


Introduction
When bilingual speakers want to convey a message, they have the option to choose linguistic elements from two languages. This often leads to code-switching, the mixed use of both languages in one coherent utterance. Being one of the most salient reflections of cross-language activation in bilingual speech, code-switching has instigated research in different research disciplines. This has resulted in linguistic (e.g., Muysken, Reference Muysken2000; Myers-Scotton, Reference Myers-Scotton2002; Poplack, Reference Poplack1980), sociolinguistic (e.g., Auer, Reference Auer1998; Myers-Scotton, Reference Myers-Scotton1993), psycholinguistic (e.g., Costa & Santesteban, Reference Costa and Santesteban2004; Hatzidaki, Branigan & Pickering, Reference Hatzidaki, Branigan and Pickering2011; Meuter & Allport, Reference Meuter and Allport1999), and neurocognitive (e.g., Moreno, Federmeier & Kutas, Reference Moreno, Federmeier and Kutas2002) perspectives on the phenomenon.
One discovery is that there appear to be regularities with respect to the position within a sentence where code-switching occurs. Corpus studies have indicated that code-switches occur more often at sentence positions that are structurally equivalent between languages than at positions that are not equivalent (e.g., Deuchar, Reference Deuchar2005; Poplack, Reference Poplack1980), and that functional elements in code-switched sentences usually come from one language only (e.g., Myers-Scotton, Reference Myers-Scotton2002). Such regularities are typically explained in terms of syntactic constraints on code-switching (e.g., Poplack, Reference Poplack1980) or in terms of principles of grammar in code-switching (e.g., MacSwan, Reference MacSwan2000; Myers-Scotton, Reference Myers-Scotton2002).
Recently, Kootstra, van Hell and Dijkstra (Reference Kootstra, van Hell and Dijkstra2010) have found that the sentence position of code-switching is not only influenced by language-internal constraints, but also by a mechanism that takes the prior linguistic context into account, namely structural priming. Structural priming refers to the tendency of speakers to repeat the sentence structure of an utterance they have just encountered. This repetition of structures has been widely observed in single-language (i.e., non-code-switched) sentences in both experimentally induced and spontaneous language production (see Pickering & Branigan, Reference Pickering and Branigan1999; Pickering & Ferreira, Reference Pickering and Ferreira2008, for reviews). Structural priming is considered to facilitate the staged process of language production (Garrod & Pickering, Reference Garrod and Pickering2004; Schober, Reference Schober and Brown2006), to stimulate mutually intelligible communication in dialogue (Pickering & Garrod, Reference Pickering and Garrod2004), and to form one of the basic mechanisms for the implicit learning of syntax (Chang, Dell & Bock, Reference Chang, Dell and Bock2006; Ferreira & Bock, Reference Ferreira and Bock2006).
In their code-switching study, Kootstra et al. (Reference Kootstra, van Hell and Dijkstra2010) examined the role of structural priming in combination with the role of word order equivalence in code-switching.Footnote 1 They asked dyads of Dutch–English bilingual speakers to take turns in completing sentence fragments by describing pictures of transitive events (e.g., a girl kicking a boy) to each other, in which they had to code-switch. The sentence fragments cued the use of the SVO (shared between Dutch and English), SOV (not shared between Dutch and English), or VSO (not shared between Dutch and English) word order. One participant was a “confederate” of the experimenter, who was scripted to use particular word orders and to code-switch at particular sentence positions. Prior to this confederate-scripted task, a baseline monologue version of this task (i.e., without a confederate) in an independent group of Dutch–English bilinguals established that bilinguals have a strong inclination to use the (shared) SVO word order, and that the sentence position of switching was dependent on whether they used a shared or non-shared word order. This indicated that shared word order indeed facilitates code-switching. The confederate-scripted version of the task provided further evidence that the participants’ syntactic choices were also influenced by their dialogue partner's (the confederate) utterances: Participants tended to use the same word order and sentence position of switching as their dialogue partner. This tendency to repeat the structural code-switching pattern they had just heard was so strong that the tendency to use the shared word order was in some conditions only half as strong as in the baseline task without a confederate. This influence of the prior utterance on the participants’ syntactic choices and sentence position of switching is evidence of structural priming in code-switching.
Thus, Kootstra et al. (Reference Kootstra, van Hell and Dijkstra2010) showed how the combination of cross-language word order equivalence (i.e., shared versus non-shared word order) and structural priming from a prior utterance influenced the production of code-switches in sentences. In doing so, they focused on structural aspects only and kept the role of other variables that may influence priming, such as lexical or speaker-related variables, constant. Therefore, now that the basic effect of structural priming in code-switching has been established, the present study focused on the role of lexical and speaker-related factors in the priming of code-switches, while controlling for word order variations. Using a structural priming technique in which Dutch–English bilinguals repeated (prime) sentences and described (target) pictures (based on Bock, Reference Bock1986), we tested to what extent the tendency to copy the sentence position of code-switching from a prime sentence to a target picture description is influenced by the following lexical factors: (i) lexical repetition between the prime sentence and target picture, and (ii) cognate status of specific words within the sentences and pictures to be expressed. We investigated the role of the speaker-related factor relative language proficiency by testing L2 learners who have a relatively low level of L2 English proficiency (ninth-grade pre-university-level secondary school children, Experiment 1) and L2 learners who have a higher level of L2 English proficiency (university students, Experiment 2).
Before describing the study, we discuss the role of lexical repetition in structural priming including a cognitive model of sentence production that is used to account for these effects, the role of cognates, and the role of relative language proficiency with respect to their potential influence on the priming of code-switches in sentences.
Structural priming and the role of lexical repetition
Structural priming was originally studied in monolingual language production to tap into syntactic processes independent of lexical processes. In a classical study, Bock (Reference Bock1986) used the guise of a memory task to have participants repeat auditorily presented prime sentences with a specific syntactic structure and then describe target pictures that were unrelated to the prime sentence but could be described with the same structure as the prime sentence. The likelihood to use a specific structure in describing the pictures increased when that structure had occurred in the prime sentence. Follow-up studies by Bock (Reference Bock1989) and Bock and Loebell (Reference Bock and Loebell1990) provided additional evidence that this structural priming even occurred in the absence of thematic, lexical, phonological, and prosodic overlap between the prime sentence and target picture. This structural priming, independent of other kinds of overlap between the prime and target, was taken to support the existence of an independent syntactic level of representation in language production.
Although evidence indicates that structural priming can occur in the absence of lexical overlap between prime and target, it is not necessarily the case that structural priming is unaffected by lexical factors. In fact, it has been found that structural priming is enhanced when the prime and target sentences contain the same word. Pickering and Branigan (Reference Pickering and Branigan1998) were the first to study this “lexical boost effect”. Using a written sentence completion task, they asked participants to complete prime sentence fragments that induced the use of a prepositional object construction (The racing driver showed the torn overall . . .) or double object construction (The racing driver showed the helpful mechanic . . .) and then to complete target sentence fragments that did not induce a particular structure (The patient showed . . .). As a critical manipulation, the verb in the prime and target sentence fragments was either repeated or not repeated (The racing driver showed the torn overall . . . vs. The racing driver gave the torn overall . . .). Structural priming was found both when the verb was repeated and when the verb was not repeated, but the priming effect was significantly larger (i.e., boosted) when the verb was repeated.
In a later study, Cleland and Pickering (Reference Cleland and Pickering2003) showed that this lexical boost effect also occurred with the repetition of nouns. They asked participants to describe complex noun phrases with different structures (The red square vs. The square that's red) to each other in a dialogue game, and found that speakers were more likely to use a particular structure when their dialogue partner had just used that structure than when their dialogue partner had used a different structure (= structural priming), and that this effect was enhanced when the head noun (square) was repeated (= lexical boost). The lexical boost effect has been replicated in different languages, methods, and speaker populations (e.g., Arai, van Gompel & Scheepers, Reference Arai, van Gompel and Scheepers2007; Branigan, Pickering & Cleland, Reference Branigan, Pickering and Cleland2000; Corley & Scheepers, Reference Corley and Scheepers2002; Gries, Reference Gries2005; Hartsuiker, Bernolet, Schoonbaert, Speybroeck & Vanderelst, Reference Hartsuiker, Bernolet, Schoonbaert, Speybroeck and Vanderelst2008; Santesteban, Pickering & McLean, Reference Santesteban, Pickering and McLean2010; van Beijsterveldt & van Hell, Reference van Beijsterveldt and van Hell2009).
Structural priming is not only studied within languages, but also across languages in bilingual speakers. The first studies on this topic investigated whether syntactic processing in bilinguals involves shared or separate systems, independent of lexical processes. Loebell and Bock (Reference Loebell and Bock2003) used a bilingual version of Bock's (Reference Bock1986) structural priming memory method, in which German–English bilinguals reproduced a sentence in a specific language with a specific structure (either German or English) and then described a picture in the other language that was lexically unrelated but could be described with the same structure as in the prime sentence. It turned out that the reproduced sentence primed structural choices in the participants’ picture descriptions. This cross-language structural priming effect in the absence of lexical overlap shows that a bilingual's syntactic representations in both languages are co-activated and can thus influence each other, independent of cross-language lexical connections. Other studies have replicated this finding in different tasks and language combinations (e.g., Bernolet, Hartsuiker & Pickering, Reference Bernolet, Hartsuiker and Pickering2007; Desmet & Declercq, Reference Desmet and Declercq2006; Hartsuiker, Pickering & Veltkamp, Reference Hartsuiker, Pickering and Veltkamp2004; Meijer & Fox Tree, Reference Meijer and Tree2003; see Hartsuiker & Pickering, Reference Hartsuiker and Pickering2008, for a review).
