \to \delta_{(1,1)} \ast (\bar f_1 \otimes \bar f_1) \ast f'_{2}$$pointwise, where  $\delta _{(1,1)}$ represents the edge between the two nodes. Combining this with (31), we conclude that Theorem 1(i) is valid.
$\delta _{(1,1)}$ represents the edge between the two nodes. Combining this with (31), we conclude that Theorem 1(i) is valid.
6.2. Proof of Theorem 1$\mathbf {(ii)}$

The following lemma gives sufficient conditions for the convergence of the third moment of the model degree distribution. The proof of Theorem 1(ii) then follows from Skorohod's coupling theorem and basic properties of size-biased distributions.
Lemma 4 Assume that  $P^{(n)} \to P$ weakly and
$P^{(n)} \to P$ weakly and  $P^{(n)}_{rs} \to P_{rs} < \infty$ for
$P^{(n)}_{rs} \to P_{rs} < \infty$ for  $rs = 10,21,32,43$, with
$rs = 10,21,32,43$, with  $P_{10} > 0$. Then the third moments of the model degree distribution converge according to
$P_{10} > 0$. Then the third moments of the model degree distribution converge according to  $\sum _s s^{3} f_n(s) \to \sum _s s^{3} {\bar f}(s) < \infty$.
$\sum _s s^{3} f_n(s) \to \sum _s s^{3} {\bar f}(s) < \infty$.
Proof. Let  $D_n = \deg _{G_n}(1)$ and let
$D_n = \deg _{G_n}(1)$ and let  $D_*$ be a random variable with the asymptotic degree distribution defined by Theorem 5. We write for short
$D_*$ be a random variable with the asymptotic degree distribution defined by Theorem 5. We write for short  $X_i = X_{n,i}$ and
$X_i = X_{n,i}$ and  $Y_i = Y_{n,i}$. Since
$Y_i = Y_{n,i}$. Since  $D_n \rightarrow D_*$ weakly, by portmanteau theorem and Fatou's lemma
$D_n \rightarrow D_*$ weakly, by portmanteau theorem and Fatou's lemma
 \begin{align*} \mathbb{E} (D_*^{3}) & = \sum_{k=0}^{\infty} \mathbb{P} (D_* > k^{1/3}) \leq \sum_{k=0}^{\infty} \liminf_n \mathbb{P} (D_n > k^{1/3})\\ & \leq \liminf_n \sum_{k=0}^{\infty} \mathbb{P}(D_n > k^{1/3})= \liminf_n \mathbb{E} (D_n^{3}). \end{align*}
\begin{align*} \mathbb{E} (D_*^{3}) & = \sum_{k=0}^{\infty} \mathbb{P} (D_* > k^{1/3}) \leq \sum_{k=0}^{\infty} \liminf_n \mathbb{P} (D_n > k^{1/3})\\ & \leq \liminf_n \sum_{k=0}^{\infty} \mathbb{P}(D_n > k^{1/3})= \liminf_n \mathbb{E} (D_n^{3}). \end{align*}It remains to show that  $\limsup _n \mathbb {E} (D_n^{3}) \leq \mathbb {E} (D_*^{3})$. Let
$\limsup _n \mathbb {E} (D_n^{3}) \leq \mathbb {E} (D_*^{3})$. Let  $z_k = \sum _{j=2}^{n} \mathbb {I} ( \{1,j\} \in E(G_{n,k}))$ be the number of neighbors of
$z_k = \sum _{j=2}^{n} \mathbb {I} ( \{1,j\} \in E(G_{n,k}))$ be the number of neighbors of  $1$ produced by the layer
$1$ produced by the layer  $k$. Then
$k$. Then  $z_k$,
$z_k$,  $1 \leq k \leq m$, are independent and
$1 \leq k \leq m$, are independent and  $D_n \leq \sum _{k=1}^{m} z_k$, so that
$D_n \leq \sum _{k=1}^{m} z_k$, so that
 \begin{align*} \mathbb{E} (D_n^{3}) \le \mathbb{E} \left( \left(\sum_{k=1}^{m} z_k\right)^{3} \right) & = m \mathbb{E} (z_1^{3}) + 6 \binom{m}{2} \mathbb{E} (z_1^{2} z_2)+ 6\binom{m}{3} \mathbb{E} (z_1 z_2 z_3)\\ & \le m \mathbb{E} (z_1^{3}) + 3(m \mathbb{E}(z_1^{2}))(m \mathbb{E}(z_1)) + (m \mathbb{E}(z_1))^{3}. \end{align*}
\begin{align*} \mathbb{E} (D_n^{3}) \le \mathbb{E} \left( \left(\sum_{k=1}^{m} z_k\right)^{3} \right) & = m \mathbb{E} (z_1^{3}) + 6 \binom{m}{2} \mathbb{E} (z_1^{2} z_2)+ 6\binom{m}{3} \mathbb{E} (z_1 z_2 z_3)\\ & \le m \mathbb{E} (z_1^{3}) + 3(m \mathbb{E}(z_1^{2}))(m \mathbb{E}(z_1)) + (m \mathbb{E}(z_1))^{3}. \end{align*}Recall that the first three moments of  $\operatorname {Bin}(n,p)$ are
$\operatorname {Bin}(n,p)$ are
 \begin{equation} \mu_1 = np, \quad \mu_2 = np + (n)_2 p^{2}, \quad \mu_3 = np + 3 (n)_2 p^{2} + (n)_3 p^{3}. \end{equation}
\begin{equation} \mu_1 = np, \quad \mu_2 = np + (n)_2 p^{2}, \quad \mu_3 = np + 3 (n)_2 p^{2} + (n)_3 p^{3}. \end{equation}Introduce the event  $A = \{1 \in V(G_{n,1}) \}$. On the event
$A = \{1 \in V(G_{n,1}) \}$. On the event  $A^{c}$ we have
$A^{c}$ we have  $z_1 = 0$. Given
$z_1 = 0$. Given  $(X_k, Y_k)$ and
$(X_k, Y_k)$ and  $A$, the random variable
$A$, the random variable  $z_k$ is
$z_k$ is  $\operatorname {Bin}(X_k-1,Y_k)$-distributed. Hence by (32)
$\operatorname {Bin}(X_k-1,Y_k)$-distributed. Hence by (32)
 \begin{align*} \mathbb{E} (z_1) = \mathbb{E}( \mathbb{E}( \mathbb{I}_A z_1 \, | \, X_1, Y_1 \, ) ) & = \mathbb{E} (\mathbb{P}(A \,| \,X_1, Y_1) \mathbb{E} (z_1 \, | \, X_1, Y_1, A) )\\ & = \mathbb{E} \left( \frac{X_1}{n} (X_1-1) Y_1 \right) = \frac{1}{n} P^{(n)}_{21}, \end{align*}
\begin{align*} \mathbb{E} (z_1) = \mathbb{E}( \mathbb{E}( \mathbb{I}_A z_1 \, | \, X_1, Y_1 \, ) ) & = \mathbb{E} (\mathbb{P}(A \,| \,X_1, Y_1) \mathbb{E} (z_1 \, | \, X_1, Y_1, A) )\\ & = \mathbb{E} \left( \frac{X_1}{n} (X_1-1) Y_1 \right) = \frac{1}{n} P^{(n)}_{21}, \end{align*}and similarly
 \begin{align*} \mathbb{E} (z_1^{2}) & = \mathbb{E} \left( \frac{X_1}{n} ( (X_1-1) Y_1 + (X_1-1)_2 Y_1^{2} ) \right) = \frac{1}{n} (P^{(n)}_{21} + P^{(n)}_{32}),\\ \mathbb{E} (z_1^{3}) & = \mathbb{E} \left( \frac{X_1}{n} ( (X_1-1) Y_1 + 3(X_1-1)_2 Y_1^{2} + (X_1-1)_3 Y_1^{3} ) \right) \\ & = \frac{1}{n} (P^{(n)}_{21} + 3 P^{(n)}_{32} + P^{(n)}_{43}) \end{align*}
\begin{align*} \mathbb{E} (z_1^{2}) & = \mathbb{E} \left( \frac{X_1}{n} ( (X_1-1) Y_1 + (X_1-1)_2 Y_1^{2} ) \right) = \frac{1}{n} (P^{(n)}_{21} + P^{(n)}_{32}),\\ \mathbb{E} (z_1^{3}) & = \mathbb{E} \left( \frac{X_1}{n} ( (X_1-1) Y_1 + 3(X_1-1)_2 Y_1^{2} + (X_1-1)_3 Y_1^{3} ) \right) \\ & = \frac{1}{n} (P^{(n)}_{21} + 3 P^{(n)}_{32} + P^{(n)}_{43}) \end{align*}Since  $P^{(n)}_{rs}$ was assumed to converge for
$P^{(n)}_{rs}$ was assumed to converge for  $rs = 10, 21, 32, 43$, it follows that
$rs = 10, 21, 32, 43$, it follows that
 \begin{equation} \limsup_n \mathbb{E} (D_n^{3}) \le \mu (P_{21} + 3 P_{32} + P_{43}) + 3 \mu^{2}(P_{21} + P_{32}) P_{21} + \mu^{3} P_{21}^{3}. \end{equation}
\begin{equation} \limsup_n \mathbb{E} (D_n^{3}) \le \mu (P_{21} + 3 P_{32} + P_{43}) + 3 \mu^{2}(P_{21} + P_{32}) P_{21} + \mu^{3} P_{21}^{3}. \end{equation}Recall that  $D_*$ may be represented as
$D_*$ may be represented as  $D_* = \sum _{j=1}^{\Lambda } H_j$ where
$D_* = \sum _{j=1}^{\Lambda } H_j$ where  $\Lambda \sim \operatorname {Poi}(\mu P_{10})$ and
$\Lambda \sim \operatorname {Poi}(\mu P_{10})$ and
 $$\mathbb{P}(H=l) = \frac{1}{P_{10}} \mathbb{E} \left(X \binom{X-1}{l}Y^{l}(1-Y)^{X-1-l} \right), \quad l=0,1,2,\ldots,$$
$$\mathbb{P}(H=l) = \frac{1}{P_{10}} \mathbb{E} \left(X \binom{X-1}{l}Y^{l}(1-Y)^{X-1-l} \right), \quad l=0,1,2,\ldots,$$where  $\operatorname {Law}(X,Y) = P$. From this and (32), we obtain
$\operatorname {Law}(X,Y) = P$. From this and (32), we obtain
 \begin{align*} \mathbb{E} (H) = \sum_{l=0}^{\infty} l \,\mathbb{P}(H=l) & = \frac{1}{P_{10}} \mathbb{E} \left(X \sum_{l=0}^{\infty} l \binom{X-1}{l}Y^{l}(1-Y)^{X-1-l} \right)\\ & = \frac{1}{P_{10}} \mathbb{E} (X (X-1) Y ) = \frac{P_{21}}{P_{10}}, \end{align*}
\begin{align*} \mathbb{E} (H) = \sum_{l=0}^{\infty} l \,\mathbb{P}(H=l) & = \frac{1}{P_{10}} \mathbb{E} \left(X \sum_{l=0}^{\infty} l \binom{X-1}{l}Y^{l}(1-Y)^{X-1-l} \right)\\ & = \frac{1}{P_{10}} \mathbb{E} (X (X-1) Y ) = \frac{P_{21}}{P_{10}}, \end{align*}and similarly
 \begin{align*} \mathbb{E} (H^{2}) & = \frac{1}{P_{10}} \mathbb{E} ( X ((X-1) Y + (X-1)_2 Y^{2}) ) = \frac{P_{21} + P_{32}}{P_{10}}, \\ \mathbb{E} (H^{3}) & = \frac{1}{P_{10}} \mathbb{E} ( X ((X-1) Y + 3(X-1)_2 Y^{2} + (X-1)_3 Y^{3}) ) \\ & = \frac{P_{21} + 3P_{32} + P_{43}}{P_{10}}. \end{align*}
\begin{align*} \mathbb{E} (H^{2}) & = \frac{1}{P_{10}} \mathbb{E} ( X ((X-1) Y + (X-1)_2 Y^{2}) ) = \frac{P_{21} + P_{32}}{P_{10}}, \\ \mathbb{E} (H^{3}) & = \frac{1}{P_{10}} \mathbb{E} ( X ((X-1) Y + 3(X-1)_2 Y^{2} + (X-1)_3 Y^{3}) ) \\ & = \frac{P_{21} + 3P_{32} + P_{43}}{P_{10}}. \end{align*}Recall that the factorial moments of  $\operatorname {Poi}(\lambda )$ are given by
$\operatorname {Poi}(\lambda )$ are given by  $\lambda ^{k}$. It follows that
$\lambda ^{k}$. It follows that
 \begin{align*} \mathbb{E} (D_*^{3}) = \mathbb{E}(\mathbb{E}(D_*^{3} \, | \, \Lambda )) & = \mathbb{E}(\Lambda \mathbb{E} (H_1^{3}) + 3(\Lambda)_2 \mathbb{E} (H_1^{2})\mathbb{E} (H_1) + (\Lambda)_3 \mathbb{E} (H_1)^{3})\\ & = \mu (P_{21} + 3P_{32} + P_{43}) + 3 \mu^{2} (P_{21} + P_{32})P_{21} + \mu^{3} P_{21}^{3} . \end{align*}
\begin{align*} \mathbb{E} (D_*^{3}) = \mathbb{E}(\mathbb{E}(D_*^{3} \, | \, \Lambda )) & = \mathbb{E}(\Lambda \mathbb{E} (H_1^{3}) + 3(\Lambda)_2 \mathbb{E} (H_1^{2})\mathbb{E} (H_1) + (\Lambda)_3 \mathbb{E} (H_1)^{3})\\ & = \mu (P_{21} + 3P_{32} + P_{43}) + 3 \mu^{2} (P_{21} + P_{32})P_{21} + \mu^{3} P_{21}^{3} . \end{align*}The claim now follows by (33).
