1. Introduction
Machine Reading Comprehension (MRC) is a challenging task in Natural Language Processing (NLP) aimed to evaluate the extent to which machines achieve the goal of natural language understanding. In order to assess the comprehension of a machine of a piece of natural language text, a set of questions about the text is given to the machine, and the responses of the machine are evaluated against the gold standard. Nowadays, MRC is known as the research area of reading comprehension for machines based on question answering (QA). Each instance in MRC datasets contains a context
 $C$
, a related question
$C$
, a related question
 $Q$
, and an answer
$Q$
, and an answer
 $A$
. Figure 1 shows some examples of the SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) and CNN/Daily Mail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015) datasets. The goal of MRC systems is to learn the predictive function f that extracts/generates the appropriate answer
$A$
. Figure 1 shows some examples of the SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) and CNN/Daily Mail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015) datasets. The goal of MRC systems is to learn the predictive function f that extracts/generates the appropriate answer
 $A$
based on the context
$A$
based on the context
 $C$
and the related question
$C$
and the related question
 $Q$
:
$Q$
:
 $$f:\left( {C,Q} \right) \to A$$
$$f:\left( {C,Q} \right) \to A$$
Furthermore, MRC systems have important applications in distinct areas, such as conversational agents (Hewlett, Jones and Lacoste Reference Hewlett, Jones and Lacoste2017; Reddy, Chen and Manning Reference Reddy, Chen and Manning2019) and customer service support (Cui et al. Reference Cui, Huang, Wei, Tan, Duan and Zhou2017a).
Although MRC is referred to as QA in some studies, these two concepts are different in the following ways:
-
• The main objective of QA systems is to answer the input questions, while the main goal of an MRC system, as the name suggests, is to demonstrate the machine’s ability in understanding natural languages through answering questions about specific context that it reads.
-
• The only input to QA systems is the question, while the inputs to MRC systems entail the question and the corresponding context, which should be used to answer the question. As a result, sometimes MRC is referred to as QA from the text (Deng and Liu Reference Deng and Liu2018).
-
• The main information source used to answer questions in MRC systems is natural language texts, while in QA systems, the structured and semi-structured data sources, such as knowledge-based ones, are commonly applied, in addition to the non-structured data like texts.
1.1. History
The history of reading comprehension for machines dates back to the 1970s when researchers identified it as a convenient way to test computer comprehension ability. One of the most prominent early studies was the QUALM system (Lehnert Reference Lehnert1977). This system was limited to handwritten scripts and could not be easily generalized to larger domains. Due to the complexity of this task, research in this area was reduced in 1980s and 1990s. In the late 1990s, Hirschman et al. (Reference Hirschman, Light, Breck and Burger1999) revived the field of MRC by creating a new dataset, including 120 stories and questions from 3rd- to 6th-grade material, followed by a workshop on comprehension test as a tool for assessing machine comprehension at ANLP/NAACL 2000.
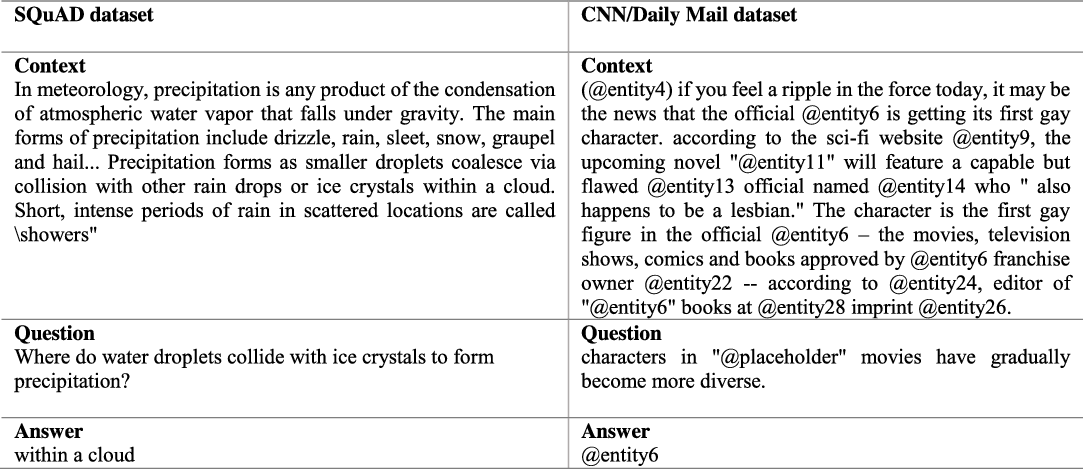
Figure 1. Samples from SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) and CNN/Daily Mail (Chen, Bolton and Manning Reference Chen, Bolton and Manning2016) datasets. The original article of the CNN/Daily Mail example can be found at https://edition.cnn.com/2015/03/10/entertainment/ feat-star-wars-gay-character
Another revolution in this field occurred between 2013 and 2015 by introducing labeled training datasets mapping (context, question) pairs to the answer. This transformed the MRC problem into a supervised learning task (Chen Reference Chen2018). Two prominent datasets in this period were the MCTest dataset (Richardson, Burges and Renshaw Reference Richardson, Burges and Renshaw2013) with 500 stories and 2000 questions and the ProcessBank dataset (Berant et al. Reference Berant, Srikumar, Chen, Vander Linden, Harding, Huang, Clark and Manning2014) with 585 questions over 200 paragraphs related to biological processes. In 2015, the introduction of large datasets such as CNN/Daily Mail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015) and SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) opened a new window in the MRC field by allowing the development of deep models.
In recent years, with the success of machine learning techniques, especially the neural networks, and the usage of recurrent neural networks to process sequential data such as texts, MRC has become an active area in the field of NLP. The goal of this paper is to categorize these studies, provide related statistics, and show the trends in this field. Some recent surveys focused on QA systems (Bouziane et al. Reference Bouziane, Bouchiha, Doumi and Malki2015; Kodra and Meçe Reference Kodra and Meçe2017). Some papers presented a partial survey on some MRC systems but did not provide a comprehensive classification of different aspects and different statistics in this field (Arivuchelvan and Lakahmi Reference Arivuchelvan and Lakahmi2017; Zhang et al. Reference Zhang, Yang, Li and Wang2019a). Ingale and Singh only provided a review on MRC datasets (Ingale and Singh Reference Ingale and Singh2019). Liu et al. (Reference Liu, Zhang, Zhang, Wang and Zhang2019c) provide a review on different aspects of neural MRC models including definitions, differences, popular datasets, architectures, and new trends based on 85 papers. In our study, we present a comprehensive review on 241 papers, analyzing and categorizing MRC studies from different aspects including problem-solving approaches, input/output, model structures, research novelties, and datasets. We also provide statistics on the amount of research attention to these aspects in different years, which are not provided in previous reviews.
1.2. Outline
In order to select papers, the queries “reading comprehension,” “machine reading,” “machine reading comprehension,” and “machine comprehension” were submitted to the Google Scholar serviceFootnote a . Also, the ACL Anthology websiteFootnote b , which includes top related NLP conferences such as ACL, EMNLP, NAACL, and CoNLL, was searched with the same queries to extract the remaining related papers. We excluded the retrieved papers that were published only on arXiv as well as the QA papers with no novelty in the MRC phase. We also excluded the papers with the conversational or dialogue MRC as subjects because these papers focus on multi-turn QA in conversational contexts with different challenges (Gupta, Rawat and Yu Reference Gupta, Rawat and Yu2020). We limited our study to the papers published in recent years, that is, from 2016 to September 2020. Table 1 shows the number of reviewed papers over different years.
Table 1. Number of reviewed papers over different years.

The contributions of this paper are as follows:
-
• Investigating recently published MRC papers from different perspectives including problem-solving approaches, system input/outputs, contributions of these studies, and evaluation metrics.
-
• Providing statistics for each category over different years and highlighting the trends in this field.
-
• Reviewing available datasets and classifying them based on important factors.
-
• Discussing specific aspects of the most-cited papers such as their contribution, their citation number, and year and venue of their publication.
The rest of this paper is organized as follows. Section 2 focuses on the main problem-solving approaches for the MRC task. The review of the papers based on the basic phases of an MRC system is presented in Section 3. Section 4 provides an analysis of the type of input/outputs of MRC systems. The recent datasets and evaluation measures are reviewed in Sections 5 and 6, respectively. In Section 7, the MRC studies are categorized based on their contributions and novelties. The most-cited papers are investigated in Section 8. Section 9 provides future trends and opportunities. Finally, the paper is concluded in Section 10.
2. Problem-solving approaches
The approaches used for developing MRC systems can be grouped into three categories: rule-based methods, classical machine learning-based methods, and deep learning-based methods.
The traditional rule-based methods use the rules handcrafted by linguistic experts. These methods suffer from the problem of the incompleteness of the rules. Also, this approach is domain-specific where for any new domain a new set of rules should be handcrafted. As an example, Riloff and Thelen (Reference Riloff and Thelen2000) present a rule-based MRC system called Quarc, which reads a short story and answers the input question by extracting the most relevant sentences. Quarc uses a separate set of rules for each question type (WHO, WHAT, WHEN, WHERE, and WHY). In this system, several NLP tools are used for parsing, part of speech tagging, morphological analysis, entity recognition, and semantic class tagging. As another example, Akour et al. (Reference Akour, Abufardeh, Magel and Al-Radaideh2011) introduce the QArabPro system, which is a system for answering reading comprehension questions in the Arabic language. It is also developed using a set of rules for each type of question and uses multiple NLP components, including question classification, query reformulation, stemming, and root extraction.