Later cross-language structural priming studies have investigated the role of lexical repetition between prime and target sentences. Bernolet et al. (Reference Bernolet, Hartsuiker and Pickering2007) investigated the lexical boost effect in the priming of noun phrase structures, but found only cross-language priming and no lexical boost effect. In another study, Schoonbaert, Hartsuiker and Pickering (Reference Schoonbaert, Hartsuiker and Pickering2007) investigated the lexical boost effect in the priming of dative structures. They had pairs of Dutch–English bilinguals describe ditransitive pictures to each other in a dialogue task. One participant was a confederate, who was scripted to produce prepositional object or double object structures in specific trials, which served as primes for the real participant's picture descriptions. The confederate described the picture in one language and the real participant described his/her target picture in the other; the lexical repetition condition was implemented by using translation equivalents of the verb in the pictures to be described. Schoonbaert et al. tested priming from Dutch (L1) to English (L2) and vice versa and found cross-language priming in both language directions. They also observed a lexical boost effect (i.e., a “translation-equivalent boost”), but only from Dutch (L1) to English (L2).
Lexical repetition in structural priming: A cognitive model of bilingual sentence production
As discussed above, structural priming and a lexical boost of this structural priming occur within a language, but also across languages. To account for within-language structural priming, Pickering and Branigan (Reference Pickering and Branigan1998) designed a model of lexical and structural processes in sentence production. In this model, which provides a specification of Roelofs’ (Reference Roelofs1992) model of the lemma stratum, lemma nodes (i.e., the base form of a word) are connected to combinatorial nodes, which specify the surface structure of the sentence with which these lemmas are produced. Thus, when a certain word (e.g., give) is produced with a certain sentence structure (e.g., prepositional-object dative), both the lemma node of give and the combinatorial node specifying the surface structure of the prepositional-object dative are activated, as well as the link between these nodes. To explain structural priming, it is assumed that there is residual activation from these nodes when a subsequent utterance is produced. When this utterance does not contain the same lemma, structural priming follows from residual activation of the combinatorial node. When the subsequent utterance does contain the same lemma as the previous utterance, structural priming follows from both residual activation of the combinatorial node and re-activation of the lemma node from the previous utterance as well as the link between the lemma node and the combinatorial node. This explains why lexical repetition between prime and target boosts structural priming.
To account for cross-language structural priming, Hartsuiker et al. (Reference Hartsuiker, Pickering and Veltkamp2004) adapted Pickering and Branigan's (Reference Pickering and Branigan1998) model to bilingual production. Like Pickering and Branigan's model, the adapted model consists of lemma nodes that are connected to combinatorial nodes. The adapted model extends the original model to bilingual processing through the assumption that lemmas from both languages are represented in an integrated network in which lemmas are linked to language nodes and share the same conceptual representation when they are translation equivalents (see Figure 1). The combinatorial nodes are connected to the lemma nodes and are thus also represented in a network that is integrated for both languages (which makes sense, considering the fact that some sentence structures are shared between languages and can therefore be linked to lemma nodes from both languages, while others are not shared between languages and can therefore only be attached to lemma nodes from one language only; see Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2007; Kootstra et al., Reference Kootstra, van Hell and Dijkstra2010).

Figure 1. Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model for the representation of lexical and combinatorial information in bilingual speakers (from Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007). “DO” and “PO” in the combinatorial nodes refer to “double object” and “prepositional object” structure in dative sentences. The model is not restricted to explaining dative sentences, however. The contents of the nodes in this depiction are just examples of the kind of information that can be represented in these nodes.
This model explains cross-language structural priming without lexical boost as follows: When a person hears or produces a sentence in a particular language, this leads to the activation of specific lemmas, a specific combinatorial node (surface sentence structure), and the link between these two nodes. When a person then produces a sentence in another language, residual activation from the combinatorial node enhances the likelihood that this combinatorial node is selected again in this sentence. The model can also explain the finding of a translation-equivalent lexical boost in cross-language structural priming (see Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007): Because translation equivalents are assumed to share the same conceptual node, processing a sentence in a particular language not only leads to activation of the specific lemmas and combinatorial node, but also to activation of the lemmas’ translation equivalents (via the conceptual node). When a person then produces a sentence that includes the translation equivalent of the previous sentence, this results in re-activation of the lemma from the previous sentence. Via the established link between this lemma node and the combinatorial node, this leads to a relatively high activation of the combinatorial node that has just been used. This explains the enhanced priming effect in the case of translation equivalents.
Although Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model can account for cross-language structural priming and a translation-equivalent lexical boost of this effect, it cannot directly account for Schoonbaert at al.'s (Reference Schoonbaert, Hartsuiker and Pickering2007) finding that the lexical boost only occurred from Dutch (L1) to English (L2). Based on the Revised Hierarchical Model of lexical representation in L2 learners (e.g., Kroll & Stewart, Reference Kroll and Stewart1994; Kroll, van Hell, Tokowicz & Green, Reference Kroll, van Hell, Tokowicz and Green2010), Schoonbaert et al. therefore made the additional assumption that the link from the lemma nodes to conceptual nodes is weaker for L2 lemmas than for L1 lemmas. This leads to a stronger link from L1 (Dutch) to L2 (English) than vice versa, which makes re-activation of the prime sentence's lemma more efficient for L1 lemmas than for L2 lemmas. This explains the asymmetrical lexical boost effect in Schoonbaert et al.'s study.
To sum up, the observed boost of structural priming through lexical repetition within and across languages is accounted for by a cognitive model in which lexical and combinatorial representations are connected within and across languages. This model allows for cross-language activation of lexical and combinatorial representations and thus enables cross-language priming to occur. As indicated by Schoonbaert et al. (Reference Schoonbaert, Hartsuiker and Pickering2007) with reference to lexical representations, priming effects are stronger when this cross-language link is stronger.
Lexical repetition in the priming of code-switches
The role of lexical repetition on structural priming in bilinguals has thus far only been studied in situations in which a prime is given in one language and a target in another, and not in situations in which both prime and target are mixed-language sentences (i.e., code-switching). The questions remain, therefore, to what extent lexical repetition influences the priming of code-switched sentences, and to what extent the model discussed above can be applied to this situation.
The focus in the present study is on the priming of the sentence position of switching. Although this is a dependent variable different from the priming of syntactic structure in the structural priming studies described above, it taps into similar processes and critically involves the interaction between lexical and structural processes. After all, in order for priming of switch position to occur, a link must be made between the surface structure of the sentence and the language membership of the words in this sentence. Activated lemmas need to be linked to language nodes and to combinatorial nodes, so that the language membership of each lemma in the surface structure of the sentence can be specified (and thus a representation of the sentence position of switching is created). Investigating the priming of code-switch position will therefore not only lead to more insight into the cognitive mechanisms of code-switched sentence production, but will also extend Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model of sentence production in bilinguals to a new speaking mode, namely code-switching, and to a new dependent variable, namely the priming of switch position.
The role of cognate words in code-switching and bilingual processing
Besides lexical repetition between a prime sentence and target utterance, sentence-level code-switching can be influenced by another lexical factor: cognates. Cognates are translation equivalents with overlapping lexical form across languages, like the Dutch–English boek–book or baby–baby. The unique cross-linguistic form and meaning overlap of cognates can be exploited to investigate cross-language activation processes in bilinguals. Many word production and word comprehension studies have shown that cognates are processed faster and more accurately than matched control words (e.g., Christoffels, Firk & Schiller, Reference Christoffels, Firk and Schiller2007; Costa, Caramazza & Sebastián-Gallés, Reference Costa, Caramazza and Sebastián-Gallés2000; Dijkstra, Miwa, Brummelhuis, Sappelli & Baayen, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Gollan & Acenas, Reference Gollan and Acenas2004; Van Assche, Duyck, Hartsuiker & Diependaele, Reference Van Assche, Duyck, Hartsuiker and Diependaele2009; van Hell & de Groot, Reference van Hell and de Groot1998). This cognate facilitation effect is typically explained by assuming that the cross-language similarity of cognates leads to a relatively high degree of cross-language activation. As a result, cognates are more resonant in the bilingual's mind than non-overlapping words, which can lead to facilitated performance in lexical tasks.