We are now ready to prove Theorem 1(ii). The proof is similar to [Reference van der Hofstad and Litvak44], Thm. 3.2, but slightly simpler because here we analyze model distributions instead of empirical distributions of random graph samples.)
Proof of Theorem 1(ii). Let  $(D_{1,n}^{*}, D_{2,n}^{*})$ be a random variable distributed according to the model bidegree distribution
$(D_{1,n}^{*}, D_{2,n}^{*})$ be a random variable distributed according to the model bidegree distribution  $f_{2,n}$ of
$f_{2,n}$ of  $G_n$. Theorem 1(i) states that
$G_n$. Theorem 1(i) states that  $(D_{1,n}^{*}, D_{2,n}^{*}) \!\to \! (D_{1}^{*}, D_{2}^{*})$ weakly. Now let
$(D_{1,n}^{*}, D_{2,n}^{*}) \!\to \! (D_{1}^{*}, D_{2}^{*})$ weakly. Now let  $\phi : \mathbb {Z}_+^{2} \to \mathbb {R}$ be a function bounded by
$\phi : \mathbb {Z}_+^{2} \to \mathbb {R}$ be a function bounded by  ${\lvert {\phi (x,y)}\rvert } \le c(1 + x^{2} + y^{2})$. Skorohod's coupling theorem ([Reference Kallenberg26], Thm. 4.30) implies that there exist a probability space and some random variables
${\lvert {\phi (x,y)}\rvert } \le c(1 + x^{2} + y^{2})$. Skorohod's coupling theorem ([Reference Kallenberg26], Thm. 4.30) implies that there exist a probability space and some random variables  $(\tilde D_{1,n}^{*}, \tilde D_{2,n}^{*}) \stackrel {d}{=} (D_{1,n}^{*}, D_{2,n}^{*})$ and
$(\tilde D_{1,n}^{*}, \tilde D_{2,n}^{*}) \stackrel {d}{=} (D_{1,n}^{*}, D_{2,n}^{*})$ and  $(\tilde D_{1}^{*}, \tilde D_{2}^{*}) \stackrel {d}{=} (D_{1}^{*}, D_{2}^{*})$ such that
$(\tilde D_{1}^{*}, \tilde D_{2}^{*}) \stackrel {d}{=} (D_{1}^{*}, D_{2}^{*})$ such that  $(\tilde D_{1,n}^{*}, \tilde D_{2,n}^{*}) \to (\tilde D_{1}^{*}, \tilde D_{2}^{*})$ almost surely. Then
$(\tilde D_{1,n}^{*}, \tilde D_{2,n}^{*}) \to (\tilde D_{1}^{*}, \tilde D_{2}^{*})$ almost surely. Then  $Z_n := \phi (\tilde D_{1,n}^{*}, \tilde D_{2,n}^{*}) \to \phi (\tilde D_{1}^{*}, \tilde D_{2}^{*}) =: Z$ almost surely. Also
$Z_n := \phi (\tilde D_{1,n}^{*}, \tilde D_{2,n}^{*}) \to \phi (\tilde D_{1}^{*}, \tilde D_{2}^{*}) =: Z$ almost surely. Also  ${\lvert {Z_n}\rvert } \le c( 1+ (\tilde D_{1,n}^{*})^{2} + (\tilde D_{2,n}^{*})^{2}) =: Z_n'$ a.s.
${\lvert {Z_n}\rvert } \le c( 1+ (\tilde D_{1,n}^{*})^{2} + (\tilde D_{2,n}^{*})^{2}) =: Z_n'$ a.s.
Denote by  $f_n$ the model degree distribution of
$f_n$ the model degree distribution of  $G_n$, and by
$G_n$, and by  $f_n^{*}$ its size-biased version. Recall that
$f_n^{*}$ its size-biased version. Recall that  $\operatorname {Law}(\tilde D_{1,n}^{*}) = \operatorname {Law}(D_{1,n}^{*})$ equals the first (equivalently, the second) marginal of
$\operatorname {Law}(\tilde D_{1,n}^{*}) = \operatorname {Law}(D_{1,n}^{*})$ equals the first (equivalently, the second) marginal of  $f_{2,n}$, and as in (4), this marginal equals
$f_{2,n}$, and as in (4), this marginal equals
 $$\sum_t f_{2,n}(s,t) = f_n^{*}(s) = \frac{s f_n(s)}{\sum_t t f_n(t)},$$
$$\sum_t f_{2,n}(s,t) = f_n^{*}(s) = \frac{s f_n(s)}{\sum_t t f_n(t)},$$hence  $\operatorname {Law}(D_{1,n}^{*}) = f^{*}_n$. We know (see, for example, [Reference Kallenberg26], Lem. 1.23) that for the size-biasing
$\operatorname {Law}(D_{1,n}^{*}) = f^{*}_n$. We know (see, for example, [Reference Kallenberg26], Lem. 1.23) that for the size-biasing  $f^{*}_n$, and for any measurable nonnegative function
$f^{*}_n$, and for any measurable nonnegative function  $\phi$,
$\phi$,
 $$\mathbb{E} (\phi(D_{1,n}^{*})) = \sum_s \phi(s) f^{*}_n(s) = \frac{\sum_s \phi(s) s f_n(s)}{\sum_s s f_n(s)} = \frac{\mathbb{E} (\phi(D_{1,n}) D_{1,n})}{\mathbb{E} (D_{1,n})},$$
$$\mathbb{E} (\phi(D_{1,n}^{*})) = \sum_s \phi(s) f^{*}_n(s) = \frac{\sum_s \phi(s) s f_n(s)}{\sum_s s f_n(s)} = \frac{\mathbb{E} (\phi(D_{1,n}) D_{1,n})}{\mathbb{E} (D_{1,n})},$$where  $\operatorname {Law}(D_{1,n}) = f_n$. Especially, for
$\operatorname {Law}(D_{1,n}) = f_n$. Especially, for  $\phi (s) = s^{2}$, it follows that
$\phi (s) = s^{2}$, it follows that
 $$\mathbb{E} ((D_{1,n}^{*})^{2}) = \frac{\mathbb{E} (D_{1,n}^{3})}{\mathbb{E} (D_{1,n})}.$$
$$\mathbb{E} ((D_{1,n}^{*})^{2}) = \frac{\mathbb{E} (D_{1,n}^{3})}{\mathbb{E} (D_{1,n})}.$$With the help of Lemma 4, we now note that
 $$\mathbb{E} ((\tilde D_{1,n}^{*})^{2}) = \frac{\mathbb{E} (D_{1,n}^{3})}{\mathbb{E} (D_{1,n})} \to \frac{\mathbb{E} (D_{1}^{3})}{\mathbb{E} (D_{1})} = \mathbb{E} ((D_{1}^{*})^{2}) < \infty,$$
$$\mathbb{E} ((\tilde D_{1,n}^{*})^{2}) = \frac{\mathbb{E} (D_{1,n}^{3})}{\mathbb{E} (D_{1,n})} \to \frac{\mathbb{E} (D_{1}^{3})}{\mathbb{E} (D_{1})} = \mathbb{E} ((D_{1}^{*})^{2}) < \infty,$$and hence  $\mathbb {E} (Z_n') \to \mathbb {E} (Z') = c(1+2 \mathbb {E} ((D_{1}^{*})^{2})) < \infty$. Lebesgue's dominated convergence theorem (see the version in [Reference Kallenberg26], Thm. 1.21) now implies that
$\mathbb {E} (Z_n') \to \mathbb {E} (Z') = c(1+2 \mathbb {E} ((D_{1}^{*})^{2})) < \infty$. Lebesgue's dominated convergence theorem (see the version in [Reference Kallenberg26], Thm. 1.21) now implies that  $\mathbb {E} (Z_n) \to \mathbb {E} (Z)$, which confirms the claim.