The second approach is based on the classical machine learning. These methods rely on a set of human-defined features and train a model for mapping input features to the output. Note that in classical machine learning-based methods, even though the handcrafted rules are not necessary, feature engineering is a critical necessity.
For example, Ng, Teo and Kwan (Reference Ng, Teo and Kwan2000) have developed a machine learning-based MRC system and introduced some of features to be extracted from a context sentence like “the number of matching words/verb types between the question and the sentence,” “the number of matching words/verb types between the question and the previous/next sentence,” “co-reference information,” and binary features like “sentence-contain-person,” “sentence-contain-time,” “sentence-contain-location,” “sentence-is-title,” and so on
The third approach uses deep learning methods to learn features from raw input data automatically. These methods require a large amount of training data to create high accuracy models. Because of the growth of available data and computational power in recent years, deep learning methods have gained state-of-the-art results in many tasks. In the MRC task, most of the recent research falls into this category. Two main deep learning architectures used by MRC researchers are the Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN).
RNNs are often used for modeling sequential data by iterating through the sequence elements and maintaining a state containing information relative to what have seen so far. Two common types of RNNs are Long Short-Term Memory (LSTM) (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997) and Gated Recurrent Unit (GRU) (Cho et al. Reference Cho, Van MerriËnboer, Gulcehre, Bahdanau, Bougares, Schwenk and Bengio2014) in uni-directional and bi-directional versions (Chen et al. Reference Chen, Bolton and Manning2016; Kobayashi et al. Reference Kobayashi, Tian, Okazaki and Inui2016; Chen et al. Reference Chen, Fisch, Weston and Bordes2017; Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Clark and Gardner Reference Clark and Gardner2018; Ghaeini et al. Reference Ghaeini, Fern, Shahbazi and Tadepalli2018; Hoang, Wiseman and Rush Reference Hoang, Wiseman and Rush2018; Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a; Liu et al. Reference Liu, Zhao, Si, Zhang, Li and Yu2018a). In MRC systems, like other NLP tasks, these architectures have been commonly used in different parts of the pipeline, such as for representing questions and contexts (Chen et al. Reference Chen, Bolton and Manning2016; Kobayashi et al. Reference Kobayashi, Tian, Okazaki and Inui2016; Chen et al. Reference Chen, Fisch, Weston and Bordes2017; Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Clark and Gardner Reference Clark and Gardner2018; Ghaeini et al. Reference Ghaeini, Fern, Shahbazi and Tadepalli2018; Hoang et al. Reference Hoang, Wiseman and Rush2018; Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a; Liu et al. Reference Liu, Zhao, Si, Zhang, Li and Yu2018a) or in higher levels of the MRC system such as the modeling layer (Choi et al. Reference Choi, Hewlett, Uszkoreit, Polosukhin, Lacoste and Berant2017b; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Li, Li and Lv Reference Li, Li and Lv2018). In recent years, the attention-based Transformer (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) has emerged as a powerful alternative to the RNN architecture. For more detailed information, refer to Section 3.
CNN is a type of deep learning model that is universally used in computer vision applications. It utilizes layers with convolution filters that are applied to local spots of their inputs (LeCun et al. Reference LeCun, Bottou, Bengio and Haffner1998). CNN models have subsequently been shown to be effective for NLP and have achieved excellent results in various NLP tasks (Kim Reference Kim2014). In MRC systems, CNN is used in the embedding phase (especially, character embedding) (Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Indurthi et al. Reference Indurthi, Yu, Back and CuayÁhuitl2018) as well as in higher-level phases (introduced in Section 3) for modeling interactions between the question and passage like in the QANet (Yu et al. Reference Yu, Dohan, Luong, Zhao, Chen, Norouzi and Le2018). QANet uses CNN and self-attention blocks instead of the RNN, which results in faster answer span detection on the SQuAD dataset (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016).
3. MRC phases
Most of the recent deep learning-based MRC systems have the following phases: embedding phase, reasoning phase, and prediction phase. Many of the reviewed papers focus on developing new structures for these phases, especially the reasoning phase.
3.1. Embedding phase
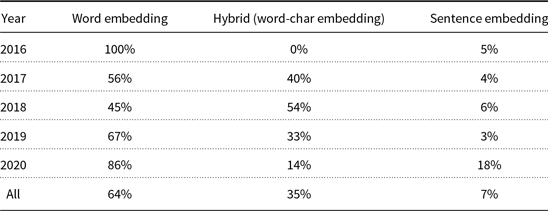
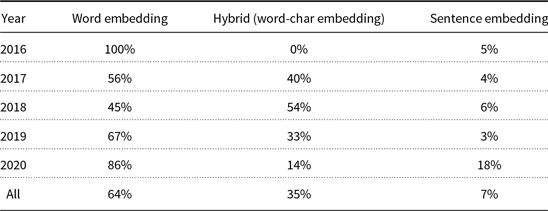
In this phase, input characters, words, or sentences are represented by real-valued dense vectors in a meaningful space. The goal of this phase is to provide question and context embedding. Different levels of embedding are used in MRC systems. Character-level and word-level embeddings can capture the properties of words, subwords, and characters, and higher-level representations can represent syntactic and semantic information of input text. Table 2 shows the statistics of various embedding methods used in the reviewed papers. Since there is not any paper that uses the character embedding as the only embedding method, there is no character embedding column in this table. For a complete list of papers categorized based on their embedding methods, refer to Table A1.
Table 2. Statistics of different embedding methods used by reviewed papers.
3.1.1. Character embedding
Some papers use character embedding as part of their embedding phase. This type of embedding is useful to overcome unknown and rare words problems (Dhingra et al. Reference Dhingra, Zhou, Fitzpatrick, Muehl and Cohen2016; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017). To generate the input representation, deep neural network models are commonly used. Inspired by Kim’s work (Kim Reference Kim2014), some papers have used CNN models to embed the input characters (Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Zhang et al. Reference Zhang, Zhu, Chen, Ling, Dai, Wei and Jiang2017; Gong and Bowman Reference Gong and Bowman2018; Kundu and Ng Reference Kundu and Ng2018a). Some other papers have used character level information captured from the final state of an RNN model like LSTM (or Bi-LSTM) and GRU (or Bi-GRU) (Wang, Yuan and Trischler Reference Wang, Yuan and Trischler2017a; Yang et al. Reference Yang, Dhingra, Yuan, Hu, Cohen and Salakhutdinov2017a; Du and Cardie Reference Du and Cardie2018; Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a; Wang et al. Reference Wang, Yu, Guo, Wang, Klinger, Zhang, Chang, Tesauro, Zhou and Jiang2018b). As another approach which uses both CNN and LSTM to embed input characters, LSTM-char CNN (Kim et al. Reference Kim, Jernite, Sontag and Rush2016) is also used in MRC literature (Prakash, Tripathy and Banu Reference Prakash, Tripathy and Banu2018). We classify these papers in two categories, CNN and RNN, and so the sum of percentages is greater than 100% in Figure 2. This figure shows the percentage of different character embedding methods over different years. Other methods include skip-gram, n-grams, and more recent methods like ELMo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018). It is clear that the use of CNN has been consistently higher than the use of RNN for character embedding in different years.

Figure 2. The percentage of different character embedding methods over different years
3.1.2. Word embedding
Word embedding is to represent the words or subwords in a numeric vector space, which is performed by two main approaches: 1) non-contextual embedding and 2) contextual embedding.
Non-contextual word embedding
Non-contextual embeddings present a single general representation for each word, regardless of its context. There are three main non-contextual embeddings: 1) one hot encoding, 2) learning word vectors jointly with the main task, and 3) using pre-trained word vectors (fixed or fine-tuned).
One hot encoding is the most basic way to turn a token into a vector. These are binary, sparse, and very high dimensional vectors with the size of the vocabulary (the number of unique words in the corpus). To represent a word w, all the vector elements are set to zero, except the one which identifies w. This approach has been less popular than other approaches in recent papers (Cui et al. Reference Cui, Liu, Chen, Wang and Hu2016; Liu and Perez Reference Liu and Perez2017).
Another popular way to represent words is learned word vectors, which delivers dense real-valued representations. In the presence of a large amount of training data, it is advised to learn the word vectors from scratch jointly with the main task (Chollet Reference Chollet2017).