A recent study by Bernolet, Hartsuiker and Pickering (in press) has shown that cognates can also influence syntactic choices in language production. Bernolet et al. (in pressReference Bernolet, Hartsuiker and Pickering) investigated structural priming of genitive constructions between Dutch and English (e.g., the fork of the girl vs. the girl's fork), in which the head nouns in the prime and target (i.e., fork) were always translation equivalents and the cognate status of the head noun was manipulated. They found that cognate status of the head noun enhanced structural priming: The likelihood of using the same type of genitive construction as in the prime sentence was higher in prime-target items with a cognate than in prime-target items with a matched control word. Bernolet et al. (in pressReference Bernolet, Hartsuiker and Pickering) explained this effect by assuming that re-activation of the lemma from the prime sentence including the link between this lemma and the combinatorial node, which necessarily involves cross-language activation, is enhanced by the cross-language activation caused by the cognate. The cross-language overlap of the cognate leads to a relatively high likelihood that the combinatorial node that is linked to the re-activated cognate lemma from the prime sentence (in one language) is also selected in the target picture description (in the other language).
Cognates can also facilitate code-switching. This notion, called triggered code-switching, was introduced by Clyne (e.g., Reference Clyne1967, Reference Clyne1980, Reference Clyne2003), who observed that the language of immigrant Australians contained many code-switches in the neighborhood of a cognate. Triggered code-switching is consistent with the cognate facilitation effect: Activating a cognate leads to a relatively high degree of cross-language activation in the bilingual's mind, which increases the likelihood of code-switching (see Broersma & de Bot, Reference Broersma and Bot2006). The triggering hypothesis has been statistically supported in corpus studies (Broersma, Reference Broersma2009; Broersma & de Bot, Reference Broersma and Bot2006; Broersma, Isurin, Bultena & de Bot, Reference Broersma2009) and recently also in experimental investigations (Kootstra, van Hell & Dijkstra, Reference Kootstra, van Hell and Dijkstra2011; Witteman, Reference Witteman2008).
Cognates can thus facilitate bilingual lexical processing, influence syntactic choices in cross-language structural priming, and increase the likelihood of code-switching. When translating these findings to the production of code-switches in sentences, it can be hypothesized that the tendency to switch at the same sentence position as in a code-switched prime sentence is stronger when the sentence contains a cognate than when it does not contain a cognate.
The role of relative language proficiency in code-switching
Another factor that potentially influences code-switching is the bilingual's relative level of proficiency in both languages. The importance of proficiency in bilingual language tasks is reflected in the finding that switch costs from L1 to L2 and vice versa are more symmetrical in speakers with a higher proficiency level in both languages than in speakers with a lower relative proficiency level (e.g., Costa & Santesteban, Reference Costa and Santesteban2004; Meuter & Allport, Reference Meuter and Allport1999). Effects of language proficiency have also been found in neuroimaging studies, which revealed that people with relatively high levels of language proficiency more often engage a common neural network for both languages than people with relatively low levels of language proficiency (Abutalebi, Cappa & Perani, Reference Abutalebi, Cappa and Perani2001; see van Heuven & Dijkstra, Reference van Heuven and Dijkstra2010, for a review).
With respect to code-switching in sentences, Poplack (Reference Poplack1980) observed that a person's level of proficiency in both languages is an important predictor of the sentence position at which bilinguals code-switch. Specifically, in her analysis of interviews with members of the Puerto-Rican community in New York, Poplack discovered that Spanish-dominant speakers mostly switched languages between sentences while balanced bilinguals switched more within sentences. She concluded from this that a bilingual's level of grammatical integration of both languages is dependent on his/her relative level of proficiency in both languages.
Relative language proficiency can thus influence the flexibility and likelihood of code-switching. The next question is to what extent proficiency influences priming of code-switches in sentences. Costa, Pickering and Sorace (Reference Costa, Pickering and Sorace2008) discussed the role of proficiency in lexical and structural priming in second language dialogue (non-code-switched). They argued that priming entails access to the linguistic representations that are primed and involves flexibility in language users to adapt their linguistic behavior to the discourse at hand. Translating this to priming of code-switched sentences, it can be hypothesized that priming is stronger in bilinguals with a high level of L2 proficiency. After all, the more proficient a person is, the easier it is to activate linguistic representations from both languages and the stronger the link between both languages will be. This makes it easier for a more proficient speaker to adapt his/her linguistic behavior to code-switches sentences in the prior discourse than for a less proficient speaker.
Likewise, it can be predicted that the sensitivity to lexical variables in the priming of code-switches (in the case of this study, lexical repetition and cognates) is higher in high-proficient than in low-proficient speakers. With respect to lexical repetition, Schoonbaert et al. (Reference Schoonbaert, Hartsuiker and Pickering2007) showed that lexical boost effects are dependent on the strength of links between lemmas and concepts in both languages. Because these links are stronger in high-proficient speakers, we expected that lexical repetition effects in the priming of code-switches are stronger in high-proficient than in low-proficient speakers. With respect to cognates, van Hell and Dijkstra (Reference van Hell and Dijkstra2002) found effects of non-target language proficiency on cognate processing in two groups of Dutch–English–French trilinguals who differed in their French proficiency. The trilinguals were presented with Dutch words that were cognates with L2 English, cognates with L3 French, or noncognates, and performed a word association or a lexical decision task. In both groups of trilinguals, cognates with L2 English were processed faster than noncognates. In the trilinguals with a low L3 French proficiency, the cognates with L3 French were responded to equally fast as the non-cognates, but in the trilinguals with a high L3 French proficiency, the cognates with L3 French were responded to faster than the non-cognates. This implies that a minimal level of proficiency is needed for cognate facilitation effects to occur. We therefore predicted that cognate effects on the priming of code-switches would be stronger in high-proficient than in low-proficient speakers.
The present study
The goal of the present study is to test to what extent bilinguals’ tendency to copy the position of code-switches from prime sentences in their description of pictures is influenced by lexical repetition between sentences, the presence of a cognate, and by the bilinguals’ relative language proficiency. The study consists of two experiments, in which we adapted Bock's (Reference Bock1986) structural priming task to a code-switching situation. Dutch–English bilinguals were asked to repeat auditorily presented code-switched (prime) sentences and describe visually presented (target) events by using a mix of Dutch and English (i.e., code-switching). Lexical repetition between prime and target and the presence of a cognate in the prime and target was manipulated. The dependent measure was whether participants switched at the same or at a different sentence position as the prime sentence in their description of the target pictures. Relative language proficiency was operationalized by testing L2 learners in an earlier phase of L2 English learning (Dutch ninth grade pre-university level secondary school students) in Experiment 1 and L2 learners at a more advanced stage of L2 English learning (Dutch university-level students) in Experiment 2.
We predicted that participants’ tendency to switch at the same position as in the prime sentence would be enhanced by lexical repetition between the prime sentence and the target picture and by the presence of a cognate in the prime sentence and target picture. We further predicted that high-proficient speakers would be more sensitive to the lexical repetition and cognate manipulations than low-proficient speakers, because high-proficient speakers have better access to both their languages and typically show larger co-activation effects in bilingual tasks than low-proficient speakers. This should make high-proficient speakers more flexible in tailoring their linguistic choices in their target picture description to the language encountered in the prime sentence.
Experiment 1: Priming of code-switches in beginning L2 learners
Method
Participants
The participants were 30 ninth-grade students in the pre-university track of a secondary school in the area of Nijmegen, the Netherlands. They were native speakers of Dutch, who had started to learn English as an L2 at school from around fifth grade onwards (i.e., from around age 10). In grades 5 and 6 (primary school), they received English classes for about one hour a week; in secondary school, they received English classes for about three to four hours a week. The participants also received German classes for three hours a week and French classes for two hours a week. All other school courses were in Dutch. In addition to classroom learning of English, the participants were exposed to English at a regular basis through television and other popular media. As revealed by their scores on an English proficiency test (L_Lex Vocabulary Test; Meara, Milton & Lorenzo-Dus, Reference Meara, Milton and Lorenzo-Dus2001), the participants had an intermediate level of performance in English, indicating that these learners perform at a level that is substantially below what would be expected from native speakers, but have a good grasp of basic English vocabulary. The participants reported that they code-switch in their daily lives and have a neutral attitude towards code-switching. An overview of the participants’ background characteristics is given in Table 1 (this table provides the background characteristics of the participants in both Experiments 1 and 2).
Table 1. Background characteristics of the participants in Experiments 1 and 2.

1 L_Lex scores between 50 and 60 are equal to TOEFL scores of 500–550, an ESU level of 5 “independent”, an IELTS score of 5, and a UCLES exams score description of FCE; L_Lex scores between 70 and 90 are equal to TOEFL scores of 550–620, an ESU level between 6 “competent” and 7 “good”, an IELTS score between 6 and 7, and a UCLES exams score description between CAE and CPE (see Meara et al., Reference Meara, Milton and Lorenzo-Dus2001).