$\mathbb {E} (Z_n) \to \mathbb {E} (Z)$, which confirms the claim.
6.3. Proof of Theorem 2
We use the two following results shown in [Reference Bloznelis and Leskelä9]. Theorem 6 and Lemma 5 give the power laws of  $D_1$ and
$D_1$ and  $D_1'$ when the assumptions of Theorem 2 hold. The first claim (11) then follows from the observation that
$D_1'$ when the assumptions of Theorem 2 hold. The first claim (11) then follows from the observation that  $D_1^{*}$ has the same distribution as
$D_1^{*}$ has the same distribution as  $1+D_1+D_1'$, and that
$1+D_1+D_1'$, and that  $D_1'$ is the dominating term. In the proof of (12), we use the fact that random variables
$D_1'$ is the dominating term. In the proof of (12), we use the fact that random variables  $D_1$,
$D_1$,  $D_2$ and
$D_2$ and  $(D_1',D_2')$ are independent and exploit the special structure of
$(D_1',D_2')$ are independent and exploit the special structure of  $(D_1',D_2')$: it is a mixture of (conditionally) independent binomial random variables.
$(D_1',D_2')$: it is a mixture of (conditionally) independent binomial random variables.
Theorem 6 ([Reference Bloznelis and Leskelä9], Thm. 4.1)
Assume that the limiting layer type distribution equals  $P(dx,dy) = p(dx)\delta _{q(x)} (dy)$ with
$P(dx,dy) = p(dx)\delta _{q(x)} (dy)$ with
 $$p(x) = (a+o(1))x^{-\alpha} \quad \text{and} \quad q(x) = (b+O(x^{{-}1/2})) x^{-\beta}$$
$$p(x) = (a+o(1))x^{-\alpha} \quad \text{and} \quad q(x) = (b+O(x^{{-}1/2})) x^{-\beta}$$as  $x \to + \infty$ with exponents
$x \to + \infty$ with exponents  $\alpha >2$,
$\alpha >2$,  $\beta \in (0,1)$ and constants
$\beta \in (0,1)$ and constants  $a,b > 0$. Then the limiting degree distribution satisfies
$a,b > 0$. Then the limiting degree distribution satisfies
 \begin{equation} \mathbb{P} (D_1 =t ) = dt^{-\delta}(1+o(1)), \quad \text{as } t \to +\infty, \end{equation}
\begin{equation} \mathbb{P} (D_1 =t ) = dt^{-\delta}(1+o(1)), \quad \text{as } t \to +\infty, \end{equation}where  $\delta = 1+ {(\alpha -2)}/{(1-\beta )}$ and
$\delta = 1+ {(\alpha -2)}/{(1-\beta )}$ and  $d=\mu (1- \beta )^{-1} a b^{\delta -1}$. The same result holds for
$d=\mu (1- \beta )^{-1} a b^{\delta -1}$. The same result holds for  $\beta = 0$ if
$\beta = 0$ if  $b<1$.
$b<1$.
Lemma 5 ([Reference Bloznelis and Leskelä9], Lem. A.4)
Consider a mixed binomial distribution  $g(r) = \sum _{k\geq 1} p_k f_k(r)$ where
$g(r) = \sum _{k\geq 1} p_k f_k(r)$ where  $f_k = \operatorname {Bin}(x_k,y_k)$ and
$f_k = \operatorname {Bin}(x_k,y_k)$ and  $(p_k)$ is a probability distribution on
$(p_k)$ is a probability distribution on  $\{1,2,\ldots \}$. Assume that as
$\{1,2,\ldots \}$. Assume that as  $k \to +\infty$
$k \to +\infty$
 $$x_k = (a+O(k^{-\xi/2}))k^{\xi}, \quad y_k = (b+O(k^{-\xi/2}))k^{-\eta}, \quad p_k = (c+o(1))k^{-\gamma},$$
$$x_k = (a+O(k^{-\xi/2}))k^{\xi}, \quad y_k = (b+O(k^{-\xi/2}))k^{-\eta}, \quad p_k = (c+o(1))k^{-\gamma},$$for some  $0 \leq \eta < \xi < \eta +2$ and
$0 \leq \eta < \xi < \eta +2$ and  $\gamma > 1$, and some
$\gamma > 1$, and some  $a,b,c > 0$ such that
$a,b,c > 0$ such that  $\eta >0$ or
$\eta >0$ or  $b<1$. Then
$b<1$. Then
 $$g(r) = (d+o(1))r^{-\delta} \quad \text{as } r \to +\infty,$$
$$g(r) = (d+o(1))r^{-\delta} \quad \text{as } r \to +\infty,$$where  $\delta = 1+ {(\gamma -1)}/{(\xi -\eta )}$ and
$\delta = 1+ {(\gamma -1)}/{(\xi -\eta )}$ and  $d= (ab)^{\delta -1} c/(\xi -\eta )$.
$d= (ab)^{\delta -1} c/(\xi -\eta )$.
Proof of Theorem 2. We first prove claim (11),  $\mathbb {P}(D_1^{*} = t) = (1+o(1))c' t^{-{(\alpha -2)}/{(1-\beta )}}$. Recall from Theorem 1 that the asymptotic bidegree distribution can be written as
$\mathbb {P}(D_1^{*} = t) = (1+o(1))c' t^{-{(\alpha -2)}/{(1-\beta )}}$. Recall from Theorem 1 that the asymptotic bidegree distribution can be written as
 \begin{equation} \mathbb{P}(D_1^{*} = s+1 , D_2^{*} = t +1) = \mathbb{P} (D_1 + D_1' = s, D_2+D_2' = t), \end{equation}
\begin{equation} \mathbb{P}(D_1^{*} = s+1 , D_2^{*} = t +1) = \mathbb{P} (D_1 + D_1' = s, D_2+D_2' = t), \end{equation}where  $D_1$ and
$D_1$ and  $D_2$ follow the distribution
$D_2$ follow the distribution  $\bar f_1$ in (6) and
$\bar f_1$ in (6) and  $(D_1', D_2')$ follows the distribution
$(D_1', D_2')$ follows the distribution  $f_2'$ in (10),
$f_2'$ in (10),  $(D_1', D_2')$ is independent of
$(D_1', D_2')$ is independent of  $(D_1, D_2)$, and
$(D_1, D_2)$, and  $D_1$ is independent of
$D_1$ is independent of  $D_2$. Note that
$D_2$. Note that  $D_1'$ is a mixed binomial random variable
$D_1'$ is a mixed binomial random variable  $D_1' \sim \operatorname {Bin}(X'-2, Y')$, where
$D_1' \sim \operatorname {Bin}(X'-2, Y')$, where  $(X',Y')$ has the distribution
$(X',Y')$ has the distribution
 $$\mathbb{P}(X'=t, Y'=q(t)) = \mathbb{P}(X'=t) = \mathbb{P}(X=t) \frac{(t)_2q(t)}{\mathbb{E}((X)_2 q(X))}, \quad t=0,1,2,\ldots$$
$$\mathbb{P}(X'=t, Y'=q(t)) = \mathbb{P}(X'=t) = \mathbb{P}(X=t) \frac{(t)_2q(t)}{\mathbb{E}((X)_2 q(X))}, \quad t=0,1,2,\ldots$$In Lemma 5, set  $x_k = k-2$,
$x_k = k-2$,  $y_k = q(k) = bk^{-\beta }$, and
$y_k = q(k) = bk^{-\beta }$, and  $p_k = (k)_2 q(k) p(k) / P_{21}$, where we note that the exponent of
$p_k = (k)_2 q(k) p(k) / P_{21}$, where we note that the exponent of  $p_k=O(k^{2-\alpha -\beta })$ is less than
$p_k=O(k^{2-\alpha -\beta })$ is less than  $-1$ by the assumption
$-1$ by the assumption  $\alpha +\beta >3$. Then
$\alpha +\beta >3$. Then
 \begin{equation} \mathbb{P}(D_1' = t) = (c' + o(1))t^{-{(\alpha-2)}/{(1-\beta)}}. \end{equation}
\begin{equation} \mathbb{P}(D_1' = t) = (c' + o(1))t^{-{(\alpha-2)}/{(1-\beta)}}. \end{equation}Denote the power law exponents of  $D_1$ (given by Theorem 6) and
$D_1$ (given by Theorem 6) and  $D_1'$ by
$D_1'$ by
 $$\alpha_{D} := 1+(\alpha-2)/(1-\beta), \quad \alpha_{D'} := (\alpha-2)/(1-\beta).$$
$$\alpha_{D} := 1+(\alpha-2)/(1-\beta), \quad \alpha_{D'} := (\alpha-2)/(1-\beta).$$A standard argument [Reference Mikosch36] shows that  $\mathbb {P}(D_1+D_1' > t) \sim \mathbb {P}(D_1 > t) + \mathbb {P}(D_1' > t)$. Now
$\mathbb {P}(D_1+D_1' > t) \sim \mathbb {P}(D_1 > t) + \mathbb {P}(D_1' > t)$. Now  $\alpha _{D} > \alpha _{D'}$ implies
$\alpha _{D} > \alpha _{D'}$ implies
 $$\mathbb{P} (D_1 + D_1' = t) = (1+o(1)) \mathbb{P}(D_1' = t).$$
$$\mathbb{P} (D_1 + D_1' = t) = (1+o(1)) \mathbb{P}(D_1' = t).$$From (35) and (36), we obtain  $\mathbb {P}(D_1^{*}=t)=(1+o(1))c' t^{-{(\alpha -2)}/{(1-\beta )}}$, thus showing (11). Let us prove (12), i.e.,
$\mathbb {P}(D_1^{*}=t)=(1+o(1))c' t^{-{(\alpha -2)}/{(1-\beta )}}$, thus showing (11). Let us prove (12), i.e.,  $\mathbb {P} ( D_1^{*} = t_1, D_2^{*} = t_2 ) = (1+o(1))c''(t_2-t_1)^{-1-{(\alpha -2)}/{(1-\beta )}} t_1^{-{(\alpha -2)}/{(1-\beta )}}$. We start with an outline of the proof. In order to determine the asymptotics of the bivariate probability (38), we use the observation that large values of mixed binomial random vector
$\mathbb {P} ( D_1^{*} = t_1, D_2^{*} = t_2 ) = (1+o(1))c''(t_2-t_1)^{-1-{(\alpha -2)}/{(1-\beta )}} t_1^{-{(\alpha -2)}/{(1-\beta )}}$. We start with an outline of the proof. In order to determine the asymptotics of the bivariate probability (38), we use the observation that large values of mixed binomial random vector  $(D_1',D_2')$ concentrate around the diagonal
$(D_1',D_2')$ concentrate around the diagonal  $D_1'=D_2'$. We justify this claim by proving that values lying far apart from the diagonal have superpolynomially small probabilities. Namely, for any
$D_1'=D_2'$. We justify this claim by proving that values lying far apart from the diagonal have superpolynomially small probabilities. Namely, for any  $s_0>0$ and all
$s_0>0$ and all  $s_0< s+\delta _s+\delta _t< t$ , we have
$s_0< s+\delta _s+\delta _t< t$ , we have
 \begin{equation} \mathbb{P}(D_1'=s,D_2'=t) \le e^{{-}c_{**}\ln^{8}t}, \end{equation}
\begin{equation} \mathbb{P}(D_1'=s,D_2'=t) \le e^{{-}c_{**}\ln^{8}t}, \end{equation}where the constant  $c_{**}>0$ depends on
$c_{**}>0$ depends on  $s_0$,
$s_0$,  $\beta$, and
$\beta$, and  $b$. The particular form of
$b$. The particular form of  $\delta _t=t^{1/2}\ln ^{4}(2+t)$ is related to the exponential bounds for binomial probabilities below. With this observation in mind, we expand the probability
$\delta _t=t^{1/2}\ln ^{4}(2+t)$ is related to the exponential bounds for binomial probabilities below. With this observation in mind, we expand the probability
 \begin{equation} \mathbb{P}(D_1^{*}=t_1+1,D_2^{*}=t_2+1) = \mathbb{P}(D_1+D_1'=t_1,D_2+D_2'=t_2) \end{equation}
\begin{equation} \mathbb{P}(D_1^{*}=t_1+1,D_2^{*}=t_2+1) = \mathbb{P}(D_1+D_1'=t_1,D_2+D_2'=t_2) \end{equation}into the sum
 \begin{equation} \sum_{(i,j)\in[0,t_1]\times [0,t_2]}\mathbb{P} (D_1'=i,D_2'=j) \mathbb{P}(D_1=t_1-i) \mathbb{P}(D_2=t_2-j), \end{equation}
\begin{equation} \sum_{(i,j)\in[0,t_1]\times [0,t_2]}\mathbb{P} (D_1'=i,D_2'=j) \mathbb{P}(D_1=t_1-i) \mathbb{P}(D_2=t_2-j), \end{equation}locate a region of  $(i,j)$ that gives the leading term (see region
$(i,j)$ that gives the leading term (see region  $A_{4}$ below) and show that the contribution of the remaining part is negligible. Note that our assumptions
$A_{4}$ below) and show that the contribution of the remaining part is negligible. Note that our assumptions  $t_2>t_1$ and
$t_2>t_1$ and  $\delta _{t_2}=o(t_2-t_1)$ make the sum (39) asymmetric.