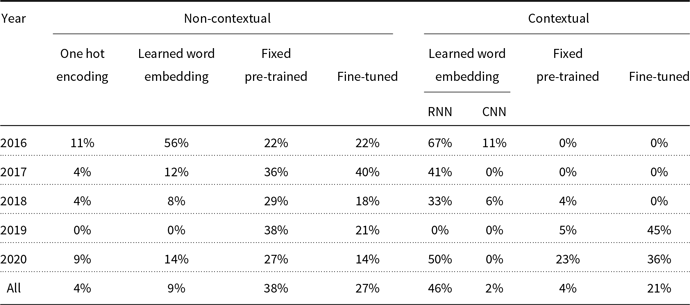
Some studies have shown that initializing word vectors with pre-trained values results in better accuracies than random initialization (Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017; Ren, Cheng and Su Reference Ren, Cheng and Su2020; Wang et al. Reference Wang, Zhang, Zhou and Li2020a; Zhou, Luo and Wu Reference Zhou, Luo and Wu2020b). This approach is especially useful in low-data scenarios (Chollet Reference Chollet2017; Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017). GloVe embedding (Pennington, Socher and Manning Reference Pennington, Socher and Manning2014) is the most common pre-trained word representation among non-contextual representations, used in the reviewed papers (Chen et al. Reference Chen, Bolton and Manning2016; Yin, Ebert and Schütze Reference Yin, Ebert and Schütze2016; Chen et al. Reference Chen, Fisch, Weston and Bordes2017; Liu et al. Reference Liu, Hu, Wei, Yang and Nyberg2017; Wang et al. Reference Wang, Yuan and Trischler2017a; Xiong, Zhong and Socher Reference Xiong, Zhong and Socher2017; Gong and Bowman Reference Gong and Bowman2018; Wang et al. Reference Wang, Yu, Guo, Wang, Klinger, Zhang, Chang, Tesauro, Zhou and Jiang2018b). Word2Vec (Mikolov et al. Reference Mikolov, Sutskever, Chen, Corrado and Dean2013) is another word embedding used in this task (Kobayashi et al. Reference Kobayashi, Tian, Okazaki and Inui2016; Chaturvedi, Pandit and Garain Reference Chaturvedi, Pandit and Garain2018; Šuster and Daelemans Reference Šuster and Daelemans2018). These pre-trained word vectors are fine-tuned (Chen et al. Reference Chen, Bolton and Manning2016; Kobayashi et al. Reference Kobayashi, Tian, Okazaki and Inui2016; Zhang et al. Reference Zhang, Zhu, Chen, Ling, Dai, Wei and Jiang2017; Clark and Gardner Reference Clark and Gardner2018; Liu et al. Reference Liu, Shen, Duh and Gao2018c; Šuster and Daelemans Reference Šuster and Daelemans2018) or left as fixed vectors (Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Shen et al. Reference Shen, Huang, Gao and Chen2017; Weissenborn, Wiese and Seiffe Reference Weissenborn, Wiese and Seiffe2017; Gong and Bowman Reference Gong and Bowman2018). Fine-tuning some keywords such as “what,” “how,” “which,” and “many” could be crucial for QA systems, while most of the pre-trained word vectors can be kept fixed (Chen et al. Reference Chen, Fisch, Weston and Bordes2017). Table 3 shows the statistics of these approaches in different years. Finally, it is worth noting that some papers use hand-designed word features such as named entity (NE) tag and part of speech (POS) tag along with embedding of words (Huang et al. Reference Huang, Zhu, Shen and Chen2018).
Table 3. Statistics of different word representation methods in the reviewed papers.

Contextual word embedding
Despite the relative success of non-contextual embeddings, they are static, so all meanings of a word are represented with a fixed vector (Ethayarajh Reference Ethayarajh2019). Different from static word embeddings, contextual embeddings move beyond word-level semantics and represent each word considering its context (surrounding words). To obtain the context-based representation of the words, two approaches can be adopted: 1) learning the word vectors jointly with the main task and 2) using pre-trained contextual word vectors (fixed or fine-tuned).
For learning the contextual word vectors, a sequence modeling method, usually an RNN, is used. For example, Chen et al. (Reference Chen, Fisch, Weston and Bordes2017) used a multi-layer Bi-LSTM model for this purpose. In Yang, Kang and Seo (Reference Yang, Kang and Seo2020) study, forward and backward GRU hidden states are combined to generate contextual representations of query and context words. Bajgar, Kadlec and Kleindienst (Reference Bajgar, Kadlec and Kleindienst2017) used different approaches for the query and context words, where the combination of forward and backward GRU hidden states is exploited for representing the context words, while the final hidden state of GRU is used for the query. On the other hand, pre-trained contextualized embeddings such as ELMo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), and GPT (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018) are deep neural language models that are trained on large unlabeled corpuses. The ELMo method (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018) obtains the contextualized embeddings by a 2-layer Bi-LSTM, while BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) and GPT (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018) are bi-directional and uni-directional Transformer-based (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) language models, respectively. These embeddings are used either besides other embeddings (Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a; Hu et al. Reference Hu, Peng, Wei, Huang, Li, Yang and Zhou2018b; Seo et al. Reference Seo, Kwiatkowski, Parikh, Farhadi and Hajishirzi2018; Lee and Kim Reference Lee and Kim2020; Ren et al. Reference Ren, Cheng and Su2020) or alone (Bauer, Wang and Bansal Reference Bauer, Wang and Bansal2018; Zheng et al. Reference Zheng, Wen, Liang, Duan, Che, Jiang, Zhou and Liu2020).
Due to the success of the contextual word embeddings in many NLP tasks, there is a clear trend toward using these embeddings in recent years (Bauer et al. Reference Bauer, Wang and Bansal2018; Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a; Hu et al. Reference Hu, Peng, Wei, Huang, Li, Yang and Zhou2018b; Wang and Bansal Reference Wang and Bansal2018). This is obvious in Table 3, where the use of fixed pre-trained and fine-tuned contextual embeddings has increased from 0% in 2016 to 23% and 36% in 2020, respectively. Note that some papers use multiple methods, so the sum of percentages in the tables may be greater than 100%.
3.1.3. Hybrid word-character embedding
The combination of word embedding and character embedding is used in some reviewed papers (Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Yang et al. Reference Yang, Dhingra, Yuan, Hu, Cohen and Salakhutdinov2017a; Zhang et al. Reference Zhang, Zhu, Chen, Ling, Dai, Wei and Jiang2017; Gong and Bowman Reference Gong and Bowman2018). Hybrid embedding tries to use the strengths of both word and character embeddings. A simple approach is to concatenate the word and character embeddings. As an example, Lee and Kim (Reference Lee and Kim2020) used GloVe as the word embedding and the output of the CNN model as the character embedding.
This approach suffers from a potential problem. Word embedding has better performance for frequent words (subwords), while it can have negative effects for representing rare words (subwords). The reverse is true for character embedding (Yang et al. Reference Yang, Dhingra, Yuan, Hu, Cohen and Salakhutdinov2017a). To solve this problem, some researchers introduced a gating mechanism which regulates the flow of information. Yang et al. (Reference Yang, Dhingra, Yuan, Hu, Cohen and Salakhutdinov2017a) used a fine-grained gating mechanism for dynamic concatenation of word and characters embedding. This mechanism uses a gate vector, which is a linear multiplication of word features (POS and NE), to control the flow of information of word and character embeddings. Seo et al. (Reference Seo, Kembhavi, Farhadi and Hajishirzi2017) used highway networks (Srivastava, Greff and Schmidhuber Reference Srivastava, Greff and Schmidhuber2015) for embedding concatenation. These networks use the gating mechanism learned by the LSTM network. According to Table 2, the use of hybrid embedding in reviewed papers has increased from 0% in 2016 to 54% in 2018. However, with the success of language model-based contextual embeddings, the direct combination of character and word embeddings has decreased thereafter.
3.1.4. Sentence embedding
Sentence embedding is a high-level representation in which the entire sentence is encoded in a single vector. It is often used along with other embeddings (Yin et al. Reference Yin, Ebert and Schütze2016). However, sentence embedding is not so popular in MRC systems, because the answer is often a sentence part, not the whole sentence.
3.2. Reasoning phase
The goal of this phase is to match the input query (question) with the input document (context). In other words, this phase determines the related parts of the context for answering the question by calculating the relevance between question and context parts. Recently, Phrase Indexed Question Answering (PIQA) model (Seo et al. Reference Seo, Kwiatkowski, Parikh, Farhadi and Hajishirzi2018) enforces complete independence between document encoder and question encoder and does not include any cross attention between question and document. In this model, each document is processed beforehand, and its phrase index vectors are generated. Then, at inference time, the answer is obtained by retrieving the nearest indexed phrase vector to the query vector.
The attention mechanism (Bahdanau, Cho and Bengio Reference Bahdanau, Cho and Bengio2015), originally introduced for machine translation, is used for this phase. In recent years, with the advent of attention-based Transformer architecture (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) as an alternative to common sequential structures like RNN, new Transformer-based language models, such as BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) and XLNet (Yang et al. Reference Yang, Dai, Yang, Carbonell, Salakhutdinov and Le2019b), have been introduced. They are used as the basis for new state-of-the-art results in MRC task (Sharma and Roychowdhury Reference Sharma and Roychowdhury2019; Su et al. Reference Su, Xu, Winata, Xu, Kim, Liu and Fung2019; Yang et al. Reference Yang, Wang, Liu, Liu, Lyu, Wu, She and Li2019a; Tu et al. Reference Tu, Huang, Wang, Huang, He and Zhou2020; Zhang et al. Reference Zhang, Luo, Lu, Liu, Bai, Bai and Xu2020a; Zhang et al. Reference Zhang, Zhao, Wu, Zhang, Zhou and Zhou2020b) by adding or modifying final layers and fine-tuning them on the target task.
