Introduction
The particularity of the bilingual memory is that it connects two language systems which can differ in many aspects (orthography, phonology, morphology and word meaning) and the consequence is that there very rarely exists term to term equivalence between languages (De Groot and Comijs, Reference De Groot and Comijs1995; Tokowicz and Kroll, Reference Tokowicz and Kroll2007). Most words are more or less ambiguous (De Groot and Van Hell, Reference De Groot, Van Hell, Kroll and De Groot2005; Prior, MacWhinney and Kroll, Reference Prior, MacWhinney and Kroll2007; Tokowicz, Prior and Kroll, Reference Tokowicz, Prior and Kroll2009), and these different meanings or senses of a word in one language may lead to multiple translations in another language. But even when a word has only one translation, the two translation equivalents do not necessarily have exactly the same meaning. It seems that with increased proficiency, bilinguals become more aware of language-specific characteristics in meaning (De Groot, Reference De Groot, Schreuder and Weltens1993), and that the semantics of the two languages become more distinct (Tokowicz and Kroll, Reference Tokowicz and Kroll2007). In general, concrete words are likely to have more similar meanings between languages than abstract words (Kolers and Gonzalez, Reference Kolers and Gonzalez1980; Van Hell and De Groot; Reference Van Hell and De Groot1998a). Moreover, there are words that have no real translation at all (e.g., the English word Thanksgiving or the French word bistrot “a kind of restaurant”, which are very culturally dependent words; Pavlenko, Reference Pavlenko1999).
One reason why the connections between translations seem very complex is that within-language ambiguities automatically have cross-language repercussions and may lead to multiple translations for a single word (Tokowicz and Kroll, Reference Tokowicz and Kroll2007). It is essential to identify factors that predict the choice of translation, because semantic equivalences are necessary to translate a word.
A great number of bilingual memory studies suggest the existence of shared representations in the semantic memory for the words in two languages (e.g., Potter, So, Von Eckhardt and Feldman, Reference Potter, So, Eckhardt and Feldman1984; De Groot, Reference De Groot1992a, Reference De Groot, Frost and Katzb; Reference De Groot, Schreuder and Weltens1993, Kroll and Stewart, Reference Kroll and Stewart1994; Kroll and De Groot, Reference Kroll, De Groot, de Groot and Kroll1997; Van Hell and De Groot, Reference Van Hell and De Groot1998a). According to one of the dominant models in the field, i.e., the distributed conceptual feature model of bilingual memory (De Groot Reference De Groot1992a, Reference De Groot, Frost and Katzb; Reference De Groot, Schreuder and Weltens1993, and its enhanced form, the distributed conceptual representation model (Van Hell and De Groot, Reference Van Hell and De Groot1998a); henceforth both models are referred to as the DCFM), the determinants of word translation are to a large extent the word type. In this model, the meaning of a word is distributed in nodes at the semantic level. Two translation equivalents can share all their nodes or just some nodes. When translating, the word's semantic representation is activated and as it shares a part of its representation with its translation equivalent, the more nodes the two words share, the faster the translation is. Concrete words are hypothesized to share more of their nodes with their translation equivalent because they have a more precise meaning which is often shared between languages. The meaning of abstract words, on the other hand, is more dependent on linguistic context and, therefore, the semantic overlap between translation equivalents is smaller. Cognate words (words with very similar or identical spelling and the same meaning in two languages, such as station in French and English) are also supposed to share more nodes than non-cognate words. A considerable number of experiments have shown results which confirm that concrete words and cognates are processed faster than abstract words and non-cognates (De Groot Reference De Groot1992a, Reference De Groot, Frost and Katzb; Reference De Groot, Schreuder and Weltens1993; De Groot, Dannenburg and Van Hell, Reference De Groot, Dannenburg and Van Hell1994; Van Hell and De Groot, Reference Van Hell and De Groot1998a, Reference Van Hell and De Grootb).
Most past studies on bilingual memory have used words with only one translation (or a clearly dominant translation, but the control has not always been very successful; see Tokowicz, Kroll, De Groot and Van Hell, Reference Tokowicz, Kroll, De Groot and Van Hell2002, for a discussion). The focus of the present study is to examine the consequences of number-of-translations of a word, and factors directly related to it, on translation performance. When a word has more than one translation, one of them can be used more often and thus be considered to be the dominant translation. In addition, when a word possesses many translations, some translations may be similar in meaning and others not. Some word characteristics, i.e., concreteness, have also been shown to influence the number of translations that a word may possess, in that concrete words tend to have fewer translations than abstract words (Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002). The fact that a word has multiple translations raises the problem of mapping the word to its “right” translation. When words only have one translation, fewer words (its translation and other semantically related words) compete for activation in a translation task. However, when words have more than one translation, more words may be activated (the multiple translations and other semantically related words), resulting in more competition between different candidates during translation.
Concerning the number of translations, we can presume that if a word possesses just one single translation equivalent, this translation can represent all the meanings of the given word (e.g., the English word tree shares a big part of its meaning with its French translation equivalent arbre). On the other hand, if a word possess multiple translation equivalents, each one often represents only a part of the whole meaning of the word (e.g., the translations woman and wife for the French word femme).
The DCFM did not in its original version account for words with multiple translations. However, by using the same principles as the model, it can be expanded so that it can account for multiple translations of a word. This is illustrated in Figure 1. In this figure, the lexical levels of each language (L1 and L2) and their shared representation at the semantic level are pictured. In the upper part of the figure, an English word with one translation equivalent is represented with its French translation (i.e., tree–arbre), and in the lower part, an English word (sheet) with two of its French translations (feuille “a sheet of paper” and drap “bedsheet”) are represented. When words have more than one translation, one can suppose that the different translations will be activated in a similar way to the different meanings of a polysemous word within a given language. Therefore, for words with multiple translations, one of the translations is often more dominant than the other. In Figure 1, feuille represents the dominant translation and drap the non-dominant translation of the English word sheet. The dominant translation would be preferentially activated in translation, at least in an out-of-context situation. There are several reasons why the dominant translation would be more activated, mainly the fact that, in terms of shared nodes, the dominant translation would share more semantic nodes with its translation than the non-dominant one. There has also been one study (Prior et al., Reference Prior, MacWhinney and Kroll2007) that has shown that for words with multiple translations, participants tend to produce the more frequent and the shorter translation. The dominance of a translation equivalent may therefore, to some extent, be due to lexical level factors such as word length and frequency. In this study, we have adopted the term dominant translation, which designates the equivalent that is most often used to translate a given word. Notice that this is not necessarily the most frequent word among the translations, but the most frequently given translation for a given word.

Figure 1. Hypothetical representation of shared semantic nodes between translation equivalents for words with one and words with more-than-one translation equivalent of which one is dominant and the other one non-dominant.
Finally, there are different reasons why a word in one language has more than one translation in another language. For example, within-language ambiguity (polysemy or homography; see Klein and Murphy, Reference Klein and Murphy2001, on the polysemy/homography dichotomy) might lead to multiple translations in another language, one translation for every sense or meaning of that word (see discussion of Sense vs. Meanings: Rodd, Gaskell and Marslen-Wilson, Reference Rodd, Gaskell and Marslen-Wilson2002); that is to say, the translation equivalents may not have the same conceptual–lexical mappings in the two languages (Prior et al., Reference Prior, MacWhinney and Kroll2007). On the other hand, a word can also have two (or more) translations when the different translations are considered synonymous with each other, so within-language synonymy can also lead to multiple translations (e.g., the French word bateau has two synonymous translations in English, boat and ship). The number of meanings of words has been shown to influence language processing of words in both monolingual research (Jastrzembski, Reference Jastrzembski1981; Azuma and Van Orden, Reference Azuma and Van Orden1997; Klein and Murphy, Reference Klein and Murphy2001; Rodd et al., Reference Rodd, Gaskell and Marslen-Wilson2002) and bilingual studies (Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002; Tokowicz and Kroll, Reference Tokowicz and Kroll2007). Figure 2 represents the semantic relations between two different translation equivalents of a word. Some translations are semantically related, in some cases even synonymous (e.g., the two translations of the English word husband in French: mari and époux). In this case, the three words (the English word and its two translation equivalents in French) share a big part of their meaning. Other translations are semantically distant (e.g., the English word nail has two translations in French, ongle “fingernail” and clou “metal nail”). In this case, the word shares part of its meaning with each of the two translation equivalents, but these do not share any common meaning. This important difference is shown in Figure 2. The semantic relatedness between the different translation equivalents of a given word will certainly have an impact on translation performance.