$\delta _{t_2}=o(t_2-t_1)$ make the sum (39) asymmetric.
Let us prove (37). In the proof, we use the upper bound for binomial probabilities
 \begin{equation} \operatorname{Bin}(x,p)(s) \le e^{{-}0.5({\delta^{2}}/{(s+\delta)})}, \quad \forall s,\delta: \, \delta>0, \ {\lvert{s-xp}\rvert} \geq \delta \end{equation}
\begin{equation} \operatorname{Bin}(x,p)(s) \le e^{{-}0.5({\delta^{2}}/{(s+\delta)})}, \quad \forall s,\delta: \, \delta>0, \ {\lvert{s-xp}\rvert} \geq \delta \end{equation}that follows from Chernoff bounds (see, e.g., Theorem 2.1 in [Reference Janson, Łuczak and Ruciński25]) combined with the simple inequality  $\mathbb {P}(X = t) \leq \min \{\mathbb {P}(X \leq t), \mathbb {P} (X \geq t) \}$ (cf. [Reference Bloznelis and Leskelä9]).
$\mathbb {P}(X = t) \leq \min \{\mathbb {P}(X \leq t), \mathbb {P} (X \geq t) \}$ (cf. [Reference Bloznelis and Leskelä9]).
Setting  $p=q(x)$ and
$p=q(x)$ and  $\delta =\delta _s$ in (40) gives
$\delta =\delta _s$ in (40) gives
 $$\operatorname{Bin}(x,q(x))(s) \le e^{{-}0.5({\delta_s^{2}}/{(s+\delta_s)})} = e^{{-}0.5 {(s\ln^{8}(2+s))}/{(s+s^{1/2}\ln^{4}(2+s))}},$$
$$\operatorname{Bin}(x,q(x))(s) \le e^{{-}0.5({\delta_s^{2}}/{(s+\delta_s)})} = e^{{-}0.5 {(s\ln^{8}(2+s))}/{(s+s^{1/2}\ln^{4}(2+s))}},$$and approximating the exponent for large  $s$ gives
$s$ gives
 \begin{equation} \max_{x:\,|s-xq(x)|\ge \delta_s}\operatorname{Bin}(x,q(x))(s) \le (1+o(1))e^{{-}0.5\ln^{8}s}. \end{equation}
\begin{equation} \max_{x:\,|s-xq(x)|\ge \delta_s}\operatorname{Bin}(x,q(x))(s) \le (1+o(1))e^{{-}0.5\ln^{8}s}. \end{equation}From (40), we also obtain that
 \begin{equation} \operatorname{Bin}(x,q(x))(s)\le e^{{-}c_*\ln^{8}(xq(x))} \quad {\text{for}} \ xq(x) > s+\delta_s, \end{equation}
\begin{equation} \operatorname{Bin}(x,q(x))(s)\le e^{{-}c_*\ln^{8}(xq(x))} \quad {\text{for}} \ xq(x) > s+\delta_s, \end{equation}where  $c_*>0$ depends on
$c_*>0$ depends on  $\beta$ and
$\beta$ and  $b$. To show (42), we write
$b$. To show (42), we write  $xq(x)$ in the form
$xq(x)$ in the form  $xq(x)=s(1+\tau )$ and give a lower bound for the ratio
$xq(x)=s(1+\tau )$ and give a lower bound for the ratio  $(xq(x)-s)^{2}/(xq(x))=s\tau ^{2}/(1+\tau )$ in the exponent of (40). For
$(xq(x)-s)^{2}/(xq(x))=s\tau ^{2}/(1+\tau )$ in the exponent of (40). For  $s^{-0.5}\ln ^{4}s\le \tau \le 1$ , this ratio is at least
$s^{-0.5}\ln ^{4}s\le \tau \le 1$ , this ratio is at least
 $$\frac{s\tau^{2}}{2} \ge \frac{\ln^{8}s}{2} \ge \frac{1}{2}\ln^{8}\left(\frac{xq(x)}{2}\right) \ge c_*\ln^{8}(xq(x)).$$
$$\frac{s\tau^{2}}{2} \ge \frac{\ln^{8}s}{2} \ge \frac{1}{2}\ln^{8}\left(\frac{xq(x)}{2}\right) \ge c_*\ln^{8}(xq(x)).$$For  $\tau \ge 1$ , the ratio is
$\tau \ge 1$ , the ratio is
 $$\frac{xq(x)}{(1+\tau)^{2}}\tau^{2} \ge \frac{xq(x)}{4} \ge c_*\ln^{8}(xq(x)).$$
$$\frac{xq(x)}{(1+\tau)^{2}}\tau^{2} \ge \frac{xq(x)}{4} \ge c_*\ln^{8}(xq(x)).$$ Now we are ready to prove (37). Since  $D_1', D_2'$ are conditionally independent and binomial, we have
$D_1', D_2'$ are conditionally independent and binomial, we have
 $$\mathbb{P}(D_1'=s, D_2'=t ) = \sum_{x\ge s} \operatorname{Bin}(x-2,q(x))(s) \, \operatorname{Bin}(x-2,q(x))(t) \, \mathbb{P}(X'=x).$$
$$\mathbb{P}(D_1'=s, D_2'=t ) = \sum_{x\ge s} \operatorname{Bin}(x-2,q(x))(s) \, \operatorname{Bin}(x-2,q(x))(t) \, \mathbb{P}(X'=x).$$Furthermore, from (41) and (42), we have
 $$\operatorname{Bin}(x-2,q(x))(s) \cdot \operatorname{Bin}(x-2,q(x))(t) \le e^{{-}c_{**}\ln^{8}t}.$$
$$\operatorname{Bin}(x-2,q(x))(s) \cdot \operatorname{Bin}(x-2,q(x))(t) \le e^{{-}c_{**}\ln^{8}t}.$$Indeed, for  $xq(x)< t-\delta _t$, the second probability is at most of order
$xq(x)< t-\delta _t$, the second probability is at most of order  $e^{-c_{**}\ln ^{8}t}$ by (41). For
$e^{-c_{**}\ln ^{8}t}$ by (41). For  $xq(x)>t-\delta _t$ we have
$xq(x)>t-\delta _t$ we have  $xq(x)>s+\delta _s$ and
$xq(x)>s+\delta _s$ and  $xq(x)\ge t/2$. Now we use (42) to bound the first binomial probability by
$xq(x)\ge t/2$. Now we use (42) to bound the first binomial probability by  $e^{-c_*\ln ^{8}(t/2)}$ from above. The proof of (37) is complete.
$e^{-c_*\ln ^{8}(t/2)}$ from above. The proof of (37) is complete.