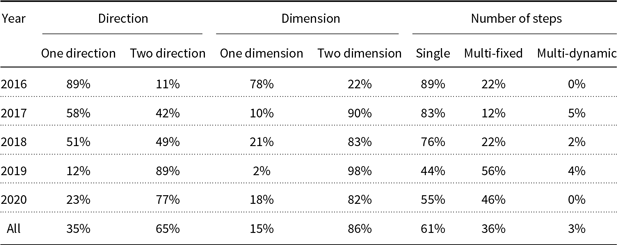
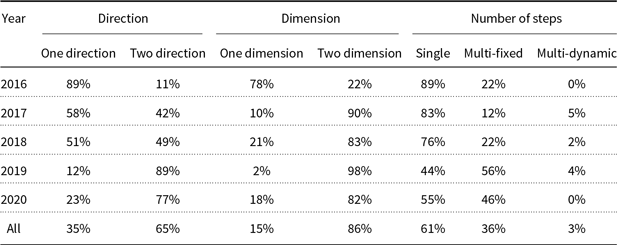
The attention mechanism used in MRC systems can be explored in three perspectives: direction, dimension, and number of steps. For the statistics, refer to Table 4.
Table 4. Statistics of different attention mechanisms used in the reasoning phase of MRC systems.
3.2.1. Direction
Some research only uses the context-to-query (C2Q) attention vector (Cui et al. Reference Cui, Liu, Chen, Wang and Hu2016; Wang and Jiang Reference Wang and Jiang2017; Weissenborn et al. Reference Weissenborn, Wiese and Seiffe2017; Huang et al. Reference Huang, Zhu, Shen and Chen2018) called one-directional attention mechanism. It signifies which query words are relevant to each context word (Cui et al. Reference Cui, Chen, Wei, Wang, Liu and Hu2017b; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017).
In bi-directional attention mechanism, query-to-context (Q2C) attention weights are also calculated (Cui et al. Reference Cui, Chen, Wei, Wang, Liu and Hu2017b; Liu et al. Reference Liu, Hu, Wei, Yang and Nyberg2017; Min, Seo and Hajishirzi Reference Min, Seo and Hajishirzi2017; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Xiong et al. Reference Xiong, Zhong and Socher2017; Clark and Gardner Reference Clark and Gardner2018) along with C2Q. It signifies which context words have the closest similarity to one of the query words and are hence critical for answering the question (Cui et al. Reference Cui, Chen, Wei, Wang, Liu and Hu2017b; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017). In Transformer-based MRC models like BERT-based models, the question and context are processed as one sequence, so the attention mechanism can be considered as bi-directional attention. As shown in Table 4, the ratio of bi-directional attention usage has increased in recent years.
3.2.2. Dimension
There are two attention dimensions in the reviewed papers: one-dimensional and two-dimensional attentions. In one-dimensional attention, the whole question is represented by one embedding vector, which is usually the last hidden state of the contextual embedding (Chen et al. Reference Chen, Bolton and Manning2016; Kadlec et al. Reference Kadlec, Schmid, Bajgar and Kleindienst2016b; Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017; Shen et al. Reference Shen, Huang, Gao and Chen2017; Weissenborn et al. Reference Weissenborn, Wiese and Seiffe2017). It does not pay more attention to important question words. On the contrary, in two-dimensional attention, every word in the query has its own embedding vector (Chen et al. Reference Chen, Fisch, Weston and Bordes2017; Cui et al. Reference Cui, Chen, Wei, Wang, Liu and Hu2017b; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Yang et al. Reference Yang, Hu, Salakhutdinov and Cohen2017b; Clark and Gardner Reference Clark and Gardner2018).
According to Table 4, 86% of all reviewed papers use two-dimensional attention. Also, the use of two-dimensional attention has increased over recent years.
3.2.3. Number of steps
According to the number of reasoning steps, three types of MRC systems can be seen: single-step reasoning, multi-step reasoning with a fixed number of steps, and dynamic multi-step reasoning.
In the single-step reasoning, question and passage matching is done in a single step. However, the obtained representation can be processed through multiple layers to extract or generate the answer (Chen et al. Reference Chen, Bolton and Manning2016; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Clark and Gardner Reference Clark and Gardner2018). In multi-step reasoning, question and passage matching is done in multiple steps such that the question-aware context representation is updated by integrating the intermediate information in each step. The number of steps can be static (Yang et al. Reference Yang, Hu, Salakhutdinov and Cohen2017b; Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a) or dynamic (Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017; Shen et al. Reference Shen, Huang, Gao and Chen2017; Song et al. Reference Song, Tang, Qian, Zhu and Wu2018). Dynamic multi-step reasoning uses a termination module to decide whether the inferred information is sufficient for answering or more reasoning steps are still needed. Therefore, the number of reasoning steps in this model depends on the complexity of the passage and question. It is obvious that in multi-step reasoning, the model complexity increases by the number of reasoning steps. In the Transformer-based MRC models, the number of steps is fixed and depends on the number of layers.
According to Table 4, about 61% of reviewed papers use single-step reasoning, but the popularity of multi-step reasoning has increased over recent years. For a detailed list of the used reasoning methods in different papers, refer to Table A2.
3.3. Prediction phase
The final output of an MRC system is specified in the prediction phase. The output can be extracted from context or generated according to context. In generation mode, a decoder module generates answer words one by one (Hewlett et al. Reference Hewlett, Jones and Lacoste2017). In some cases, multiple choices are presented to the system, and it must select the best answer according to the question and passage(s) (Greco et al. Reference Greco, Suglia, Basile, Rossiello and Semeraro2016). These multi-choice systems can be seen in both extractive and generative models based on whether the answer choices occur in the passage or not.
The extraction mode is implemented in different forms. If the answer is a span of context, the start and end indices of the span are predicted in many studies by estimating the probability distribution of indices over the entire context (Chen et al. Reference Chen, Fisch, Weston and Bordes2017; Wang and Jiang Reference Wang and Jiang2017; Xiong et al. Reference Xiong, Zhong and Socher2017; Yang et al. Reference Yang, Dhingra, Yuan, Hu, Cohen and Salakhutdinov2017a; Yang et al. Reference Yang, Hu, Salakhutdinov and Cohen2017b; Clark and Gardner Reference Clark and Gardner2018).
In some studies, the candidate chunks (answers) are extracted first, which are ranked by a trained model. These chunks can be sentences (Duan et al. Reference Duan, Tang, Chen and Zhou2017; Min et al. Reference Min, Seo and Hajishirzi2017) or entities (Sachan and Xing Reference Sachan and Xing2018). In the Ren et al. (Reference Ren, Cheng and Su2020) study, after extracting the candidate chunks from various contexts, a linear transformation is used along with a sigmoid function to compute the score of the answer candidates.
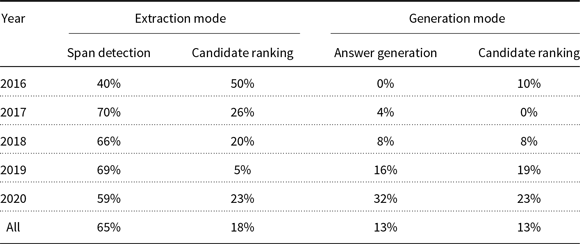
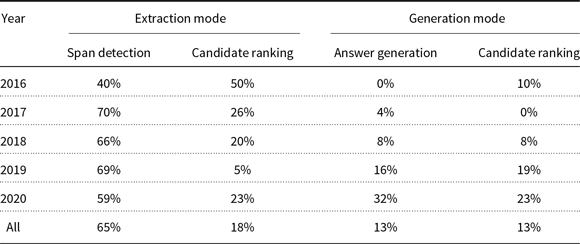
Table 5 shows the statistics of these categories in the reviewed papers. It is clear that most papers (65%) extract the answer span in the passage(s). It seems that developing rich span-based datasets like SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) is the reason for this popularity. Also, the generation-based papers have increased from 10% in 2016 to 55% in 2020 (sum of the answer generation and candidate ranking columns in the generation mode). For more details, refer to Table A3.
Table 5. Statistics of different prediction phase categories in the reviewed papers.
4. Input/Output-based analysis
4.1. MRC systems input
The inputs to an MRC system are question and passage texts. The passage is often referred to as context. Moreover, in some systems, the candidate answer list is part of the input.
4.1.1. Question
Input questions can be grouped into three categories: factoid questions, non-factoid questions, and yes/no questions.