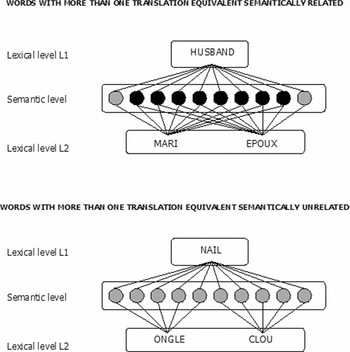
Figure 2. Hypothetical representation of shared semantic nodes between translation equivalents for words with two translations when the two translations are semantically related and when the translations are semantically unrelated.
All of the above-mentioned factors can also be related to other word characteristics, such as frequency or concreteness. An advantage of concrete words compared to abstract words has been reported in many monolingual studies using several tasks (e.g., lexical decision, memory tasks; James, Reference James1975; Schwanenflugel and Shoben, Reference Schwanenflugel and Shoben1983; Kroll and Merves, Reference Kroll and Merves1986; Païvio, Reference Païvio1986; Schwanenflugel, Harnishfeger and Stowe, Reference Schwanenflugel, Harnishfeger and Stowe1988; De Groot, Reference De Groot1989), and bilingual studies (e.g., recognition, association and production tasks; Païvio, Clark and Lambert, Reference Païvio, Clark and Lambert1988; De Groot, Reference De Groot1992a; De Groot et al., Reference De Groot, Dannenburg and Van Hell1994; De Groot and Comijs, Reference De Groot and Comijs1995; Van Hell and De Groot, Reference Van Hell and De Groot1998a, Reference Van Hell and De Grootb; Tokowicz and Kroll, Reference Tokowicz and Kroll2007). In monolingual research, the concreteness effect was explained initially in the framework of the dual coding model (e.g., Païvio, Reference Païvio1986). According to this model, concrete words are coded twice, in one verbal and one image representation, whereas abstract words are only coded verbally. The activation of the two codes are additive and concrete words are hence processed faster and memorized better. Later accounts attribute the concreteness effect to differences in the context availability of concrete and abstract words (Schwanenflugel et al., Reference Schwanenflugel, Harnishfeger and Stowe1988). It is easier to generate a context for concrete words than for abstract words because concrete words are strongly associated to only a few concepts whereas abstract words are weakly associated to a great number of concepts. Finally, distributed memory models (Masson, Reference Masson, Besner and Humphreys1991; De Groot, Reference De Groot, Frost and Katz1992b) suppose that concrete words would be represented by more semantic nodes than abstract words and would therefore find a stable state faster.
Two bilingual studies have shown effects of both concreteness and number-of-translations on translation production (Schönpflug, Reference Schönpflug1997; Tokowicz and Kroll, Reference Tokowicz and Kroll2007). The authors presented the hypothesis that concrete and abstract words may differ in the number-of-translations they possess. Norming studies (Schönpflug, Reference Schönpflug1997; Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002) have indeed shown that concrete words tend to have only one translation whereas abstract words tend to have more than one translation. Kroll and Tokowicz (Reference Kroll, Tokowicz and Nicol2001) proposed that the classical concreteness effect observed in bilingual research (De Groot, Reference De Groot1992a; De Groot et al., Reference De Groot, Dannenburg and Van Hell1994; Van Hell and De Groot, Reference Van Hell and De Groot1998a, Reference Van Hell and De Grootb) is potentially due to the fact that concrete words with one translation were compared to abstract words with more than one translation.
The findings presented in Tokowicz and Kroll (Reference Tokowicz and Kroll2007) reveal an interaction between the factors “number-of-translations” and “concreteness”: a concreteness effect was observed for words with more than one translation but not for words with only one translation. Thus, the explanation that the concreteness effect observed in bilingual research is only due to comparing concrete words with one translation to abstract words with more than one translation is not sufficient to explain the concreteness effect in translation, since a concreteness effect is observed for words with more than one translation. It seems, though, that concreteness and number-of-translations influence the translation process but neither factor explains the entire set of relations between translation equivalents. In their Experiment 3, a lexical decision task with concrete and abstract words that differed in ambiguity (i.e., number of meanings), Tokowicz and Kroll (Reference Tokowicz and Kroll2007) explored whether the concreteness effect in bilingual studies was due to a general property of conceptual representation or to unique aspects of conceptual access during cross-language processing. The results show that in this task, as well, there was an interaction between concreteness and ambiguity. They concluded that the interaction is a manifestation of a general property of conceptual representation and that no specific model of concreteness is needed to explain concreteness effects in bilingual studies. This is particularly important to our study because we included concreteness to show that the translation (recognition) is conceptually mediated.
To test the influence of number-of-translations, and the factors that are related to it, on the processing of translation equivalents, we conducted three experiments using the translation recognition task (TRT; De Groot, Reference De Groot1992a, De Groot and Comijs, Reference De Groot and Comijs1995). In this task, participants have to decide as quickly and as accurately as possible whether two words, presented on a computer screen, are translation equivalents or not. This task is supposed to be easier than the classical translation-production task, in that the translation equivalents only have to be recognized, not produced. However, word processing in the translation-recognition task appears to be similar to word processing in the translation-production task, even though the semantic effect in the L1–L2 direction is a little weaker in the translation-recognition task (De Groot and Comijs, Reference De Groot and Comijs1995). Furthermore, in this task, a larger number of words pairs, including more difficult ones, can be tested, and it can be applied to less proficient bilinguals than production tasks (De Groot and Comijs, Reference De Groot and Comijs1995). This task also permits to test different translations for certain words (i.e., the dominant and the non-dominant translations). This would have been difficult to investigate in a translation-production task, since participants, in general, tend to produce the dominant translation.
Experiment 1: Effects of number-of-translations and concreteness in the L1–L2 direction of translation
The main goal of Experiment 1 is to test the influence of number-of-translations in translation recognition. Number-of-translations seems to depend on word ambiguity and influences both bilingual representations and performance, especially in production tasks (see Prior et al., Reference Prior, MacWhinney and Kroll2007).
According to the DCFM (De Groot, Reference De Groot, Frost and Katz1992b; Van Hell and De Groot, Reference Van Hell and De Groot1998a, Reference Van Hell and De Grootb) our hypotheses are that: (1) translations of words with only one translation will be recognized faster than translations of words with more-than-one translation; (2) dominant translations will be recognized faster than non-dominant translations; and (3) concrete pairs will be recognized faster than abstract pairs.
These three expected effects have the same underlying logic, namely, the more nodes the two words to be recognized as translations share, the faster the recognition process will be. It has been shown that words with multiple translations are considered less semantically similar to their translations than words with only one translation (Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002) and that lower semantic similarity leads to slower and less accurate performance in translation production (Tokowicz et al., Reference Tokowicz, Prior and Kroll2009). According to these findings, the semantic overlap between a word and its unique translation may be hypothesized to be more complete than the overlap between a word and its multiple translations. One-translation pairs should therefore be processed faster than more-than-one-translation pairs. This effect may, however, be in some extent due to competition between the different candidates for translation at the lexical level.
A word is also assumed to share more semantic nodes with its dominant translation than with its non-dominant translation. Consequently, the dominant translation would be the most available candidate because it would be more activated than the non-dominant translation during the recognition process. That is to say, in translation recognition, the first word presented will preferentially activate (or pre-activate) its dominant translation. It will therefore be faster to respond “yes” to this word than to another word which might be presented (the non-dominant translation).
Finally, according to the DCFM, concrete words share more of their meaning with their translation equivalents than abstract words. Concrete pairs have indeed been shown to be generally recognized faster as translations than abstract words (De Groot, Reference De Groot1992a, Reference De Groot, Frost and Katzb; De Groot et al., Reference De Groot, Dannenburg and Van Hell1994; De Groot and Comijs, Reference De Groot and Comijs1995). Consequently, we predict that concrete pairs will be processed faster than abstract pairs. In addition, we examine the possible interaction between number-of-translations and concreteness by using concrete and abstract words with one and more-than-one translation.
In the translation recognition task, used in this experiment, we suppose that in order to respond “yes”, the participant has to find a partly common representation for the word and its translation at the semantic level (mutually activated by the word and its translation), and this common part has to be big enough to accept the two candidates as translations. When there is no common representation (e.g., semantically dissimilar non-translation pairs) or a small common part of the representations activated (e.g., semantic associates that are not translation equivalents), a “no” response is given. It has, however, been shown with the same task (TRT) that if there is common activation for words that are not translations but semantic associates, then the consequence is that the “no” response is generally delayed (Talamas, Dufour and Kroll, Reference Talamas, Kroll and Dufour1999; Sunderman and Kroll, Reference Sunderman and Kroll2006; Guasch, Sánchez-Casas, Ferré and García-Albea, Reference Guasch, Sánchez-Casas, Ferré and García-Albea2008).