2 Five-point scale: 1 = irritating; 5 = fun.
3 Five-point scale: 1 = never; 5 = regularly.
Materials
The priming task involved auditorily presented sentences and visually presented pictures to be described. A critical trial consisted of a combination of an auditory code-switched prime sentence and a target picture that was to be described using a code-switched sentence. Both the sentences and the pictures represented transitive events involving an actor, action, patient, and prepositional phrase (e.g., a boy looking at a monkey near a forest). A total of 24 critical prime-target trials were constructed from a pool of 8 actors, 8 actions, 24 patients, 6 prepositions, and 24 nouns in the prepositional phrase (which were distributed evenly across the 24 prime-target trials). These words were matched between Dutch and English on lemma log frequency (Dutch: M = 1.44, SD = 0.60; English: M = 1.50, SD = 0.61) and length in number of letters (Dutch: M = 4.75, SD = 1.56; English: M = 4.88, SD = 1.37), as obtained from the web-based Celex lexical database (http://celex.mpi.nl; Baayen, Piepenbrock & van Rijn, Reference Baayen, Piepenbrock and van Rijn1993). A list of all words that were used to construct the stimuli as well as a list of all critical prime sentences and target pictures is given in the appendix.
The manipulation of lexical repetition between the prime sentence and target picture is illustrated in Table 2. Lexical repetition between the prime sentence and target picture was manipulated by using either the same or a different patient object (the underlined words in Table 2) in the prime sentence (in which the patient object is presented auditorily) and target picture (in which the patient object is presented visually as one of the depicted entities). Thus, lexical repetition was manipulated by means of the repetition of the entity representing the patient object in the prime sentence and the target picture. Because the participants were free to decide the sentence position of code-switching in their target picture descriptions (see “Procedure” section), the extent to which this repetition manipulation led to repetition of the same patient object in the same language as in the prime sentence or to its translation equivalent depended on the participant's sentence position of switching.
Table 2. Examples of the critical stimuli in each condition of Experiment 1.

Note: The underlined words are the critical words that are manipulated for lexical repetition and cognate status. The italicized words refer to the part of the prime sentence that is switched into English.
Cognate status was also manipulated in the patient of the primes and targets: The patient object was either a cognate or a matched control word. When the patient in the target picture was a cognate, the patient in the prime sentence was also always a cognate (bal “ball” – bal in case of lexical repetition, gitaar “guitar” – bal in case of no lexical repetition). Likewise, when the patient in the picture was a non-cognate, the patient in the prime sentence was also a non-cognate. The Dutch and English cognates and non-cognates were matched on frequency (Dutch cognates: M = 1.35, SD = 0.62; Dutch non-cognates: M = 1.49, SD = 0.58; English cognates: M = 1.41, SD = 0.63; English non-cognates: M = 1.58, SD = 0.59) and length (Dutch cognates: M = 4.71, SD = 1.63; Dutch non-cognates: M = 4.79, SD = 1.53; English cognates: M = 4.88, SD = 1.54; English non-cognates: M = 4.88, SD = 1.19). See Table 2 for an example of the cognate manipulation.
The syntactic structure in the prime sentences was the same in all critical trials (NP + VP + PP), and was syntactically equivalent between Dutch and English. The stimulus materials could therefore not lead to syntactic conflicts between Dutch and English, which are known to constrain code-switching; see Kootstra et al. (Reference Kootstra, van Hell and Dijkstra2010). The code-switch in the prime sentence was always located directly after the patient object (the underlined word in Table 2) and was always from Dutch into English. All critical target pictures were depicted with Dutch and English flags, which served as a cue for participants to use both Dutch and English in describing the picture.
In addition to the critical stimuli, 72 filler sentences and 72 filler pictures were included. Just as in Bock's classic structural priming task (e.g., Bock, Reference Bock1986; Loebell & Bock, Reference Loebell and Bock2003), these sentences and pictures were not coupled in terms of prime-target combinations (like in the critical trials), but were independent of each other. This was done to create stimulus lists in which there was no predictable trial sequence of pictures after sentences and thus to disguise the priming manipulation in the critical trials (see the “Procedure” section below for how filler trials and critical trials were ordered). All filler sentences and pictures were based on lexical materials different from those used for the critical stimuli. The filler sentences consisted of 24 all-Dutch sentences (e.g., de politieman waarschuwt de inbreker “the policeman warns the burglar” or de tennisser geeft een bloem aan zijn tegenstander “the tennis player gives a flower to his opponent”), 24 all-English sentences (similar to the all-Dutch examples, but then in English), and 24 code-switched sentences in which the sentence position of the code-switch was varied, so that the likelihood of strategic behavior with respect to the sentence position of switching in the critical trials was reduced (e.g., de tennisser geeft a flower to his opponent or de tennisser gives a flower to his opponent, etc.). To avoid any possible influence of syntactic constraints on code-switching, the syntactic structures of the code-switched filler sentences were always shared between Dutch and English. The filler pictures consisted of 24 pictures to be described in Dutch only (depicted with a Dutch flag), 24 pictures to be described in English only (depicted with an English flag), and 24 pictures to be described using both Dutch and English (depicted with Dutch and English flags). The filler word stimuli were also used to create practice trials.
All target pictures (both critical and filler pictures) were black line drawings on a white background that were easy to identify. The pictures were adapted from pictures used in previous studies on code-switched sentence production (Kootstra et al., Reference Kootstra, van Hell and Dijkstra2010) and a picture database for psycholinguistic research (Szekely et al., Reference Szekely, Jacobsen, D'Amico, Devescovi, Andonova and Herron2004). To make sure that participants could unambiguously identify the agent and the patient in the pictures, the agent was always animate and was always depicted on the left side of the picture. All sentences (both critical and filler sentences) were recorded by a female native speaker of Dutch who is highly proficient in English.
The 24 critical stimuli and 72 filler sentences and pictures were combined into four stimulus lists. In each list, all four experimental conditions were represented six times. Each critical prime-target combination occurred only once in each list, and was rotated across conditions between each list. Each list was randomized into two versions, in which we ensured that the occurrence of a code-switch or a non-code-switch trial was unpredictable and evenly distributed across the list.
Procedure
The participants were tested individually in a quiet room. They were seated in front of a laptop and were then instructed for the experimental task. The task was the same as Bock's structural priming task (e.g., Bock, Reference Bock1986; Loebell & Bock, Reference Loebell and Bock2003), but adapted to a code-switching situation. The participants were told that they would be performing a memory task in which they would be presented with sentences and pictures in a random order. Some of these sentences and pictures would be presented more than once within the experimental session, and it was the participants’ task to decide for each sentence or picture whether they had encountered it before in the task. These instructions were purely a cover task to disguise the priming manipulation. Priming in the critical trials was implemented by systematically coupling the presented sentences with the subsequent target picture into prime-target combinations (see the “Materials” section).
The instructions for the sentence trials (i.e., the prime sentences in critical trials) were as follows. A sentence was presented auditorily through the speakers of the laptop. Participants were instructed to listen to the sentence and then to repeat it aloud. After having repeated the sentence, participants had to decide whether they had heard this sentence before in the task by pressing the “1” (yes) or “0” (no) key on the keyboard of their laptop. Pressing this key automatically initiated the next trial. The instructions for picture trials (i.e., the target items in the critical trials) were to describe each picture appearing on their screen by means of a complete sentence, including an actor, verb, patient, and a prepositional phrase. Pictures with a Dutch flag had to be described in Dutch only, pictures with an English flag in English only, and pictures with both a Dutch and an English flag by means of a combination of Dutch and English. In these latter pictures, participants were instructed to begin in Dutch and end in English, and to switch languages only once in each picture description. The participants were free to decide at what position in the sentence they would switch. After having described the picture, participants had to decide whether they had seen the picture before in the task by pressing the “1” (yes) or “0” (no) key on the keyboard. Pressing a key automatically initiated the next trial.
To give the participants the impression that they were presented with a randomly ordered series of pictures and sentences, we combined the critical prime-target combinations with the separate sentence fillers and picture fillers. To create prime-target trials (i.e., the critical items), critical picture trials were always preceded by a critical sentence trial. Filler pictures and sentences were randomly presented in the stimulus lists, not in the same order as the experimental prime-target combinations but as separate pictures and sentences, respectively. Fillers were never placed between a critical prime sentence and target picture. The filler items were also the items that were sometimes repeated to make the participants’ memory task (i.e., the cover task of this experiment) functional. A total of 36 filler items (18 sentence trials and 18 picture trials) were repeated in the task. See Figure 2 for an illustration of the trial sequence in the experiment.

Figure 2. Example of trial sequences in the experimental task (based on Bock, Reference Bock1986). This figure shows the components of an experimental trial as well as the placement of filler trials relative to experimental trials. The instructions for participants in the filler sentence trials and filler picture trials were the same as the experimental sentence trials and picture trials, respectively.
After the instructions, each participant first completed a block of eight practice trials and then completed one of the eight experimental versions described in the “Materials” section. The experiment was conducted on a laptop using E-prime. Responses were recorded and transcribed. After the experiment, participants filled in a language history questionnaire and then performed the L_Lex vocabulary task. A testing session lasted about 45 minutes.
Scoring and analysis
The dependent variable was whether or not the participant's sentence position of switching in the target picture description was the same as in the prime sentence. Target picture descriptions of critical trials were coded as (i) having the same switch position as in the prime sentence, (ii) having a different switch position as the prime sentence, or (iii) other. The “other” responses contained all picture descriptions that were unscorable because (i) no switch or more than one switch was made, (ii) an unfinished sentence or different sentence structure than the priming sentence was used, or (iii) the critical word was not used. The statistical analysis was based on all responses except the “other” responses.