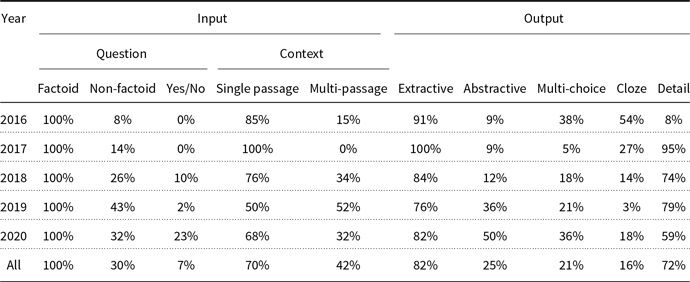
Factoid questions are questions that can be answered with simple facts expressed in short text answers like a personal name, temporal expression, or location (Jurafsky and Martin Reference Jurafsky and Martin2019). For example, the answer to the question “Who founded Virgin Airlines?” is a personal name; or questions “What is the average age of the onset of autism?” and “Where is Apple Computer based?” have number and location as an answer, respectively. In other words, the answers to factoid questions are one or more entities or a short expression. Because of its simplicity compared to other types, most research in MRC literature has focused on this type of question (Chen et al. Reference Chen, Fisch, Weston and Bordes2017; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Clark and Gardner Reference Clark and Gardner2018; Huang et al. Reference Huang, Zhu, Shen and Chen2018).
Non-factoid questions, on the other hand, are open-ended questions that usually require long and complex passage-level answers, such as descriptions, opinions, and explanations (Hashemi et al. Reference Hashemi, Aliannejadi, Zamani and Croft2020). For example, “Why does Queen Elizabeth sign her name Elizabeth?” “What is the difference between MRC and QA?” and “What do you think about MRC?” are instances of non-factoid questions. In our reviewed papers, 32% of works focus on non-factoid questions. Because of their difficulty, the systems dealing with non-factoid questions have often lower accuracies (Wang et al. Reference Wang, Guo, Liu, He and Zhao2016; Tan et al. Reference Tan, Wei, Yang, Du, Lv and Zhou2018a; Wang et al. Reference Wang, Yu, Chang and Jiang2018a).
Yes/No questions, as indicated by their name, have yes or no as answers. According to our investigation, the papers which deal with this type of question consider other types of questions as well (Li et al. Reference Li, Li and Lv2018; Liu et al. Reference Liu, Wei, Sun, Chen, Du and Lin2018b; Zhang et al. Reference Zhang, Wu, He, Liu and Su2018).
Refer to Table 6 for the statistics of input/output types in MRC systems. It is clear from the table that the popularity of non-factoid and yes/no questions is increased. Note that since some papers focus on multiple question types, the sum of percentages is greater than 100% in this table.
4.1.2. Context
The input context can be a single passage or multiple passages. It is obvious that as the context gets longer, finding the answer becomes harder and more time-consuming. Until now, most of the papers have focused on a single passage (Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Wang et al. Reference Wang, Yang, Wei, Chang and Zhou2017b; Yang et al. Reference Yang, Dhingra, Yuan, Hu, Cohen and Salakhutdinov2017a; Yang et al. Reference Yang, Hu, Salakhutdinov and Cohen2017b; Zhang et al. Reference Zhang, Zhu, Chen, Ling, Dai, Wei and Jiang2017). But multiple passages MRC systems are becoming more popular (Xie and Xing Reference Xie and Xing2017; Huang et al. Reference Huang, Zhu, Shen and Chen2018; Liu et al. Reference Liu, Wei, Sun, Chen, Du and Lin2018b; Wang et al. Reference Wang, Yu, Guo, Wang, Klinger, Zhang, Chang, Tesauro, Zhou and Jiang2018b). According to Table 6, only 4% of the reviewed papers focused on multiple passages in 2016, but this ratio has increased in recent years reaching 52% and 32% in 2019 and 2020, respectively.
4.2. MRC systems output
The output of MRC systems can be classified into two categories: abstractive (generative) output and extractive (selective) output.
In the abstractive mode, the answer is not necessarily an exact span in the context and is generated according to the question and context. This output type is especially suitable for non-factoid questions (Greco et al. Reference Greco, Suglia, Basile, Rossiello and Semeraro2016; Choi et al. Reference Choi, Hewlett, Uszkoreit, Polosukhin, Lacoste and Berant2017b; Tan et al. Reference Tan, Wei, Yang, Du, Lv and Zhou2018a).
In the extractive mode, the answer is a specific span of the context (Liu et al. Reference Liu, Hu, Wei, Yang and Nyberg2017; Min et al. Reference Min, Seo and Hajishirzi2017; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Yang et al. Reference Yang, Hu, Salakhutdinov and Cohen2017b; Liu et al. Reference Liu, Shen, Duh and Gao2018c). This output type is appropriate for factoid questions; however, it is possible that the answer to a factoid question may be generative or the answer to a non-factoid question may be extractive. For example, the answer to a non-factoid question may be a whole sentence which is extracted from the context.
There has generally been more focus on extractive MRC systems, but according to Table 6, the popularity of abstractive MRC systems has increased over recent years. From another point of view, MRC outputs can be categorized as multiple-choice style, cloze style, and detail style:
-
• In the multiple-choice style mode, the answer is one of the multiple candidate answers that must be selected from a predefined set
 $A$
containing
$k$
candidate answers:
where
$$A = \left\{ {{a_1}{\rm{,}} \ldots {\rm{,}}{a_k}} \right\},$$
${a_j}$
can be a word, a phrase, or a sentence with length
${l_j}$
:
$${a_j} = \left( {{a_{j{\rm{,}}1}}{\rm{,}}{a_{j{\rm{,}}2}}{\rm{,}} \ldots {\rm{,}}{a_{j{\rm{,}}{l_j}}}} \right)$$
$A$
containing
$k$
candidate answers:
where
$$A = \left\{ {{a_1}{\rm{,}} \ldots {\rm{,}}{a_k}} \right\},$$
${a_j}$
can be a word, a phrase, or a sentence with length
${l_j}$
:
$${a_j} = \left( {{a_{j{\rm{,}}1}}{\rm{,}}{a_{j{\rm{,}}2}}{\rm{,}} \ldots {\rm{,}}{a_{j{\rm{,}}{l_j}}}} \right)$$
-
• In the cloze style mode, the question includes a blank that must be filled as an answer according to the context. In the available cloze style datasets, the answer is an entity from the context.
-
• In the detail style mode, there is no candidate or blank, so the answer must be extracted or generated according to the context. In extractive mode, the answer must be a definite range in the context, so it can be shown as
$\left( {{a_{start}},\;{a_{end}}} \right),{\rm{\;}}$
where
${{\rm{a}}_{{\rm{start}}}}$
and
${a_{end}}$
are, respectively, the start and end indices of the answer in the context. In generative mode, on the other hand, the answer can be generated from any custom vocabulary
$V$
, and it is not limited to the context words.










As shown in Table 6, most of the reviewed papers (72%) have focused on the detail style mode. Also, about 100%, 70%, and 82% of the reviewed papers have focused on factoid questions, multi-passage context, and extractive answers, respectively, due to their lower complexity and existence of rich datasets. For a more detailed categorization of papers based on their input/outputs, refer to Table A4.
Table 6. Statistics of input/output types in MRC systems.
5. MRC datasets
Rich datasets are the first prerequisite for having accurate machine learning models. Especially, deep neural network models require high volumes of training data to achieve good results. For this reason, in recent years, many researchers have focused on collecting big datasets. For example, Stanford Question Answering Dataset (SQuAD) (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016), which is a popular MRC dataset used in many studies, includes over 100,000 training samples.
MRC datasets can be categorized according to their volume, domain, question type, answer type, context type, data collection method, and language.
In terms of domain, MRC datasets can be classified into two categories: open domain and closed domain. Open domain datasets contain diverse subjects, while closed domain datasets focus on specific areas such as the medical domain. For example, the SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) dataset, which contains Wikipedia articles, is an open domain dataset, and emrQA (Pampari et al. Reference Pampari, Raghavan, Liang and Peng2018), BIOMRC (Pappas et al. Reference Pappas, Stavropoulos, Androutsopoulos and McDonald2020), LUPARCQ (Horbach et al. Reference Horbach, Aldabe, Bexte, de Lacalle and Maritxalar2020) are a closed domain dataset with biology as its subject.
There are two data collection approaches in MRC datasets, automatic approach, and crowdsourcing approach. The former generates questions/answers without direct human interventions. For instance, datasets that contain cloze style questions, such as Children’s Book Test dataset (Hill et al. Reference Hill, Bordes, Chopra and Weston2016), are generated by removing important entities from text. Also, in some datasets, questions are automatically extracted from the search engine’s user logs (Nguyen et al. Reference Nguyen, Rosenberg, Song, Gao, Tiwary, Majumder and Deng2016) or real reading comprehension tests (Lai et al. Reference Lai, Xie, Liu, Yang and Hovy2017).
On the other hand, in the crowdsourcing approach, humans generate questions, answers, or select related paragraphs. Of course, a dataset can be generated by a combination of these two approaches. For instance, in MS MARCO (Nguyen et al. Reference Nguyen, Rosenberg, Song, Gao, Tiwary, Majumder and Deng2016), questions have been generated automatically, while these questions have been answered and evaluated by crowdsourcing.