The number-of-translations effect (i.e., cross-language ambiguity effect) has been explained as due to active competition between the two translations at the moment of production (Tokowicz and Kroll, Reference Tokowicz and Kroll2007). On the other hand, in other recognition tasks, lexical decision, for instance, ambiguous items are processed faster than non-ambiguous items. The processing advantage for ambiguous words (with multiple meanings) in lexical decision has been explained by the fact that the super-threshold activation of any node will suffice to respond that the letter string is a word (Azuma and Van Orden, Reference Azuma and Van Orden1997; Rodd et al., Reference Rodd, Gaskell and Marslen-Wilson2002). The TRT is different from both of these tasks. In the TRT, a link has to be made between the translation equivalents for a “yes” response. We assume that this comparison process will be more difficult to make if other semantic nodes, which do not correspond to the semantic representation of the word to be recognized as a translation, are activated at the same time (passive competition at the semantic level). It will thus be easier to respond “yes” to unambiguous words (one-translation pairs) than to ambiguous words (more-than-one-translation pairs).
Method
Participants
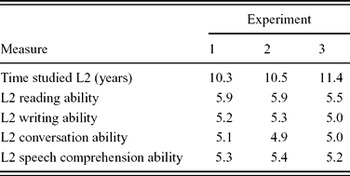
The sample consisted of 24 native speakers of French studying English, in their third or fourth year of studies at the University of Montpellier, France. They had studied English for 10.3 years on average. After the experiment, the participants evaluated themselves on their written and oral comprehension and production skills in English. The language history questionnaire data is shown in Table 1. The participants were divided into two groups (A and B) in order to avoid repetition of some words.
Table 1. Language history questionnaire data by Experiment (1, 2 and 3).

Note. Reading, writing, conversation and speech comprehension skills were rated on a 7-point scale, with 1 indicating the lowest level of ability and 7 indicating “as good as in French”. All participants began to study English at elementary school or before.
Materials and design
The experimental stimuli consisted of 150 French–English word pairs (90 translation pairs and 60 non-translation pairs; see Appendix A). All the words were nouns, adjectives or adverbs. The words in the different conditions were matched on French and English word frequency (Lexique 2 (New, Pallier, Brysbaert and Ferrand, Reference New, Pallier, Brysbaert and Ferrand2004) for the French words, and CELEX (Baayen, Piepenbrock and Gulikers, Reference Baayen, Piepenbrock and Gulikers1995) for the English words) and word length. Half of the pairs were concrete and half abstract. Concrete words had a concreteness level higher than 6, and abstract words had a concreteness lower than 4.5 on a 7-point scale (French words: Flieller and Tournois, Reference Flieller and Tournois1994; Desrochers and Bergeron, Reference Desrochers and Bergeron2000; English words: Païvio, Yuille and Madigan, Reference Païvio, Yuille and Madigan1968; Brown and Ure, Reference Brown and Ure1969; Friendly, Franklin, Hoffman and Rubin, Reference Friendly, Franklin, Hoffman and Rubin1982).
There were three types of translation pairs, according to the number-of-translations and dominance of the translations. The pairs were composed of 30 French words with their unique English translation equivalent (15 concrete pairs, e.g., reine–queen, and 15 abstract pairs, e.g., libre–free); 30 French words with more-than-one translation equivalents in English, coupled with their dominant translation (15 concrete pairs, e.g., femme–woman, and 15 abstract pairs, e.g., doux–soft); finally, the same 30 French words with more-than-one translation (that is why there are 90 translation equivalent pairs) coupled with their non-dominant translation (15 concrete pairs, e.g., femme–wife, and 15 abstract pairs, e.g., doux–sweet). The lexical properties of the words to be recognized as translations in Experiment 1 are shown in Table 2.
Table 2. Means and standard deviations (in parentheses) of the lexical properties (word length and log frequency) of the words to be recognized as translations in Experiment 1.

In order to classify the words as having only one translation or more than one translation, and for the latter, the dominant and non-dominant translation, a pilot study made up of three tests had been conducted (Laxén, Reference Laxén2007). Forty undergraduates studying English at the University of Montpellier, France, participated in each test, and none participated in more than one test. In the first one, participants were instructed to write down the first translation they could think of for each item on the list (in order to test the translation probability; see Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002; Prior et al., Reference Prior, MacWhinney and Kroll2007). The second test (not used to our knowledge in other translation studies, but similar to association tasks, e.g., Van Hell and De Groot, Reference Van Hell and De Groot1998b), was intended to incite participants to provide translations other than the dominant one. Here, participants were asked to give all the translations that they knew for each item. The third test was designed to test whether participants, in addition to the words they produced in the two first tests, accepted other translations of a word. They were given four possible translation equivalents for the words to be translated and they had to mark the words which they would use as translations. In addition, they were asked to rate the frequency with which they would use the chosen words with a scale from 1 (seldom) to 5 (very often).
Words that were only given one translation in the two first tests by 90% of the participants were classified as having only one translation. This resulted in classifying 40% of the words as having only one translation, and the rest as having two or more translations. In addition, for words with more-than-one translations, one was classified as dominant and the other as non-dominant. The dominant translation is the word which is the most frequently given as a translation and which has the highest rating on the “frequency of translation” scale in the third test. In the experiments, the non-dominant translations also had to be given in one of the first tests and had to be recognized as a translation by at least 50% of the participants in the third test.
The dominance of the translation equivalents was counterbalanced within the experimental lists (all the participants saw as many dominant as non-dominant translation pairs).
The pairs that were not translation equivalents were divided into two classes: 30 concrete pairs (ventre “stomach”–church) and 30 abstract pairs (argot “slang”–wild). They were matched on word length and word frequency to the translation pairs. The two words in a non-translation pair were not semantically associated in any obvious way. Care was also taken that the experimental pairs did not share a cognate, homographic or homophonic relation with one another or with any other common French or English word. An additional set of sixteen French–English word pairs similar to the ones used in the experiment was used for the practice trials.
So as to be able to test the two translation equivalents for the French words having two translations, two experimental lists were constructed to avoid any repetition of words within lists (e.g., list A doux–sweet and list B doux–soft). The pairs where the French words have only one translation equivalent and the non-translation pairs were the same in both lists.
To summarize, each experimental list consisted of 120 French–English word pairs (60 concrete and 60 abstract). Half of the pairs were translation equivalents and the other half were non-translations. The 60 pairs of translation equivalents were divided into four classes of 15 pairs (concrete and abstract one-translation pairs, and concrete and abstract more-than-one-translation pairs), depending on the word concreteness and the number-of-translations that the French word possesses.
Procedure
Participants were presented with two words and were instructed to respond as quickly and as accurately as possible whether or not the presented words were translation equivalents, by pressing one of two designated keys. They always responded “yes” with their dominant hand and “no” with their non-dominant hand. The words were written in Verdana 24 in lower-case letters, white lettering on a black background.
The 16 practice trials were presented in a random order followed by the 120 test trials also in random order. A break was provided in the middle of the test trials.
Each trial consisted of the following sequence: first there was a blank screen for 100 milliseconds (ms), this was immediately followed by a fixation point (*) in the middle of the screen for 500 ms, then the French word of the pair was presented in the middle of the screen for 240 ms (a time considered sufficiently long to recognize the word but not sufficient to translate it; see De Groot and Comijs, Reference De Groot and Comijs1995). After another blank screen (for 100 ms), the English word appeared one line below the place where the French word had been presented. The English word remained on the screen until the participants responded. The inter-trial interval was 1500 ms. Reaction times (RT) were recorded by the computer program in milliseconds from the onset of the second word to the moment the response key was pressed. Participants were tested individually and the experiment took about 15 minutes. At the end of the experiment, participants completed the language history questionnaire.
Results
Data trimming
Data from all 24 participants was analyzed. Errors were excluded from the reaction time analyses and treated as missing values. This procedure resulted in the exclusion of 5.5% of the data. Reaction times that were 2.5 SDs above or below a given participant's mean response latency in that experimental condition were replaced with the participant's mean in that condition. This resulted in replacing 2.0% of the data. For each analysis on critical trials (translation pairs only), two analyses of variance were performed, one treating subjects as a random factor (F 1), the other treating items as a random factor (F 2). A 2 (concreteness: concrete, abstract) by 3 (number-of-translations: one-translation pairs, more-than-one translation with its dominant translation [hereafter called dominant pairs] and more-than-one translation with its non-dominant translation [hereafter called non-dominant pairs]) repeated measures analysis of variance (ANOVA) was conducted on mean subject RTs and errors (F 1). The corresponding 2 × 3 ANOVA was performed on the mean item RTs and errors, treating the two factors as between-item variables. Planned comparisons corrected for multiple comparisons were performed on significant effects when hypotheses on the effect had been made.