We tested to what extent the participants’ likelihood to switch at the same versus a different position as in the prime sentence (i.e., the ratio between switching at the same position as in the prime sentence and switching at a position different from that in the prime sentence) was influenced by lexical repetition between prime and target (repetition of the patient object) and by the presence of a cognate in the prime and target. The analysis was performed using a mixed-effects logistic regression analysis (see Baayen, Davidson & Bates, Reference Baayen, Davidson and Bates2008) with random intercepts for participants and items and by-participant random slopes for the lexical repetition and cognate factors, using the lme4 package (Bates, Maechler & Dai, Reference Bates, Maechler and Dai2007) in R version 2.7.2 (R Development Core Team, 2008). By-item random slopes were not included, because the items were already counterbalanced across conditions. The analysis always contained both manipulated variables (Lexical Repetition and Cognate Status) as fixed main effects, in which the baseline intercept (i.e., reference category) was No Repetition for lexical repetition and No Cognate for cognate status (i.e., the effect of lexical repetition is the effect of lexical repetition against no lexical repetition; the effect of cognates is the effect of the presence of a cognate against the absence of a cognate). Interaction effects that did not significantly improve the model's fit (as indicated by a chi square test) were left out of the model. The coefficients of the mixed-effects analysis (Table 4) are given in log-odds.
Results
Four items were excluded from the analysis because they attracted more than 50% of “other” responses. On the remaining 20 items participants produced a total of 600 picture descriptions. Of these descriptions, 52 (8.66%) were scored as “other” and discarded from the analysis. The “other” responses occurred about equally often across the four conditions (11 in the Lexical Repetition & Cognate condition; 13 in the No Lexical Repetition & Cognate condition; 13 in the Lexical Repetition & No Cognate condition; 15 in the No Lexical Repetition & No Cognate condition). The analysis is based on the remaining 548 picture descriptions.
Table 3 gives the proportions per condition that the participants switched at the same position as in the prime sentence and the proportions per condition that the participants switched at a position different from that in the prime sentence. A summary of the mixed-effects model on the ratio between switching at the same sentence position and switching at a different sentence position that best fits the data is given in Table 4. The analysis yielded a significant main effect of lexical repetition and a marginally significant effect of cognate status. The proportion of switches at the same position as in the prime sentence was significantly higher when the patient object was repeated (.56; see Table 3) than when it was not repeated (.39; see Table 3) and marginally significantly higher when the patient object was a cognate (.49; see Table 3) than when it was not a cognate (.46; see Table 3). The interaction between lexical repetition and cognate status did not significantly improve the fit of the model (χ2(1) = 0.555, p = .456).
Table 3. Proportions of response types per condition, Experiments 1 and 2.
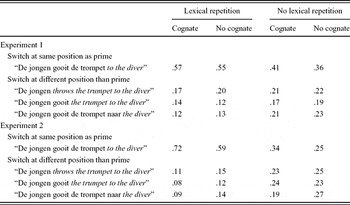
Note: All proportions are column proportions. Mean proportions of switching at the same position as in the prime sentence for the manipulated variables independently were for Experiment 1: Lexical repetition .56, No lexical repetition .39, Cognate .49, No cognate .46; for Experiment 2: Lexical repetition .66, No lexical repetition .30, Cognate .53, No cognate .42.
Table 4. Summary of mixed-effects logistic regression analyses for variables predicting the likelihood that participants switched at the same position as in the prime sentence rather than at a different position; Experiments 1 and 2, and the combined analysis.
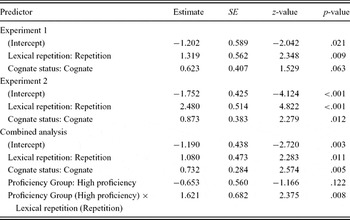
Notes: Standard deviations of random effect terms were for Experiment 1: 2.44 for by-participants random intercepts, 2.58 for by-participants random slopes for the lexical repetition effect, 1.58 for by-participants random slopes for the cognate effect, and 1.07 for by-items random intercepts; Experiment 2: 1.81 for by-participants random intercepts, 2.27 for by-participants random slopes for the lexical repetition effect, 1.46 for by-participants random slopes for the cognate effect, and 0.25 for by-items random intercepts; combined analysis: Standard deviations of random effect terms were 2.05 for by-participants random intercepts, 2.18 for by-participants random slopes for the lexical repetition effect, 1.61 for by-participants random slopes for the cognate effect, and 0.58 for by-items random intercepts.
The p-values are based on one-tailed hypotheses.
Discussion
Experiment 1 showed that the tendency of intermediate level L2 learners to copy the switch position of a code-switched prime sentence in describing pictured events is enhanced by lexical repetition between the prime sentence and target picture. This effect is consistent with earlier findings of a lexical boost effect on structural priming in non-code-switched speech (Arai et al., Reference Arai, van Gompel and Scheepers2007; Branigan et al., Reference Branigan, Pickering and Cleland2000; Cleland & Pickering, Reference Cleland and Pickering2003; Corley & Scheepers, Reference Corley and Scheepers2002; Gries, Reference Gries2005; Hartsuiker et al., Reference Hartsuiker, Bernolet, Schoonbaert, Speybroeck and Vanderelst2008; Pickering & Branigan, Reference Pickering and Branigan1998; Santesteban et al., Reference Santesteban, Pickering and McLean2010; van Beijsterveldt & van Hell, Reference van Beijsterveldt and van Hell2009), and in particular with Schoonbaert et al.'s (Reference Schoonbaert, Hartsuiker and Pickering2007) study of lexical boost effects on cross-language structural priming in bilinguals.
A novel aspect of our findings is that lexical repetition effects were observed in code-switched speech. This extends the mechanisms of lexical repetition in sentence priming – thus far only investigated in single-language sentences – to code-switched sentences. Furthermore, lexical boost effects were until recently only explored for the priming of structural choices and word order in ditransitive sentences and complex noun phrases. The present findings indicate that lexical priming effects also apply to other aspects of sentence production, namely the positioning of a code-switch in a sentence.
The marginally significant effect of cognate status in Experiment 1 makes it difficult to draw conclusions on the role of cognates in the priming of code-switches. It could reflect that the role of cognates in the priming of code-switched sentences is limited in general, but it is also possible that the cognate effect did not reach significance because the participants in this experiment were relatively low-proficient speakers of English. This second option would be consistent with earlier results on cognate processing, which indicated that cognate effects may vary as a function of proficiency (van Hell & Dijkstra, Reference van Hell and Dijkstra2002). To gain more insight into the role of proficiency, both with respect to lexical repetition and the presence of cognates, priming of code-switches was studied in highly-proficient bilinguals in Experiment 2.
Experiment 2: Priming of code-switches in advanced L2 learners
Method
Participants
The participants were 27 students from Radboud University Nijmegen, the Netherlands. Like the participants in Experiment 1, they were native speakers of Dutch. They had received similar English classes as the participants in Experiment 1 until their enrollment in university, and were also exposed to English through popular media. The participants were further exposed to English through the reading of English course literature at university. Their scores on the L_Lex English vocabulary task confirmed that they were advanced learners of English, and they reported to code-switch in their daily lives and to have a neutral attitude towards code-switching. Compared to the participants in Experiment 1, the participants in Experiment 2 had received significantly more years of English language classes (t(55) = 10.03, p < .001) and had a significantly higher level of proficiency in English as measured by the L_Lex Vocabulary Test (t(55) = 7.56, p < .001). An overview of the participants’ background characteristics is given in Table 1.
Materials, procedure, scoring and analysis
The materials, procedure, scoring and analysis were identical to those of Experiment 1.
Results
The same four items as in Experiment 1 were discarded from the analysis, for the same reason as in Experiment 1. In the remaining 20 items the participants produced a total of 540 picture descriptions. We discarded 27 responses (5%) from the analysis, because these were scored as “other”. The “other” responses occurred about equally often across the four conditions (6 in the Lexical Repetition & Cognate Condition; 7 in the No lexical Repetition & Cognate Condition; 6 in the Lexical Repetition & No Cognate condition; 8 in the No Lexical Repetition & No Cognate condition). The analysis is based on the remaining 513 responses.
Table 3 gives the proportions of response types per condition. A summary of the mixed-effects model that best fits the data is given in Table 4. The analysis yielded significant main effects of lexical repetition and cognate status. The proportion of switches at the same position as in the prime sentence was significantly higher when the patient object was repeated (.66; see Table 3) than when it was not repeated (.30; see Table 3). The proportion of switches at the same position as in the prime sentence was also significantly higher when the patient object was a cognate (.53; see Table 3) than when it was not a cognate (.42; see Table 3). The interaction of lexical repetition with cognates did not significantly improve the fit of the model (χ2(1) = 0.155, p = .694).