Now we evaluate (39). Given  $0<\varepsilon <0.1$, let
$0<\varepsilon <0.1$, let
 $$t_1^{*}=\varepsilon \min\{t_1, t_2-t_1\}, \quad t_2^{*}=\begin{cases} (t_2/\varepsilon^{1+\alpha_D})^{1/\alpha_D} & {\text{for}} \ 2t_1>t_2, \\ \varepsilon t_2, & {\text{for}} \ 2t_1< t_2. \end{cases}$$
$$t_1^{*}=\varepsilon \min\{t_1, t_2-t_1\}, \quad t_2^{*}=\begin{cases} (t_2/\varepsilon^{1+\alpha_D})^{1/\alpha_D} & {\text{for}} \ 2t_1>t_2, \\ \varepsilon t_2, & {\text{for}} \ 2t_1< t_2. \end{cases}$$We split  $[0,t_1]\times [0,t_2]=A_0\cup A_1\cup A_2\cup A_3$, where
$[0,t_1]\times [0,t_2]=A_0\cup A_1\cup A_2\cup A_3$, where
 \begin{align*} A_0 & = [0, t_1/2]\times [0,t_1/2], \quad A_1 = ( [0, t_1- t_1^{*}]\times[0,t_2-t_2^{*}] ) \setminus A_0, \\ A_2 & = (t_1-t_1^{*}, t_1]\times[0,t_2], \quad A_3 = [0,t_1-t_1^{*}]\times (t_2-t_2^{*}, t_2], \end{align*}
\begin{align*} A_0 & = [0, t_1/2]\times [0,t_1/2], \quad A_1 = ( [0, t_1- t_1^{*}]\times[0,t_2-t_2^{*}] ) \setminus A_0, \\ A_2 & = (t_1-t_1^{*}, t_1]\times[0,t_2], \quad A_3 = [0,t_1-t_1^{*}]\times (t_2-t_2^{*}, t_2], \end{align*}and split  $A_2=A_{4}\cup A_{5}\cup A_{6}$, where
$A_2=A_{4}\cup A_{5}\cup A_{6}$, where
 \begin{align*} & A_{4} = \{(i,j): t_1-t_1^{*}\le i\le t_1, \ i-3\delta_i\le j\le i+3\delta_{t_2}\},\\ & A_{5} = \{ (i,j): t_1-t_1^{*}\le i\le t_1, \ 0\le j< i-3\delta_i \}, \\ & A_{6} = \{ (i,j): t_1-t_1^{*}\le i\le t_1, \ i+3\delta_{t_2}< j\le t_2\}. \end{align*}
\begin{align*} & A_{4} = \{(i,j): t_1-t_1^{*}\le i\le t_1, \ i-3\delta_i\le j\le i+3\delta_{t_2}\},\\ & A_{5} = \{ (i,j): t_1-t_1^{*}\le i\le t_1, \ 0\le j< i-3\delta_i \}, \\ & A_{6} = \{ (i,j): t_1-t_1^{*}\le i\le t_1, \ i+3\delta_{t_2}< j\le t_2\}. \end{align*}We denote  ${\mathcal {R}}=t_1^{-\alpha _{D'}}(t_2-t_1)^{-\alpha _D}$ and write for short
${\mathcal {R}}=t_1^{-\alpha _{D'}}(t_2-t_1)^{-\alpha _D}$ and write for short
 \begin{align*} S_{A_k}& =\sum_{(i,j)\in A_k}h(i,j),\\ h(i,j)& = \mathbb{P} (D_1'=i,D_2'=j) \mathbb{P} (D_1=t_1-i) \mathbb{P}(D_2=t_2-j). \end{align*}
\begin{align*} S_{A_k}& =\sum_{(i,j)\in A_k}h(i,j),\\ h(i,j)& = \mathbb{P} (D_1'=i,D_2'=j) \mathbb{P} (D_1=t_1-i) \mathbb{P}(D_2=t_2-j). \end{align*}In order to determine the asymptotics of (39), we split
 $$\mathbb{P}(D_1+D_1'=t_1,\, D_2+D_2'=t_2) = S_{A_0}+S_{A_1}+S_{A_2}+S_{A_3},$$
$$\mathbb{P}(D_1+D_1'=t_1,\, D_2+D_2'=t_2) = S_{A_0}+S_{A_1}+S_{A_2}+S_{A_3},$$and show that
 \begin{align} & S_{A_2}=(1+o_{\varepsilon}(1))\mathbb{P}(D_2=t_2-t_1)\mathbb{P}(D_1'=t_1)+o({\mathcal{R}}), \end{align}
\begin{align} & S_{A_2}=(1+o_{\varepsilon}(1))\mathbb{P}(D_2=t_2-t_1)\mathbb{P}(D_1'=t_1)+o({\mathcal{R}}), \end{align} \begin{align} & S_{A_0}+S_{A_1}+S_{A_3}\le c\varepsilon {\mathcal{R}}+c\varepsilon^{{-}2\alpha_D}t_1^{1-\alpha_D}{\mathcal{R}}+ o({\mathcal{R}}). \end{align}
\begin{align} & S_{A_0}+S_{A_1}+S_{A_3}\le c\varepsilon {\mathcal{R}}+c\varepsilon^{{-}2\alpha_D}t_1^{1-\alpha_D}{\mathcal{R}}+ o({\mathcal{R}}). \end{align}Here  $o_{\varepsilon }(1)\to 0$ as
$o_{\varepsilon }(1)\to 0$ as  $\varepsilon \to 0$ and
$\varepsilon \to 0$ and  $t_1,t_2\to +\infty$ so that
$t_1,t_2\to +\infty$ so that  $\delta _{t_2}=o(t_2-t_1)$. Note that (38), (43), (44) imply
$\delta _{t_2}=o(t_2-t_1)$. Note that (38), (43), (44) imply
 $$\mathbb{P}(D_1^{*}=t_1+1,D_2^{*}=t_2+1) = (1+o(1))\mathbb{P}(D_2=t_2-t_1)\mathbb{P}(D_1'=t_1).$$
$$\mathbb{P}(D_1^{*}=t_1+1,D_2^{*}=t_2+1) = (1+o(1))\mathbb{P}(D_2=t_2-t_1)\mathbb{P}(D_1'=t_1).$$Invoking the asymptotic formulae (34), (36) for probabilities  $\mathbb {P}(D_2=t_2-t_1)$ and
$\mathbb {P}(D_2=t_2-t_1)$ and  $\mathbb {P}(D_1'=t_1)$ as
$\mathbb {P}(D_1'=t_1)$ as  $t_2-t_1\to +\infty$ and
$t_2-t_1\to +\infty$ and  $t_1\to +\infty$, we obtain (12).
$t_1\to +\infty$, we obtain (12).
We complete the proof by showing (43) and (44). We first prove (44). Using the inequalities (see (11), (34))
 \begin{align*} & \mathbb{P}(D_1=t_1-i) \le c t_1^{-\alpha_D}, \quad \mathbb{P}(D_2=t_2-j) \le ct_2^{-\alpha_D} \quad \text{for} \ (i,j)\in A_0, \\ & \mathbb{P}(D_1=t_1-i)\le c (t_1^{*})^{-\alpha_D}, \quad \mathbb{P}(D_2=t_2-j)\le c(t_2^{*})^{-\alpha_D} \quad {\text{for}} \ (i,j)\in A_1,\\ & \quad \sum_{(i,j)\in A_1}\mathbb{P}(D_1'=i,D_2'=j) \le \mathbb{P}(D_1'\ge t_1/2)+\mathbb{P}(D_2'\ge t_1/2) \le ct_1^{1-\alpha_{D'}}, \end{align*}
\begin{align*} & \mathbb{P}(D_1=t_1-i) \le c t_1^{-\alpha_D}, \quad \mathbb{P}(D_2=t_2-j) \le ct_2^{-\alpha_D} \quad \text{for} \ (i,j)\in A_0, \\ & \mathbb{P}(D_1=t_1-i)\le c (t_1^{*})^{-\alpha_D}, \quad \mathbb{P}(D_2=t_2-j)\le c(t_2^{*})^{-\alpha_D} \quad {\text{for}} \ (i,j)\in A_1,\\ & \quad \sum_{(i,j)\in A_1}\mathbb{P}(D_1'=i,D_2'=j) \le \mathbb{P}(D_1'\ge t_1/2)+\mathbb{P}(D_2'\ge t_1/2) \le ct_1^{1-\alpha_{D'}}, \end{align*}we bound the sums
 \begin{equation} \begin{aligned} S_{A_0} & \le c t_1^{-\alpha_D} t_2^{-\alpha_D} \sum_{(i,j)\in A_0} \mathbb{P}(D_1'=i, D_2'=j) \le ct_1^{-\alpha_D} t_2^{-\alpha_D} = o({\mathcal{R}}),\\ S_{A_1} & \le c (t_1^{*})^{-\alpha_D} (t_2^{*})^{-\alpha_D} \sum_{(i,j)\in A_1} \mathbb{P}(D_1'=i, D_2'=j) \\ & \le c(t_1^{*})^{-\alpha_D} (t_2^{*})^{-\alpha_D} t_1^{1-\alpha_{D'}}. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} S_{A_0} & \le c t_1^{-\alpha_D} t_2^{-\alpha_D} \sum_{(i,j)\in A_0} \mathbb{P}(D_1'=i, D_2'=j) \le ct_1^{-\alpha_D} t_2^{-\alpha_D} = o({\mathcal{R}}),\\ S_{A_1} & \le c (t_1^{*})^{-\alpha_D} (t_2^{*})^{-\alpha_D} \sum_{(i,j)\in A_1} \mathbb{P}(D_1'=i, D_2'=j) \\ & \le c(t_1^{*})^{-\alpha_D} (t_2^{*})^{-\alpha_D} t_1^{1-\alpha_{D'}}. \end{aligned} \end{equation}Note that the quantity in (45) equals  $c\varepsilon (t_2-t_1)^{-\alpha _D}t_2^{-1}t_1^{1-\alpha _{D'}}\le c\varepsilon {\mathcal {R}}$ for
$c\varepsilon (t_2-t_1)^{-\alpha _D}t_2^{-1}t_1^{1-\alpha _{D'}}\le c\varepsilon {\mathcal {R}}$ for  $2t_1>t_2$. For
$2t_1>t_2$. For  $2t_1\le t_2$ this quantity equals
$2t_1\le t_2$ this quantity equals  $c\varepsilon ^{-2\alpha _D} t_2^{-\alpha _D} t_1^{1-\alpha _D-\alpha _{D'}} \le c\varepsilon ^{-2\alpha _D}t_1^{1-\alpha _D}{\mathcal {R}}.$
$c\varepsilon ^{-2\alpha _D} t_2^{-\alpha _D} t_1^{1-\alpha _D-\alpha _{D'}} \le c\varepsilon ^{-2\alpha _D}t_1^{1-\alpha _D}{\mathcal {R}}.$
Next, we estimate  $S_{A_3}$. We have
$S_{A_3}$. We have
 \begin{align} S_{A_3} & \le \sum_{(i,j)\in A_3} \mathbb{P}(D_1'=i, D_2'=j) \le \sum_{(i,j)\in A_3} e^{{-}c_{**}\ln^{8}{j}} \end{align}
\begin{align} S_{A_3} & \le \sum_{(i,j)\in A_3} \mathbb{P}(D_1'=i, D_2'=j) \le \sum_{(i,j)\in A_3} e^{{-}c_{**}\ln^{8}{j}} \end{align} \begin{align} & \le t_1t_2 e^{{-}c_{**}\ln^{8}(t_2-t_2^{*})} \le e^{{-}c_{**}'\ln^{8}t_2} = o({\mathcal{R}}). \end{align}
\begin{align} & \le t_1t_2 e^{{-}c_{**}\ln^{8}(t_2-t_2^{*})} \le e^{{-}c_{**}'\ln^{8}t_2} = o({\mathcal{R}}). \end{align}The first inequality of (46) is obvious. The second one follows from (37). To verify the condition  $i+\delta _i+\delta _j< j$ for
$i+\delta _i+\delta _j< j$ for  $(i,j)\in A_3$ we write
$(i,j)\in A_3$ we write
 $$i+\delta_i+\delta_j \le t_1 + \delta_{t_1} + \delta_{t_2} < t_2-t_2^{*} \le j.$$
$$i+\delta_i+\delta_j \le t_1 + \delta_{t_1} + \delta_{t_2} < t_2-t_2^{*} \le j.$$Note that the second inequality above follows from the fact that  $\delta _{t_2}=o(t_2-t_1)$. In particular, this inequality is obvious for
$\delta _{t_2}=o(t_2-t_1)$. In particular, this inequality is obvious for  $2t_1< t_2$. For
$2t_1< t_2$. For  $2t_1>t_2$ the inequality follows from
$2t_1>t_2$ the inequality follows from  $t_2^{*}<\delta _{t_2}$ (note that
$t_2^{*}<\delta _{t_2}$ (note that  $\alpha _{D}>2$).