Reaction time and error data
The reaction time and error data are shown in Table 3. An overall effect of number-of-translations was found in the response latency [F 1(2,46) = 31.89, p < .001; F 2(1,84) = 26.25, p < .001] as well as in the error analysis [F 1(2,46) = 36.99, p < .001; F 2(1,84) = 5.97, p < .01]. Planned comparisons showed that one-translation pairs were recognized faster than both kinds of more-than-one-translation pairs, for dominant pairs [F 1(1,23) = 4.55, p < .05; but F 2(1,56) = 1.62, n.s.] as well as non-dominant pairs [F 1(1,23) = 38.48, p < .001; but F 2(1,56) = 46.44, p < .001]). Furthermore, dominant pairs were recognized significantly faster than non-dominant pairs [F 1(1,23) = 37.64, p < .001; but F 2(1,56) = 30.70, p < .001]. In the error analysis, one-translation pairs and dominant pairs did not differ [all F < 1, n.s.]. However, non-dominant pairs were less accurately recognized than both one-translation pairs [F 1(1,23) = 53.56, p < .001; F 2(1,84) = 5.66, p < .05] and dominant pairs [F 1(1,23) = 46.00, p < .001; F 2(1,84) = 1.28, p < .01].
Table 3. Reaction times (in ms, standard deviations in parentheses) and error rates from Experiment 1.

The response latency analysis showed a marginally significant effect of concreteness [F 1(1,23) = 3,40, .05 < p < .10; but F 2(1,84) = 1.02, n.s.]. Concrete pairs were processed faster than abstract pairs but no overall concreteness effect was observed in the error analyses. However, number-of-translations interacted with concreteness, but only in the error analyses by participants [F 1(2,46) = 4.71, p < .05; but F 2(2,84) = 1.22, n.s.]. The planned comparisons showed that there was an inverse concreteness effect for non-dominant pairs [F 1(1,23) = 4.69, p < .05; but F 2(1,84) = 2.38, n.s.]. More errors were made for concrete pairs than for abstract pairs when the participant has to estimate the equivalency between a word and its non-dominant translation.
Discussion
The main result of Experiment 1 is that number-of-translations across languages affect the translation recognition process as it has been shown to affect translation production. As can be seen in Figure 3, one-translation pairs were recognized faster than both kinds of more-than-one-translation pairs.

Figure 3. Concreteness effect in function of number and dominance of the translation in Experiment 1 (responses latencies in ms).
We assume that one-translation pairs were processed faster than more-than-one-translation pairs because words with one translation seem to be more semantically similar to their translation than words with multiple translations (Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002). Therefore, within a model of distributed representation of the bilingual memory, one-translation pairs would share more nodes at the semantic level, and this larger semantic overlap would result in faster response latencies. Moreover, in translation recognition, the first word presented would pre-activate essentially the translation equivalent (and not other words) at the lexical level, so there would be less lexical-level competition as well. Both accounts (less competition at the lexical level or more complete semantic overlap at the semantic level for one-translation pairs) can explain the findings of this experiment. And, most certainly, the advantage of one-translation pairs is due to facilitation (i.e., less competition) at both the lexical and the semantic levels.
Dominant translations were also processed faster than non-dominant translations. This is thought to be due to greater semantic overlap between the word and its dominant translation by comparison with a word and its non-dominant translation. It could, however, also be due to the fact that the word will pre-activate the dominant translation preferentially to the non-dominant translation because it is used more often.
A marginally significant effect of concreteness was also observed. Concrete words were processed faster than abstract words. An interaction between number-of-translations and concreteness has been observed in previous studies (Schönpflug, Reference Schönpflug1997; Tokowicz and Kroll, Reference Tokowicz and Kroll2007): a concreteness effect was observed for more-than-one-translation pairs but not for one-translation pairs. In this study, however, even if the difference between concrete and abstract words is smaller for one-translation pairs than for more-than-one-translation pairs the interaction did not reach significance (see Figure 3). The only significant effect concerning concreteness was a reversed effect of concreteness in the error analysis for the non-dominant translations: fewer errors were made for abstract pairs than for concrete pairs. It seems, though, that it is easier to accept a non-dominant translation for an abstract word than for a concrete word.
In this experiment, we used only one direction of translation (L1–L2), but our next experiment was conducted to examine if the competition between the different translations of a word will occur in both directions of translation.
Experiment 2: Effects of number-of-translations and concreteness in both directions of translation
To enable us to generalize the results of Experiment 1, we tested a partly new set of words in the L1–L2 direction of translation and a set of words in the L2–L1 direction of translation. In both directions of translation, we expected faster response latencies and fewer errors for one-translation pairs compared to more-than-one-translation pairs, and faster responses latencies for dominant translations compared to non-dominant translations. Concerning concreteness, we assumed that concrete words should be processed faster than abstract words.
According to the DCFM, translation depends on how many semantic nodes are shared by two translation equivalents. Consistent with this, the number of shared elements should be the same in the two directions of translation (even if the links may be weaker in the L2–L1 direction; De Groot, Reference De Groot, Schreuder and Weltens1993), and therefore the translation performance should not differ for words in the two directions. Consequently, we expected a number-of-translations effect in both directions of translation. In addition, we predicted an effect of dominance of the translation for the same reasons. A word shares more semantic features with its dominant translation than with its non-dominant translation.
Concerning concreteness, the DCFM predicts that there should be a concreteness effect in both directions of translation due to the fact that the shared semantic elements are the same, although, if links are weaker in the L2–L1 direction, the concreteness effects might also be weaker. On the other hand, the Revised Hierarchical Model (RHM; Kroll and Stewart, Reference Kroll and Stewart1994) clearly predicts stronger influence of semantic factors in the L1–L2 direction than in the L2–L1 direction because the translation route is not the same. In the L1–L2 direction, translation is achieved via the conceptual level whereas in the L2–L1 direction it goes directly from L2 words to L1 words via the lexical level. Semantics therefore influences translation more in the L1–L2 direction of translation.
Method
Participants
Thirty-two participants drawn from the same population as in Experiment 1 participated in Experiment 2. The language history questionnaire data is shown in Table 1. As in Experiment 1, the participants were divided into two groups (A and B) to avoid the repetition of some words.
Material
The stimuli were 120 French–English word pairs (in the L1–L2 condition) and 120 English–French word pairs (in the L2–L1 condition), giving a total of 240 word pairs (see Appendix B and C). Different words were used in the two language conditions (for translation equivalents and for non-translations) to enable us to control number-of-translations in the two directions of translation and to enable participants to see both directions of translation without the repetition of words. The words were nouns, adjectives and adverbs of three to eight letters. The word frequency was higher than nine occurrences per million in both languages (cf. references of Experiment 1).
For both language conditions, 72 word pairs were translation equivalents and 48 were not. For the translation equivalent pairs, 24 (in both directions of translation) were composed of words that have no other (common) translation equivalent (e.g., milk–lait). Half of the pairs were composed of concrete words and half of abstract words. The other pairs were composed of words with more-than-one translations (half concrete, half abstract). In one condition the word is paired with its dominant translation (e.g., maison–house, 24 pairs) and in the other condition the word is paired with its non-dominant translation (e.g., maison–home, 24 pairs) (same procedure for selection of dominance as in Experiment 1). The lexical properties of the words to be recognized as translations in Experiment 2 are shown in Table 4. For the words with two translations, both were tested, but each participant only saw one of the two possible translations. All participants saw the same number of translation and non-translation pairs (48 of both), the same number of one-translation pairs as more-than-one-translation pairs (24 of both) and the same number of dominant and non-dominant translations pairs (12 of both).
Table 4. Means (and standard deviations in parentheses) of the lexical properties (word length and log frequency) of the words to be recognized as translations in Experiment 2.

The non-translation pairs are matched with the translation pairs on word frequency, word length and concreteness. In the non-translation pairs, the two words do not have any evident orthographical, phonological or semantic relations.
Two experimental lists were constituted in the same manner and for the same reasons as in Experiment 1 (the dominant translation in one list and the non-dominant translation in the other list for the two translation pairs, and the same one-translation and non-translation pairs in the two lists).
Procedure
The procedure was almost the same as in Experiment 1; therefore, only the differences between the two will be presented in what follows. The words were written in Verdana 36 in lower-case letters, white lettering on a black background.
All the participants saw two experimental blocks (two times 48 pairs) in the L1–L2 condition and two experimental blocks in the L2–L1 condition. The presentation order of the direction of translation recognition was counterbalanced across participants. The order of presentation of the word pairs within a block was randomized for each participant. Sixteen practice trials were presented before the first experimental block in both languages, followed by the 96 test trials divided in two blocks in each language and with a break between the blocks. The experiment took about twenty minutes.