Discussion
The proficient Dutch–English bilinguals in Experiment 2 code-switched more often at the same sentence position as in the prime sentence when the prime sentence and target picture description contained the same patient object than when the prime sentence and target picture did not contain the same patient object. This corroborates the findings from the less proficient bilinguals in Experiment 1 and shows once again that lexical repetition not only influences the priming of structural choices in non-code-switched speech but also affects the position of the switch in code-switched sentences.
The participants’ responses in Experiment 2 were also influenced by the presence of a cognate in the prime-target pairs: Participants more often switched at the same position as in the prime sentence when the prime sentence and target picture description contained a cognate than when they contained a non-cognate control. This cognate effect is related to earlier findings of cognate-triggered code-switching (Broersma, Reference Broersma2009; Broersma & de Bot, Reference Broersma and Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, de Bot, Isurin, Winford and de Bot2009; Kootstra et al., Reference Kootstra, van Hell and Dijkstra2011; Witteman, Reference Witteman2008), to cognate facilitation effects in studies on bilingual lexical processing (e.g., Christoffels et al., Reference Christoffels, Firk and Schiller2007; Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Gollan & Acenas, Reference Gollan and Acenas2004; Van Assche et al., Reference Van Assche, Duyck, Hartsuiker and Diependaele2009; van Hell & de Groot, Reference van Hell and de Groot1998; van Hell & Dijkstra, Reference van Hell and Dijkstra2002), and to Bernolet et al.'s (in press) finding that cognates boost cross-language structural priming in one-language (i.e., non-code-switched) sentence production. The fact that cognate effects were significant in the high-proficiency group and only marginally significant in the low-proficiency group (Experiment 1) suggests that sensitivity to cognates depends on relative language proficiency, as has also been found by van Hell and Dijkstra (Reference van Hell and Dijkstra2002) in a task that measured lexical processing by bilinguals in a monolingual context.
Combined analysis of Experiments 1 and 2
To further examine the role of L2 language proficiency in the priming of code-switches in sentences, we performed a combined analysis in which the responses from participants in Experiments 1 and 2 were directly compared. This was done by merging the data from Experiments 1 and 2 and including “Proficiency Group” as an additional fixed-effect predictor to the predictors that were already included in the separate analyses of Experiments 1 and 2. The baseline intercept of this proficiency group predictor was Low Proficiency (so the reported effect of proficiency group is the effect of High Proficiency against Low Proficiency). We again used mixed-effects logistic regression for the statistical analysis, employing the same procedure as in Experiments 1 and 2.
Table 4 summarizes the combined analysis. The analysis yielded main effects of lexical repetition and cognate status, as well as a significant interaction effect of lexical repetition by participant group. The lexical repetition effect was similar to the effect found in Experiments 1 and 2: Priming of switch position was higher when the patient object was repeated than when it was not. The cognate effect was similar to the effect found in Experiment 2: Priming of switch position was higher when the critical nouns in the prime and target were cognates rather than non-cognates. The interaction of lexical repetition by participant group is new. As shown in Figure 3, which depicts the effect of lexical repetition per participant group for both the cognate and non-cognate conditions (expressed in odds ratios, so that a connection is made to the mixed-effects logistic regression analysis; see Table 3 for the scores per condition in proportions), the effect of lexical repetition was smaller in the low-proficiency group (Experiment 1) than in the high-proficiency group (Experiment 2). Other interaction effects (i.e., the interaction of cognate by proficiency group and the three-way interaction of lexical repetition by cognate by proficiency group) were not significant and did not improve the fit of the model (model with interaction of cognate by proficiency group: χ2(1) = 0.949, p = .329; model with three-way interaction: χ2(3) = 1.084, p = .781).

Figure 3. Effects of lexical repetition and cognate status per proficiency group, expressed in terms of the odds ratio that participants switched at the same position as in the prime sentence (versus at a different position than in the prime sentence).
Although the interaction effect of proficiency with the lexical repetition manipulation is consistent with our hypotheses on the role of relative language proficiency, it is somewhat surprising that we did not find an interaction effect of cognate status with proficiency group. After all, the cognate effect was significant in the high-proficient group and only marginally significant in the low-proficiency group. Likewise, earlier research on cognate processing demonstrated that cognate effects are modulated by language proficiency (van Hell & Dijkstra, Reference van Hell and Dijkstra2002). A closer inspection of the data suggests that an interaction of cognate status with proficiency group may be present when only the lexical repetition data are considered: The cognate effect in the lexical repetition condition seems clearly larger in the high-proficiency group than in the low-proficiency group (see Figure 3). We tested this in a mixed-effects analysis in which we only included the lexical repetition data. This analysis indeed yielded a significant interaction effect of cognate status by participant group (B = 0.836; SE B = 0.456; z = 1.830; p = .034, one-tailed, based on the directional hypothesis that L2 co-activation effects from cognates are stronger in speakers with a high L2 proficiency than speakers with a low L2 proficiency). To confirm whether this interaction effect was indeed only present in the lexical repetition data, we also performed the same analysis in the no lexical repetition data. This analysis indeed yielded no significant interaction effect of cognate status by participant group (B = 0.295; SE B = 0.511; z = 0.576; p = .282, one-tailed).
To sum up, the combined analysis demonstrated that relative language proficiency influences the sensitivity to lexical factors in the priming of code-switches in sentences. The effect of lexical repetition was higher in high-proficient L2 speakers than in low-proficient L2 speakers, indicating that the high-proficiency group was more sensitive to the lexical variations in the prime sentence than the low-proficiency group. In addition, when only the lexical repetition data were considered, the high-proficient participants showed stronger effects of cognate status than the low-proficient participants. This implies that cross-language activation associated with cognates is stronger in high-proficient than in low-proficient bilinguals, which helps the high-proficient bilinguals to copy the switch position from the prime sentence.
General discussion
The goal of this study was to examine the role of lexical repetition, cognates, and language proficiency in the priming of code-switches in Dutch–English bilinguals. Using a structural priming task in which participants repeated code-switched prime sentences and then code-switched in describing a target picture, we tested whether in target picture descriptions the tendency to switch at the same position as in the prime sentence was influenced by repetition of the patient object between the prime sentence and target picture and by the presence of a cognate in the prime-target pair. In both low-proficient L2 speakers (Experiment 1) and high-proficient L2 speakers (Experiment 2), the tendency to repeat the switch position of the prime sentence was enhanced by lexical repetition. Priming of switch position was also enhanced by the presence of a cognate, but only in the high-proficient speakers. A combined analysis in which the responses of the low- and high-proficient L2 speakers were directly compared revealed that the effect of lexical repetition and, in the lexical repetition data, cognate status were stronger in the high-proficient L2 speakers than in the low-proficient L2 speakers.
Lexical repetition and cognates thus influence the priming of code-switches in bilingual speakers and the sensitivity to these lexical factors in the priming of code-switches depends on the bilinguals’ L2 proficiency level. This indicates that both lexical variables (lexical repetition and cognate status) and speaker variables (proficiency) work together in a sentence-level process, namely the priming of code-switches in sentences. These results have implications for cognitive perspectives on sentence production in bilingual speakers, as will be discussed below.
The role of lexical repetition in the priming of code-switches
The finding that lexical repetition enhanced the likelihood to switch at the same sentence position as in the prime sentence is related to earlier findings of a lexical boost effect on structural priming within and across languages in single language, non-switched sentences (Arai et al., Reference Arai, van Gompel and Scheepers2007; Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2007; Branigan et al., Reference Branigan, Pickering and Cleland2000; Cleland & Pickering, Reference Cleland and Pickering2003; Corley & Scheepers, Reference Corley and Scheepers2002; Gries, Reference Gries2005; Hartsuiker et al., Reference Hartsuiker, Bernolet, Schoonbaert, Speybroeck and Vanderelst2008; Pickering & Branigan, Reference Pickering and Branigan1998; Santesteban et al., Reference Santesteban, Pickering and McLean2010; Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007; van Beijsterveldt & van Hell, Reference van Beijsterveldt and van Hell2009). The lexical repetition finding extends the lexical boost effect to the production of code-switched sentences.
The lexical repetition results are also related to a recent study by Hatzidaki et al. (Reference Hatzidaki, Branigan and Pickering2011), who investigated co-activation between languages in the production of subject–verb agreement in one-language and mixed-language sentences. Hatzidaki et al. asked Greek–English and English–Greek bilingual speakers to complete English or Greek nouns that were either the same or different in number across languages (e.g., the money is/are useful, in which money is singular in English and plural in Greek). They found effects of incongruent agreement between the subject nouns and completed verb responses in the nouns that differed in number across languages. This is evidence of syntactic co-activation between languages, and especially shows how lexical information (the number of specific nouns) can influence structural processes (the encoding of subject–verb agreement) in both one-language and code-switched sentences. This influence of lexical information on structural processes, which implies a link between lexical and structural processes in models of language production, is also reflected in our effects of lexical repetition on the production of code-switches in sentences.