$\alpha _{D}>2$).
We secondly prove (43). We split  $S_{A_2} = S_{A_4}+ S_{A_5}+S_{A_6}$ and show that
$S_{A_2} = S_{A_4}+ S_{A_5}+S_{A_6}$ and show that  $S_{A_4}$ satisfies (43) while
$S_{A_4}$ satisfies (43) while  $S_{A_5}+S_{A_6}=o({\mathcal {R}})$. We derive the latter bound using (37), which implies
$S_{A_5}+S_{A_6}=o({\mathcal {R}})$. We derive the latter bound using (37), which implies
 \begin{align*} & \mathbb{P}(D_1'=i, D_2'=j) \le ce^{{-}c_{**}\ln^{8}i} \le e^{{-}c_{**}'\ln^{8} t_1} \quad {\text{for}} \ (i,j)\in A_{5}, \\ & \mathbb{P}(D_1'=i, D_2'=j) \le ce^{{-}c_{**}\ln^{8}j} \le e^{{-}c_{**}'\ln^{8}t_2} \quad {\text{for}}\ (i,j)\in A_{6}. \end{align*}
\begin{align*} & \mathbb{P}(D_1'=i, D_2'=j) \le ce^{{-}c_{**}\ln^{8}i} \le e^{{-}c_{**}'\ln^{8} t_1} \quad {\text{for}} \ (i,j)\in A_{5}, \\ & \mathbb{P}(D_1'=i, D_2'=j) \le ce^{{-}c_{**}\ln^{8}j} \le e^{{-}c_{**}'\ln^{8}t_2} \quad {\text{for}}\ (i,j)\in A_{6}. \end{align*}In the very last step, we invoked inequalities  $\ln j \ge \ln (3\delta _{t_2}) \ge 0.5\ln t_2$. For
$\ln j \ge \ln (3\delta _{t_2}) \ge 0.5\ln t_2$. For  $(i,j)\in A_{5}$ we will use, in addition, the inequality
$(i,j)\in A_{5}$ we will use, in addition, the inequality  $\mathbb {P}(D_2=t_2-j)\le c(t_2-t_1)^{-\alpha _D}$. We have
$\mathbb {P}(D_2=t_2-j)\le c(t_2-t_1)^{-\alpha _D}$. We have
 $$S_{A_5} \le c(t_2-t_1)^{-\alpha_D} \sum_{(i,j)\in A_5} \mathbb{P}(D_1'=i,D_2'=j) \le c (t_2-t_1)^{-\alpha_D} t_1^{2} e^{{-}c'_{**}\ln^{8}t_1}.$$
$$S_{A_5} \le c(t_2-t_1)^{-\alpha_D} \sum_{(i,j)\in A_5} \mathbb{P}(D_1'=i,D_2'=j) \le c (t_2-t_1)^{-\alpha_D} t_1^{2} e^{{-}c'_{**}\ln^{8}t_1}.$$Here  $t_1^{2}$ bounds the number of summands in the double sum. We conclude that
$t_1^{2}$ bounds the number of summands in the double sum. We conclude that  $S_{A_5}\le c (t_2-t_1)^{-\alpha _D}e^{-c''_{**}\ln ^{8}t_1}=o({\mathcal {R}})$. The proof of
$S_{A_5}\le c (t_2-t_1)^{-\alpha _D}e^{-c''_{**}\ln ^{8}t_1}=o({\mathcal {R}})$. The proof of  $S_{A_6}=o({\mathcal {R}})$ is simpler,
$S_{A_6}=o({\mathcal {R}})$ is simpler,
 \begin{equation} S_{A_6} \le \sum_{(i,j)\in A_6} \mathbb{P}(D_1'=i,D_2'=j) \le t_1t_2e^{{-}c'_{**}\ln^{8}t_2} \le e^{{-}c''_{**}\ln^{8}t_2} = o({\mathcal{R}}), \end{equation}
\begin{equation} S_{A_6} \le \sum_{(i,j)\in A_6} \mathbb{P}(D_1'=i,D_2'=j) \le t_1t_2e^{{-}c'_{**}\ln^{8}t_2} \le e^{{-}c''_{**}\ln^{8}t_2} = o({\mathcal{R}}), \end{equation}where  $t_1t_2$ bounds the number of summands in the double sum.
$t_1t_2$ bounds the number of summands in the double sum.
Now consider  $S_{A_4}$. Denote
$S_{A_4}$. Denote  $h'_{i,j}= \mathbb {P}(D_1'=i,D_2'=j) \mathbb {P}(D_1=t_1-i)$ and put
$h'_{i,j}= \mathbb {P}(D_1'=i,D_2'=j) \mathbb {P}(D_1=t_1-i)$ and put
 $$S'_{A_4} = \sum_{(i,j)\in A_4} h'_{i,j}, \quad S'_{A_2} = \sum_{(i,j)\in A_2} h'_{i,j}, \quad S^{*}=\sum_{t_1-t_1^{*}\le i\le t_1}\sum_{j\ge 0}h'_{i,j}.$$
$$S'_{A_4} = \sum_{(i,j)\in A_4} h'_{i,j}, \quad S'_{A_2} = \sum_{(i,j)\in A_2} h'_{i,j}, \quad S^{*}=\sum_{t_1-t_1^{*}\le i\le t_1}\sum_{j\ge 0}h'_{i,j}.$$Note that uniformly in  $(i,j)\in A_4$, we have
$(i,j)\in A_4$, we have
 \begin{equation} \mathbb{P}(D_2=t_2-j) = (1+o_{\varepsilon}(1))\mathbb{P}(D_2=t_2-t_1), \end{equation}
\begin{equation} \mathbb{P}(D_2=t_2-j) = (1+o_{\varepsilon}(1))\mathbb{P}(D_2=t_2-t_1), \end{equation}where  $o_{\varepsilon }(1)\to 0$ as
$o_{\varepsilon }(1)\to 0$ as  $\varepsilon \to 0$ and
$\varepsilon \to 0$ and  $t_1,t_2\to +\infty$,
$t_1,t_2\to +\infty$,  $(t_2-t_1)/\delta _{t_2}\to +\infty$. Furthermore, uniformly in
$(t_2-t_1)/\delta _{t_2}\to +\infty$. Furthermore, uniformly in  $t_1-t_1^{*}\le i\le t_1$, we have as
$t_1-t_1^{*}\le i\le t_1$, we have as  $t_1\to +\infty$
$t_1\to +\infty$
 \begin{equation} \mathbb{P}(D_1'=i) = (1+o_{\varepsilon}(1))\mathbb{P}(D_1'=t_1). \end{equation}
\begin{equation} \mathbb{P}(D_1'=i) = (1+o_{\varepsilon}(1))\mathbb{P}(D_1'=t_1). \end{equation}Now, using (49), we write
 \begin{equation} S_{A_4}= (1+o_{\varepsilon}(1))\mathbb{P}(D_2=t_2-t_1) S'_{A_4}. \end{equation}
\begin{equation} S_{A_4}= (1+o_{\varepsilon}(1))\mathbb{P}(D_2=t_2-t_1) S'_{A_4}. \end{equation}Then, proceeding as in the proof of  $S_{A_5}+S_{A_6}=o({\mathcal {R}})$ above, we approximate
$S_{A_5}+S_{A_6}=o({\mathcal {R}})$ above, we approximate
 \begin{equation} S'_{A_4}=S'_{A_2} + O(e^{{-}c'_{**}\ln^{8}t_1}) + O(e^{{-}c''_{**}\ln^{8}t_2}). \end{equation}
\begin{equation} S'_{A_4}=S'_{A_2} + O(e^{{-}c'_{**}\ln^{8}t_1}) + O(e^{{-}c''_{**}\ln^{8}t_2}). \end{equation}Finally, we evaluate  $S'_{A_2}$. We write
$S'_{A_2}$. We write  $S'_{A_2}$ in the form
$S'_{A_2}$ in the form  $S'_{A_2} = S^{*}-R^{*}$, where
$S'_{A_2} = S^{*}-R^{*}$, where
 \begin{align*} R^{*} & = \sum_{t_1-t_1^{*}\le i\le t_1} \sum_{j> t_2} \mathbb{P}(D_1'=i, D_2'=j) \mathbb{P}(D_1=t_1-i) \\ & \le \sum_{t_1-t_1^{*}\le i\le t_1} \sum_{j> t_2}e^{{-}c_{**}\ln^{8}j} \\ & \le t_1e^{{-}c_{**}''\ln^{8}t_2} = o({\mathcal{R}}), \end{align*}
\begin{align*} R^{*} & = \sum_{t_1-t_1^{*}\le i\le t_1} \sum_{j> t_2} \mathbb{P}(D_1'=i, D_2'=j) \mathbb{P}(D_1=t_1-i) \\ & \le \sum_{t_1-t_1^{*}\le i\le t_1} \sum_{j> t_2}e^{{-}c_{**}\ln^{8}j} \\ & \le t_1e^{{-}c_{**}''\ln^{8}t_2} = o({\mathcal{R}}), \end{align*}where in the first inequality, we use (37) and  $\mathbb {P}(D_1=t_1-i)\le 1$. We apply (50) to the sum
$\mathbb {P}(D_1=t_1-i)\le 1$. We apply (50) to the sum  $S^{*}$,
$S^{*}$,
 \begin{align*} S^{*} & = \sum_{t_1-t_1^{*}\le i\le t_1} \mathbb{P}(D_1'=i) \mathbb{P}(D_1=t_1-i) \\ & = (1+o_{\varepsilon}(1))\mathbb{P}(D_1'=t_1) \sum_{t_1-t_1^{*}\le i\le t_1} \mathbb{P}(D_1=t_1-i) \\ & = (1+o_{\varepsilon}(1))\mathbb{P}(D_1'=t_1). \end{align*}
\begin{align*} S^{*} & = \sum_{t_1-t_1^{*}\le i\le t_1} \mathbb{P}(D_1'=i) \mathbb{P}(D_1=t_1-i) \\ & = (1+o_{\varepsilon}(1))\mathbb{P}(D_1'=t_1) \sum_{t_1-t_1^{*}\le i\le t_1} \mathbb{P}(D_1=t_1-i) \\ & = (1+o_{\varepsilon}(1))\mathbb{P}(D_1'=t_1). \end{align*}We conclude that  $S'_{A_2} = (1+o_{\varepsilon }(1))\mathbb {P}(D_1'=t_1)+o({\mathcal {R}})$. Now (51), (52) imply
$S'_{A_2} = (1+o_{\varepsilon }(1))\mathbb {P}(D_1'=t_1)+o({\mathcal {R}})$. Now (51), (52) imply
 $$S_{A_4}=(1+o_{\varepsilon}(1)) \mathbb{P}(D_2=t_2-t_1) \mathbb{P}(D_1'=t_1)+o({\mathcal{R}}).$$
$$S_{A_4}=(1+o_{\varepsilon}(1)) \mathbb{P}(D_2=t_2-t_1) \mathbb{P}(D_1'=t_1)+o({\mathcal{R}}).$$The proof of (43) is complete.