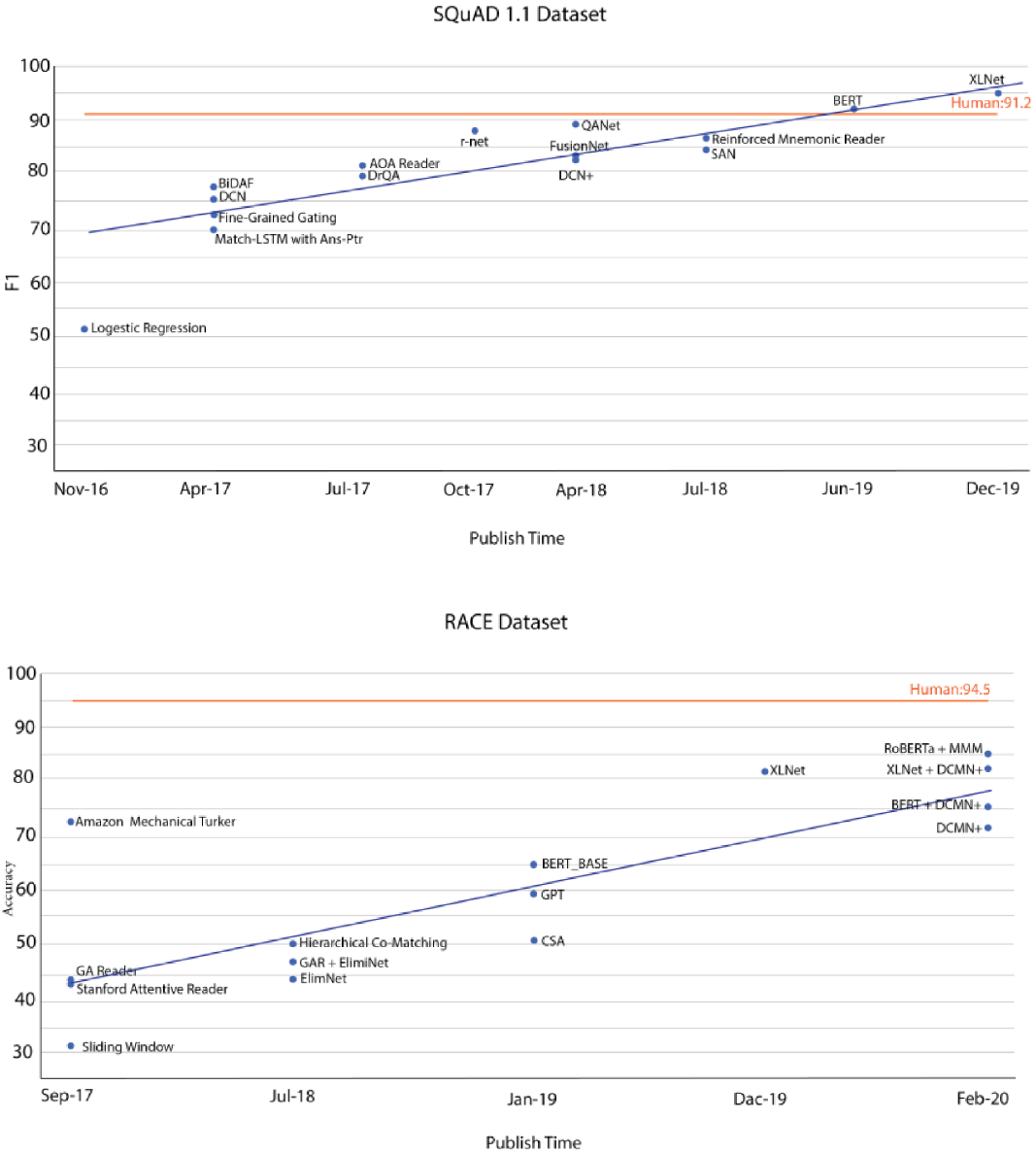
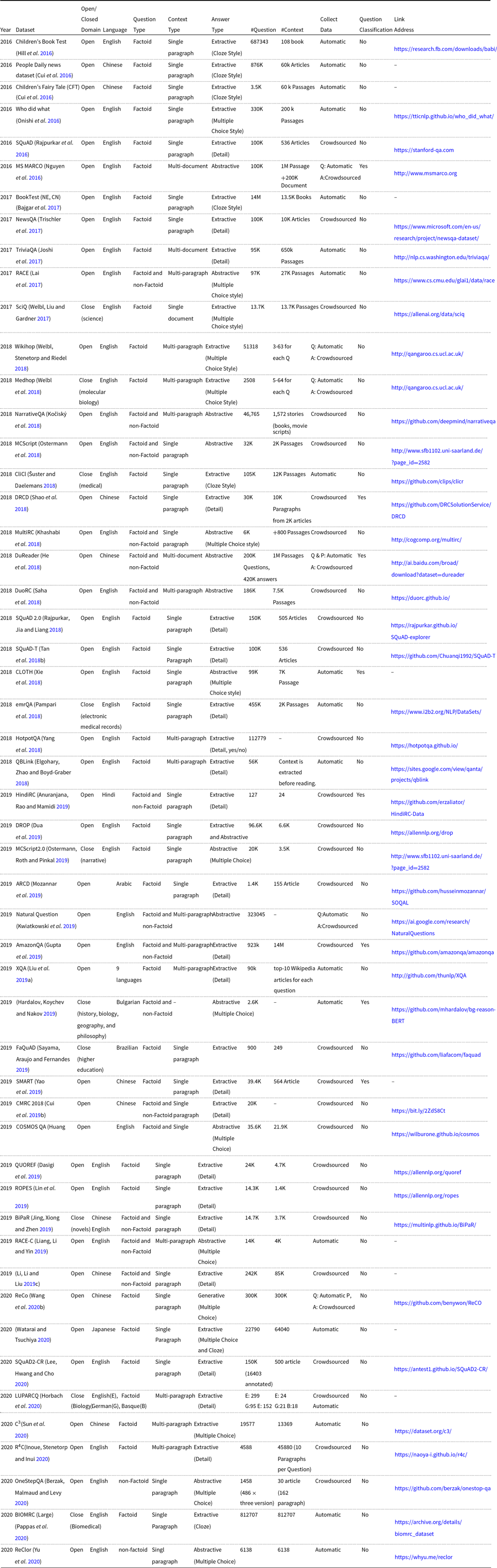
Table 7 shows a detailed list of the datasets proposed from 2016-2020 in chronological order. In this table, the datasets with a link address are publicly available. Finally, Figure 3 shows the progress made on two representative datasets, SQuAD1.1 and RACE, as representatives of the advancements in the field. Note that only the articles available in our reviewed papers are reported in this figure. According to this figure, the state-of-the-art model’s performance on SQuAD1.1 dataset increased from about 0.7 in 2017 to super human level of 0.95 in 2019. For the RACE dataset, despite the progress made in the accuracy from around 0.4 in 2017 to around 0.8 in 2020, it is still under the human-level performance which shows that this dataset is more challenging.
Table 7. MRC datasets proposed from 2016 to 2020. (A: Answer, P: passage, Q: Question)
6. MRC evaluation measures
Based on the system output type, different evaluation metrics are introduced. We classify these measures into two categories: extractive metrics and generative metrics.
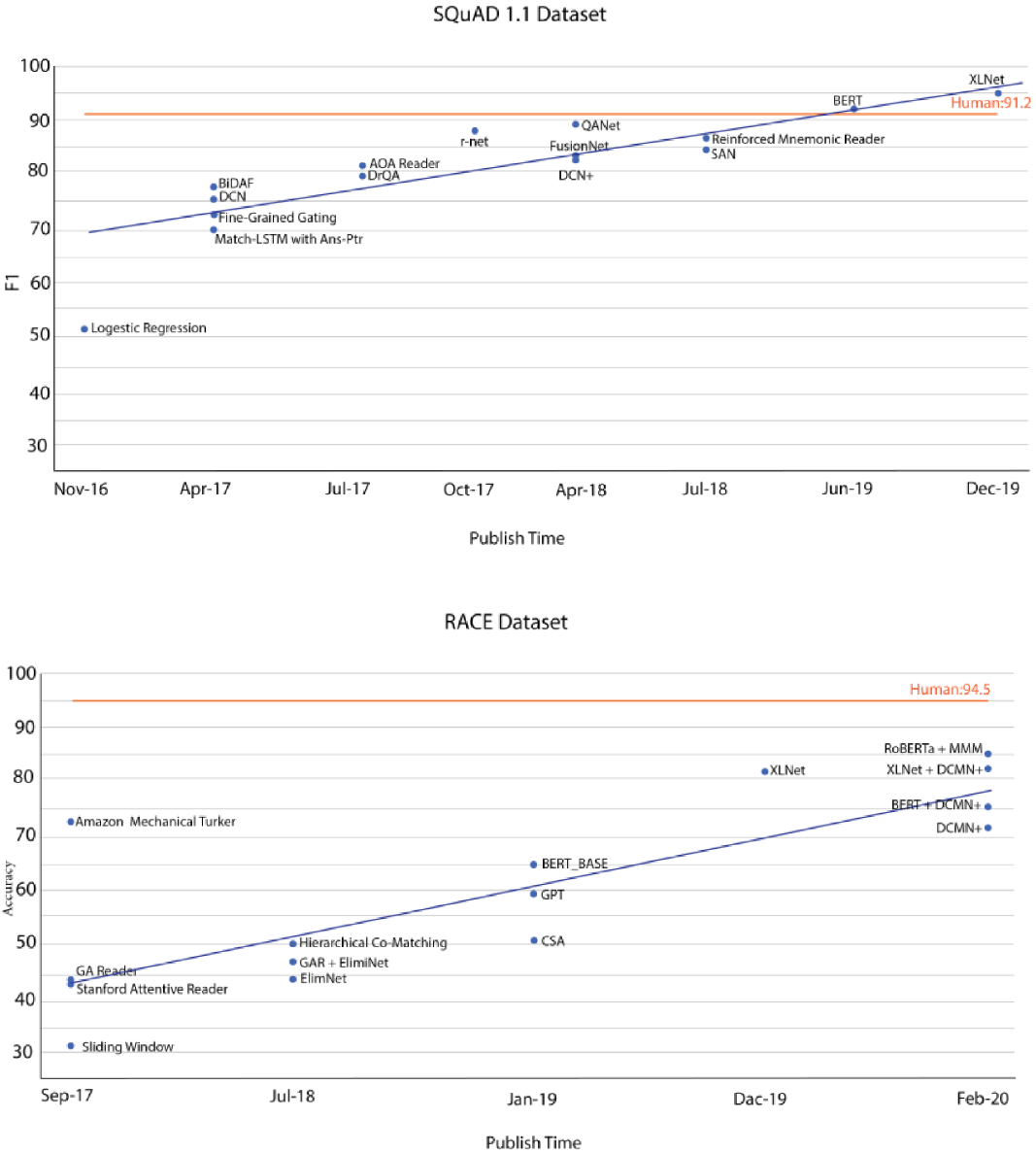
Figure 3. The progress made on two datasets: SQuAD1.1 (top) and RACE (down). The data points are taken from https://rajpurkar.github.io/SQuAD-explorer and http://www.qizhexie.com/data/RACE_leaderboard.html, respectively. Only the articles available in our reviewed papers are reported.