The link between lexical and structural processes is represented in Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model on cross-language structural priming in sentence production. To explain our lexical repetition effect on the priming of sentence position of switching in terms of this model, it is first necessary to specify how the sentence position of switching is represented in Hartsuiker et al.'s model. To recapitulate, Hartsuiker et al. extended Pickering and Branigan's (Reference Pickering and Branigan1998) notion of a connection between lemma nodes (lexical representations) and combinatorial nodes (surface structure representations) with the assumption that each lemma node is connected to a language node (i.e., the language membership of each lemma is specified; see Figure 1). To obtain a representation of the sentence position of switching, this language membership needs to be specified for each slot in the linear surface structure that is spelled out in the combinatorial node. This can be covered in the model by the link between the language nodes, lemma nodes, and combinatorial nodes. When lemma nodes and combinatorial nodes are linked, this also creates a link between the combinatorial nodes and the language nodes. Because the combinatorial nodes are supposed to include an exact specification of the sentence's surface structure in terms of linear order (see Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2007; Pickering, Branigan & McLean, Reference Pickering, Branigan and McLean2002), the link between lemma nodes, language nodes, and combinatorial nodes automatically leads to a specification of the language membership of each word in the sentence's linear surface structure that is represented in the combinatorial nodes (see Figure 4). This specification represents the sentence position at which a code-switch takes place. Priming of this sentence position of switching can then occur because of residual activation of this specification of language membership information per slot in the linear surface structure from the prime sentence.

Figure 4. A representation of the sentence position of code-switching in terms of Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model of the representation of lexical and combinatorial information in bilingual speakers. This specific depiction expresses a prepositional-object structure (PO), but the model can also be applied to other sentence structures. The model also incorporates the notion that cognates cause cross-language activation (via the dotted line from the cognate word bal [ball] to the LB node). For the sake of conciseness, determiners were not included in the example sentence.
Note that this explanation of the sentence position of switching is only possible when the combinatorial node provides not just a specification of constituent structure, but also a specification of the linear word order that is used with this constituent structure. This is consistent with research by Bernolet et al. (Reference Bernolet, Hartsuiker and Pickering2007) and Pickering et al. (Reference Pickering, Branigan and McLean2002), who demonstrated that constituent structure and linear word order is combined in one representation. Note also that this account of the sentence position of switching predicts switching difficulties in syntactic structures that are not shared between languages, as found in Kootstra et al. (Reference Kootstra, van Hell and Dijkstra2010). That is, a non-shared combinatorial node is difficult to link to lemma nodes from multiple languages. This hinders the use of lemmas from both languages in such structures.
Based on the representation of sentence position of switching in terms of Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model, the lexical repetition effects that were found in this study can be explained quite straightforwardly. Priming of sentence position without lexical repetition can occur because of residual activation of the link between the language nodes and combinatorial nodes from the prime sentence, which specifies language membership information per slot in the linear surface structure. This residual activation enhances the likelihood that the same specification of language membership information per slot in the linear surface structure is re-activated, leading to priming of switch position. Priming of sentence position with lexical repetition, however, follows not only from residual activation of the link between the language nodes and combinatorial nodes from the prime sentence, but also from re-activation of the lemma from the prime sentence, including the established link between the language nodes, the lemma, and the combinatorial nodes. This explains the facilitative effects of lexical repetition on the priming of code-switches in sentences.
At a more general level, the lexical repetition effect in the priming of code-switched sentences illustrates the importance of repetition and priming as mechanisms of language production. Many studies on code-switching and language production are based on models of language production in which speakers generate utterances “from scratch” by means of a multi-staged process from conceptualization to articulation (e.g., Levelt, Roelofs & Meyer, Reference Levelt, Roelofs and Meyer1999; Myers-Scotton & Jake, Reference Myers-Scotton and Jake1995). Our findings show that repetition and priming have a major influence on this language production process. The residual activation of recently encountered linguistic items can create “shortcuts” in the production process, leading to priming between utterances, thereby facilitating the flow of language production (see Garrod & Pickering, Reference Garrod and Pickering2004; Schober, Reference Schober and Brown2006). Importantly, such priming effects not only occur in artificial laboratory environments, but also in natural discourse situations. Indeed, priming between utterances is a central mechanism of language use in social interaction, leading to linguistic alignment and increased mutual understanding between interlocutors (see Ferreira & Bock, Reference Ferreira and Bock2006; Pickering & Garrod, Reference Pickering and Garrod2004). Although our study was situated in a relatively artificial laboratory setting in which no dialogue partners were involved, it still shows the basic principles of priming and repetition between sentences in the production of code-switched sentences.
The role of cognates in the priming of code-switches
The finding that cognates enhanced the likelihood of participants to switch at the same position as in the prime sentence is consistent with earlier findings of cognate facilitation in bilingual lexical processing (e.g., Christoffels et al., Reference Christoffels, Firk and Schiller2007; Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Gollan & Acenas, Reference Gollan and Acenas2004; Van Assche et al., Reference Van Assche, Duyck, Hartsuiker and Diependaele2009; van Hell & de Groot, Reference van Hell and de Groot1998) and with the observation in corpus research that code-switches occur more frequently in clauses with a cognate than in clauses without a cognate (Broersma, Reference Broersma2009; Broersma & de Bot, Reference Broersma and Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, de Bot, Isurin, Winford and de Bot2009). Our cognate findings especially relate to Bernolet et al.'s (in press) finding of a cognate boost on cross-language structural priming. These studies all suggest that cognates cause an increased level of co-activation of languages in the bilingual mind, resulting in facilitated processing of multiple languages.
The cognate effect can be explained in terms of Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model of bilingual sentence production, but only by making the additional assumption that cognates result in an increased lexical co-activation of languages (see the dotted line in Figure 4). This assumption was also made by Bernolet et al. (in pressReference Bernolet, Hartsuiker and Pickering) in their study on cognate effects in cross-language structural priming of non-code-switched sentences. Bernolet et al. argued that co-activation of languages caused by cognates enhances re-activation of the lemma from the prime sentence and its established link with the combinatorial node of the prime sentence via a feedback mechanism. Because the lemma in the prime sentence was in a different language than the lemma for the target picture description, re-activation of this lemma from the prime sentence necessarily involves co-activation between languages. This co-activation is facilitated when the lemma is a cognate, because cognates themselves lead to co-activation.
A similar explanation of cognate facilitation can be given for the findings in the present study, although the explanation of our findings cannot be based on re-activation of the lemma from the prime sentence. That is, Bernolet et al.'s study was based on a situation in which the cognate (e.g., vork) in the prime sentence was the translation equivalent of the cognate (fork) in the target sentence. In our study, cognate effects were found irrespective of whether the same or a different cognate was present in the prime sentence and target picture, so our cognate effects cannot be attributed to re-activation of the lemma from the prime sentence. Still, just like re-activation of the lemma from the prime sentence in Bernolet et al.'s cross-language structural priming study, activation of the link between language nodes and combinatorial nodes in a code-switched sentence (which specifies the sentence position of code-switching) necessarily involves the co-activation of elements from both languages. Similar to Bernolet et al.'s explanation of a cognate boost on re-activation of the lemma from the prime sentence, it can then be argued that re-activation of the link between language nodes and combinatorial nodes, which leads to priming of switch position, is boosted by the co-activation caused by the cognate in these sentences.
Based on this explanation, we also concur with Bernolet et al. (in pressReference Bernolet, Hartsuiker and Pickering) that there is feedback from phonological-level representations (form overlap in cognates) to higher-level representations (link between language nodes and combinatorial nodes). Such feedback is also in line with models on structural priming in dialogue contexts, which are based on an interactive framework that allows for full resonance of linguistic representations within and between speakers (i.e., the interactive alignment model; Pickering & Garrod, Reference Pickering and Garrod2004; see Kootstra et al., Reference Kootstra, van Hell and Dijkstra2010, for an extension of the interactive alignment model to code-switching).
For future research, it may be interesting to investigate whether cognate effects are modulated by the direction of switching. As found by Costa et al. (Reference Costa, Caramazza and Sebastián-Gallés2000), cognate effects are stronger when naming in the non-dominant language than in the dominant language. Translating this to the context of code-switching, it may well be that triggering of the non-selected language caused by cognates is stronger when switching from a weaker to a stronger language than vice versa. Indeed, Witteman (Reference Witteman2008) found that cognates reduced switching costs in self-paced reading only when switching from L2 to L1. Bultena, Dijkstra and van Hell (Reference Bultena, Dijkstra and van Hell2011) found similar effects in cross-linguistic shadowing. By investigating the effect of switch direction on cognate effects, more insight can be gained into the role of cognates in code-switching, especially into the interaction between cognates and L2 proficiency in code-switching (after all, directionality effects depend on a person's relative proficiency level in these languages), which in this study was only observed in the lexical repetition conditions.