6.4. Correlation of the limiting bidegree distribution
Let us analyze the Pearson correlation coefficient  $\operatorname {Cor}(D_1^{*}, D_2^{*})$ of the limiting bidegree distribution in Theorem 1.
$\operatorname {Cor}(D_1^{*}, D_2^{*})$ of the limiting bidegree distribution in Theorem 1.
Proposition 1 For any  $\mu \in (0,\infty )$ and any probability measure
$\mu \in (0,\infty )$ and any probability measure  $P$ on
$P$ on  $\mathbb {Z}_+ \times [0,1]$ such that
$\mathbb {Z}_+ \times [0,1]$ such that  $0 < P_{10}, P_{21} < \infty$ and
$0 < P_{10}, P_{21} < \infty$ and  $P_{32}, P_{43} < \infty$, the random variables
$P_{32}, P_{43} < \infty$, the random variables  $(D_1^{*}, D_2^{*})$ in (8) satisfy
$(D_1^{*}, D_2^{*})$ in (8) satisfy
 $$\operatorname{Cor}(D_1^{*}, D_2^{*}) = \frac{P_{21}( P_{43} + P_{33}) - P_{32}^{2}} {P_{21}(P_{43} + P_{32}) - P_{32}^{2} + \mu P_{21}^{2} ( P_{21} + P_{32})}.$$
$$\operatorname{Cor}(D_1^{*}, D_2^{*}) = \frac{P_{21}( P_{43} + P_{33}) - P_{32}^{2}} {P_{21}(P_{43} + P_{32}) - P_{32}^{2} + \mu P_{21}^{2} ( P_{21} + P_{32})}.$$Proof. Recall the distribution of  $(D_1', D_2')$,
$(D_1', D_2')$,
 $$f'_{2}(s,t) = \int_{\mathbb{Z}_+{\times} [0,1]} \operatorname{Bin}(x-2,y)(s) \operatorname{Bin}(x-2,y)(t) \frac{(x)_2 y P(dx,dy)}{P_{21}}.$$
$$f'_{2}(s,t) = \int_{\mathbb{Z}_+{\times} [0,1]} \operatorname{Bin}(x-2,y)(s) \operatorname{Bin}(x-2,y)(t) \frac{(x)_2 y P(dx,dy)}{P_{21}}.$$If  $B$ is a
$B$ is a  $\operatorname {Bin}(x-2, y)$-distributed random variable, then
$\operatorname {Bin}(x-2, y)$-distributed random variable, then  $\mathbb {E}( B) = (x-2)y$ and
$\mathbb {E}( B) = (x-2)y$ and  $\mathbb {E}( (B)_2) = (x-2)_2 y^{2}$, from which we conclude that
$\mathbb {E}( (B)_2) = (x-2)_2 y^{2}$, from which we conclude that  $\mathbb {E}( B^{2}) = \mathbb {E} ((B)_2) + \mathbb {E} (B) = (x-2)_2 y^{2} + (x-2)y$. Because
$\mathbb {E}( B^{2}) = \mathbb {E} ((B)_2) + \mathbb {E} (B) = (x-2)_2 y^{2} + (x-2)y$. Because  $(x-2)(x)_2 = (x)_3$, it follows that
$(x-2)(x)_2 = (x)_3$, it follows that
 $$\mathbb{E} (D'_1) = \int (x-2)y \frac{(x)_2 y P(dx,dy)}{P_{21}} = \frac{P_{32}}{P_{21}}.$$
$$\mathbb{E} (D'_1) = \int (x-2)y \frac{(x)_2 y P(dx,dy)}{P_{21}} = \frac{P_{32}}{P_{21}}.$$Further, by noting that  $(x-2)_2 (x)_2 = (x)_4$, we see that
$(x-2)_2 (x)_2 = (x)_4$, we see that
 $$\mathbb{E} ((D'_1)^{2}) = \int ( (x-2)_2 y^{2} + (x-2) y ) \frac{(x)_2 y P(dx,dy)}{P_{21}} = \frac{P_{43} + P_{32}}{P_{21}}.$$
$$\mathbb{E} ((D'_1)^{2}) = \int ( (x-2)_2 y^{2} + (x-2) y ) \frac{(x)_2 y P(dx,dy)}{P_{21}} = \frac{P_{43} + P_{32}}{P_{21}}.$$Hence  $D'_1$ has a finite second moment, and variance equal to
$D'_1$ has a finite second moment, and variance equal to
 \begin{equation} \operatorname{Var}( D'_1 ) = \frac{P_{43} + P_{32}}{P_{21}} - \left( \frac{P_{32}}{P_{21}} \right)^{2}. \end{equation}
\begin{equation} \operatorname{Var}( D'_1 ) = \frac{P_{43} + P_{32}}{P_{21}} - \left( \frac{P_{32}}{P_{21}} \right)^{2}. \end{equation}Similarly, the conditional independence of  $D_1'$ and
$D_1'$ and  $D'_2$, together with the formula
$D'_2$, together with the formula  $(x-2)^{2} (x)_2 = (x-2) (x)_3 = (x)_4 + (x)_3$, implies that
$(x-2)^{2} (x)_2 = (x-2) (x)_3 = (x)_4 + (x)_3$, implies that
 $$\mathbb{E}( D'_1 D'_2) = \int ( (x-2)y )^{2} \frac{(x)_2 y P(dx,dy)}{P_{21}} = \frac{P_{43} + P_{33}}{P_{21}},$$
$$\mathbb{E}( D'_1 D'_2) = \int ( (x-2)y )^{2} \frac{(x)_2 y P(dx,dy)}{P_{21}} = \frac{P_{43} + P_{33}}{P_{21}},$$and hence, noting that  $D'_1$ and
$D'_1$ and  $D'_2$ are identically distributed,
$D'_2$ are identically distributed,
 \begin{equation} \operatorname{Cov}(D'_1, D'_2)= \frac{P_{43} + P_{33}}{P_{21}} - \left( \frac{P_{32}}{P_{21}} \right)^{2}. \end{equation}
\begin{equation} \operatorname{Cov}(D'_1, D'_2)= \frac{P_{43} + P_{33}}{P_{21}} - \left( \frac{P_{32}}{P_{21}} \right)^{2}. \end{equation}Recall next that  $D_1$ follows the compound Poisson distribution
$D_1$ follows the compound Poisson distribution  $\bar f_1 = \operatorname {CPoi}(\lambda , g)$, and that the variance of
$\bar f_1 = \operatorname {CPoi}(\lambda , g)$, and that the variance of  $\operatorname {CPoi}(\lambda , g)$ equals
$\operatorname {CPoi}(\lambda , g)$ equals  $\lambda \int x^{2} g(dx)$ ([Reference Daykin, Pentikäinen and Pesonen18], Eq. (3.2.13)). A simple computation confirms that the second moment of
$\lambda \int x^{2} g(dx)$ ([Reference Daykin, Pentikäinen and Pesonen18], Eq. (3.2.13)). A simple computation confirms that the second moment of  $g$ in (7) equals
$g$ in (7) equals  ${(P_{32} + P_{21})}/{P_{10}}$. Hence it follows that
${(P_{32} + P_{21})}/{P_{10}}$. Hence it follows that  $D_1$ has a finite second moment with
$D_1$ has a finite second moment with
 \begin{equation} \operatorname{Var}(D_1) = \lambda \frac{P_{32} + P_{21} }{P_{10}}. \end{equation}
\begin{equation} \operatorname{Var}(D_1) = \lambda \frac{P_{32} + P_{21} }{P_{10}}. \end{equation}The mutual independence of  $D_1$,
$D_1$,  $D_2$, and
$D_2$, and  $(D_1',D_2')$ implies that
$(D_1',D_2')$ implies that  $\operatorname {Cov}(D_1^{*}, D_2^{*}) = \operatorname {Cov}(D'_1, D'_2)$ and
$\operatorname {Cov}(D_1^{*}, D_2^{*}) = \operatorname {Cov}(D'_1, D'_2)$ and  $\operatorname {Var}(D_1^{*}) = \operatorname {Var}(D_1) + \operatorname {Var}(D_1')$, so that
$\operatorname {Var}(D_1^{*}) = \operatorname {Var}(D_1) + \operatorname {Var}(D_1')$, so that
 \begin{equation} \operatorname{Cor}(D_1^{*}, D_2^{*})= \frac{\operatorname{Cov}(D'_1, D'_2)}{\operatorname{Var}(D_1) + \operatorname{Var}(D_1')}. \end{equation}
\begin{equation} \operatorname{Cor}(D_1^{*}, D_2^{*})= \frac{\operatorname{Cov}(D'_1, D'_2)}{\operatorname{Var}(D_1) + \operatorname{Var}(D_1')}. \end{equation}By plugging (53)–(55) into (56), we conclude that
 $$\operatorname{Cor}(D^{*}_1,D^{*}_2) = \frac{\frac{P_{43} + P_{33}}{P_{21}} - ( \frac{P_{32}}{P_{21}} )^{2}} {\frac{P_{43} + P_{32}}{P_{21}} - ( \frac{P_{32}}{P_{21}} )^{2} + \lambda \frac{P_{32} + P_{21} }{P_{10}}}.$$
$$\operatorname{Cor}(D^{*}_1,D^{*}_2) = \frac{\frac{P_{43} + P_{33}}{P_{21}} - ( \frac{P_{32}}{P_{21}} )^{2}} {\frac{P_{43} + P_{32}}{P_{21}} - ( \frac{P_{32}}{P_{21}} )^{2} + \lambda \frac{P_{32} + P_{21} }{P_{10}}}.$$By recalling that  $\lambda = \mu P_{10}$, the claim follows.
$\lambda = \mu P_{10}$, the claim follows.