6.1. Extractive metrics
These metrics are used for the extractive outputs. Table 8 shows the statistics of these measures in the reviewed papers.
-
• F1 score: The harmonic mean of precision and recall is a common extractive metric for evaluating MRC systems. It takes into account the system output and the ground truth answer as bag-of-tokens (words). Precision is calculated as the number of correctly predicted tokens divided by the number of all predicted tokens. The recall is also the number of correctly predicted tokens divided by the number of ground truth tokens. The final F1 score is then obtained by averaging over all question-answer pairs.
-
• Exact Match (EM) . This is the percentage of answers that exactly match with the correct answers. If there are multiple answers to a question in a dataset, a match with at least one of the answers is considered as an exact match. Some QA systems such as multiple-choice QA systems (Zhang et al. Reference Zhang, Wu, Zhou, Duan, Zhao and Wang2020c) or sentence selection QA systems (Min et al. Reference Min, Seo and Hajishirzi2017) call this measure as accuracy (ACC) instead of EM.
-
• Mean Average Precision (MAP). This measure is used when the system returns several answers along with their ratings. The MAP for a set of question-answer pairs is the mean of Average Precision scores (AveP) for each one. AveP is an evaluation measure used in information retrieval systems which evaluates a ranked list of documents in response to a given query. AveP for a single query is calculated by taking the mean of the precision scores obtained after each relevant document is retrieved, with relevant documents that are not retrieved receiving a precision score of zero (Turpin and Scholer Reference Turpin and Scholer2006). In MRC literature, the ranked list of answers for a given question is evaluated.
-
• Mean Reciprocal Rank (MRR). This is a common evaluation metric for factoid QA systems introduced in TREC QA track 1999. According to the definition presented in the “Evaluation of Factoid Answers” Section of the “Speech and Language Processing” book (Jurafsky and Martin Reference Jurafsky and Martin2019), MRR evaluates a ranked list of answers based on the inverse of the rank of the correct answer. For example, if the rank of the correct answer in the output list of a system is 4, the reciprocal rank score for that question would be 1/4. This measure is then averaged for all questions in the test set.
-
• Precision@K. This measure is also borrowed from information retrieval literature. It is the number of correct answers in the first k returned answers without considering the position of these correct ones (Manning, Raghavan and Schütze Reference Manning, Raghavan and Schütze2008).
-
• Hit@K or Top-K. Hit@K, which is equivalent to the Top-K accuracy, counts the number of samples where their first k returned answers include the correct answer.
Table 8. Statistics of evaluation measures used in reviewed papers.

6.2. Generative metrics
The metrics used for evaluating the performance of generative MRC systems are the same metrics used for machine translation and summarization evaluation. Table 8 shows the statistics of these measures in the reviewed papers.
-
• Recall-Oriented Understudy for Gisting Evaluation (ROUGE). This measure compares a system-generated answer with the human-generated one (Lin Reference Lin2004). It is defined as the recall of the system based on the n-grams, that is, the number of correctly generated n-grams divided by the total number of n-grams in the human-generated answer.
-
• BiLingual Evaluation Understudy (BLEU). This metric was first introduced for evaluating the output of machine translation task. It is defined as the precision of the system based on the n-grams, that is, the number of correctly generated n-grams divided by the total number of n-grams in the system-generated answer (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002).
-
• Metric for Evaluation of Translation with Explicit Ordering (METEOR). This measure is designed to fix some weaknesses of the popular BLEU measure. METEOR is based on an alignment between the system output and reference output. It introduces a penalty for adjacent tokens that cannot be mapped between the reference and system output. For this, unigrams are grouped into longer chunks if they are adjacent in both reference and system output. The more adjacent unigrams, the fewer chunks and the fewer penalty will be (Banerjee and Lavie Reference Banerjee and Lavie2005).
-
• Consensus-based Image Description Evaluation (CIDEr). This measure is initially introduced for evaluating the image description generation task (Vedantam, Lawrence Zitnick and Parikh Reference Vedantam, Lawrence Zitnick and Parikh2015). It is based on the n-gram matching of the system output and reference output in the stem or root forms. According to this measure, the n-grams that are not in the reference output should not be in the system output. Also, the common n-grams in the dataset are less informative and have lower weights.
Figure 4 shows the ratio of the used extractive/generative measures in the reviewed papers. According to this figure, the generative measures have been more popular in recent years than in 2016 and 2017. The obvious reason for this is the trend toward developing abstractive MRC systems. For more details, refer to Table A5.
7. Research contribution
The contribution of MRC research can be grouped into four categories: developing new model structures, creating new datasets, combining with other tasks and improvement, and introducing new evaluation measures. Table 9 shows the statistics of these categories. Note that some studies have more than one contribution type, so the sum of some rows is greater than 100%. For example, Ma, Jurczyk and Choi (Reference Ma, Jurczyk and Choi2018) introduced a new dataset from the “Friends” sitcom transcripts and developed a new model architecture as well. For more details, refer to Table A6.
Table 9. Statistics of different research contributions to MRC task in the reviewed papers.


Figure 4. Ratio of reviewed papers (%) for extractive/generative evaluation metrics
7.1. Developing new model structures
Many MRC papers have focused on developing new model structures to address the weaknesses of previous models. Most of them developed new internal structures (Cui et al. Reference Cui, Liu, Chen, Wang and Hu2016; Kadlec et al. Reference Kadlec, Schmid, Bajgar and Kleindienst2016b; Kobayashi et al. Reference Kobayashi, Tian, Okazaki and Inui2016; Cui et al. Reference Cui, Chen, Wei, Wang, Liu and Hu2017b; Dhingra et al. Reference Dhingra, Liu, Yang, Cohen and Salakhutdinov2017; Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2017; Shen et al. Reference Shen, Huang, Gao and Chen2017; Xiong et al. Reference Xiong, Zhong and Socher2017; Hu et al. Reference Hu, Peng, Huang, Qiu, Wei and Zhou2018a; Huang et al. Reference Huang, Zhu, Shen and Chen2018). Some others changed the system inputs. For example, in Chen et al. (Reference Chen, Fisch, Weston and Bordes2017) study, in addition to word vectors, linguistic features such as NE and POS vectors have also been used as the input to the model. Also, some papers introduced a new way of entering the input into the system. For example, Hewlett et al. (Reference Hewlett, Jones and Lacoste2017) proposed breaking the context into overlapping windows and entering each window as an input to the system.
7.2. Creating new datasets
One of the main reasons for advancing the MRC research in recent years is the introduction of rich datasets. Many studies have focused on creating new datasets with new features in recent years (Nguyen et al. Reference Nguyen, Rosenberg, Song, Gao, Tiwary, Majumder and Deng2016; Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016; Joshi et al. Reference Joshi, Choi, Weld and Zettlemoyer2017; Lai et al. Reference Lai, Xie, Liu, Yang and Hovy2017; Trischler et al. Reference Trischler, Wang, Yuan, Harris, Sordoni, Bachman and Suleman2017; He et al. Reference He, Liu, Liu, Lyu, Zhao, Xiao, Liu, Wang, Wu and She2018; Šuster and Daelemans Reference Šuster and Daelemans2018). The main trend is to develop multi-document datasets, abstractive style outputs, and more complex questions that require more advanced reasoning. Also, some papers focus on customizing the available datasets instead of creating new ones. For example, Horbach et al. (Reference Horbach, Aldabe, Bexte, de Lacalle and Maritxalar2020) proposed to turn existing datasets, such as SQuAD and NewsQA, into interactive datasets. Some other papers added annotations to the existing datasets to provide interpretable clues for investigating the models’ behavior as well as to prevent models from exploiting biases and annotation artifacts. For example, SQuAD 2.0 (Rajpurkar et al. Reference Rajpurkar, Jia and Liang2018) was created by adding unanswerable questions to SQuAD, and SQuAD2-CR (Lee et al. Reference Lee, Hwang and Cho2020) was developed by adding causal and relational annotations to unanswerable questions in SQuAD 2.0. Similarly,
 ${R^4}C$
(Inoue et al. Reference Inoue, Stenetorp and Inui2020) was created by adding derivations to questions in hotpotQA.