Results
Data trimming
Data from all 32 participants were analyzed. Errors were excluded from the response latency analyses and treated as missing values. This procedure resulted in the exclusion of 5.2% of the data. Reaction times that were 2.5 SDs above or below a given participant's mean response latency in that experimental condition were replaced with the participant's mean in that same condition. This resulted in replacing 4.5% of the data. For each analysis of interest (only results for translation pairs are reported here), two analyses of variance were performed, one treating subjects as a random factor (F 1), the other treating items as a random factor (F 2). A 2 (direction of translation: L1–L2, L2–L1) by 2 (concreteness: concrete, abstract) by 3 (number-of-translations: one translation, more-than-one translation when dominant translation, more-than-one translation when non-dominant translation) repeated measures ANOVA were performed on the mean subject RTs and errors. As the materials were not perfectly matched on frequency in all conditions (due to the fact that concrete words tend to be less frequent than abstract words) we performed an ANCOVA instead of an ANOVA in the item analysis, entering frequency as a covariate. The 2 × 2 × 3 ANCOVA was performed on the mean item RTs and errors, treating the three factors as between-item variables. Planned comparisons corrected for multiple comparisons were performed on significant effects when hypothesis on the effect had been made.
Reaction time data
The reaction time and error data are shown in Table 5. In the reaction time data, we observed a main effect of number-of-translations [F 1(2,62) = 34.87, p < .001; F 2(2,131) = 22.82, p < .001] as in Experiment 1. The planned comparisons showed that one-translation pairs were recognized faster than more-than-one-translation pairs for both dominant pairs [F 1(1,31) = 8,29, p < .01; but F 2(1,131) = 2.08, n.s.] and non-dominant pairs [F 1(1,31) = 61.91, p < .001; F 2(1,131) = 24.32, p < .001]). In addition, for more-than-one-translation pairs, dominant pairs were recognized significantly faster than non-dominant pairs [F 1(1,31) = 24,11, p < .001; F 2(1,131) = 24.31, p < .001].
Table 5. Reaction times (in ms, standard deviations in parentheses) and error rates from Experiment 2.

The results also showed a main effect of direction of translation [F 1(1,31) = 8.91, p < .01; F 2(1,131) = 13.52, p < .001]. Contrary to the predictions of RHM (Kroll and Stewart, Reference Kroll and Stewart1994), the L1–L2 translation direction (503 ms) was slightly faster than the L2–L1 direction (551 ms). These findings are in line with other studies that have shown that L1–L2 translation is not slower than L2–L1 translation, and is often even faster (De Groot et al., Reference De Groot, Dannenburg and Van Hell1994, Experiment 1; De Groot and Poot, Reference De Groot and Poot1997; Van Hell and De Groot, Reference Van Hell and De Groot1998a; Duyck and Brysbeart, Reference Duyck and Brysbaert2004, Experiment 1).
No overall concreteness effect was observed in the reaction time analysis [all Fs, n.s.].
The main question of interest in this experiment was whether number-of-translations influences translation recognition latencies in the two directions of translation. The interaction between the two variables was significant [F 1(2,62) = 8.57, p < .001; F 2(2,131) = 3.79, p < .05]. The planned comparisons show that in the L1–L2 direction of translation, one-translation pairs and dominant pairs did not differ [F 1 and F 2 < 1, n.s.], but one-translation pairs were recognized faster than non-dominant translations [F 1(1,31) = 21.46, p < .001; F 2(1,131) = 7.68, p < .01]. In the L2–L1 direction of translation, one-translation pairs were processed faster than both dominant pairs [F 1(1,31) = 10.31, p < .01; but F 2(1,131) = 1.53, n.s.] and non-dominant pairs [F 1(1,31) = 63.48, p < .001; F 2(1,131) = 40.03, p < .001]. Moreover, dominant translations were recognized faster than non-dominant translations in both the L1–L2 [F 1(1,31) = 14.41, p < .001; but F 2(1,131) = 3.79, p < .053] and in the L2–L1 direction of translation [F 1(1,31) = 20.24, p < .001; F 2(1,131) = 25.64, p < .001]. The results also showed that there was no effect of direction of translation for one-translation pairs [F 1 and F 2 < 1, n.s.], but there was an effect of direction of translation for more-than-one-translation pairs both for the dominant [F 1(1,31) = 4.81, p < .05; but F 2(1,131) = 1.50, n.s.] and the non-dominant pairs [F 1(1,31) = 14.25, p < .001; F 2(1,131) = 18.89, p < .001]. Both dominant and non-dominant translations were processed more slowly in the L2–L1 direction of translation.
The other important question we tried to answer is whether a concreteness effect would be obtained in the two directions of translation. As reported above, there was no overall effect of concreteness, but concreteness interacted with direction of translation [F 1(1,31) = 4.21, p < .05; but F 2 < 1, n.s.]. The planned comparisons showed that concrete pairs were processed faster than abstract pairs only in the L1–L2 direction of translation [F 1(1,31) = 5.10, p < .05; but F 2(1,131) = 1.67, n.s.] but not in the L2–L1 translation direction [F 1 and F 2 < 1, n.s.].
Concreteness also interacted with number-of-translations [F 1(1,31) = 6.32, p < .01]. The planned comparisons showed that there was no concreteness effect for one-translation pairs [F 1 and F 2, n.s.], nor for the dominant translation [F 2 < 1, n.s.], but concrete pairs were processed faster than abstract pairs for the non-dominant pairs [F 1(1,31) = 6.68, p < .05; F 2(1,131) = 11.07, p < .01].
Figures 4 and 5 illustrate the differences between one-translation pairs compared to dominant and non-dominant more-than-one-translation pairs in both directions of translation.

Figure 4. Effects of number-of-translations and dominance in the L1–L2 direction of translation in Experiment 2 (responses latencies in ms).
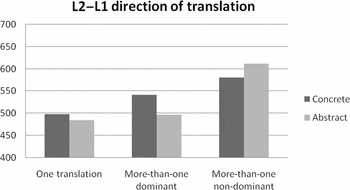
Figure 5. Effects of number-of-translations and dominance in the L2–L1 direction of translation in Experiment 2 (responses latencies in ms).
Error data
The three-way interaction between the main variables (number-of-translations, direction of translation and concreteness) was significant in the subject error analyses [F 1(2,62) = 5.75, p < .01], and marginal in the item analyses [F 2(2,131) = 2.95, p < .06].
All of the main effect analyses confirmed the response latency data: there was a main effect of number-of-translations [F 1(2,62) = 33.37, p < .001; F 2(1,131) = 23.51, p < .001]. The planned comparisons showed that more errors were made for non-dominant pairs than for both one-translation pairs [F 1(1,31) = 44.20, p < .001; F 2(1,131) = 39.66, p < .001] and dominant pairs [F 1(1,31) = 29.09, p < .001; F 2(1,131) = 30.03, p < .001] but one-translation pairs and dominant pairs did not differ [F 1 and F 2 < 1, n.s.].
There was also a main effect of direction of translation [F 1(2,62) = 18.23, p < .001; F 2(1,131) = 7.49, p < .01]; fewer errors were made for L1–L2 pairs than for L2–L1 pairs. No main effect of concreteness was observed in the error analysis [F 1(1,31) = 1.04, n.s.; F 2 < 1, n.s.].
The only significant interaction in the error analyses was between number-of-translations and direction of translation [F 1(1,31) = 10.71, p < .001; F 2(1,131) = 4.79, p < .01]. The planned comparisons show no effect of direction of translation for both one-translation pairs and for dominant more-than-one-translation pairs [all Fs < 1, n.s.]. But for the non-dominant more-than-one-translation pairs, more errors are made in the L2–L1 direction of translation than in the L1–L2 direction [F 1(1,31) = 17.56, p < .001; F 2(1,131) = 16.60, p < .001].
Discussion
The findings of Experiment 2 confirmed the results obtained in Experiment 1, in that generally one-translation pairs were processed faster than more-than-one-translation pairs. For more-than-one pairs the dominant translation was also recognized faster than the non-dominant translation.
A concreteness effect was found but only in the L1–L2 direction of translation as predicted by the RHM. Furthermore, the pattern of results in the L1–L2 direction of translation is similar to those obtained by Tokowicz and Kroll (Reference Tokowicz and Kroll2007), in that concrete and abstract one-translation pairs do not differ, but there is a concrete word advantage for more-than-one-translation pairs (see Figure 4).
An overall effect of direction of translation was also found: the L1–L2 translation direction was faster than the L2–L1 direction. The RHM predicts a concreteness effect for the L1–L2 direction of translation because this direction is conceptually driven. However, the fact that translation is conceptually driven is supposed to take time compared to when it is lexically driven (in L2–L1 direction of translation), so these findings are difficult to interpret within this framework. Our results are more in line with the DCFM, considering that L2–L1 links may be weaker (De Groot, Reference De Groot, Frost and Katz1992b).