The role of proficiency in the priming of code-switches
The analysis in which the data of the low- and high-proficient L2 speakers were combined showed that the effects of lexical repetition and cognates were stronger in the high-proficient speakers than in the low-proficient speakers. This demonstrates the importance of relative language proficiency in code-switching. Although corpus research by Poplack (Reference Poplack1980) and Poulisse and Bongaerts (Reference Poulisse and Bongaerts1994) already suggested that L2 proficiency is an important factor in code-switching in sentences, the influence of proficiency was not yet experimentally tested and also not yet applied to the role of lexical factors in the priming of code-switches. Our proficiency findings substantiate Costa et al.'s (Reference Costa, Pickering and Sorace2008) prediction (on non-code-switched language production) that priming will be most successful in language users that are able to activate and select linguistic representations from both languages in a smooth and flexible manner. Because earlier research has shown that lexical access to both languages as well as the link between both languages is stronger in high-proficient speakers than in low-proficient speakers (e.g., Costa & Santesteban, Reference Costa and Santesteban2004; Kroll & Stewart, Reference Kroll and Stewart1994; Meuter & Allport, Reference Meuter and Allport1999; Poulisse & Bongaerts, Reference Poulisse and Bongaerts1994; van Hell & Dijkstra, Reference van Hell and Dijkstra2002), this ability to flexibly adapt one's linguistic behavior to a previously encountered utterance will be higher in high-proficient speakers than in low-proficient speakers. This is exactly what we found.
The observed interaction of proficiency with lexical repetition is in line with Schoonbaert et al.'s (Reference Schoonbaert, Hartsuiker and Pickering2007) addition to Hartsuiker et al.'s (Reference Hartsuiker, Pickering and Veltkamp2004) model on lexical and combinatorial representations in bilinguals. To account for their finding that lexical boost effects only occurred from L1 to L2, they proposed that the strength of the lexical boost effect depends on the strength of cross-language lexical links, which are determined by relative proficiency in the L1 and L2. Our effects of stronger lexical repetition in L2 learners with a relatively high level of proficiency than in L2 learners with a relatively low level of proficiency support this proposal: In low-proficient L2 speakers, the link between L2 lemmas and their concepts is relatively weak compared to the link between L1 lemmas and their concepts, which makes it difficult to switch between languages, as is also expressed in the asymmetrical switch costs found in single-word language switching by unbalanced bilinguals (e.g., Costa & Santesteban, Reference Costa and Santesteban2004; Meuter & Allport, Reference Meuter and Allport1999). In high-proficient L2 speakers, these links between lemmas and conceptual representations are more equal in strength between L1 and L2. This makes it easier to switch from one language to the other, and enhances sensitivity to priming of code-switches in sentences. The observed interaction of proficiency with cognate status further supports earlier research on bilingual lexical processing that sensitivity to cognates is dependent on the bilingual's relative language proficiency (e.g., van Hell & Dijkstra, Reference van Hell and Dijkstra2002). Our findings show that this cognate effect is not only present in lexical processes, but also in sentence-level processes.
It is important to note that the role of proficiency as found in our study can be task-specific. That is, using both languages in one sentence – which was the task in this study – is facilitated by increased proficiency because of increased co-activation of both languages. However, in tasks that require production in one language and therefore require a higher degree of language control (see Green, Reference Green1998, Reference Green2011), increased proficiency may result in increased competition between languages, making this task more difficult for high-proficient speakers (although of course high-proficient speakers will probably also have had many opportunities to practice their task control) It is important, therefore, that bilingual language production models incorporate a task specification in which not only language choice itself but also the priority of this language choice is expressed. The model discussed in this study does not include such a task specification, because it only provides a representation of the lemma stratum and is not a complete model of all stages of language production. An example of a task specification in language production models is the language task schema in Green's (Reference Green1998) inhibitory control model. Task specifications can also be implemented in the kind of language production model discussed in Kroll, Bobb and Wodniecka (Reference Kroll, Bobb and Wodniecka2006; based on Poulisse & Bongaerts, Reference Poulisse and Bongaerts1994), by adding weight to the language cue (at the conceptual level) in accordance with the priority of adhering to this language cue during production.
An avenue for future research on the role of proficiency is to investigate more specific aspects of proficiency in the priming of bilingual speech. In this study, proficiency was operationalized by testing a group of relatively inexperienced learners of L2 English and a group of more experienced learners of L2 English with a similar basic level of intelligence (pre-university level secondary school students versus university students). Although these learners clearly differed in L2 proficiency (see Table 1), they also differed in age. Future research may investigate learners of the same age with a wider range of L2 proficiency (see e.g., Ojima, Nakata & Kakigi, Reference Ojima, Nakata and Kakigi2005, in the domain of sentence comprehension) Such an approach may also provide more insight into the interaction of proficiency with cognates, which in this study was indeed present, but only in the lexical repetition conditions. Because we studied relatively homogeneous groups of learners, within-group analyses of proficiency were not possible. In addition, linguistic behavior is not only influenced by proficiency, but also by more general cognitive and social properties, such as L1 and L2 working memory (e.g., Michael & Gollan, Reference Michael, Gollan, Kroll and de2005), people's sociability (e.g., Dijksterhuis & Bargh, Reference Dijksterhuis, Bargh and Zanna2001; Giles, Coupland & Coupland, Reference Giles, Coupland, Coupland, Giles, Coupland and Coupland1991), and their motivation for language learning (e.g., Dörnyei, Reference Dörnyei2003). By investigating the roles of such learner factors in addition to proficiency, future studies could provide novel insights into how different learner characteristics influence sentence production in bilingual speakers.
Conclusion
This study presented experimental evidence on the role of lexical repetition, cognates, and language proficiency in the priming of code-switched sentences in Dutch–English bilingual speakers. The results clarify the interactive cognitive mechanisms underlying sentence-level code-switching, demonstrating that code-switching is a multi-dimensional process in which lexical and speaker-related factors work in concert. In addition, the study extends and substantiates a bilingual version of Pickering and Branigan's (Reference Pickering and Branigan1998) model on lexical and combinatorial processes in sentence production (Hartsuiker et al., Reference Hartsuiker, Pickering and Veltkamp2004; Schoonbaert et al., Reference Schoonbaert, Hartsuiker and Pickering2007), which up to now was only tested with single-language sentences. We argue that the model is capable of accounting for the priming of sentence position of code-switching under the assumption that each slot in the linear surface structure of a sentence is tagged for language. Although this assumption follows from the architecture of the model, it had not yet been explicitly formulated and studied. Within this model, we were able to explain our code-switching findings by postulating (i) that lexical repetition makes it easier to re-activate the link between language nodes, lexical nodes, and combinatorial nodes that leads to the priming of code-switch position, and (ii) that cognates and high L2 proficiency levels increase the level of cross-language activation in language production, thus facilitating priming of code-switches in sentences. All in all, the present study shows how general psycholinguistic models of language production and research on code-switching in sentences can mutually inform each other.
Appendix. Pool of words from which the critical stimuli were created and list of all critical stimuli
All cognates with an asterisk are cognates with an identical pronunciation in Dutch and English. In all analyses reported in this study, the outcomes were the same when these identically pronounced cognates were excluded compared to when they were included.
Pool of words
Actors
boy – jongen; farmer – boer; fireman – brandweerman; girl – meisje; painter – schilder;
sailor – matroos; wizard – tovenaar; woman – vrouw
Verbs
call – roepen; carry – dragen; kick – schoppen; paint – beschilderen; push – duwen; put – zetten/leggen; throw – gooien; watch – bekijken
Patients
Cognates: arm – arm*; baby – baby*; ball – bal; book – boek*; cactus – cactus; clock – klok*; clown – clown*; finger – vinger; harp – harp*; heart – hart; helicopter – helikopter; nest – nest*; pen – pen*; penguin – pinguin; piano – piano*; puzzle – puzzel; ring – ring*; robot – robot*; rose – roos; sock – sok*; taxi – taxi; tent – tent*; trumpet – trompet; wolf – wolf
Control words: axe – bijl; bag – tas; bird – vogel; bottle – fles; car – auto; carrot – wortel; chicken – kip; city – stad; dog – hond; donkey – ezel; girl – meisje; lion – leeuw; mirror – spiegel; monkey – aap; rabbit – konijn; rope – touw; scarf – sjaal; shark – haai; snail – slak; stone – steen; towel – handdoek; turtle – schildpad; window – raam; witch – heks
Prepositions
above – boven; behind – achter; from – van/vanuit; near – bij; on – op; to/toward – naar
Nouns in the prepositional phrase
attic – zolder; building – gebouw; butcher – slager; chair – stoel; cinema – bioscoop; granny – oma; forest – bos; garden – tuin; diver – duiker; ceiling – plafond; livingroom – woonkamer; mouth – mond; paint – verf; painting – schilderij; paper – krant; road – weg; salesman – verkoper; shed – schuur; shop – winkel; suitcase – koffer; table – tafel; tree – boom; wall – muur; zoo – dierentuin
List of all critical stimuli
The lines with a P represent prime sentences and the lines with a T represent target pictures. The lines with [+c] and [–c] represent the conditions in which a cognate was present or not present, respectively. Likewise, the lines with [+lr/–lr] represent the conditions in which the patient object of the prime sentence was repeated or not repeated, respectively, in the target picture. The patient object before the slash (/) is repeated in the target picture; the patient object after the slash is not repeated in the target picture. The italicized elements in the prime sentences refer to the part in the sentences that was switched to English.
1.

2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
