6.5. Proof of Lemma 1
Let  $(X,Q)$ and
$(X,Q)$ and  $(Y,R)$ be mutually independent random vectors, both distributed according to
$(Y,R)$ be mutually independent random vectors, both distributed according to  $P$. Then
$P$. Then
 $$P_{21} P_{43} + P_{21} P_{33} - P_{32}^{2} = \mathbb{E} (f(X,Q,Y,R)),$$
$$P_{21} P_{43} + P_{21} P_{33} - P_{32}^{2} = \mathbb{E} (f(X,Q,Y,R)),$$where
 $$f(x, q, y, r) = (x)_2 q (y)_4 r^{3} + (x)_2 q (y)_3 r^{3} - (x)_3 q^{2} (y)_3 r^{2}.$$
$$f(x, q, y, r) = (x)_2 q (y)_4 r^{3} + (x)_2 q (y)_3 r^{3} - (x)_3 q^{2} (y)_3 r^{2}.$$On the other hand, by applying the identity  $(y)_4 + (y_3) = (y-2)^{2} (y)_2$, we find that
$(y)_4 + (y_3) = (y-2)^{2} (y)_2$, we find that
 \begin{align*} f(x, q, y, r) & = (x)_2 (y)_2 (y-2)^{2} q r^{3} - (x)_3 q^{2} (y)_3 r^{2} \\ & = (x)_2 (y)_2 q r ( (y-2)^{2} r^{2} - (x-2)(y-2)qr ). \end{align*}
\begin{align*} f(x, q, y, r) & = (x)_2 (y)_2 (y-2)^{2} q r^{3} - (x)_3 q^{2} (y)_3 r^{2} \\ & = (x)_2 (y)_2 q r ( (y-2)^{2} r^{2} - (x-2)(y-2)qr ). \end{align*}Therefore,
 $$f(x, q, y, r) + f(y, r, x, q) = (x)_2 (y)_2 q r ( (x-2) q - (y-2) r )^{2} \ge 0.$$
$$f(x, q, y, r) + f(y, r, x, q) = (x)_2 (y)_2 q r ( (x-2) q - (y-2) r )^{2} \ge 0.$$By symmetry,  $\mathbb {E} (f(X,Q,Y,R)) = \mathbb {E} (f(Y,R,X,Q))$, and hence we may conclude that
$\mathbb {E} (f(X,Q,Y,R)) = \mathbb {E} (f(Y,R,X,Q))$, and hence we may conclude that
 $$P_{21} P_{43} + P_{21} P_{33} - P_{32}^{2} = \tfrac 12 \mathbb{E} ( f(X,Q,Y,R) + f(Y,R,X,Q) ) \ge 0.$$
$$P_{21} P_{43} + P_{21} P_{33} - P_{32}^{2} = \tfrac 12 \mathbb{E} ( f(X,Q,Y,R) + f(Y,R,X,Q) ) \ge 0.$$6.6. Proof of Theorem 3
We only sketch the proof in the case where  ${m}/{n} \to \mu \in (0,\infty )$. Let
${m}/{n} \to \mu \in (0,\infty )$. Let  $(D_{1,n}^{*}, D_{2,n}^{*})$ be a random variable distributed according to the model bidegree distribution
$(D_{1,n}^{*}, D_{2,n}^{*})$ be a random variable distributed according to the model bidegree distribution  $f_{2,n}$ of
$f_{2,n}$ of  $G_n$. By applying Theorem 1(ii) with
$G_n$. By applying Theorem 1(ii) with  $\phi (x,y) = x$, and then with
$\phi (x,y) = x$, and then with  $\phi (x,y) = x^{2}$, we find that
$\phi (x,y) = x^{2}$, we find that  $\operatorname {Var}(D_{1,n}^{*}) \to \operatorname {Var}(D_{1}^{*})$. Observe next that for
$\operatorname {Var}(D_{1,n}^{*}) \to \operatorname {Var}(D_{1}^{*})$. Observe next that for  $\phi (x,y) = xy$,
$\phi (x,y) = xy$,  ${\lvert {\phi (x,y)}\rvert } \le 2(x^{2}+y^{2})$. Hence Theorem 1(ii) also implies that
${\lvert {\phi (x,y)}\rvert } \le 2(x^{2}+y^{2})$. Hence Theorem 1(ii) also implies that  $\operatorname {Cov}(D_{1,n}^{*},D_{2,n}^{*}) \to \operatorname {Cov}(D_{1}^{*},D_{2}^{*})$. Hence the claim follows by Proposition 1.
$\operatorname {Cov}(D_{1,n}^{*},D_{2,n}^{*}) \to \operatorname {Cov}(D_{1}^{*},D_{2}^{*})$. Hence the claim follows by Proposition 1.
6.7. Proof of Theorem 4
Because  $f_{2,n}$ has identical marginals, we see that
$f_{2,n}$ has identical marginals, we see that
 $$\rho_\textrm{Ken}(f_{2,n}) = \frac{\int \phi \, d (f_{2,n} \otimes f_{2,n}) - ( \int \phi_1 \, d (f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) )^{2} } {\int \phi_1^{2} \, d (f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) - ( \int \phi_1 \, d (f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) )^{2}},$$
$$\rho_\textrm{Ken}(f_{2,n}) = \frac{\int \phi \, d (f_{2,n} \otimes f_{2,n}) - ( \int \phi_1 \, d (f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) )^{2} } {\int \phi_1^{2} \, d (f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) - ( \int \phi_1 \, d (f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) )^{2}},$$where  $\phi _1(x_1,y_1) = \operatorname {sgn}(x_1-y_1)$,
$\phi _1(x_1,y_1) = \operatorname {sgn}(x_1-y_1)$,  $\phi (x_1,x_2,y_1,y_2) = \phi _1(x_1,y_1) \phi _1(x_2,y_2)$ are bounded (and trivially continuous) functions defined on
$\phi (x_1,x_2,y_1,y_2) = \phi _1(x_1,y_1) \phi _1(x_2,y_2)$ are bounded (and trivially continuous) functions defined on  $\mathbb {Z}_+^{2}$ and
$\mathbb {Z}_+^{2}$ and  $\mathbb {Z}_+^{4}$, respectively. Theorem 1 implies that
$\mathbb {Z}_+^{4}$, respectively. Theorem 1 implies that  $f_{2,n} \to \bar f_2$ weakly as probability measures on
$f_{2,n} \to \bar f_2$ weakly as probability measures on  $\mathbb {Z}_+^{2}$. Hence also
$\mathbb {Z}_+^{2}$. Hence also  $f_{2,n} \otimes f_{2,n} \to \bar f_2 \otimes \bar f_2$ and
$f_{2,n} \otimes f_{2,n} \to \bar f_2 \otimes \bar f_2$ and  $f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \to \bar f^{(1)}_2 \otimes \bar f^{(1)}_2$ weakly. We conclude that
$f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \to \bar f^{(1)}_2 \otimes \bar f^{(1)}_2$ weakly. We conclude that  $\rho _\textrm {Ken}(f_{2,n}) \to \rho _\textrm {Ken}( \bar f_2 )$.
$\rho _\textrm {Ken}(f_{2,n}) \to \rho _\textrm {Ken}( \bar f_2 )$.
To verify the claim for Spearman's rank correlation, we apply the representation ([Reference Nešlehová38], Sect. 4.3)
 $$\rho_{\text{Spe}} (f_{2,n}) = \frac{ \mathbb{P}( (X^{(1)}-Y^{(2)})(X^{(2)}-Z^{(2)}) > 0) - \mathbb{P}((X^{(1)}-Y^{(2)})(X^{(2)}-Z^{(2)}) < 0)} {\frac{1}{3}\sqrt{1 - \mathbb{P}(X^{(1)}=Y^{(1)}=Z^{(1)})} \sqrt{1 - \mathbb{P}(X^{(2)}=Y^{(2)}=Z^{(2)})} },$$
$$\rho_{\text{Spe}} (f_{2,n}) = \frac{ \mathbb{P}( (X^{(1)}-Y^{(2)})(X^{(2)}-Z^{(2)}) > 0) - \mathbb{P}((X^{(1)}-Y^{(2)})(X^{(2)}-Z^{(2)}) < 0)} {\frac{1}{3}\sqrt{1 - \mathbb{P}(X^{(1)}=Y^{(1)}=Z^{(1)})} \sqrt{1 - \mathbb{P}(X^{(2)}=Y^{(2)}=Z^{(2)})} },$$where  $(X^{(1)},X^{(2)}), (Y^{(1)},Y^{(2)}), (Z^{(1)},Z^{(2)})$ are mutually independent and
$(X^{(1)},X^{(2)}), (Y^{(1)},Y^{(2)}), (Z^{(1)},Z^{(2)})$ are mutually independent and  $f_{2,n}$- distributed. By applying the formula
$f_{2,n}$- distributed. By applying the formula  $\mathbb {P}(W > 0) - \mathbb {P}(W < 0) = \mathbb {E} ( 1(W>0) - 1(W<0)) = \mathbb {E} (\operatorname {sgn}(W))$ with
$\mathbb {P}(W > 0) - \mathbb {P}(W < 0) = \mathbb {E} ( 1(W>0) - 1(W<0)) = \mathbb {E} (\operatorname {sgn}(W))$ with  $W = (X^{(1)}-Y^{(2)})(X^{(2)}-Z^{(2)})$, and noting that
$W = (X^{(1)}-Y^{(2)})(X^{(2)}-Z^{(2)})$, and noting that  $f_{2,n}$ has identical marginals, this can be rewritten as
$f_{2,n}$ has identical marginals, this can be rewritten as
 $$\rho_\textrm{Spe}(f_{2,n}) = 3 \frac{ \int \phi \, d( f_{2,n} \otimes f_{2,n} \otimes f_{2,n}) } {\int \psi \, d( f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) },$$
$$\rho_\textrm{Spe}(f_{2,n}) = 3 \frac{ \int \phi \, d( f_{2,n} \otimes f_{2,n} \otimes f_{2,n}) } {\int \psi \, d( f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \otimes f^{(1)}_{2,n}) },$$where  $\phi (x_1,x_2,y_1,y_2,z_1,z_2) = \operatorname {sgn}( (x_1-y_2)(x_2-z_2) )$ and
$\phi (x_1,x_2,y_1,y_2,z_1,z_2) = \operatorname {sgn}( (x_1-y_2)(x_2-z_2) )$ and  $\psi (x_1,y_1,z_1) = 1 - 1(x_1=y_1=z_1)$ are bounded (and trivially continuous) functions on
$\psi (x_1,y_1,z_1) = 1 - 1(x_1=y_1=z_1)$ are bounded (and trivially continuous) functions on  $\mathbb {Z}_+^{6}$ and
$\mathbb {Z}_+^{6}$ and  $\mathbb {Z}_+^{3}$, respectively. The second claim follows by noting that
$\mathbb {Z}_+^{3}$, respectively. The second claim follows by noting that  $f_{2,n} \otimes f_{2,n} \otimes f_{2,n} \to \bar f_2 \otimes \bar f_2 \otimes \bar f_{2}$ and
$f_{2,n} \otimes f_{2,n} \otimes f_{2,n} \to \bar f_2 \otimes \bar f_2 \otimes \bar f_{2}$ and  $f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \to \bar f^{(1)}_2 \otimes \bar f^{(1)}_2 \otimes \bar f^{(1)}_{2}$ weakly.
$f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \otimes f^{(1)}_{2,n} \to \bar f^{(1)}_2 \otimes \bar f^{(1)}_2 \otimes \bar f^{(1)}_{2}$ weakly.
Acknowledgments
This work was supported by COSTNET COST Action 15109. JK was supported by the Magnus Ehrnrooth Foundation.