Another interesting finding was the interaction between translation direction and number-of-translations. The most important finding of Experiment 2 is that number-of-translation influence translation recognition in both directions of translation. Competition between different candidates affects both forward and backward translation. However, the interaction is due to the fact that for words with only one translation there was no effect of direction of translation, as if it was very easy to recognize the translation of these words independently of the input language. The dominant and the non-dominant translations were faster to recognize in the L1–L2 direction of translation than in the L2–L1 direction. These results could be in line with the sense model (Finkbeiner, Reference Finkbeiner2002; Finkbeiner, Forster, Nicol and Nakamura, Reference Finkbeiner, Forster, Nicol and Nakamura2004, a developed form of the DCFM).
According to this model, there is an asymmetry of word knowledge between the two languages of the bilingual person. The L1 (dominant language) word representations are more complete than the L2 (non-dominant language) word representations. An L1 prime may activate all, or at least more, of the meanings of an L2 target word than an L2 word can activate an L1 word. Consequently, it should be easier and faster to accept the translations in the L1–L2 direction than in the L2–L1 direction of translation. Nevertheless, this logic would predict facilitation even for one-translation pairs in the L1–L2 direction; this is not in line with our findings. However, it has been shown (Tokowicz et al., Reference Tokowicz, Kroll, De Groot and Van Hell2002; Prior et al., Reference Prior, MacWhinney and Kroll2007) that the representations of words with only one translation are more semantically similar than words with more-than-one translation. Therefore, for one-translation pairs, the L2 word is perhaps capable of pre-activating the L1 translation equivalent almost as well as the L1 word can pre-activate the L2 translation equivalent. On the other hand, for more-than-one-translation pairs, the L1 word, for which the participant has a more extensive representation, would activate a greater part of the representation of its L2 translation than the L2 word would. The consequence would be that translation recognition for more-than-one-translation pairs would be faster in the L1–L2 direction of translation than in the L2–L1 direction. This is actually what we observed in Experiment 2.
Another possibility, suggested by Tokowicz et al. (Reference Tokowicz, Prior and Kroll2009), is that baseline differences in the level of ambiguity affect translation speed. The authors found an advantage for the L1–L2 direction of translation, although only for one-translation pairs. They suggested that ambiguity is greater in the L1–L2 direction. This is likely to be true, at least when more words are known in the L1 than in the L2. Moreover, English words (L2 in this study, and also in Tokowicz et al., Reference Tokowicz, Prior and Kroll2009) have been shown to be very ambiguous (Prior et al., Reference Prior, MacWhinney and Kroll2007) due to the fact that many English words are class ambiguous (a word in English can be a noun and/or an adjective and/or an adverb and/or a verb). Spanish words (tested in Prior et al., Reference Prior, MacWhinney and Kroll2007), like French words (that we tested), are seldom class ambiguous. Our pilot study (Laxén, Reference Laxén2007) confirmed this possibility: the English words were translated on average by 1.91 words while the French words had 1.50 translations on average. So, in line with this, two interpretations are possible to explain the L1–L2 translation direction advantage: (1) it is possible that the L2 words in our study have overall more translations than the L1 words, which would mean that the English L2 translation of a less ambiguous French L1 word would be easier to recognize than a French L1 translation of a more ambiguous English L2 word; and/or (2) the fact that word knowledge in L1 is greater would make it more difficult to find the right translation in this direction.
Kroll and Tokowicz (Reference Kroll, Tokowicz and Nicol2001) have hypothesised that longer translation latencies for words with two translations are due to lexical-level competition (in translation production): less competition is expected for words with one translation than for words with multiple translations. In order to clarify this question as to whether number-of-translations effect can be explained only as lexical-level competition, we conducted a new experiment with two different kinds of “more-than-one-translation” pairs, which could be hypothesized to differ in the shared part of their semantic representation, according to the DCFM. The idea was that if the number-of-translations factor can be explained only by lexical-level competition, then only the fact that a word has two translations would influence the translation process. As a consequence, the processing of the two different types of more-than-one-translation pairs would not differ. On the contrary, if translation is conceptually mediated, word processing would be dependent on the semantic representations of words, and therefore the two types of “more-than-one-translation” pairs would be processed differently because their (hypothesized) semantic representations are different.
Experiment 3: Effect of number of translations and semantic relatedness between multiple translations
The focus of this experiment was to examine the influence of different semantic relations between the multiple translations of a given word. A word may have several translations because the different translations in the other language are synonymous (e.g., husband in English has two synonymous translations in French: mari and époux), or it can have several translations because it is a polysemic or homonymic word (e.g., light, which can be translated as both lumière “light bulb” and léger “low-fat” in French). Consequently, within-language synonymy and polysemy increase the level of ambiguity of the words to be translated and lead to multiple translations.
If the two languages have partly shared representations at the semantic level, and if, moreover, an important part of the translation process is completed at the semantic level, then the two different types of more-than-one-translation pairs (i.e., semantically related and semantically unrelated) should be processed differently. When the two translations of a word are semantically related (they are more or less synonymous), the presentation of the word to be translated will activate its semantic representation, which constitutes an important part of the semantic representation of both of its translations. In this case, there is no significant difference between the semantic representations of the three words, and therefore little competition at the semantic level (there would, although, be lexical-level competition in a production task, but the production component is absent in translation recognition).
On the other hand, if the two translations are semantically unrelated, they do not share any, or at least not much, of their semantic representation. In this case there are separate semantic representations for the two words (which are unequally activated due to differences in dominance), and the consequence would be semantic-level competition between the two translations (i.e., the dominant and the non-dominant translation).
We assume that the dominant translation will be automatically activated in both cases. In the case of semantically related pairs, the activated semantic representation of the dominant translation is a part of the semantic representation of the non-dominant translation, thus the representations of the two words are activated. This would make it quite easy to accept even the non-dominant translation as a translation of the first word presented. On the other hand, the non-dominant, semantically unrelated, translation will be harder to accept because its semantic representation is not pre-activated, or at least less pre-activated.
The predictions are that: (1) one-translation pairs will be processed faster than more-than-one-translation pairs, independently of semantic relatedness between the different translations of the first word; (2) dominant translations will be processed faster than non-dominant translations (for the same reasons as in Experiment 1 and 2); and (3) semantically related pairs will be processed faster than semantically unrelated pairs because the three words share their semantic representation in one case and not in the other. We also predict an interaction between dominance and semantic relatedness (for more-than-one-translation pairs only): the dominant and non-dominant translations of a semantically related pair will show a smaller effect of dominance than the semantically different pairs because the shared part of the semantic representation between the dominant and the non-dominant translation is bigger for semantically related pairs.
Method
Participants
Participants were 24 native French speakers, studying English for the fourth or fifth year at the University of Montpellier, France. They had studied English for 10.2 years, on average. They evaluated themselves after the experimental session (see the language history questionnaire data in Table 1). Participants were divided into two groups (A and B) to avoid repetition of some words.
Material
The stimuli were 100 French–English word pairs (in the L1–L2 condition; see Appendix D) and 100 English–French word pairs (in the L2–L1 condition; see Appendix E). Different words were used in the two language conditions (for translation equivalents and for non-translations, for the same reasons as in Experiment 2). The words were nouns, adjectives and adverbs of three to nine letters. The word frequency was higher than 10 occurrences per million in both languages.
In both language conditions 60 pairs were translation equivalents and 40 pairs were not. For the translation equivalent pairs, 20 (in both language conditions) are composed of words that have no other (common) translation equivalent (the one-translation pairs). The more-than-one-translation pairs are composed of 20 semantically related pairs and 20 semantically unrelated pairs. For both conditions, half of the pairs are composed of a word and its dominant translation (10 dominant semantically related pairs, e.g., ville–town, and 10 dominant semantically unrelated pairs e.g., argent–money) and the other half of a word and its non-dominant translation (10 non-dominant semantically related pairs, e.g., ville–city, and 10 non-dominant semantically unrelated pairs, e.g., argent–silver). All experimental conditions were matched on concreteness.
Words were tested for semantic relatedness in both languages in a pilot study (Laxén, Reference Laxén2007). In this study, 80 undergraduates studying English at the University of Montpellier (France) estimated the semantic relatedness between word pairs. Eighty French word pairs and 80 English word pairs were tested. The two words of a pair could be translated by the same word in the other language. Half of the pairs were synonymous (e.g., boat and ship, which are translations of the French word bateau) and the other half were not (e.g., cool and expense for the French word frais), according to the thesaurus (Collins Thesaurus in English and Larousse Dictionnaire de Synonymes in French). Participants were asked to rate the semantic relatedness between the two words on a scale from 0 (very distant) to 5 (very similar). They were not told about the bilingual aspect of the material. The findings of this pilot study enabled us to distinguish semantically related pairs (an average score higher than 3.3/5) from semantically unrelated pairs (an average score smaller than 1.7/5). The lexical properties of the words to be recognized are presented in Table 6. Care was taken not to use cognates or interlingual homographs.