${R^4}C$
(Inoue et al. Reference Inoue, Stenetorp and Inui2020) was created by adding derivations to questions in hotpotQA.
7.3. Combining with other tasks
Simultaneous learning of multiple tasks (multi-task learning) (Collobert and Weston Reference Collobert and Weston2008) and exploiting the learned knowledge from one task in another task (transfer learning) (Ruder Reference Ruder2019) have been promising directions for obtaining better results, especially in the data-poor setting. As an example, Wang et al. (Reference Wang, Yuan and Trischler2017a) trained their MRC task with a question generation task and achieved better results. Besides these approaches, some papers exploit other task solutions as sub-modules in their MRC system. As an example, Yin et al. (Reference Yin, Ebert and Schütze2016) used a question classifier and a natural language inference (NLI) system as two sub-modules in their MRC system.
7.4. Introducing new evaluation measures
Reliable assessment of an MRC system is still a challenging topic. While some systems go beyond human performance in specific datasets such as SQuAD by the current measures (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016), further investigation shows that these systems fail to achieve a thorough and true understanding of human language (Jia and Liang Reference Jia and Liang2017; Wang and Bansal Reference Wang and Bansal2018). In these papers, the passage is successfully edited to mislead the model. These papers can be seen as a measure to evaluate the true comprehension of systems. Also, some papers have evaluated the required comprehension and reasoning capabilities for solving the MRC problem in available datasets (Chen et al. Reference Chen, Bolton and Manning2016; Sugawara et al. Reference Sugawara, Inui, Sekine and Aizawa2018).
8. Hot MRC papers
Table 10 shows the top papers in different years from 2016-2020 based on the number of citations in the Google Scholar service until September 2020. For all years but 2020, ten papers have been selected; while for the year 2020, just five papers have been chosen because the number of citations in this year is not enough in the time of writing the paper. According to this table, hot papers often introduce a new successful model structure or a new dataset.
Table 10. Hot papers based on the number of citations in the Google Scholar service until September 2020.

9. Future trends and opportunities
The MRC task has witnessed a great progress in recent years. Especially, like other NLP tasks, fine-tuning the pre-trained language models like BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) and XLNet (Yang et al. Reference Yang, Dai, Yang, Carbonell, Salakhutdinov and Le2019b) on the target task has achieved an impressive success in MRC task, such that many state-of-the-art systems use these language models. However, they suffer from some shortcomings, which make them far from the real reading comprehension. In the following, we list some of these challenges and new trends in the MRC field:
-
• Out-of-domain distributions: Despite the high accuracy of the current MRC models on test samples from their training distribution, they are too fragile for out-of-domain distributed data. To address this shortcoming, some recent papers focused on improving the generalization capability of MRC models (Fisch et al. Reference Fisch, Talmor, Jia, Seo, Choi and Chen2019; Wang et al. Reference Wang, Gan, Liu, Liu, Gao and Wang2019e; Nishida et al. Reference Nishida, Nishida, Saito, Asano and Tomita2020).
-
• Multi-document MRC: One important challenge in the MRC task is the multi-hop reasoning, which is to infer the answer from multiple texts. These texts can be either several paragraphs of a document (Frermann Reference Frermann2019; Tay et al. Reference Tay, Wang, Luu, Fu, Phan, Yuan, Rao, Hui and Zhang2019) or heterogeneous paragraphs from multiple documents (Tu et al. Reference Tu, Huang, Wang, Huang, He and Zhou2020). One of the new trends is to use the graph structures, such as graph neural networks, for multi-hop reasoning (Ding et al. Reference Ding, Zhou, Chen, Yang and Tang2019; Tu et al. Reference Tu, Wang, Huang, Tang, He and Zhou2019; Song et al. Reference Song, Wang, Yu, Zhang, Florian and Gildea2020; Tu et al. Reference Tu, Huang, Wang, Huang, He and Zhou2020).
-
• Numerical reasoning: Many questions in real-world applications require numerical inference including addition, subtraction, comparison, and so on. For example, consider the following question from DROP dataset (Dua et al. Reference Dua, Wang, Dasigi, Stanovsky, Singh and Gardner2019) which needs a subtraction: “How many more dollars was the Untitled (1981) painting sold for than the 12 million dollar estimation?” Developing MRC models capable of numerical reasoning has become more popular in recent years, especially after the creation of numerical datasets such as DROP (Dua et al. Reference Dua, Wang, Dasigi, Stanovsky, Singh and Gardner2019; Ran et al. Reference Ran, Lin, Li, Zhou and Liu2019; Chen et al. Reference Chen, Liang, Yu, Zhou, Song and Le2020).
-
• No-answer questions: One of the new trends that makes the MRC systems more usable in real-world applications is to enable models to identify the questions which cannot be answered using the given context. With the development of datasets containing this kind of questions, such as SQuAD 2.0 (Rajpurkar et al. Reference Rajpurkar, Jia and Liang2018) and Natural Questions (Kwiatkowski et al. Reference Kwiatkowski, Palomaki, Redfield, Collins, Parikh, Alberti, Epstein, Polosukhin, Devlin and Lee2019), more attention has been paid to this issue (Back et al. Reference Back, Chinthakindi, Kedia, Lee and Choo2020; Liu et al. Reference Liu, Gong, Fu, Yan, Chen, Jiang, Lv and Duan2020a; Zhang et al. Reference Zhang, Wu, Zhou, Duan, Zhao and Wang2020c).
-
• Non-factoid questions: Answering non-factoid questions, such as why and opinion questions, often requires generating answers rather than selecting a span of context. The accuracy of the existing models in answering these questions is still far from the desired level. In recent years, several datasets which contain non-factoid questions have attracted more attention to this kind of questions (Saha et al. Reference Saha, Aralikatte, Khapra and Sankaranarayanan2018; Gupta et al. Reference Gupta, Kulkarni, Chanda, Rayasam and Lipton2019; Berzak et al. Reference Berzak, Malmaud and Levy2020).
-
• Low-resource language datasets and models: It is worth noting that most available datasets are in resource-rich languages, such as English and Chinese. Creating new datasets and models for low-resource languages and developing them in the multi-lingual or multi-task setting can also be seen as a new trend in this field (Jing et al. Reference Jing, Xiong and Zhen2019; Amirkhani et al. Reference Amirkhani, Jafari, Amirak, Pourjafari, Jahromi and Kouhkan2020; Gupta and Khade Reference Gupta and Khade2020; Yuan et al. Reference Yuan, Shou, Bai, Gong, Liang, Duan, Fu and Jiang2020a).
10. Conclusion
The MRC, as a hot research topic in NLP, focuses on reading the document(s) and answering the corresponding questions. The main goal of an MRC system is to gain a comprehensive understanding of text documents to be able to justify and respond to related questions. In this paper, we presented an overview of the variable aspects of recent MRC studies, including approaches, internal architecture, input/output type, research contributions, and evaluation measures. We reviewed 241 papers published during 2016-2020 to investigate recent studies and find new trends.
Based on the question type, MRC papers are categorized into factoid, non-factoid, and yes/no questions. In addition, the input context is categorized into single or multiple passages. According to the results of statistics, a trend toward non-factoid questions and multiple passages was obvious in recent years. The output types are classified into extractive and abstractive outputs. From another point of view, the output types are categorized as multiple choice, cloze, and detail styles. The statistics showed that although the extractive outputs have been more popular, the abstractive outputs are becoming more popular in recent years.
Furthermore, we reviewed the developed datasets along with their features, such as data volume, domain, question type, answer type, context type, collection method, and data language. The number of developed datasets has increased in recent years, and they are in general more challenging than previous datasets. Regarding research contributions, some papers develop new model structures, some introduce new datasets, some combine MRC tasks with other tasks, and others introduce new evaluation measures. The majority of papers developed novel model structures or introduced new datasets. Moreover, we presented the most-cited papers, which indicate the most popular datasets and models in the MRC literature. Finally, we mentioned the possible future trends and important challenges of available models, including the issues related to out-of-domain distributions, multi-document MRC, numerical reasoning, no-answer questions, non-factoid questions, and low-resource languages.
Appendix
Table A1. Reviewed papers categorized based on their embedding phase

Table A2. Reviewed papers categorized based on their reasoning phase

Table A3. Reviewed papers categorized based on their prediction phase

Table A4. Reviewed papers categorized based on their input/output

Table A5. Reviewed papers categorized based on their evaluation metric

Table A6. Reviewed papers categorized based on their novelties