Table 6. Means (standard deviations in parentheses) of the lexical properties (word length and log frequency) of the words to be recognized as translations in Experiment 3.

Non-translation pairs were also matched with translation pairs on word frequency and word length. In non-translation pairs, the two words do not have any obvious orthographical, phonological or semantic relations.
Each participant saw all the 40 non-translation pairs and 40 translation pairs (all the participants saw all the one-translation pairs (20), but only one of the two possible translations for words with two translations (20 pairs). All the participants saw as many semantically related as unrelated pairs, and as many dominant as non-dominant pairs. Furthermore, 14 word pairs with the same characteristics as the experimental material were used as practice trials.
Procedure
The same procedure as in Experiment 2 was used.
Results
Data trimming
Data from all 24 participants was analyzed. Errors were excluded from the analyses and treated as missing values. This procedure resulted in the exclusion of 4.1% of the data. Reaction times 2.5 SDs above or below a given participant's mean response latency in that experimental condition were replaced with the participant's mean in that condition. This resulted in replacing 3.3% of the data.
Once again, reaction time analyses were conducted on data from correct trials only. For each analysis of interest (only results of translation pairs are reported here), two analyses of variance were performed, one treating subjects as a random factor (F 1), the other treating items as a random factor (F 2). A 2 (direction of translation: L1–L2, L2–L1) by 3 (number-of-translations: one translation, more-than-one translation when dominant translation, more-than-one translation when non-dominant translation) repeated measures ANOVA was performed on the mean subject RTs and errors. As the material was not perfectly matched on frequency between all conditions, we performed an ANCOVA instead of an ANOVA in the item analysis, entering frequency as a covariant. The 2 × 3 ANCOVA corresponding to the ANOVA in the subject analysis was then performed on the mean item RTs and errors, treating the three factors as between-item variables. In addition, due to the fact that the semantic similarity factor was only present in the more-than-one-translation condition, another analysis was performed in which the one-translation pairs were eliminated. We ran a 2 (language: L1–L2, L2–L1) by 2 (dominance of the translations: more-than-one translation when dominant translation, more-than-one translation when non-dominant translation) by 2 (semantic similarity: semantically similar, semantically dissimilar) repeated measures ANOVA on the mean subject RTs and errors. The corresponding 2 × 2 × 2 ANCOVA was performed on the mean item RTs and errors, treating the two factors as between-item variables. Significant analyses were followed up by planned comparisons corrected for multiple comparisons when hypothesis had been made on the effects.
Reaction time and error data for all translation pairs
The reaction time and error data are shown in Table 7. As in Experiments 1 and 2, a general effect of number-of-translations was observed in both reaction time [F 1(1,23) = 28.42, p < .001; F 2(1,78) = 32.02, p < .001] and error analyses [F 1(1,23) = 21.64, p < .001; F 2(1,78) = 12.02, p < .01]. The planned comparisons showed that one-translation pairs were processed faster than dominant pairs [F 1(1,23) = 20.25, p < .001; F 2(1,107) = 10.94, p < .001] and non-dominant pairs [F 1(1,23) = 103.83, p < .001; F 2(1,107) = 63.86, p < .001]. For more-than-one-translation pairs, dominant pairs were also processed significantly faster than non-dominant pairs [F 1(1,23) = 38.12, p < .001; F 2(1,107) = 19.39, p < .001]. The error analyses were also in line with the results of Experiments 1 and 2 in that non-dominant pairs were recognized less accurately than both one-translation pairs [F 1(1,23) = 33.35, p < .001; F 2(1,107) = 21.85, p < .001] and dominant pairs [F 1(1,23) = 19.70, p < .001; F 2(1,107) = 10.26, p < .01], and in that one-translation pairs did not differ from dominant pairs [F 1(1,23) = 1.34, n.s.; F 2(1,107) = 1.65, n.s.].
Table 7. Mean reaction times (in ms, standard deviations in parentheses) and error rates from Experiment 3.

Note. Semantic relatedness is a characteristic of only more-than-one translation pairs.
There was no main effect of direction of translation (F < 1, n.s.) and no interaction between number-of-translations and direction of translation in the response latency analysis. However, a direction of translation effect was obtained in the error analysis [F 1(1,23) = 4.72, p < .05; but F 2(1,107) = 1.49, n.s.]: more errors were made in the L1–L2 direction of translation than in the L2-L1 direction.
Analyses on semantic similarity and dominance for more-than-one translations
The semantic relatedness factor (semantically related vs. semantically unrelated) interacted with dominance of translations (dominant translation vs. non-dominant translation) in the response latency analyses [F 1(1,23) = 17.37, p < .001; F 2(1,71) = 2.81; .05 < p < .10] and in the error analyses [F 1(1,23) = 12.98, p < .01; F 2(1,71) = 5.91, p < .05]. The planned comparisons showed that dominant translations were recognized faster than non-dominant translations for both related [F 1(1,23) = 17.37, p < .001; F 2(1,71) = 2.97, .05 < p < .10] and unrelated pairs [F 1(1,23) = 27.53, p < .001; F 2(1,71) = 17.88, p < .001]. Participants also responded more accurately for dominant pairs than non-dominant pairs when unrelated pairs were processed [F 1(1,23) = 21.17, p < .001; F 2(1,71) = 12.96, p < .001], but no difference on accuracy was observed for related pairs [F 1(1,23) = 1.86, n.s.; F 2 < 1, n.s.]. The results also yield an effect of semantic relatedness in the response latency analyses. When the two translations were related in meaning the translation was faster than when the two translations were unrelated in meaning, for both dominant [F 1(1,23) = 13.84, p < .01; F 2(1,71) = 4.24, p < .05] and non-dominant translations [F 1(1,23) = 30.45, p < .001; F 2(1,71) = 22.50, p < .001]. Fewer errors were also made in the related condition than in the unrelated condition for non-dominant translations [F 1(1,23) = 30.25, p < .001; F 2(1,71) = 28.23, p < .001], although only marginally for the dominant translations [F 1(1,23) = 7.38, p < .05; F 2(1,71) = 3.53, p < .07].
As can be seen in Figures 6 and 7, the semantic relatedness effect is stronger for the non-dominant translations (it is easier to accept the non-dominant translations when it is related in meaning with the dominant translation than when it is unrelated), and the dominance effect is stronger for the unrelated pairs (the difference between the dominant and non-dominant translation is more significant for unrelated pairs than for related pairs).

Figure 6. Effects of number-of-translation and semantic relatedness in the L1–L2 direction of translation in Experiment 3 (responses latencies in ms).
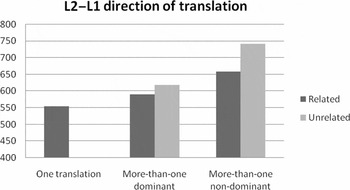
Figure 7. Effects of number-of-translation and semantic relatedness in the L2–L1 direction of translation in Experiment 3 (responses latencies in ms).
Discussion
The findings of this experiment confirmed those obtained in Experiments 1 and 2 on the importance of number-of-translations of a word during the translation recognition process. Once again, one-translation pairs were recognized more quickly than more-than-one-translation pairs, and dominant pairs were recognized faster and more accurately than non-dominant pairs. Furthermore, this was the case regardless of the type of relation between the two translations of the more-than-one-translation pairs (semantically related or unrelated) and direction of translation. No main effect or interactions of direction of translation was found in Experiment 3. This suggests that the effects of the other factors are similar in the two directions of translations.
Moreover, this experiment was conducted to observe whether different types of semantic relations (cf. semantically related and unrelated pairs) between the multiple translations of a given word do influence translation recognition. The results indeed showed a semantic relatedness effect for both the dominant and the non-dominant pairs. When the different translations of a word are related in meaning, the recognition is faster than when the translations are unrelated.
These experiments showed that the translation recognition time was determined to a large extent by: (1) the number-of-translations of a word: word pairs were recognized faster as translations when they only have one translation (i.e., one-translation pairs) than when they have more than one translation; (2) the dominance of the translation equivalents: word pairs were recognized faster as being translations when the word was shown with its dominant translation (i.e., dominant pairs) compared to when it was presented with its non-dominant translation (i.e., non-dominant pairs); and (3) the semantic overlap between the respective translations: word pairs with more-than-one translation were processed faster when the two translations were semantically related than when they were semantically unrelated.
These findings clearly show that semantic relatedness between the different translations influences the recognition process. Yet the effect of relatedness was stronger for non-dominant translations than for dominant translations (as shown in Figures 6 and 7). This seems to confirm our hypothesis: when a word is presented with its non-dominant translation (a word that is not anticipated by the participant), it is faster and/or easier (shorter reaction times and fewer errors) to accept when it is semantically related to the dominant translation than when it is semantically unrelated. These results are congruent with distributed models of semantic memory, where activation of word meaning results in an activation of the semantic units of the word. In the translation recognition task, when the first word is presented, it will activate its semantic units; then, a second word (the dominant or non-dominant translation or a non-translation word) is presented and the participant has to decide whether the two words are translations of each other. If the second word is the non-dominant translation but still shares several semantic units (1) with the first word presented and (2) with the word that was anticipated by the participant (i.e., the dominant translation), it will be recognized quicker than if it is a non-dominant translation that shares (1) fewer units with its translation and further does not share (2) any units with the dominant (anticipated) translation.
These results suggest that number-of-translations have repercussions not only at the lexical level (more competition between multiple translations) but also at the semantic level (greater semantic overlap when the different translations are synonymous). So, the number-of-translations effect cannot be entirely explained as lexical-level competition. The fact that semantically related translations are processed faster than semantically unrelated translations constitutes evidence that the recognition process involves the semantic level to accept the different translations of a word.
General discussion
In the three experiments presented in this study, we examined different factors that influence translation recognition performance. The main goal of our work was to examine the influence of number-of-translations and the factors related to it, namely dominance of multiple translations, semantic relatedness of multiple translations and concreteness, on the translation recognition process. All these factors can increase translation ambiguity and clearly influence the degree of competition during the translation performance. The results showed that when a word has only one translation, the recognition of its translation is faster than if it has more-than-one translation. The dominant translation is also always recognized more quickly than the non-dominant translation. Moreover, more-than-one-translation pairs are recognized overall more quickly when they have two semantically related translations than when they have two semantically unrelated translations. In addition, concrete words are generally processed faster than abstract words, at least in the L1–L2 direction of translation.
In what concerns the direction of translation, our results are not in line with the RHM, which predicts faster translation latencies in the L2–L1 direction of translation. The present results show no direction of translation effect in Experiment 3, and even an advantage of the L1–L2 direction of translation in Experiment 2. This is not an isolated observation; other studies have shown faster responses latencies in forward than backward translation (e.g., De Groot et al., Reference De Groot, Dannenburg and Van Hell1994; De Groot and Poot, Reference De Groot and Poot1997; Duyck and Brysbaert, Reference Duyck and Brysbaert2004). Actually, the reversed effect of language is not predicted by either the RHM or the DCFM. However, the superiority of the L1–L2 condition is consistent with translation priming experiments where L1 primes are more efficient than L2 primes. Finkbeiner et al. (Reference Finkbeiner, Forster, Nicol and Nakamura2004) explain this advantage by the fact that L1 primes activate a greater part of the L2 word representation than do L2 primes. This could also be the case in translation recognition. However, Tokowicz et al. (Reference Tokowicz, Prior and Kroll2009) observed an L1–L2 direction advantage in translation production. They put forward another explanation of the L1–L2 advantage, which is that baseline differences in the level of ambiguity affect translation speed; greater ambiguity could be due to greater word knowledge in the L1 or to differences in baseline ambiguity between languages (Laxén, Reference Laxén2007; Prior et al., Reference Prior, MacWhinney and Kroll2007). The available findings on direction of translation effects in translation recognition and translation performance do not permit us to identify the causal factors underlying the direction of translation effect. Further studies are needed to assess, for instance, the effect of differences in baseline ambiguity in different experimental languages.
Our data, collected in translation recognition where the participant has to establish an equivalence between two words in different languages, shows similar patterns of findings as those obtained in translation production (Schönpflug, Reference Schönpflug1997; Tokowicz and Kroll, Reference Tokowicz and Kroll2007). First of all, one-translation pairs (unambiguous pairs) were recognized faster than more-than-one-translation pairs (ambiguous pairs). In addition, concrete words showed a smaller effect of number-of-translation than abstract words. However, our study is the first, to our knowledge, which explicitly tests both the dominant and the non-dominant translation of words with multiple translations. The dominance effect can be studied with the translation recognition task but less easily in production tasks, because participants generally give the dominant translation as a response. The results show that dominant translations are recognized faster than non-dominant translations. We have supposed that this is due to larger semantic overlap between the word and its dominant translation than between the word and its non-dominant translation. However, dominance may not be interpreted only at the semantic level, the dominant translation is often the most frequently used translation as well, and therefore lexical-level connexions may also be stronger between the word and its dominant translation.
The translation recognition task also allowed us to study more precisely the influence of semantic relatedness between the multiple translations. We tested words that had two semantically related translations and words that had two semantically unrelated translations. The results showed that the two translations were overall better recognized when they where semantically related to each other than when they were unrelated. Yet, Tokowicz et al. (Reference Tokowicz, Prior and Kroll2009) have reported that the different kinds of ambiguity of two translation words (synonymous [cf. form ambiguous] and polysemic [cf. meaning ambiguous]) did not influence translation production. This is not in line with our findings. Nonetheless, in their study the semantic similarity was covaried before the influence of type of translation was taken into account. This may have hidden the effect of the different kinds of ambiguity, as words with two synonymous translations tend to be more similar in meaning to both of their translations than words with two different meaning translations are to their translations. More importantly, Tokowicz et al. (Reference Tokowicz, Prior and Kroll2009) showed that semantic similarity facilitated translation production. Therefore, the results of their and our study are in line with the predictions of the DCFM on bilingual memory. Additionally, our results show that semantic relatedness between the multiple translations influence translation in both directions of translation. This leads us to believe that rather than assuming that the two directions of translation use different routes (one lexical, the other semantic), one possibility may be that in both cases translation is conceptually driven, although mediation at this level is dependent on language proficiency and word type (that would determine the quality and quantity of semantic information of the words). One can also suppose a dual route activation in both directions of translation, as proposed by Duyck and Brysbaert (Reference Duyck and Brysbaert2004), where the translation results from activation of both levels (semantic and lexical).
In brief, our main results are in accordance with the predictions made by Tokowicz and Kroll (Reference Tokowicz and Kroll2007). They predicted that unambiguous pairs (words with one translation or a clear dominant translation) would be processed faster than ambiguous words (words with multiple translations). Second, ambiguous words that share much of their semantic representation with their translation equivalent will be processed faster than ambiguous words that share few elements of their semantic representation with their translation equivalent. If we assume that the dominant translation shares more semantic elements with its translation than the non-dominant one, our results confirm the previous prediction. In addition, for words with two translations, words that are less ambiguous and thus have more semantically similar translations are recognised faster than more ambiguous words. If we assume that our semantically related pairs are less ambiguous than our semantically unrelated pairs, our results confirm this prediction as well.
Finally, as can be seen, words tend to vary along multiple dimensions (frequency, concreteness, ambiguity, etc.), each of which may contribute to how easily they are translated. In this study, we have shown that different factors influence translation recognition. These factors also tend to interact. For instance, concrete words tend to have more precise meanings (which they, moreover, often share with their translation equivalent; Van Hell and De Groot, Reference Van Hell and De Groot1998a, Reference Van Hell and De Grootb); they are less ambiguous, and therefore tend to have only one translation. The semantic overlap between concrete words with one translation and their translation equivalents would be greater, and that would make them easier to translate. On the other hand, abstract words often have less precise meanings, which makes them more ambiguous and they therefore tend to have more than one translation. The semantic overlap between the translation equivalents for these words would be smaller, and that would make them more difficult to translate. The fact that a word has two translations that are semantically related also increases the semantic overlap between the translation equivalents, compared to when the two translations are unrelated in meaning. Models of the bilingual memory must be capable of explaining the differences of word characteristics and their consequences on bilingual language processing. The advantage of a distributed model of semantic memory is that all kinds of semantic overlap between words can be represented, from almost complete overlap to no overlap at all. Thus translation equivalents, and also cross-language semantic associates, can be represented. We have therefore been able to represent the hypothetical overlaps between different types of translation equivalents in the DCFM (De Groot, Reference De Groot, Frost and Katz1992b; Van Hell and De Groot, Reference Van Hell and De Groot1998b), even if the model did not include multiple translations in its original version. Moreover, if we take into account the proportion of the complete semantic representation of the translation, activated by a lexical representation of an L1 or an L2 word, as suggested in the sense model (Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004), our findings can be explained in the light of this model.
Conclusion
The main aim of this research was to describe several aspects of words that may influence the translation process. During translation, many factors can lead to response competition at both the lexical and the semantic levels. At the lexical level, the competition seems to depend to a large extent on the number of candidates for translation. At the semantic level, the response competition seems to depend on the degree of similarity between one word and its translations (and the relatedness between them). Future bilingual studies and models will have to take these new considerations into account.